Chapter 3 Data Cleaning
3.1 Data Import
- 과제를 위해 주어진 Data를 import 한뒤, 데이터가 어떻게 생겼는지 확인해봅니다.
library(haven)
library(dplyr)##
## Attaching package: 'dplyr'## The following objects are masked from 'package:stats':
##
## filter, lag## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, unionlibrary(tidyverse)## ─ Attaching packages ──────────────────── tidyverse 1.3.1 ─## ✓ ggplot2 3.3.3 ✓ purrr 0.3.4
## ✓ tibble 3.1.2 ✓ stringr 1.4.0
## ✓ tidyr 1.1.3 ✓ forcats 0.5.1
## ✓ readr 1.4.0## ─ Conflicts ───────────────────── tidyverse_conflicts() ─
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()library(dplyr)
library(kableExtra)##
## Attaching package: 'kableExtra'## The following object is masked from 'package:dplyr':
##
## group_rows# data 변수에 sav 데이터를 넣어줍니다.
data <- read_spss("cleaning.sav")
# 데이터를 확인합니다.
nrow(data)
# 관측치 n = 490개
glimpse(data)- 주요 변수는 아래와 같습니다.
col[12] gender
col[13] age
col[14] manipulation check *bogus
col[15~17] ehtic
col[18~21] fair
col[22] gender_equal *bogus
col[23~41] NFC
col[42] education
col[43] AI tech
col[45] condition (제지, 동조)3.2 Data Preperation
3.2.1 Missing Data check
naniar 패키지의 miss_var_summary, gg_miss_var 함수를 사용하여 결측치를 확인해봅니다.
VIM 패키지의 aggr 함수로 함께 사용해보았습니다.
library(naniar)
library(VIM)## Loading required package: colorspace## Loading required package: grid## VIM is ready to use.## Suggestions and bug-reports can be submitted at: https://github.com/statistikat/VIM/issues##
## Attaching package: 'VIM'## The following object is masked from 'package:datasets':
##
## sleepmiss_var_summary(data)## # A tibble: 45 x 3
## variable n_miss pct_miss
## <chr> <int> <dbl>
## 1 ethic_2 92 18.8
## 2 ethic_3 91 18.6
## 3 fair_1 91 18.6
## 4 ethic_1 89 18.2
## 5 fair_3 89 18.2
## 6 gender_equal_4 88 18.0
## 7 NFC1_2 88 18.0
## 8 NFC1_3 88 18.0
## 9 fair_2 87 17.8
## 10 fair_4 87 17.8
## # … with 35 more rowsgg_miss_var(data)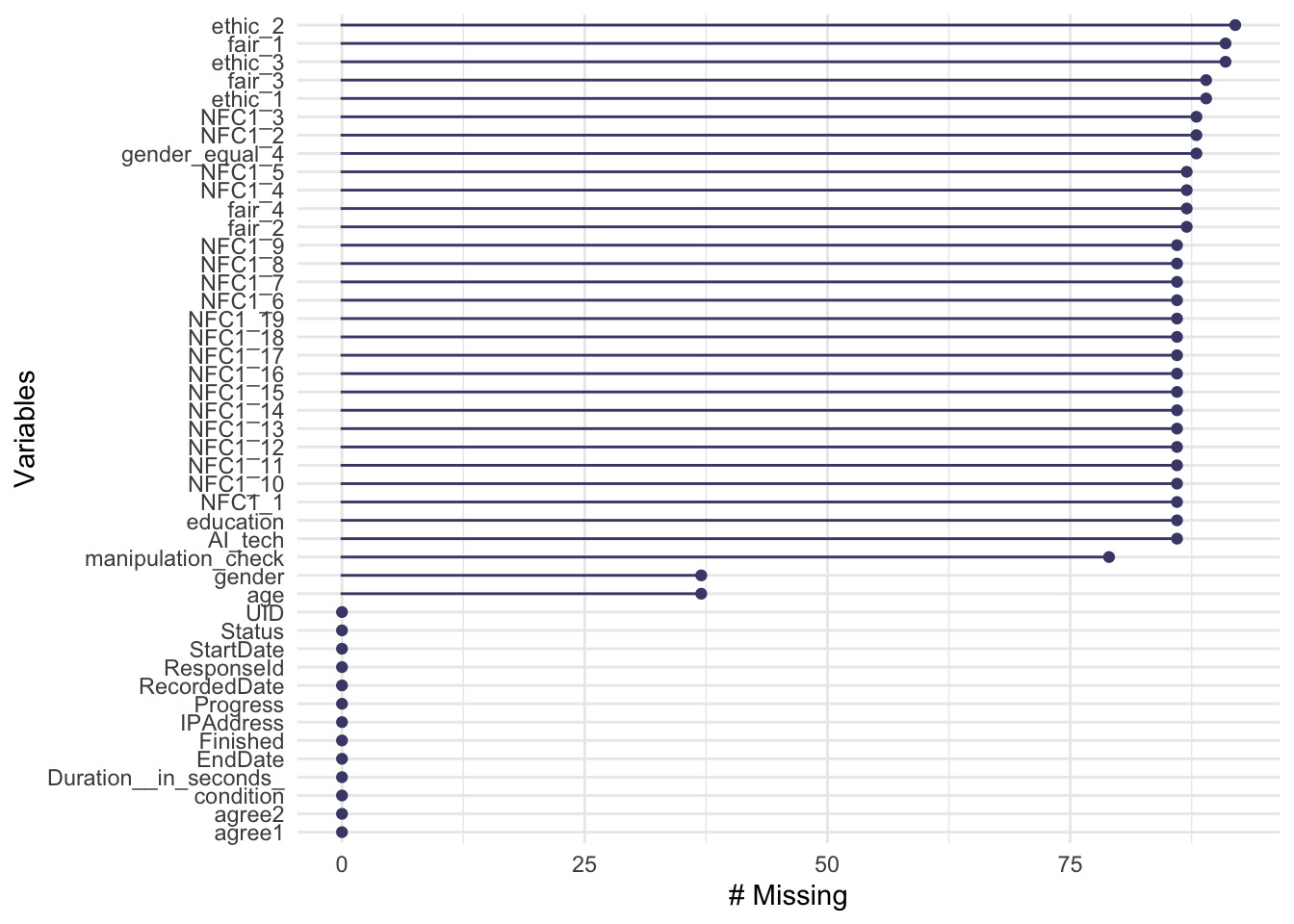
aggr(data)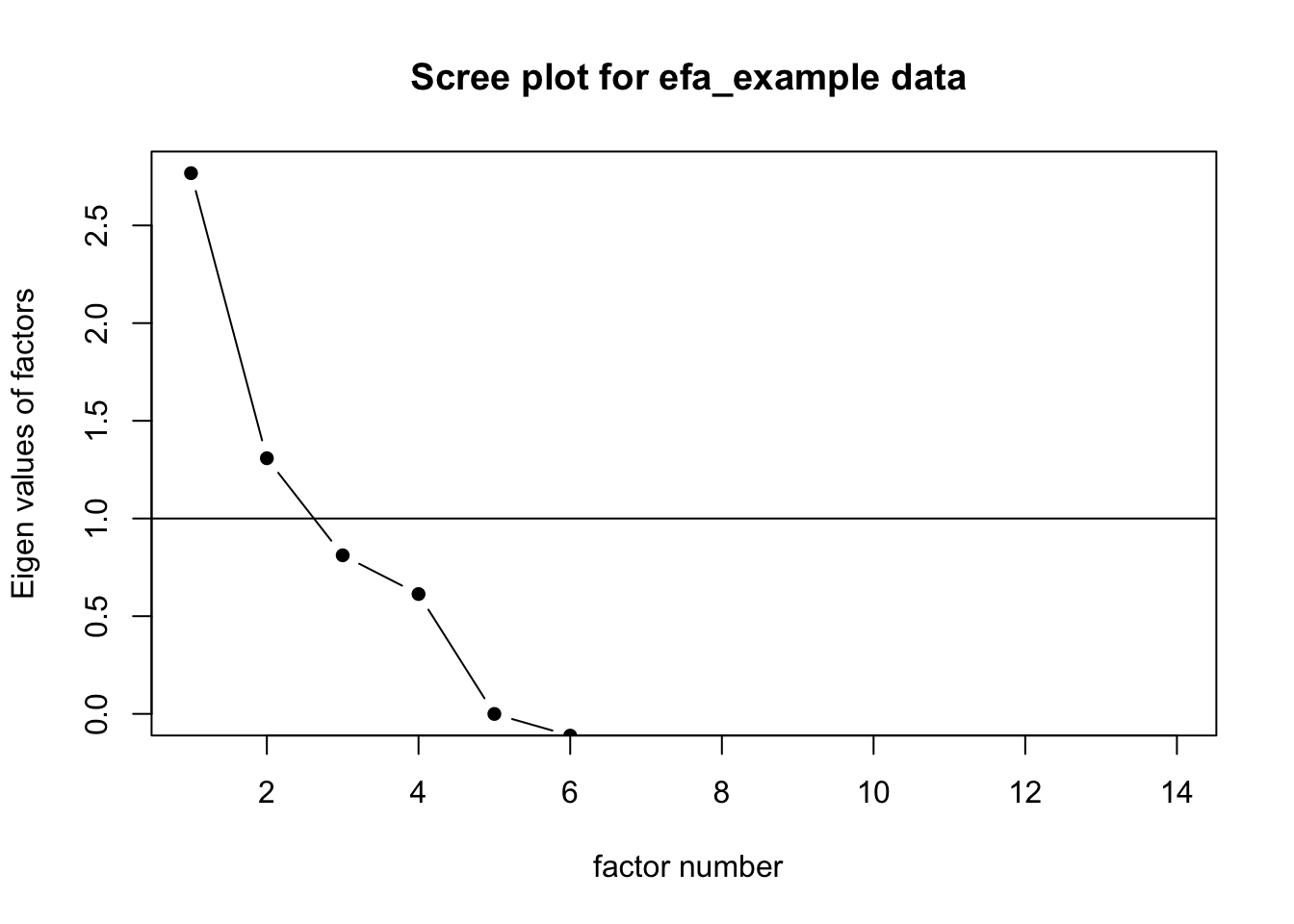
- 개인적으로는 gg_miss_var,aggr 함수가 결측치를 한눈에 확인할 수 있어서 편한 것 같습니다.
- 총 490개 응답값 중, 92개 ~ 37개까지 결측치가 있습니다.
- 생각보다 Missing Data가 많아서, 우선 불성실 응답부터 제거해보겠습니다.
3.2.2 Duration in seconds
- 가장 먼저 응답 시간을 보겠습니다.
- 초 단위 기록을 조금 더 보기 편하게 분단위로 변환한 뒤, 요약해서 보겠습니다.
library(lubridate)##
## Attaching package: 'lubridate'## The following objects are masked from 'package:base':
##
## date, intersect, setdiff, uniondata$Duration__in_seconds_%>%
seconds_to_period() %>%
summary()## Min. 1st Qu. Median
## "5S" "4M 39.25S" "8M 12S"
## Mean 3rd Qu. Max.
## "14M 9.79795918367347S" "11M 30.75S" "1d 2H 3M 51S"- max 1일 2시간 걸린 사람도 있고, min 5초 걸린 사람도 있습니다.
- boxplot을 그려보면, 이상치 때문에 데이터 분포를 제대로 살펴보기 어렵습니다.
data$Duration__in_seconds_ %>% boxplot()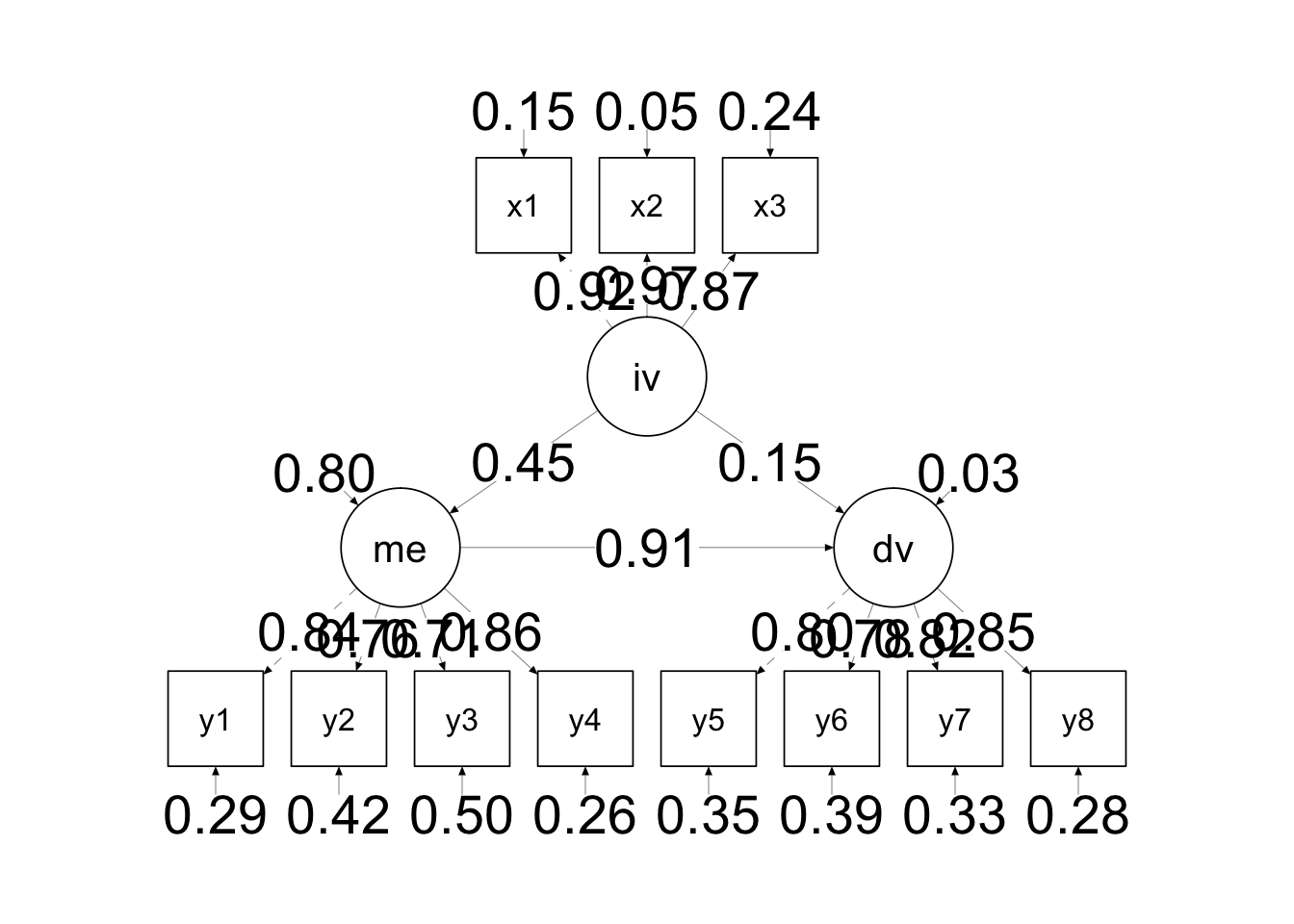
Figure 3.1: raw data boxplot
- 우선 말도 안되는 극단치를 제거하고, 다시 boxplot을 그려보겠습니다.
- 지금부터 수정하는 data 변수는 modified_data로 할당하겠습니다.
# 최대값 위치 확인 : 154행 관측치
which(data$Duration__in_seconds_ == max(data$Duration__in_seconds_))## [1] 154# 최대값 제거 : 1월 8일부터 1월 9일까지 응답하신 데이터를 확인한 뒤
data[154, ]## # A tibble: 1 x 45
## StartDate EndDate Status IPAddress Progress
## <dttm> <dttm> <dbl+lbl> <chr> <dbl>
## 1 2020-01-08 15:25:23 2020-01-09 17:29:14 0 [IP Address] 182.209.108.40 100
## # … with 40 more variables: Duration__in_seconds_ <dbl>, Finished <dbl+lbl>,
## # RecordedDate <dttm>, ResponseId <chr>, agree1 <dbl+lbl>, agree2 <dbl+lbl>,
## # gender <dbl+lbl>, age <dbl>, manipulation_check <dbl+lbl>,
## # ethic_1 <dbl+lbl>, ethic_2 <dbl+lbl>, ethic_3 <dbl+lbl>, fair_1 <dbl+lbl>,
## # fair_2 <dbl+lbl>, fair_3 <dbl+lbl>, fair_4 <dbl+lbl>,
## # gender_equal_4 <dbl+lbl>, NFC1_1 <dbl+lbl>, NFC1_2 <dbl+lbl>,
## # NFC1_3 <dbl+lbl>, NFC1_4 <dbl+lbl>, NFC1_5 <dbl+lbl>, NFC1_6 <dbl+lbl>,
## # NFC1_7 <dbl+lbl>, NFC1_8 <dbl+lbl>, NFC1_9 <dbl+lbl>, NFC1_10 <dbl+lbl>,
## # NFC1_11 <dbl+lbl>, NFC1_12 <dbl+lbl>, NFC1_13 <dbl+lbl>, NFC1_14 <dbl+lbl>,
## # NFC1_15 <dbl+lbl>, NFC1_16 <dbl+lbl>, NFC1_17 <dbl+lbl>, NFC1_18 <dbl+lbl>,
## # NFC1_19 <dbl+lbl>, education <dbl+lbl>, AI_tech <dbl+lbl>, UID <chr>,
## # condition <chr># 제거해줍니다.
modified_data <- data[-154, ]- 다시 boxplot을 그려보겠습니다.
modified_data$Duration__in_seconds_ %>% boxplot()
Figure 3.2: modified data boxplot
- 이제 이상치들이 확연하게 많이 보입니다.
- 이상 값 제거 시, 3표준편차를 기준으로 활용하기도 하지만, 편의상 저는 IQR을 활용해서 진행하겠습니다.

이상치 한눈에 보기(출처: 실무에 써먹는 머신러닝(with R))
\[하위\ 이상값은\\ 1분위수 - 1.5 \times (IQR:3분위수 - 1분위수) \ 보다\ 작은\ 값\]
\[상위\ 이상값은 \\ 3분위수 + 1.5 \times (IQR:3분위수 - 1분위수) \ 보다\ 큰\ 값 \]
# 상위 이상값(1,299초) 보다 큰 값 : 총 38개
modified_data[which(modified_data$Duration__in_seconds_ > summary(modified_data$Duration__in_seconds_)[5] + 1.5 * IQR(modified_data$Duration__in_seconds_)), ] %>% nrow()## [1] 38# 하위 이상값 확인 : 없음
modified_data[which(modified_data$Duration__in_seconds_ < summary(modified_data$Duration__in_seconds_)[2] - 1.5 * IQR(modified_data$Duration__in_seconds_)), ] %>% nrow()## [1] 0# 상위 이상값 초과하는 데이터 38개 제거
modified_data[-which(modified_data$Duration__in_seconds_ > summary(modified_data$Duration__in_seconds_)[5] + 1.5 * IQR(modified_data$Duration__in_seconds_)), ] -> modified_data- boxblot을 그려보면 아래와 같습니다.
modified_data$Duration__in_seconds_ %>% boxplot()
Figure 3.3: modified data boxplot
- 하위 극단치는 없는 것으로 나왔지만, 40문항이 넘는 설문을 1분도 안걸려서 했다는
것은 상식적으로 이해할 수 없습니다.
- 1분 미만으로 진행한 사람이 71명, 1분~2분 미만이 11명, 2분 ~ 3분이 13명이므로
우선 1분 미만 응답자 데이터를 제거해주고자 하는데, 대화문을 읽는 시간이 1분정도
소요된다고 했으므로, 2분 미만 데이터를 모두 삭제합니다.
# 1분 미만 : 71명
modified_data[which(modified_data$Duration__in_seconds_ < 60), ] %>% nrow()## [1] 71# 2분 미만 : 82명
modified_data[which(modified_data$Duration__in_seconds_ < 120), ] %>% nrow()## [1] 82# 3분 미만 : 95명
modified_data[which(modified_data$Duration__in_seconds_ < 180), ] %>% nrow()## [1] 95# 1분 미만 71명 데이터 제거
modified_data[-which(modified_data$Duration__in_seconds_ < 120), ] -> modified_data
# 제거 후 남은 응답 ; 365개
modified_data %>% nrow()## [1] 369- 처음 490개 응답값 중, 110개가 날라가고 365개의 응답값이 남았습니다.
3.2.3 Bogus/Instructed Item
- 이제 Bogus/Instructed Item을 활용해서 불성실 응답을 제거해보겠습니다.
- 불성실 응답을 제거하기 위해 아래와 같이 세개의 item이 들어가 있습니다.
- col[14] manipulation_check item : 정답은 4번
- col[22] gender_equal : 정답은 6번 매우 그렇다
- col[32]NFC1_10 : 정답은 1번 전혀 그렇지 않다. - Duration으로 불성실 응답을 제거한 380명의 데이터에서 정답을 몇명이 맞췄는지 확인해보겠습니다.
# 세 문제 모두 정답 찍은 인원 : 268명
modified_data %>%
subset(manipulation_check %in% "4") %>%
subset(gender_equal_4 %in% "6") %>%
subset(NFC1_10 %in% "1") %>%
nrow()## [1] 268# 두 문제만 정답 찍은 인원 : 320명
modified_data %>%
subset(manipulation_check %in% "4") %>%
subset(gender_equal_4 %in% "6") %>%
nrow()## [1] 320# 한 문제만 정답 찍은 인원 : 365명
modified_data %>%
subset(manipulation_check %in% "4") %>%
nrow()## [1] 365- 세 문항 모두 정답으로 응답한 인원은 총 268명입니다.
- 세 문항 모두 정답으로 한 인원의 응답 데이터만 사용하기에는 너무 마음이 아픕니다.
- 일단 정답자들의 Missing Data 현황을 확인해봅니다.
# 3문제 정답자는 1~5개 missing
modified_data %>%
subset(manipulation_check %in% "4") %>%
subset(gender_equal_4 %in% "6") %>%
subset(NFC1_10 %in% "1") %>%
miss_var_summary()## # A tibble: 45 x 3
## variable n_miss pct_miss
## <chr> <int> <dbl>
## 1 ethic_3 5 1.87
## 2 fair_1 4 1.49
## 3 ethic_1 3 1.12
## 4 ethic_2 3 1.12
## 5 fair_3 3 1.12
## 6 NFC1_2 2 0.746
## 7 NFC1_3 2 0.746
## 8 fair_2 1 0.373
## 9 fair_4 1 0.373
## 10 NFC1_4 1 0.373
## # … with 35 more rows# 2문제 정답자도 1~5개 missing
modified_data %>%
subset(manipulation_check %in% "4") %>%
subset(gender_equal_4 %in% "6") %>%
miss_var_summary()## # A tibble: 45 x 3
## variable n_miss pct_miss
## <chr> <int> <dbl>
## 1 ethic_2 5 1.56
## 2 ethic_3 5 1.56
## 3 fair_1 4 1.25
## 4 ethic_1 3 0.938
## 5 fair_3 3 0.938
## 6 NFC1_2 2 0.625
## 7 NFC1_3 2 0.625
## 8 fair_2 1 0.312
## 9 fair_4 1 0.312
## 10 NFC1_4 1 0.312
## # … with 35 more rows# 1문제 정답자는 1~6개 missing
modified_data %>%
subset(manipulation_check %in% "4") %>%
miss_var_summary()## # A tibble: 45 x 3
## variable n_miss pct_miss
## <chr> <int> <dbl>
## 1 ethic_2 6 1.64
## 2 ethic_3 5 1.37
## 3 fair_1 5 1.37
## 4 ethic_1 3 0.822
## 5 fair_3 3 0.822
## 6 gender_equal_4 2 0.548
## 7 NFC1_2 2 0.548
## 8 NFC1_3 2 0.548
## 9 fair_2 1 0.274
## 10 fair_4 1 0.274
## # … with 35 more rows- missing data가 최대 5개~6개로 1문제 정답자나 3문제 정답자나 거의 동일합니다.
- missing data만 처리하고 사용하고자 하는 강한 욕망에 사로잡혀, 우선 manipulation_check 항목 정답자 기준으로 데이터를 정제합니다.
modified_data %>% subset(manipulation_check %in% "4") -> modified_data
modified_data %>% nrow()## [1] 3653.2.4 Impute missing data
- 이제 최초 490개의 관찰값 중 365개의 값이 남았습니다.
- Missing Data가 얼마나 있는지 체크하고, Impute 해보겠습니다.
miss_var_summary(modified_data)## # A tibble: 45 x 3
## variable n_miss pct_miss
## <chr> <int> <dbl>
## 1 ethic_2 6 1.64
## 2 ethic_3 5 1.37
## 3 fair_1 5 1.37
## 4 ethic_1 3 0.822
## 5 fair_3 3 0.822
## 6 gender_equal_4 2 0.548
## 7 NFC1_2 2 0.548
## 8 NFC1_3 2 0.548
## 9 fair_2 1 0.274
## 10 fair_4 1 0.274
## # … with 35 more rowsaggr(modified_data)
- Missing Data의 종류는 아래와 같이 구분할 수 있습니다.
| 구분 | 내용 |
|---|---|
| MCAR(missing Completely at random) | 변수의 종류, 값과 상관 없이 무작위적으로 나타나는 결측치 |
| MAR(missing at random) | 누락된 변수가 특정 변수와 관련되었지만, 그 변수값과 관계 없이 누락 된 경우 |
| MNAR(missing at not random) | 누락된 변수 값과 누락된 이유가 관련 이있는 경우 |
- 저는 MCAR 이라고 가정하고, Multiple Imputation 방법을 활용하여 결측치를 채워넣고자 합니다.
Multiple Imputation은 시뮬레이션을 반복하여 누락된 데이터를 채우는 method of choice입니다.
시뮬레이션을 통해 누락된 자료를 채운 complete dataset을 3~10개정도 만듭니다.
누락된 자료는 몬테카를로 방법을 사용해서 채워지고, 각 dataset에 통계방법을 적용하여 통계결과 및 신뢰구간을 비교하여 최적의 대체값으로 대체합니다.
R에서는 이를 위한 mice 패키지를 기본 제공해줍니다.
mice 패키지에 따라 imputation을 진행해보겠습니다.
mice 패키지를 활용하면 위의 방법 외에도 Decision Tree, KNN등의 통계적 방법을 사용하여 결측치를 대체할 수 있습니다.
library(mice)##
## Attaching package: 'mice'## The following object is masked from 'package:stats':
##
## filter## The following objects are masked from 'package:base':
##
## cbind, rbindlibrary(broom.mixed)# Imputation 할 수 있도록 label을 제거하고, 숫자만 남길 수 있도록 data 형태를 간단하게 변경해줍니다.
modified_data[, 10:45] -> modified_data_num
modified_data_num[, -35] -> modified_data_num
modified_data_num$condition## [1] "제지" "제지" "제지" "동조" "동조" "동조" "동조" "동조" "동조" "제지"
## [11] "동조" "제지" "동조" "동조" "동조" "동조" "동조" "제지" "동조" "제지"
## [21] "동조" "동조" "제지" "동조" "제지" "동조" "제지" "동조" "동조" "동조"
## [31] "제지" "제지" "동조" "제지" "제지" "제지" "제지" "동조" "동조" "제지"
## [41] "동조" "제지" "동조" "제지" "동조" "동조" "제지" "동조" "제지" "제지"
## [51] "동조" "제지" "제지" "동조" "동조" "제지" "동조" "제지" "동조" "동조"
## [61] "동조" "동조" "제지" "동조" "제지" "제지" "제지" "제지" "제지" "제지"
## [71] "제지" "동조" "제지" "제지" "제지" "동조" "동조" "제지" "제지" "동조"
## [81] "동조" "제지" "제지" "동조" "제지" "동조" "제지" "동조" "제지" "제지"
## [91] "제지" "제지" "동조" "동조" "제지" "동조" "제지" "제지" "동조" "동조"
## [101] "제지" "동조" "제지" "제지" "동조" "동조" "동조" "제지" "제지" "제지"
## [111] "동조" "제지" "제지" "동조" "제지" "동조" "동조" "제지" "제지" "동조"
## [121] "제지" "동조" "제지" "동조" "제지" "동조" "제지" "제지" "동조" "제지"
## [131] "동조" "동조" "제지" "제지" "동조" "제지" "제지" "제지" "동조" "제지"
## [141] "제지" "제지" "동조" "제지" "제지" "제지" "동조" "제지" "제지" "제지"
## [151] "제지" "동조" "동조" "동조" "동조" "동조" "제지" "동조" "제지" "제지"
## [161] "동조" "동조" "동조" "동조" "제지" "제지" "동조" "동조" "제지" "동조"
## [171] "동조" "제지" "제지" "동조" "동조" "동조" "제지" "동조" "동조" "제지"
## [181] "제지" "동조" "제지" "제지" "제지" "동조" "동조" "제지" "제지" "동조"
## [191] "제지" "제지" "제지" "동조" "동조" "동조" "동조" "동조" "제지" "제지"
## [201] "제지" "제지" "제지" "제지" "제지" "제지" "동조" "동조" "제지" "동조"
## [211] "제지" "동조" "동조" "동조" "제지" "동조" "동조" "동조" "동조" "동조"
## [221] "동조" "동조" "제지" "제지" "제지" "동조" "제지" "제지" "제지" "제지"
## [231] "동조" "동조" "동조" "동조" "동조" "동조" "동조" "동조" "제지" "제지"
## [241] "제지" "제지" "제지" "제지" "제지" "동조" "동조" "동조" "제지" "제지"
## [251] "제지" "동조" "동조" "제지" "제지" "동조" "동조" "동조" "제지" "동조"
## [261] "동조" "동조" "동조" "동조" "제지" "동조" "제지" "동조" "제지" "제지"
## [271] "제지" "동조" "동조" "동조" "제지" "동조" "동조" "제지" "동조" "제지"
## [281] "동조" "제지" "제지" "제지" "동조" "제지" "동조" "제지" "제지" "제지"
## [291] "동조" "제지" "동조" "제지" "제지" "제지" "제지" "동조" "동조" "동조"
## [301] "제지" "제지" "동조" "동조" "동조" "제지" "동조" "제지" "동조" "동조"
## [311] "제지" "제지" "동조" "동조" "동조" "동조" "동조" "동조" "동조" "동조"
## [321] "동조" "제지" "동조" "제지" "동조" "동조" "동조" "동조" "제지" "동조"
## [331] "동조" "제지" "제지" "제지" "제지" "동조" "제지" "제지" "제지" "동조"
## [341] "동조" "동조" "제지" "동조" "제지" "제지" "동조" "동조" "제지" "제지"
## [351] "제지" "동조" "동조" "동조" "동조" "동조" "동조" "제지" "제지" "제지"
## [361] "제지" "동조" "제지" "동조" "동조"
## attr(,"label")
## [1] "condition"
## attr(,"format.spss")
## [1] "A2000"
## attr(,"display_width")
## [1] 15# condition 동조 0, 제지 1 변환 및 확인
gsub("동조", "0", modified_data_num$condition) -> modified_data_num$condition_re
gsub("제지", "1", modified_data_num$condition_re) -> modified_data_num$condition_re
table(modified_data_num$condition)##
## 동조 제지
## 186 179table(modified_data_num$condition_re)##
## 0 1
## 186 179# gender 남자 0, 여자 1 변환 및 확인
gsub("1", "0", modified_data_num$gender) -> modified_data_num$gender_re
gsub("2", "1", modified_data_num$gender_re) -> modified_data_num$gender_re
table(modified_data_num$gender)##
## 1 2
## 178 187table(modified_data_num$gender_re)##
## 0 1
## 178 187# condition 열 제거
modified_data_num[, -35] -> modified_data_num
# SPSS label 제거
modified_data_num %>% sapply(haven::zap_label) -> modified_data_number
# 숫자 형태 데이터 프레임으로 변수 변환
apply(modified_data_number, 2, as.numeric) %>% as.data.frame(stringAsFactor = FALSE) -> modified_data_df# 5개의 Dataset을 만들어줍니다.
imputation <- mice(modified_data_df, m = 5)##
## iter imp variable
## 1 1 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 1 2 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 1 3 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 1 4 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 1 5 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 2 1 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 2 2 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 2 3 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 2 4 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 2 5 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 3 1 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 3 2 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 3 3 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 3 4 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 3 5 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 4 1 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 4 2 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 4 3 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 4 4 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 4 5 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 5 1 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 5 2 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 5 3 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 5 4 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 5 5 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5## Warning: Number of logged events: 4# 가장 단순한 회귀분석 모형을 적용해서 5개 모델의 fit을 측정합니다.
imp_fit <- with(imputation, lm(NFC1_1 ~ ethic_1 + fair_1))
model_pool <- pool(imp_fit)
# 5개의 dataset은 Predictive mean matching 방법을 주로 활용했음을 알 수 있습니다.
imputation## Class: mids
## Number of multiple imputations: 5
## Imputation methods:
## agree1 agree2 gender age
## "" "" "" ""
## manipulation_check ethic_1 ethic_2 ethic_3
## "" "pmm" "pmm" "pmm"
## fair_1 fair_2 fair_3 fair_4
## "pmm" "pmm" "pmm" "pmm"
## gender_equal_4 NFC1_1 NFC1_2 NFC1_3
## "pmm" "" "pmm" "pmm"
## NFC1_4 NFC1_5 NFC1_6 NFC1_7
## "pmm" "pmm" "" ""
## NFC1_8 NFC1_9 NFC1_10 NFC1_11
## "" "" "" ""
## NFC1_12 NFC1_13 NFC1_14 NFC1_15
## "" "" "" ""
## NFC1_16 NFC1_17 NFC1_18 NFC1_19
## "" "" "" ""
## education AI_tech condition_re gender_re
## "" "" "" ""
## PredictorMatrix:
## agree1 agree2 gender age manipulation_check ethic_1 ethic_2
## agree1 0 0 1 1 0 1 1
## agree2 0 0 1 1 0 1 1
## gender 0 0 0 1 0 1 1
## age 0 0 1 0 0 1 1
## manipulation_check 0 0 1 1 0 1 1
## ethic_1 0 0 1 1 0 0 1
## ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_1
## agree1 1 1 1 1 1 1 1
## agree2 1 1 1 1 1 1 1
## gender 1 1 1 1 1 1 1
## age 1 1 1 1 1 1 1
## manipulation_check 1 1 1 1 1 1 1
## ethic_1 1 1 1 1 1 1 1
## NFC1_2 NFC1_3 NFC1_4 NFC1_5 NFC1_6 NFC1_7 NFC1_8 NFC1_9
## agree1 1 1 1 1 1 1 1 1
## agree2 1 1 1 1 1 1 1 1
## gender 1 1 1 1 1 1 1 1
## age 1 1 1 1 1 1 1 1
## manipulation_check 1 1 1 1 1 1 1 1
## ethic_1 1 1 1 1 1 1 1 1
## NFC1_10 NFC1_11 NFC1_12 NFC1_13 NFC1_14 NFC1_15 NFC1_16
## agree1 1 1 1 1 1 1 1
## agree2 1 1 1 1 1 1 1
## gender 1 1 1 1 1 1 1
## age 1 1 1 1 1 1 1
## manipulation_check 1 1 1 1 1 1 1
## ethic_1 1 1 1 1 1 1 1
## NFC1_17 NFC1_18 NFC1_19 education AI_tech condition_re
## agree1 1 1 1 1 1 1
## agree2 1 1 1 1 1 1
## gender 1 1 1 1 1 1
## age 1 1 1 1 1 1
## manipulation_check 1 1 1 1 1 1
## ethic_1 1 1 1 1 1 1
## gender_re
## agree1 0
## agree2 0
## gender 0
## age 0
## manipulation_check 0
## ethic_1 0
## Number of logged events: 4
## it im dep meth out
## 1 0 0 constant agree1
## 2 0 0 constant agree2
## 3 0 0 constant manipulation_check
## 4 0 0 collinear gender_re# 결과 요약값을 보면 다음과 같습니다.
# 회귀분석 결과, 회귀분석에 활용된 변수가 모두 유의하지 않게 나왔습니다.
# 이 연구에서 사용된 변수에 대한 이해가 부족하기에 회귀식을 이론적 배경에 맞춰 작성하는 것이 어렵기 때문입니다.
summary(model_pool)## term estimate std.error statistic df p.value
## 1 (Intercept) 2.95978647 0.19999221 14.7995086 359.8198 0.0000000
## 2 ethic_1 -0.01349261 0.07630813 -0.1768175 359.3531 0.8597514
## 3 fair_1 0.02420274 0.07264023 0.3331864 359.6561 0.7391877# densityplot으로 결측치 대체시 분포도 확인해볼 수 있습니다.
# 빨간색이 결측치를 채운 값 분포이고, 파란색이 이미 채워져 있는 값 분포인데, 딱 봐도 차이가 좀 납니다.
densityplot(imputation)
- 회귀분석을 이용해서 결측치 대체가 어렵기에, 지도학습인 Decision Tree를 활용하여 결측치를 대체합니다.
# 의사결정나무로 결측치 대체하기 (minbucket은 말단 노드가 포함하는 최소 가지 수)
imputation <- mice(modified_data_df, method = "cart", minbucket = 4)##
## iter imp variable
## 1 1 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 1 2 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 1 3 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 1 4 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 1 5 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 2 1 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 2 2 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 2 3 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 2 4 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 2 5 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 3 1 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 3 2 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 3 3 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 3 4 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 3 5 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 4 1 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 4 2 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 4 3 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 4 4 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 4 5 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 5 1 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 5 2 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 5 3 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 5 4 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5
## 5 5 ethic_1 ethic_2 ethic_3 fair_1 fair_2 fair_3 fair_4 gender_equal_4 NFC1_2 NFC1_3 NFC1_4 NFC1_5## Warning: Number of logged events: 4# 결측치가 채워진 complete data를 만들어줍니다.
complete_data <- complete(imputation)- 이를 통해 결측치가 없는 365개의 관찰값이 있는 데이터를 얻을 수 있습니다.
3.3 Reverse Item
3.3.1 Label 확인
- 위 문항 중 라벨을 보면서 역문항을 찾아내야 합니다.
View함수로 열을 직접 보면서 확인할 수도 있지만,labelled 함수를 사용하면 조금 더 간단하게 SPSS의 라벨을 확인할 수 있습니다.
library(labelled)
var_label(data)## $StartDate
## [1] "Start Date"
##
## $EndDate
## [1] "End Date"
##
## $Status
## [1] "Response Type"
##
## $IPAddress
## [1] "IP Address"
##
## $Progress
## [1] "Progress"
##
## $Duration__in_seconds_
## [1] "Duration (in seconds)"
##
## $Finished
## [1] "Finished"
##
## $RecordedDate
## [1] "Recorded Date"
##
## $ResponseId
## [1] "Response ID"
##
## $agree1
## [1] "본 연구의 연구 목적을 이해하고 연구에 참여하기를 희망합니다."
##
## $agree2
## [1] "연구 도중 자유롭게 참여를 철회할 수 있음을 이해하였습니다."
##
## $gender
## [1] "귀하의 성별은 무엇입니까?"
##
## $age
## [1] "귀하의 (만) 나이를 기입하십시오."
##
## $manipulation_check
## [1] "앞서 본 대화에서 [Field-agent_name]에게 의견을 물어본 직업은 무엇이었습니까? (정답=4번)"
##
## $ethic_1
## [1] "[Field-agent_name]은 도덕적으로 올바르게 반응했다"
##
## $ethic_2
## [1] "[Field-agent_name]의 반응은 윤리적으로 바람직했다"
##
## $ethic_3
## [1] "[Field-agent_name]의 반응에는 도덕적으로 문제가 있다_R"
##
## $fair_1
## [1] "[Field-agent_name]은 공정했다"
##
## $fair_2
## [1] "[Field-agent_name]은 객관적이었다"
##
## $fair_3
## [1] "[Field-agent_name]은 중립적이었다"
##
## $fair_4
## [1] "[Field-agent_name]은 편견을 가지고 있다_R"
##
## $gender_equal_4
## [1] "이 질문에는 '매우 그렇다'에 표시해 주십시오."
##
## $NFC1_1
## [1] "다음 문항에 얼마나 동의하십니까? - 나는 단순한 문제보다 복잡한 문제를 더 선호한다"
##
## $NFC1_2
## [1] "다음 문항에 얼마나 동의하십니까? - 나는 생각을 많이 필요로 하는 책무(책임)를 즐기는 편이다"
##
## $NFC1_3
## [1] "다음 문항에 얼마나 동의하십니까? - 생각하는 것은 재미있지 않다_R"
##
## $NFC1_4
## [1] "다음 문항에 얼마나 동의하십니까? - 나는 사고 능력을 많이 필요로 하는 일보다는 생각을 별로 안 해도 되는 일을 선호한다_R"
##
## $NFC1_5
## [1] "다음 문항에 얼마나 동의하십니까? - 나는 깊이 생각해야 하는 상황은 가급적 피하려고 한다_R"
##
## $NFC1_6
## [1] "다음 문항에 얼마나 동의하십니까? - 나는 긴 시간 동안 열심히 심사숙고하는 일에 만족감을 느낀다"
##
## $NFC1_7
## [1] "다음 문항에 얼마나 동의하십니까? - 나는 필요한 수준 이상으로 심사숙고하지 않는다_R"
##
## $NFC1_8
## [1] "다음 문항에 얼마나 동의하십니까? - 나는 장기적인 일보다 그날 그날의 할 일들에 대해 생각하는 것을 선호한다_R"
##
## $NFC1_9
## [1] "다음 문항에 얼마나 동의하십니까? - 나는 한번 배우고 나면 생각을 별로 안 해도 되는 일들을 좋아한다_R"
##
## $NFC1_10
## [1] "다음 문항에 얼마나 동의하십니까? - 이 문항을 읽으셨다면 전혀 그렇지 않다에 표기해 주십시오."
##
## $NFC1_11
## [1] "다음 문항에 얼마나 동의하십니까? - 나의 사고능력을 사용해서 최고가 되고 싶다"
##
## $NFC1_12
## [1] "다음 문항에 얼마나 동의하십니까? - 나는 새로운 해결책을 찾아야 하는 일이 즐겁다"
##
## $NFC1_13
## [1] "다음 문항에 얼마나 동의하십니까? - 새로운 사고방식을 배우는 일은 별로 즐겁지 않다_R"
##
## $NFC1_14
## [1] "다음 문항에 얼마나 동의하십니까? - 나는 풀어야만 하는 수수께끼로 가득 찬 인생을 선호한다"
##
## $NFC1_15
## [1] "다음 문항에 얼마나 동의하십니까? - 나는 추상적인 사고를 즐긴다"
##
## $NFC1_16
## [1] "다음 문항에 얼마나 동의하십니까? - 나는 생각을 별로 하지 않아도 되는 적당히 중요한 일보다는 지적이고 어렵더라도 더 중요한 일을 선호한다"
##
## $NFC1_17
## [1] "다음 문항에 얼마나 동의하십니까? - 나는 머리를 많이 써야하는 일을 마치고 나면 만족감보다는 안도감을 더 느낀다_R"
##
## $NFC1_18
## [1] "다음 문항에 얼마나 동의하십니까? - 나는 무언가가 일을 처리할 수 있다는 것이 중요하지, 그 원리에 대해서는 관심이 없다_R"
##
## $NFC1_19
## [1] "다음 문항에 얼마나 동의하십니까? - 나와 관계없는 일에 대해서도 심사숙고 하곤 한다"
##
## $education
## [1] "귀하의 최종 학력은 무엇입니까?"
##
## $AI_tech
## [1] "귀하는 직업이나 학업 등의 과정에서 인공지능을 사용하거나 인공지능 기술을 접한 경험이 있으십니까?"
##
## $UID
## [1] "UID"
##
## $condition
## [1] "condition"- 확인 결과, 역문항은 다음과 같습니다.
col[17] ethic_3
col[21] fair_4
col[25] NFC1_3
col[26] NFC1_4
col[27] NFC1_5
col[29] NFC1_7
col[30] NFC1_8
col[31] NFC1_9
col[35] NFC1_13
col[39] NFC1_17
col[40] NFC1_18- 척도를 확인해보니 6점 척도를 사용한 것 같습니다.
- 6점 척도는 7로 빼주면 간단하게 역문항을 정상문항으로 변경할 수 있습니다.
- 앞서 만들어둔 complete data를 활용합니다.
complete_data$ethic_3 %>% unique()## [1] 3 5 2 1 6 4complete_data$fair_4 %>% unique()## [1] 4 3 1 5 2 6complete_data$NFC1_7 %>% unique()## [1] 3 5 4 2 1 63.3.2 Reverse 척도 변환
- 역문항은 새로운 새롭게 변수를 생성해서 넣어보겠습니다.
- Reverse 문항을 다시 Reverse했으므로, 변수명_RR 로 저장하겠습니다.
complete_data$ethic_3_RR <- 7 - complete_data$ethic_3
complete_data$fair_4_RR <- 7 - complete_data$fair_4
complete_data$NFC1_3_RR <- 7 - complete_data$NFC1_3
complete_data$NFC1_4_RR <- 7 - complete_data$NFC1_4
complete_data$NFC1_5_RR <- 7 - complete_data$NFC1_5
complete_data$NFC1_7_RR <- 7 - complete_data$NFC1_7
complete_data$NFC1_8_RR <- 7 - complete_data$NFC1_8
complete_data$NFC1_9_RR <- 7 - complete_data$NFC1_9
complete_data$NFC1_13_RR <- 7 - complete_data$NFC1_13
complete_data$NFC1_17_RR <- 7 - complete_data$NFC1_17
complete_data$NFC1_17_RR <- 7 - complete_data$NFC1_17
complete_data$NFC1_18_RR <- 7 - complete_data$NFC1_18- 역문항 변환이 잘 되었는지는 table 함수로 간단하게 확인할 수 있습니다.
- 변환 후 1~6 개수와 변환 전 1~6개수가 대칭을 이루고 있는 것을 확인할 수 있습니다.
- Missing Data가 있는지 마지막으로 확인 후, sav 파일로 저장해줍니다.
complete_data$ethic_3_RR %>% table()## .
## 1 2 3 4 5 6
## 14 47 58 105 98 43complete_data$ethic_3 %>% table()## .
## 1 2 3 4 5 6
## 43 98 105 58 47 14complete_data$fair_4_RR %>% table()## .
## 1 2 3 4 5 6
## 45 70 80 65 67 38complete_data$fair_4 %>% table()## .
## 1 2 3 4 5 6
## 38 67 65 80 70 45complete_data$NFC1_3_RR %>% table()## .
## 1 2 3 4 5 6
## 10 41 96 106 84 28complete_data$NFC1_3 %>% table()## .
## 1 2 3 4 5 6
## 28 84 106 96 41 10complete_data$NFC1_4_RR %>% table()## .
## 1 2 3 4 5 6
## 22 66 115 102 47 13complete_data$NFC1_4 %>% table()## .
## 1 2 3 4 5 6
## 13 47 102 115 66 22complete_data$NFC1_5_RR %>% table()## .
## 1 2 3 4 5 6
## 25 64 106 117 45 8complete_data$NFC1_5 %>% table()## .
## 1 2 3 4 5 6
## 8 45 117 106 64 25complete_data$NFC1_7_RR %>% table()## .
## 1 2 3 4 5 6
## 13 53 107 123 58 11complete_data$NFC1_7 %>% table()## .
## 1 2 3 4 5 6
## 11 58 123 107 53 13complete_data$NFC1_8_RR %>% table()## .
## 1 2 3 4 5 6
## 23 57 146 98 34 7complete_data$NFC1_8 %>% table()## .
## 1 2 3 4 5 6
## 7 34 98 146 57 23complete_data$NFC1_9_RR %>% table()## .
## 1 2 3 4 5 6
## 28 60 122 107 40 8complete_data$NFC1_9 %>% table()## .
## 1 2 3 4 5 6
## 8 40 107 122 60 28complete_data$NFC1_13_RR %>% table()## .
## 1 2 3 4 5 6
## 7 45 78 125 85 25complete_data$NFC1_13 %>% table()## .
## 1 2 3 4 5 6
## 25 85 125 78 45 7complete_data$NFC1_17_RR %>% table()## .
## 1 2 3 4 5 6
## 17 73 144 94 29 8complete_data$NFC1_17 %>% table()## .
## 1 2 3 4 5 6
## 8 29 94 144 73 17complete_data$NFC1_17_RR %>% table()## .
## 1 2 3 4 5 6
## 17 73 144 94 29 8complete_data$NFC1_17 %>% table()## .
## 1 2 3 4 5 6
## 8 29 94 144 73 17complete_data$NFC1_18_RR %>% table()## .
## 1 2 3 4 5 6
## 13 38 100 137 64 13complete_data$NFC1_18 %>% table()## .
## 1 2 3 4 5 6
## 13 64 137 100 38 13# Missing Data 없는지 확인
sum(is.na(complete_data))## [1] 0# sav 파일로 저장
write_sav(complete_data, "complete_data_2021303531.sav")3.4 과제 제출물
- agree 문항 두개를 삭제하고, 변수 계산을 진행해서 최종 데이터를 만들어줍니다.
library(stargazer)##
## Please cite as:## Hlavac, Marek (2018). stargazer: Well-Formatted Regression and Summary Statistics Tables.## R package version 5.2.2. https://CRAN.R-project.org/package=stargazerlibrary(xtable)
library(knitr)
# agree 문항 삭제
complete_data <- complete_data[, -1:-2]
# Ethic, Fair, NFC 평균으로 계산
complete_data %>%
select(ethic_1, ethic_2, ethic_3_RR) %>%
apply(1, mean) -> complete_data$Ethic
complete_data %>%
select(fair_1, fair_2, fair_3, fair_4_RR) %>%
apply(1, mean) -> complete_data$Fair
complete_data %>%
select(NFC1_1, NFC1_2, NFC1_3_RR, NFC1_4_RR, NFC1_5_RR, NFC1_6, NFC1_7_RR, NFC1_8_RR, NFC1_9_RR, NFC1_10, NFC1_11, NFC1_12, NFC1_13_RR, NFC1_14, NFC1_15, NFC1_16, NFC1_17_RR, NFC1_18_RR, NFC1_19) %>%
apply(1, mean) -> complete_data$NFC
# 필요한 열만 뽑아서 최종 데이터 만들기
complete_data %>% select(condition_re, gender_re, age, Ethic, Fair, NFC, education, AI_tech) -> Final_data
# sav 파일로 저장
write_sav(Final_data, "Final_data_2021303531.sav")3.4.1 연령, 성비, 각 척도의 평균과 표준편차
- 이제 변수 계산을 통해 결과표를 작성하는 일만 남았습니다.
- 먼저 Gender, Ethic, Fair, NFC의 평균, 표준편차, 중앙값, 최소값, 최대값을 표로 나타냅니다.
# 이제 html 형태로 기초통계표를 출력해봅니다.
# 1-1) gender, Ethic, Fair, NFC 평균, 표준편차, 중앙값, 최소값, 최대값
stargazer(Final_data[3:6], title = "Descriptive statistics", digits = 2, type = "html", out = "Final_data.html", summary.stat = c("n", "mean", "sd", "median", "min", "max"))| Statistic | N | Mean | St. Dev. | Median | Min | Max |
| age | 365 | 40.91 | 12.50 | 40 | 20 | 69 |
| Ethic | 365 | 3.87 | 1.19 | 4.00 | 1.00 | 6.00 |
| Fair | 365 | 3.73 | 1.25 | 3.75 | 1.00 | 6.00 |
| NFC | 365 | 3.38 | 0.60 | 3.47 | 1.26 | 5.05 |
- 이번에는 성별의 빈도수를 표로 나타냅니다.
# 1-2) 성비 Frequency Table
table(Final_data[2]) -> tbl2
rownames(tbl2)[1:2] <- c("남자", "여자")
tbl2 %>% knitr::kable(format = "html", caption = "Gender/Age Frequency Table",col.names = c('성별','인원 수'))| 성별 | 인원 수 |
|---|---|
| 남자 | 178 |
| 여자 | 187 |
3.4.2 조건별/성별 인원
gsub("0", "동조", Final_data$condition_re) -> Final_data$condition_re
gsub("1", "제지", Final_data$condition_re) -> Final_data$condition_re
gsub("0", "남자", Final_data$gender_re) -> Final_data$gender_re
gsub("1", "여자", Final_data$gender_re) -> Final_data$gender_re
Final_data %>%
group_by(condition_re, gender_re) %>%
summarise(total = n()) %>%
knitr::kable(format = "html", col.names = c("조건", "성별", "인원 수"))%>%
kableExtra::scroll_box(width = "100%", height = "200px")## `summarise()` has grouped output by 'condition_re'. You can override using the `.groups` argument.| 조건 | 성별 | 인원 수 |
|---|---|---|
| 동조 | 남자 | 85 |
| 동조 | 여자 | 101 |
| 제지 | 남자 | 93 |
| 제지 | 여자 | 86 |
3.4.3 조건별/성별 각 척도 평균과 표준편차
Final_data %>%
group_by(condition_re, gender_re) %>%
summarise(
total = n(),
Ethic_mean = mean(Ethic),
Ethic_sd = sd(Ethic),
Fair_mean = mean(Fair),
Fair_sd = sd(Fair),
NFC_mean = mean(NFC),
NFC_sd = sd(NFC)
) %>%
knitr::kable(format = "html", digits = 2)%>%
kableExtra::scroll_box(width = "100%", height = "200px")## `summarise()` has grouped output by 'condition_re'. You can override using the `.groups` argument.| condition_re | gender_re | total | Ethic_mean | Ethic_sd | Fair_mean | Fair_sd | NFC_mean | NFC_sd |
|---|---|---|---|---|---|---|---|---|
| 동조 | 남자 | 85 | 3.59 | 1.10 | 3.47 | 1.01 | 3.49 | 0.62 |
| 동조 | 여자 | 101 | 3.21 | 1.13 | 2.94 | 1.14 | 3.23 | 0.63 |
| 제지 | 남자 | 93 | 4.35 | 1.04 | 4.24 | 1.19 | 3.44 | 0.55 |
| 제지 | 여자 | 86 | 4.40 | 1.02 | 4.36 | 1.04 | 3.40 | 0.56 |