Capítulo 3 Árboles de decisión
La selección de los atributos más informativos no es suficiente para segmentar los casos. Si seleccionamos un único atributo, la segmentación será muy simple. Si seleccionamos varios, deberemos determinar cómo combinarlos. Un árbol de decisión es quizá la forma más sencilla de algoritmo ya que consiste en una serie de preguntas de respuesta «sí» o «no» que llevan a preguntas sucesivas hasta tomar una decisión.
La figura 3.1 presenta un ejemplo de segmentación en forma de árbol. Partiendo de la parte superior, el árbol segmenta los datos de manera que cada lado corresponde a un único camino. Imaginemos que queremos clasificar un sujeto llamado Claudio, de 40 años, sin empleo y con unos ahorros de 115 000 €. Comenzando en la parte superior, como no tiene «empleo», tomamos el camino de la derecha. El siguiente nodo es el de los «ahorros», como son superiores a 50 000 €, tomamos de nuevo el camino de la derecha hasta el nodo «edad». El valor es 40, de manera que vamos a la izquierda que nos indica que la predicción es que no será moroso. Normalmente, más que saber la categoría en la queda clasificado un sujeto, lo que retornará el algoritmo será la probabilidad de que acabe dentro de esa categoría. En ese caso, las ramas del árbol incluirán las probabilidades en vez de un valor simple.
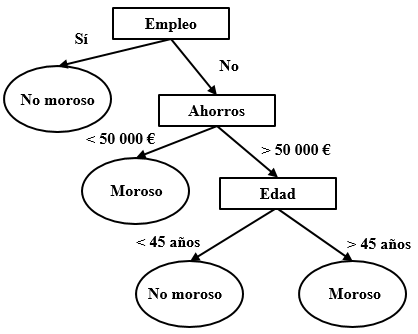
Figure 3.1: Ejemplo de árbol de clasificación simple
Veamos otro ejemplo. La noche del 14 al 15 de abril de 1912, el «Titanic» se hundió al chocar contra un iceberg en su viaje inaugural. Sobrevivieron unas 700 personas de entre las 2200, entre pasajeros y tripulación, que viajaban en el buque. Diversos estudios han mostrado que las posibilidades de salvarse dependían de diversos factores.
Podemos intentar construir un algoritmo que sea capaz de predecir si un determinado viajero se salvará o no. Para ello contamos con un fichero con los datos correspondientes a 1309 pasajeros disponible en: https://biostat.app.vumc.org/wiki/pub/Main/DataSets/titanic3.xls. Entre las variables predictoras encontramos la clase en la que viajaba cada pasajero («pclass» con tres posibles valores: “primera”, “segunda” o “tercera”), el tratamiento (“Mr”, “Mrs”, “Miss”, “Master”, etc.), el sexo («sex»), la edad («age»), la tarifa («fare») o el puerto de embarque («embarked» que adopta tres valores: “Southampton”, “Cherbourg” o “Queenstown”), entre otras variables. La variable de respuesta («survived») indica si cada pasajero sobrevivió (“1”) o no (“0”). El ejercicio es puramente teórico puesto que el suceso no va a repetirse, pero puede resultar un reto intelectual. El portal Kaggle.com incluye competiciones en ciencia de datos siguiendo siempre la misma dinámica: se ofrece a los participantes un conjunto de datos (training set) para construir su algoritmo y, a continuación, se mide el rendimiento con un nuevo fichero de datos (test set).
Una manera muy sencilla de enfrentarse al problema sería predecir que nadie sobrevivió. De esta manera tan simple clasificamos correctamente el 62% de los casos (el 62% de los pasajeros perdieron la vida). Podemos complicar ligeramente el árbol de clasificación y afirmar que todos los hombres perecieron mientras que todas las mujeres sobrevivieron. Con esta afirmación nuestro algoritmo ha mejorado y el porcentaje de casos clasificados correctamente se ha elevado hasta el 78% (los marcados en gris en la figura 3.2).
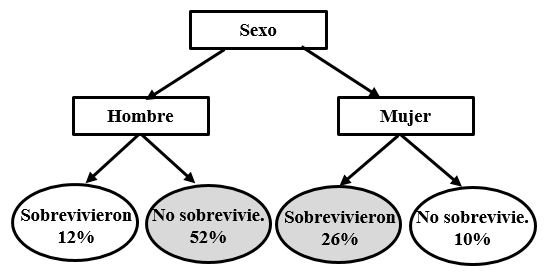
Figure 3.2: Ejemplo de árbol de clasificación simple
A partir de esta formulación tan simple podemos determinar si se producen mejoras como resultado de introducir reglas más sofisticadas (por ejemplo, una nueva regla que determine que los hombres que viajaban en primera clase se salvaron mientras que el resto perecieron).
3.1 Creación de un árbol de decisión con R
Comenzaremos con el ejemplo de la morosidad del capítulo anterior. Es posible que tengamos problemas porque la información está en formato character. Si es así, la convertimos a factor. Lo podemos hacer campo a campo.
morosidad <- read.table("morosidad.txt", header=T, sep = "\t")
morosidad$Ahorros <- as.factor(morosidad$Ahorros)
morosidad$Vivienda <- as.factor(morosidad$Vivienda)
morosidad$Moroso <- as.factor(morosidad$Moroso)También es posible hacer la transformación para todo el dataframe con el paquete dplyr.
library(dplyr)
morosidad <- morosidad%>%mutate_if(is.character, as.factor)Ahora vamos a crear un árbol de decisión que nos permita determinar la probabilidad de que un nuevo cliente sea o no moroso. Para ello, utilizaremos el paquete party. Este paquete tiene una función llamada ctree() que será la que usaremos para crear el árbol. Su sintaxis básica es ctree(formula, data). En formula indicaremos la variable respuesta y las variables predictoras y en data los datos con los que alimentaremos el algoritmo.
library(party)
arbol_morosidad <- ctree(formula = Moroso ~ Ahorros + Vivienda, data = morosidad)A continuación, visualizamos el árbol.
plot(arbol_morosidad)
Volvamos ahora sobre el ejemplo de las setas del ejercicio 2. Utilizando el dataset completo, se observaba que la característica que aporta mayor información sobre el carácter comestible o venenoso de una seta es su olor. Podemos utilizar esta información para construir un árbol de decisión.
bolets_tot <- read.table("bolets_total.txt", header=T, sep = "\t")
bolets_tot2 <- bolets_tot%>%mutate_if(is.character, as.factor)
arbol_bolets <- ctree(classes ~ odor, bolets_tot2)
plot(arbol_bolets)
Veamos un tercer ejemplo. Una escuela de inglés ha hecho una prueba de nivel a 200 niños de entre 5 y 11 años. Para cada uno tenemos el resultado de una prueba de escritura y otra de lectura. Finalmente, sabemos si los niños son hablantes nativos de inglés o no. El Cuadro 3.1 presenta un extracto con los 10 primeros casos.
| Edad | Lectura | Escritura | Nativo |
|---|---|---|---|
| 5 | 25 | 32 | si |
| 6 | 26 | 37 | si |
| 11 | 30 | 50 | no |
| 7 | 29 | 40 | si |
| 11 | 32 | 55 | si |
| 10 | 30 | 53 | si |
| 7 | 27 | 34 | no |
| 11 | 31 | 56 | si |
| 5 | 26 | 32 | si |
| 7 | 27 | 34 | no |
A partir de los datos de edad, lectura y escritura, vamos a crear un árbol de decisión que nos permita determinar si un niño es nativo.
nativos <- read.table("nativos.txt", header=T, sep = "\t")En vez de trabajar con todos los datos, vamos a seleccionar las primeras 105 entradas que almacenamos en el objeto nativos_1.
nativos_1 <- nativos[c(1:105), ]
nativos_1$Nativo <- as.factor(nativos_1$Nativo)A continuación, creamos el árbol utilizando la función ctree. Indicamos que la variable que queremos predecir es la probabilidad de que un niño sea nativo basándonos en tres variables predictoras: edad, lectura y escritura. Almacenamos el resultado en un objeto denominado arbol y lo representamos.
arbol <- ctree(Nativo ~ Edad + Lectura + Escritura, data = nativos_1)
plot(arbol)
Prueba ahora a repetir el proceso con los datos de los 200 niños. Verás que el árbol se vuelve más complejo.
3.2 Ejercicio 3. Prescripción de lentillas
Una óptica que ha recopilado la siguiente información sobre una muestra de clientes: edad, patología, astigmatismo y lacrimosidad. A partir de estos datos, se indica si la persona debe llevar lentes de contacto (blandas o rígidas) o si no es conveniente que use lentes de contacto. El objetivo de la actividad es elaborar un árbol de decisión en RStudio para determinar la prescripción adecuada para un joven con lacrimosidad reducida.
| edad | patologia | astigmatismo | lacrimosidad | lentes |
|---|---|---|---|---|
| adolescente | miopia | no | reducida | no |
| adolescente | miopia | no | normal | suaves |
| adolescente | miopia | si | reducida | no |
| adolescente | miopia | si | normal | rigidas |
| adolescente | hipermetropia | no | reducida | no |
| adolescente | hipermetropia | no | normal | suaves |
| adolescente | hipermetropia | si | reducida | no |
| adolescente | hipermetropia | si | normal | rigidas |
| joven | miopia | no | reducida | no |
| joven | miopia | no | normal | suaves |
De manera opcional, es posible realizar un segundo ejercicio para determinar si, en un bar, dejar una tarjeta con un chiste junto a la cuenta incrementa las posibilidades de obtener una propina . Un estudio investigó esta cuestión entre los clientes que acudían solos a la terraza de un resort de la costa francesa y pedían un espresso. El camarero dividió aleatoriamente los 211 clientes de una semana en tres grupos. Junto a la cuenta, el primer grupo recibía una tarjeta con un chiste, el segundo grupo recibía una tarjeta de publicidad de un restaurante local y el tercer grupo no recibía ninguna tarjeta. En todos los casos, el camarero anotaba si el cliente dejaba o no propina.
El objetivo de la actividad es elaborar un árbol de decisión en RStudio para determinar si el camarero recibirá o no una propina en función del tipo de tarjeta que deje al cliente. El dataset (disponible en: https://vincentarelbundock.github.io/Rdatasets/csv/Stat2Data/TipJoke.csv) contiene la siguiente información:
Card: Type of card used (Ad, Joke, or None)
Tip: 1=customer left a tip or 0=no tip
Ad: Indicator for Ad card (1=ad card left or 0=no ad card)
Joke: Indicator for Joke card (1=joke card left or 0=no joke card)
None: Indicator for no card (1=no card left or 0=ad or joke card left)
Fuente: Gueguen, Nicholas (2002). The effects of a joke on tipping when it is delivered at the same time as the bill. Journal of Applied Social Psychology, 32 (9), 1955-1963. https://doi.org/10.1111/j.1559-1816.2002.tb00266.x