Para realizar un regresión logística en R se utiliza la función glm. Esta función se utiliza para ajustar modelos lineales generalizados, especificados dando una descripción simbólica del predictor lineal y una descripción de la distribución de errores.
Ejemplo 1
Se desea identificar las variables asociadas al bajo peso al nacer. Para ello, se parte del data frame “birthwt2” que fue construida con anterioridad en la clase de medidas de asociación y riesgo. Se describen a continuación los pasos para la elaboración de un modelo de regresión logística en R. Puede descargar la base de datos de aquí
X low age lwt race smoke ptl ht ui ftv bwt
1 85 No 19 182 black No 0 No Yes 0 2523
2 86 No 33 155 other No 0 No No 3 2551
3 87 No 20 105 white Yes 0 No No 1 2557
4 88 No 21 108 white Yes 0 No Yes 2 2594
5 89 No 18 107 white Yes 0 No Yes 0 2600
6 91 No 21 124 other No 0 No No 0 2622
attach(birthwt2) # Para no tener problemas con los nombresstr(birthwt2)
Se parte del supuesto que todas la variables del dataframe pudieran estar asociadas al bajo peso al nacer. Por ello se construye un modelo con todas las variables y se comenzarán a eliminar variables hasta quedarnos con un modelo adecuado.
Modelo incial
mod1 <-glm(low~age+lwt+race+smoke+ptl+ht+ui+ftv, family ="binomial", data = birthwt2)summary(mod1)
Call:
glm(formula = low ~ age + lwt + race + smoke + ptl + ht + ui +
ftv, family = "binomial", data = birthwt2)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 1.361119 1.104589 1.232 0.21786
age -0.029549 0.037031 -0.798 0.42489
lwt -0.015424 0.006919 -2.229 0.02580 *
raceblack 0.391764 0.537609 0.729 0.46618
racewhite -0.880496 0.440778 -1.998 0.04576 *
smokeYes 0.938846 0.402147 2.335 0.01957 *
ptl 0.543337 0.345403 1.573 0.11571
htYes 1.863303 0.697533 2.671 0.00756 **
uiYes 0.767648 0.459318 1.671 0.09467 .
ftv 0.065302 0.172394 0.379 0.70484
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 234.67 on 188 degrees of freedom
Residual deviance: 201.28 on 179 degrees of freedom
AIC: 221.28
Number of Fisher Scoring iterations: 4
table(race)
race
other black white
67 26 96
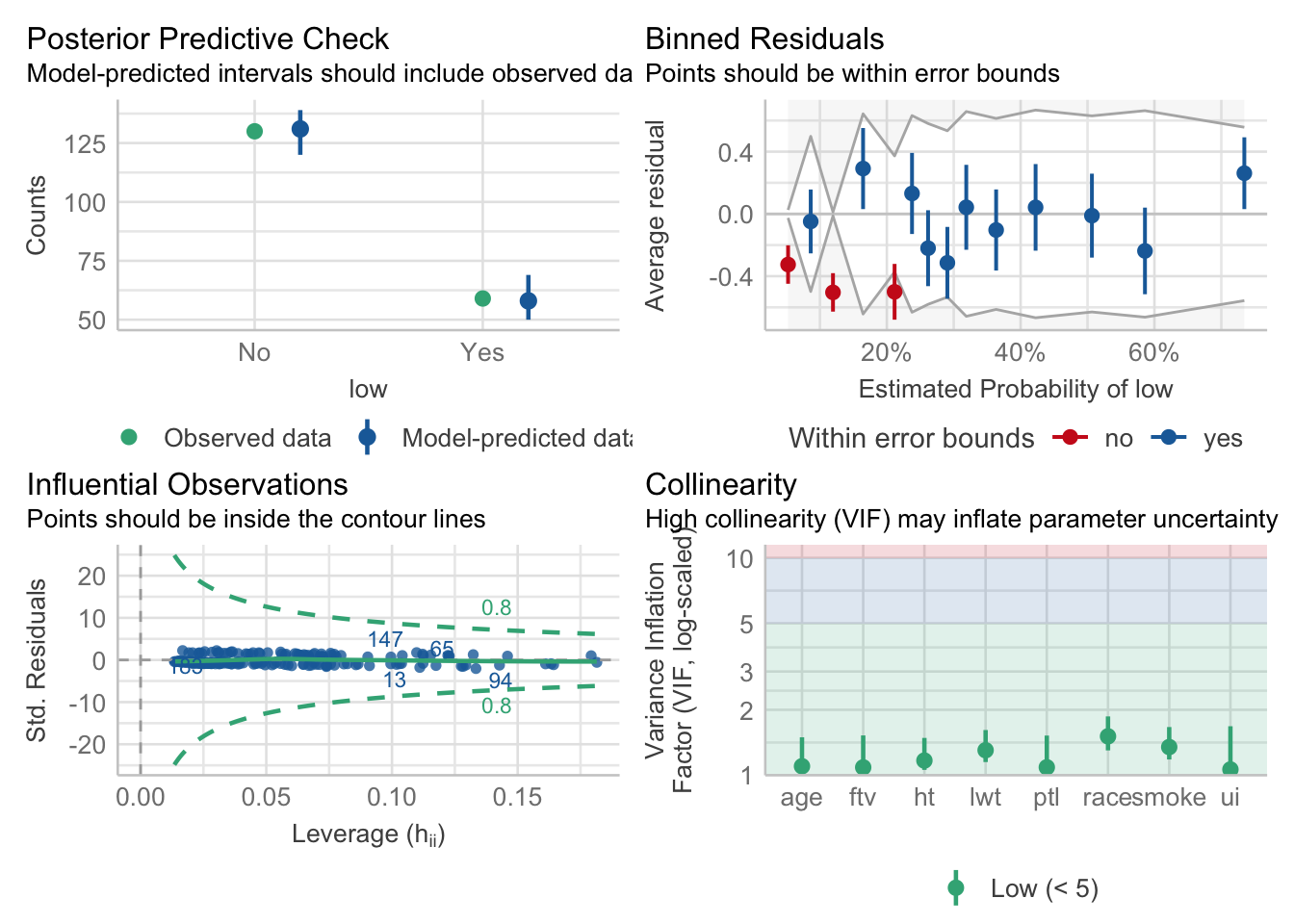
Supuestos del modelo
performance::check_model(mod1)
Binned residual plot
Un “binned residual plot” es una herramienta útil en el análisis de regresión para evaluar la adecuación de un modelo a los datos. En un binned residual plot, estos residuos se agrupan (“binning”) en intervalos basados en los valores predichos o alguna otra variable relevante, y luego se analizan colectivamente.
Aspectos Clave del Binned Residual Plot
Eje Horizontal: Muestra los valores predichos por el modelo o alguna variable independiente de interés.
Eje Vertical: Muestra los residuos o alguna medida resumida de los residuos (como la media o mediana) para cada grupo.
Interpretación
Residuos Cerca de Cero: Idealmente, la media (o mediana) de los residuos en cada bin debería estar cerca de cero. Esto indica que el modelo está haciendo predicciones precisas en ese rango.
Patrón Aleatorio: La ausencia de patrones sistemáticos sugiere que el modelo se ajusta bien a los datos. Un patrón aleatorio de puntos alrededor de la línea de residuo cero es un buen signo.
Patrones en los Residuos: La presencia de patrones, como una tendencia lineal o curvilínea, esto sugiere que el modelo no está capturando alguna relación subyacente en los datos.
Variabilidad Constante: La dispersión de los residuos debería ser más o menos constante a través de los diferentes bins. Si la variabilidad de los residuos cambia significativamente (por ejemplo, aumenta con valores predichos mayores), esto puede indicar heterocedasticidad, lo que sugiere que las suposiciones del modelo podrían no ser apropiadas.
Outliers: Los valores atípicos pueden ser identificados en un binned residual plot. Si hay muchos outliers o si estos siguen un patrón, puede ser necesario revisar el modelo o investigar más sobre estos casos.
Forward, backward and stepwise logistic regression
Para realizar una regresión por pasos se parte de los mismo principios de la regresión lineal múltiple
Creación del modelo vacio y modelo completo
modelo.vacio <-glm(low~1,family ="binomial")modelo.completo <-glm(low~age+lwt+race+smoke+ptl+ht+ui, family ="binomial")summary(modelo.vacio)
Call:
glm(formula = low ~ 1, family = "binomial")
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.790 0.157 -5.033 4.84e-07 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 234.67 on 188 degrees of freedom
Residual deviance: 234.67 on 188 degrees of freedom
AIC: 236.67
Number of Fisher Scoring iterations: 4
summary(modelo.completo)
Call:
glm(formula = low ~ age + lwt + race + smoke + ptl + ht + ui,
family = "binomial")
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 1.326038 1.104915 1.200 0.23009
age -0.027070 0.036452 -0.743 0.45772
lwt -0.015183 0.006928 -2.192 0.02841 *
raceblack 0.401584 0.538868 0.745 0.45613
racewhite -0.861635 0.439191 -1.962 0.04978 *
smokeYes 0.923349 0.400853 2.303 0.02125 *
ptl 0.541755 0.346264 1.565 0.11768
htYes 1.833696 0.691765 2.651 0.00803 **
uiYes 0.758597 0.459389 1.651 0.09867 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 234.67 on 188 degrees of freedom
Residual deviance: 201.43 on 180 degrees of freedom
AIC: 219.43
Number of Fisher Scoring iterations: 4
forward
modelo.forward <-step(modelo.vacio, scope =list(lower=modelo.vacio,upper=modelo.completo), direction ="forward")
Call:
glm(formula = type ~ glu + age + ped + bmi + npreg, family = "binomial",
data = Pima.tr)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -9.938059 1.541571 -6.447 1.14e-10 ***
glu 0.031809 0.006667 4.771 1.83e-06 ***
age 0.039286 0.020967 1.874 0.06097 .
ped 1.811417 0.661048 2.740 0.00614 **
bmi 0.079672 0.032649 2.440 0.01468 *
npreg 0.103142 0.064517 1.599 0.10989
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 256.41 on 199 degrees of freedom
Residual deviance: 178.47 on 194 degrees of freedom
AIC: 190.47
Number of Fisher Scoring iterations: 5
Estimación de OR
Seleccione su modelo final y luego estime los OR y sus intervalos de confianza con el siguiente código:
exp(modelo.final$coefficients)
exp(confint(modelo.final))
Ejericios de tarea
Ejericio 1. Tarea
Introducción
La Organización Mundial de la Salud ha estimado que cada año ocurren 12 millones de muertes a nivel mundial debido a enfermedades cardíacas. La mitad de las muertes en Estados Unidos y otros países desarrollados se deben a enfermedades cardiovasculares. El pronóstico temprano de las enfermedades cardiovasculares puede ayudar en la toma de decisiones sobre cambios en el estilo de vida en pacientes de alto riesgo y, a su vez, reducir las complicaciones. Esta investigación tiene como objetivo identificar los factores de riesgo más relevantes de la enfermedad cardíaca, así como predecir el riesgo general utilizando la regresión logística. Puede consultar más información en aquí
Base de datos
Fuente
El conjunto de datos está disponible públicamente en el sitio web de Kaggle, y proviene de un estudio cardiovascular en curso sobre los residentes de la ciudad de Framingham, Massachusetts. El objetivo de la clasificación es predecir si el paciente tiene un riesgo a 10 años de enfermedad coronaria futura (CHD, por sus siglas en inglés). El conjunto de datos proporciona información de los pacientes. Incluye más de 4,000 registros y 15 atributos.
Variables
Cada atributo es un potencial factor de riesgo. Hay factores de riesgo demográficos, conductuales y médicos.La base de datos contiene las siguientes varialbles:
A continuación se describen las variables de la base de datos y su significado
Demographic varibles:
Sex: male or female (Nominal)
Age: Age of the patient;(Continuous - Although the recorded ages have been truncated to whole numbers, the concept of age is continuous) Behavioral
Current Smoker: whether or not the patient is a current smoker (Nominal)
Cigs Per Day: the number of cigarettes that the person smoked on average in one day.(can be considered continuous as one can have any number of cigarettes, even half a cigarette.)
Medical( history) viriables
BP Meds: whether or not the patient was on blood pressure medication (Nominal)
Prevalent Stroke: whether or not the patient had previously had a stroke (Nominal)
Prevalent Hyp: whether or not the patient was hypertensive (Nominal)
Diabetes: whether or not the patient had diabetes (Nominal) Medical(current) variables
Tot Chol: total cholesterol level (Continuous)
Sys BP: systolic blood pressure (Continuous)
Dia BP: diastolic blood pressure (Continuous)
BMI: Body Mass Index (Continuous)
Heart Rate: heart rate (Continuous - In medical research, variables such as heart rate though in fact discrete, yet are considered continuous because of large number of possible values.)
10 year risk of coronary heart disease CHD (binary: “1”, means “Yes”, “0” means “No”)
Objetivo
Relizar modelos de regresión lógistica para identificar variables asociadas al riesgo cardiovascular a los diez años
Puede descargar la base de datos de aquí Puede encontrar más información sobre el resultado en: https://www.kaggle.com/datasets/dileep070/heart-disease-prediction-using-logistic-regression
Deberá realizar lo siguiente:
Análisis vibariado agrupando por la variable TenYearCHD para identificar variables asociadas al riesgo cardivascular que puedieran incluirse en el modelo
Seleccionar y ajustar un modelo de regresión logística con las variables seleccionadas
Evaluar los supuestos del modelo
Realizar la prueba de Hosmer-Lemeshow
Calcular la pseudo \(R^2\)
Estimar los OR y sus intervalos de confianza
Interpretar sus OR
Concluir
Como ayuda a su análisis se muestra una tabla con el análisis bivariado
Characteristic
0, N = 3,594
1
1, N = 644
1
p-value
2
male
1,476 (41%)
343 (53%)
<0.001
age
48 (42, 55)
55 (48, 61)
<0.001
education
<0.001
1
1,397 (40%)
323 (51%)
2
1,106 (32%)
147 (23%)
3
599 (17%)
88 (14%)
4
403 (11%)
70 (11%)
Unknown
89
16
currentSmoker
1,761 (49%)
333 (52%)
0.2
cigsPerDay
0 (0, 20)
3 (0, 20)
0.005
Unknown
27
2
BPMeds
83 (2.3%)
41 (6.5%)
<0.001
Unknown
42
11
prevalentStroke
14 (0.4%)
11 (1.7%)
<0.001
prevalentHyp
991 (28%)
325 (50%)
<0.001
diabetes
69 (1.9%)
40 (6.2%)
<0.001
totChol
232 (205, 261)
241 (214, 272)
<0.001
Unknown
41
9
sysBP
127 (116, 141)
139 (125, 158)
<0.001
diaBP
81 (74, 88)
86 (78, 95)
<0.001
BMI
25.3 (23.0, 27.9)
26.2 (23.5, 28.9)
<0.001
Unknown
9
10
heartRate
75 (68, 83)
75 (68, 85)
0.2
Unknown
0
1
glucose
78 (71, 86)
79 (72, 90)
<0.001
Unknown
338
50
1
n (%); Median (IQR)
2
Pearson’s Chi-squared test; Wilcoxon rank sum test; Fisher’s exact test
a base de datos bmd.csv contiene datos un grupo de pacientes con fracturas y un grupo de pacientes sin fracturas. Utilizando las variables AGE, SEX, BMI and BMD cree un modelo de regresión logística. Utilice la variable fracture como variable dependiente para la construcción de este modelo. Seleccione el mejor modelo posible manualmente y utilizando el algoritmo de stepwise. Estime para estos modelos el OR y realice una interpretación de los mismos.
Ejercicio 2.
El conjunto de datos bdiag.csv incluye varios detalles de imágenes de pacientes a los que se les realizó una biopsia para detectar cáncer de mama.
La variable Diagnóstico clasifica el tejido biopsiado como M = maligno o B = benigno. Con esta base de datos estime;
El mejor modelo de forma manual
El mejor modelo utilizando el stepwise
OR y sus IC
Interprete sus resultados
Ejercicio 3.
El conjunto de datos SBI.csv contiene información de más de 2300 niños que acudieron a los servicios de emergencia con fiebre y se les realizó una prueba de infección bacteriana grave. El resultado sbi tiene 4 categorías: No aplicable (sin infección) / UTI / Pneum / Bact
Cree un modelo de regresión de logística para identificar a los pacientes sin infección o aquellos pacientes con cualquiera de las infecciones (UTI/Pneum/Bact). Si es necesario cree una variable. Para este modelo seleccione aquellas variables que aportan significativamente al modelo. Estime los OR y sus intervalos de confianza. Interprete este modelo.
Ejercicio 4.
Utilizando la base de datos salt_tension_arterial.csv realice un modelo de regresión logística para identificar las variables asociadas a la hipertensión (Más de 140 mmHg). Seleccione las variables que aportan significativamente al modelo. Estime los OR y sus intervalos de confianza. Interprete este modelo.
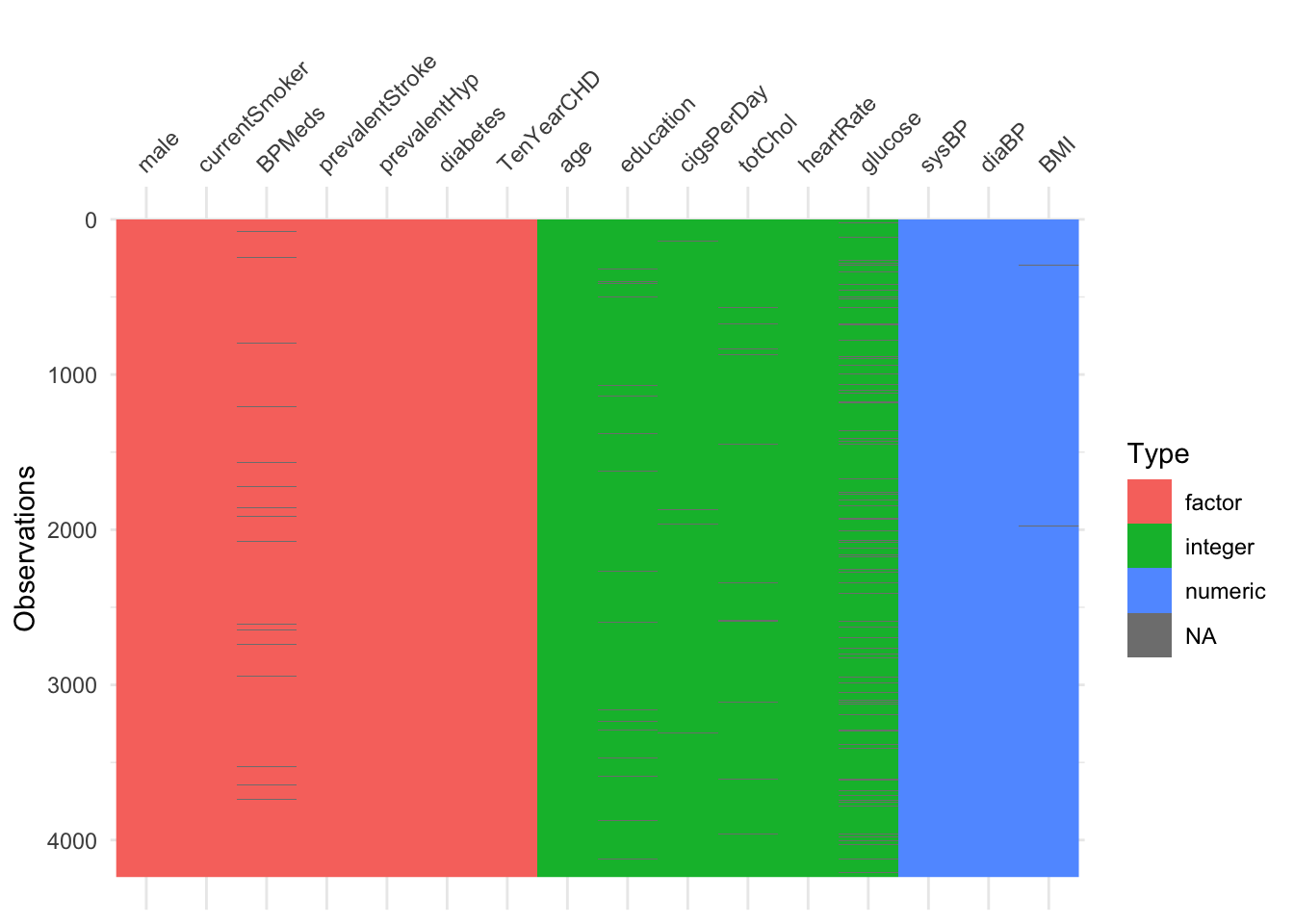
Para poder hacer el modelo de regresión logística se debe de tener en cuenta que no debe de haber NA. El siguiente código se utiliza para identificar si hay NA en la base de datos:
df <-na.omit(df)visdat::vis_dat(df)
Ahora si podemos hacer el modelo de regresión logística
Moedelo regresión forward
MASS::stepAIC(glm(TenYearCHD ~ ., family ="binomial", data = df), direction ="both")
# Extraer los coeficientes y la matriz de covarianzas del modelocoeficientes <-coef(modelo.final)vcov_matriz <-vcov(modelo.final)# Calcular OR e ICOR <-exp(coeficientes)se <-sqrt(diag(vcov_matriz))ci_lower <-exp(coeficientes -1.96* se)ci_upper <-exp(coeficientes +1.96* se)# Crear un data frame con los resultadosresultado <-data.frame(Variable =names(coeficientes),OR = OR,IC_Lower = ci_lower,IC_Upper = ci_upper)# Visualizar los resultadosprint(resultado)