z <- c(34, 47, 25, 14)
sort(z)[1] 14 25 34 47เป็นขั้นตอนการทำงานที่เสียเวลาเป็นอย่างมากถ้าผู้อ่านไม่ความรู้ในการจัดการข้อมูลให้พร้อมใช้งานเพื่อนำไปวิเคราะห์หรืออสร้างกราฟต่อไป วิธีการจัดการกับข้อมูลด้วยวิธีต่างๆ นั้นมีมากมาย เพื่อให้ข้อมูลเหล่านี้เป็นไปตามวัตถุประสงค์ที่ต้องการ เช่น
แปลงข้อมูลให้อยู่ในรูปแบบที่ถูกต้อง เช่นจากตัวเลขเป็นข้อความ เปลี่ยนตัวเลขเป็นตัวแปรเชิงกลุ่ม ฯลฯ
แก้ไขหรือนำข้อมูลที่ผิดพลาดหรือไม่ถูกต้องหรือสูญหายออกไป
สร้างตัวแปรใหม่หรือแปลงรูปแบบข้อมูลเพื่อให้เหมาะสมกับการวิเคราะห์หรือการประมวลผลที่ต้องการ
จัดระเบียบข้อมูลให้อยู่ในรูปแบบที่เหมาะสมสำหรับการนำไปใช้งานต่อไป เช่นการจัดเรียงข้อมูล (sort) การกรองข้อมูล (filter) หรือการรวมข้อมูล (merge)
การเตรียมข้อมูลอาจประกอบด้วยขั้นตอนต่างๆ เช่น
การเชื่อมต่อกับแหล่งข้อมูลและดึงข้อมูลมาจากแหล่งต่างๆ เช่นจากฐานข้อมูล Yahoo Finance
การทำความสะอาดข้อมูล (data cleaning) โดยการตรวจสอบและแก้ไขข้อผิดพลาดที่อาจเกิดขึ้นในข้อมูล เช่น ข้อมูลที่หายไป (missing data) ข้อมูลที่ซ้ำซ้อน (duplicate data) หรือข้อมูลที่ไม่ถูกต้อง
การแปลงรูปแบบข้อมูล (data transformation) เพื่อให้ข้อมูลมีรูปแบบที่ถูกต้องหรือเข้ากันได้กับการวิเคราะห์ที่ต้องการทำ เช่น การแปลงรูปแบบข้อมูลวันที่และเวลา การแปลงข้อมูลทางภูมิศาสตร์ หรือการแปลงข้อมูลที่เป็นตัวอักษรให้เป็นตัวเลข
การกรองข้อมูล (data filtering) เพื่อเลือกเฉพาะข้อมูลที่ต้องการใช้งานเท่านั้น
การจัดระเบียบข้อมูล (data reordering) เพื่อเรียงลำดับข้อมูลตามลำดับที่เหมาะสมหรือตามเกณฑ์ที่กำหนด
การรวมข้อมูล (data merging) เพื่อรวมข้อมูลจากแหล่งต่างๆ เข้าด้วยกันเพื่อให้ได้ข้อมูลที่มีขอบเขตและความละเอียดที่มากขึ้น
การเตรียมข้อมูลนี้เป็นกระบวนการสำคัญในการวิเคราะห์ข้อมูล การสร้างกราฟ การนำข้อมูลไปใส่ตัวแบบทางสถิติหรือการเรียนรู้ด้วยเครื่องจักร การนำไปใช้งานต่อไป เนื่องจากถ้าข้อมูลที่มีคุณภาพและมีรูปแบบที่ถูกต้องจะช่วยให้การวิเคราะห์และการประมวลผลข้อมูลเป็นอย่างถูกต้องและมีประสิทธิภาพมากยิ่งขึ้น
เมื่อได้รับข้อมูลมาแล้ว โดยส่วนมากจะอยู่ในรูปแบบของตาราง ที่เป็นเวคเตอร์หรือกรอบข้อมูล ในบทนี้จะสนใจข้อมูลที่เป็นเวคเตอร์และกรอบข้อมูลเท่านั้น
เมื่อเรามีข้อมูลในรูปแบบเวคเตอร์ หรือกรอบข้อมูล เราสามารถทำอะไรได้บ้างกับเวคเตอร์หรือกรอบข้อมูล ซึ่งการเรียงลำดับเป็นปัญหาพื้นฐานที่สุดแบบหนึ่งที่จะต้องเจอ
โดยปกติจะเป็นการเรียงลำดับจากน้อยไป ใช้ได้กับข้อมูลทุกกระเภท
z <- c(34, 47, 25, 14)
sort(z)[1] 14 25 34 47z2 <- c("A", "b", "AA", "0")
sort(z2)[1] "0" "A" "AA" "b" การเรียงลำดับด้วยตัวอักษร จะเรียงลำดับด้วยพยัญชนะตัวแรกมาเปรียบเทียบกัน ถ้ามีเป็นตัวเดียวกัน ให้นำพยัญชนะตัวที่สองที่เปรียบกัน ทำแบบนี้ไปเรื่อยๆ ก็จะได้การเรียงลำดับด้วยตัวอักษร
ถ้าต้องการเรียงลำดับจากมากไปน้อย ให้เพิ่มคำสั่งภายใน คือ
decreasing = TRUEเช่น
sort(x = z, decreasing = TRUE)[1] 47 34 25 14หรือ
sort(x = z2, decreasing = TRUE)[1] "b" "AA" "A" "0" เป็นเรียงลำดับตามเลขตำแหน่ง เมื่อเรียงจากน้อยไปมาก
| ก่อนเรียงลำดับ | |
|---|---|
| ลำดับ | ค่าภายใน |
| 1 | 34 |
| 2 | 47 |
| 3 | 25 |
| 4 | 14 |
เมื่อเรียงลำดับจะได้
sort(x = z)[1] 14 25 34 47| หลังเรียงลำดับ | |
|---|---|
| ลำดับ | ค่าภายใน |
| 4 | 14 |
| 3 | 25 |
| 1 | 34 |
| 2 | 47 |
โดยคำสั่ง order( ) หมายถึง
order(x = z)[1] 4 3 1 2ถ้าต้องการกำหนดจากมาไปน้อยให้ใช้
order(x = z, decreasing = TRUE) [1] 2 1 3 4เป็นการสลับทิศทางของเวคเตอร์จากซ้ายเป็นขวา
rev(x = z)[1] 14 25 47 34ทำให้การเรียงดำดับจากมากไปน้อยทำได้โดย
rev(x = sort(x = z))[1] 47 34 25 14ตัวอย่างการประยุกต์ใช้งาน
กำหนดเวตเตอร์ของวัน และจำนวนลูกค้าที่เข้าร้านดังนี้
day <- c("Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday")
customer <- c(100, 80, 90, 120, 150, 140, 130)คำถาม วันไหนที่มีลูกค้าเข้าร้านมากที่สุด?
ii <- order(x = customer, decreasing = TRUE)
day[ii][1] "Friday" "Saturday" "Sunday" "Thursday" "Monday" "Wednesday"
[7] "Tuesday" หรือ
ii <- rev(x = order(x = customer))
day[ii][1] "Friday" "Saturday" "Sunday" "Thursday" "Monday" "Wednesday"
[7] "Tuesday" การเรียงลำดับในกรอบข้อมูล
Data <- data.frame(day, customer)
Data day customer
1 Monday 100
2 Tuesday 80
3 Wednesday 90
4 Thursday 120
5 Friday 150
6 Saturday 140
7 Sunday 130วันไหนที่ลูกค้าน้อยที่สุด?
Data[order(x = Data$customer), ] day customer
2 Tuesday 80
3 Wednesday 90
1 Monday 100
4 Thursday 120
7 Sunday 130
6 Saturday 140
5 Friday 150การเรียงลำดับข้อมูลตัวแปรประเภทเชิงกลุ่ม (categorical) ในอาร์จะเรียกตัวแปรนี้ว่าตัวแปรปัจจัย (factor)
จากเวคเตอร์ day ถ้าเรียงดำดับจากน้อยไปมาก จะได้
DAY <- sort(day)
DAY[1] "Friday" "Monday" "Saturday" "Sunday" "Thursday" "Tuesday"
[7] "Wednesday"ซึ่งไม่ถูกต้อง ตัวแปรนี้จะต้องถูกสร้างด้วยคำสั่ง factor( ) และกำหนดลำดับภายในเสียก่อน
DAY <- factor(x = DAY, levels = day)
DAY <- sort(DAY)ก็จะได้ข้อมูลเชิงกลุ่มที่ถูกต้องได้ ตัวแปรประเภทนี้ถูกใช้อย่างมากในการวิเคราะห์ทางสถิติอื่นๆ รวมถึงการสร้างกราฟประเภทต่างๆด้วย
ข้อมูลที่อยู่แล้วในบ้างครั้ง เราอาจจะไม่ต้องการใช้ทั้งหมด อาจต้องการใช้งานเพียงบางส่วน พิจารณาเฉพาะข้อมูลที่เป็นไปตามเงื่อนไขเท่านั้น วิธีที่จะได้เซตย่อยที่ต้องการมีหลายวิธีเช่น
สมมุติจากเวคเตอร์ DAY ต้องการ วันจันทร์ วันพุธ วันศุกร์ และวันอาทิตย์
DAY[c(1, 3, 5, 7)][1] Monday Wednesday Friday Sunday
Levels: Monday Tuesday Wednesday Thursday Friday Saturday Sunday# เลข 1-7 หารเศษด้วย 2 มีค่าไม่เท่า 0
re <- c(1:7) %% 2 != 0
re[1] TRUE FALSE TRUE FALSE TRUE FALSE TRUEนำค่าไปใส่ในเวคเตอร์ DAY จะได้ (TRUE คือแสดงว่า FALSE ไม่ต้องแสดงค่า)
DAY[re][1] Monday Wednesday Friday Sunday
Levels: Monday Tuesday Wednesday Thursday Friday Saturday Sundaysubset(x = DAY, subset = (DAY == "Monday")|(DAY == "Wednesday")| (DAY == "Thursday")|
(DAY == "Sunday"))[1] Monday Wednesday Thursday Sunday
Levels: Monday Tuesday Wednesday Thursday Friday Saturday Sundayหรือต้องการค่า customer ต่อวันที่มากกว่าหรือเท่ากับ 120
customer[1] 100 80 90 120 150 140 130customer[c(4, 5, 6, 7)][1] 120 150 140 130customer[customer >= 120][1] 120 150 140 130subset(x = customer, subset = customer >= 120)[1] 120 150 140 130ศึกษาคำสั่ง subset( ) เพิ่มเติมได้จาก
help(subset)เชตย่อยของกรอบข้อมูลมีได้หลากหลายกรณี เช่น การเลือกตัวแปรแค่บ้างตัวไปใช้ หรือเลือกข้อมูลที่ต้องการไปใช้ โดยจะมีเงื่อนไขที่กำหนดหรือไม่ก็ได้ และการเลือกตัวแปรบ้างตัวและข้อมูลที่เข้าเงื่อนไขเท่านั้น
ในการทางวิทยาศาสตร์ข้อมูล เมื่อได้ข้อมูลมาสำหรับตัวแบบตัวสินใจด้วยการเรียนรู้ของเครื่องจักร จำเป็นจะต้องแบ่งข้อมูลออก 2 กลุ่มเช่น ข้อมูลสำหรับการเรียนรู้ (train data) และข้อมูลสำหรับการทดสอบ (test data)
ตัวอย่างจากข้อมูล mtcars ต้องแบ่งข้อมูลออกเป็น 2 กลุ่มโดยใช้สัดส่วน 80/20 คือ ข้อมูลร้อยละ 80 สำหรับการเรียนรู้ และข้อมูลร้อยละ 20 สำหรับการทดสอบ ทำได้ดังนี้ จำนวนข้อมูลทั้งหมด
str(mtcars)'data.frame': 32 obs. of 11 variables:
$ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
$ cyl : num 6 6 4 6 8 6 8 4 4 6 ...
$ disp: num 160 160 108 258 360 ...
$ hp : num 110 110 93 110 175 105 245 62 95 123 ...
$ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
$ wt : num 2.62 2.88 2.32 3.21 3.44 ...
$ qsec: num 16.5 17 18.6 19.4 17 ...
$ vs : num 0 0 1 1 0 1 0 1 1 1 ...
$ am : num 1 1 1 0 0 0 0 0 0 0 ...
$ gear: num 4 4 4 3 3 3 3 4 4 4 ...
$ carb: num 4 4 1 1 2 1 4 2 2 4 ...ดังนั้น ข้อมูลสำหรับการเรียนรู้ตั้งแต่ 1 ถึง 26 และสำหรับทดสอบ คือข้อมูลที่เหลือสำหรับทดสอบ คือ ตัวที่ 27 ถึง 32
mtcars.trian <- mtcars[1:26, ]
mtcars.test <- mtcars[27:32,]คือการเลือกข้อมูลออกไปตั้งแต่ 1 ตัวแปรขึ้นไป
เช่นเลือกตัวแปร cyl ออกไปจาก mtcars.test เป็นตัวกรอบข้อมูลใหม่ ชื่อว่า mtcars.t
mtcars.t <- mtcars.test[, 2]
str(mtcars.t) num [1:6] 4 4 8 6 8 4หรือ
mtcar.t <- mtcars.test$cyl
str(mtcar.t) num [1:6] 4 4 8 6 8 4หมายเหตุ ถ้าเลือกออกไป 1 ตัวด้วยคำสั่งข้างบย mtcar.t จะเป็นตัวแปรเวคเตอร์ ไม่ใช่กรอบข้อมูล
is.vector(mtcar.t)[1] TRUEการเลือกตัวแปรออกไปตั้งแต่ 2 ตัวขึ้นไปจาก mtcars.test เช่น เลือก hp cyl และ gear นำไปใส่ในตัวแปรชื่อ mtcar.t2
mtcars.t2 <-data.frame(hp = mtcars.test$hp,
cyl = mtcars.test$cyl,
gear = mtcars.test$gear)
str(mtcars.t2)'data.frame': 6 obs. of 3 variables:
$ hp : num 91 113 264 175 335 109
$ cyl : num 4 4 8 6 8 4
$ gear: num 5 5 5 5 5 4หรือใช้วิธี เลือกจากลำดับของตัวแปร
mtcars.t2 <- mtcars.test[,c(4, 2, 10)]
str(mtcars.t2)'data.frame': 6 obs. of 3 variables:
$ hp : num 91 113 264 175 335 109
$ cyl : num 4 4 8 6 8 4
$ gear: num 5 5 5 5 5 4หรือจะใช้วิธีสร้างเวคเตอร์ของชื่อตัวตัวแปรที่ต้องการ ดังนี้
mtcars.t2 <- mtcars.test[,c("hp", "cyl", "gear")]
str(mtcars.t2)'data.frame': 6 obs. of 3 variables:
$ hp : num 91 113 264 175 335 109
$ cyl : num 4 4 8 6 8 4
$ gear: num 5 5 5 5 5 4ก็คือการสร้างเวคเตอร์ ของลำดับข้อมูลต้องการใส่ลงไปในกรอบข้อมูล เหมือนกับกรณีข้อมูลสำหรับการเรียนรู้ หรือข้อมูลสำหรับทดสอบ
จากกรอบข้อมูล mtcars.t2
mtcars.t2 hp cyl gear
Porsche 914-2 91 4 5
Lotus Europa 113 4 5
Ford Pantera L 264 8 5
Ferrari Dino 175 6 5
Maserati Bora 335 8 5
Volvo 142E 109 4 4ต้องการข้อมูลที่มีค่า hp > 200
# สร้างเวคเตอร์เงื่อนที่ hp >200
condi <- mtcars.t2$hp > 200
condi[1] FALSE FALSE TRUE FALSE TRUE FALSEใส่ condi ลงไปใน mtcars.t2
mtcars.t2[condi, ] hp cyl gear
Ford Pantera L 264 8 5
Maserati Bora 335 8 5หรือใช้คำสั่ง subset
# สามารถใส่ชื่อตัวแปรที่ต้องการ และเงื่อนไขลงไปได้เลย
subset(x = mtcars.t2, subset = hp > 200) hp cyl gear
Ford Pantera L 264 8 5
Maserati Bora 335 8 5จะเห็นว่าการใช้คำสั่ง subset ง่ายกว่า
ถ้ามีเงื่อนไขมากกว่า 1 อย่าง เช่น จาก mtcars.t2 ต้องการ hp<200 และ cyl = 6 สามารถใช้คำสั่ง subset ได้ดังนี้
# & คือตัวดำเนินการตรรกศาสตร์ และ(and)
subset(x = mtcars.t2, subset = (hp < 200)&(cyl == 6)) hp cyl gear
Ferrari Dino 175 6 5จาก mtcar.train ต้องการข้อมูลที่ hp > 200 และ ไม่ได้มี 4 gears และต้องการเพียงตัวแปร hp, gear และ disp
subset(x = mtcars.trian,
subset = (gear != 4)&(hp >200),
select = c(hp, gear, disp)) hp gear disp
Duster 360 245 3 360
Cadillac Fleetwood 205 3 472
Lincoln Continental 215 3 460
Chrysler Imperial 230 3 440
Camaro Z28 245 3 350เป็นคำสั่งที่ปรโยชน์มาก สำหรับการเปลี่ยนค่าตัวเลขให้ ตัวแปรกลุ่ม (factor) ที่กำหนด ยกตัวแปรเช่น ต้องการเปลี่ยนคะแนนเป็นเกรดโดยมีเงื่อนไขดังนี้
| คะแนน | เกรด |
|---|---|
| 0-49 | F |
| 50-59 | D |
| 60-69 | C |
| 70-79 | B |
| 80-100 | A |
มีนักเรียน 20 คนได้คะแนนดังนี้
set.seed(12)
score <- sample(x = 40:85, size = 20)
score [1] 41 65 55 66 44 81 67 73 47 82 57 75 84 52 63 43 71 64 77 78cut(x = score,
breaks = c(0, 49, 59, 69, 79, 100),
labels = c("F", "D", "C", "B", "A")) [1] F C D C F A C B F A D B A D C F B C B B
Levels: F D C B Abreaks กำหนดขอบของตัวเลขที่ต้องการจะตัด โดยเริ่มจากเลขต่ำสุด ไปจนถึงตัวเลขสูงสุด
levels คือช่วงตัวเลขต้องการเป็นเปลี่ยนตัวชื่อกลุ่มที่ต้องการ
ถ้ามีนักเรียนเพิ่มขึ้นมาอีก 2 คน โดยได้คะแนน 0 และ 100 ตามลำดับ เมื่อทำการตัดเกรดเหมือนเดิมจะได้
score <- c(score, c(0, 100))
cut(x = score,
breaks = c(0, 49, 59, 69, 79, 100),
labels = c("F", "D", "C", "B", "A")) [1] F C D C F A C B F A D B A D C
[16] F B C B B <NA> A
Levels: F D C B Aจะว่า นร. ที่ได้คะแนน 0 จะไม่ถูกตัดเกรด เพราะ รูปแบบการทำงานของคำสั่งคือ
(0,49] = F, (49, 59] = D, (60, 69] = C, (70, 79] = B, (79, 100] = A ดังนั้นถ้าต้องการร่วมค่าตำ่สุดคือ 0 ให้กำหนด include.lowest = TRUE เพิ่มลงไปในคำสั่ง cut( )
grade <- cut(x = score,
breaks = c(0, 49, 59, 69, 79, 100),
labels = c("F", "D", "C", "B", "A"), include.lowest = TRUE)
grade [1] F C D C F A C B F A D B A D C F B C B B F A
Levels: F D C B Aเมื่อได้ตามที่ต้องการแล้ว ก็สามารถนำตัวแปรทั้งมารวมกันได้เป็นกรอบข้อมูล
student.grade <- data.frame(score, grade)
str(student.grade)'data.frame': 22 obs. of 2 variables:
$ score: num 41 65 55 66 44 81 67 73 47 82 ...
$ grade: Factor w/ 5 levels "F","D","C","B",..: 1 3 2 3 1 5 3 4 1 5 ...คำสั่ง merge( ) ในอาร์สามารถทำให้รวมกรอบข้อมูลตั้งแต่สองกรอบข้อมูลขึ้นไป โดยแต่ละกรอบข้อมูลจะมี จะมีอย่างน้อย 1 ตัวแปรที่มีชื่อเดียวกัน

ตัวอย่าง
มีข้อมูลพนักงาน 10 คนประกอบไปด้วยตัวแปร เลขพนักงาน ชื่อพนักงาน เงินเดือน อายุ ตำแหน่ง สามารถสุ่มข้อมูลได้ดังนี้
##Sample datasets
set.seed(61)
employee_id <- paste("ID:", 1:10)
employee_name <- c("Keng", "Pie", "Norm", "Bua",
"Jack","Joke", "Matha", "Kan",
"Boat", "Song")
employee_salary <- round(rnorm(10, mean = 2000, sd = 200))
employee_age <- round(rnorm(10, mean = 50, sd = 7))
employee_position <- c("Researcher", "Lecturer", "TA",
rep("Technician", 7))นำข้อมูลนี้มาสร้างกรอบข้อมูล A และ B โดย
A <- data.frame(id = employee_id[1:8],
name = employee_name[1:8],
month_salary = employee_salary[1:8])
knitr::kable(A)| id | name | month_salary |
|---|---|---|
| ID: 1 | Keng | 1924 |
| ID: 2 | Pie | 1925 |
| ID: 3 | Norm | 1656 |
| ID: 4 | Bua | 2070 |
| ID: 5 | Jack | 1723 |
| ID: 6 | Joke | 1962 |
| ID: 7 | Matha | 2141 |
| ID: 8 | Kan | 2103 |
ii <- c(1:4,6:10)
B <- data.frame(id = employee_id[ii],
name = employee_name[ii],
age = employee_age[ii],
position = employee_position[ii])
knitr::kable(B)| id | name | age | position |
|---|---|---|---|
| ID: 1 | Keng | 41 | Researcher |
| ID: 2 | Pie | 40 | Lecturer |
| ID: 3 | Norm | 53 | TA |
| ID: 4 | Bua | 64 | Technician |
| ID: 6 | Joke | 39 | Technician |
| ID: 7 | Matha | 53 | Technician |
| ID: 8 | Kan | 56 | Technician |
| ID: 9 | Boat | 54 | Technician |
| ID: 10 | Song | 44 | Technician |
เป็นคำสั่งในชุดคำสั่ง knitr เพื่อแสดงข้อมูลแปรประเภทกรอบข้อมูลให้ออกมาอยู่รูปตารางที่สวยงาม สำหรับเอกสารแบบ HTML หรือ pdf
การควบรวมแบบนี้ เป็นพื้นฐานที่เจอได้บ่อย
โดยการพิจารณาตัวแปรเดียวกันในแต่กรอบข้อมูล ว่ามีค่าใดตัวเดียวกันที่เหมือนกันบ้าง แล้วจะนำตัวแปรที่เหลือในแต่ กรอบมาเรียงต่อกันจากซ้ายไปขวา
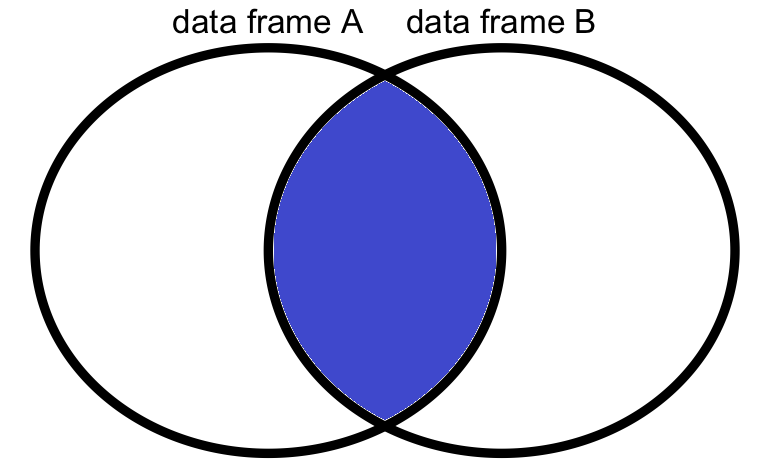
จากกรอบข้อมูล และ A มีตัวแปรที่เหมือนกันกับกรอบข้อมูล B คือ id และ name เมื่อทำการควบรวมด้วยคำสั่ง merge( ) แบบ inner join
จะเห็นว่า ID:5 จากตัวแปร ID และ ชื่อ Jack จากตัวแปร name กรอบข้อมูล A ไม่มี และ ID:9 และ ID:10 จากตัวแปร ID และ ชื่อ Boat และ Song จากตัวแปร name กรอบข้อมูล B ไม่มี เมื่อควบรวมกัน
merge(x = A, y = B) id name month_salary age position
1 ID: 1 Keng 1924 41 Researcher
2 ID: 2 Pie 1925 40 Lecturer
3 ID: 3 Norm 1656 53 TA
4 ID: 4 Bua 2070 64 Technician
5 ID: 6 Joke 1962 39 Technician
6 ID: 7 Matha 2141 53 Technician
7 ID: 8 Kan 2103 56 Technicianเป็นการควบรวมค่าตัวแปรที่เหมือนกัน โดยไม่มีการตัดภายในตัวแปรเดียวกันที่อีกตารางทิ้งไป
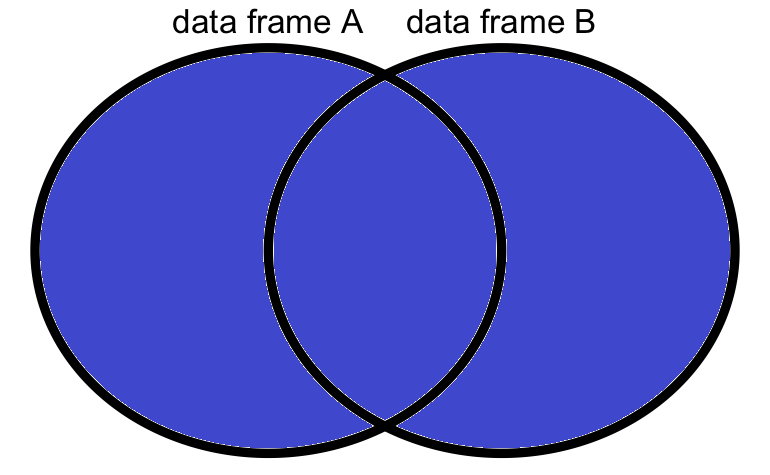
ทำได้โดย กำหนด all = TRUE ในคำสั่ง merge( )
merge(x = A, y = B, all = TRUE) id name month_salary age position
1 ID: 1 Keng 1924 41 Researcher
2 ID: 10 Song NA 44 Technician
3 ID: 2 Pie 1925 40 Lecturer
4 ID: 3 Norm 1656 53 TA
5 ID: 4 Bua 2070 64 Technician
6 ID: 5 Jack 1723 NA <NA>
7 ID: 6 Joke 1962 39 Technician
8 ID: 7 Matha 2141 53 Technician
9 ID: 8 Kan 2103 56 Technician
10 ID: 9 Boat NA 54 Technicianจะสังเกตุได้ว่า ค่าตัวแปรใดที่อีกกรอบข้อมูลไม่ ให้ค่าเป็น NA
คือการควบรวมที่เก็บทุกค่าของกรอบข้อมูลทางซ้ายไว้ทั้งหมด

ทำได้กำหนดค่า all.x = TRUE ในคำสั่ง merge
AB <- merge(x = A, y = B, all.x = TRUE)
AB id name month_salary age position
1 ID: 1 Keng 1924 41 Researcher
2 ID: 2 Pie 1925 40 Lecturer
3 ID: 3 Norm 1656 53 TA
4 ID: 4 Bua 2070 64 Technician
5 ID: 5 Jack 1723 NA <NA>
6 ID: 6 Joke 1962 39 Technician
7 ID: 7 Matha 2141 53 Technician
8 ID: 8 Kan 2103 56 Technicianเหมือนกับการทำ left join แต่เป็นการเก็บกรอบข้อมูลทางซ้ายมือไว้ทั้งหมด
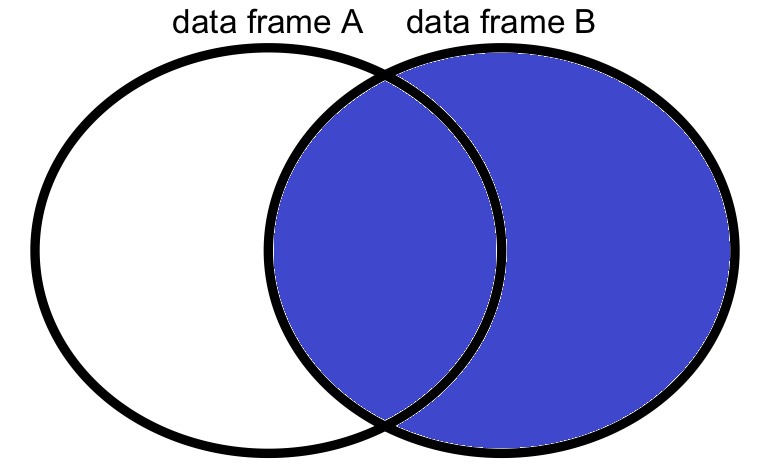
ทำได้กำหนดค่า all.y = TRUE ในคำสั่ง merge
merge(x = A, y = B, all.y = TRUE) id name month_salary age position
1 ID: 1 Keng 1924 41 Researcher
2 ID: 10 Song NA 44 Technician
3 ID: 2 Pie 1925 40 Lecturer
4 ID: 3 Norm 1656 53 TA
5 ID: 4 Bua 2070 64 Technician
6 ID: 6 Joke 1962 39 Technician
7 ID: 7 Matha 2141 53 Technician
8 ID: 8 Kan 2103 56 Technician
9 ID: 9 Boat NA 54 Technicianในกรณีที่ตัวแปรเวคเตอร์ หรือค่าของตัวแปรบางตัวในกรอบข้อมูลมีการสูญหายไป เช่น
Vec <- c(1,2,NA, 5)
Vec [1] 1 2 NA 5หรือค่าจากการควบรวมตารางที่ผ่านมี จะมีค่า NA ปรากฎ ซึ่งเราจะต้องทำการแก้ไขค่า NA ที่ เกิดขึ้น ถ้าไม่แก้ไขอาจจะเกิดปัญหาได้ เช่น
ถ้าต้องการหาค่าเฉลี่ยของเวคเตอร์ Vec จะไม่สามารถคำนวณได้เพราะมีค่า NA อยู่เวคเตอร์
mean(Vec)[1] NAถ้าต้องการทราบว่า มีจำนวนสูญหายเท่าไหร่? มีวิธีการแก้ปัญหาดังนี้
sum(is.na(x = Vec))[1] 1จากผลลัพธ์ที่ได้แสดงว่ามีข้อมูลสูญหาย 1 ตัว และถ้าเวคเตอร์นี้ไม่มีข้อมูลสูญหายจะมีค่าเท่ากับ 0
สำหรับกรอบข้อมูล เช็คได้โดยคำสั่ง colSums(is.na( ))
colSums(is.na(AB)) id name month_salary age position
0 0 0 1 1 ผลลัพธ์ของตัวแปรใดที่มีค่าเป็น 0 แสดงไม่มีค่า NA ปรากฎอยู่ในตัวแปรนั้น และถ้ามีค่าเป็นจำนวนเต็มบวกอยู่ในตัวแปรใด ก็จะทราบว่ามีค่า NA อยู่เป็นจำนวนเท่าไหร่
วิธีแก้ปัญหาเมื่อพบว่ามีค่า NA ปรากฎคือ
!is.na( ) โดยทำได้ดังนี้
Vec[!is.na(Vec)][1] 1 2 5สำหรับกรอบข้อมูลถ้าแถวใด ที่ปรากฎค่า NA ให้ลบข้อมูลทั้งแถวนั้นทิ้งไป ด้วย คำสั่ง na.omit( ) ดังนี้
na.omit(AB) id name month_salary age position
1 ID: 1 Keng 1924 41 Researcher
2 ID: 2 Pie 1925 40 Lecturer
3 ID: 3 Norm 1656 53 TA
4 ID: 4 Bua 2070 64 Technician
6 ID: 6 Joke 1962 39 Technician
7 ID: 7 Matha 2141 53 Technician
8 ID: 8 Kan 2103 56 Technician# จำลองช้อที่สูญหาย
set.seed(12)
Vec.m <- sample(x = c(2:5, NA), size = 10, replace = TRUE)
Vec.m [1] 3 3 4 NA NA 5 3 4 3 NAขั้นที่ 1 หาค่าเฉลี่ยด้วย คำสั่ง mean( ) ที่ไม่นำข้อมูลที่เป็น NA เข้าคำนวณ ด้วยการเพิ่มคำสั่ง na.rm = TRUE
M1 <- mean(Vec.m, na.rm = TRUE)
M1[1] 3.571429หรือคำนวณค่ามมัธยฐาน ด้วยคำสั่ง median( ) โดยที่ไม่นำข้อมูลที่เป็น NA เข้ามาคำนวณ ด้วยการเพิ่มคำสั่ง na.rm = TRUE
M2 <- median(Vec.m, na.rm = TRUE)
M2[1] 3ค้นหาตำแหน่งที่ ข้อมูลมีค่า NA ด้วยคำสั่ง is.na( )
Na.Position <-is.na(Vec.m)
Na.Position [1] FALSE FALSE FALSE TRUE TRUE FALSE FALSE FALSE FALSE TRUEแสดง NA ในเวคเตอร์
Vec.m[Na.Position][1] NA NA NAหลังจากนั้นแทนลงไปด้วยด้วยคำสั่ง
Vec.m[Na.Position] <- M1
Vec.m [1] 3.000000 3.000000 4.000000 3.571429 3.571429 5.000000 3.000000 4.000000
[9] 3.000000 3.571429หรือจะแทนด้วยมัธยฐานก็ทำเหมือนกัน
Vec.m[Na.Position] <- M2
Vec.m [1] 3 3 4 3 3 5 3 4 3 3เป็นคำสั่งที่ค้นหาค่าเวคเตอร์ที่ต้องการ อยู่ตำแหน่งใด
จาก Vec.m ต้องการทราบว่า ตำแหน่งใดใน Vec.m มีค่าเท่ากับ 5
which(Vec.m == 5)[1] 6หรือมีค่าเท่ากับ 4 หรือ 5
which((Vec.m == 4)|(Vec.m == 5))[1] 3 6 8เราสามารถใช้คำสั่ง which( ) ในการค้นหาค่า NA ในเวคเตอร์ได้เช่นเดียวกัน
จำลองข้อมูลที่สูญหายอีกครั้ง
set.seed(12)
Vec.m <- sample(x = c(2:5, NA), size = 10, replace = TRUE)
Vec.m [1] 3 3 4 NA NA 5 3 4 3 NAด้วยการคำสั่ง which( ) เราไม่สามารถกำหนดคำสั่งแบบนี้โดยตรงได้
which(Vec.m == NA)integer(0)เพราะ NA ไม่มีค่าอยู่จริง จึงไม่สามารถการเปรียบเทียบแบบนี้ได้ต้องใช้
which(is.na(Vec.m))[1] 4 5 10ส่วนการแทนค่าก็ทำเหมือนตัวอย่างก่อนหน้าได้ทันที
Vec.m[which(is.na(Vec.m))] <- M2
Vec.m [1] 3 3 4 3 3 5 3 4 3 3สำหรับตัวแปรกรอบข้อมูล ถ้าตัวแปรในกรอบข้อมูลมีค่าสูญหายเกิดขึ้น ถ้าสามารถใช้วิธีการเดียวกันเวคเตอร์มาใช้ได้ และถ้าต้องการแก้ไขเปลี่ยนค่า NA ไปเป็นค่าที่ต้องการทีละตัวแปร แต่ถ้าจำนวนตัวแปรมีมากวิธีการนี้ อาจจะไม่เหมาะสม
set.seed(12)
Vec.m <- sample(x = c(2:5, NA), size = 10, replace = TRUE)
Vec.n <- sample(x = c(7:9, NA), size = 10, replace = TRUE)
Data.mn <- data.frame(Vec.m, Vec.n)
Data.mn Vec.m Vec.n
1 3 8
2 3 7
3 4 8
4 NA NA
5 NA 8
6 5 8
7 3 9
8 4 NA
9 3 7
10 NA NAการศึกษาการเขียนโปรแกรมเพิ่มเติมจะช่วยได้มาก ซึ่งในหลังสือเล่มไม่ได้กล่าวถึง เพราะไม่มีความจำเป็นต้องใช้ก็ได้
ในแต่ละตัวแปร ให้แทน NA ด้วยค่าเฉลี่ย สามารถเขียนโปรแกรมทำซ้ำได้ดังนี้
for (i in 1:2){
Data.mn[is.na(Data.mn[,i]), i] <- mean(x = Data.mn[,i], na.rm = TRUE)
}
Data.mn Vec.m Vec.n
1 3.000000 8.000000
2 3.000000 7.000000
3 4.000000 8.000000
4 3.571429 7.857143
5 3.571429 8.000000
6 5.000000 8.000000
7 3.000000 9.000000
8 4.000000 7.857143
9 3.000000 7.000000
10 3.571429 7.857143ก่อนจะกล่าวถึง การใช้คำสั่ง aggregate( ) จะกล่าวถึงลักษณะปัญหาที่เจอก่อน โดยยกตัวอย่าง ข้อมูลจากข้อมูลที่จำลองขึ้นมา
set.seed(12)
N <- 100
height <- round(rnorm(n = N, mean = 160, sd = 3), digits = 2)
gender <- sample(x = c("Male", "Female"), size = N, replace = TRUE)
faculty <- sample(x = c("ECON", "SCI","BUS"), size = N, replace = TRUE)
stu.data <- data.frame(height, gender, faculty)เป็นข้อมูลส่วนสูงตามเพศในแต่ละคณะในการคำนวณค่าสถิติพรรณาด้วยอาร์ เราสามารถใช้คำสั่ง summary( )
summary(stu.data) height gender faculty
Min. :153.6 Length:100 Length:100
1st Qu.:158.3 Class :character Class :character
Median :159.7 Mode :character Mode :character
Mean :159.9
3rd Qu.:161.5
Max. :166.2 ถ้าต้องการ ส่วนสูงเฉลี่ยแยกตามเพศ จะต้องทำการเขียนคำสั่ง
Male<- subset(x = stu.data, subset = gender =="Male")
mean(Male$height)[1] 159.6386และ
Female<- subset(x = stu.data, subset = gender =="Female")
mean(Female$height)[1] 160.2464ถ้าสมมุติ ตัวแปรนี้มี ทั้งหมด 6 กลุ่มก็จะเขียนคำสั่งแบบเดิมถึงหกครั้ง ซึ่งเป็นการเสียเวลา อย่างมาก คำสั่ง aggregate( ) จึงเข้าช่วยแก้ปัญหานี้ได้
aggregate(x, data, FUN) x: การเขียนคำสั่งแบบ formal (ตัวแปรซ้ายมือขึ้นอยู่กับตัวแปรทางขวามือ)
data: กรอบข้อมูล
Fun: คำสั่งที่ต้องการใช้งาน โดยเขียนแต่ชื่อ เช่น mean median เป็นต้นโดยไม่ต้องมีวงเล็บเปิด ( )
ตัวอย่าง ต้องการค่าเฉลี่ยส่วนสูงแยกตามเพศ
aggregate(x = height~gender, data = stu.data, FUN = mean) gender height
1 Female 160.2464
2 Male 159.6386หมายถึง น้ำหนักขึ้นอยู่เพศ
ตัวแปรทางซ้ายมือควรเป็นตัวเลข และตัวแปรทางขวามือควรเป็นตัวแปรกลุ่ม (catagorical) หรือ factor
หรือต้องการความแปรปวนของส่วนสูงแต่ละคณะ
aggregate(x = height~faculty, data = stu.data, FUN = var) faculty height
1 BUS 7.144774
2 ECON 7.681056
3 SCI 5.486135aggregate(x = height~faculty+gender, data = stu.data, FUN = mean) faculty gender height
1 BUS Female 160.9383
2 ECON Female 160.3171
3 SCI Female 159.6127
4 BUS Male 159.6530
5 ECON Male 159.6135
6 SCI Male 159.6519จะได้ตารางส่วนสูงเฉลี่ย ของ นศ.หญิงมาจากคณะบริหาร ไปจนถึง นศ.ชายจากคณะวิทยาศาสตร์
อย่างลืมใช้คำสั่ง colnames( ) เพื่อเปลี่ยนชื่อตัวแปรให้สื่อความหมายมากขึ้น
MEAN <- aggregate(x = height~faculty+gender, data = stu.data, FUN = mean)
colnames(MEAN)[3] <- "mean of height"
MEAN faculty gender mean of height
1 BUS Female 160.9383
2 ECON Female 160.3171
3 SCI Female 159.6127
4 BUS Male 159.6530
5 ECON Male 159.6135
6 SCI Male 159.6519One-Hot Encoding เป็นกระบวนการแปลงตัวแปรกลุ่ม (categorical) เป็นตัวแปรใหม่ตามจำนวนกลุ่มที่มี รูปแบบของตัวเลข 0 หรือ 1
| ID | group |
|---|---|
| 01 | \("\)A\("\) |
| 02 | \("\)B\("\) |
| 03 | \("\)B\("\) |
| 04 | \("\)A\("\) |
| ID | A | B |
|---|---|---|
| 01 | 1 | 0 |
| 02 | 0 | 1 |
| 03 | 0 | 1 |
| 04 | 1 | 0 |
data <- data.frame(
ID = c("01", "02", "03", "04"),
group = c("A", "B", "B", "A")
)library(reshape2)
New_data <- dcast(data = data, ID~group,
fun.aggregate = length)
New_data ID A B
1 01 1 0
2 02 0 1
3 03 0 1
4 04 1 0คำสั่ง dummy_cols( ) ก็สามารถทำ one hot encoded ได้
library(fastDummies)
New_data <- dummy_cols(data,
select_columns = "group") #column name
New_data ID group group_A group_B
1 01 A 1 0
2 02 B 0 1
3 03 B 0 1
4 04 A 1 0![]()
# install.packages("tidyverse")
# หรือ
# install.packages("dplyr")
library(dplyr)เป็นชุดคำสั่งสำหรับการจัดการข้อมูล (data manipulation) สำหรับวัตถุประเภทกรอบข้อมูลหรือวัตถุประเภทกรอบข้อมูลที่สร้างโดยคำสั่ง tibble ชุดคำสั่งนี้ที่เป็นส่วนหนึ่งของชุดคำสั่งในจักรวาล tidyverse การจะใช้ชุดคำสั่งนี้ให้มีประสิทธิภาพ หรือใช้งานได้ดี ผู้อ่านต้องมีความเข้าใจในการใช้ตัวดำเนินการ pipe operator (|>) เป็นอย่างดี และคำสั่งต่างๆ ในชุดคำสั่ง dplyr จะเป็นคำกริยา (verbs) ในภาษาอังกฤษ ประโยชน์ของชุดคำสั่งนี้คือ รูปแบบคำสั่งที่เข้าใจได้ง่ายและสามารถแก้ไขได้เรวดเร็วมากกว่า ชุดคำสั่งจากโปรแกรมพื้นฐาน
ปัญหาเบื้องต้นสำหรับกรอบข้อมูลจากคำสั่ง dplyr ที่นิยมใช้มี 5 คำสั่งคือ
mutate( ) การสร้างตัวแปรใหม่จากกรอบข้อมูลเดิมที่มีอยู่
select( ) การเลือกตัวแปรบางตัวจากกรอบข้อมูลเพื่อนำไปใช้งาน
filter( ) การกรองข้อมูลในแต่ละตัวแปรภายใต้เงื่อนไขที่ต้องการ ในกรอบข้อมูล
arrange( ) การเรียงค่าในตัวแปรจากกรอบข้อมูล
summarise( ) การคำนวณค่าสถิติจากตัวแปรที่สนใจ หรือเงื่อนไขที่กำหนด จากกรอบข้อมูล
ตัวอย่างกรอบข้อมูลที่จำลองขึ้นมา คือ ตัวแปร group ที่มีค่าคือ A หรือ B และตัวแปร score ที่เก็บข้อมูลคะแนน(คะแนนเต็มคือ 100)
set.seed(1)
N <- 6
Data <- data.frame(
group = sample(LETTERS[1:2], size = N,
replace = TRUE),
score = sample(80:100, size = N,
replace = TRUE) )
Data group score
1 A 90
2 B 93
3 A 97
4 A 98
5 B 80
6 A 100คือการสร้างตัวแปร ขึ้นมาใหม่จากกรอบข้อมูลเดิมที่มีอยู่ เช่นต้องการสร้างตัวแปรใหม่ชื่อ percent จากค่า \(\dfrac{score}{100}\times 100\) ในหน่วยเปอร์เซ็นต์
Data |>
mutate(percent = paste0(score, "%")) group score percent
1 A 90 90%
2 B 93 93%
3 A 97 97%
4 A 98 98%
5 B 80 80%
6 A 100 100%คือการเลือกตัวแปรที่ต้องการไปใช้ เช่จ ต้องการตัวแปร group และ percent เท่านั้น
Data |>
mutate(percent = paste0(score, "%")) |>
select(group, percent) group percent
1 A 90%
2 B 93%
3 A 97%
4 A 98%
5 B 80%
6 A 100%คือการพิจารณากรองข้อมูลจากเงื่อนไขที่ต้องการ เช่น ในตัวแปร group ต้องการข้อมูลที่อยู่ ในกลุ่ม A เท่านั้น
Data |>
filter(group == "A") group score
1 A 90
2 A 97
3 A 98
4 A 100คือการเรียงลำดับค่าในกรอบข้อมูลโดยขึ้นกับตัวแปรที่ต้องการ โดยมีค่าตั้งต้นคือการเรียงจากน้อยไปมาก
# เรียงช้อมูลในตารางใหม่ตามค่า score
Data |>
arrange(score) group score
1 B 80
2 A 90
3 B 93
4 A 97
5 A 98
6 A 100สำหรับการเรียงจากมากไปน้อยให้ นำตัวแปรที่ต้องการไปใส่ไว้ในฟังก์ชัน desc( )
Data |>
arrange(desc(score)) group score
1 A 100
2 A 98
3 A 97
4 B 93
5 A 90
6 B 80คือการคำนวณค่าสถิติที่ต้องการโดย สามารถเลือกใช้เฉพาะค่าทางสถิติที่ต้องการใช้จริงๆ เท่านั้น โดยจะต้องตั้งชื่อตัวแปรใหม่ตามสถิติที่เลือกใช้ด้วย ดังตัวอย่างนี้
Data |>
summarise(OBS = n( ),
AVERAGE = mean(score),
SD = sd(score),
MIN = min(score),
MAX = max(score)) OBS AVERAGE SD MIN MAX
1 6 93 7.321202 80 100ในการกรณีที่สนใจการคำนวณค่าสถิติแบบ แยกตามกลุ่มของตัวแปร เช่น ค่าสถิติที่สนใจ แยกตาม กลุ่ม A และกลุ่ม B ก็จำเป็นจะต้องใช้คำสั่ง group_by( ) เพื่อจะแนกกลุ่มจากตัวแปรที่ต้องการก่อนการคำนวณทางสถิติที่ต้องการ
Data |>
group_by(group) |>
summarise(OBS = n( ),
AVERAGE = mean(score),
SD = sd(score),
MIN = min(score),
MAX = max(score))# A tibble: 2 × 6
group OBS AVERAGE SD MIN MAX
<chr> <int> <dbl> <dbl> <int> <int>
1 A 4 96.2 4.35 90 100
2 B 2 86.5 9.19 80 93เป็นการเช็คค่าตัวแปรประเภทกลุ่ม (categorical) ว่ามีค่าอะไรบ้างในตัวแปรนี้ เช่น
Data |> distinct(group) group
1 A
2 Bเป็นการเลือกข้อมูลตามหมายเลขแถวที่ต้องการ เช่นต้องการค่าในแถวที่ 2 ถึง 5
Data |> slice(2:5) group score
1 B 93
2 A 97
3 A 98
4 B 80เทียบเคียงได้กับคำสั่ง str( ) ในคำสั่งมาตราฐาน
Data |> glimpse( )Rows: 6
Columns: 2
$ group <chr> "A", "B", "A", "A", "B", "A"
$ score <int> 90, 93, 97, 98, 80, 100เป็นการดึงด่าในตัวแปรของกรอบข้อมูลออกมาเป็นวัตถุแบบเวคเตอร์ โดยสามารถใช้ตัวเลข แทนลำดับในคอลัมภ์ หรือจะใช้จากชื่อตัวแปรก็ได้ เช่น
Data |> pull(var = 2)[1] 90 93 97 98 80 100หรือ
Data |> pull(var = score)[1] 90 93 97 98 80 100ถ้าต้องการให้ค่าในเวคเตอร์มีชื่อ ก็สามารถทำได้
Data |> pull(var = score, name = group) A B A A B A
90 93 97 98 80 100 เป็นคำสั่ง การจัดการเรียงลำดับตัวแปรในกรอบข้อมูลใหม่
Data |> relocate(2, 1) score group
1 90 A
2 93 B
3 97 A
4 98 A
5 80 B
6 100 Aหรือ
Data |> relocate(score, group) score group
1 90 A
2 93 B
3 97 A
4 98 A
5 80 B
6 100 Aตือการเปลี่ยนชื่อตัวแปรในกรอบข้อมูลนั่นเอง จากชขื่อ group เป็น GROUP และจากชื่อ score เป็น SCORE
Data |> rename(GROUP = group, SCORE = score) GROUP SCORE
1 A 90
2 B 93
3 A 97
4 A 98
5 B 80
6 A 100สำหรับนับจำนวนข้อมูลของตัวแปร ซึ่งอาจจะเป็นการนับตัวแปรกลุ่มเพียงตัวเดียวหรือมากกว่าหนึ่งตัวก็ได้ เช่น
Data |> count(group) group n
1 A 4
2 B 2ใช้สำหรับเงื่อนไขกรณี \(a \leq X \leq b\) เช่นเลือกข้อมูลจากตัวแปร score ที่ \(93 \leq score \leq 98\)
ถ้าไม่ใช้คำสั่ง between( )
Data |> filter(score >= 93 & score <= 98) group score
1 B 93
2 A 97
3 A 98หรือ
Data |> filter(score >= 93) |>
filter(score <= 98) group score
1 B 93
2 A 97
3 A 98ถ้าใช้คำสั่ง between( )
Data |> filter(between(score, left = 93, right = 98)) group score
1 B 93
2 A 97
3 A 98จะใช้งานเหมือนกับคำสั่ง ifelse( ) ในคำสั่งพื้นฐาน เช่นถ้า ค่า score มากกว่า 95 จะให้ค่าเป็น \("\)very good\("\) ถ้าไม่ใช่ ให้ค่าเป็น \("\)good\("\) ในตัวแปรใหม่ ชื่อ feeling
Data |>
mutate(feeling = if_else(score > 95,
true = "very good",
false = "good")) group score feeling
1 A 90 good
2 B 93 good
3 A 97 very good
4 A 98 very good
5 B 80 good
6 A 100 very goodการเปลี่ยนโครงสร้างข้อมูล (reshape data) คือการเปลี่ยนลักษณะข้อมูลในกรอบข้อมูลเดิมไปสู่รูปแบบที่ต้องการ เช่น การนำชื่อตัวแปรไปเป็นข้อมูลของตัวแปรใหม่ และข้อมูลในตัวแปรเดิมจะเป็นข้อมูลของตัวแปรใหม่อีกตัวที่สร้างข้ึน เช่น การเก็บข้อมูลคะแนนวิชาคณิตศาสตร์ ก่อนเรียน (pretest) และ หลังเรียน (posttest)
โดยมีคะแนนตามตารางดังนี้
| name | pretest | postest |
|---|---|---|
| student 1 | 28 | 31 |
| student 2 | 23 | 40 |
| student 3 | 26 | 43 |
| student 4 | 20 | 47 |
เมื่อต้องการสร้าง ตารางข้อมูลใหม่ โดยตัวแปรใหม่คือ test โดยมีค่าเป็นคำว่า pretest และ posttest และตัวแปรใหม่อีกตัวชื่อว่า score ซึ่งมาจากคะแนนของ pretest และ posttest นั้นเอง จะได้ตารางใหม่คือ
| name | test | score |
|---|---|---|
| student 1 | pretest | 28 |
| student 1 | postest | 31 |
| student 2 | pretest | 23 |
| student 2 | postest | 40 |
| student 3 | pretest | 26 |
| student 3 | postest | 43 |
| student 4 | pretest | 20 |
| student 4 | postest | 47 |
หรือตารางคะแนนคะแนนคณิตศาสตร์ จะถูกสร้างขึ้นมาจากตารางคะแนนคณิตศาตร์ใหม่ก็ได้ สำหรับตารางแรก จะถูกใช้สำหรับการทดสอบผลการเรียนรู้ระหว่างคะแนนก่อนเรียนและหลังเรียน ส่วนตารางที่สองจะเหมาะสำหรับนำไปการวาดกราฟกล่อง (boxplot) ด้วยชุดคำสั่งพื้นฐานหรือ ggplot2
ปัญหานี้ ถ้าใช้โปรแกรมอาร์ สามารถใช้ชุดคำสั่ง tidyr ได้
การติดตั้งคำสั่ง
install.packages("tidyr")การเรียกใช้งาน
library(tidyr)ตัวอย่างข้อมูลจากตารางคณิตศาสตร์ สร้างจาก
set.seed(1)
N <- 4
name <- paste("student", 1:4)
pretest <- sample(20:30, size = N)
postest <- sample(30:50, size = N)
data <- data.frame(name, pretest, postest)
data name pretest postest
1 student 1 28 31
2 student 2 23 40
3 student 3 26 43
4 student 4 20 47data.reshape <- pivot_longer(data = data,
cols = 2:3,
names_to = "test",
values_to = "score")
data.reshape# A tibble: 8 × 3
name test score
<chr> <chr> <int>
1 student 1 pretest 28
2 student 1 postest 31
3 student 2 pretest 23
4 student 2 postest 40
5 student 3 pretest 26
6 student 3 postest 43
7 student 4 pretest 20
8 student 4 postest 47คำสั่งภายในที่จำเป็นประกอบด้วย
data กรอบข้อมูลที่ต้องการแปลง
cols เวคเตอร์ตำแหน่งของชื่อตัวแปรที่ต้องการ
name_to ชื่อตัวแปรใหม่ที่ใช้ตัวเก็บชื่อตัวแปรจากคำสั่ง cols
value_to ชื่อตัวแปรใหม่ที่แสดงข้อมูลในตัวแปรที่เลือกจากคำสั่ง cols
ถ้าตารางข้อมูลอยู่ในรูปแบบของตารางคะแนนคณิตศาสตร์ใหม่ ถ้าต้องการให้ตารางอยู่รูปตารางคะแนนคณิตศาสตร์ สามารถใช้คำสั่ง pivot_wider( ) ได้ดังนี้
pivot_wider(data = data.reshape,
names_from = "test",
values_from = "score")# A tibble: 4 × 3
name pretest postest
<chr> <int> <int>
1 student 1 28 31
2 student 2 23 40
3 student 3 26 43
4 student 4 20 47คำสั่งภายในที่จำเป็นประกอบด้วย
data กรอบข้อมูลที่ต้องการแปลง
name_from การนำข้อมูลในตัวแปรที่ต้องการไปสร้างเป็นชื่อตัวแปร
value_from การนำค่าในตัวแปรที่ต้องการไปใส่เป็นข้อมูลของตัวแปรจากคำสั่ง name_from
ข้อสังเกตุ ผลลัพธ์จากคำสั่ง pivot_longer( ) และ pivot_wider( ) จะได้วัตถุหรือกรอบข้อมูลอีกแบบหนึ่งที่เรียกว่า tibble และสามารถใช้คำสั่งที่เกี่ยวข้องกับกรอบข้อมูลได้ทั้งหมด
tibble เป็นรูปแบบของข้อมูลที่เพื่อจัดเก็บข้อมูลในรูปแบบของตาราง (table) ซึ่งมีความคล้ายคลึงกับกรอบข้อมูล data frame ในการแสดงผลของตารางแบบ tibble จะบอกชนิดของข้อมูลในทุกตัวแปรด้วยเช่น
data.reshape# A tibble: 8 × 3
name test score
<chr> <chr> <int>
1 student 1 pretest 28
2 student 1 postest 31
3 student 2 pretest 23
4 student 2 postest 40
5 student 3 pretest 26
6 student 3 postest 43
7 student 4 pretest 20
8 student 4 postest 47ในขณะที่กรอบข้อมูลแบบปกติจะไม่แสดงชนิดของข้อมูลในแต่ละตัวแปร
data name pretest postest
1 student 1 28 31
2 student 2 23 40
3 student 3 26 43
4 student 4 20 47สามารถสร้างได้ด้วยคำสั่ง tibble( ) หรือแปลงจากกรอบข้อมูลไปเป็น tibble ด้วยคำสั่ง as.tibble()
as_tibble(data)# A tibble: 4 × 3
name pretest postest
<chr> <int> <int>
1 student 1 28 31
2 student 2 23 40
3 student 3 26 43
4 student 4 20 47คำสั่งนี้ จะอยู่ในชุดคำสั่ง tidyr ด้วย
คำสั่งอื่นในชุดคำสั่ง tidyr สามารถอ่านได้จากคู่มือ Wickham et al. (2024) และรูปแบบปัญหาลักษณะนี้ ยังมีอีกหลายรูปแบบ ผู้เขียนเพียงนำเสนอเฉพาะตัวอย่างที่สำคัญเท่านั้น
ชุดคำสั่งนี้เป็นส่วนหนึ่งของชุดคำสั่ง tidyverse หรือ จะเรียกใช้จากเรียกใช้จากชุดคำสั่ง forcats ก็ได้
การติดตั้งชุดคำสั่ง
install.packages("tidyverse")
# หรือ
install.packages("forcats")การเรียกใช้งาน
library("tidyverse")
# หรือ
library("forcats")![]()
ชุดคำสั่งนี้ จะใช้สำหรับการบริหารจัดตัวแปรประเภทกลุ่ม (factor) โดยเฉพาะ และตัวแปรประเภทตัวอักษรก็สามารถใช้ได้ เพราะตัวแปรตัวษรเป็นตัวแปรชนิดหนึ่ง ที่มีการเรียงลำดับค่าในตัวแปร ตามลำดับตัวอักษรหรือพยัญชนะ ใช้กับตัวแปรหรือวัตถุแบบเวคเตอร์เท่านั้น โดยรูปแบบของปัญหาที่ใช้ ชุดคำสั่งนี้จัดการ มีคำสั่งหลักดังนี้
fct_reorder( ): การเปลี่ยนแปลงลำดับของตัวแปรกลุ่มโดยตัวแปรอื่น
fct_infreq( ): การเปลี่ยนแปลงลำดับโดยใช้ความค่าของความถี่
fct_relevel( ): การเปลี่ยนแปลงลำดับด้วยค่าที่ต้องการ
fct_reorder(.f, .x, .fun = median).f คือ ตัวแปรvector ประเภทตัวอักษร หรือกลุ่ม
.x คือ เวคเตอร์ของตัวเลข
.fun ค่าของฟังก์ที่ต้องการใช้ในการคำนวณจากตัวแปร .x โดยฟังก์ชันหรือค่าค่าสถิติที่กำหนดมาให้เป็นเบื้องต้น คือ median
ตัวอย่างการใช้งาน
set.seed(1)
group <- c(rep("A", 20), rep("B", 30), rep("C", 25),rep("D", 35))
score1 <- sample(41:70, size = 20, replace = TRUE)
score2 <- sample(70:80, size = 30, replace = TRUE)
score3 <- sample(50:70, size = 25, replace = TRUE)
score4 <- sample(65:95, size = 35, replace = TRUE)
student <- data.frame(Group = group,
score = c(score1,score2,score3, score4))
Da <- aggregate(score ~ Group, data = student, FUN = median)
Da Group score
1 A 54
2 B 76
3 C 59
4 D 83จากข้อมูลถ้าเราสร้าง boxplot จะได้
student |>
ggplot( ) +
aes(x = Group, y = score) +
geom_boxplot( )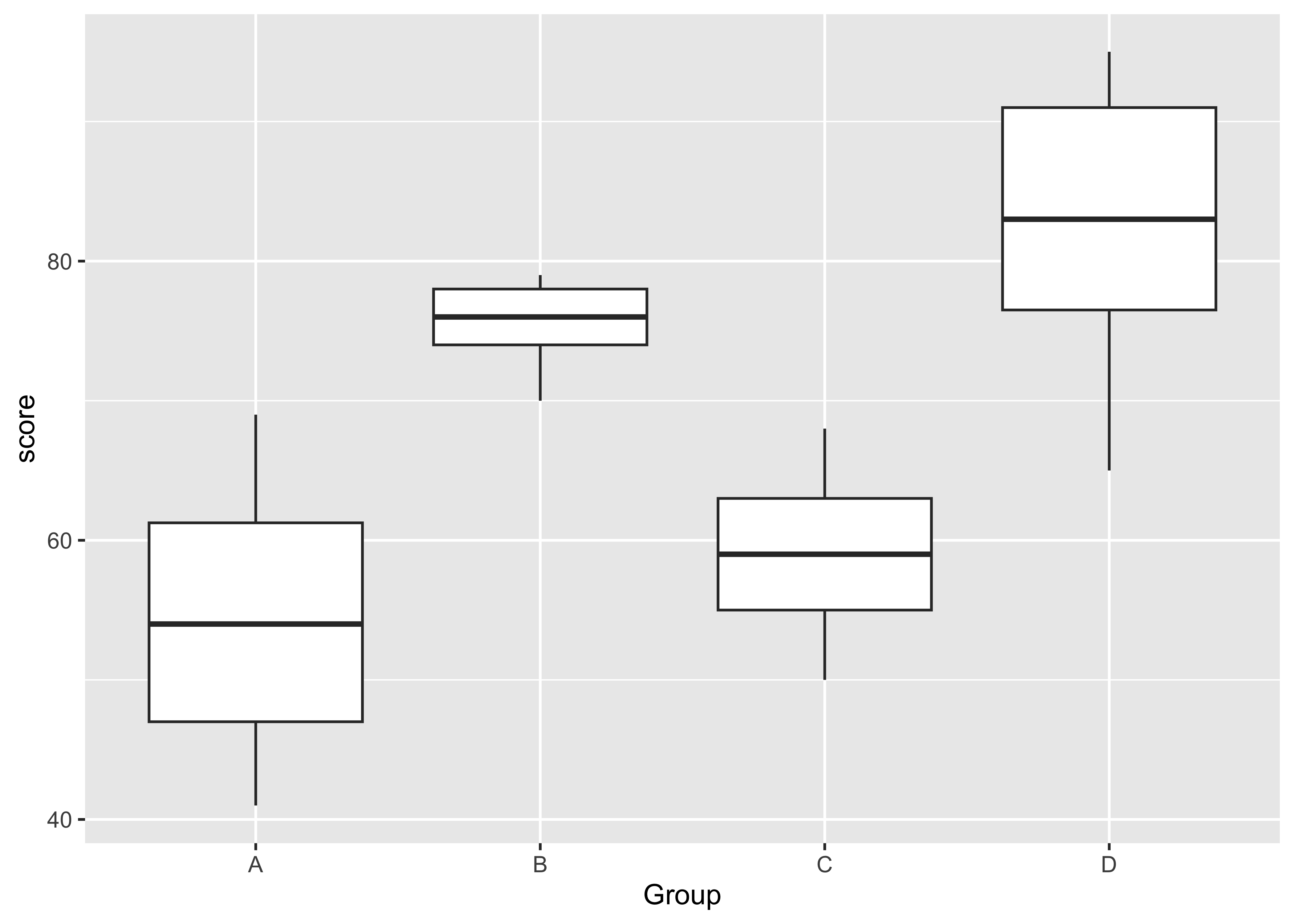
ในบ้างครั้งอาจจะต้องมีการเรื่องลำดับตามค่า median ในแต่ละกลุ่ม
student |>
ggplot( ) +
aes(x = fct_reorder(.f = Group,.x = score), y = score) +
geom_boxplot( )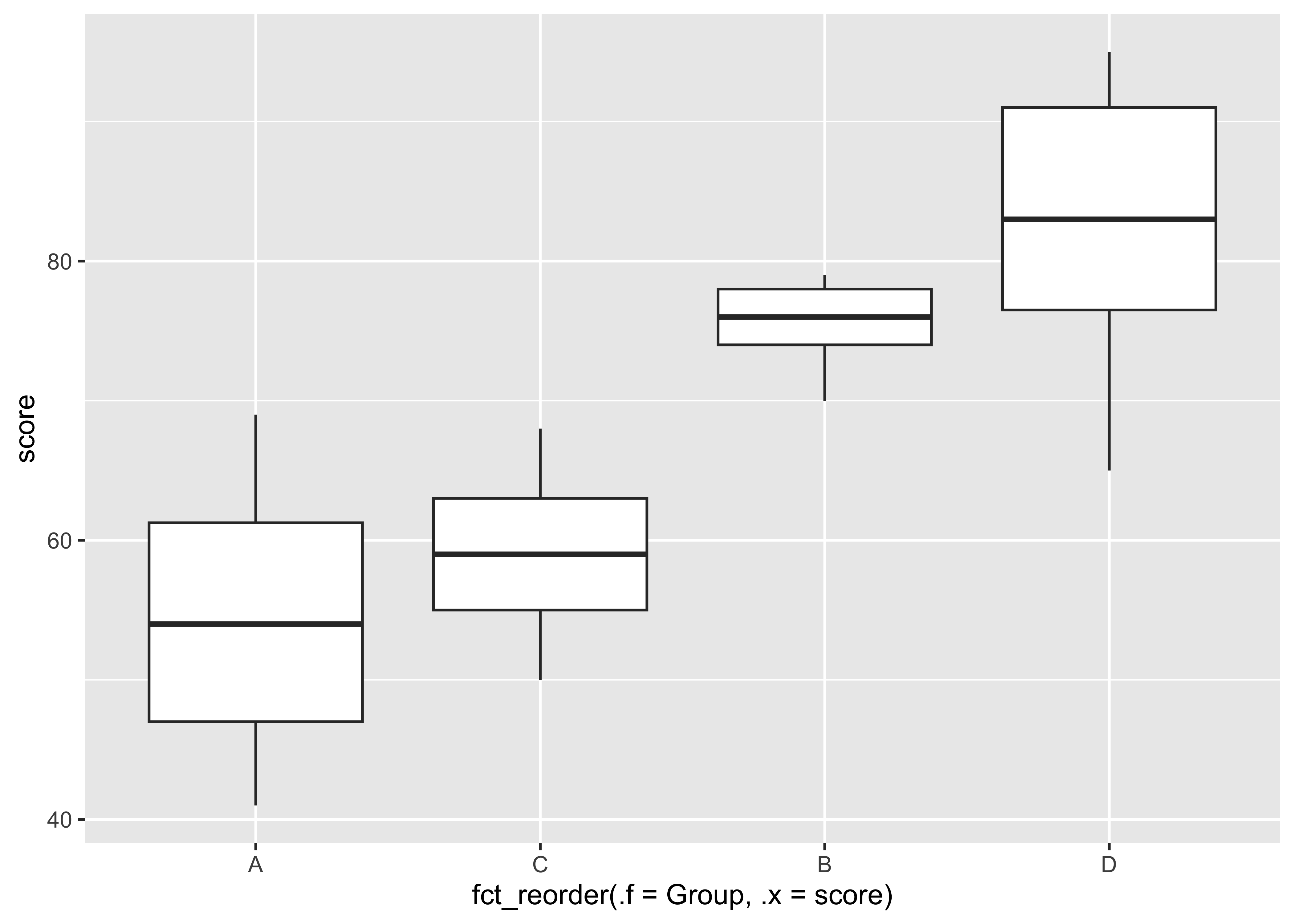
หรือ
Da <- aggregate(score ~ Group, data = student, FUN = mean)
Da Group score
1 A 54.30000
2 B 75.83333
3 C 59.56000
4 D 82.85714fct_reorder(.f = Da$Group, .x = Da$score)[1] A B C D
Levels: A C B Dถ้าต้องการสร้างกราฟแท่ง
Da |>
ggplot( ) +
aes(x = Group, y = score)+
geom_bar(stat = "identity")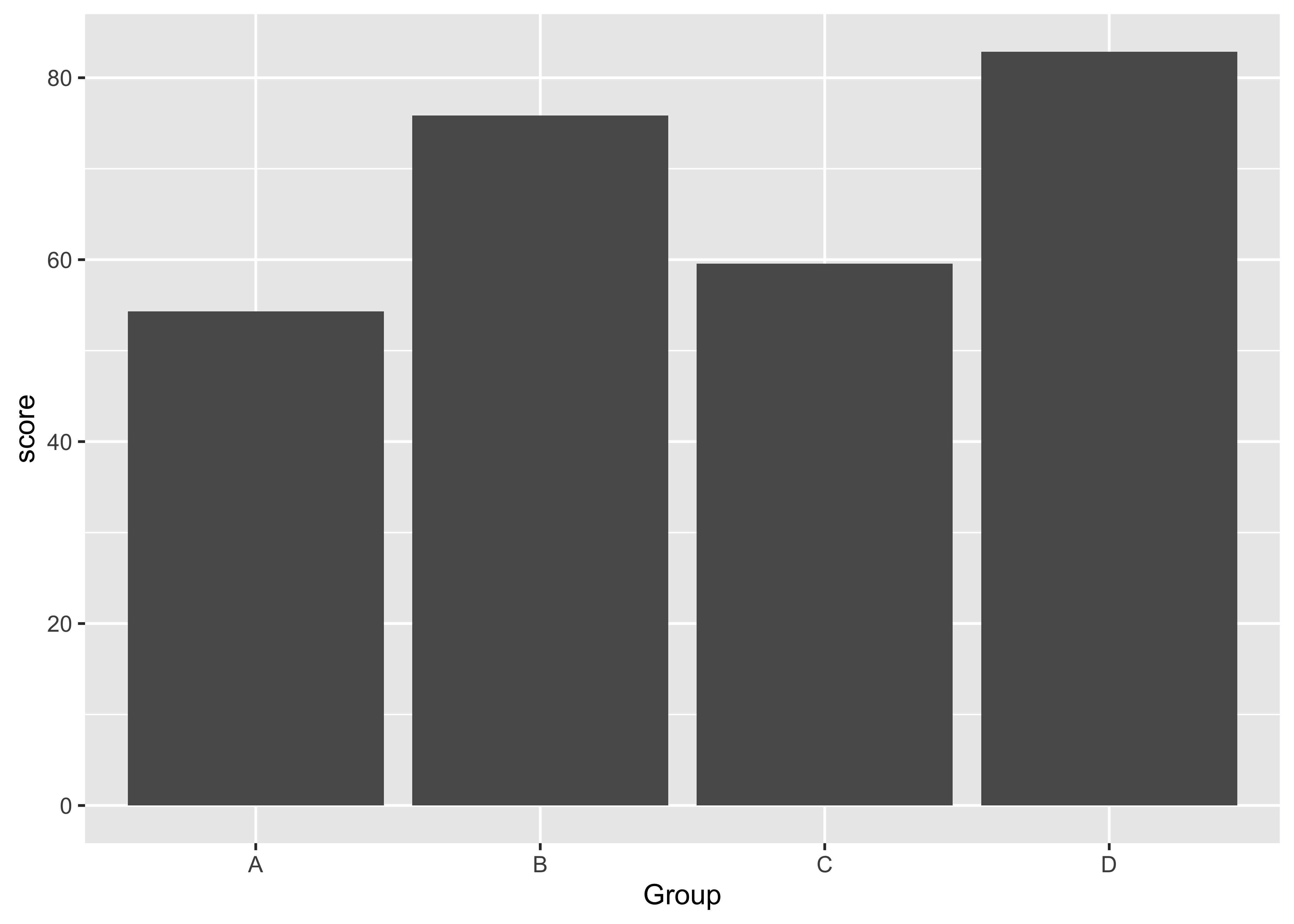
ถ้าต้องการเรียงลำดับ
fct_reorder(.f = Da$Group, .x = Da$score, .fun = mean)[1] A B C D
Levels: A C B Dหรือนำไปใช้สร้างกราฟแท่งแบบเรียงลำดับ
Da |>
ggplot( ) +
aes(x = fct_reorder(.f = Group, .x = score, .fun = mean), y = score)+
geom_bar(stat = "identity")
การการสร้างตัวแปรกลุ่มแบบเรียงลำดับโดยจำนวนสามารถสมาชิกที่ปรากฏ จากน้อยไปมาก โดยใช้คำสั่ง fct_infreq( )
fct_infreq(f = "ตัวแปรหรือวัตถุแบบเวคเตอร์ที่ต้องการเรียงลำดับ")เช่น
table(student$Group)
A B C D
20 30 25 35 จะเห็นว่า จำนวนสามารถที่เรียงจากน้อยไปมาก คือ A C B และ D ตามลำดับ ดังนี้ถ้าต้องการเปลี่ยนตัวแปร Group ในกรอบข้อข้อมูล student เป็นตัวแปรกลุ่ม โดยใช้ความถี่เป็นเกณฑ์ ทำได้ดังนี้
student$Group <- fct_infreq(f = student$Group)
str(student$Group) Factor w/ 4 levels "D","B","C","A": 4 4 4 4 4 4 4 4 4 4 ...หรือจะใช้คำสั่งจาก dplyr โดยใช้ตัวดำเนินการไปป์ ช่วยก็ได้
student <- student |>
mutate(Group = fct_infreq(f = Group))
str(student$Group) Factor w/ 4 levels "D","B","C","A": 4 4 4 4 4 4 4 4 4 4 ...เป็นการตัวลำดับของตัวแปรตามที่เราต้องการ โดยอาจจะใช้บางฟังก์ชันหรือบางคำสั่ง เพื่อใช้ในการเรียงลำดับใหม่ ก็ได้ โดยคำสั่งที่ใช้คือ fct_relevel( )
fct_relevel( .f = ตัวแปรหรือวัตถุเวคเตอร์แบบกลุ่มที่ต้องการเรียงดำดับใหม่,
c("ค่าของ levels ที่ต้องการเปลี่ยนจะมีกี่ตัวก็ได้"),
after = เลขตัวแหน่งของ level ที่ต้องการเปลี่ยนโดยมีค่ามาตราฐานคือนำไปไว้หน้าสุด)ตัวอย่างการใช้งาน จากเวคเตอร์ group ที่สร้างมาแล้วจากตัวอย่างข้างบน ทำการเปลี่ยนเป็นตัวแปรกลุ่ม โดยจัดระดับจากตัวอักษร A B C และ D ตามลำดับ
group <- factor(x = group, levels = c("A", "B", "C", "D"))
str(group) Factor w/ 4 levels "A","B","C","D": 1 1 1 1 1 1 1 1 1 1 ...ตัวอย่างการใช้งาน
ถ้าต้องเรียงลำดับใหม่เป็น D A B C
fct_relevel(.f = group, "D") [1] A A A A A A A A A A A A A A A A A A A A B B B B B B B B B B B B B B B B B
[38] B B B B B B B B B B B B B C C C C C C C C C C C C C C C C C C C C C C C C
[75] C D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D
Levels: D A B Cถ้าต้องการเรียงลำดับใหม่จาก เป็น B C A D
fct_relevel(.f = group, "A", after = 2) [1] A A A A A A A A A A A A A A A A A A A A B B B B B B B B B B B B B B B B B
[38] B B B B B B B B B B B B B C C C C C C C C C C C C C C C C C C C C C C C C
[75] C D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D
Levels: B C A Dถ้าต้องการเรียงลำดับแบบย้อนกลับ คือ D C B A สามารถใช้คำสั่ง rev( ) ช่วย
fct_relevel(.f = group, rev) [1] A A A A A A A A A A A A A A A A A A A A B B B B B B B B B B B B B B B B B
[38] B B B B B B B B B B B B B C C C C C C C C C C C C C C C C C C C C C C C C
[75] C D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D
Levels: D C B Aหรือทำโดยวิธีปกติ ก็ได้
fct_relevel(.f = group, c("D", "C", "B", "A")) [1] A A A A A A A A A A A A A A A A A A A A B B B B B B B B B B B B B B B B B
[38] B B B B B B B B B B B B B C C C C C C C C C C C C C C C C C C C C C C C C
[75] C D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D D
Levels: D C B Aคำสั่งอื่นๆ ของชุด คำสั่ง forcats ยังมีอีกหลายคำสั่ง ผู้เขียนเพียงนำเสนอปัญหาพื้นฐานที่ผู้เขียนพบเจอในการทำงานเท่านั้น ผู้อ่านสามารถศึกษาเพิ่มเติมจาก เวบไซต์ https://forcats.tidyverse.org/index.html หรือคู่มือการใช้งานก็ได้ Wickham (2023)
\(~\)