3.4 Conjugate Gradient
Conjugate gradient methods represent a kind of steepest descent approach “with a twist”. With steepest descent, we begin our minimization of a function \(f\) starting at \(x_0\) by traveling in the direction of the negative gradient \(-f^\prime(x_0)\). In subsequent steps, we continue to travel in the direction of the negative gradient evaluated at each successive point until convergence.
The conjugate gradient approach begins in the same manner, but diverges from steepest descent after the first step. In subsequent steps, the direction of travel must be conjugate to the direction most recently traveled. Two vectors \(u\) and \(v\) are conjugate with respect to the matrix \(A\) if \(u^\prime Av = 0\).
Before we go further, let’s take a concrete example. Suppose we want to minimize the quadratic function \[ f(x) = \frac{1}{2} x^\prime Ax - x^\prime b \] where \(x\) is a \(p\)-dimensional vector and \(A\) is a \(p\times p\) symmetric matrix. Starting at a point \(x_0\), both steepest descent and conjugate gradient would take us in the direction of \(p_0 = -f^\prime(x_0) = b-Ax_0\), which is the negative gradient. Once we have moved in that direction to the point \(x_1\), the next direction, \(p_1\) must satisfy \(p_0^\prime A p_1 = 0\). So we can begin with the steepest descent direction \(-f^\prime(x_1)\) but then we must modify it to make it conjugate to \(p_0\). The constraint \(p_0^\prime Ap_1=0\) allows us to back calculate the next direction, starting with \(-f^\prime(x_1)\), because we have \[ p_0^\prime A\left(-f^\prime - \frac{p_0^\prime A(-f^\prime)}{p_0^\prime Ap_0}p_0\right)=0. \] Without the presence of the matrix \(A\), this is process is simply Gram-Schmidt orthogonalization. We can continue with this process, each time taking the steepest descent direction and modifying it to make it conjugate with the previous direction. The conjugate gradient process is (somewhat) interesting here because for minimizing a \(p\)-dimensional quadratic function it will converge within \(p\) steps.
In reality, we do not deal with exactly quadratic functions and so the above-described algorithm is not feasible. However, the nonlinear conjugate gradient method draws from these ideas and develops a reasonable algorithm for finding the minimum of an arbitrary smooth function. It has the feature that it only requires storage of two gradient vectors, which for large problems with many parameters, is a significant savings in storage versus Newton-type algorithms which require storage of a gradient vector and a \(p\times p\) Hessian matrix.
The Fletcher-Reeves nonlinear conjugate gradient algorithm works as follows. Starting with \(x_0\),
Let \(p_0 = -f^\prime(x_0)\).
Solve \[ \min_{\alpha>0} f(x_0 + \alpha p_0) \] for \(\alpha\) and set \(x_1=x_0+\alpha p_0\).
For \(n = 1, 2, \dots\) let \(r_n = -f^\prime(x_n)\) and \(r_{n-1}=-f^\prime(x_{n-1})\). Then set \[ \beta_n = \frac{r_n^\prime r_n}{r_{n-1}^\prime r_{n-1}}. \] Finally, update \(p_{n} = r_n + \beta_n * p_{n-1}\), and let \[ x_{n+1} = x_n + \alpha^\star p_{n}, \] where \(\alpha^\star\) is the solution to the problem \(\min_{\alpha > 0}f(x_n + \alpha p_n)\). Check convergence and if not converged, repeat.
It is perhaps simpler to describe this method with an illustration. Here, we show the contours of a 2-dimensional function.
f <- deriv(~ x^2 + y^2 + a * x * y, c("x", "y"), function.arg = TRUE)
a <- 1
n <- 40
xpts <- seq(-3, 2, len = n)
ypts <- seq(-2, 3, len = n)
gr <- expand.grid(x = xpts, y = ypts)
feval <- with(gr, f(x, y))
z <- matrix(feval, nrow = n, ncol = n)
par(mar = c(5, 4, 1, 1))
contour(xpts, ypts, z, nlevels = 20)
x0 <- -2.5 ## Initial point
y0 <- 1.2
points(x0, y0, pch = 19, cex = 2)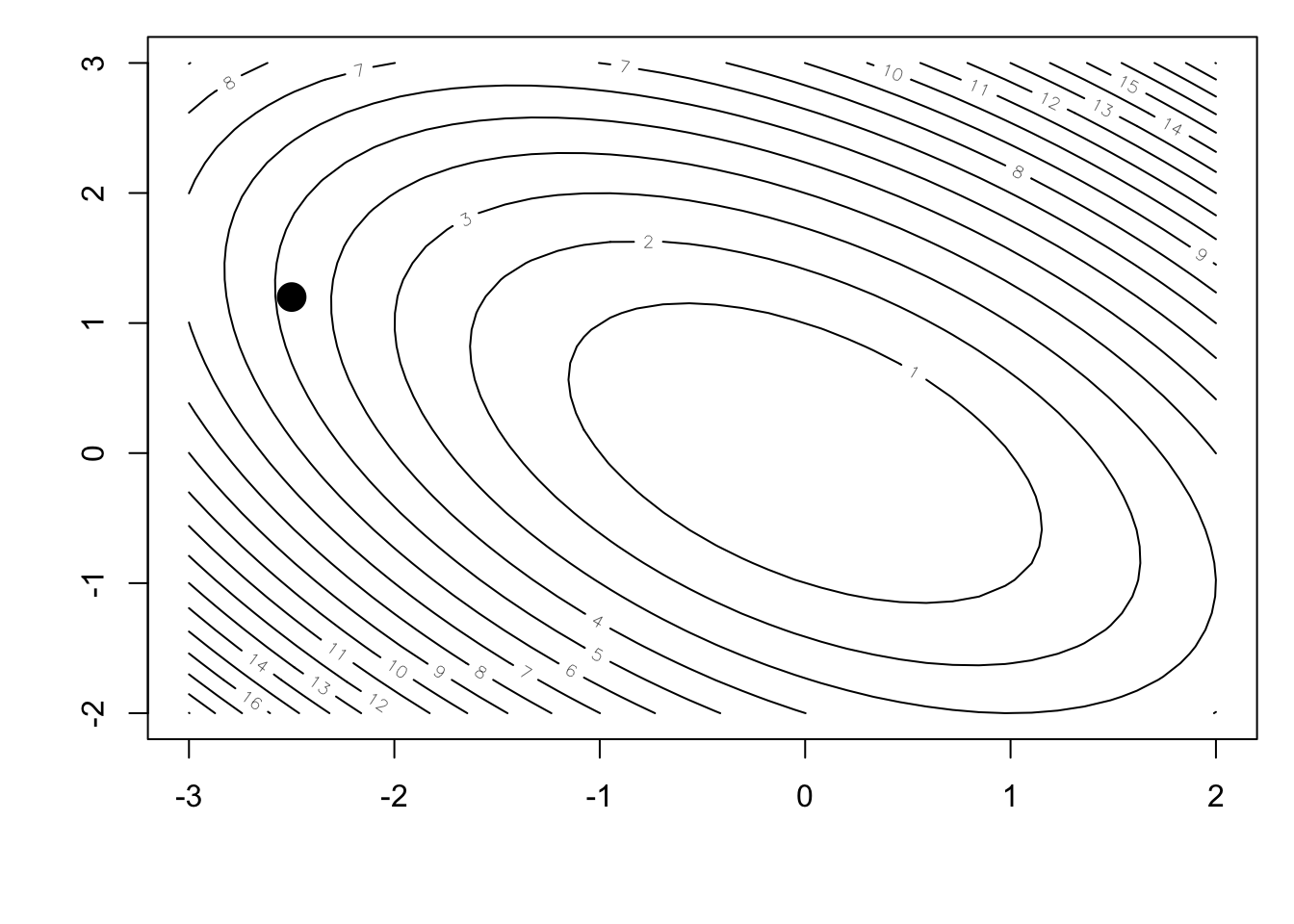
We will use as a starting point the point \((-2.5, 1.2)\), as indicated in the figure above.
From the figure, it is clear that ideally we would be able to travel in the direction that would take us directly to the minimum of the function, shown here.
par(mar = c(5, 4, 1, 1))
contour(xpts, ypts, z, nlevels = 20)
points(x0, y0, pch = 19, cex = 2)
arrows(x0, y0, 0, 0, lwd = 3, col = "grey")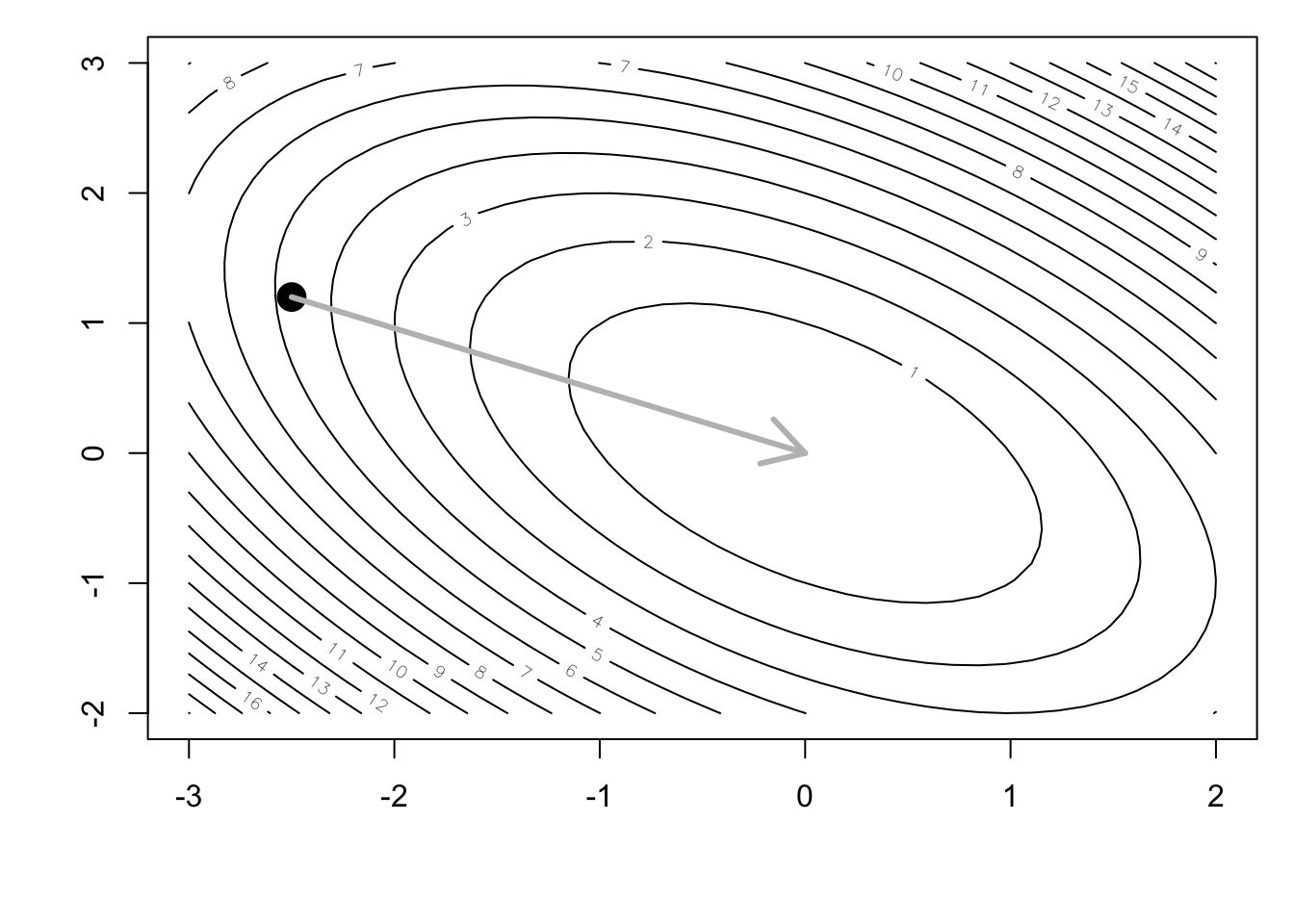
If only life were so easy? The idea behind conjugate gradient is the construct that direction using a series of conjugate directions. First we start with the steepest descent direction. Here, we extract the gradient and find the optimal \(\alpha\) value (i.e. the step size).
f0 <- f(x0, y0)
p0 <- drop(-attr(f0, "gradient")) ## Get the gradient function
f.sub <- function(alpha) {
ff <- f(x0 + alpha * p0[1], y0 + alpha * p0[2])
as.numeric(ff)
}
op <- optimize(f.sub, c(0, 4)) ## Compute the optimal alpha
alpha <- op$minimumNow that we’ve computed the gradient and the optimal \(\alpha\), we can take a step in the steepest descent direction
x1 <- x0 + alpha * p0[1]
y1 <- y0 + alpha * p0[2]and plot our progress to date.
par(mar = c(5, 4, 1, 1))
contour(xpts, ypts, z, nlevels = 20)
points(x0, y0, pch = 19, cex = 2)
arrows(x0, y0, 0, 0, lwd = 3, col = "grey")
arrows(x0, y0, x1, y1, lwd = 2)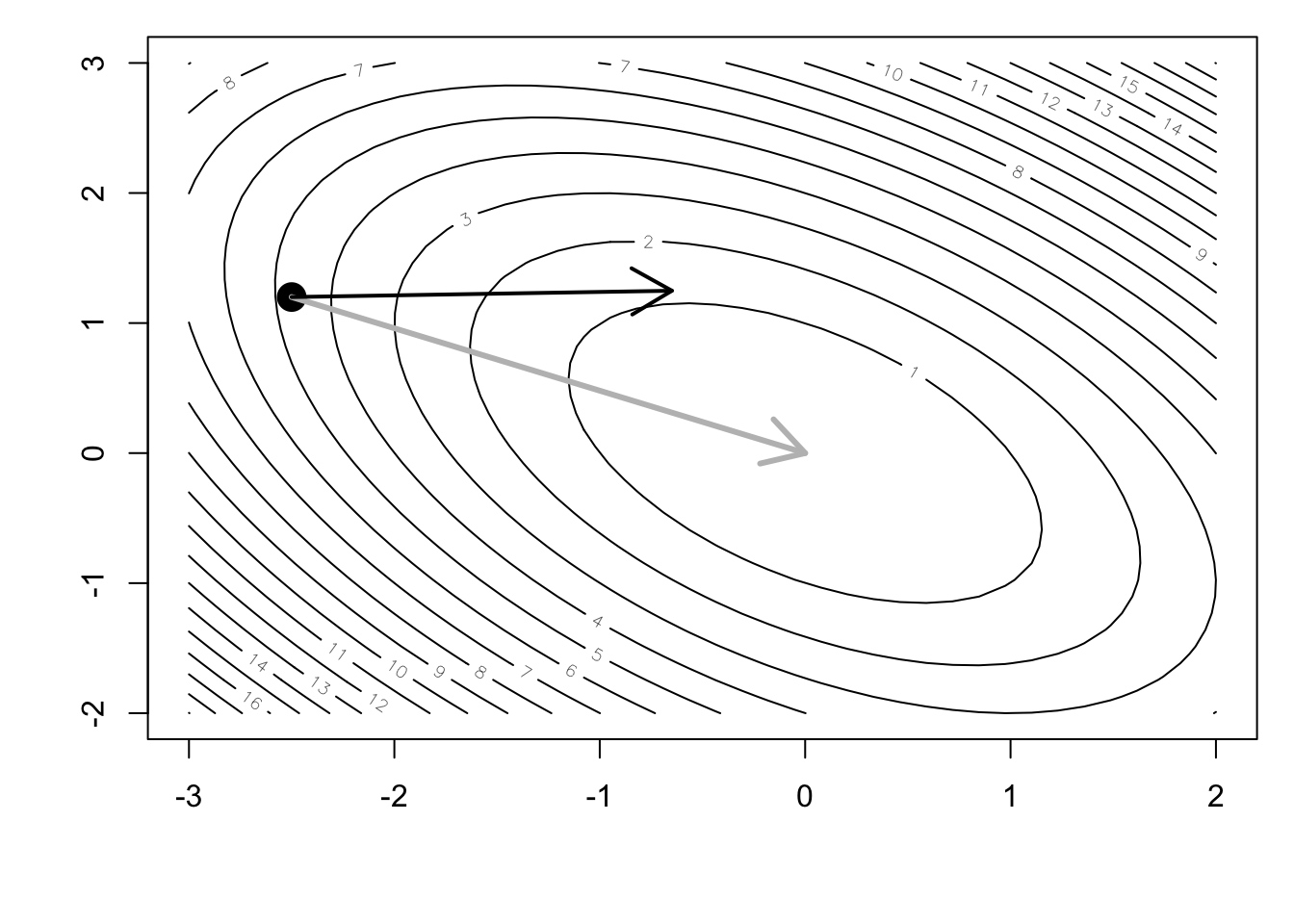
Now we need to compute the next direction in which to travel. We begin with the steepest descent direction again. The figure below shows what direction that would be (without any modifications for conjugacy).
f1 <- f(x1, y1)
f1g <- drop(attr(f1, "gradient")) ## Get the gradient function
p1 <- -f1g ## Steepest descent direction
op <- optimize(f.sub, c(0, 4)) ## Compute the optimal alpha
alpha <- op$minimum
x2 <- x1 + alpha * p1[1] ## Find the next point
y2 <- y1 + alpha * p1[2]Now we can plot the next direction that is chosen by the usual steepest descent approach.
par(mar = c(5, 4, 1, 1))
contour(xpts, ypts, z, nlevels = 20)
points(x0, y0, pch = 19, cex = 2)
arrows(x0, y0, 0, 0, lwd = 3, col = "grey")
arrows(x0, y0, x1, y1, lwd = 2)
arrows(x1, y1, x2, y2, col = "red", lwd = 2, lty = 2)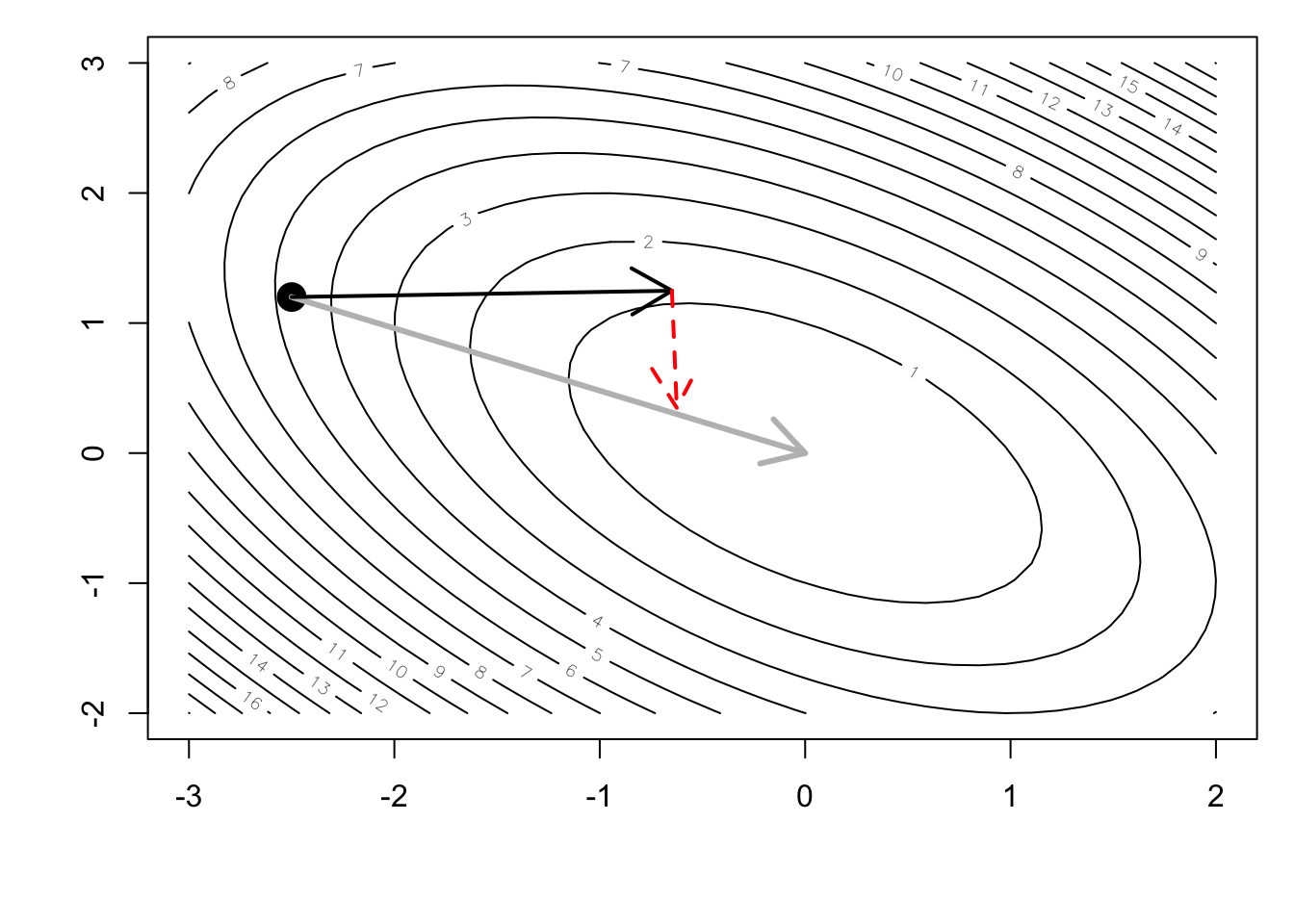
However, the conjugate gradient approach computes a slightly different direction in which to travel.
f1 <- f(x1, y1)
f1g <- drop(attr(f1, "gradient"))
beta <- drop(crossprod(f1g) / crossprod(p0)) ## Fletcher-Reeves
p1 <- -f1g + beta * p0 ## Conjugate gradient direction
f.sub <- function(alpha) {
ff <- f(x1 + alpha * p1[1], y1 + alpha * p1[2])
as.numeric(ff)
}
op <- optimize(f.sub, c(0, 4)) ## Compute the optimal alpha
alpha <- op$minimum
x2c <- x1 + alpha * p1[1] ## Find the next point
y2c <- y1 + alpha * p1[2]Finally, we can plot the direction in which the conjugate gradient method takes.
par(mar = c(5, 4, 1, 1))
contour(xpts, ypts, z, nlevels = 20)
points(x0, y0, pch = 19, cex = 2)
arrows(x0, y0, 0, 0, lwd = 3, col = "grey")
arrows(x0, y0, x1, y1, lwd = 2)
arrows(x1, y1, x2, y2, col = "red", lwd = 2, lty = 2)
arrows(x1, y1, x2c, y2c, lwd = 2)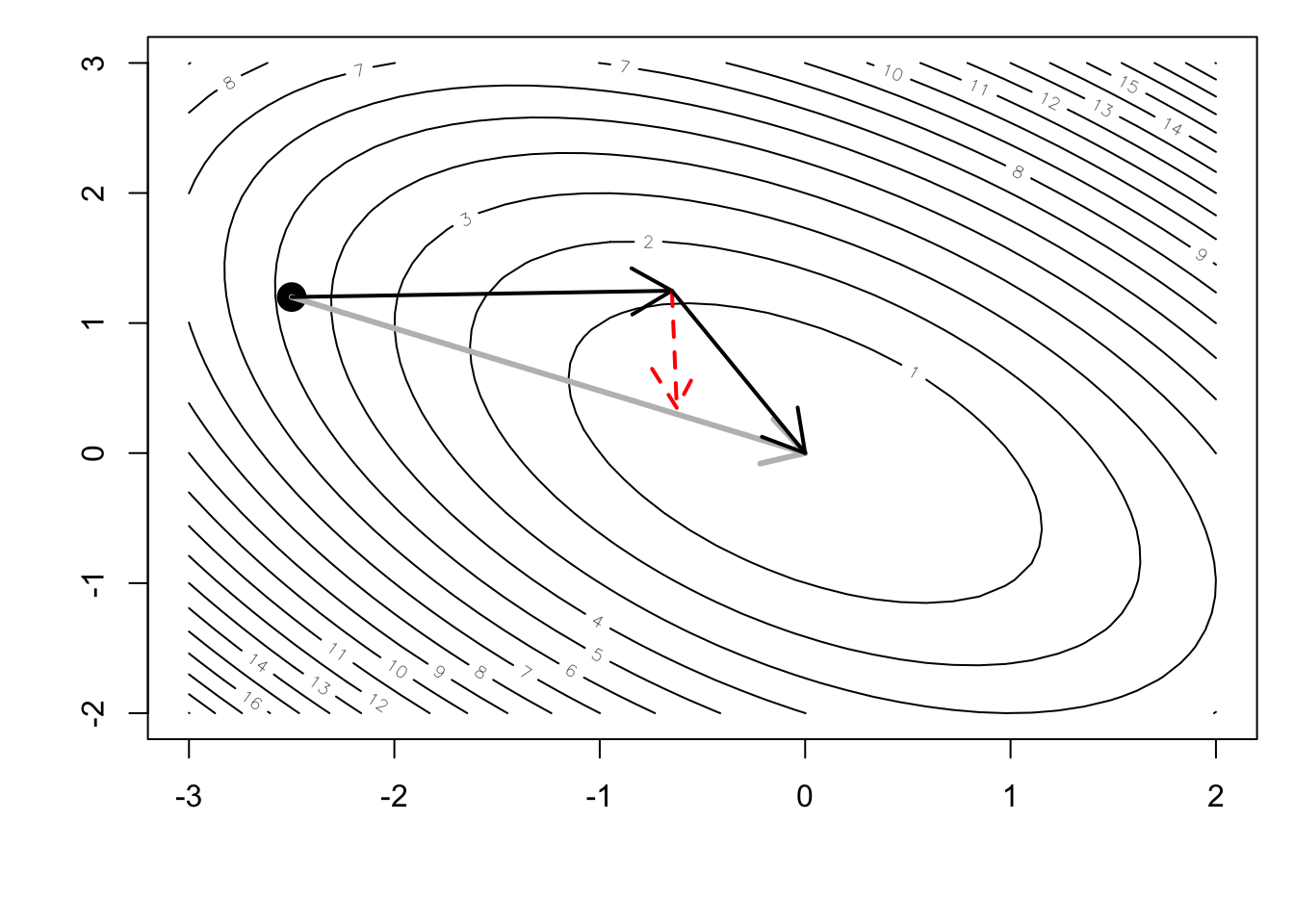
In this case, because the target function was exactly quadratic, the process converged on the minimum in exactly 2 steps. We can see that the steepest descent algorithm would have taken many more steps to wind its way towards the minimum.