Bab 4 Penyajian Data
Penyajian Data adalah proses pengorganisasian, visualisasi, dan interpretasi data agar lebih mudah dipahami dan dapat diambil kesimpulan. Dalam konteks analisis data, penyajian dilakukan dengan menggunakan berbagai alat dan metode visualisasi seperti tabel, grafik, dan diagram, tergantung pada jenis datanya (kualitatif atau kuantitatif).
4.1 Memuat Dataset
Pertama-tama, kita memuat dataset (skincare) yang akan digunakan dalam analisis ini.
# Memuat dataset dari CSV
skincare = read.csv("Data/skincare.csv", sep = ";")
# Menampilkan data awal dengan kable
head(skincare)## ID_Responden Jenis_Kelamin Usia Pendapatan Preferensi_Produk
## 1 1 Wanita 31 2268166 Haircare
## 2 2 Pria 21 2345555 Makeup
## 3 3 Wanita 56 5512972 Haircare
## 4 4 Wanita 18 2280645 Makeup
## 5 5 Pria 51 5246913 Makeup
## 6 6 Wanita 40 4040500 Skincare
## Frekuensi_Pembelian Cara_Pembelian Tingkat_Kepuasan Tanggal_Pembelian
## 1 3 Online 1 2021-01-01
## 2 5 Online 2 2021-01-02
## 3 2 Offline 1 2021-01-03
## 4 5 Offline 3 2021-01-04
## 5 2 Offline 4 2021-01-05
## 6 2 Offline 4 2021-01-06
## Jumlah_Pembelian
## 1 2
## 2 3
## 3 9
## 4 3
## 5 7
## 6 64.2 Data Kualitatif
Data kualitatif biasanya menggambarkan kategori atau kelompok, seperti jenis kelamin, preferensi produk, atau cara pembelian. Penyajian data kualitatif bisa dilakukan dengan:
4.2.1 Tabel Distribusi Frekuensi
Misalkan anda ingin menampilkan kolom Preferensi_Produk: dapat dilakukan dengan cara menggunakan table() dan kemudian mengonversinya ke dalam data frame.
# Memeriksa nama kolom dalam dataset
# names(skincare)
# Menghitung frekuensi
frekuensi <- table(skincare$Preferensi_Produk)
# Mengonversi tabel frekuensi ke dalam data frame
table_distribusi <- as.data.frame(frekuensi)
# Mengganti nama kolom secara manual
colnames(table_distribusi) <- c("Kategori Produk", "Frekuensi")
# Menampilkan tabel distribusi
table_distribusi## Kategori Produk Frekuensi
## 1 Haircare 391
## 2 Makeup 339
## 3 Skincare 365Cara yang lebih sederhana untuk membuat tabel distribusi dan langsung memberi nama kolom adalah dengan menggunakan dplyr. Berikut ini adalah contohnya:
# Memuat library dplyr
library(dplyr)
# Membuat tabel distribusi menggunakan kolom yang benar
table_distribusi <- skincare %>%
count(Preferensi_Produk, name = "Frekuensi") %>%
rename("Kategori Produk" = Preferensi_Produk) %>%
arrange(desc(Frekuensi)) # Mengurutkan dari yang terbesar ke terkecil
# Menampilkan tabel distribusi
table_distribusi## Kategori Produk Frekuensi
## 1 Haircare 391
## 2 Skincare 365
## 3 Makeup 3394.2.2 Diagram Batang
Diagram Batang adalah jenis grafik yang digunakan untuk menampilkan dan membandingkan frekuensi atau jumlah dari kategori yang berbeda. Dalam diagram batang, setiap kategori diwakili oleh sebuah batang, dan panjang atau tinggi batang tersebut mencerminkan nilai yang terkait, seperti jumlah frekuensi atau proporsi.
Untuk membuat diagram batang dari data yang telah Anda siapkan menggunakan dplyr, Anda dapat melanjutkan dengan menggunakan ggplot2. Berikut adalah langkah-langkah lengkapnya, mulai dari menghitung frekuensi hingga membuat diagram batang.
library(ggplot2)
# Membuat diagram batang
ggplot(table_distribusi, aes(x = `Kategori Produk`,
y = Frekuensi,
fill = `Kategori Produk`)) +
geom_bar(stat = "identity") +
geom_text(aes(label = Frekuensi),
position = position_stack(vjust = 1.05), # Mengatur posisi label
color = "black", size = 3) + # atur warna & ukuran label
labs(title = "Diagram Batang Distribusi Preferensi Produk",
x = "Kategori Produk",
y = "Frekuensi") +
scale_fill_brewer(palette = "Set2") + # Menggunakan palet warna
theme_minimal() +
theme(legend.position = "none") + # Menyembunyikan legenda
coord_flip() # diagram menjadi horizontal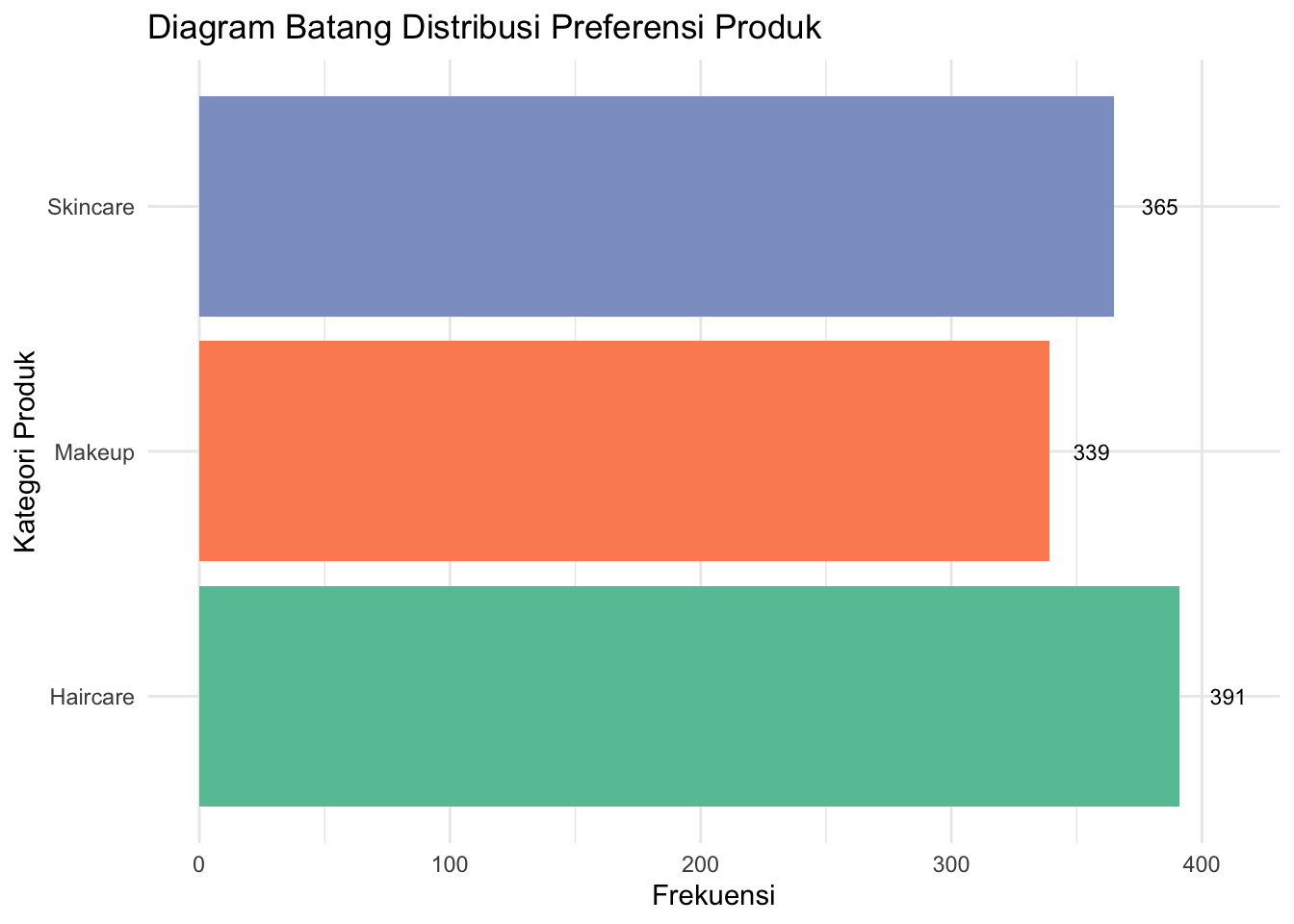
Jika anda ingin mengonversi visualisasi ggplot2 menjadi interaktif menggunakan plotly, Anda bisa menggunakan fungsi ggplotly() dari paket plotly. Ini memungkinkan Anda mengubah diagram batang statis dari ggplot2 menjadi grafik interaktif. Pastikan Anda sudah memuat library plotly sebelum menjalankan kode ini.
# Memuat library yang diperlukan
library(ggplot2)
library(plotly)
# Membuat diagram batang dengan ggplot2
p <- ggplot(table_distribusi, aes(x = `Kategori Produk`,
y = Frekuensi,
fill = `Kategori Produk`)) +
geom_bar(stat = "identity") +
geom_text(aes(label = Frekuensi),
position = position_stack(vjust = 1.1),
color = "black", size = 3) + # posisi,warna dan label
labs(title = "Diagram Batang Distribusi Preferensi Produk",
x = "Kategori Produk",
y = "Frekuensi") +
scale_fill_brewer(palette = "Set1") + # Menggunakan palet warna
theme_minimal() +
theme(legend.position = "none") + # Menyembunyikan legenda
coord_flip() # diagram horizontal
# Mengonversi ggplot menjadi plotly untuk interaktif
plotly_plot <- ggplotly(p)
# Menampilkan plot interaktif
plotly_plotCara lainnya untuk membuat diagram batang interaktif langsung dengan plotly adalah menggunakan fungsi plot_ly() tanpa terlebih dahulu membuat grafik dengan ggplot2. Anda bisa membuat grafik langsung dari data yang sudah diolah dalam table_distribusi.
## Loading required package: viridisLite# Menambahkan warna kustom berbeda untuk setiap kategori
colors <- c("#e78ac3","#66c2a5", "#fc8d62", "#a6d854", "#ffd92f")
# Menggunakan palet warna dari viridis
# colors <- viridis(n = nrow(table_distribusi), option = "D")
# Membuat diagram batang horizontal dengan plotly dan warna berbeda
plot_ly(data = table_distribusi,
x = ~Frekuensi,
y = ~`Kategori Produk`,
type = 'bar',
orientation = 'h', # Membuat diagram batang horizontal
marker = list(color = colors)) %>%
layout(title = "Diagram Batang Distribusi Preferensi Produk",
xaxis = list(title = "Frekuensi"),
yaxis = list(title = "Kategori Produk"),
showlegend = FALSE) # Menyembunyikan legendaStruktur Diagram Batang
- Sumbu X (horizontal): Mewakili kategori yang akan dibandingkan.
- Sumbu Y (vertikal): Mewakili nilai frekuensi atau jumlah untuk setiap kategori.
- Batang: Tinggi atau panjang batang menunjukkan seberapa besar nilai dari kategori tersebut.
Penerapan Diagram Batang
Diagram batang digunakan untuk:
- Membandingkan Kategori: Membandingkan frekuensi atau nilai antar kategori, seperti penjualan produk.
- Data Kategorikal: Menampilkan distribusi frekuensi data yang bersifat kategorikal.
- Hasil Survei: Menyajikan pilihan responden dalam survei.
- Perubahan dari Waktu ke Waktu: Melacak perubahan kategori dari waktu ke waktu, seperti dalam diagram batang kelompok.
- Menyoroti Tren: Mengidentifikasi pola atau tren dalam data.
4.2.3 Diagram Lingkaran
Diagram lingkaran (pie chart) adalah visualisasi data yang menunjukkan proporsi atau persentase dari suatu total. Setiap bagian dari lingkaran mewakili kontribusi kategori tertentu terhadap keseluruhan.
Berikut adalah cara membuat diagram lingkaran sederhana menggunakan ggplot2 untuk data table_distribusi, yang menunjukkan distribusi kategori produk:
# Memuat library yang diperlukan
library(ggplot2)
# Menghitung posisi label
table_distribusi <- table_distribusi %>%
# Menghitung persentase dan posisi label di tengah-tengah segmen
dplyr::mutate(Proporsi = Frekuensi / sum(Frekuensi) * 100,
Posisi = cumsum(Frekuensi) - Frekuensi / 2)
# Membuat diagram donat dengan label
ggplot(table_distribusi, aes(x = 2,
y = Frekuensi,
fill = `Kategori Produk`)) +
geom_bar(stat = "identity", width = 1) +
coord_polar("y", start = 0) +
labs(title = "Diagram Donat Distribusi Preferensi Produk") +
theme_void() +
xlim(0.5, 2.5) +
scale_fill_brewer(palette = "Set2") +
# Menambahkan label persentase
geom_text(aes(y = Posisi, label = paste0(round(Proporsi, 1), "%")),
color = "white", size = 4) # Warna dan ukuran label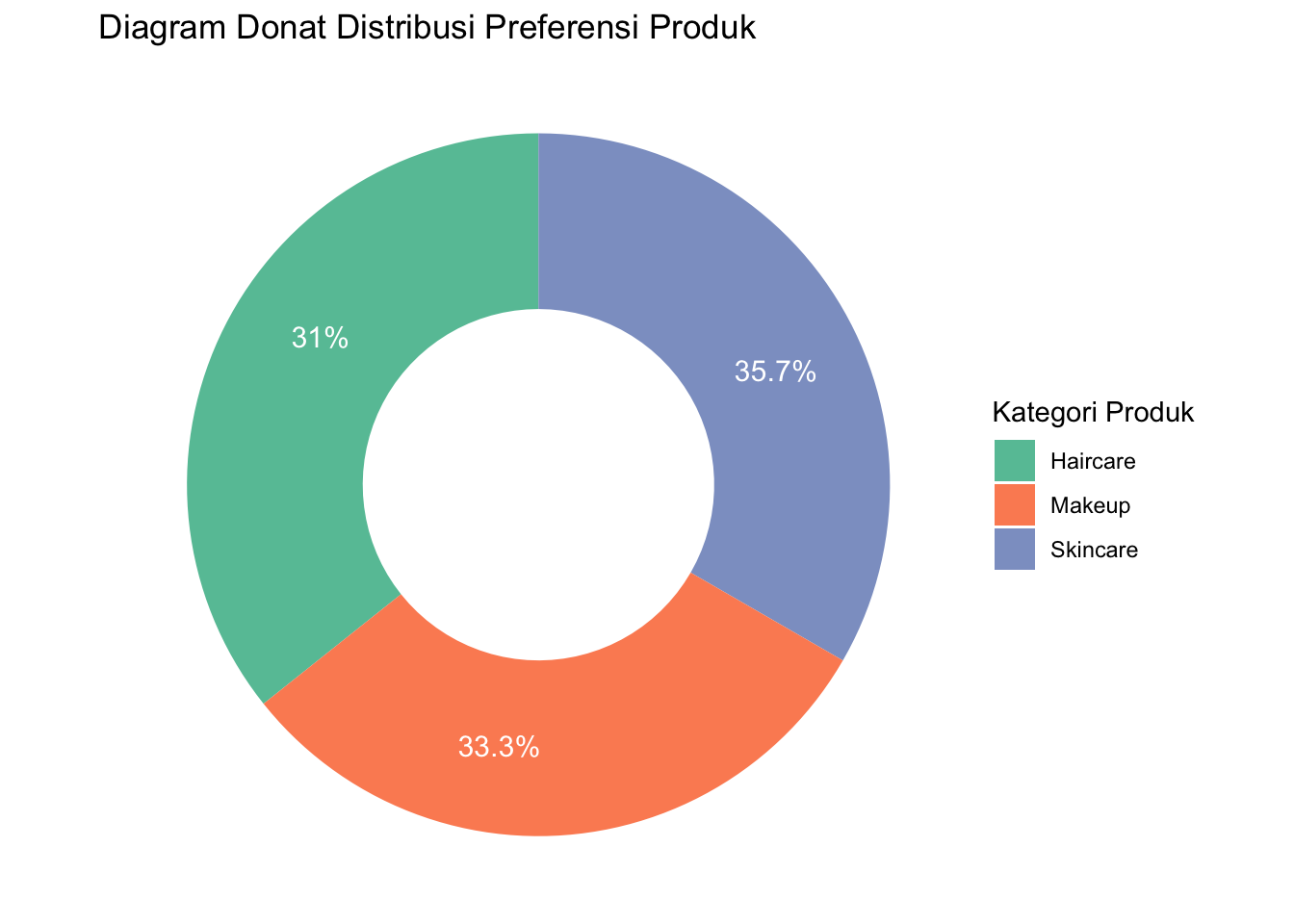
Berikut adalah konversi diagram lingkaran dari ggplot2 ke plotly. Kode ini akan menghasilkan diagram lingkaran interaktif dengan data yang sama
# Memuat library yang diperlukan
library(plotly)
library(RColorBrewer)
# Membuat diagram lingkaran dengan plotly
plot_ly(table_distribusi,
labels = ~`Kategori Produk`,
values = ~Frekuensi,
type = 'pie',
textinfo = 'label+percent', # label dan persentase
insidetextorientation = 'radial', # teks di dalam irisan
marker = list(colors = brewer.pal(n = nrow(table_distribusi),
name = "Set3"))) %>%
layout(title = "Diagram Lingkaran Distribusi Preferensi Produk",
showlegend = TRUE) # Menampilkan legendaUntuk membuat diagram donat (donut chart) menggunakan plotly, Anda bisa menggunakan fungsi plot_ly() dan mengatur parameter untuk menciptakan efek donat. Berikut adalah langkah-langkahnya:
# Memuat library yang diperlukan
library(plotly)
# Membuat diagram donat dengan plotly
plot_ly(table_distribusi,
labels = ~`Kategori Produk`,
values = ~Frekuensi,
type = 'pie',
textinfo = 'label+percent', # label dan persentase
insidetextorientation = 'radial', # teks di dalam irisan
hole = 0.5, # Mengatur ukuran lubang
marker = list(colors = RColorBrewer::brewer.pal(n = nrow(table_distribusi),
name = "Set2"))) %>%
layout(title = "Diagram Donat Distribusi Preferensi Produk",
showlegend = TRUE) # Menampilkan legendaStruktur Diagram Lingkaran
- Lingkaran Utama: Merepresentasikan total keseluruhan data.
- Irisan (Slices): Bagian dari lingkaran yang menunjukkan proporsi setiap kategori.
- Label: Menyediakan nama kategori dan seringkali menyertakan persentase atau nilai.
- Legends: Menjelaskan warna atau pola untuk membedakan kategori.
- Warna: Setiap irisan diberi warna berbeda untuk meningkatkan keterbacaan.
- Total: Kadang-kadang ditampilkan di tengah lingkaran untuk menunjukkan keseluruhan (100%)
Penerapan Diagram Lingkaran
Diagram lingkaran digunakan untuk:
- Menunjukkan Proporsi: Visualisasi proporsi setiap kategori terhadap total.
- Data Kategorikal: Menampilkan perbandingan antar kategori.
- Hasil Survei: Menunjukkan pilihan responden.
- Analisis Sederhana: Memudahkan analisis tanpa detail rumit.
- Membandingkan Kategori Kecil: Cocok untuk kategori yang relatif sedikit.
4.3 Data Kuantitatif
Data kuantitatif menggambarkan variabel numerik seperti usia, pendapatan, dan jumlah pembelian. Penyajian data kuantitatif dapat dilakukan dengan:
4.3.1 Diagram Histogram
Histogram adalah representasi grafis dari distribusi data numerik yang berbentuk batang (bar chart), di mana sumbu horizontal (x-axis) menunjukkan rentang nilai atau interval (bin), dan sumbu vertikal (y-axis) menunjukkan frekuensi atau jumlah data dalam setiap rentang.
Digunakan untuk menunjukkan distribusi data. Berikut adalah contoh pembuatan diagram histogram menggunakan data dari dataset skincare. Saya akan menggunakan kolom yang umum seperti Pendapatan. Jika kolom yang dimaksud berbeda, silakan ganti sesuai kebutuhan.
# Membuat histogram menggunakan base R
hist(skincare$Pendapatan,
main = "Histogram Distribusi Pendapatan",
xlab = "Pendapatan",
ylab = "Frekuensi",
col = "#66c2a5",
border = "white") # Mengatur warna dan border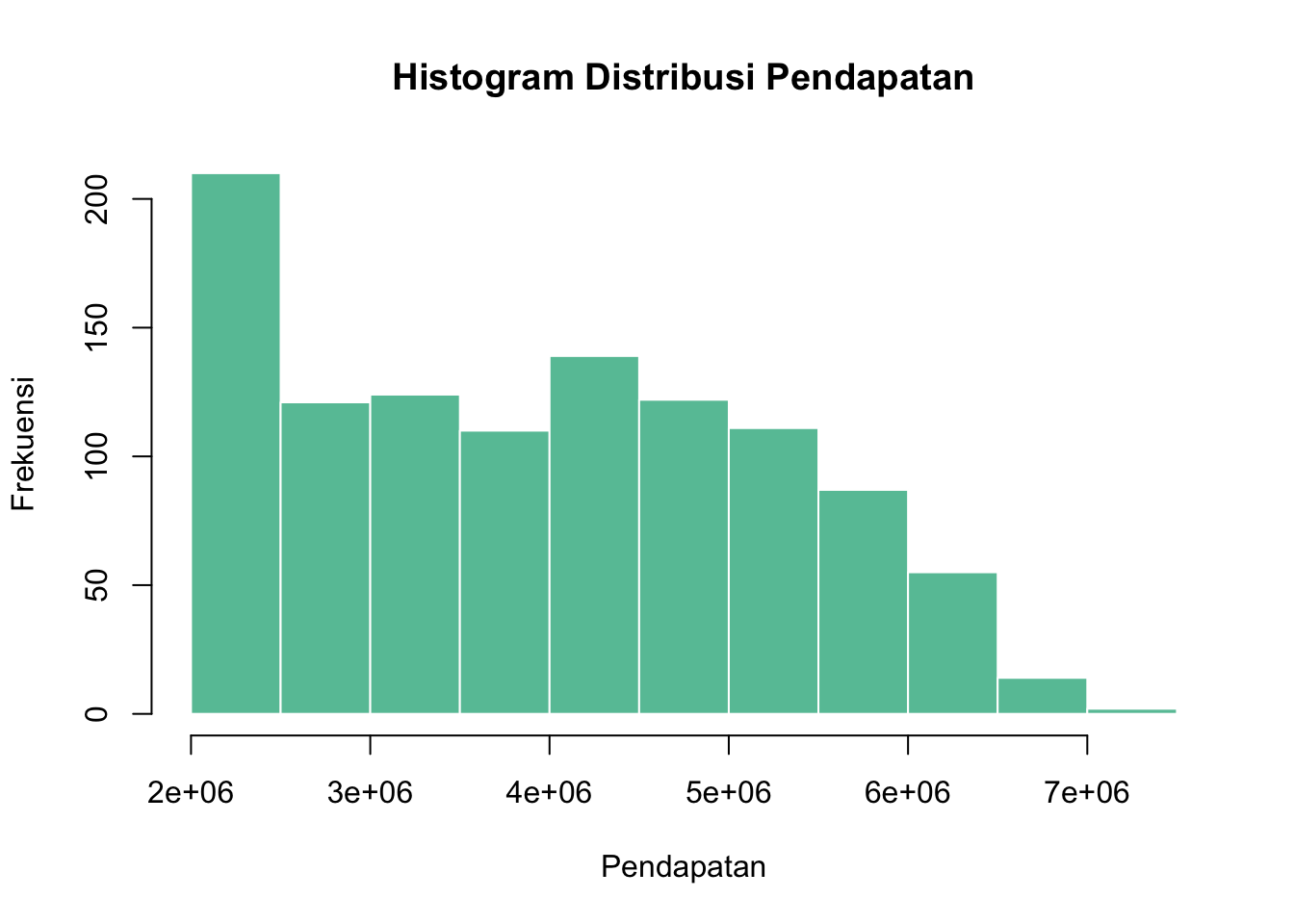
Untuk membuat histogram menggunakan plotly, Anda dapat menggunakan fungsi plot_ly() yang menyediakan opsi interaktif untuk visualisasi. Berikut adalah cara membuat histogram distribusi Pendapatan dari dataset skincare dengan plotly.
# Memuat library yang diperlukan
library(plotly)
# Membuat histogram dengan variasi warna
plot_ly(data = skincare,
x = ~Pendapatan,
type = "histogram",
marker = list(color = RColorBrewer::brewer.pal(n = 3, name = "Set2")[1],
line = list(color = "white", width = 1))) %>%
layout(title = "Histogram Distribusi Pendapatan",
xaxis = list(title = "Pendapatan"),
yaxis = list(title = "Frekuensi"))Struktur Histogram
Histogram adalah grafik batang yang menunjukkan distribusi frekuensi data. Komponennya meliputi:
- Sumbu X: Interval kelas data.
- Sumbu Y: Frekuensi atau jumlah data dalam setiap interval.
- Batang: Tinggi batang mewakili frekuensi data dalam interval tersebut.
Histogram membantu memvisualisasikan pola distribusi data numerik, seperti simetri atau kecondongan (skewness).
4.3.2 Diagram Garis
Diagram garis adalah jenis grafik yang digunakan untuk menunjukkan perubahan nilai dari satu atau lebih variabel seiring waktu. Grafik ini sangat berguna untuk mengidentifikasi tren dan pola dalam data, terutama jika data tersebut bersifat numerik dan berurutan.
Misalkan kita memiliki dataset skincare dengan kolom Tanggal dan Pendapatan. Berikut adalah contoh bagaimana cara membuat diagram garis dengan ggplot2:
# Memuat library yang diperlukan
library(dplyr)
library(ggplot2)
# Mengonversi kolom Tanggal menjadi tipe Date jika belum
skincare$Tanggal <- as.Date(skincare$Tanggal)
# Mengelompokkan data berdasarkan bulan dan tahun
data_bulanan <- skincare %>%
mutate(Bulan = format(Tanggal, "%Y-%m")) %>% # format "YYYY-MM"
group_by(Bulan) %>% # Mengelompokkan
summarise(Total_Jumlah_Pembelian = sum(Jumlah_Pembelian, na.rm = TRUE))
# Membuat diagram garis untuk pendapatan bulanan
ggplot(data = data_bulanan, aes(x = as.Date(paste0(Bulan, "-01")), y = Total_Jumlah_Pembelian)) +
geom_line(color = "#49c7a9", size = 1) + # warna dan ukuran garis
geom_point(color = "#e55ac6", size = 2) + # titik pada data
labs(title = "Diagram Garis Distribusi TotalJumlah_Pembelian per Bulan",
x = "Bulan",
y = "Total Jumlah_Pembelian") +
theme_minimal() # Menggunakan tema minimal## Warning: Using `size` aesthetic for lines was
## deprecated in ggplot2 3.4.0.
## ℹ Please use `linewidth` instead.
## This warning is displayed once every
## 8 hours.
## Call
## `lifecycle::last_lifecycle_warnings()`
## to see where this warning was
## generated.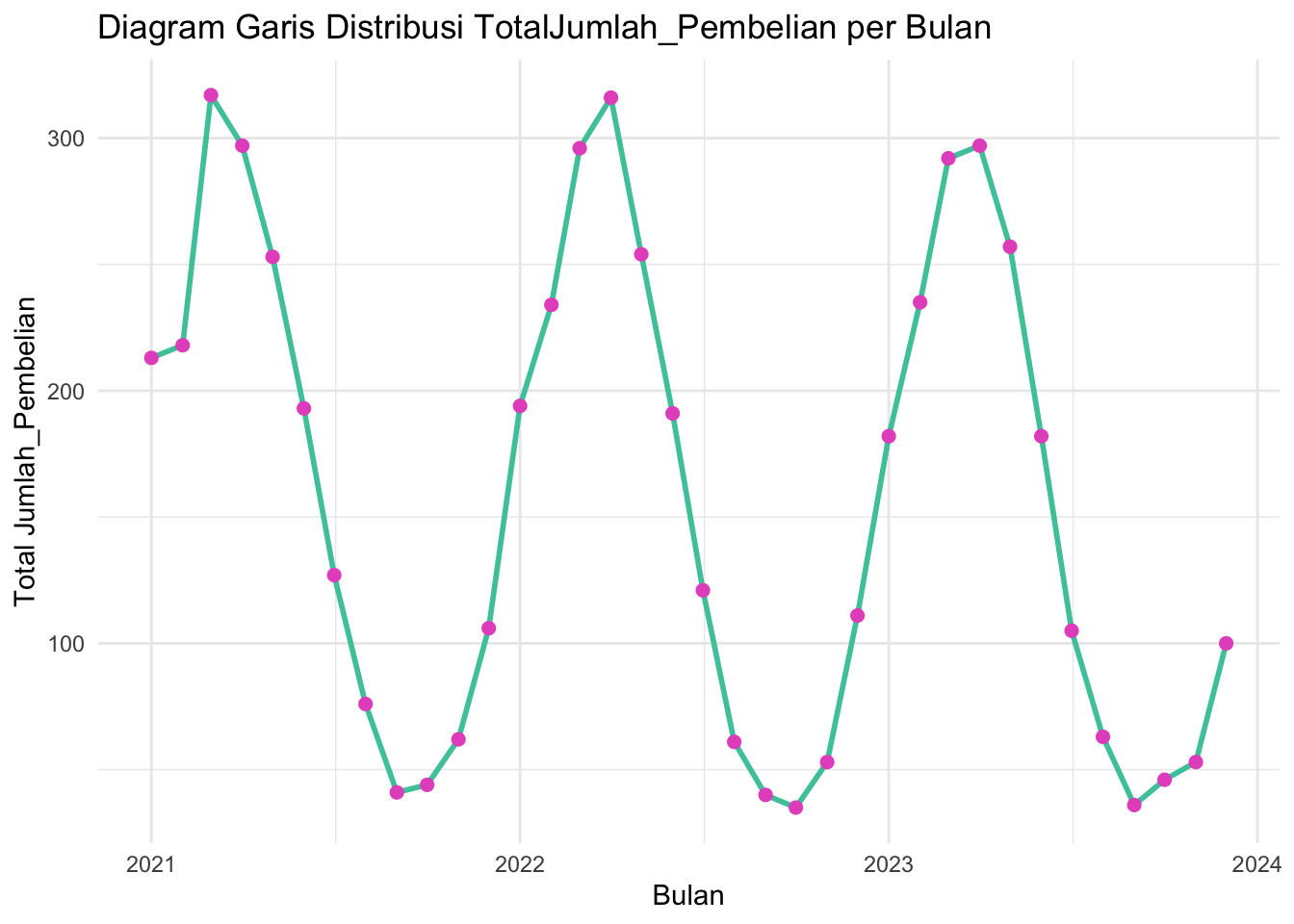
Untuk membuat diagram garis yang menunjukkan total pendapatan per hari menggunakan Plotly, Anda dapat mengikuti langkah-langkah berikut. Kode di bawah ini mengelompokkan data berdasarkan tanggal dan menghitung total pendapatan setiap hari, kemudian memvisualisasikannya menggunakan Plotly.
# Memuat library yang diperlukan
library(dplyr)
library(plotly)
# Mengonversi kolom Tanggal menjadi tipe Date jika belum
skincare$Tanggal <- as.Date(skincare$Tanggal)
# Mengelompokkan data berdasarkan bulan dan tahun
data_bulanan <- skincare %>%
mutate(Bulan = format(Tanggal, "%Y-%m")) %>%
group_by(Bulan) %>%
summarise(Total_Jumlah_Pembelian = sum(Jumlah_Pembelian, na.rm = TRUE))
# Membuat plot interaktif menggunakan Plotly
plot <- plot_ly(data = data_bulanan,
x = ~as.Date(paste0(Bulan, "-01")),
y = ~Total_Jumlah_Pembelian,
type = 'scatter',
mode = 'lines+markers',
line = list(color = "#49c7a9", width = 2),
marker = list(color = "#e55ac6", size = 6)) %>%
layout(title = "Diagram Garis Distribusi Total Jumlah Pembelian per Bulan",
xaxis = list(title = "Bulan"),
yaxis = list(title = "Total Jumlah Pembelian"),
showlegend = FALSE)
# Tampilkan plot
plotStruktur Diagram Garis
- Sumbu: X (Waktu) dan Y (Nilai).
- Titik Data: Menunjukkan nilai untuk kombinasi X dan Y.
- Garis: Menghubungkan titik data untuk menunjukkan tren.
- Label: Judul, label sumbu, dan label data (opsional).
- Legends: Menunjukkan kategori jika ada lebih dari satu garis.
- Tema: Mengatur tampilan (warna, gaya).
4.3.3 Diagram Boxplot
# Memuat library yang diperlukan
library(ggplot2)
library(ggrepel) # Library untuk menghindari label yang saling bertumpukan
library(dplyr) # Library untuk manipulasi data
# Menghitung nilai quartiles dan statistik lainnya
stat_summary <- skincare %>%
summarise(
Min = min(Usia, na.rm = TRUE),
Q1 = quantile(Usia, 0.25, na.rm = TRUE),
Median = median(Usia, na.rm = TRUE),
Q3 = quantile(Usia, 0.75, na.rm = TRUE),
Max = max(Usia, na.rm = TRUE)
)
# Membuat Boxplot untuk Usia dan menambahkan nilai quartiles
boxplot <- ggplot(skincare, aes(x = "", y = Usia)) + # Dummy x axis
geom_boxplot(outlier.shape = NA, fill = "#49c7a9", color = "#49c7a9") +
labs(title = "Distribusi Usia dengan Nilai Quartiles",
y = "Usia",
x = NULL) +
theme_minimal()
# Menambahkan garis median ke plot
boxplot <- boxplot +
geom_hline(yintercept = stat_summary$Median,
linetype = "dashed", color = "red") + # Garis median
geom_text(aes(x = 1, y = stat_summary$Median,
label = paste(" Q2 (Median):", stat_summary$Median)),
vjust = -0.5, color = "red") +
geom_text(aes(x = 1, y = stat_summary$Q1,
label = paste("Q1:", stat_summary$Q1)), vjust = -0.5, color = "blue") +
geom_text(aes(x = 1, y = stat_summary$Q3,
label = paste("Q3:", stat_summary$Q3)), vjust = -0.5, color = "green") +
geom_text(aes(x = 1, y = stat_summary$Min,
label = paste("Min:", stat_summary$Min)), vjust = -0.5, color = "purple") +
geom_text(aes(x = 1, y = stat_summary$Max,
label = paste("Max:", stat_summary$Max)), vjust = -0.5, color = "orange")
# Tampilkan plot
print(boxplot)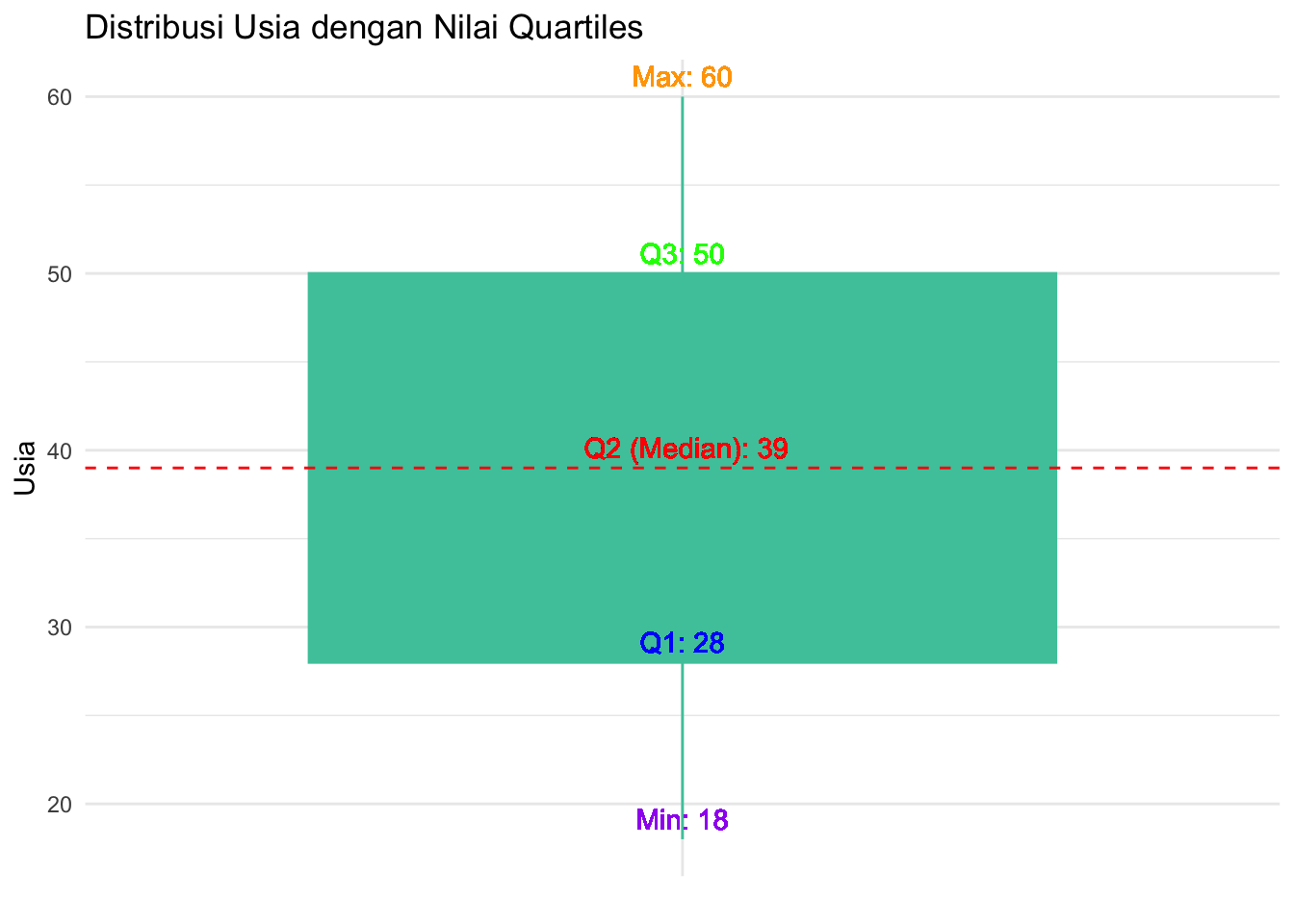
# Memuat library yang diperlukan
library(plotly)
# Membuat Violin Plot untuk Usia dengan label ID Pelanggan
violin_plot <- plot_ly(
data = skincare,
y = ~Usia, # Hanya Usia untuk sumbu y
type = 'violin', # Tipe plot violin
box = list(visible = TRUE), # Menampilkan boxplot di dalam violin
points = "all", # Menampilkan semua poin
jitter = 0.3, # Menambahkan sedikit jitter pada poin
text = ~paste("ID Pelanggan:", ID_Responden,
"<br>Usia:", Usia), # Menampilkan ID Pelanggan dan Usia
hoverinfo = "text", # Menampilkan label pada hover
marker = list(color = "#49c7a9"), # Warna marker
fillcolor = I("rgba(73, 199, 169, 0.5)")# Warna fill violin
) %>%
layout(
title = "Distribusi Usia dengan Label ID Pelanggan",
yaxis = list(title = "Usia"),
xaxis = list(showticklabels = FALSE), # Tidak menampilkan label x-axis
showlegend = FALSE
)
# Tampilkan plot
violin_plot4.4 Multivariat Data
Data multivariat adalah data yang melibatkan lebih dari dua variabel pada waktu yang sama. Penyajian data multivariat sering menggunakan:
4.4.1 Scatter Plot Matrix
Menampilkan hubungan antara banyak variabel numerik.
## Registered S3 method overwritten by 'GGally':
## method from
## +.gg ggplot2# Seleksi variabel numerik
numerical_data <- skincare %>% select_if(is.numeric)
# Membuat scatter plot matrix dengan GGally
ggpairs(numerical_data) +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) 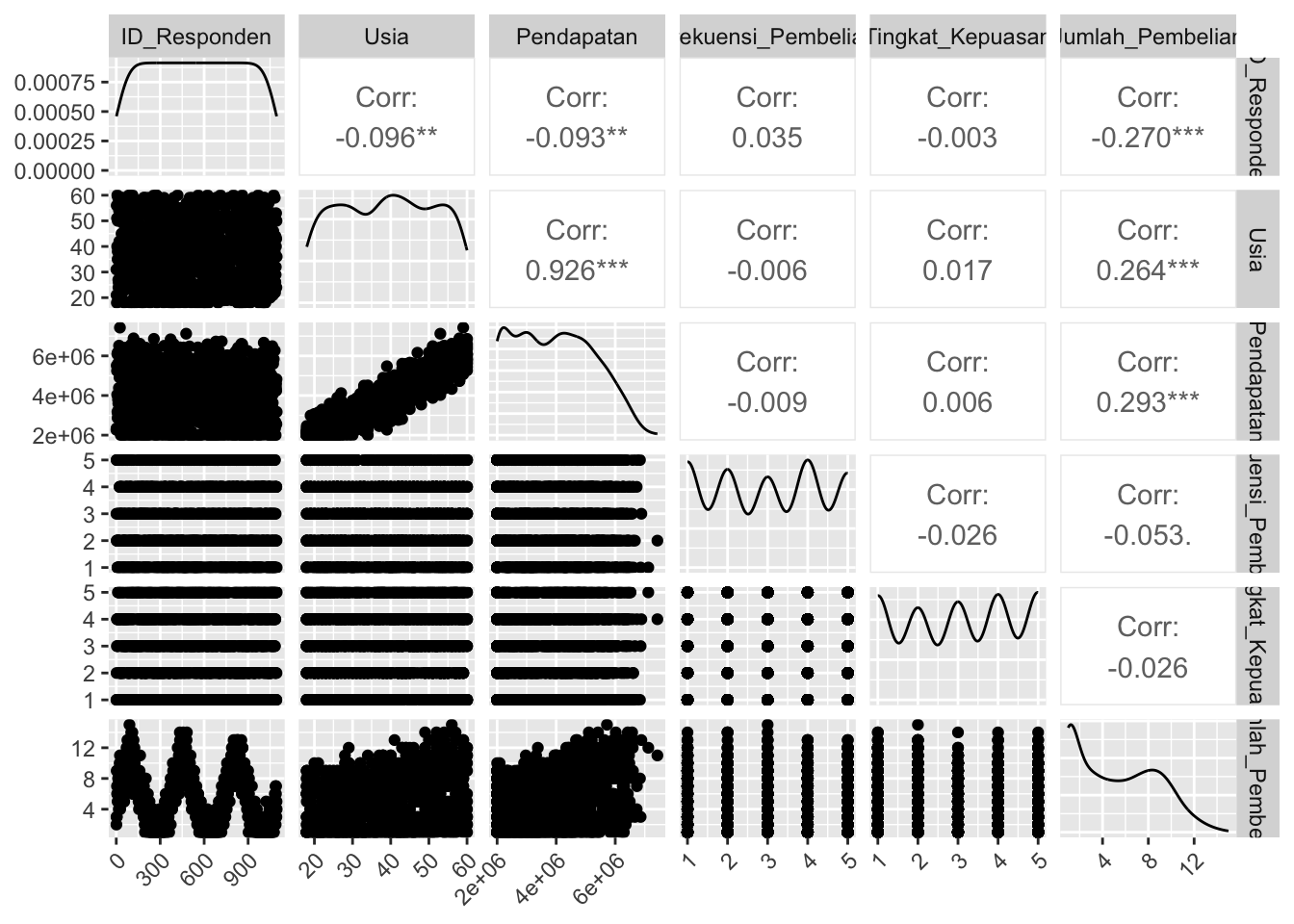
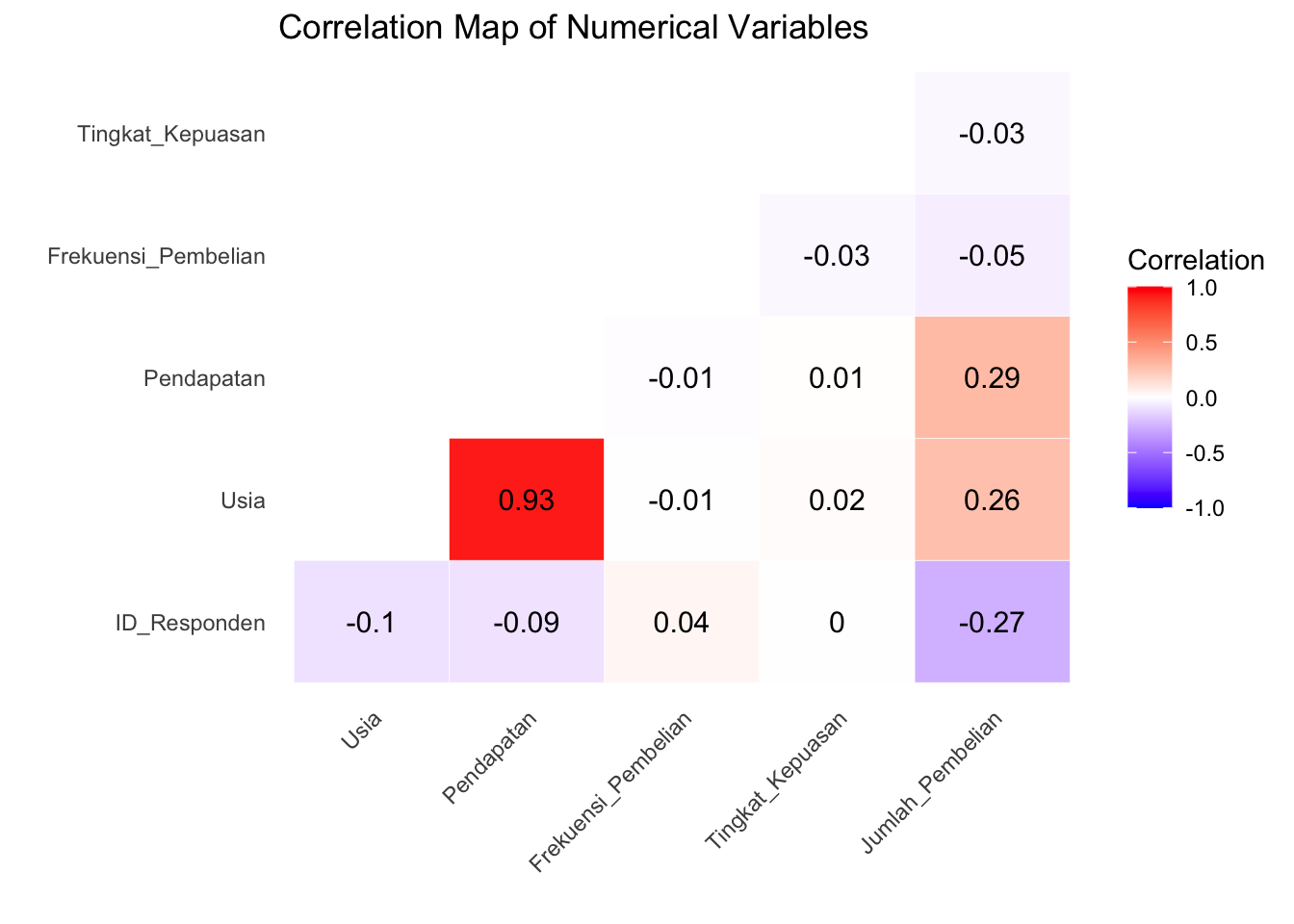
4.4.2 Heatmap
Menampilkan korelasi antar variabel dalam bentuk visual.
library(ggplot2)
library(reshape2)
library(dplyr)
# Seleksi variabel numerik
numerical_data <- skincare %>% select_if(is.numeric)
# Menghitung matriks korelasi
cor_matrix <- cor(numerical_data)
# Mengubah matriks korelasi menjadi format long
cor_matrix_melted <- melt(cor_matrix)
# Filter hanya segitiga atas (untuk pasangan unik)
cor_matrix_melted <- cor_matrix_melted %>%
filter(as.numeric(Var2) < as.numeric(Var1))
# Membuat heatmap korelasi dengan ggplot2
ggplot(cor_matrix_melted, aes(Var1, Var2, fill = value)) +
geom_tile(color = "white") +
scale_fill_gradient2(low = "blue", high = "red", mid = "white", midpoint = 0, limit = c(-1, 1),
name = "Correlation") +
geom_text(aes(label = round(value, 2)), color = "black", size = 4) + # Menambahkan nilai korelasi pada kotak
theme_minimal() +
labs(title = "Correlation Map of Numerical Variables", x = "", y = "") +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
theme(panel.grid.major = element_blank()) # Menghilangkan grid