Zufallsvariablen sind Funktionen aus dem Ergebnisraum in die Menge der reellen Zahlen. Es ist natürlich möglich, nicht nur eine solche Funktion zu betrachten, sondern mehrere gleichzeitig. Man erhält dann mehrere Zufallsvariablen, die jedoch alle vom gleichen zugrundeliegenden Zufallsvorgang abhängen und auf dem gleichen Ergebnisraum \(\Omega\) basieren. Ordnet man diese Zufallsvariablen in Form eines Vektors an, dann spricht man von einem Zufallsvektor (engl. random vector). Man sagt auch, dass die Zufallsvariablen eine gemeinsame Verteilung (engl. joint distribution) haben. Auch die beiden Begriffe univariat und multivariat werden häufig verwendet, wenn von einer oder mehreren Zufallsvariablen die Rede ist.
Gemeinsame Verteilungen sind erheblich interessanter und vielseitiger als eindimensionale Zufallsvariablen, weil sie auch Zusammenhänge und Abhängigkeiten zwischen den Variablen beschreiben können.
Beispiel: Kleinere und größere Augenzahl
Zwei Würfel werden geworfen. Die Zufallsvariable \(X\) sei die kleinere Augenzahl, die Zufallsvariable \(Y\) die größere Augenzahl. Die beiden Zufallsvariablen \(X\) und \(Y\) basieren auf dem gleichen Ergebnisraum. Sie haben eine gemeinsame Verteilung. Das lässt sich etwa so veranschaulichen: \[
\begin{array}{lclcl}
\mathbb{R}& X & \Omega & Y & \mathbb{R}\\\hline
1 & \longleftarrow & 11 & \longrightarrow & 1\\
1 & \longleftarrow & 12 & \longrightarrow & 2\\
1 & \longleftarrow & 13 & \longrightarrow & 3\\
1 & \longleftarrow & 14 & \longrightarrow & 4\\
1 & \longleftarrow & 15 & \longrightarrow & 5\\
1 & \longleftarrow & 16 & \longrightarrow & 6\\
1 & \longleftarrow & 21 & \longrightarrow & 2\\
2 & \longleftarrow & 22 & \longrightarrow & 2\\
2 & \longleftarrow & 23 & \longrightarrow & 3\\
\vdots && \vdots&&\vdots\\
5 & \longleftarrow & 65 & \longrightarrow & 6\\
6 & \longleftarrow & 66 & \longrightarrow & 6
\end{array}
\]
Beispiel: Aktienportfolio mit zwei Aktien
Wir betrachten die Tagesrenditen von zwei Aktien an einem zukünftigen Tag. Sei \(X\) die Tagesrendite der Volkswagenaktie und \(Y\) die Tagesrendite von BASF. Dann haben \(X\) und \(Y\) eine gemeinsame Verteilung. Die gemeinsame Verteilung hat mehr Informationen als die beiden einzelnen Verteilungen für sich genommen. In der gemeinsamen Verteilung stecken auch Informationen über die Art des Zusammenhangs. Das ist z.B. wichtig, wenn man das Risiko seines Portfolios managen will.
Im folgenden gehen wir Schritt für Schritt fast genauso vor wie bei den univariaten Zufallsvariablen in Kapitel 3.
5.1 Verteilungsfunktion
Alle wichtigen Eigenschaften der Verteilung einer univariaten Zufallsvariable werden durch ihre Verteilungsfunktion beschrieben. Wie lässt sich die Idee einer Verteilungsfunktion auf Zufallsvektoren übertragen?
Definition: Gemeinsame Verteilungsfunktion
Sei \(\Omega\) eine Ergebnismenge, seien \(X:\Omega \longrightarrow \mathbb{R}\) und \(Y:\Omega\longrightarrow \mathbb{R}\) zwei Zufallsvariablen. Dann ist \[
F_{X,Y}(x,y) =P(X\leq x,Y\leq y)
\] die gemeinsame Verteilungsfunktion (engl. joint cumulative distribution function) von \(X\) und \(Y\).
Wenn aus dem Kontext eindeutig hervorgeht, um welchen Zufallsvektor bzw. um welche Zufallsvariablen es sich handelt, können die Subindizes entfallen. Die gemeinsame Verteilungsfunktion lässt sich leicht auf mehr als zwei Zufallsvariablen verallgemeinern. Da die Notation dann etwas unübersichtlicher wird, beschränken wir uns auf den Fall von zwei Zufallsvariablen. Alle wichtigen Konzepte lassen sich auch gut in diesem Fall verstehen.
Eigenschaften der gemeinsamen Verteilungsfunktion:
\(F_{X,Y}(x,y)=P(X\leq x,Y\leq y)\) ist monoton steigend (aber nicht unbedingt streng monoton steigend) in \(x\) und \(y\).
Es gilt \(\lim_{x\to -\infty}F_{X,Y}(x,y)=0\) und \(\lim_{y\to -\infty}F_{X,Y}(x,y)=0\).
Es gilt \(\lim_{z\to \infty}F_{X,Y}(z,z) =1\).
5.2 Gemeinsam diskrete Zufallsvariablen
Im univariaten Fall haben wir uns auf zwei Klassen von Zufallsvariablen beschränkt, nämlich diskrete und stetige Zufallsvariablen. Das lässt sich leicht auf den mehrdimensionalen Fall verallgemeinern.
Definition: Gemeinsam diskrete Zufallsvariablen
Zwei Zufallsvariablen \(X\) und \(Y\) heißen gemeinsam diskret (engl. jointly discrete), wenn es endlich viele oder abzählbar unendlich viele Werte \(x_1,x_2,\ldots\) und \(y_1,y_2,\ldots\) gibt, so dass \[
\sum_{j}\sum_{k}p_{jk}=1
\] mit \(p_{jk}=P(X=x_j,Y=y_k)\).
Gemeinsam diskrete Zufallsvariablen haben eine gemeinsame Wahrscheinlichkeitsfunktion (engl. joint probability function), nämlich \[
f_{X,Y}(x,y) =\left\{
\begin{array}{ll}
p_{jk} & \quad \text{wenn }x=x_{j}\text{ und }y=y_{k} \\
0 & \quad \text{sonst.}
\end{array}\right.
\] Wenn die Zahl der unterschiedlichen möglichen Werte, die \(X\) und \(Y\) annehmen können, nicht allzu groß ist, dann kann man die gemeinsamen Wahrscheinlichkeiten übersichtlich in Form einer Wahrscheinlichkeitstabelle darstellen: \[
\begin{array}{c|ccc}
X\backslash Y & y_{1} & \ldots & y_{K} \\ \hline
x_{1} & p_{11} & \ldots & p_{1K} \\
\vdots& \vdots & & \vdots \\
x_{J} & p_{J1} & \ldots & p_{JK}
\end{array}
\]
Beispiel: Kleinere und größere Augenzahl
Zwei Würfel werden geworfen. Die gemeinsame Wahrscheinlichkeitsfunktion der beiden Zufallsvariablen \(X\): “kleinere Augenzahl” und \(Y\): “größere Augenzahl” sieht als Wahrscheinlichkeitstabelle so aus: \[
\begin{array}{c|cccccc}
X\backslash Y & 1 & 2 & 3 & 4 & 5 & 6 \\ \hline
1 & \frac{1}{36} & \frac{2}{36} & \frac{2}{36} & \frac{2}{36} & \frac{2}{36} & \frac{2}{36} \\
2 & 0 & \frac{1}{36} & \frac{2}{36} & \frac{2}{36} & \frac{2}{36} & \frac{2}{36} \\
3 & 0 & 0 & \frac{1}{36} & \frac{2}{36} & \frac{2}{36} & \frac{2}{36} \\
4 & 0 & 0 & 0 & \frac{1}{36} & \frac{2}{36} & \frac{2}{36} \\
5 & 0 & 0 & 0 & 0 & \frac{1}{36} & \frac{2}{36} \\
6 & 0 & 0 & 0 & 0 & 0 & \frac{1}{36}
\end{array}
\] Der Wert der gemeinsamen Verteilungsfunktion an der Stelle \((x,y)=(5.3, 2)\) gibt die Wahrscheinlichkeit an, dass \(X\le 5\) ist und gleichzeitig \(Y\le 2\). Diese Wahrscheinlichkeit ergibt sich, indem man alle Wahrscheinlichkeiten aus der Tabelle addiert, die in den ersten beiden Spalten (\(Y\le 2\)) und in den ersten fünf Zeilen (\(X\le 5.3\)) stehen. Man erhält \[
F_{X,Y}(5.3,2)=\frac{1}{36}+\frac{2}{36}+\frac{1}{36}=\frac{4}{36}=\frac{1}{9}.
\]
5.3 Gemeinsam stetige Zufallsvariablen
Definition: Gemeinsam stetige Zufallsvariablen
Die Zufallsvariablen \(X\) und \(Y\) heißen gemeinsam stetig (engl. jointly continuous), falls es eine Funktion \(f_{X,Y}\) gibt mit \[
F_{X,Y}(x,y)=\int_{-\infty }^{y}\int_{-\infty }^{x}f_{X,Y}(u,v)dudv.
\] Die Funktion \(f_{X,Y}\) heißt gemeinsame Dichte oder Dichtefunktion (engl. joint density function) von \(X\) und \(Y\).
Wenn die Verteilungsfunktion partiell differenzierbar ist, dann erhält man die Dichte, indem man die Verteilungsfunktion nach beiden Argumenten ableitet, \[
f_{X,Y}(x,y)=\frac{\partial^2}{\partial x\partial y}F_{X,Y}(x,y).
\] Da die Verteilungsfunktion monoton steigend ist, kann die Dichte nie negativ sein (sie kann jedoch in einigen Bereichen 0 sein). Für \(x,y\in\mathbb{R}\) gilt also \[
f_{X,Y}(x,y)\ge 0.
\] Das gesamte Volumen unter der Dichte beträgt 1, \[
\int_{-\infty }^{\infty }\int_{-\infty }^{\infty }f_{X,Y}(x,y)dxdy=1.
\] Die gemeinsame Dichte zweier Zufallsvariablen kann man sich als Gebirge mit einem Volumen von 1 vorstellen. Die Bereiche \((x,y)\), in denen das Gebirge hoch ist, kommen mit einer höheren Wahrscheinlichkeit vor, als die Bereiche, in denen es niedrig ist.
Die verschiedenen Arten der grafischen Darstellung werden nun für eine konkrete gemeinsame Dichte vorgestellt. Die Dichte der beiden Zufallsvariablen \(X\) und \(Y\) sei für \(x,y\in\mathbb{R}\)\[
f(x,y)=\frac{2e^{-x-y}}{(1+e^{-x}+e^{-y})^3}.
\]
In der folgenden 3D-Abbildung, die Sie mit der Maus bewegen können (allerdings leider nicht auf einem Tablet), erkennt man, dass die Dichte um den Punkt \((0,0)\) herum besonders hoch ist. Die gemeinsame Realisation von \(X\) und \(Y\) wird also mit hoher Wahrscheinlichkeit irgendwo in der Nähe des Nullpunkts liegen. Außerdem ist eine leichte Asymmetrie zu erkennen. Es ist sehr unwahrscheinlich, dass sowohl \(X\) als auch in \(Y\) beide größer als 3 sind. Hingegen kann es (wenn auch mit eher kleiner Wahrscheinlichkeit) passieren, dass beide Zufallsvariable kleiner als \(-3\) sind.
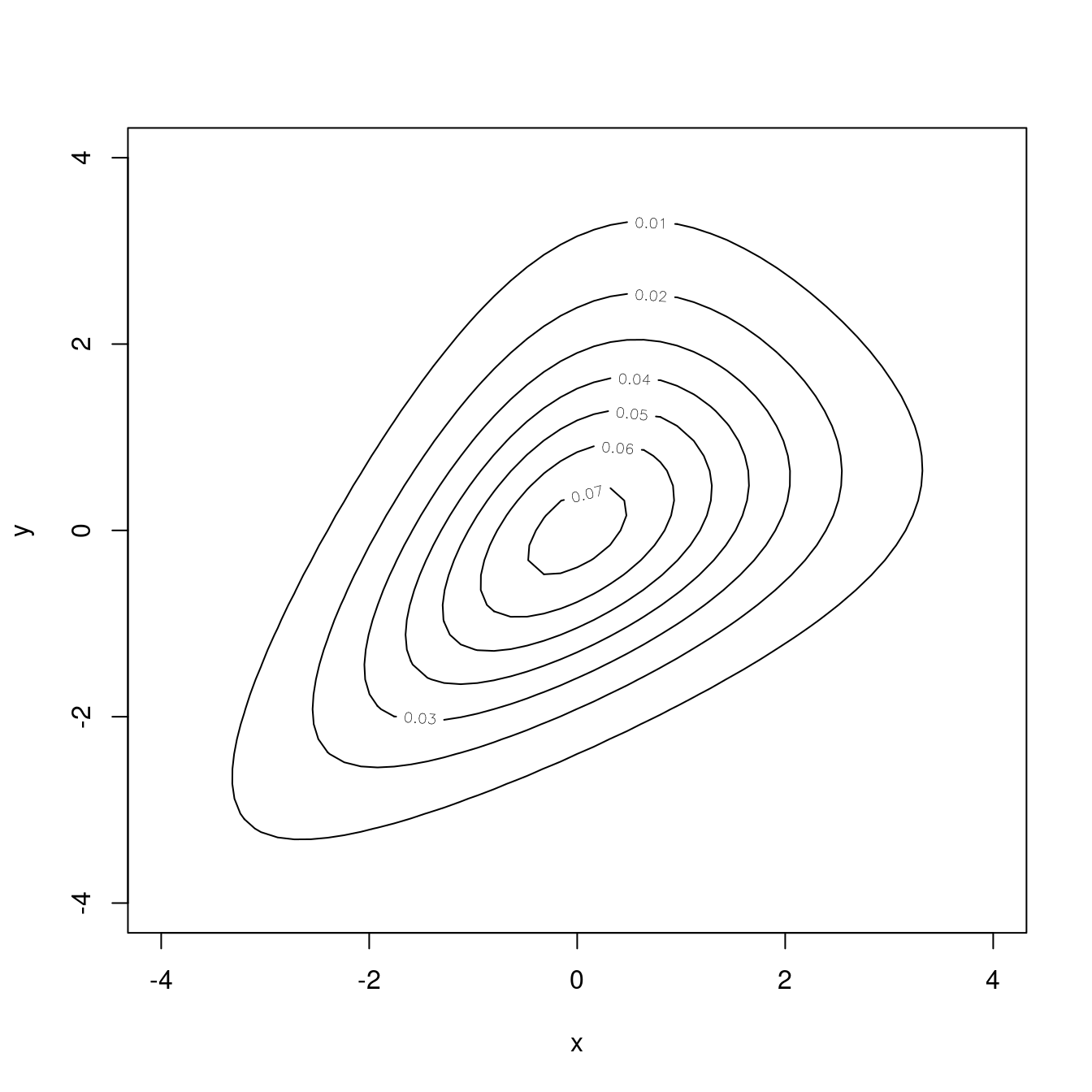
Weitere Möglichkeiten, ein Dichtegebirge grafisch darzustellen, sind Contour-Plots und Image-Plots. In einem Contour-Plot sieht man die Höhenlinien der Dichtefunktion wie auf einer normalen Landkarte. In einem Image-Plot werden die Höhen durch Farben repräsentiert.
Der Contour-Plot für die obige Dichte sieht so aus:
R-Code zeigen
# Die Vektoren x und y und die Matrix f wurden weiter oben berechnet.contour(x, y, f,xlab="x", ylab="y")
Ein Vorteil des Contour-Plots besteht darin, dass man leicht erkennen kann, wo die Dichte hoch ist. Ein farbiger Image-Plot der gleichen Dichte zeigt folgendes Bild:
R-Code zeigen
# Die Vektoren x und y und die Matrix f wurden weiter oben berechnet.filled.contour(x, y, f,xlab="x", ylab="y")
Wenn man sich für die Wahrscheinlichkeit interessiert, dass die Zufallsvariable in einem bestimmten Bereich landet, muss man das Volumen der Dichte über diesem Bereich berechnen. Für einen rechteckigen Bereich \([a_1,b_1]\times [a_2,b_2]\) berechnet man das Doppel-Integral \[
P(a_1< X \le b_1, a_2 < Y\le b_2)=\int_{a_2}^{b_2}\int_{a_1}^{b_1}
f(x,y)dxdy.
\] Lässt man das Rechteck unendlich groß werden, ergibt sich das Gesamtvolumen 1. Die Herleitung des Doppelintegrals ist in vielen Fällen umständlich, in manchen Fällen sogar in geschlossener Form unmöglich. Numerische Verfahren erlauben jedoch eine approximative Berechnung der Wahrscheinlichkeit. In dem folgenden Beispiel ist die Dichte des Zufallsvektors von einer Form, die eine geschlossene Herleitung des Doppelintegrals erlaubt.
Beispiel: Gemeinsame Dichte
Der gemeinsam stetig verteilte Zufallsvektor \((X,Y)\) hat die gemeinsame Dichtefunktion \[
f(x,y)=\left\{
\begin{array}{ll}
x+y^2 & \text{ wenn }0\le x \le 1.11963\text{ und }0\le y\le 1\\
0 & \text{ sonst.}
\end{array}
\right.
\] Die obere Intervallgrenze (\(1.11963\)) für \(x\) ist gerundet, streng genommen lautet die Obergrenze \((\sqrt{19}-1)/3)\). Dieser Wert stellt sicher, dass das gesamte Volumen unter der Dichte 1 ergibt.
Wie groß ist die Wahrscheinlichkeit, dass \(X\) in dem Intervall \([0.5,0.75]\) und gleichzeitig \(Y\) in dem Intervall \([0.2,0.5]\) liegt? Diese Wahrscheinlichkeit ergibt sich als das Doppelintegral \[
P(0.5< X\le 0.75,0.2<Y\le 0.5)=
\int_{0.2}^{0.5}\int_{0.5}^{0.75}(x+y^2)dxdy.
\] Zuerst bestimmen wir das innere Integral. Es ist \[
\int_{0.5}^{0.75}(x+y^2)dx=\left.\frac{1}{2}x^2+xy^2\right|_{0.5}^{0.75}=0.25y^2+0.15625.
\] Dieser Ausdruck wird nun in das äußere Integral eingesetzt. Man erhält \[
\int_{0.2}^{0.5}(0.25y^2+0.15625)dy=
\left. \frac{1}{12}y^3+0.15625y\right|_{0.2}^{0.5}=
0.056625.
\] Die Wahrscheinlichkeit, das die Realisation des Zufallsvektors in dem Rechteck \([0.5,0.75]\times[0.2,0.5]\) liegt, beträgt also 5.7 Prozent.
5.4 Randverteilungen
Alle Informationen über die gemeinsame Verteilung eines Zufallsvektors \((X,Y)\) sind in der gemeinsamen Dichte oder der gemeinsamen Verteilungsfunktion enthalten. In manchen Situationen interessiert man sich jedoch gar nicht für die gemeinsame Verteilung, sondern nur für die Verteilung einer der beiden Variablen.
Definition: Randverteilung
Als Randverteilung (engl. marginal distribution) bezeichnet man die Verteilung einer Zufallsvariablen eines Zufallsvektors, wenn die restlichen Zufallsvariablen des Zufallsvektors ignoriert werden.
Die Randverteilungen lassen sich besonders einfach aus der gemeinsamen Verteilungsfunktion \(F_{X,Y}(x,y)\) ableiten. Es gilt nämlich
wobei \(F_X\) und \(F_Y\) die Randverteilungsfunktionen von \(X\) und \(Y\) sind. Man erhält also die Randverteilungsfunktionen, indem man die jeweils andere Variable gegen unendlich gehen lässt.
Wenn \(X\) und \(Y\) gemeinsam diskret verteilt sind, ergeben sich die Randwahrscheinlichkeitsfunktionen aus der gemeinsamen Wahrscheinlichkeitsfunktion,
Man sagt auch, dass man \(y\) “herausintegriert”, um die Randdichte von \(X\) zu erhalten, und umgekehrt.
Beispiel: Randdichte
Der gemeinsam stetig verteilte Zufallsvektor \((X,Y)\) hat die gemeinsame Dichtefunktion \[
f_{X,Y}(x,y)=\left\{
\begin{array}{ll}
x+y^2 & \text{ wenn }0\le x \le 1.11963\text{ und }0\le y\le 1\\
0 & \text{ sonst.}
\end{array}
\right.
\] Wie sehen die beiden Randdichten aus? Die Randdichte von \(X\) erhält man, indem man \(y\) “herausintegriert”. Wenn \(x\) nicht in dem Interval \([0,1.11963]\) liegt, ist die Randdichte offensichtlich 0. Wir betrachten darum nur den Fall, dass \(x\) in dem Intervall liegt. Dann gilt
für \(y\in [0,1]\). Für \(y\not\in [0,1]\) ist die Dichte \(f_Y(y)=0\).
5.5 Unabhängigkeit
Definition: Unabhängigkeit
Zwei Zufallsvariablen \(X\) und \(Y\) heißen stochastisch unabhängig oder unabhängig (engl. independent), wenn für alle \(x,y\in\mathbb{R}\) gilt \[
F_{X,Y}(x,y)=F_X(x)\cdot F_Y(y).
\]
Wenn die Zufallsvariablen nicht unabhängig sind, nennt man sie abhängig. Sowohl bei abhängigen als auch bei unabhängigen Zufallsvariablen gilt, dass die Randverteilungen aus der gemeinsamen Verteilung hergeleitet werden können. Im Gegensatz dazu ist die Herleitung der gemeinsamen Verteilung aus den Randverteilungen nur möglich, wenn die Zufallsvariablen unabhängig sind.
Wenn \(X\) und \(Y\) gemeinsam diskret verteilt sind, dann gilt bei Unabhängigkeit für alle \(j\) und \(k\)\[
p_{jk}=p_{j\cdot}\cdot p_{\cdot k}.
\]
Zwei Würfel werden geworfen. Die gemeinsame Wahrscheinlichkeitsfunktion der beiden Zufallsvariablen \(X\): “kleinere Augenzahl” und \(Y\): “größere Augenzahl”. Sind \(X\) und \(Y\) unabhängig? Um diese Frage zu beantworten, betrachten wir die gemeinsame Wahrscheinlichkeit \(P(X=6, Y=1)\). Sie ist offensichtlich 0, denn die kleinere Augenzahl \(X\) kann niemals größer sein als die größere Augenzahl \(Y\). Wir wissen aber bereits, dass \(P(X=6)>0\) und \(P(Y=1)>0\) sind. Damit ist die Bedingung für Unabhängigkeit verletzt und \(X\) und \(Y\) sind abhängig voneinander.
Wenn \(X\) und \(Y\) gemeinsam stetig verteilt sind, ergibt sich bei Unabhängigkeit die gemeinsame Dichte als Produkt der beiden Randdichten, \[
f_{X,Y}(x,y)=f_X(x)\cdot f_Y(y).
\]
Der gemeinsam stetig verteilte Zufallsvektor \((X,Y)\) hat die gemeinsame Dichtefunktion \[
f_{X,Y}(x,y)=\left\{
\begin{array}{ll}
x+y^2 & \text{ wenn }0\le x \le 1.11963\text{ und }0\le y\le 1\\
0 & \text{ sonst.}
\end{array}
\right.
\] Sind \(X\) und \(Y\) unabhängig? Die beiden Randdichten wurden bereits weiter oben ermittelt. Wir werten sie an den beiden willkürlich ausgewählten Stellen \(x=2/3\) und \(y=0.2\) aus.
Das Produkt ist also \(0.67158\). Setzt man \(x=2/3\) und \(y=0.2\) in die gemeinsame Dichte ein, erhält man \[
f(2/3, 0.2)=2/3+0.2^2=0.70667.
\] Die beiden Werte sind nicht gleich. Die Zufallsvariablen \(X\) und \(Y\) sind also nicht unabhängig.
5.6 Bedingte Verteilungen
Wir betrachten wieder eine gemeinsame Verteilung von zwei Zufallsvariablen \(X\) und \(Y\). Während man sich bei den Randverteilungen fragt, wie eine Zufallsvariable verteilt ist, wenn man die andere ignoriert, stellt man sich bei bedingten Verteilungen die Frage, wie eine Zufallsvariable verteilt ist, wenn man den Wert der anderen Zufallsvariable kennt (oder annimmt).
Definition: Bedingte Verteilung
Als bedingte Verteilung (engl. conditional distribution) bezeichnet man die Verteilung einer Zufallsvariable einer gemeinsamen Verteilung, wenn die andere Zufallsvariable auf einen bestimmten Wert fixiert wird.
Wie ist \(X\) (die bedingte Variable) verteilt, wenn man weiß (oder annimmt), dass \(Y\) (die bedingende Variable) den Wert \(y\) hat? Oder umgekehrt: Wie ist \(Y\) (bedingte Variable) verteilt, wenn man \(X\) kennt (bedingende Variable)? Bedingte Verteilungen sind deswegen in der Ökonomik wichtig, weil sie Informationsstände abbilden können. Die Bedingung gibt an, welche Information ein Agent hat.
Für gemeinsam diskrete Verteilungen mit \[
p_{jk}=P(X=x_j, Y=y_k)
\] für \(j=1,\ldots,J\) und \(k=1,\ldots,K\) gilt: Die bedingte Verteilung von \(X\) gegeben \(Y=y_k\) ist für \(j=1,\ldots,J\)\[
P(X=x_j|Y=y_k)=\frac{P(X=x_j,Y=y_k)}{P(Y=y_k)}.
\] Es gibt also nicht nur eine bedingte Verteilung von \(X\), sondern \(k\) (nämlich für jeden möglichen Wert von \(Y\) eine).
Vertauscht man die beiden Variablen, so ergeben sich die bedingten Verteilungen von \(Y\) gegeben \(X=x_j\). Sie sind für festes \(j\) und \(k=1,\ldots,K\)\[
P(Y=y_k|X=x_j)=\frac{P(X=x_j,Y=y_k)}{P(X=x_j)}.
\]
Ein Blick auf die Wahrscheinlichkeitstabelle zeigt, dass die bedingte Verteilung sich aus einer Zeile oder Spalte der Tabelle ergibt, indem man diese Zeile oder Spalte durch den zugehörigen Wert der Randverteilung dividiert. Aus der fett markierten ersten Spalte erhält man beispielsweise die bedingte Verteilung von \(X\) gegeben \(Y=y_1\), indem man die Spalteneinträge durch \(p_{\cdot 1}\) teilt. \[
\begin{array}{c|ccc|c}
X\backslash Y & y_{1} & \ldots & y_{K} & \\ \hline
x_{1} & \boldsymbol{p_{11}} & \ldots & p_{1K}& p_{1\cdot}\\
\vdots& \boldsymbol{\vdots} & & \vdots &\vdots\\
x_{J} & \boldsymbol{p_{J1}} & \ldots & p_{JK}& p_{J\cdot} \\\hline
& \boldsymbol{p_{\cdot 1}} & \ldots & p_{\cdot K}
\end{array}
\]
Für gemeinsam stetige Verteilungen mit der gemeinsamen Dichte \(f_{X,Y}(x,y)\) gilt: Die bedingte Dichte von \(X\) gegeben \(Y=y\) ist \[
f_{X|Y=y}(x)=\frac{f_{X,Y}(x,y)}{f_Y(y)}.
\] Es gibt also wiederum nicht nur eine bedingte Verteilung von \(X\), sondern nun sogar unendlich viele (nämlich für jeden Wert \(y\) aus dem Träger von \(Y\) eine).
Durch Vertauschen von \(X\) und \(Y\) erhält man die bedingte Verteilung von \(Y\) gegeben \(X=x\). Die bedingte Dichte lautet \[
f_{Y|X=x}(y)=\frac{f_{X,Y}(x,y)}{f_X(x)}.
\]
Wenn \(X\) und \(Y\) unabhängig sind, dann sind alle bedingten Verteilungen gleich der Randverteilung. Das gilt sowohl für gemeinsam stetige als auch für gemeinsam diskrete Verteilungen. Die Herleitung ist einfach, wenn man die Definition der Unabhängigkeit berücksichtigt. Als Beispiel sehen wir uns den stetigen Fall an. Die bedingte Dichte von \(X\) gegeben \(Y=y\) ist \[
f_{X|Y=y}(x)=\frac{f_{X,Y}(x,y)}{f_Y(y)}.
\] Bei Unabhängigkeit gilt \(f_{X,Y}(x,y)=f_X(x)f_Y(y)\), so dass \[
f_{X|Y=y}(x)=\frac{f_X(x)f_Y(y)}{f_Y(y)}=f_X(x).
\] Unabhängigkeit bedeutet also mit anderen Worten, dass die Information \(Y=y\) keinen Einfluss auf die Form der Verteilung von \(X\) hat. Die Verteilung von \(X\) hängt bei Unabhängigkeit nicht davon ab, welchen Wert \(Y\) annimmt (und umgekehrt).
Beispiel: Bedingte Dichte
Der gemeinsam stetig verteilte Zufallsvektor \((X,Y)\) hat die gemeinsame Dichtefunktion \[
f_{X,Y}(x,y)=\left\{
\begin{array}{ll}
x+y^2 & \text{ wenn }0\le x \le 1.11963\text{ und }0\le y\le 1\\
0 & \text{ sonst.}
\end{array}
\right.
\] Wie sieht die bedingte Dichte von \(Y\) gegeben \(X=0.8\) aus? Für die Herleitung braucht man die Randdichte von \(X\). Sie wurde bereits hergeleitet, \[
f_X(x)=x+\frac{1}{3}.
\] Man erhält als bedingte Dichte von \(Y\) gegeben \(X=0.8\)
Bedingte Verteilungen sind univariate Verteilungen. Für jeden Wert der bedingenden Zufallsvariable ergibt sich eine univariate Verteilung. Im Allgemeinen sind sie alle unterschiedlich, aber das muss nicht unbedingt so sein. Wenn \(X\) und \(Y\) unabhängig sind, dann sind die univariaten bedingten Verteilungen alle gleich.
Für univariate Verteilungen kann man all die Parameter berechnen, die in Kapitel 3 eingeführt wurden, z.B. den Erwartungswert oder die Varianz. Man spricht dann von bedingten Erwartungswerten und bedingten Varianzen. Die gängige Notation ist \(E(X|Y=y)\) und \(Var(X|Y=y)\). Für jeden Wert der bedingenden Zufallsvariable \((Y=y)\) erhält man einen bedingten Erwartungswert und eine bedingte Varianz. Es handelt sich quasi um Funktionen von \(y\). Für gemeinsam stetige Zufallsvariablen berechnet man den bedingten Erwartungswert als \[
E(X|Y=y)=\int_{-\infty}^\infty x f_{X|Y=y}(x)dx
\] und die bedingte Varianz als \[
Var(X|Y=y)=\int_{-\infty}^\infty (x-E(X|Y=y))^2 f_{X|Y=y}(x)dx.
\] Die Formeln sind vollständig analog zu den Formeln in Kapitel 3.6 und Kapitel 3.7. Nur wird die Dichte durch die auf \(Y=y\) bedingte Dichte ersetzt (und im Fall der Varianz der Erwartungswert durch den bedingten Erwartungswert). Für gemeinsam diskret verteilte Zufallsvariablen geht man analog vor.
Beispiel: Bedingte Erwartungswerte
Der gemeinsam stetig verteilte Zufallsvektor \((X,Y)\) hat die gemeinsame Dichtefunktion \[
f_{X,Y}(x,y)=\left\{
\begin{array}{ll}
x+y^2 & \text{ wenn }0\le x \le 1.11963\text{ und }0\le y\le 1\\
0 & \text{ sonst.}
\end{array}
\right.
\] Zur Berechnung des bedingten Erwartungswerts von \(Y\) gegeben \(X=x\) benötigt man die bedingte Dichte. Wir haben sie im letzten Beispiel hergeleitet. Sie ist für gegebenes \(x\)
für \(0\le y \le 1\). Damit ergibt sich der bedingte Erwartungswert
\[\begin{align*}
E(Y|X=x)&=\int_{-\infty}^\infty y f_{Y|X=x}(y)dy\\
&=\int_0^1 y \frac{x+y^2}{x+1/3}dy\\
&=\frac{x}{x+1/3}\int_0^1 ydy+\frac{1}{x+1/3}\int_0^1y^3dy\\
&=\frac{x}{x+1/3}\cdot\frac{1}{2}+\frac{1}{x+1/3}\cdot\frac{1}{4}\\
&=\frac{2x}{4x+4/3}+\frac{1}{4x+4/3}\\
&=\frac{2x+1}{4x+4/3}\\
&=\frac{6x+3}{12x+4}.
\end{align*}\]
Für jeden Wert von \(x\) in dem Intervall \([0,1.11963]\) erhält man einen anderen bedingten Erwartungswert für \(Y\). Grafisch lässt sich das so darstellen:
x <-seq(from=0, to=1.11963, length=200)plot(x, (6*x+3)/(12*x+4), type="l",xlab="x", ylab="E(Y|X=x)",main="Bedingte Erwartungswerte von Y")
Der Erwartungswert von \(Y\) ist also bei kleinen Werten von \(x\) größer als bei großen Werten. Wenn bekannt ist, dass \(X\) den Wert 1 annimmt, dann erwartet man für \(Y\) im Mittel ungefähr den Wert 0.55. Ist \(X\) dagegen nur knapp über 0, dann erwartet man im Mittel für \(Y\) fast 0.75.