My_vector <- c(1,2,4,6)
typeof(My_vector)[1] "double"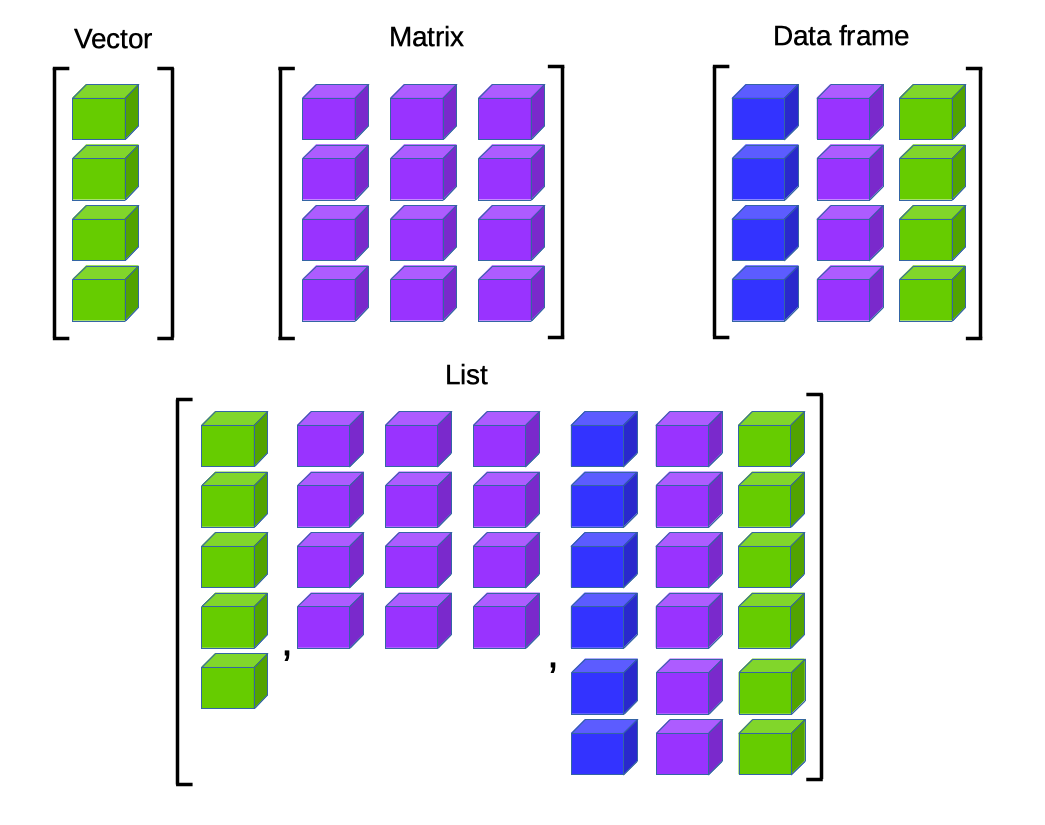
ในภาษาภาษาอาร์มีโครงสร้างข้อมูลหลายประเภทที่ใช้ในการจัดเก็บและการจัดการข้อมูลต่างๆ ซึ่งในหนังสือเล่มนี้สนใจโครงสร้างข้อมูลดังนี้
เวกเตอร์ (vector): เป็นโครงสร้างข้อมูลที่เก็บค่าของประเภทเดียวกัน ตั้งแต่ 1 ตัวขึ้นไป
เมทริกซ์ (matrix): เป็นโครงสร้างข้อมูลที่มีจำนวนแถวและจำนวนหลักที่ต้องระบุลำดับของข้อมูล โดยเมทริกซ์จะเก็บค่าของประเภทเดียวกัน เช่นเดียวกับเวคเตอร์
กรอบข้อมูล (data frame): เป็นโครงสร้างข้อมูลที่เก็บข้อมูลเป็นแถวและคอลัมน์ คล้ายกับตารางในฐานข้อมูล โดยแต่ละคอลัมน์สามารถเก็บข้อมูลของประเภทต่างๆ ได้
ลิสต์ (list): เป็นโครงสร้างข้อมูลที่เก็บค่าที่ไม่จำเป็นต้องเป็นประเภทเดียวกัน โดยสามารถเก็บอ็อบเจ็กต์หรือข้อมูลประเภทอื่น ๆ ภายในลิสต์ได้
ปัจจัย (factor): เป็นวัตถุแบบเวคเตอร์ที่ใช้ในการจัดเก็บข้อมูลประเภทข้อความหรือข้อมูลกลุ่ม (categorical) ที่สามารถจัดระดับ (levels) ก่อนหลัง ต่ำสูง หรือมากไปน้อยได้ โดยใช้ไม่จำเป็นต้องเป็นตัวเลข และจะมีประโยชน์ในกรณีที่สร้างกราฟและความจำเป็นต้องเรียงลำดับก่อนหลังตามชื่อที่ต้องการ
โครงสร้างข้อมูลในอาร์ ช่วยให้ผู้ใช้สามารถจัดเก็บและจัดการข้อมูลได้อย่างมีประสิทธิภาพ และมีคำสั่งและฟังก์ชันที่ใช้ในการทำงานกับแต่ละโครงสร้างข้อมูล อย่างไรก็ตาม ควรใช้โครงสร้างข้อมูลที่เหมาะสมกับงานและข้อมูลที่ต้องการจัดเก็บและประมวลผล

เวกเตอร์เป็นโครงสร้างข้อมูลพื้นฐานที่สุดในอาร์ โครงสร้างข้อมูลนี้จะต้องเป็นข้อมูลประเภทเดียวกันทั้งหมด คือ ตัวเลข จำนวนเต็ม จำนวนเชิงซ้อน ตรรกะ อักษร หรือแบบ factor เท่านั้น มีหลายวิธีในการสร้างเวกเตอร์ เช่น การรวมเวกเตอร์ตั้งแต่สองตัวขึ้นไป การใช้ลำดับ หรือการใช้ตัวสร้างข้อมูลแบบสุ่ม
เราสามารถใช้คำสั่ง tyoeof( ) ในชนิดชนิดของข้อมูลในเวกเตอร์ได้
คำสั่งนี้เป็นคำสั่งพื้นฐาน สำหรับการสร้างเวคเตอร์ใดๆ ถ้าต้องการสร้างตัวแปรเวคเตอร์ ก็เพียงกำหนดชื่อที่ต้องการ และใช้ตังดำเนินการ <- ในการกำหนดค่าที่ต้องการต้องคำสั่ง c( )
ตัวอย่าง
My_vector <- c(1,2,4,6)
typeof(My_vector)[1] "double"เวกเตอร์ยังสามารถเป็นประเภทข้อมูลใดก็ได้ ดังนั้น เราสามารถสร้างเวกเตอร์อักษร ตรรกะ หรือข้อมูลประเภทอื่นๆ เช่น
province <- c("Chaing Mai", "CHaing Rai", "Bangkok", "Trang")
class(province) [1] "character"logic <- c(TRUE, TRUE, FALSE, TRUE)
class(logic) [1] "logical"ข้อมูลภายในเวคเตอร์จะต้องเป็นประเภทเดียวกันเท่านั้น มิฉะนั้น ทุกค่าในเวคเตอร์จะถูกเปลี่ยนเป็นตัวอักษรทั้งหมด เช่น
mix_vector <- c(TRUE, "Correct", 8, 2.2)
mix_vector [1] "TRUE" "Correct" "8" "2.2" typeof(mix_vector) [1] "character"ค่าภายในของเวคเตอร์สามารถตั้งชื่อให้ได้ เช่น
my_fruit <- c(orange = 4, apple = 6)
my_fruitorange apple
4 6 และสามารถกำหนดชื่อภายในเวคเตอร์ ขึ้นมาภายหลัง โดยใช้คำสั่ง names( )
my_fruit <- c(1, 2, 4, 6)
names(my_fruit) <- c("apple", "orange", "mango", "watermelon")
my_fruit apple orange mango watermelon
1 2 4 6 แต่ถ้า ใช้คำสั่ง names( ) โดยไม่มีการกำหนดค่า จะเป็นการแสดงชื่อของค่าภายในเวคเตอร์ถ้ามี
names(my_fruit)[1] "apple" "orange" "mango" "watermelon"ถ้ามีตัวแปรเวคเตอร์ ตั้งแต่ 2 ตัวขึ้น เราสามารถใช้คำสั่ง c( ) ในการรวมเวคเตอร์ทั้งหมดเป็นเวคเตอร์ตัวเดียวได้ เช่น
x <- c(1, 2, 3)
y <- c(4, 5, 6)
z <- c(x, y)
z[1] 1 2 3 4 5 6จะเห็นว่าเวคเตอร์ z เกิดจาการรวมเวคเตอร์ x และ y
ข้อควรระวัง ลำดับก่อน-หลังมีผลต่อการรวมกันของเวคเตอร์
c(y, x)[1] 4 5 6 1 2 3จะเห็นว่า c(x,y) และ c(y,x) ให้ผลลัพธ์ที่แตกต่างกัน
เป็นการรวมกันสองเวคเตอร์ในลักษณะของแทรกลงไปยังตำแหน่งที่ต้องการ
รูปแบบการใช้
append(x, values, after = length(x))x เวคเตอร์ที่จะถูกแทรก
values เวคเตอร์ที่จะใช้แทรก
after ตำแหน่งของเวคเตอร์ x ที่ต้องการแทรก
ตัวอย่าง แทรกเวคเตอร์ c(\("\)c\("\), \("\)h\("\), \("\)g\("\)) หลังตำแหน่งที่ 1 ในเวคเตอร์ A
A <- c("a", "f")
append(x = A, value = c("c", "h", "g"), after = 1)[1] "a" "c" "h" "g" "f"แทรกเวคเตอร์ c(\("\)c\("\), \("\)h\("\), \("\)g\("\)) หลังตำแหน่งที่ 2 ในเวคเตอร์ A
A <- c("a", "f")
append(x = A, value = c("c", "h", "g"), after = 2)[1] "a" "f" "c" "h" "g"เวคเตอร์ว่าง จะถูกใช้สำหรับเตรียมที่จะกำหนดค่าให้ในอนาคต ตัวอย่างที่พบคือในการทำซ้ำ(loop)
ตัวอย่างเช่น ถ้าไม่มีการสร้างเวคเตอร์ว่างขึ้นมาก่อน การทำซ้ำนี้ จะไม่สามารถเกิดขึ้นได้
for (i in 1:10) {
my_vector[i] <- i
}Error: object 'my_vector' not foundmy_vectorError in eval(expr, envir, enclos): object 'my_vector' not foundการทำซ้ำเกิดขึ้นได้ เพราะมีการสร้างเวคเตอร์เปล่าขึ้นมาก่อนการทำซ้ำ
my_vector <- c( )
for (i in 1:10) {
my_vector[i] <- i
}
my_vector [1] 1 2 3 4 5 6 7 8 9 10หนังสือเล่มไม่ได้สนใจ เรื่องการทำงานซ้ำแบบต่างๆ เช่นการทำซ้ำภายใต้จำนวนครั้งที่ต้องการ การทำซ้ำจนครบตามเงื่อนไข
หัวข้อต่อไปจะพิจารณาตัวดำเนินการชนิดต่างๆ ของเวคเตอร์ที่มีขนาดมิติหรือจำนวนข้่อมูลเท่่ากันเท่านั้น ยกเว้น มีเวคเตอร์มีค่าเพียงตัวเดียว หือขนาดมิติหรือจำนวนข้อมูลเพียง 1 ค่า ดำเนินการกับเวคเตอร์ที่มีขนาดต่างกัน
ตัวดำเนินการนี้จะทำได้ต้องเป็นเวคเตอร์ที่มีค่าเป็นตัวเลขหรือตรรกศาสตร์เท่านั้น
vector_1 <- c(1,2,3)
vector_2 <- c(4,5,6)vector_1 + vector_2 # การบวก[1] 5 7 9vector_1 - vector_2 # การลบ[1] -3 -3 -3vector_1 * vector_2 # การคูณ[1] 4 10 18vector_1 / vector_2 # การหาร[1] 0.25 0.40 0.503*(vector_1 + vector_2) # การคูณด้วยค่าคงที่ หลังจากการบวกกันของเวคเตอร์[1] 15 21 27vector_1^vector_2 # การยกกำลัง[1] 1 32 729เป็นการดำเนินการพีชคณิตของเวคเตอร์ เฉพาะที่อยู่ในลำดับหรือในตำแหน่งเดียวกันเท่านั้น
3^vector_2ลองสังเกตุและพิจารณาผลลัพธ์ว่าเป็นอย่างไร
เป็นการเปรียบเทียบค่าภายในเวคเตอร์ที่มีตำแหน่งตรงกันเท่านั้น
x <- c(1, 5)
y <- c(4, 0)
x > y [1] FALSE TRUEx <- c(1, 5, 1)
y <- c(4, 0, 1)
x != y [1] TRUE TRUE FALSEถ้าต้องการสร้างลำดับของจำนวนเต็มจากเลขจำนวนเต็ม a ไปจนถึงเลขจำนวนเต็ม b โดยมีค่าเพิ่มขึ้นทีละ 1 หรือลดลงทีละ 1 ขึ้นอยู่กับว่า ค่า a น้่อยกว่าหรือมากกว่า b สามารถใช้คำสั่ง a:b ในการสร้างได้ เช่น
1:4[1] 1 2 3 4-2:0[1] -2 -1 0-2:-6[1] -2 -3 -4 -5 -6ต่อไปเป็นคำสั่ง seq( ) การสร้างลำดับที่เพิ่่มหรือลดลงเป็นจำนวนที่เท่ากัน หรือจะกำหนด จำนวนลำดับที่ต้่องการให้มีก็ได้
สร้างลำดับจากเลข 1 ถึง 5 โดยมีจำนวนลำดับทั้งหมด 6 ตัว
seq(from = 1, to = 5, length.out = 6)[1] 1.0 1.8 2.6 3.4 4.2 5.0สร้างลำดับจากเลข 1 ถึง 5 โดยเพิ่มขึ้นครั้งละ .75
seq(from = 1, to = 5, by = .75)[1] 1.00 1.75 2.50 3.25 4.00 4.75สังเกตุได้ว่า ลำดับตัวสุดท้ายมีค่าไม่เกิน 5
สร้างลำดับจากเลข 5 ถึง 0 โดยลดลงขึ้นครั้งละ -1
seq(from = 5, to = 0, by = -1)[1] 5 4 3 2 1 0คำสั่ง rep( )
การสร้างเวคเตอร์ที่ต้องการขึ้นมาเป็นจำนวนที่กำหนด
สร้างเวคเตอร์ 1 ขึ้นมา 5 ตัว
rep(x = 1, times = 5)[1] 1 1 1 1 1สร้างเวคเตอร์ c(1, 2) ขึ้นมา 3 ชุดต่อกัน
rep(x = c(1,2), times = 3)[1] 1 2 1 2 1 2สร้างเวคเตอร์ 1 ขึ้นมา 3 ครั้ง และเวคเตอร์ 2 อีก 3 ครั้ง
rep(x = c(1,2), each = 3)[1] 1 1 1 2 2 2สร้างเวคเตอร์ 1 ขึ้นมา 3 ครั้ง และเวคเตอร์ 2 อีก 3 ครั้ง ทั้งหมด 2 ชุด
rep(x = c(1,2), each = 3, times = 2) [1] 1 1 1 2 2 2 1 1 1 2 2 2ในทางสถิติข้อมูลทุกชนิดเป็นการสุ่มขึ้นมาจากประชากร
สำหรับภาษาอาร์ มีคำสั่งมากมายที่เป็นการสร้างลำดับสุ่มที่มาจากการแจกแจงแบบต่างๆ เช่นการแจกแจงแบบปรกติ (Normal Distribution) หรือการแจงแจกทวิภาค (ฺBinomial Distribution) เป็นต้น
ตัวอย่างเช่น ถ้าต้องการโยนลูกเต๋า จำนวน 10 ครั้ง สามารถใช้คำสั่ง sample( ) ได้
ลูกเต๋ามีเลขทั้งหมด 1, 2, 3, 4, 5, 6 โอกาสที่จะได้เลขใด เลขหนึ่งจากทั้งหมดความน่าจะเป็นเท่ากัน
โดยคำสั่ง sample( ) ด้านล่างอ่านได้ สุ่มตัวเลข 1-6 จำนวน 10 ครั้ง โดยที่การสุ่มแต่ละครั้งเป็นการสุ่มแบบคืนที่
sample(x = 1:6, size = 10, replace = TRUE) [1] 1 5 4 2 5 6 4 6 4 6ตัวอย่างถัดไป ต้องจับฉลากจากตัวเลข 0-99 โดยใบแรกที่จับได้ได้รับรางวัลที่ และจับฉลากขึ้นอีกใบ จะได้รางวัลที่ 2 จะเห็นว่าการสุ่มนี้เป็นการสุ่มแบบคืนที่ สามารถใช้คำสั่งได้ดังนี้
sample(x = 0:99, size = 2, replace = FALSE)[1] 22 30การสุ่มแต่ครั้่งมีความน่าจะเป็นน้อยมากๆจนเกือบจะเท่ากับ 0 ที่คอมพิวเตอร์แต่ละเครื่องจะสุ่มตัวเลขออกได้ชุดเดียวกัน สำหรับเวคเตอร์จำนวนจริง ดังนั้นถ้าต้องการให้คอมพิวเตอร์ทุกเครื่องที่ใช้่คำสั่งแบบเดียวกัน ให้มีค่าจากการสุ่มเท่ากัน จำเป็นจะต้องกำหนดตัวเลขชุดเดียวกันขึ้นมาก่อน เพื่อกำหนดรูปการสุ่ม นั้นคือคำสั่ง set.seed( ) สามารถใช้งานได้ดังนี้
set.seed(1)
sample(x = 0:99, size = 2, replace = FALSE)[1] 67 38เลข 1 ในคำส่ัง set.seed เป็นตัวเลขจำนวนเต็มเท่าไหร่ก็ได้ เมื่อมีการกำหนดค่าให้แล้ว เมื่อสร้างเลขสุ่มจากคำสั่งเดียวกัน จะได้ค่าเดียวกันเสมอไม่ว่าจะทำงานกับคอมพิวเตอร์เครื่องไหนก็ตาม
เป็นการนับจำนวนข้อมูลในเวคเตอร์ว่ามีอยู่ทั้งกี่ตัว หรือมีกี่มิติ โดยใช้คำสั่ง length( )
my_vector <- c("vector", "sequence", "rnorm", "runif")
n <- length(my_vector)
n[1] 4จากคำสั่งจะพบว่า my_vector มีความยาวเท่ากับ 4 หรือมีสมาชิก 4 ตัว
ไม่ว่าจะเป็นโครงสร้างข้อมูลแบบใด เราสามารถเข้าถึงค่าต่างๆ ภายในโครงสร้างนั้นด้วยการเพิ่มเครื่องหมาย [ ] ตามหลังชื่อแปรของโครงสร้างข้อมูล แล้วจึงค่อยเพิ่มตัวเลขตำแหน่งที่ต้องการต่อไป
เช่น จากเวคเตอร์ my_vector ถ้าต้องการใช้งานหรือแสดงผลข้อมูลลำดับที่ 2 สามารถทำได้โดย
my_vector[2][1] "sequence"ถ้าต้องการแสดงผลค่าภายในเวคเตอร์ตั้งแต่ 2 ค่าขึ้นไป จะต้องสร้างเวคเตอร์ของเลขดัชนี ที่ระบุตำแหน่งที่ต้องการ เช่น ต้องการแสดงค่า ตำแหน่ง 4 และ 1
my_vector[c(4, 1)][1] "runif" "vector"อาร์ได้สร้างตัวแปรชื่อ letters และ LETTERS ไว้ให้สำหรับตัวอักษรภาษาอังกฤษพิมพ์เล็ก และพิมพ์ใหญ่ตามลำดับ
letters [1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q" "r" "s"
[20] "t" "u" "v" "w" "x" "y" "z"LETTERS [1] "A" "B" "C" "D" "E" "F" "G" "H" "I" "J" "K" "L" "M" "N" "O" "P" "Q" "R" "S"
[20] "T" "U" "V" "W" "X" "Y" "Z"การแสดงผลหรือเข้าถึงค่าในเวคเตอร์ที่ตำแหน่งต่างๆ
แสดงค่าแรก
letters[1][1] "a"แสดงค่าที่ 3 และ 4
letters[c(3, 4)][1] "c" "d"แสดงค่าสุดท้าย
letters[length(letters)][1] "z"แสดงเฉพาะลำดับที่เป็นจำนวนคู่
letters[seq(from = 2, to = length(letters), by = 2)] [1] "b" "d" "f" "h" "j" "l" "n" "p" "r" "t" "v" "x" "z"แสดงเฉพาะลำดับที่เป็นจำนวนคี่
letters[seq(from = 1, to = length(letters), by = 2)] [1] "a" "c" "e" "g" "i" "k" "m" "o" "q" "s" "u" "w" "y"ลำดับทางตรรกศาตร์คือ ลำดับที่ที่สมารชิกทุกตัวมีว่าเพียงเป็น 0 หรือ 1 เท่านั้น หรือเป็นลำดับที่ ทีค่าเป็น TRUE หรือ FALSE เท่านั้นก็ได้
ในการเข้าภึงค่าด้วยลำดับตรรกศาสตร์ จำนวนลำดับทั้งหมดจะต้องมีค่าเท่ากับจำนวนสมาชิกในตัวแปรเวคเตอร์ที่พิจารณา
ลำดับนี้มักเกิดจากการเปรียบค่าของสมาชิกภายในเวคเตอร์ เช่น กำหนดให้
set.seed(1)
Vec <- sample(x = 1:20, size = 10)
Vec [1] 4 7 1 2 13 19 11 17 14 3จะสมาชิกตัวที่เท่าไหร่บ้างมีค่ามากกว่า 10 โดยการดำเนินการเปรียบเทียบจะได้
Vec > 10 [1] FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE TRUE FALSEผลลัพธ์ที่ได้ จะออกมาเป็นลำดับตรรกศาสตร์ ถ้ามีค่าเป็น FALSE แสดงว่าค่าของสมาชิกในเวคเตอร์นั้น มีค่าน้อยกว่าหรือเท่ากับ 10 ถ้ามีค่าเป็น TRUE แสดงว่าค่าของสมาชิกในเวคเตอร์มีค่ามากกว่า 10
ถ้าต้องการแสดงค่าที่สมาชิกมีค่ามากกว่า 10 ทำได้โดย
Vec[Vec > 10][1] 13 19 11 17 14ถ้าต้องการให้โค้ดที่อ่านง่ายขึ้น อาจจะกำหนดตัวแปรขึ้นมาใหม่ก็ได้
Check <- Vec > 10
Vec[Check][1] 13 19 11 17 14ตัวอย่างการนำไปใช้
กำหนดให้ ตัวแปร temp หมายถึง อุณหภูมิเฉลี่ยของแต่เดือนในรอบ 1 ปี และตัวแปร month คือชืิ่อของเดือนในภาษาอังกฤษ โดยกำหนดให้มีค่าดังนีิ้
temp <- c( 22.52, 18.70, 19.61, 22.79, 29.38, 30.19,
33.16, 36.97, 33.29, 28.98, 24.31, 22.43)
month <- c("January", "February", "March", "April","May", "June",
"July", "August", "September","October", "November", "December")เดือนใดบ้างที่มีอุณหภูมิมากกว่า 30
month[temp > 30][1] "June" "July" "August" "September"temp > 30 คือลำดับตรรกศาสตร์
temp > 30 [1] FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE FALSE FALSE FALSEถ้าสนใจว่าเดือนใดบ้างที่ มีอุณหภูมิอยู่ระหว่าง 25 ถึง 35 ในทางคณิตสาสตร์ก็คือ \(25<\text{ temp }<35\) สามารถโดยใช้ตัวดำเนินการเปรียบเทียบและตรรกศาสตรได้ คือ
month[temp > 25 | temp < 35] [1] "January" "February" "March" "April" "May" "June"
[7] "July" "August" "September" "October" "November" "December" ุ่ถ้าต้องการลบสามารถบ้างตัวในเวคเตอร์ออกไป สามารถทำได้โดยใช้เลขจำนวนเต็มลบ ที่ระบุตำแหน่งที่ต้องการ เช่น
ต้องการนำเดือน ก.ค. ถึง ธ.ค. ออกไปจากเวคเตอร์ month ก็คือทำสมาชิกตำแหน่งที่ 7 ถึง 12 ออกไปนั่นคือ
month[-7:-12][1] "January" "February" "March" "April" "May" "June" ถ้าต้องการสร้างเวคเตอร์อักษร \("\)ID:1\("\) \("\)ID:2\("\) ไปเรื่อยๆ จนถึง \("\)ID:10000\("\) จะทำอย่างไร?
ID <- paste("ID:", 1:1000)
str(ID) chr [1:1000] "ID: 1" "ID: 2" "ID: 3" "ID: 4" "ID: 5" "ID: 6" "ID: 7" ...หรือ
ID <- paste0("ID:", 1:1000)
str(ID) chr [1:1000] "ID:1" "ID:2" "ID:3" "ID:4" "ID:5" "ID:6" "ID:7" "ID:8" ...ข่้อสังเกตุ คำสั่ง paste( ) จะมีการเว้นวรรค แต่ คำสั่ง paste0( ) จะนำตั้งสองคำ มาเชื่อมต่อกัน
ในการเชื่อมแต่กันแต่ละ จะใช้กี่ประโยคก็ได้ แต่ต้องมีเครื่องหมายหมาย , เช่น
paste("ID:", 1:5, "CMU")[1] "ID: 1 CMU" "ID: 2 CMU" "ID: 3 CMU" "ID: 4 CMU" "ID: 5 CMU"
โครงสร้างข้อมูลแบบเมตริกซ์เป็นโครงสร้างการจัดเก็บข้อมูลในรูปแบบของตารางที่มีการอ้างอิงตำแหน่งของข้อมูลด้วยเลขแถว (row) และเลขหลัก (column) และข้อมูลทั้งหมดในเมตริกซ์เป็นข้อมูลชนิดเดียวกันทั้งหมดเท่านั้น เช่นเดียวกับโครงสร้างข้อมูลแบบเวคเตอร์
ภาษาอาร์จะเริ่มการสร้างโครงสร้างข้อมูลแบบเมเตริกซ์จากเวคเตอร์ โดยนำมาตัดเป็นท่อนๆ มาวางเป็นแถว(วางตามแนวนอน) หรือวางเป็นหลัก(วางตามแนวตั้ง) โดยกำหนดจำนวนหลักหรือจำนวนแถวที่ต้องการ ถ้าเวคเตอร์ที่มีจำนวนข้อมูล \(k\) ตัว สามารถสร้างเมตริกซ์ได้ขนาด \(m\times n\) ตัว หรือ \(k = m\times n\), โดยที่ \(m\) และ \(n\) เป็นจำนวนเต็มบวก โดยใช้คำสั่ง matrix(data =)
matrix(data, nrow, ncol, byrow = FALSE)data คือเวคเตอร์ที่ต้องการสร้างเป็นเมตริกซ์
nrow เลขจำนวนเต็มของจำนวนแถวที่ต้องการ
ncol เลขจำนวนเต็มของจำนวนหลักที่ต้องการ
byrow FALSE คือ การวางท่อนของเวคเตอร์ทีละหลัก
ตัวอย่าง
vec <- 5:10
vec[1] 5 6 7 8 9 10ถ้าต้องการ \[\begin{bmatrix}5&8\\6&9\\7&10\end{bmatrix}\] จะใช้
matrix(data = vec, ncol = 2) [,1] [,2]
[1,] 5 8
[2,] 6 9
[3,] 7 10หรือ
matrix(data = vec, nrow = 3) [,1] [,2]
[1,] 5 8
[2,] 6 9
[3,] 7 10หรือ
matrix(data = vec, ncol = 2, nrow = 3) [,1] [,2]
[1,] 5 8
[2,] 6 9
[3,] 7 10ถ้าต้องการ \[\begin{bmatrix}5&6\\7&8\\9&10\end{bmatrix}\]
matrix(data = vec, ncol = 2, byrow = TRUE) [,1] [,2]
[1,] 5 6
[2,] 7 8
[3,] 9 10หรือ
matrix(data = vec, nrow = 3, byrow = TRUE) [,1] [,2]
[1,] 5 6
[2,] 7 8
[3,] 9 10ถ้าหากมีข้อมูลเวคเตอร์ประเภทเดียวกันและมีขนาดหรือจำนวนเท่ากันตั้งแต่ 2 เวคเตอร์ขึ้นไป หรือจะทำซ้ำเวคเตอร์ก็ทำได้ คำสั่ง
คำสั่ง rbind( ) คือการนำเวคเตอร์แต่ละตัวมาต่อกันเป็นแถวตามลำดับ คำสั่ง cbind( ) คือการนำเวคเตอร์แต่ละตัวมาต่อกันที่ละหลักตามลำดับนั้นเอง
x <- 1:3
y <- 4:6
z <- 7:9ต่อกันเป็นแถว จำนวน 3 แถว
xyz.r <- rbind(x, y, z)
xyz.r [,1] [,2] [,3]
x 1 2 3
y 4 5 6
z 7 8 9ต่อกันเป็นหลัก จำนวน 3 หลัก
xyz.c <- cbind(x, y, z)
xyz.c x y z
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9คำสั่ง class( ) ตรวจสอบชนิดของโครงสร้างข้อมูล
class(xyz.c)[1] "matrix" "array" typeof( ) ตรวจสอบชนิดของข้อมูลภายในเมตริกซ์
typeof(xyz.r) [1] "integer"ตัวอย่างเมตริกซ์ตรรกศาตร์ และเมตริกซ์ตัวอักษร
matrix(data = c(TRUE, TRUE, FALSE, TRUE), ncol = 2) [,1] [,2]
[1,] TRUE FALSE
[2,] TRUE TRUEmatrix(data = c("red", "green", "orange", "black"), ncol = 2) [,1] [,2]
[1,] "red" "orange"
[2,] "green" "black" สำหรับหาจำนวนแถวและหลักในเมตริกซ์ เช่นจาก
my_matrix <- cbind(x, y)
my_matrix x y
[1,] 1 4
[2,] 2 5
[3,] 3 6ขนาดของเมตริกซ์คือ
dim(my_matrix)[1] 3 2ค่าแรกคือจำนวนแถว และค่าที่สองคือจำนวนหลัก นั้นคือ เมตริกซ์ my_matrix มีจำนวน 3 แถวกับ 2 หลัก
คำสั่งพื้นฐานสำหรับข้อมูลแบบเมตริกซ์ ให้ A เป็นข้อมูลแบบเมตริกซ์
| คำสั่ง | คำอธิบาย |
|---|---|
| dim( ) | หาจำนวนแถวและจำนวนหลัก |
| nrow( ) | หาจำนวนแถว |
| ncol( ) | หาจำนวนหลัก |
| diag( ) | เวคเตอร์ของเมตริกซ์แนวทแยง |
| %*% | การคูณกันแบบเมตริกซ์ |
| cbind( ), rbind( ) | รวมกันทีะละหลัก/รวมกันทีละแถว |
| t( ) | เมทริกซ์สลับเปลี่ยน (transpose matrix) |
| solve(A) | เมตริกซ์ผกผัน (inverse matrix) |
| solve(A, b) | แก้สมการเชิงเส้น Ax =b |
| det(A) | หาดีเทอร์มิแนนต์ (determinant) |
ตัวอย่าง
\[mat.A =\begin{bmatrix}5&7\\6&8\end{bmatrix},~mat.B =\begin{bmatrix}9&11\\10&12\end{bmatrix} ,~b =\begin{bmatrix}5\\6\end{bmatrix}\]
mat.A <- matrix(data = 5:8, nrow = 2)
mat.B <- matrix(data = 9:12, nrow = 2)
b <- c(5,6)หาจำนวนแถว
nrow(mat.A)[1] 2หาจำนวนหลัก
nrow(mat.A)[1] 2เวคเตอร์ของเมตริกซ์แนวทแยง
diag(mat.B)[1] 9 12รวมเมตริกซ์กันทีละหลัก
cbind(mat.A, mat.B) [,1] [,2] [,3] [,4]
[1,] 5 7 9 11
[2,] 6 8 10 12รวมเมตริกซ์กันทีละแถว
rbind(mat.A, mat.B) [,1] [,2]
[1,] 5 7
[2,] 6 8
[3,] 9 11
[4,] 10 12เมทริกซ์สลับเปลี่ยน (transpose)
t(mat.A) [,1] [,2]
[1,] 5 6
[2,] 7 8เมตริกซ์ผกผัน (inverse)
solve(mat.A) [,1] [,2]
[1,] -4 3.5
[2,] 3 -2.5แก้สมการเชิงเส้น Ax = b
solve(mat.A, b)[1] 1 0หาดีเทอร์มิแนนต์ (determinant)
det(mat.A)[1] -2การคูณกันแบบเมตริกซ์
mat.A %*% mat.B [,1] [,2]
[1,] 115 139
[2,] 134 162ข้อควรระวัง ถ้าใช้ * เฉยๆ จะการคูณระหว่างสมาชิกที่อยู่ในแถวและหลักเดียวกันเท่านั้น
mat.A * mat.B [,1] [,2]
[1,] 45 77
[2,] 60 96เมตริกซ์ยกกำลังก็เช่นเดียวกัน ควรใช้่
mat.A %*% mat.A [,1] [,2]
[1,] 67 91
[2,] 78 106ไม่ใช่
mat.A^2 [,1] [,2]
[1,] 25 49
[2,] 36 64rownames( ) คือการตั้งชื่อให้ทุกแถวในเมตริกซ์
เช่นถ้าต้องการ ตั้งชื่อให้แถว 1 และแถว 2 ในเมตริกซ์ mat.A ด้วยชื่อ \("\)row 1\("\) และ \("\)row 2\("\)
rownames(mat.A) <- paste("row", 1:2)
mat.A [,1] [,2]
row 1 5 7
row 2 6 8colnames( ) คือการตั้งชื่อให้ทุกหลักในเมตริกซ์
เช่นถ้าต้องการ ตั้งชื่อให้หลักที่ 1 และหลักที่ 2 ในเมตริกซ์ mat.A ด้วยชื่อ \("\)col 1\("\) และ \("\)col 2\("\)
colnames(mat.A) <- paste("col", 1:2)
mat.A col 1 col 2
row 1 5 7
row 2 6 8matrix_name[เวคเตอร์ลำดับของแถวที่ต้องการ, เวคเตอร์ลำดับของหลักที่ต้องการ]
จาก \[mat.A =\begin{bmatrix}5&7\\6&8\end{bmatrix}\] เช่นต้องการ เข้าถึงค่าของเมตริกซ์ mat.A แถวที่ 2 หลักที่ 2
mat.A[2, 2][1] 8หลักที่ 1 ทั้งหมด
mat.A[1:2, 1]row 1 row 2
5 6 หรือเขียนโดยย่อ
mat.A[,1]row 1 row 2
5 6 แถวที่ 2 ทั้งหมด
mat.A[2, 1:2]col 1 col 2
6 8 หรือเขียนโดยย่อ
mat.A[2, ]col 1 col 2
6 8 การเขียนย่อ จะใช้ได้เมื่อต้องการเข้าถึงสามารถในแถวทั้งหมด หรือสมาชิกในหลักทั้งหมดเท่านั้น
กระสลับตัวแหน่งในเมตริกซ์ ก็สามารถทำได้เช่นกัน
mat.A[c(2, 1), c(2, 1)] col 2 col 1
row 2 8 6
row 1 7 5การคือการนำค่าที่ไม่ต้องการออกไป ด้วยด้วยการนำเครื่องหมาย - ไว้เลขดัชนีลำดับของแถวหรือหลักที่ไม่ต้องการ
mat.C <- cbind(mat.A, mat.B)
colnames(mat.C) <- paste("col", 1:4)
mat.C col 1 col 2 col 3 col 4
row 1 5 7 9 11
row 2 6 8 10 12ไม่ต้องการ หลักที่ 3
mat.C[ , -3] col 1 col 2 col 4
row 1 5 7 11
row 2 6 8 12ไม่ต้องการ หลักที่ 1 และ 4
mat.C[ , c(-1, -4)] col 2 col 3
row 1 7 9
row 2 8 10ไม่ต้องการ หลักที่ 1 และ 3 และแถวที่ 1
mat.C[ -1, c(-1, -3)]col 2 col 4
8 12 การลบข้อมูลเมตริิกซืออกจากหน่วยความจำก็คือการใช้คำสั่ง rm( )
rm(mat.C)หรือ กำหนดให้ตัวแปรเมทริกซ์ที่ต้องการมีค่าเท่ากับ NULL
mat.A <- NULL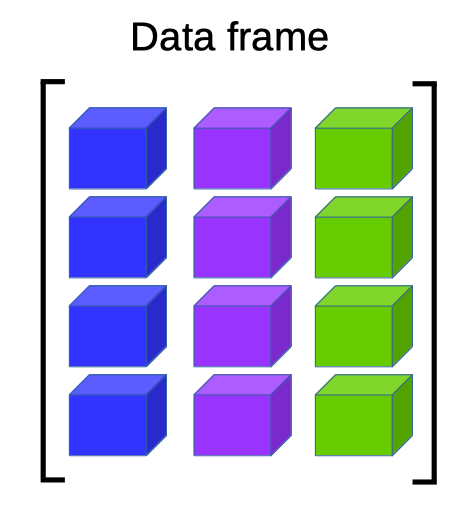
กรอบข้อมูลการเก็บข้อมูลที่ได้รับความนิยมอย่างมากในอาร์ เพราะในการประมวลผลข้อมูลทางสถิติจะอยู่ในรูปของกรอบข้อมูล เรียกอีกอย่างว่าตารางก็ได้ กรอบเป็นเป็นเมตริกซ์แบบทั่วไป มีคุณสมบัติว่าข้อมูลในแต่ละแถว ไม่เป็นจำเป็นต้องชนิดเดียวกัน ขอเพียงมีข้อมูลเหมือนกันตลอดทั้งแถวเท่านั้น และกรอบข้อมูลในอาร์จะต้องชื่อตัวแปรของแต่แถวเสมอ เพียงให้ง่ายต่อการนำไปใช้ไปงาน
เพราะว่าในการวิเคราะห์ข้อมูลทางสถิตินั้น ข้อมูลที่วิเคราะห์ประกอบไปด้วยตัวแปรหรือชนิดของข้อมูลที่หลากหลาย เช่น ถ้าต้องการเก็บข้อมูลของนักศึกษาจำนวน 100 คน ข้อมูลต่างๆ ที่เก็บจะเป็นทั้งแบบ ตัวเลข ตัวอักษร ตรรกศาสตร์ หรือตัวแปรปัจจัย(factor) เช่น
เพศ (character)
อายุ (double)
บ้านเกิด (character)
เป็นนักศึกษา ม.เชียงใหม่หรือไม่ (logical)
ระดับการศึกษา (สามารถเรียงลำดับจากระดับการศึกษาต่ำสุดไปหา ค่าสูงสุดได้) (factor)
ถ้าทำการจัดเก็บแยกกันเป็นตัวแปรต่างหาก จะมีความยุ่งยากในการเรียกใช้งานเพื่อวิเคราะห์ แต่ถ้าเก็บอยู่แบบเมตริกซ์ ข้อมูลทั้งหมด จะถูกเปลี่ยนไปตัวอักษรทั้งหมด นี่คือเหตุผลว่าทำไมเราถึงต้องเก็บข้อมูลเป็นโครงสร้างแบบกรอบข้อมูล
จะต้องตั้งชื่อให้กับทุกหลัก(ชื่อตัวแปร)
ถ้ามีการต้องชื่อในแต่ละแถวไม่ควรตั้งชื่อซ้ำกัน(ไม่ควรเก็บข้อมูลจากตัวอย่างเดียวกันซ้ำหรือแถวที่ i หมายถึงข้อมูลชุดที่ i )
ข้อมูลแต่ละหลัก จะเป็นข้อมูลชนิดใดก็ได้ แต่ต้องเหมือนกันทั้งแถว
จำนวนข้อมูลในแต่ละแถวต้องมีจำนวนเท่ากัน
ข้อมูลจากในบางแถว บางหลักอาจเป็นข้อมูลสูญหายได้ (missing data) ในอาร์จะแสดงค่าด้วย NA
กรอบข้อมูลเกิดจากข้อมูลแบบเวคเตอร์ที่มีขนาดเท่ากัน หลากหลากชนิดของข้อมูลหลายตัวตัวนำมาต่อรวมกัน ด้วยคำสั่ง data.frame( ) ตัวอย่างเช่น ถ้ามีเวคเตอร์ fruit price และ unit ตามลำดับ และมีค่าดังต่อไปนี้
fruit <- c("mango", "orange", "apple")
price<- c(30, 50, 60)
unit <- c(5,8,7)ถ้าต้องการสร้างข้อมูลนี้ ด้วยชื่อตัวแปร TH.fruit ทำได้ดังนี้
TH.fruit <- data.frame(fruit, price, unit)
TH.fruit fruit price unit
1 mango 30 5
2 orange 50 8
3 apple 60 7ถ้าต้องการตั้งชื่อตัวแปรในแต่ละหลักใหม่โดยการเติม s ต่อท้ายทั้งหมด ทำได้โดยโดยการกำหนดชื่อตัวแปรดังนี้
TH.fruit <- data.frame(fruits = fruit,
prices = price,
units = unit)
TH.fruit fruits prices units
1 mango 30 5
2 orange 50 8
3 apple 60 7ข้อสังเกตุ fruits = fruit หมายถึง ตัวแปรชื่อ fruits มาจากเวคเตอร์ fruit ที่มีอยู่แล้ว prices และ units ก็มีความหมายเดียวกัน
ในการเช็คข้อมูลภายในกรอบข้อมูล ให้ใช้คำสั่ง str( )
str(TH.fruit)'data.frame': 3 obs. of 3 variables:
$ fruits: chr "mango" "orange" "apple"
$ prices: num 30 50 60
$ units : num 5 8 7จะได้ว่า กรอบข้อมูล TH.fruit มีตัวแปร 3 ตัว และมีตัวอย่าง 3 ตัว โดยที่ตัวแปร fruits เป็นชนิดตัวอักษร ตัวแปร price เป็นตัวเลข และตัวแปร unit เป็นตัวเลข
month.name ชื่อเดือน
month.name [1] "January" "February" "March" "April" "May" "June"
[7] "July" "August" "September" "October" "November" "December" month.abb ชื่อเดือนโดยย่อ
month.abb [1] "Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct" "Nov" "Dec"ตัวอย่างต่อไป เป็นตัวอย่างของ เวคเตอร์ข้อมูลที่เกี่ยวข้องกับสภาพอากาศ
temp อุณหภูมิ
humidity ความชื่น
rain ปริมาณน้ำฝน
temp <- c(20.37, 18.56, 18.4, 21.96, 29.53, 28.16,
36.38, 36.62, 40.03, 27.59, 22.15, 19.85)
humidity <- c(88, 86, 81, 79, 80, 78, 71, 69, 78, 82, 85, 83)
rain <- c(72, 33.9, 37.5, 36.6, 31.0, 16.6, 1.2, 6.8, 36.8, 30.8, 38.5, 22.7)ถ้าต้องการสร้างกรอบข้อมูลชื่อ weather โดยมีตัวแปรภายในดังต่อไปนี้
weather <- data.frame(month = month.abb,
temperature = temp,
humidity = humidity,
rain = rain)คำสั่ง head( ) คือการแสดงข้อมูลในกรอบข้อมูลทั้งหมด 6 แถวแรก
head(weather) month temperature humidity rain
1 Jan 20.37 88 72.0
2 Feb 18.56 86 33.9
3 Mar 18.40 81 37.5
4 Apr 21.96 79 36.6
5 May 29.53 80 31.0
6 Jun 28.16 78 16.6คำสั่ง tail( ) คือการแสดงข้อมูลในกรอบข้อมูลทั้งหมด 6 แถวสุดท้าย)
tail(weather) month temperature humidity rain
7 Jul 36.38 71 1.2
8 Aug 36.62 69 6.8
9 Sep 40.03 78 36.8
10 Oct 27.59 82 30.8
11 Nov 22.15 85 38.5
12 Dec 19.85 83 22.7เป็นคำสั่งที่แสดงว่าสถิติพรรณา ของตัวแปรในกรอบข้อมูลทั้งหมด
ถ้าตัวแปรเป็นประเภทตัวอักษร จะแสดงจำนวนข้อมูลทั้งหมด ถ้าตัวแปรเป็นตัวเลข จะแสดงค่า ตำ่สุด(Min) ค่าคลอไทล์ที่ 25 50 และ 75 ค่าเฉลี่ย(mean) และค่าสูงสุด(max) ของตัวแปรทุกตัวที่เป็นตัวเลข
summary(weather) month temperature humidity rain
Length:12 Min. :18.40 Min. :69.0 Min. : 1.20
Class :character 1st Qu.:20.24 1st Qu.:78.0 1st Qu.:21.18
Mode :character Median :24.87 Median :80.5 Median :32.45
Mean :26.63 Mean :80.0 Mean :30.37
3rd Qu.:31.24 3rd Qu.:83.5 3rd Qu.:36.98
Max. :40.03 Max. :88.0 Max. :72.00 สำหรับการทำงานบน Rmarkdown ถ้าต้องการผลลัพธ์ นี้ในรูปของตารางให้ใช้คำสั่ง kable( ) จาก ชุดคำสั่ง knitr สามารถแสดงผลตารางบนเอกสารแบบ HTML Word และ PDF ได้
library(knitr)
kable(summary(weather))หรือจะใช้คำส่ัง kable แบบนี้ก็ได้ (สำหรับการใช้งานแบบมืออาชีพ)
knitr::kable(summary(weather))| month | temperature | humidity | rain | |
|---|---|---|---|---|
| Length:12 | Min. :18.40 | Min. :69.0 | Min. : 1.20 | |
| Class :character | 1st Qu.:20.24 | 1st Qu.:78.0 | 1st Qu.:21.18 | |
| Mode :character | Median :24.87 | Median :80.5 | Median :32.45 | |
| NA | Mean :26.63 | Mean :80.0 | Mean :30.37 | |
| NA | 3rd Qu.:31.24 | 3rd Qu.:83.5 | 3rd Qu.:36.98 | |
| NA | Max. :40.03 | Max. :88.0 | Max. :72.00 |
วิธีที่ 1 ใช้วิธีการเดียวกับโครงสร้างข้อมูลแบบเมตริกซ์ทุกประการ ผู้อ่านสามารถย้อนกลับดูที่หัวก่อนหน้านีได้
วิธีที่ 2 การเข้าถึงข้อมูลในกรอบข้อมูลทีละตัวแปร ใช้ตัวเครื่องหมาย $ ตามหลังชื่อตัวแปรกรอบข้อมูล และตามด้วยชื่อตัวแปรภายในที่ต้องการ ถ้าใช้ RStudio เมื่อพิมพ์ไปจนถึงเครื่องหมาย $ โปรแกรมจะขึ้นตัวแปรภายในให้เลือกทั้งหมด โดยอัตโนมัติ
เช่น ต้องการ เข้าถึง ตัวแปร month ในกรอบข้อมูล weather ทำได้โดย
weather$month [1] "Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct" "Nov" "Dec"จะได้ข้อมูลทั้งหมดปรากฏในลักษณะของการแสดงผลแบบเวคเตอร์
ถ้าต้องการข้อมูลตัวใดตัวหนึ่ง ให้ต่อท้ายด้วยเครื่อง[ ] เหมือนกับข้อมูลแบบเวคเตอร์ทุกประการ โดยภายในวงเล็บ ให้ใส่ เวคเตอร์จำนวนเต็มของตำแหน่งที่ต้องการ เช่น ต้องการตำแหน่งที่ 10-12 นั่นคืิอ
weather$month[10:12][1] "Oct" "Nov" "Dec"ถ้าต้องการตำแหน่งที่เป็นเลขคี่ทั้งหมด
weather$month[seq(from = 1, to = 11, by = 2)][1] "Jan" "Mar" "May" "Jul" "Sep" "Nov"คำสั่ง attach( ) เป็นเข้าถึงตัวแปรของกรอบข้อมูลได้โดยตรง โดยไม่ต้องพิมพ์ชื่อกรอบข้อมูลที่ต้องการก่อน
กรอบข้อมูล cars เป็นข้อมูลที่เรียกใช้งานได้ทันที
str(cars)'data.frame': 50 obs. of 2 variables:
$ speed: num 4 4 7 7 8 9 10 10 10 11 ...
$ dist : num 2 10 4 22 16 10 18 26 34 17 ...มีตัวแปร 2 ตัวคือ speed และ dist ถ้าไม่ใช้คำสั่ง attach( ) ก่อนจะไม่ได้เข้าถึงข้อมูลแปร speed หรือ dist ได้ เช่น
speedError in eval(expr, envir, enclos): object 'speed' not foundการใช้คำสั่ง detach( )
attach(cars)จะทำให้การใช้งานตัวแปร speed เหมือนเป็นเวคเตอร์ได้ทันที
speed[1:2][1] 4 4dist[-c(1:45)][1] 70 92 93 120 85และเมื่อต้องการยกเลิกการเข้าถึงตัวแปรในกรอบข้อมูลโดยตรง ก็ใช้คำสั่ง detach( )
detach(cars)ทดสอบการถูกเลิก
speedError in eval(expr, envir, enclos): object 'speed' not foundจากกรอบข้อมูล cars คำอธิบายเพิ่มของแต่ละตัวแปรคือ
speed: เป็นความเร็วมีหน่วยเป็นไมลต่อชม. mph (miles per hour)
dist: ระยะทางที่ใช้ในการหยุดรถมีหน่วยเป็น ฟุต (ft) numeric stopping distance (ft).
ถ้า เราต้องการ สร้างตัวใหม่ คือความเร็วมีหน่วยเป็นกิโลเมตรต่อชม. และตัวแปรระยะทางใหม่ที่มีหน่วยเป็นเมตร ดังนั้น สูตรการแปลงได้จากสมการข้างล่างนี้
\[\text{kilometer} = \dfrac{\text{miles}}{0.62137}\text{ and meters} = \dfrac{\text{feet}}{3.2808}\]
ดังนั้นถ้าให้ตัวแปรใหม่ชื่อ kph สำหรับความเร็วในหน่วยกิโลเมตร และตัวแปร meters สำหรับระยะทางหยุดรถในหน่วยเมตร สามารถทำได้ดังนี้
สร้างตัวแปรใหม่ในกรอบข้อมูล แล้วจึงกำหนดค่าที่ต้องการให้
cars$kph <- cars$speed/0.62137ทางซ้ายมือ cars$kph คือการตั้งชื่อตัวแปรใหม่ว่า kph ในกรอบข้อมูล cars โดยกำหนดค่าให้จากเวคเตอร์ cars$speed/0.62137
cars$meters <- cars$dist / 3.2808ทางซ้ายมือ cars$meters คือการตั้งชื่อตัวแปรใหม่ว่า meters ในกรอบข้อมูล cars โดยกำหนดค่าให้จากเวคเตอร์ cars$dist/ 3.2808
str(cars)'data.frame': 50 obs. of 4 variables:
$ speed : num 4 4 7 7 8 9 10 10 10 11 ...
$ dist : num 2 10 4 22 16 10 18 26 34 17 ...
$ kph : num 6.44 6.44 11.27 11.27 12.87 ...
$ meters: num 0.61 3.05 1.22 6.71 4.88 ...โดยการตรวจสอบโดยคำสั่ง str( ) พบว่ามีตัวแปรเพิ่มขึ้นมาอีก 2 ตัว
โหลดข้อมูล cars กลับมาเหมือนเดิม
data(cars)
str(cars)'data.frame': 50 obs. of 2 variables:
$ speed: num 4 4 7 7 8 9 10 10 10 11 ...
$ dist : num 2 10 4 22 16 10 18 26 34 17 ...วิธีต่อไปคือสร้างเวคเตอร์ที่ต้องการขึ้นมาก่อน ดังนี้
kph <- cars$speed / 0.62137
meters <- cars$dist / 3.2808แล้วจึงรวมกรอบข้อมูล cars กับเวคเตอร์ที่สร้างขึ้นมาใหม่ ด้่วยคำสั่ง cbind( )
cars <- cbind(cars[, c(1, 2)], kph, meters)
str(cars)'data.frame': 50 obs. of 4 variables:
$ speed : num 4 4 7 7 8 9 10 10 10 11 ...
$ dist : num 2 10 4 22 16 10 18 26 34 17 ...
$ kph : num 6.44 6.44 11.27 11.27 12.87 ...
$ meters: num 0.61 3.05 1.22 6.71 4.88 ...วิธีที่ 1 กำหนดให้ตัวแปรที่ไม่ต้องการ มีค่าเป็น NULL เช่นต้องการลบตัวแปร meters ออกจาก cars ทำได้โดย
cars$meters <- NULL
str(cars)'data.frame': 50 obs. of 3 variables:
$ speed: num 4 4 7 7 8 9 10 10 10 11 ...
$ dist : num 2 10 4 22 16 10 18 26 34 17 ...
$ kph : num 6.44 6.44 11.27 11.27 12.87 ...วิธีที่ 2 การกำหนดค่าในกรอบใหม่ เขียนทับลงบนกรอบข้อมูลเดิม เช่นถ้าไม่ต้องการตัวแปร kph แล้ว การแสดงผลตัวแปร speed และ dist คือ
cars[, 1:2]การกำหนดค่าให้กับตัวแปรเดิม ก็คือ
cars <- cars[, 1:2]ทำการตรวจสอบ
str(cars)'data.frame': 50 obs. of 2 variables:
$ speed: num 4 4 7 7 8 9 10 10 10 11 ...
$ dist : num 2 10 4 22 16 10 18 26 34 17 ...
ในอาร์โครงสร้างข้อมูลแบบลิสต์ เป็นรูปแบบการเก็บข้อมูลแบบเวคเตอร์ โดยที่แต่ละตำแหน่งในลิสต์ จะเป็นโครงสร้างข้อมูลใดก็ได้ อีก ไม่ว่าจะเป็นเวคเตอร์ เมตริกซ์ กรอบข้อมูล หรือแม้แต่จะเก็บลิสต์กก็ได้
ประโยชน์ของการเก็บข้อมูลในรูปแบบนี้ของอาร์ ก็คือในการโปรแกรมภาษาอาร์ จะสามารถนำผลจากการคำควณจากคำสั่งออกมาเป็นโครงสร้างข้อมูลชนิดใด ชนิดหนึ่งเท่ากันนั้น ในกรณีที่ ผลลัพธ์ จากการทำงานในหลายรูปแบบ โครงสร้างข้อมูลแบบลิสต์จึงมีประโยชน์มาก สำหรับการใช้ปกติใช้เพียงกรอบข้อมูลก็เพียงพอแล้ว
เราสามารถสร้างลิสต์ เพื่อรวบรวมโครงสร้างข้อมูลที่หลากหลายด้วยคำสั่ง list( ) รูปแบบการใช้งานเหมือนกับคำสั่ง c( ) ตัวอย่างเช่น
x <- c(45, 12, 56, 14, 16)
y <- cars[1:5, ]
z <- matrix(data =1:12, ncol = 4)ในการใช้คำสั่ง list( ) จะได้
my_list <- list(x, y, z)
my_list[[1]]
[1] 45 12 56 14 16
[[2]]
speed dist
1 4 2
2 4 10
3 7 4
4 7 22
5 8 16
[[3]]
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12จากผลลัพธ์ จะสั่งเกตุได้ว่าถ้าต้องการ เข้าถึงค่าเวคเตอร์ c(45, 12, 56, 14, 16) ทำได้โดย
my_list[[1]][1] 45 12 56 14 16และถ้าต้องการเข้าข้อมูล ตัวที่ 2 ที่มีค่า 12
my_list[[1]][2][1] 12ถ้าต้องการเข้าถึงกรอบข้อมูล
my_list[[2]] speed dist
1 4 2
2 4 10
3 7 4
4 7 22
5 8 16ถ้าต้องเข้าถึงตัวแปร speed
my_list[[2]]$speed[1] 4 4 7 7 8หรือ
my_list[[2]][,1][1] 4 4 7 7 8ถ้าต้องเข้าถึงตัวแปร speed ค่า 1 และ 5
my_list[[2]]$speed[c(1,5)][1] 4 8หรือ
my_list[[2]][c(1,5), 1][1] 4 8ก็เพื่อให้การเข้าข้อมูลภายในลิสต์มีความสะดวกมากขึ้นถ้า มีการเรียกใช้งานตามชื่อตัวแปร สามารถใช้คำสั่ง list( ) เหมือนเดิมโดยการกำหนดชื่อลงไป เหมือนคำสั่ง c( ) กัน
named_list <- list(A = x, B = y, C = z)
named_list$A
[1] 45 12 56 14 16
$B
speed dist
1 4 2
2 4 10
3 7 4
4 7 22
5 8 16
$C
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12ส่วนวิธีการเข้าถึงข้อมูลภายในลิสต์นั้น ทำได้โดย การอ้างอิงแบบเดิม เหมือนเนื้อหาด้านบนหรือเข้าถึงตัวแปร ด้วยเครื่องเครื่องหมาย $ ก่อน
การเข้าตัวแปรเมตริกซ์ C ทั้งหมด
named_list$C [,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12การเข้าถึงบ้างค่าในเมตริกซ์ C
named_list$C[1:2, 3][1] 7 8หรือการเข้าถึงกรอบข้อมูล B ตัวแปร dist
named_list$B$dist[1] 2 10 4 22 16เป็นข้อมูลประเภทตัวอักษร (character) ที่มีคุณสมบัติในการจัดลำดับ หรือกำหนดค่าเป็นตัวเลขให้ได้ เช่น คำตอบจากแบบสอบถามความพึงพอใจ มีคะแนน 1-5 เรียงจากไม่ชอบ ไปจนถึงพึ่งพอใจมากที่สุด
อีกตัวอย่างของข้อมูลที่ไม่ใช่ตัวเลข แต่เรารู้ลำดับก่อนกลังได้ทันที คือ ชื่อเดือนทั้ง 12 ในหนึ่งปี เราสามารถตอบคำถามได้ว่า เดือนใดที่มาก่อนเดือน มี.ค. เดือนใดอยู่หลัง ต.ค. เป็นต้น ซึ่งตัวแปรประเภทนี้ จะถูกนำไปใช้ในการเรียงลำดับจากน้อยไปมาก หรือมากไปน้อย
ถ้าไม่ทำข้อมูลรูปของข้อมูลปัจจัย จะเกิดปัญหาอะไรขึ้น
set.seed(1)
Sale.unit <- data.frame( month = month.abb,
unit = rpois(n = 12, lambda = 30 ))ถ้าต้องการสร้างกราฟแท่ง ด้วยชุดคำสั่ง ggplot2
library(ggplot2)
ggplot(data = Sale.unit) +
aes(x = month, y =unit) +
geom_bar(stat= "identity")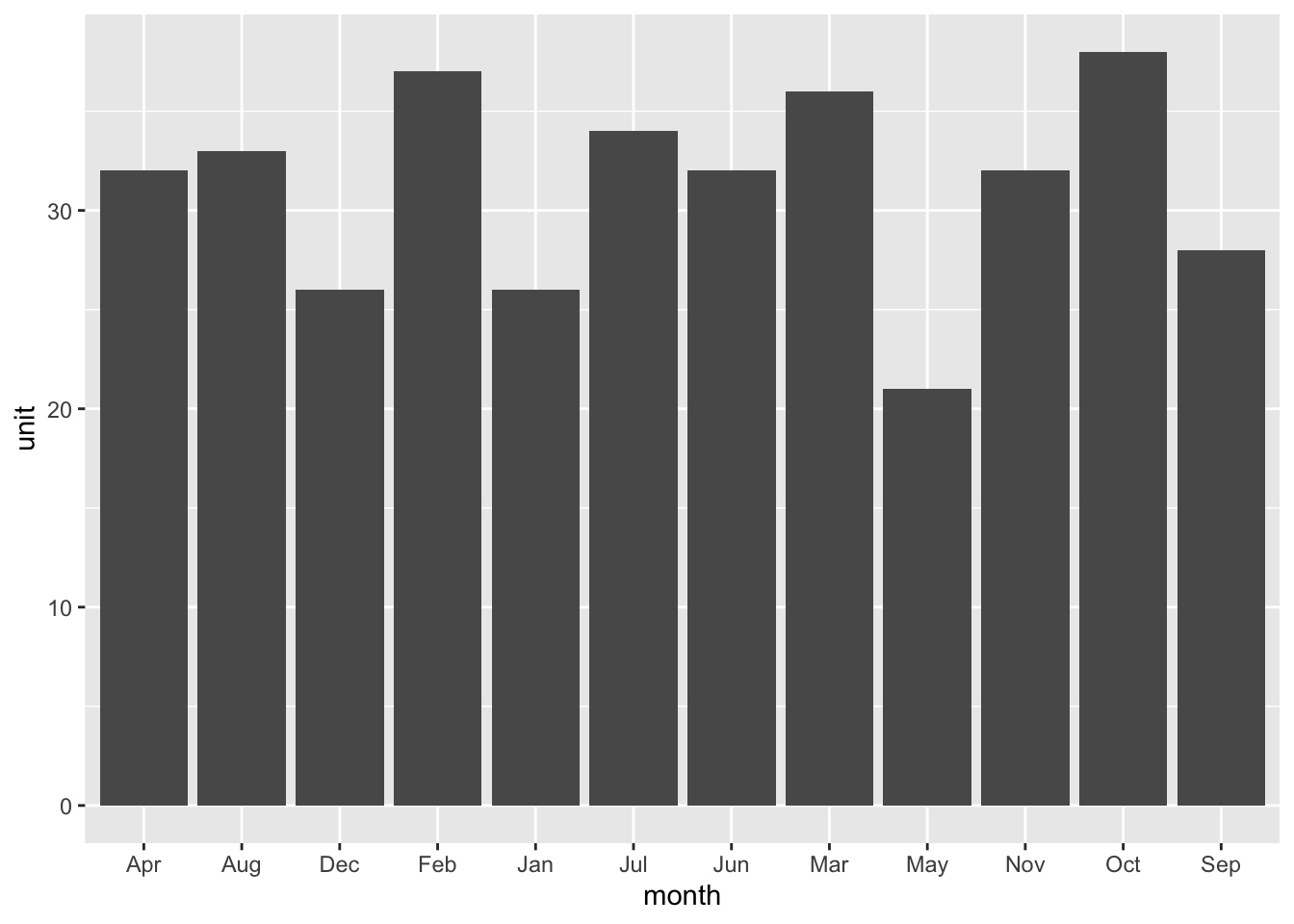
จะเห็นมีการเรียงลำดับเดือนที่ไม่ถูกต้อง
ดังนั้นในการสร้างข้อมูลปัจจัยอย่างง่ายในอาร์ทำได้โดยใช้คำสั่ง
factor(x = วัตถุแบบเวคเตอร์ตัวแปรอักษรตั้งแต่ 2 ค่าขึ้นไป , levels = เวคเตอร์ของระดับในสมาชิกทั้งหมด(ห้ามใส่ซ้ำกัน)x คือใส่เวคเตอร์ตัวอักษรที่ต้องการจะเปลี่ยน
levels คือเวคเตอร์ของระดับทั้งหมดเรียงน้อยไปมาก
หมายเหตุ สามารถใช้คำสั่ง unique( ) ในการหาสมาชิกของเวคเตอร์แบบตัวอักษรทั้งหมดในเวคเตอร์ได้
เปลี่ยนเวคเตอร์ตัวษรของเดือน ให้เป็นข้อมูลปัจจัย
month <- factor(x = month.abb, levels = month.abb)ทำการคำนวณเหมือนเดิมอีกครั้ง
set.seed(1)
Sale.unit <- data.frame( month = month,
unit = rpois(n = 12, lambda = 30 ))
ggplot(data = Sale.unit) +
aes(x = month, y =unit) +
geom_bar(stat= "identity")
จะเห็นว่ากราฟที่ได้มีเรียงลำดับเดือนได้อย่างถูกต้อง
ตัวอย่าง
สุ่มตัวอย่าง นศ. ชั้นปีที่ 1 ถึงชั้นปีที่ 4 ภาษาอังกฤษ คือ freshman sophomore junior และ senior ตามลำดับ
ถ้าสุ่มตัวอย่างขึ้นมา 100 คน ได้จำนวน นศ. ดังนี้
set.seed(100)
student <- sample (x = c("freshman", "sophomore", "junior", "senior"),
size = 100, replace = TRUE)
table(student)student
freshman junior senior sophomore
18 32 24 26 จะเห็นว่ามีเรียงลำดับขั้นปี ที่ไม่ถูกต้อง ต้องเปลี่ยนตัวแปร student เป็นข้อมูลปัจจัย
student <- factor(x = student,
levels = c("freshman", "sophomore", "junior", "senior"))
table(student)student
freshman sophomore junior senior
18 26 32 24 เมื่อมีการเรียงลำดับที่ถูกต้อง และต้องการกสร้างกราฟ ก็จะได้ภาพกราฟที่มีการเรียงลำดับถูกต้อง
barplot(table(student))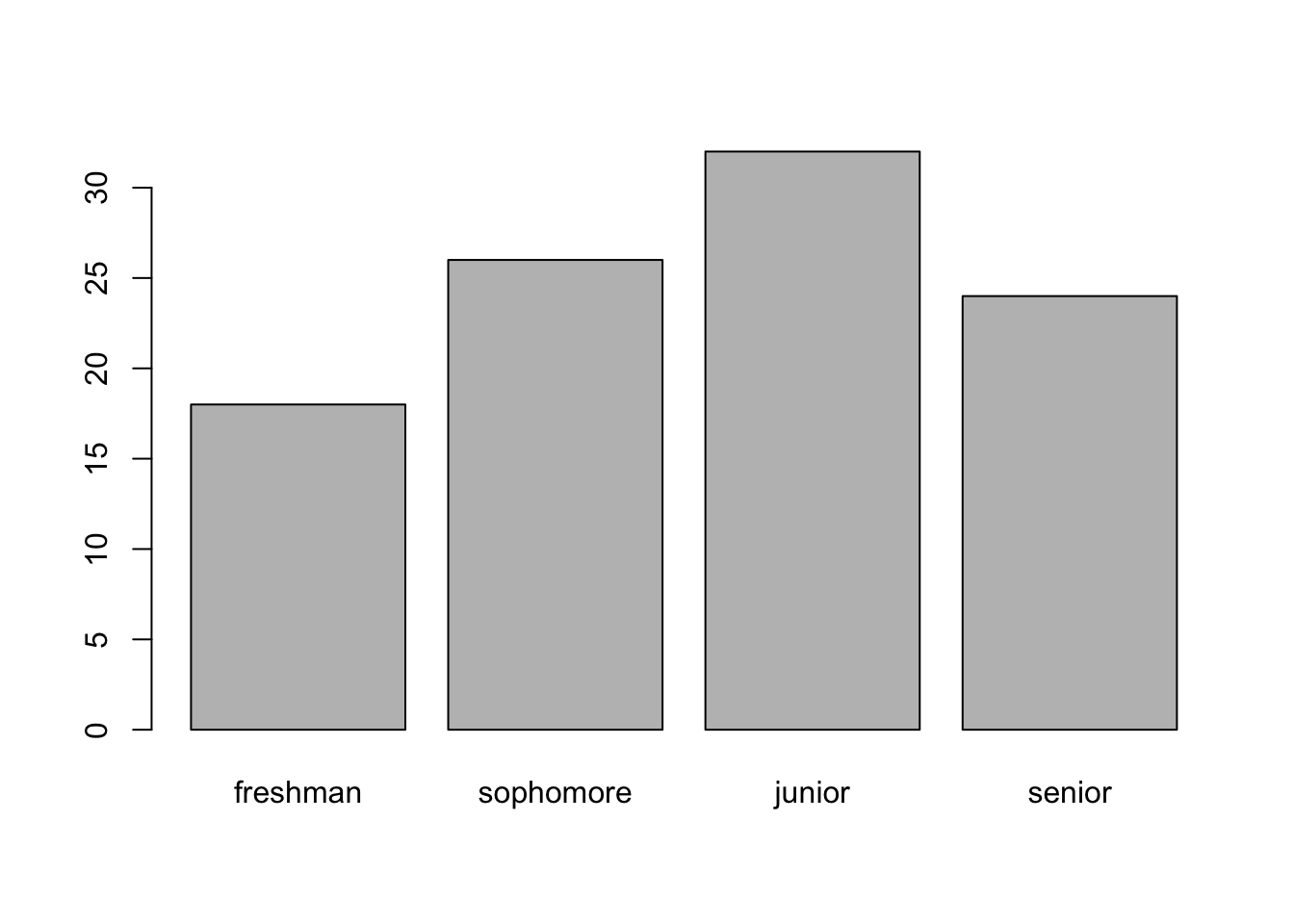
คำสั่งที่เกี่ยวข้องการกับสร้างกราฟ จะอยู่เนื้อหาบนที่ 7 และ 8
ข้อมูลอนุกรมเวลาในอาร์สามารถเป็นโครงสร้างข้อมูลแบบเวคเตอร์ เมตริกซ์ หรือกรอบข้อมูลได้ โดยลักษณะสำคัญ คือการตั้งชื่อให้ข้อมูลในแต่ละแถวด้วยหน่วยของเวลา สำหรับตัวแปรอนุกรมเวลานี้ จะพิจารณา เฉพาะหน่วยเวลาที่เป็นเดือนและปีเท่านั้น ถ้าเป็นวันเดืิอน จะกล่าวอีกครั้งในบท 10 เพราะควรใช้ข้อมูลที่เป็นอนุกรมเวลาแบบ xts
เป็นคำสั่งการสร้างอนุกรมเวลาจาก เวคเตอร์ เมตริกซ์ และกรอบข้อมูล
ts(data , frequency, start = c(year, month))data เวคเตอร์ เมคริกซ์ หรือ กรอบข้อมูล
start เวคเตอร์ตัวเลขจำนวนเต็มของปี และเดือนที่ต้องการ
frequency 12 รายเดือน และ 4 คือราย 3 เดือน
ตัวอย่างข้อมูลที่เป็นเวคเตอร์
set.seed(12345)
customer <- rpois(n = 12, lambda = 100)
customer [1] 105 107 98 95 123 105 97 116 95 103 105 92แปลงไปสู่ข้อมูลอนุกรมเวลารายเดือน โดยเริ่มจาก 1 ม.ค. 2022
ts(data = customer, start = c(2022, 1), frequency = 12) Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
2022 105 107 98 95 123 105 97 116 95 103 105 92หรือแปลงเป็นข้อมูลราย 3 เดือน
ts(data = customer, start = c(2022, 1), frequency = 4) Qtr1 Qtr2 Qtr3 Qtr4
2022 105 107 98 95
2023 123 105 97 116
2024 95 103 105 92ตัวอย่างข้อมูลแบบเมตริกซ์
customer.m <- matrix(data = customer, nrow = 6)
customer.m [,1] [,2]
[1,] 105 97
[2,] 107 116
[3,] 98 95
[4,] 95 103
[5,] 123 105
[6,] 105 92สามารถแปลงไปเป็นอนุกรมเวลารายเดือน
ts(data = customer.m, start = c(2022, 1), frequency = 12) Series 1 Series 2
Jan 2022 105 97
Feb 2022 107 116
Mar 2022 98 95
Apr 2022 95 103
May 2022 123 105
Jun 2022 105 92รายสามเดือน
ts(data = customer.m, start = c(2022, 1), frequency = 4) Series 1 Series 2
2022 Q1 105 97
2022 Q2 107 116
2022 Q3 98 95
2022 Q4 95 103
2023 Q1 123 105
2023 Q2 105 92ตัวอย่างข้อแบบกรอบข้อมูล
set.seed(122)
income <- rnorm(n = 24, mean = 10000, sd = 100)
company <- data.frame(customer, income)แปลงเป็นอนุกรมเวลารายเดือน
ts(data = company, start = c(2022, 1), frequency = 12) customer income
Jan 2022 105 10131.070
Feb 2022 107 9912.415
Mar 2022 98 10019.952
Apr 2022 95 10046.595
May 2022 123 9819.794
Jun 2022 105 10144.874
Jul 2022 97 10029.885
Aug 2022 116 10036.181
Sep 2022 95 9899.306
Oct 2022 103 9974.300
Nov 2022 105 9986.787
Dec 2022 92 9915.837
Jan 2023 105 10027.425
Feb 2023 107 9753.741
Mar 2023 98 9784.660
Apr 2023 95 10115.918
May 2023 123 10068.974
Jun 2023 105 10088.025
Jul 2023 97 9905.663
Aug 2023 116 10071.907
Sep 2023 95 9946.217
Oct 2023 103 9947.735
Nov 2023 105 9894.708
Dec 2023 92 10010.152รายสามเดือน
ts(data = company, start = c(2022, 1), frequency = 4) customer income
2022 Q1 105 10131.070
2022 Q2 107 9912.415
2022 Q3 98 10019.952
2022 Q4 95 10046.595
2023 Q1 123 9819.794
2023 Q2 105 10144.874
2023 Q3 97 10029.885
2023 Q4 116 10036.181
2024 Q1 95 9899.306
2024 Q2 103 9974.300
2024 Q3 105 9986.787
2024 Q4 92 9915.837
2025 Q1 105 10027.425
2025 Q2 107 9753.741
2025 Q3 98 9784.660
2025 Q4 95 10115.918
2026 Q1 123 10068.974
2026 Q2 105 10088.025
2026 Q3 97 9905.663
2026 Q4 116 10071.907
2027 Q1 95 9946.217
2027 Q2 103 9947.735
2027 Q3 105 9894.708
2027 Q4 92 10010.152ข้อมูลนี้ ก็จะเหมาะสำหรับการวิเคราะห์ด้้วยตัวแบบอนุกรมเวลา หรือการสร้างภาพข้อมูลด้วยกราฟเส้น