Chapter 9 Advanced Regression and Nonparametric Approaches
9.1 Ridge Regression
9.1.1 Regression on Housing Dataset - Some Exp. Vars.
M_OLS <- lm(data=Train_Data, SalePrice ~ .)
head(coef(M_OLS),10) %>% round(3)## (Intercept) `Overall Qual` `Year Built` `Mas Vnr Area` `Central Air`Y
## -14136063.894 6975.925 494.582 33.382 -3745.363
## `Gr Liv Area` `Lot Frontage` `1st Flr SF` `Bedroom AbvGr` `TotRms AbvGrd`
## 37.229 -14.959 13.369 -2353.038 914.5599.1.2 Complexity in Model Coefficients
We’ve thought about complexity in terms of the number of terms we include in a model, as well as whether we include quadratic terms and higher order terms and interactions
We can also think about model complexity in terms of the coefficients \(b_1, \ldots, b_p\).
Larger values of \(b_1, \ldots, b_p\) are associated with more complex models. Smaller values of \(b_1, \ldots, b_p\) are associated with less complex models. When \(b_j=0\), this mean variable \(j\) is not used in the model.
9.1.3 Ridge Regression Penalty
- We’ve seen that in ordinary least-squares regression, \(b_0, b_1, \ldots, b_p\) are chosen in a way that to minimizes
\[ \displaystyle\sum_{i=1}^n (y_i -\hat{y}_i)^2 = \displaystyle\sum_{i=1}^n (y_i -(b_0 + b_1x_{i1} + b_2{x_i2} + \ldots +b_px_{ip}))^2 \]
- When \(p\) is large, and we want to be careful of overfitting, a common approach is to add a “penalty term” to this function, to incentivize choosing low values of \(b_1, \ldots, b_p\).
Specifically, we minimize:
\[ \begin{aligned} & \displaystyle\sum_{i=1}^n (y_i -\hat{y}_i)^2 + \lambda\displaystyle\sum_{j=1}^pb_j^2\\ = & \displaystyle\sum_{i=1}^n (y_i -(b_0 + b_1x_{i1} + b_2x_{i2} + \ldots + b_px_{ip}))^2 + \lambda\displaystyle\sum_{j=1}^pb_j^2 \end{aligned} \]
where \(\lambda\) is a pre-determined positive constant.
Larger values of \(b_j\) typically help the model better fit the training data, thereby making the first term smaller, but also make the second term larger.
The idea is the find optimal values of \(b_0, b_1, \ldots, b_p\) that are large enough to allow the model to fit the data well, thus keeping the first term (SSR) small, while also keeping the penalty term small as well.
9.1.4 Choosing \(\lambda\)
The value of \(\lambda\) is predetermined by the user. The larger the value of \(\lambda\), the more heavily large \(b_j's\) are penalized. A value of \(\lambda=0\) corresponds to ordinary least-squares.
\[ \begin{aligned} Q=& \displaystyle\sum_{i=1}^n (y_i -\hat{y}_i)^2 + \lambda\displaystyle\sum_{j=1}^pb_j^2\\ = & \displaystyle\sum_{i=1}^n (y_i -(b_0 + b_1x_{i1} + b_2x_{i2} + \ldots + b_px_{ip}))^2 + \lambda\displaystyle\sum_{j=1}^pb_j^2 \end{aligned} \]
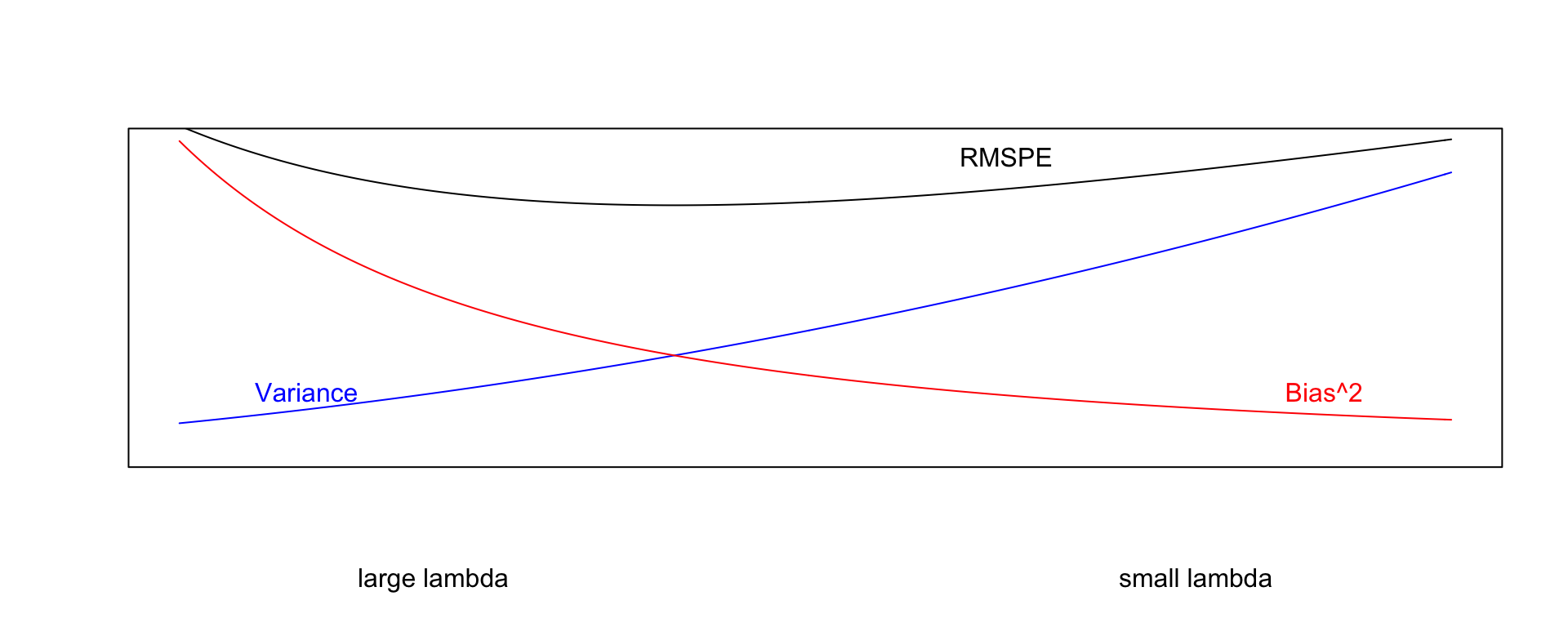
9.1.5 Optimal value of \(\lambda\)
- Small values of \(\lambda\) lead to more complex models, with larger \(|b_j|\)’s.
- As \(\lambda\) increases, \(|b_j|\)’s shrink toward 0. The model becomes less complex, thus bias increases, but variance decreases.
- We can use cross validation to determine the optimal value of \(\lambda\)
9.1.6 Standardizing
Train_sc <- Train_Data %>% mutate_if(is.numeric, scale)It is important to standardize each explanatory variable (i.e. subtract the mean and divide by the standard deviation).
This ensures each variable has mean 0 and standard deviation 1.
Without standardizing the optimal choice of \(b_j\)’s would depend on scale, with variables with larger absolute measurements having more influence.
We’ll standardize the response variable too. Though this is not strictly necessary, it doesn’t hurt. We can always transform back if necessary.
Standardization is performed using the
scalecommand in R.
9.1.7 Ridge Regression on Housing Dataset
control = trainControl("repeatedcv", number = 10, repeats=10)
l_vals = 10^seq(-3, 3, length = 100)
set.seed(11162020)
Housing_ridge <- train(SalePrice ~ .,
data = Train_sc, method = "glmnet", trControl=control ,
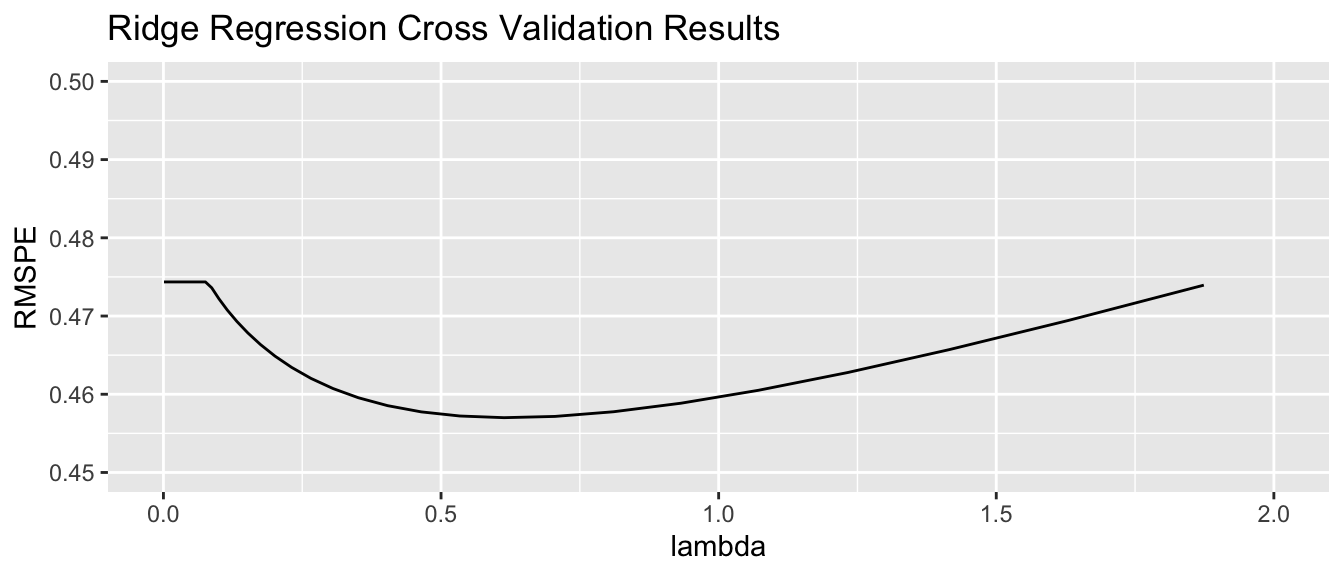
tuneGrid=expand.grid(alpha=0, lambda=l_vals))Housing_ridge$bestTune$lambda## [1] 0.61359079.1.8 Ridge Regression on Housing Dataset
control = trainControl("repeatedcv", number = 10, repeats=10)
l_vals = 10^seq(-3, 3, length = 100)
set.seed(11162020)
Housing_ridge <- train(SalePrice ~ .,
data = Train_sc, method = "glmnet", trControl=control ,
tuneGrid=expand.grid(alpha=0, lambda=l_vals))Housing_ridge$bestTune$lambda## [1] 0.61359079.1.9 Ridge Regression MSPE by \(\lambda\)
9.1.10 Ridge Regression Coefficients for Optimal Model
## OLS Coeff Ridge Coeff
## `Overall Qual` 0.121728754 0.10435284
## `Year Built` 0.187102422 0.03451303
## `Mas Vnr Area` 0.080212607 0.06202880
## `Central Air`Y -0.046191694 0.04289126
## `Gr Liv Area` 0.237623291 0.00000000
## `Lot Frontage` -0.004290945 0.07967743
## `1st Flr SF` 0.069910650 0.01020597
## `Bedroom AbvGr` -0.022457937 0.07194208
## `TotRms AbvGrd` 0.017574153 0.013422249.1.11 OLS and Ridge Predictions
library(glmnet)
MAT <- model.matrix(SalePrice~., data=Train_sc)
ridge_mod <- glmnet(x=MAT, y=Train_sc$SalePrice, alpha = 0, lambda=Housing_ridge$bestTune$lambda )| y | OLS Pred | Ridge Pred | OLS Resid | Ridge Resid | |
|---|---|---|---|---|---|
| 859 | -0.6210832 | -0.4637429 | -0.4651589 | -0.1573403 | -0.1559243 |
| 1850 | 0.6800520 | 1.1897467 | 1.0528536 | -0.5096947 | -0.3728016 |
| 1301 | -0.4545873 | -0.4527781 | -0.4958630 | -0.0018092 | 0.0412758 |
| 981 | -0.6408161 | -0.6626212 | -0.7711186 | 0.0218051 | 0.1303025 |
| 2694 | -0.7937457 | -0.8679455 | -0.7543093 | 0.0741997 | -0.0394365 |
| 2209 | -0.7906625 | -0.6955254 | -0.6449779 | -0.0951370 | -0.1456845 |
9.1.12 Choosing \(b_j\) in OLS
In OLS, we choose \(b_0, b_1, \ldots, b_p\) are chosen in a way that minimizes
\[ \displaystyle\sum_{i=1}^n (y_i -\hat{y}_i)^2 = \displaystyle\sum_{i=1}^n (y_i -(b_0 + b_1x_{i1} + b_2x_{i2} + \ldots + b_px_{ip}))^2 \]
OLS: \(\displaystyle\sum_{i=1}^n (y_i -\hat{y}_i)^2\)
sum((y-Pred_OLS)^2)## [1] 56.94383Ridge: \(\displaystyle\sum_{i=1}^n (y_i -\hat{y}_i)^2\)
sum((y-Pred_Ridge)^2)## [1] 127.1331Not surprisingly the OLS model achieves smaller \(\displaystyle\sum_{i=1}^n (y_i -\hat{y}_i)^2\). This has to be true, since the OLS coefficients are chosen to minimize this quantity.
9.1.13 Choosing \(b_j\) in Ridge Regression
In ridge regression, \(b_0, b_1, \ldots, b_p\) are chosen in a way that minimizes
\[ \begin{aligned} Q=& \displaystyle\sum_{i=1}^n (y_i -\hat{y}_i)^2 + \lambda\displaystyle\sum_{j=1}^pb_j^2\\ = & \displaystyle\sum_{i=1}^n (y_i -(b_0 + b_1x_{i1} + b_2x_{i2} + \ldots + b_px_{ip}))^2 + \lambda\displaystyle\sum_{j=1}^pb_j^2 \end{aligned} \]
OLS: \(\displaystyle\sum_{i=1}^n (y_i -\hat{y}_i)^2 + \lambda\displaystyle\sum_{j=1}^pb_j^2\)
sum((y-Pred_OLS)^2) + 0.6136*sum(coef(M_OLS_sc)[-1]^2) ## [1] 373.1205Ridge: \(\displaystyle\sum_{i=1}^n (y_i -\hat{y}_i)^2 + \lambda\displaystyle\sum_{j=1}^pb_j^2\)
sum((y-Pred_Ridge)^2) + 0.6136*sum((Ridge_coef)[-1]^2)## [1] 130.3375We see that the ridge coefficients achieve a lower value of Q than the OLS ones.
9.1.14 Lasso Regression
Lasso regression is very similar to ridge regression. Coefficients \(b_0, b_1, \ldots, b_p\) are chosen in a way that to minimizes
\[ \begin{aligned} & \displaystyle\sum_{i=1}^n (y_i -\hat{y}_i)^2 + \lambda\displaystyle\sum_{j=1}^p|b_j|\\ = & \displaystyle\sum_{i=1}^n (y_i -(b_0 + b_1x_{i1} + b_2x_{i2} + \ldots + b_px_{ip}))^2 + \lambda\displaystyle\sum_{j=1}^p|b_j| \end{aligned} \]
9.2 Decision Trees
9.2.1 Basics of Decision Trees
A decision tree is a flexible alternative to a regression model. It is said to be nonparametric because it does not involve parameters like \(\beta_0, \beta_1, \ldots \beta_p\).
A tree makes no assumption about the nature of the relationship between the response and explanatory variables, and instead allows us to learn this relationship from the data.
A tree makes prediction by repeatedly grouping together like observations in the training data.
We can make predictions for a new case, by tracing it through the tree, and averaging responses of training cases in the same terminal node.
9.2.2 Decision Tree Example
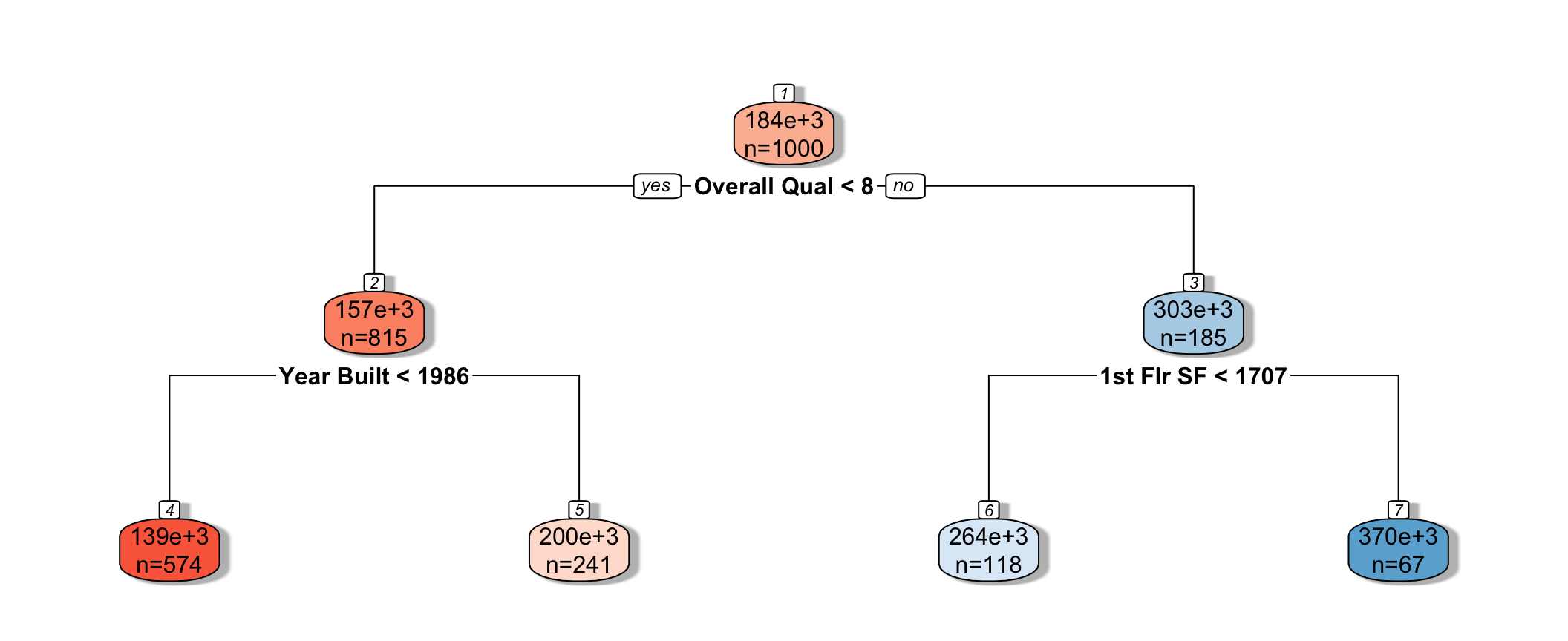
The predicted price of a House with overall quality 7, and was built in 1995 is $200,000.
The predicted price of a House overall quality 8 and 1,750 sq. ft. on the first floor is $370,000.
9.2.3 Partitioning in A Decision Tree
For a quantitative response variable, data are split into two nodes so that responses in the same node are as similar as possible, while responses in the different nodes are as different as possible.
Let L and R represent the left and right nodes from a possible split. Let \(n_L\) and \(n_R\) represent the number of observations in each node, and \(\bar{y}_L\) and \(\bar{y}_R\) represent the mean of the training data responses in each node.
For each possible split, involving an explanatory variable, we calculate:
\[ \displaystyle\sum_{i=1}^{n_L} (y_i -\bar{y}_L)^2 + \displaystyle\sum_{i=1}^{n_R} (y_i -\bar{y}_R)^2 \]
- We choose the split that minimizes this quantity.
9.2.4 Partitioning Example
## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] [,13] [,14]
## x1 8 2 8 1 8 6 2 5 1 8 4 10 9 8
## x2 5 3 1 1 4 3 8 1 10 8 6 5 0 2
## y 253 64 258 21 257 203 246 114 331 256 213 406 326 273
## [,15]
## x1 6
## x2 1
## y 155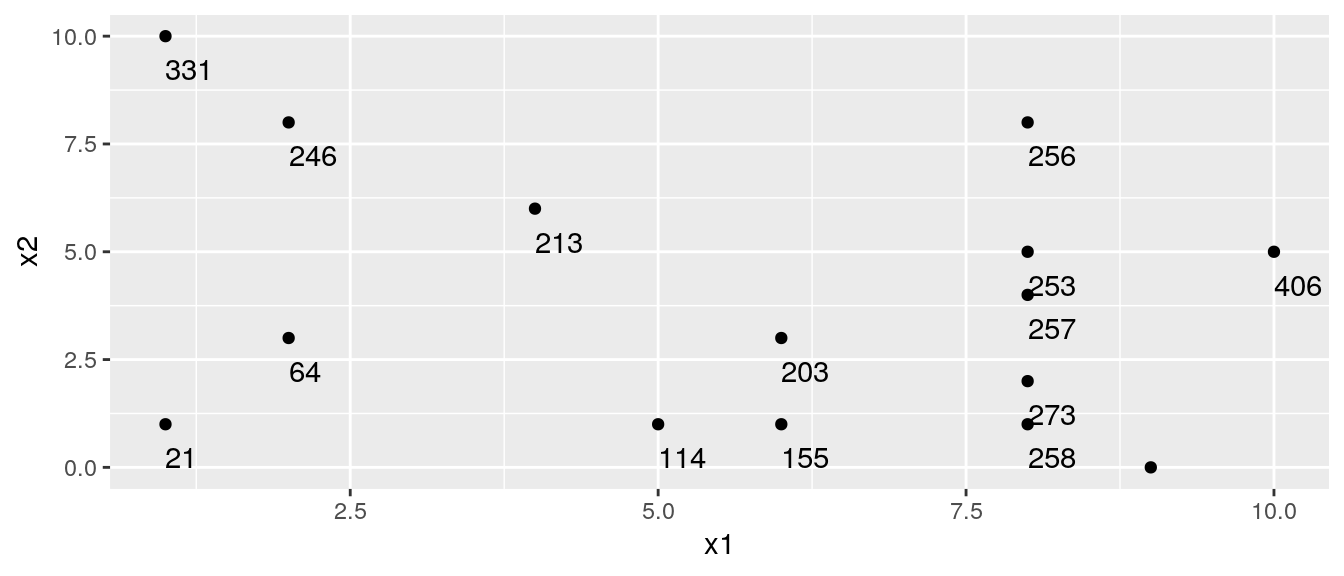
9.2.5 One Possible Split (\(x_1 < 5.5\))
We could split the data into 2 groups depending on whether \(x_1 < 5.5\).
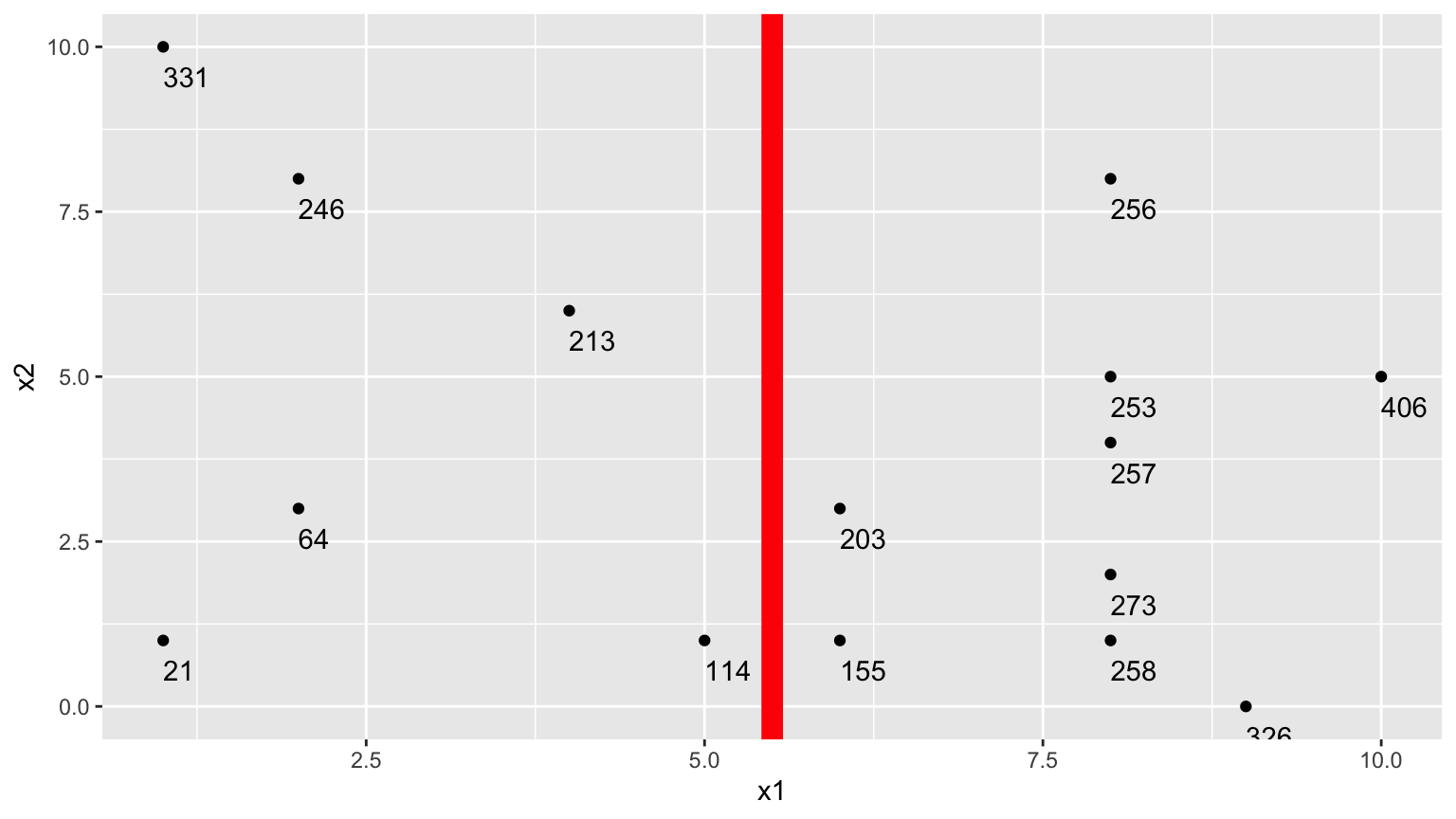
9.2.6 One Possible Split (\(x_1 < 5.5\)) (cont.)
- \(\bar{y}_L = (331+246+213+21+64+114)/6 \approx 164.84\)
- \(\bar{y}_R = (203+155+256+253+257+273+258+326+406)/9 \approx 265.22\)
\[ \begin{aligned} & \displaystyle\sum_{i=1}^{n_L} (y_i -\bar{y}_L)^2 \\ & =(331-164.83)^2+(246-164.33)^2 + \ldots+(114-164.33)^2 \\ & =69958.83 \end{aligned} \]
\[ \begin{aligned} \displaystyle\sum_{i=1}^{n_R} (y_i -\bar{y}_R)^2 \\ & =(203-265.22)^2+(155-265.22)^2 + \ldots+(406-265.22)^2 \\ & =39947.56 \end{aligned} \]
- 69958.83 + 39947.56 = 109906.4
9.2.7 Second Possible Split (\(x_1 < 6.5\))
We could split the data into 2 groups depending on whether \(x_1 < 6.5\).
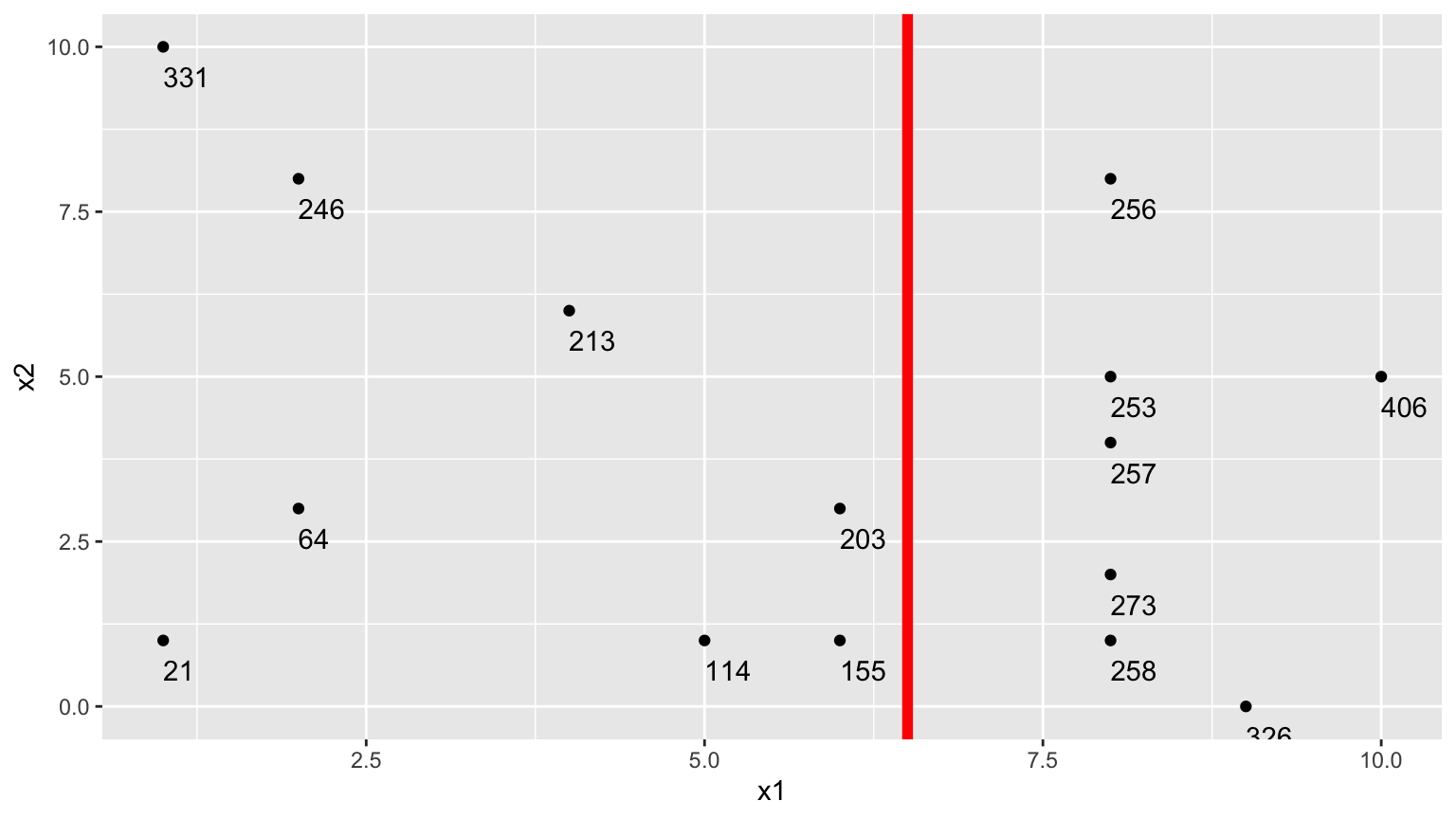
9.2.8 Second Possible Split (\(x_1 < 6.5\)) (cont.)
- \(\bar{y}_L = (331+246+213+21+64+114 + 203+155)/8 \approx 168.375\)
- \(\bar{y}_R = (256+253+257+273+258+326+406)/7 \approx 289.857\)
\[ \begin{aligned} & \displaystyle\sum_{i=1}^{n_L} (y_i -\bar{y}_L)^2 \\ & =(331-168.375)^2+(246-168.375)^2 + \ldots+(203-168.375)^2 \\ & =71411.88 \end{aligned} \]
\[ \begin{aligned} \displaystyle\sum_{i=1}^{n_R} (y_i -\bar{y}_R)^2 \\ & =(203-289.857)^2+(155-289.857)^2 + \ldots+(406-289.857)^2 \\ & =19678.86 \end{aligned} \]
- 71411.88 + 19678.86 = 91090.74
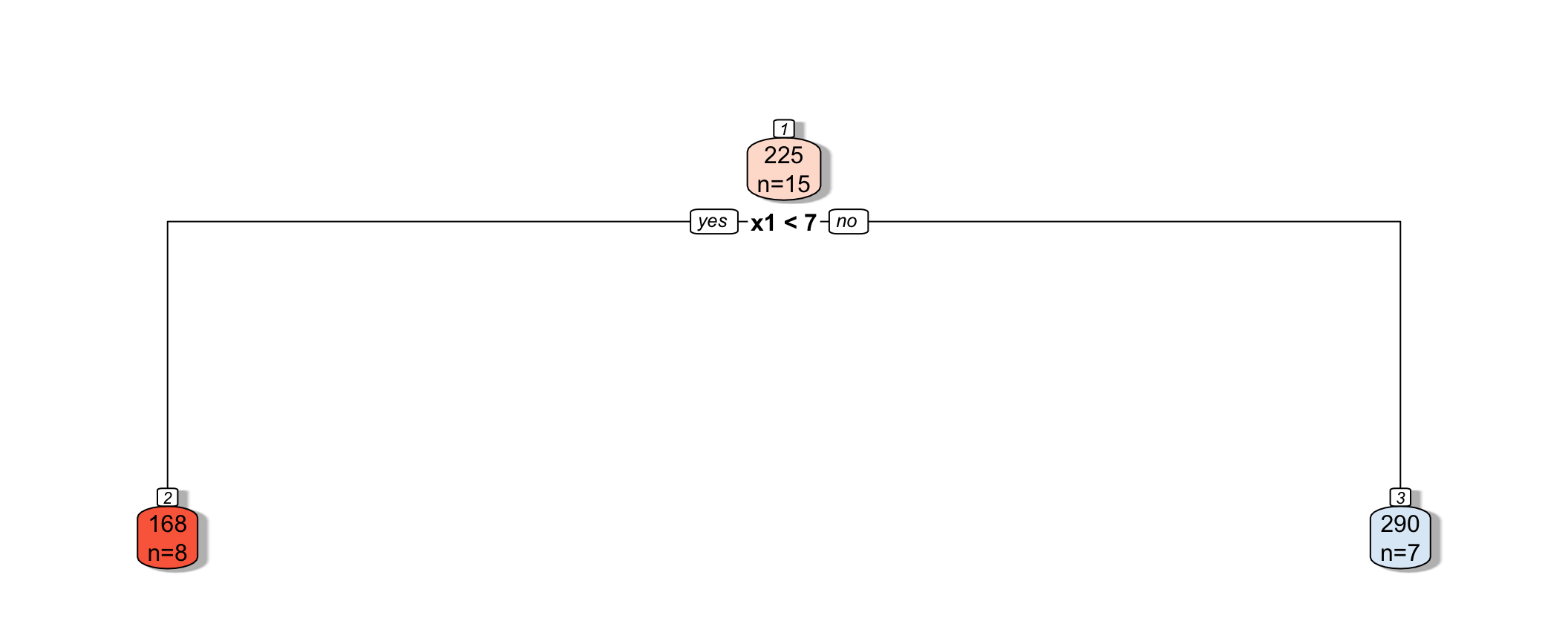
The split at \(x1 < 6.5\) is better than \(x_1<5.5\)
9.2.9 Third Possible Split (\(x_2 < 5.5\))
We could split the data into 2 groups depending on whether \(x_2 < 5.5\).
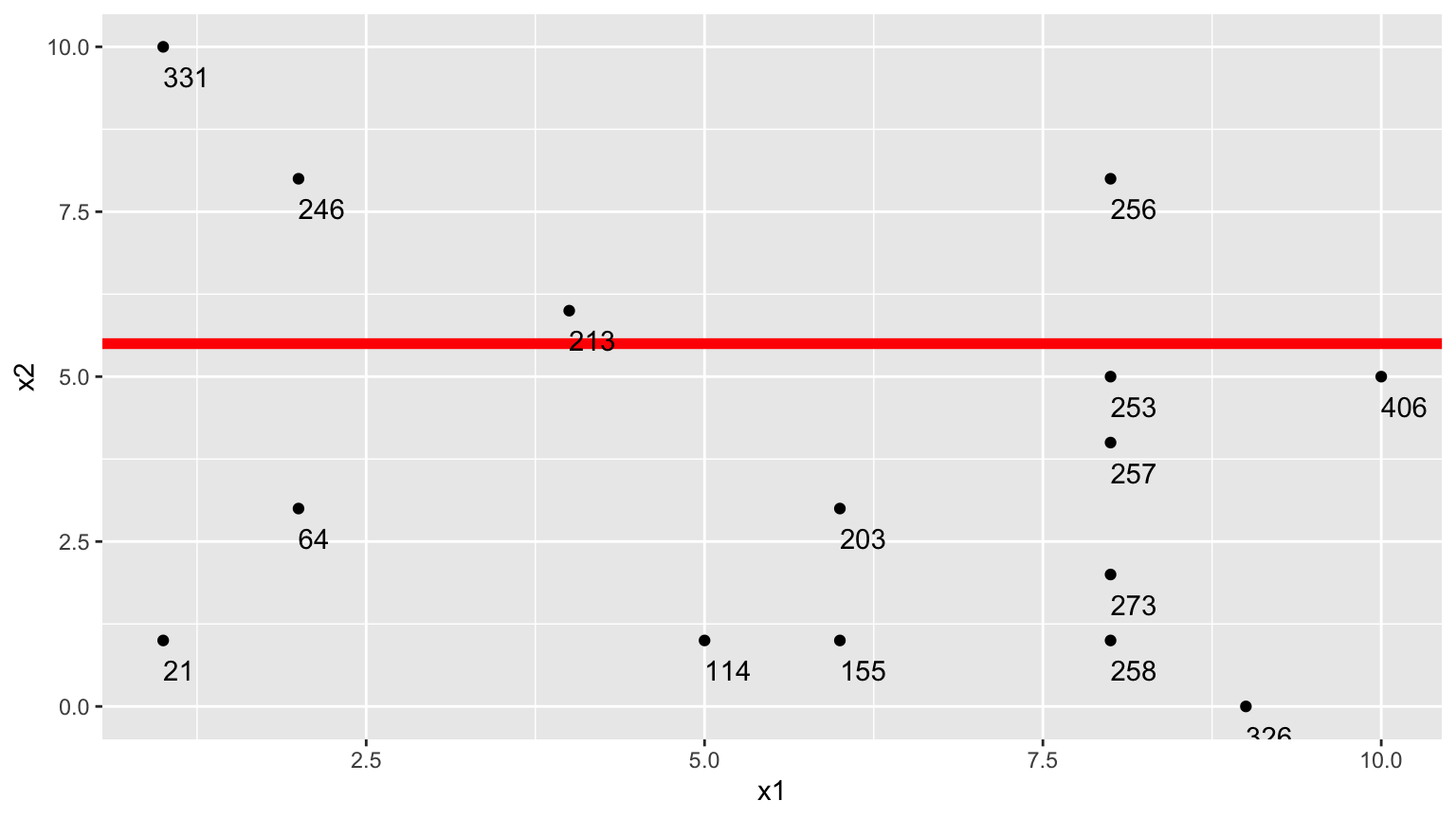
9.2.10 Third Possible Split (\(x_2 < 5.5\)) (cont.)
- \(\bar{y}_L = (331+246+213+256)/4 \approx 261.5\)
- \(\bar{y}_R = (21 + 64 + \ldots + 406)/11 \approx 211.82\)
\[ \begin{aligned} & \displaystyle\sum_{i=1}^{n_L} (y_i -\bar{y}_L)^2 \\ & =(331-261.5)^2+(246-261.5)^2 + (213-261.5)^2+(256-261.5)^2 \\ & =7453 \end{aligned} \]
\[ \begin{aligned} \displaystyle\sum_{i=1}^{n_R} (y_i -\bar{y}_R)^2 \\ & =(21-211.82)^2+(64-211.82)^2 + \ldots+(406-211.82)^2 \\ & =131493.6 \end{aligned} \]
- 7453 + 131493.6 = 138946.6
9.2.11 Comparison of Splits
Of the three split’s we’ve calculated, \(\displaystyle\sum_{i=1}^{n_L} (y_i -\bar{y}_L)^2 + \displaystyle\sum_{i=1}^{n_R} (y_i -\bar{y}_R)^2\) is minimized using \(x_1 < 6.5\).
In fact, if we calculate all possible splits over \(x_1\) and \(x_2\), \(\displaystyle\sum_{i=1}^{n_L} (y_i -\bar{y}_L)^2 + \displaystyle\sum_{i=1}^{n_R} (y_i -\bar{y}_R)^2\) is minimized by splitting on \(x_1 < 6.5\)
9.2.12 First Split
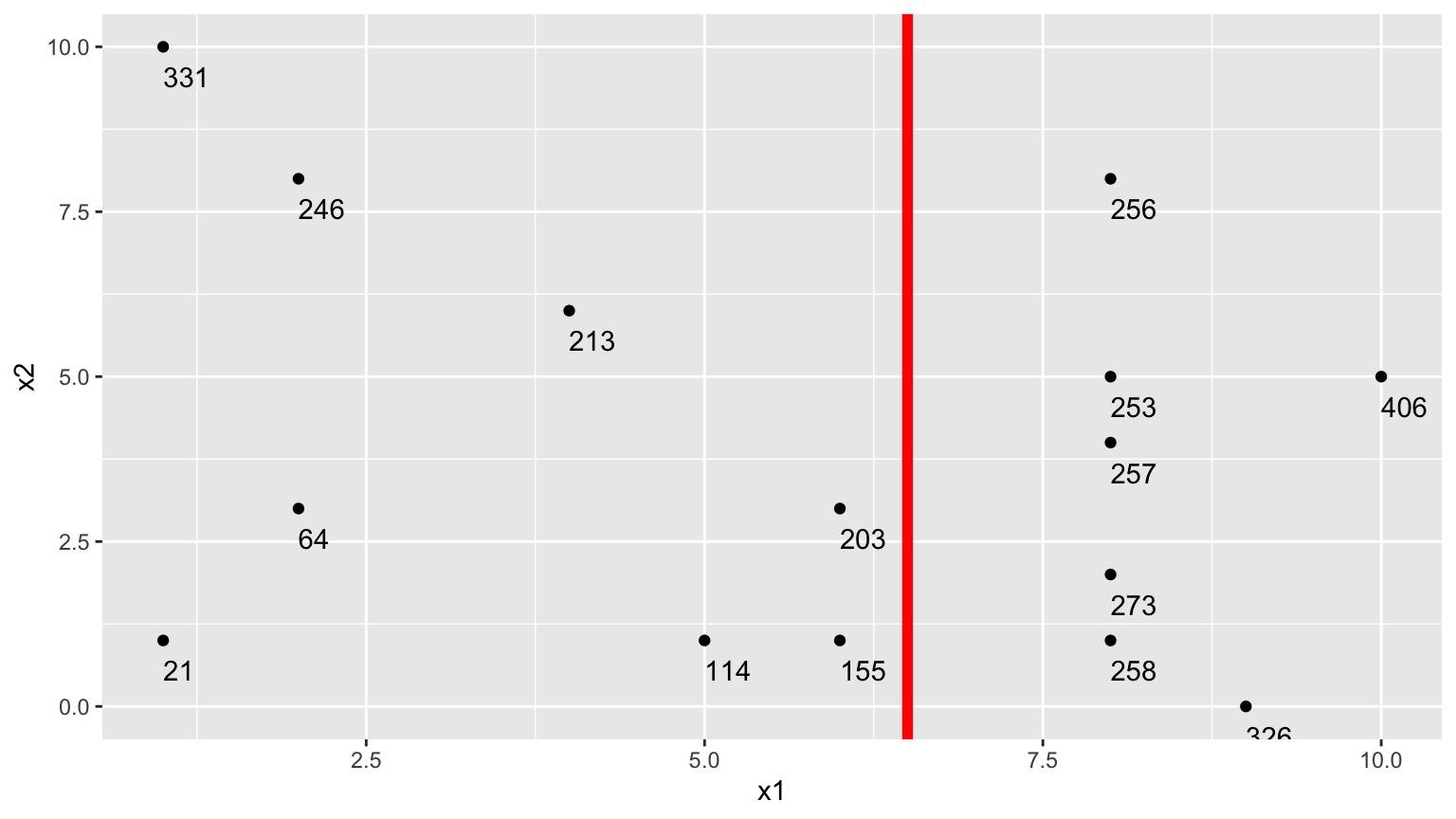
9.2.13 First Split in the Tree
9.2.14 Next Splits
- Next, we find the best splits on the resulting two nodes. It turns out that the left node is best split on \(x_2 < 4.5\), and the right node is best split on \(x_1 < 8.5\).
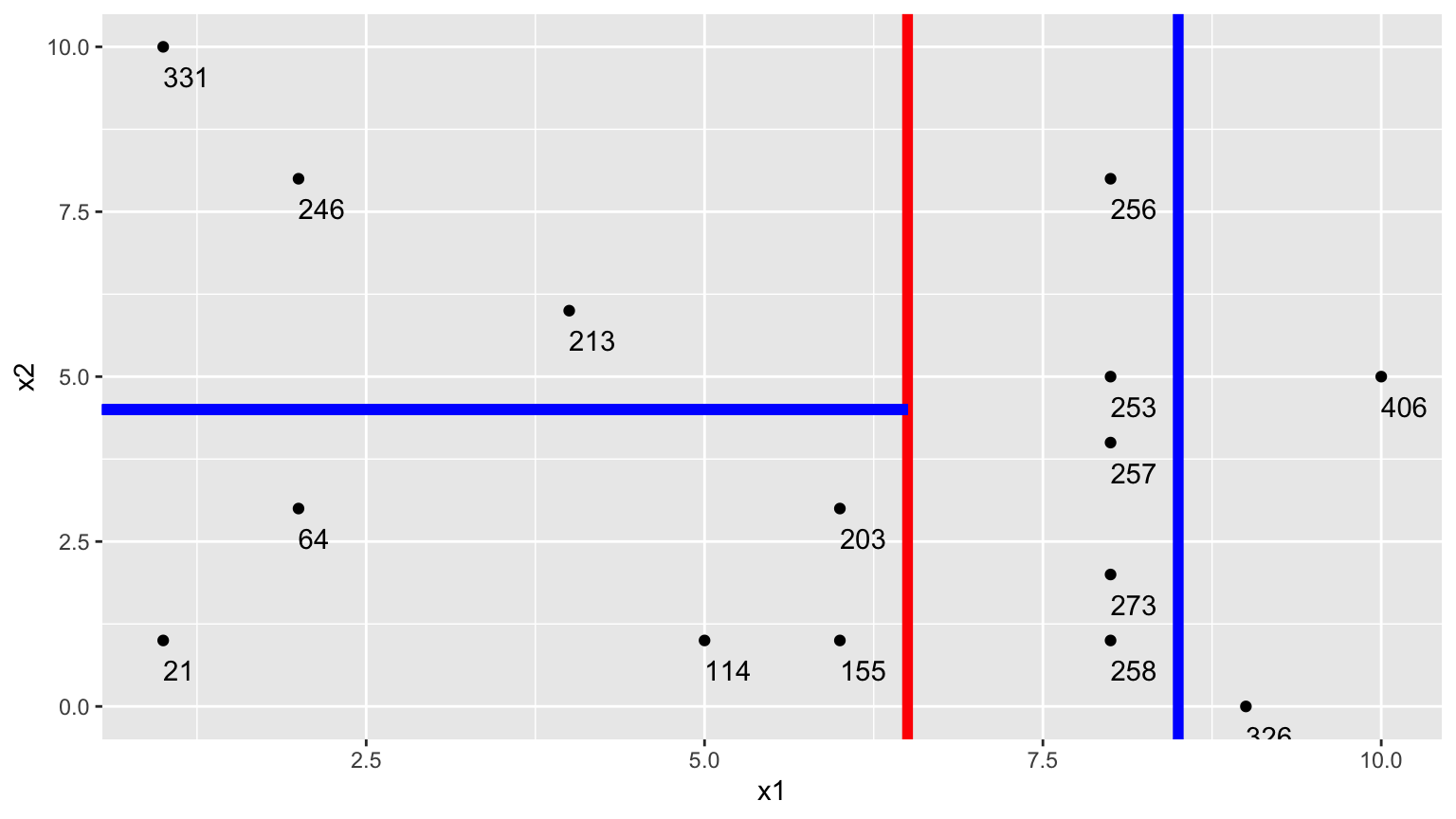
9.2.15 Next Splits in Tree
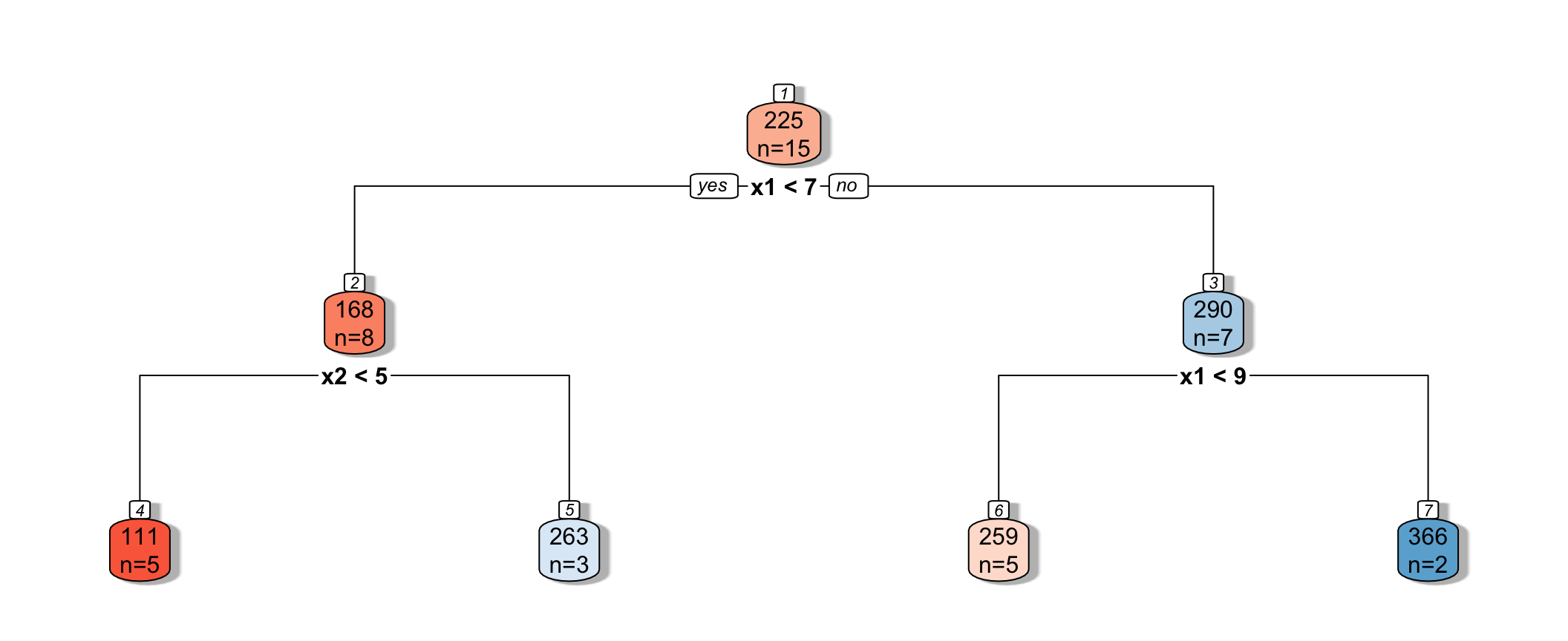
9.2.16 Recursive Partitioning
- Splitting continues until nodes reach a certain predetermined minimal size, or until change improvement in model fit drops below a predetermined value
9.2.17 Tree on Housing Data
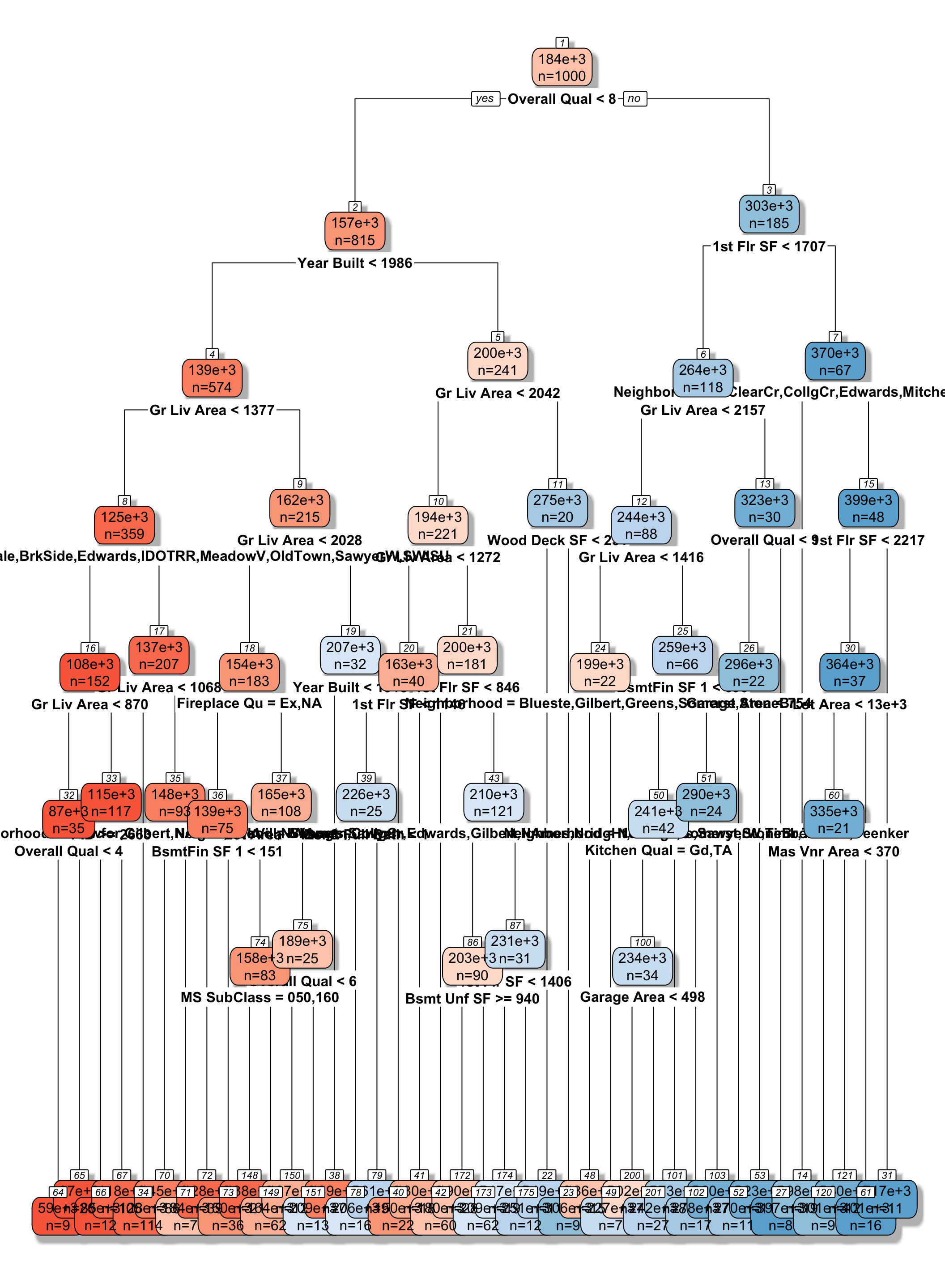
9.2.18 Model Complexity in Trees
The more we partition data into smaller nodes, the more complex the model becomes.
As we continue to partition, bias decreases, as cases are grouped with those that are more similar to themselves. On the other hand, variance increases, as there are fewer cases in each node to be averaged, putting more weight on each individual observation.
Splitting into too small of nodes can lead to drastic overfitting. In the extreme case, if we split all the way to nodes of size 1, we would get RMSE of 0 on the training data, but should certainly not expect RMSPE of 0 on the test data.
The optimal depth of the tree, or minimal size for terminal nodes can be determined using cross-validation.
the
rpartpackage uses a complexity parametercp, which determines how much a split must improve model fit in order to be made. Smaller values ofcpare associated with more complex tree models.
9.2.19 Cross-Validation on Housing Data
cp_vals = 10^seq(-8, 1, length = 100)
#cp_vals = c(0.00000001, 0.00001)
colnames(Train_sc) <- make.names(colnames(Train_sc))
#colnames(Train_Data) <- make.names(colnames(Train_Data))
set.seed(11162020)
Housing_Tree <- train(data=Train_sc, SalePrice ~ ., method="rpart", trControl=control,
tuneGrid=expand.grid(cp=cp_vals))
Housing_Tree$bestTune## cp
## 52 0.0004328761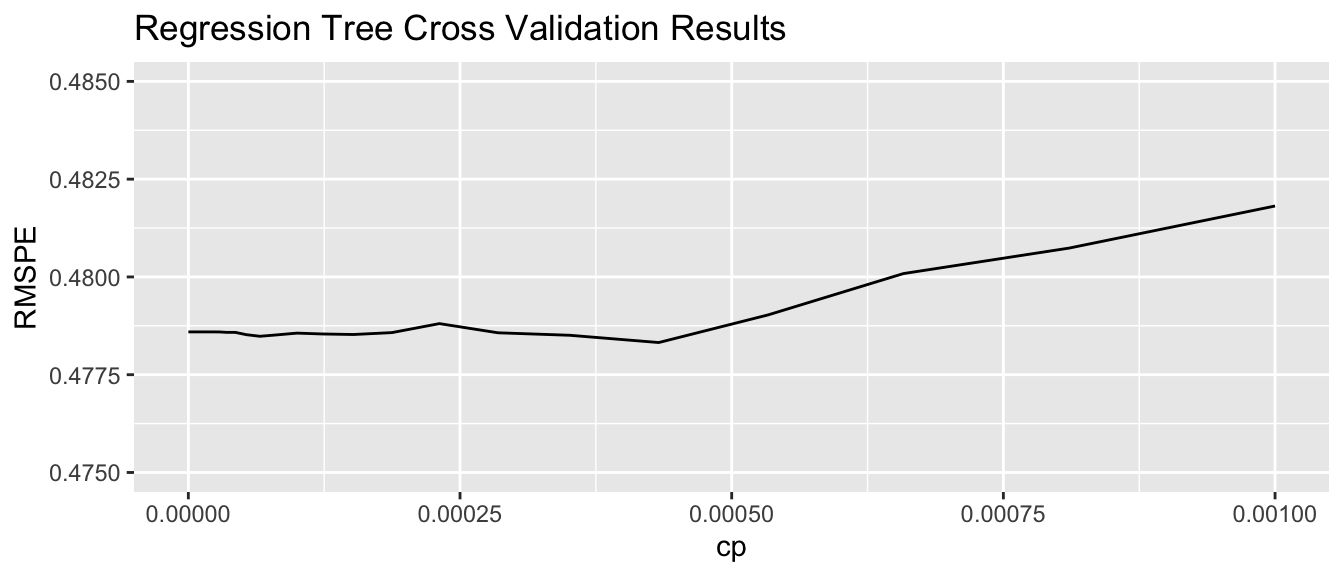
9.2.20 Comparing OLS, Lasso, Ridge, and Tree
min(Housing_OLS $results$RMSE)## [1] 0.5634392min(Housing_ridge$results$RMSE)## [1] 0.4570054min(Housing_lasso$results$RMSE)## [1] 0.4730365min(Housing_Tree$results$RMSE)## [1] 0.481814In this situation, the tree outperforms OLS, but does not do as well as lasso or ridge. The best model will vary depending on the nature of the data. We can use cross-validation to determine which model is likely to perform best in prediction.
9.2.21 Random Forest
A popular extension of a decision tree is a random forest.
A random forest consists of many (often ~10,000) trees. Predictions are made by averaging predictions from individual trees.
In order to ensure the trees are different from each other:
- each tree is grown from a different bootstrap sample of the training data.
- when deciding on a split, only a random subset of explanatory variables are considered.
- each tree is grown from a different bootstrap sample of the training data.
Growing deep trees ensures low bias. In a random forest, averaging across many deep trees decreases variance, while maintaining low bias.
9.3 Regression Splines
9.3.1 Regression Splines
We’ve seen that we can use polynomial regression to capture nonlinear trends in data.
A regression spline is a piecewise function of polynomials.
Here we’ll keep thing simple by focusing on a spline with a single explanatory variable. Splines can also be used for multivariate data.
9.3.2 Price of 2015 New Cars
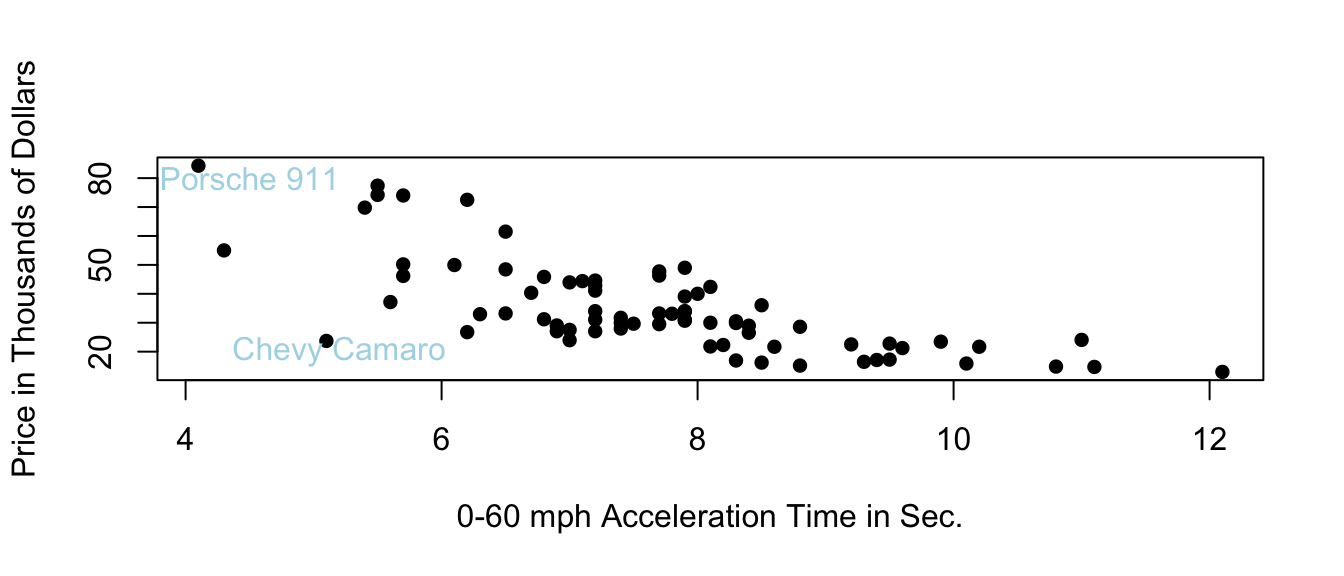
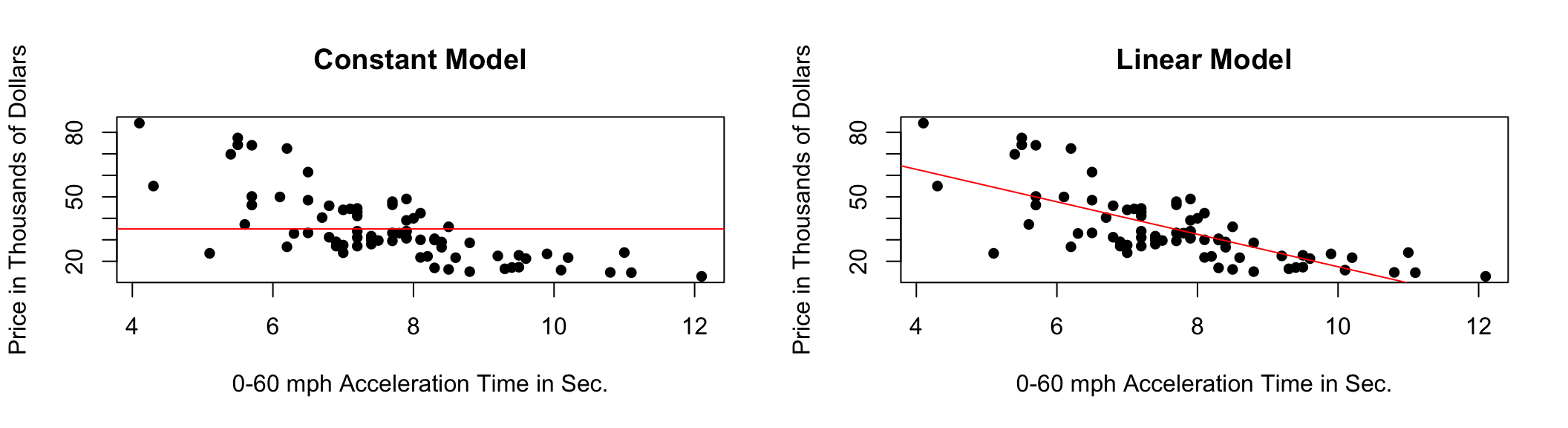
9.3.3 Two Models with High Bias
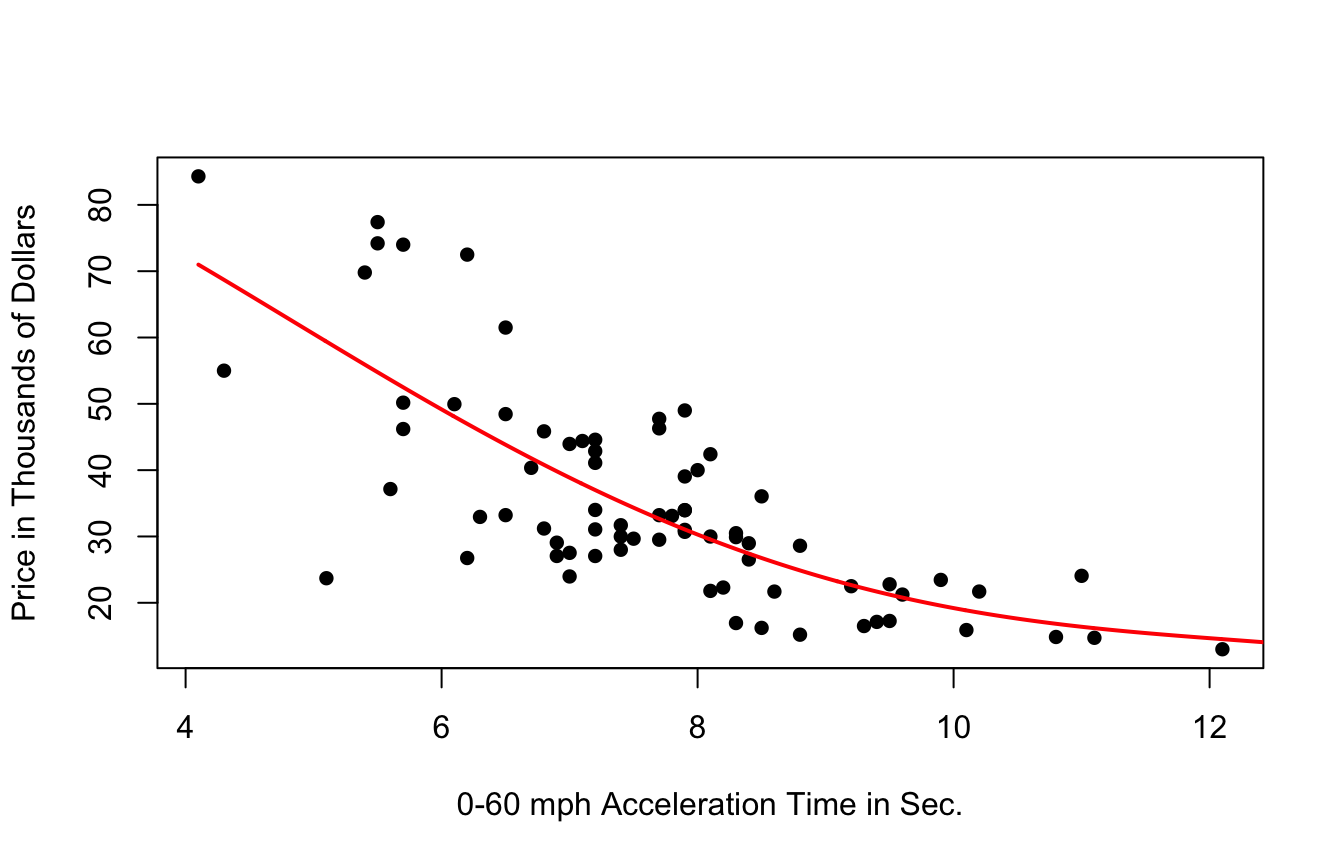
9.3.4 Cubic Model
9.3.5 Cubic Splines
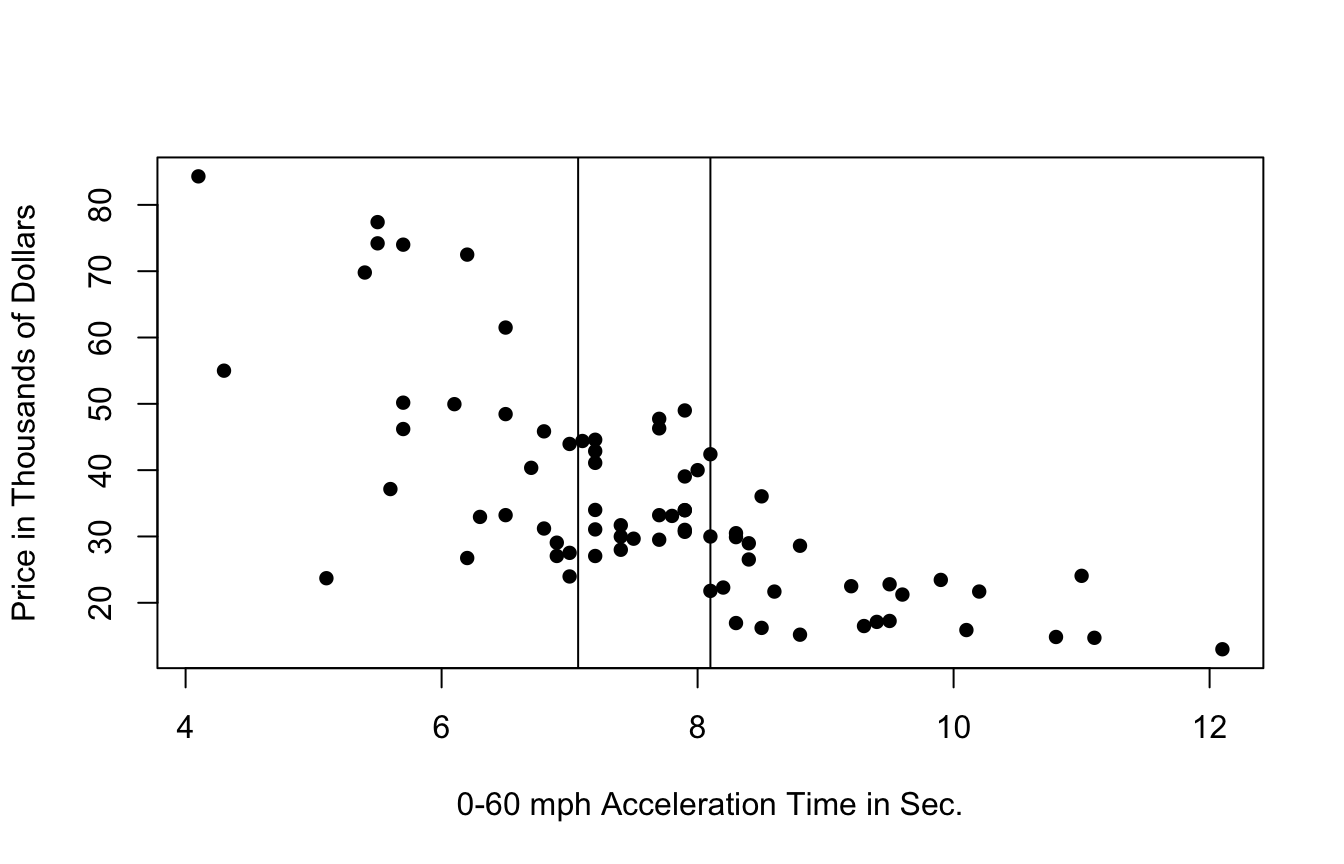
9.3.6 Cubic Splines
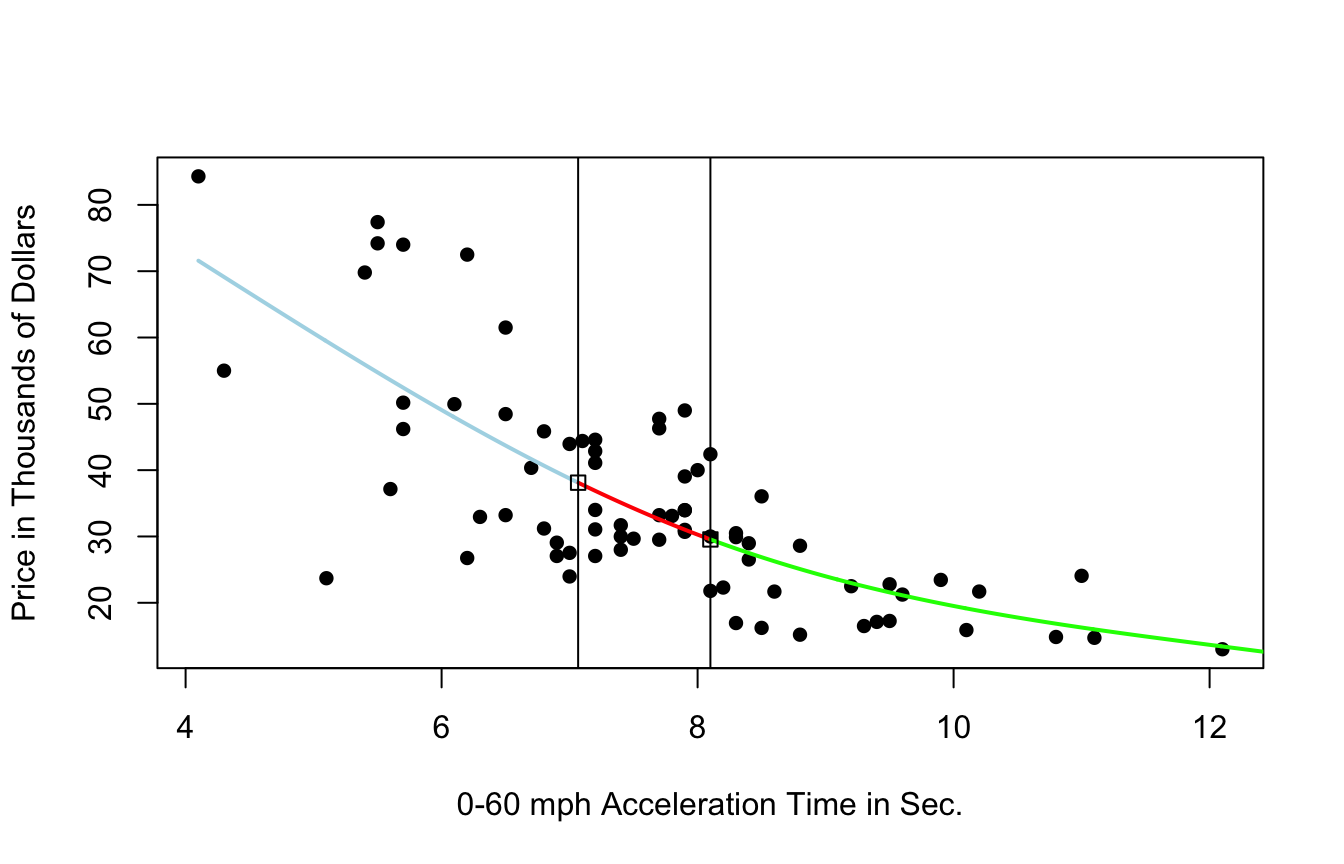
- region boundaries are called knots
9.3.7 Cubic Spline with 5 Knots
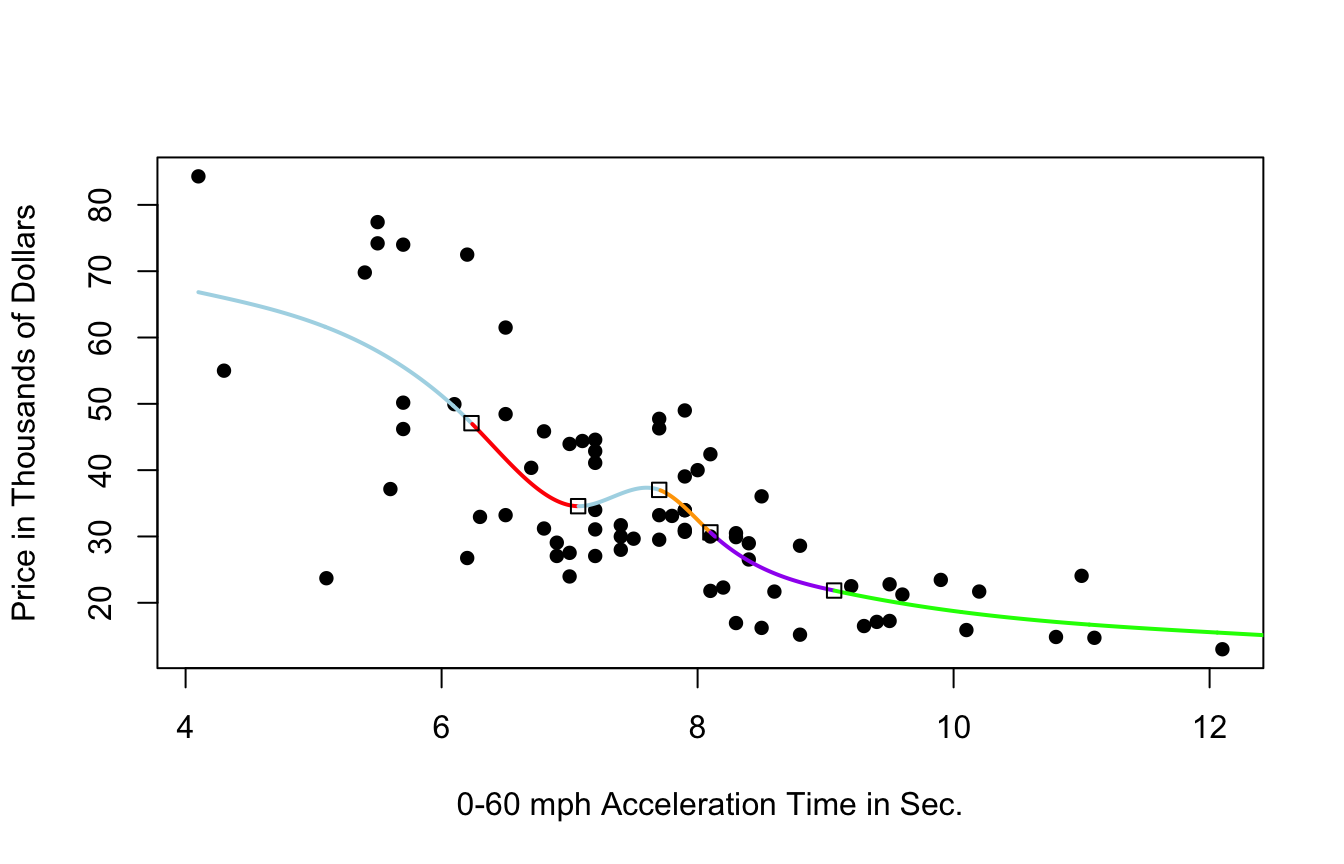
9.3.8 Cubic Spline with 10 Knots
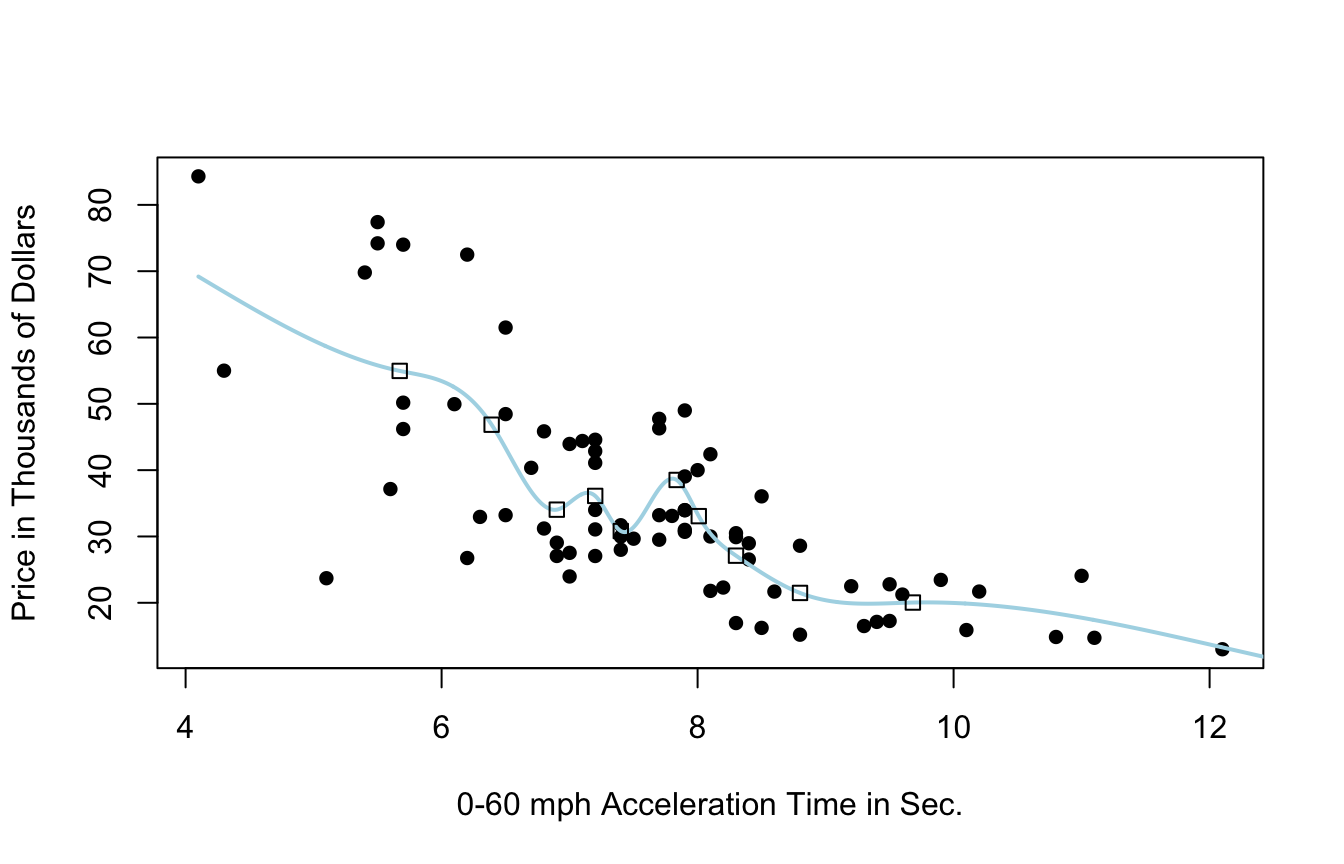
9.3.9 Cubic Spline with 20 Knots
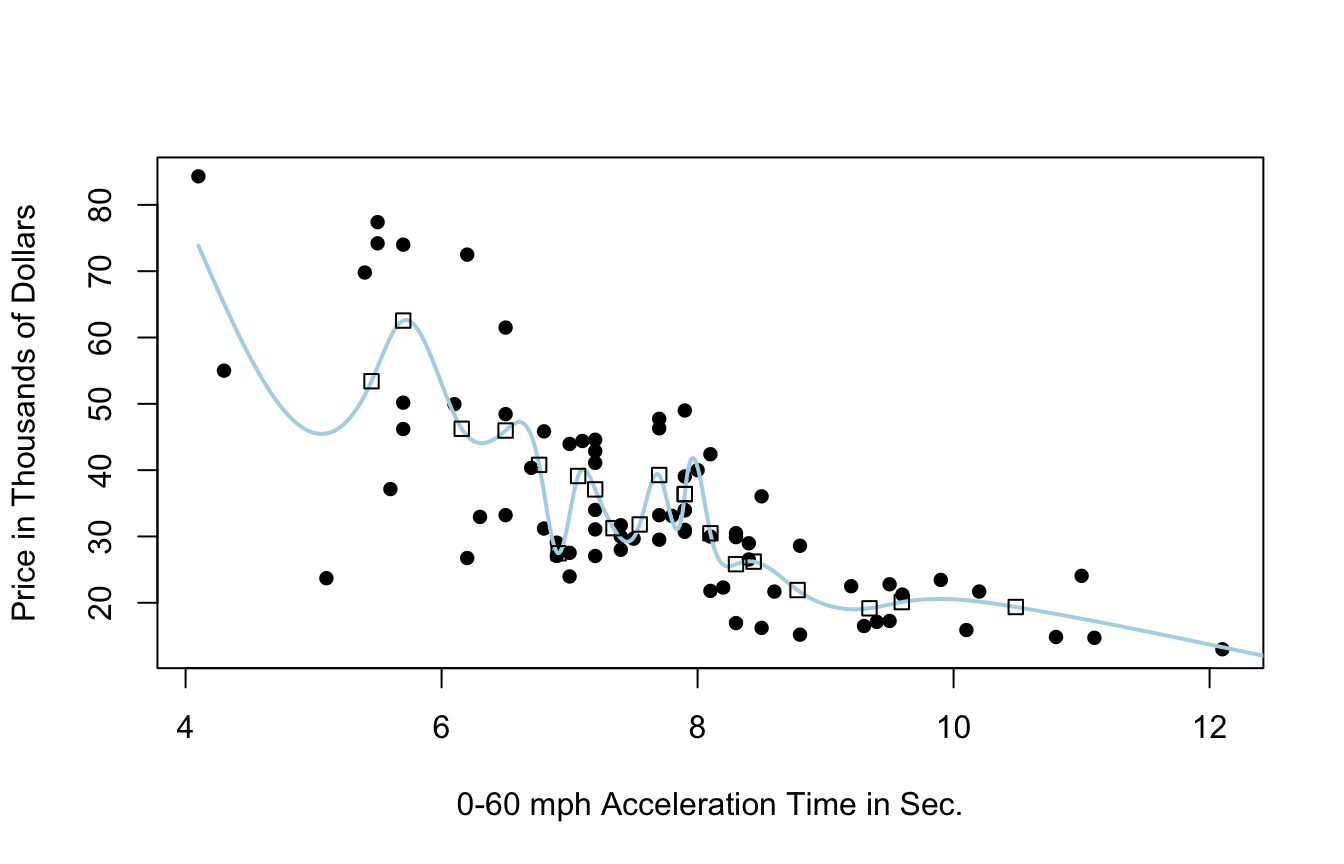
9.3.10 Model Evaluation
- predicted price for 35 new 2015 cars not in original dataset
- calculated mean square prediction error (MSPE)
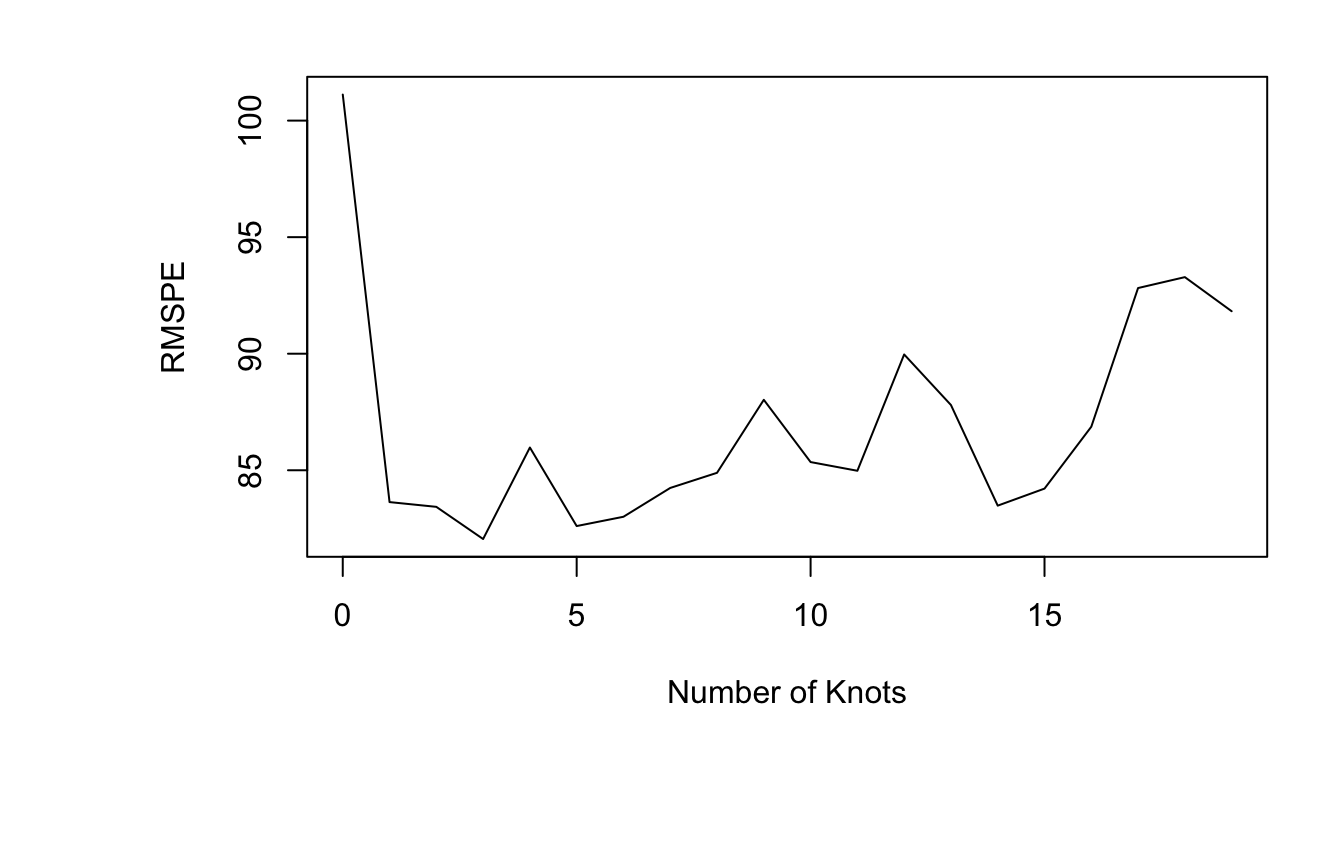
9.3.11 Implementation of Splines
Important Considerations:
- how many knots
- where to place knots
- degree of polynomial
The best choices for all of these will vary between datasets and can be assessed through cross-validation.
—>