Modul 4: k Nearest Neighbors - EKSEMPEL
library(caret)
library(openxlsx)
library(dplyr)
library(patchwork)
library(recipes)
##
## Vedhæfter pakke: 'recipes'
## Det følgende objekt er maskeret fra 'package:stats':
##
## step
library(rsample)Om beregning af afstand
# deldatasæt bestående af observation 2, 3, 4
bolig_eks <- bolig[2:4, ]
# vis deldatasæt
View(bolig_eks)Valg af afstandsmål
# beregn afstand mellem Grundareal for observation 2, 3, 4 v.hj.a. L1 (også kaldet "Manhattan")
dist(bolig_eks[, c("Grundareal", "Boligareal")], method = "minkowski", p = 1)
## 2 3
## 3 510
## 4 685 217
dist(bolig_eks[, c("Grundareal", "Boligareal")], method = "manhattan")
## 2 3
## 3 510
## 4 685 217
# kontrolberegning for de første to observationer
abs(1149 - 1568) + abs(120 - 211)
## [1] 510# beregn afstand mellem Grundareal for observation 2, 3, 4 v.hj.a. L2 (også kaldet "Euclidian")
dist(bolig_eks[, c("Grundareal", "Boligareal")], method = "euclidian")
## 2 3
## 3 428.7680
## 4 618.9709 197.1218
dist(bolig_eks[, c("Grundareal", "Boligareal")], method = "minkowski", p = 2)
## 2 3
## 3 428.7680
## 4 618.9709 197.1218
# kontrolberegning for de første to observationer
(abs(1149 - 1568) ^ 2 + abs(120 - 211) ^ 2) ^ (1 / 2)
## [1] 428.768# beregn afstand mellem Grundareal for observation 2, 3, 4 v.hj.a. L3
dist(bolig_eks[, c("Grundareal", "Boligareal")], method = "minkowski", p = 3)
## 2 3
## 3 420.4259
## 4 615.3021 196.0803
# kontrolberegning for de første to observationer
(abs(1149 - 1568) ^ 3 + abs(120 - 211) ^ 3) ^ (1 / 3)
## [1] 420.4259Om standardisering
bolig_rec <- recipe(Salgspris ~ ., data = bolig_eks)
summary(bolig_rec)
## # A tibble: 10 x 4
## variable type role source
## <chr> <chr> <chr> <chr>
## 1 Postnummer numeric predictor original
## 2 Vejnavn nominal predictor original
## 3 Husnummer nominal predictor original
## 4 Salgsdato date predictor original
## 5 Opførselsår numeric predictor original
## 6 Antal.værelser numeric predictor original
## 7 Grundareal numeric predictor original
## 8 Boligareal numeric predictor original
## 9 Tidligere.solgt nominal predictor original
## 10 Salgspris numeric outcome originalCentrering
bolig_tmp <- step_center(bolig_rec, Grundareal)
bake(prep(bolig_tmp), bolig_eks)
## # A tibble: 3 x 10
## Postnummer Vejnavn Husnummer Salgsdato Opførselsår Antal.værelser Grundareal Boligareal Tidligere.solgt
## <dbl> <fct> <fct> <date> <dbl> <dbl> <dbl> <dbl> <fct>
## 1 2800 Vinagervej 15 2006-12-28 1954 5 -345. 120 Nej
## 2 2800 Vinagervej 21 2014-02-27 1951 5 74.3 211 Nej
## 3 2800 Vinagervej 23 2014-03-23 1955 7 270. 190 Ja
## # ... with 1 more variable: Salgspris <dbl>
# kontrolberegning
bolig_eks$Grundareal - mean(bolig_eks$Grundareal)
## [1] -344.66667 74.33333 270.33333Skalering
bolig_tmp <- step_scale(bolig_rec, Grundareal)
bake(prep(bolig_tmp), bolig_eks)
## # A tibble: 3 x 10
## Postnummer Vejnavn Husnummer Salgsdato Opførselsår Antal.værelser Grundareal Boligareal Tidligere.solgt
## <dbl> <fct> <fct> <date> <dbl> <dbl> <dbl> <dbl> <fct>
## 1 2800 Vinagervej 15 2006-12-28 1954 5 3.66 120 Nej
## 2 2800 Vinagervej 21 2014-02-27 1951 5 4.99 211 Nej
## 3 2800 Vinagervej 23 2014-03-23 1955 7 5.61 190 Ja
## # ... with 1 more variable: Salgspris <dbl>
# kontrolberegning
bolig_eks$Grundareal / sd(bolig_eks$Grundareal)
## [1] 3.657301 4.990991 5.614864Normalisering
bolig_tmp <- step_normalize(bolig_rec, Grundareal)
bake(prep(bolig_tmp), bolig_eks)
## # A tibble: 3 x 10
## Postnummer Vejnavn Husnummer Salgsdato Opførselsår Antal.værelser Grundareal Boligareal Tidligere.solgt
## <dbl> <fct> <fct> <date> <dbl> <dbl> <dbl> <dbl> <fct>
## 1 2800 Vinagervej 15 2006-12-28 1954 5 -1.10 120 Nej
## 2 2800 Vinagervej 21 2014-02-27 1951 5 0.237 211 Nej
## 3 2800 Vinagervej 23 2014-03-23 1955 7 0.860 190 Ja
## # ... with 1 more variable: Salgspris <dbl>
# kontrolberegning
(bolig_eks$Grundareal - mean(bolig_eks$Grundareal)) / sd(bolig_eks$Grundareal)
## [1] -1.0970842 0.2366052 0.8604790Kategorisk til numerisk
bolig_tmp <- step_integer(bolig_rec, Tidligere.solgt)
bake(prep(bolig_tmp), bolig_eks)
## # A tibble: 3 x 10
## Postnummer Vejnavn Husnummer Salgsdato Opførselsår Antal.værelser Grundareal Boligareal Tidligere.solgt
## <dbl> <fct> <fct> <date> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2800 Vinagervej 15 2006-12-28 1954 5 1149 120 2
## 2 2800 Vinagervej 21 2014-02-27 1951 5 1568 211 2
## 3 2800 Vinagervej 23 2014-03-23 1955 7 1764 190 1
## # ... with 1 more variable: Salgspris <dbl>Dato til numerisk
bolig_tmp <- step_date(bolig_rec, Salgsdato, features = "decimal")
# Hvis 1/1 er dag nr. 0 i år 2006, så er 28/12 dag nr. 361,
# dvs. 28/12 2006 er 2006 + 361/365 = 2006,989 som decimal
bake(prep(bolig_tmp), bolig_eks)$Salgsdato_decimal
## [1] 2006.989 2014.156 2014.222Samlet klargøring af datasæt
bolig_rec <- recipe(Salgspris ~ ., data = bolig_eks)
bolig_rec <- step_date(bolig_rec, Salgsdato, features = "decimal")
bolig_rec <- step_integer(bolig_rec, Tidligere.solgt)
bolig_rec <- step_normalize(bolig_rec, all_numeric())
bolig_rec_final <- bake(prep(bolig_rec), bolig_eks)
View(bolig_rec_final)Estimation af knn model
Klargøring af datasæt
set.seed(4321)
split <- initial_split(bolig, 2/3)
train <- training(split)
test <- testing(split)
rec <- recipe(Salgspris ~ ., data = train)
rec <- step_date(rec, Salgsdato, features = "decimal")
rec <- step_integer(rec, Tidligere.solgt)
rec <- step_normalize(rec, all_numeric())
rec <- step_rm(rec, -all_numeric()) # fjern evt alle tiloversblivende numerisks søjler eller omdan til dummies
rec <- prep(rec)Valg af k
# mulige værdier af k
tunegrid <- data.frame(k = floor(seq(1, 60, length = 20)))# valg af k UDEN cross validation
model_single <- train(rec, data = train, method = 'knn', tuneGrid = tunegrid)
plot(model_single)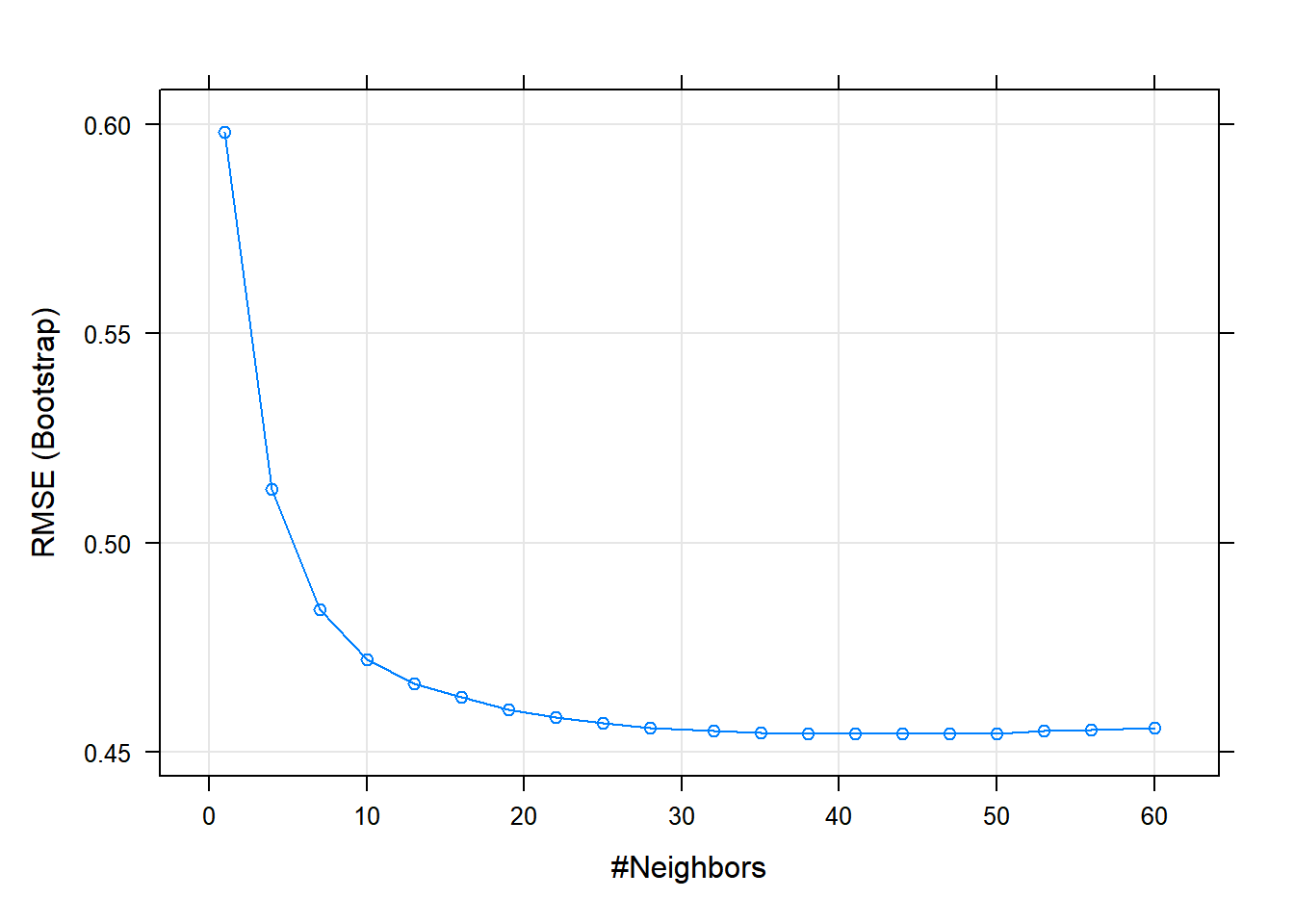
# bedste model (værdi af k) ud fra "RMSE"
(best_single_k <- model_single$results$k[which.min(model_single$results$RMSE)])
## [1] 38# valg af k MED cross validation
cvControl <- trainControl(method = 'cv', number = 5)
model_cv <- train(rec, data = train, method = 'knn', tuneGrid = tunegrid, trControl = cvControl)
plot(model_cv)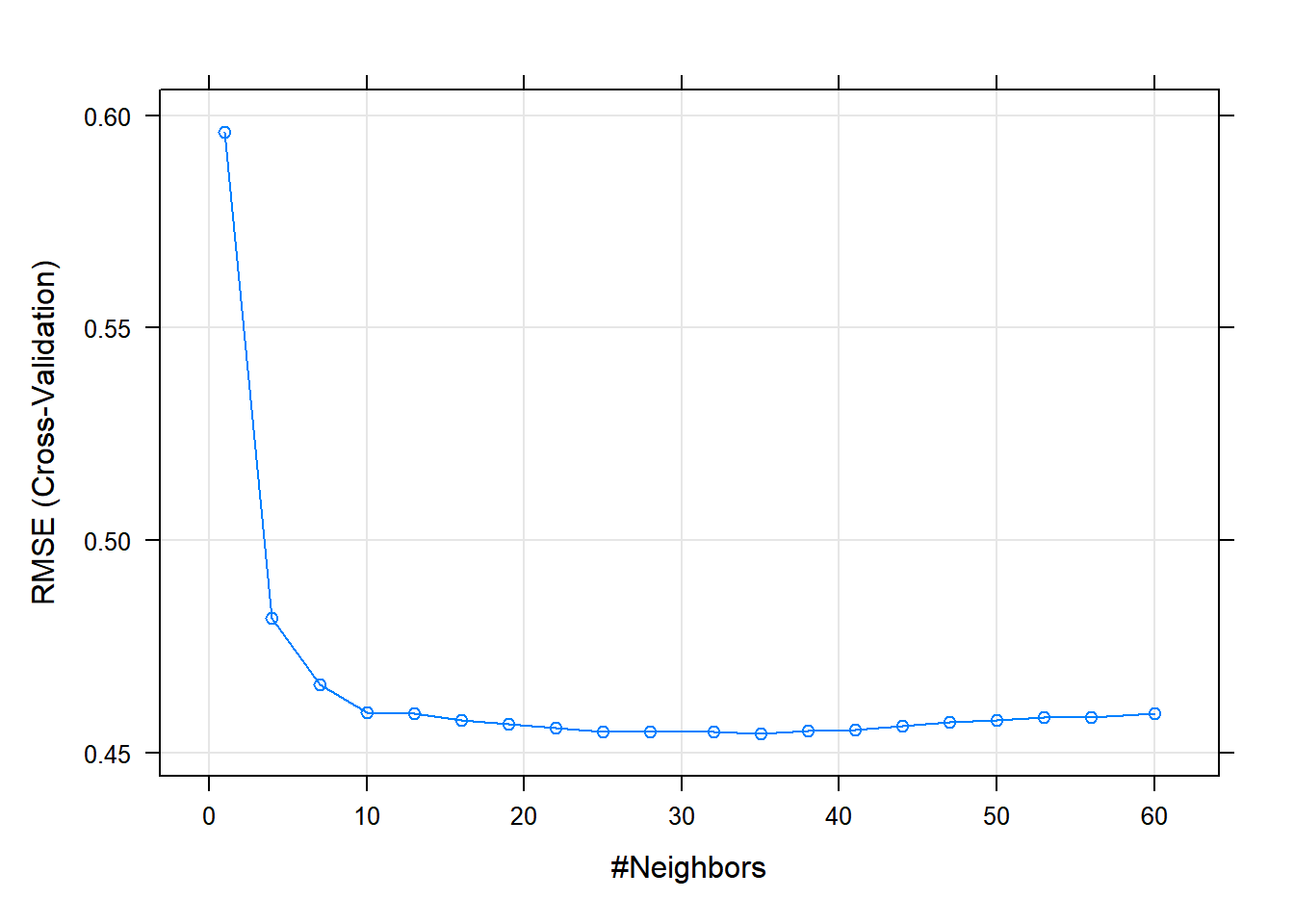
# bedste model (værdi af k) ud fra "RMSE"
(best_cv_k <- model_cv$results$k[which.min(model_cv$results$RMSE)])
## [1] 35# sammenlign modeller med og uden cross validation
library(patchwork)
plot1 <- ggplot(model_single) + geom_vline(aes(xintercept = best_cv_k), linetype = 2, col = 'blue')
plot2 <- ggplot(model_cv) + geom_vline(aes(xintercept = best_cv_k), linetype = 2, col = 'blue')
(plot1 / plot2) 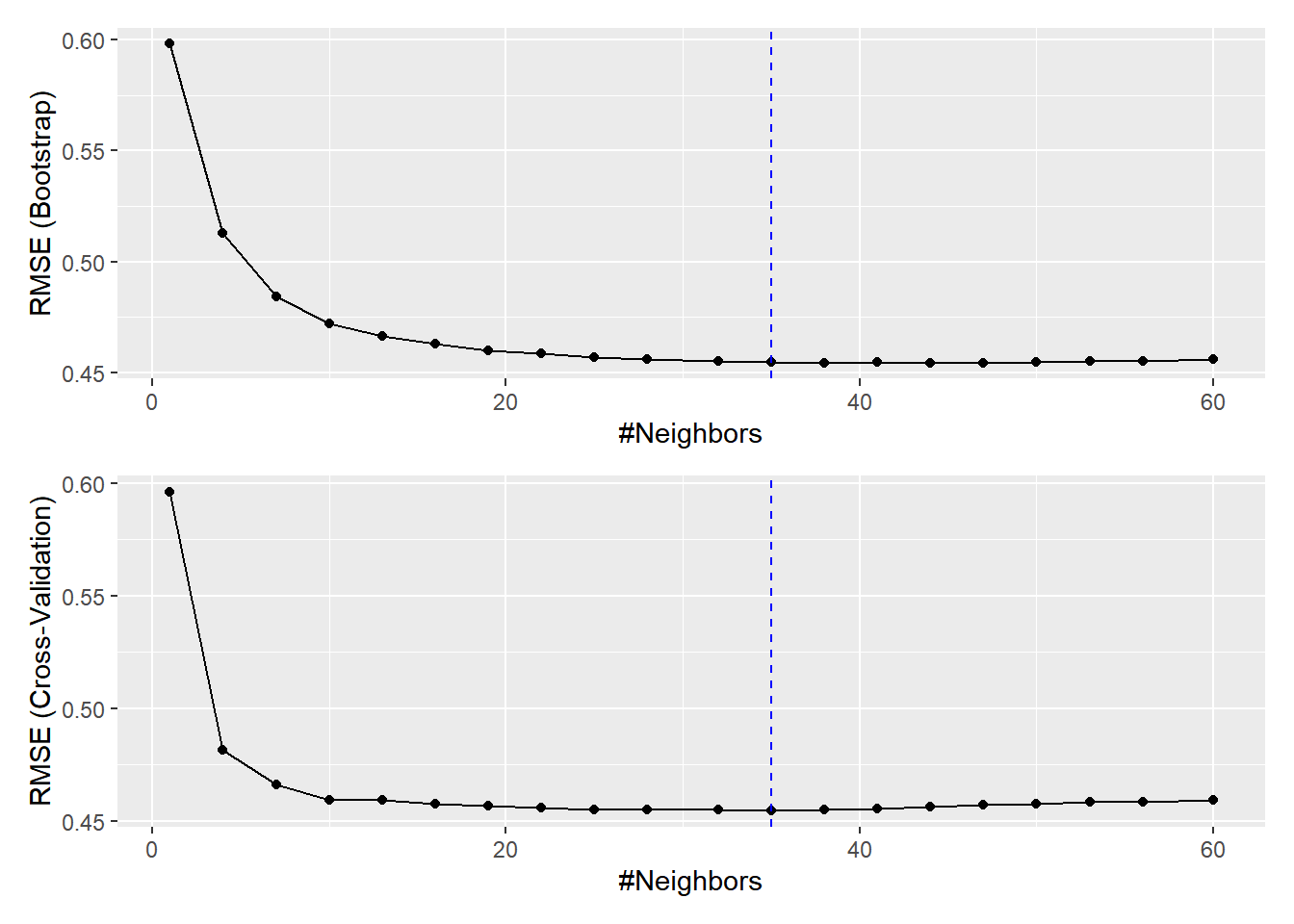
Evaluéring af samlet model fit
options(scipen = 10)
observeret <- bake(rec,test)$Salgspris# model UDEN krydsvalidering
predikteret_single <- predict(model_single, newdata = test)
postResample(predikteret_single, observeret)
## RMSE Rsquared MAE
## 0.4494603 0.7992843 0.2911687
# kontrolberegning af modelevaluering
# RMSE:
sqrt(mean( (observeret - predikteret_single)^2 ))
## [1] 0.4494603
# MAE:
mean( abs(observeret - predikteret_single) )
## [1] 0.2911687
# Rsquared (fra lineær regressionsanalyse):
cor(observeret, predikteret_single)^2
## [1] 0.7992843# model MED krydsvalidering
predikteret_cv <- predict(model_cv, newdata = test)
postResample(predikteret_cv, observeret)
## RMSE Rsquared MAE
## 0.4506071 0.7982401 0.2913565Evaluéring af vigtigste variable (features)
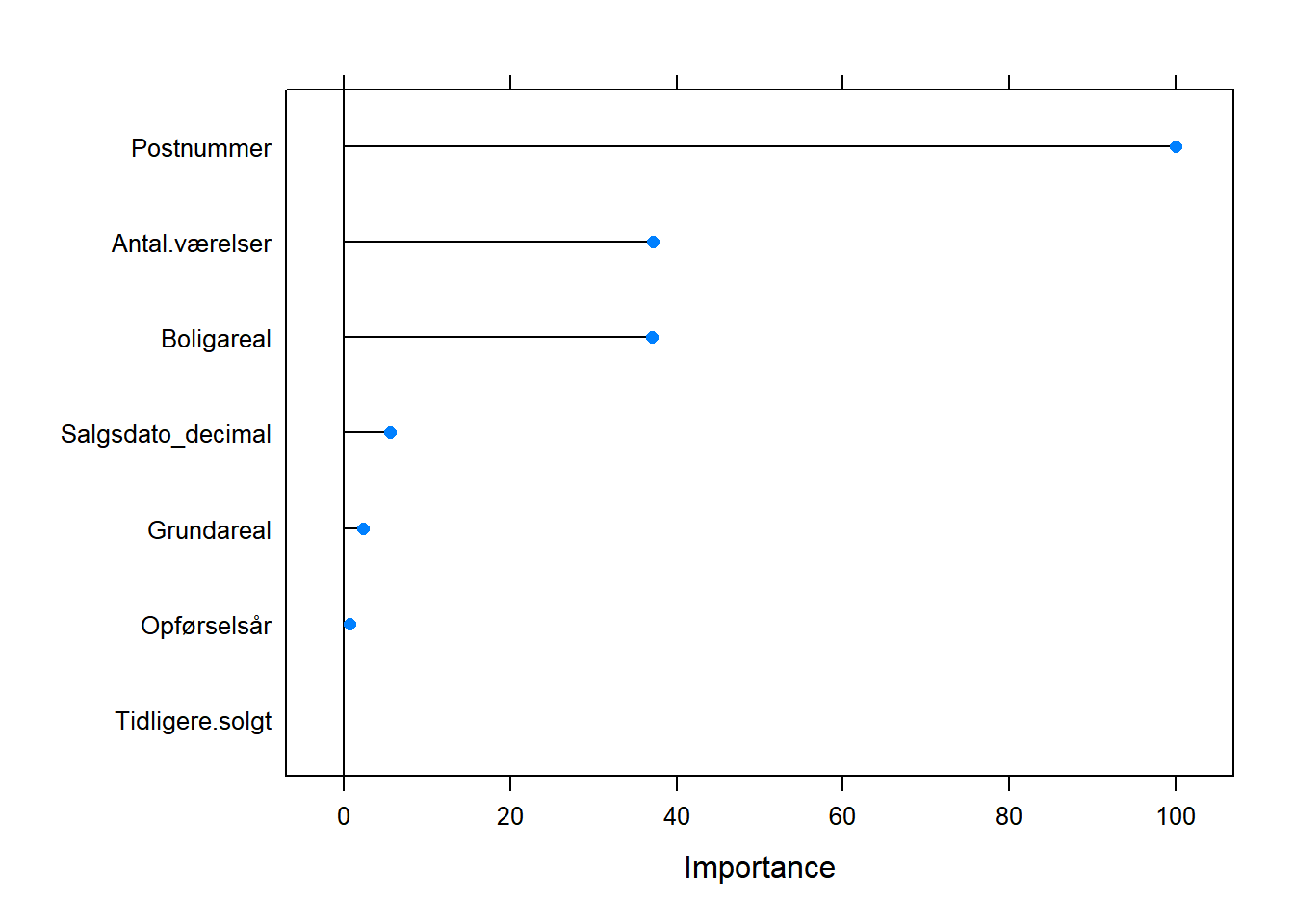
# model MED krydsvalidering
importance <- varImp(model_cv)# visualisering af variablens betydning
ggplot(importance)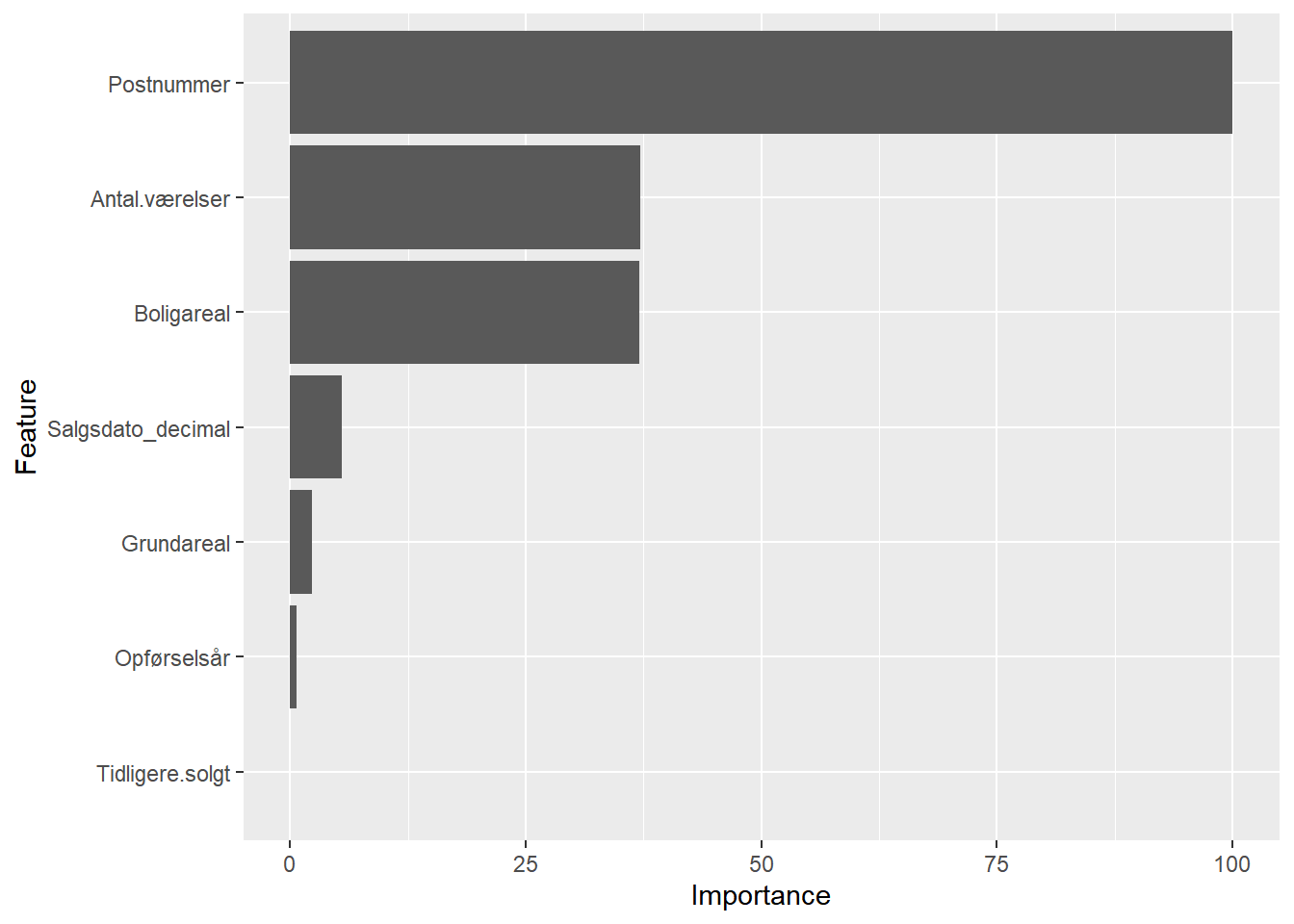
plot(importance)