Bölüm12 Kelime Torbaları / Bag of Words
Metin madenciliğinin bir çok tanımı olmasına rağmen, herhangi bir metin dosyasından öngörü üretmek amacı ile yapılan her türlü süzme/damıtma işlemi metin madenciliği olarak nitelendirilebilir.
Her türlü metin madenciliği için belirli bir iş akış şeması bulunur. Bu akış 6 ana maddeden oluşur: 1. Araştırma sorusunun ortaya konması. 2. Toplanacak metin belirlenmesi 3. Toplanan metnin amaca yönelik olarak düzenlenmesi. 4. Metin üzerinde süzme/damıtma işlemlerinin yapılması 5. Analizler 6. Sonuçlar ve öngörülerin raporlanması.
Anlaşılacağı üzere aslında bu adımlar aslında araştırma sorusu kullanılarak, metni düzensiz yapısından düzenli yapıya çevirmek olarak özetlenebilir. Aşağıdaki görsel bu süreçleri özetlemektedir.
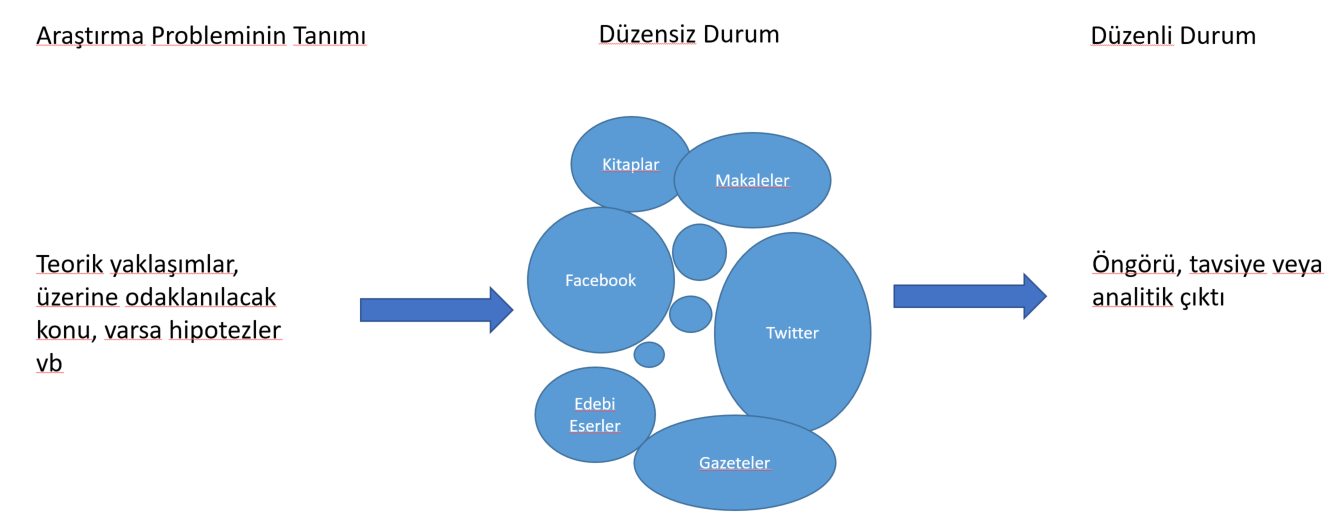
Metin Madenciliği İş Akışı
Günümüzde metin madenciliği “anlamsal/semantik işleme” ve “kelime torbalarının işlenmesi” olarak adlandırılabilecek iki temel yaklaşım üzerinden yapılmaktadır. Semantik işlemede kelimelerin türü ve sırasına önem verilir. Cümleler ağaç dallarına benzer şekilde kelime grupları ve kelimeler halinde alt kısımlara ayrılır ve incelenir. Bu bölümün konusu olan kelime torbaları yaklaşımında ise kelimelerin türü ve sırası önemli değildir, her bir kelime ayrı bir nesne olarak incelenir.
Bir metinde en fazla kullanılan kelimeleri ortaya koyan ilk örneğimize geçelim. Kelime frekansları bir metni anlayabilmek için bize fikir verebilir. Bu işlem için qdap paketinde bulunan freq_terms() fonksiyonunu kullanacağız. İlk başta bir metin adı ile bir metin dosyası yaratalım. Takiben qdap paketini ve ilgili fonksiyonu metinde en fazla tekrar eden 3 kelimeyi bulmak için kullanalım. Aşağıdaki kodu inceleyiniz.
library(qdap)
metin <- "Süper Lig’in eski ve başarılı takımlarından biri olan
Gençlerbirliği, tarihi epey geçmiş yıllara uzanan, yaşayan tarih
niteliğinde spor kulüplerimizden biridir. Ankara ekibidir. Evet
diğer branşları da mevcuttur, yani gerçek anlamda bir spor kulübüdür.
Ama herkes onu futbol branşıyla daha çok tanıdığı için Gençlerbirliği
dendiği zaman akla hemen yeşil sahalar gelmektedir. Süper Lig tarihinde
üçüncülük elde edebilmiş ve dengi kulüplere göre UEFA Kupası’nda çok
önemli aşamalara gelmiş olan Gençlerbirliği, isminin farklılığıyla da
dikkat çeken bir Anadolu kulübüdür. Genelde “….spor” takısı hiç eksik
olmaz biliyorsunuz..Şimdi de Gençlerbirliği’nin kaç yılında nasıl
kurulduğuna kısaca bir göz atalım"
kelimeler <- freq_terms(metin, 3)
plot(kelimeler)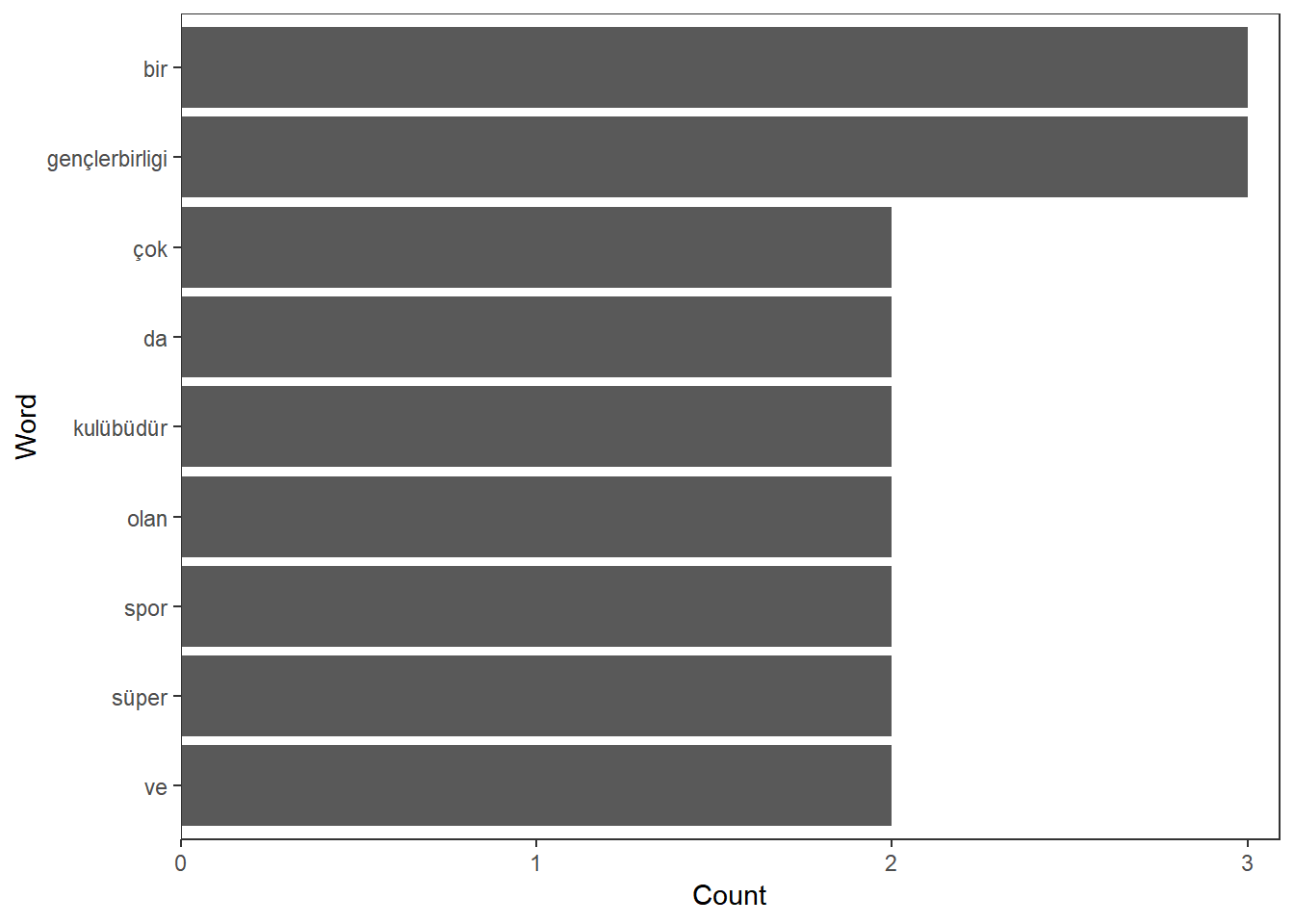
Görüldüğü gibi kodumuz metin içerisinde en fazla tekrar eden kelimeleri ortaya çıkardı. Bu ufak metinden bile Gençlerbirliği hakkında yeterli bilgi sahibi oluyoruz!
12.1 Vcorpus ile corpus hazırlama
Şimdi gelin metin madenciliğinde kullanmak üzere bir “kitaplık/corpus” yaratalım. Corpus terimini farklı metinlerden bir araya gelmiş büyük bir meta metin olarak düşünebilirsiniz. Elimizde Twitter’da kahve hastaginden toplanmış 500 gözlemli bir veri seti bulunuyor. Bu veri tabanına bir göz atalım
## 'data.frame': 500 obs. of 16 variables:
## $ text : chr "Where to next? . . . #travel #coffee #wanderlust #travelgram #travelstories #humpday #pictureoftheday" "Coffeeeee....!!! . . #madrid #coffee #morning #goodvibes #riu #producer #film #filmmaker #shooting #life #love" "RT @HoneybeeCoffee1: #WIN a Coffee Hamper with a selection of 8 varieties of our delicious fresh #coffee + 2 ha"| __truncated__ "The secret to a great cappuccino.#barista #cappuccino #baristalife #coffee #friends #centralperksg @FriendsTV" ...
## $ favorited : logi FALSE FALSE FALSE FALSE FALSE FALSE ...
## $ favoriteCount: num 0 0 0 0 0 0 0 0 0 1 ...
## $ replyToSN : chr NA NA NA NA ...
## $ created : POSIXct, format: "2018-02-07 09:07:55" "2018-02-07 09:07:42" ...
## $ truncated : logi TRUE TRUE FALSE TRUE TRUE FALSE ...
## $ replyToSID : chr NA NA NA NA ...
## $ id : chr "961164611931254785" "961164557346660354" "961164463641636864" "961164175702740997" ...
## $ replyToUID : chr NA NA NA NA ...
## $ statusSource : chr "<a href=\"https://ifttt.com\" rel=\"nofollow\">IFTTT</a>" "<a href=\"http://twitter.com/download/iphone\" rel=\"nofollow\">Twitter for iPhone</a>" "<a href=\"http://twitter.com/download/android\" rel=\"nofollow\">Twitter for Android</a>" "<a href=\"http://twitter.com\" rel=\"nofollow\">Twitter Web Client</a>" ...
## $ screenName : chr "SChristidouCom" "Shakirarodrigo" "RebeccaNdaisy" "centralperksg" ...
## $ retweetCount : num 0 0 157 0 0 0 3 0 1 0 ...
## $ isRetweet : logi FALSE FALSE TRUE FALSE FALSE FALSE ...
## $ retweeted : logi FALSE FALSE FALSE FALSE FALSE FALSE ...
## $ longitude : chr NA NA NA NA ...
## $ latitude : chr NA NA NA NA ...Gördüğünüz gibi kahve veri tabanımızda istediğimiz metin dışında diğer değişkenler de bulunuyor. Öncelikli olarak, “text” sütunu altında toplanmış metin kısmını bu veri tabanından bir vektör halinde ayrıştıralım. Aşağıdaki kodu inceleyiniz.
kahve.metin <- kahve.df$textOluşturduğumuz bu vektördeki ilk tweet metnine bir göz atalım
head(kahve.metin, 1)## [1] "Where to next? . . . #travel #coffee #wanderlust #travelgram #travelstories #humpday #pictureoftheday"Şimdi bu metni incelenecek bir corpus haline getirmek için tm() paketinin VectorSource() ve VCorpus fonksiyonlarını kullanacağız.
library(tm)
kahve.kaynak <- VectorSource(kahve.metin)
kahve.corpus <- VCorpus(kahve.kaynak)VCorpus nesnesini aslında bir iç içe geçmiş listeler olarak düşünebiliriz. Bu iç içe geçmiş listede esas incelemek istediğimiz metin ve bu metine ait metadata bulunur. Yapı bu olunca subset işleminin iki defa yapılması gerekir. Aşağıdaki örnek kod corpusumuzu, corpusdaki 15. tweeti ve bu tweet içinde bulunan metni ortaya çıkarıyor.
# kahve.corpusu çağıralım
kahve.corpus## <<VCorpus>>
## Metadata: corpus specific: 0, document level (indexed): 0
## Content: documents: 500# kahve.corpus içindeki 15. tweeti çağıralım
kahve.corpus[[15]]## <<PlainTextDocument>>
## Metadata: 7
## Content: chars: 135# kahve.corpus içindeki 15. tweetin metnine bakalım
kahve.corpus[[15]][1]## $content
## [1] "RT @RHensleigh: Don't you just fancy a lovely hot #coffee? Well our coffee shop is open 7 days a week from 9am-4pm So whenever you feel"tm paketindeki DataframeSource() fonksiyonu ile elinizde bulunan herhangi bir veri tabanında içerik olarak kodlanmış metinleri de corpus haline çevirebiliriz. Ancak DataframeSource() fonksiyonu belirli bir format gerektirir. Buna göre 1. Veri tabanını birinci sütunun adı doc_id olmalı ve her satır için ayrı bir sayı içermeli 2. Veri tabanının ikinci sütununun adı text olmalı ve encoding olarak UTF-8 kullanmalı (çoğunlukla bu encoding kullanılır) 3. Veri tabanının üçüncü ve sonraki sütunları metadata olarak kullanılmalı
Örnek için önce verimizi yaratalım
doc_id <- c(1,2,3)
text <- c("Kırmızı kara burası Ankara",
"Burası Ankara buradan çıkış yok",
"Ankara'nın bağları büklüm büklüm yolları")
tezahurat <- c("Evet", "Evet", "Hayır")
metin.veri <- data.frame(doc_id, text, tezahurat)Şimdi yukarıdaki yöntem ile corpusumuzu yaratalım
# DataframeSource ile kaynak yaratalım
data.kaynak <- DataframeSource(metin.veri)
# Kaynağı VCorpus ile corpus haline çevirelim
data.gb.corpus<- VCorpus(data.kaynak)
# Corpus a göz atalım
data.gb.corpus## <<VCorpus>>
## Metadata: corpus specific: 0, document level (indexed): 1
## Content: documents: 3# Corpusun ikinci elemanının içeriğine bakalım
data.gb.corpus[[2]][1]## $content
## [1] "Burasi Ankara buradan çikis yok"12.2 Metin Temizliği
Corpusumuzu yaratmış olmamıza rağmen, bu corpusu kullanabilmemiz için üzerinde bir dizi metin temizliği uygulaması yapılması gerekir. Farkettiğiniz gibi Twitter kullanarak oluşturduğumuz kahve.corpus objesi içindeki metin bir dizi okunmaz karakter içeriyor. Bu ve bazı diğer temizlik işlemleri için temel R, qdap ve tm paketlerinde bulunan bir dizi fonksiyonu kullanacağız.
tolower()tüm karakterleri küçük harf haline getirir.removePunctuation()tüm noktalama işaretlerini yok ederremoveNumbers()metin içindeki sayıları yok eder- `
stripWhitespace()fazladan boşlukları kaldırır.
Örnek olarak ilk başta temizleyeceğimiz metni hazırlayalım
pis.metin <- "<b>Erken</b> kalkmıştı, saat ekranı
4 A.M. gösteriyordu. Gerçekten çok\ erkendi.
Sadece %10 uyanıktı, kendine bir kahve yapmaya karar verdi."Şimdi bazı temizleme fonksiyonlarını kullanalım
options(width = 40)
#tm ile temizlik
# Hepsi küçük harf
tolower(pis.metin)## [1] "<b>erken</b> kalkmisti, saat ekrani\n4 a.m. gösteriyordu. gerçekten çok erkendi.\nsadece %10 uyanikti, kendine bir kahve yapmaya karar verdi."# Noktalamaları kaldır
removePunctuation(pis.metin)## [1] "bErkenb kalkmisti saat ekrani\n4 AM gösteriyordu Gerçekten çok erkendi\nSadece 10 uyanikti kendine bir kahve yapmaya karar verdi"# Sayıları kaldır
removeNumbers(pis.metin)## [1] "<b>Erken</b> kalkmisti, saat ekrani\n A.M. gösteriyordu. Gerçekten çok erkendi.\nSadece % uyanikti, kendine bir kahve yapmaya karar verdi."# Fazladan boşlukları kaldır
stripWhitespace(pis.metin)## [1] "<b>Erken</b> kalkmisti, saat ekrani 4 A.M. gösteriyordu. Gerçekten çok erkendi. Sadece %10 uyanikti, kendine bir kahve yapmaya karar verdi."#qdap ile temizlik
library(qdap)
# Parantez içindeki metni kaldır
bracketX(pis.metin)## [1] "Erken kalkmisti, saat ekrani 4 A.M. gösteriyordu. Gerçekten çok erkendi. Sadece %10 uyanikti, kendine bir kahve yapmaya karar verdi."Sizin de aklınıza gelebileceği gibi bu tür analizlerin işe yaramayan gereksiz/dolgu kelimeleri de içerme tehlikesi bulunur. Metin temizliğinde yapılacak bir diğer iş analizlerde işimize yaramayan bu gereksiz kelimeleri analizden ayıklamak olacaktır. Bir çok zaman gereksiz kelimeler listesine kendimiz kelimeler eklemek zorunda kalabiliriz. Bu işi yapmanın birden fazla yolu bulunuyor. Kullandığımız R paketleri Türkçe için dolgu kelimeleri içermediğinden bu kelimeleri bizim bulup paketin içinde bulunan bir dile -örneğin İngilizce- eklememiz gerekiyor. Bu işlem için aşağıdaki adımları takip ediniz.
- Kitabın dropbox linkinde bulunan “stopwords-tr.txt” dosyasını bilgisayarınıza indiriniz.
- İndirdiğiniz dosyayı herhangi bir metin editörü (Notepad, MS Word vb.) açıp içindekileri kopyalayınız.
- Bilgisayarınızda “english.dat” isimli dosyayı aratarak bulunuz, bulduktan sonra aynı şekilde bir metin editörü (Notepad, MS Word vb.) açınız, kopyaladıklarınızı metnin sonuna yapıştırınız, aynı isim ile kaydediniz.
Bu işlemi gerçekleştirdiğimizde İngilizce ile Türkçe dolgu kelimelerini aynı anda içeren bir dosya yarattığımızdan paketin İngilizce için kullandığı dolgu kelimeler dosyasını Türkçe metinler için de kullanılabilir hale getirmiş olduk. Bu dosyanın içeriğine stopwords("en") komutu ile bakabilirsiniz.
Her ne kadar bu kelimeler sıkça kullanılan dolgu kelimeler olsa da, üzerinde çalıştığınız her proje için fazladan bazı kelimelerin listeye eklenmesi gerekir. Örneğin #kahve için “kahve” kelimesinin çokça görünüyor olması sürpriz olmaz. Dolayısıyla bu kelimeyi analizimizden çıkartmamız uygun olabilir. Bu işlemi gerçekleştiren aşağıdaki kodu inceleyiniz.
# Dolgu kelimelerin ayıklanması
removeWords(pis.metin, stopwords("en"))## [1] "<b>Erken</b> kalkmisti, saat ekrani\n4 A.M. gösteriyordu. Gerçekten çok erkendi.\nSadece %10 uyanikti, kendine bir kahve yapmaya karar verdi."# "Kahve" kelimesinin yeni.dolgu vektörü halinde dolgu
# kelimeler listesine eklenmesi:
yeni.dolgu <- c("kahve", stopwords("en"))
# Yeni liste ile dolgu kelimelerin ayıklanması
removeWords(pis.metin, yeni.dolgu)## [1] "<b>Erken</b> kalkmisti, saat ekrani\n4 A.M. gösteriyordu. Gerçekten çok erkendi.\nSadece %10 uyanikti, kendine bir yapmaya karar verdi."tm paketinin bir diğer önemli özelliği kelimelerin köklerini stemDocument() fonksiyonu ile ayrıştırabilmesidir. Örneğin stemDocument(c("computational", "computer", "computation")) "comput", "comput", "comput" sonucunu üretir. Tüm bu kelimelerin bizim analizimizde “computer” olarak tanımlanmasını sağlayacak kodu aşağıda bulabilirsiniz.
# Computer vektörünü yaratalım
computer <- c("computational", "computerize", "computation")
# Kökünü ayıralım: kok.doc
kok.doc <- stemDocument(computer)
# Tamamlama sözlüğünü yaratalım: comp.soz
comp.soz<- "computer"
# kok tamamlama işlemini yapalım: kok.tamam
kok.tamam<- stemCompletion(kok.doc, comp.soz)
# Sonuca bakalım
kok.tamam## comput computer comput
## "computer" "computer" "computer"tm paketinde bulunan tm_map fonksiyonu temizleme işlemlerini corpus üzerinde uygular. Böylece tek tek kelimeler yerine tüm corpus üzerinde metin düzenlemesi yapmak mümkün olur. Daha önce öğrendiğimiz tüm fonksiyonları içeren kendi yazdığımız bir fonksiyon örneğini aşağıda görebilirsiniz. Lütfen kodu inceleyip nasıl çalıştığını yorumlayınız.
temiz_corpus <- function(corpus){
corpus <- tm_map(corpus, stripWhitespace)
corpus <- tm_map(corpus, removePunctuation)
corpus <- tm_map(corpus, content_transformer(tolower))
corpus <- tm_map(corpus, removeWords, c(stopwords("en"), "coffee"))
return(corpus)
}
#fonksiyonumuzu tweetlerden oluşturduğumuz kahve.corpus üzerinde uygulayalım
temiz.kahve.corpus <- temiz_corpus(kahve.corpus)
#Temizlenmiş formattaki yüzüncü tweet
temiz.kahve.corpus[[100]][1]## $content
## [1] "rt picolounge ever wondered done heres darcie showing lovelounging loungey latteart glossop ht"#Orjinal formdaki yüzüncü tweet
kahve.df$text[100]## [1] "RT @PicoLounge: Ever wondered how it's done? Here's Darcie showing you how #LoveLounging #loungey ##Coffee #LatteArt #Glossop ht"12.3 DTM ve TDM
Temizlenmiş corpusumuzu bir veri matrisi haline getirerek analizimize devam edelim. Bu işlem için iki seçeneğimiz bulunuyor: DTM (Document Term Matrix) veya TDM (Term Document Matrix). DTM seçeneğinde her bir döküman ayrı bir satıra yerleştirilir ve sütunlarda da kelimelerin frekansları bulunur. TDM seçeneğinde ise her bir döküman ayrı bir sütuna yerleştirilir ve satırlarda da kelime frekansları bulunur. DTM seçeneği yazarları birbirleri ile karşılaştırmak veya zaman serisi analizleri için seçilebilir. Bu işlem için tm paketindeki DocumentTermMatrix() fonksiyonunu kullanacağız. Temizlediğimiz #kahve corpusumuzu DTM haline getiren kodu aşağıda bulabilirsiniz.
# Corpusumuzdan dtm yaratalim: kahve.dtm
kahve.dtm <- DocumentTermMatrix(temiz.kahve.corpus)
# kahve.dtm verisine bakalım
kahve.dtm## <<DocumentTermMatrix (documents: 500, terms: 2057)>>
## Non-/sparse entries: 4007/1024493
## Sparsity : 100%
## Maximal term length: 35
## Weighting : term frequency (tf)# kahve.dtm yi normal matirs haline çevirelim: kahve.m
kahve.m <- as.matrix(kahve.dtm)
# kahve.m nin boyutlarına bakalım
dim(kahve.m)## [1] 500 2057# Bir kısmına göz atalım
kahve.m[1:5, 5:10]## Terms
## Docs 127 1633 1st 2012 201718coffee
## 1 0 0 0 0 0
## 2 0 0 0 0 0
## 3 0 0 0 0 0
## 4 0 0 0 0 0
## 5 0 0 0 0 0
## Terms
## Docs 2018
## 1 0
## 2 0
## 3 0
## 4 0
## 5 0Benzer bir işlemi TDM için de yapabiliriz. TDM’nin dil analizleri için tercih edildiğini hatırlatalım. Aşağıdaki kod elimizdeki Twitter verisi ile bir TDM yaratıp bunu matris formatına çeviriyor
# Corpusumuzdan tdm yaratalim: kahve.tdm
kahve.tdm <- TermDocumentMatrix(temiz.kahve.corpus)
# kahve.tdm verisine bakalım
kahve.tdm## <<TermDocumentMatrix (terms: 2057, documents: 500)>>
## Non-/sparse entries: 4007/1024493
## Sparsity : 100%
## Maximal term length: 35
## Weighting : term frequency (tf)# kahve.tdm yi normal matirs haline çevirelim: kahve.m.tdm
kahve.m.tdm <- as.matrix(kahve.tdm)
# Matrisin boyutlarına bakalım
dim(kahve.m.tdm)## [1] 2057 50012.4 Metin Madenciliğinde Görselleştirme
Metin madenciliğinin en önemli bileşkelerinden biri bulgularını farklı şekilde görselleştirebilmesidir. Bu bölümde düzenlediğimiz verilerin farklı görseller ile daha anlaşılır hale getirmeye çalışacağız.
İlk olarak sık kullanılan kelimelerin grafiğini çizmeye çalışalım.
# satır toplamlarını bulalım: satır.toplam.kahve
satır.toplam.kahve <- rowSums(kahve.m.tdm)
# Toplamları büyükten küçüğe sıralıyalım
satır.toplam.kahve <- sort(satır.toplam.kahve, decreasing = TRUE)
# En fazla tekrarlanan 10 kelimeyi bulalım
satır.toplam.kahve[1:10]## morning day good
## 94 30 29
## mug cup work
## 29 27 25
## love now coffeetime
## 24 23 21
## ready
## 20# Sütun grafiğini çizelim
barplot(satır.toplam.kahve[1:10], col = "tan", las = 2)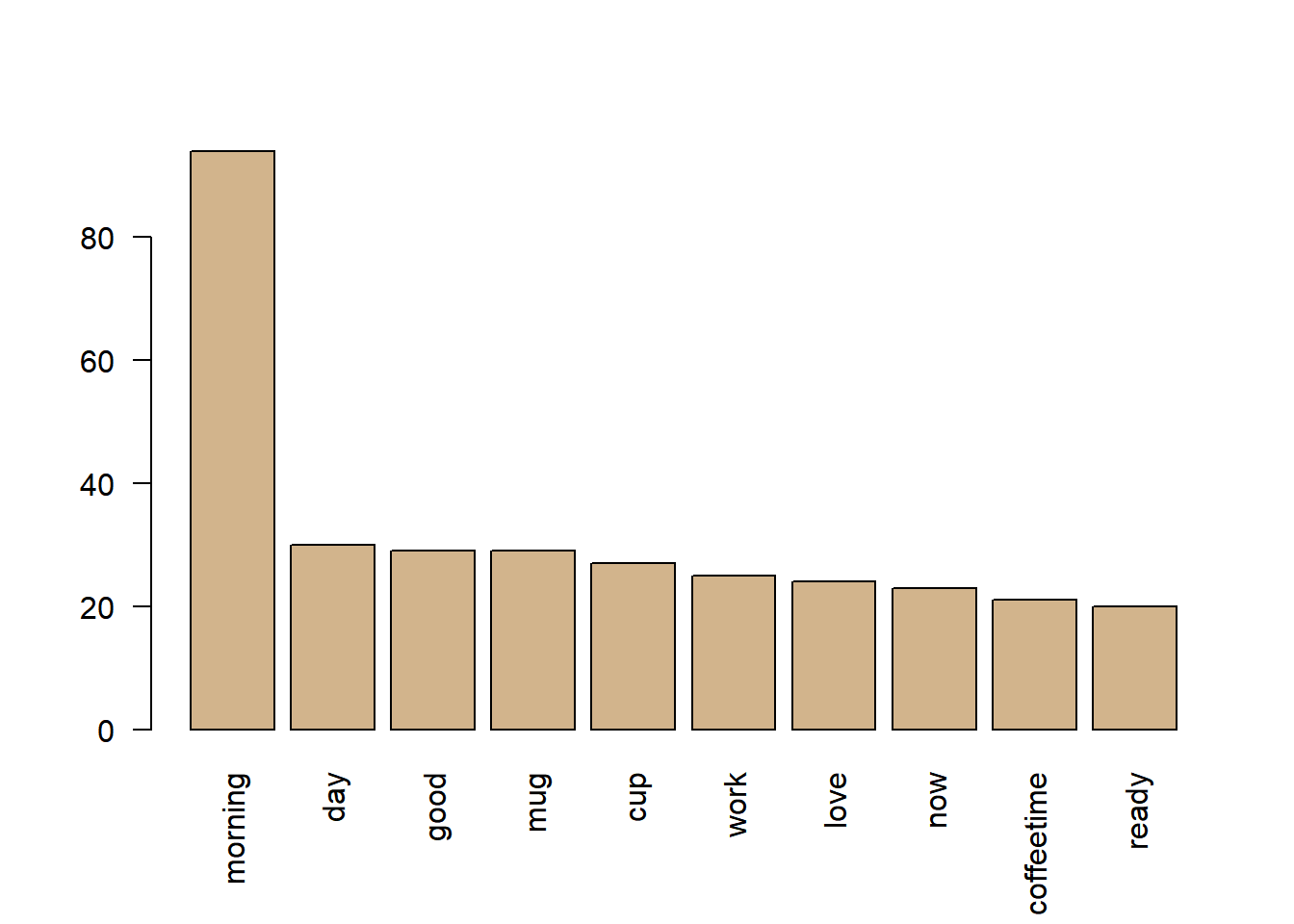
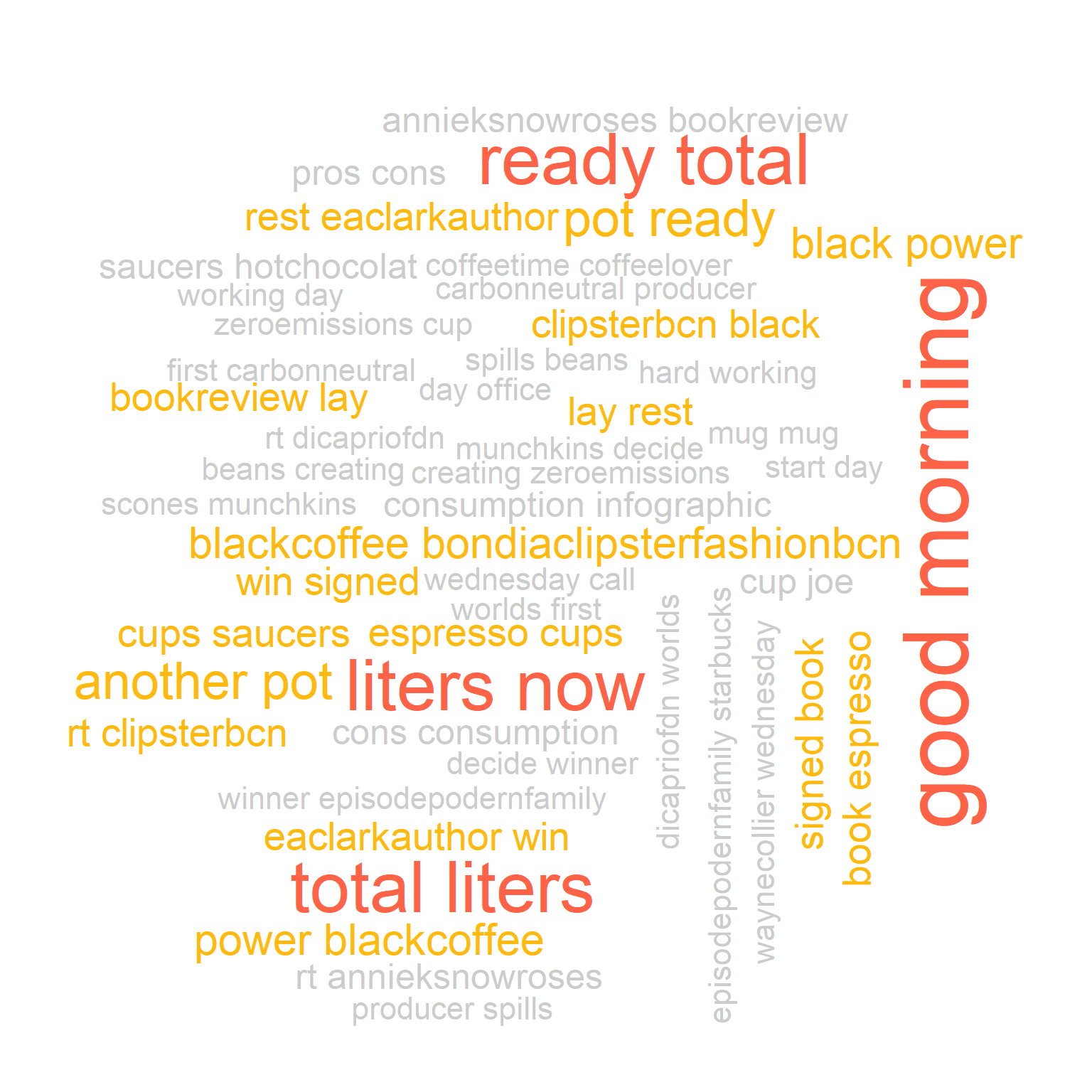
Metin madenciliğinde kelime bulutları sıkça kullanılan bir diğer görselleştirme aracıdır. Metin frekansı ile buluttaki görünüm arasında ilişki kuran bu grafiklere yöntemi sık kullanılmasına rağmen oldukça dikkatli yorumlama gerektirir. Kahve ile ilgili corpusumuzu kullanarak duruma bir göz atalım. Bu iş için worldcloud paketini kullanacağız.
library(wordcloud)
# Kelime frekanslarını yaratalım
kahve.kelime.frekans <- data.frame(term = names(satır.toplam.kahve), num = satır.toplam.kahve )
# kelime frekanslarını kullanarak kelime bulutunu yaratalım
wordcloud(kahve.kelime.frekans$term, kahve.kelime.frekans$num,
max.words = 100, colors = "blue")
wordcloud paketinin colors() fonksiyonu ile kelime bulutumuza makyaj yapabiliriz
# kelime frekanslarını kullanarak kelime bulutunu yaratalım
library(wordcloud)
wordcloud(kahve.kelime.frekans$term, kahve.kelime.frekans$num,
max.words = 100,
colors = c("grey80", "darkgoldenrod1", "tomato"))
Metin madenciliği görsellerinde kelime bulutları yerine kelimelerin birbirleri ile olan ilişkilerini de ortaya koyan metin-ağ grafiklerini kullanmak işlediğimiz metin ile ilgili daha anlamlı sonuçlar doğuracaktır. qdap paketindeki word_associate() fonksiyonu bu grafikleri kolayca oluşturmamızı sağlar. Aşağıdaki koda bir göz atalım
library(qdap)
word_associate(kahve.df$text, match.string = c("mug"),
stopwords = c(Top200Words),
network.plot = TRUE, cloud.colors = c("gray85", "darkred"))## Warning in text2color(words = V(g)
## $label, recode.words = target.words,
## colors = label.colors): length of
## colors should be 1 more than length of
## recode.words## row group unit text
## 1 3 all 3 RT @HoneybeeCoffee1: #WIN a Coffee Hamper with a selection of 8 varieties of our delicious fresh #coffee + 2 hand painted coffee mugs! To
## 2 5 all 5 #WIN a Coffee Hamper with a selection of 8 varieties of our delicious fresh #coffee + 2 hand painted coffee mugs!
## 3 13 all 13 RT @TypeDrawn: Get shit done mug #mug #startup #motivation #coffee #hustle #garyvee
## 4 26 all 26 #coffeelover hands free coffee mug carriers shoulder strap #coffee #tea #onthego #starbucks #costa #tealover #hydrate #drink
## 5 50 all 50 Adventure in life is good, consistency in coffee even better. #coffee #cafe #caffeine #hot #mug #drink
## 6 78 all 78 BLUE PATTERNvia @redbubble #mug #coffee #tea #caf #th #blue #bleu #motifs #geometric #abstract #redbubble
## 7 84 all 84 New Stock of TNT Coffee & Grab an MJs Mug #coffee #cuppa #mug #morning #tnt #tntcoffee #gym #mjsgym #tewkesbury
## 8 175 all 175 Morning coffee in my muggle mug. #morning #coffee #muggle #mug #Harrypotter #gay #Gaylife
## 9 176 all 176 Drink your morning coffee in style from one of our beautifully crafted, Soho mugs Which design is your favourite?
## 10 219 all 219 Do you collect coffee mugs? We have over 600 different designs for coffee cups. And they make great gifts. Take a l
## 11 289 all 289 RT @winewankers: Our sort of #coffee mug! #wine
## 12 320 all 320 #Lecce Italian Coffee Mug. via @zazzle #Italy #Coffee #Gifts
## 13 321 all 321 Check out what I found. Art Deco mugs By Chris Rogers a pair via @eBay_UK #tea #breakfast
## 14 366 all 366 RT @zarraL3: @ScottyPsBigMug COFFEE at 5am an early start to the day @ScottGPatterson#DesperateHousewife #Coffee h
## 15 384 all 384 RT @Brdmeadowdesign: Cream and black vertical stripes' Mug by broadmeadow#homedecor #kitchen #Coffee #87RT
## 16 395 all 395 On Sale in my eBay Store - #Coffee Mug Monogram Brand High Grade Coffee Logo #Decorative #Collectible #Vintage
## 17 399 all 399 There's a chance this is whiskey mug #mug #gift #coffee #funny
## 18 400 all 400 This is a designer mug #design #mug #coffee
## 19 401 all 401 Fuck off, hi mug #mug #coffee #fuck
## 20 402 all 402 Fuck off, hi mug #mug #coffee #fuck
## 21 403 all 403 Create something today Mug #mug #coffee #creative #art #design
## 22 404 all 404 This is a designer mug #design #mug #coffee
## 23 411 all 411 #Starbucks #coffee 12 fl oz #porcelain #mug Microwave Dishwa #sale
## 24 454 all 454 RT @kcscloset14ebay: Check out Roscher Large #coffee Mug You're Amazing White Red Black New Valentines DayGift #ValentinesDay2018
## 25 462 all 462 RT @winewankers: Our sort of #coffee mug! #wine
## 26 470 all 470 But first #coffee from my beloved #Batman #coffeemug on #CastleMickinik #Beard #Ahmidudestyle
## 27 495 all 495 [SALE] Cancer Zodiac Birth Sign Graphic #coffee #mug #porcelain 12 visit our ebay store# Add title
title(main = "Kahve ve Fincan")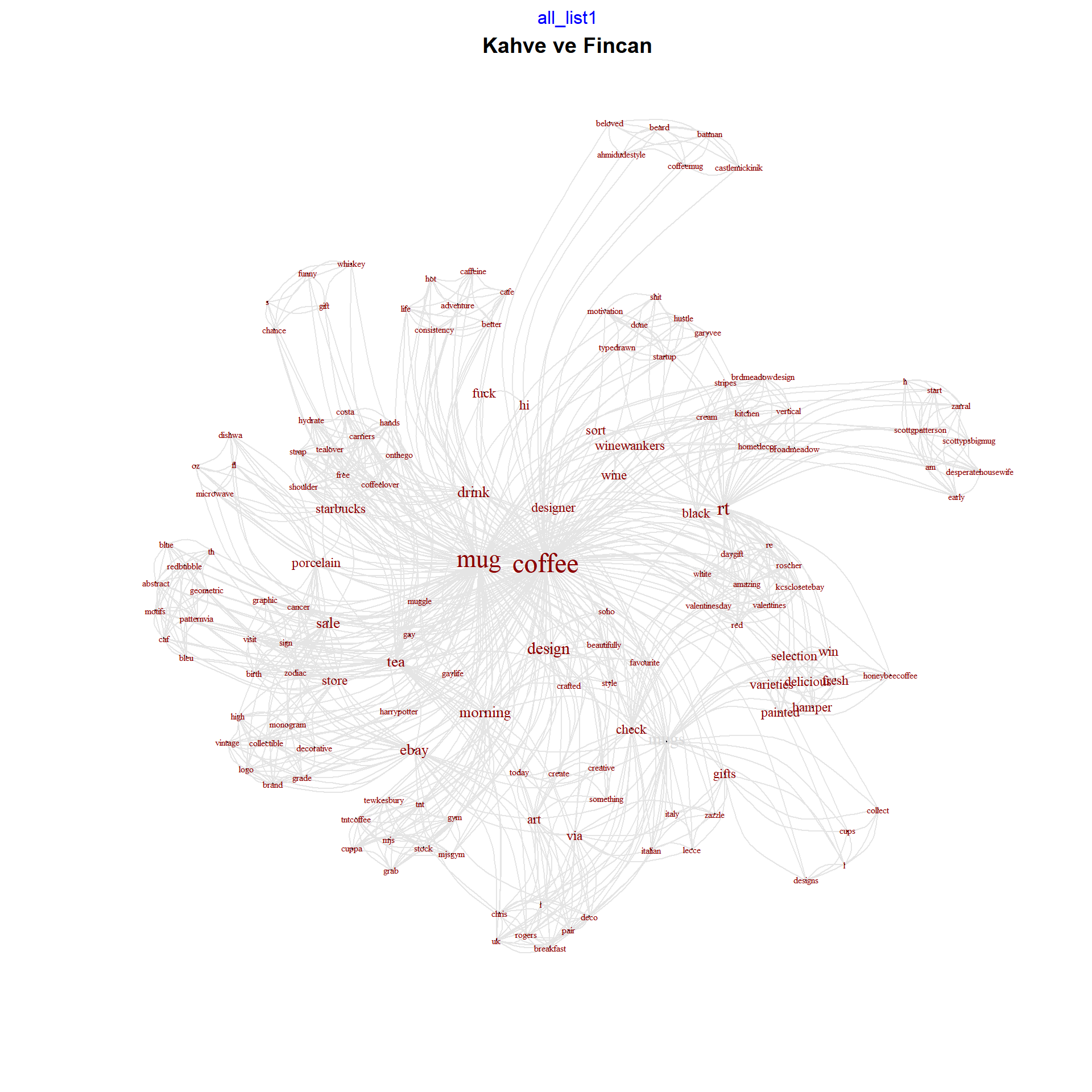
12.5 Kelime Kümeleri / Word Clustering
Metin madenciliğinde kelime kümeleri uzaklık matrisleri ile hesaplanıp dendogramlar ile görselleştirilir. Bu hesaplamalar için ise daha önceden oluşturduğumuz term-document-matrix (TDM) dosyaları kullanılır. TDM verisi elinizde olduğunda matristeki her satırın birbirinden uzaklığını stats paketinde bulunan dist() fonksiyonu ile hesaplayabiliriz. Buradaki kelimelerin birbirlerine uzaklığı/yakınlığı coğrafi uzaklık olarak düşünebiliriz. Nasıl ki birbirine yakın coğrafi bölgeler benzer özellikleri paylaşması açısından gruplanabilir, kelime gruplarında da aynı mantık ile gruplanması sonucunda dendogramlar oluşur. Uzaklıkların hesabından sonra gene stats paketindeki hclust() fonksiyonu kullanılarak kümeleme analizi gerçekleştirilir. Son olarak da sonuçlar görselleştirilir.
Aşağıdaki basit örneğe bir göz atalım: Bu veri setinde 4 ilimizin aldıkları 3 aylık yağış miktarları raporlanmış. Aldığı yağış miktarına göre şehirleri kümeleyen kodu aşağıda bulabilirsiniz.
#Şehirlerin aldıkları yağışları içeren ufak bir veri tabanı yaratalım
şehir <- c("Ankara", "Eskişehir", "Artvin", "Mersin")
miktar <- c(39,39,72,18)
yagis <- data.frame(şehir, miktar)
# yağış miktarlarındaki farklılıkları hesaplayalım
yagis.fark <- dist(yagis[, 2])
# oluşan matrise bakalım
yagis.fark## 1 2 3
## 2 0
## 3 33 33
## 4 21 21 54# Kümelemeyi yapalım
kumeleme <- hclust(yagis.fark)
# Sonucu görselleştirelim
plot(kumeleme, labels = yagis$şehir)
Yukarıdaki mantık dahilinde elimizdeki TDM’yi kullanarak kahve tweetleri ile ilgili dendogramımızı yaratalım. Bu iş için öncelikle TDM içinde bulunan kelimeleri sınırlamamız gerekir. Sizlerin de farkedebileceği gibi DTM ve TDM ler çoğunlukla “0” değeri içeren hücrelerden oluşmaktadır. Bunun sebebi her kelimenin her dökümanda kullanılmıyor olmasıdır. Bu da dendogramların çok parçalı hale gelmesine yol açar. TDM üzerindeki seyrekleştirme işi (sparse) tm paketindeki removeSparseTerms() fonksiyonu ile yapılır. Önerilen TDM içerisinde 25 ila 70 terim bulunmasıdır. Fonksiyondaki sparse() argümanını 1 değerine yaklaştırdığımızda terim sayısı azalır, aksine 0 değerine yaklaştırdığımızda elimizdeki terim sayısı artar. Buradaki karar araştırma sorusu doğrultusunda verilir. Aşağıdaki kodda bu işlem yapılmaktadır.
library(tm)
# kahve_tdm nin boyutlarına bakalım
dim(kahve.tdm)## [1] 2057 500# Birinci seyrekleştirme işlemi
kahve.tdm1 <- removeSparseTerms(kahve.tdm, sparse = 0.95)
# İkinici seyrekleştirme işlemi
kahve.tdm2 <- removeSparseTerms(kahve.tdm, sparse = 0.98)
# Print tdm1
kahve.tdm1## <<TermDocumentMatrix (terms: 4, documents: 500)>>
## Non-/sparse entries: 169/1831
## Sparsity : 92%
## Maximal term length: 7
## Weighting : term frequency (tf)# Print tdm2
kahve.tdm2## <<TermDocumentMatrix (terms: 39, documents: 500)>>
## Non-/sparse entries: 690/18810
## Sparsity : 96%
## Maximal term length: 11
## Weighting : term frequency (tf)İki farklı sparse() değerinin yarattığı farklı sonuçlara dikkat ediniz: Birinci işlemde sadece 4 terim oluşurken ikinci işlemde 39 terim oluştu.
Şimdi dendogramımızı oluşturabiliriz. Bu noktada oluşan endogami yorumlama açısından bazı noktalara dikkat edilmesi gerektiğini tekrar hatırlatmak gerekir. Dendogramlar size bazı ipuçları verse de tüm hikayeyi anlamak açısından yetersizdir, hatta kimi zaman yanlış yönlendirici bile olabilir. Bu yüzden oluşan kümeleri dikkatle incelemeli, araştırma soruları ve teori ile uyumu sürekli denetlenmelidir. Dendogramı oluşturmak için kullanacağımız dist() fonksiyonu için ilk başta TDM’yi önce bir matris haline ve takiben bir veri tabanı haline çevirmemiz gerekir. Aşağıdaki kod yukarıda hazırladığımız 39 terim içeren TDM üzerinden bu işlemleri gerçekleştirmektedir.
# matrisi oluşturalım
kahve.tdm.m <- as.matrix(kahve.tdm2)
# veri tabanını oluşturalım
kahve.tdm.vt <- as.data.frame(kahve.tdm.m)
# kelimeler arası mesafeleri hesaplayalım
kahve.mesafe <- dist(kahve.tdm.vt)
# Kümeleme işlemini yapalım
kahve.kume <- hclust(kahve.mesafe)
# Dendogramı çizelim
plot(kahve.kume)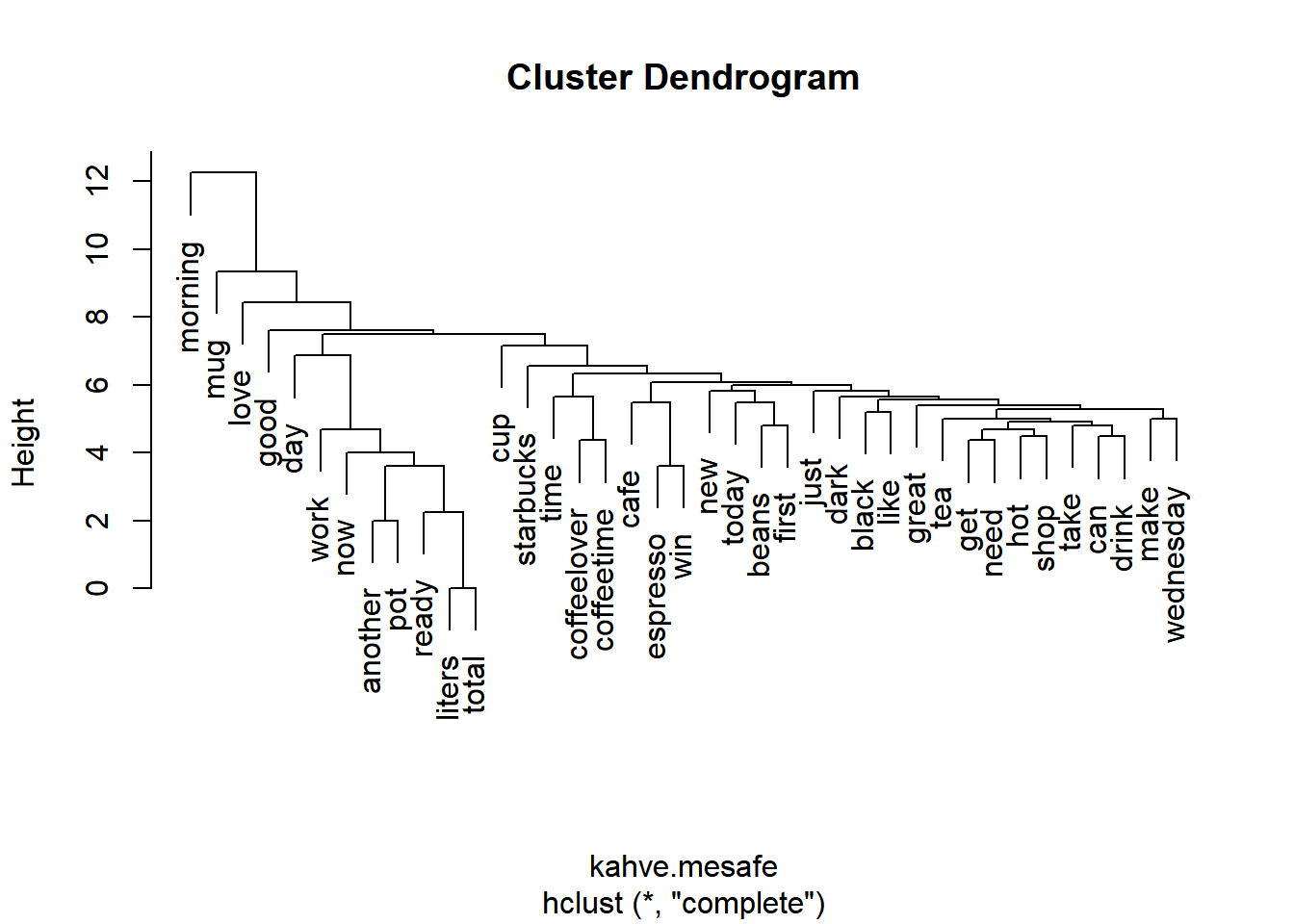
Kelimeler arasındaki bağlantıyı görselleştirmek için bir diğer yol ise tm paketindeki findAssocs() fonksiyonunu kullanmaktır. Bu fonksiyon seçtiğiniz bir kelime ile TDM’nin içindeki kelimeler arasındaki korelasyonu hesaplar. 0 ve 1 değerleri arasında değişen korelasyon katsayısı 1 değerine yaklaştıkça kelimelerin sıklıkla beraber kullanıldığı anlamına gelir. findAssocs() fonksiyonu için argümanlar TDM ismi, seçtiğiniz kelime, ve istediğiniz minimum korelasyon katsayısı şeklinde tanımlanır. Aşağıdaki kod #kahve TDM’sini, “work/iş” kelimesi üzerinden inceleyerek bu işlemi gerçekleştiriyor.
# Korelasyonları hesaplayalım
korelasyonlar <- findAssocs(kahve.tdm, "work", 0.2)
# View the venti associations
korelasyonlar## $work
## liters total
## 0.71 0.71
## ready now
## 0.61 0.56
## pot another
## 0.55 0.50
## 11oclockcatchup 830am
## 0.37 0.37
## catchupmeeting dream
## 0.37 0.37
## festivalpals friday
## 0.37 0.37
## fuelling hard
## 0.37 0.37
## managementteam office
## 0.37 0.34
## working manchester
## 0.31 0.30
## meetings team
## 0.26 0.26
## monday
## 0.20# korelasyonları veri tabanı haline çevirelim
korelasyonlar.df <- list_vect2df(korelasyonlar)[, 2:3]
# grafikleyelim
library(ggplot2)
library(ggthemes)
ggplot(korelasyonlar.df, aes(y = korelasyonlar.df [, 1])) +
geom_point(aes(x = korelasyonlar.df [, 2]),
data = korelasyonlar.df , size = 3) +
theme_gdocs()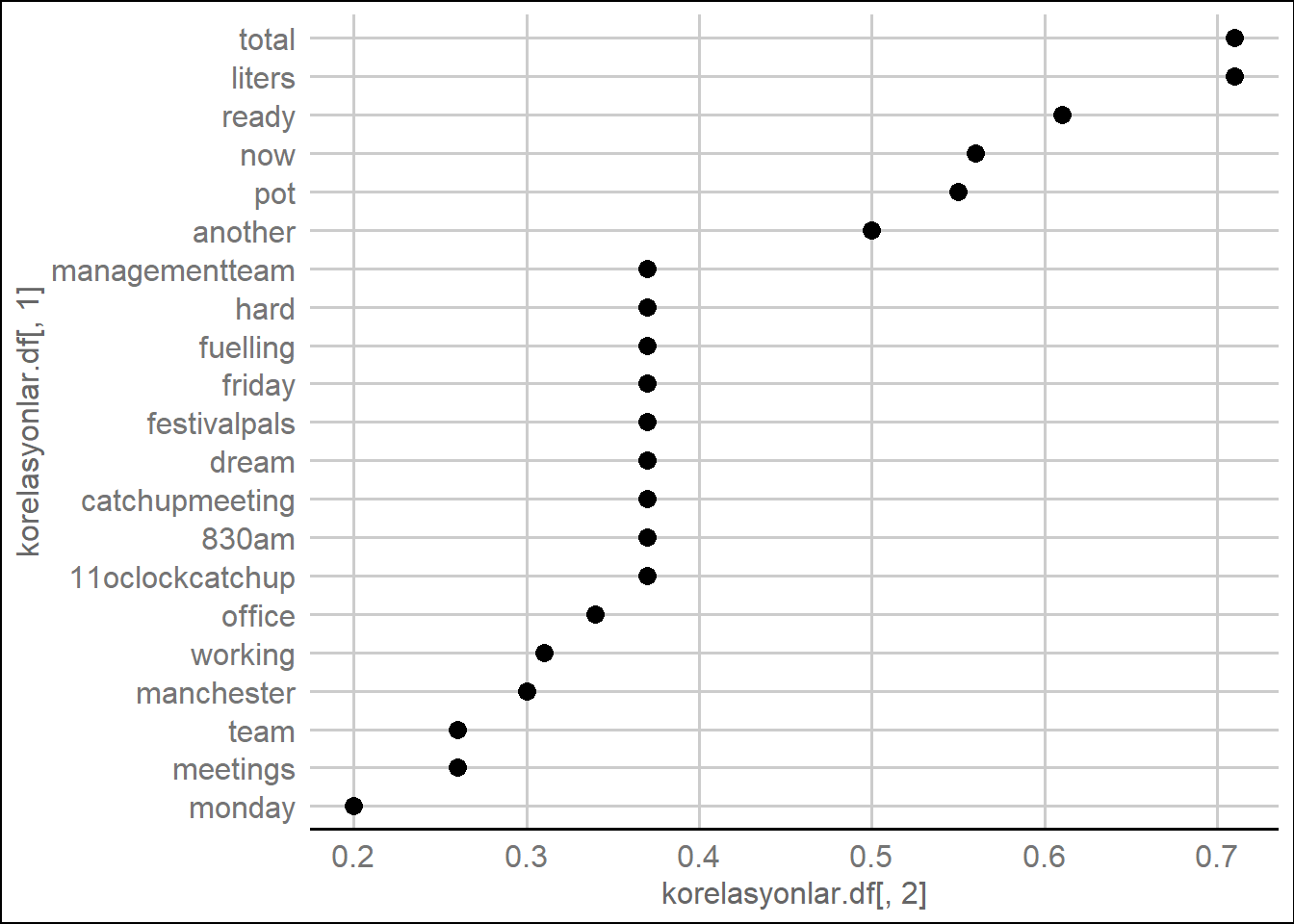
12.6 Birden Fazla Kelime ile Çalışmak
Şimdiye kadar oluşturduğumuz TDM ve DTM’ler analizler için hep tek kelimeden oluşan terimleri kullandı. Metin madenciliğinde analizler tek kelime incelemeleri ile başlasa da, araştırma sorularının cevaplanması için çoğu zaman çoklu kelime gruplarının da incelenmesi gerekir. Bu şekilde kelimelerin kendi başlarına kullanıldıklarında ifade ettiği anlamlara ek olarak, bir grup halinde kullanıldıklarında ifade ettikleri anlamlar da analize eklenmiş olur. Bir örnek vermek gerekirse “kötü” ve “kahve” kelimelerinin kendi başlarına kullandıklarında bir anlam, her iki kelime “kötü kahve” şeklinde kullanıldığında ise başka bir anlam ifade eder, “kötü kahve” kelime grubunun analize katılması sonuçları doğrudan etkileyebilir.
Kelime grupları yaratmak için RWeka paketini kullanacağız. Aşağıdaki kod kahve ile ilgili tweetlerden bi-gram yani ikili kelime grupları oluşturan “kelime.grubu.olustur” adında bir fonksiyon oluşturuyor.
kelime.grubu.olustur <- function(x)
NGramTokenizer(x, Weka_control(min = 2, max = 2))Daha sonra bu oluşturduğumuz fonksiyonu TDM üzerinde uyguluyoruz
library(RWeka)
# İkili kelime grubu matrisimizi oluşturalım
ikili.kelime <- DocumentTermMatrix(
temiz.kahve.corpus,
control = list(tokenize = kelime.grubu.olustur))
# oluşan DTM'ye bakalım
ikili.kelime## <<DocumentTermMatrix (documents: 500, terms: 3133)>>
## Non-/sparse entries: 3879/1562621
## Sparsity : 100%
## Maximal term length: 47
## Weighting : term frequency (tf)Elde ettiğimiz ikli kelime gruplarından oluşan yeni DTM’nin kelime bulutunu çizelim.
#Matrisi yaratalım
ikili.kelime.m <- as.matrix(ikili.kelime)
#Frekansları hesaplayalım
frekans.ikili.kelime <- colSums(ikili.kelime.m)
#ikili kelimele gruplarını oluşturalım
ikili.kelime.grup <- names(frekans.ikili.kelime)
library(wordcloud)
wordcloud(ikili.kelime.grup, frekans.ikili.kelime, max.words = 50,
colors = c("grey80", "darkgoldenrod1", "tomato"))