6 Analisis Data
Setelah melalui tahap survei dan pengelolaan data, langkah selanjutnya yang perlu dilakukan adalah menganalisis data. Proses analisis data ini sangat penting untuk dapat merangkum dan mensintesis data yang telah dikumpulkan selama survei. Dalam analisis data, Anda akan menarik kesimpulan penting dari data mentah yang telah dikumpulkan. Hal ini dapat menjadi tantangan yang menarik, sekaligus menyenangkan, sama seperti pekerjaan lapangan. Melalui proses analisis data, Anda akan merasa puas karena berhasil menghasilkan kesimpulan yang didukung oleh data aktual yang telah Anda kumpulkan sebelumnya. Oleh karena itu, analisis data merupakan tahap yang sangat penting dalam penyusunan laporan ilmiah yang mudah dipahami oleh pembaca.
Tujuan utama dari analisis data adalah untuk menerjemahkan sejumlah besar informasi yang bersifat numerik dan kompleks menjadi bentuk yang mudah dipahami dan singkat. Ada banyak cara untuk melakukannya dan metode yang dapat dipelajari, namun bab ini bertujuan untuk memberikan gambaran umum tentang berbagai pendekatan untuk mendeskripsikan dan menganalisis data menggunakan metode survei yang sudah dijelaskan sebelumnya. Teori dasar dan mendalam mengenai metode statistik yang digunakan diluar lingkup panduan ini, namun anda dapat mempelajari lebih dalam pada literatur berikut ini (Cook & Wheater, 2000; Fielding, 2006; Henderson & Seaby, 2008; Legendre & Legendre, 2012; Margalef, 1973).
6.1 Kekayaan dan keseragaman spesies
Dalam kajian survei, anda mungkin ingin menjelaskan data temuan spesies dalam hal kekayaan komunitas. Secara sederhana, hal ini dapat dibuat dengan melaporkan jumlah spesies dan individu yang ditemukan. Metode yang lainnya adalah melibatkan perhitungan indeks keanekaragaman dan keseragaman. Di sini, proporsi relatif setiap spesies dalam seluruh komunitas digunakan untuk membuat indikator keanekaragaman (biasanya indeks ini akan bernilai tinggi saat ada banyak spesies dengan kelimpahan yang sama - yaitu tidak ada satu spesies pun yang mendominasi). Sebaliknya, indikator keseragaman dapat dihasilkan yang menggambarkan seberapa seimbang proporsi relatif spesiesnya (keseragaman rendah dikaitkan dengan kasus di mana satu spesies mendominasi komunitas yang disurvei). Anda dapat mempelajari lebih dalam mengenai indek kekayaan dan keseragaman pada literatur berikut ini; . Contoh indeks yang biasa digunakan tersaji pada Tabel 6.1.
| Index | Keterangan | Formula |
|---|---|---|
| Shannon - Wiener | Memperhitungkan jumlah individu dari masing-masing spesies yang ditemukan dalam suatu area atau habitat. Semakin tinggi nilai indeks Shannon-Wiener, semakin besar jumlah dan kemerataan spesies dalam suatu komunitas | \[ H' = -\sum_{i=1}^{S}p_i \ln p_i \] S adalah jumlah spesies, dan pi adalah proporsi jumlah individu pada spesies ke-i. Nilainya jarang melebihi 4. |
| Margalef | Mengukur kekayaan spesies relatif terhadap kelimpahan spesies dalam suatu komunitas. Nilai indeks yang lebih tinggi menunjukkan tingkat keanekaragaman yang lebih tinggi dalam suatu komunitas. | \[ \text{Margalef} = \frac{S-1}{\ln(N)} \] N adalah jumlah total individu dalam sampel atau komunitas |
| Pielou Evennes | Mengukur seberapa merata spesies didistribusikan dalam suatu komunitas. Nilai indeksnya berkisar dari 0 hingga 1, dengan 1 menunjukkan distribusi yang sempurna atau keseragaman yang maksimal, sementara 0 menunjukkan distribusi yang sangat tidak merata atau keseragaman yang minimal. | \[ J' = \frac{H'}{\ln(S)} \] |
| Simpson | mengukur dominasi suatu spesies dalam suatu komunitas. Indeks ini menghasilkan nilai antara 0 dan 1, di mana nilai 1 menunjukkan bahwa hanya ada satu spesies yang mendominasi komunitas, sementara nilai 0 menunjukkan adanya keanekaragaman maksimum. Perhitungan indeks Simpson didasarkan pada proporsi relatif jumlah individu dari masing-masing spesies dalam suatu komunitas | \[ D = \sum_{i=1}^S p_i^2 \] |
6.2 Perbedaan komposisi spesies
Terdapat banyak cara untuk mengukur perbedaan komposisi spesies berdasarkan pada dua pendekatan yang berbeda. Pendekatan pertama mengevaluasi apakah dua atau lebih komunitas memiliki spesies yang sama berdasarkan jumlah spesies yang dimiliki secara bersama dibandingkan dengan spesies yang ditemukan hanya di salah satu komunitas. Pendekatan kedua melihat tumpang tindih tidak hanya pada tingkat spesies tetapi juga pada kelimpahan masing-masing spesies. Tabel 6.2 adalah beberapa contoh yang biasa digunakan.
| Index | Tipe data | Keterangan | Formula |
|---|---|---|---|
| Jaccard index | Presence / absence | Merupakan salah satu rumus yang paling sederhana, namun rumus ini tidak mempertimbangkan spesies yang tidak hadir pada kedua komunitas yang dibandingkan. | \[ J = \frac{a}{a + b + c} \]
|
| Sørensen index | Presence / absence | Mirip dengan pengukuran Jaccard namun memberikan bobot yang lebih besar pada spesies yang ditemukan bersama di kedua komunitas. | \[ S_{S} = \frac{2c}{a+b} \]
|
| Bray-Curtis index | Kelimpahan | Mengukur perbedaan antara komunitas berdasarkan kelimpahan relatif spesies yang dihadirkan dan yang tidak dihadirkan dalam masing-masing komunitas. Semakin besar nilai indeks ini, semakin berbeda pula komposisi spesies antar-komunitas | \[ BC_{d} = \frac{\sum_{k=1}^S{|a_{ik} - a_{jk}|}}{\sum_{k=1}^S{(a_{ik} + a_{jk})}} \]
|
6.3 Faktor Lingkungan terhadap Kelimpahan Spesies
Generalized Linear Model (GLM) / model linier umum adalah sebuah pendekatan analisis statistik yang dapat digunakan dalam analisis ekologi untuk memprediksi dan menjelaskan hubungan antara variabel respons dan satu atau lebih variabel prediktor dengan mempertimbangkan asumsi khusus mengenai distribusi data dan hubungan antara variabel.
Pendekatan ini cocok digunakan dalam analisis data ekologi karena data ekologi umumnya bersifat tidak normal, terdapat variasi yang besar dalam data, dan hubungan antar variabel seringkali bersifat kompleks. Dalam analisis ekologi, GLM dapat digunakan untuk mempelajari pengaruh faktor lingkungan, prediktor biologis, dan faktor-faktor lainnya terhadap variabel respons seperti biomassa, kelimpahan, atau keanekaragaman spesies.
Contoh penerapan GLM dalam analisis ekologi adalah ketika kita ingin memahami faktor-faktor apa saja yang mempengaruhi kelimpahan populasi suatu spesies di suatu habitat. Kita dapat mengumpulkan data tentang kelimpahan spesies tersebut dan variabel lingkungan yang mungkin mempengaruhinya seperti jenis tanah, kelembaban, dan suhu. Selanjutnya, kita dapat menggunakan GLM untuk mengidentifikasi variabel lingkungan yang signifikan dalam mempengaruhi kelimpahan spesies tersebut dan memprediksi kelimpahan spesies di suatu habitat dengan mempertimbangkan faktor-faktor lingkungan yang signifikan.
Sebagai contoh, kita dapat menggunakan GLM untuk mempelajari pengaruh suhu dan kelembaban terhadap kelimpahan burung di suatu hutan. Dalam studi ini, kita dapat mengumpulkan data tentang kelimpahan burung, suhu, dan kelembaban di beberapa titik di hutan yang berbeda. Selanjutnya, kita dapat menggunakan GLM untuk memprediksi kelimpahan burung di suatu titik berdasarkan suhu dan kelembaban di titik tersebut. Dengan demikian, kita dapat memahami hubungan antara suhu, kelembaban, dan kelimpahan burung di hutan tersebut.
6.4 Analisis pola dan struktur dalam komunitas
Analisis pola dan struktur dalam komunitas membahas cara-cara untuk menganalisis struktur dan pola dalam komunitas biologis. Dua teknik utama yang digunakan dalam analisis ini adalah klaster dan ordinasi. Klaster digunakan untuk mengelompokkan spesies dalam kelompok-kelompok yang saling berhubungan berdasarkan kesamaan atribut. Sementara itu, ordinasi memproyeksikan data ke ruang multi-dimensi yang lebih rendah, sehingga memudahkan pemahaman tentang pola yang tersembunyi dalam data.
6.4.1 Dendogram klaster
Dendrogram klaster adalah representasi visual dari hasil analisis klaster yang digunakan untuk menggambarkan hubungan kekerabatan antara individu atau kelompok dalam dataset. Dendrogram biasanya berupa diagram pohon yang terdiri dari simpul dan cabang. Simpul mewakili individu atau kelompok, sedangkan cabang menggambarkan jarak atau kesamaan antara simpul.
Dalam analisis klaster, dendrogram dapat digunakan untuk memvisualisasikan cara di mana kelompok atau individu saling terkait. Dendrogram dapat membantu dalam mengidentifikasi pola dan struktur dalam data, termasuk mengidentifikasi kelompok yang saling terkait.
Contoh penggunaan dendrogram dalam ekologi adalah ketika membandingkan keanekaragaman spesies antara lokasi yang berbeda. Dengan menggunakan dendrogram, dapat dilihat bagaimana spesies-spesies yang serupa terkait satu sama lain dalam setiap lokasi dan bagaimana lokasi tersebut terkait satu sama lain dalam hal keanekaragaman spesies.
6.4.2 Ordinasi
Ordinasi adalah metode statistik multivariat yang digunakan untuk menganalisis hubungan antara objek dalam ruang multivariat. Metode ini sering digunakan untuk mengeksplorasi pola-pola dalam data ekologi, seperti data keanekaragaman spesies dan komposisi vegetasi. Dalam analisis ordinasi, data yang dianalisis direduksi menjadi beberapa dimensi yang lebih sedikit, biasanya dua atau tiga, yang memungkinkan visualisasi pola-pola yang terkandung dalam data. Dua metode yang umum digunakan dalam analisis pola dan struktur dalam komunitas adalah Multidimensional Scaling (MDS) dan Canonical Correspondence Analysis (CCA).
MDS digunakan untuk menggambarkan pola-pola keanekaragaman dalam sebuah diagram dua atau tiga dimensi. Metode ini memproyeksikan data keanekaragaman hayati ke dalam ruang yang lebih rendah dimensi. Sebagai contoh, jika kita memiliki data keanekaragaman hayati untuk beberapa lokasi, maka MDS dapat membantu kita untuk memvisualisasikan perbedaan antara lokasi-lokasi tersebut.
Sementara itu, CCA merupakan metode statistik multivariat yang digunakan untuk mengevaluasi hubungan antara pola keanekaragaman hayati dan variabel lingkungan. Dengan CCA, kita dapat mengevaluasi bagaimana faktor-faktor lingkungan seperti suhu, curah hujan, dan ketersediaan nutrisi mempengaruhi keanekaragaman hayati.
Kedua metode ini sering digunakan dalam studi-studi ekologi untuk mengevaluasi perbedaan dalam pola keanekaragaman hayati antar lokasi atau dalam rentang waktu tertentu. Misalnya, sebuah studi dapat menggunakan MDS untuk memvisualisasikan perbedaan dalam keanekaragaman hayati antara beberapa lokasi, dan kemudian menggunakan CCA untuk mengevaluasi faktor lingkungan yang mempengaruhi pola-pola keanekaragaman tersebut.
6.5 Kepadatan Spesies (Distance sampling)
Salah satu analisis yang paling populer untuk memperkirakan kepadatan satwa adalah dengan menggunakan metode Distance sampling, metode tersebut pada dasarnya mengukur jarak objek dari sebuah garis atau titik deteksi. Objek yang dimaksud biasanya adalah hewan atau kelompok hewan (yang disebut klaster), maupun tanda satwa (seperti suara burung, kotoran, sarang, hingga semburan paus).
Metode konvensional distance sampling (CDS) dijelaskan oleh (Buckland et al., 2005), dan variasi lainnya dibahas dalam (Buckland et al., 2004). Daftar referensi yang lengkap, mencakup pengembangan metodologi dan aplikasi praktis metode tersebut, dapat ditemukan di Online distance sampling course. Untuk dapat menerapkan aplikasi ini, setidaknya ada 3 asumsi yang harus dipenuhi:
- Objek tepat pada garis atau titik dideteksi dengan pasti. Secara konseptual, objek pada jarak yang dekat harus selalu dapat terdeteksi. Namun, asumsi ini kadang dilanggar, misalnya pada survei menggunakan perahu untuk mamalia laut di mana satwa di bawah perahu tidak terdeteksi. Solusi untuk ini adalah menggunakan lebih dari satu pengamat yang berjalan beriringan (Borchers et al., 2006)
- Objek tidak bergerak. Secara konseptual, kita mengukur objek saat hewan tersebut pertama kali terdeteksi. Jika hewan tersebut berpindah dari tempat semula, itu tidak masalah, yang penting adalah individu yang sama tidak diukur kembali.
- Pengukuran yang tepat. Sebisa mungkin, jarak objek dari garis atau titik harus diukur dengan seakurat mungkin. Selalu gunakan alat bantu seperti distometer jika memungkinkan.
Dengan memahami dan memenuhi asumsi-asumsi ini, analisis distance sampling dapat memberikan perkiraan yang andal mengenai kepadatan satwa dan dapat digunakan untuk studi ekologi dan konservasi.
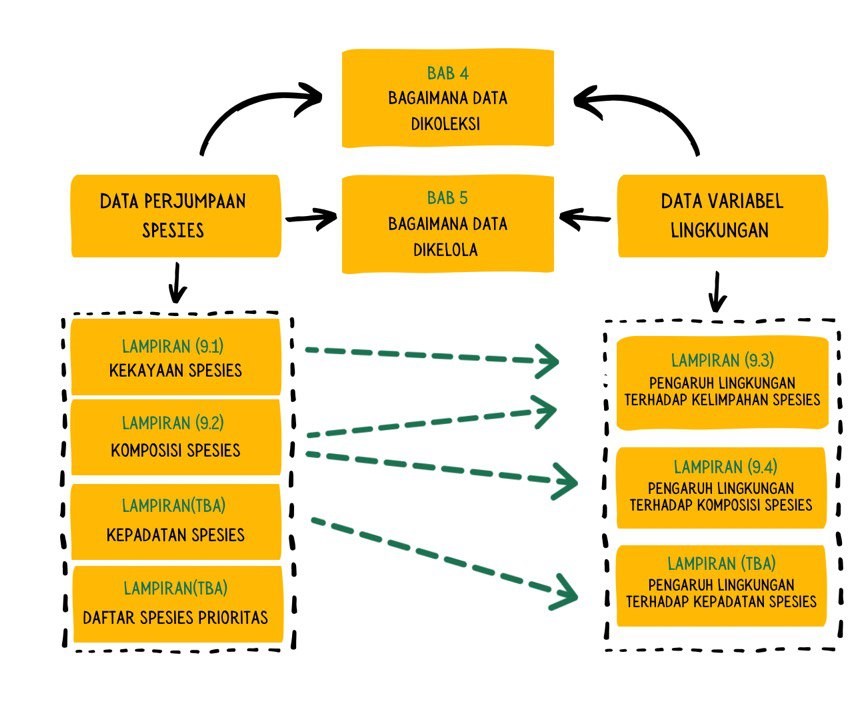
Bab ini hanya sebagian kecil dari keseluruhan teknik yang dapat anda pelajari dan aplikasikan dalam survei yang telah anda lakukan. Untuk memperdalam pemahaman anda, penjelasan yang lebih mendetail akan dipraktikan pada lampiran 3 dan diagram analisa yang dapat anda lakukan dari data yang anda miliki tersaji pada Gambar 6.1 berikut ini.