Chapter 2 Multiple Linear Regression
In this chapter we review multiple linear regression and in particular the Ordinary Least Squares (OLS) estimator. We investigate the challenges which arise in the high-dimensional setting where the number of covariates is large compared to the number of observations, i.e. \(p>>n\). We discuss model selection and introduce subset- and stepwise-regression.
2.1 Notation
We will typically denote the covariates by the symbol \(X\). If \(X\) is a vector, its components can be accessed by subscripts \(X_j\). The response variable will be denoted by \(Y\). We use uppercase letters such as \(X\), \(Y\) when referring to the generic aspects of a variable. Observed values are written in lowercase; hence the \(i\)th observed value of \(X\) is written as \(x_i\) (where \(x_i\) is again a scalar or vector). Matrices are represented by bold uppercase letters; for example, a set of \(n\) input p-vectors \(x_i\), \(i=1,\ldots,n\) would be represented by the \(n\times p\) matrix \(\bf{X}\). All vectors are assumed to be column vectors, the \(i\)th row of \(\bf{X}\) is \(x_i^T\).
2.2 Ordinary least squares
Given a vector of inputs \(X=(X_1,X_2,\ldots,X_p)\), in multiple regression we predict the output \(Y\) via the linear model:
\[ \hat{Y}=\hat\beta_0+\sum_{j=1}^{p}X_j\hat\beta_j.\]
The term \(\beta_0\) is the intercept. If we include the constant variable 1 in \(X\), include \(\hat\beta_0\) in the vector of coefficients \(\hat\beta\), then we can write
\[\hat{Y}=X^T\hat\beta.\]
How do we fit the linear model to a set of training data (i.e. how do we obtain the estimator \(\hat \beta\))? We typically use ordinary least squares (OLS) where we pick the coefficient \(\beta\) to minimize the residual sum of squares
\[\begin{eqnarray*} \textrm{RSS}(\beta)&=&\sum_{i=1}^{n}(y_i-x_i^T\beta)^2\\ &=&(\textbf{y} - \textbf{X} \beta)^T (\textbf{y} - \textbf{X} \beta)\\ &=&\|\textbf{y} - \textbf{X} \beta\|^2_2. \end{eqnarray*}\]
If the matrix \(\bf X^T \bf X\) is nonsingular, then the solution is given by
\[\hat\beta=(\bf X^T \bf X)^{-1}\bf X^T \bf y.\]
Thus, the prediction at the new input point \(X_{\rm new}\) is
\[\begin{align*} \hat{Y}&=\hat{f}(X_{\rm new})\\ &=X_{\rm new}^T\hat\beta\\ &=X_{\rm new}^T(\textbf{X}^T \textbf{X})^{-1}\textbf{X}^T \textbf{y}. \end{align*}\]
Figures 2.1 and 2.2 show two geometric representations of the OLS estimator. In Figure 2.1 the \(n\) data points \((y_i,x_{i1},\ldots,x_{ip})\) randomly spread around a \(p\)-dimensional hyperplane in a \(p+1\)-dimensional space; the random spread only occurs parallel to the y-axis and the hyperplane is defined via \(\hat \beta\). Figure 2.2 shows a different representation where the vector \(\bf y\) is a single point in the \(n\)-dimensional space \({\bf R}^n\); the fitted \(\hat {\bf y}\) is the orthogonal projection onto the \(p\)-dimensional subspace of \({\bf R}^n\) spanned by the vectors \({\bf x}_1,\ldots,{\bf x}_p\).
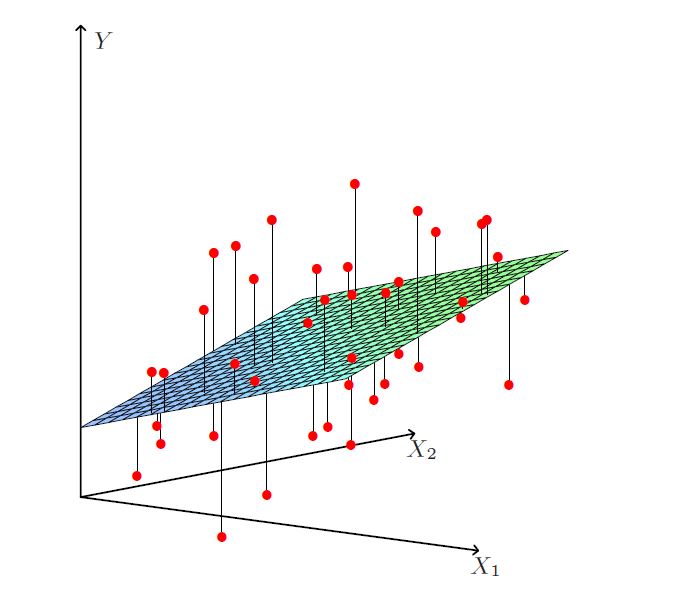
Figure 2.1: Data points spreading around the p-dimensional OLS hyperplane.
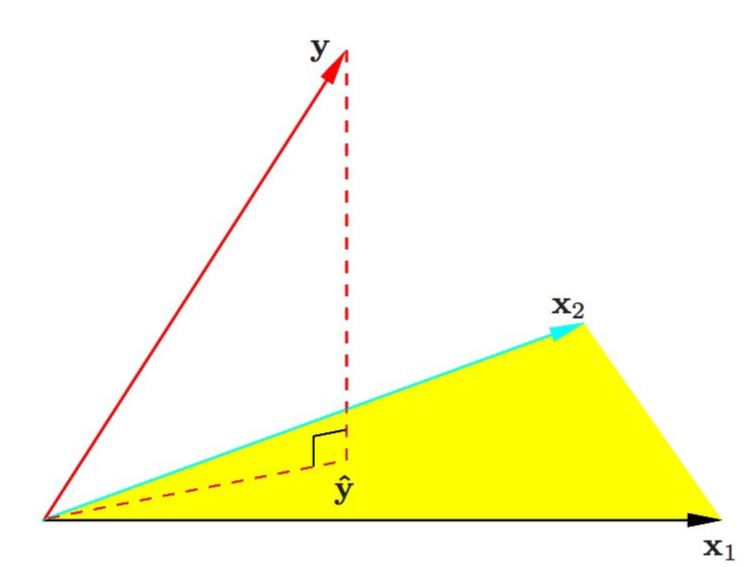
Figure 2.2: OLS fit \(\hat{\textbf{y}}\) as the orthogonal projection of \(\textbf{y}\) onto subspace spanned by covariates.
2.3 Overfitting
Overfitting refers to the phenomenon of modelling the noise rather than the signal. In case the true model is parsimonious (few covariates driving the response \(Y\)) and data on many covariates are available, it is likely that a linear combination of all covariates yields a higher likelihood than a combination of the few that are actually related to the response. As only the few covariates related to the response contain the signal, the model involving all covariates then cannot but explain more than the signal alone: it also models the error. Hence, it overfits the data.
We illustrate overfitting by generating artificial data. We simulate \(n=10\) training data points, take \(p=15\) and \(X_{i1},\ldots,X_{ip}\) i.i.d. \(N(0,1)\). We assume that the response depends only on the first covariate, i.e. \(Y_i=\beta_1 X_{i1}+\epsilon_i\), where \(\beta_1=2\) and \(\epsilon_i\) i.i.d. \(N(0,0.5^2)\).
set.seed(1)
n <- 10
p <- 15
beta <- c(2,rep(0,p-1))
# simulate covariates
xtrain <- matrix(rnorm(n*p),n,p)
ytrain <- xtrain%*%beta+rnorm(n,sd=0.5)
dtrain <- data.frame(xtrain)
dtrain$y <- ytrainWe fit a univariate linear regression model with X1 as covariate and print the summary.
##
## Call:
## lm(formula = y ~ X1, data = dtrain)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.59574 -0.41567 -0.06222 0.18490 0.97592
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.1002 0.1785 -0.561 0.59
## X1 1.8070 0.2373 7.614 6.22e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.5558 on 8 degrees of freedom
## Multiple R-squared: 0.8787, Adjusted R-squared: 0.8636
## F-statistic: 57.97 on 1 and 8 DF, p-value: 6.223e-05The coefficient for X1 is close to the true value. The R squared value \(R^2=\) 0.88 indicates that the model fits the data well. In order to explore what happens if we add noise covariates, we re-fit the model with an increasing number of covariates, i.e. \(p=4\), \(8\) and \(15\).
fit4 <- lm(y~X1+X2+X3+X4,data=dtrain)
fit8 <- lm(y~X1+X2+X3+X4+X5+X6+X7+X8,data=dtrain)
fit15 <- lm(y~.,data=dtrain) #all 15 covariatesThe next plot shows the data points (black circles) together with the fitted values (red crosses).
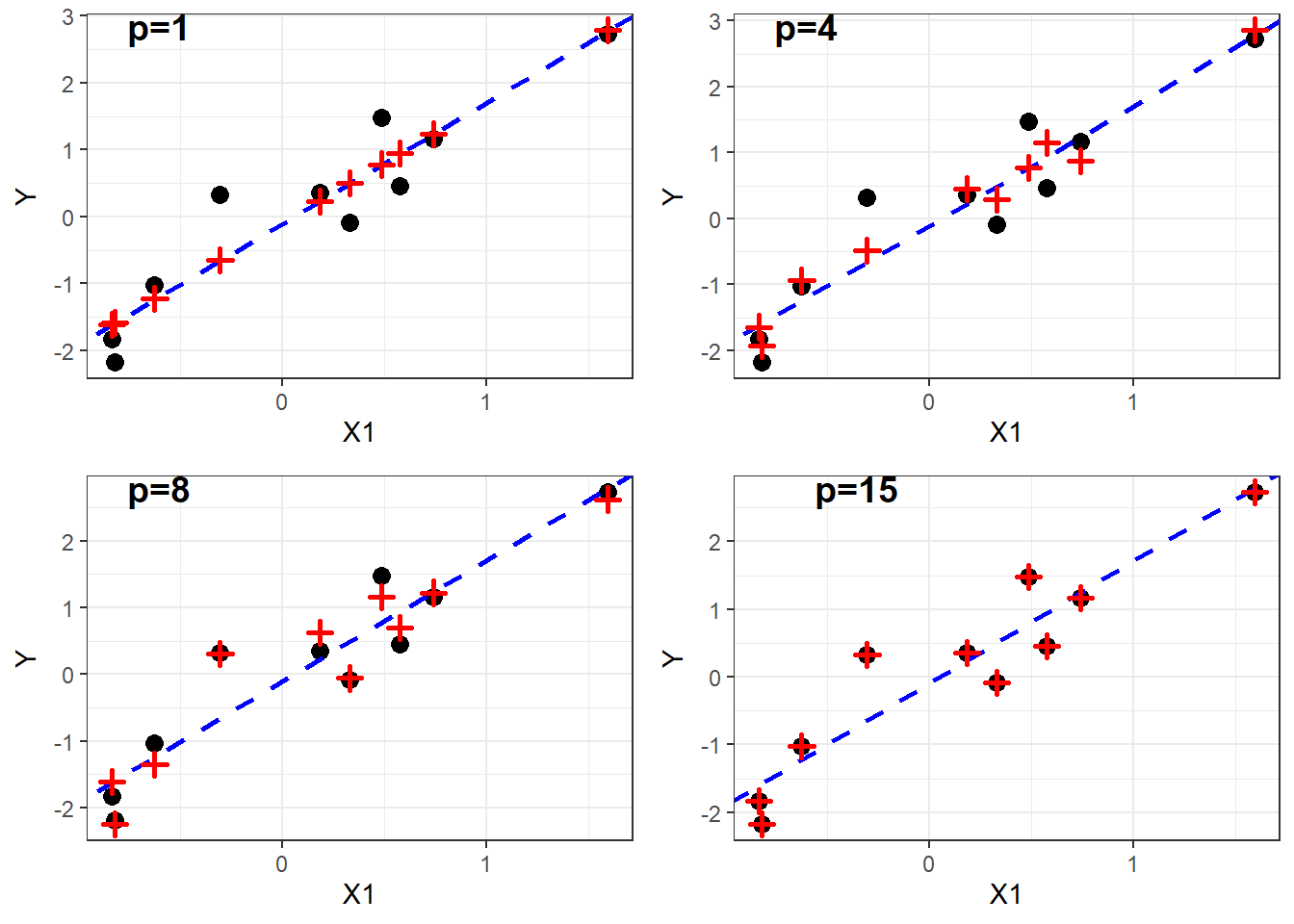
Figure 2.3: Observed and fitted values for models with increasing \(p\).
With increasing \(p\) the fitted values start to deviate from the true model (blue line) and they move closer towards the observed data points. Finally, with \(p=15\), the fitted values match perfectly the data, i.e. the model captures the noise and overfits the data. In line with these plots we note that the R squared values increase with \(p\).
| model | R2 |
|---|---|
| p=1 | 0.88 |
| p=4 | 0.90 |
| p=8 | 0.98 |
| p=15 | 1.00 |
The following figure shows the regression coefficients for the different models. The larger the \(p\), the bigger the discrepancy to the true coefficients.
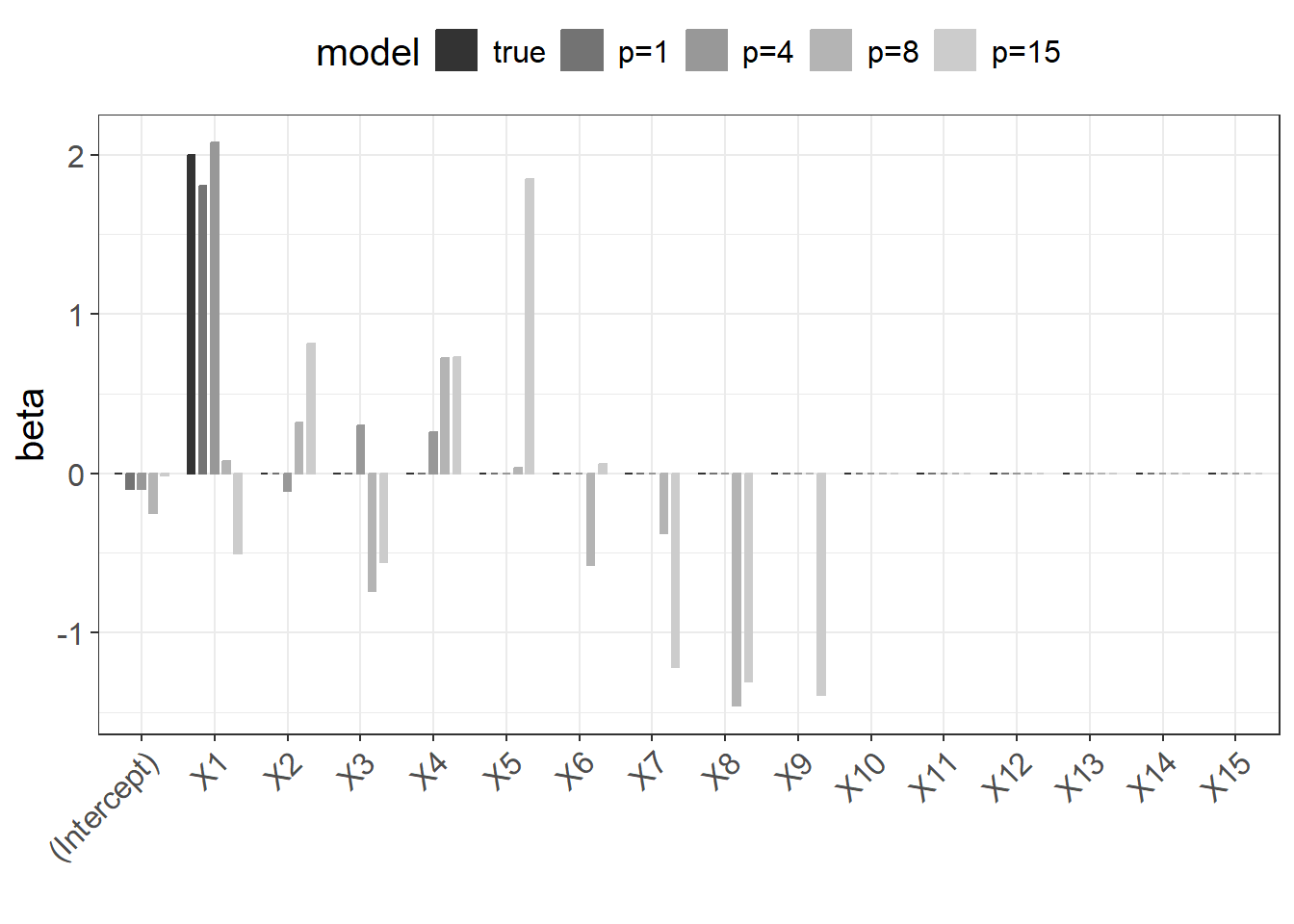
Figure 2.4: Regression coefficients for models with increasing \(p\).
This becomes even more evident when calculating the mean squared error between the estimated and true coefficients.
| mse | |
|---|---|
| p=1 | 0.02 |
| p=4 | 0.04 |
| p=8 | 0.84 |
| p=15 | 1.63 |
The summary of the full model with \(p=15\) indicates that something went wrong.
##
## Call:
## lm(formula = y ~ ., data = dtrain)
##
## Residuals:
## ALL 10 residuals are 0: no residual degrees of freedom!
##
## Coefficients: (6 not defined because of singularities)
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.01592 NaN NaN NaN
## X1 -0.50138 NaN NaN NaN
## X2 0.81492 NaN NaN NaN
## X3 -0.56052 NaN NaN NaN
## X4 0.72667 NaN NaN NaN
## X5 1.84831 NaN NaN NaN
## X6 0.05759 NaN NaN NaN
## X7 -1.21460 NaN NaN NaN
## X8 -1.30908 NaN NaN NaN
## X9 -1.39005 NaN NaN NaN
## X10 NA NA NA NA
## X11 NA NA NA NA
## X12 NA NA NA NA
## X13 NA NA NA NA
## X14 NA NA NA NA
## X15 NA NA NA NA
##
## Residual standard error: NaN on 0 degrees of freedom
## Multiple R-squared: 1, Adjusted R-squared: NaN
## F-statistic: NaN on 9 and 0 DF, p-value: NAThere is a note saying “no residual degrees of freedom”. Furthermore, many entries in the table of coefficients are not available and a note says that coefficients cannot be calculated because of singularities. What has happened? In fact, the OLS estimator as introduced above is not well defined. The design matrix \(\bf X\) is rank deficient (\({\rm rank}({\bf X})=n< p\)) and therefore the matrix \({\bf X}^T {\bf X}\) is singular (not invertible). We can check this by calculating the determinant.
## [1] -2.8449e-81In this simulation exercise we illustrated the problem of overfitting. We have seen that the models with large \(p\) fit the data very well, but the estimated coefficients are far off from the truth. In practice we do not know the truth. How do we know when a model is overfitting and how do we decide what a “good” model is? Shortly we will introduce the Generalization Error which will shed light on this question.
We end this section with the helpful 10:1 rule:
In order to avoid overfitting the number of predictors (or covariates) p should be less than n/10. This rule can be extended to binary and time-to-event endpoints. For binary endpoints we replace \(n\) with \(\min\{n_0,n_1\}\) and for time-to-event with \(n_{\rm events}\).
2.4 Generalization error
The ultimative goal of a good model is to make good predictions for the future. That is we need to assess how the fitted model generalizes beyond the “observed” data. Conceptually, given new input data \(x_{\rm new}\), the model provides a prediction \(\hat{Y}=\hat{f}(x_{\rm new})\). The Generalization Error is the expected discrepancy between the prediction \(\hat{Y}=\hat{f}(x_{\rm new})\) and the actual outcome \(Y_{\rm new}\)
\[{\rm Err}(x_{\rm new})=E[(Y_{\rm new}-\hat{f}(x_{\rm new}))^2].\] One can show that this error can be decomposed into three terms
\[\begin{eqnarray} {\rm Err}(x_{\rm new})&=&\sigma_{\epsilon}^2+{\rm Bias}^2(\hat{f}(x_{\rm new})) + {\rm Var}(\hat{f}(x_{\rm new})), \end{eqnarray}\]
where the first term is the irreducible error (or “noise”), the second term describes the systematic bias from the truth and the third term is the variance of the predictive model. For linear regression the expected variance can be approximated by \(\sigma^2_{\epsilon} \frac{p}{N}\). Complex models (with large number of covariates) have typically a small bias but a large variance. Therefore the equation above is referred to as the bias-variance dilemma as it describes the conflict in trying simultaneously minimize both sources of error, bias and variance.
How do we calculate the Generalization Error in practice? The most simple approach is to separate the data into a training and testing set (see Figure 2.5). The model is fitted (or “trained”) on the training data and the Generalization Error is calculated on the test data and quantified using the root-mean-square error (RMSE)
\[ {\rm RMSE}= \sqrt{\frac{\sum_{i=1}^{n_{\rm test}}(y_{\rm test,i}-\hat y_{i})^2}{n_{\rm test}}}.\]

Figure 2.5: Splitting the data into training set and test sets.
We illustrate this based on the dummy data. First we simulate test data.
# simulate test data
xtest <- matrix(rnorm(n*p),n,p)
ytest <- xtest%*%beta+rnorm(n,sd=0.5)
dtest <- data.frame(xtest)
dtest$y <- ytestNext, we take the fitted models and make predictions on the test data
# prediction
pred1 <- predict(fit1,newdata = dtest)
pred4 <- predict(fit4,newdata = dtest)
pred8 <- predict(fit8,newdata = dtest)
pred15 <- predict(fit15,newdata = dtest)and we calculate the RMSE.
# rmse
rmse <- data.frame(
RMSE(pred1,ytest),RMSE(pred4,ytest),
RMSE(pred8,ytest),RMSE(pred15,ytest)
)
colnames(rmse) <- paste0("p=",c(1,4,8,15))
rownames(rmse) <- "RMSE"
kable(rmse,digits=2,booktabs=TRUE,
caption="RMSE for models with increasing p.")| p=1 | p=4 | p=8 | p=15 | |
|---|---|---|---|---|
| RMSE | 0.54 | 0.63 | 3.28 | 3.7 |
The models with \(p=1\) and \(4\) achieve a good error close to the “irreducible” \(\sigma_{\epsilon}\). On the other hand the predictions obtained with \(p=8\) and \(15\) are very poor (RMSEs are 6 to 8-fold larger).
2.5 Model selection
We will shortly see that the approaches which we introduce do not only fit one single model but they explore a whole series of models (indexed as \(m=1,\ldots,M\)). Model selection refers to the choice of an optimal model achieving a low generalization error. A plausible approach would be to fit the different models to the training data and then select the model with smallest error on the test data. However, this is an illegitimate approach as the test data has to be kept untouched for the final evaluation of the selected model. Therefore we guide model selection by approximating the generalization error using training data only. We review now two such approximations, namely, cross-validation and the Akaike information criterion (AIC).
K-fold cross-validation approximates the prediction error by splitting the training data into K chunks as illustrated below (here \(K=5\)).
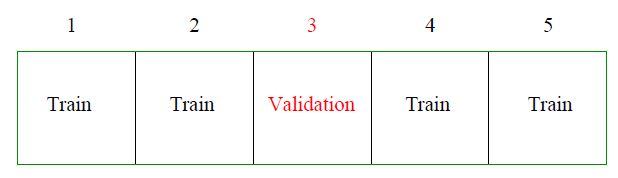
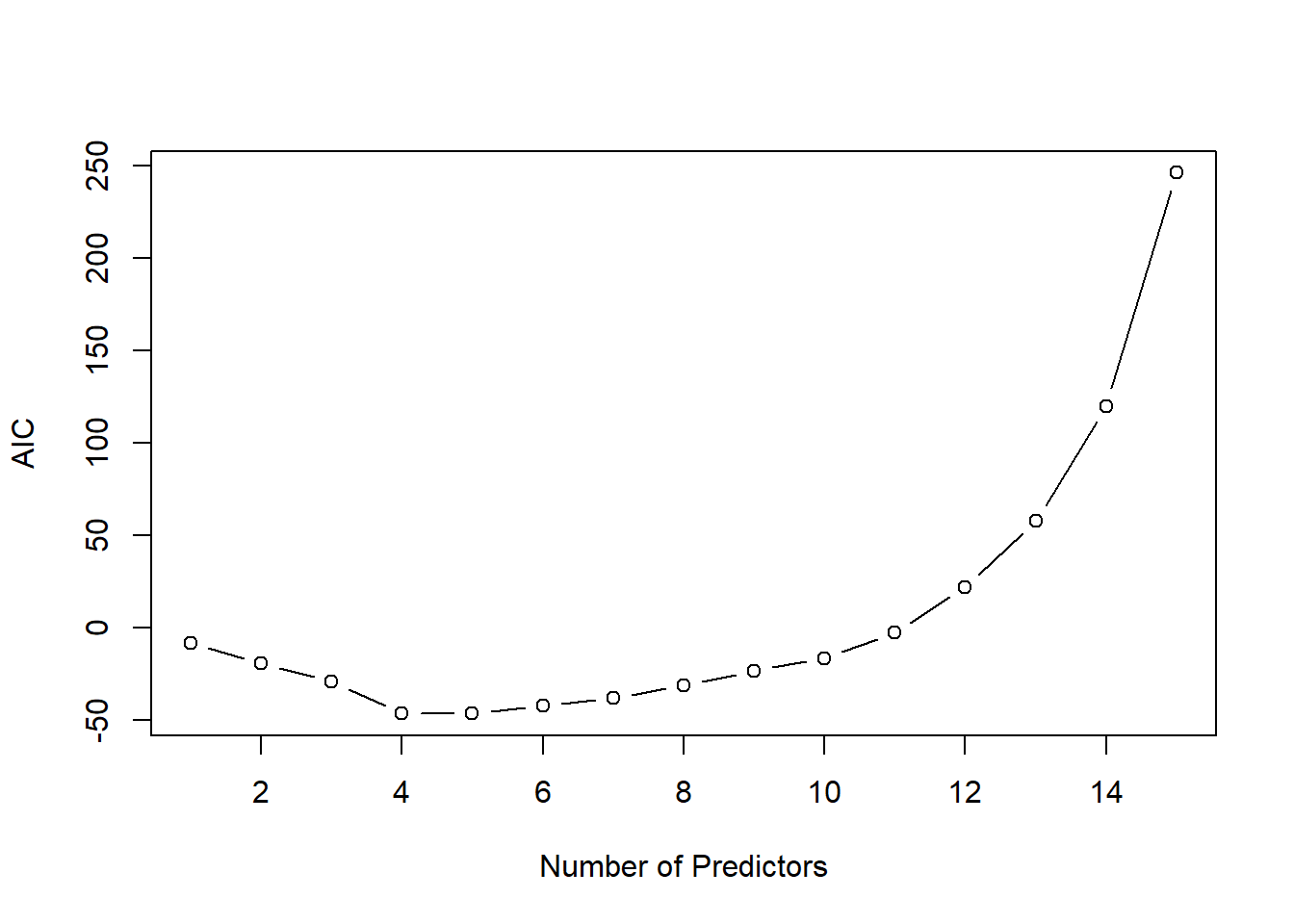
Each chunk is then used as “hold-out” validation data to estimate the error of \(m\)th model trained on the other \(K-1\) data chunks. In that way we obtain \(K\) error estimates and we typically take the average as the cross-validation error of model \(m\) (denoted by \({\rm CV}_m\)). The next plot shows a typical cross-validation error plot. This curve attains its minimum at a model with \(p_m=4\) (\(p_m\) is the number of included predictors in model \(m\)).
The AIC approach is founded in information theory and selects the model with smallest AIC
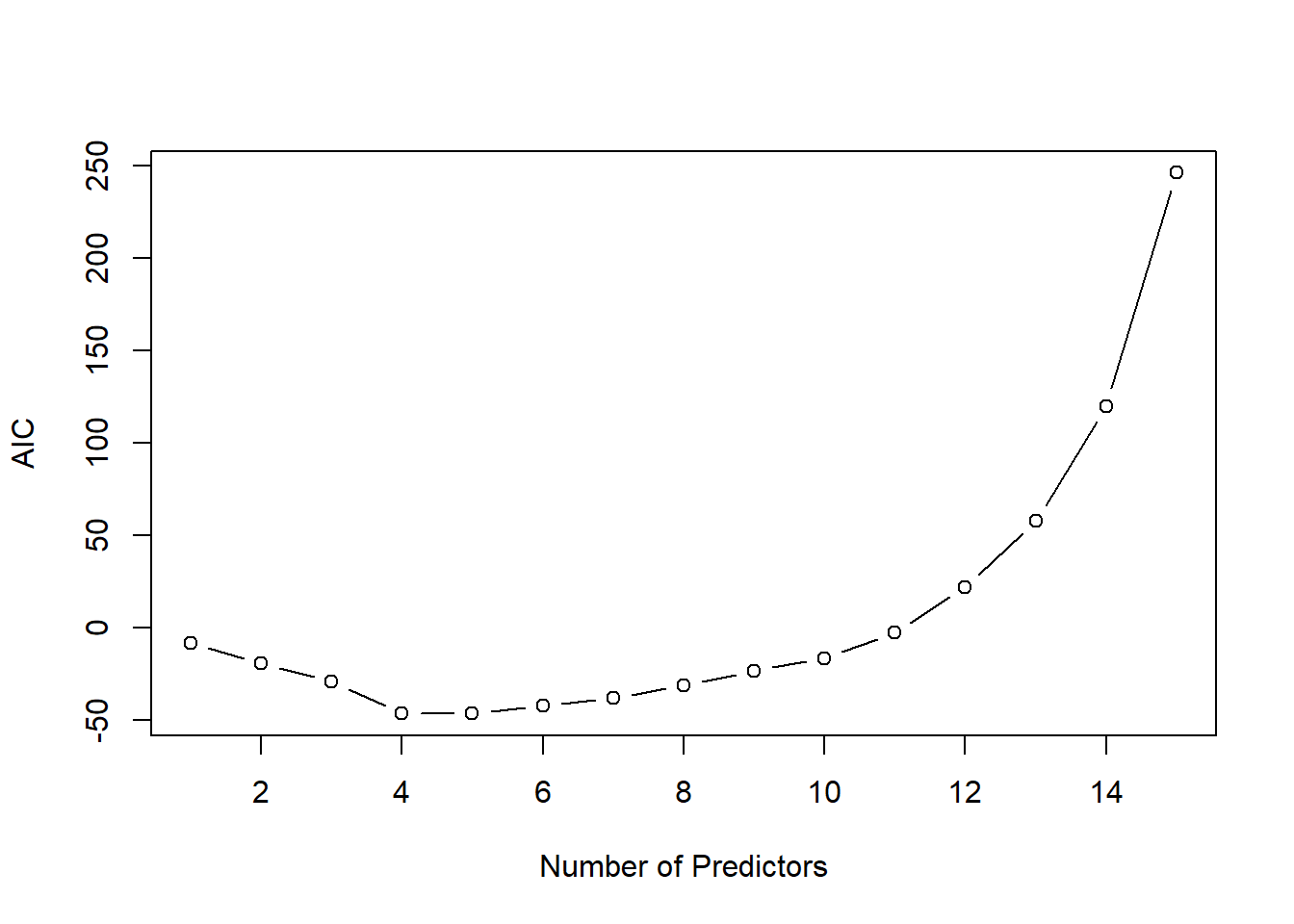
\[ {\rm AIC}_m=-2\;{\rm loglik}+2\;p_{m}. \] Thus, AIC rewards goodness of fit (as assessed by the likelihood function loglik) and penalizes model complexity (by the term \(2 p_m\)). The figure below shows for the same example the AIC curve. Also the AIC approaches suggests to use a model with \(p_m=4\) predictors.
2.6 Subset- and stepwise regression
We have seen that multiple regression falls short in the high-dimensional context. It leads to overfitting and as a result in large estimates of regression coefficients. Augmentation of the least-squares optimization with constraints on the regression coefficients can decrease the risk of overfitting. In the following we will discuss methods which minimize the residual sum of squares, \(\rm{RSS}(\beta)\), under some constraints on the parameter \(\beta\).
The most common approach to impose constraints is subset selection. In this approach we retain only a subset of the variables, and eliminate the rest from the model. OLS is used to estimate the coefficients of the inputs that are retained. More formally, given a subset \(S\subset\{1,\ldots,p\}\) we solve the optimization problem
\[ \hat{\beta}_{S}=\text{arg}\!\!\!\!\!\min\limits_{\beta_j=0\;\forall j\notin S}\!\!\!\textrm{RSS}(\beta). \]
It is easy to show that this is equivalent to OLS regression based on subset \(S\) covariates, i.e.
\[ \hat{\beta}_{S}=(\textbf{X}_S^T \textbf{X}_S)^{-1}\textbf{X}_S^T \textbf{y}. \]
In practice we need to explore a sequence of subsets \(S_1,\ldots,S_M\) and choose an optimal subset by either a re-sampling approach or by using an information criterion (see Section 2.5). There are a number of different strategies available. Best subsets regression consists of looking at all possible combinations of covariates. Rather than search though all possible subsets, we can seek a good path through them. Two popular approaches are backward stepwise regression which starts with the full model and sequentially deletes covariates, whereas forward stepwise regression starts with the intercept, and then sequentially adds into the model the covariate that most improves the fit.
In R we can use regsubsets from the leaps package or stepAIC from the MASS package to perform subset- and stepwise regression. For example to perform forward stepwise regression based on AIC we proceed as follows.
# Forward regression
fit0 <- lm(y~1,data=dtrain)
up.model <- paste("~", paste(colnames(dtrain[,-(p+1)]), collapse=" + "))
fit.fw <- stepAIC(fit0,
direction="forward",
scope=
list(lower=fit0,
upper=up.model)
,
trace = FALSE
)We can summarize the stepwise process.
kable(as.data.frame(fit.fw$anova),digits=3,booktabs=TRUE
,caption="Inclusion of covariates in forward stepwise regression.")| Step | Df | Deviance | Resid. Df | Resid. Dev | AIC |
|---|---|---|---|---|---|
| NA | NA | 9 | 22.468 | 10.095 | |
| + X1 | 1 | 20.017 | 8 | 2.450 | -10.064 |
| + X4 | 1 | 0.883 | 7 | 1.567 | -12.535 |
| + X9 | 1 | 0.376 | 6 | 1.191 | -13.277 |
Finally we can retrieve the regression coefficients of the optimal model. Note that the p-values reported in Table 2.5 are invalid.
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 0.210 | 0.157 | 1.334 | 0.231 |
| X1 | 1.611 | 0.243 | 6.624 | 0.001 |
| X4 | -0.508 | 0.205 | -2.475 | 0.048 |
| X9 | -0.322 | 0.234 | -1.376 | 0.218 |