2 描述統計與作圖
本單元介紹如何以R語言讀入資料並做初步分析,包含描述統計、作圖。
2.1 讀入檔案
以xlsx套件的read.xlsx()函數或readxl套件的read_xlsx()函數來讀入上個單元中所存出的gData1.xlsx檔。
## # A tibble: 6 × 8
## 學號 性別 組別 出席 影片 期中考 期末考 總成績
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 102368014 M 9 8.5 82.6 32 28 56.0
## 2 102368018 M 10 9.5 82.9 66 59 78.8
## 3 102368024 F 9 8 82.6 69 68 81.2
## 4 102368027 F 9 8 82.6 68 83.5 86.0
## 5 102368030 F 11 0 66.5 39 30 45.2
## 6 100368033 M 4 12 73.3 58 79 82.12.2 描述統計
計算單一變項、多個變項的描述統計量。
2.2.1 計算單一變項的平均數、變異數和標準差
可用mean()、var()和sd()來檢視總成績的平均數、變異數和標準差。
mean(gData1$總成績)## [1] 74.33021
var(gData1$總成績)## [1] 126.1945
sd(gData1$總成績)## [1] 11.23363可用pastecs套件中的stat.desc()函數來檢視總成績的描述統計量。
## nbr.val nbr.null nbr.na min max
## 5.700000e+01 0.000000e+00 0.000000e+00 4.517778e+01 1.000000e+02
## range sum median mean SE.mean
## 5.482222e+01 4.236822e+03 7.615556e+01 7.433021e+01 1.487931e+00
## CI.mean.0.95 var std.dev coef.var skewness
## 2.980684e+00 1.261945e+02 1.123363e+01 1.511314e-01 -1.319156e-01
## skew.2SE kurtosis kurt.2SE normtest.W normtest.p
## -2.085114e-01 5.845899e-03 4.690725e-03 9.834611e-01 6.243284e-012.2.2 計算多個變項的描述統計量
若要同時計算多項成績的描述統計,需使用第三方套件,例如pastecs套件的stat.desc()函數。
stat.desc(gData1, basic=TRUE, desc=TRUE, norm=TRUE, p=0.95)## 學號 性別 組別 出席 影片 期中考
## nbr.val NA NA 57.000000000 5.700000e+01 5.700000e+01 57.0000000
## nbr.null NA NA 0.000000000 1.000000e+00 0.000000e+00 0.0000000
## nbr.na NA NA 0.000000000 0.000000e+00 0.000000e+00 0.0000000
## min NA NA 1.000000000 0.000000e+00 6.653333e+01 29.0000000
## max NA NA 12.000000000 1.200000e+01 8.433333e+01 89.0000000
## range NA NA 11.000000000 1.200000e+01 1.780000e+01 60.0000000
## sum NA NA 341.000000000 5.900000e+02 4.424583e+03 3132.0000000
## median NA NA 6.000000000 1.100000e+01 7.691667e+01 55.0000000
## mean NA NA 5.982456140 1.035088e+01 7.762427e+01 54.9473684
## SE.mean NA NA 0.443196430 3.060493e-01 7.378552e-01 1.7633169
## CI.mean NA NA 0.887829134 6.130904e-01 1.478102e+00 3.5323481
## var NA NA 11.196115288 5.338972e+00 3.103253e+01 177.2293233
## std.dev NA NA 3.346059666 2.310622e+00 5.570685e+00 13.3127504
## coef.var NA NA 0.559312026 2.232295e-01 7.176473e-02 0.2422819
## skewness NA NA 0.234149681 -2.123849e+00 -4.829443e-01 0.2879258
## skew.2SE NA NA 0.370107150 -3.357048e+00 -7.633627e-01 0.4551080
## kurtosis NA NA -1.217954593 5.573908e+00 -9.842022e-01 -0.2269468
## kurt.2SE NA NA -0.977281597 4.472480e+00 -7.897197e-01 -0.1821012
## normtest.W NA NA 0.939578114 7.297347e-01 8.923611e-01 0.9706089
## normtest.p NA NA 0.006802493 6.467050e-09 1.042615e-04 0.1791033
## 期末考 總成績
## nbr.val 57.00000000 5.700000e+01
## nbr.null 1.00000000 0.000000e+00
## nbr.na 0.00000000 0.000000e+00
## min 0.00000000 4.517778e+01
## max 104.00000000 1.000000e+02
## range 104.00000000 5.482222e+01
## sum 3389.00000000 4.236822e+03
## median 57.00000000 7.615556e+01
## mean 59.45614035 7.433021e+01
## SE.mean 2.41277279 1.487931e+00
## CI.mean 4.83336470 2.980684e+00
## var 331.82393484 1.261945e+02
## std.dev 18.21603510 1.123363e+01
## coef.var 0.30637769 1.511314e-01
## skewness -0.08459996 -1.319156e-01
## skew.2SE -0.13372236 -2.085114e-01
## kurtosis 1.06201488 5.845899e-03
## kurt.2SE 0.85215623 4.690725e-03
## normtest.W 0.97173381 9.834611e-01
## normtest.p 0.20188192 6.243284e-01也可以用psych套件的describe()函數。參數type設定為2是由於偏態和峰度的計算方式有三種,type=2的值與SPSS相同。
## vars n mean sd median trimmed mad min max range skew
## 出席 1 57 10.35 2.31 11.00 10.79 1.48 0.00 12.00 12.00 -2.24
## 影片 2 57 77.62 5.57 76.92 78.02 8.23 66.53 84.33 17.80 -0.51
## 期中考 3 57 54.95 13.31 55.00 54.47 14.83 29.00 89.00 60.00 0.30
## 期末考 4 57 59.46 18.22 57.00 59.27 16.31 0.00 104.00 104.00 -0.09
## 總成績 5 57 74.33 11.23 76.16 74.31 12.14 45.18 100.00 54.82 -0.14
## kurtosis se
## 出席 6.55 0.31
## 影片 -0.88 0.74
## 期中考 -0.03 1.76
## 期末考 1.43 2.41
## 總成績 0.24 1.49也可以用vtable套件的st()函數來做,會有較美觀的表格。
| Variable | N | Mean | Std. Dev. | Min | Pctl. 25 | Pctl. 75 | Max |
|---|---|---|---|---|---|---|---|
| 出席 | 57 | 10.351 | 2.311 | 0 | 9.5 | 12 | 12 |
| 影片 | 57 | 77.624 | 5.571 | 66.533 | 73.333 | 82.583 | 84.333 |
| 期中考 | 57 | 54.947 | 13.313 | 29 | 44 | 64 | 89 |
| 期末考 | 57 | 59.456 | 18.216 | 0 | 49.5 | 70.5 | 104 |
| 總成績 | 57 | 74.33 | 11.234 | 45.178 | 66.567 | 81.194 | 100 |
2.2.3 分組計算單一變項的描述性統計量
若要分組計算單一變項(如總成績)的描述性統計量,可用aggregate()函數。
## gender x
## 1 F 73.43611
## 2 M 75.32366## gender x
## 1 F 11.80451
## 2 M 10.69725也可以用第三方套件pastecs的stat.desc()函數來做。
by(gData1$總成績, gData1$性別, stat.desc, basic = FALSE, norm = TRUE)## gData1$性別: F
## median mean SE.mean CI.mean.0.95 var std.dev
## 74.37222222 73.43611111 2.15519916 4.40787720 139.34650223 11.80451194
## coef.var skewness skew.2SE kurtosis kurt.2SE normtest.W
## 0.16074533 -0.35283642 -0.41326154 -0.10010120 -0.06010311 0.96695587
## normtest.p
## 0.45958396
## ------------------------------------------------------------
## gData1$性別: M
## median mean SE.mean CI.mean.0.95 var std.dev
## 77.4555556 75.3236626 2.0586874 4.2316925 114.4312289 10.6972533
## coef.var skewness skew.2SE kurtosis kurt.2SE normtest.W
## 0.1420172 0.2638189 0.2945380 -0.4395158 -0.2519967 0.9706505
## normtest.p
## 0.61908102.2.4 分組計算多個變項的描述性統計量
若要分組計算多個變項的描述性統計量,可用aggregate()函數,或使用psych套件中的describeBy()。
## gender 出席 影片 期中考 期末考 總成績
## 1 F 10.28333 76.92611 53.13333 59.35000 73.43611
## 2 M 10.42593 78.40000 56.96296 59.57407 75.32366
describeBy(gData1[,4:5], list(gender=gData1$性別),type=2)##
## Descriptive statistics by group
## gender: F
## vars n mean sd median trimmed mad min max range skew kurtosis
## 出席 1 30 10.28 2.59 11.00 10.81 1.48 0.00 12.00 12.0 -2.58 8.21
## 影片 2 30 76.93 6.11 76.74 77.30 8.66 66.53 84.33 17.8 -0.29 -1.24
## se
## 出席 0.47
## 影片 1.12
## ------------------------------------------------------------
## gender: M
## vars n mean sd median trimmed mad min max range skew kurtosis
## 出席 1 27 10.43 2.01 11.00 10.72 1.48 5.00 12.00 7.0 -1.39 1.13
## 影片 2 27 78.40 4.90 77.12 78.78 7.09 66.53 84.33 17.8 -0.77 -0.17
## se
## 出席 0.39
## 影片 0.94要漂亮一點的表格可以用vTable套件。
| Variable | N | Mean | Std. Dev. | Min | Pctl. 25 | Pctl. 75 | Max |
|---|---|---|---|---|---|---|---|
| 出席 | 57 | 10.351 | 2.311 | 0 | 9.5 | 12 | 12 |
| 影片 | 57 | 77.624 | 5.571 | 66.533 | 73.333 | 82.583 | 84.333 |
| 期中考 | 57 | 54.947 | 13.313 | 29 | 44 | 64 | 89 |
| 期末考 | 57 | 59.456 | 18.216 | 0 | 49.5 | 70.5 | 104 |
| 總成績 | 57 | 74.33 | 11.234 | 45.178 | 66.567 | 81.194 | 100 |
st(gData1, group='性別')| Variable | N | Mean | SD | N | Mean | SD |
|---|---|---|---|---|---|---|
| 組別 | 30 | 5.8 | 3.316 | 27 | 6.185 | 3.431 |
| 出席 | 30 | 10.283 | 2.585 | 27 | 10.426 | 2.008 |
| 影片 | 30 | 76.926 | 6.11 | 27 | 78.4 | 4.9 |
| 期中考 | 30 | 53.133 | 12.822 | 27 | 56.963 | 13.797 |
| 期末考 | 30 | 59.35 | 19.297 | 27 | 59.574 | 17.301 |
| 總成績 | 30 | 73.436 | 11.805 | 27 | 75.324 | 10.697 |
2.3 資料作圖和相關
初步畫直方圖、箱型圖和散布圖,並計算變項之間的相關。
2.3.2 箱型圖
以boxplot()來繪製箱型圖。
boxplot(gData1$總成績, ylab="分")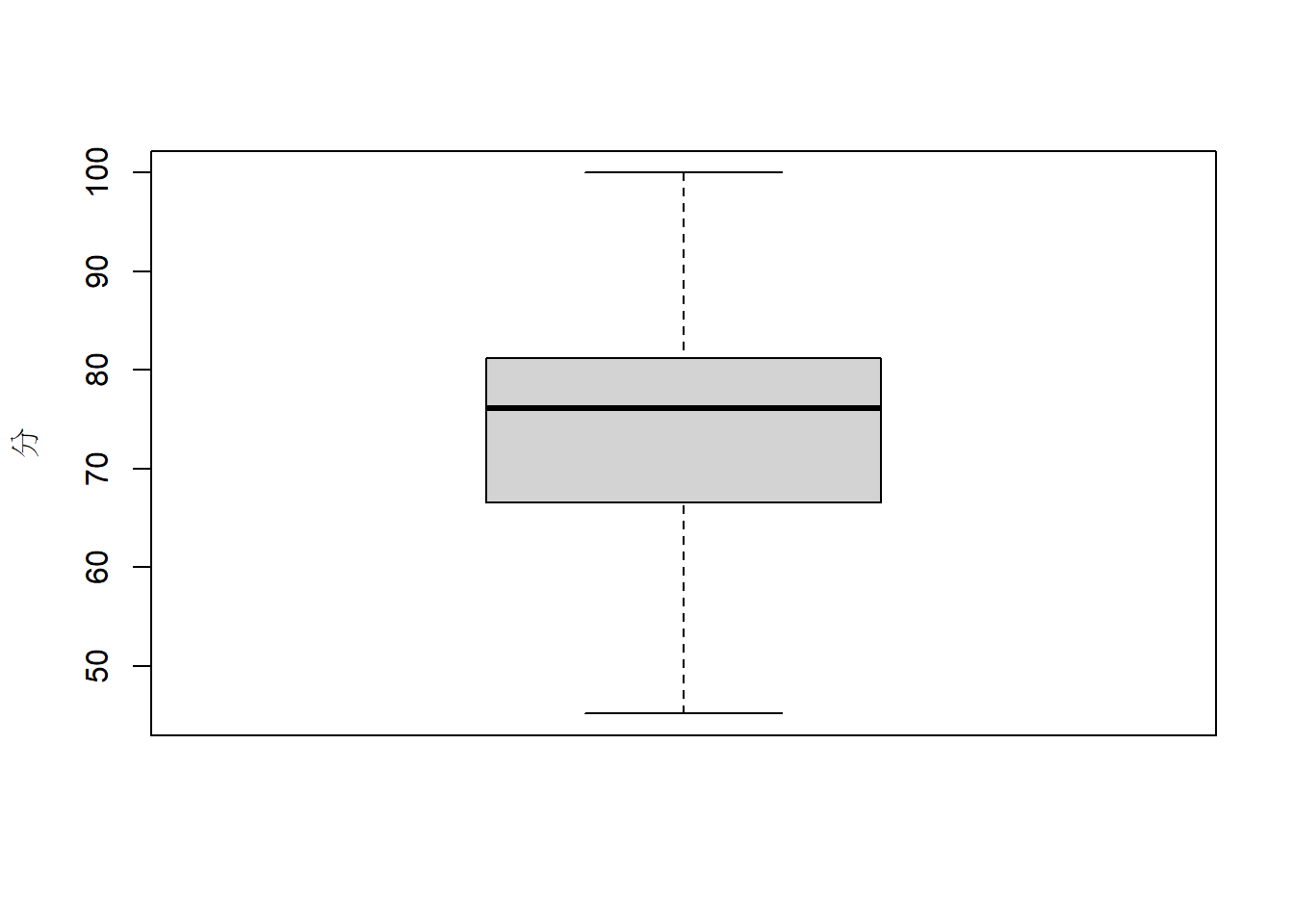
分組畫箱型圖。
boxplot(gData1$總成績~gData1$性別, xlab="性別", ylab="分")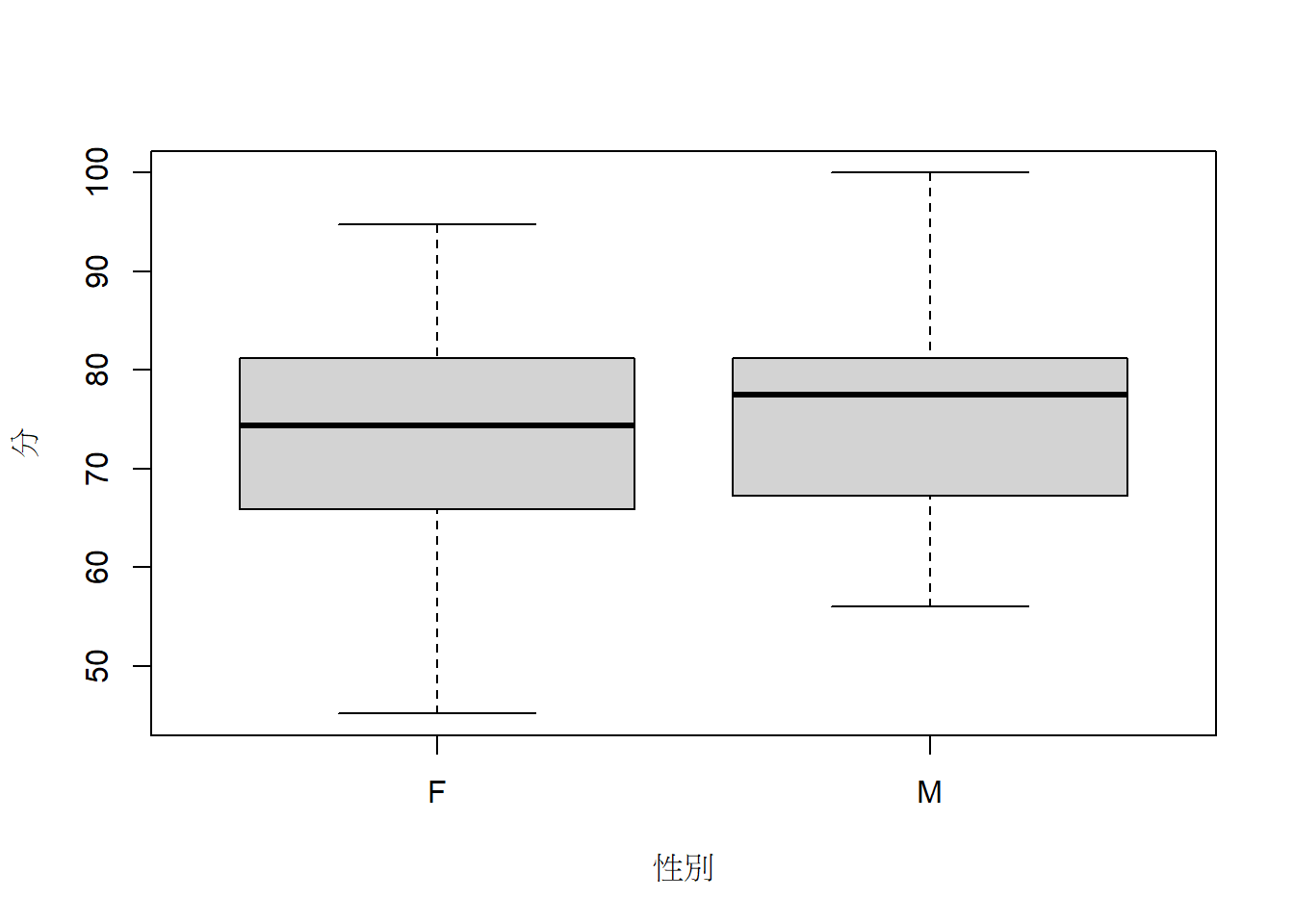

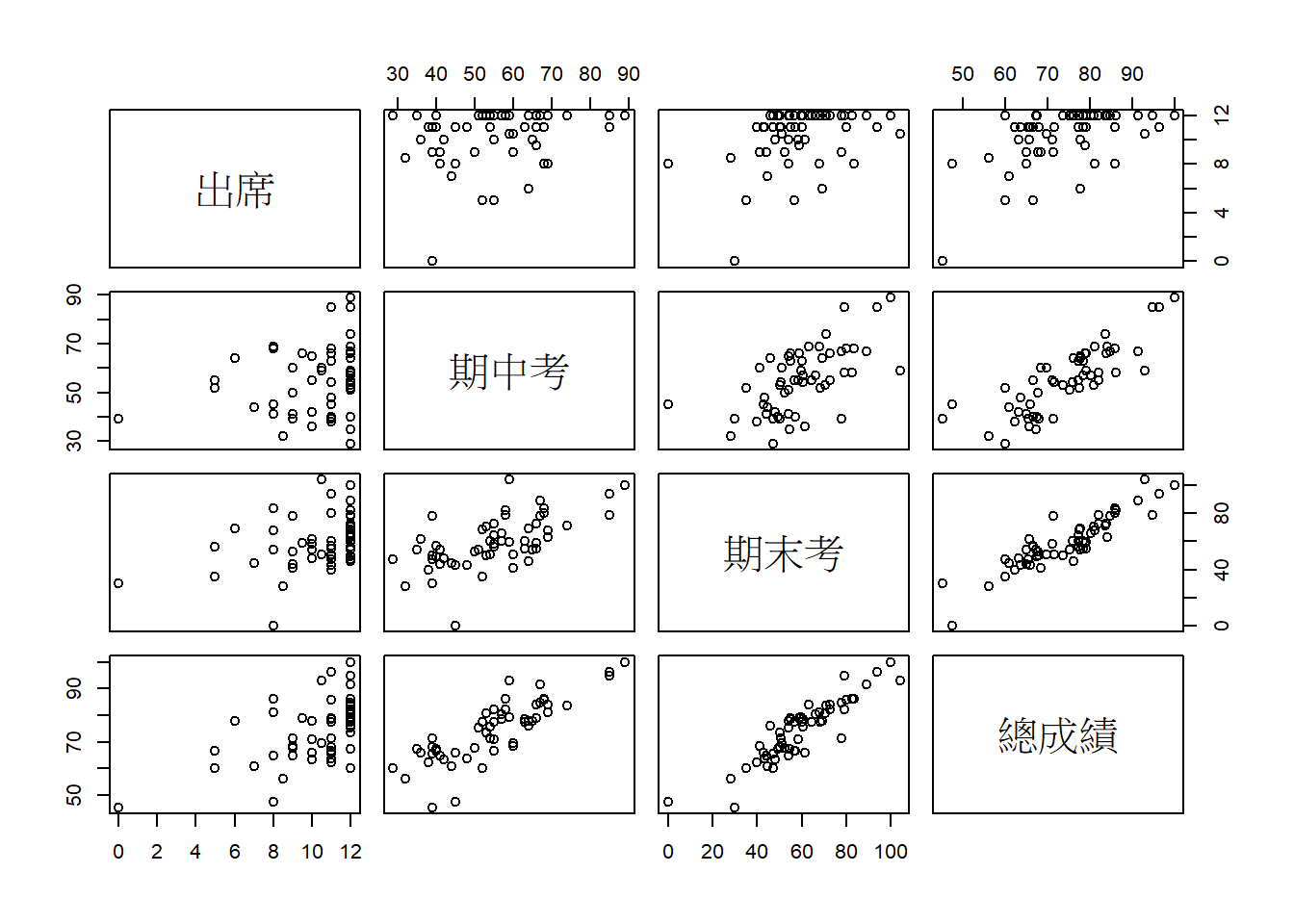
2.3.4 計算相關與繪圖
2.3.4.1 計算相關
以cor()計算兩變項的相關,或以cor.test()得到相關和檢定值。
cor(gData1$出席, gData1$總成績)## [1] 0.5360227
cor.test(gData1$出席, gData1$總成績)##
## Pearson's product-moment correlation
##
## data: gData1$出席 and gData1$總成績
## t = 4.7089, df = 55, p-value = 1.73e-05
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.3201738 0.6989657
## sample estimates:
## cor
## 0.5360227cor()可計算多個變項的相關,若要得到檢定結果,可用Hmisc()的rcorr()函數。
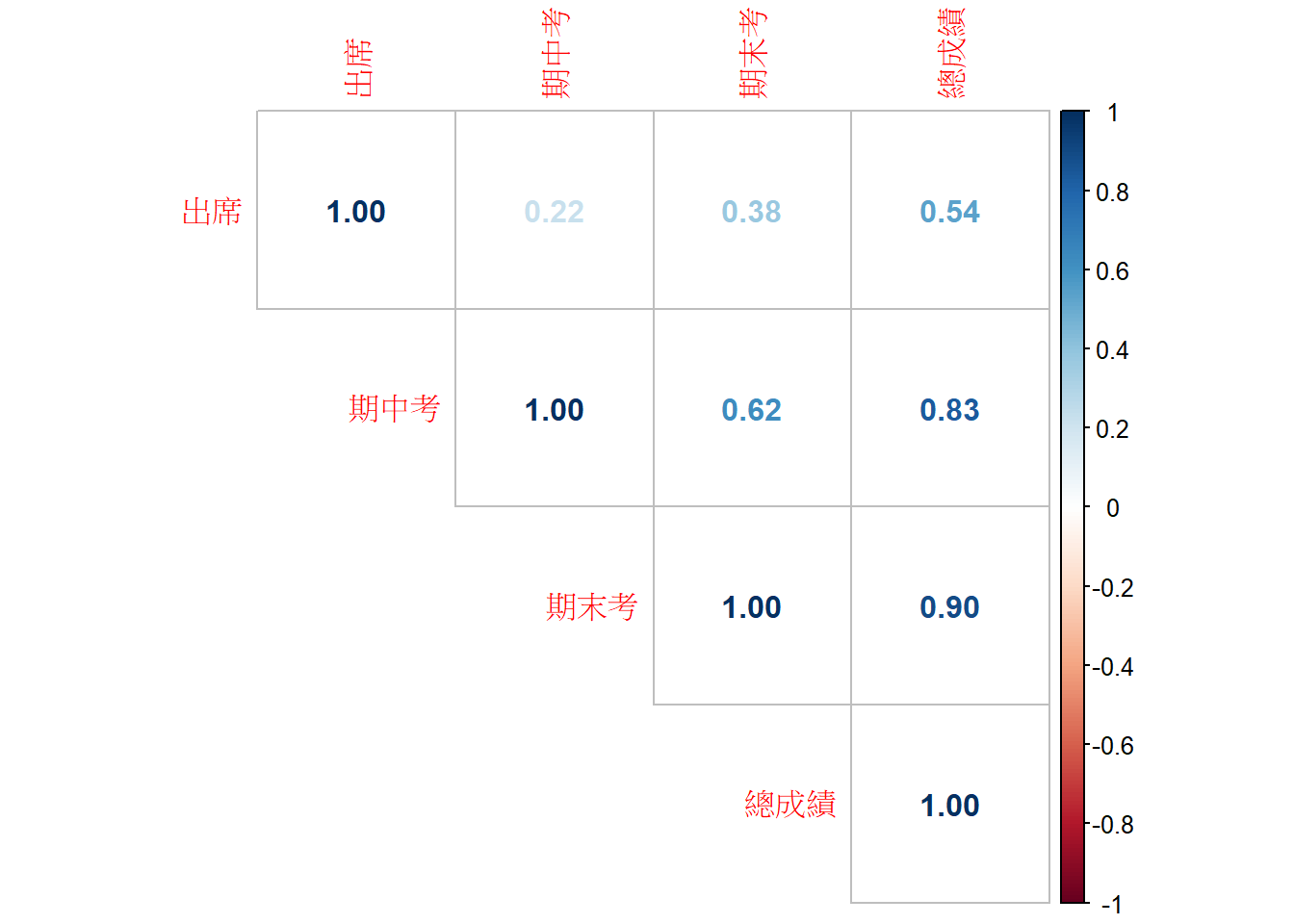
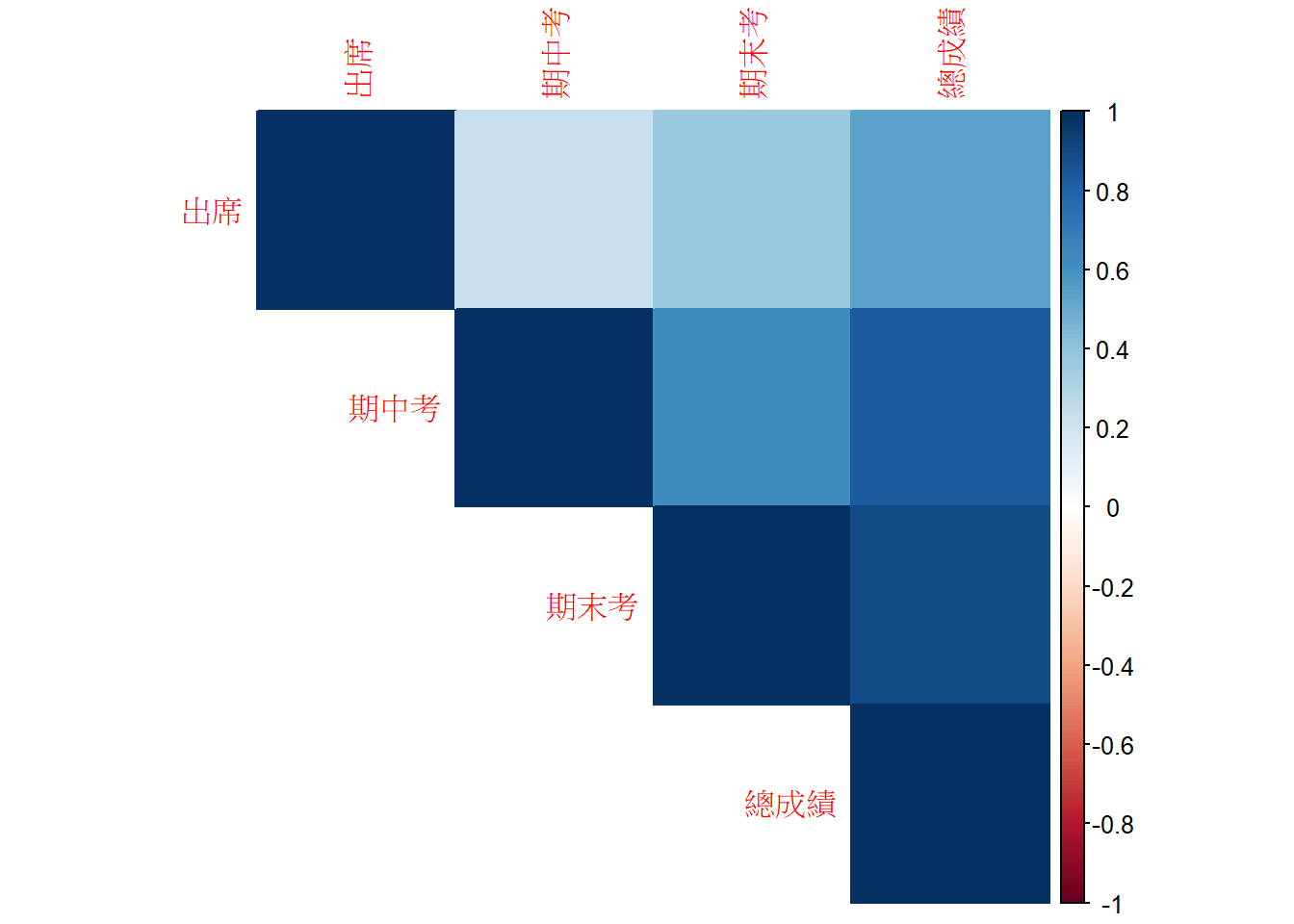
cor(gData2)## 出席 期中考 期末考 總成績
## 出席 1.0000000 0.2220785 0.3760520 0.5360227
## 期中考 0.2220785 1.0000000 0.6211838 0.8319727
## 期末考 0.3760520 0.6211838 1.0000000 0.8983073
## 總成績 0.5360227 0.8319727 0.8983073 1.0000000
library(Hmisc)
rcorr(data.matrix(gData2))## 出席 期中考 期末考 總成績
## 出席 1.00 0.22 0.38 0.54
## 期中考 0.22 1.00 0.62 0.83
## 期末考 0.38 0.62 1.00 0.90
## 總成績 0.54 0.83 0.90 1.00
##
## n= 57
##
##
## P
## 出席 期中考 期末考 總成績
## 出席 0.0969 0.0039 0.0000
## 期中考 0.0969 0.0000 0.0000
## 期末考 0.0039 0.0000 0.0000
## 總成績 0.0000 0.0000 0.0000