Chapter 5 Réaliser le DAG
En résumé, le graph dirigé acyclique (DAG) sert à :
- poser les hypothèses a priori concernant les structures causales sous-jacentes
- identifier l’estimand (ce que l’on veut estimer) qui pourra répondre à l’objectif
- construire le modèle d’estimation, basés sur l’identification des facteurs de confusion, des médiateurs et des colliders
- discuter les possibles biais, notamment la confusion résiduelle et les biais de sélection.
Il doit doit être réalisé le plus tôt possible. Il existe un article synthétique et pragmatique avec des recommandations pour réaliser un DAG ici.
L’outil Dagitty peut être utilisé pour dessiner un DAG en ligne. Cet outil donne la commande qui permet de répliquer le DAG dans R. L’outil en ligne est simple d’accès, mais il ne donne pas forcément des DAG très lisibles, notamment lorsqu’il y a de nombreuses variables, et il ne permet pas de regrouper certaines variables dans une seule “boite”. Le package Dagitty a cependant d’autres fonctions utiles comme celle qui permet de tester la cohérence du DAG avec les données.
5.1 DAG théorique
Ce DAG est réalisé complètement a priori, à partir de la question de recherche, et ne dépend pas des données disponibles. Il permettra notamment d’identifier et discuter de la confusion résiduelle et des biais de sélection possibles.
Exemple de code :
g <- dagitty('dag {
"Environnement et mode de vie enfance" [pos="-0.944,-0.977"]
"Environnement social précoce" [pos="-1.845,-1.166"]
"Sexe naissance" [exposure,pos="-2.025,0.576"]
"décès avant 23" [adjusted,pos="-0.286,1.038"]
"environnement et mode de vie 23 ans" [pos="0.071,-0.500"]
"outcome 44 ans" [outcome,pos="1.298,0.585"]
"pas de données" [adjusted,pos="0.678,0.953"]
"tabagisme 23 ans" [pos="0.114,0.185"]
"Environnement et mode de vie enfance" -> "décès avant 23"
"Environnement et mode de vie enfance" -> "environnement et mode de vie 23 ans"
"Environnement et mode de vie enfance" -> "outcome 44 ans"
"Environnement et mode de vie enfance" -> "pas de données"
"Environnement social précoce" -> "Environnement et mode de vie enfance"
"Environnement social précoce" -> "décès avant 23"
"Environnement social précoce" -> "environnement et mode de vie 23 ans"
"Environnement social précoce" -> "outcome 44 ans"
"Environnement social précoce" -> "pas de données"
"Environnement social précoce" -> "tabagisme 23 ans"
"Sexe naissance" -> "Environnement et mode de vie enfance"
"Sexe naissance" -> "décès avant 23"
"Sexe naissance" -> "environnement et mode de vie 23 ans"
"Sexe naissance" -> "outcome 44 ans"
"Sexe naissance" -> "pas de données"
"Sexe naissance" -> "tabagisme 23 ans"
"décès avant 23" -> "pas de données"
"environnement et mode de vie 23 ans" -> "outcome 44 ans"
"environnement et mode de vie 23 ans" -> "pas de données"
"environnement et mode de vie 23 ans" -> "tabagisme 23 ans"
"tabagisme 23 ans" -> "outcome 44 ans"
}
')
plot(g)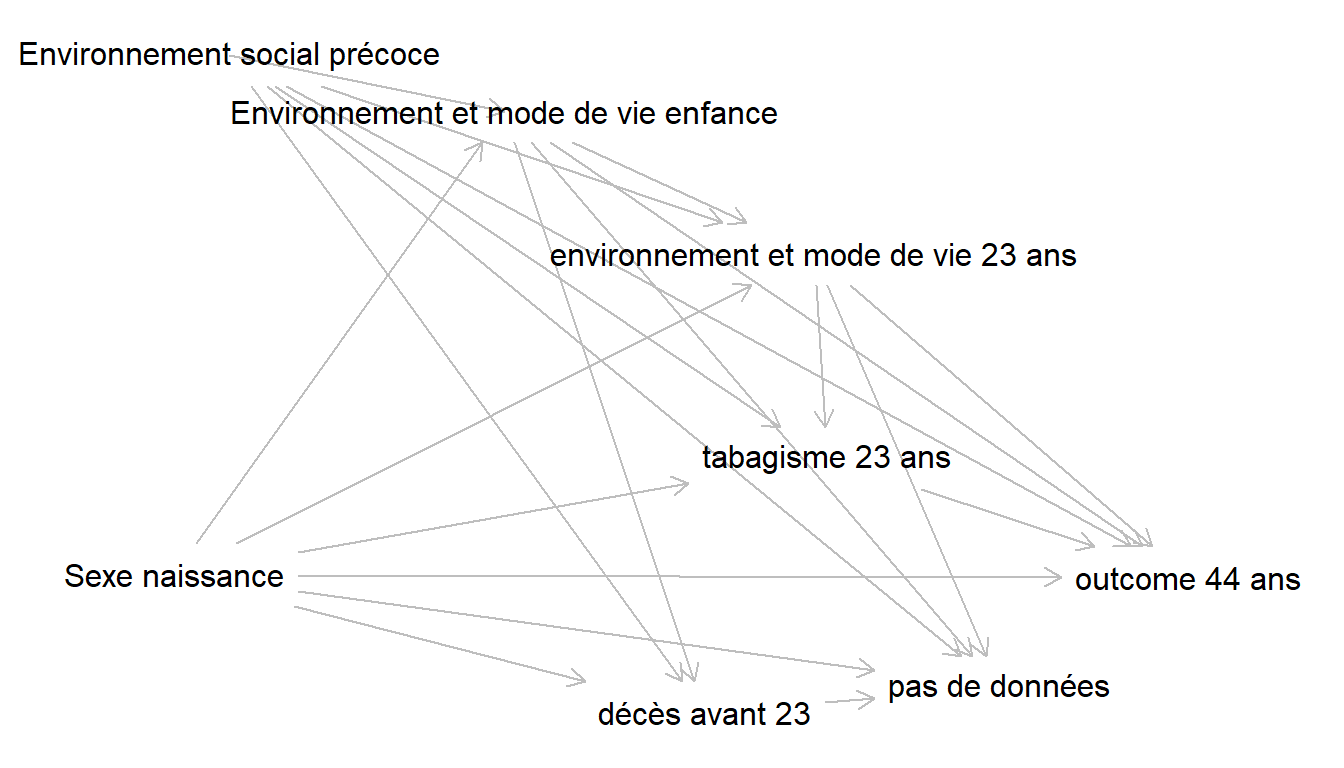
5.2 DAG pragmatique
On peut réaliser un DAG plus pragmatique (qui ne serait pas un DAG à proprement parlé) pour identifier la fonction (exposure, outcome, mediator, collider, confouder) des variables uilisées, selon ce qu’on veut estimer et selon les variables disponibles.

Pour répondre, à la première question (total effect of exposure on outcome), on utilisera l’exposition (sexe) et l’outcome. Le niveau d’éducation de la mère peut être inclue dans le modèle comme exposition compétitive pour améliorer la précision de l’estimation, même s’il ne s’agit pas d’un facteur de confusion à proprement parlé.
Pour répondre à la 2ème question, on ajoute le tabagisme comme médiateur. Le niveau d’éducation de la mère est un facteur de confusion du lien M->Y. On n’a pas utilisé ici de variables de confusion intermédiaire, bien qu’il y en ait probablement (relatif à l’environnement et mode de vie de l’enfance et debut de l’âge adulte comme on l’a identifié dans le 1er DAG).
5.3 Test des données
g3 <- dagitty('dag {
t0_mother_scol_crt [pos="-2.070,-0.609"]
dead_44 [outcome,pos="0.569,-0.170"]
t4_tabac_2cl [pos="-0.543,-0.170"]
t0_baby_sex [exposure,pos="-2.070,-0.170"]
t0_mother_scol_crt -> dead_44
t0_mother_scol_crt -> t4_tabac_2cl
t4_tabac_2cl -> dead_44
t0_baby_sex -> t4_tabac_2cl
}')
base_num <- data.frame(lapply(base, function(x) as.numeric(x)))
base_num <- base_num %>% select(-c("ncdsid", "t8_SBP")) %>% na.omit()
r <- localTests(g3, base_num)
r## estimate p.value 2.5% 97.5%
## d_44 _||_ t0_b_ | t0___, t4__ -0.01742561 0.6597980 -0.09473863 0.06009589
## t0_b_ _||_ t0___ -0.03169786 0.4224556 -0.10875209 0.04573398r.signif <- r[r$p.value < 0.05,]
r.signif## [1] estimate p.value 2.5% 97.5%
## <0 lignes> (ou 'row.names' de longueur nulle)rm(base_num)
rm(r)A priori, le DAG est compatible avec les données. Notamment, il n’y a pas de lien entre le sexe à la naissance et le niveau d’éducation de la mère (l’absence de flèche sont les hypothèses les plus fortes).