第 1 章 R基础
1.1 R studio
当你第一次打开Rstudio时,出现的界面会是以下这个样子1.1: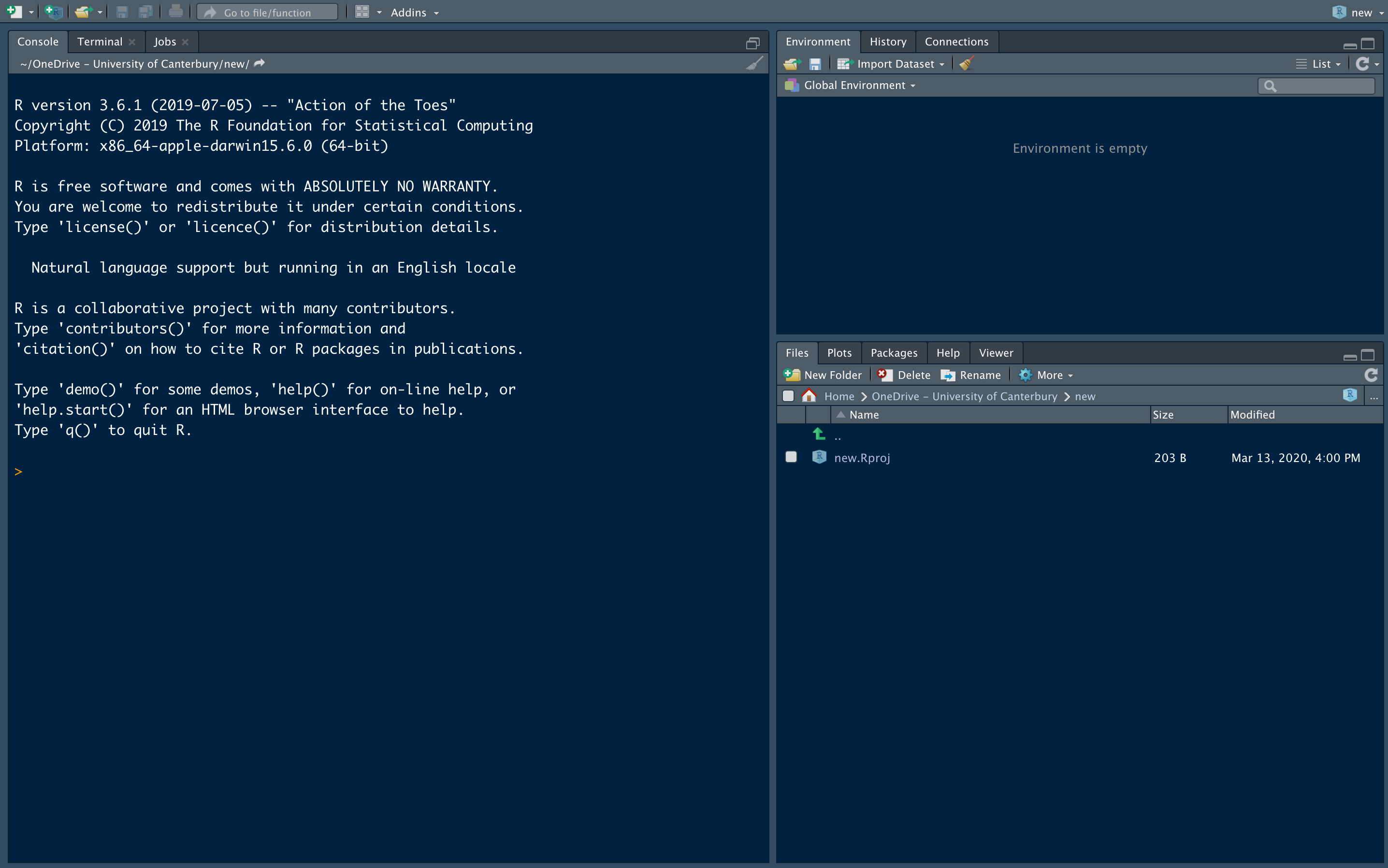
图1.1: R studio 界面说明
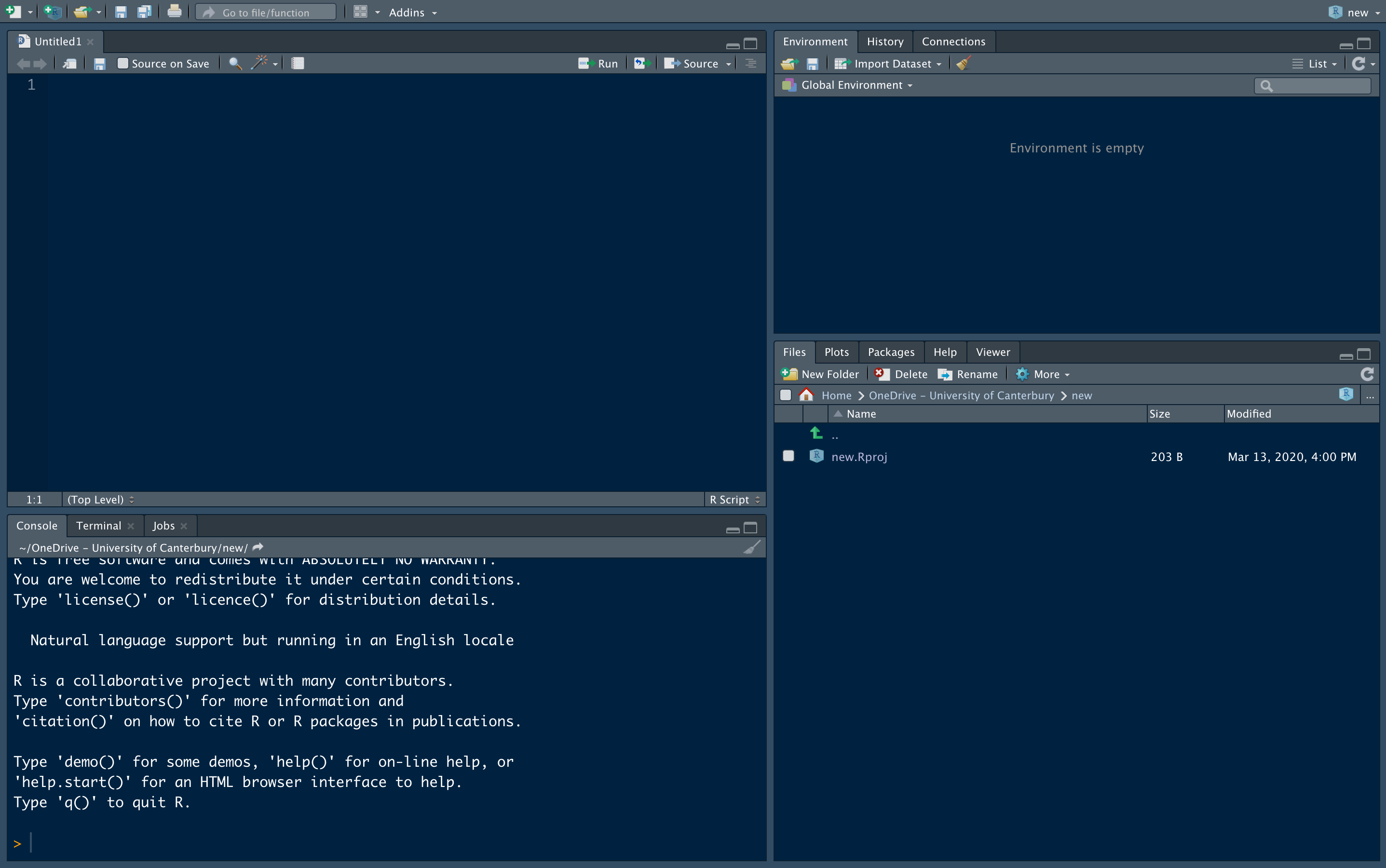
图1.2: R studio 界面说明
对R script进行命名,方便保存,我们可以将我们要写的代码都在R script里完成,并且可以长久保存,这样我们以后再调用现在的代码就会很方便。每次我们在开始一个新的工作环境之前,我们需要设置一个工作路径,具体可以点击file > new project...,设置新项目的名称,以及所在位置,点击确定,就会出现一个新的工作环境,这时候你可以将你所有的代码和数据保存在这个工作项目里,方便以后查找使用。左下方的区域是每次code运行后显示界面,会显示你每次运行代码以后,R给你的回应。右上角包括,数据环境,历史和connections, 数据环境会显示你所有生成的数据,历史是可以方便你追踪你所有运行过的代码,connections是可以跟你的R studio账号链接,以便以后你发布你生成的程序等成果。右下角的区域就比较重要了,分别为:files, plots, packages,help 和viewer,其中files可以显示 你工作路径里面包含的所有文件,方便你查找,plots选项是可以实时显示你要plot出来的图,方便你查阅与调整,packages是可以方便你安装大部分安装包,进入packages 界面后,点击install按钮,输入安装包名称就可以自动下载安装。我们通常会遇到这样或那样的error,当我们不知道怎么办时,可以通过help界面里进行搜索进行查找,R help 非常强大,每个安装包的代码都会有详细的解释,而且大部分都会给出简单的例子供你参考,非常有帮助。viewer 界面是可以动态显示图像和视频的,也可以用来显示模型训练进程等,后续会介绍到。
1.2 简单运算
首先我们先了解一下如何用R做数学运算,比如说简单的加减乘除:你只需要输入数字,然后用 +, -, *,/来表示加减乘除,就可以完成,非常方便,如简单一点的例子:
10+2
## [1] 12
10-2
## [1] 8
10*2
## [1] 20
10/2
## [1] 5如果涉及到稍微复杂一点的数学运算,比如即有加减,又有乘除,则需要用到()来把先加减的数字先括起来,,再去做乘除,如下:
(10+2)/3#加括号后,是先算10+2的和,然后再除以3
## [1] 4
10+2/3#如果不加括号,公式会先算乘除,后算加减
## [1] 10.66667
(10+2)*3
## [1] 36
(102-23+443)/30*2
## [1] 34.8这里要提醒一下,R里面的所有符合,都必须是英文符号,例如::,"", ,, ., [],{}等,如果使用中文符号则会报错, 例如:
(10+2)/3 #英文符号无报错
## [1] 4
#(10+2)/3## 中文符号,报错
#Error: unexpected input in "�"因此,当你觉得你的代码没错的时候,但是运行就会报错,记得检查一下中英文切换。
当然,也还可以进行其他运算,如求角度的sin,cos和 tan的值,求log值等。
sin(30)
## [1] -0.9880316
cos(30)
## [1] 0.1542514
tan(30)
## [1] -6.405331
log(10)
## [1] 2.302585
log10(20)
## [1] 1.30103
logb(10,base = exp(1))
## [1] 2.302585当我们要计算的数据太长时,我们也可以对一个数据进行命名,然后在进行相关运算,例如下面的例子。R里面一般都用<-表示,例如:x<- 10, =也是可以被R接受的,如:x= 10, 但通常用<- 比较多,因为有些时候=可能会在同一行代码中出现不同意思,容易报错。
x <-10 #让x 等于10
y <- 20 #让y 等于20
z<- 30 #让z 等于30
(x+y)/z #先计算x+y的和,再除以z
## [1] 1
x+y/z #先计算y/z,再加x
## [1] 10.666671.3 数据形式
R里面数据集有好几种形式,在实际运算中,不同形式的数据格式可能会对结果产生很大的影响,这里我简单介绍一下最常见的几种形式:
1.3.1 Factor
x <- c('DBH','Height','site' )
str(x)#在R里面想要查看数据的格式,可以用str(), 就是 structure 的意思
## chr [1:3] "DBH" "Height" "site"factor的形式一般都是用来分组,数据的表现形式一般以""形式显示。
1.3.2 Number
x <- c(1,2,3,4,5,6,7)
str(x) #在R里面想要查看数据的格式,可以用str(), 就是 structure 的意思
## num [1:7] 1 2 3 4 5 6 7
x <- c(1.2,2.34,3.42,4.4,5.12,6.5,7.334)
x # x这时候是带小数点的数据,不是整数,如果想把x变成整数集,可以使用as.integer()代码
## [1] 1.200 2.340 3.420 4.400 5.120 6.500 7.334
str(x) # 这时候再看x 就是整数集了
## num [1:7] 1.2 2.34 3.42 4.4 5.12 ...1.3.3 Interger
x <- c(1.2,2.34,3.42,4.4,5.12,6.5,7.334)
x # x这时候是带小数点的数据,不是整数,如果想把x变成整数集,可以使用as.integer()代码
## [1] 1.200 2.340 3.420 4.400 5.120 6.500 7.334
x <- as.integer(x)
str(x) # 这时候再看x 就是整数集了
## int [1:7] 1 2 3 4 5 6 71.3.4 Vector
x <- c(a = 1, b = 2)
x
## a b
## 1 2
is.vector(x)
## [1] TRUEvector 产生给定长度和模式的向量.
1.3.5 Character
x <- c(a = 1, b = 2)
x
## a b
## 1 2
str(as.character(x))
## chr [1:2] "1" "2"character 是创建字符集。
当我们想转换一个数据集的数据形式,通常会用到as.后面加上你想要的形式名称,比如 number,character等,我们了解了数据形式以后,会对我们后续的数据处理与模型构建当中起到很大的帮助,避免走很多弯路。
1.4 创建数据集
我们已经大致了解了几种常用的数据形式,接下来我们聊聊如何创建数据集,也就是dataframe, 我们可以把很多组数据整合到一起创建数据集,以便做数据运算与整理,比如下面的例子, 假设我们有三个地点,5个家系,每个家系5个单株的树木生长数据,包括树高、胸径枝下高等数据,我们对这些数据进行整合,从数据类型上看,地点、家系肯定是 factor因子数据,而每个单株的树高、胸径和枝下高是数值,所以应该是 number 数据,对于每个树高、胸径和枝下高数据的总长度应该是:3地点 * 5家系 * 5单株= 75。在搞懂各个变量的数据形式以后,我们可以进行以下操作来进行数据集构建:
site <- rep(c('site1','site2', 'site3' ),each = 25,len=75)#每个地点5个家系5株树,所以每个家系25株数据,总共75株。
families <- rep(c('f1', 'f2','f3','f4','f5'),each = 5,len=75) #每个家系5株树,总共75株。
dbh <- sample(x =rep(c(10:15,15:20,23:28, 10.5:20.5,20:30)), size = 75, replace = TRUE) #随机一组数据
height <- sample(x = 10.8:30.8, size = 75, replace = TRUE) #随机一组数据
zhi_height <- sample(x = 10.1:15.5, size = 75, replace = TRUE) #随机一组数据
## 整合这5个变量成为一个数据集
growth <- cbind.data.frame(site,families,dbh,height,zhi_height)
head(growth) # 查看前6列数据
## site families dbh height zhi_height
## 1 site1 f1 26.0 22.8 12.1
## 2 site1 f1 19.5 24.8 11.1
## 3 site1 f1 18.5 27.8 11.1
## 4 site1 f1 24.0 29.8 11.1
## 5 site1 f1 27.0 10.8 12.1
## 6 site1 f2 23.0 22.8 11.1
tail(growth) # 查看后6列数据
## site families dbh height zhi_height
## 70 site3 f4 24 14.8 12.1
## 71 site3 f5 12 17.8 13.1
## 72 site3 f5 15 11.8 13.1
## 73 site3 f5 10 30.8 10.1
## 74 site3 f5 29 28.8 11.1
## 75 site3 f5 19 18.8 11.1
str(growth) # 查看数据集形式
## 'data.frame': 75 obs. of 5 variables:
## $ site : chr "site1" "site1" "site1" "site1" ...
## $ families : chr "f1" "f1" "f1" "f1" ...
## $ dbh : num 26 19.5 18.5 24 27 23 18.5 26 20 12 ...
## $ height : num 22.8 24.8 27.8 29.8 10.8 22.8 18.8 17.8 21.8 18.8 ...
## $ zhi_height: num 12.1 11.1 11.1 11.1 12.1 11.1 11.1 15.1 15.1 13.1 ...1.5 导入数据
以上是简单的数据创建,当然在实际实验当中我们可能有大批量的数据记录在excel当中,或者其他软件生成的数据,因此需要用R先从外部导入数据,然后才能进行相关分析。所以接下来我简单给你大家介绍以下如何导入其他软件生成的数据。不同的软件生成的数据形式一般都不同,我们这里主要介绍几种常用的,例如包括excel格式、txt格式、csv格式、rds格式、光谱数据 ENVI格式、以及SPSS和 SAS 等其他常用软件格式数据, 格式,另外如何保存为R常用的数据格式,方便以后调用。
1.5.1 导入Excel数据
读取excel 格式数据,需要调用readxl 安装包。如何没有安装 readxl 这个安装包,可以先进行安装,通过 install.packages()来实现:install.packages("readxl").
#install.packages("readxl")
library("readxl") # 调取这个安装包
# xlsx 格式
data_impor <- read_excel( 'my_data.xlsx' ) # 你的excel 文件的位置路径
# xls 格式
data_impor <- read_excel( 'my_data.xls' ) # 你的excel 文件的位置路径这里我默认是从我的工作路径读取,当然你可以指定文件路径告诉R去读取,比如Windows系统用户:d:/download/my_data.xls, 这里是指 在d盘中的download 文件夹里读取 my_data.xls这个数据。 MAC用户为:/download/my_data.xls,注意这里的必须使用 /来进行文件查找,而不是 \。
当然你也可以选择指定读取的excel 表格中哪一个的表格,比如:
my_data <- read_excel("my_data.xls", sheet = "data")
# 或者指定第几个sheet
my_data <- read_excel("my_data.xlsx", sheet = 2)1.5.2 导入 txt数据
R语言中基础包就可以直接读取txt格式数据,这里要用到这个代码:read.table,例如:
my_data <- read.table('mydata.txt',header = T,sep = "")
my_data这里header = T的意思是把第一行作为标题,sep是告诉R这个文件字段分隔符分割方式,具体可以调用 ?read.table来查看这个代码的详细设置。
1.5.3 导入csv数据
R语言中基础包也可以可以直接读取txt格式数据,可以用read.table,也可以用 read.csv 来实现例如:
my_data <- read.table('mydata.csv',header = T,sep = ",")
my_data <- read.csv('mydata.csv',header = T,sep = ",")1.5.4 导入rds数据
R语言中基础包也可以可以直接读取rds 格式数据,可以用readRDS 来实现例如:
my_data <- readRDS('mydata.rds',header = T,sep = ",")1.5.5 导入高光谱ENVI数据
高光谱文件会有两个file, 一个是数据文件,一个是hdr标题文件,两个文件是同一个名称命名,数据文件没有扩展名,而标题文件的扩展名为 .hdr,以下为简单的读取方式,这里需要用到一个专门处理高光谱数据的安装包 hyperSpec:
library(hyperSpec)
## sas 文件
my_data <- read.ENVI( 'data_hyper',headerfile= 'data_hyper.hdr' )1.5.6 导入SPSS和SAS文件
library(haven)
## sas 文件
my_data <- read_sas('mydata.sas')
## spass 文件
my_data <- read_sav('mydata.sav')1.5.7 批量导入数据
在实际操作中,我们往往会有多个或者成百上千个相同类型数据,一般数目较少的的话,我们可以通过复制粘贴在同一个exel里面,然后在导入到R软件中进行分析,但是如果有成百上千数据的话,靠人工复制粘贴是很费时间和人力的,在R里面我们可以通过for loop 语句进行批量操作,非常方便,这里比如我们一个文件夹里有一批原始光谱数据,这光谱数据是从光谱仪中产生的,他们的数据形式是完全相同的数据形式,首先我们来读取其中一个数据,
# setwd("/Users/yanjieli/Library/Mobile Documents/com~apple~CloudDocs/R book/hyperspectra data")
# getwd()
file_names <- list.files(path="hyperspectra data") #
#列出目标文件夹里面的所有文件名
temp_dataset <- read.table(paste0('hyperspectra data/',file_names[1]), header=T,sep = ',',fill = TRUE)#读取其中一个数据,这里我们读取第一个。
head(temp_dataset)
## X8994.82461 X0.20584
## 1 8990.967 0.20587
## 2 8987.110 0.20583
## 3 8983.253 0.20576
## 4 8979.396 0.20573
## 5 8975.539 0.20592
## 6 8971.682 0.20626可以看出,每个数据包括两列内容,第一列为光谱位点,第二列为光谱值,接下来我们要对这个文件夹里面的所有相似数据形式进行批量读取:
# setwd("/Users/yanjieli/Library/Mobile Documents/com~apple~CloudDocs/R book/bookdown-chinese-master/hyperspectra data/")
file_names <- list.files(path="hyperspectra data") # 列出目标文件夹里面的所有文件名
dataset <- list()# 设置一个空的list文件
## 1st method
for ( i in 1:length(file_names))# length()是表示总共有几个文件,然后下面依次读取文件
{
temp_dataset <- read.table(paste0('hyperspectra data/',file_names[i]), header=,sep = ',',fill = TRUE)# 读取第i个数据
x <- temp_dataset[1]## 提取第一列光谱范围
dataset[[i]] <-cbind(temp_dataset[,2])# 合并每个数据的第2列
rm(temp_dataset)# 去除临时数据
}
datasetq <- cbind (x,do.call(cbind, dataset))## 将list 文件整合到一个数据集
colnames(datasetq) <-c("wavenumber",file_names)## 给每个列命名
rownames(datasetq) <- round(datasetq[,1],0)# 给每一行命名,将数据的第一行作为名字, round的意思为取小数据点后几位,这里取0,也就是取整数。
datasetq <-datasetq[,-1]## 去除第一行
data <- t(datasetq)## t的意思是对数据进行转置
data <- data.frame(data)# 将数据变为数据集形式
names(data) <- sub("^X", "", names(data))# 去除没有列的X
dim(data)
## [1] 28 1296
library(DT)
datatable(data,escape =F,options = list(pageLength = 5)
)这样,我们就把所有的数据读取出来了,接下来就可以进行数据分析了。
1.6 保存数据
在R中,我们会进行很多数据清洗工作,当我们得到我们想要的数据集后我们最好把它保存起来,以防丢失。常用的r保存文件形式为 csv和 txt 格式,这个格式R比较容易读取,在数据量不太大的时候,保存为这个数据形式是很方便的,但是如果数据集比较大,csv格式的文件size保存起来就会很大,往往拖延保存和读取进程,而且当我们用excel去读取调看的时候,会卡死,因此我这里推荐把数据保存为R特有的 rds 格式,这个格式会保存原始文件所有形式,你无需设置header 和sep等参数,原始数据集的数据形式会全部保存,非常方便。而且这个文件格式相当于压缩了文件,大大缩小了保存文件的大小,节省了尤其是大文件的读取时间。
1.6.1 保存为csv 文件
比如我们保存我们批量读取的数据 data:
## 保存为csv 文件
write.csv(data,'my_data.csv')File size (MB) : 288.7kb
1.6.2 保存为txt文件
## 保存为rds 文件
write.csv(data,'my_data.txt')File size (MB) : 288.7kb
1.6.3 保存为rds文件
## 保存为rds 文件
saveRDS(data,'my_data.rds')File size (MB) : 139.5kb,对比各个保存文件的大小,很明显,rds文件格式的size要比csv和txt小的多。