Capítulo 1 Introducción
Durante las últimas décadas se ha incrementado enormemente nuestra capacidad para recoger datos en torno a cualquier actividad. En el ámbito empresarial, por ejemplo, se recopila una gran cantidad de información sobre los procesos de producción y distribución de productos y servicios, comportamiento de los usuarios, rendimiento de las campañas de marketing, etc. No solo sobre la propia organización. También está disponible abundante información sobre las características del conjunto del mercado, de los competidores, etc. Esta amplia disponibilidad de datos ha acrecentado el interés por utilizarlos para extraer información que otorgue una ventaja competitiva a las organizaciones.
Este interés no es nuevo. Las organizaciones siempre han dedicado recursos a recopilar y analizar información. Sin embargo, el incremento en el volumen de datos disponibles ha venido acompañado del desarrollo de herramientas informáticas que permite analizarlos de forma mucho más efectiva utilizando técnicas de una disciplina que se ha dado en denominar ciencia de datos (data science) o minería de datos (data mining) y que Foreman (2014, p. xiv) define así:
Data science is the transformation of data using mathematics and statistics into valuable insights, decisions, and products.
De manera similar, Spiegelhalter (2019, p. 11) describe la ciencia de datos en los siguientes términos:
We are in an age of data science, in which large and complex data sets are collected from routine sources such as traffic monitors, social media posts and internet purchases, and used as a basis for technological innovations such as optimizing travel routes, targeted advertising or purchase recommendation systems. Statistical training is increasingly seen as just one necessary component of being a data scientist, together with skills in data management, programming and algorithm development, as well as proper knowledge of the subject matter.
Este documento describe las principales técnicas para la recopilación y el análisis de datos a gran escala. Para comprender los fundamentos de estas técnicas utilizaremos R, un entorno y lenguaje de programación con un enfoque al análisis estadístico.
1.1 Tipos de algoritmos
La idea de fondo detrás de la ciencia de datos es enfrentarse a problemas prácticos utilizando datos históricos para crear un algoritmo (una fórmula) que ofrezca una respuesta a cada nuevo caso, con escasa o nula necesidad de intervención humana. En esencia, estos algoritmos permiten hacer dos tipos de tareas:
Clasificación: indicar qué tipo de situación estamos observando. Por ejemplo, determinar si el objeto que hay en una fotografía es un gato o una montaña.
Predicción: indicar qué ocurrirá bajo unas determinadas circunstancias. Por ejemplo, ¿qué tiempo hará la próxima semana?, ¿qué ocurrirá con los precios de los valores en bolsa?, ¿qué productos adquirirá un determinado cliente?
A menudo oímos hablar de estas actividades como «inteligencia artificial», es decir algoritmos en máquinas para llevar a cabo tareas que normalmente requerirían intervención humana. Estos algoritmos se basan en el análisis estadístico de grandes ficheros de datos y han dado lugar a ejemplos notables como los sistemas de traducción automática que, sin conocimientos de gramática, son capaces de traducir a partir de un inmenso archivo de documentos. Estos programas no intentan aprender a partir de la codificación del conocimiento y la experiencia humanas, sino a partir de un gran número de ejemplos, mediante un proceso de prueba y error.
El cambio que ha permitido el desarrollo de la ciencia de datos es la escala de datos disponibles, los llamados big data. Podemos hablar de big data en dos sentidos: el número de casos incluidos en la base de datos, que pueden ser millones de personas, de tweets, de colegios, de estrellas, etc.; y las características de cada uno de esos casos (por ejemplo, para cada uno de los millones de individuos en la base de datos podemos tener información sobre millones de genes).
Una manera habitual de clasificar los algoritmos de análisis de datos es distinguir entre los dirigidos al aprendizaje supervisado y los dirigidos al aprendizaje no supervisado.
Los algoritmos de aprendizaje supervisado trabajan con datos etiquetados (Figura 1.1). El algoritmo intenta clasificar un nuevo caso comparándolo con los incluidos en las categorías que ya tenía etiquetadas. Dentro de los algoritmos de aprendizaje supervisado, encontramos algoritmos de clasificación —como los árboles de decisión, las redes neuronales o los clasificadores bayesianos, que agrupan los datos en categorías— o la regresión lineal, que no devuelve una categoría, sino un valor numérico para una variable que deseamos estimar.

Figure 1.1: Aprendizaje supervisado
Los algoritmos de aprendizaje no supervisado trabajan con datos no etiquetados (Figura 1.2). Dentro de esta categoría, nos centraremos en los algoritmos de agrupamiento (clustering) que, como su nombre indica, pretenden agrupar los objetos en función de sus características.
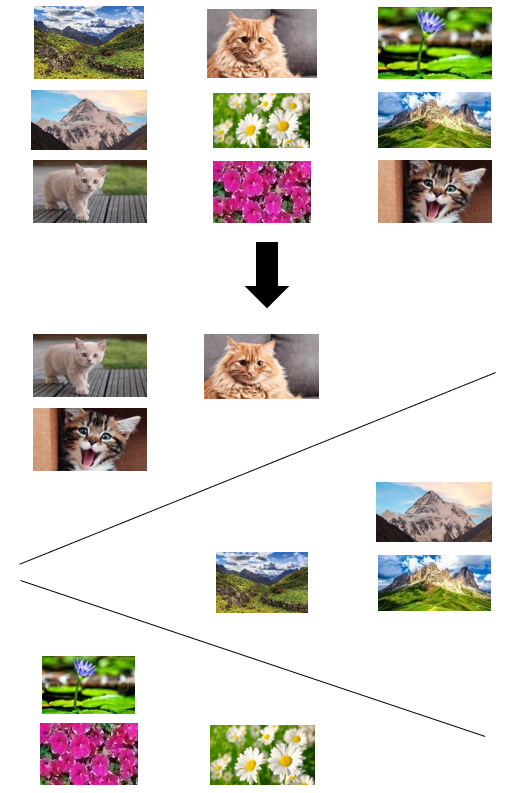
Figure 1.2: Aprendizaje no supervisado
Por su parte, Provost y Fawcett (2013, p. 19-23) distinguen nueve tipos de algoritmos de análisis de datos masivos.
Clasificación: son algoritmos que intentan predecir a qué categoría pertenece cada individuo de un conjunto. Generalmente se trabaja con categorías excluyentes. Por ejemplo, podemos intentar predecir quiénes, de entre nuestros clientes, responderán —o no— a una determinada oferta. En este caso clasificaremos cada cliente en una de las dos posibles categorías: los que aceptarán la oferta y los que no. A menudo, la respuesta será una estimación de la probabilidad de que un cliente pertenezca a cada categoría.
Regresión: intentan predecir el valor de una variable para un determinado individuo. Por ejemplo, predecir la frecuencia con la que un usuario utilizará un servicio a partir de los datos históricos de uso del servicio por parte de otros usuarios de características similares.
Similarity matching: identifica individuos similares a partir de los datos de los que disponemos sobre ellos. Esta aproximación está en la base de algunos de los métodos más habituales para hacer recomendaciones, encontrando personas similares a un usuario determinado en función de los productos comunes que les agradan o que han comprado.
Clustering: consiste en agrupar individuos u objetos en función de su similitud. Por ejemplo, determinar si nuestros usuarios forman grupos o segmentos.
Co-occurrence grouping: pretende encontrar asociaciones entre entidades a partir de las transacciones que comparten. Por ejemplo, determinar qué productos acostumbran a comprarse juntos. Es similar al clustering, pero mientras que éste último agrupa objetos a partir de sus atributos, la agrupación (grouping) se basa en las transacciones conjuntas. Algunos sistemas de recomendación también lo utilizan (“las personas que compraron X también compraron Y”).
Profiling: intenta caracterizar el comportamiento típico de un grupo. A menudo la identificación de comportamientos anómalos se utiliza para detectar fraudes.
Link prediction: intenta predecir conexiones entre elementos. Por ejemplo, en redes sociales se puede predecir que, si X e Y comparten un número elevado de amigos, es posible que deseen ser amigos. También permite hacer recomendaciones.
Data reduction: intenta reducir les dimensiones de grandes ficheros de datos.
Causal modelling: tiene por objetivo determinar qué acontecimientos y acciones influyen sobre otros. Por ejemplo, determinar hasta qué punto una campaña publicitaria es efectiva o nos estamos dirigiendo a clientes interesados en el servicio que ofrecemos y que lo habrían adquirido igualmente, aunque no hubiera habido una campaña. Requiere la utilización de métodos experimentales u observacionales con control de variables perturbadoras.
1.2 Entorno de trabajo R
R es un entorno y lenguaje de programación con un enfoque al análisis estadístico muy popular para el análisis de datos masivos. Cualquier usuario puede publicar paquetes que extienden la configuración básica.
Uno de los objetivos de este curso es familiarizarnos con el entorno de trabajo que proporciona R i el integrated development environment (IDE) RStudio. Podemos descargar ambos programas desde las siguientes direcciones. Es importante hacer la instalación en este orden, primero instalar R y, después, RStudio.
RStudio: https://www.rstudio.com
RStudio está dividido en cuatro paneles (Figura 1.3).
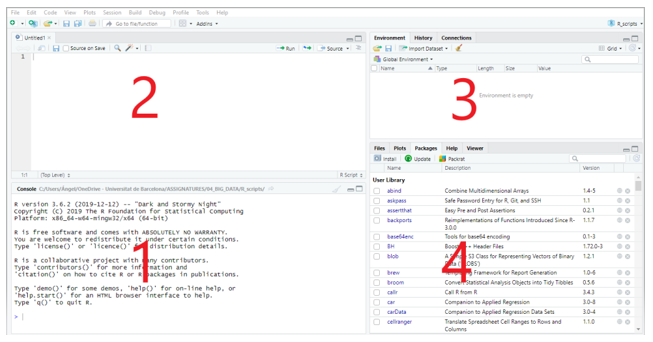
Figure 1.3: Interficie de RStudio
Consola (1): aquí es donde R espera que le demos instrucciones. Para ejecutarlas y obtener el resultado pulsamos «Intro». La primera vez que abras RStudio esta sección ocupará toda la parte izquierda de la pantalla.
Scripts (2): trabajar en la consola es muy limitado ya que las instrucciones se han de introducir una a una. Lo habitual es trabajar con scripts o ficheros de instrucciones que podemos guardar y compartir. Para ver esta sección en la pantalla debes abrir un script nuevo («File > New File > R Script»). Otra opción, aún mejor, es crear ficheros R Markdown con código y narrativa.
Entorno, etc. (3) que incluye diversas pestañas: Environment (donde se irán registrando los objetos creados en la sesión de trabajo); History (se registran las instrucciones ejecutadas); y Connections.
Ficheros, etc. (4) que incluye las pestañas Files, Plots, Packages, Help y Viewer. De momento, destacaremos la pestaña Packages, que proporciona un listado de los paquetes disponibles en R y los que han sido cargados en la sesión. A través de las opciones de esta pestaña podemos instalar nuevos paquetes o actualizar los existentes.
Lo más habitual será trabajar con scripts en el panel 2 de la figura. Allí escribiremos las funciones que queremos ejecutar. Asimismo, podemos añadir comentarios que, para diferenciarlos de las funciones, irán precedidos del signo # (para convertir un texto en comentario también es posible seleccionarlo y pulsar «Ctrl + Shift + C»). Aunque se pueden ejecutar varias funciones de una sola vez, normalmente ejecutaremos los script línea a línea. De esta manera, si se produce un error, sabremos inmediatamente en qué línea se encuentra. Para ejecutar una línea de código, situamos en ella el cursor y pulsamos «Run» o «Ctrl + Intro».
A menudo utilizaremos paquetes (libraries) que extienden la configuración básica de R. Para utilizar un paquete primero tendremos que instalarlo (esto lo haremos una única vez) y llamarlo (esto habrá que hacerlo cada vez que abramos una sesión en R). Es recomendable hacer la llamada al paquete al inicio del script. A continuación, tienes los dos comandos para instalar y ejecutar el paquete rworldmap:
install.packages("rworldmap")
library(rworldmap)A medida que trabajemos con R iremos acumulando ficheros (datos, scripts, resultados de los análisis, figuras, etc.). Para mantener organizada la información, es recomendable trabajar con «proyectos» (projects). Cada proyecto tiene su propio directorio, de manera que, al indicar un fichero que queremos utilizar, no es necesario detallar la ruta para acceder, sino que R lo buscará en el directorio del proyecto. En el caso de proyectos de envergadura, es conveniente crear subdirectorios de datos, scripts y outputs.
1.3 Elementos básicos de R
En su versión más simple, es posible utilizar R como una calculadora. Si introducimos en la consola 2+2, R nos devuelve el resultado.
2+2## [1] 4Al ejecutar el código, el resultado se muestra en la consola. Sin embargo, muchas veces será útil guardarlo en un objeto para poder reutilizarlo. En R el concepto de objeto es esencial. En R cualquier cosa puede ser un objeto: una cifra, una palabra, una tabla de datos, una figura, etc. Por tanto, un objeto puede ser algo muy simple o algo muy complejo.
Para crear un objeto, simplemente le damos un nombre y le asignamos un valor usando el operador <-
objeto_1 <- 48Acabamos de crear un objeto llamado objeto_1 y le hemos asignado el valor 48. Es importante evitar los espacios en blanco en los nombres de objetos. Generalmente se sustituyen por «_» o por «.» Tampoco podemos iniciar el nombre de un objeto con un dígito.
Ahora creamos un segundo objeto:
objeto_2 <- "buenos días"En el «Entorno» de RStudio podemos ver los objetos creados, sus valores y el tipo de objeto que RStudio les ha asignado. Si asignamos un nuevo valor a un objeto, R lo sustituye sin avisarnos por lo que hay que ser precavido para evitar borrar información involuntariamente:
objeto_2 <- 34Ahora tenemos dos objetos del mismo tipo y podemos combinarlos:
objeto_3 <- objeto_1 + objeto_2
print(objeto_3)## [1] 82Otro tipo de objeto son los vectores. Vamos a crear un vector concatenando 8 cifras:
vector_1 <- c(2, 3, 1, 6, 4, 3, 3, 7)Pedimos la media del vector y la guardamos en un nuevo objeto llamado media_vector_1:
media_vector_1 <- mean(vector_1)
print(media_vector_1)## [1] 3.625En los ejemplos anteriores hemos visto objetos que contenían dos tipos de valores: numéricos (numeric) y caracteres (character). R considera dos tipos más de información: enteros (integers, números enteros, sin decimales) y lógicos (logical, que adopta dos posibles valores: TRUE o FALSE).
Por lo que hace a las estructuras de datos, ya hemos visto los vectores (vectors). Además, R incluye datos en matrices (matrices o arrays), listas (lists) y dataframes. Este último tipo de estructura será la que utilizaremos con mayor asiduidad durante este curso. Un dataframe es un objeto bidimensional con filas y columnas. Es similar a una matriz, con la diferencia de que mientras la matriz sólo contiene datos de un tipo, los dataframes pueden combinar diferentes tipos de datos. Normalmente, en un dataframe cada fila corresponde a una observación individual y cada columna a una variable. En definitiva, un dataframe es similar a una hoja de cálculo en Microsoft Excel o en LibreOffice Calc.
A continuación se muestra un ejemplo de dataframe.
## Nombre Color Edad Peso
## 1 Amelia Amarillo 66 74.5
## 2 Daniel Rojo 25 69.1
## 3 Emma Verde 22 77.8
## 4 Lucas Rojo 30 71.1
## 5 Matilde Rojo 38 72.3
## 6 Pablo Verde 35 67.2A pesar de que es posible introducir datos directamente en R (por ejemplo, creando vectores), lo más habitual es importarlos desde una hoja de cálculo. Hay múltiples funciones para hacerlo. Una forma sencilla es guardar el fichero como un texto separado por tabulaciones e importarlo desde RStudio con la función read.table. En el ejemplo que viene a continuación, se ha importado desde R un fichero llamado «muestra.txt» con tres parámetros que indican que los datos tienen encabezamientos, están separados por tabulaciones y el símbolo que utilizamos para separar los decimales es la coma. Una vez importados, los datos se guardan en un objeto llamado muestra.
muestra <- read.table (file = "muestra.txt", header = TRUE, sep = "\t", dec = ",")Ahora podemos trabajar con el objeto muestra, obteniendo un resumen estadístico de sus datos:
summary(muestra)## Nombre Color Edad Peso
## Length:6 Length:6 Min. :22.00 Min. :67.20
## Class :character Class :character 1st Qu.:26.25 1st Qu.:69.60
## Mode :character Mode :character Median :32.50 Median :71.70
## Mean :36.00 Mean :72.00
## 3rd Qu.:37.25 3rd Qu.:73.95
## Max. :66.00 Max. :77.80También podemos obtener datos de un campo concreto (que se indica con el símbolo «$»), como la media de las edades:
mean(muestra$Edad)## [1] 36Como ya hemos visto, esta media puede guardarse en otro objeto para seguir trabajando con ella:
media_edad <- mean(muestra$Edad)
media_edad## [1] 36Para hacer un recuento de datos:
recuento <- table(muestra$Color)
recuento##
## Amarillo Rojo Verde
## 1 3 2Podríamos filtrar los registros que cumplen una determinada condición, ordenar los datos siguiendo algún criterio, etc.
1.4 Ejercicio 1. Familiarizarse con R i RStudio
El ejercicio 1 presenta algunas actividades para familiarizarte con R i RStudio.
Instala R i RStudio en tu ordenador.
Inicia RStudio. Crea un nuevo proyecto en un nuevo directorio («File > New Project» en el menú principal). Puedes utilizar este directorio para guardar las actividades del curso.
Crea un script nuevo dentro de este proyecto («File > New File > R Script»). Guárdalo con el nombre «Ejercicio_1» o similar. Consulta la pestaña Files (panel inferior derecho) para comprobar que se ha guardado en el directorio correcto.
Explora los paneles de RStudio para familiarizarte con las diferentes pestañas.
En el editor de scripts, escribe
help(mean)o?meany ejecuta la orden (Run). Observa que el texto de ayuda se abre en una pestaña de ayuda del panel inferior derecho. Examina las partes del texto de ayuda y los ejemplos del final.Crea un objeto llamado
primer_numy asígnale el valor 42 usando el operador<-. A continuación, crea otro objeto llamadoprimer_textoy asígnale el valor “mi primer texto”. Comprueba en la pestaña Environment que se han creado correctamente.Asigna el valor “mi segundo texto” al objeto
primer_texto. Observa qué ocurre en Environment. Para mostrar el valor del objeto introduce su nombre en la consola.Crea una hoja de cálculo con cinco observaciones de tres variables. Impórtala desde RStudio en un objeto llamado
primer_dataframe.No olvides guardar tu script. Si quieres, puedes cerrar tu proyecto seleccionando «File > Close Project». No obstante, no es obligatorio que lo hagas. Si no lo haces, la próxima vez que abras RStudio volverás a estar en este mismo proyecto.