Chapter 5 Final Remarks on ML Application and Conclusions
5.1 Final Remarks on ML Application
This work was attempted to bring new insight to the oil and gas companies in the era of big data and data analytics. Here in this work, we call for “Decision-Driven” approach rather than “Data-Driven” approach. In the case f building the machine learning model, the main difference between these two approaches is in the Decision Driven approach, we only collect, analyze, find the pattern in the data that has following four characteristics(Bratvold and Begg 2010);
- We must be able to view the result of the model (here the model is machine learning algorithm)
- The model found from the data must have the potential to change our prior belief in the decision context
- The model must have the ability to change the decision on the hand
- The value added to the decision through model must exceed its cost
We argue that the Data-Driven approach where the data in it’s oneself considered as the value and it is the main focus of the decision may ultimately lead to sub-optimal allocation of time and resource of the corporation.
Then, another area that is needed to be discussed is answering this question:
- Which type of “Decision” has the most qualification to be addressed and answered using a machine learning method?
The author believes that the classification in the Figure 5.1 could be very helpful to answer this question. According to that, for any Decision that has three following characteristics, machine learning could provide the best insight for making a better decision in the ‘timely’ manner:
- The “Decision” repeats often (it means the same decision is faced repeatably)
- The “Decision” needs the data to be made
- The “Decision” is not consequential (having a very important impact)
The author concludes that while the “Decision” for well placement maybe not the best candidate to be addressed using the machine learning models (Since it does not repeats much and most of the time it is an important decision for corporations); the following areas can be gain the most advantages from ML models (considering the aforementioned three characteristics):
Geo-steering the well in order to achieve a best possible zone of the reservoir
Classification and characterization of the petrophysical characteristics of the reservoir rock
These two areas are among the potential application to get benefit from ML models in order to “Automate the Decision Making”.
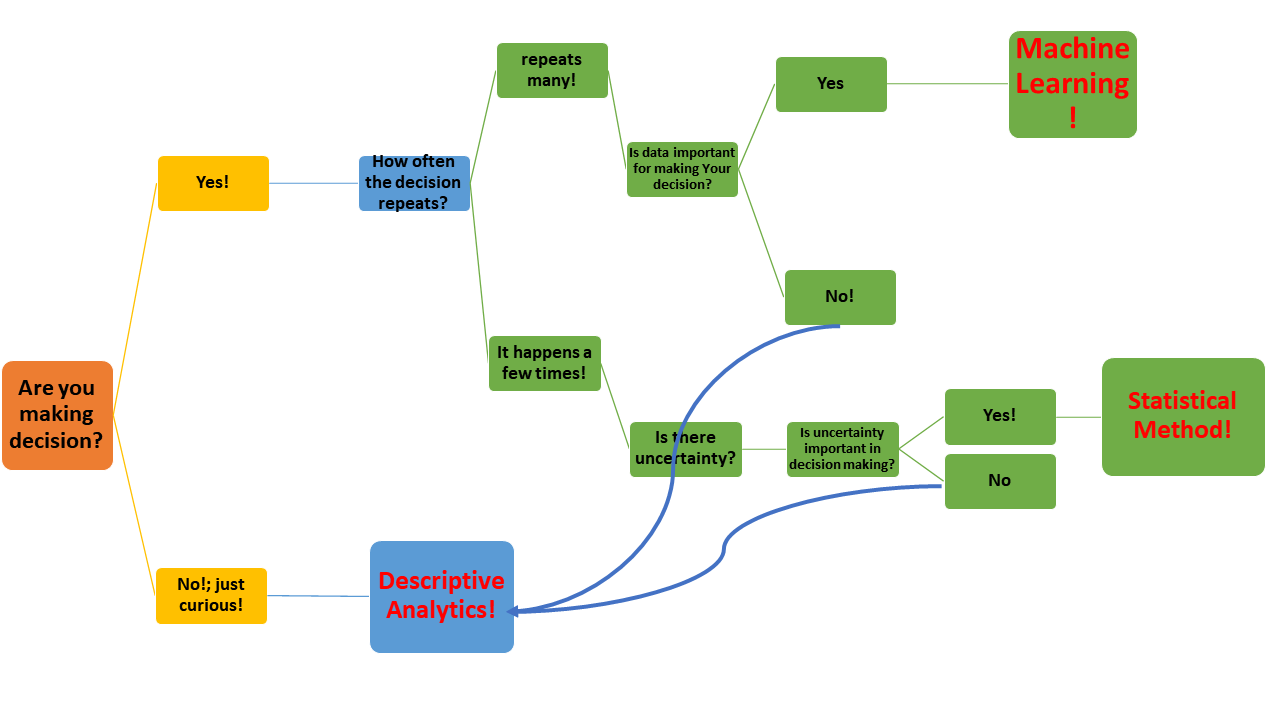
Figure 5.1: From Cassie Kozyrkov (Chief Decision Scientist at Google), Keynote speaker in DAAG 2019 conference
5.2 Conclusions
Considering this work, the key messages and conclusion of this work could be summarized as follows:
The subsurface modeling in the Reservoir Engineering deals with sparse data sets with tens of the features. One approach for feature selection is using fully data-driven techniques such as Principal Component Analysis (PCA) or Backward Feature Elimination (BFE). We found here that the Physical -Based features like the Fast Marching Method (FMM) carry important geological information and could be used as an alternative representation of geology while retaining the physical parameters involved in the flow of the oil and gas.
The machine learning based model could provide the very efficient and fast proxy for complex and slow full physical based simulators which in application like optimization, could be very helpful. However, two areas need further attention:
- When coming from a complex model to the more simplification of the ‘truth model’, the part of accuracy will be sacrificed. The research in ML application must have analysis about the trade-off between speed and accuracy.
- In the ML model developed in this work, it was assumed the training data set here is “Historical Data” that was fed to the ML to make a prediction about the future field. In fact, that training data set is the ‘sample’ while we are considering to make a prediction about the population. Here, the challenging statistical question comes that how much training data set is representative of the population of the data set?
In the framework of decision analysis, in this study, the value of machine learning in a particular decision context was analyzed. This analysis (considering the final result of the data analytics as the information for decision) will be helpful for the companies to prioritize the value of future data analytic project based on their expected value. The framework explained in chapter 3 can fully be used for any other data gathering process.
There is an essential need in the domain of the Reservoir Engineering to build a fast model for optimization where the current commercial numerical simulators take even days to have several thousand iterations. The Proxy model and the robust optimization (RO) framework proposed in this work has a clear application: thousands of forwarding reservoir evaluations can be realized in 100X faster to help decision maker make a decision in a “timely” manner. This offers a practical new alternative to full reservoir simulations which requires massive computational resources and time to perform the same numbers of iterations.
References
Bratvold, Reidar, and Steve Begg. 2010. Making Good Decisions. Society of Petroleum Engineers.