3.1 Steepest Descent
Perhaps the most obvious direction to choose when attempting to minimize a function \(f\) starting at \(x_n\) is the direction of steepest descent, or \(-f^\prime(x_n)\). This is the direction that is orthogonal to the contours of \(f\) at the point \(x_n\) and hence is the direction in which \(f\) is changing most rapidly at \(x_n\).

Direction of steepest descent.
The updating procedure for a steepest descent algorithm, given the current estimate \(x_n\), is then
\[ x_{n+1} = x_n - \alpha_n f^\prime(x_n) \]
While it might seem logical to always go in the direction of steepest descent, it can occasionally lead to some problems. In particular, when certain parameters are highly correlated with each other, the steepest descent algorithm can require many steps to reach the minimum.
The figure below illustrates a function whose contours are highly correlated and hence elliptical.

Steepest descent with highly correlated parameters.
Depending on the starting value, the steepest descent algorithm could take many steps to wind its way towards the minimum.
3.1.1 Example: Multivariate Normal
One can use steepest descent to compute the maximum likelihood estimate of the mean in a multivariate Normal density, given a sample of data. However, when the data are highly correlated, as they are in the simulated example below, the log-likelihood surface can be come difficult to optimize. In such cases, a very narrow ridge develops in the log-likelihood that can be difficult for the steepest descent algorithm to navigate.
In the example below, we actually compute the negative log-likelihood because the algorith is designed to minimize functions.
set.seed(2017-08-10)
mu <- c(1, 2)
S <- rbind(c(1, .9), c(.9, 1))
x <- MASS::mvrnorm(500, mu, S)
nloglike <- function(mu1, mu2) {
dmv <- mvtnorm::dmvnorm(x, c(mu1, mu2), S, log = TRUE)
-sum(dmv)
}
nloglike <- Vectorize(nloglike, c("mu1", "mu2"))
nx <- 40
ny <- 40
xg <- seq(-5, 5, len = nx)
yg <- seq(-5, 6, len = ny)
g <- expand.grid(xg, yg)
nLL <- nloglike(g[, 1], g[, 2])
z <- matrix(nLL, nx, ny)
par(mar = c(4.5, 4.5, 1, 1))
contour(xg, yg, z, nlevels = 40, xlab = expression(mu[1]),
ylab = expression(mu[2]))
abline(h = 0, v = 0, lty = 2)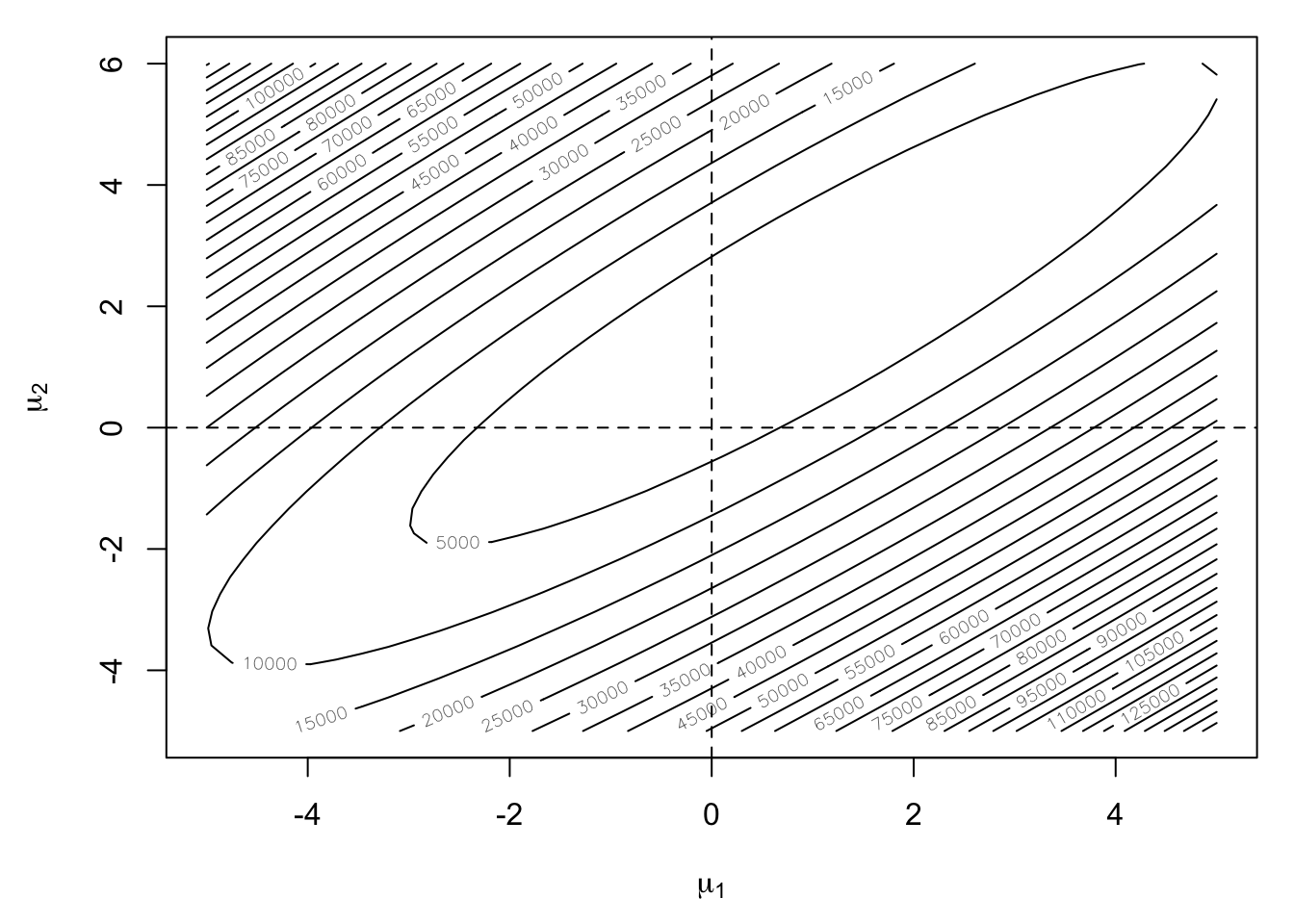
Note that in the figure above the surface is highly stretched and that the minimum \((1, 2)\) lies in the middle of a narrow valley. For the steepest descent algorithm we will start at the point \((-5, -2)\) and track the path of the algorithm.
library(dplyr, warn.conflicts = FALSE)
norm <- function(x) x / sqrt(sum(x^2))
Sinv <- solve(S) ## I know I said not to do this!
step1 <- function(mu, alpha = 1) {
D <- sweep(x, 2, mu, "-")
score <- colSums(D) %>% norm
mu + alpha * drop(Sinv %*% score)
}
steep <- function(mu, n = 10, ...) {
results <- vector("list", length = n)
for(i in seq_len(n)) {
results[[i]] <- step1(mu, ...)
mu <- results[[i]]
}
results
}
m <- do.call("rbind", steep(c(-5, -2), 8))
m <- rbind(c(-5, -2), m)
par(mar = c(4.5, 4.5, 1, 1))
contour(xg, yg, z, nlevels = 40, xlab = expression(mu[1]),
ylab = expression(mu[2]))
abline(h = 0, v = 0, lty = 2)
points(m, pch = 20, type = "b")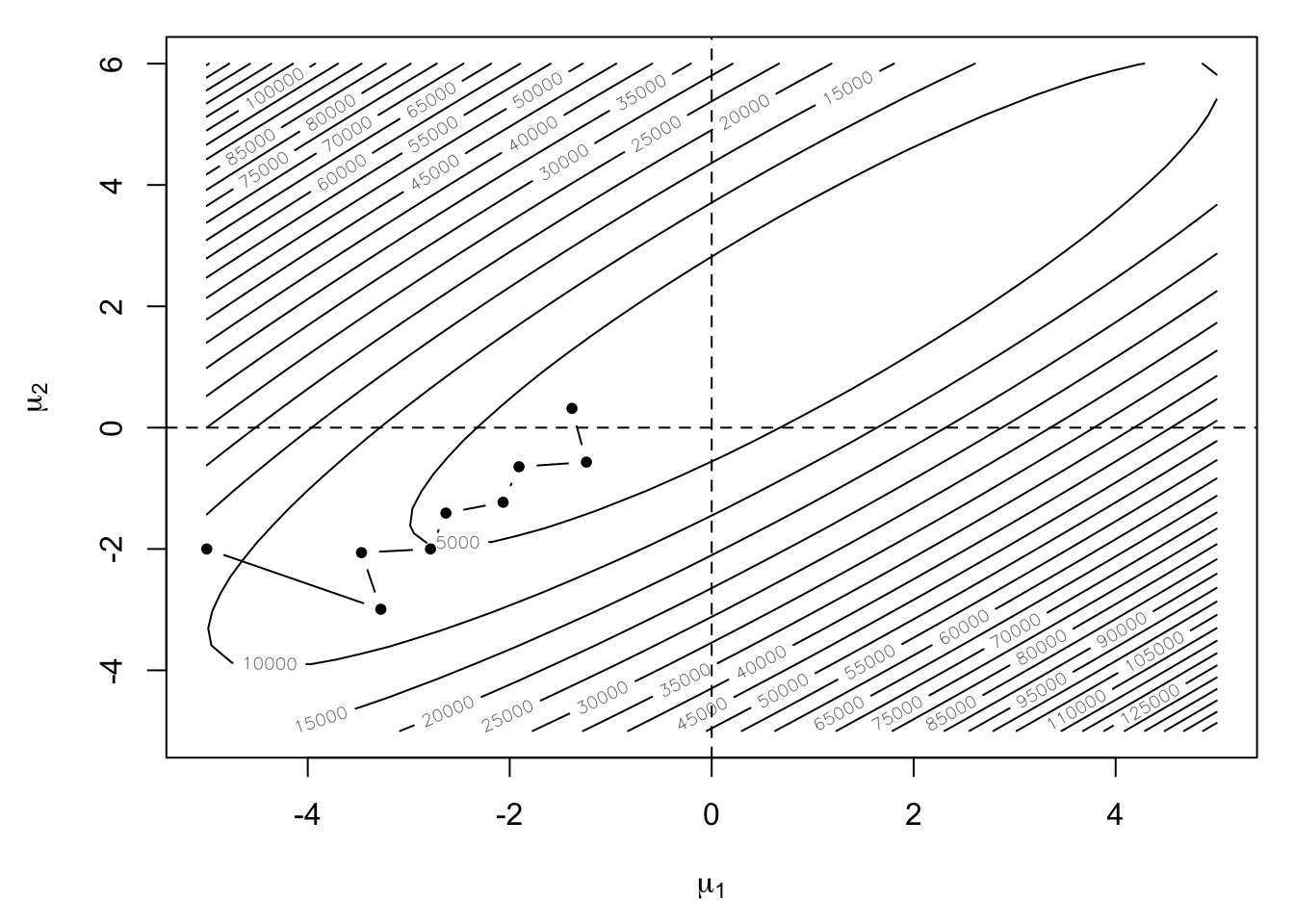
We can see that the path of the algorthm is rather winding as it traverses the narrow valley. Now, we have fixed the step-length in this case, which is probably not optimal. However, one can still see that the algorithm has some difficulty navigating the surface because the direction of steepest descent does not take one directly towards the minimum ever.