Chapter 3 Introduction to Data Mining
Hi there. I’m Dr Brit Davidson and I wear many hats at the moment… I am 60% of the working week a Data Science Consultant at Nova Systems International (an Aerospace Engineering company), 40% an Assistant Professor of Analytics at the University of Bath, and in my free time, I am also the ‘Chief Data Scientist’ at a tech start up called Lets Think, and I am an Honorary Lecturer in Digital Health Engineering at the University of Bristol.
Welcome to the living textbook and I hope you enjoy it and find something useful as it ever-expands. I’ll give you a little background about me, I started actually in biochemistry and physics, where I bizarrely made some shifts and ended up with a form of management degree and went onto do a PhD in behavioural science and cybersecurity. I basically spend day in, day out doing various forms of analytics, from data cleaning, processing, basic to advanced statistics, onto types of machine learning, and a lot of work regarding measurement and the implications of issues in measurement on data analytics. I use data from a variety of devices, from smartphone digital traces, reddit content, through to deepweb forum data. Essentially, I have an extensive set of data analysis skills that I hope to pass onto you in this course.
This book will (try to) prepare you with a variety of tools where you will be able to clean, process, and get insights from various forms of data. We will look at typical rows and columns data (think of an excel sheet) through to text analysis. To be clear, this class will give you introductions of many types of analysis seen within data mining, this by no means is exhaustive, where each week is a field in and of itself that you could spend years learning. I aim to give you insights and to get you to start writing your own .R scripts that will get you started with data mining processes.
3.1 What is Data Mining?
So, what data mining? There are a vast number of definitions of this, which is somewhat dependent on what discipline you come from, where a management scholar might have a different view or series of connotations attached to a term when compared with an engineer. However, broadly, data mining is the study of collecting, cleaning, processing, analyzing, and gaining useful insights from data. A wide variation exists in terms of the problem domains, applications, formulations, and data representations that are encountered in real applications. Essentially, data mining is all about data processing and gaining insights from data, which will naturally encompass a wide number of techniques.
The term data mining does come with some connotations, for instance ‘cherry picking’ or ‘gold mining’, where we mine data and only report on specific trends/patterns/relationships that fit what we were looking for. This is a very specific and negative connotation of data mining, which is why it is important to consider definitions of terms. A more appropriate term might be “knowledge mining from data,” or simply knowledge mining. Nevertheless, mining is a vivid term characterizing the process that finds a small set of precious nuggets from a great deal of raw material. Thus, such a misnomer carrying both “data” and “mining” became a popular choice. In addition, many other terms have a similar meaning to data mining—for example, knowledge mining from data, knowledge extraction, data/pattern analysis, data archaeology, and data dredging.
What is the data mining process?

Figure 1. Data Mining Process
Data cleaning (to remove noise and inconsistent data) – this is perhaps the most important part of the process, as the decisions made here will impact the rest of the data analytics pipelines
Data integration (where multiple data sources may be combined) – for example, working with healthcare data, we might merge medical records with death records or prescribed medication records in order to look at patterns across these data.
Data selection (where data relevant to the analysis task are retrieved from the database) – for instance, we might have a dataset that contains 100s of columns, but realistically we are only interested in 20 columns, so we might subset our data and only focus on these columns of interest. Similarly, this relates to data collection, where if we wanted to analyze someone’s smartphone usage, we might only collect specific data form their phones (e.g., names and times of app usage, rather than capturing battery life, location, etc).
Data transformation (where data are transformed and consolidated into forms appropriate for mining by performing summary or aggregation operations)
Data mining (an essential process where intelligent methods are applied to extract data patterns) – this will include general statistics, data visualisation, and sometimes machine learning
Pattern evaluation (to identify the truly interesting patterns representing knowledge based on interestingness measures)
Knowledge presentation (where visualization and knowledge representation techniques are used to present mined knowledge to users) – this is a critical stage, where we must ensure we do not over stretch any of our results and findings
3.1.1 How can big data help?
Watch this video, Big Data in Practice: Using Big Data to Improve Healthcare Services (https://www.youtube.com/watch?v=7t75CNC34vU&ab_channel=TEDxTalksTEDxTalksVerified).
For example:
Please consider the following: 1. Do you feel the data were appropriate presented?
Was the data presently clearly and in a way that is easy to interpret and understand?
Why? Why not?
What would make this clearer? (e.g., axis labels, color schemes?)
Do you think the insights come across in the data visualization?
3.1.2 What are the techniques in data mining?
This figure gives a great overview of all of the techniques you might come across in a data mining pipeline. However, it is important to remember this is not necessarily exhaustive! There is great creativity that can come with data analysis and this provides an idea of different fields. Again, every discipline will have norms in regard to quantitative approaches, where seemingly ‘common’ techniques may be very foriegn to new applications and therefore, it is important to read widely and consider as many approaches as you can to address a problem. There are always multiple ways to solve something – just remember to justify why you’ve chosen a particular approach.
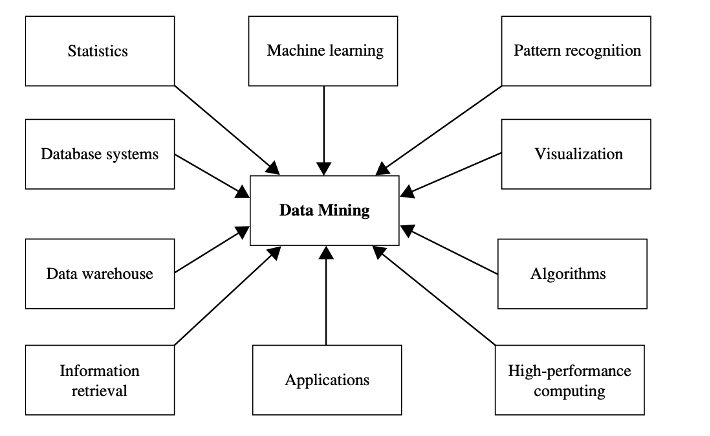
Figure 3. Fields feeding into Data Mining/Analtics
Statistics! A statistical model is a set of mathematical functions that describe the behavior of the objects in a target class in terms of random variables and their associated probability distributions. Statistics research develops tools for prediction and forecasting using data and statistical models. Statistical methods can be used to summarize or describe a collection of data, which we will look at next week. Statistics is useful for mining various patterns from data as well as for understanding the underlying mechanisms generating and affecting the patterns.
Machine learning! Machine learning investigates how computers can learn (or improve their performance) based on data. For instance, writing or deploying algorithms to automatically learn to recognize complex patterns and make intelligent decisions based on data. For example, image recognition, handwriting recognition, spam filtering, customer segmentation. Here, on this course, we will look only at UNSUPERVISED MACHINE LEARNING, which we will learn about in week 4. So far in this textbook, we cover a variety of unsupervised methods… soon to be added are supervised machine learning methods…
Information retrieval! Information retrieval (IR) is the science of searching for documents or information in documents. We will look at text mining, which will provide an overview of how to process, clean, and get simple insights from textual data. This section will continue to be developed.
More to be added…!
3.2 Ethics of Data Mining
Here we are going to focus more specifically on biases that can and do occur in data analytics. These issues will be present when doing any types of data analysis, machine learning, or AI. This is critically important to be aware of, especially as we have more data and continue to automate various analyses. However, it is important to consider some other ethical issues more broadly (e.g., informed consent of data use and reuse). This is also key as data analytics requires data in the first place, which may be collected by the company or researcher themselves, or it might be secondary data analysis.
3.2.1 Bias in Data Mining (more to be added)
We have discussed the various stages of the data mining process… and bias can creep into all of these stages, from data cleaning through to knowledge presentation. However, the story does not end there… biases can occur even before data cleaning in the data collection stage. Why is understanding bias and when it comes into our data and data pipelines?
Well, for example… A child wearing sunglasses is labeled as a “failure, loser, nonstarter, unsuccessful person,” is just one of the many systemic biases exposed by ImageNet Roulette, an art project that applies labels to user-submitted photos by sourcing its identification system from the original ImageNet database. ImageNet, which has been one of the instrumental datasets for advancing AI, has deleted more than half a million images from its “person” category since this instance was reported in late 2019. Earlier in 2019, researchers showed how Facebook’s ad-serving algorithm for deciding who is shown a given ad exhibits discrimination based on race, gender, and religion of users. There have been reports of commercial facial-recognition software (notably Amazon’s Rekognition, among others) being biased against darker-skinned women.
3.2.2 Bias in Data Mining, cont.
With the rapid adoption of AI across a variety of sectors, including in areas such as justice and health care, technologists and policy makers have raised concerns about the lack of accountability and bias associated with AI-based decisions. From AI researchers and software engineers to product leaders and consumers, a variety of stakeholders are involved in the AI pipeline. The necessary expertise around AI, datasets, and the policy and rights landscape that collectively helps uncover bias is not uniformly available among these stakeholders. As a consequence, bias in AI systems can compound inconspicuously.
So, where can bias come into play? Lets look at a few closer…this by far is not exhaustive!
3.2.2.1 Sampling Bias
There are a number of other sampling biases, which can be seen across different types of data, from digital traces, image databases, to psychometric survey data. Types of sampling bias are extremely common and seen across a lot of datasets, which is why if you are ever collecting data, trying to gather a ‘representative’ sample can be extremely expensive.
For instance; [note: this is not an exhaustive list…]
Self-selection bias, where people with specific characteristics are more likely to agree to partake than other participants. For example, when attempting to assess the effect of a test preparation course in increasing participant’s test scores, significantly higher test scores might be observed among students who choose to participate in the preparation course itself… this means causality is difficult, as the students who took the course may have performed significantly higher with or without the course than those who did not.
Non-response bias, where people who do not partake in a survey are systematically or statistically different to those who did. For example, if a survey was wanting to examine a sensitive topic (e.g., mental health), those who are suffering with symptoms and are not receiving enough help may refuse to particulate despite they may be the key participants the survey wanted to reach.
Undercoverage or underrepresentation bias, where certain people or groups are underrepresented. For example: A facial recognition algorithm training set may have a disproportionate number of white or lighter-skinned faces than dark-skinned faces, which then leads to good performances on white or light-skinned faces but poor performance in recognizing darker-skinned faces.
Survivorship bias, where significant findings will be over-represented in comparison to non-significant findings. For example, in many academic journals there is an emphasis on significant results, which can result in scholars ‘cherry picking’ results. This is bad practice, where this will not tell the whole story. This is slowly changing with Open Science Practices (we will come back to this!)
3.2.2.2 Measurement Bias
Measurement is inherently complex. This relates to how you measure something and when errors or uncertainties can creep in.
3.2.2.2.1 Constructs and Theory
We can begin more theoretically, where we measure ‘constructs’ – however, what is a construct? This is broadly an abstract concept that we then try to ‘operationalise’ whereby measure it as a variable. Educational and psychological constructs are generally attributes of people, situations, or treatments presumed to be reflected in test performance, ratings, or other observations. We take it on faith that the universe of our observations can be ordered and subsequently explained with a comparatively small number of constructs. Many constructs relating to people and psychology are latent (e.g., happiness, mood, morality, kindness, performance). By nature, these constructs are ‘unseen’ or hypothetical as they are abstract. These latent abstractions of the variable of interest that is deemed unobservable, therefore allows us to understand relationships more generally—allowing us to observe the unobservable.
However, the ways in which these latent variables are defined, of course, is critically important. If we consider anxiety for example, how would we measure it? Is a survey (e.g., GAD7) the best way? Can we do it via digital traces? What about if we use Galvanic Skin Response (GSR) instead? How is anxiety different to stress? How would we capture that in a measure? What does anxiety mean to someone from a different culture? How do they understand anxiety? Does it match?
The questions around the conceptualization of this variable is endless…this of course means that each person trying to develop a way to measure a construct, each measure may be very different… and therefore, how do we know which is right? Please read this article [https://psyarxiv.com/6durk/] to look into an interesting example of technology usage and the way it is measured.
3.2.2.2.2 Device, Tool, or Method
Alongside the way we think about how to approach measuring a construct… the way in which we capture data can also have errors. For example, if we were using a smartphone app to collect smartphone usage patterns, the app might break and we have missing data. Similarly, if we are using a device to measure heart rate and the device is not calibrated, we will have errors present.
To read more about these kinds of error, please read this article [https://arxiv.org/pdf/1907.08228.pdf], which gives an extremely comprehensive overview of errors in data, particularly focused on digital trace data. Similarly, this short article [https://psyarxiv.com/8abzy/] is an important read, which examines the balance between new technologies for better measurement alongside being able to understand what these data can actually infer about the participants. This is also discussed in this article [https://psyarxiv.com/3z6qm/], which specifically focuses on using digital data for mental health prediction.
Returning to the example of ‘technology use’ in the article referenced in the theoretical section of measurment bias, we will consider the impacts of using different ways of measuring the same construct. Briefly, it is common in psychological science to measure technology use (time spent on a device) using surveys (self-reported) methodologies rather than getting the actual time spent on the device from the device itself. In terms of self-reported technology use, there are 2 key ways to measure technology use: (1) time estimates (e.g., asking: how long did you spend on your smartphone today?) or (2) surveys (e.g., smartphone addiction scale).
The issue here is that scholars use these self-reproted methods instead of actual usage captured from the device, which assumes self-reported measures are indeed a proxy for actual technology use… however, this is of course, not the case. Please read the following two articles to better understand why measurement is critical, [https://www.nature.com/articles/s41562-021-01117-5] and [https://tmb.apaopen.org/pub/7rdjtyqu/release/2].
3.2.2.3 Label Bias
Label bias is associated with inconsistencies in the labeling process. If we were labelling data for a training set, each person labelling data may have different styles and preferences that get reflected in the labels created. A common instance of label bias arises when different annotators assign differing labels to the same type of object (e.g., grass vs. lawn, painting vs. picture). This is common in qualitative data analysis, too, where you see ‘Inter-rate reliability’ statistics to understand how much agreement there was between labelling.
Yet another type of label bias can happen when the subjective biases of evaluators affect labeling. For example, in a task of annotating emotions experienced in a text, the labels could be biased by the subjective preferences of annotators such as their culture, beliefs, and introspective capabilities. Confirmation bias, which is the human tendency to search for, interpret, focus on, and remember information in a way that confirms one’s preconceptions, is closely related to this type of label bias. Thus, labels may be assigned based on prior belief rather than objective assessments.
A third type of label bias can arise from the peak end effect. This is a type of memory-related cognitive bias in which people judge an experience based largely on how they felt at its peak (i.e., its most intense point) and at its end, rather than based on the total sum or average of every moment of the experience.15 For example, some annotators may give more importance to the last part of a conversation (rather than the entire conversation) in assigning a label.
3.2.2.4 Confounding Bias
Bias can arise in the modelling technique used learns the wrong relations by not taking into account all the information in the data or if it misses the relevant relations between features and target outputs. Confounding bias originates from common causes that affect both inputs and outputs. For example, admissions to a graduate school are based on the person’s previous grade point average. There might be other factors, however, such as ability to get coaching, which in turn may be dependent on sensitive attributes such as race; and these factors may determine the grade point average and admission rates. As a result, spurious relations between inputs and outputs are introduced and thus can lead to bias.
A special type of confounding bias is the omitted variable, which occurs when some relevant features are not included in the analysis. This is also related to the problem of model underfitting.
Another type of confounding bias is the use of proxy variables (as mentioned above regarding the various ways to measure technology use). Even if sensitive variables such as race, gender, etc. are not considered for decision making, certain other variables used in the analysis might serve as “proxies” for those sensitive variables. For example, zip code might be indicative of race, as people of a certain race might predominantly live in a certain neighborhood. This type of bias is also commonly referred to as indirect bias or indirect discrimination.