Bölüm7 R ile Veri Temizliği
Gerçek hayatta kullanacağımız veriler yapacağımız analizler dikkate alındığında hiçbir zaman düzenli ve kusursuz bir şekilde bulunmazlar. Bu durumun iki temel nedeni vardır. Birincisi çoğunlukla veri tabanları bizim araştırma sorularımızı yanıtlamak için kullanacağımız veriden daha fazlasını içerirler. İkincisi ise teknik nedenlerden dolayıdır: veri hatalı kodlanmış olabilir, nasıl kodlandığı anlaşılmaz durumda olabilir, değişken isimlerini içermiyor olabilir vb. Bu yüzden araştırmacılar analizlerinden önce muhakkak verilerine bakmalı ve gerekli temizliği yapmalıdırlar. Özellikle araştırmacıların günümüzde büyük veri (Big Data) ile sıklıkla çalışılmak zorunda kaldığı düşünüldüğünde veri temizliğinin önemi de daha net bir şekilde görünür. Zira veri büyüdükçe analizlerde hata yapma ihtimali de artar ve bu hataların nerede yapıldığını bulmak zorlaşır. Aslına bakılırsa veri temizliği, veri analizi sürecinin vazgeçilmez bir parçasıdır. Veri analizi sürecini toplama, temizleme, modelleme ve raporlama olarak düşünürsek ikinci aşamada bulunan temizlemenin düzgün yapılmadığı durumlarda modelleme ve raporlama aşamaları da doğru bir şekilde yapılamaz. Ayrıca veri temizleme bu dört aşamadan en fazla vakit alanıdır: yakın zamanda yayınlanan bir rapora göre araştırmacılar vakitlerinin yüzde ellisi ile sekseni arasında değişen bir kısmını veri temizliğine ayırmaktadırlar.4 Veri temizliğinin önemi maalesef birçok kaynakta atlanmakta ve gerekli önem verilmemektedir.
Bu bölümde veri temizliğini üç aşamada ele alacağız. Birincisi “ham verinin incelenmesi”, ikincisi “verinin düzenlenmesi” üçüncüsü ise “verinin analiz için hazırlanması” olarak adlandırılabilir. En son bölümde ise tüm bu aşamaları birleştireceğiz.
7.1 Ham Verinin İncelenmesi
Veri temizliğinde ilk aşama olan ham verinin incelenmesi aşaması kendi içerisinde üç ayrı işlem gerektirir
- Verinin yapısının anlaşılması
- Veriye bakmak
- Verinin görselleştirilmesi
Çalışma dizinimizde bulunan ve ülkelerdeki seçimler ile ilgili olduğunu bildiğimiz “ulkeler.csv” veri tabanını “ulkeler” adı altında R’a tanıtalım ve yapısına bir göz atalım.5
library(readr)
ulkeler <- read_csv("ulkeler.csv")
ulkeler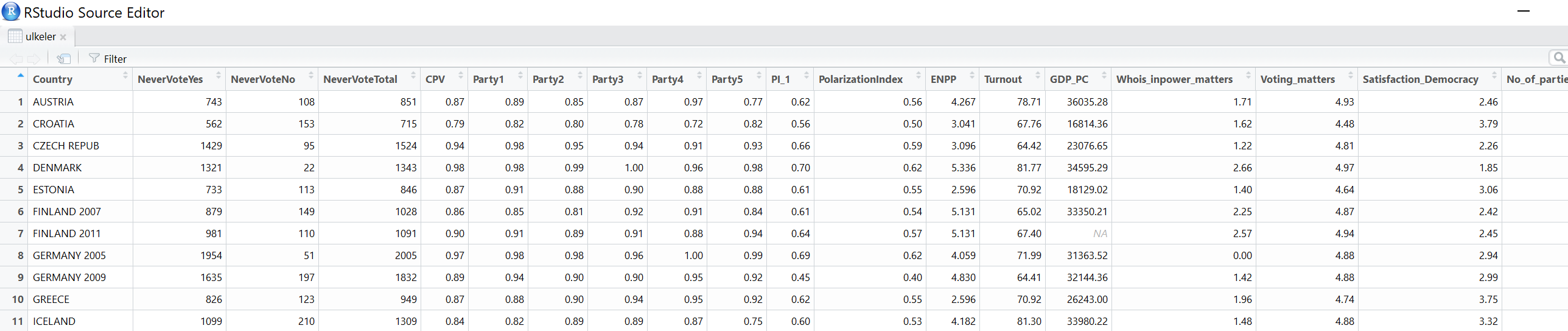
Satır ve sütunlar halinde organize dilmiş bu tablo formatındaki veri tabanı ilk bakışta temiz gibi görünse de biraz daha yakından bakıldığında bazı sorunları olduğunu fark edeceksiniz. Örneğin değişkenlerin yerleştiği sütunlardaki bazı başlıkların - 5. sütundaki CPV gibi- ne anlama geldiğini bu yapıda anlayamayız.
Şimdilik bu düşünceleri bir kenara bırakıp verimizin yapısını anlamak için kullanacağımız R fonksiyonlarını inceleyelim. class() fonksiyonu ile verimizin yapısını kontrol edebiliriz. Hatırlarsanız R üzerinde çalışacağı nesneleri vektörler, matrisler, veri tabanları gibi farklı kategoriler ile sınıflar. Veriye ait boyutlar dim() fonksiyonu ile kontrol edilirken, sütun isimlerini ise names() fonksiyonu ile görebiliriz.
“ulkeler” nesnesinin sınıfını, boyutlarını ve sütun isimlerini kontrol eden kodları sırasıyla aşağıda bulabilirsiniz
class(ulkeler)## [1] "tbl_df" "tbl" "data.frame"“ulkeler.csv” dosyasını readr paketine ait read_csv() fonksiyonu ile R içine aktardığımızdan ulkeler nesnesinin sınıfı (class) hem “tibble” hem de “data.frame” olarak raporlandı. Buradan bu R nesnesinin satırlardan ve sütunlardan oluşan bir yapıya sahip olduğunu ve her sütunun farklı ölçüm seviyelerinde ölçülmüş (numerik, karakter, faktör vb.) değişkenleri temsil ettiğini anlıyoruz.
dim (ulkeler)## [1] 27 27R çıktısından bu veri tabanının 27 satır ve 27 sütundan oluştuğunu anlıyoruz. Hatırlarsanız bu bilgiyi dosyayı read_csv() fonksiyonunu kullanarak açtığımızda ve “ulkeler” nesnesini konsolda çağırdığımızda da görmüştük. Unutulmamalıdır ki dim() fonksiyonu ilk olarak satır sonra sütun sayısını raporlar.
names(ulkeler)## [1] "Country" "NeverVoteYes"
## [3] "NeverVoteNo" "NeverVoteTotal"
## [5] "CPV" "Party1"
## [7] "Party2" "Party3"
## [9] "Party4" "Party5"
## [11] "PI_1" "PolarizationIndex"
## [13] "ENPP" "Turnout"
## [15] "GDP_PC" "Whois_inpower_matters"
## [17] "Voting_matters" "Satisfaction_Democracy"
## [19] "No_of_parties_competing" "Threshold"
## [21] "european" "EU6"
## [23] "EU9" "EU15"
## [25] "EU" "NonEU"
## [27] "Ideology"Yukarıdaki çıktıda da bu veri tabanında bulunan 27 değişkenin isimleri görünmektedir.
Verinin yapısının anlaşılması için kritik olan bir diğer fonksiyon ise str() fonksiyonudur. Bu fonksiyon ile verinin yapısı (structure) anlaşılabilir ve anlamlı bir özet oluşturulur. Bu fonksiyonu daha önce de kullanmıştık. Burada ise bir bakıma daha kullanışlı olan ve dplyr paketine ait glimpse() fonksiyonundan bahsedeceğiz. Aşağıdaki kod ilk başta paketi bilgisayara indirip R oturumuna ekleyecek ve daha sonra glimpse() fonksiyonu ile verinin yapısına bakacaktır
install.packages("dplyr")
library(dplyr)library(dplyr )
glimpse(ulkeler)## Observations: 27
## Variables: 27
## $ Country <chr> "AUSTRIA", "CROATIA", "CZECH REPUB", "...
## $ NeverVoteYes <int> 743, 562, 1429, 1321, 733, 879, 981, 1...
## $ NeverVoteNo <int> 108, 153, 95, 22, 113, 149, 110, 51, 1...
## $ NeverVoteTotal <int> 851, 715, 1524, 1343, 846, 1028, 1091,...
## $ CPV <dbl> 0.87, 0.79, 0.94, 0.98, 0.87, 0.86, 0....
## $ Party1 <dbl> 0.89, 0.82, 0.98, 0.98, 0.91, 0.85, 0....
## $ Party2 <dbl> 0.85, 0.80, 0.95, 0.99, 0.88, 0.81, 0....
## $ Party3 <dbl> 0.87, 0.78, 0.94, 1.00, 0.90, 0.92, 0....
## $ Party4 <dbl> 0.97, 0.72, 0.91, 0.96, 0.88, 0.91, 0....
## $ Party5 <dbl> 0.77, 0.82, 0.93, 0.98, 0.88, 0.84, 0....
## $ PI_1 <dbl> 0.62, 0.56, 0.66, 0.70, 0.61, 0.61, 0....
## $ PolarizationIndex <dbl> 0.56, 0.50, 0.59, 0.62, 0.55, 0.54, 0....
## $ ENPP <dbl> 4.27, 3.04, 3.10, 5.34, 2.60, 5.13, 5....
## $ Turnout <dbl> 78.7, 67.8, 64.4, 81.8, 70.9, 65.0, 67...
## $ GDP_PC <dbl> 36035, 16814, 23077, 34595, 18129, 333...
## $ Whois_inpower_matters <dbl> 1.71, 1.62, 1.22, 2.66, 1.40, 2.25, 2....
## $ Voting_matters <dbl> 4.93, 4.48, 4.81, 4.97, 4.64, 4.87, 4....
## $ Satisfaction_Democracy <dbl> 2.46, 3.79, 2.26, 1.85, 3.06, 2.42, 2....
## $ No_of_parties_competing <int> 15, 56, 26, 9, 23, 17, 17, 25, 27, 23,...
## $ Threshold <int> 1, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1,...
## $ european <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,...
## $ EU6 <int> 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0,...
## $ EU9 <int> 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 1, 0,...
## $ EU15 <int> 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0,...
## $ EU <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1,...
## $ NonEU <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0,...
## $ Ideology <dbl> 6.00, 5.55, 5.00, 5.00, 4.33, 5.00, 5....Verinin yapısının anlaşılması için kullanılan diğer bir fonksiyon ise summary() (summary/özetle) fonksiyonudur.
summary(ulkeler)## Country NeverVoteYes NeverVoteNo NeverVoteTotal
## Length:27 Min. : 235 Min. : 22 Min. : 259
## Class :character 1st Qu.: 728 1st Qu.:102 1st Qu.: 900
## Mode :character Median : 879 Median :139 Median :1091
## Mean :1047 Mean :172 Mean :1220
## 3rd Qu.:1384 3rd Qu.:218 3rd Qu.:1501
## Max. :2072 Max. :406 Max. :2169
##
## CPV Party1 Party2 Party3
## Min. :0.510 Min. :0.490 Min. :0.560 Min. :0.500
## 1st Qu.:0.790 1st Qu.:0.820 1st Qu.:0.790 1st Qu.:0.835
## Median :0.870 Median :0.890 Median :0.890 Median :0.890
## Mean :0.836 Mean :0.856 Mean :0.846 Mean :0.863
## 3rd Qu.:0.910 3rd Qu.:0.935 3rd Qu.:0.935 3rd Qu.:0.940
## Max. :0.980 Max. :0.980 Max. :0.990 Max. :1.000
##
## Party4 Party5 PI_1 PolarizationIndex
## Min. :0.450 Min. :0.400 Min. :0.370 Min. :0.33
## 1st Qu.:0.780 1st Qu.:0.782 1st Qu.:0.560 1st Qu.:0.50
## Median :0.880 Median :0.920 Median :0.620 Median :0.55
## Mean :0.853 Mean :0.847 Mean :0.594 Mean :0.53
## 3rd Qu.:0.950 3rd Qu.:0.950 3rd Qu.:0.650 3rd Qu.:0.58
## Max. :1.000 Max. :1.000 Max. :0.700 Max. :0.62
## NA's :1
## ENPP Turnout GDP_PC Whois_inpower_matters
## Min. :2.12 Min. :48.2 Min. : 7333 Min. :0.00
## 1st Qu.:2.90 1st Qu.:63.5 1st Qu.:18627 1st Qu.:1.45
## Median :4.06 Median :70.9 Median :29294 Median :1.84
## Mean :3.88 Mean :69.4 Mean :27045 Mean :1.86
## 3rd Qu.:4.63 3rd Qu.:76.7 3rd Qu.:34899 3rd Qu.:2.34
## Max. :6.75 Max. :83.2 Max. :47305 Max. :3.53
## NA's :1
## Voting_matters Satisfaction_Democracy No_of_parties_competing
## Min. :4.28 Min. :1.85 Min. : 7.0
## 1st Qu.:4.80 1st Qu.:2.36 1st Qu.:15.5
## Median :4.87 Median :2.77 Median :18.0
## Mean :4.82 Mean :2.80 Mean :23.8
## 3rd Qu.:4.93 3rd Qu.:3.29 3rd Qu.:25.5
## Max. :4.98 Max. :3.79 Max. :97.0
##
## Threshold european EU6 EU9
## Min. :0.000 Min. :0.000 Min. :0.000 Min. :0.000
## 1st Qu.:0.000 1st Qu.:1.000 1st Qu.:0.000 1st Qu.:0.000
## Median :1.000 Median :1.000 Median :0.000 Median :0.000
## Mean :0.519 Mean :0.889 Mean :0.148 Mean :0.222
## 3rd Qu.:1.000 3rd Qu.:1.000 3rd Qu.:0.000 3rd Qu.:0.000
## Max. :1.000 Max. :1.000 Max. :1.000 Max. :1.000
##
## EU15 EU NonEU Ideology
## Min. :0.000 Min. :0.000 Min. :0.000 Min. :4.11
## 1st Qu.:0.000 1st Qu.:0.500 1st Qu.:0.000 1st Qu.:5.00
## Median :0.000 Median :1.000 Median :0.000 Median :5.11
## Mean :0.481 Mean :0.741 Mean :0.259 Mean :5.18
## 3rd Qu.:1.000 3rd Qu.:1.000 3rd Qu.:0.500 3rd Qu.:5.53
## Max. :1.000 Max. :1.000 Max. :1.000 Max. :6.50
## Görüldüğü üzere summary() fonksiyonu numerik değerlere ait minimum değer, maximum değer, ortalama, çeyrekler gibi birçok hesaplamayı aynı anda yaparak raporladı. Numerik olmayan değişkenlere ait raporlamayı değişik bir biçimde yaptığına dikkat ediniz.
Bu fonksiyonlar anlamlı da olsa verinin kendisine bakmak verinin anlaşılması için yapılabilecek belki de en anlamlı harekettir. Bu noktada head() fonksiyonu işimize çok yarar.
head(ulkeler)## # A tibble: 6 x 27
## Country NeverVoteYes NeverVoteNo NeverVoteTotal CPV Party1 Party2
## <chr> <int> <int> <int> <dbl> <dbl> <dbl>
## 1 AUSTRIA 743 108 851 0.87 0.89 0.85
## 2 CROATIA 562 153 715 0.79 0.82 0.8
## 3 CZECH ~ 1429 95 1524 0.94 0.98 0.95
## 4 DENMARK 1321 22 1343 0.98 0.98 0.99
## 5 ESTONIA 733 113 846 0.87 0.91 0.88
## 6 FINLAN~ 879 149 1028 0.86 0.85 0.81
## # ... with 20 more variables: Party3 <dbl>, Party4 <dbl>, Party5 <dbl>,
## # PI_1 <dbl>, PolarizationIndex <dbl>, ENPP <dbl>, Turnout <dbl>,
## # GDP_PC <dbl>, Whois_inpower_matters <dbl>, Voting_matters <dbl>,
## # Satisfaction_Democracy <dbl>, No_of_parties_competing <int>,
## # Threshold <int>, european <int>, EU6 <int>, EU9 <int>, EU15 <int>,
## # EU <int>, NonEU <int>, Ideology <dbl>Bu fonksiyon önceden tanımlı olarak verinin ilk 6 satırını bize getirir. Daha fazla veya daha az satır gözlemlemek istersek fonksiyonun “n” argümanını kullanabiliriz. Örneğin ilk 10 satırı gözlemlemek istersek fonksiyonu “head(ulkeler, n=10)” şeklinde güncellememiz gerekir.
Çoğu zaman veriyi anlamanın en kolay yolu veriyi görsel hale getirmektir. Çok basit bir grafik ile başlayalım
hist(ulkeler$GDP_PC)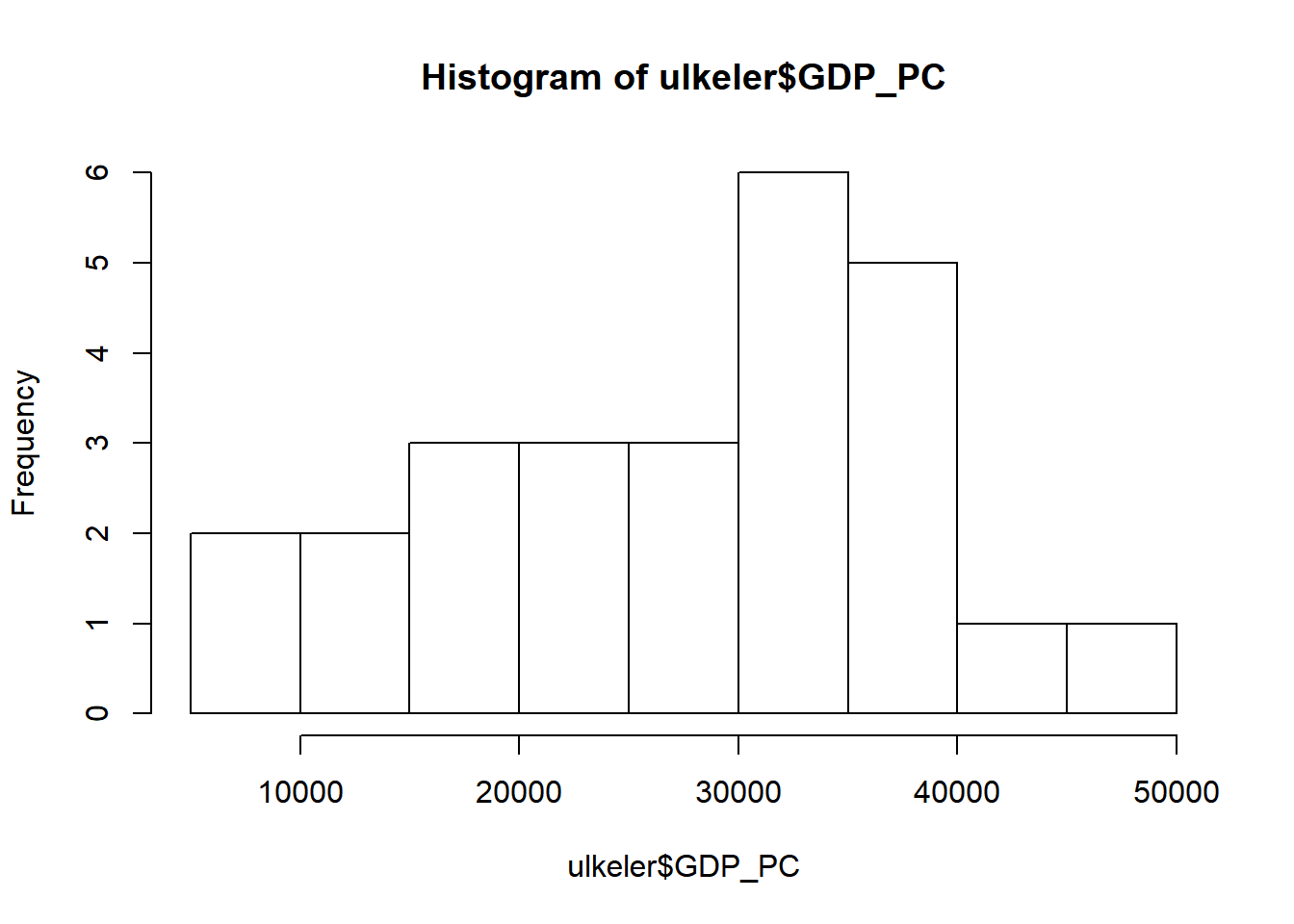
Yukarıdaki grafikte kişi başına düşen gayri safi milli hasıla (GDP_PC) x eksenine ülke frekansları ise y eksenine yerleştirilmiş durumdadır. Grafiği incelediğimizde veri tabanında bulunan ülkelerin 11 tanesinin kişi başına düşen gayri safi milli hasılasının 30000 ve 40000 dolar arasında olduğunu anlıyoruz. Böylece verinin dağılımı hakkında, ilk ve basit gözlemleri yapmış oluyoruz.
Diğer basit ama veri hakkında önemli bilgiler sağlayan görselleştirme fonksiyonu plot() fonksiyonudur. plot() fonksiyonu ile iki nümerik değişken arasındaki ilişki en yalın bir şekilde anlaşılır. Aşağıdaki grafik veri tabanında bulunan kutuplaşma endeksi ile gelir arasındaki ilişkiyi görselleştirmektedir.
plot(ulkeler$GDP_PC, ulkeler$PolarizationIndex)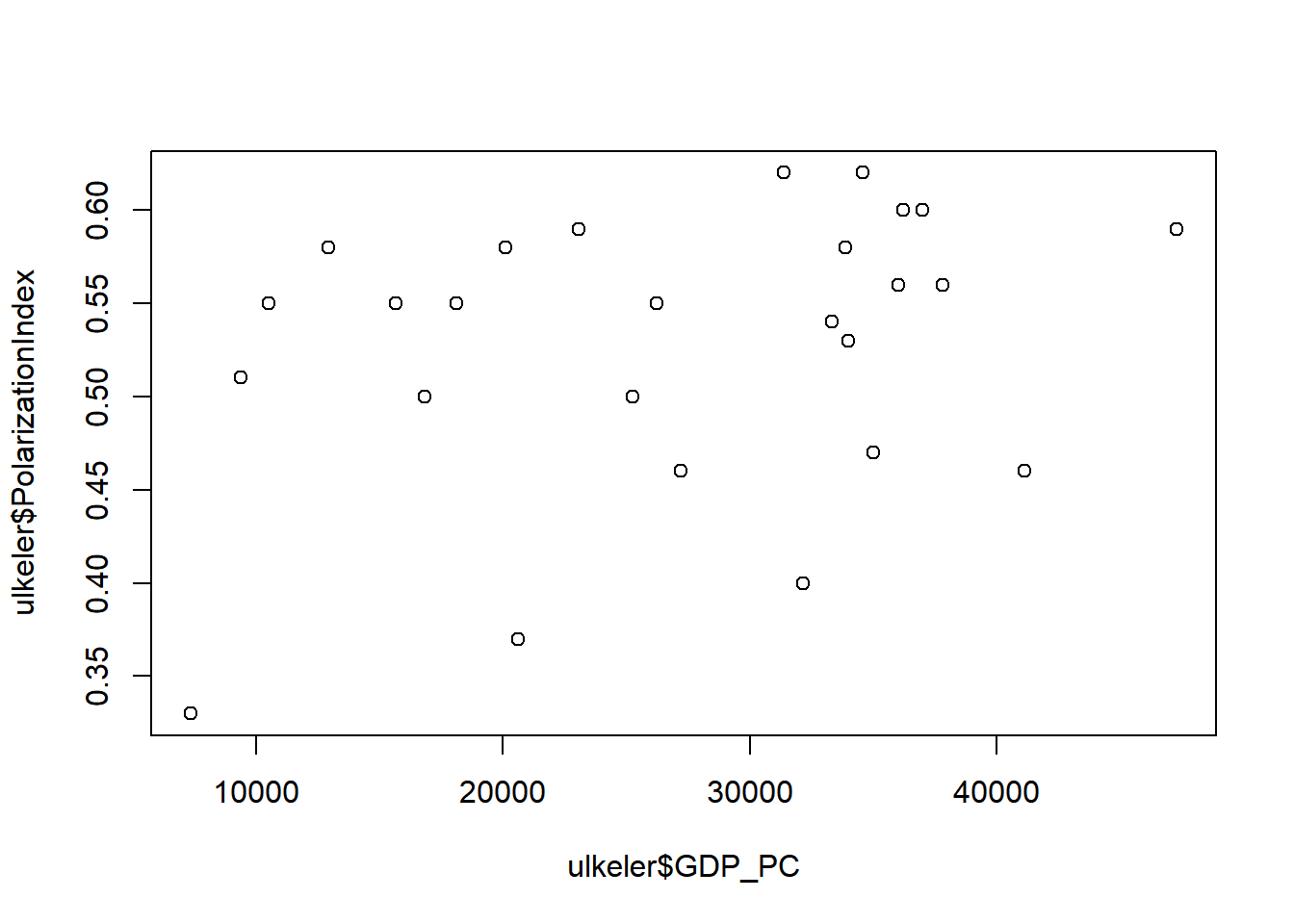
Hatırlayacağınız gibi yukarıdaki kodda kullanılan “$” işareti veri tabanı ile değişken arasındaki bağı kurmaya yarar. “Saçınım grafiği” olarak da adlandırılan bu grafikten gelir ile kutuplaşma arasında dikkat çekici bir ilişki bulunmadığını anlayabiliyoruz.
7.2 Verinin Düzenlenmesi
Bir veri tabanının düzenli/tertipli sayılabilmesi için birkaç özelliği içermesi gerekir. Bir veri tabanının gözlemlerin satırlarda değişkenlerin ise sütunlarda tanımlandığı ölçülmüş bir grup değerden oluştuğunu biliyoruz. Bu noktada gözlem birimi kavramını da konuya dahil etmemiz gerekiyor. Veri tabanlarının düzenli sayılabilmesi için tek bir gözlem birimi içeriyor olması gerekir. Yani bir veri tabanının aynı anda hem insanların özelliklerini (yaş, cinsiyet vb) hem de ülkelerin özelliklerini (gelir, coğrafi konum vb) aynı anda satırlara yerleştirmemesi gerekir. Ayrıca veri tabanının düzenli olabilmesi için:
- Her bir değer aynı anda hem bir değişkene hem de bir gözleme bağlı olmalıdır.
- Değişkenler gözlemler boyunca aynı değişken özelliğini ölçmelidir ve
- Gözlemler de sadece değişkenlere ait değerleri barındırmalıdır.
Şimdi bu ilkeler dahilinde aşağıdaki veriye bir göz atalım:
| isim | yaş | kahverengi | mavi | diğer | boy |
|---|---|---|---|---|---|
| Ali | 34 | 0 | 0 | 1 | 170 |
| Ayşe | 42 | 0 | 1 | 0 | 165 |
| Can | 70 | 1 | 0 | 0 | 178 |
| Mert | 19 | 0 | 0 | 1 | 190 |
Yukarıdaki veride tek bir gözlem birimi olduğunu (insanlar), ve gözlemlerin satırlara değişkenlerin ise sütunlara yerleştiğini görebiliyoruz. Fakat “kahverengi” “mavi” ve “diğer” sütun başlıklarının aslında bir değişkene ait (göz rengi) değerler olduğunu düşünürsek bu başlıkların sütun başlarında olması gereken değişken isimleri değil o değişkene ait değerler olduğunu görürüz. Bu veri tabanlarında sıkça karşılaşılan bir durumdur.
Veri tabanları aynı zamanda formatlarına göre geniş ve uzun olarak da sınıflandırılırlar. Geniş olarak formatlanmış veri tabanlarında veriye ait özellikler yatay düzlemde anlatılırken, uzun formatta ise bu özellikler dikey olarak anlatılır.
Yukarıda anlatılan ilkeler dahilinde verimizi düzenli hale getirmek için tidyr paketini kullanacağız. Aşağıdaki koddaki komutlar için daha önce örnekleri verildiği gibi “install.packages(”tidyr“) komutu ile tidyr paketini indirmeniz ve”library(tidyr)" komutu ile aktif R oturumunuza eklemeniz gerekmektedir.
Örneklerimiz için öncelikle “genis_vt” adı altında geniş formatlı bir veri tabanı yaratalım
sutun <- c("x", "y")
A <- c(1,4)
B <- c (2,5)
C <- c(3,6)
genis_vt <- data.frame(sutun, A, B, C)print(genis_vt)## sutun A B C
## 1 x 1 2 3
## 2 y 4 5 6Geniş formatta olan bu veri tabanını uzun formata çevirmek için, yani sütunları satırlara taşımak için, tidyr içindeki gather() fonksiyonunu kullanacağız.
gather(genis_vt, referans, yeni_deger, -sutun)## sutun referans yeni_deger
## 1 x A 1
## 2 y A 4
## 3 x B 2
## 4 y B 5
## 5 x C 3
## 6 y C 6Yukarıdaki örnekte geniş formattaki “A”, “B” ve “C” sütunlarındaki bilgiler artık uzun formatta “yeni” olarak tanımladığımız sütunda yer aldı. Böylece referans sütunumuz ile ilişkili ikili veriler yaratmış olduk. gather() fonksiyonunun kullanımını incelediğimizde ilk argüman olarak veri tabanını (genis_vt), sonra referans sütunumuzun ismini (referans), sonra bu sütuna bağlı yeni değer sütununu (yeni deger) ve son olarak yeni tabloda istemediğimiz sütunu/değişkeni (sutun) tanımladığımızı görürüz.
İkinci olarak spread() fonksiyonunu kullanarak uzun formattaki veriyi geniş formata çevirelim. Bu fonksiyonun kullanımı gather() fonksiyonuna benzer: ilk argüman olarak veri tabanını (uzun_vt), sonra referans değeri taşıyan sütun ismini(referans) ve en son olarak değerleri içeren sütunu (yeni_deger) fonksiyona eklememiz gerekir
spread(uzun_vt, referans, yeni_deger)## sutun A B C
## 1 x 1 2 3
## 2 y 4 5 6Kimi zamanlarda bazı sütunlar/değişkenler iki ayrı bilgiyi aynı anda sunuyor olabilir. İki farklı tedavi çeşidini farklı hastalar üzerinde farklı tarihlerde deneyen bir doktorun tuttuğu veriye bir göz atalım:
doktor## hasta tedavi yil_ay sonuc
## 1 X A 2010-5 1
## 2 Y B 2010-7 2
## 3 X C 2012-5 4
## 4 Y A 2012-8 6
## 5 X B 2014-7 8
## 6 Y C 2014-4 9Görüldüğü üzere veri tabanı “yil_ay” değişkeni içerisinde tedavinin yılını ve ayını aynı sütunda kodlamış. Bu iki bilgiyi ayırmak için tidyr içindeki seperate() (ayır) fonksyonu kullanılır. Fonksiyonun argümanları, veri tabanının adını (doktor), ayrıştırılacak sütunun adını (yil_ay) ve yeni sütunların isimlerini içerir.
doktor_a <- separate(doktor, yil_ay, c("yil", "ay"))
doktor_a## hasta tedavi yil ay sonuc
## 1 X A 2010 5 1
## 2 Y B 2010 7 2
## 3 X C 2012 5 4
## 4 Y A 2012 8 6
## 5 X B 2014 7 8
## 6 Y C 2014 4 9Kimi zaman ise farklı değişkenleri birleştirmek isteyebiliriz. Bu durumda kullanacağımız fonksiyon aynı paketteki unite() (birleştir) fonksiyonudur. Argümanları ise sırasıyla veri tabanı ismi, yeni birleşik sütun ismi, birleştirilecek sütunların ismi olarak tanımlanır.
doktor_b <- unite(doktor_a, yil_ay, yil, ay)
doktor_b## hasta tedavi yil_ay sonuc
## 1 X A 2010_5 1
## 2 Y B 2010_7 2
## 3 X C 2012_5 4
## 4 Y A 2012_8 6
## 5 X B 2014_7 8
## 6 Y C 2014_4 9Verinin düzensiz halde olmasına bir başka örnek ise değişkenlerin hem sütunlarda hem de satırlarda aynı anda kaydedildiği veri tabanlarında görülür. Aşağıdaki veriyi inceleyin
evcil## isim evcil_hayvan adet
## 1 Can Kedi 1
## 2 Can Köpek 1
## 3 Can Kus 2
## 4 Cem Kedi 1
## 5 Cem Köpek 1
## 6 Cem Kus 4
## 7 Ela Kedi 2
## 8 Ela Köpek 1
## 9 Ela Kus 3Gelin bu veri tabanını evcil_hayvan değişikenindeki kategorileri ayrı değişkenler olarak tanımlayıp tekrar düzenleyelim.
evcil_yeni <- spread(evcil, evcil_hayvan, adet)
evcil_yeni## isim Kedi Köpek Kus
## 1 Can 1 1 2
## 2 Cem 1 1 4
## 3 Ela 2 1 3Yukarıdaki kodda spread() fonksiyonun aldığı üç argümana dikkat ediniz. Kodda ilk argüman veri tabanı, ikinci argüman sütunlara ayırmak istediğimiz değişkenin adı (evcil_hayvan) ve üçüncü argüman da bu yeni sütunun alacağı değerleri barındıran değişken (adet) olarak tanımlandı.
7.3 Verinin Analiz İçin Hazırlanması
Yukarıdaki iki aşama tamamlandıktan sonra veri temizliği için son aşama olan verinin analiz için hazırlanması aşamasına geçilebilir. Verinin analizi öncelikli olarak analizde kullanılacak değişken tiplerinin saptanmasını ve gerekiyorsa yeniden düzenlenmesini gerektirir. Değişken tipleri “Temel R” bölümünde ele alınmıştı ama burada tekrar etmekte fayda var.
İlk olarak “karakter” (character) tipinden bahsedelim. Bu tipteki değişkenlerin etrafın da muhakkak “çift tırnak” (“”) işareti bulunur. Çift tırnak içindeki ifade sayı bile olsa R (örneğin “123”, “10.67” gibi) bu değişkeni character değişken olarak algılar. İkinci tip ise “numerik” (numeric) değişkenlerdir. Bu değişkenler sayı ile ifade edilirler ve ondalıklı olabilirler. Üçüncü tip değişken “tam sayı” (integer) değişkenleridir ve sayının sonunda “L” harfi taşırlar: 1223L veya 3L gibi. Dördüncü tip değişken “mantıksal” (Logical) değişkenlerdir ve daha önce de çokça gördüğümüz gibi “TRUE”, “FALSE” ve kayıp veri anlamına gelen “NA” değerlerini alırlar. Son olarak ise kategorik değişkenler ile çalışırken kullanılan ve factor() komutuyla oluşturulan “faktör” (factor) değişkeninden bahsedebiliriz.
class() fonksiyonu değişkenin tipini anlamak için en sık başvurulan fonksiyondur. Aşağıdaki örneklere göz atalım
class("123")## [1] "character"class("Gençlerbirliği")## [1] "character"class(3.54)## [1] "numeric"class(45L)## [1] "integer"class(factor("Gençlerbirliği"))## [1] "factor"class(NA)## [1] "logical"Analizler için çoğunlukla veri tabanı içindeki sütunlarda ifade edilen değişkenlerin tiplerini değiştirmek zorunda kalırız. Bazı temel örneklere bakalım.
as.character(2018)## [1] "2018"Yukarıdaki as.character()fonksiyonu sayı olan 2018’i character değişken tipine çevirmek için kullanılır. Aşağıda “as.” ile başlayan tüm fonksiyonlar aynı işlevi görür.
as.numeric(TRUE)## [1] 1as.integer(99)## [1] 99as.factor("Gençlerbirliği")## [1] Gençlerbirligi
## Levels: Gençlerbirligias.logical(0)## [1] FALSEYukarıdaki örneklerde hatırlanması gereken en önemli nokta mantıksal değişkenlerin sayı olarak ifade edildiklerinde aldıkları değerlerdir. Bu bağlamda R içerisinde TRUE sayısal olarak 1 değerini alırken, FALSE 0 değerini alır.
Yukarıdaki örnekler dışında R içerisinde tarih (date) ve zaman (time) değişkenleri de kullanılır. Tarih ve zaman kullanımı bu değişkenler çoğunlukla character tipinde saklandığı için veri tabanlarının kullanımlarında çeşitli sorunlar yaratır. Bu sorunları aşmak için lubridate paketini kullanmanızı öneririm. Oldukça geniş kullanıma sahip olan bu paketin en sık kullanılan fonksiyonu ymd() character olarak kaydedilmiş bir değişkeni tarih değişkenine yıl, ay ve gün olarak çevirmeye yarar. Aşağıdaki örnekte iki farklı şekilde ve character tipinde tanımlanmış tarihleri çeviren kodu görebilirsiniz. lubridate paketinin tüm fonksiyonları için lütfen paketin yardım dosyasını inceleyiniz.
ymd("1923 04 14")## [1] "1923-04-14"ymd("1923-04-14")## [1] "1923-04-14"glimpse() fonksiyonu ile yapısına göz attığımız ülkelerdeki kutuplaşma ile ilgili veri tabanına tekrar bir göz atın. Değişken ismini takiben değişkenlerin tiplerinin yazıldığını görebilirsiniz. (“dbl” değişken tipi numeric değişken tipinin başka bir ifadesidir.) Burada ilk sütunda bulunan değişkenin ülkelerin isimlerini character tipi ile kaydettiğini görüyoruz. Aşağıdaki kod bu değişkeni factor değişken haline çevirmektedir. “$” ve “<-” işaretlerinin kullanımına ayrıca dikkat ediniz.
ulkeler$Country <- factor(ulkeler$Country)
levels(ulkeler$Country)## [1] "AUSTRIA" "CROATIA" "CZECH REPUB"
## [4] "DENMARK" "ESTONIA" "FINLAND 2007"
## [7] "FINLAND 2011" "GERMANY 2005" "GERMANY 2009"
## [10] "GREECE" "ICELAND" "IRELAND"
## [13] "LATVIA" "NETHERLANDS 2006" "NETHERLANDS 2010"
## [16] "NEW ZEALAND" "NORWAY" "POLAND"
## [19] "PORTUGAL" "SLOVAKIA" "SLOVENIA"
## [22] "SOUTH AFRIC" "SPAIN" "SWEDEN"
## [25] "SWITZERLAND" "THAILAND" "TURKEY"Veri tabanlarında düzensiz bir şekilde karakter dizisi halinde tanımlanmış değişkenlerin (strings) temizlenmesi de sıkça karşılaşılan bir gerekliliktir. Bu sevimsiz işi stringr paketi mümkün olduğunca kolaylaştırır. Paketin en fazla kullanılan fonksiyonlarından biri olan str_trim() değişken isminde bulunan fazladan karakterleri silmeye yarar. Aynı paketteki str_pad() ise değişkenlerin sağ veya sol tarafına karakter eklenmesi için kullanılır.
str_trim(" Gençlerbirliği ")## [1] "Gençlerbirligi"str_pad("4578", width = 6, side = "left", pad="9")## [1] "994578"Herhangi bir vektörün içinde herhangi bir “string”in bulunup bulunmadığını anlamak için aynı paketteki str_detect() fonksiyonu kullanılır. Benzer bir şekilde bir vektörün içinde bulunan bir string başka bir string ile str_replace() ile değiştirilebilir. Fonksiyonun sonuçlarını ve argümanlarının kullanımını inceleyip anlamaya çalışınız.
takimlar <- c("Genclerbirligi", "Ankaragucu", "Besiktas")
str_detect(takimlar, "Besiktas")## [1] FALSE FALSE TRUEstr_replace(takimlar, "Besiktas", "Hacettepe")## [1] "Genclerbirligi" "Ankaragucu" "Hacettepe"stringr paketi dışında R ile beraber gelen temel paketteki bazı komutlar da string değişkenlerinin düzenlenmesi için sıkça kullanılır. Örneğin tolower() string içindeki tüm karakterleri küçük harf haline çevirirken, toupper() büyük harf haline çevirir.
Bir veri tabanında veri temizliği sırasında dikkat edilmesi gereken bir diğer konu ise “kayıp veri”dir (missing data). R kayıp veriyi “NA” ile gösterir. Ancak veri tabanını SPSS gibi başka bir yazılımdan aktarmışsak, bu yazılımların kayıp veri için kullandıkları ifadeleri de kontrol etmeliyiz. Bir veri tabanındaki kayıp verinin miktarının ve nerede olduğunun bulunması analiz için kritik olabilir. Örneğin araştırmacı kayıp verinin bulunduğu gözlemleri saptayıp analizin dışında bırakmak isteyebilir. Bu durumda tüm veri tabanının çıplak gözle izlenip kayıp verinin bulunması işlemi mümkün olmaz. Aşağıdaki kod içinde kayıp veri bulunan 4x3 lük basit bir veri tabanı yaratıp, bu veri tabanını bazı fonksiyonlar kullanarak kayıp veri açısından incelemektedir.
vt <- data.frame( A = c(1, NA, 8, NA),
B = c(3, NA, 88, 23),
C = c(2, 45, 3, 1)) summary(vt)## A B C
## Min. :1.00 Min. : 3.0 Min. : 1.0
## 1st Qu.:2.75 1st Qu.:13.0 1st Qu.: 1.8
## Median :4.50 Median :23.0 Median : 2.5
## Mean :4.50 Mean :38.0 Mean :12.8
## 3rd Qu.:6.25 3rd Qu.:55.5 3rd Qu.:13.5
## Max. :8.00 Max. :88.0 Max. :45.0
## NA's :2 NA's :1Daha önce de kullandığımız summary() fonksiyonu NA avcılığı için çok kullanışlıdır. Gördüğünüz gibi küçük veri tabanımızdaki NA lar summary() fonksiyonu ile her bir değişken için en alt satırda raporlandı: Buna göre A değişkeninde 2, B değişkeninde 1 adet kayıp veri bulunurken C değişkeninde hiç kayıp veri bulunmamaktadır. Eğer NA değerlerini içeren gözlemleri analizinizden çıkartarak işlem yapmak isterseniz na.omit() fonksiyonunu kullanabilirsiniz.
na.omit(vt)## A B C
## 1 1 3 2
## 3 8 88 3Görüldüğü üzere na.omit() ile vt veri tabanında NA içeren 2. ve 4. gözlemler ayıklanmış oldu.
Analiz için veri temizliği hakkında değinilmesi gereken son nokta “uç değerler”in (outliers) saptanması ve gerekiyorsa ayıklanması hususudur. Uç değerlerin değişkenlerin dağılımının içinde bulunması nadiren normal olarak değerlendirilir. Eğer uç değerler bir değişken için hatalı olarak kaydedilmişse/kodlanmışsa bu değişkenin uç değerlerden ayıklanmadan analizi de hatalı sonuç üretecektir. Örneğin cevaplayıcıların yaşını kaydeden değişkende “250” veya “-1” gibi bir değer varsa bellidir ki bu değer hatalı olarak kodlanmıştır. Bazı uç değerleri içeren aşağıdaki veri tabanı üzerinde çeşitli fonksiyonları kullanarak uç değer avına çıkalım.
vt2 <- data.frame(A = rnorm(100, 50, 10),
B = c(rnorm(99, 50, 10), 500),
C = c(rnorm(99, 50, 10), -1))
summary(vt2)## A B C
## Min. :27.4 Min. : 21 Min. :-1.0
## 1st Qu.:45.3 1st Qu.: 41 1st Qu.:42.7
## Median :51.0 Median : 48 Median :50.3
## Mean :50.6 Mean : 52 Mean :49.5
## 3rd Qu.:57.3 3rd Qu.: 54 3rd Qu.:56.9
## Max. :74.0 Max. :500 Max. :75.5summary() fonksiyonu ile ortaya çıkan raporda görebiliyoruz ki B değişkenine ait bir “500” değeri ve C değişkenine ait bir “-1” değeri bulunuyor. Bu noktada bu değerlerin uç değer olup olmadığını söylemek mümkün olmasa da şüpheleri ortadan kaldırmak için diğer bazı fonksiyonları, örneğin basit görselleştirme fonksiyonlarını kullanalım.
hist(vt2$B)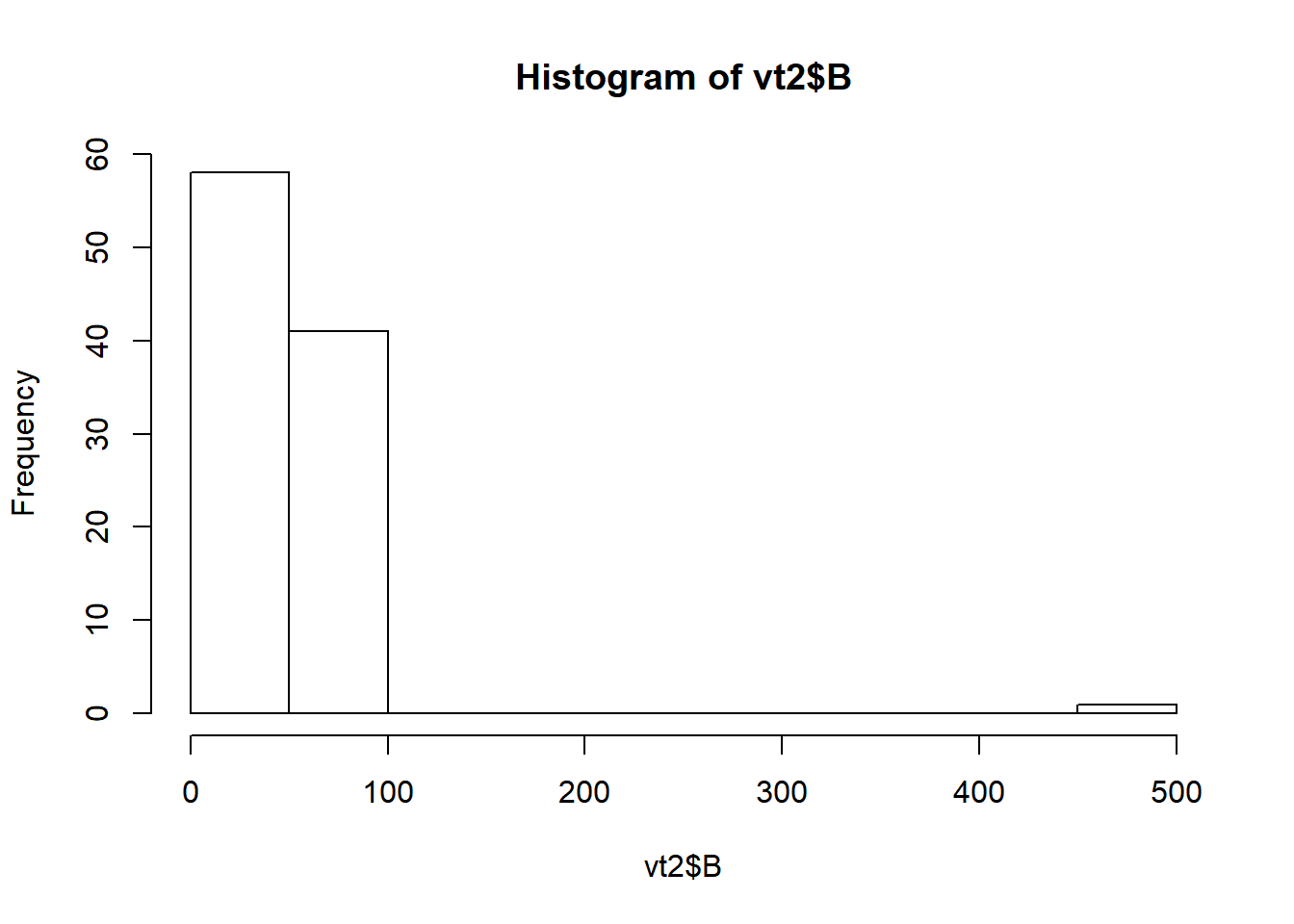
Veri tabanındaki B sütunu için çizdiğimiz bu grafik ile bu değişkene ait değerlerin çoğunun 100’ün altında olduğunu 500 değerinin ise dağılımda kendi başına ayrı bir yerde durduğunu görebiliyoruz. Ancak bu bile 500 değerinin ayıklanması gereken bir uç değer olup olmadığını anlamaya yetmeyebilir. Bu noktada geri dönüp B değişkeni için 500 değerinin olası bir değer olup olmadığını sorgulamak ve bu sorgulamaya göre karar vermek en doğrusu olacaktır.
https://www.nytimes.com/2014/08/18/technology/for-big-data-scientists-hurdle-to-insights-is-janitor-work.html?_r=0↩
Bu dosyaya https://goo.gl/M8jsc7 adresinden ulaşabilirsiniz.↩