Chapter 8 Plotting with aggregation
When we have many many data points, we have to think about how to aggregate data points into a small number of marks on the graph. However, there is a trade-off between seeing as much detail possible and being overwhelmed. In this chapter we will explore ways to aggregate data points without losing too much detail.
8.1 Univariate
Given a single variable, we often want to know what values are common and what values are rare. To visualize this, we will primarily compare marks along a common axis (the most accurate EPT). The only question is we have is how indicate how common particular values are.
8.1.1 Small samples
If we only have a few observations, then we can just graph them along an axis. If we have too many data points, we’ll have problems with over-plotting.
Another trick that works with more data, is to not use dots but rather lines. This is called a rug plot. The smaller width of the lines reduces, but don’t completely mitigate, the over-plotting issue.
 A rug plot layer is often used in conjunction with another graph such as a
scatter plot.
A rug plot layer is often used in conjunction with another graph such as a
scatter plot.
8.1.2 Histograms
When we have a moderate size of data, graphing dots exactly on an axis doesn’t work and results in over plotting and it is difficult to see where the data cluster. Instead we’ll stack the dots in columns along the axis and call this a dotplot.
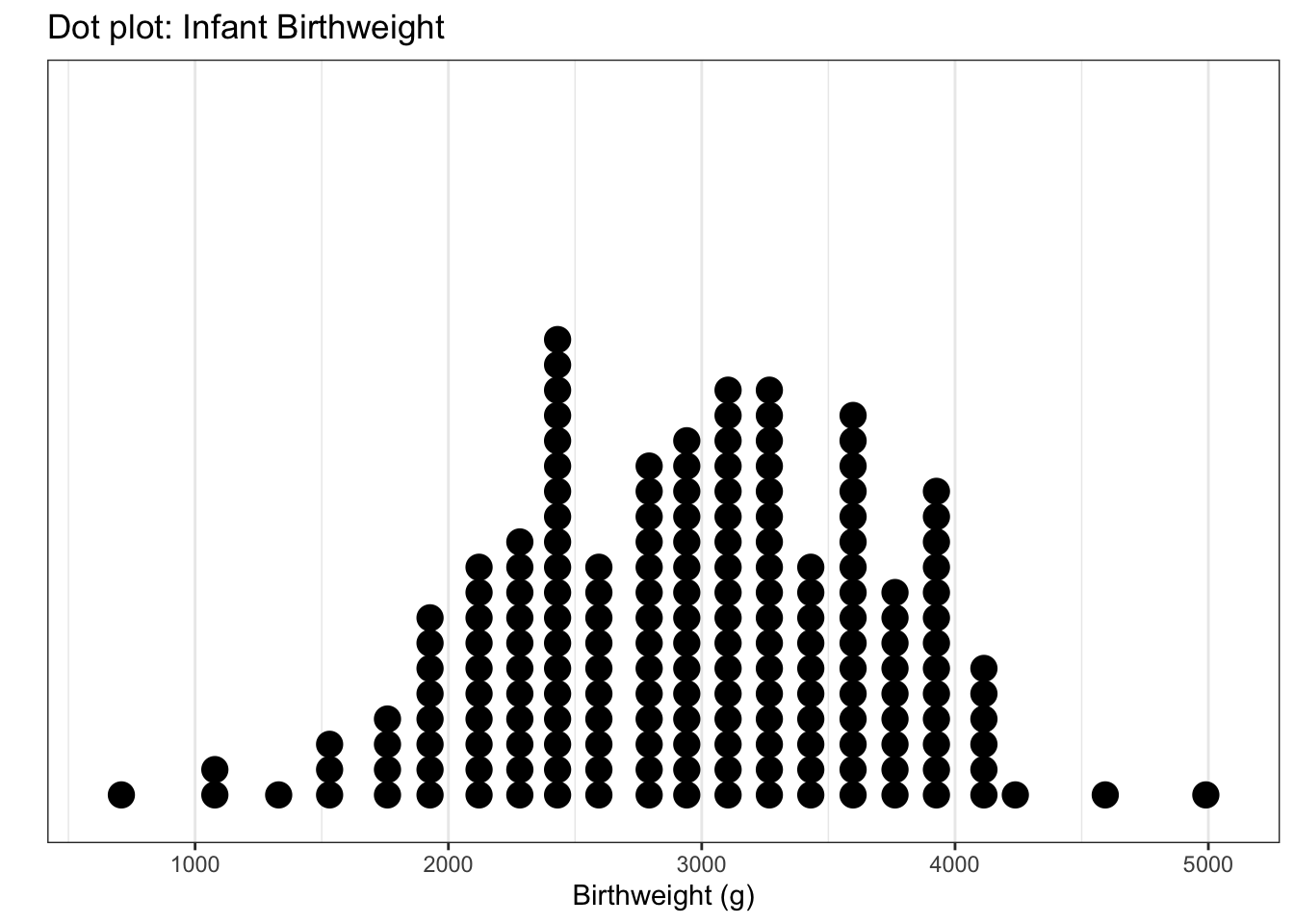
Each dot represents an observation, but the x-values have been rounded into group values. So we have lost some precision. Another common version of this is a histogram, where the y-axis represents how many observations fall into each bin.
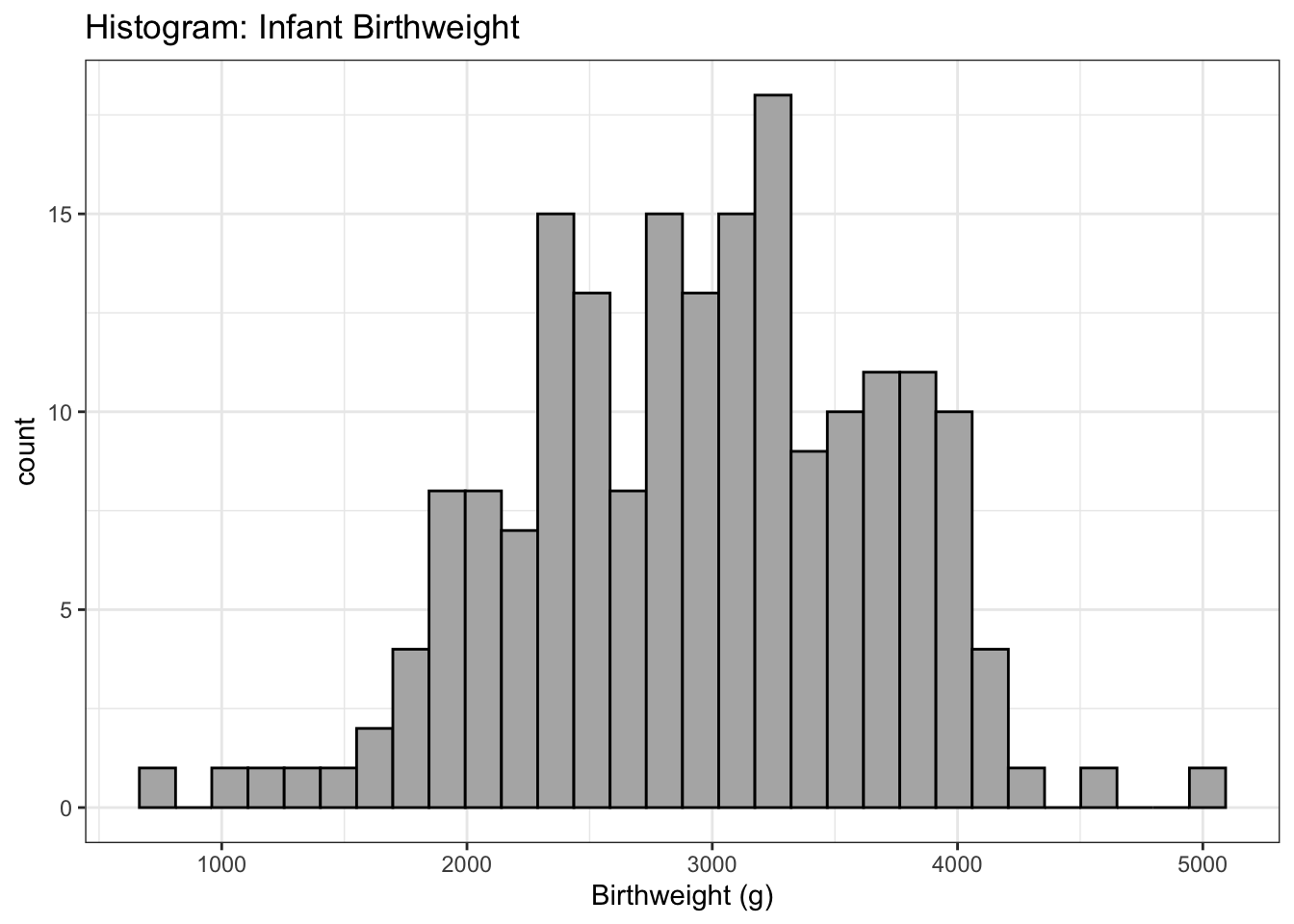
The choice of how many bins to include can make a dramatic difference in a graph. In particular, I don’t believe that there is any biological reason to think the dip near 2700 grams is real. I believe that is is actually just an artifact of the data I have. Instead we should consider changing the number of bins.
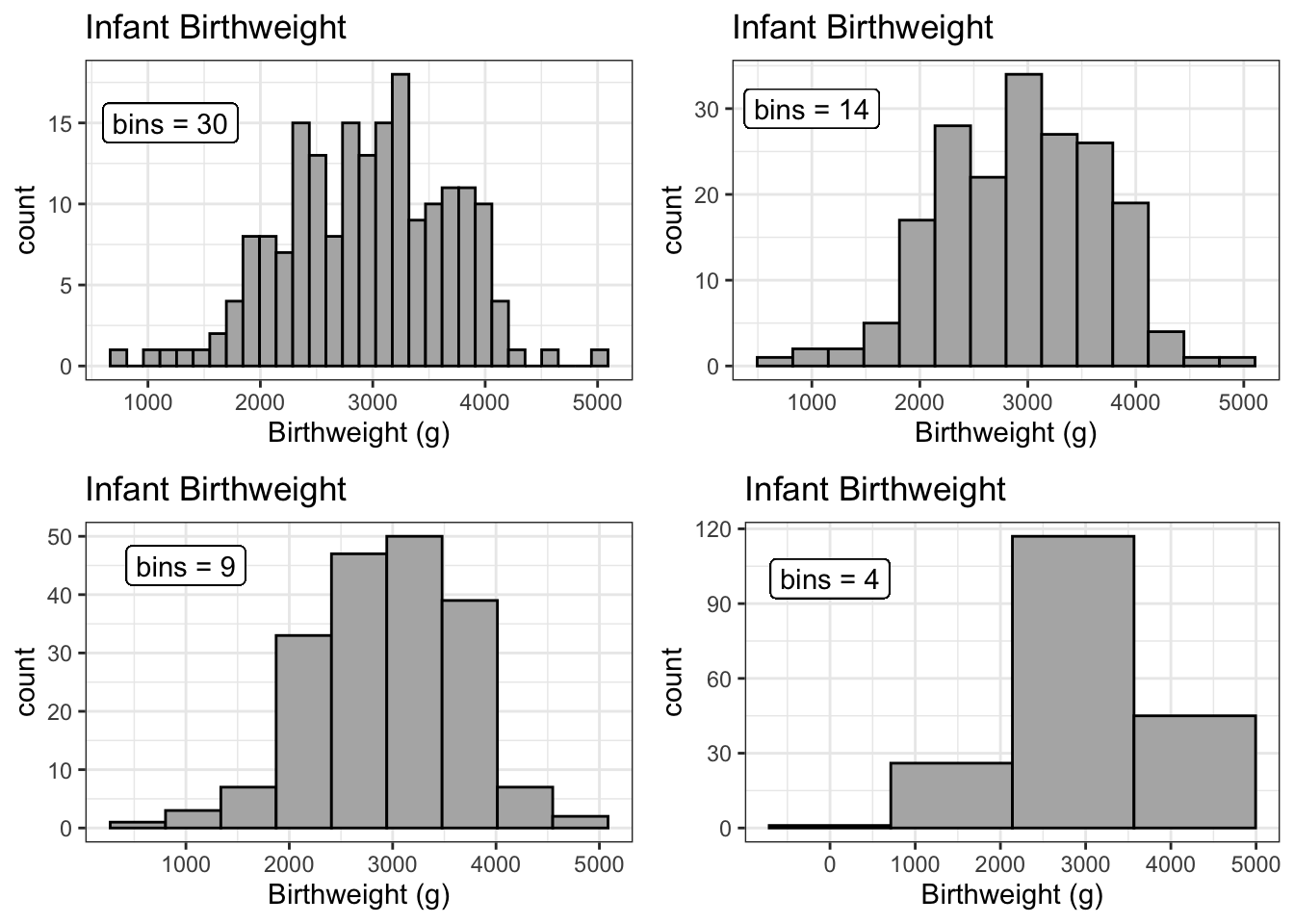
Histograms often have a y-axis that is labeled as density. Density is just a re-scaling such that the area of the bars sums up to one. As such, we often don’t care too much about the y-axis because all we care about is the relative area of the bars. Because of that, people often don’t even bother labeling the y-axis of a histogram if the data set size is large.
8.1.3 Density plots
Histograms suffer from being to angular or pointy. Another solution is call a kernel density smoother that mathematically smooths over the heights of the histogram bars.
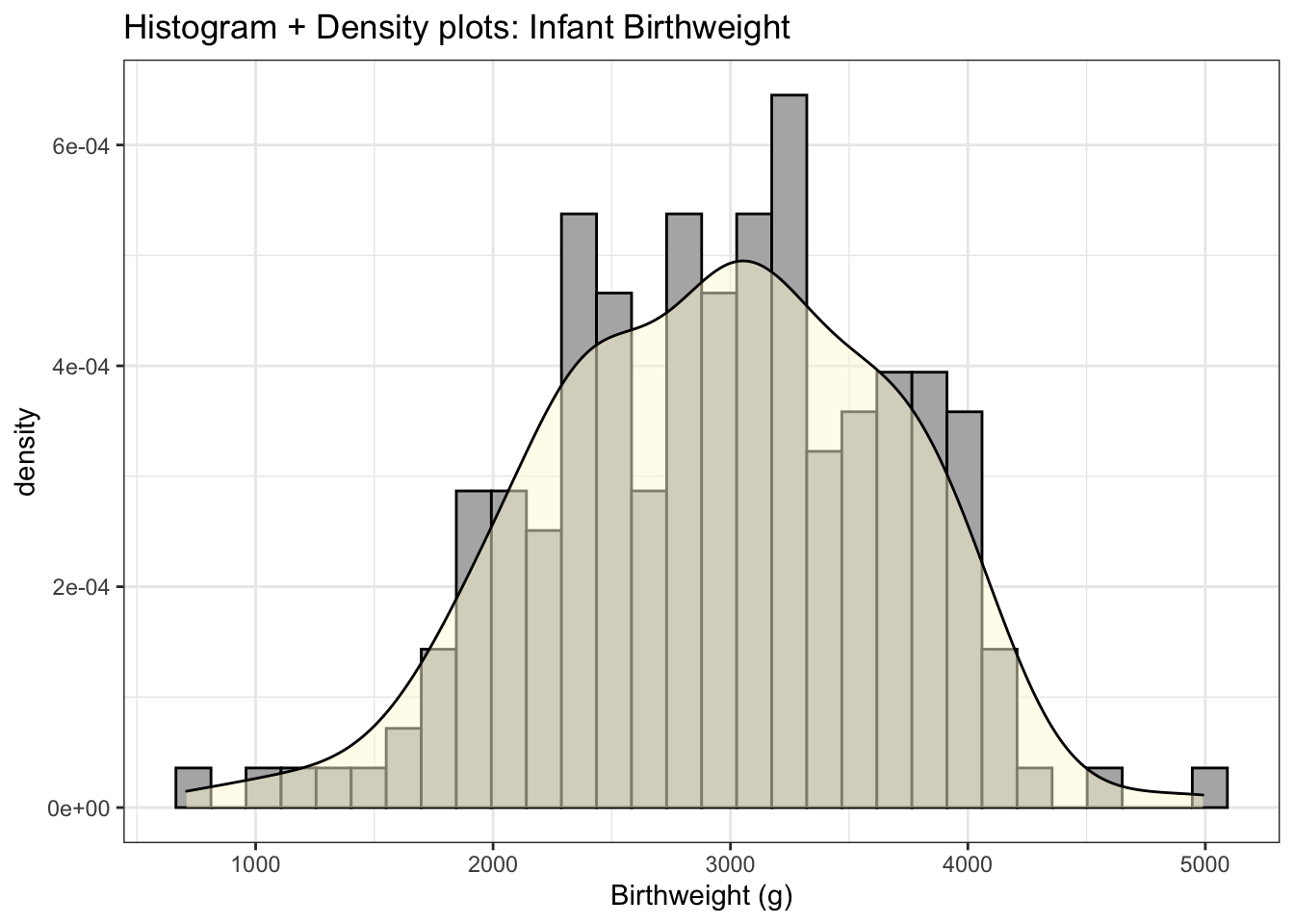
As with histograms, the y-axis of a density plot is scaled so that the area under the curve is one. Density values are fairly useless for most audiences and again people often remove the y-axis.
8.1.4 Faceting
One of my favorite ways to display multiple distributions is to group each distribution into it’s own plot in a process often referred to as faceting.
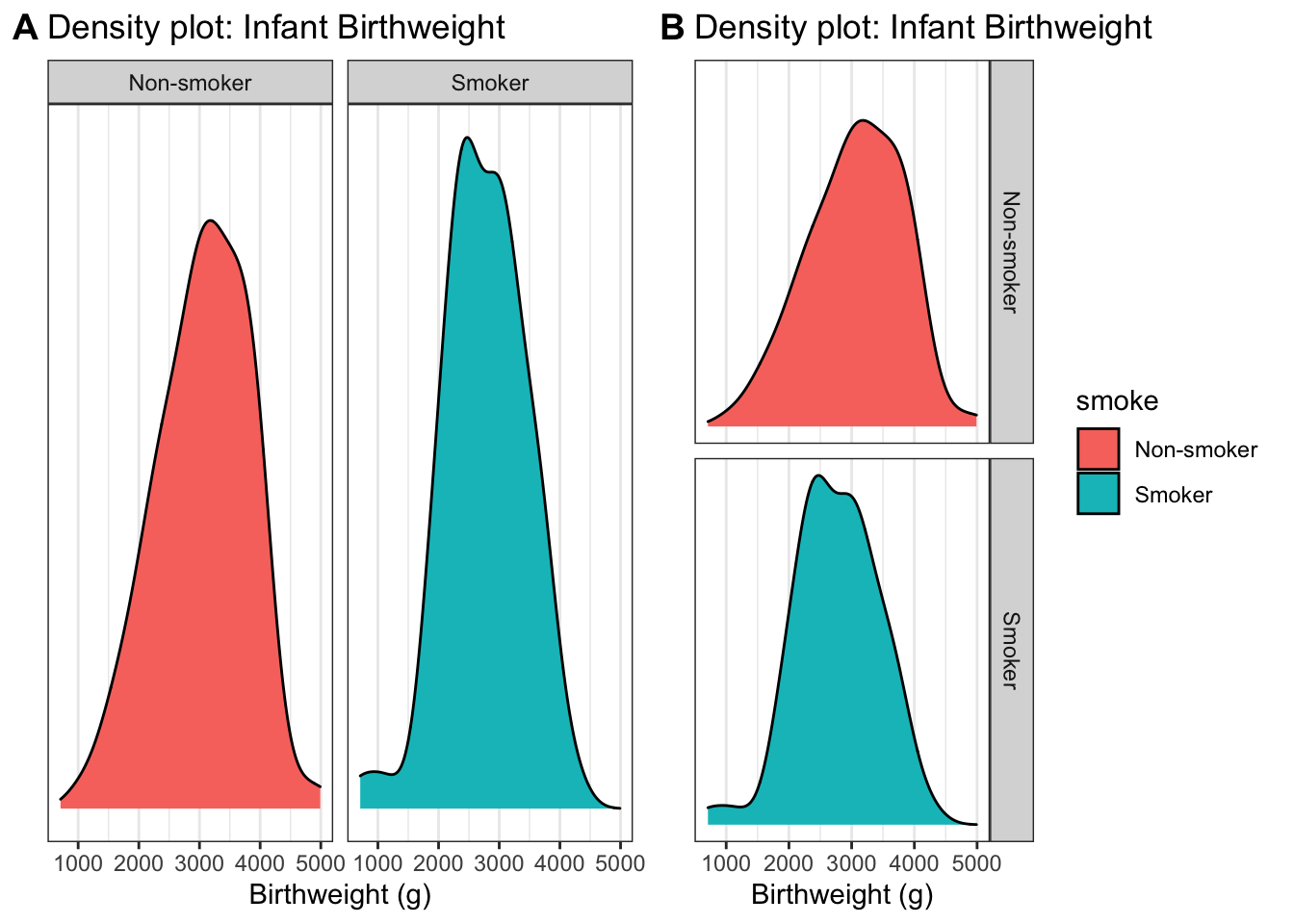
By choosing to put the two graphs on top of the other, it becomes clear that the smoker’s tend to give birth to smaller infants. This fact isn’t clear in the side-by-side graphs.
8.1.5 Stacking
Stacking the distribution involes laying each distribution on top of each other, so that the zero of the top curve follows the curve on the bottom. You can visualize the B chart having the Non-smoker density graph just melt onto the smoker density.
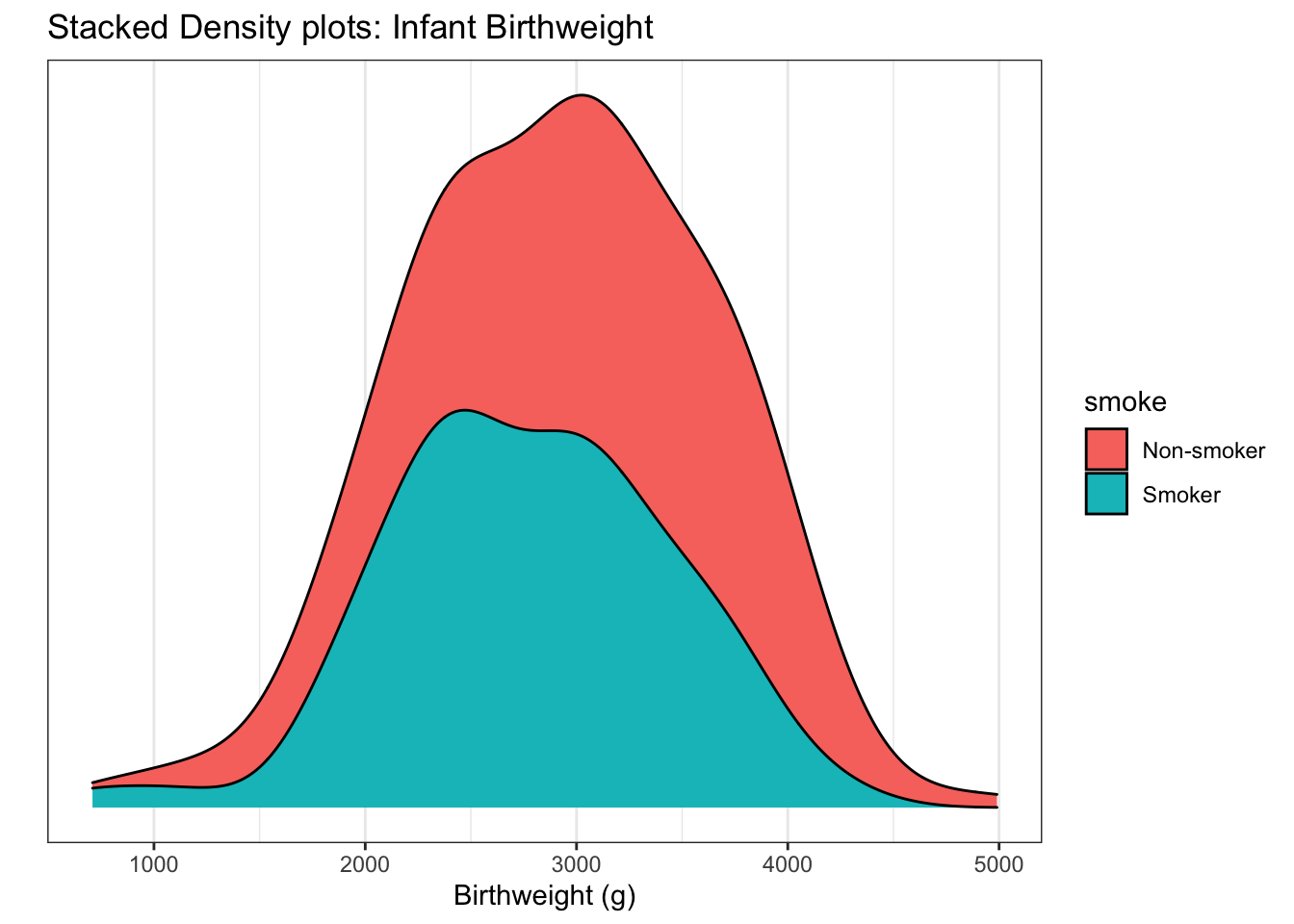 I really don’t like this graph because it is very hard to see where the peak
of the non-smoker curve is. This stacking trick works well enough when we have
proportions but isn’t good here.
I really don’t like this graph because it is very hard to see where the peak
of the non-smoker curve is. This stacking trick works well enough when we have
proportions but isn’t good here.
8.1.6 Overlapping curves
Another option is to graph the densities, but allow them to overlap each other
and be a bit see-thru.
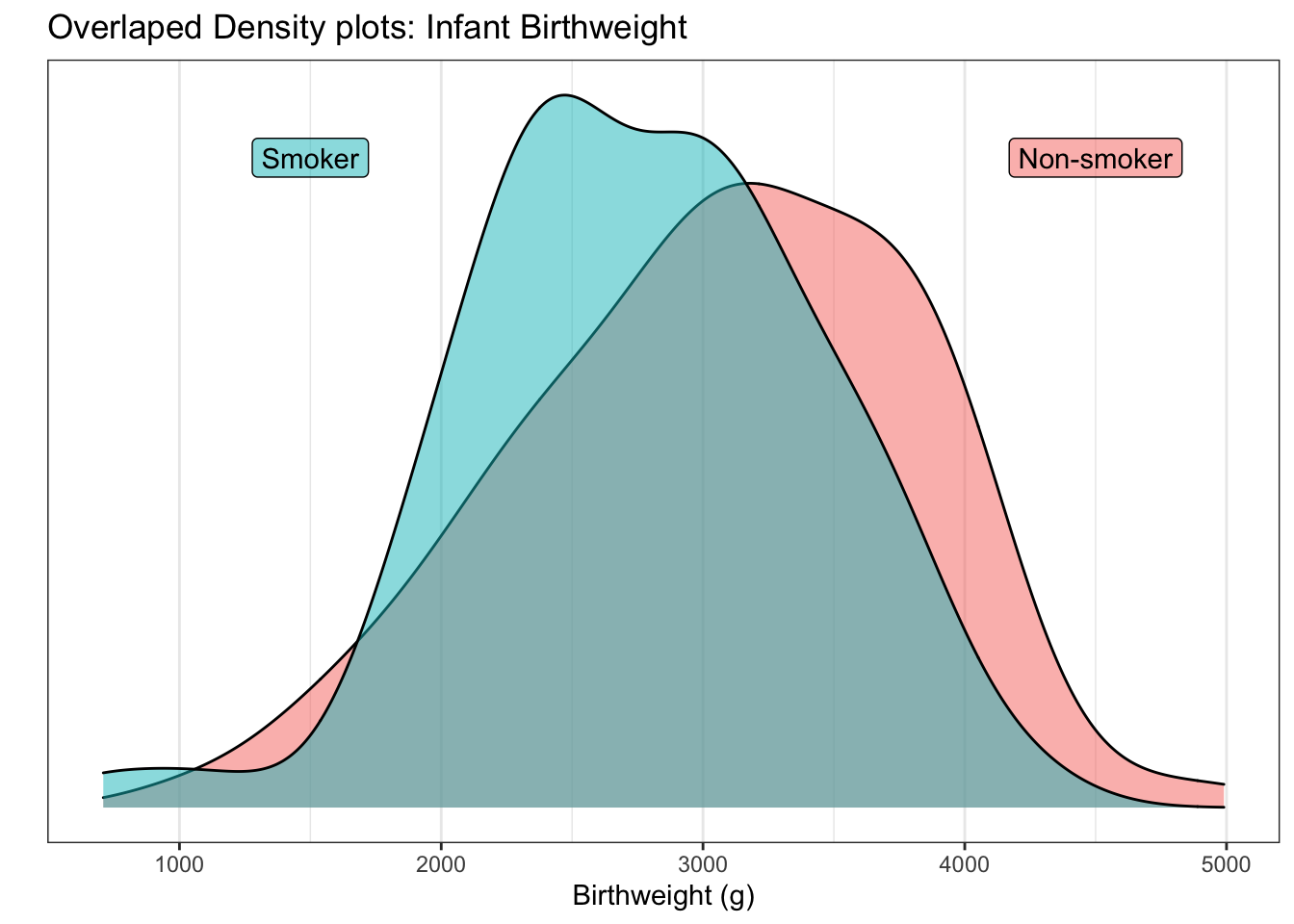
For seeing shifts in the center of the distribution, overlapping curves is quite powerful.
8.2 Bivariate (one continuous, one categorical)
Next we’ll consider comparing many different distributions. In our example, we’ll investigate the daily maximum temperature in Lincoln Nebraska in 2016 and we show the temperature distribution for each month. Therefore we’ll have 12 different distributions to compare.
8.2.1 Box plots
Box plots are a traditional way to display a distribution and the box contains
the middle 50% of the data points.
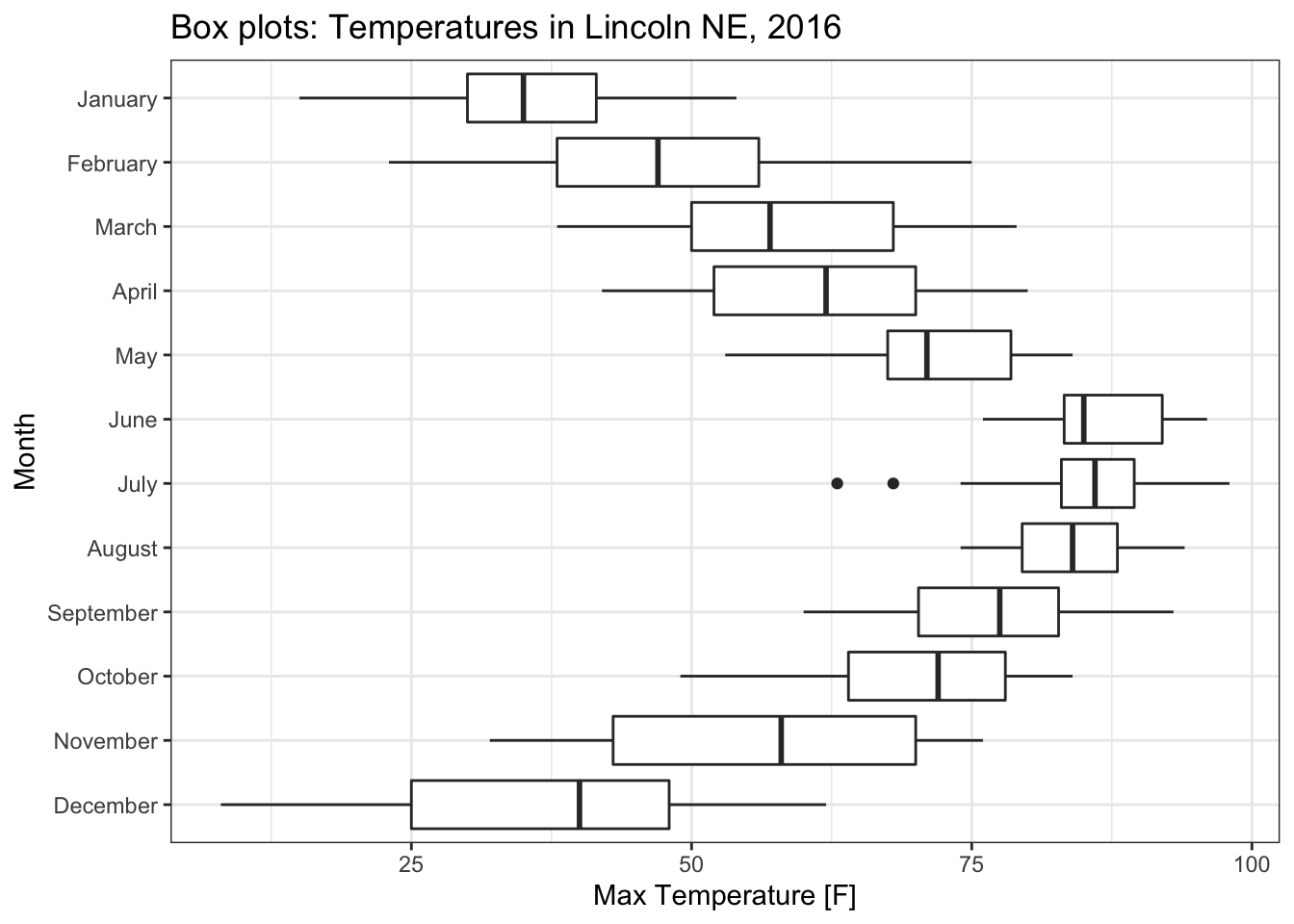 While box plots are quite commonly used, they summarize the data too much and
a lot of interesting detail is lost in this summary.
While box plots are quite commonly used, they summarize the data too much and
a lot of interesting detail is lost in this summary.
8.2.2 Ridge Plots
If we have a bunch of overlapping curves, but we stagger them along the y-axis, we get a type of graph called a ridge graph.
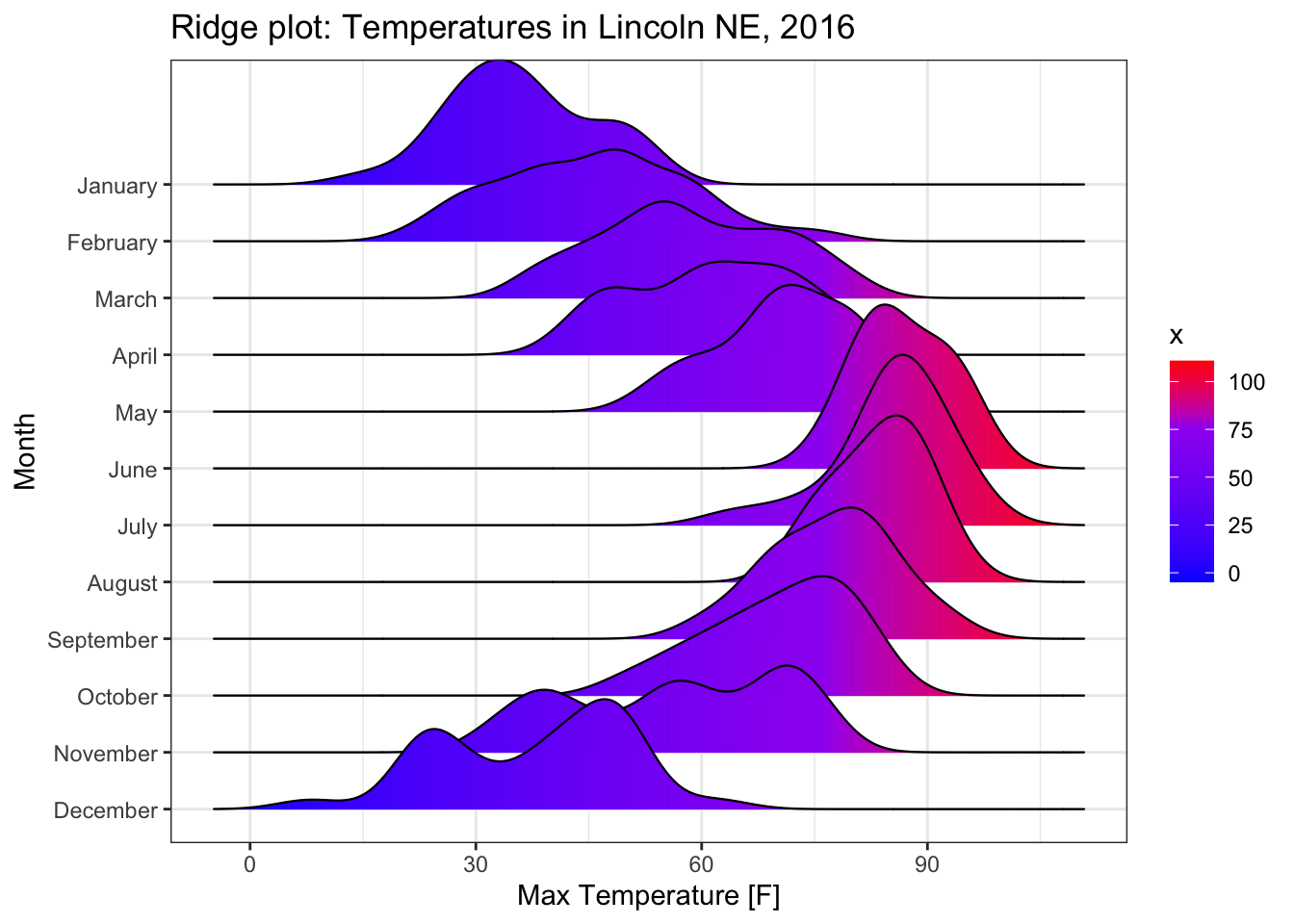
Notice that in density plots, there were two peaks in December with the lower peak corresponding to a cold snap. That detail is lost in the boxplots.
8.2.3 Violin Plots
An alternative to ridge plots a graph called a violin plot. This takes the density plots and mirrors them. Then we’ll display them with no overlap in the different distributions.
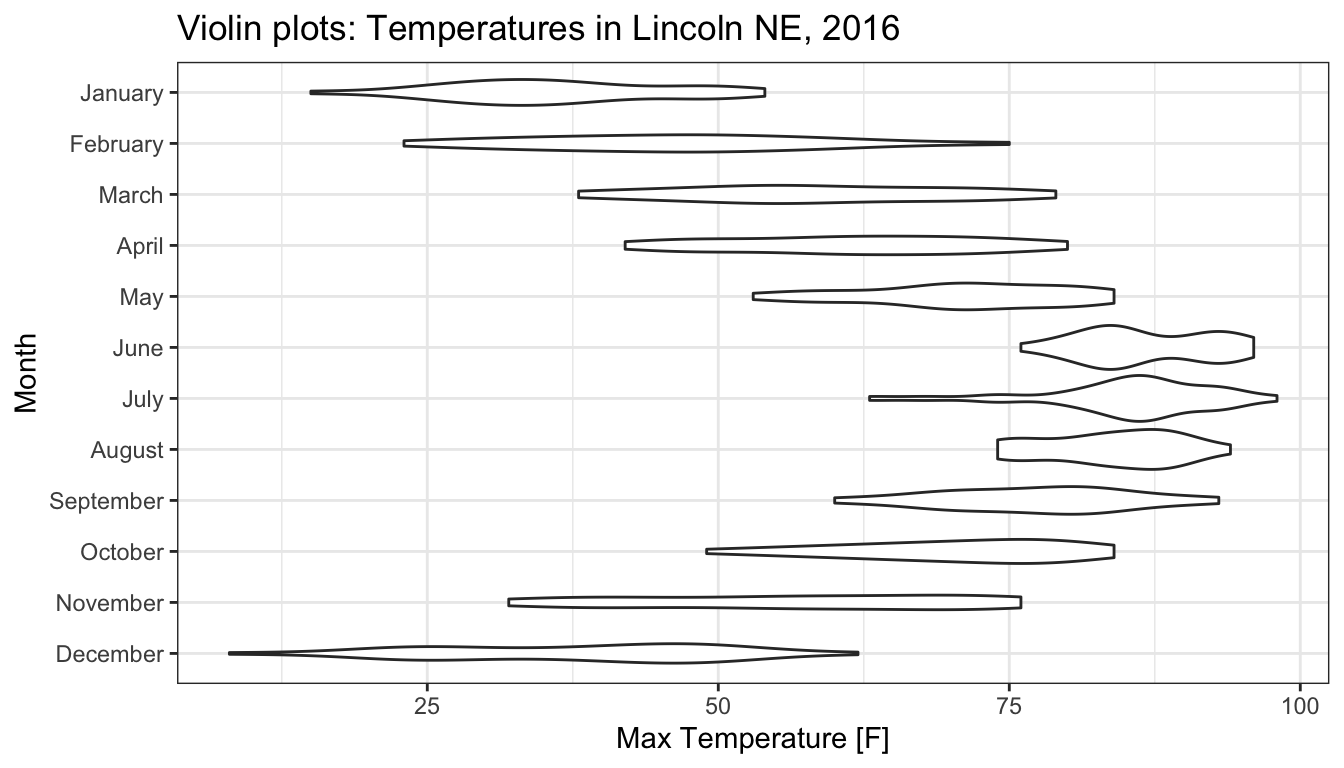 Now we can see the two peaks in December, but the three peaks in November have
been flattened out because the amount of space necessary to show it would require
that the densities overlap.
Now we can see the two peaks in December, but the three peaks in November have
been flattened out because the amount of space necessary to show it would require
that the densities overlap.
Ridge line and violin plots are great alternatives to box plots and the choice to have the density plots overlap or not is up to the user.
We’ve previously looked at how to display information along a single dimension. Now we consider showing data in multiple dimensions and deal with issues that arise when we have potentially lots of data. Just as histograms avoid showing each data point, we’ll finally develop the 2-dimensional analog.
8.3 Bivariate (two continuous)
8.3.1 Scatter plots
Our basic idea is to build off of a scatter plot. This visualizes the relationship between two continuous variables.
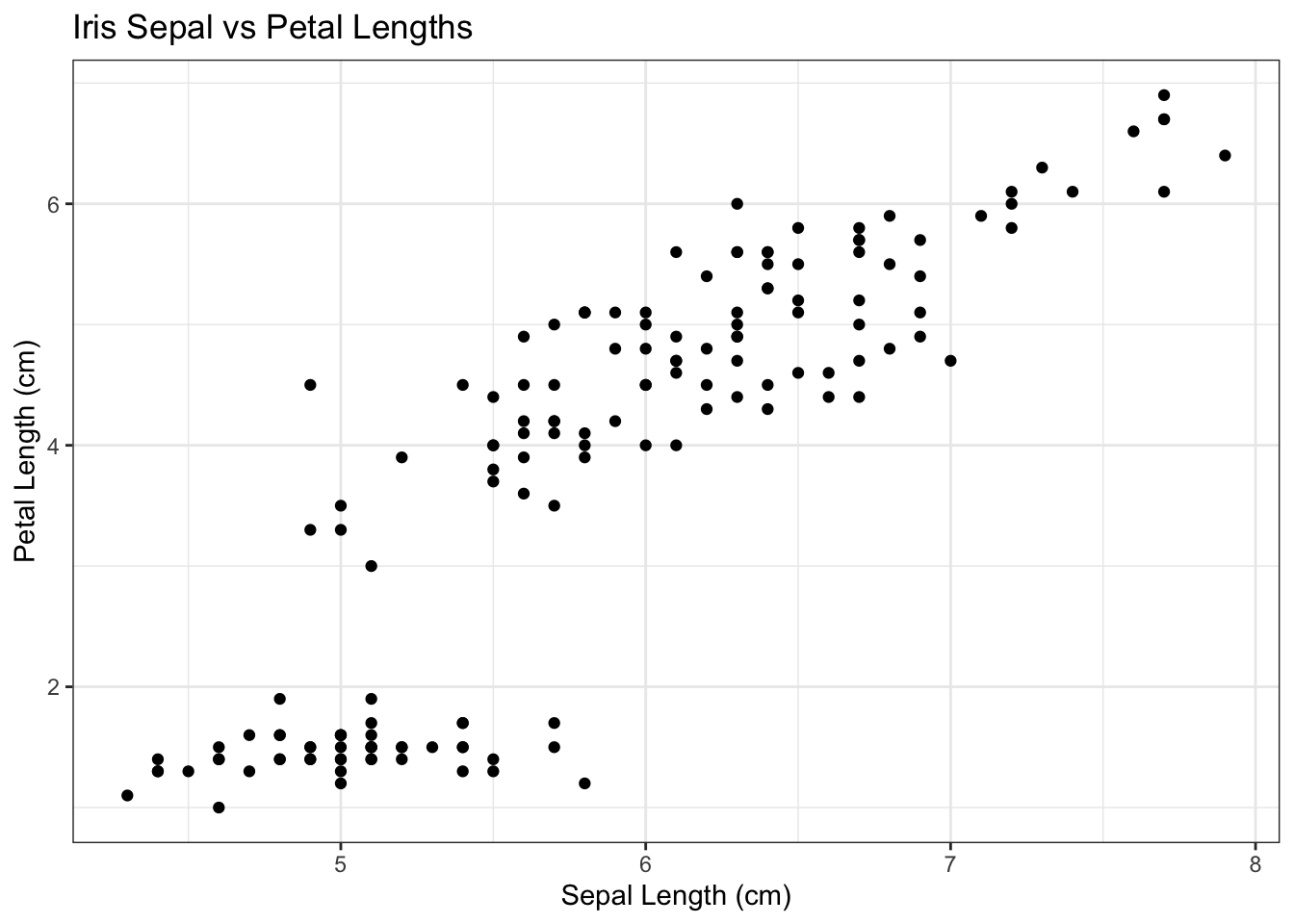
In a scatter plot we can see the relationship between two variables. We can see the relationship among more variables (either continuous or discrete) by adding Size, Color, and Shape.
We could also add other categorical variables by adding faceting. With this combination we can visualize the relationship between up to 6 different variables.
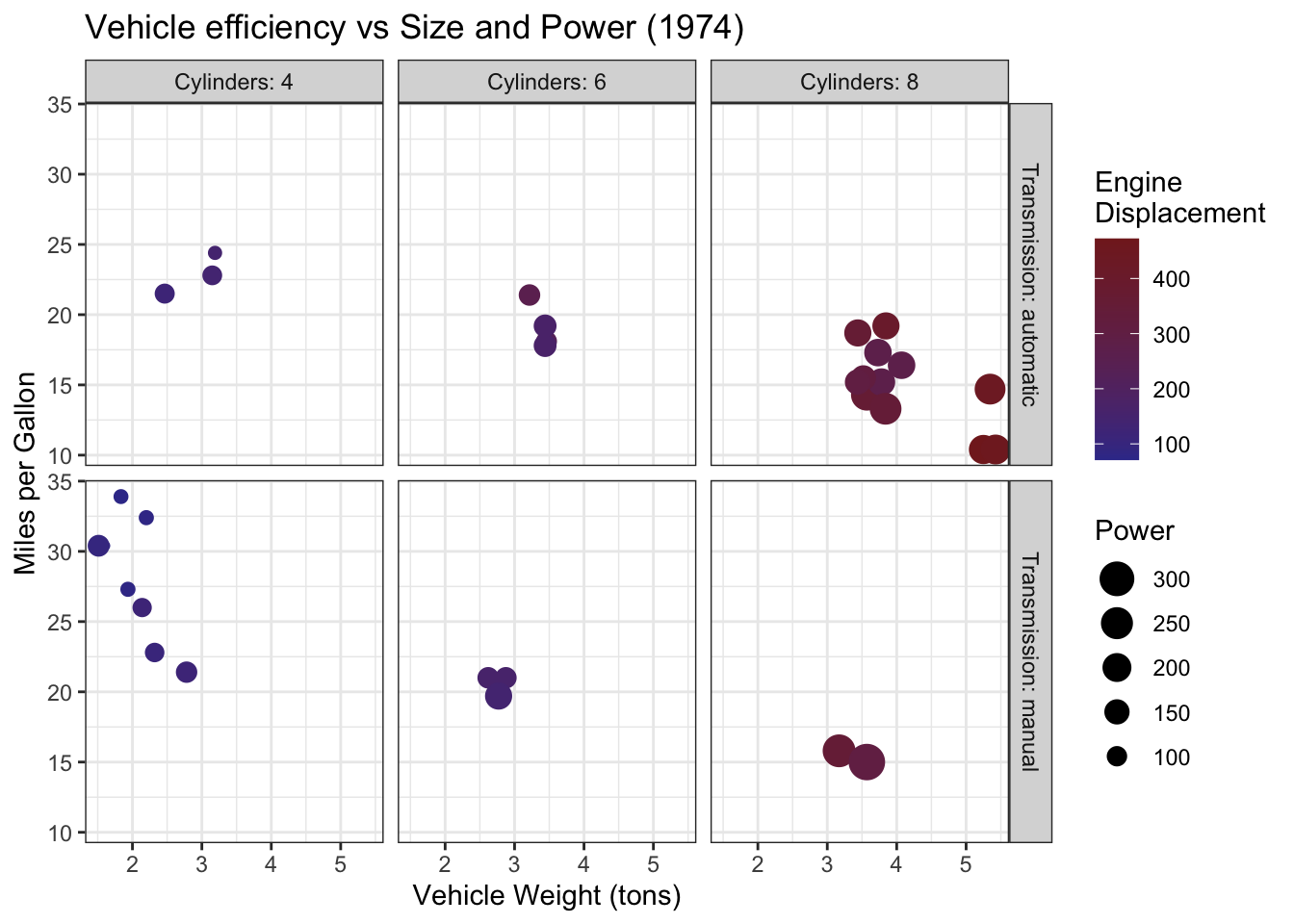
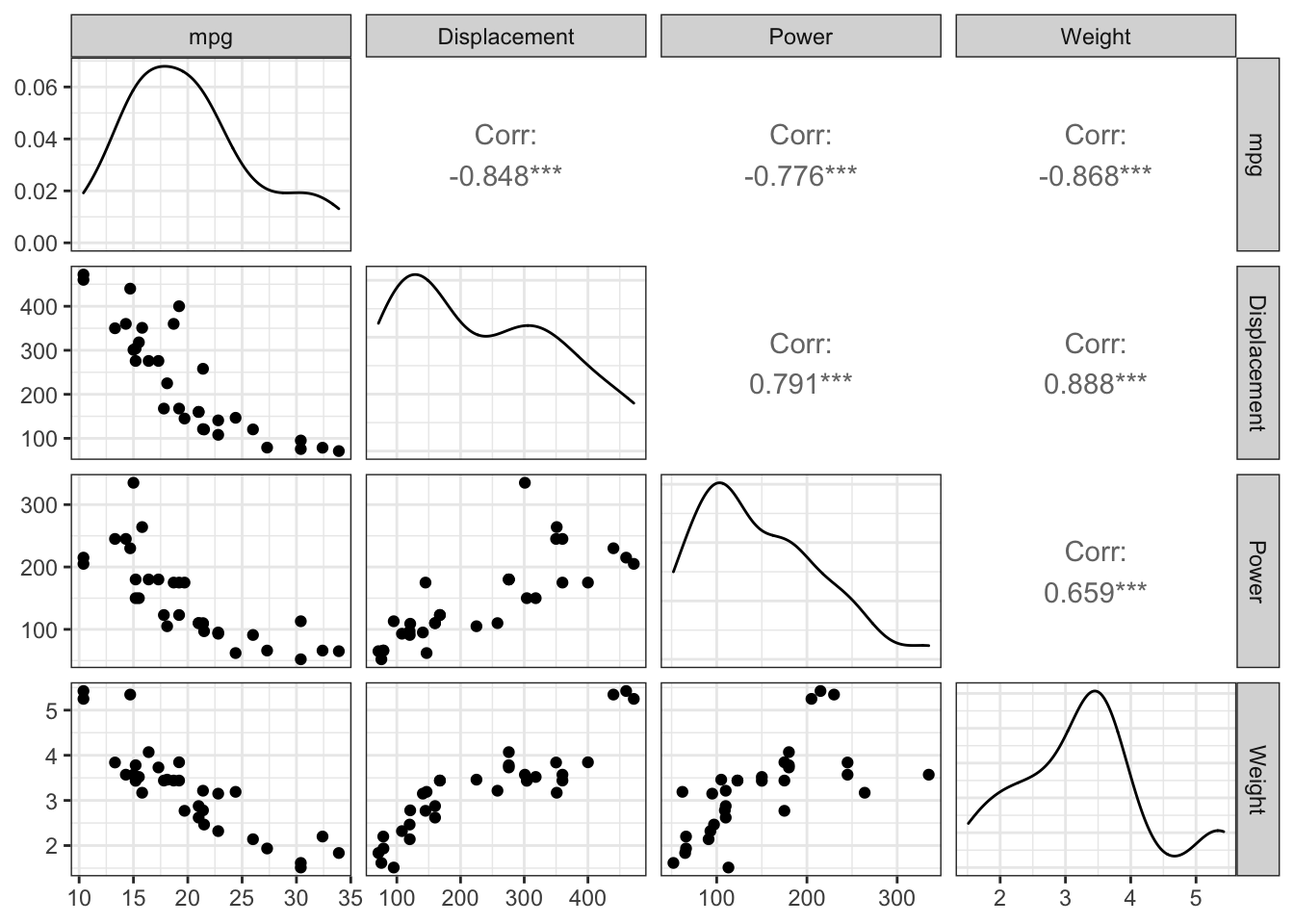
8.3.2 Pairs plots (All-vs-all scatterplots)
Sometimes we have a data set with several different variables of quantitative
variables. One thing we could do is just make all possible pairs of scatter plots.
In a pairs plot, we make a grid of graphs where x-axis or y-axis remains
consistent as we move across the columns or rows of the grid.
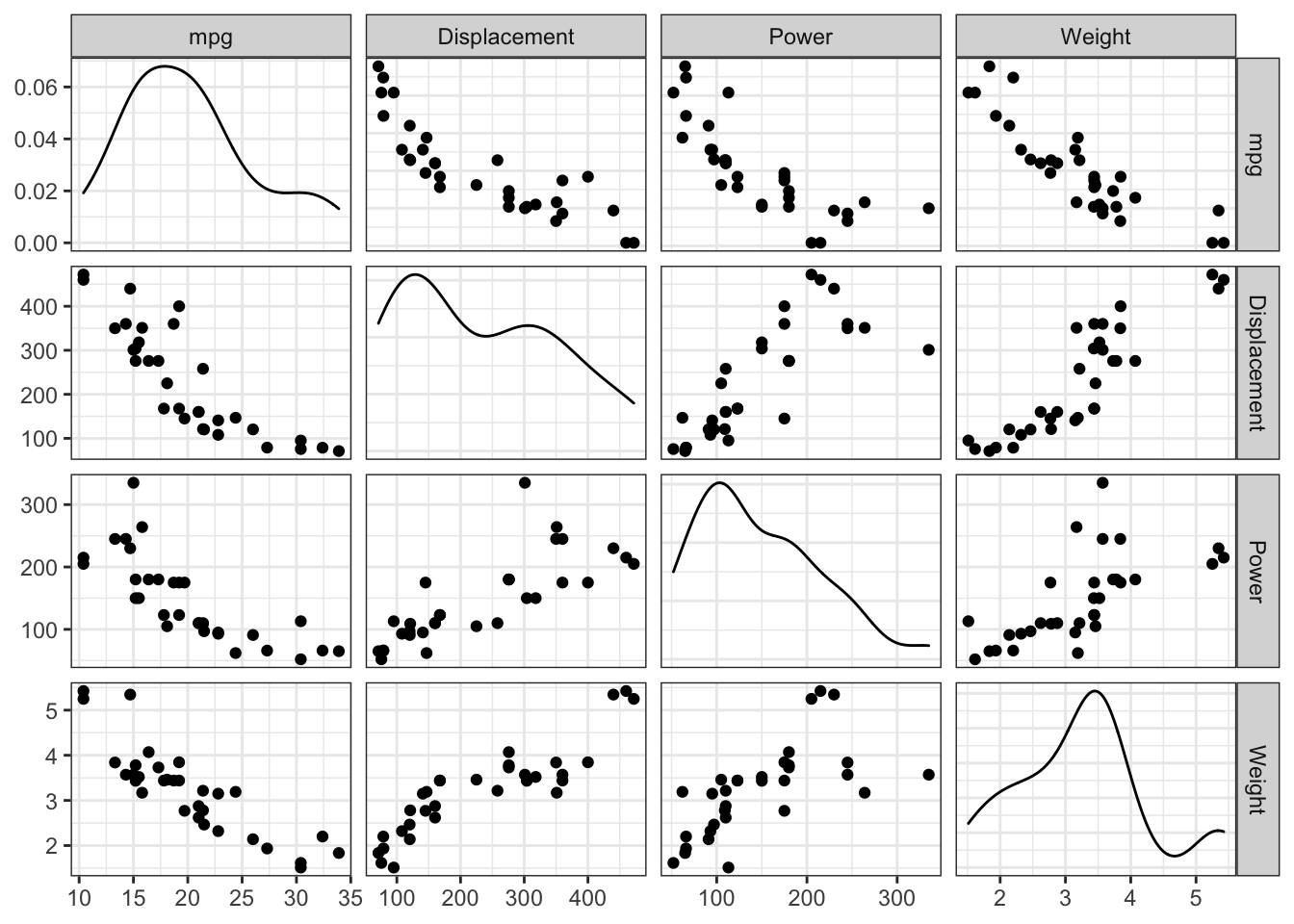
To make this graph in Tableau, you’ll follow do the following: 1. Make sure your data has a column that uniquely identifies each point. (You might denote these as an ID column.) 2. Put all of the variables onto the shelf spaces (each variable on both the x and y selves). Notice at this point it is aggregating all of the data into a single point on the graph. 3. Finally drag the ID column onto the Detail Card (in the All Marks tab) which essentially refines the scale at which the aggregation happens. In this case, we want the aggregation to do nothing so we’ll sum (or average) of the single data point in each level of your ID variable.
8.3.3 Correlation Plots
8.3.3.1 Pearson’s Correlation Coefficient
We first consider Pearson’s correlation coefficient, which is a statistics that measures the strength of the linear relationship between the predictor and response. Consider the following Pearson’s correlation statistic \[r=\frac{\sum_{i=1}^{n}\left(\frac{x_{i}-\bar{x}}{s_{x}}\right)\left(\frac{y_{i}-\bar{y}}{s_{y}}\right)}{n-1}\] where \(x_{i}\) and \(y_{i}\) are the x and y coordinate of the \(i\)th observation. Notice that each parenthesis value is the standardized value of each observation. If the x-value is big (greater than \(\bar{x}\)) and the y-value is large (greater than \(\bar{y}\)), then after multiplication, the result is positive. Likewise if the x-value is small and the y-value is small, both standardized values are negative and therefore after multiplication the result is positive. If a large x-value is paired with a small y-value, then the first value is positive, but the second is negative and so the multiplication result is negative.
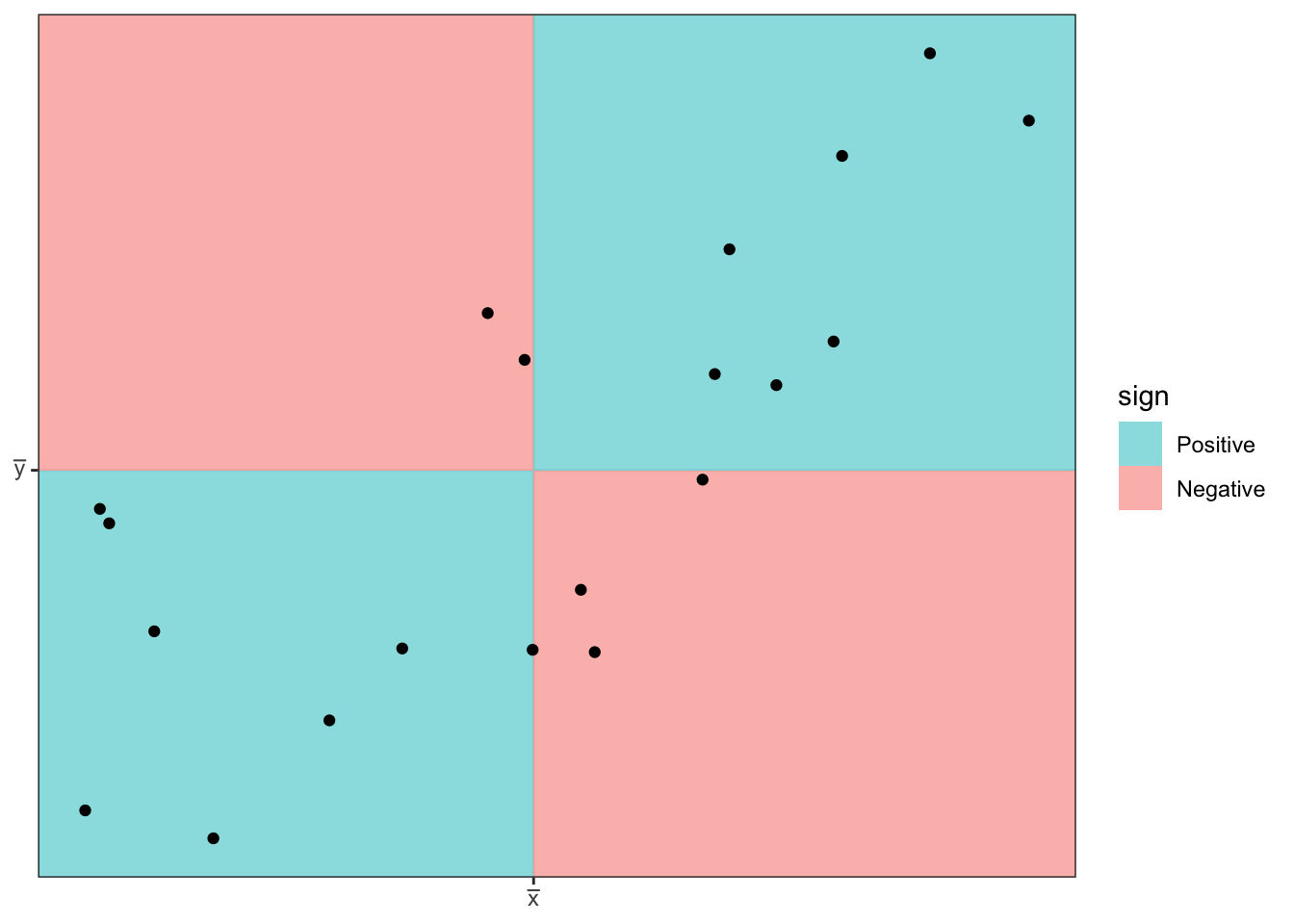
The following are true about Pearson’s correlation coefficient:
- \(r\) is unit-less because we have standardized the \(x\) and \(y\) values.
- \(-1\le r\le1\) because of the scaling by \(n-1\)
- A negative \(r\) denotes a negative relationship between \(x\) and \(y\), while a positive value of \(r\) represents a positive relationship.
- \(r\) measures the strength of the linear relationship between the predictor and response.
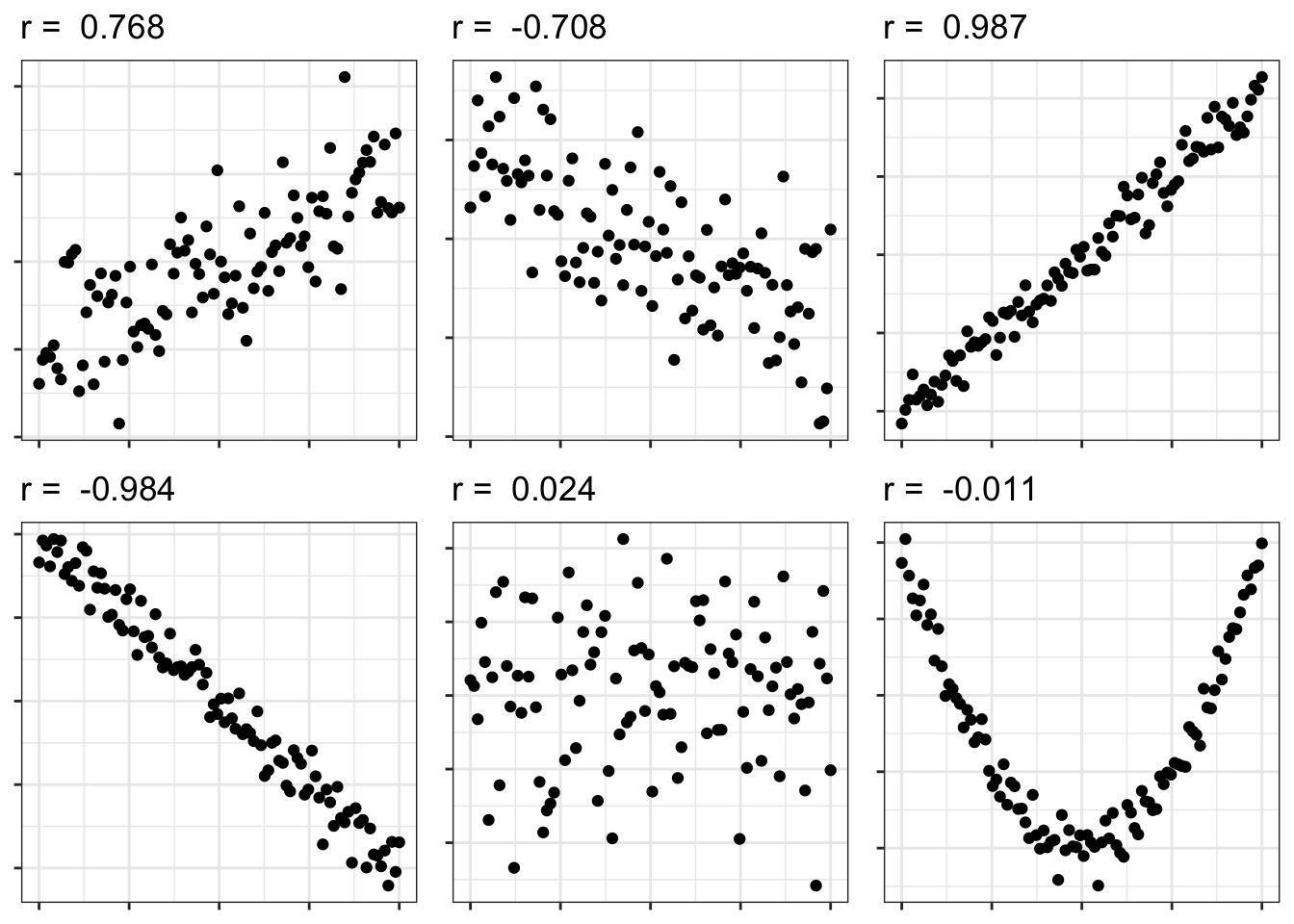
8.3.4 Overplotting
8.3.4.1 Transparency
Wilke’s book uses and example of departure time of day versus the delay amount for all the flights out of New York City in 2013. The story to take home is that longer delays tend to happen later in the afternoon or evening rather than in the morning. Wilke uses these data to argue that over plotting is annoying and that a heat map can help out.
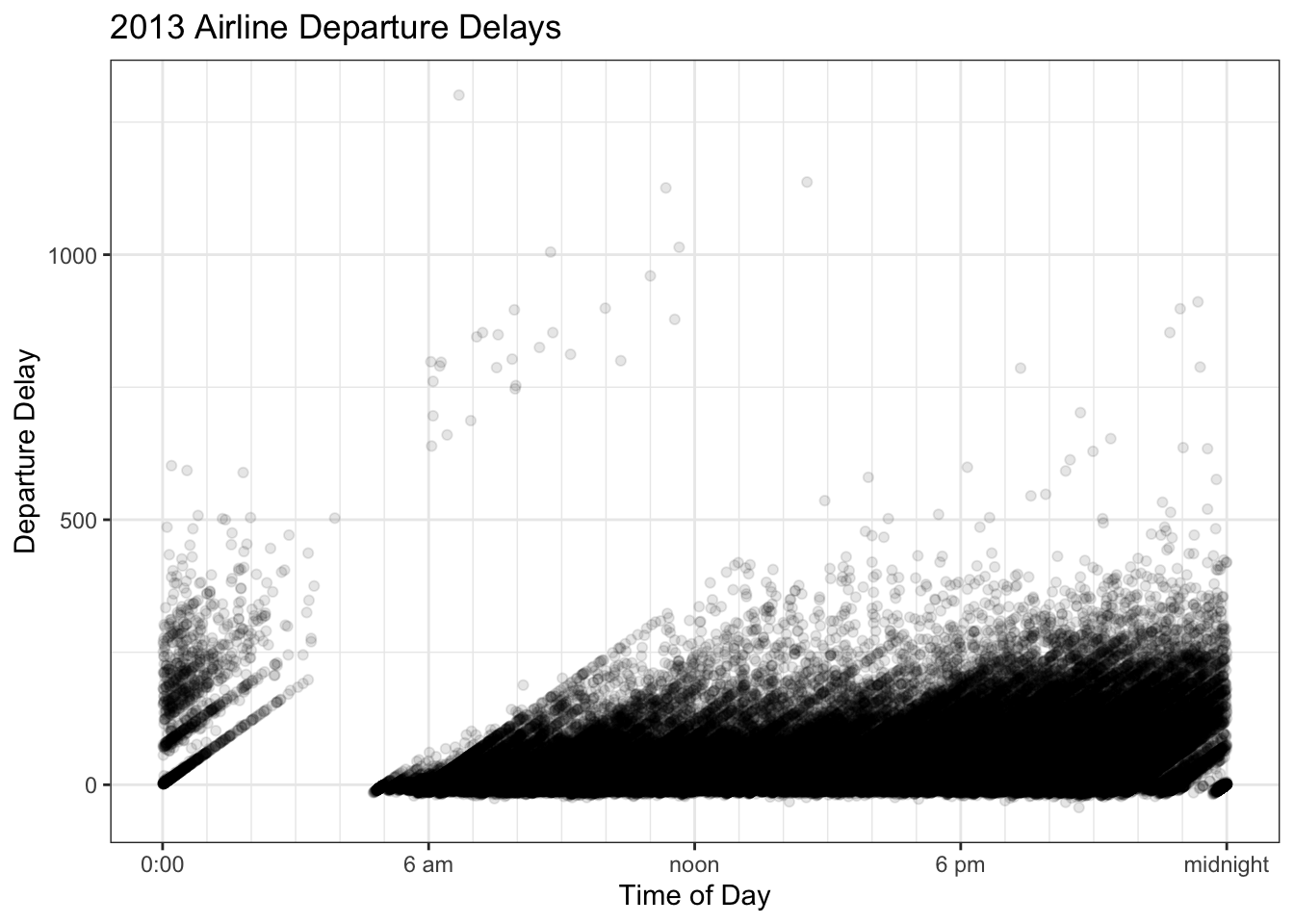
8.3.4.2 Intensity Maps
No matter how much we adjust the transparency, we can’t really fix this because there is so much data. If for each area on the graph, we count how many observations fall into the region, we can color the area based on how many observations are in the region.
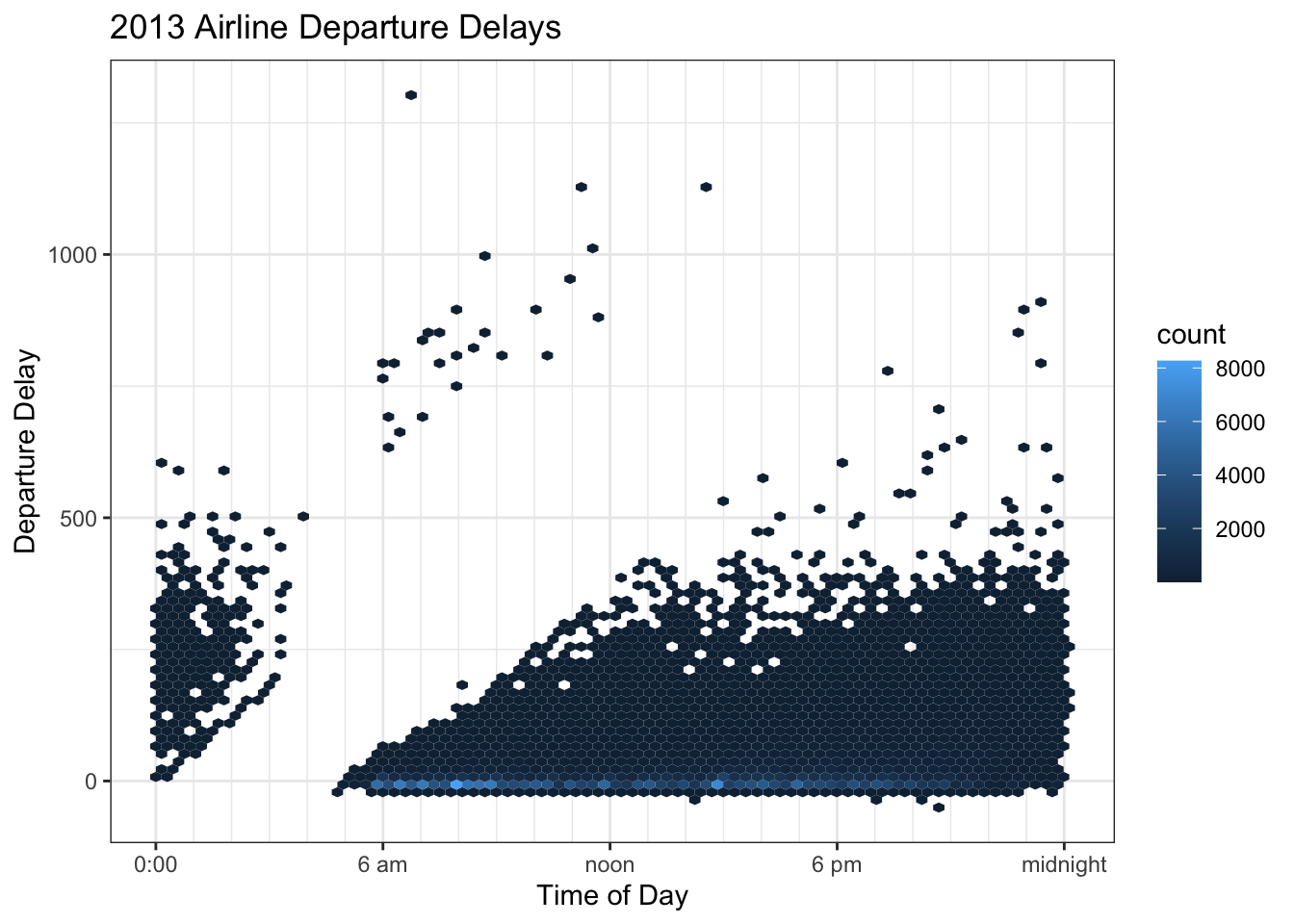
This graph leads me to think that MOST flights are quite late, when if fact, they aren’t. This is due to the problem of “proportional pixels.” There is so much space and color devoted to flights that are more than 30 minutes late that the viewer can’t help but have that impression.
| delay | n | proportion |
|---|---|---|
| (-30,-10] | 12465 | 0.03794 |
| (-10,0] | 187620 | 0.5711 |
| (0,10] | 45598 | 0.1388 |
| (10,30] | 34543 | 0.1051 |
| (30,60] | 21710 | 0.06608 |
| (60,120] | 16858 | 0.05132 |
| (120,180] | 5830 | 0.01775 |
| (180,Inf] | 3893 | 0.01185 |
Because we are interested in the time distribution of significant delays, and early departures are usually only by a couple of minutes, we’ll we’ll take a log\(_{10}\) transformation of all the delays greater than 10 minutes. We’ll also modify the color scale so that hexagons with a small count fade into the background and are white and hexagons with relatively large counts have a noticable color.
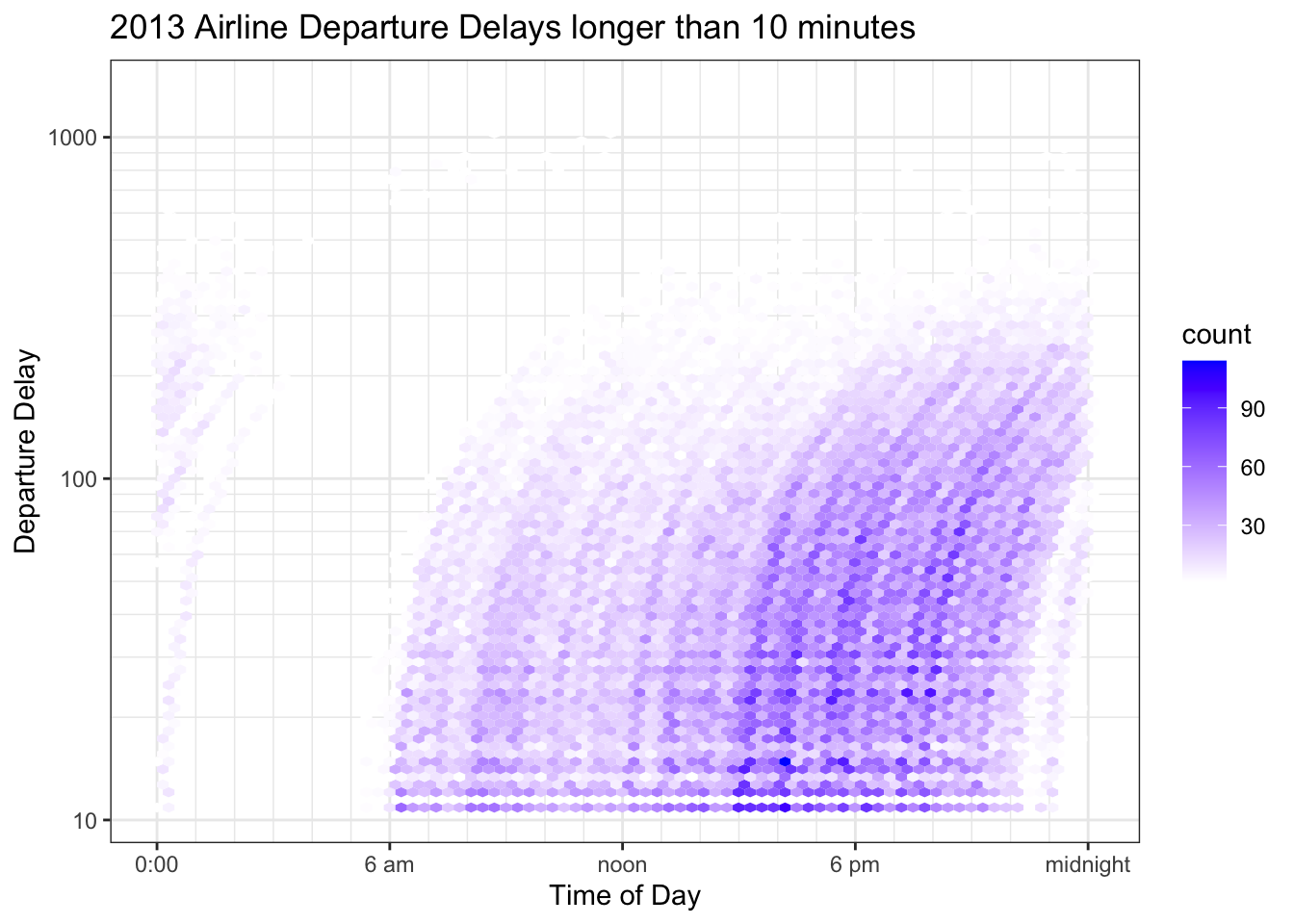
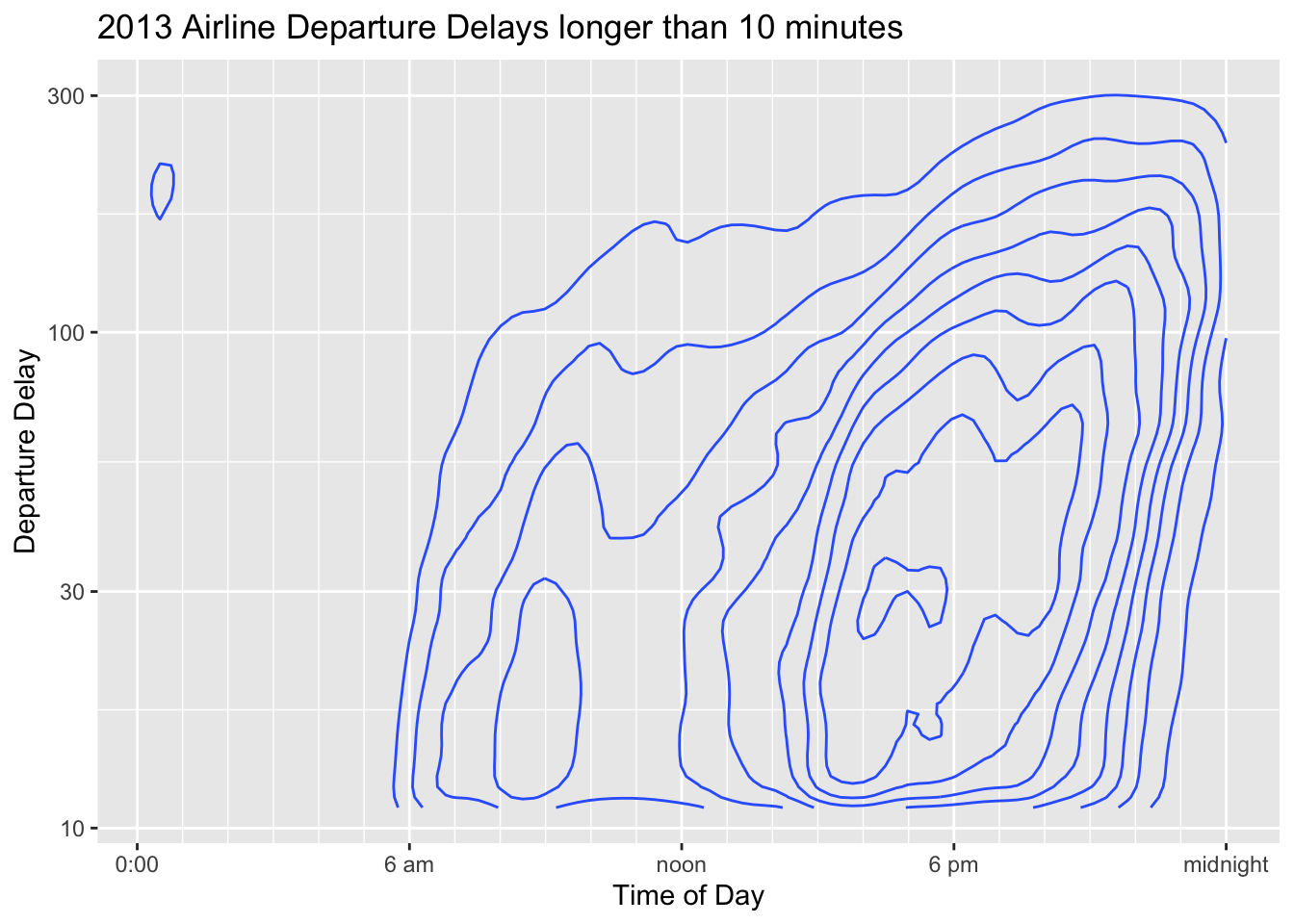
8.3.4.3 Contour Plots
Contour plots are similar to density plots, but for two-axis. The lines mark out regions of similar probability and we read it similarly as a topological map that shows elevation. In this case we can see that the most frequent delays are around 30 minutes long and occur near 5 pm. There is also a local peak of 20 minute delays around 10 am.
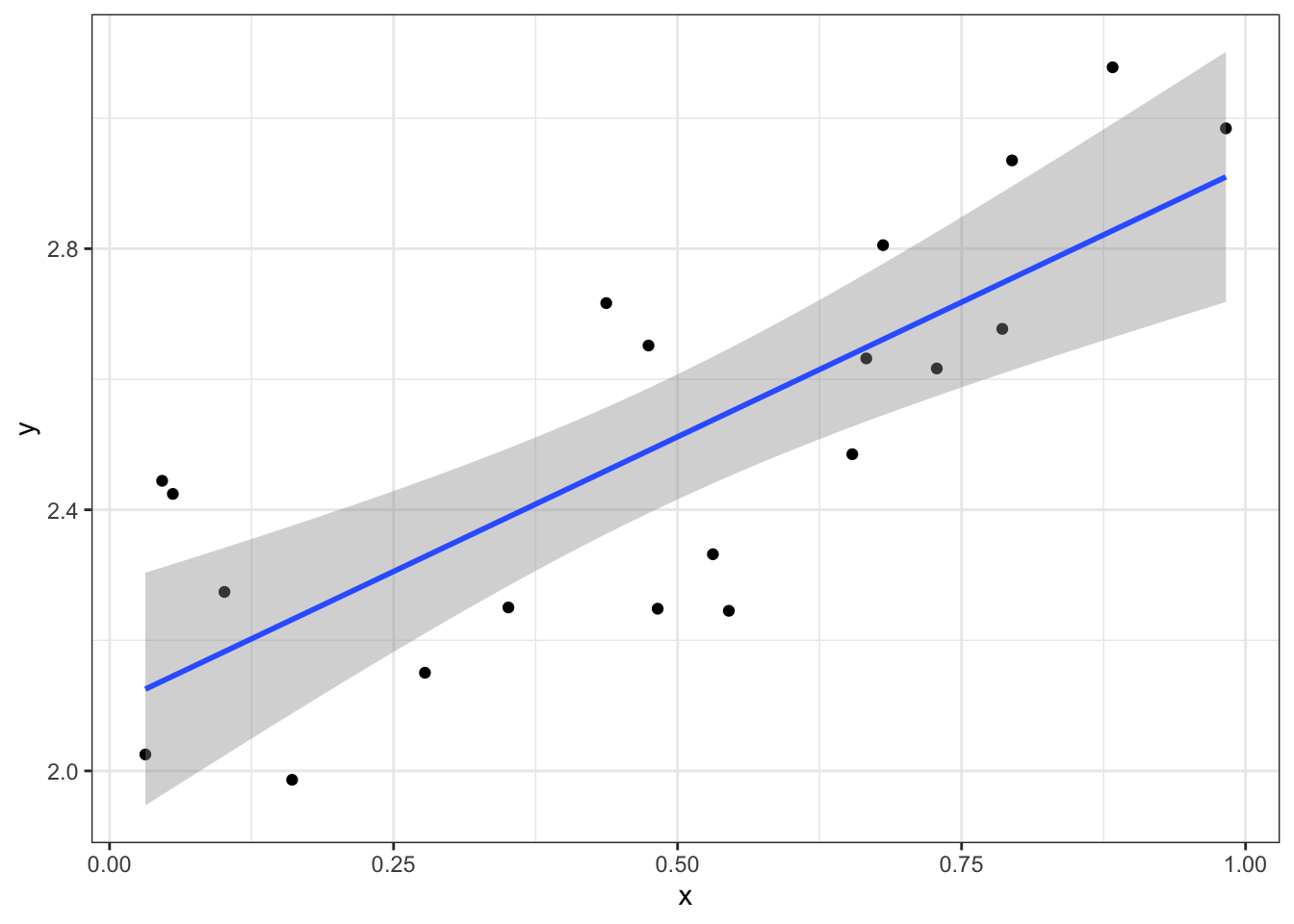
8.3.5 Regression Lines
Often I want to add a trend line to a scatter plot. This line is the line that fits through the data “the best,” where “the best” minimizes the sum of the squared vertical distances between the data points and the trend line.
In Tableau, click the analytics tab and drag the trend line icon onto the graph. You can then select the shape of the line you’d like to add.
8.4 Plot building process
Often I find myself making a bunch of graphs and none of them show something interesting. The following is my usual path of investigation in situations where I have several (3 or more) variables and I want to understand how they relate to each other. Below is a recommended analysis path, but shouldn’t be taken as the only path towards finding an interesting visualization in a data set.
Identify the strongest or most interesting relationships. If there is an obvious response variable, I will examine all the others as predictors to the response. I then approximately rank them as to which variable most strongly predicts the response. If there isn’t a obvious response, I’ll look at the pairs plot and pick out the strongest relationship.
Start with the strongest relationship with those variables on the x and y axis. Preferentially, I’ll use quantitative variables for these. Next add other variables to the graph as attributes high on the EPT scale (size, color) or on the grouping scale (panels, shape). The critical aspect is that I want to select the most important relationship to be displayed via the x and y axis and then other relationships added on top via the other graph attributes.
Look at the graphs you’ve produced and ask yourself how they relate to the question of interest. What about the graphs stands out and what is pertinent? This step requires thinking very critically about the topic and identifying why any trends you see could be happening. Often times, I see hints at something at this stage but it isn’t very clear because the graphical presentation isn’t tuned to show it well.
Once you have a suggestion of something interesting, think about how you could modify the graph to more clearly show it. Use your knowledge of Elementary Perception Tasks to decide to, for example, add trend lines, changing the panel nesting order, and getting rid of extraneous complications.
8.5 Exercises
Read Chapters 12 and 18 from Claus Wilke’s Fundamentals of Data Visualization. book. Feel free to skip section 12.3.
We will use a smaller version of the diamonds data set that Wilke uses in his Chapter 18. You can download it from my GitHub site in a .csv file. We will examine price, carats, cut (Fair, Good, Very Good, Premium, and Ideal), color (J - D), and clarity (I1, SI2, SI1, VS2, VS1, VVS2, VVS1, IF), where the category labels I’ve given are from worst to best.
- In Tableau, make sure the sort order for all of the categorical variables is as I listed above.
- Had I not told you that clarity level IF is the best clarity, what graphs could you make to figure that out? Create and show a graph that demonstrates this and explain your graph. Hint, make a sequence of graphs with see how the relationship changes across clarity levels.
- If the diamond clarity isn’t good, the diamond cutter won’t worry too much about the quality of cut. Make a graph that demonstrates that and explain your reasoning.
- While in principle it is possible for the diamond carats to be any number, they are often cut to be some common carat size. Create a visualization that shows this and discuss how the carat size changes as the cut and clarity improve.
From the Gapminder.com website, I’ve downloaded a bunch of interesting covariates about countries. You can find my data set at my GitHub site in a .csv file. The variables I’ve included include the country region, year, population size, population growth, percent of population with basic sanitation, GDP per capita, Total GDP, life expectancy, adult male and female labor force participation rates.
Fertility is the number of children per woman, so a fertility rate of 2 children per woman is a stable population. For this question, create some version of the graphs presented in this chapter. We will address geographic maps in the next chapter.- For all the following questions, only consider the year 2015.
- Investigate the relationship between GDP and GDP_per_capita. Why should we prefer to work with GDP_per_capita when comparing standards of living between, say, the United States and Canada?
- Investigate the relationship between life expectancy, fertility, and GDP_per_capita. Do these relationships seem to vary by region? Comment on your graphs and relationships that you observe.
- Investigate the relationship relationship between life expectancy, adult female labor force participation and fertility. Does this vary by region? Comment on your graphs and relationships that you observe.
Consider a research question you are interested in. The topic could be about anything but you should consider accessibility of data to address the problem. For this problem, you aren’t expected to find data sources and do the data wrangling and graphing, but rather develop a plan.
- Propose a broad topic/question of interest. Identify broad trends that have occurred and what data and graphics might support that.
- Consider the how the trend identified in part (a) might vary across different sub-groups? Are there sub-groups where the general relationship doesn’t hold or where the relationship is even stronger? What could be driving those relationships and what data would you need to support your ideas?
- Of the data you proposed using in parts (a) and (b), how accessible do you think the data will be. Specify at least one solid lead one finding the data even if you haven’t gotten all the specifics figured out.