Capitulo 2 Empezando con RStudio
Aspectos básicos:
Usaremos '#' para los comentarios.
Usaremos ';' para separar comandos en una línea.
Usaremos '{ ... }' para agrupar comandos.Comandos de consola
setwd(ruta) # Cambiar directorio de trabajo
getwd() # Leer directorio de trabajo
rm(x) # Borrar objetos
q() # Abandonar R
history() # Historial de acciones2.1 Tipos de datos
2.1.1 Declaracion de variables/objetos y operaciones aritmeticas:
Los resultados los podemos guardar en una variable usando ‘<-’ o ‘=’.
El origen del uso de <- viene de las tuberias (pipeline) en algunos sistemas operativos y lenguajes de programación y es la usada en el lenguaje R casi por convenio. Los nombres de variables deben empezar con una letra y pueden contener letras, números, _ y el punto.
Podemos utilizar cualquiera de las operaciones aritmeticas, al igual que en cualquier otro lenguaje de programacion como pueden ser +, -, *, /, etc
2.1.2 Tipos Basicos
A diferencia de otros lenguajes, R tiene tipos simplificados, como puede ser Numeric, incluyendo cualquier valor numerico, desde los naturales a los reales.
Podemos hacer uso de las funciones class y str para analizar la estructura de los objetos. str nos devuelve mas informacion que class.
Algunos ejemplos de tipos son:
# Numeros enteros
edad <- 45L
class(edad) ==> Integer
# Numeros reales
peso <- 76.8
class(peso) ==> Numeric
# Cadenas de caracteres
mi.cadena <- "Control de peso"
class(mi.cadena) ==> Character
# Numeros complejos
c1 <- 2+3i
class(c1) ==> Complex
# Numeros binarios
b1 <- raw(2)
class(b1) ==> RawPara realizar comprobaciones sobre tipos hacemos uso de ‘is.’ seguido de un tipo de datos. La orden comprobará si la variable es de ese tipo de datos.
Para realizar conversiones de tipo lo hacemos con ‘as.’ seguido del tipo al que queremos convertir la variable. En el caso de que una conversión no sea posible, se mostrará la constante NA, que significa Not Available.
2.2 Estructuras de Datos
A continuación se mostrarán las estructuras de datos principales que usaremos a lo largo de la asignatura.
Estaran divididos según su dimensión:
- Unidimensionales: Vector, Lista.
- Bidimensionales: Matriz, Data Frame
- N-Dimensiones: Array (no se verán)
2.2.1 Vectores
Todos los elementos que forman parte del vector deben tener el mismo tipo basico.
Para construir un vector usaremos el operador combine ‘c()’.
## [1] 1 2 3 4 5Los vectores atómicos son siempre de una dimensión. Si anidamos, R aplana los datos (flat).
Tambien podemos crear vectores de la siguiente forma:
# Haciendo uso de expresiones para generar sucesiones de numeros:
v1 <- 1:10
v1a <- 10:1
# Haciendo uso de la funcion sequence 'seq':
v2 <- seq(1, 10, 3) # Secuencia desde 1 a 10 saltando de 3 en 3
v2b <- seq(from=2, to=10, by=0.1)
v2c <- seq(from=0, to=100,length.out=5) # Secuencia de tamaño 5 con numeros comprendidos entre 0 y 100
# Haciendo uso de la funcion replicate 'rep':
v3 <- rep(c(1, 2), times=3) # Secuencia replicando el vector [1,2] 3 veces
v3 <- rep(c(1, 2), each=3) # Al igual que el anterior pero intercalando el resultadoLa diferencia entre usar combine c() o no reside en que combine puede tomar mas de un tipo diferente y convertirlo autmaticamente, por ejemplo:
## chr [1:11] "1" "2" "3" "4" "5" "6" "7" "8" "9" "10" "15"Podemos realizar operaciones aritmeticas sobre vectores. R evalúa 1 por 1 los elementos del vector aplicando la operacion que hayamos usado.
Algunas funciones sobre vectores son las siguientes:
length(v) # Devuelve el tamaño del vector
min(v) # Devuelve el valor mínimo del vector
max(v) # Devuelve el valor máximo del vector
sum(v) # Suma todos los valores del vector
mean(v) # Devuelve la media aritmetica de los valores del vector (debe ser numérico o lógico)
median(v) # Devuelve la mediana del vector
append(v, elem) # Añade un elemento al vector v en la ultima posicion. Tambien se puede especificar la posicion.
sort(v) # Ordena el vector de menor a mayor
order(v) # Devuelve un vector sustituyendo los valores por su orden ascendente
rev(v) # Devuelve el vector invertido
sample(n) # Genera un vector de tamaño n con valores aleatorios desde 1 a n
unique(v) # Devuelve el vector sin repeticiiones
which(x) # Devuelve un vector con los indices del vector logico x, ej: which(v1 > 3)
which.min(v) # Devuelve el indice del elemento mínimo del vector
which.max(v) # Devuelve el indice del elemento máximo del vector
plot(v) # Sirve para generar una representación X-Y simpleReciclaje: Hay que tener cuidado a la hora de realizar operaciones con vectores de distinto tamaño, R recicla el vector más pequeño, repitiendo los valores de dicho vector, hasta llegar a la dimension del vector mayor.
Los operadores de comparación son los típicos en otros muchos lenguajes: ==, !=, <, >, <=, >=
Adicionalmente existen los operadores logicos any, all, que comprobaran si alguno o todos los elementos del vector cumplen un predicado logico. Tambien podemos hacer uso de is.na para comprobar si alguna posicion tiene NA
El acceso al contenido de una posicion de un vector se usan los corchetes. Hay que tener en cuenta que podemos acceder a la vez a más de un elemento:
- Usando el operador c()
- Indicando el rango pIini:pFin
- Mezclando ambas formas
Podemos descartar indices haciendo uso del ‘-’, poner condiciones con operadores lógicos y podemos almacenar los indices haciendo uso del comando which:
v1[c(2,4)] # los elementos 2 y 4 de v1
v1[-(3:6)] # los elementos de v1 menos del 3 al 6
v1[v1>30] # elementos de v1 mayores que 30
indices1 <- which(v1>50) # posiciones cuyo valor sea mayor que 50
v1[indices1] # los valores de esos índices
v1 < 50 # devuelve vector lógico con vector con TRUE FALSE dependiendo si cumple condición
v1[v1 <50] # valores que cumplen la condición 2.2.2 Factor
Es un vector con información de los valores presentes en el vector (denominados ‘levels’). R utiliza una representación compacta para este tipo de datos. Sirven para manejar variables categóricas, como pueden ser rangos de edades, colores, o días de la semana.
## [1] 1 -1 1 0 2 5
## Levels: -1 0 1 2 5A continuacion se muestra un ejemplo de una tienda de ropa (tallas):
tallas <- c('m', 'g', 'S', 'S','m', 'M')
tallas_ordenado <- factor(tallas,
ordered = TRUE,
levels = c("S", "m", "M", "g"),
labels = c("S", "M", "M", "G"))
plot(tallas_ordenado)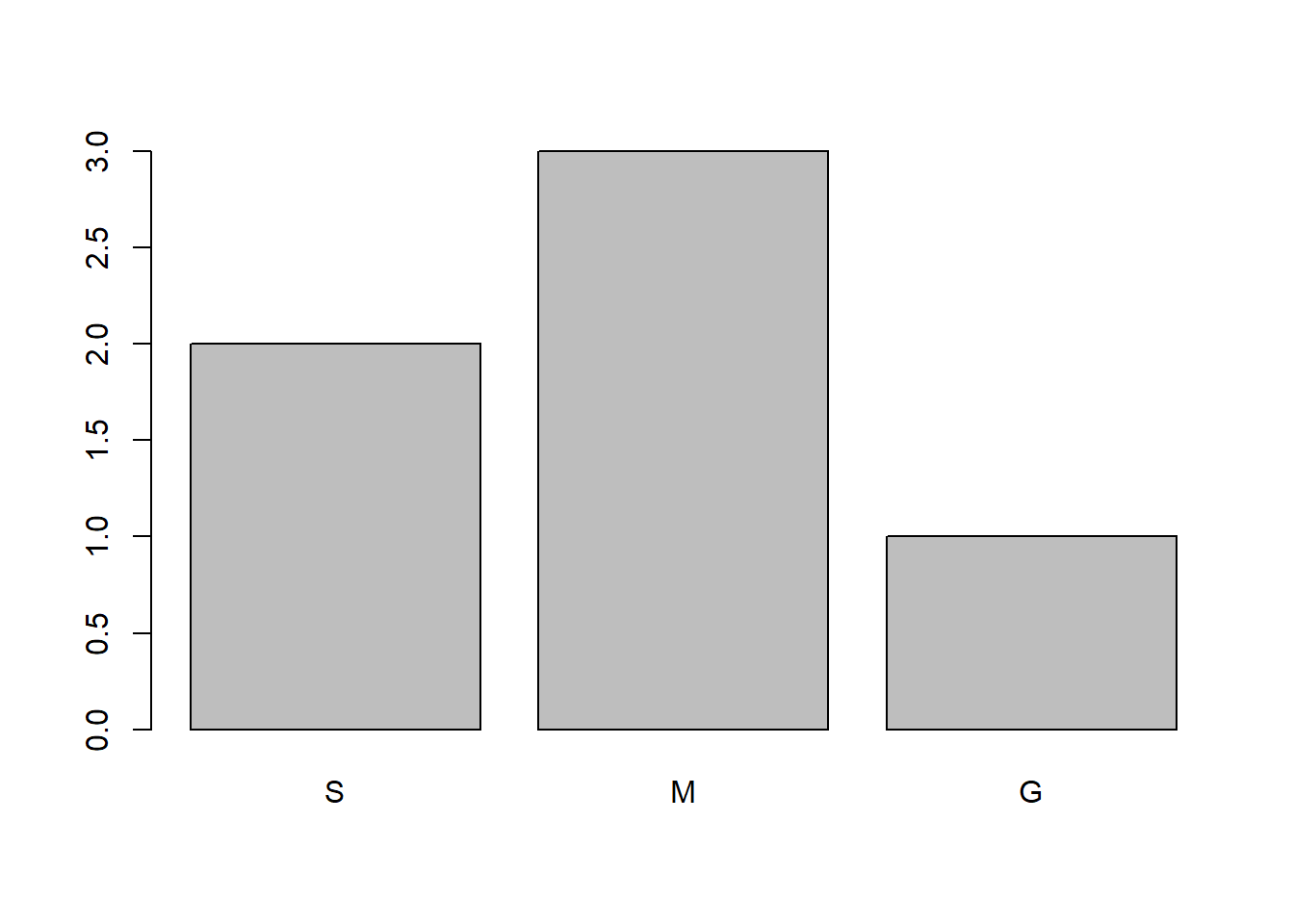
2.2.3 Listas
Una lista es un vector de objetos de tipos distintos que estan agrupados.
alumno1 <- list(nombre = "Luis", no.asignaturas = 4, nombre.asignaturas = c("Lab1", "Lab2", "Lab3"))
alumno1
alumno1$nombre # acceder al dato nombre
alumno1$nombre.asignaturas # acceder al dato asignaturas
alumno1$nombre.asignaturas[1] # acceder a la primera asignatura
# IMPORTANTE: Ver la diferencia entre los siguientes comandos
alumno1[1]
class(alumno1[1]) # List
alumno1[[1]]
class(alumno1[[1]]) # CharacterEl comnado ‘unlist’ aplana una lista.
2.2.4 Matrices
Para crear una matriz usaremos el comando ‘matrix()’
## [,1] [,2] [,3]
## [1,] 1 3 5
## [2,] 2 4 6M2 <- matrix(1:4, nrow = 2, ncol = 3) # al usar 1:4 y querer crear una matriz 2x3 (6 elementos), se aplica reciclaje## Warning in matrix(1:4, nrow = 2, ncol = 3): la longitud de los datos [4] no es
## un submúltiplo o múltiplo del número de columnas [3] en la matriz## [,1] [,2] [,3]
## [1,] 1 3 1
## [2,] 2 4 2Los comnados rbind y cbind combinan vectores por filas o columnas respectivamente.
El comando dim nos sirve para consultar la dimension de una matriz o para poder redimensionar vectores
## [,1] [,2] [,3]
## f1 1 2 3
## f2 4 5 6
## f3 7 8 9## f1 f2 f3
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 9## [,1] [,2] [,3] [,4]
## [1,] 1 4 7 10
## [2,] 2 5 8 11
## [3,] 3 6 9 12A continuacion se muestran las operaciones matriciales básicas:
A+B; A*B # Suma y Multiplicación elemento a elemento
A%*%B # Multiplicación matricial
t(A) # Traspuesta
det(A) # Determinante
solve(A) # Inversa
diag(A) # Devuelve la diagonal
upper.tri(A) # Devuelve los elementos situados en la diagonal superior de la matriz
lower.tri(A) # Devuelve los elementos situados en la diagonal inferior de la matriz
b <- c(2,3,1)
x <- solve(A,b); x # Resolver un sistema de ecuaciones (Ax=b)
eigen(A) # Calcular autovalores y autovectores2.2.5 Data Frames
Los Data Frames son matrices que pueden almacenar datos de distinto tipo: una matriz de listas.
## alumnos edad
## 1 Luis 21
## 2 Antonio 20
## 3 Daniel 22Es importante el uso correcto de [] o [[]]. Con [] accedemos a las columnas que indiquemos entre corchetes, pero devuelve un data frame. Si queremos acceder al vector que está dentro del data frame usaremos [[]].
Los comandos D1$alumnos y D1[[1]] devuelven lo mismo.
Si ponemos , dentro de los corchetes, antes de la coma se seleccionan filas, después de la coma se seleccionan las columnas. Si antes o despues de la coma no se pone nada significa o todas las filas o todas las columnas. A continuacion se muestran algunos ejemplos del funcionamiento:
## alumnos edad
## 1 Luis 21## alumnos edad
## 1 Luis 21
## 2 Antonio 20## [1] Luis Antonio
## Levels: Antonio Daniel Luis## alumnos edad
## 1 Luis 21
## 2 Antonio 20
## 3 Daniel 22## [1] 20 21## [1] Luis Antonio Daniel
## Levels: Antonio Daniel Luis## alumnos edad
## 1 Luis 21
## 2 Antonio 20
## 3 Daniel 22Usaremos rbind y cbind con listas o con data frames para conseguir un nuevo data frame:
# Uniendo dos listas
alumno1 <- list(nombre = "Luis", no.asignaturas = 3, nombre.asignaturas = c("Lab1", "Lab2", "Lab3"))
df1 <- as.data.frame(alumno1);
df1## nombre no.asignaturas nombre.asignaturas
## 1 Luis 3 Lab1
## 2 Luis 3 Lab2
## 3 Luis 3 Lab3alumno2 <- list(nombre = "Antonio", no.asignaturas = 3, nombre.asignaturas = c("Lab2", "Lab1", "Lab3"))
df2 <- as.data.frame(alumno2)
mi.df1 <- rbind(df1, df2)
mi.df1## nombre no.asignaturas nombre.asignaturas
## 1 Luis 3 Lab1
## 2 Luis 3 Lab2
## 3 Luis 3 Lab3
## 4 Antonio 3 Lab2
## 5 Antonio 3 Lab1
## 6 Antonio 3 Lab3# Añadir columna a data drame
alumno1b <- list(apellido = "Fernandez", ciudad= c("Málaga", "Málaga", "Sevilla"))
df1b <- as.data.frame(alumno1b)
df1b## apellido ciudad
## 1 Fernandez Málaga
## 2 Fernandez Málaga
## 3 Fernandez Sevilla## nombre no.asignaturas nombre.asignaturas apellido ciudad
## 1 Luis 3 Lab1 Fernandez Málaga
## 2 Luis 3 Lab2 Fernandez Málaga
## 3 Luis 3 Lab3 Fernandez SevillaSe pueden combinar dos data.frames con una columna igual con el comando merge:
# Construyo primer data frame
a1 <- c("Luis","Antonio","Daniel")
e1 <- c(21,20,22)
D1 <- data.frame(alumnos=a1,edad=e1)
D1## alumnos edad
## 1 Luis 21
## 2 Antonio 20
## 3 Daniel 22## alumnos ciudad
## 1 Luis Madrid
## 2 Daniel Córdoba
## 3 Ángel Málaga## alumnos edad ciudad
## 1 Daniel 22 Córdoba
## 2 Luis 21 MadridAl igual que en vectores, se pueden realizar consultas de valores de una columna que cumplan una condición, colocando dicha condición entre [].
2.3 Entrada y Salida
2.3.1 Entrada:
2.3.2 Salida:
write.table(data frame, file=“nombre del fichero”)
2.3.3 Acceso a datasets
data() # Lista de datasets incorporados en R
data(Loblolly) # Cargar dataset Loblolly
head(Loblolly) # Devuelve la primera o ultima parte de una estructura de datos o funcion
data(package="arules") # Cargar dataset en paquetes
library() # Lista de paquetes disponibles
installed.packages() # Ver paquetes instalados2.4 Funciones
Para poder definir funciones haremos uso de la siguiente notacion:
2.5 Estructuras de control
Al igual que otros lenguajes de programación, podemos encontrar las siguientes estructuras de control:
- Estructuras condicionales
- if, else
- Ciclos o bucles
- for : repeticion de un bloque un numero de veces
- while : repetir un bloque mientras se cumpla una condición
- repeat : repetir un bloque hasta que se cumpla una condición
Usaremos las ordenes break y next para interrumpir un bucle.
2.6 Programacion funcional
Una funcion de orden superior es una función que como argumento usa otra función.
En este curso haremos uso principalmente de las funciones lapply y sapply de la familia apply.
2.6.1 apply
Aplica una función f a cada elemento sobre una dimension de una matriz.
M <- matrix(rnorm(100),10,10) # Genera variables aleatorias normales multivariadas en el espacio dado
apply(M,1,mean) # Calcula la media de cada fila de la matriz## [1] -0.25444981 -0.11562548 -0.12041699 0.07490218 0.34551005 0.30746168
## [7] 0.60817818 0.12460402 -0.56791206 -0.33520371## [1] -0.6278445107 0.8321398986 -0.0009707176 -0.1254584764 0.1625682817
## [6] -0.4636520782 0.2123078771 -0.2877479985 -0.1879856603 0.5536914428## [1] -2.5444981 -1.1562548 -1.2041699 0.7490218 3.4551005 3.0746168
## [7] 6.0817818 1.2460402 -5.6791206 -3.3520371## [1] -6.278445107 8.321398986 -0.009707176 -1.254584764 1.625682817
## [6] -4.636520782 2.123078771 -2.877479985 -1.879856603 5.5369144282.6.2 lapply
Va tomando cada elemento de una lista, evalúa la función que aparece al final de lapply a cada elemento seleccionado de la lista y devuelve una lista con todos los resultados.
## $alumno1
## [1] 2.5 3.7 6.0
##
## $alumno2
## [1] 5.0 6.7 10.0## $alumno1
## [1] 4.066667
##
## $alumno2
## [1] 7.233333## [1] "list"2.6.3 sapply
El funcionamiento es similar a lapply. Toma una lista como entrada e itera sobre cada elemento de la lista aplicando la funcion f a cada elemento x. Sin embargo, sapply devuelve un vector si cada f(x) tiene longitud 1 o devuelve una matriz si cada f(x) tiene logitud mayor a 1:
## $alumno1
## [1] 2.5 3.7 6.0
##
## $alumno2
## [1] 5.0 6.7 10.0## alumno1 alumno2
## 4.066667 7.233333## [1] "numeric"Usaremos sapply con un dataset que se almacenará en R en un data.frame.
#Si aplicamos sapply con la funcion mean, si existen valores NA tendremos como resultado NA para esas columnas, por lo que tenemos que o bien introducir valores para las casillas NA, o descartarlas
airquality <- airquality[!is.na(airquality$Ozone), ]
airquality <- airquality[!is.na(airquality$Solar.R), ]
# Tambien se podria hacer uso de la funcion predefinida 'na.omit()'
sapply(airquality, mean)## Ozone Solar.R Wind Temp Month Day
## 42.099099 184.801802 9.939640 77.792793 7.216216 15.945946