5 Plots in 2.3 and 2.4 with base R
This section will show you (one way of) how to generate those plots in Slide 2.3&2.4 with base R.
5.1 Set up
We will be using the StudentSurvey dataset from Lock5withR package for the first couple of plots and again, using dotPlot() from mosaic package, HotDogs, ImmuneTea datasets from Lock5withR are used for boxplots.
Also, a dataset named Default from ISLR is used in side-by-side graphs.
library(Lock5withR)
library(mosaic)
library(ISLR)
library(latex2exp)5.2 Histogram of pulse data from StudentSurvey
Get the pulse data from StudentSurvey.
dataPulse = Lock5withR::StudentSurvey$Pulse5.2.1 mean and standard devation
meanPulse = mean(dataPulse)
stdPluse= sd(dataPulse)
hist(dataPulse, breaks = seq(35,135,5),
ylim=c(0,75), xlim=c(30,135), main='', xlab='Pulse',
right=TRUE, xaxt="n", yaxt="n")
axis(side = 1, at = seq(30,135,10))
axis(side = 2, at = seq(0,80,10))
abline(h=seq(0,80,5), col="gray", lty=3)
abline(v=seq(meanPulse-2*stdPluse,meanPulse+2*stdPluse,stdPluse), lty=2, col='red')
text(x=seq(meanPulse-2*stdPluse,meanPulse+2*stdPluse,stdPluse),
y= rep(75,5),
c(TeX(r'($\bar{x}-2s$)'),TeX(r'($\bar{x}-s$)'),TeX(r'($\bar{x}$)'),TeX(r'($\bar{x}+s$)'),TeX(r'($\bar{x}+2s$)')))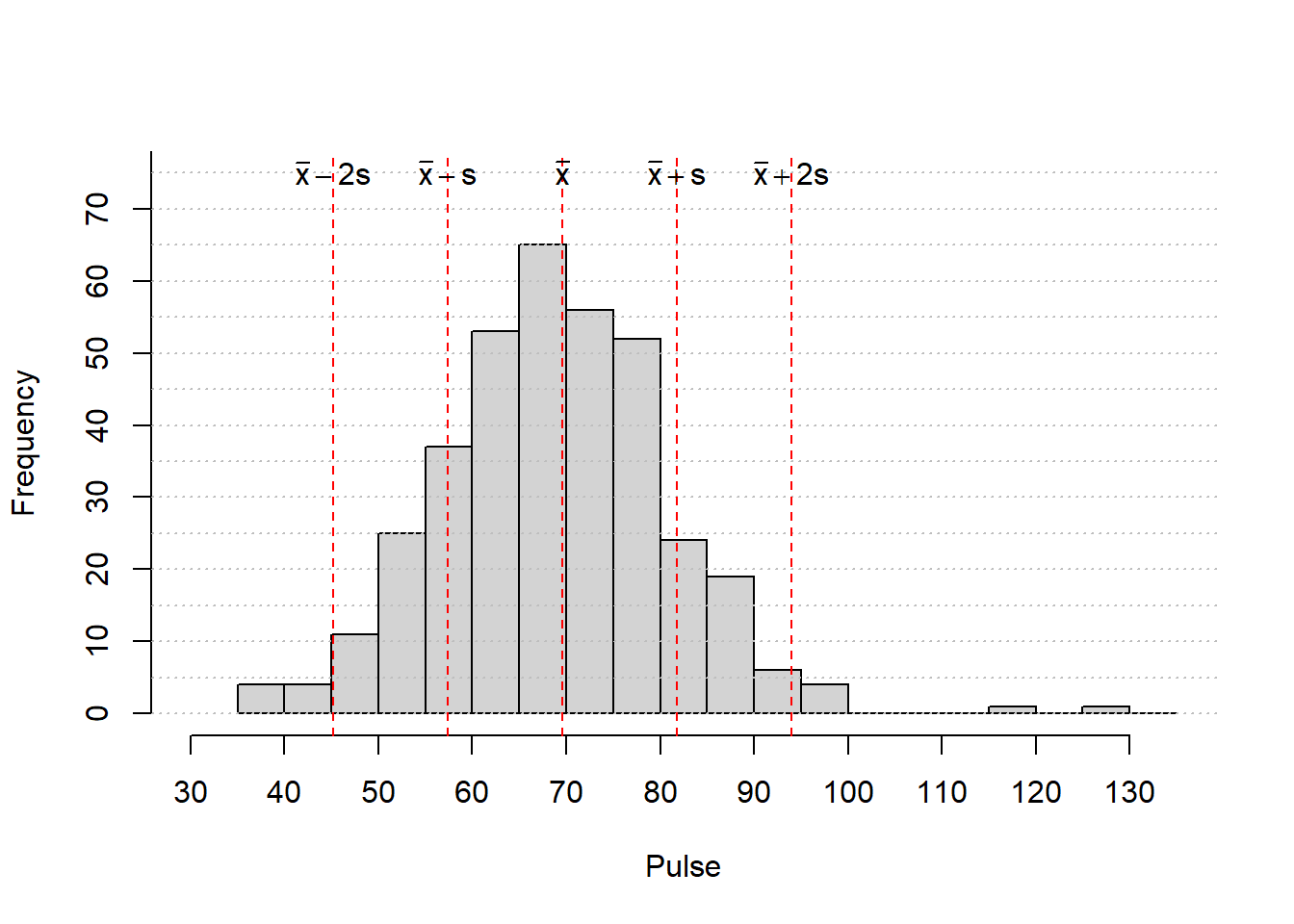
when giving breakpoints, the default for R is that the histogram cells are right-closed (left open) intervals of the form (a,b]. We can change this with the right=FALSE option, which would change the intervals to be of the form [a,b).
5.2.2 The 95% rule
If a distribution of data is approximately symmetric and bell-shaped, about 95% of the data should fall within two standard deviations of the mean.
hist(dataPulse, breaks = seq(35,135,5),
ylim=c(0,75), xlim=c(30,135), main='', xlab='Pulse',
right=FALSE, xaxt="n", yaxt="n")
axis(side = 1, at = seq(30,135,10))
axis(side = 2, at = seq(0,80,10))
abline(h=seq(0,80,5), col="gray", lty=3)
abline(v=c(42.5, 97.5), lty=2, col='blue')
text(x=42.5-4, y = 60, 42.5)
text(x=97.5+4, y = 60,97.5)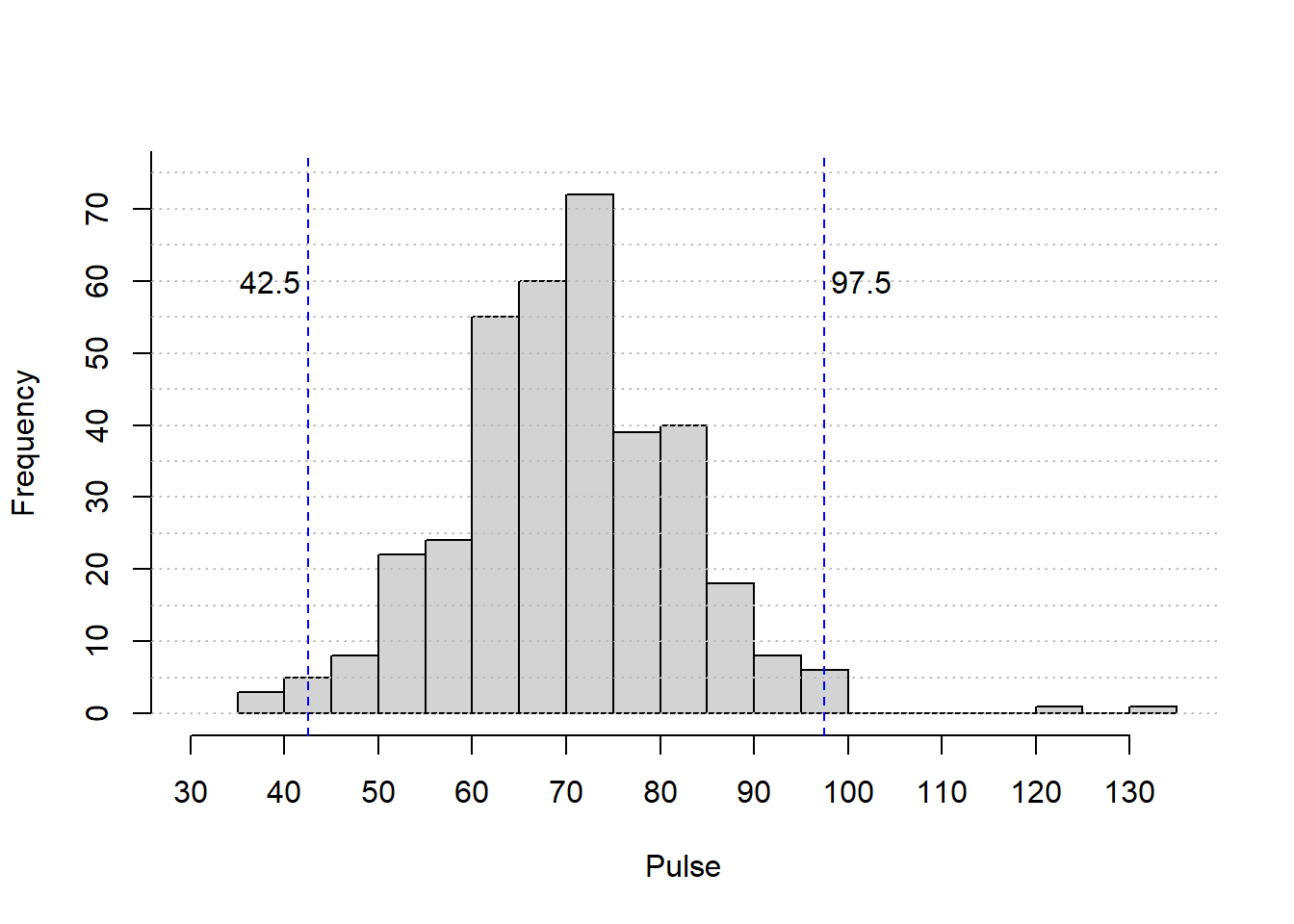
- The sample mean is approximately \(\bar{x} = 70\) (actual sample mean is \(\bar{x} = 69.6\))
- The sample standard deviation is approximately \(s = (95 - 40)/4 = 13.75\), where we guessed that 95% of the data values were between 40 and 95(actual sample standard deviation is \(s = 12.2\)).
- Hence, we expect 95% of the pulse rates in this sample to be in the interval \((\bar{x}-2s, \bar{x}+2s,) = (70 - 27.5, 70 + 27.5) = (42.5, 97.5)\)
Note: a range of values are possible here, but they should be similar to this one.
5.2.3 25th and 50th percentiles
The Pth percentile is the value of a quantitative variable which is greater than P percent of the data.
Let’s use the same histogram of the pulse rates to estimate the 25th and 50th percentiles.
hist(dataPulse, breaks = seq(35,135,5),
ylim=c(0,75), xlim=c(30,135), main='', xlab='Pulse',
right=FALSE, xaxt="n", yaxt="n")
axis(side = 1, at = seq(30,135,10))
axis(side = 2, at = seq(0,80,10))
abline(h=seq(0,80,5), col="gray", lty=3)
abline(v=quantile(dataPulse, c(.25, .5)),lty=2, col='green')
text(x=quantile(dataPulse, 0.25)-3, y = 75, quantile(dataPulse, 0.25))
text(x=quantile(dataPulse, 0.50)+3, y = 75, quantile(dataPulse, 0.50))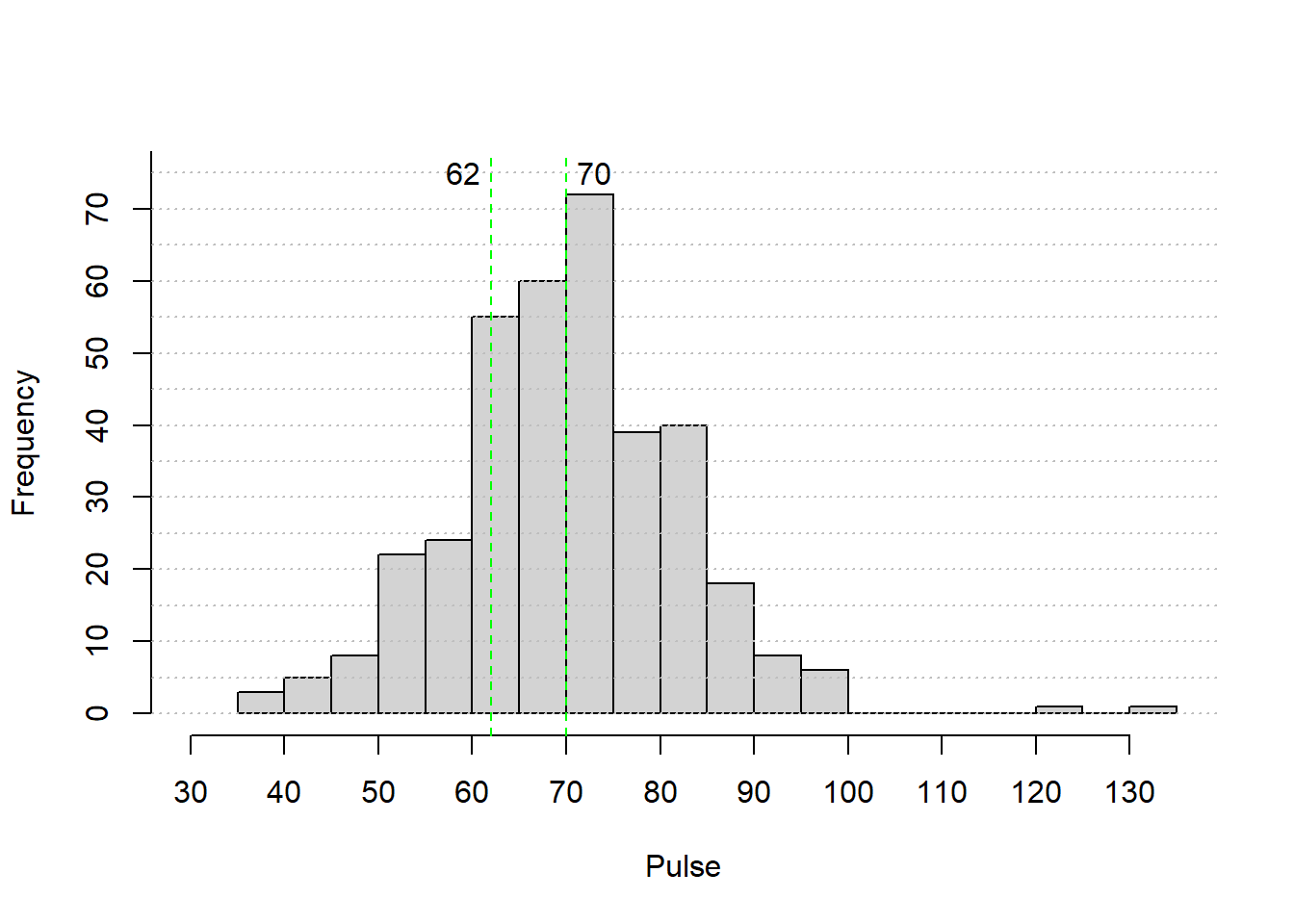
- For the 50th percentile (the median), we want to find the middle of the data (half the cases are above the median and half are below). Our guess, based on the histogram, is 70 (somewhere between 60 and 75 is fine - the actual value is 70).
- For the 25th percentile, we need to find a value for which 25% of the data values are below it and 75% are above it. Our guess, based on the histogram, is 55 (somewhere between 50 and 70 is fine - the actual value is 62).
5.3 Dotplot of exercise hours data from StudentSurvey
Randomly select 100 exercise hours data9 from the StudentSurvey, set a seed10 so the result is consistent.
set.seed(11)
dataExer <- sample_n(Lock5withR::StudentSurvey %>%
filter(is.na(Exercise) == FALSE) %>%
select(Exercise), 100)
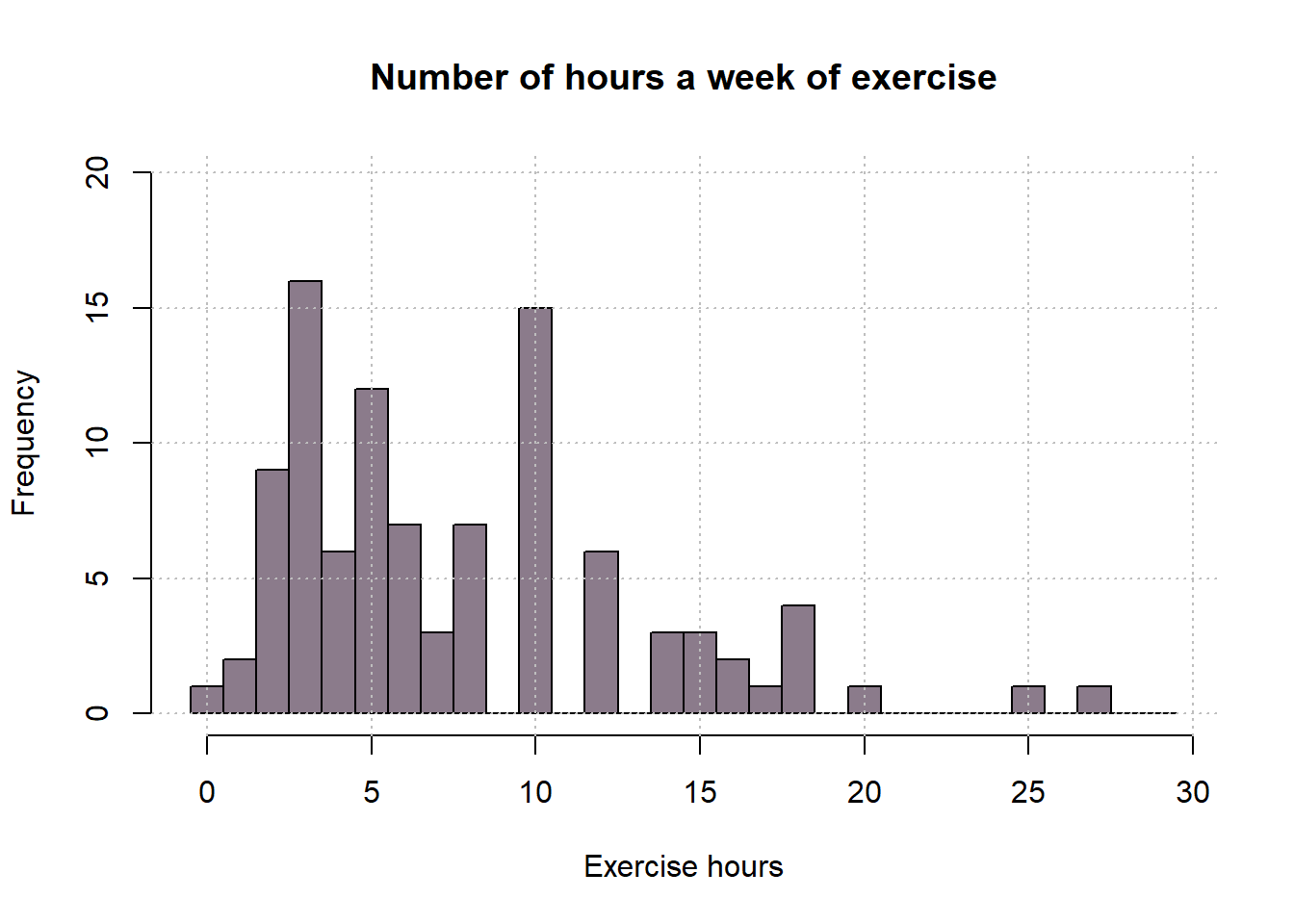
dataExer <- arrange(dataExer, Exercise)5.3.1 Distribution
exerciseDot <- dotPlot(dataExer[1:100,],
breaks=seq(-0.5, 29.5, by=1),
main='Number of hours a week of exercise',
xlab = 'Exercise hours', ylab='Frequency', col='thistle4')
exerciseDot$x.scales$tick.number = 10
exerciseDot$y.limits=c(-2,20)
exerciseDot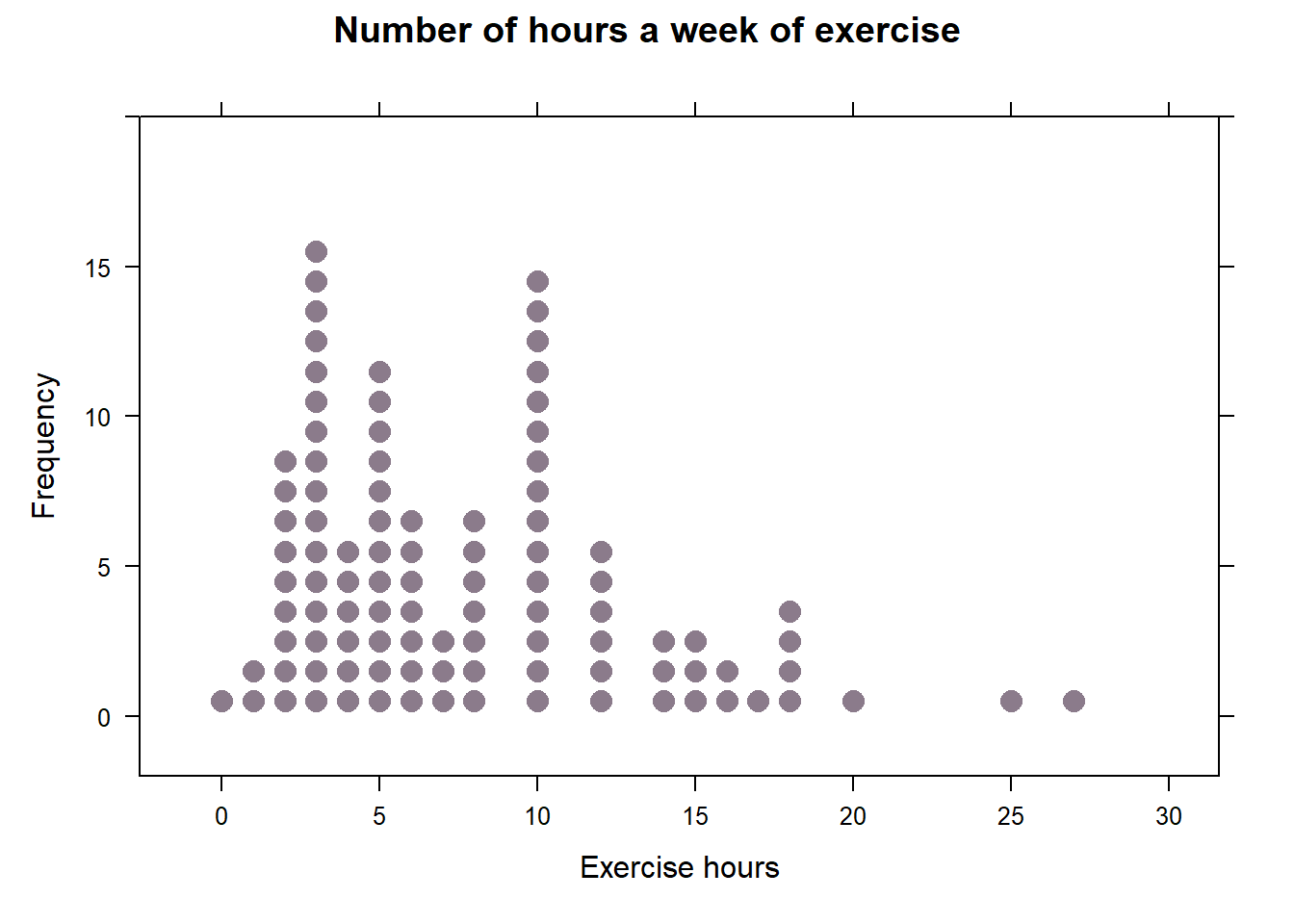
5.3.2 5th and 90th percentiles
Since there are 100 cases, the 5th percentile is the 5th dot from left, likewise, 90th percentile is the 11th dot from right.
exerciseDot$panel = function(x, y, ...){
panel.dotPlot(dataExer[1:100,],
breaks=seq(-0.5, 29, by=1),right=TRUE,
main='Number of hours a week of exercise',
xlab = 'Exercise hours', ylab='Frequency', col='thistle4')
panel.dotPlot(dataExer[5,1],breaks=seq(-0.5, 29.5, by=1),col='red',right=TRUE)
panel.dotPlot(dataExer[90,1],breaks=seq(-0.5, 29.5, by=1),col='blue',right=TRUE)
}
exerciseDot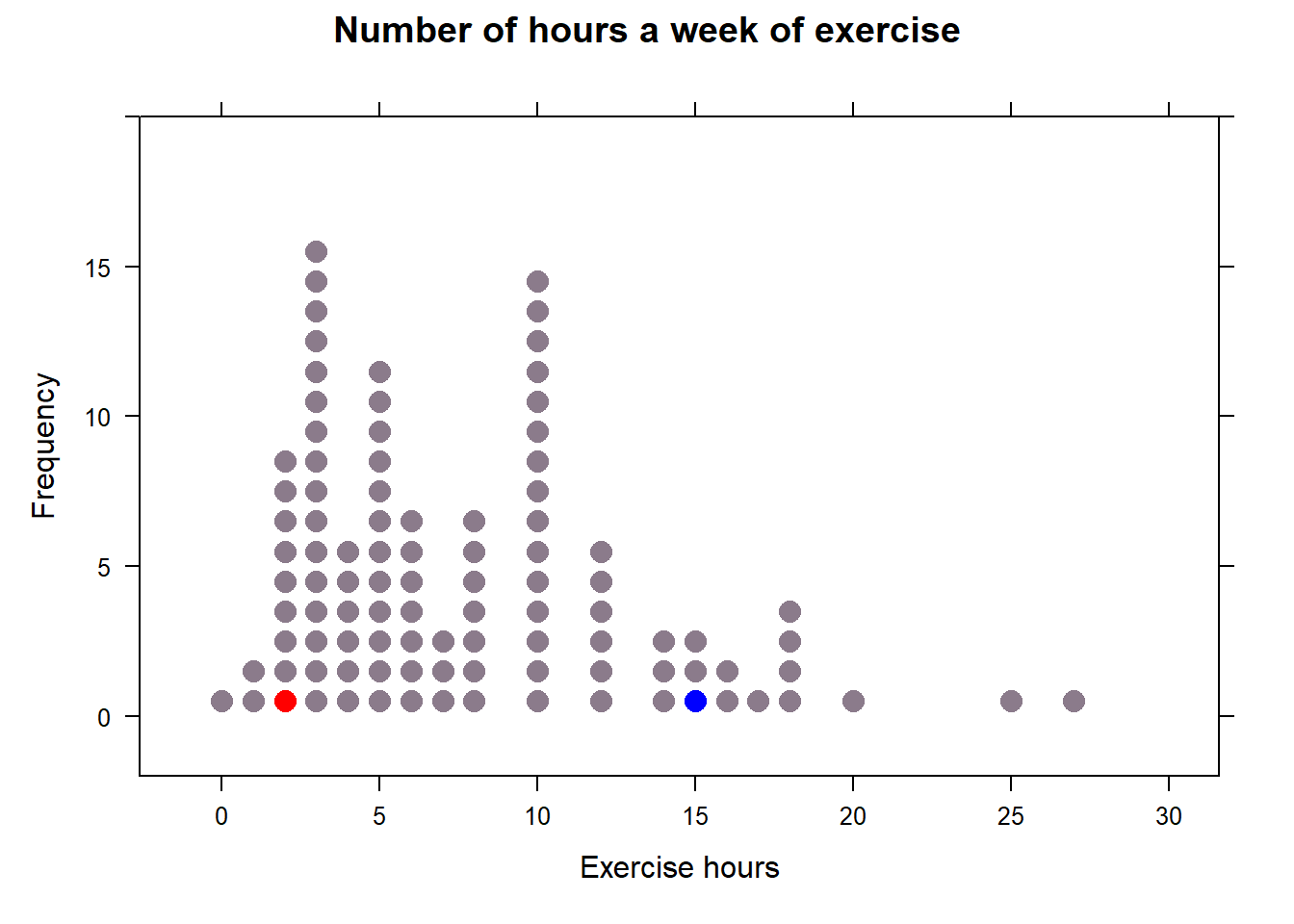 Note, since the 3rd to 8th percentile has the same value in this case, so the red dot is not in exact 5th place. Same situation for the blue dot. We can fix this problem by using
Note, since the 3rd to 8th percentile has the same value in this case, so the red dot is not in exact 5th place. Same situation for the blue dot. We can fix this problem by using plot_ly() in the next chapter.
5.4 Boxplots
5.4.1 World Gross of all Hollywood movies in 2011
Remember which three movies have the top gross?
boxMovie <- boxplot(HollywoodMovies2011$WorldGross,
horizontal = TRUE, main='All Hollywood Movies in 2011',
xlab='World gross (in millions of dollars)')
abline( v=seq(0,1400,200), col="gray", lty=3)
# outliers
outNum = length(boxMovie$out)
outx <- 800
outy <- 0.7
text(outx,outy, paste('Outliers(',outNum,')',sep=''))
arrows(x0=rep(outx, outNum), y0=rep(outy+0.05,outNum),
x1=boxMovie$out[1:outNum], y1= 0.95,
length=0.1)
# top 3
topx <- 1100
topy <- 1.3
text(topx,topy, 'Top 3 World Gross')
arrows(x0=seq(topx+20,topx-20,by=-20), y0=rep(topy-0.05,3),
x1=sort(boxMovie$out,decreasing = TRUE)[1:3], y1= 1.05,
length=0.1)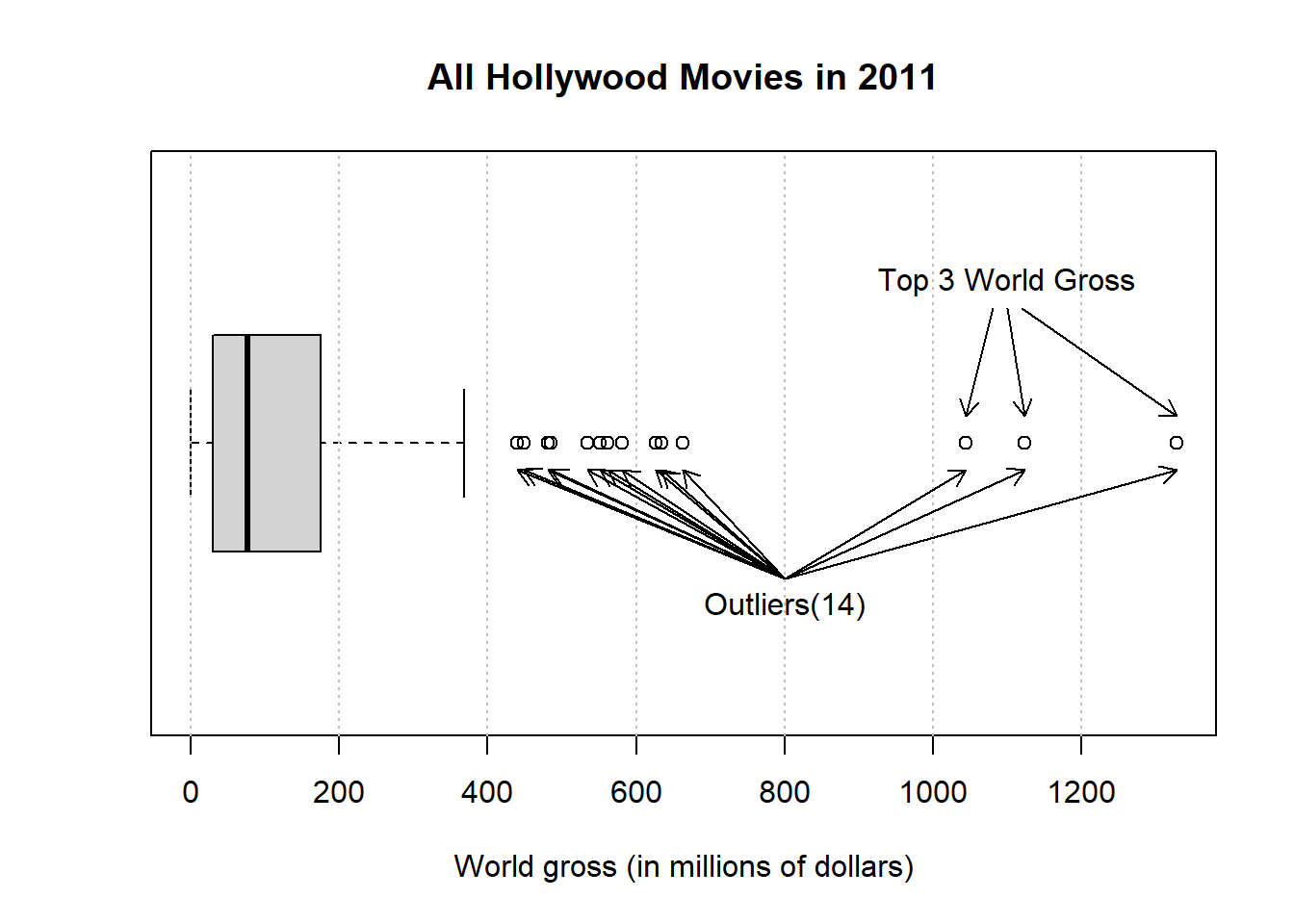
5.4.2 Hot Dog Eating
How many hot dogs can you eat in 10 minutes?
The boxplot below shows the number of hot dogs eaten by the winners of Nathan’s Famous hot dog eating contest 2002-2015.11
boxHD<- boxplot(HotDogs$HotDogs, horizontal = TRUE, ylim=c(44,71),
main='Hot Dog Eating', xlab='Hot Dogs Consumed')
abline( v=seq(45,70,5), col="gray", lty=3)
# m, Q3, Q1
text(x=boxHD$stats[2:4,], y=rep(1.3,3),
c(paste('Q1(',boxHD$stats[2,],')',sep=''),
paste('median(',boxHD$stats[3,],')',sep=''),
paste('Q3(',boxHD$stats[4,],')',sep='')))
# IQR
text(x=boxHD$stats[3,], y= 1.45,
paste('IQR=Q3-Q1=',boxHD$stats[4,]-boxHD$stats[2,], sep=''))
# max, min
text(x=boxHD$stats[c(1,5),], y=rep(0.8,2),
c(paste('min(',boxHD$stats[1,],')',sep=''),
paste('max(',boxHD$stats[5,],')',sep='')))
# range
text(x=57, y= 0.65,
paste('range=max-min=',boxHD$stats[5,]-boxHD$stats[1,], sep=''))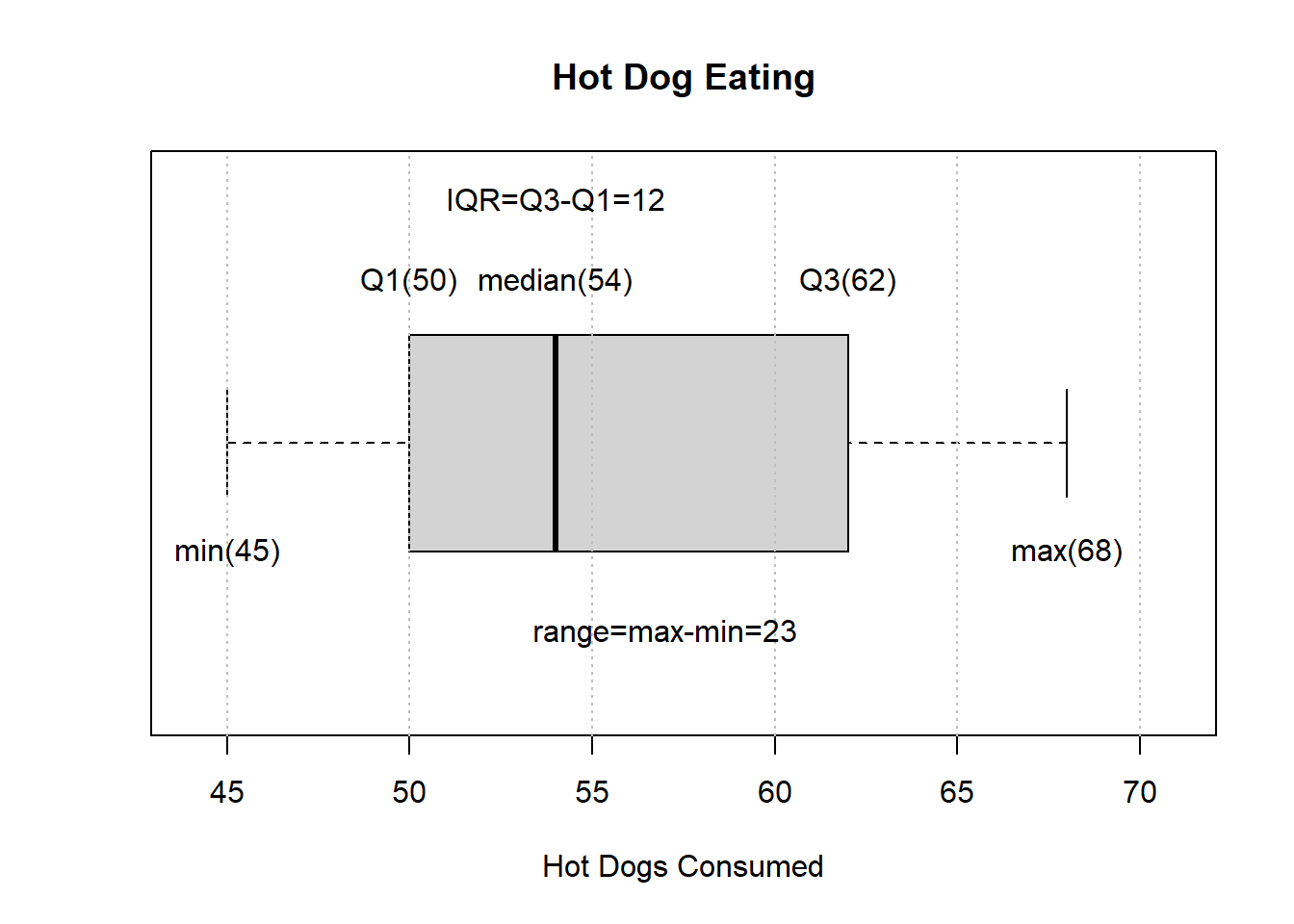
5.5 Side-by-side Graphs
One of the best ways to visualise differences in groups is to use side-by-sideplots (dotplots, histograms, or boxplots), where each plot uses a commonnumerical axis.
5.5.1 Higher SAT Vs. TV hours
Who watches more TV, students that score higher on their Math or English exam? The variables of interest here are TV (quantitative variable for the number of hours spent watching TV per week) and Best Exam (categorical variable with two categories: Math and Verbal). This data comes from the StudentSurvey dataset, where the participants are students.12
- Side-by-side boxplot allow us to easily compare the median,IQR and the range of the groups.
- Side-by-side dotplot/histogram allow us to compare the shape,central tendency and the variability of the groups.
survey <- na.omit(Lock5withR::StudentSurvey[c("HigherSAT", "TV")])
survey <- survey[survey$HigherSAT != "",]
satTVDot <- mosaic::dotPlot(survey$HigherSAT ~
survey$TV|survey$HigherSAT,
xlab='TV Hours',
breaks = seq(0,40,1), layout=c(1,2))
satTVBox <- bwplot(survey$HigherSAT ~ survey$TV,
xlab='TV Hours', ylab='HigherSAT',
horizontal = TRUE, fill='grey')
print(satTVBox, position = c(0, 0, 0.5, 1), more = TRUE)
print(satTVDot, position = c(0.5, 0, 1, 1))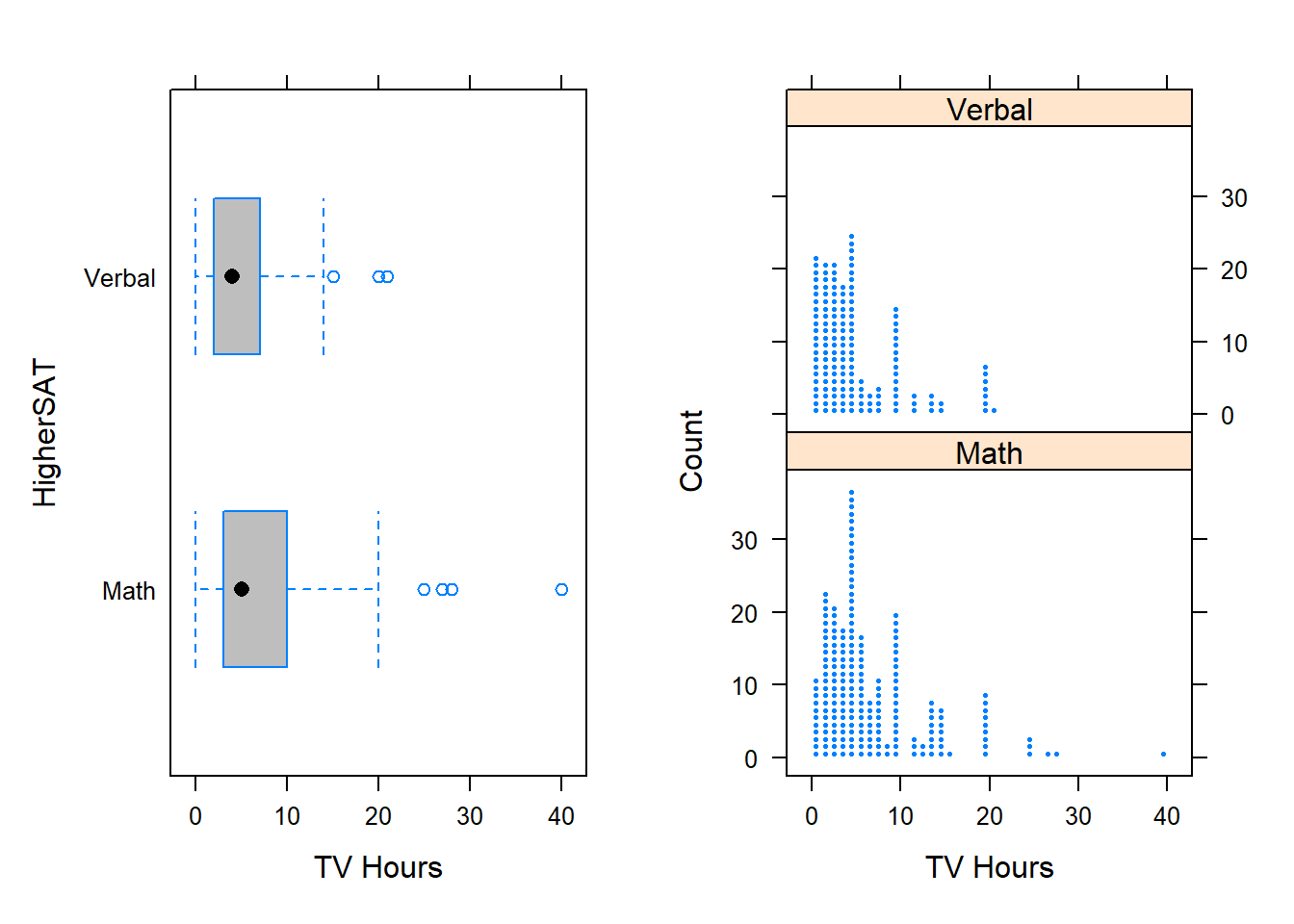
Many observations can be made about the distributions, let’s list some below:
- Using the side-by-side boxplots (or dotplots), we see that both distributions are skewed to the right (the data values are piled up on the left). The skew is greater for Math, so the mean will likely be higher for Math.
- There are outliers for both Math and Verbal (students that watch a lot of TV)
- The medians are similar
- The IQR is larger for Math than Verbal.
- For Verbal, students in the study that watched more than approximately 10hours of TV were considered outliers. However, for Math, outliers weregreater than 20 hours of TV.
5.5.2 Credit Card Default Data
5.5.2.1 Income of defaulters
Customers that defaulted on their credit card payments (Default = Yes) and their annual Income. 13
bwplot(Default$default~Default$income, horizontal = TRUE,
main='Income of Credit Card Defaulters',
xlab='Income($)', ylab='Default',
par.settings = list(
plot.symbol = list(col= c("black", "black")),
box.rectangle = list(col= c("blue", "red"),
fill= c('blue', 'red'),
alpha=0.2),
box.umbrella = list(col= c("blue", "red")),
box.dot = list(col= c("blue", "red"))))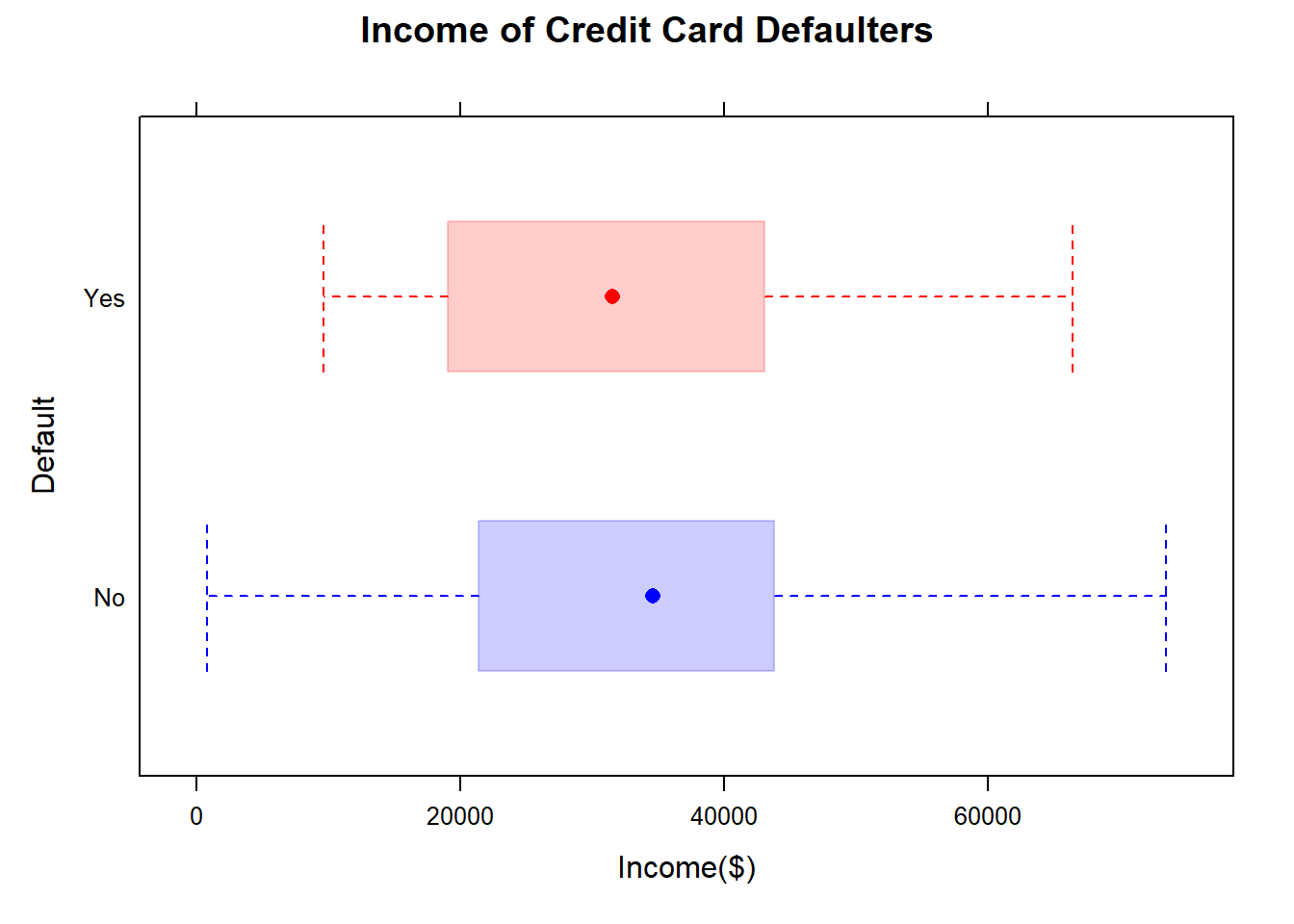
Here is another example of side-by-side boxplots. The credit card dataset contains a number of variables including whether a person has defaulted on their credit card payments (categorical variable: Default = Yes or Default = No)and their annual income (quantitative variable). The side-by-side boxplots show that the distributions of annual income for defaulters and non-defaulters are similar (we cannot differentiate defaulters and non-defaulters based on annual income). The medians and IQR are similar, but the range for non-defaulters is larger.
5.5.2.2 Balance of defaulters
- Customers that defaulted on their credit card payments (Default = Yes) and the average Balance that the customer had remaining on their credit card after making their monthly payment. 14
bwplot(Default$default~Default$balance, horizontal = TRUE,
main='Balance of Credit Card Defaulters',
xlab='Balance($)', ylab='Default',
par.settings = list(
plot.symbol = list(col= c("black", "black")),
box.rectangle = list(col= c("blue", "red")),
box.umbrella = list(col= c("blue", "red")),
box.dot = list(col= c("blue", "red"))))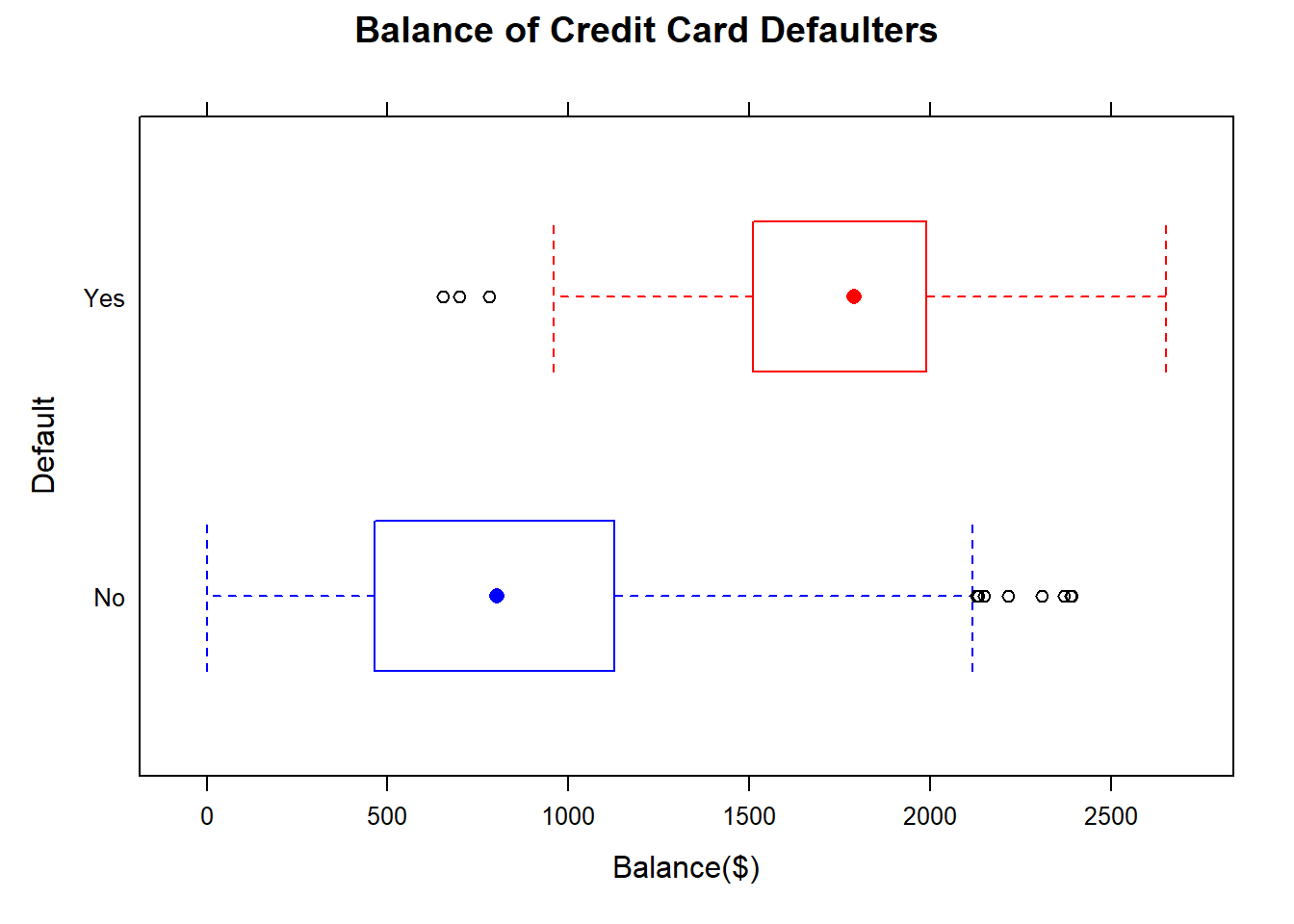
Another quantitative variable in the credit card dataset is Balance - the average balance that the customer had remaining on their credit card account after making their monthly payment. The side-by-side boxplots show that the distributions of Balance for defaulters and non-defaulters are very different.The median for defaulters is much larger than the median for non-defaulters,the IQRs do not overlap and outliers were present in both groups.Unsurprisingly, customers with larger credit card balances in these data were more likely to default on their monthly payments.
5.5.2.3 Income of students non-students
- Side-by-side histograms allow us to compare the shape, central tendency, and the variability of the students or non-students based on their Income.15
histogram(Default$student~Default$income|Default$student, type='count',
xlab='Income($)', main='Income of Students and non-students',
ylab='Count',
breaks=seq(0,80000,1250), layout=c(1,2),right=FALSE)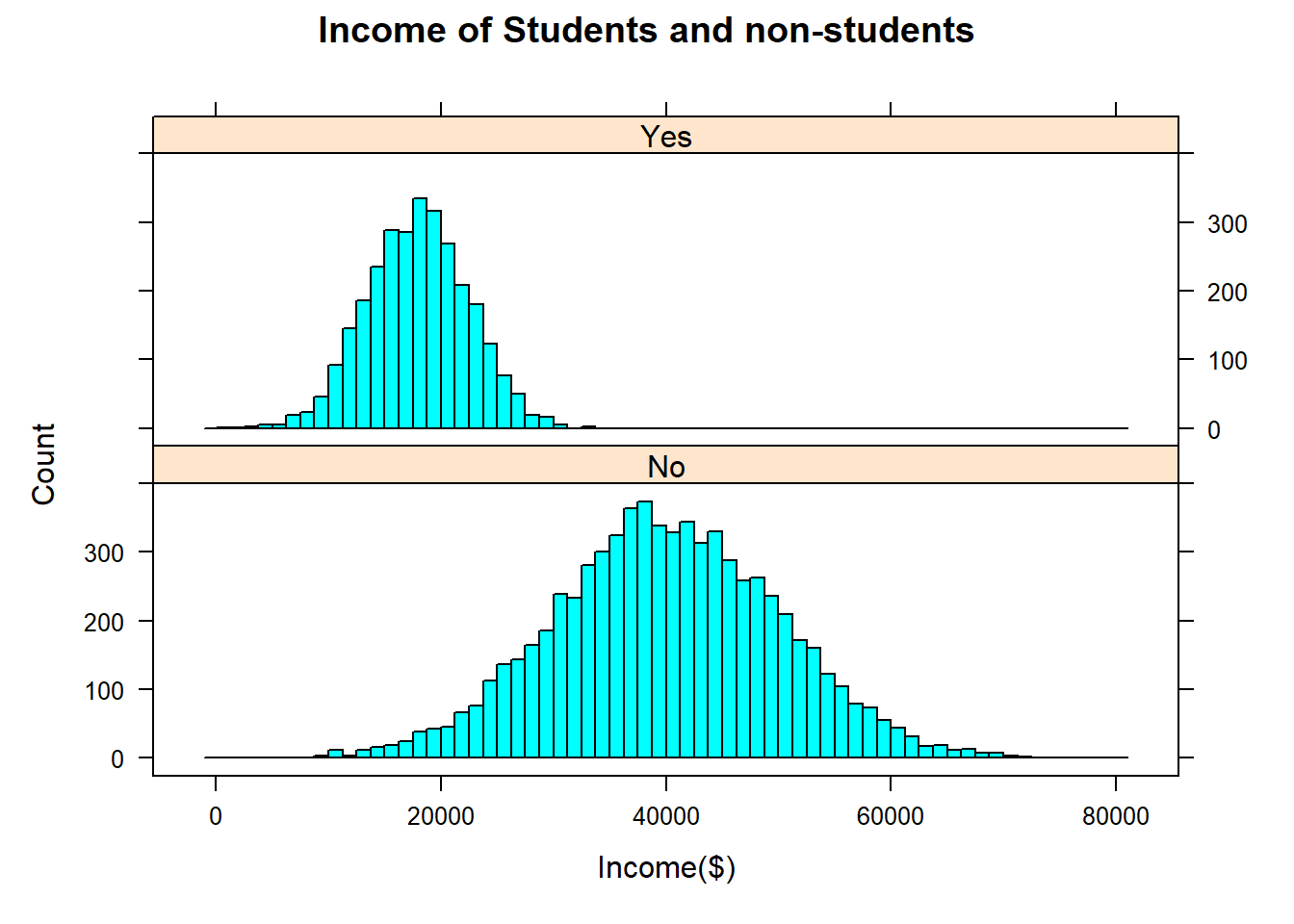
Another categorical variable in the credit card dataset is Student – whether the credit carder holder is a student or not (Student = Yes or Student = No).The side-by-side histograms show that the distributions of annual income for students and non-students are different, but they do have similar shapes(both are symmetric and bell-shaped). Students tended to have lower annual incomes with less spread (smaller standard deviation) than non-students for these data.
5.5.3 Tea and Immune System
- Participants were randomised to drink five or six cups of either tea or coffee everyday for two weeks(both drinks have caffeine but only tea has L-theanine) Kamath et al. (2003)
- After two weeks, blood samples were exposed to an antigen, and production of interfereon gamma(immune system response) was measured
- Explanatory variable: tea or coffee
- Response variable: measure of interferon gamma
ImmuneTea$Drink <- factor(ImmuneTea$Drink , levels=c("Tea", "Coffee"))
bwplot(ImmuneTea$Drink~ImmuneTea$InterferonGamma,
xlab='Interferon Gamma', main='Tea and Immune system',
scales=list(x=list(at=seq(0,60,5))),
par.settings = list(box.rectangle = list(col= c("green", "brown"),
fill= c("green", "brown"),
alpha=0.2),
box.umbrella = list(col= c("green", "brown")),
box.dot = list(col= c("green", "brown"))),
horizontal = TRUE)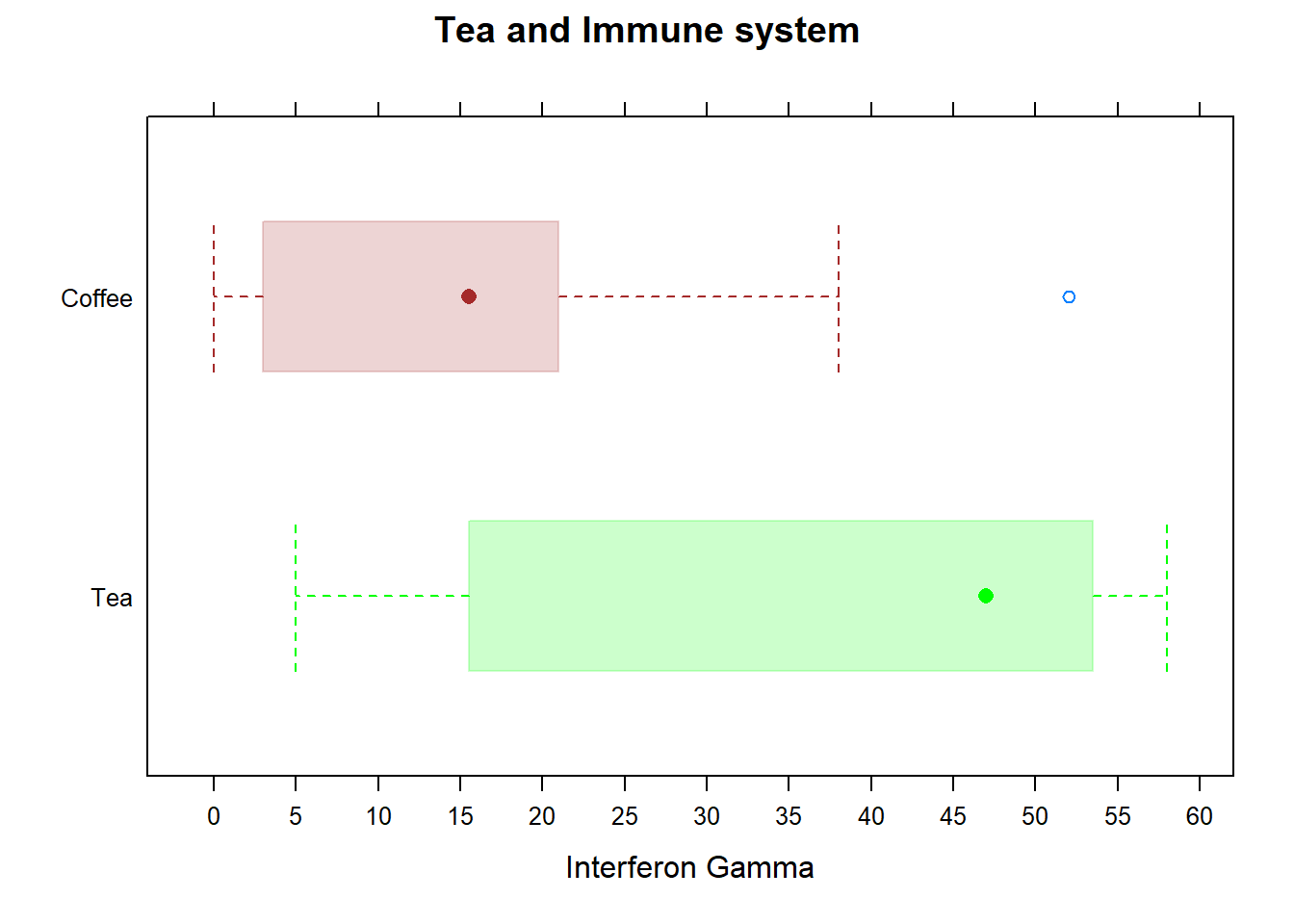
From the side-by-side box plots, we see that there is a difference between the distributions of Interferon Gamma for coffee and tea drinkers. Half of the coffee drinkers have Interferon Gamma levels less than 15 compared to only 25% of the tea drinkers. Furthermore, more than half of the tea drinkers have Interferon Gamma values above what’s considered an outlier for coffee drinkers. It looks like tea drinkers do have higher levels of interferon gamma. However, to test claims like this, we need to use formal statistical tests, which will be covered later in STAT101.