Chapter 11 Associations between continuous variables
Motivating scenarios: We are interested to estimate an association between two continuous variables, and test if this association is differs from zero.
Learning goals: By the end of this chapter you should be able to
- Summarize the association between to continuous variables as
- Covariance AND
- Correlation
- Covariance AND
- Estimate uncertainty in these estimates by
- By bootstrapping AND
- Naively taking
R’s output at face value.
- By bootstrapping AND
- Test the null hypothesis of no association by
- A permutation test
- Naively accepting
R’s output at face value.
- A permutation test
11.1 Associations between continuous variables
One of the most common statistical questions we come across is “are the two variables associated?”
For instance, we might want to know if people who study more get better grades.
Such an association would be quite interesting, and if it arises in a randomized controlled experiment, it would suggest that studying caused this outcome.
11.2 Example: Disease and sperm viability
It is hypothesized that there is a trade off between investment in disease resistance and reproduction. To look into this, Simmons and Roberts (2005), assayed sperm viability and lysozyme activity (a measure of defense against bacteria) in 39 male crickets. Let’s use this to explore associations between continuous variables.
ggplot(crickets , aes(x = spermViability, y = lysozyme))+
geom_point()+
labs(x = "Sperm viability (%)", y = expression(paste("Lysozyme activity (",mm^2,")"))). One extreme outlier was removed to simplify the analysis for purposes of explanation (it would not be removed in a real study).](Applied-Biostats_files/figure-html/cricketsdat-1.png)
Figure 11.1: Association between reproduction (measured as sperm viability) and immunity (measured as the diameter of lysozyme). Data from Simmons and Roberts (2005) are available here. One extreme outlier was removed to simplify the analysis for purposes of explanation (it would not be removed in a real study).
11.3 Summarizing associations between two categorical variables
We focus on two common summaries of associations between two continuous variables, X and Y, the covariance and the correlation.
Both these summaries describe the tendency for values of X and Y to jointly deviate from the mean.
- If larger values of X tend to come with larger values of Y the covariance (and correlation) will be positive.
- If smaller values of X tend to come with larger values of Y the covariance (and correlation) will be negative.
- A covariance (or correlation) of zero means that – on average – X and Y don’t predictably deviate from their means in the same direction. This does not guarantee that X and Y are independent – if they are related by a curve rather than a line, X could predict Y well even if the covariance (or correlation) was zero. It does mean that the best fit line between X and Y will be flat.
For both these summaries X and Y are arbitrary - the covariance between sperm viability and lysozyme activity is the same as the covariance between lysozyme activity and sperm viability.
11.3.1 Covariance
The covariance quantifies the shared deviation of X and Y from the mean as follows:
\[\begin{equation} \begin{split} \text{Sample covariance between X and Y} = Cov(X,Y) &=\frac{\sum{\Big((X_i-\overline{X})\times (Y_i-\overline{Y})\Big)}}{n-1}\\ \end{split} \tag{11.1} \end{equation}\]
The numerator in Eq. (11.1) is known as the ‘Sum of Cross Products’. This should remind you of the numerator in the variance calculation (Sum of squares = \(\sum(X-\overline{X})(X-\overline{X})\)) – in fact the covariance of X with itself is its variance. The covariance can range from \(-\infty\) to \(\infty\), but in practice cannot exceed the variance in X or Y.
Some algebra can rearrange Eq. (11.1) to become Eq. (11.2). These two different looking equations are identical. Often, computing the covariance from (11.1) is more convenient, but this isn’t always true.
\[\begin{equation} \begin{split} \text{Sample covariance between X and Y} = Cov(X,Y) &= \frac{n-1}{n}(\overline{XY} - \overline{X} \times \overline{Y})\\ \end{split} \tag{11.2} \end{equation}\]
This is also equal to \(Cov(X,Y) = \frac{n-1}{n}(\overline{XY} - \overline{X} \times \overline{Y})\). Which is sometimes easier to work with.
We can calculate the covariance by explicitly writing our math out in R or by using the cov() function:
crickets %>%
mutate(x_prods = (spermViability-mean(spermViability)) * (lysozyme-mean(lysozyme))) %>%
summarise(n = n(),
sum_x_prods = sum(x_prods),
cov_math_a = sum_x_prods / (n-1),
cov_math_b = (n/(n-1)) * sum(mean(spermViability * lysozyme) -
mean(spermViability) * mean(lysozyme)),
cov_r = cov(spermViability, lysozyme))## # A tibble: 1 × 5
## n sum_x_prods cov_math_a cov_math_b cov_r
## <int> <dbl> <dbl> <dbl> <dbl>
## 1 40 -54.1 -1.39 -1.39 -1.39Reassuringly we get the same result for all derivations– higher quality sperm come from parents with less lysozyme activity.
Covariance - a visual explanation
Some people have trouble intuiting a covariance, as the mean of the product of the difference X and Y and their means (just typing it is a mouthful).
So I’m hoping the visuals in Fig 11.2 help – if they don’t then skip them. To calculate the covariance,
- Draw a rectangle around a given data point and the means of X and Y.
- Find the area of that rectangle.
- If X is less than its mean and Y is greater than its mean (or vice versa) put a negative sign in front of this area.
- Do this for all data points.
- Add this all up and divide by \(n - 1\).
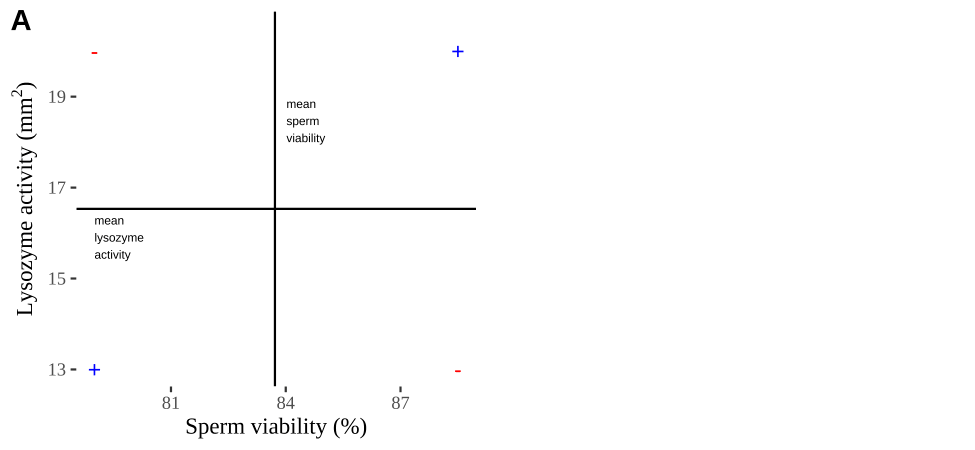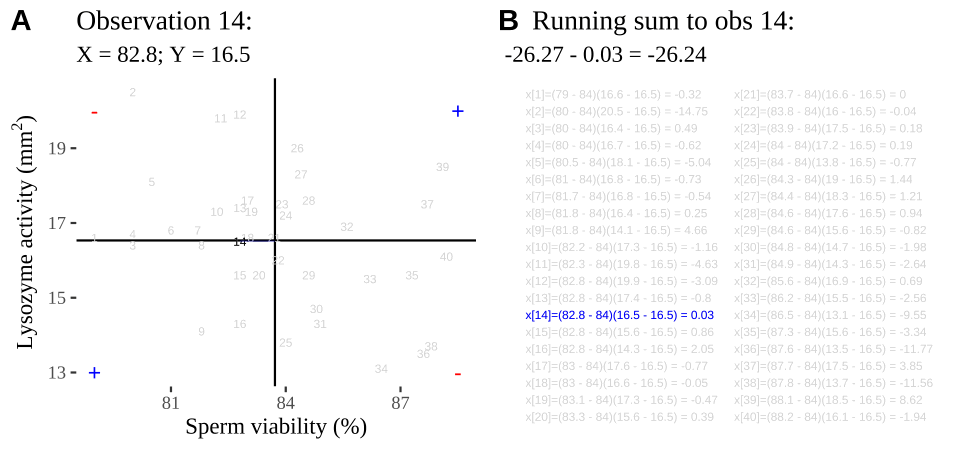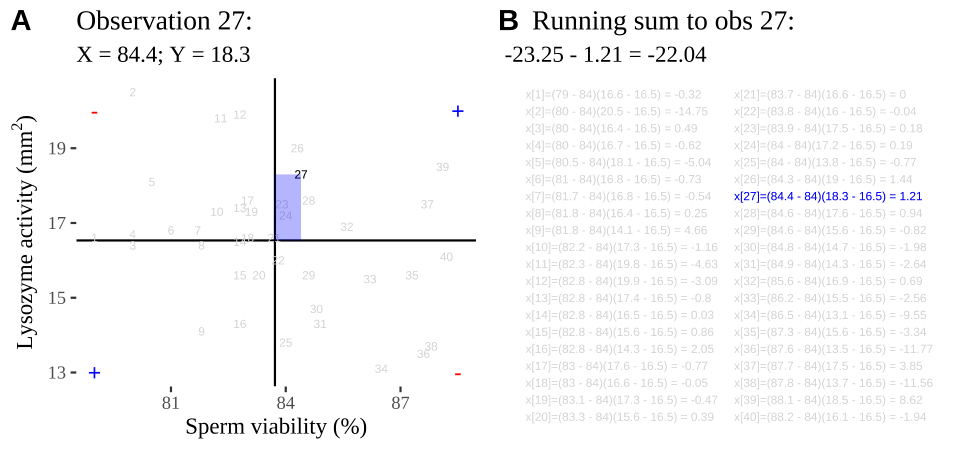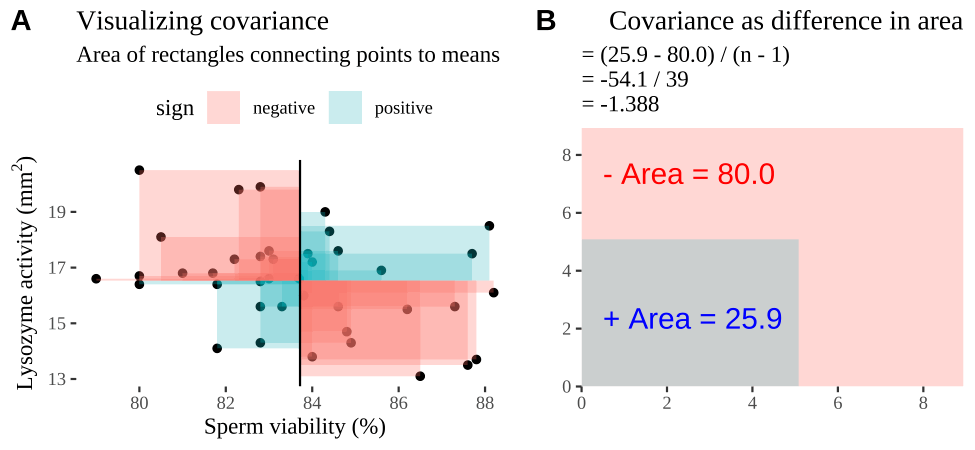
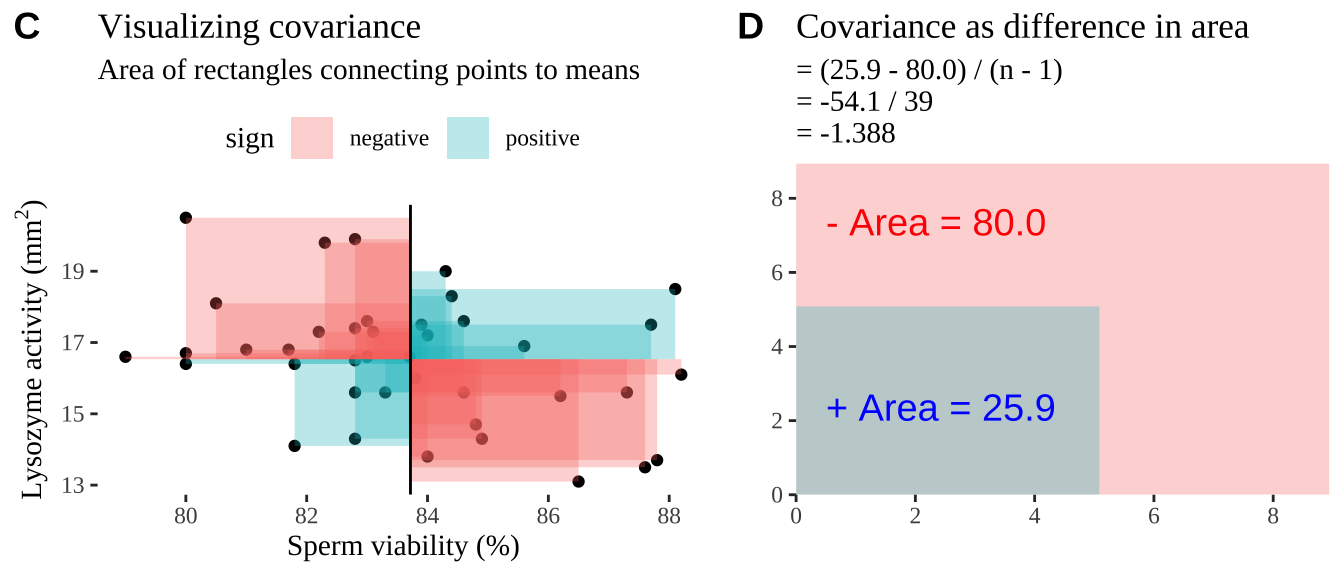
Figure 11.2: Visualizing covariance as areas from the mean. A) Animation of a rectangles around the \(i^{th}\) data point and the mean sperm motility (x), and lysozyme activity (y), looped over all n observations. Values in the top left and bottom right quadrants are colored in red because x and y deviate from their means in different directions. Values in the bottom right and top left quadrants are colored in blue because they deviate from their means in the same direction. B) The area of the \(i^{th}\) rectangle, with a running sum of cross products. C) All rectangles in A shown at the same time. D) The sum of positive (blue) and negative (red) areas.
11.3.2 Correlation
We found a covariance in sperm viability and lysozyme activity of -1.388. Is this large or small – I don’t know.
We therefore usually present a more interpretable summary of the association between variables – the correlation, which standardizes the covariance by dividing through by the product of the standard deviations in X and Y, \(s_X\) and \(s_Y\), respectively:
\[\begin{equation} \begin{split} \text{Sample corelation between X and Y} = Cor(X,Y) &= \frac{Cov(X,Y)}{s_X \times s_Y}\\ \end{split} \tag{11.2} \end{equation}\]
Again we can push through with math, or use the cor() function in R to find the correlation
crickets %>%
summarise(n = n(),
cov_r = cov(spermViability, lysozyme),
cor_math = cov_r / (sd(spermViability) * sd(lysozyme)),
cor_r = cor(spermViability, lysozyme))## # A tibble: 1 × 4
## n cov_r cor_math cor_r
## <int> <dbl> <dbl> <dbl>
## 1 40 -1.39 -0.328 -0.328So the correlation is -0.328. It’s not clear if this is a substantial correlation – as this depends on our field and expectations etc. But we can meaningfully compare this to correlations between any other traits to put it in a broader context.
11.4 Bootstrap to quatify uncertainty
Like all estimates, a sample correlation (or covariance) can deviate from the population parameter by chance.
Again we can use the bootstrap – resampling from our sample with replacement to approximate the sampling distribution — to quantify the impact of sampling error on our estimates.
Bootstrap to quatify uncertainty: Step 1. Resample.
We first make many bootstrap replicates by resampling our data with replacement to make many new potential data sets (each the same size as our data).
crickets_many_resamples <- crickets %>%
rep_sample_n(size = nrow(crickets), replace = TRUE, reps = 100000 ) So, we now have a data set of 4 million resampled combinations of sperm viability and lysozyme activity, in 100,000 groups of forty. (I only show the first thousand values in table below).
Bootstrap to quantify uncertainty: Step 2. Summarize each resample.
We then summarize each bootstrap replicate with our estimate of interest – for now we’ll focus on the correlation, but we could have chosen the covariance if we wanted.
crickets_boots <- crickets_many_resamples %>%
summarise(cor_vals = cor(spermViability, lysozyme))This data set contains 100,000 values – each one is an estimate of the correlation for a different bootstrap replicate.
So, this is the bootstrapped sampling distribution. (I only show the first thousand values in table below).
Bootstrap to quantify uncertainty: Step 3. Summarize the bootstrap distribution.
Now that we’ve approximated the sampling distribution, we can use it to summarize the uncertainty in our estimate. Remember our common summaries of uncertainty:
- The standard error which describes the expected deviation between a parameter and an estimate of as the standard deviation of the sampling distribution.
crickets_SE <- summarise(crickets_boots, se = sd(cor_vals))
crickets_SE## # A tibble: 1 × 1
## se
## <dbl>
## 1 0.143- A confidence interval which puts reasonable bounds on our estimate.
crickets_CI <- crickets_boots %>%
summarise(CI = quantile(cor_vals, prob = c(0.025,.975))) %>%
mutate( bound = c("lower","upper"))
crickets_CI## # A tibble: 2 × 2
## CI bound
## <dbl> <chr>
## 1 -0.583 lower
## 2 -0.0222 upperWe can visualize the bootstrapped distribution, with red dashed lines denoting 95% confidence intervals.
ggplot(crickets_boots, aes(x = cor_vals)) +
geom_histogram(bins = 100, color = "white", size = .3)+
geom_vline(data = crickets_CI, aes(xintercept = CI),
color = "red", lty = 2 )+
theme_light()+
scale_y_continuous(expand = c(0,0))+
scale_x_continuous(limits = c(-1,1), expand = c(0,0))+
labs(title = "Bootstrap distribution of correlations",
subtitle = "Sperm viability & lysozyme size in crickets.")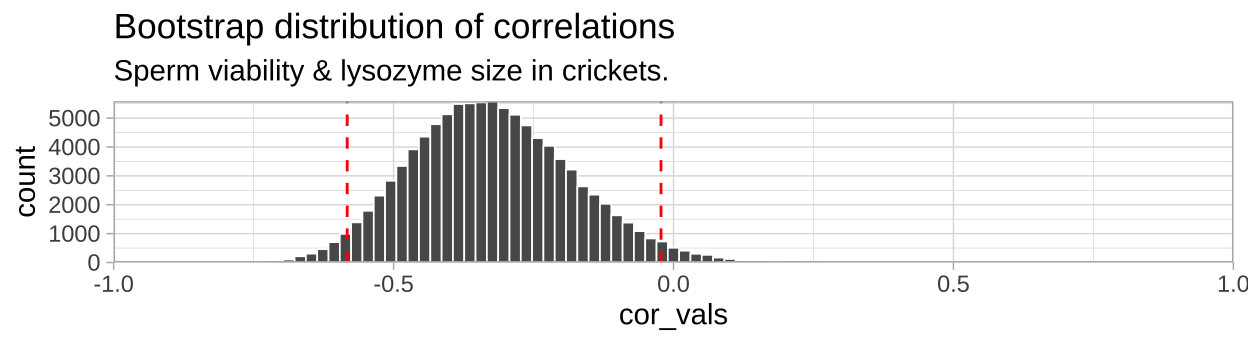
So we find find a negative correlation between sperm motility and lyzosyme activity, with an estimated correlation coefficient of -0.328, and Standard error of 0.1433, and a 95% confidence interval between -0.583 and -0.022.
11.5 Testing the null hypothesis of no association
So, we estimate a negative correlation between sperm viability and lysozyme activity. As our 95% confidence interval excluded zero, it seems unlikely that the data came from a null population with a true correlation of zero. Now, let’s formally test the null hypothesis that such an association could easily be generated by chance sampling from a null population with a true correlation of zero. Here’s how we do it!
- State the null hypothesis and its alternative.
- Null hypotheses: There is NO linear association between our two variables. e.g. Crickets with more viable sperm do not have more or less lysozyme activity, on average, than crickets with less viable sperm.
- Alternate hypotheses: There is a linear association between our two variables. e.g. Crickets with more viable sperm do have more or less lysozyme activity, on average, than crickets with less viable sperm.
- Null hypotheses: There is NO linear association between our two variables. e.g. Crickets with more viable sperm do not have more or less lysozyme activity, on average, than crickets with less viable sperm.
- Calculate a test statistic to summarize our data.
- Compare the observed test statistic to the sampling distribution of this statistic from the null model.
- Interpret these results. If the test statistic is in an extreme tail of this sampling distribution, we reject the null hypothesis, otherwise we do not.
11.5.1 By permutation
First let’s test this null by permutation. Remember in permutation we generate a sampling distribution under the null by shuffling explanatory and response variables. We need a test statistic – so let’s take the correlation. (p-values and conclusions will be the same if we chose the covariance).
11.5.1.1 Shuffle labels for many replicates
- Use the
rep_sample_n()function withreplace = FALSEto make a bunch of identical copies of our data (the orders will be shuffled, but all data will be there and associations will be maintained).
- So we the shuffle the explanatory variable (sperm viability) across the response (lysozyme activity) for each replicate to generate data from the null.
# shuffle the relationship between explanatory and response variable
n_perms <- 100000
crickets_many_perm <- crickets %>%
rep_sample_n(size = nrow(crickets), replace = FALSE, reps = n_perms ) %>%
group_by(replicate) %>%
mutate(spermViability = sample(spermViability, replace = FALSE))Unlike bootstrapping, here every observation in our initial data set is present in each permuted sample - but we’ve randomly swapped spermViability across individuals with known lysozyme activity. The permutation thus reflects the null model of no association because we’ve randomly associated X and Y many times. So, we now have a data set of 4 million reshuffled combinations of sperm viability and lysozyme activity, in 100,000 groups of forty. (I only show the first thousand values in table below).
11.5.1.2 And summarize permuted data
Now let us summarize our permuted data to approximate the sampling distribution under the null. Again we’ll focus on the correlation, but we could have used a different test statistic, like the covariance.
crickets_perms <- crickets_many_perm %>%
summarise(cor_vals = cor(spermViability, lysozyme))This data set contains 100,000 values – each one is an estimate of the correlation for a different permuted replicate. This is the null sampling distribution generate by permutation.
11.5.1.3 Let’s compare the correlations of permuted data to what we found in the real data
crickets_cor <- crickets %>%
summarise(obs_cor = cor(spermViability, lysozyme)) %>%
pull()
crickets_perms <- crickets_perms %>%
mutate(actual_cor = crickets_cor,
as_or_more_extreme = (abs(cor_vals) >= abs(crickets_cor)))Let’s have a look at these permuted summaries and how they compare to the actual data. (I only show the first thousand values in table below).
11.5.1.4 Plot the permuted data
ggplot( crickets_perms , aes(x = cor_vals, fill = as_or_more_extreme))+
geom_histogram() +
scale_fill_manual(values = c("grey","black"))+
theme_tufte()+
theme(legend.position = "bottom")+
labs(title = "Permuted distribution of cricket data.")+
annotate(x = -.5,y =10000, label = sprintf("p = %s", pull(cricket_p_val)%>%round(digits = 3)), geom = "text")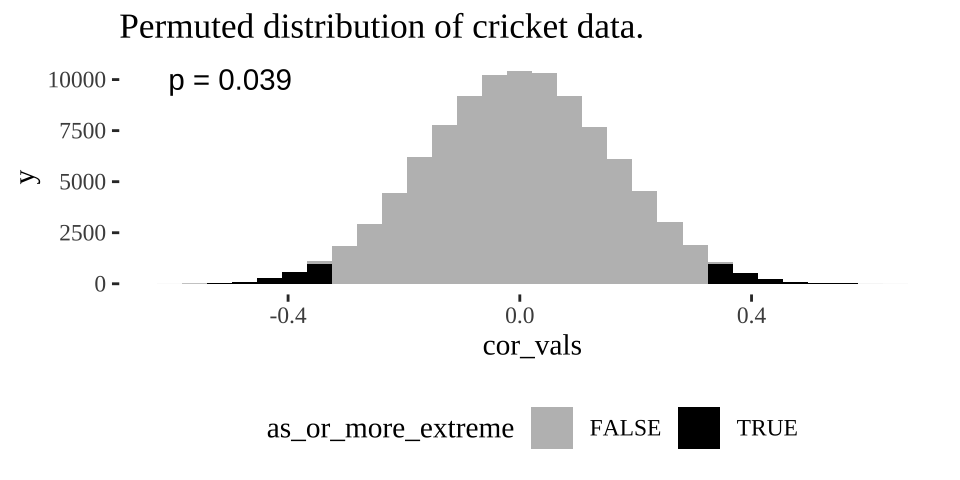
Figure 11.3: Distribution of permuted correlation coefficients in cricket data. Fewer than five percent of permutations generate correlations as or more extreme then the actual correlation of -0.328 (P < 0.05).
11.5.1.5 Find a p-value
Remember the p-value is the probability that we would observe our test statistic, or something more extreme if the null were true. While it is clear from Figure 11.3 that it would be quite strange to see a result as extreme as we did if the null were true, we want to quantify this weirdness with a p-value.
We can approximate a p-value as the proportion of permutations with a correlation as or more extreme as our observed correlation:
cricket_p_val <- crickets_perms %>%
summarise(pvalue = mean(as_or_more_extreme))
cricket_p_val ## # A tibble: 1 × 1
## pvalue
## <dbl>
## 1 0.037811.5.2 With math
The permutation above did the job. We came to a solid conclusion. But there are a few downsides
- It can be a bit slow – it takes my computer like ten seconds to permute this data set 100,000 times. While ten seconds isn’t a lot of time it would add up if for example we wanted to do this for large datasets with millions of variables.
- It is influenced by chance. Ever permutation will have a slightly different p-value due to the chance outcomes of random shuffling. While this shouldn’t impact our conclusions it’s a bit unsatisfying.
For these reasons, we usually only apply a permutation to cases where data do not meet the assumptions of the more traditional mathematical approach.
Later in this term we will think a lot about the t-distribution, which is a common and handy statistical distribution. A t-value of one means our estimate is one standard error away from the parameter specified by the null, a t-value of two means our estimate is one standard error away… etc.. etc… etc…
For now know:
- We can approximate the standard error of the correlation, \(SE_r\), as \(\sqrt{\frac{1-r^2}{n-2}}\), where \(r\) is our estimated correlation coefficient. So for the cricket data - we can approximate the standard error as \(\sqrt{\frac{1- (-0.328)^2}{40-2}} = 0.153\), a value similar to but not identical to the SE of
pull(crickets_SE) %>%round(digits = 3)we estimated from the permutation. Don’t stress about this slight difference – this is statistics – we want to be approximately right.
- We can find \(t\) as \(r / SE_r\) – approximately
-0.328/0.153 = -2.14in our case.
- In many cases we can use this \(t\) value and the sample size to estimate significance. We’ll track this down in a later class.
- Calculating the confidence interval is gross.
- R can do stats for us.
We can test the null hypothesis of zero correlation with the cor.test() function in R. The cor.test() function needs x and y as vectors so we have to pull() them out of our tibble.
cor.test(x = crickets %>% pull(spermViability),
y = crickets %>% pull(lysozyme))##
## Pearson's product-moment correlation
##
## data: crickets %>% pull(spermViability) and crickets %>% pull(lysozyme)
## t = -2.1393, df = 38, p-value = 0.03889
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## -0.58012395 -0.01821532
## sample estimates:
## cor
## -0.3278643We find a P-value nearly identical to what we got by permutation and a confidence interval pretty close to ours…. WoooHooo stats works.
Note that R’s test output is easy for humans to read but hard for us to analyze further. The tidy() function in the broom package can tidy this output.
library(broom)
cor.test(x = crickets %>% pull(spermViability),
y = crickets %>% pull(lysozyme)) %>%
tidy()## # A tibble: 1 × 8
## estimate statistic p.value parameter conf.low conf.high method alternative
## <dbl> <dbl> <dbl> <int> <dbl> <dbl> <chr> <chr>
## 1 -0.328 -2.14 0.0389 38 -0.580 -0.0182 Pearson's… two.sided
11.5.3 Care in interpreting (and running) correlation coefficients.
The correlation looks at how \(X\) and \(Y\) jointly deviate from their means. As such, interpreting a correlation is only meaningful when both \(X\) and \(Y\) are random.
Additionally, correlations summarize linear relationships and will fail to capture more complex relationships between variables.
Finally, the \(t\) test-based approach assumes that both variable come from a normal distribution… more on this later.
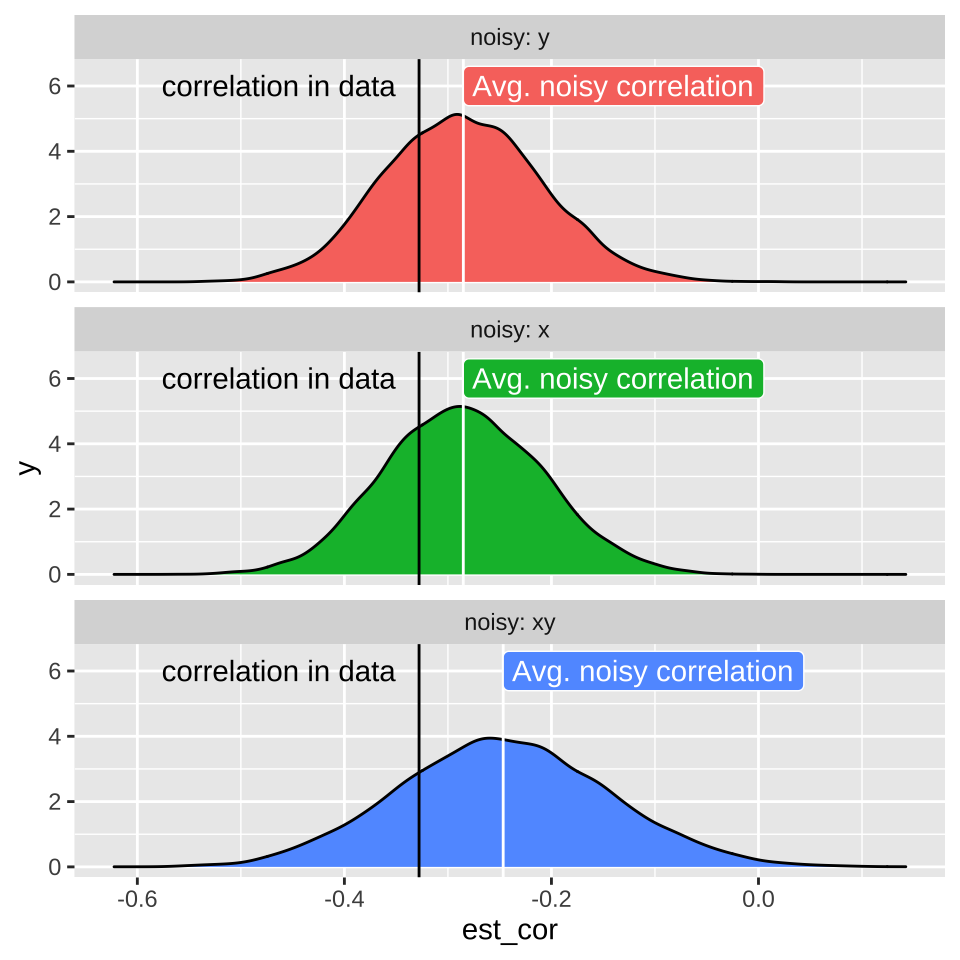
11.6 Attenuation: Random noise in X and/or Y brings correlations closer to zero.
We rarely measure all values of X and Y perfectly. In this example
- Each measurement of sperm viability will differ from the individual’s true sperm viability % because of sampling error.
- Lysozyme activity will be off because of both sampling error and imprecision of the ruler etc…
If we are lucky this imprecision is randomly distributed across the true values for each data point.
Such random imprecision impacts our estimate of the correlation because random noise will impact each observation of \(X\) and \(Y\) independently. As such their measured association will be, on average weaker (i.e. closer to zero), than the actual correlation in the real world. This is called attenuation. Two consequences of attenuation are
- Even if imprecision in each value of \(X\) and \(Y\) is unbiased, our estimated correlation will biased to be closer to zero than the actual correlation. Therefore measured correlations are, on average underestimates of true correlations.
- The more precise each measurement, the less bias in our estimate of the correlation coefficient.
11.6.1 Attenuation demonstration
Don’t take my word for the reality of attenuation - let’s simulate it! Let’s take our crickets data set with an actual correlation of, -0.328, and pretend this is a real population.
Now, let’s use the jitter() function to add
- Random noise in \(X\),
spermViability.
- Random noise in \(Y\),
lysozyme
- Random noise in both variables,
And compare our estimated correlation in these noisier estimates to our initial estimate of the correlation. To do so, let’s first copy our initial data set a bunch on times with the rep_sample_n() function in the infer package. In both cases lets add a standard deviation’s random noise
n_reps <- 10000
many_crickets <- crickets %>%
rep_sample_n(size = nrow(crickets), replace = FALSE, reps = n_reps)
noisy_x <- many_crickets %>%
mutate(spermViability = jitter(spermViability, amount = sd(spermViability) )) %>%
summarise(est_cor = cor(spermViability, lysozyme)) %>%
mutate(noisy = "x")
noisy_y <- many_crickets %>%
mutate(lysozyme = jitter(lysozyme, amount = sd( lysozyme) )) %>%
summarise(est_cor = cor(spermViability, lysozyme)) %>%
mutate(noisy = "y")
noisy_xy <- many_crickets %>%
mutate(lysozyme = jitter(lysozyme, amount = sd( lysozyme)),
spermViability = jitter(spermViability, amount = sd(spermViability) )) %>%
summarise(est_cor = cor(spermViability, lysozyme)) %>%
mutate(noisy = "xy")
### Make a plot
bind_rows(noisy_x, noisy_y, noisy_xy) %>%
mutate(noisy = fct_reorder(noisy, est_cor)) %>%
ggplot(aes(x = est_cor , fill = noisy)) +
facet_wrap(~noisy, labeller = "label_both", ncol = 1) +
geom_density(show.legend = FALSE) +
geom_vline(xintercept = crickets %>% summarise(cor(spermViability, lysozyme)) %>% pull() ) +
geom_vline(data = . %>% group_by(noisy) %>% summarise(est_cor = mean(est_cor)),
aes(xintercept = est_cor), color = "white")+
annotate(x = crickets %>% summarise(cor(spermViability, lysozyme)) %>% pull() ,
y = 6, label = "correlation in data", geom = "text", hjust = 1.1)+
geom_label(data = . %>% group_by(noisy) %>% summarise(est_cor = mean(est_cor)),
aes(y=6),label = "Avg. noisy correlation", hjust = 0, color = "white", show.legend = FALSE)+
scale_y_continuous(limits = c(0,6.5))