Chapter 2 Visualizing and characterizing variability
This workshop will attempt to teach you some of the basics of the data science workflow, as imagined by Wickham and Grolemund:
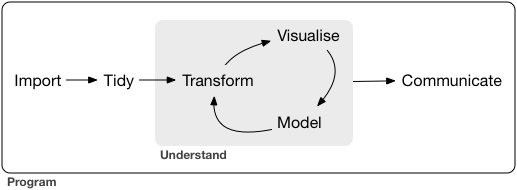
via Wickham and Grolemund (2017)
Notice that this graphic already includes a cycle– this is an important part of the process! It is unlikely (impossible) that you could work linearly through a data science project.
It is tempting to focus on the modeling aspect of the cycle, and miss the other elements. But, recall
“90% of data science is wrangling data, the other 10% is complaining about wrangling data.”@evelgab at #rstatsnyc
— David Robinson (@drob) April 20, 2018
Statistics is the practice of using data from a sample to make inferences about some broader population of interest. Data is a key word here. In the pre-bootcamp prep, you explored the first simple steps of a statistical analysis: familiarizing yourself with the structure of your data and conducting some simple univariate analyses.
We are doing all our work in the programming language R, and I am going to show you one way to do the tasks. However, one of the powers of R is that there are many ways to “say” the same thing in R. In fact, part of my research is about studying the various syntaxes in R (sometimes called Domain Specific Languages). I characterize the three main syntaxes as:
- base
R. If you have usedRbefore, it is highly likely you have seen this syntax before. I don’t use it much (anymore). This syntax is characterized by dollar signs$and square brackets[ , ]. - formula syntax. We will be using this syntax for modeling, but you can also do many other tasks in it, using
mosaicfor statistics, and thenlatticeofggformulagraphics - tidyverse syntax. This is most of what I use for data wrangling and data visualization. Main packages include
ggplot2anddplyr. You can use the convenience packagetidyverseto install and load many of the packages.
If you want to see a comparison between these three syntaxes, see my cheatsheet in the “contributed” section of the RStudio Cheatsheets page.
2.1 Pre-bootcamp review
What did you learn about
hiphop_cand_lyrics?Did exploring the
hiphop_cand_lyricsdataset raise any questions for you?What was the variability like in the
salaryvariable in theSalariesdataset?What do you think might explain the variability in
salary?
We are going to try to use plots and models to explain this variability.
2.1.1 Variable types, redux
It may be useful to think about variables as
- response variable: this is the one we’re the most interested in, which we think might “respond.”
- explanatory variable(s): these are the ones we think might “explain” the variation in the response.
Before building any models, the first crucial step in understanding relationships is to build informative visualizations.
2.1.2 Visualizing variability (in breakout rooms)
Run through the following exercises which introduce different approaches to visualizing relationships. In doing so, for each plot:
- examine what the plot tells us about relationship trends & strength (degree of variability from the trend) as well as outliers or deviations from the trend.
- think: what’s the take-home message?
We’ll do the first exercise together.
You (hopefully!) need to re-load the Salaries dataset. (If you don’t, that probably means you saved your workspace the last time you closed RStudio, talk to me or a TA about how to clear your workspace.)
- Sketches How might we visualize the relationships among the following pairs of variables? Checking out the structure on just a few people might help:
## rank discipline yrs.since.phd yrs.service sex salary
## 1 Prof B 19 18 Male 139750
## 2 Prof B 20 16 Male 173200
## 3 AsstProf B 4 3 Male 79750
## 4 Prof B 45 39 Male 115000
## 5 Prof B 40 41 Male 141500
## 6 AssocProf B 6 6 Male 97000
## 7 Prof B 30 23 Male 175000
## 8 Prof B 45 45 Male 147765
## 9 Prof B 21 20 Male 119250
## 10 Prof B 18 18 Female 129000salaryvs.yrs.since.phdsalaryvs.yrs.servicesalaryvs.disciplinesalaryvs.yrs.since.phdanddiscipline(in one plot)salaryvs.yrs.since.phdandsex(in one plot)
- Scatterplots of 2 quantitative variables
By default, the response variable (\(Y\)) goes on the y-axis and the predictor (\(X\)) goes on the x-axis.
Again, you (hopefully!) need to re-load ggplot2 in order to run this code.
ggplot(Salaries, aes(x = yrs.since.phd, y = salary))
ggplot(Salaries, aes(x = yrs.since.phd, y = salary)) +
geom_point()
ggplot(Salaries, aes(x = yrs.since.phd, y = salary)) +
geom_text(aes(label = discipline))
# practice: make a scatterplot of salary vs. yrs.service- Side-by-side plots of 1 quantitative variable vs. 1 categorical
ggplot(Salaries, aes(x = salary, fill = discipline)) +
geom_density()
ggplot(Salaries, aes(x = salary, fill = discipline)) +
geom_density(alpha = 0.5)
ggplot(Salaries, aes(x = salary)) +
geom_density() +
facet_wrap(~discipline)
# practice: make side-by-side boxplots of salary by rank- Scatterplots of 2 quantitative variables plus a categorical
If yrs.since.phd and discpline both explain some variability in salary, why not look at all the variables at once?
- Plots of 3 quantitative variables
Think back to our sketches. How might we include information about yrs.service in our plots?
2.2 Modeling: choose, fit, assess, use
As we look at these pictures, we begin to build mental models in our head. Statistical models are much like mental models (they help us generalize and make predictions) but of course, more rigorous. No matter which model we are using, we will use the CFAU framework,
- Choose
- Fit
- Assess
- Use
We’re going to begin with linear models, which are one of the simplest ways to model.
2.3 Linear models
A linear model is a supervised learning method, in that we will use ground truth to help us fit the model, as well as assess how good our model is.
With regression, your input is
\[ x = (x_1, x_2, \dots, x_k) \] and the output is a quantitative \(y\). We can “model” \(y\) by \(x\) by finding
\[ y = f(x) + \epsilon \]
where \(f(x)\) is some function of \(x\), and \(\epsilon\) are errors/residuals. For simple linear regression, \(f(x)\) will be the equation of a line.
Specifically, we use the notation
\[ Y = \beta_0 + \beta_1\cdot X + \epsilon, \, \epsilon \sim N(0, \sigma_\epsilon) \] although we are primarily concerned with the fitted model,
\[ \hat{Y} = \hat{\beta_0} + \hat{\beta_1}\cdot X \] Notice that there is no \(\epsilon\) in the fitted model. If we want, we can calculate
\[ \epsilon_i = y_i - \hat{y}_i \] for each data point, to get an idea of how “off” the model is.
The coefficients \(\hat{\beta_0}\) and \(\hat{\beta_1}\) are useful for interpreting the model.
\(\hat{\beta_0}\) is the intercept coefficient, the average \(Y\) value when \(X=0\)
\(\hat{\beta_1}\) is the slope, the amount that we predict \(Y\) to change for a 1-unit change in \(X\)
We can use our model to predict \(y\) for new values of \(y\), explain variability in \(y\), and describe relationships between \(y\) and \(x\).
2.4 Linear models in R
The syntax for linear models is different than the tidyverse syntax, and instead is more similar to the syntax for lattice graphics.
The general framework is
goal ( y ~ x , data = mydata )
We’ll use it for modeling.
Given how the data looked in the scatterplot we saw above, it seems reasonable to choose a simple linear regression model. We can then fit it using R.
We’re using the assignment operator to store the results of our function into a named object.
I’m using the assignment operator <-, but you can also use =. As with many things, I’ll try to be consistent, but I often switch between the two.
The reason to use the assignment operator here is because we might want to do things with our model output later. If you want to skip the assignment operator, try just running lm(salary ~ yrs.since.phd, data = Salaries) in your console to see what happens.
Now, we want to move on to assessing and using our model. Typically, this means we want to look at the model output (the fitted coefficients, etc). If we run summary() on our model object we can look at the output.
The p-values are quite significant, which might lead us to assess that the model is pretty effective.
We could visualize the model using ggplot2, by adding an additional geom_,
ggplot(Salaries, aes(x = yrs.since.phd, y = salary)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE)geom_smooth can use other methods, but we want a linear model. And we’ll talk about standard errors eventually, but for now we’ll turn them off.
We can also use the model for description. To write this model out in our mathematical notation,
\[ \widehat{\texttt{salary}} = 91718.7 + 985.3\cdot \texttt{yrs.since.phd} \]
What would this model predict for the salary of a professor who had just finished their PhD?
What does the model predict for a professor who has had their PhD for 51 years?
What was the observed salary value for the person with 51 years of experience?
What is the residual?
To assess further, we can compare it to a “null” model, where we don’t use a predictor (Instead, we just use the mean as the model for every observation).
We can run two models and visualize them to compare! The first is the average, and the second is the least squares regression line. We can think of the latter as a the null model where \(\beta_1 = 0\) and \(\hat{y} = \bar{y}\). Which model do you think is better?
modMean <- lm(salary ~ 1, data = Salaries)
summary(modMean)
p1 <- ggplot(Salaries, aes(x = yrs.since.phd, y = salary)) + geom_point()
p1 + geom_abline(slope = 0, intercept = 113706)
p1 + geom_smooth(method = lm, se = FALSE)2.4.1 Linear model with one categorical predictor
We thought that rank probably explained some of the variability in salary as well. We could make another simple linear regression model using just rank as a predictor,
What is the estimated model formula?
What?! It seems like something is missing. This is because R splits categorical predictors up into a reference group (the first alphabetically) and indicators for the other groups. Here, Assistant Professors are the reference group and and
\[ \text{rankAssocProf} = \left\{ \begin{array}{ll} 1 \text{ if AssocProf} \\ 0 \text{ otherwise} \end{array} \right. \text{ and } \text{rankProf} = \left\{ \begin{array}{ll} 1 \text{ if Prof} \\ 0 \text{ otherwise} \end{array} \right. \]
In other words, rank is turned into 3 “dummy variables”:
\[\begin{eqnarray*} \begin{pmatrix} Prof \\ Prof\\ AsstProf\\ Prof\\ Prof\\ AssocProf \end{pmatrix} \rightarrow AsstProf = \begin{pmatrix} 0 \\ 0 \\ 1 \\ 0 \\ 0 \\ 0 \end{pmatrix}, AssocProf = \begin{pmatrix} 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 1 \end{pmatrix}, Prof = \begin{pmatrix} 1 \\ 1 \\ 0 \\ 1 \\ 1 \\ 0 \end{pmatrix} \end{eqnarray*}\]
Since these sum to 1, we only need to put 2 into our model and leave the other out as a reference level. With these ideas in mind, interpret all coefficients in your model. HINT: Plug in 0’s and 1’s to obtain 3 separate models for the different ranks
How are the model coefficients related to the salaries across rank? (That is, what’s the dual meaning of these coefficients?)
2.5 Multiple linear regression
Once we move beyond a single predict, we are no longer doing “simple” linear regression, and are instead doing “multiple” linear regression.
one quantitative response variable, more than one explanatory variable \[ Y = \beta_0 + \beta_1 \cdot X_1 + \beta_2 \cdot X_2 + \cdots + \beta_p \cdot X_p + \epsilon, \text{ where } \epsilon \sim N(0, \sigma_\epsilon) \]
Parallel slopes
More specifically, consider the case where X_1 is quantitative, but X_2 is an indicator variable. Then,
\[\begin{eqnarray*} \hat{Y} |_{ X_1, X_2 = 0} &= \hat{\beta}_0 + \hat{\beta}_1 \cdot X_1 \\ \hat{Y} |_{ X_1, X_2 = 1} &= \hat{\beta}_0 + \hat{\beta}_1 \cdot X_1 + \hat{\beta}_2 \cdot 1 \\ &= \left( \hat{\beta}_0 + \hat{\beta}_2 \right) + \hat{\beta}_1 \cdot X_1 \end{eqnarray*}\] This is called a parallel slopes model. (Why?)
Let’s consider both yrs.since.phd and rank in our model at once. Let’s build our model,
It’s more challenging to visualize this model, because ggplot2 by default won’t create this “parallel slopes” model. However, there is a specialty geom_ from the moderndive package that will help us. (I don’t think I told you to install this package, but you could get it with install.packages("moderndive") if you wanted to follow along very closely.)
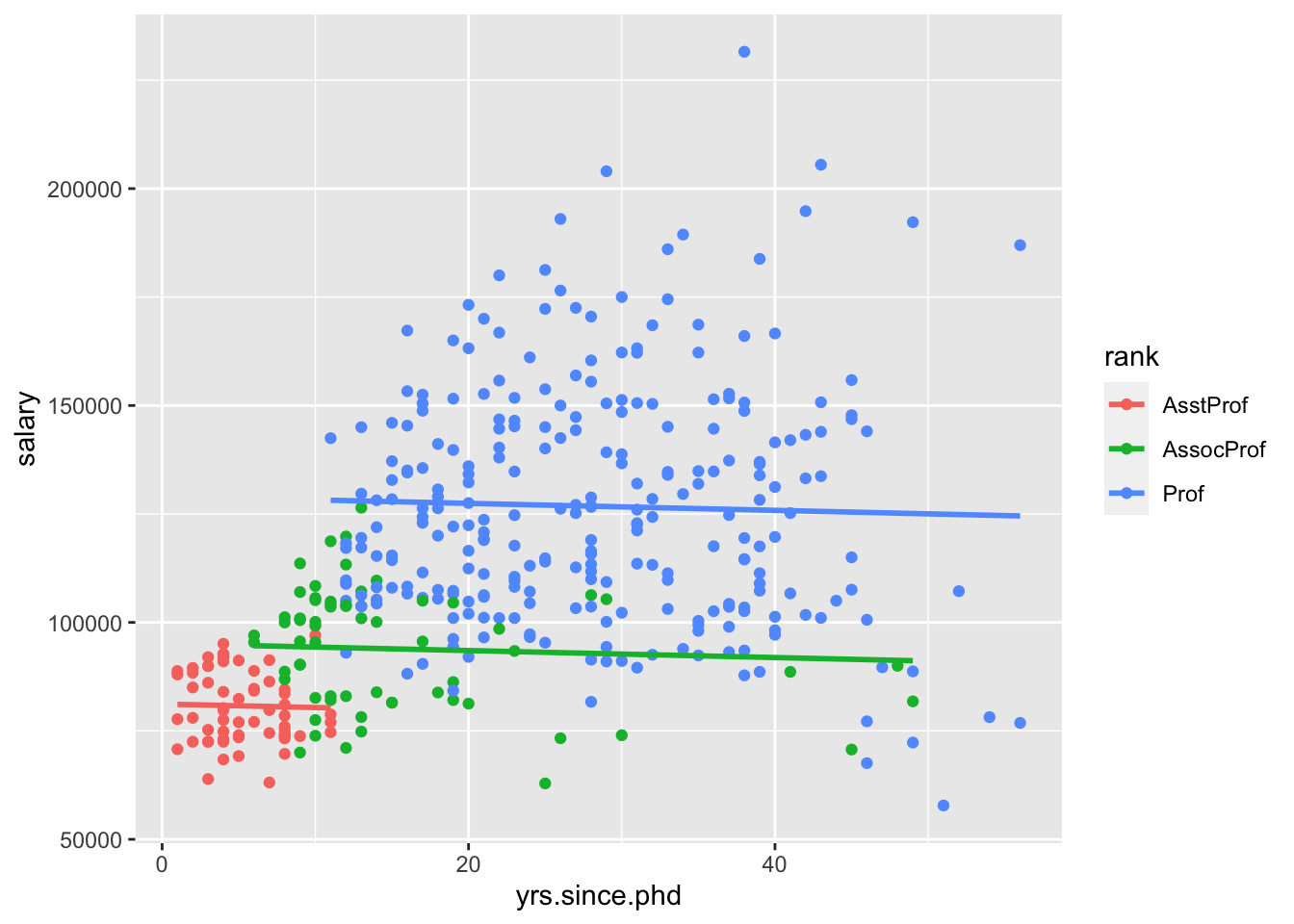
Interpret all the model coefficients by applying the techniques you learned above. These interpretations will differ from those in m1 and m2 – coefficients are defined / interpreted differently depending upon what other predictors are in the model. HINT:
First write out the estimated model formula: salary = ___ + ___ yrs.since.phd + ___ rankAssocProf + ___ rankProf
Then, notice that the presence of a categorical variable results in the separation of the model formula by group. To this end, plug in 0’s and 1’s to obtain 3 separate model formulas for the ranks:
salary = ___ + ___ yrs.since.phd.
Is there anything that strikes you as odd about this model? Do you have any concerns about the variables we are including?
Let’s try another model with a categorical variable and a quantitative variable. This time, let’s use discipline as our categorical variable.
Again, I’ll visualize that relationship for you,
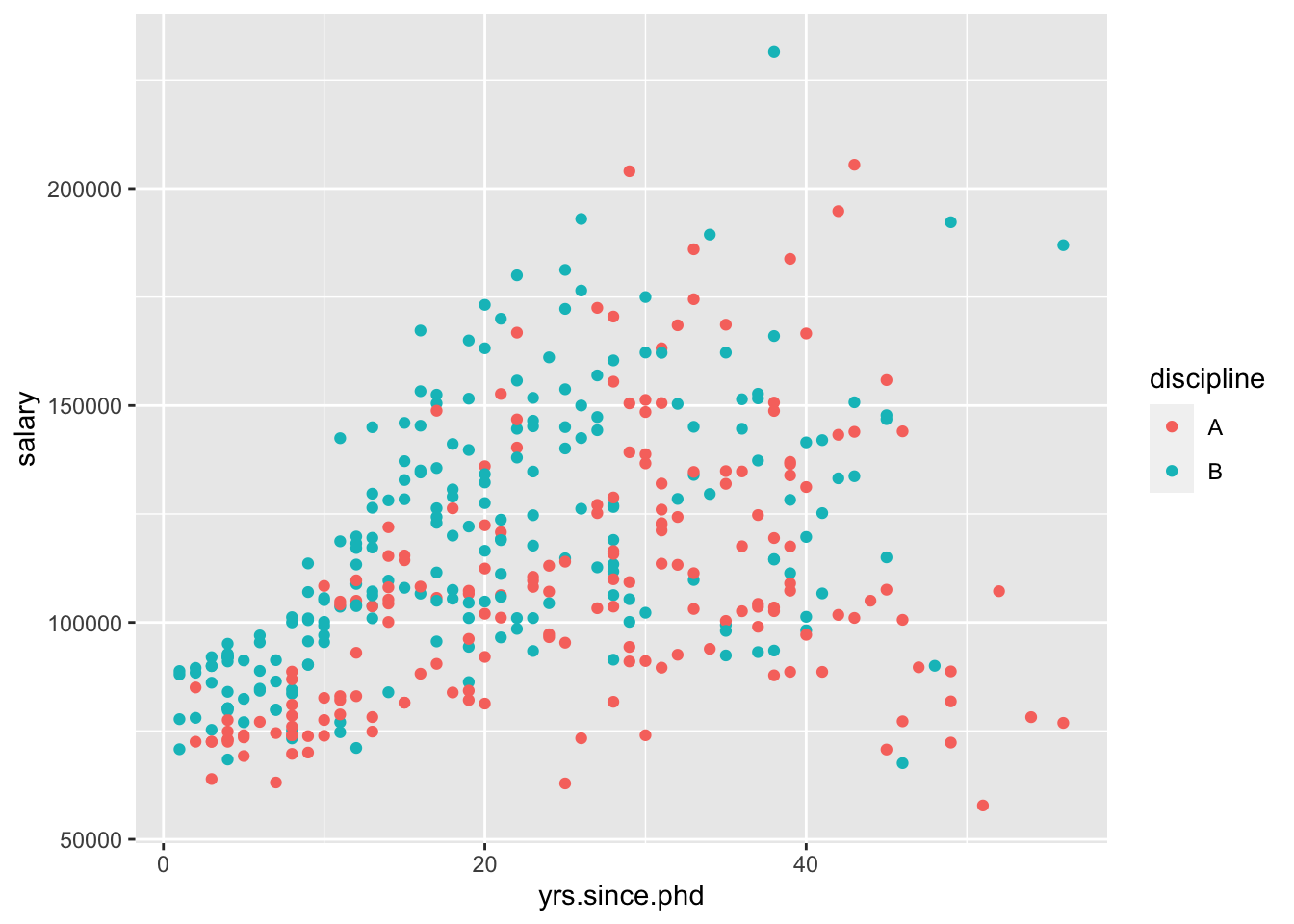
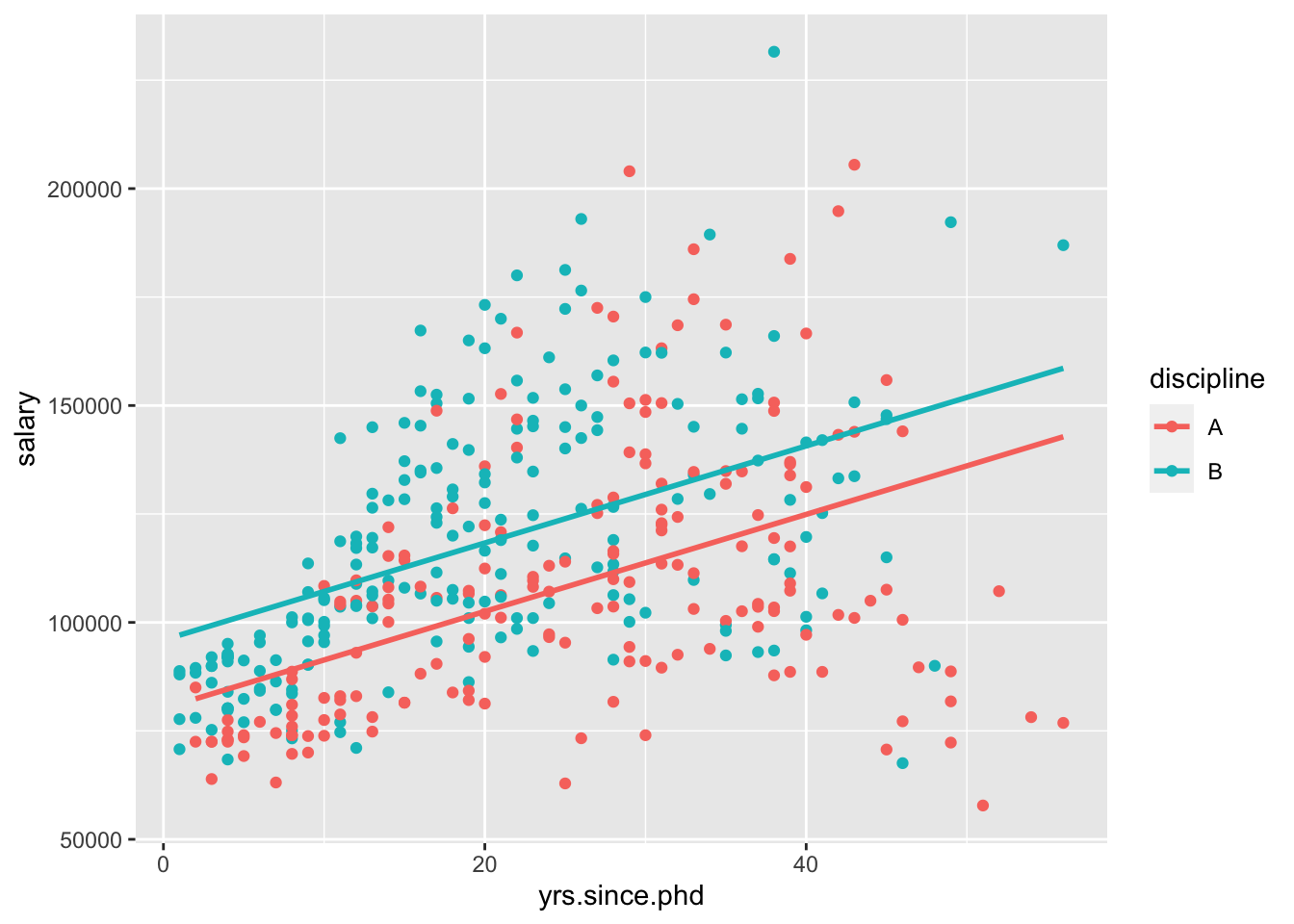
This model assumes that the relationship between yrs.since.phd and salary is the same between disciplines. However, we could include an interaction between the two variables,
Now, we can visualize this using standard ggplot2 geom_s,
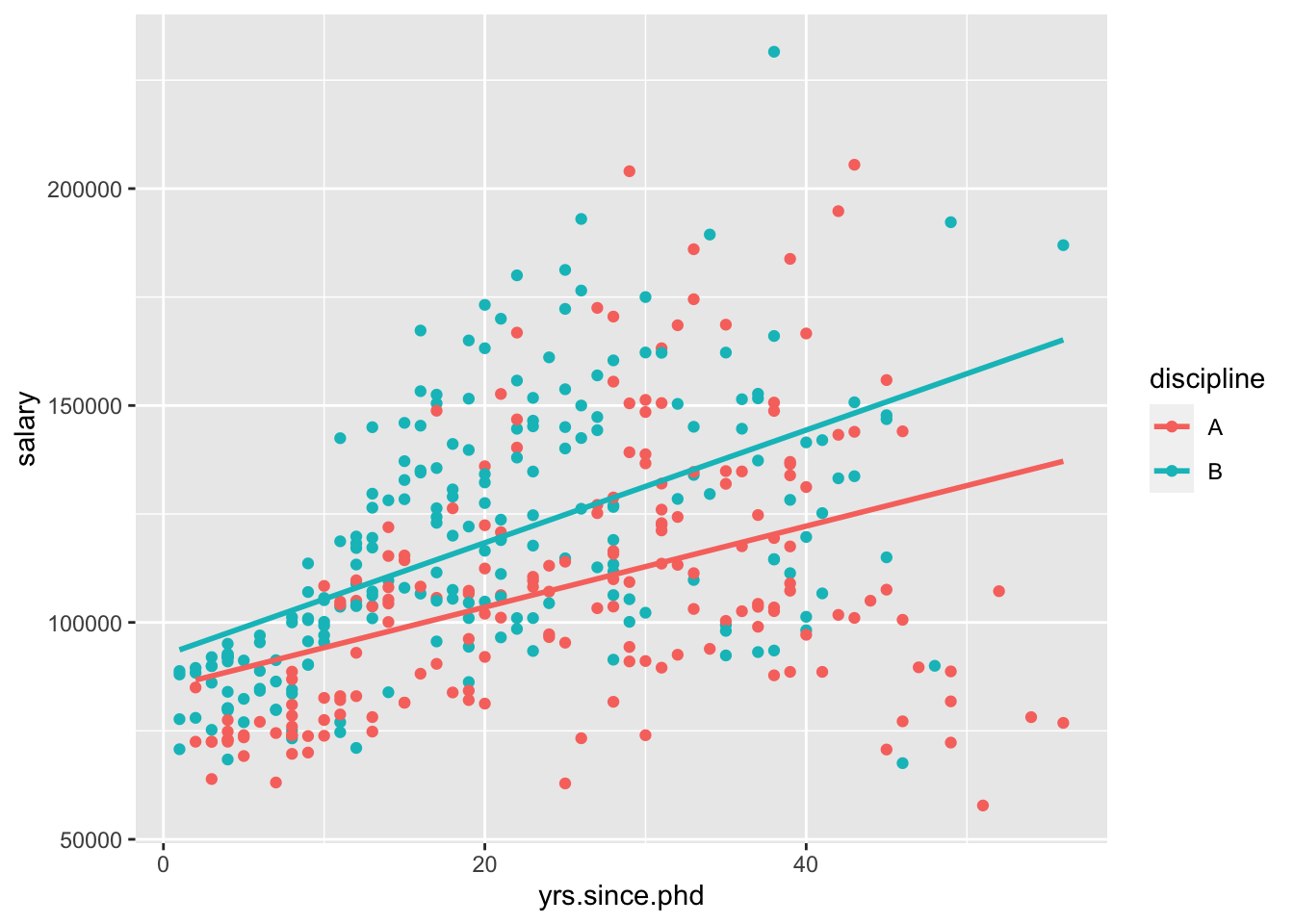
Which of those two models do you prefer?
2.5.1 Models with 2 quantitative predictors
Let’s include both yrs.since.phd and yrs.service in one model.
If we were going to visualize this model, what would it look like?
Interpret the yrs.service coefficient.
2.5.2 Models with 2 categorical predictors
We could fit a model with rank and sex as our two predictors,
2.6 Homework
Before we meet next time, I’d like you to try some visualization and modeling on your own.
- Start a new RMarkdown document
- Load the following packages at the top of your Rmd:
dplyr,ggplot2,fivethirtyeight,skimr - When interpreting visualizations, models, etc, be sure to do so in a contextually meaningful way.
- This homework is a resource for you. Record all work that is useful for your current learning & future reference. Further, try your best, but don’t stay up all night trying to finish all of the exercises! We’ll discuss any questions / material you didn’t get to tomorrow.
For this assignment, you will need an additional package I forgot to tell you to install before! So, run the following code in your Console:
Do not include this code in your RMarkdown document, otherwise you will re-download the package every time you knit!
Once the package has downloaded, you can load the package and load the data
 Horst, Hill, and Gorman (2020)
Horst, Hill, and Gorman (2020)
You should read about the data in the documentation,
Let response variable \(Y\) be the length in mm of a penguin’s flipper and \(X\) be their body mass in grams. Then the (population) linear regression model of \(Y\) vs \(X\)
is
\[ Y=\beta_0+\beta_1\cdot X+ \epsilon \]
Note that the \(\beta_i\) represent the population coefficients. We can’t measure all penguins, thus don’t know the “true” values of the \(\beta_i\). Rather, we can use sample data to estimate the\(\beta_i\) by \(\hat{\beta}_i\).
That is, the sample estimate of the population model trend is
\[ Y=\hat{\beta}_0+\hat{\beta}_1\cdot X \] In choosing the “best” estimates \(\hat{\beta}_i\), we’re looking for the coefficients that best describe the relationship between \(Y\) and \(X\) among the sample subjects. In the visual below, we can see that the red line does a better job at capturing this relationship than the blue line does:
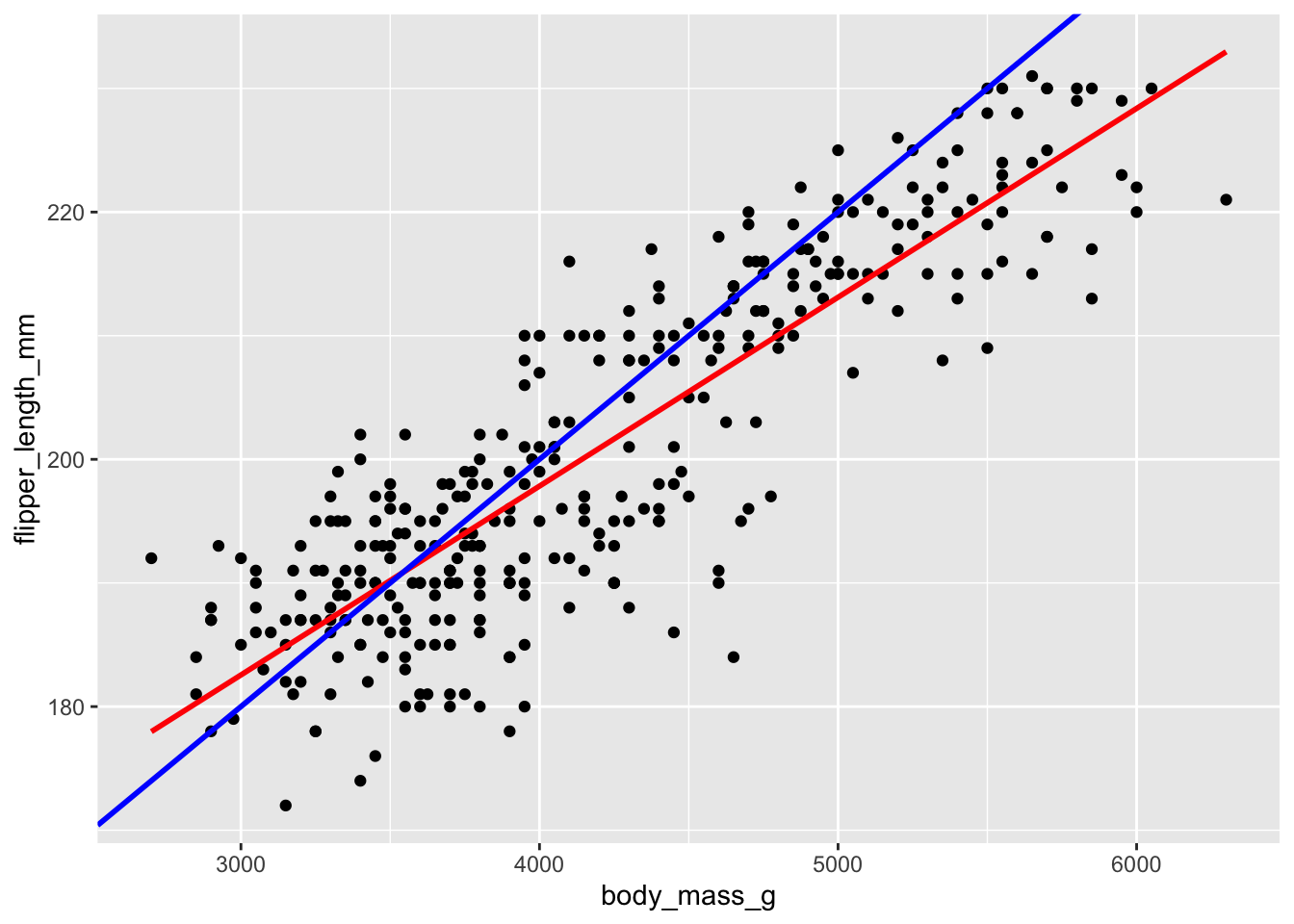
Mainly, on average, the individual points fall closer to the red line than the blue line. The distance between an individual observation and its model value (prediction) is called a residual.
\[ \epsilon_i = y_i - \hat{y}_i \] Let’s use our sample data to estimate the population model.
- Fit a simple linear regression, and look at the summary:
What is the equation of the fitted model?
Interpret the slope and the intercept.
Make predictions for the flipper length of the following two penguins:
## # A tibble: 2 x 4
## species island flipper_length_mm body_mass_g
## <fct> <fct> <int> <int>
## 1 Adelie Torgersen 181 3750
## 2 Gentoo Biscoe 210 4200What are the residuals for these two penguins?
penguin_modis anlm“object.” Not only does it contain info about the model coefficients, it contains the numerical values of the residuals (residuals) and model predictions (fitted.values) for each penguin in the data set:
You can print out all the residuals in the data frame by doing something like,
See if you can confirm that the mean residual equals 0. This property always holds for regression models!
Calculate the standard deviation of the residuals. Where does this information appear in
summary(penguinmod)(within rounding error)? SIDENOTE: The Residual standard error is calculated slightly differently than the standard deviation of residuals. Let \(\epsilon_i\) denote a residual for case \(i\), \(n\) as sample size, and \(k\) the number of coefficients in our model (here we have 2), then the standard deviation of residuals are
\[ \frac{\sum_{i=1}^n \epsilon_i^2}{n-1} \] whereas the residual standard error is
\[
\frac{\sum_{i=1}^n \epsilon_i^2}{n-k}
\]
Now that you have thought a lot about a simple linear regression model, explore some more variables. Try making plots to see if you can find other variables that help explain some variability in flipper_length_mm.
Then, try out a variety of models. Try using more than one variable, making parallel slopes, including interaction effects, etc. You can name your models as you go, but I am most interested in your “final” favorite model.
- Write down your favorite model,
Why is this your preferred model? What is good about it?
How would you visualize your model object?
References
Horst, Allison Marie, Alison Presmanes Hill, and Kristen B Gorman. 2020. Palmerpenguins: Palmer Archipelago (Antarctica) Penguin Data. https://doi.org/10.5281/zenodo.3960218.
Wickham, Hadley, and Garrett Grolemund. 2017. R for Data Science. O’Reilly. https://r4ds.had.co.nz.