Chapter 12 Analyse par groupes
12.1 Au préalable
On peut regrouper les médiateurs par catégories par exemple : comportements, caractéristiques socio-économique, réseau social. Pour étudier la part médié par chaque de ces facteurs, il faut faire des hypothèses a priori sur la séquence causale qui les lie.
Par exemple :
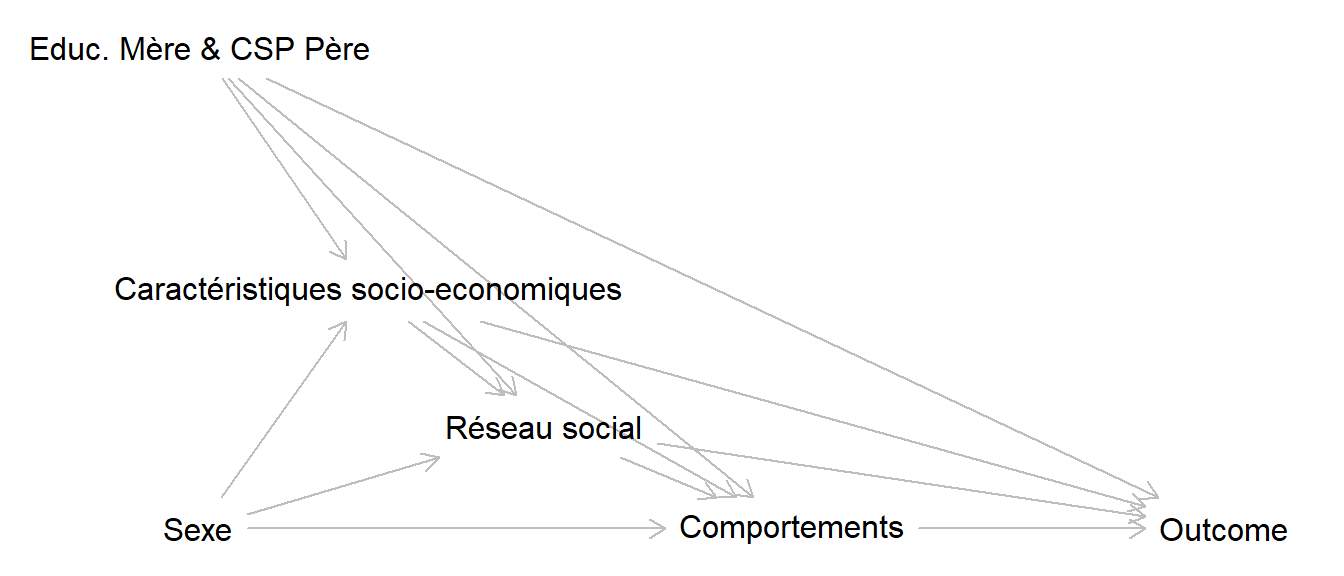
Cette séquence causale est très discutable, notamment parce que ces médiateurs ont été mesurés à la même vague. Des analyses de sensibilité pourrait être réalisées afin d’évaluer d’autres scénarii.
A partir de ce schéma, si l’on veut :
- mesurer la part médiée par les caractéristiques socio-économiques, les variables relatives au réseau social et aux comportements ne doivent pas être inclues.
- mesurer la part médiée par le réseau social, les variables relatives aux comportements ne doivent pas être inclues et les caractéristiques socio-économiques doivent être inclues comme facteurs de confusion intermédiaires (confouders de M->Y + descendants de X).
- mesurer la part médiée par les comportements, les variables relatives aux comportements et aux caractéristiques socio-économiques doivent être inclues comme facteurs de confusion intermédiaires.
12.2 Caractéristiques socio-économiques
exp1 <- cmest(
data = base3, # base
model = "gformula", # approach, defaut is rb (regression-based)
# if postc is not empty only gformula or msm
estimation = "imputation", # method of estimation. "imputation" is conterfactual estimation
inference = "bootstrap", # method for se and CI
nboot = 100, # defaut is 200
EMint = FALSE, # interaction exposure mediator
multimp = TRUE, # imputation multiple des DM
m = 10,
outcome = "t8_SBP",
exposure = "t0_baby_sex",
mediator = c("t4_litteraciepbm",
"t4_numeraciepbm",
"t4_act_read",
"t4_O_level"),
basec = c("t0_mother_scol_crt",
"t0_fathers_csp_defav"), # confusion baseline
#postc = c() # confusion intermédiaire
yreg = "linear", # outcome regression model
a = "Homme", # "active" value of exposure
astar = "Femme", # "control" value of exposure
mreg = list("logistic",
"logistic",
"logistic",
"logistic"), # regression model for each mediator
mval = list("Non",
"Non",
"Oui",
"Oui") # ref for M
) ; set.seed(28062022)type | effect | ci.low | ci.high |
cde | 9.82 | 7.72 | 12.97 |
pnde | 9.82 | 7.72 | 12.97 |
tnde | 9.82 | 7.72 | 12.97 |
pnie | 0.81 | -0.11 | 2.13 |
tnie | 0.81 | -0.11 | 2.13 |
te | 10.63 | 8.32 | 14.35 |
pm | 0.08 | -0.01 | 0.19 |
La part médiée par les caractéristiques socio-économiques identifiées est de : 7.56% (95CI = [-1.29 to 18.56]). C’est à dire qu’on explique une partie des différences de TAS par des caractéristiques socio-économiques différentes entre les hommes et les femmes au début de l’age adulte (mais de façon non significative).
12.4 Comportements
exp1 <- cmest(
data = base3, # base
model = "gformula", # approach, defaut is rb (regression-based)
# if postc is not empty only gformula or msm
estimation = "imputation", # method of estimation. "imputation" is conterfactual estimation
inference = "bootstrap", # method for se and CI
nboot = 100, # defaut is 200
EMint = FALSE, # interaction exposure mediator
multimp = TRUE, # imputation multiple des DM
m = 10,
outcome = "t8_SBP",
exposure = "t0_baby_sex",
mediator = c("t4_act_sport",
"t4_tabac_2cl",
"t4_drink_everyday"),
basec = c("t0_mother_scol_crt",
"t0_fathers_csp_defav"),# confusion baseline
postc = c("t4_litteraciepbm",
"t4_numeraciepbm",
"t4_act_read",
"t4_O_level",
"t4_hadchildren",
"t4_married",
"t4_act_friend",
"t4_religious"), # confusion intermédiaire
yreg = "linear", # outcome regression model
a = "Homme", # "active" value of exposure
astar = "Femme", # "control" value of exposure
mreg = list("logistic",
"logistic",
"logistic"), # regression model for each mediator
mval = list("Oui",
"Non",
"Non"), # ref for M
postcreg = list("logistic",
"logistic",
"logistic",
"logistic",
"logistic",
"logistic",
"logistic",
"logistic") # ref for M
) ; set.seed(28062022)type | effect | ci.low | ci.high |
cde | 11.87 | 9.51 | 16.22 |
rpnde | 11.87 | 9.51 | 16.22 |
rtnde | 11.87 | 9.51 | 16.22 |
rpnie | -1.23 | -3.83 | -0.42 |
rtnie | -1.23 | -3.83 | -0.42 |
te | 10.64 | 7.75 | 13.93 |
pm | -0.11 | -0.47 | -0.04 |
La part médiée par les caractéristiques socio-économiques identifiées est de : -11.5% (95CI = [-46.51 to -3.66]). C’est à dire que si les hommes et les femmes avaient les mêmes caractéristiques comportementales au début de l’age adulte, leur différence en terme de TAS seraient encore plus large de 11.5% .
Finalement, il semble que si on n’observe pas de médiation globalement, via l’ensemble des médiateurs (approche 1), c’est parce que les différences de comportements augmentent les différences de TAS alors que le réseau social et les caractéristiques socio-économiques les diminuent.