第 20 章 作者信息提取
提取文献题录,是一件比较繁琐的工作。我这里使用tidyESI宏包尝试解决,目前还不完美,还需要不断的探索,欢迎大家PR。
library(tidyverse)
library(here)20.1 最小案例数据
d <- read_rds(here("data", "example.rds")) %>%
select(UT, AF, C1, RP)
d作者信息栏
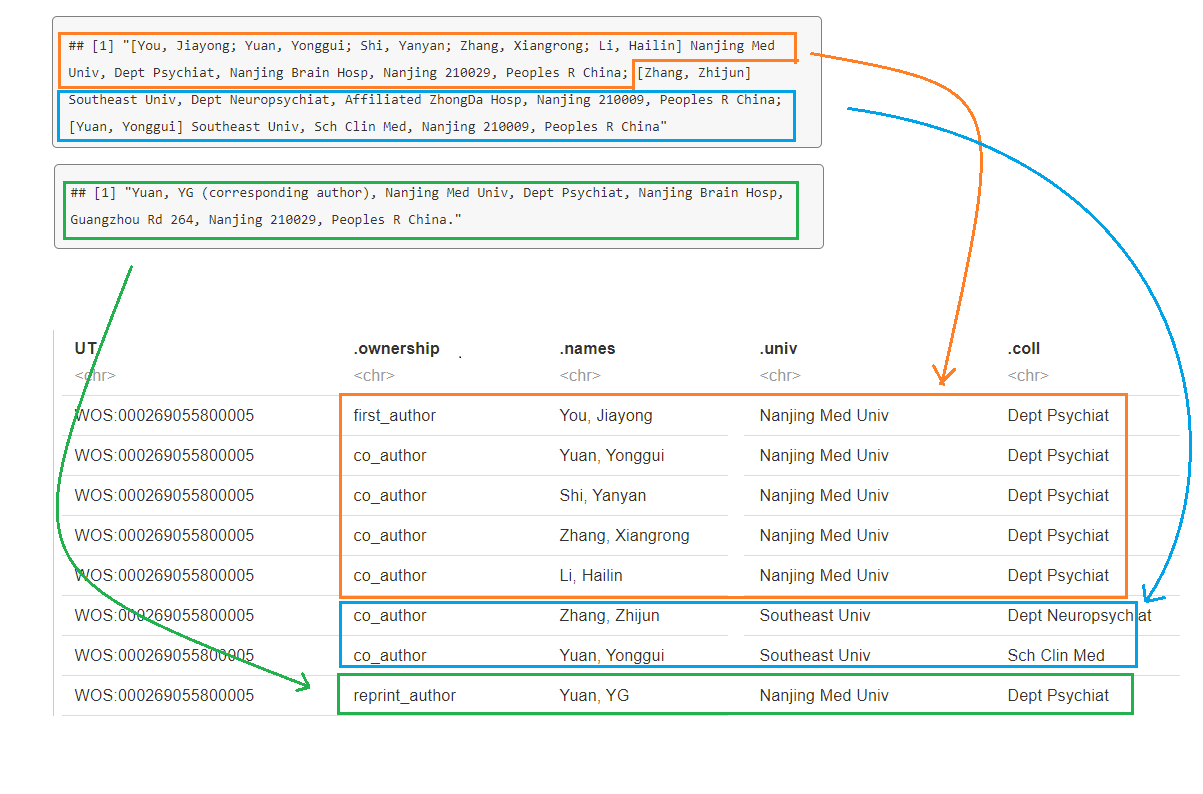
d$C1## [1] "[You, Jiayong; Yuan, Yonggui; Shi, Yanyan; Zhang, Xiangrong; Li, Hailin] Nanjing Med Univ, Dept Psychiat, Nanjing Brain Hosp, Nanjing 210029, Peoples R China; [Zhang, Zhijun] Southeast Univ, Dept Neuropsychiat, Affiliated ZhongDa Hosp, Nanjing 210009, Peoples R China; [Yuan, Yonggui] Southeast Univ, Sch Clin Med, Nanjing 210009, Peoples R China"
## [2] "[Geng, Fan; Yuan, Zhulin] SE Univ, Sch Energy & Environm, Nanjing 210096, Peoples R China; [Geng, Fan; Yan, Yaming; Luo, Dengshan; Wang, Hongsheng; Li, Bin; Xu, Dayong] China Natl Tobacco Corp, Key Lab Tobacco Proc Technol, Zhengzhou 450001, Peoples R China"通讯作者信息栏
d$RP## [1] "Yuan, YG (corresponding author), Nanjing Med Univ, Dept Psychiat, Nanjing Brain Hosp, Guangzhou Rd 264, Nanjing 210029, Peoples R China."
## [2] "Geng, F (corresponding author), SE Univ, Sch Energy & Environm, Nanjing 210096, Peoples R China."20.2 说明
提取归属信息,整理成5列
- 归属 .ownership
- 姓名 .names
- 地址 .addr
- 学校 .univ
- 学院 .coll
一篇文章如果有3个作者,那么归属为1个“first_author,” 2个“co_author,” 返回的结果还会包括通讯作者“reprint_author”。一般情况下,通讯作者来自这3个作者中的一个或者几个,因此,这条题录,最终会返回有3+n行,这里的n是指通讯作者的个数,通讯作者不分前后。(通讯作者都要搞几个,唉,学术啊)
.ownership .names .addr .univ .coll first_author co_author co_author reprint_author 作者地址如果有多个,这个作者信息就会出现多次,比如,作者地址有同济大学物理学院和中科院高能所,那么作者信息会出现两行,这两行只是地址不同,其它信息是一样的。如果刚好又是第一作者,那么他的两个地址都会标上“first_author”。更特殊点,如果第一作者地址有同济大学物理学院和同济大学计算机学院,即一个学院不同学院,那么在统计的时候,会认为作者以第一作者身份,分别为物理学院和计算机学院贡献一篇。因此,在后期统计时,需要先地址筛选,再统计。
20.3 提取
library(tidyESI)
res <- d %>%
rowwise() %>%
mutate(
info = list(ownership_extract(AF, C1, RP))
) %>%
ungroup()
# resres %>%
head(3) %>%
select(UT, info) %>%
unnest(cols = c(info)) %>%
select(UT, .ownership, .names, .univ, .coll)