5.1 Laplace Approximation
The first technique that we will discuss is Laplace approximation. This technique can be used for reasonably well behaved functions that have most of their mass concentrated in a small area of their domain. Technically, it works for functions that are in the class of \(\mathfrak{L}^2\), meaning that \[ \int g(x)^2\,dx < \infty \] Such a function generally has very rapidly decreasing tails so that in the far reaches of the domain we would not expect to see large spikes.
Imagine a function that looks as follows
We can see that this function has most of its mass concentrated around the point \(x_0\) and that we could probably approximate the area under the function with something like a step function.
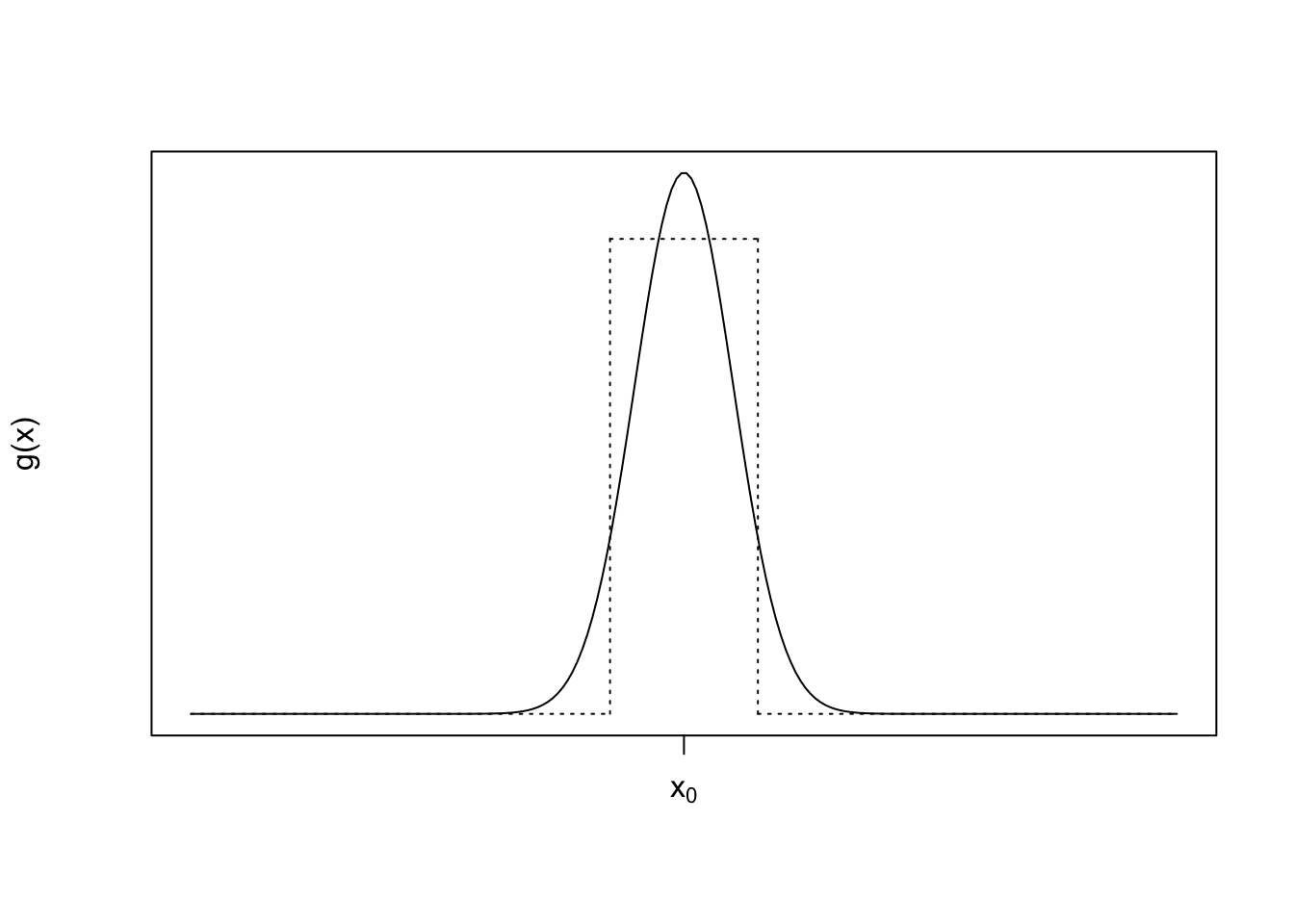 The benefit of using something like a step function is that the area under a step function is trivial to compute. If we could find a principled and automatic way to find that approximating step function, and it were easier than just directly computing the integral in the first place, then we could have an alternative to computing the integral. In other words, we could perhaps say that
\[
\int g(x)\,dx \approx g(x_0)\varepsilon
\]
for some small value of \(\varepsilon\).
The benefit of using something like a step function is that the area under a step function is trivial to compute. If we could find a principled and automatic way to find that approximating step function, and it were easier than just directly computing the integral in the first place, then we could have an alternative to computing the integral. In other words, we could perhaps say that
\[
\int g(x)\,dx \approx g(x_0)\varepsilon
\]
for some small value of \(\varepsilon\).
In reality, we actually have some more sophisticated functions that we can use besides step functions, and that’s how the Laplace approximation works. The general idea is to take a well-behaved uni-modal function and approximate it with a Normal density function, which is a very well-understood quantity.
Suppose we have a function \(g(x)\in\mathfrak{L}^2\) which achieves its maximum at \(x_0\). We want to compute \[ \int_a^b g(x)\, dx. \]
Let \(h(x) = \log g(x)\) so that we have \[ \int_a^b g(x)\,dx = \int_a^b \exp(h(x))\,dx \]
From here we can take a Taylor series approximation of \(h(x)\) around the point \(x_0\) to give us
\[ \int_a^b \exp(h(x))\,dx \approx \int_a^b\exp\left(h(x_0) + h^\prime(x_0)(x-x_0) + \frac{1}{2}h^{\prime\prime}(x_0)(x-x_0)^2\right)\,dx \]
Because we assumed \(h(x)\) achieves its maximum at \(x_0\), we know \(h^\prime(x_0) = 0\). Therefore, we can simplify the above expression to be
\[ = \int_a^b\exp\left(h(x_0) + \frac{1}{2}h^{\prime\prime}(x_0)(x-x_0)^2\right)\,dx \] Given that \(h(x_0)\) is a constant that doesn’t depend on \(x\), we can pull it outside the integral. In addition, we can rearrange some of the terms to give us \[ = \exp(h(x_0)) \int_a^b \exp\left(-\frac{1}{2}\frac{(x-x_0)^2}{-h^{\prime\prime}(x_0)^{-1}}\right)\,dx \]
Now that looks more like it, right? Inside the integral we have a quantity that is proportional to a Normal density with mean \(x_0\) and variance \(-h^{\prime\prime}(x_0)^{-1}\). At this point we are just one call to the pnorm() function away from approximating our integral. All we need is to compute our normalizing constants.
If we let \(\Phi(x\mid \mu, \sigma^2)\) be the cumulative distribution function for the Normal distribution with mean \(\mu\) and variance \(\sigma^2\) (and \(\varphi\) is its density function), then we can write the above expression as
\[\begin{eqnarray*} & = & \exp(h(x_0)) \sqrt{\frac{2\pi}{-h^{\prime\prime}(x_0)}} \int_a^b \varphi(x\mid x_0,-h^{\prime\prime}(x_0)^{-1})\,dx\\ & = & \exp(h(x_0)) \sqrt{\frac{2\pi}{-h^{\prime\prime}(x_0)}} \left[ \Phi\left(b\mid x_0,-h^{\prime\prime}(x_0)^{-1}\right) - \Phi\left(a\mid x_0,-h^{\prime\prime}(x_0)^{-1}\right) \right] \end{eqnarray*}\]
Recall that \(\exp(h(x_0)) = g(x_0)\). If \(b=\infty\) and \(a = -\infty\), as is commonly the case, then the term in the square brackets is equal to \(1\), making the Laplace approximation equal to the value of the function \(g(x)\) at its mode multiplied by a constant that depends on the curvature of the function \(h\).
One final note about the Laplace approximation is that it replaces the problem of integrating a function with the problem of maximizing it. In order to compute the Laplace approximation, we have to compute the location of the mode, which is an optimization problem. Often, this problem is faster to solve using well-understood function optimizers than integrating the same function would be.
5.1.1 Computing the Posterior Mean
In Bayesian computations we often want to compute the posterior mean of a parameter given the observed data. If \(y\) represents data we observe and \(y\) comes from the distribution \(f(y\mid\theta)\) with parameter \(\theta\) and \(\theta\) has a prior distribution \(\pi(\theta)\), then we usually want to compute the posterior distribution \(p(\theta\mid y)\) and its mean, \[ \mathbb{E}_p[\theta] = \int \theta\, p(\theta\mid y)\,d\theta. \] We can then write
\[\begin{eqnarray*} \int \theta\,p(\theta\mid y)\,dx & = & \frac{ \int\theta\,f(y\mid\theta)\pi(\theta)\,d\theta }{ \int f(y\mid\theta)\pi(\theta)\,d\theta }\\ & = & \frac{ \int\theta\,\exp(\log f(y\mid\theta)\pi(\theta))\,d\theta }{ \int\exp(\log f(y\mid\theta)\pi(\theta)\,d\theta) } \end{eqnarray*}\] Here, we’ve used the age old trick of exponentiating and log-ging.
If we let \(h(\theta) = \log f(y\mid\theta)\pi(\theta)\), then we can use the same Laplace approximation procedure described in the previous section. However, in order to do that we must know where \(h(\theta)\) achieves its maximum. Because \(h(\theta)\) is simply a monotonic transformation of a function proportional to the posterior density, we know that \(h(\theta)\) achieves its maximum at the posterior mode.
Let \(\hat{\theta}\) be the posterior mode of \(p(\theta\mid y)\). Then we have
\[\begin{eqnarray*} \int \theta\,p(\theta\mid y)\,dx & \approx & \frac{ \int\theta \exp\left( h(\hat{\theta}) + \frac{1}{2}h^{\prime\prime}(\hat{\theta})(\theta-\hat{\theta})^2 \right)\,d\theta }{ \int \exp\left( h(\hat{\theta}) + \frac{1}{2}h^{\prime\prime}(\hat{\theta})(\theta-\hat{\theta})^2 \right)\,d\theta }\\ & = & \frac{ \int\theta \exp\left( \frac{1}{2}h^{\prime\prime}(\hat{\theta})(\theta-\hat{\theta})^2 \right)\,d\theta }{ \int \exp\left( \frac{1}{2}h^{\prime\prime}(\hat{\theta})(\theta-\hat{\theta})^2 \right)\,d\theta }\\ & = & \frac{ \int \theta \sqrt{\frac{2\pi}{-h^{\prime\prime}(\hat{\theta})}} \varphi\left(\theta\mid\hat{\theta},-h^{\prime\prime}(\hat{\theta})^{-1}\right) \,d\theta }{ \int \sqrt{\frac{2\pi}{-h^{\prime\prime}(\hat{\theta})}} \varphi\left(\theta\mid\hat{\theta},-h^{\prime\prime}(\hat{\theta})^{-1}\right) \,d\theta }\\ & = & \hat{\theta} \end{eqnarray*}\]
Hence, the Laplace approximation to the posterior mean is equal to the posterior mode. This approximation is likely to work well when the posterior is unimodal and relatively symmetric around the model. Furthermore, the more concentrated the posterior is around \(\hat{\theta}\), the better.
5.1.1.1 Example: Poisson Data with a Gamma Prior
In this simple example, we will use data drawn from a Poisson distribution with a mean that has a Gamma prior distribution. The model is therefore
\[\begin{eqnarray*} Y \mid \mu & \sim & \text{Poisson}(\mu)\\ \mu & \sim & \text{Gamma}(a, b) \end{eqnarray*}\] where the Gamma density is \[ f(\mu) = \frac{1}{b^{a}\Gamma(a)}\mu^{a - 1}e^{-\mu/b} \]
In this case, given an observation \(y\), the posterior distribution is simply a Gamma distribution with shape parameter \(y + a\) and scale parameter \((1 + 1/b)\).
Suppose we observe \(y = 2\). We can draw the posterior distribution and prior distribution as follows.
make_post <- function(y, shape, scale) {
function(x) {
dgamma(x, shape = y + shape,
scale = 1 / (1 + 1 / scale))
}
}
set.seed(2017-11-29)
y <- 2
prior.shape <- 3
prior.scale <- 3
p <- make_post(y, prior.shape, prior.scale)
curve(p, 0, 12, n = 1000, lwd = 3, xlab = expression(mu),
ylab = expression(paste("p(", mu, " | y)")))
curve(dgamma(x, shape = prior.shape, scale = prior.scale), add = TRUE,
lty = 2)
legend("topright", legend = c("Posterior", "Prior"), lty = c(1, 2), lwd = c(3, 1), bty = "n")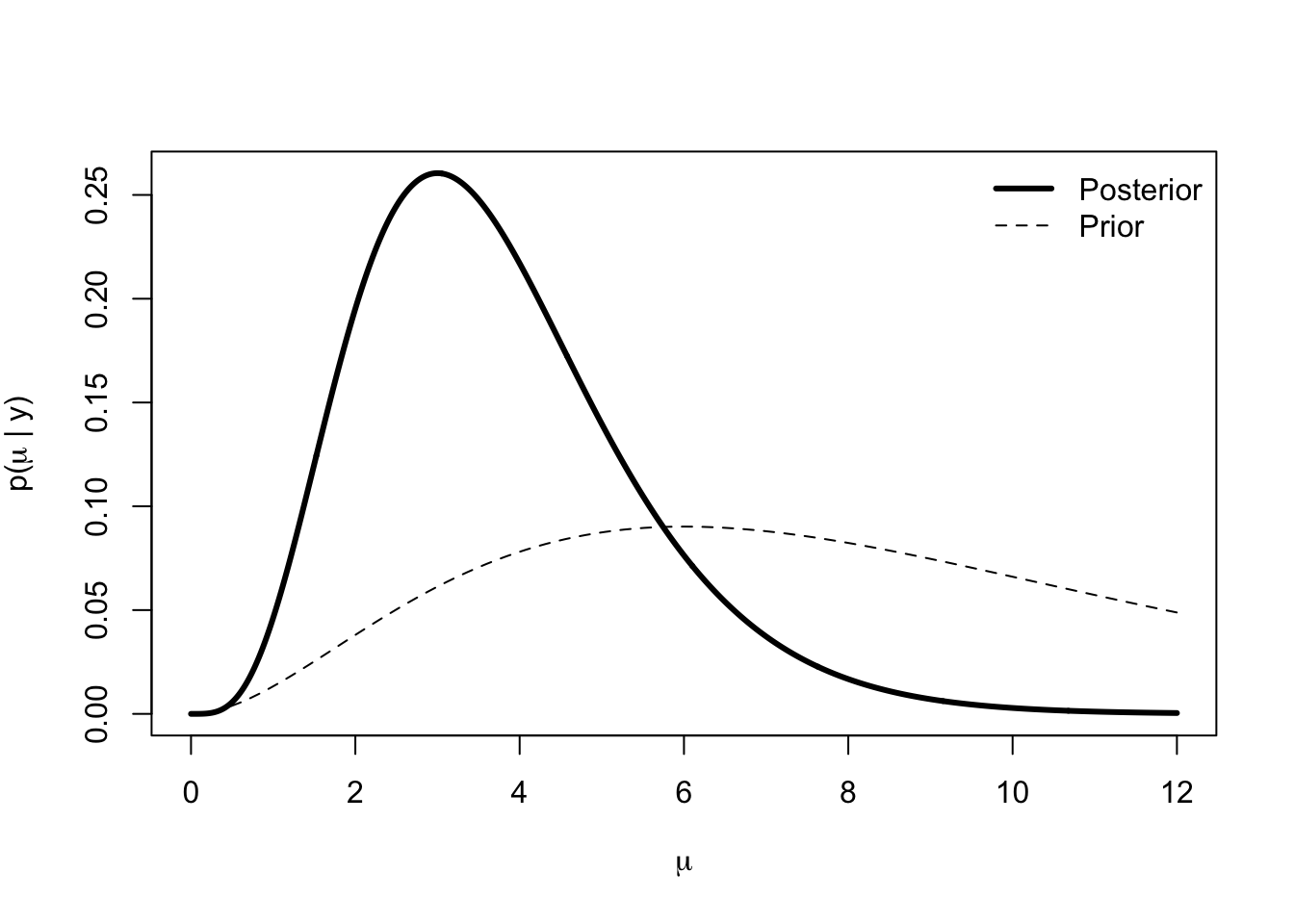
Because this is a Gamma distribution, we can also compute the posterior mode in closed form.
pmode <- (y + prior.shape - 1) * (1 / (1 + 1 / prior.scale))
pmode[1] 3We can also compute the mean.
pmean <- (y + prior.shape) * (1 / (1 + 1 / prior.scale))
pmean[1] 3.75From the skewness in the figure above, it’s clear that the mean and the mode should not match.
We can now see what the Laplace approximation to the posterior looks like in this case. First, we can compute the gradient and Hessian of the Gamma density.
a <- prior.shape
b <- prior.scale
fhat <- deriv3(~ mu^(y + a - 1) * exp(-mu * (1 + 1/b)) / ((1/(1+1/b))^(y+a) * gamma(y + a)), "mu", function.arg = TRUE)Then we can compute the quadratic approximation to the density via the lapprox() function below.
post.shape <- y + prior.shape - 1
post.scale <- 1 / (length(y) + 1 / prior.scale)
lapprox <- Vectorize(function(mu, mu0 = pmode) {
deriv <- fhat(mu0)
grad <- attr(deriv, "gradient")
hess <- drop(attr(deriv, "hessian"))
f <- function(x) dgamma(x, shape = post.shape, scale = post.scale)
hpp <- (hess * f(mu0) - grad^2) / f(mu0)^2
exp(log(f(mu0)) + 0.5 * hpp * (mu - mu0)^2)
}, "mu")Plotting the true posterior and the Laplace approximation gives us the following.
curve(p, 0, 12, n = 1000, lwd = 3, xlab = expression(mu),
ylab = expression(paste("p(", mu, " | y)")))
curve(dgamma(x, shape = prior.shape, scale = prior.scale), add = TRUE,
lty = 2)
legend("topright",
legend = c("Posterior Density", "Prior Density", "Laplace Approx"),
lty = c(1, 2, 1), lwd = c(3, 1, 1), col = c(1, 1, 2), bty = "n")
curve(lapprox, 0.001, 12, n = 1000, add = TRUE, col = 2, lwd = 2)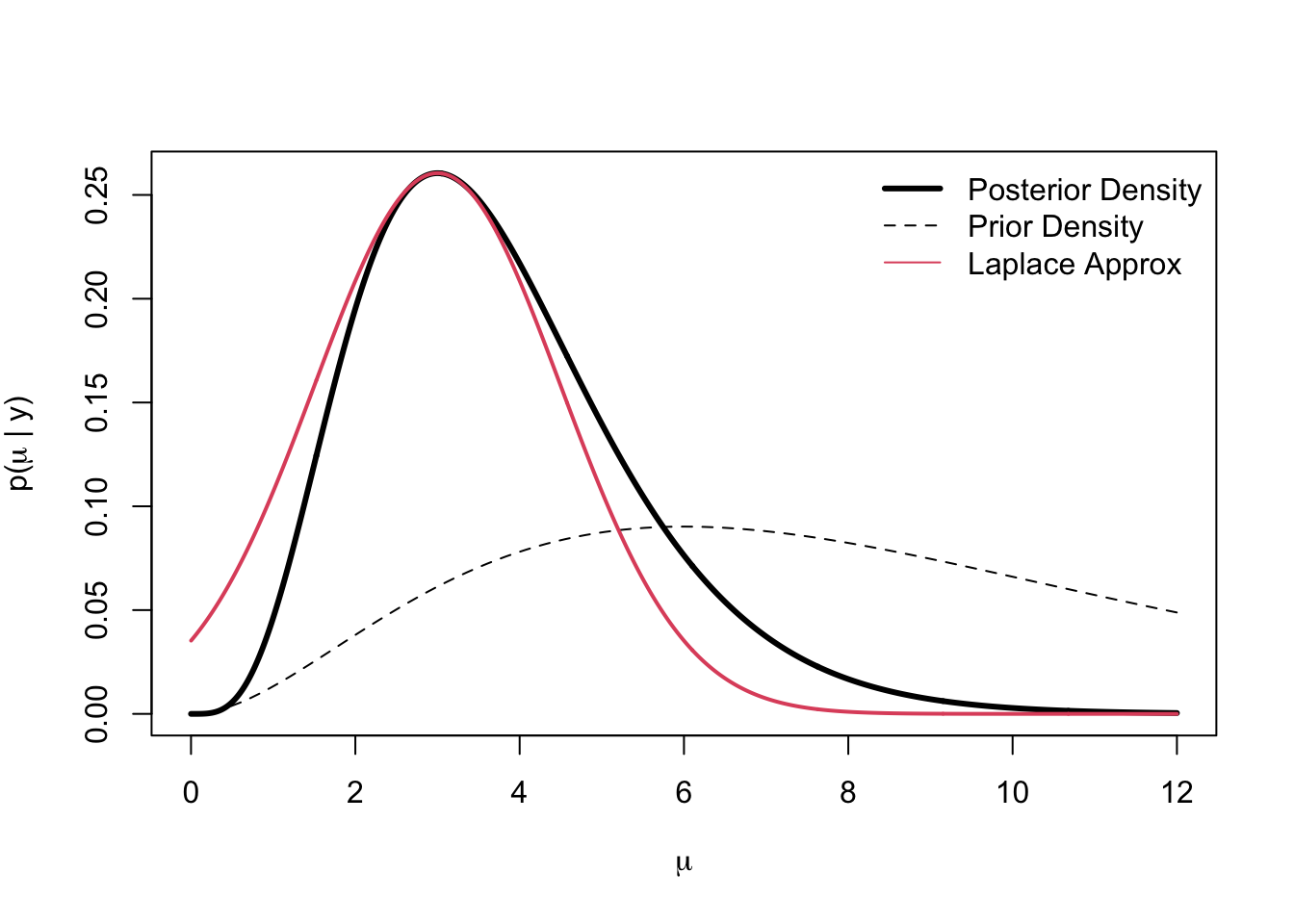
The solid red curve is the Laplace approximation and we can see that in the neighborhood of the mode, the approximation is reasonable. However, as we move farther away from the mode, the tail of the Gamma is heavier on the right.
Of course, this Laplace approximation is done with only a single observation. One would expect the approximation to improve as the sample size increases. In this case, with respect to the posterior mode as an approximation to the posterior mean, we can see that the difference between the two is simply
\[ \hat{\theta}_{\text{mean}} - \hat{\theta}_{\text{mode}} = \frac{1}{n + 1/b} \]
which clearly goes to zero as \(n\rightarrow\infty\).