Kapitel 9 Multipel regression and replikation
I det här avsnittet ska vi återskapa en del av en analys från en tidigare publicerad studie (https://doi.org/10.1080/14616696.2023.2220014). Att återskapa analyser är en viktig del av vetenskapen, eftersom de resultat vi producerar inte är tillförlitliga om de inte kan återskapas av någon annan med samma data. Det bästa sättet att uppnå detta är att spara koden som vi använde för att skapa vår analys och dela den öppet. På så sätt kan andra bygga vidare på det vi har gjort tidigare och försöka replikera våra resultat med andra data, vilket dramatiskt ökar tillförlitligheten i våra resultat. Därefter kan de använda dessa resultat som grund för andra analyser i framtiden.
En ytterligare fördel är att om vi någonstans har gjort ett misstag (förhoppningsvis inte, men det händer!) så kan det upptäckas av någon annan, och vi kan då göra en korrigering. Utan att dela vår analyskod vore inget av detta möjligt.
Att replikera analyser är också ett utmärkt sätt för studenter att lära sig, eftersom de kan se resultaten i det större sammanhanget av en artikel som inkluderar teori, dialog med tidigare forskning, beskrivning av data och metod på ett vetenskapligt sätt, hur forskarna valde att rapportera resultaten samt vilka slutsatser de drog.
9.1 Multipel linjär regression i tre steg
I de föregående avsnitten analyserade vi förtroendet för polisen bland den svenska befolkningen med hjälp av en enkät som bygger på ett representativt urval. Vi har dock goda skäl att tro att förtroende är särskilt viktigt bland grupper som har en hög sannolikhet att uppleva diskriminering. Och även om vi är intresserade av faktorer som kan minska förtroendet (såsom att utsättas för diskriminering), är vi också intresserade av faktorer som kan bygga upp förtroende, till exempel att få stöd från sociala serviceorganisationer. Detta är ett utmärkt tillfälle att använda multipla regressionsanalyser.
Vi kommer att undersöka dessa möjligheter med ett dataset som har utformats av Europeiska kommissionens Byrå för grundläggande rättigheter (FRA) specifikt för att studera minoritetsgrupper, och vi kommer att fokusera på romer – en grupp som ofta upplever diskriminering.
Öppna datasetet “roma_krim” från Canvas.
Alla förtroende variablerna kallades ‘x_trust’ och de sträcker sig från 0-10, 0-10, där 0 = ‘inget förtroende’ och 10 = ‘fullständigt förtroende’.
9.1.1 Steg ett
I första steget vi ska hantera datan och beskriva datan.
## Rows: 7,947
## Columns: 29
## $ id <dbl> 43872, 43873, 43875, 43881, 43885, 43888, 43894, 43896, 43901, 43903, 43909, 43913, 43915, 43916, 43919, 43925, 43927,…
## $ country <chr> "Bulgaria", "Bulgaria", "Bulgaria", "Bulgaria", "Bulgaria", "Bulgaria", "Bulgaria", "Bulgaria", "Bulgaria", "Bulgaria"…
## $ discrim_prevalance_color <dbl> 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 4, 4, 2, 2, 4, 1, 3, 1, 3, 1, 2, 1, 1, 1, NA, 1, NA, 1, 4, 1, 2, 5, 5, 1, 5, 5, 5, 2, 2,…
## $ discrim_prevalance_origin <dbl> 2, 2, 2, 2, 2, 2, 2, 3, 2, 1, 4, 5, 1, 2, 4, 5, 1, 1, 4, 1, 1, 1, 1, 1, 3, 1, 3, 1, 4, 1, 1, 4, 5, 1, 5, NA, NA, 2, 2,…
## $ discrim_prevelance_religion <dbl> 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 1, 4, 3, 2, 1, 1, NA, 1, 1, 1, 2, 1, 1, 1, 2, NA, 3, 1, 3, 1, 1, 5, NA, 1, 2, NA, NA, 2,…
## $ corruption_exp <chr> "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No"…
## $ stop_by_police <chr> "No", "No", "No", "Within last year", "No", "No", "No", "1 year or longer", "No", "No", "No", "1 year or longer", "1 y…
## $ police_assault <chr> "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No"…
## $ police_trust <dbl> 6, 6, 5, 7, 7, 3, 6, 1, 8, 10, 0, 6, 8, 0, 7, 0, 0, 0, 0, 0, 10, 0, 5, 0, 2, 0, 10, 7, 9, 9, 5, 0, 10, NA, 0, 0, 4, 10…
## $ muni_trust <dbl> 6, 9, 9, 8, 6, 5, 6, 5, 8, 10, 10, 10, 9, 10, 6, 0, 6, 10, 0, 6, 10, 0, 10, 6, 4, 9, 10, 1, 0, 6, 1, 9, 0, NA, 0, 10, …
## $ parlament_trust <dbl> 5, 0, 2, 3, 4, 5, 4, 0, 7, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 3, 0, 0, 0, 0, 0, NA, 0, 0, 0, 5, 5, …
## $ legal_trust <dbl> 1, 4, 4, 2, 2, 4, 2, 2, 7, 10, 0, 6, 8, 0, 0, 0, 0, 0, 0, 5, 10, 0, 0, 0, 1, 8, 10, 8, 0, 10, 0, 0, NA, NA, 0, 0, 5, 7…
## $ politicians_trust <dbl> 3, 4, 3, 4, 5, 3, 5, 0, 8, 0, 0, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 7, 0, 10, 3, 2, 0, NA, 0, 0, 0, 8, 2,…
## $ party_trust <dbl> 4, 4, 3, 3, 5, 4, 5, 0, 8, 5, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 7, 0, 7, 3, 2, 0, NA, 0, 0, 0, 7, 0, …
## $ eu_parliment_trust <dbl> 5, 6, 3, 4, 4, 4, 5, 2, 9, 3, 0, 10, 8, 6, 0, 2, 0, 0, 0, 4, 0, 7, 10, 0, 5, 9, 10, NA, 2, 9, 9, 8, NA, NA, 0, NA, 0, …
## $ discrim_all <chr> "Yes", "No", "No", "No", "No", "No", "No", "No", "No", "No", "Yes", "No", "No", "Yes", "No", "No", "No", "No", "No", "…
## $ financial_support <dbl> 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 1…
## $ job_support <dbl> 2, 2, 2, 2, 2, 1, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2…
## $ training_support <dbl> 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2…
## $ document_support <dbl> 1, 1, 2, 1, 1, 1, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2…
## $ housing_support <dbl> 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2…
## $ medical_support <dbl> 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2…
## $ language_support <dbl> 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2…
## $ n_household <dbl> 1, 2, 6, 4, 3, 6, 2, 5, 2, 6, 4, 2, 1, 3, 6, 2, 5, 3, 7, 4, 4, 2, 7, 5, 3, 5, 3, 2, 2, 1, 2, 3, 7, 4, 2, 6, 3, 3, 5, 1…
## $ age <dbl> 54, 46, 42, 42, 52, 27, 60, 21, 67, 48, 30, 41, 44, 47, 42, 34, 66, 34, 53, 31, 19, 69, 35, 33, 17, 20, 52, 57, 60, 60…
## $ gender <dbl> 2, 1, 2, 1, 2, 2, 2, 1, 1, 2, 2, 1, 2, 1, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 1, 2, 2, 2, 2, 1, 1, 1, 2, 1, 2, 1, 2, 2, 2, 2…
## $ paid_work <chr> "Unpaid/Unemployed", "Unpaid/Unemployed", "Unpaid/Unemployed", "Paid Work", "Unpaid/Unemployed", "Unpaid/Unemployed", …
## $ highest_ed <chr> "Medium", "Medium", "Medium", "Medium", "Medium", "Low", "Medium", "Medium", "Medium", "Medium", "Medium", "Medium", "…
## $ marital_status <chr> "Divorced/Seperated/Widowed", "Married", "Married", "Married", "Married", "Never Married", "Divorced/Seperated/Widowed…| Unique | Missing Pct. | Mean | SD | Min | Median | Max | Histogram | |
|---|---|---|---|---|---|---|---|---|
| id | 7947 | 0 | 60902.0 | 9799.3 | 43872.0 | 61332.0 | 77655.0 |  |
| discrim_prevalance_color | 6 | 2 | 3.2 | 1.2 | 1.0 | 3.0 | 5.0 | 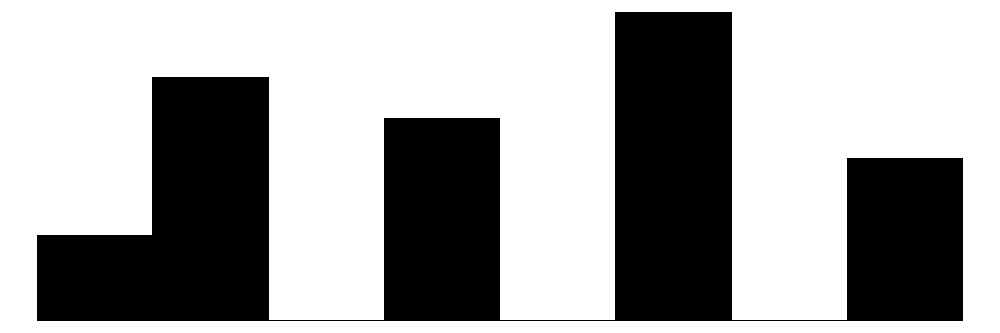 |
| discrim_prevalance_origin | 6 | 3 | 3.3 | 1.2 | 1.0 | 4.0 | 5.0 | 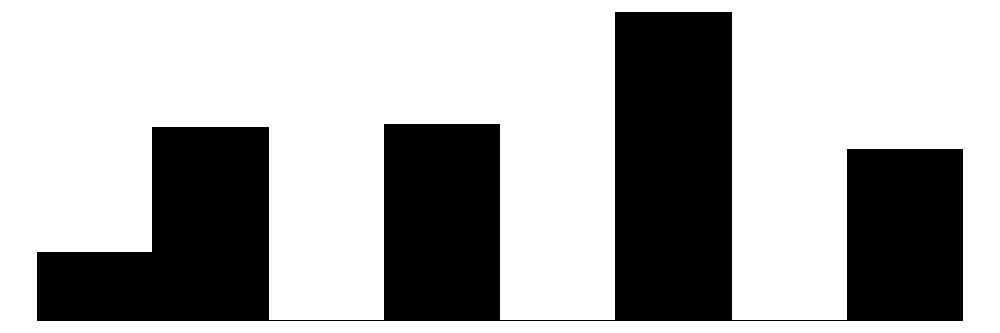 |
| discrim_prevelance_religion | 6 | 5 | 2.5 | 1.1 | 1.0 | 2.0 | 5.0 | 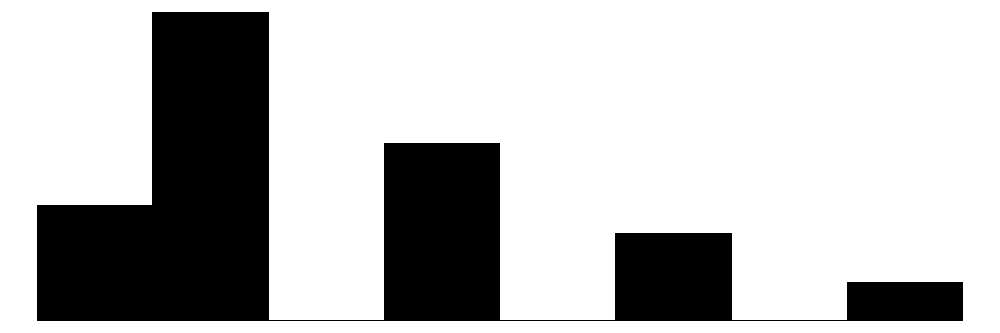 |
| police_trust | 12 | 2 | 4.6 | 3.1 | 0.0 | 5.0 | 10.0 |  |
| muni_trust | 12 | 3 | 5.2 | 3.0 | 0.0 | 5.0 | 10.0 |  |
| parlament_trust | 12 | 5 | 3.6 | 2.9 | 0.0 | 3.0 | 10.0 | 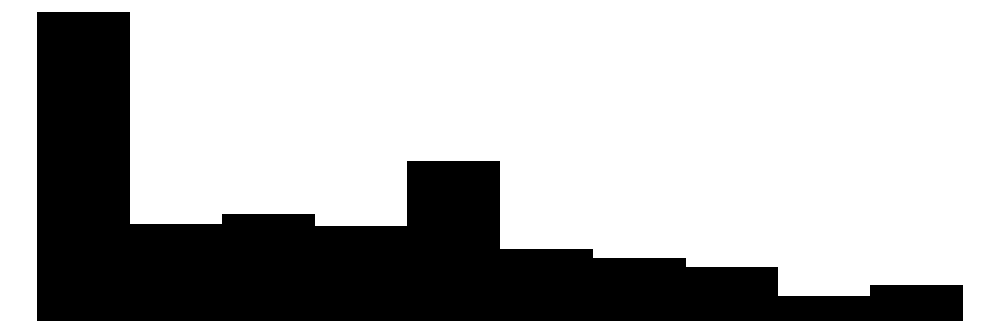 |
| legal_trust | 12 | 4 | 4.1 | 3.0 | 0.0 | 4.0 | 10.0 | 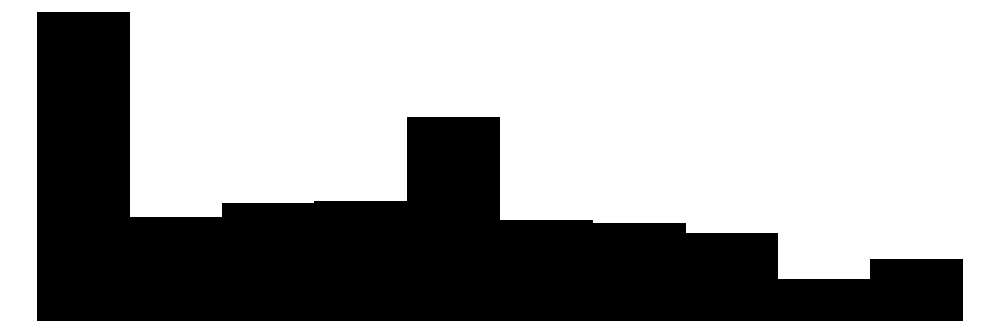 |
| politicians_trust | 12 | 4 | 3.0 | 2.7 | 0.0 | 3.0 | 10.0 | 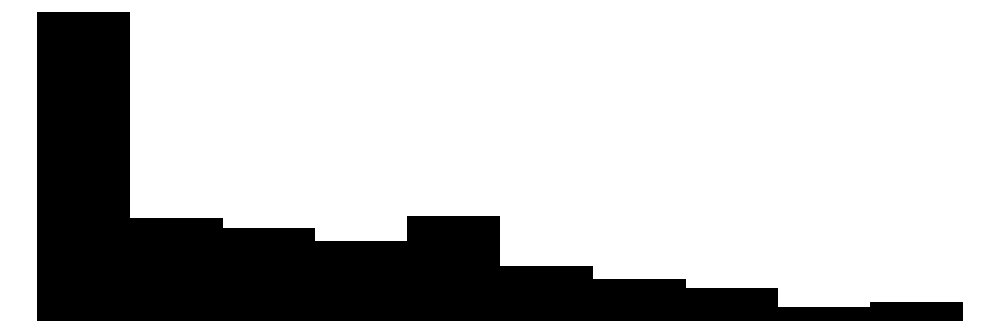 |
| party_trust | 12 | 4 | 3.0 | 2.7 | 0.0 | 3.0 | 10.0 | 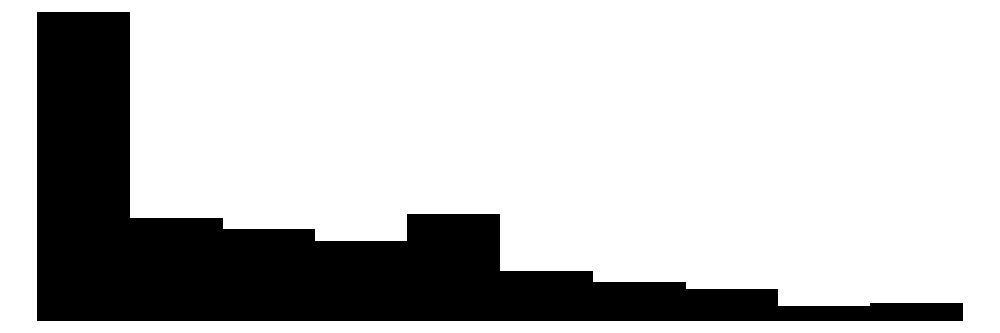 |
| eu_parliment_trust | 12 | 9 | 4.0 | 3.0 | 0.0 | 4.0 | 10.0 |  |
| financial_support | 6 | 0 | 3.0 | 10.5 | 1.0 | 2.0 | 99.0 |  |
| job_support | 6 | 0 | 3.0 | 10.1 | 1.0 | 2.0 | 99.0 |  |
| training_support | 6 | 0 | 3.1 | 10.6 | 1.0 | 2.0 | 99.0 |  |
| document_support | 6 | 0 | 3.0 | 10.4 | 1.0 | 2.0 | 99.0 |  |
| housing_support | 6 | 0 | 3.1 | 10.6 | 1.0 | 2.0 | 99.0 |  |
| medical_support | 6 | 0 | 2.8 | 9.3 | 1.0 | 2.0 | 99.0 |  |
| language_support | 6 | 0 | 3.3 | 11.3 | 1.0 | 2.0 | 99.0 |  |
| n_household | 18 | 0 | 4.3 | 2.2 | 1.0 | 4.0 | 20.0 | 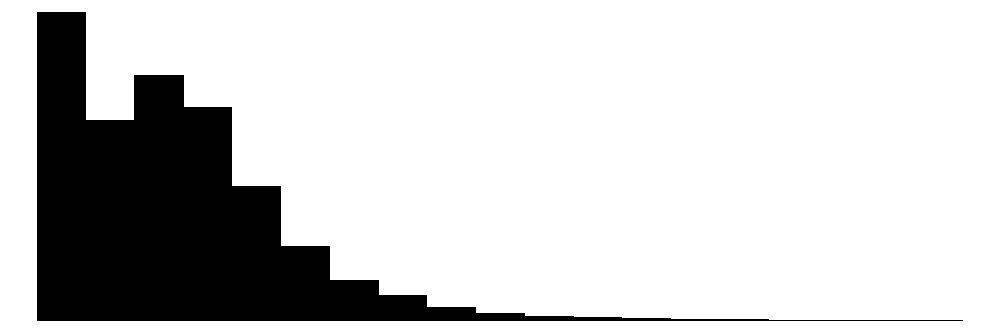 |
| age | 70 | 0 | 40.0 | 15.9 | 16.0 | 38.0 | 85.0 |  |
| gender | 2 | 0 | 1.5 | 0.5 | 1.0 | 2.0 | 2.0 |  |
| N | % | |||||||
| country | Bulgaria | 1078 | 13.6 | |||||
| Croatia | 538 | 6.8 | ||||||
| Czech Republic | 817 | 10.3 | ||||||
| Greece | 508 | 6.4 | ||||||
| Hungary | 1171 | 14.7 | ||||||
| Portugal | 553 | 7.0 | ||||||
| Romania | 1408 | 17.7 | ||||||
| Slovakia | 1098 | 13.8 | ||||||
| Spain | 776 | 9.8 | ||||||
| corruption_exp | No | 7545 | 94.9 | |||||
| Yes | 248 | 3.1 | ||||||
| NA | 154 | 1.9 | ||||||
| stop_by_police | 1 year or longer | 627 | 7.9 | |||||
| No | 6017 | 75.7 | ||||||
| Within last year | 1194 | 15.0 | ||||||
| NA | 109 | 1.4 | ||||||
| police_assault | No | 7679 | 96.6 | |||||
| Yes | 167 | 2.1 | ||||||
| NA | 101 | 1.3 | ||||||
| discrim_all | No | 4363 | 54.9 | |||||
| Yes | 3382 | 42.6 | ||||||
| NA | 202 | 2.5 | ||||||
| paid_work | Paid Work | 1413 | 17.8 | |||||
| Self Employed | 493 | 6.2 | ||||||
| Unpaid/Unemployed | 6023 | 75.8 | ||||||
| NA | 18 | 0.2 | ||||||
| highest_ed | High | 958 | 12.1 | |||||
| Low | 1539 | 19.4 | ||||||
| Medium | 5436 | 68.4 | ||||||
| NA | 14 | 0.2 | ||||||
| marital_status | Divorced/Seperated/Widowed | 1276 | 16.1 | |||||
| Married | 4474 | 56.3 | ||||||
| Never Married | 2141 | 26.9 | ||||||
| NA | 56 | 0.7 |
UTBILDNINGSKONTROLL
Beskriv datan. Vad är skalan för de olika variablerna? Hur mycket saknas det datan? Finns det någonting konstigt i vaderna?
Vad kan vi lära oss om variabeln “förtroende för polisen” genom att göra en histogram?
Kan vi gör en histogram med variablen ‘stop_by_police’?
För syftet med den här workshopen har jag tagit fram ett ”nästan rent” dataset, men jag har lämnat kvar ett par saker som fortfarande behöver fixas för övning. En av dem är ”könsvariabeln”.
Koda om ‘gender’ att blir ‘Man’ och ‘kvinna’ kalla det någonting annat
library(dplyr)
roma_krim$kon_text <- case_match(roma_krim$gender,
1 ~ "Man",
2 ~ "Kvinna",
.default = NA)
#och det är alltid bra att dubbel kolla att det gick hur det borde.
table(roma_krim$gender, roma_krim$kon_text)##
## Kvinna Man
## 1 0 3591
## 2 4356 0Sen kan vi också konvertera alla variabler som är ‘charachter’ till facotor (eller kategorisk). R brukar behandlar variabler som är ‘charachter’ som faktor, men med vissa funktioner det kan skapa lite problem så vi kan byta alla av de på samtidigt med den följande
Vi kan också se i datan att det finns 3 variabler som kallades för ‘discrim_prevalance_X’. Dessa variabler är en mätning för hur mycket diskriminering respondenten tror finns i deras samhälle när det gäller till olika faktorer. Det här är någonting vi vill kontrolera för senare men fokuset av undersökning handlar inte om någonting specifik till deras uppfattning om hur vanligt diskriminering är i samhället. Därför är det bäst att skapa en index variabel fast istället av att bara summa upp alla värden från varje respondent vi ska ge var en medelvärdet från hur de svarade till alla.
För det här vi kan använda dplyr och ‘mutate()’ att skapa ett nytt variabel som kallades för ‘discrim_prevalance_all’. En hjälpsam tips för mig är att när man ser %>% eller |> bara läsa den som det står för ‘sen gör det här’ Först vi berätta R att vi vill titta in till datan %>% fokusera genomgåends rad %>% mutate(). Funktionen mutate funkar med många andra funktioner men i det här fallet vi skapa ett nytt med mean() funktionen.
roma_krim<- roma_krim %>% rowwise() %>% mutate(discrim_prevalance_all=
mean(c(discrim_prevalance_color, discrim_prevalance_origin, discrim_prevelance_religion), na.rm=T))
hist(roma_krim$discrim_prevalance_all)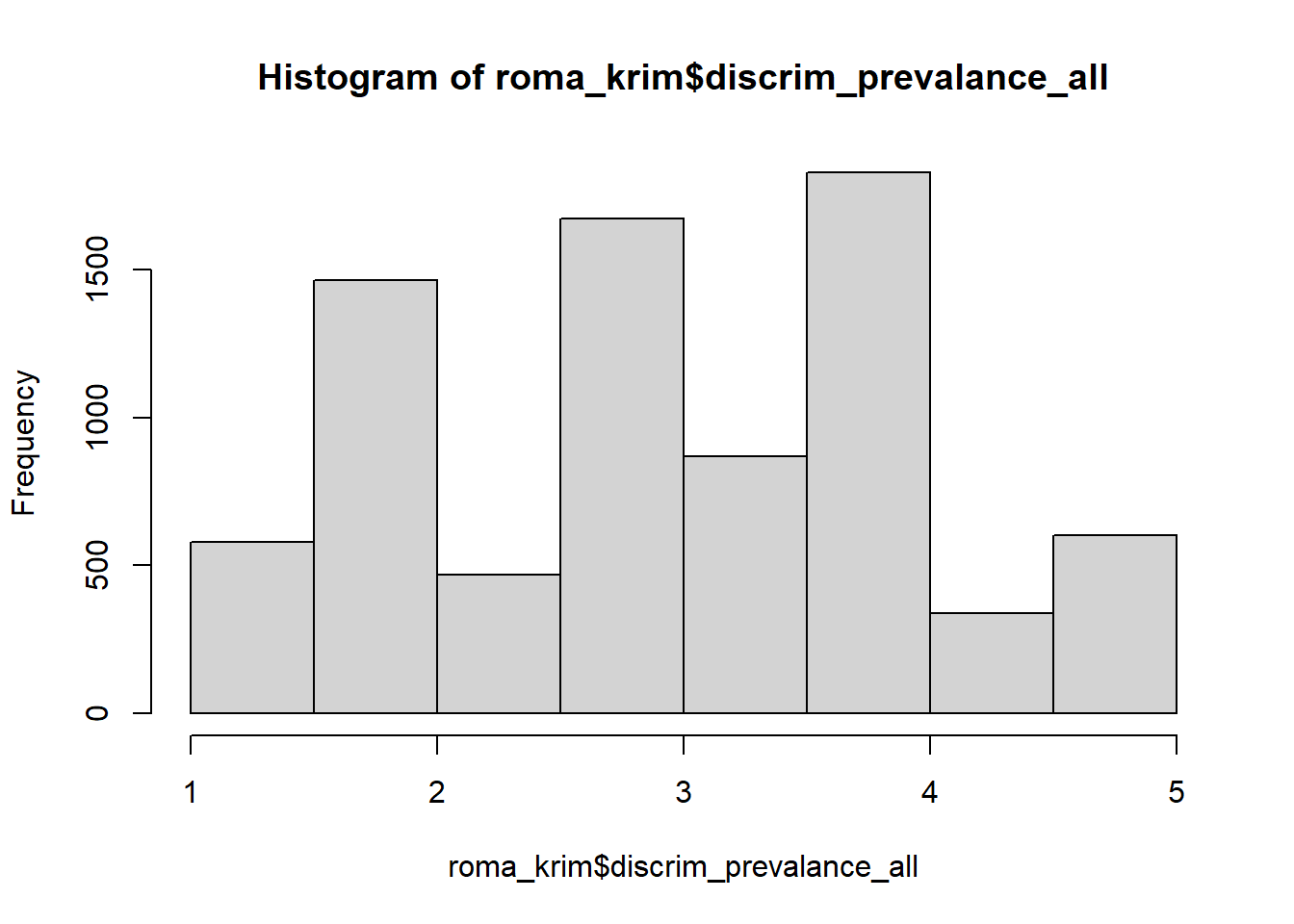
Vi också behöver samlar ihop alla som svarade att de har tagit emot någon slags stöd på grund av deras etnicitet. När man behöver ta specifik värden från flera variabel den ‘ifelse()’ funktion är jätteanvändbart. Funktionen funkar nästan som en mening ‘OM’, ‘SEN’, ‘ANNARS’. I denna fall vi säger OM deltagaren svarade 1, SEN byta till ‘Yes’, ANNARS ‘No’. Men eftersom vi har flera variabel vi kan lägga till en steg men ‘|’ som bara översättas som ‘ELLER’. Då kan ni läser hela funktionen i exempeln.
roma_krim$received_support <- ifelse(roma_krim$financial_support == 1 |
roma_krim$job_support == 1 |
roma_krim$training_support == 1 |
roma_krim$document_support == 1 |
roma_krim$housing_support == 1 |
roma_krim$language_support == 1 |
roma_krim$medical_support == 1, "Yes", "No")
roma_krim$received_support <- relevel(as.factor(roma_krim$received_support), ref = "No")Och nu kan vi bygga en snyggt tabell med alla variabel från analysen i artikeln. Det finns alltid många olika sätt i R att göra saker, men tabel1 funktionen från paketet med samma namn är ganska smidigt. Det är också lätt att skapa ett snabbt korstabell med en gruppering variabel. Först vi skapa en vanligt tabell.
library(table1)
table1(~ discrim_all + discrim_prevalance_all+ corruption_exp + stop_by_police + police_assault + received_support + n_household + age + kon_text + paid_work + highest_ed + marital_status, data = roma_krim)| Overall (N=7947) |
|
|---|---|
| discrim_all | |
| No | 4363 (54.9%) |
| Yes | 3382 (42.6%) |
| Missing | 202 (2.5%) |
| discrim_prevalance_all | |
| Mean (SD) | 3.03 (1.03) |
| Median [Min, Max] | 3.00 [1.00, 5.00] |
| Missing | 129 (1.6%) |
| corruption_exp | |
| No | 7545 (94.9%) |
| Yes | 248 (3.1%) |
| Missing | 154 (1.9%) |
| stop_by_police | |
| 1 year or longer | 627 (7.9%) |
| No | 6017 (75.7%) |
| Within last year | 1194 (15.0%) |
| Missing | 109 (1.4%) |
| police_assault | |
| No | 7679 (96.6%) |
| Yes | 167 (2.1%) |
| Missing | 101 (1.3%) |
| received_support | |
| No | 5177 (65.1%) |
| Yes | 2769 (34.8%) |
| Missing | 1 (0.0%) |
| n_household | |
| Mean (SD) | 4.25 (2.25) |
| Median [Min, Max] | 4.00 [1.00, 20.0] |
| age | |
| Mean (SD) | 40.0 (15.9) |
| Median [Min, Max] | 38.0 [16.0, 85.0] |
| kon_text | |
| Kvinna | 4356 (54.8%) |
| Man | 3591 (45.2%) |
| paid_work | |
| Paid Work | 1413 (17.8%) |
| Self Employed | 493 (6.2%) |
| Unpaid/Unemployed | 6023 (75.8%) |
| Missing | 18 (0.2%) |
| highest_ed | |
| High | 958 (12.1%) |
| Low | 1539 (19.4%) |
| Medium | 5436 (68.4%) |
| Missing | 14 (0.2%) |
| marital_status | |
| Divorced/Seperated/Widowed | 1276 (16.1%) |
| Married | 4474 (56.3%) |
| Never Married | 2141 (26.9%) |
| Missing | 56 (0.7%) |
Sen vi kan skapa en till gruperat med land. Vi gör detta med att använda ‘|’ sen lägga till ‘country’
tabel_grouped<-table1(~ discrim_all + discrim_prevalance_all+ corruption_exp + stop_by_police + police_assault + received_support + n_household + age + kon_text + paid_work + highest_ed + marital_status | country,, data = roma_krim)
tabel_grouped| Bulgaria (N=1078) |
Croatia (N=538) |
Czech Republic (N=817) |
Greece (N=508) |
Hungary (N=1171) |
Portugal (N=553) |
Romania (N=1408) |
Slovakia (N=1098) |
Spain (N=776) |
Overall (N=7947) |
|
|---|---|---|---|---|---|---|---|---|---|---|
| discrim_all | ||||||||||
| No | 812 (75.3%) | 273 (50.7%) | 328 (40.1%) | 199 (39.2%) | 746 (63.7%) | 153 (27.7%) | 1000 (71.0%) | 462 (42.1%) | 390 (50.3%) | 4363 (54.9%) |
| Yes | 258 (23.9%) | 249 (46.3%) | 454 (55.6%) | 307 (60.4%) | 357 (30.5%) | 400 (72.3%) | 398 (28.3%) | 581 (52.9%) | 378 (48.7%) | 3382 (42.6%) |
| Missing | 8 (0.7%) | 16 (3.0%) | 35 (4.3%) | 2 (0.4%) | 68 (5.8%) | 0 (0%) | 10 (0.7%) | 55 (5.0%) | 8 (1.0%) | 202 (2.5%) |
| discrim_prevalance_all | ||||||||||
| Mean (SD) | 2.46 (1.14) | 3.27 (1.07) | 3.58 (0.673) | 3.42 (0.812) | 3.18 (1.01) | 2.55 (0.747) | 2.86 (0.962) | 3.30 (0.983) | 2.87 (1.06) | 3.03 (1.03) |
| Median [Min, Max] | 2.33 [1.00, 5.00] | 3.33 [1.00, 5.00] | 3.67 [1.00, 5.00] | 3.33 [1.00, 5.00] | 3.33 [1.00, 5.00] | 2.33 [1.00, 5.00] | 2.67 [1.00, 5.00] | 3.33 [1.00, 5.00] | 2.67 [1.00, 5.00] | 3.00 [1.00, 5.00] |
| Missing | 30 (2.8%) | 16 (3.0%) | 3 (0.4%) | 4 (0.8%) | 18 (1.5%) | 0 (0%) | 36 (2.6%) | 22 (2.0%) | 0 (0%) | 129 (1.6%) |
| corruption_exp | ||||||||||
| No | 1032 (95.7%) | 528 (98.1%) | 776 (95.0%) | 457 (90.0%) | 1159 (99.0%) | 543 (98.2%) | 1295 (92.0%) | 989 (90.1%) | 766 (98.7%) | 7545 (94.9%) |
| Yes | 30 (2.8%) | 8 (1.5%) | 26 (3.2%) | 45 (8.9%) | 3 (0.3%) | 5 (0.9%) | 46 (3.3%) | 77 (7.0%) | 8 (1.0%) | 248 (3.1%) |
| Missing | 16 (1.5%) | 2 (0.4%) | 15 (1.8%) | 6 (1.2%) | 9 (0.8%) | 5 (0.9%) | 67 (4.8%) | 32 (2.9%) | 2 (0.3%) | 154 (1.9%) |
| stop_by_police | ||||||||||
| 1 year or longer | 41 (3.8%) | 60 (11.2%) | 46 (5.6%) | 77 (15.2%) | 112 (9.6%) | 89 (16.1%) | 23 (1.6%) | 73 (6.6%) | 106 (13.7%) | 627 (7.9%) |
| No | 978 (90.7%) | 292 (54.3%) | 643 (78.7%) | 265 (52.2%) | 853 (72.8%) | 367 (66.4%) | 1331 (94.5%) | 853 (77.7%) | 435 (56.1%) | 6017 (75.7%) |
| Within last year | 47 (4.4%) | 184 (34.2%) | 106 (13.0%) | 161 (31.7%) | 196 (16.7%) | 92 (16.6%) | 32 (2.3%) | 143 (13.0%) | 233 (30.0%) | 1194 (15.0%) |
| Missing | 12 (1.1%) | 2 (0.4%) | 22 (2.7%) | 5 (1.0%) | 10 (0.9%) | 5 (0.9%) | 22 (1.6%) | 29 (2.6%) | 2 (0.3%) | 109 (1.4%) |
| police_assault | ||||||||||
| No | 1062 (98.5%) | 507 (94.2%) | 787 (96.3%) | 493 (97.0%) | 1150 (98.2%) | 541 (97.8%) | 1363 (96.8%) | 1030 (93.8%) | 746 (96.1%) | 7679 (96.6%) |
| Yes | 4 (0.4%) | 29 (5.4%) | 23 (2.8%) | 14 (2.8%) | 10 (0.9%) | 6 (1.1%) | 13 (0.9%) | 38 (3.5%) | 30 (3.9%) | 167 (2.1%) |
| Missing | 12 (1.1%) | 2 (0.4%) | 7 (0.9%) | 1 (0.2%) | 11 (0.9%) | 6 (1.1%) | 32 (2.3%) | 30 (2.7%) | 0 (0%) | 101 (1.3%) |
| received_support | ||||||||||
| No | 833 (77.3%) | 314 (58.4%) | 406 (49.7%) | 364 (71.7%) | 810 (69.2%) | 263 (47.6%) | 1002 (71.2%) | 677 (61.7%) | 508 (65.5%) | 5177 (65.1%) |
| Yes | 245 (22.7%) | 224 (41.6%) | 411 (50.3%) | 144 (28.3%) | 361 (30.8%) | 290 (52.4%) | 406 (28.8%) | 421 (38.3%) | 267 (34.4%) | 2769 (34.8%) |
| Missing | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) | 1 (0.1%) | 1 (0.0%) |
| n_household | ||||||||||
| Mean (SD) | 3.97 (2.18) | 5.20 (2.74) | 3.97 (1.88) | 5.35 (2.46) | 4.22 (2.52) | 3.60 (1.71) | 4.09 (2.13) | 4.54 (2.23) | 3.94 (1.78) | 4.25 (2.25) |
| Median [Min, Max] | 4.00 [1.00, 15.0] | 5.00 [1.00, 20.0] | 4.00 [1.00, 15.0] | 5.00 [1.00, 18.0] | 4.00 [1.00, 20.0] | 4.00 [1.00, 11.0] | 4.00 [1.00, 16.0] | 4.00 [1.00, 14.0] | 4.00 [1.00, 14.0] | 4.00 [1.00, 20.0] |
| age | ||||||||||
| Mean (SD) | 42.7 (15.9) | 35.2 (13.1) | 39.3 (15.8) | 36.2 (13.9) | 41.2 (16.5) | 44.9 (19.0) | 40.9 (16.1) | 38.2 (14.8) | 38.1 (14.5) | 40.0 (15.9) |
| Median [Min, Max] | 41.0 [16.0, 85.0] | 33.0 [16.0, 78.0] | 37.0 [16.0, 85.0] | 33.0 [16.0, 85.0] | 39.0 [16.0, 85.0] | 41.0 [16.0, 85.0] | 38.0 [16.0, 85.0] | 36.0 [16.0, 84.0] | 37.0 [16.0, 85.0] | 38.0 [16.0, 85.0] |
| kon_text | ||||||||||
| Kvinna | 615 (57.1%) | 290 (53.9%) | 430 (52.6%) | 279 (54.9%) | 624 (53.3%) | 292 (52.8%) | 787 (55.9%) | 570 (51.9%) | 469 (60.4%) | 4356 (54.8%) |
| Man | 463 (43.0%) | 248 (46.1%) | 387 (47.4%) | 229 (45.1%) | 547 (46.7%) | 261 (47.2%) | 621 (44.1%) | 528 (48.1%) | 307 (39.6%) | 3591 (45.2%) |
| paid_work | ||||||||||
| Paid Work | 203 (18.8%) | 25 (4.6%) | 237 (29.0%) | 53 (10.4%) | 399 (34.1%) | 20 (3.6%) | 217 (15.4%) | 177 (16.1%) | 82 (10.6%) | 1413 (17.8%) |
| Self Employed | 17 (1.6%) | 5 (0.9%) | 19 (2.3%) | 125 (24.6%) | 4 (0.3%) | 114 (20.6%) | 161 (11.4%) | 27 (2.5%) | 21 (2.7%) | 493 (6.2%) |
| Unpaid/Unemployed | 856 (79.4%) | 508 (94.4%) | 559 (68.4%) | 330 (65.0%) | 765 (65.3%) | 418 (75.6%) | 1023 (72.7%) | 891 (81.1%) | 673 (86.7%) | 6023 (75.8%) |
| Missing | 2 (0.2%) | 0 (0%) | 2 (0.2%) | 0 (0%) | 3 (0.3%) | 1 (0.2%) | 7 (0.5%) | 3 (0.3%) | 0 (0%) | 18 (0.2%) |
| highest_ed | ||||||||||
| High | 17 (1.6%) | 55 (10.2%) | 267 (32.7%) | 8 (1.6%) | 175 (14.9%) | 1 (0.2%) | 94 (6.7%) | 319 (29.1%) | 22 (2.8%) | 958 (12.1%) |
| Low | 126 (11.7%) | 149 (27.7%) | 47 (5.8%) | 298 (58.7%) | 191 (16.3%) | 244 (44.1%) | 179 (12.7%) | 70 (6.4%) | 235 (30.3%) | 1539 (19.4%) |
| Medium | 935 (86.7%) | 334 (62.1%) | 501 (61.3%) | 202 (39.8%) | 800 (68.3%) | 308 (55.7%) | 1133 (80.5%) | 705 (64.2%) | 518 (66.8%) | 5436 (68.4%) |
| Missing | 0 (0%) | 0 (0%) | 2 (0.2%) | 0 (0%) | 5 (0.4%) | 0 (0%) | 2 (0.1%) | 4 (0.4%) | 1 (0.1%) | 14 (0.2%) |
| marital_status | ||||||||||
| Divorced/Seperated/Widowed | 168 (15.6%) | 54 (10.0%) | 152 (18.6%) | 64 (12.6%) | 199 (17.0%) | 89 (16.1%) | 244 (17.3%) | 184 (16.8%) | 122 (15.7%) | 1276 (16.1%) |
| Married | 508 (47.1%) | 295 (54.8%) | 447 (54.7%) | 281 (55.3%) | 598 (51.1%) | 412 (74.5%) | 826 (58.7%) | 669 (60.9%) | 438 (56.4%) | 4474 (56.3%) |
| Never Married | 399 (37.0%) | 189 (35.1%) | 212 (25.9%) | 162 (31.9%) | 366 (31.3%) | 52 (9.4%) | 327 (23.2%) | 219 (19.9%) | 215 (27.7%) | 2141 (26.9%) |
| Missing | 3 (0.3%) | 0 (0%) | 6 (0.7%) | 1 (0.2%) | 8 (0.7%) | 0 (0%) | 11 (0.8%) | 26 (2.4%) | 1 (0.1%) | 56 (0.7%) |
Nu kan vi beskriva datan ordentligt.
UTBILDNINGSKONTROL
Vilken ny information fick vi med dessa ändringar?
9.1.2 Andra steget
Gör en enkel linjär regression där “police_trust” är den beroende variabeln och “discrim_all” är den oberoende variabeln. Variabeln ‘discrim_all’ skapas av flera variabel i samma sätt som ‘received_support’ variabeln. Kolla in artikelns data avsnitt om vilka område av sociala liv mätas.
Snabb anteckning: Kommer ihåg tidigare när vi sade att formeln för den linjära regressions modellen liknade R-funktionen lm()?
Algebran för att skapa en linje är y= b + mx. Där y är en punkt på en linje som bestäms av värdet på skärningspunkten (b) plus värdet på lutningen (x) multipliceras av värdet på x. I en regressions modell är y det förväntade värdet av den beroende variabeln, vilket är en punkt på en linje som bestäms av värdet på skärningspunkten plus en lutning som vi kallar en koefficient multipliceras av värdet på den oberoende variabeln x.
I vårt nuvarande exempel skulle det se ut så här: police trust = intercept + coefficient*discrim_all
Och formeln i den linjära modell funktionen är:
lm(police_trust~ discrim_all, data= roma_krim) EASY!
##
## Call:
## lm(formula = police_trust ~ discrim_all, data = roma_krim)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.1775 -2.1775 0.0409 2.0409 6.0409
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 5.17753 0.04583 113.0 <2e-16 ***
## discrim_allYes -1.21841 0.06922 -17.6 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.993 on 7589 degrees of freedom
## (356 observations deleted due to missingness)
## Multiple R-squared: 0.03922, Adjusted R-squared: 0.03909
## F-statistic: 309.8 on 1 and 7589 DF, p-value: < 2.2e-16UBILDNINGSKONTROLL
Vad säger resultaten från linjär regressionsanalysen om sambandet mellan förtroende för polisen och diskrimination?
Vad är det predicerad värdet för förtroende för polisen för en person som svarade Yes på diskrim variabeln?
Nu vi kan skapa en plot av de förvantade värden för förtroende i polis med plot_model() funktionen. Att visualisera sambandet mellan variablerna är förmodligen bästa sätt att kunna avgöra styrkan och riktningen av sambandet.
## Some of the focal terms are of type `character`. This may lead to unexpected results. It is recommended to convert these variables to
## factors before fitting the model.
## The following variables are of type character: `discrim_all`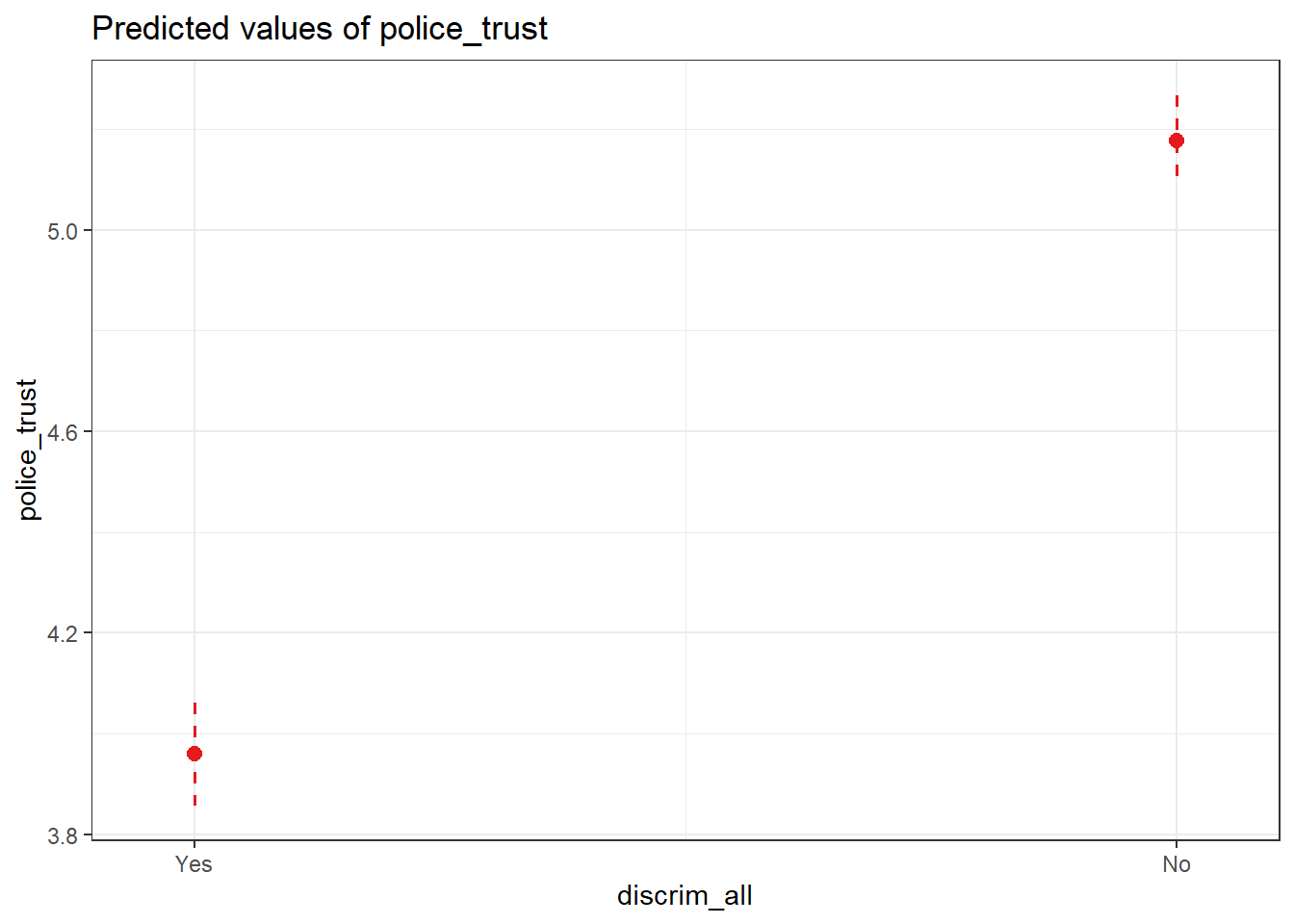
UBILDNINGSKONTROLL Hitta de värden du beräknade från regressions-tabellen i plotten? Hur bör vi tolka interceptet i denna plot?
9.1.3 Tredje steget
Om vi ville vi skulle kunna göra om ett nytt modell för varje oberoende variabel av intresse i analysen. Men om vi vill ser hur starkt sambandet mellan förtroende i polisen är med var en variabel när vi hålla de andra ‘konstant’ då göra vi en en multivariat eller multipel linjär regression genom att lägga till stop_by_police, police_assault, och received_support.
m_multi<- lm(police_trust~ discrim_all + stop_by_police + police_assault + received_support, data = roma_krim)
summary(m_multi)##
## Call:
## lm(formula = police_trust ~ discrim_all + stop_by_police + police_assault +
## received_support, data = roma_krim)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.3454 -2.2952 -0.1387 2.2259 7.9603
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4.99847 0.13182 37.918 < 2e-16 ***
## discrim_allYes -1.05024 0.07301 -14.385 < 2e-16 ***
## stop_by_policeNo 0.20668 0.12881 1.604 0.1086
## stop_by_policeWithin last year -0.36465 0.15059 -2.421 0.0155 *
## police_assaultYes -1.54389 0.24525 -6.295 3.24e-10 ***
## received_supportYes 0.14025 0.07343 1.910 0.0562 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.979 on 7424 degrees of freedom
## (517 observations deleted due to missingness)
## Multiple R-squared: 0.04959, Adjusted R-squared: 0.04895
## F-statistic: 77.47 on 5 and 7424 DF, p-value: < 2.2e-16Till sist kan vi lägga till de andra kontroll variabler vi tror kan påverkar båda våra oberoende variabler av intresse och den beroende variabel.
m_all<-lm(police_trust~ discrim_all + discrim_prevalance_all+
corruption_exp + stop_by_police +
police_assault + received_support +
n_household + age + kon_text + paid_work +
highest_ed + marital_status +
country, data= roma_krim)Nu istället av att titta på modellen med summary() funktionen, vi ska använda modelsummary() att ser alla tre att jämföra koefficienterna
modeller <- list("Modell 1" = m_discrim,
"Modell 2" = m_multi,
"Modell 3" = m_all)
library(modelsummary)
tabell_all <- modelsummary(modeller,
stars = TRUE)
tabell_all| Modell 1 | Modell 2 | Modell 3 | |
|---|---|---|---|
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 | |||
| (Intercept) | 5.178*** | 4.998*** | 5.778*** |
| (0.046) | (0.132) | (0.283) | |
| discrim_allYes | -1.218*** | -1.050*** | -0.674*** |
| (0.069) | (0.073) | (0.079) | |
| stop_by_policeNo | 0.207 | 0.153 | |
| (0.129) | (0.133) | ||
| stop_by_policeWithin last year | -0.365* | -0.461** | |
| (0.151) | (0.151) | ||
| police_assaultYes | -1.544*** | -1.451*** | |
| (0.245) | (0.247) | ||
| received_supportYes | 0.140+ | 0.191** | |
| (0.073) | (0.074) | ||
| discrim_prevalance_all | -0.396*** | ||
| (0.038) | |||
| corruption_expYes | -0.779*** | ||
| (0.203) | |||
| n_household | 0.032+ | ||
| (0.017) | |||
| age | 0.008** | ||
| (0.003) | |||
| kon_textMan | 0.021 | ||
| (0.075) | |||
| paid_workSelf Employed | -0.328+ | ||
| (0.169) | |||
| paid_workUnpaid/Unemployed | -0.214* | ||
| (0.097) | |||
| highest_edLow | -0.674*** | ||
| (0.146) | |||
| highest_edMedium | -0.614*** | ||
| (0.116) | |||
| marital_statusMarried | -0.065 | ||
| (0.103) | |||
| marital_statusNever Married | 0.239+ | ||
| (0.124) | |||
| countryCroatia | 1.167*** | ||
| (0.169) | |||
| countryCzech Republic | 0.417** | ||
| (0.153) | |||
| countryGreece | 2.145*** | ||
| (0.179) | |||
| countryHungary | 0.762*** | ||
| (0.134) | |||
| countryPortugal | 0.046 | ||
| (0.171) | |||
| countryRomania | 1.011*** | ||
| (0.125) | |||
| countrySlovakia | 0.018 | ||
| (0.143) | |||
| countrySpain | 0.172 | ||
| (0.147) | |||
| Num.Obs. | 7591 | 7430 | 7163 |
| R2 | 0.039 | 0.050 | 0.100 |
| R2 Adj. | 0.039 | 0.049 | 0.097 |
| AIC | 38187.8 | 37313.6 | 35596.6 |
| BIC | 38208.6 | 37362.0 | 35775.4 |
| Log.Lik. | -19090.901 | -18649.790 | -17772.309 |
| F | 309.792 | ||
| RMSE | 2.99 | 2.98 | 2.89 |
UBILDNINGSKONTROLL Vad säger resultaten från regressionsanalysen om sambandet mellan förtroende för polisen och de oberoende variablerna?
Hur kan vi förstå förändringarna i resultaten mellan steg 2 och 3?
Det kan vara svårt att jämföra koeffieienter med bara en tabell. Vi kan också plotta de med plot_models() funktionen.
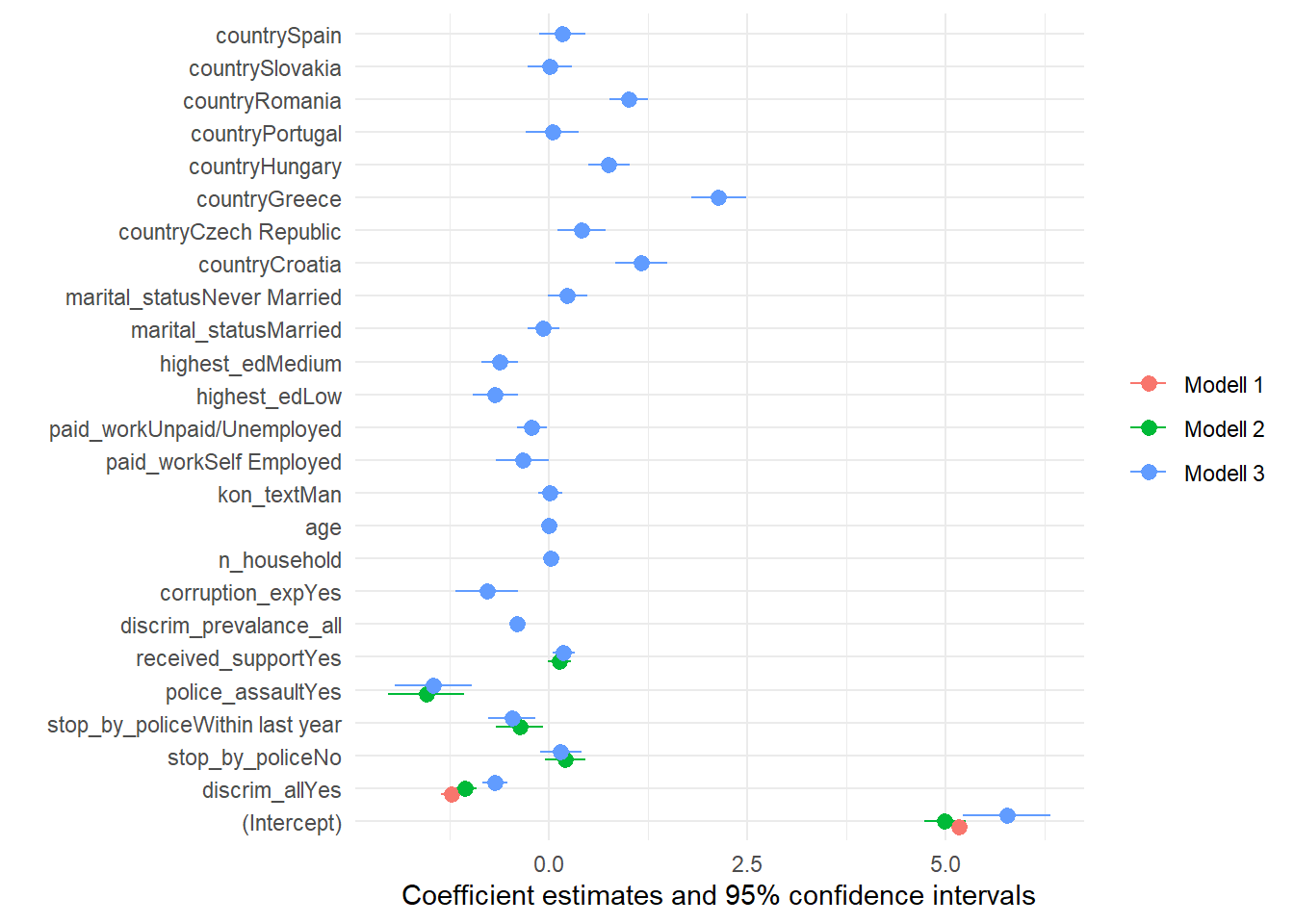
Det är liten svårt att ser betydelsefullt information. Eftersom vi är bara intresserad av oberoende variablerna av intresse vi kan ta ut och visa bara dessa. Vi kan också lägga till en linje som visa ‘noll’.
modelplot(modeller, coef_map = c('discrim_allYes',
'stop_by_policeNo',
'stop_by_policeWithin last year',
'police_assaultYes',
'received_supportYes'))+
geom_vline(xintercept = 0)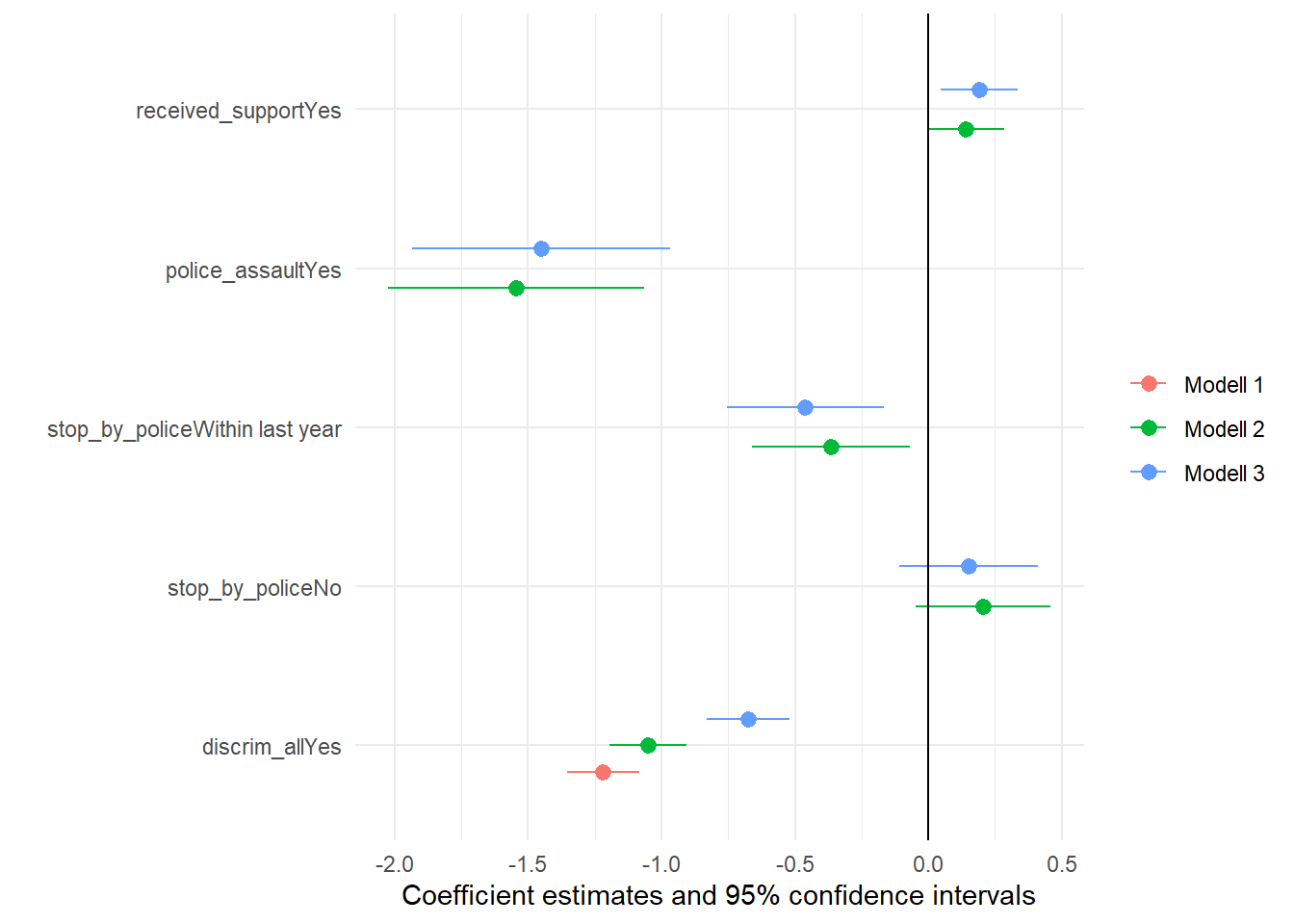
UTBILDNINGSKONTROL
Vad säger dessa plots?
Nu har ni gjort om en del av analysen från tabel 2 >i artikeln. Kolla om Koefficienterna från m_all >matcha med kolumn ‘Police’. Gör det?
Upprepa nu steg 1-3, men istället för “förtroende för polisen” analysera “förtroende för politiker” med variabeln “politicians_trust”.
När du är klar med förtroende för politiker analysen, eftersom både beroende variablerna ha den samma nivå, kommer från samma dataset och ha exakt samma regressions modeller, då kan vi jämföra modellen att utforska vilka oberoende variabler förklara de olika beroende variabler på olika sätt.
Att göra den vi bara byta ut modeller och namna den någonting annat. Ett exempel skulle kunna vara:
modeller_jamfor <- list(“Modell Polis” = m_all, “Modell Politiker” = YOURMODELHERE)
tabell_jamfor <- modelsummary(modeller_jamfor, stars = TRUE) tabell_jamfor
Och när ni har fått den att funkar, vi kan plotta koefficienterna också med den samma modelplot() funktion från tidigare men ersätta ‘modeller’ med den nytt list ‘modeller_jamfor’
UTBILDNINGSKONTROL Är ålder en bra prediktor för förtroende för polisen? Är ålder en bra prediktor för förtroende för politiker? Från denna snabba analys skulle du säga att respondenternas oro över diskriminering är en bra prediktor för förtroende för polisen, förtroende för politiker eller båda? Motivera ditt svar.