Kapitel 4 Grundläggande datahantering.
Följande är delvis baserat boken Statistical Inference via Data Science: A ModernDive into R and the Tidyverse (Second Edition) Kapitel 1, men innehållet är något kondenserat och anpassat för våra behov på den här kursen.
4.1 Att läsa in data i R.
I det här avsnittet skall vi gå igenom hur en läser in data i R från en csv-fil. Detta är en av de vanligast filtyperna för att lagra data i, och den som ni oftast kommer att stöta på. Det är den enda filtypen vi kommer att använda under kursen. Givetvis finns det fler filtyper, och flera sätt att läsa in dem i R på. Vi kommer dock bara att gå igenom inläsning av csv-data på den här kursen.
Vi kommer gå igenom två olika metoder: en som använder det som kallas “bas R”, det vill säga helt vanlig R-kod som endast använder grundläggande funktioner som redan finns inbyggda i R, och en liknande metod som dock bygger på ett paket som heter readr.
Anledningen till att en ibland vill använda readr istälet för Rs grundläggande funktioner är för att detta är ett snabbare sätt att läsa in data på, vilket kan vara bra om vi arbetar med väldigt stora dataset. Oftast räcker det dock gott och väl med bas R.
Det första du behöver göra är att skapa ett projekt och öppna ett nytt skript. Om du inte har gjort det så titta i avsnitt ovan.
Det andra du behöver göra är att ladda ned filen
NTU_2017-2021.csvfrån Canvas. Du hittar filen på samma modul som den här övningsboken. Efter att ha laddat ned filen är det mycket viktigt att du lägger den i samma mapp som ditt R-projekt. Detta gör att vi kan läsa in den i RStudio genom att bara använda filnamnet (detta mycket enklare än att skriva en lång och krånglig sökväg!). Passa också på att ladda ned Kodboken (“Kodbok NTU 2017-2021.pdf”Kodbok NTU 2017-2021.pdf) för detta de Nationella Trygghetsundersökningarna från samma sida i Canvas. En kodbok är ett dokument som talar om för oss hur undersökningen har genomförts och vad olika variabler och variabelvärden betyder om dessa inte skulle vara döpta på ett enkelt sätt i filen. Kodboken kommer alltså att hjälpa oss längre fram.Det tredje vi behöver göra är att ladda ned och öppna ett paket som heter
readr. Detta gör vi genom att först ladda ned “readr” med Rsinstall.packages()-funktion och sedan öppna “readr” med Rslibrary()-funktion. Skriv ininstall.packages("readr")i ditt skript, markera kodavsnittet och kör koden (genom att tryckaCtrl+ENTEReller klicka påRun). Gör sedan samma sak medlibrary()-funktionen.
Vi är nu redo att läsa in och börja utforska vår data.
Först prövar vi metoden med bas R. Precis som vi gick igenom i avsnitt 2.6 så arbetar vi i R med objekt, och när vi läser in data så gör vi det genom att skapa ett nytt objekt, som kommer att innehålla den data vi vill läsa in.
Vi döper vår data till “ntu1721” så att vi kommer ihåg att detta är alla Nationella Trygghetsundersökningar från 2017 till 2021.
Funktionen read.csv() kan kombineras med flera olika argument. Det är inte jätteviktigt för er att veta exakt vilka argument just nu. I det här fallet måste vi dock använda argumentet sep = ";" för att tala om för R att filen använder semikolon för att skilja mellan olika observationer.
Det gör inte jättemycket om du inte förstod detta. Men det kan vara bra att känna till att om du försöker ladda in data från en csv-fil och du får varningsmeddelanden eller data ser väldigt konstigt ut så är det en vanlig felkälla att datafilen använder en viss typ av skiljetecken (exempelvis komma-tecken) för att skilja mellan värdena i csv-filen, medan R försöker läsa in och tolka datan genom att leta efter en annan typ av skiljetecken (exempelvis ett semi-kolon “;”).
Vi har ni läst in vår datafil och sparat den i ett objekt som en data frame. Som du kanske kommer ihåg från avsnitt 2.2 så är en data frame ett kalkylblad med variabler i kolumnerna, och individuella observationer i raderna. Precis som ett vanlig excel-ark.
Vi kan kontrollera om vårt objekt faktiskt är en data frame genom följande kod som använder funktionen is.data.frame() och som ger oss ett svar, sant eller falskt:
## [1] TRUEVi kan använda den inbygda funktionen i R som heter head() för att enkelt inspektera de översta sex raderna i “ntu1721”. (Vi behöver alltså inte ladda ned något särskilt paket för att använda denna funktion, den är en del av Rs grundläggande språk, det som kallas bas R).
## region kalvikt husvikt insamlingsår referensår Kon alder_8 alder_4 SV_UTL_BAKGRUND Utbildning3 Famtyp4 bostad2 Kommungrupper_kat3
## 1 Väst 50,1085332453444 25,0542666226722 2017 2016 1 8 4 NA 1 1 1 3
## 2 Stockholm 48,1433157913322 24,0716578956661 2017 2016 1 8 4 1 3 1 2 1
## 3 Syd 48,0168043800187 48,0168043800187 2017 2016 1 8 4 NA 1 1 NA 3
## 4 Syd 21,8743624344349 21,8743624344349 2019 2018 1 8 4 1 3 3 1 3
## 5 Väst 372,128645380248 372,128645380248 2019 2018 2 8 4 3 1 3 2 2
## 6 Väst 83,568572888694 83,568572888694 2019 2018 2 8 4 1 2 3 NA 3
## A1 A2A_01 A2A_02 A2A_03 A2A_04 A2A_05 A2A_06 A2BB A3A A3B A4 A5 B1 B2 B3 B4 B5 B6A B6B B6C B6D C1 C2A C2B C3 C4 C5A C5B C6 C7 C8A C8B C9 C10 C11 C12
## 1 1933 0 1 0 0 0 0 2 1 1 2 8 4 2 3 4 4 4 5 4 4 1 5 2 5 5 6 NA 1 3 NA NA 3 3 5 2
## 2 1933 0 1 0 0 0 0 2 3 2 6 8 1 1 1 1 1 2 2 1 2 1 1 NA 4 5 6 NA 5 4 NA NA 5 4 5 5
## 3 1933 0 1 0 0 0 0 NA 4 1 1 8 4 3 4 4 3 3 3 3 3 2 2 NA 5 5 6 NA 3 3 NA NA 5 4 5 2
## 4 1938 1 0 0 0 0 0 1 1 1 6 8 3 4 6 6 6 6 3 6 3 3 2 NA 5 5 6 1 5 5 NA NA 5 5 5 5
## 5 1938 1 0 0 0 0 0 1 3 2 2 8 1 1 1 1 2 2 2 2 1 1 4 NA 2 2 6 1 2 3 NA NA 2 2 3 2
## 6 1938 1 0 0 0 0 0 NA NA 1 2 8 2 1 2 3 2 4 4 2 2 1 3 NA 2 2 4 NA 2 6 NA NA 4 3 3 2
## C13 C14AA C14BB C14CC C14DD C14EE C14FF C14GG C14HH C14ii C15 C16 D1 D1A_KAPAT D2 D2A_KAPAT D3 D3A_KAPAT D4 D4A_KAPAT D5 D5A_KAPAT D6 D6A_KAPAT D7
## 1 2 1 2 NA NA NA NA NA NA NA 5 1 2 NA 2 NA 2 NA 2 NA 2 NA 2 NA 2
## 2 3 3 4 4 NA NA NA NA 4 4 5 3 3 NA 2 NA 2 NA 2 NA 2 NA 2 NA 2
## 3 2 NA NA NA NA NA NA NA NA NA 2 2 2 NA 2 NA 2 NA 2 NA 2 NA 2 NA 2
## 4 3 4 4 4 2 4 4 4 4 4 5 6 3 NA 2 NA 2 NA 2 NA 2 NA 2 NA 2
## 5 2 1 2 2 1 1 3 3 3 4 2 1 2 NA 2 NA 2 NA 2 NA 2 NA 2 NA 2
## 6 2 1 2 1 2 3 3 3 3 2 1 1 1 1 3 NA 2 NA 2 NA 2 NA 2 NA 2
## D7A_KAPAT D8 D8A_KAPAT D9 D9A_KAPAT D9B D9C D10 D10A_KAPAT D10B D11 D11A_KAPAT D12 D13 D13A_KAPAT D14 D14A_KAPAT D15 E1 E2A E2B E3 E4A E4B E4C E4D E4E
## 1 NA 2 NA 2 NA NA NA 2 NA NA 2 NA NA 2 NA 2 NA 2 2 NA NA NA NA NA NA NA NA
## 2 NA 2 NA 2 NA NA NA 2 NA NA 2 NA NA 2 NA 2 NA 2 2 NA NA NA NA NA NA NA NA
## 3 NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA 2 NA 3 NA NA NA NA NA NA NA NA NA
## 4 NA 2 NA 2 NA NA NA 2 NA NA 2 NA NA 2 NA 2 NA 2 2 NA NA NA NA NA NA NA NA
## 5 NA 2 NA 2 NA NA NA 2 NA NA 2 NA NA 2 NA 2 NA 2 2 NA NA NA NA NA NA NA NA
## 6 NA 2 NA 2 NA NA NA 2 NA NA 2 NA NA 2 NA 2 NA 3 2 NA NA NA NA NA NA NA NA
## E5AA E5BB E6x E7AA E7BB E7CC E8AA E8BB E8CC
## 1 NA NA NA NA NA NA NA NA NA
## 2 NA NA NA NA NA NA NA NA NA
## 3 NA NA NA NA NA NA NA NA NA
## 4 2 NA NA NA NA NA NA NA NA
## 5 2 NA NA NA NA NA NA NA NA
## 6 2 NA NA NA NA NA NA NA NAVi får då en utskrift som visar variabelnamn i kolumner, samt de sex översta radernas olika värden på dessa variabler. Detta är ett bra första sätt att bekanta sig med ett datamaterial.
Som du kanske märkte tar det lite tid att läsa in en såpass stor datafil. En större fil tar ännu längre tid. Vi prövar därför metod nummer två, att använda funktionen read_csv() från paketet readr. För att använda denna funktion som måste vi alltså först ha laddat ned och öppnat paketet readr.
## Warning: One or more parsing issues, call `problems()` on your data frame for details, e.g.:
## dat <- vroom(...)
## problems(dat)## Rows: 375590 Columns: 1
## ── Column specification ────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## chr (1): region;kalvikt;husvikt;insamlingsår;referensår;Kon;alder_8;alder_4;SV_UTL_BAKGRUND;Utbildning3;Famtyp4;bostad2;Kommungrupper_kat3;A1;A2A_01;A2A...
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Åh fan! Som du märker får vi ett varningsmeddelande. Någonting verkar vara fel.
Vi kan återigen använda funktionen head() för att enkelt inspektera de översta fem raderna i vår nya data frame “ntu1721_readr” för att försöka förstå vad felet består av.
## # A tibble: 6 × 1
## region;kalvikt;husvikt;insamlingsår;referensår;Kon;alder_8;alder_4;SV_UTL_BAKGRUND;Utbildning3;Famtyp4;bostad2;Kommungrupper_kat3;A1;A2A_01;A2A_02;A2A_0…¹
## <chr>
## 1 Väst;50,1085332453444;25,0542666226722;2017;2016;1;8;4; ;1;1;1;3;1933;0;1;0;0;0;0;2;1;1;2;8;4;2;3;4;4;4;5;4;4;1;5;2;5;5;6; ;1;3; ; ;3;3;5;2;2;1;2; ; ; ; …
## 2 Stockholm;48,1433157913322;24,0716578956661;2017;2016;1;8;4;1;3;1;2;1;1933;0;1;0;0;0;0;2;3;2;6;8;1;1;1;1;1;2;2;1;2;1;1; ;4;5;6; ;5;4; ; ;5;4;5;5;3;3;4;4;…
## 3 Syd;48,0168043800187;48,0168043800187;2017;2016;1;8;4; ;1;1; ;3;1933;0;1;0;0;0;0; ;4;1;1;8;4;3;4;4;3;3;3;3;3;2;2; ;5;5;6; ;3;3; ; ;5;4;5;2;2; ; ; ; ; ; ;…
## 4 Syd;21,8743624344349;21,8743624344349;2019;2018;1;8;4;1;3;3;1;3;1938;1;0;0;0;0;0;1;1;1;6;8;3;4;6;6;6;6;3;6;3;3;2; ;5;5;6;1;5;5; ; ;5;5;5;5;3;4;4;4;2;4;4;…
## 5 Väst;372,128645380248;372,128645380248;2019;2018;2;8;4;3;1;3;2;2;1938;1;0;0;0;0;0;1;3;2;2;8;1;1;1;1;2;2;2;2;1;1;4; ;2;2;6;1;2;3; ; ;2;2;3;2;2;1;2;2;1;1;3…
## 6 Väst;83,568572888694;83,568572888694;2019;2018;2;8;4;1;2;3; ;3;1938;1;0;0;0;0;0; ; ;1;2;8;2;1;2;3;2;4;4;2;2;1;3; ;2;2;4; ;2;6; ; ;4;3;3;2;2;1;2;1;2;3;3;3…
## # ℹ abbreviated name:
## # ¹`region;kalvikt;husvikt;insamlingsår;referensår;Kon;alder_8;alder_4;SV_UTL_BAKGRUND;Utbildning3;Famtyp4;bostad2;Kommungrupper_kat3;A1;A2A_01;A2A_02;A2A_03;A2A_04;A2A_05;A2A_06;A2BB;A3A;A3B;A4;A5;B1;B2;B3;B4;B5;B6A;B6B;B6C;B6D;C1;C2A;C2B;C3;C4;C5A;C5B;C6;C7;C8A;C8B;C9;C10;C11;C12;C13;C14AA;C14BB;C14CC;C14DD;C14EE;C14FF;C14GG;C14HH;C14ii;C15;C16;D1;D1A_KAPAT;D2;D2A_KAPAT;D3;D3A_KAPAT;D4;D4A_KAPAT;D5;D5A_KAPAT;D6;D6A_KAPAT;D7;D7A_KAPAT;D8;D8A_KAPAT;D9;D9A_KAPAT;D9B;D9C;D10;D10A_KAPAT;D10B;D11;D11A_KAPAT;D12;D13;D13A_KAPAT;D14;D14A_KAPAT;D15;E1;E2A;E2B;E3;E4A;E4B;E4C;E4D;E4E;E5AA;E5BB;E6x;E7AA;E7BB;E7CC;E8AA;E8BB;E8CC`Detta ser väldigt tokigt ut. Notera alla semikolon (“;”) i den utskrift vi får. Det verkar som att R inte har förstått att filens olika värden separeras av semikolon. Detta är för att funktionen read_csv() använder vanliga kommatecken för att skilja mellan värden. Om vi vill att R skall förstå att datafilen använder semikolon för att separera värden så kan vi istället använda funktionen read_csv2().
Här finns det alltså i paketet readr olika funktioner med olika namn (“read_csv” och “read_csv2”) som läser och tolkar olika skiljetecken i csv-filen. Detta i motsats till read.csv()-funktionen i bas R där vi istället var tvungna att skriva in ett argument sep = ";" för att instruera R att leta efter semi-kolon istället för kommatecken.
Vi prövar alltså med funktionen read_csv2() och ser om vårt problem löser sig.
## ℹ Using "','" as decimal and "'.'" as grouping mark. Use `read_delim()` for more control.## Warning: One or more parsing issues, call `problems()` on your data frame for details, e.g.:
## dat <- vroom(...)
## problems(dat)## Rows: 375590 Columns: 110## ── Column specification ────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ";"
## chr (1): region
## dbl (108): kalvikt, husvikt, insamlingsår, referensår, Kon, alder_8, alder_4, SV_UTL_BAKGRUND, Utbildning3, Famtyp4, bostad2, Kommungrupper_kat3, A1, A2...
## lgl (1): E7CC
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.## # A tibble: 6 × 110
## region kalvikt husvikt insamlingsår referensår Kon alder_8 alder_4 SV_UTL_BAKGRUND Utbildning3 Famtyp4 bostad2 Kommungrupper_kat3 A1 A2A_01 A2A_02
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Väst 50.1 25.1 2017 2016 1 8 4 NA 1 1 1 3 1933 0 1
## 2 Stockholm 48.1 24.1 2017 2016 1 8 4 1 3 1 2 1 1933 0 1
## 3 Syd 48.0 48.0 2017 2016 1 8 4 NA 1 1 NA 3 1933 0 1
## 4 Syd 21.9 21.9 2019 2018 1 8 4 1 3 3 1 3 1938 1 0
## 5 Väst 372. 372. 2019 2018 2 8 4 3 1 3 2 2 1938 1 0
## 6 Väst 83.6 83.6 2019 2018 2 8 4 1 2 3 NA 3 1938 1 0
## # ℹ 94 more variables: A2A_03 <dbl>, A2A_04 <dbl>, A2A_05 <dbl>, A2A_06 <dbl>, A2BB <dbl>, A3A <dbl>, A3B <dbl>, A4 <dbl>, A5 <dbl>, B1 <dbl>, B2 <dbl>,
## # B3 <dbl>, B4 <dbl>, B5 <dbl>, B6A <dbl>, B6B <dbl>, B6C <dbl>, B6D <dbl>, C1 <dbl>, C2A <dbl>, C2B <dbl>, C3 <dbl>, C4 <dbl>, C5A <dbl>, C5B <dbl>,
## # C6 <dbl>, C7 <dbl>, C8A <dbl>, C8B <dbl>, C9 <dbl>, C10 <dbl>, C11 <dbl>, C12 <dbl>, C13 <dbl>, C14AA <dbl>, C14BB <dbl>, C14CC <dbl>, C14DD <dbl>,
## # C14EE <dbl>, C14FF <dbl>, C14GG <dbl>, C14HH <dbl>, C14ii <dbl>, C15 <dbl>, C16 <dbl>, D1 <dbl>, D1A_KAPAT <dbl>, D2 <dbl>, D2A_KAPAT <dbl>, D3 <dbl>,
## # D3A_KAPAT <dbl>, D4 <dbl>, D4A_KAPAT <dbl>, D5 <dbl>, D5A_KAPAT <dbl>, D6 <dbl>, D6A_KAPAT <dbl>, D7 <dbl>, D7A_KAPAT <dbl>, D8 <dbl>, D8A_KAPAT <dbl>,
## # D9 <dbl>, D9A_KAPAT <dbl>, D9B <dbl>, D9C <dbl>, D10 <dbl>, D10A_KAPAT <dbl>, D10B <dbl>, D11 <dbl>, D11A_KAPAT <dbl>, D12 <dbl>, D13 <dbl>,
## # D13A_KAPAT <dbl>, D14 <dbl>, D14A_KAPAT <dbl>, D15 <dbl>, E1 <dbl>, E2A <dbl>, E2B <dbl>, E3 <dbl>, E4A <dbl>, E4B <dbl>, E4C <dbl>, E4D <dbl>, …Nu verkar det fungera!
Det ser det mesta likadant ut som den första filen “ntu1721” som vi läste in. Men inte helt och hållet likadant. Det är för att funktionen read_csv() och read_csv2() inte skapar objekt av typen data frames. Istället skapar det ett objekt av typen tibble. Det är inte jätteviktigt att veta skillnaden mellan dessa två sätt att lagra data, då båda fungerar på ungefär samma sätt och lagrar variabler i kolumner och individella observationer i raderna. En tibble fungerar i de allra flesta fall precis som en data frame men kan kortfattat beskrivas som en uppdaterad data frame där årtal av erfarenheter har gjort att programmerare justerat vissa saker. Man kan tänka på data frame som en iphone 7 och tibble som en iphone 15. De är i grunden samma sak, men en tibble är en uppdaterad version med några nya funktioner. För våra behov kan vi för det mesta ignorera dessa skillnader.
Det som du kanske märker är dock att vi får lite mer information i utskriften när vi använder funktionen head() på data som lagras i en tibble gällande exempelvis vilken typ av varibel de olika kolumnerna är (exemplvis
Som du kanske också noterar står det att # 102 more variables: följt av flera namngivna variabler. Det är så att vi har att göra med ett dataset med ganska många variabler (110 för att vara exakt!), och de blir helt enkelt för många att skriva ut. Precis som att vi bara ser de 6 översta raderna (av totalt 375590!). Detta är en av uppdateringarna som skiljer en tibble från en data frame. En data frame skriver ut alla variabler i en ganska ful och krånglig utskrift i konsolpanelen, medan en tibble bara ger oss de första variablerna och sedan talar om för oss att det finns fler variabler att granska, om vi är intresserade.
UTBILDNINGSKONTROLL
Vilken typ av objekt är vårt objekt “ntu1721_readr” ?
Data frame
Tibble
Charachter
Doubble
Vad betyder värdena som står inskrivna på rad 2 i vårt objekt “ntu1721_readr” ?
Raderna är variabler, det olika värden som variablen visar beror på att olika personer har svarat olika saker (i det här fallet på frågor i den Nationella Trygghetsundersökningen)
Raderna är enskilda observationer (i det här fallet vad en enskild respondent har svarat på frågor i den Nationella Trygghetsundersökningen)
Vad betyder värdena som står inskrivna på kolumnerna i vårt objekt “ntu1721_readr” ?
Kolumnerna är variabler, det olika värden som variablen visar beror på att olika personer har svarat olika saker (i det här fallet på frågor i den Nationella Trygghetsundersökningen)
Kolumnerna är enskilda observationer (i det här fallet vad en enskild respondent har svarat på frågor i den Nationella Trygghetsundersökningen)
4.2 Utforska data
Vi fortsätter att utforska vårt dataset från Nationella Trygghetsundersökningen som vi i det förgående steget 3.1 har läst in och sparat some ett objekt ntu1721 i R.
Vi kommer att gå igenom tre funktioner för att närmare bekanta oss med data:
- View()-funktionen i bas R.
- glimpse()-funktionen som ingår i ett paket som heter dplyr.
- tecknet
$som låter oss utforska enskilda variabler i ett objekt av typen data frame eller i en tibble.
Och ytterligare två funktioner som vi kan använda tillsammans med ovanstående:
- summary()-funktionen i bas R som låter oss utforska enskilda variablers fördelning.
- subset()-funktionen
Som du märker så kommer vi att behöva ha tillgång till paketen dplyr och knitr.
UTBILDNINGSKONTROLL
Ladda ned paketen
dplyrochknitrgenom att använda Rs grundläggandeinstall-packages()-funktion.
4.2.1 View() funktionen
Funktionen View() låter oss utforska hela datasetet (en hel data frame eller en hel tibble) i en separat pop-up ruta. Detta gör att vi kan bläddra och scrolla genom hela hela detta dataset och se alla variabler/kolumner och alla observationer/rader.
Pröva själv genom att skriva in View(ntu1721), antingen direkt i konsolpanelen och klicka ENTER, eller i ditt R skript där du sedan markerar kodavsnittet och trycker Ctrl+ENTER. Observera att R är teckenkänsligt och att du måste ge kommandot med ett stort “V”, det vill säga View(ntu1721) och inte view(ntu1721).
Om du tittar i kolumnen längst till vänster i pop-up rutan för ntu1721 så ser du en kolumn med siffror. Dessa är siffror radnumren för detta dataset. En rad är en observation av någonting. I det här fallet är vår observationsenhet en person (en respondent) som har svarat på den Nationella Trygghetsundersökningen. I kolumnerna finner du variablerna med variablernas namn längst upp. I detta fall motsvarar variablerna frågorna som personenn/respondent har besvarat i enkäten. Kolumnerna är alltså variablerna/enkätfrågorna, och raderna är individuella personer och deras svar på respektive fråga.
Andra dataset kan ha andra typer av värden. Exemeplvis kan en rad utgöras av ett visst datum och variablerna av hur många cyklar, fotgängare och hundar som passerar över ett visst övergångsställe. Det behöver alltså inte vara frågor i en enkät, utan det kan vara andra typer av observationer. Grunderna med variabler i kolumner och individuella observationer i raderna är dock desamma.
Växla tillbaka från pop-up rutan för objektet ntu1721 till ditt R skript genom att föra muspekaren över ditt R skript och klicka på det. Precis som du byter mellan två flikar i en vanlig webblsäsare. Du kan också stänga pop-up rutan för ntu1721 genom att klicka på det lilla krysset i fliken.
4.2.2 glimpse() funktionen
Ett annat sätt att utforska ett dataset, alltså ett objekt av typen data frame eller tibble, är att använda glimpse()-funktionen som ingår i dplyr-paketet. Således kan du bara använda glimpse()-funktionen efter att du har laddat dplyr-paketet genom att köra kommandot library(dplyr).
UTBILDNINGSKONTROLL
Installera och öppna paketet
dplyr
## Rows: 375,590
## Columns: 110
## $ region <chr> "Väst", "Stockholm", "Syd", "Syd", "Väst", "Väst", "Väst", "Mitt", "Syd", "Väst", "Stockholm", "Syd", "Väst", "Syd", "Väst", "V…
## $ kalvikt <chr> "50,1085332453444", "48,1433157913322", "48,0168043800187", "21,8743624344349", "372,128645380248", "83,568572888694", "59,7535…
## $ husvikt <chr> "25,0542666226722", "24,0716578956661", "48,0168043800187", "21,8743624344349", "372,128645380248", "83,568572888694", "29,8767…
## $ insamlingsår <int> 2017, 2017, 2017, 2019, 2019, 2019, 2019, 2019, 2019, 2020, 2020, 2020, 2020, 2020, 2020, 2017, 2017, 2017, 2017, 2017, 2017, 2…
## $ referensår <int> 2016, 2016, 2016, 2018, 2018, 2018, 2018, 2018, 2018, 2019, 2019, 2019, 2019, 2019, 2019, 2016, 2016, 2016, 2016, 2016, 2016, 2…
## $ Kon <int> 1, 1, 1, 1, 2, 2, 2, 1, 1, 2, 2, 2, 1, 2, 1, 2, 2, 2, 2, 1, 1, 2, 2, 1, 2, 1, 1, 2, 2, 2, 2, 1, 1, 1, 2, 2, 1, 1, 2, 2, 1, 2, 1…
## $ alder_8 <int> 8, 8, 8, 8, 8, 8, 8, 8, 8, 7, 7, 7, 7, 7, 7, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8…
## $ alder_4 <int> 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4…
## $ SV_UTL_BAKGRUND <int> NA, 1, NA, 1, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 3, 1, 1, 3, NA, 3, 1, 1, 1, 1, 1, 1, 1, NA, 1, NA, 1, 3, 3, 1, 1, 3, 1, 1, NA, 1…
## $ Utbildning3 <int> 1, 3, 1, 3, 1, 2, 1, 1, 3, 1, 3, 2, 2, 3, 2, 1, 2, 1, 3, 3, 2, 1, 3, 2, 2, 3, 3, 2, 2, 1, 2, 1, 1, NA, 1, 1, 3, 1, 1, 2, 3, 3, …
## $ Famtyp4 <int> 1, 1, 1, 3, 3, 3, 3, NA, 1, 1, 1, 1, 1, 1, 1, 3, 3, NA, 3, 3, 3, 3, 3, 1, 3, 1, 1, 3, 3, 3, NA, 1, 1, 1, 3, 3, 1, 1, 3, 3, 1, 3…
## $ bostad2 <int> 1, 2, NA, 1, 2, NA, 1, NA, 1, 2, 1, 1, 2, 2, 1, 1, 1, 1, 2, 2, 1, 2, 2, 1, 2, 1, 1, 2, 2, NA, 2, 2, 1, 2, 2, 2, 2, 1, 2, 2, 1, …
## $ Kommungrupper_kat3 <int> 3, 1, 3, 3, 2, 3, 1, 3, 3, 1, 1, 3, 3, 1, 3, 1, 3, 3, 2, 3, 3, 3, 2, 2, 2, 2, 3, 1, 1, 3, 3, 3, 2, 1, 2, 1, 1, 3, 3, 1, 2, 2, 2…
## $ A1 <int> 1933, 1933, 1933, 1938, 1938, 1938, 1938, NA, 1938, 1947, 1947, 1947, 1947, 1947, 1947, 1933, 1933, 1933, 1933, 1933, 1933, 193…
## $ A2A_01 <int> 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 0…
## $ A2A_02 <int> 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1…
## $ A2A_03 <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ A2A_04 <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ A2A_05 <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ A2A_06 <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ A2BB <int> 2, 2, NA, 1, 1, NA, NA, NA, 2, 2, 2, 2, 2, 2, 2, 1, 1, 1, 2, 1, 1, 1, 1, 2, 1, 2, 2, 1, NA, 1, NA, 2, 2, NA, 1, NA, 2, 2, NA, N…
## $ A3A <int> 1, 3, 4, 1, 3, NA, 1, NA, 1, 3, 1, 1, 3, 3, 1, 1, 2, 1, 3, 3, 1, 3, 3, 1, 3, 1, 1, 3, 3, 4, 3, 3, 1, 3, 3, 3, 3, 1, 3, 3, 1, 3,…
## $ A3B <int> 1, 2, 1, 1, 2, 1, 1, NA, 1, 3, 1, 1, 3, 2, 1, 1, NA, 1, 2, 3, 1, 3, 3, 1, 3, 1, 1, 2, 2, 3, 2, 3, 1, 2, 2, 3, 3, 1, 2, 3, 1, 2,…
## $ A4 <int> 2, 6, 1, 6, 2, 2, 2, 2, 6, 2, 5, 4, 3, 3, 5, 2, NA, 2, 6, 6, 3, 2, 3, 2, 2, 3, 5, 1, 3, 2, 2, 2, 2, NA, 2, 2, 6, 1, 2, 5, 4, 5,…
## $ A5 <int> 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 9, 8, 8, 8, 8, NA, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, …
## $ B1 <int> 4, 1, 4, 3, 1, 2, 3, 5, 2, 1, 2, 2, 2, 3, 1, 5, NA, 2, 3, 1, 1, 2, 2, 2, 2, 3, 1, 2, 2, 3, 2, 3, 6, 2, 4, 2, 1, 3, 3, 3, 3, 2, …
## $ B2 <int> 2, 1, 3, 4, 1, 1, 3, 5, 2, 1, 2, 2, 2, 2, 2, 5, NA, 2, 4, 1, 1, 6, 2, 2, 2, 4, 2, 2, 3, 3, 1, 5, 6, 3, 3, 2, 2, 3, 2, 3, 4, 2, …
## $ B3 <int> 3, 1, 4, 6, 1, 2, 6, 3, 2, 1, 2, 2, 2, 3, 2, 5, NA, NA, 3, 2, 1, 6, 6, 1, 6, 4, 2, 3, 4, 4, 2, 4, 6, 6, 6, 2, 2, 6, 6, 3, 2, 6,…
## $ B4 <int> 4, 1, 4, 6, 1, 3, 6, 3, 3, 2, 2, 2, 2, 4, 1, 5, NA, 2, 3, 1, 1, 6, 6, 2, 6, 4, 1, 3, 3, 2, 2, 3, 6, 6, 6, 2, 1, 6, 6, 3, 2, 2, …
## $ B5 <int> 4, 1, 3, 6, 2, 2, 3, 3, 2, 1, 6, 2, 2, 3, 2, 4, 2, NA, 3, 3, 1, 6, 2, 2, 4, 4, 2, 3, 2, 6, 2, 3, 5, 6, 6, 6, 2, 6, 6, 3, 4, 3, …
## $ B6A <int> 4, 2, 3, 6, 2, 4, 3, 3, 2, 4, 2, 2, 2, 3, 1, 5, 3, NA, 2, 1, 1, 3, 2, 2, 4, 4, 2, 6, 3, 2, 2, 3, 6, 6, 6, 6, 2, 6, 6, 3, 2, 2, …
## $ B6B <int> 5, 2, 3, 3, 2, 4, 3, 3, 3, 2, 2, 2, 2, 5, 3, 5, 2, NA, 4, 2, 1, 6, 3, 2, 4, 4, 2, 3, 1, 3, 2, 3, 6, 6, 6, 6, 2, 3, 6, 4, 3, 4, …
## $ B6C <int> 4, 1, 3, 6, 2, 2, 6, 4, 2, 1, 2, 2, 2, 3, 2, 5, 2, NA, 2, 1, 1, 6, 3, 2, 4, 4, 3, 3, 3, 3, 2, 4, 5, 4, 6, 6, 2, 3, 6, 3, 4, 3, …
## $ B6D <int> 4, 2, 3, 3, 1, 2, 6, 4, 3, 1, 2, 2, 2, 4, 2, 5, 2, 1, 3, 2, 1, 6, 3, 2, 4, 4, 2, 3, 2, 6, 2, 3, 5, 2, 6, 6, 2, 3, 2, 3, 3, 4, 2…
## $ C1 <int> 1, 1, 2, 3, 1, 1, 1, 2, 1, 1, 2, 1, 2, 1, 1, 2, 2, 2, 1, 1, 2, 1, 1, 2, 1, 3, 2, 2, 1, 1, 2, 2, NA, 1, 1, 1, 2, 2, 2, 1, 2, 1, …
## $ C2A <int> 5, 1, 2, 2, 4, 3, 5, 2, 2, 2, 1, 5, 2, 2, 2, 1, 5, 5, 5, 1, 1, 5, 5, 1, 5, 1, 1, 3, 5, 4, 5, 2, 5, 5, 5, 5, 1, 5, 2, 5, 2, 5, 2…
## $ C2B <int> 2, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 1, NA, NA, NA, NA, 1, 1, 1, NA, NA, 1, 1, NA, 2, NA, NA, NA, 2, NA, 3, NA, 3, 1, 1, …
## $ C3 <int> 5, 4, 5, 5, 2, 2, 4, 5, 3, 3, 5, 5, 5, 4, 5, 4, 5, 5, 5, 5, 5, 5, 4, 5, 2, 5, 5, NA, 1, 1, 5, 3, 5, 4, 5, 5, 5, 5, 5, 2, 5, 4, …
## $ C4 <int> 5, 5, 5, 5, 2, 2, 5, 5, 3, 3, 5, 5, 5, 3, 5, 4, 5, 5, 5, 5, 5, 5, 5, 5, 2, 4, 5, NA, 1, 4, 5, 2, 5, 4, 5, 5, 5, 4, 5, 5, 5, 5, …
## $ C5A <int> 6, 6, 6, 6, 6, 4, 6, 6, 5, 2, 1, 3, 4, 6, 5, 6, 6, 6, 6, NA, 5, 6, 6, 6, 6, 6, 4, 6, 1, 6, 6, NA, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6,…
## $ C5B <int> NA, NA, NA, 1, 1, NA, 1, NA, NA, NA, NA, NA, NA, 3, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ C6 <int> 1, 5, 3, 5, 2, 2, 4, 4, 3, 3, 2, 2, 4, 3, 4, 4, 4, 4, 5, 5, 3, 4, 5, 2, 2, 4, 2, 3, 1, 2, 5, NA, 4, 2, 4, 4, 4, 4, 5, 4, 3, 4, …
## $ C7 <int> 3, 4, 3, 5, 3, 6, 4, 3, 3, 3, 2, 2, 3, 3, 4, 4, 5, 5, 5, 5, 4, 6, 4, 2, 6, 4, 4, 6, 6, 6, 6, NA, 5, 6, 6, 6, 4, 4, 1, 4, 2, 6, …
## $ C8A <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, 2, 2, 2, 4, 1, 4, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ C8B <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ C9 <int> 3, 5, 5, 5, 2, 4, 5, 3, 3, 4, 3, 2, 5, 4, 4, 5, 5, 5, 5, 5, 5, 5, 5, 4, 2, 5, 5, 5, 2, 5, 5, NA, 5, 4, 5, 5, 5, 5, 5, 5, 3, 5, …
## $ C10 <int> 3, 4, 4, 5, 2, 3, 2, 3, 3, 3, 3, 2, 4, 3, 4, 4, 5, 5, 5, 5, 5, 4, 4, 4, 2, 4, 5, 4, 1, 3, 5, NA, 5, 4, 5, 4, 5, 5, 5, 4, 2, 5, …
## $ C11 <int> 5, 5, 5, 5, 3, 3, 5, 5, 5, 4, 4, 4, 5, 4, 5, 5, 5, 5, 5, 5, 5, 5, 5, NA, 4, 5, 5, 5, 4, 5, 5, NA, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5,…
## $ C12 <int> 2, 5, 2, 5, 2, 2, 2, 3, 3, 3, 2, 1, 3, 2, 2, 4, 5, 5, 5, 5, 5, 1, 3, 3, 2, 4, 3, 5, 2, 2, 5, NA, 5, 5, 5, 5, 4, 4, 2, 3, 1, 3, …
## $ C13 <int> 2, 3, 2, 3, 2, 2, 4, 4, 3, 3, 3, 2, 3, 4, 3, 3, 3, 3, 3, 3, 3, 2, 3, 3, 2, 3, 3, 4, 1, 2, 3, NA, 4, 2, 3, 3, 4, 4, 3, 4, 2, 3, …
## $ C14AA <int> 1, 3, NA, 4, 1, 1, NA, NA, 3, 3, 3, 4, 4, 2, 2, 4, 4, 4, 3, 3, 3, 3, 1, 3, 2, 4, 4, 2, NA, NA, 4, NA, 4, 1, 4, 4, 2, 3, 3, 4, 4…
## $ C14BB <int> 2, 4, NA, 4, 2, 2, 1, 1, 3, 3, 3, 2, 4, 2, 2, 4, NA, 4, 3, 4, 4, 3, 3, 3, 3, 4, 4, 2, NA, 1, 4, NA, 4, 1, 4, 4, 3, 2, 3, 4, 3, …
## $ C14CC <int> NA, 4, NA, 4, 2, 1, NA, NA, 4, 4, 2, 4, 4, 3, 2, 4, NA, 4, 4, 4, 4, 2, 2, 3, 2, 4, 4, 3, NA, NA, 4, NA, 4, 1, 4, 4, 2, 3, 4, 4,…
## $ C14DD <int> NA, NA, NA, 2, 1, 2, 1, NA, 2, 3, 2, 2, 2, 1, 2, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ C14EE <int> NA, NA, NA, 4, 1, 3, 1, NA, 3, 3, 3, 3, 2, 1, 2, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ C14FF <int> NA, NA, NA, 4, 3, 3, NA, NA, 3, 3, 3, 4, 4, 2, 3, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ C14GG <int> NA, NA, NA, 4, 3, 3, NA, NA, 4, 3, 3, 4, 3, 3, 3, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ C14HH <int> NA, 4, NA, 4, 3, 3, NA, NA, 4, 4, 3, 3, 3, 3, 3, 4, NA, 4, 4, 4, 4, 4, 3, 3, 4, 4, 4, 2, 1, 2, 4, NA, 4, 1, 4, 4, 3, 4, 4, 4, 4…
## $ C14ii <int> NA, 4, NA, 4, 4, 2, NA, NA, 4, 4, 4, 4, 4, 4, 3, 4, NA, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 3, NA, 3, 4, NA, 4, 1, 4, 4, 3, 4, 4, 4, …
## $ C15 <int> 5, 5, 2, 5, 2, 1, 6, 3, 3, 5, 6, 6, 1, 5, 3, 4, 6, 5, 6, 1, 1, 6, 2, NA, 5, 4, 5, 2, 3, 2, 5, 3, 5, 2, 5, 5, 2, 4, 6, 6, 2, 3, …
## $ C16 <int> 1, 3, 2, 6, 1, 1, 1, 1, 2, 1, 2, 2, 2, 1, 2, 3, 1, 2, 2, 2, 6, 1, 1, 1, 2, 2, 4, 6, 1, 3, 6, 3, 3, 1, 3, 1, 1, 2, 1, 2, 1, 1, 1…
## $ D1 <int> 2, 3, 2, 3, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 2, 2, 2, 2, 3, 3, 2, 3, 3, 2, 2, 3, 2, 3, 3, 2, 2, 2, 3, 2, 2, 2, 2, 2, 2, 2…
## $ D1A_KAPAT <int> NA, NA, NA, NA, NA, 1, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
## $ D2 <int> 2, 2, 2, 2, 2, 3, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 3, 2, 2, 3, 2, 2, 2, 3, 3, 3, 2, 2, 2, 3, 3, 2, 2, 2, 2, 2, 2, 2…
## $ D2A_KAPAT <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 1, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
## $ D3 <int> 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, NA, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, …
## $ D3A_KAPAT <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 1, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
## $ D4 <int> 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2…
## $ D4A_KAPAT <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ D5 <int> 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2…
## $ D5A_KAPAT <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 2, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
## $ D6 <int> 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2…
## $ D6A_KAPAT <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ D7 <int> 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2…
## $ D7A_KAPAT <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ D8 <int> 2, 2, NA, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, …
## $ D8A_KAPAT <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ D9 <int> 2, 2, NA, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, …
## $ D9A_KAPAT <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ D9B <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ D9C <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ D10 <int> 2, 2, NA, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, …
## $ D10A_KAPAT <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ D10B <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ D11 <int> 2, 2, NA, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, …
## $ D11A_KAPAT <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ D12 <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, 2, 2, 2, 2, 2, 2, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ D13 <int> 2, 2, NA, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, NA, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,…
## $ D13A_KAPAT <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ D14 <int> 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, NA, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, …
## $ D14A_KAPAT <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ D15 <int> 2, 2, 3, 2, 2, 3, 3, 2, 2, 2, 2, 2, 2, 3, 2, 2, NA, 2, 2, 2, 2, 2, 3, 2, 2, 2, 2, 2, 3, 3, 2, 2, 2, 2, 2, 2, 3, 3, 2, 2, 3, 3, …
## $ E1 <int> 2, 2, NA, 2, 2, 2, 2, 2, 2, 2, 2, 1, 1, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, …
## $ E2A <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 1, 1, NA, NA, NA, NA, 2, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ E2B <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 1, 1, NA, NA, NA, NA, 1, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ E3 <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 2, 2, NA, NA, NA, NA, 2, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ E4A <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 2, 1, NA, NA, NA, NA, 1, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ E4B <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 2, 1, NA, NA, NA, NA, 1, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ E4C <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 2, 1, NA, NA, NA, NA, 1, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ E4D <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 1, 1, NA, NA, NA, NA, 1, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ E4E <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 3, 3, NA, NA, NA, NA, 2, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
## $ E5AA <int> NA, NA, NA, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ E5BB <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ E6x <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ E7AA <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ E7BB <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ E7CC <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ E8AA <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ E8BB <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
## $ E8CC <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…Som du märker så får vi ett annat perspektiv med funktionen glimpse(). Istället för att, som vi har lärt oss, läsa raderna som enskilda observationer för ett specifikt objekt så som en person, och kolumnerna som variabler så som specifika enkätfrågor, så hamnar nu allting på raderna. Vårt dataset ÄR fortfarande likadant och vi har inte på något sätt förändrat objektet ntu1721, men vi tittar på den data som finns lagrad i ntu1721 på ett annorlunda sätt.
Först ser vi, eftr varje $, namnet på respektive variabler. Exempelvis $ insamlingsår. Därefter anges vilken datatyp som $ variabeln representerar inom glimpse()-funktionen är orienterad mot variabler. Det är alltså ett bra sett att få en överblick av de variabler som finns i ett dataset. Som du kanske kommer ihåg (eller om du scrollar upp lite) så såg vi ju bara ett begränsat antal variabler när vi exempelvis använde oss av funktionen head(), helt enkelt eftersom att det finns så många variabler i vårt dataset.
UTBILDNINGSKONTROLL
Vilken typ av data representrar “chr”?
Vilken typ av data representrar “int”?
Vad betyder “NA” som finns på vissa av raderna?
4.2.3 Dollartecknet “$”
Tecknet $ står här faktiskt inte för Dollar, utan det är ett tecken som representerar ett objekt som ingår i ett annat objekt. Oftast en variabel som ingår i en data frame eller en tibble. Detta framgår inte minst när vi använder funktionen glimpse() som vi gjorde ovan.
Det är ett användbart tecken om vi vill utforska en enskild variabel. Att kalla på en enskild variabel ur ett dataset görs alltså genom att först skriva datasetets namn, följt av $ följt av variabelns namn. Om vi exempelvis skriver ntu1721_read$insamlingsår får vi ut precis alla värden den här variabeln antar. I det här fallet vilket år som respondenten har fyllt i enkäten. Men eftersom att vi har över 375 tusen svar så skriver vi inte ut dem här. Istället kommer detta dollartecken att bli användbart i nästa avsnitt.
4.2.4 Ytterliggare användbara funktioner för att utforska data:
4.2.4.1 summary()
Istället för att alltså skriva ut vilket år som alla våra 375 tusen respondenter fyllde i den Nationeall Trygghetsundersökningen så skall vi testa att summera datan. Det kan vi göra genom en grundfunktion i bas R som heter summary().
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 2017 2018 2019 2019 2020 2021Här kan vi se att det lägsta värdet som variabeln antar är “2017” och att det högsta värdet är “2021”. Vi ser också exempelvis medianen och medelvärdet (“2019”), samt första och tredje kvartilen.
Värt att veta är att summary()-funktionen endast ger oss användbar information om vi arbetar med kontinuerliga variabler (alltså det som i R kallas för “Integer”/heltal eller “Double”/tal med decimaler) eller faktorvariabler. Om vi försöker summera exempelvis en variabel med text (“Character”) så fungerar detta, men informationen är inte så användbar:
## Length Class Mode
## 375590 character character4.2.4.2 subset()
En användbar funktion när vi arbetar med ett stort datamaterial som vårat (som innehåller över 375 tusen observationer!) kan vara att dela upp datamaterialet. Ibland kan det även vara så att vi har ett visst analytiskt intresse av att bara titta på exempelvis rädsla för brott bland män eller kvinnor. Eller bara det senaste årets mätningar för att titta på de mest aktuella siffrorna över förtroende för polisen. I båda dessa fall kan subset()-funktionen hjälpa oss!
subset() fungerar på så vis att vi specificerar vilket dataset vi vill utföra funktionen på, och vad det är vi vill filtrera datasetet genom. Här får vi nytta av all den här krångliga “booliska algebran” och villkoren som ni kanske minns (annars se avsnitt 2.2 Villkor). subset() bygger nämligen på två argument. Dessa argument separeras av ett kommatecken, såhär: subset(ntu1721, insamlingsår == 2021) där den första delen alltså är det dataset som vi vill utföra funktionen på, och den andra delen specificerar att vi endast vill behålla de som besvarate enkäten år 2021.
En bra regel är att alltid spara alla transformationer som vi gör, så när vi kör subset()-funktionen så sparar vi resultatet i ett nytt objekt som vi kallar för “ntu2021”. Vi kan då komma åt data som endast är insamlad under år 2021.
UTBILDNINGSKONTROLL
Inspektera det nya datasetet:
Är det en data frame eller en tibble?
Hur många rader/observationer innehåller datasetet?
Hur många kolumner/variabler innehåller datasetet?
Vad heter variabeln variabeln på rad 10 om du använder glimpse()-funktionen på det nya datasetet?
Öppna kodboken Kodbok “NTU 2017-2021.pdf” (om du inte tidigare laddade ned denna hittar du den på samma sida i Cannvas som du hittade datafilen “NTU_2017-2021.csv”). Bläddra till sida 3. Där ser du hur variabeln Kon (kön) är kodad. Använd denna information för att utifrån datasetet “ntu2021” skapa ett nytt datamaterial som du namnger “ntu_kvinnor” med bara kvinnor i. Inspektera detta nya dataset med de tekniker du lärt dig hittils. Vad ser du om du kör kommandot
summary(ntu_kvinnor$Kon)?
4.3 Transformera data
Efter att ha lärt oss grunderna i hur en utforskar data så skall vi snabbt gå igenom hur en också förändrar data i R. Faktum är att vi redan varit lite inne på detta när vi har använt subset()-funktionen, även subset() i huvudsak begränsar data snarare än förändrar den.
Varför vill end å förändra data? Det kan finnas flera skäl. Ibland kan det handla om att vi vill reducera mängden information. Vi kanske vill reducera ålder (en kontinuerlig variabel) till ålderskategorier, eller inkomst till inkomstkategorier. Eller så vill vi slå ihop alla som bor i “Norrbotten” och “Västerbotten” till “Övre Norrland”.
Det kan också handla om att R har läst in data på ett som vi upplever det lite felaktigt sätt. Eftersom att analyser i R är känsliga för hur vin klassificerar data så kan det vara bra att se över sitt datamaterial så att alla variabler är korrekt angivna. Exempelvis kan vi föreställa oss att vi har ett datamaterial med en variabel som heter “Utsatthet_typ” med variabelvärdena 1-4 där de som har blivit utsatta för våldsbrott ha fått ett värdet “1”, de som blivit utsatta för egendomsbrott har fått värde “2”, de som har blivit utsatta fär bedrägeri har fått värde “3” och de som blivit utsatta för någon form av sexualbrott har fått värde “4”. Och så har vi en kodbok som talar om för oss vilket värde som motsvarar vilken av dessa etiketter. Vi upplever att detta är en variabel på nominalskalenivå, och att det borde vara en faktor. Men när vi läste in vår .csv-fil har R tolkat detta som att vi har att göra med en kontinuerlig variabel av typen Integer (heltal).
Skälen att transformera variabler kan alltså se lite olika ut. vi ska nu gå igenom några vanliga och grundläggande sätt att transformera variabler på. Dock långt ifrån alla.
4.3.1 Förändra datatyp/variabeltyp
Vi börjar med det enklaste först, att ändra hur R tolkar en viss variabel. Som i exemplet ovan så har i vårat dataset ntu21 flera variabler där variabelvärdena består av siffror, men som vi genom att läsa kodboken kan att dessa siffror reprenterar en viss etikett. Exempelvis om vi tittar på variabeln ntu21$Kon så antar den värdena 1 eller 2. R tolkar detta som att vi har att göra med en kontinuerlig variabel av typen integer (heltal).
## [1] TRUE## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.000 1.000 2.000 1.527 2.000 2.000Vi vet dock att detta är en nominalskalevariabel, som i R borde vara av typen faktor. Vi skall alltså ändra hur R tolkar denna variabel, så att R tolkar och behandlar den som en faktor. Detta är en enkel process som görs genom att använda den grundläggande funktionen as.factor() i R. Vi ger R kommandot att variabeln ntu21$Kon skall tolkas som faktor genom att köra koden nedan:
Vi kan kontrollera att förändringen faktiskt är genomförd genom att köra nedanstående kod:
## [1] TRUEVi tittar också på vad som nu händer om vi vill utforska variabeln med summary()-funktionen:
## 1 2
## 35144 39207Vi ser nu att R har förenklat den information vi får ta del av genom summary()-funktionen så att vi kan se att 35144 respondenter har svarat “1” och 39207 respondenter har svarat “2” på vår variabel “Kön”. Genom att konsultera kodboken kan vi se att “1” representerar Man och “2” representerar Kvinna. Kanske är detta med 1:or och 2:or dock inte helt önskvärt, så om vi inte hela tiden vill hålla på och bläddre i kodboken kan vi faktiskt döpa om dem.
4.3.2 Transformera enskilda faktorer
Faktorvariabler (alltså kategoriska variabler som kan vara antingen nominalskalor som Kön eller Politiskt parti, eller ordinalskalevariabler som exempelvis mäts med skalor som “Ofta” “Ibland” “Sällan” “Aldrig”) kan vi förändra genom funktionen case_match() från paketet dplyr.
För att använda case_match måste vi alltså öppna paketet dplyr med hjälp av library()-funktionen.
case_match() fungerar genom att vi specificerar ett antal argument på det här sättet: case_match(x, "old_values" ~ "new_value", .default = NULL) därvi istället för x skriver in vår variabel, istället för old_values skriver in det värde på variabeln vi vill ändra, och istället för new_value skriver in det nya värde vi vill att variabeln skall anta. Argumentet new_value kan skrivas med eller utan “citattecken” beroende på om vi vill göra den nya variabeln till en numerisk variabel eller en textvariabel (detta kommer att bli tydligt aldelles strax i vårt exempel).
Argumentet “.default =” specificerar vad som skall hända med alla gamla variabelvärden som vi inte täcker i vår kod. Det vanligaste är att en specificerar att dessa skall vara NA alltså att de skall räknas som svarsbortfall (NA står för not available, men det är inte så viktigt). Om du inte skriver något argument för “.default =” så kommer R automatiskt att räkna alla andra värden som NA.
I det här fallet vill vi förändra faktorvariabeln ntu21$Kon så att värde “1” blir “Man” och värde “2” blir “Kvinna”. Vi vill också att andra svarsbortfall skall specificeras som “NA”. Detta gör vi genom att köra följande kod (OBS! Kom ihåg att ladda dplyr först genom att köra koden library(dplyr) ):
Notera att vi döpte den nya variabeln till “Kon_text”. Det betyder att vi fortfarande har kvar den gamla variabeln, och får en ny variabel med “Man”/“Kvinna” istället för “1”/“2”. Att skapa nya variabler snarare än att skriva över de gamla är ofta att rekommendera.
För att summera resultaten kan vi dock återigen använda oss av summary()-funktionen:
## Length Class Mode
## 74351 character characterVänta! Någonting har hänt med vår variabel. R verkar inte längre läsa den som en faktorvariabel, utan som en renodlad textvariabel (Character). I många avvseenden är detta samma sak och ingenting viktig, men som ni märker får vi inte längre någon användbar data när vi ger kommandot med summary()-funktionen. Lyckligtvis kan vi göra om samma process som i avsnitt 3.3.1 och helt enkelt tala om för R att vi vill att den nya variabeln “Kon_text” skall tolkas som en faktorvariabel.
Vi kontrollerar, och nu verkar allting fungera!
## Kvinna Man
## 39207 35144Och för att illustrera hur “.default =” argumentet fungerar kan vi låta bli att skriva "2" ~ "Kvinna" och se vad som händer då:
ntu2021$Kon_test <- case_match(ntu2021$Kon,
"1" ~ "Man",
"2" ~ "Kvinna",
.default = NA)
ntu2021$Kon_test <- as.factor(ntu2021$Kon_test)
summary(ntu2021$Kon_test)## Kvinna Man
## 39207 35144Vi ser då att alla gamla värden som vi inte specificerar ett nytt värde för automatiskt räknas som “NA”, det vill säga svarsbortfall.
Och för att illustrera att grundregeln är att “.default =” ger oss NA kan vi faktiskt ta bort detta argument:
ntu2021$Kon_test2 <- case_match(ntu2021$Kon,
"1" ~ "Man")
ntu2021$Kon_test2 <- as.factor(ntu2021$Kon_test2)
summary(ntu2021$Kon_test2)## Man NA's
## 35144 39207Vi ser här att om vi låter bli att skriva ut något argument för “.default =” så utgår R från att dessa skall vara NA.
Vi kan dock använda “.default =” argumentet till att säga exempelvis att alla övriga värden itne skall vara just bortfall/NA, utan att de skall vara en egen giltig observation som vi till exempel kan döpa till just “Övriga”:
ntu2021$Kon_test3 <- case_match(ntu2021$Kon,
"1" ~ "Man",
.default = "Övriga")
ntu2021$Kon_test3 <- as.factor(ntu2021$Kon_test3)
summary(ntu2021$Kon_test3)## Man Övriga
## 35144 39207Vi kan såklart också slå ihop existerande kategorier. Vi kan exempelvis ta variabeln ntu2021$alder_8 som är ålder i 8 kategorier, och göra om den till en variabel som vi kan döpa till ntu2021$alder_3 som endast skiljer mellan “ung”,” “medelålders”, och “äldre”. När vi gör detta vill vi alltså slå samman flera kategorier, exemplvis att alla mellan 16 och 34 år skall klassificeras som “Ung”. Då har vi nytta av den grundläggande funktionen c() i bas R, där c står för “Combine”. Vi kan använda c() för att specificera flera olika gamla värden som allihop skall anta ett likadant nytt värde:
## [1] FALSEVi noterar först att ntu2021$alder_8 inte är en faktor. För att fortsätta så börjar vi alltså med att göra om ntu2021$alder_8 till en faktorvariabel.
## [1] TRUEVi fortsätter genom att titta på fördelningen på ntu2021$alder_8 som en faktorvariabel.
summary(ntu2021$alder_8) #I kodboken ser vi att 1 = 16-19; 2 = 20-24; 3 = 25-34; 4 = 35-44; 5; 45-54; 6 = 55-64; 7 = 65-74; 8 = 75-84.## 1 2 3 4 5 6 7 8
## 5589 4558 8707 7639 10033 12637 14706 10482ntu2021$alder_3 <- case_match(ntu2021$alder_8,
c("1", "2", "3") ~ "Ung",
c("4", "5") ~ "Medelålder",
c("6", "7", "8") ~ "Äldre",
.default = NA)
ntu2021$alder_3 <- as.factor(ntu2021$alder_3)
summary(ntu2021$alder_3)## Äldre Medelålder Ung
## 37825 17672 18854Vi kan faktiskt förenkla det sista steget i kodningsprocessen något genom att skriva ihop koden på det här sättet, så att vår nya variabel ntu2021$alder_3 blir en faktorvariabel redan på en gång genom att placerar vår case_match()-funktion inom parantensen för vår as.factor()-funktion på det här sättet:
ntu2021$alder_3 <- as.factor(case_match(ntu2021$alder_8,
c("1", "2", "3") ~ "Ung",
c("4", "5") ~ "Medelålder",
c("6", "7", "8") ~ "Äldre",
.default = NA))
summary(ntu2021$alder_3)## Äldre Medelålder Ung
## 37825 17672 18854Obs! En vanlig felkälla här brukar vara att en glömmer att sätta rätt antal paranteser i slutet av kommandot. Varje öppen parantes måste motsvaras av en stängd parantes. I detta fall behöver vi ha två stängda paranteser på slutet på det här sättet as.factor(case_match())
4.3.3 Transformera enskilda kontinuerliga/numeriska variabler (Integer och Double)
Ibland kan en ha att göra med kontinuerliga variabler som en av olika skäl vill göra om till kategoriska variabler. Ett exempel kan vara för att variabeln inte är normalfördelad, exempelvis för att antingen väldigt låga tal eller väldigt höga tal är överrepresenterade, vilket gör variabeln mindre bra att använda i till exempel en regressionsanalys (mer om detta senare).
I det här exemplet skall vi titta på de som under 2021 i Nationella Trygghetsundersökningen uppgett att de har blivit utsatta för cykelstöld. De som svarat ja fick en uppföljande fråga som rörde antal gånger de fått sin cykel stulen. Denna variabel heter i vårt dataset ntu2021$D1A_KAPAT (ni kan också slå upp variabeln “D1A_KAPAT” i kodboken, sida 17).
Denna variabel har en väldigt skev fördelning med nästan samtliga observationer samlade vid väldigt låga tal, vilket vi kan se i följande histogram (vi skall gå igenom hur vi arbetar med exempelvis histogram och andra former av datavisualisering längre ned i avsnitt 4). Det finns alltså skäl att förenkla denna variabel genom att slå ihop flera värden på den gamla variabeln till kategorier i en ny variabel.
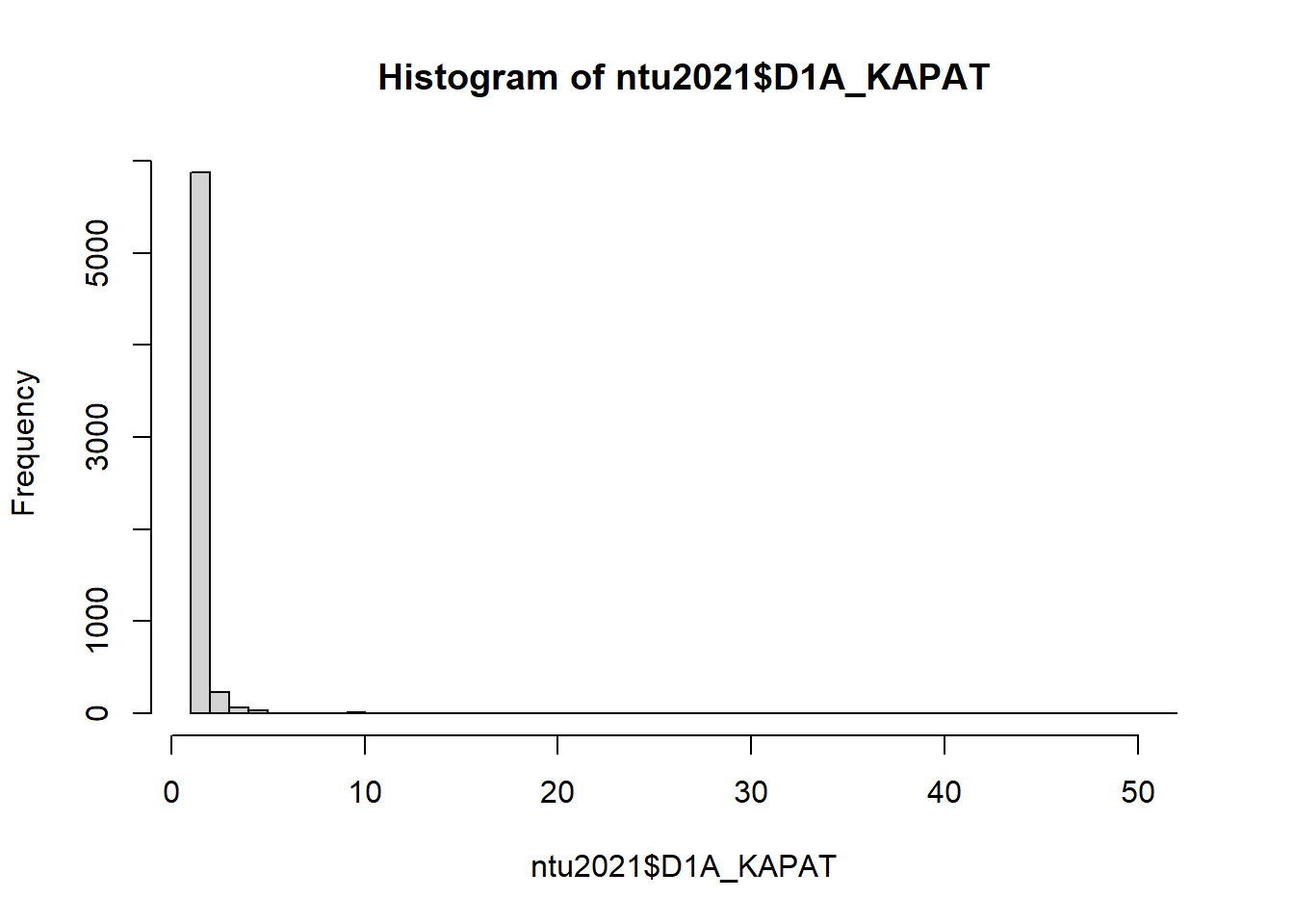
Vi börjar med att utforska variabeln med hjälp av summary()-funktionen:
## [1] TRUENotera gärna att vi med summary()-funktionen kan få ut information om variabeln som en kontinuerlig variabel (Heltal/Integer) och då se minimum, maximum, medelvärde, median och kvartiler.
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 1.000 1.000 1.000 1.414 1.000 52.000 68108Vi kan också välja att inom summary()-funktionen placera en as.factor()-funktion och genom att tala om för R att behandla variabeln som en faktor se hur ofta som respondenterna har svarat ett visst värde.
Exempelvis är det totalt 69 respondenter som har svarat att de fått sin cykel stulen fyra gånger.
## 1 2 3 4 5 6 7 8 9 10 12 13 15 20 22 35 50 52 NA's
## 4770 1100 231 69 31 6 4 3 1 12 2 2 2 1 1 1 1 6 68108Det verkar som att de flesta bara har blivit utsatta för en cykelstöld, och att det vanligaste därefter är två cykelstölder. Efter dessa två värden minskar antalet observationer drastiskt. Notera också att vi har ett väligt stor mängd svarsbortfall (NA). Detta beror på att endast de som svarat att de har fått sin cykel stulen har svarat på frågan om hur många gånger de blivit utsatta för cykelstöld. Alla som inte har fått sin cykel stulen räknas därför här som svarsbortfall.
Baserat på denna information tänker vi att vi vill göra en ny variabel där vi skiljer mellan de som fått sån cykel stulen “En gång”, “Två gånger” och “Tre eller fler gånger”. Det betyder att målet med vår variabeltransoformationen är att alla respondenter som har svarat att de fått sin cykel stulen 3 gånger och hela vägen upp till 52 gånger i vår nya variabel skall få samma värde “Tre eller fler gånger”.
Vi vill också ha med alla dem som inte har blivit utsatta för cykelstöld eller som vi saknar uppgift för (NA) som en egen kategori “Ingen gång / Uppgift saknas”.
För att göra detta använder vi återigen funktionen case_match() från paketet dplyr. För att använda case_match måste vi alltså öppna paketet dplyr med hjälp av library()-funktionen.
Vi döper vår nya variabel till ntu2021$D1A_kat där “kat” får stå för “kategorier”. I den här koden kommer vi att använda ett kolon-tecken “:” för att tala om för R att vi vill att en hel serie av värden i den gamla variabeln allihop skall få ett och samma värde i den nya variabeln. Närmare bestämt vill vi att alla värden mellan 3 och 52 (max) skall ges det nya värdet “Tre eller fler gånger”.
ntu2021$D1A_kat <- as.factor(case_match(ntu2021$D1A_KAPAT,
1 ~ "En gång",
2 ~ "Två gånger",
c(3:52) ~ "Tre eller fler gånger",
.default = "Ingen gång/Ingen uppgift"))
summary(ntu2021$D1A_kat) ## En gång Ingen gång/Ingen uppgift Tre eller fler gånger Två gånger
## 4770 68108 373 1100Notera att vi återigen använder ett förenklat kodförfarande där vi på en gång sepceificerar att vår nya variabel ntu2021$D1A_kat skall vara en faktor genom att placera case_match()-funktionen inom parantesen för as.factor()-funktionen.
Notera också att vi använder argumentet “.default =” för att specificera att alla övriga värden (alltså alla NA) som “Ingen gång/Ingen uppgift”.
4.3.4 Skapa index-variabler
Den sista typen av variabeltransformation vi skall gå igenom är hur en skapar index-variabler. Ibland vill vi använda sammansatta index för att kunna ställa flera frågor om samma, störe, fenomen. Exempelvis frågor om förtrående för polis respektive domstolar som indikatorer på det större fenomenet förtroende för rättsväsendet som helhet. Jämfört med att använda en enskild fråga som indikator så har ett sammansatt index fördelen av att jämna ut slumpmässiga variationer i enskilda frågesvar. En vanlig uppfattning inom socialvetenskaperna, där kriminologi ingår, är att en indexvariabel som vi tänker oss mäter ett större eller underliggande fenomen kan hanteras som en kontinuerlig variabel, även om de olika indikatorerna (de olika enkätfrågor som vi använder för att skapa vårt index) är på ordinalskalenivå.
I det här fallet skall vi skapa ett additivt index, där vi summerar svaren i flera olika frågor som rör förtroende för rättsväsendet. Vi tänker oss alltså att det finns ett underliggande, större fenomen som vi kallar för förtroende för rättsväsendet, och att genom att fråga om respondenternas förtroende för exempelvis polis och åklagare så kan vi få information om detta underliggande, större fenomen: förtroende för rättsväsendet.
I vårt datamaterial så har vi fyra stycken variabler B2, B3, B4 och B5 som mäter respondenternas förtroende för polisen; åklagarna; dostolarna; kriminalvården. Frågorna är ställda som “Hur stort eller litet förtroende har du för ____s sätt att bedriva sitt arbete?” Och respondenterna har svarat med en Likertskala från 1:Mycket stort till 5:Mycket litet. Respondenterna har också kunnat svara 6:Ingen åsikt/vet inte.

Vi vill nu alltså summera dessa ordinalskalevariabler till ett additivt index som tillsammans möter det större fenoment förtroende för rättsväsendet, som vi sedan kommer att behandla som en kontinuerlig variabel när vi gör med avancerade analyser längre fram. Som några av er kanske har noterat så går dock inte att bara summera dessa variabler rakt av.
Varför? Jo, för att svarskalan inkluderar 6:Ingen åsikt/vet inte. Det betyder att svarsskalan inte går rangordna från högt till lågt förtroende. Lyckligtvis kan vi tala om för R att vi vill att alla som svarat 6:Ingen åsikt/vet inte skall räknas som svarsbortfall (NA).
Vi måste alltså börja med att rensa dessa variablers svarsskalor. Det gör vi med en grundläggande funktion från bas R som heter replace() där vi måste specificera två argument: replace(x, x == old_vale, new_value där x står för den variabel vi vill förändra, olda _value står för det värde på variabeln vi vill ersätta med ett new_vale / nytt värde. Vi döper de nya variablerna till “_rensad”.
ntu2021$B2_rensad <- replace(ntu2021$B2, ntu2021$B2 == 6, NA)
ntu2021$B3_rensad <- replace(ntu2021$B3, ntu2021$B3 == 6, NA)
ntu2021$B4_rensad <- replace(ntu2021$B4, ntu2021$B4 == 6, NA)
ntu2021$B5_rensad <- replace(ntu2021$B5, ntu2021$B5 == 6, NA)Vi kan kontrollera en av variablerna för att vara säkra på att alla “6” nu räknas som svarsbortfall (NA):
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 1.000 2.000 2.000 2.462 3.000 5.000 2567Nu är resten av processen ganska enkel, vi behöver bara skapa en ny variabel som summerar alla de fyra variabler vi är intresserade av. Detta gör vi genom att döpa en ny variabel till nut2021$fortroende_index och specificera att denna skall få summan av de övriga variablerna genom att helt enkelt summera (plussa ihop) dem:
ntu2021$fortroende_index <- ntu2021$B2_rensad +
ntu2021$B3_rensad +
ntu2021$B4_rensad +
ntu2021$B5_rensadVi kan inspektera den nya variabeln, som borde gå från 4 (4 variabler * 1 det lägst svarsvärdet) till 20 (4 variabler * 5 det högsta svarsvärdet):
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 4.00 8.00 10.00 10.54 13.00 20.00 19265Det verkar fungera! Vår nya variabel sträcker sig från 4 (maximalt förtroende) till 20 (minimalt förtroende).
Men vänta! Det verkar ju konstigt att vår variabel som heter “förtroende index” skall sträcka sig från högt till lågt förtroende. Borde vi inte vända på den?
Att vända på ett index är väldigt enkelt. För att göra det tar vi helt enkelt det maximala värdet på variabeln, vilket är 20 - variabeln.
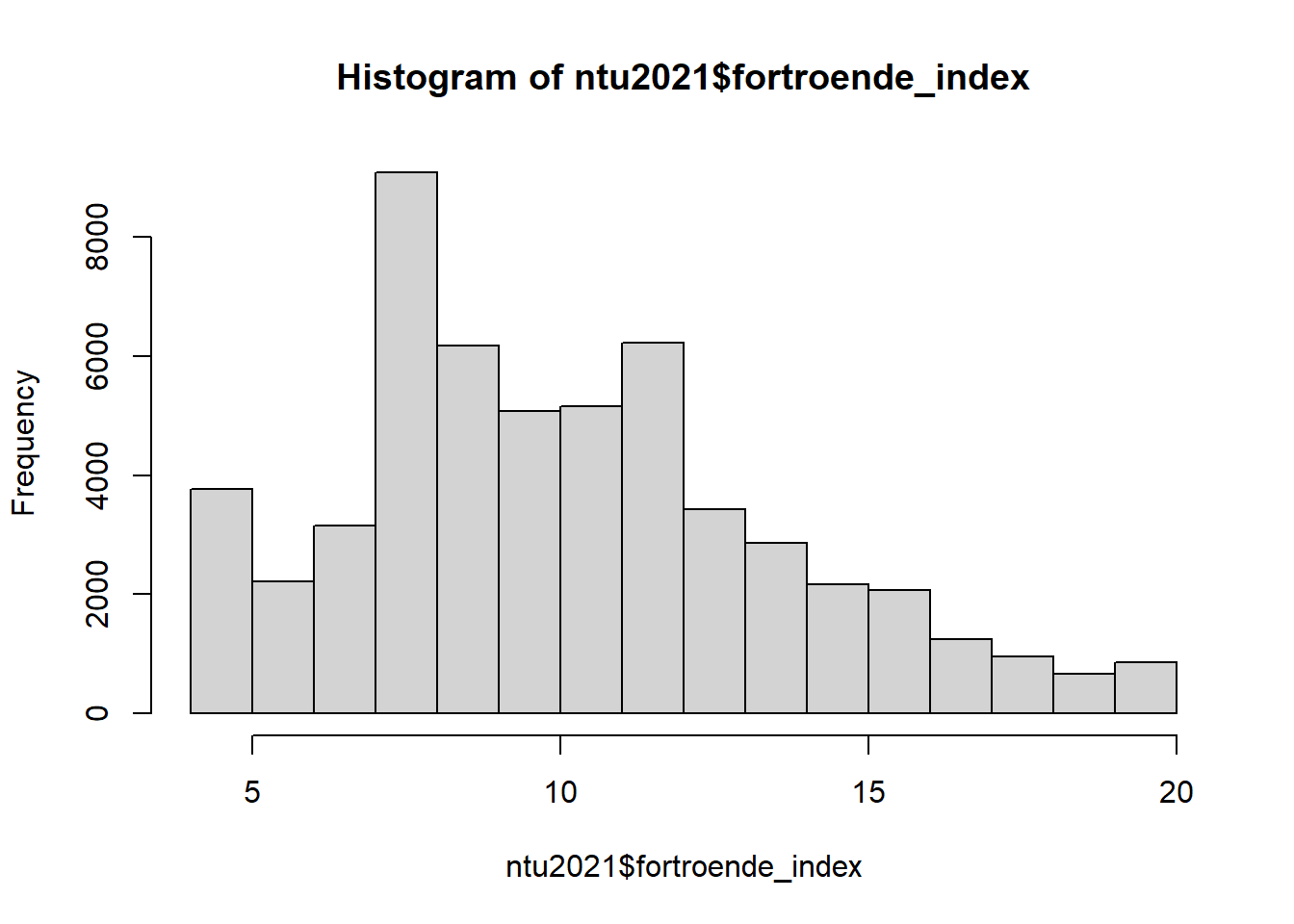
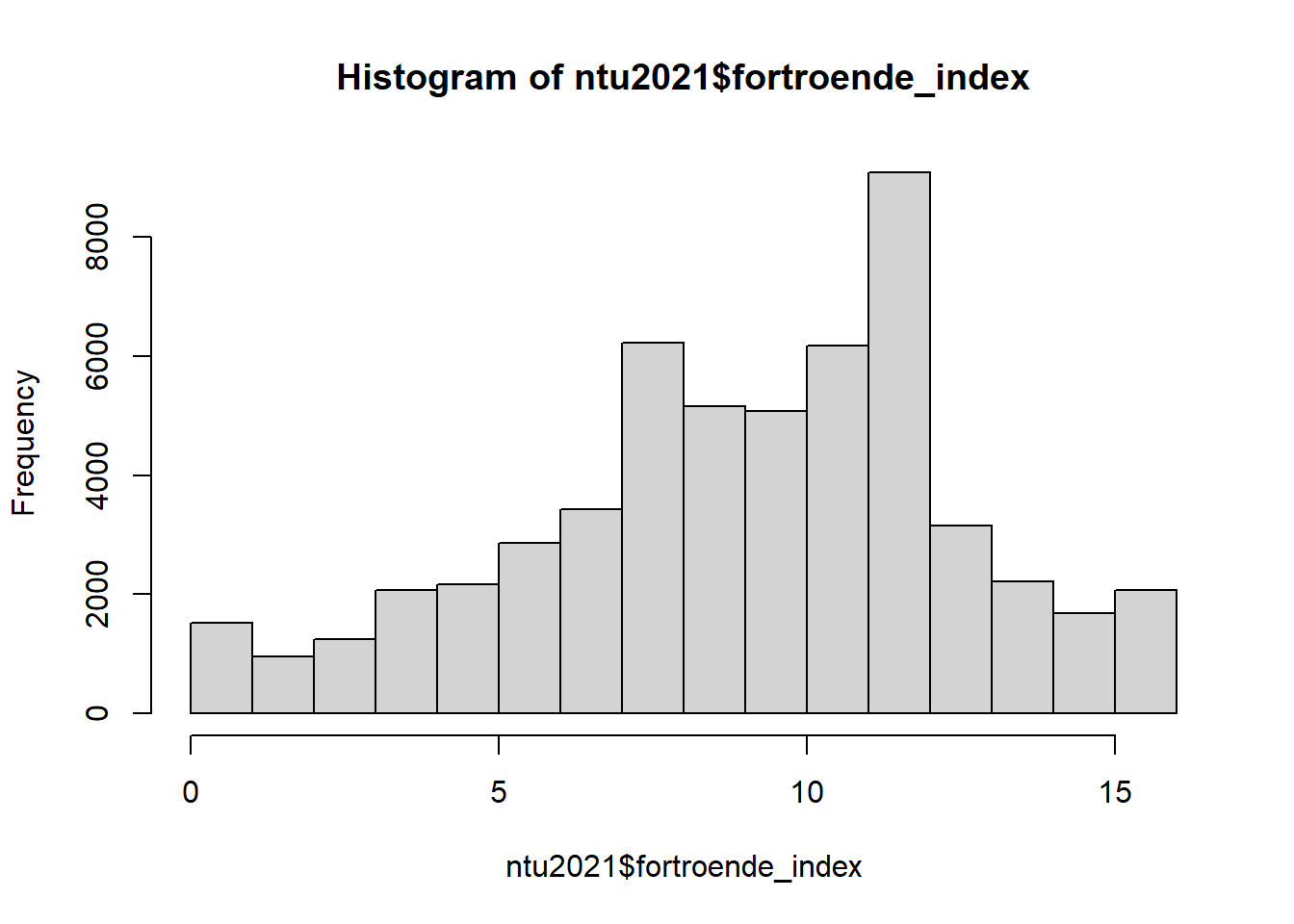
Som du kan se på histogrammen över variabelns fördelning så har vi alltså lyckats vända på vårt index, så att vi nu har ett index där låga värden betyder litet förtroende och höga värden betyder mycket förtroende för rättsväsendet! Notera också att skalan nu går mellan 0 (mycket litet) till 16 (mycket stort) förtroende. Det känns mer reimligt än att ha en variabel som börjar på det väldigt arbiträra värdet 4.
Nu är vi alltså färdiga med att skapa vårt index.
Men hur kan vi egentligen vara säkra på att vårat index faktiskt är ett bra mått på förtroende för rättsväsendet? I kursboken stode det ju någonting om reliabilitet..?
Det första vi kan göra i JUST VÅRAT FALL är att jämföra vårt index över förtroende för rättsväsendet med variabeln/frågan B1 där respeondentarna faktiskt har svarat på frågan: “Om du tänker dig rättsväsendet som en helhet. Hur stort eller litet förtroende har du för rättsväsendet?”
Vi kan jämföra variationen i vårt index med variationen i denna enskilda variabel, B1, genom att titta på hur de korrelerar med varandra (mer om korrelation senare). Ett värde närmare 0 betyder svag eller ingen korrelation, alltså inget samband, och ett värde närmare 1 betyder stark korrelation, ett starkt samband. I vårt fall är korrelationen r = -.82 Vilket alltså är ett mycket starkt samband. Vi tycks därmed ha fångat in det vi vill mäte genom att skapa ett index av våra fyra frågor. Minustecknet i det här fall betyder bara att korrelationen är negativ, vilket beror på att vi har vänt på vårt index så att högre värden betyder högre förtroende. Svarsskalan på variabeln B1 utgår dock från att låga värden är högt förtroende, och tvärtom. (Det gör inget om du tycker att dett verkar krågligt just nu, det viktiga här är att förstå hur vi skapar ett index och om vi har lyckats skapa ett bra index eller inte).
ntu2021$B1_rensad <- replace(ntu2021$B1, ntu2021$B1 == 6, NA)
cor.test(ntu2021$B1_rensad, ntu2021$fortroende_index)##
## Pearson's product-moment correlation
##
## data: ntu2021$B1_rensad and ntu2021$fortroende_index
## t = -336.05, df = 54568, p-value < 2.2e-16
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## -0.8238201 -0.8183530
## sample estimates:
## cor
## -0.8211054I det här fallet hade vi tur. Vi hade ju redan en fråga som mätte just förtroende för rättsväsendet som helhet som vi kunde jämföra vårt index mot. Ofta har en dock inte den lyxen!
Det finns dock ett mer formellt test av ett index relabilitet som heter “Chronbach’s alpha”. Det mäter hur väl tre eller fler variabler samvarierar med varandra. Det går från 0 till 1 och tolkas på ungefär samma sätt som en korrelation mellan två varabler. Normalt sett brukar en inom socialvetenskaperna anse att ett “Chronbach’s alpha”-värde på över 0.7 är bra och gott nog för att skapa ett index.
För att utföra ett “Chronbach’s alpha”-test på våra fyra variabler så behöver vi installera och öppna ett paket som heter psych vilket innehåller en funktion som heter alpha().
Testet i sig är ganska enkelt att producera. Det enda vi behöver göra är att skapa en ny data frame som bara innehåller de fyra variabler vi är intresserade av att testa. Vi gör detta med den grundläggande funktionen i bas R som heter data.frame(), där vi inom parantsen helt enkelt skriver de variabler från ntu2021 som vi vill ska ingå i vår nya, begränsade data frame. Variablerna måste separeras av ett komma, men det är det enda. Vi kan döpa detta objekt till B2_5.
Sedan behöver vi bara ge kommandot alpha() med vårt objekt inom parantseserna. Här finns det en sak som gör vårt liv lite krångligare, och det är att det finns flera paket som använder kommandot alpha() på lite olika sätt. Vi kan tvinga R att använda alpha()-funktionen från just psych paketet genom att skriva på följande sätt: psych::alpha(). Då talar vi om för R att vi skall använda funktionen ifrån psych-paketet.
##
## Reliability analysis
## Call: psych::alpha(x = B2_5)
##
## raw_alpha std.alpha G6(smc) average_r S/N ase mean sd median_r
## 0.87 0.87 0.84 0.62 6.4 0.00079 2.6 0.89 0.59
##
## 95% confidence boundaries
## lower alpha upper
## Feldt 0.87 0.87 0.87
## Duhachek 0.87 0.87 0.87
##
## Reliability if an item is dropped:
## raw_alpha std.alpha G6(smc) average_r S/N alpha se var.r med.r
## ntu2021.B2_rensad 0.85 0.85 0.81 0.66 5.7 0.00094 0.01284 0.59
## ntu2021.B3_rensad 0.80 0.79 0.72 0.56 3.9 0.00129 0.00046 0.56
## ntu2021.B4_rensad 0.82 0.81 0.75 0.59 4.4 0.00116 0.00123 0.59
## ntu2021.B5_rensad 0.85 0.85 0.81 0.65 5.6 0.00094 0.01511 0.63
##
## Item statistics
## n raw.r std.r r.cor r.drop mean sd
## ntu2021.B2_rensad 71784 0.82 0.81 0.70 0.66 2.5 0.99
## ntu2021.B3_rensad 61971 0.89 0.89 0.87 0.80 2.6 1.05
## ntu2021.B4_rensad 64130 0.87 0.86 0.83 0.75 2.7 1.14
## ntu2021.B5_rensad 60603 0.81 0.81 0.70 0.66 2.8 1.01
##
## Non missing response frequency for each item
## 1 2 3 4 5 miss
## ntu2021.B2_rensad 0.13 0.48 0.24 0.12 0.04 0.03
## ntu2021.B3_rensad 0.12 0.40 0.29 0.12 0.06 0.17
## ntu2021.B4_rensad 0.12 0.35 0.27 0.16 0.09 0.14
## ntu2021.B5_rensad 0.08 0.34 0.37 0.15 0.07 0.18Denna utskrift i konsolpanelen ger oss en hel del information, och mycket av det är användbart för en lite mer avancerad användare. Men vi nöjer oss med att läsa av fältet som heter “raw_alpha” där vi ser att vårt alpha-värde är .87. Alltså en bra bit över det alpha-värde om .70 som generellt anses vara acceptabelt. Vi kan alltså säga att våra fyra variabler i hög utsträckning samvarierar, och därför tycks mätta samma underliggade, större fenomen nämligen förtroende för rättsväsendet. Vårt index som vi skapat med informationen från dessa fyra förtroendevariabler (för polise, åklagarna, domstolarna och kriminalvården) har alltså hög reliabilitet.
UTBILDNINGSKONTROLL
Variablerna B6A, B6B, B6C och B6D mäter olika aspekter av allmänhetens förtroende för att rättsväsendet som helhet samt polisen bemöter såväl brottsoffer som misstänkta på ett bra sätt. Gå igenom stegen ovan för att skapa ett index, men gör det för dessa variabler B6A till B6D. Notera särskilt att, precis som i det föregående exemplet, så har dessa variabler en svarsskala som inkluderar 6:Ingen åsikt/Vet inte, vilket är ett värde vi vill behandla som svarsbortfall så att vi bara får svar som handlar om hur stort eller litet förtroende människor har för rättsväsendets bemötande av misstänkta och offer.
Döp detta nya index till bemotande_index.
Kom ihåg att vända på indexet så att det går från litet förtroende för rättsväsendets bemötande (låga värden) till stort förtroende för rättsväsendets bemötande (höga värden)
Om du använder summary()-funktionen, hur ser fördelningen i indexet ut?
Är detta ett bra mått på allmänhetens förtroende för rättväsendets bemötande av offer och misstänkta? Vad har indexet för Cronbahcs alpha-värde?
Hur väl korrelerar detta bemotande_index med vårt tidigare skapade fortroende_index?
Detta avslutar avsnittet om olika sätt att transformera data.
output: html_document date: “2025-09-17” —