Bölüm6 R’a Veri Yükleme
Bu bölümde ilk olarak değişik veri tabanı formatlarını R’a nasıl aktaracağımızı inceleyeceğiz. R, tablo formatındaki veri, Excel verisi, web üzerindeki html ve JSON verisi ve STATA, SPSS gibi farklı istatistiki yazılımlara ait birçok veri tabanı formatı ile işlem yapabilir. Daha sonra ise yüklenen veri tabanlarının temizlenerek analizler için hazır hale getirilmesi için gerekenler anlatılacaktır.
6.1 Tablo Formatındaki Verilerin Yüklenmesi
Düz tablolar halinde saklanmış veriler çoğunlukla .csv (comma separated value) formatında kaydedilir. R bu tipteki veri tabanlarını okumak için ilk kurulumla içerisinde önceden yüklü (default) olarak gelen utils paketinin read.csv() fonksiyonunu kullanır. Bu noktada daha önce ele almadığımız teknik bir noktaya değinmek zorundayız. R ve RStudio ilk çalışmaya başladığında kendisine otomatik olarak bir “çalışma klasörü/working directory” belirler. Yüklemek istediğimiz veri tabanlarını da ilk olarak bu çalışma klasöründe arar. Üzerinde çalışmak istediğiniz veri tabanını bu çalışma klasörüne kopyalamamız işlerimizi bir hayli kolaylaştırır. Eğer bu işlemi yapmazsak, yani veri tabanımız çalışma klasörünüzde değil ise, veri tabanının bulunduğu klasörü R’a tanımlamak zorunda kalırız ki bu durum farklı işletim sistemlerinde farklı yazım gerektirdiğinden çok tavsiye edilmez. Çalışma klasörünüzü R menüsünü kullanarak “Session/Set Working Directory” seçenekleri ile tanımlayabilirsiniz.
Şimdi çalışma klasöründe bulunan “dt.csv” isimli tablo formatındaki veri tabanını “tablo_veri” adı ile R’a aktaralım ce yapısını str() fonksiyonu ile sorgulayalım.
tablo_veri <- read.csv("dt.csv", stringsAsFactors = FALSE, header = TRUE)str(tablo_veri)## 'data.frame': 1000 obs. of 23 variables:
## $ idnum : int 517 297 811 461 607 186 879 887 622 423 ...
## $ cinsiyet : chr "Erkek" "Kadin" "Kadin" "Erkek" ...
## $ bolge : chr "Guney" "Guney" "Kuzey" "Kuzey" ...
## $ gelir : int 22559 12072 40815 44135 48246 15263 4122 6345 35840 46321 ...
## $ egitim : int 1 5 1 1 1 2 1 2 2 1 ...
## $ muhafazakar : int 2 2 2 3 2 2 1 3 1 3 ...
## $ liberal : int 4 3 5 5 3 5 5 4 5 5 ...
## $ milliyetci : int 2 1 1 3 1 3 1 1 1 1 ...
## $ p1 : int 1 1 0 0 0 0 0 0 1 0 ...
## $ p2 : int 1 1 1 1 1 1 1 0 1 1 ...
## $ p3 : int 0 0 0 1 0 0 0 1 0 0 ...
## $ siyasete_guven : int 88 10 44 58 22 45 11 21 93 17 ...
## $ yas : int 34 30 58 31 54 27 61 76 43 30 ...
## $ gocmenler : int 22 55 99 98 90 87 10 26 56 72 ...
## $ oy : chr "PartiB" "PartiB" "PartiB" "PartiC" ...
## $ kurtaj : chr "DurumaGore" "Yasaklansin" "Serbest" "Serbest" ...
## $ sendikalasma : int 24 22 14 10 10 13 8 25 1 4 ...
## $ gelenek : int 1 1 1 1 1 1 1 1 1 0 ...
## $ bagis : int 11 28 50 0 0 0 0 13 0 36 ...
## $ askere_guven : num -1.152 1.421 0.107 -0.641 0.382 ...
## $ adalete_guven : num 2.98 2.93 2.81 2.67 2.51 ...
## $ burokrasiye_guven: num 2.649 2.035 0.299 3.134 1.451 ...
## $ meclise_guven : num 2.98 2.93 2.81 2.67 2.51 ...Görüldüğü üzere read.csv() fonksiyonunu stringsAsFactors = FALSE ve header=TRUE argümanları ile beraber kullandık. İlk argüman R’a yüklediğimiz veri tabanında bulunan ve nümerik olmayan değişkenleri (strings) faktör değişkeni değil karakter/metin formatında aktardı. Bu argümanı kullanıp kullanmamak değişkenleri hangi tipte istediğiniz ile alakalıdır. İkincisi ise veri tabanında bulunan ilk satırı değişken isimleri olarak kullandı. Veri tabanının durumunu “Global Environment” penceresindeki veri tabanı ismine tıklayarak kontrol edebilirsiniz.
“tablo_veri” veri tabanına baktığımızda 22 değişken üzerinde 1000 gözlem içeren bir veri tabanı olduğunu anlıyoruz. R, değişkenleri virgül verine “tab” ile ayrılmış (tab delimited files) “.txt” uzantılı metin dosyalarını açmak için read.delim(), diğer formatlardaki “.txt” dosyalarının açılması için ise read.table() fonksiyonlarını kullanır. Her iki tipin kullanımı read.csv() fonksiyonu gibi olsa da farklılıklar için yardım dosyasını kontrol etmeniz gerekecektir.
Daha önce de söylendiği gibi R her türlü işlemin daha kolayca yapılabilmesi için kullanıcıları tarafından yazılmış olan paketler kullanır. R’a veri aktarımı için kullanılan birçok paket bulunmasına rağmen en kullanışlı olanlarından biri readr paketidir. readr hızı ve kullanım kolaylığı açısından diğer paketlerden farklılaşır. Her paket kullanımı için yapıldığı gibi readr paketini de kullanmak için ilk başta paketi indirmeli ve sonra da R oturumuna eklemeliyiz. Aşağıdaki komutlar ile bu işi yapıp daha sonra “dt.csv” dosyasını readr paketinin read.csv() fonksiyonu ile R’a aktaralım:
# Paketin indirilmesi ve R oturumuna eklenmesi
install.packages("readr")
library(readr)Bu işlemi takiben read_csv() fonksiyonu ile dosyamızı “veri2” adı ile R’a aktarıyoruz.
veri2 <- read_csv("dt.csv")read_csv() fonksiyonu, veriyi “tibble” adı verilen bir format ile saklar. Konsola “veri2” yazıp incelediğimizde bu işlem sonucunda oluşan “tibble” a ait 1000 satır(gözlem) ve 22 sütun (değişken) olduğunu görüyoruz. Ayrıca her sütunda bulunan değişkenlere ait isimler ve bu değişkenlerin türleri de raporlandı. Tibble veri formatı ileride ele alacağımız bazı paketler içerisinde de kullanılacağından, data aktarımı için bu fonksiyonu kullanmanızı öneririm. readr hakkında diğer bilgilere ulaşmak için yardım dokümanına bakabilirsiniz.
6.2 Excel Verilerinin Yüklenmesi
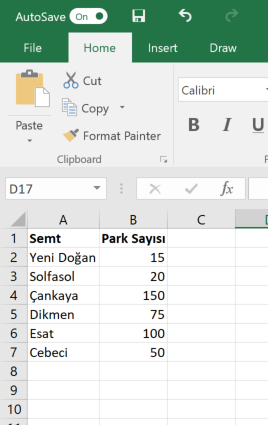
Çalışmalarınız sırasında sıklıkla verilerin MS Excel formatında olduğunu göreceksiniz. Excel dosyalarını R içerisinde açmak için birçok paket bulunsa da, biz burada readxl paketini inceleyeceğiz. Excel dosyaları sheet adı verilen sayfalardan oluşan defterlere benzer. Veri ise bu sayfalar içerisinde tablo formatında işlenmiş şekli ile yer alır. readxl istersek defterin tümünü istersek de gerekli sayfayı R içine aktarır. Aşağıda, Ankara’da 2010 yılında bazı semtlerdeki park sayısını raporlayan basit bir excel verisini görebilirsiniz1
Tablo şeklindeki bu veri Excel dosyasının “2010” isimli sayfasında kayıtlı. Aynı dosyada 2020“yılında olması beklenen park sayıları da”2020" adı altında bir başka sayfada kaydedilmiş olsun.
Caption
readxl Excel verisini okumak için iki temel fonksiyon kullanır: excel_sheets() ve read_excel(). Birincisi Excel dosyası içerisinde bulunan sayfaları listelerken ikincisi ise istenilen sayfadaki veriyi “tibble” olarak R içine aktarır. Aşağıdaki örnekte “parklar.xslx” dosyasını R içerisine aktaran kodu görebilirsiniz.
install.packages("readxl")library(readxl)
#Excel dosyasındaki sayfaları görmek için
excel_sheets("parklar.xlsx")## [1] "2010" "2020"#İstenilen sayfayı R içine aktarmak için
read_excel("parklar.xlsx", sheet = "2020")## # A tibble: 6 x 2
## Semt `Park Sayisi`
## <chr> <dbl>
## 1 Yeni Dogan 20
## 2 Solfasol 22
## 3 Çankaya 160
## 4 Dikmen 100
## 5 Esat 80
## 6 Cebeci 60readxl fonksiyonu aslında bundan fazlasını da yapabilmektedir. Örneğin farklı argümanlar kullanarak sütun isimlerini değiştirebilir, veya değişkenlerin tiplerini ayarlayabilirsiniz. Bahsedilen bu argümanlarını görmek için yardım dokümasyonuna bakabilirsiniz.
6.3 Web Üzerindeki Verilerin Yüklenmesi
Günümüzde istediğimiz veriyi çoğunlukla web ortamında buluyoruz. R Internet’ten veri çekme konusunda da bize çeşitli olanaklar sağlar. Web üzerinde bulduğumuz veriyi ilk olarak bilgisayarımıza indirip, daha sonra R ortamına aktarma seçeneğimiz bulunsa da eğer bilgisayarımız Internet’e bağlı ise bu işlemi doğrudan da daha önce öğrendiğimiz paketleri kullanarak yapabiliriz. Örneğin readr paketi ile “http://www.asdf.net/veriler/” adresinde bulunan “qwe.csv” dosyasını R kullanarak incelemek istiyor olalım. Bu durumda yazacağımız kod aşağıdaki gibi olacaktır:2
read_csv(http://www.asdf.net/veriler/qwe.csv)Dosyanın yerini web üzerinde doğru yazdığımız zaman aynı kendi bilgisayarımızdan yüklüyormuş gibi bu veriyi R içine aktarmamız mümkündür.
Web üzerinden veri toplamakta kullanılan paketlerden bir olan hhtr ile istediğimiz web sayfası içeriklerini R nesneleri olarak (vektör, matris vb.) saklamak mümkündür. Aslında Internet ortamından bir dosya istediğimizde http üzerinde “GET” (getir) isimli bir talepte bulunuruz. hhtr paketi bu komutu kendi içinde GET() fonksiyonu üzerinden çalıştırır. Bu fonksiyon sonuç (response) olarak ilgilendiğimiz veriyi içeren bir R nesnesi oluşturur. Bu nesnenin içeriği content() (içerik) fonksiyonu ile incelenir. Eğer istediğimiz verinin hangi tipte bir R nesnesi olacağını tanımlamamışsak (karakterlerden oluşan bir vektör, bir liste veya ham R objesi) R en iyi tahminde bulunmaya çalışır. Aşağıdaki kodda ilk olarak hhtr paketinin yüklenmesi ve daha sonra bahsedilen işlemlerin yapılması örneklendirilmektedir.
install.packages("httr")library(httr)
# adresi getirelim ve sonuc adı ile kaydelim
adres <- "https://emretoros.weebly.com/publications.html"
sonuc <- GET(adres)
# sonuc nesnesini inceleyelim
sonuc## Response [https://emretoros.weebly.com/publications.html]
## Date: 2018-10-18 06:17
## Status: 200
## Content-Type: text/html; charset=UTF-8
## Size: 31.1 kB
## <!DOCTYPE html>
## <html lang="en">
## <head><script src="/gdpr/gdprscript.js?buildTime=1539820446&hasRemindMe...
## <title>PUBLICATIONS - EMRE TOROS</title><meta property="og:site_name" ...
## <meta property="og:title" content="PUBLICATIONS" />
## <meta property="og:description" content="SSCI Publications Toros, E., C...
## <meta property="og:url" content="http://emretoros.weebly.com/publication...
##
##
##
## ...# content fonksiyonu ile içeriği ham içerik olarak tanımlayalım
ham_icerik <- content(sonuc, as ="raw")
# ham_icerik nesnesinin ilk kısmına göz atalım
head(ham_icerik)## [1] 3c 21 44 4f 43 54Örnekte verilen web sayfasını ziyaret ederseniz aslında son olarak oluşan R nesnesinin web sayfasındaki veri ile alakalı olmadığını görebilirsiniz. Aynı içeriği metin (text) olarak elde etmek istersek aşağıdaki kodu kullanabiliriz
# content fonksiyonu ile içeriği metin olarak çekelim
metin_icerik <- content(sonuc, as ="text")
# ham_icerik nesnesinin ilk kısmına göz atalım
head(metin_icerik)R içeriği bir http kodu olarak içeriye aktardı. Fark edileceği üzere bu R nesnesi hayli karışık ve istenilen verinin kolayca içerisinden alınabileceği türde bir yapıya sahip değil. Şanslıyız ki web üzerindeki veriler sadece html kodu olarak bulunmuyor. R web verisi için sıkça JSON formatını kullanır. JSON formatı html nin aksine basit, tutarlı ve hem insanlar hem de bilgisayarlar tarafından kolayca okunabilen bir formattır. Bu durum JSON formatının Web API yazılımları tarafından sıkça kullanılmasına yol açar. API (Application Programming Interface) yazılımları meydana getiren rutin ve protokollere verilen isimdir, ve yazılımların kendi arasındaki iletişimini düzenler. Sınırsız sayıda API bulunmasına rağmen, bizim burada ilgilendiğimiz API uygulamaları veri toplanması için kullanacağımız Web API uygulamaları olacak. Daha basitçe söylersek Web API yazılımları kullanarak ilgilendiğimiz bilginin barındığı sunucuya (server) bağlanıp veri alıp göndereceğiz. Twitter yazılımını ele alalım. Twitter kullanıcıların ilgilendikleri tweetleri indirebilmeleri ve analiz etmeleri için “https://dev.twitter.com/rest/public” adresinde bir API yazılımı barındırmaktadır. Gerekli işlemleri yaptıktan sonra daha önce yaptığımız gibi GET() fonksiyonunu kullanarak belli adreslerdeki bilgiyi, örneğin belli bir kullanıcıya ait tweetleri çekebiliriz. API sayesinde Twitter isteğimizi işler ve bize geri yollar.
jsonlite Web üzerinde JSON formatındaki veriyi R içine aktarmaya yarayan R paketlerinden biridir. Filmler hakkındaki veriyi JSON formatına çeviren “OMDb API” üzerinden “Şaban Oğlu Şaban” filmine ait veriyi indiren aşağıdaki kodu inceleyin3. Bu kod sonuç olarak (response) bir liste nesnesi oluşturacak. Kod aynı zamanda oluşan listeyi as.data.frame() fonksiyonu ile bir veri tabanı haline çeviriyor. Environment penceresinde oluşan veri tabanına tıklayarak indirdiğiniz veriyi inceleyebilirsiniz.
install.packages("jsonlite")library(jsonlite)
saogsa <- as.data.frame(fromJSON("http://www.omdbapi.com/?i=tt0253614&apikey=26dfe1bd"))6.4 Diğer İstatistik Yazılımlarına Ait Veri Dosyalarının Yüklenmesi
Bu bölümde son olarak STATA ve SPSS yazılımlarının kullandıkları veri formatlarını R içine aktaran haven paketini inceleyeceğiz. STATA ve SPSS veri dosyalarını “.dta” ve “.sav” uzantıları ile saklar. haven her iki formatı da R içerisine hızlı, kolay ve etkin bir şekilde aktarır. İlk olarak haven paketini indirelim ve R oturumuna ekledikten sonra çalışma dizinimizde bulunan “stata.dta” dosyasını R içine aktaralım
install.packages("haven")library(haven)
stata <- read_stata("stata.dta")Konsol penceresine “stata” yazdığınızda, bu veri tabanının 27 satır ve 27 sütunluk tibble formatındaki raporunu görebilirsiniz.
Aynı işlemi çalışma klasörümüzde bulunan “.sav” uzantılı “spss.sav” dosyası için yapalım. Bu dosya SPSS formatında saklanmış bir dosyadır.
library(haven)
spss <- read_spss("spss.sav")Konsol penceresine “spss yazdığınızda, bu veri tabanının 218 satır ve 29 sütunluk tibble formatındaki raporunu görebilirsiniz.
Gerçek veri değildir.↩
Veri gerçek değildir, uygulama için kurgulanmıştır.↩
Kodda kullanılan web linki http://www.omdbapi.com/ adresinde bulunan OMDb API kullanılarak üretilmiştir↩