Guide R
2021-09-18
Chapter 1 Module I: Introduction to data
1.1 Estadística computacional
La estadística computacional es una nueva rama de la estadística que se caracteriza por su apoyo en la capacidad de una computadora para llevar a cabo tareas repetiticas y autoamticas que análiticamente o a mano serían muy díficiles sino es que imposibles. Es un enfoque se se basa en el modelado, remuestreo, cross-validatios y visualización sofisticada. Cuando termines tu curso y tengas un ratito libre, te recomiendo leer este famoso paper para comprender también la tensión entre la estadística tradicional y la computacional.
1.2 Bienvenido a R
R es un lenguaje de programación diseñado por estadísticos para estadísticos, aunque ha encontrado gran aceptación entre computólogos, cientícos de datos, científicos sociales, científicos de ciencias naturales, el gremio business, médicos, entre otras profesiones.
Por el contrario, R studio es un IDE (integrated development environment) que se refiere a software para hacer aplicaciones que combina herramientas de desarrollo en una misma interfaz gráfica.
1.3 Repositorios
Un repositorio es un espacio centralizado donde se almacena, organiza, mantiene y difunde información digital, habitualmente archivos informáticos, que pueden contener trabajos científicos, conjuntos de datos o software . Los repositorios tienen sus inicios en los años 90, en el área de la física y las matemáticas, donde los académicos aprovecharon la red para compartir sus investigaciones con otros colegas. Este proceso es valioso porque aceleraba el ciclo científico de publicación y revisión de resultados.
Para poder integrar un documento de R necesitamos de distintos documentos auxiliares: imagenes, otros scripts de R o python, archivos BIB, archivos CSL, archivos latex y lo más importante.
Cuando R Y Rmd integran un documento necesita tener todos sus archivos auxiliares a la mano, por eso debemos trabajar en una sola carpeta. Además si tenemos más carpetas dentro de nuestra subcarpeta, entonces para acceder a sus contenidos tenemos que poner la ubicación exacta de la carpeta en nuestro documento.
De esta manera podemos crear pequeñas librerias donde ponemos todos los ingredientes y las instrucciones para que cualquier persona replique nuestro trabajo y documento.
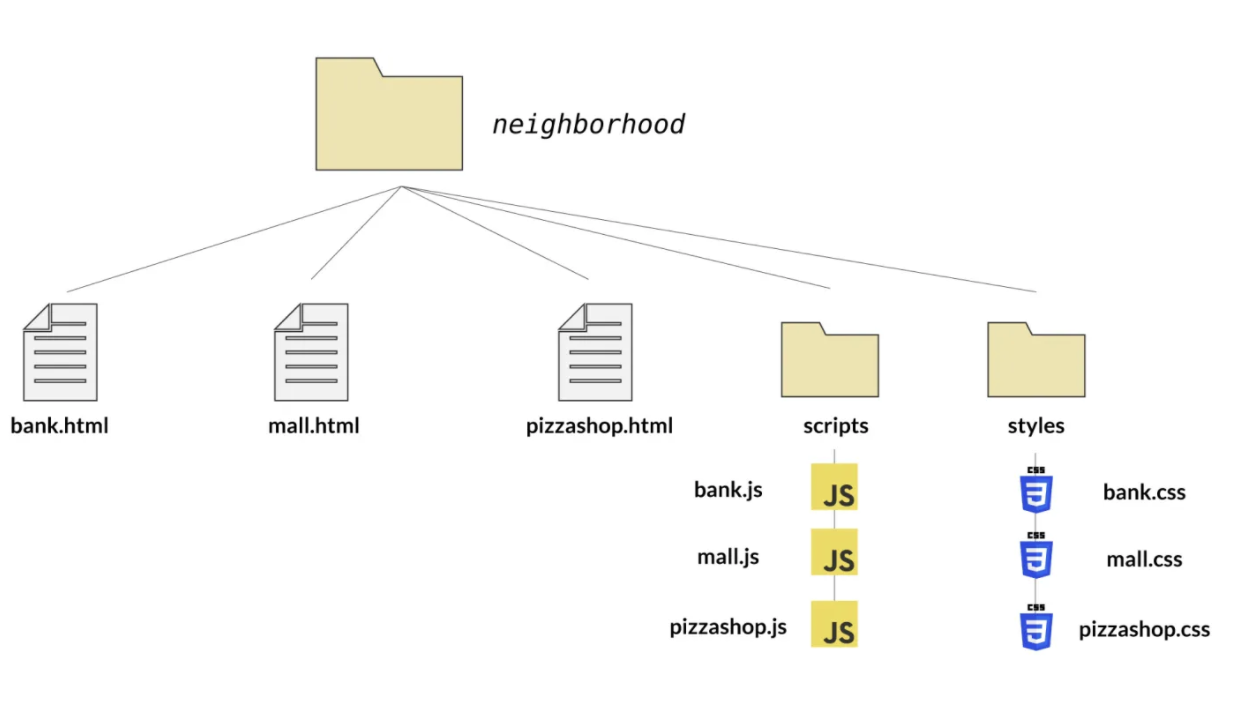
Esta es la estructura de una pagina de internet
1.4 Sintaxis básica
Notemos que al abrir una ventana de R Studio nos encontramos con 4 pantallas. La de mayor tamaño es nuestra área de trabajo, ahí redactaremos nuestros scripts, es algo así como nuestro taller. Debajo de ella encontramos la consola (history tab), que nos brinda información del trabajo que está realizando R studio en el momento y el historial de comandos que hemos usado. A la derecha, arriba, está la pantalla de ambiente que nos brinda información sobre el ambiente en el que estamos trabajando, por ejemplo, qué paquetes hemos llamado, qué variables hemos definido y qué bases de datos están activas. Finalmente, a la derecha, debajo, tenemos una pequeña pantalla de utilidades por ejemplo para identificar la carpeta donde estamos trabajando, ver todos los paquetes que tenemos o ver las gráficas que estamos mostrando.
Pantalla de R Studio
En general vamos a trabajar en R scripts. Por lo que el primer paso es ir a la pestaña de file y abrir un R Script. En los R scripts podemos construir aplicaciones para limpiar y analizar datos, entre otras cosas. Para correr un R script tenemos diferentes opciones: podemos correr todo el script de un jalón (lo cuál es muy útil si el script tiene un solo proposito, por ejemplo, limpiar una base) o bien podemos correrlo por cachos. Para correrlo por cachitos basta con poner el cursos antes del código que queremos correr y oprimir el botón Run.
1.4.1 Paquetes
Al ser un software abierto, R permite que cualquier usuario integre comandos, algoritmos y bases de datos en paquetes listos para que cualquier usuario los use, esto ha permitido que R se mantenga actualizado de manera muy orgánica, lo que lo ha propulsado como uno de los lenguajes de progamación estadísitca más usados, por ejemplo frente a STATA o SPSS donde al no ser softwares abiertos el control de los paquetes está centralizado por ellos.
Para instalar un paquete hay que llamar al comando install.packages y le vamos a indicar como parámetro (denotaremos como parámetro cualquier información adicional que tengamos que dar al comando) entre comillas el nombre del paquete que queremos instalar.
Por ejemplo, en el SG, se menciona que se trabajara muy de cerca con el paquete mosaic, por lo que procederemos a instalarlo.
install.packages("mosaic")Una vez instalado un paquete, este se guarda para siempre y ya no tenemos que volverlo a instalar.
Sin embargo, una cosa es instalar un paquete y otra cosa es usarlo. Para usar un paquete tenemos que invocarlo. Para eso usamos el comando library y le indicamos el nombre del paquete como parámetro pero esta vez sin comillas.
library(mosaic)## Registered S3 method overwritten by 'mosaic':
## method from
## fortify.SpatialPolygonsDataFrame ggplot2##
## The 'mosaic' package masks several functions from core packages in order to add
## additional features. The original behavior of these functions should not be affected by this.##
## Attaching package: 'mosaic'## The following objects are masked from 'package:dplyr':
##
## count, do, tally## The following object is masked from 'package:Matrix':
##
## mean## The following object is masked from 'package:ggplot2':
##
## stat## The following objects are masked from 'package:stats':
##
## binom.test, cor, cor.test, cov, fivenum, IQR, median, prop.test,
## quantile, sd, t.test, var## The following objects are masked from 'package:base':
##
## max, mean, min, prod, range, sample, sum1.5 Variables
Para comenzar a trabajar con datos debemos definir variables. En R se definen con los signos <- como se muestra a continuación.
x<-24
y<-10
# de esta manera ahora podemos usar x en lugar de 24 y y en lugar de 10
24/10## [1] 2.4x/y## [1] 2.4Cada declaración u operación debe tomar una sola línea, si usamos una línea para más declaraciones u operaciones simplemente nos regresará un error.
1.6 Importar datos
Podemos importar datos de diferentes maneras: por ejemplo, desde una URL, desde nuestros archivos locales o bien desde algún paquete. Dependiendo el tipo de extensión de la base (es decir .csv, .json .xls, .txt, etc) vamos a necesitar diferentes paquetes. A continuación te muesto como importar algunos datos.
Desde una base de datos local
# el paquete dplyer nos permite importar una variada cantidad de datos
library(dplyr)
# en este caso, importamos los datos guardados en la carpeta donde está el script con el nombre de data.csv y los guardamos en una variable local llamada data.
data<-read.csv("data.csv")Desde una base de datos de un paquete
# si el paquete está ya cargado simplemente corremos el comando data() con el nombre de la base de datos entre comillas como parámetro
data("Titanic")
# Posteriormente la convertimos a un data.frame
data<-as.data.frame(Titanic)Otras maneras
Estas dos maneras son practicamente el 90% de los casos prácticos de importación de datos. En un futuro valdría la pena aprender a importar desde una URL, desde un archivo de texto plano y desde un excel, aunque no son triviales. Por ejemplo en cuanto a la URL a veces se requiere de indicar otros parámetros ad hoc al tipo de hipervinculo. En cuanto a excel, es recomendable limpiar el excel antes pues muchas veces los datos trabajados en excel no respetan un formato limpio de datos, es decir se usan comandos como combinar filas o columnas; se ponen titulos, subtitulos por encima de las variables; se usan columnas y filas no necesarias como por ejemplo una fila de “suma total,” etc.
Para aprender más sobre buenas prácticas en el almacenamiento de datos se recomienda leer este paper cuando se termine su curso.
1.7 Tipos de bases de datos
En general hay distintas maneras de almacenar datos. Podemos guardarlos como matrices, como tablas o como bases de datos de R. Cada una tiene sus ventajas y desventajas.
Vectores
Losvectores son estructuras de datos de una sola dimensión, es decir tienen un tamaño \(n \cdot 1\). Para crearlos debemos crear una variable seguido de c y entre parentesis indicar los elementos de la lista separados con coma.
vector1<-c(1,2,3)
# si quieremos usar valores de caracter debemos ponerlos entre comillas
# en general no debemos mezclar tipo de datos distintos en un solo vector
vector2<-c("Eduardo","Pedro","Ramos")
vector1## [1] 1 2 3vector2## [1] "Eduardo" "Pedro" "Ramos"Matrices
Las matrices en R emulan a las matrices en matemáticas. Son estructuras de datos exclusivamente numéricas que tienen la ventaja que permiten hacer trabajo númerico y matemático muy rápido. Por ejemplo, hay ciertos modelos y comandos que solo funcionan con datos en una matriz.
data<-matrix( c(
c(1,2,3),
c(1,3,2),
c(1,3,6)),
nrow=3,
ncol=3)
data## [,1] [,2] [,3]
## [1,] 1 1 1
## [2,] 2 3 3
## [3,] 3 2 6Data frame
El r data frame es la manera predilecta de trabajar en r pues muchos de los paquetes más importantes basan su funcionamiento en esta estructura. Además permite combinar distintos tipos de datos en una sola tabla y ademas tiene funcionalidades muy buenas.
# creamos vectores
peso<-c(100,80,85)
edad<-c(21,31,27)
nombre<-c("Juan","Pedro","Ramos")
# creamos data frame
data<-data.frame(nombre,peso,edad)
data## nombre peso edad
## 1 Juan 100 21
## 2 Pedro 80 31
## 3 Ramos 85 27# probamos funcionalidades
summary(data) #summary nos brinda un breve análisis estadísitco.## nombre peso edad
## Length:3 Min. : 80.00 Min. :21.00
## Class :character 1st Qu.: 82.50 1st Qu.:24.00
## Mode :character Median : 85.00 Median :27.00
## Mean : 88.33 Mean :26.33
## 3rd Qu.: 92.50 3rd Qu.:29.00
## Max. :100.00 Max. :31.00Finalmente, podemos acceder a cualquier vector de la base de datos en un data frame con el simbolo $, como se muestra a continuación:
# imprimimos vector
data$peso## [1] 100 80 85# aplicamos un comando solo a ese vector
summary(data$peso) ## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 80.00 82.50 85.00 88.33 92.50 100.001.8 Buenas prácticas
Redactar código es como redactar en general: el proposito es que cualquier persona pueda entender lo que estamos haciendo por ello es muy buena practica espaciar nuestro código(darle enters y espacios cuando lo creamos pertinente) y además comentarlo. Para comentar un código se usa el # seguido de espacio y del comentario.
# Esta es una suma
2+2## [1] 4En cuanto a la estructura del código es buena práctica indicar con comentarios apartados o capitulos del código y comenzar primero por los paquetes. Por ejemplo, el siguiente script es un buen ejemplo:
# I-paquetes
library(mosaic)
library(dplyr)
#II-datos
data<-read.csv("datos.csv")
#III-análisis
hist(data$variable1)