Chapter 7 두 집단 비교 t test
HR 데이터 분석 시, 많이 활용하는 방법 중 하나가 집단 간 차이 분석입니다.
직급, 세대, 남성/여성, 학력, 신입/경력 등 다양한 관점에서 집단을 나누고, 어떤 차이가 있는지 살펴보면서 Insight를 얻어냅니다.
직급에 따른 차이 (G1,G2,G3,G4)를 확인하거나, 소속 본부 간 차이, 상/하위 집단 간 인식 차이 등을 확인 할 때 주로 사용하며, 두 집단의 차이는 T-test, 세 집단 이상의 차이는 ANOVA 및 사후검정(multiple comparison) 을 통해 확인합니다.
아래와 같이 t test와 ANOVA 에 대해 설명해주는 표가 있어서, 가져와 보았습니다.
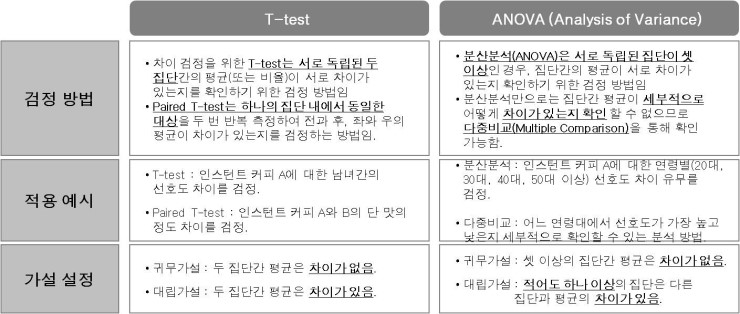
T test와 ANOVA 검정 (출처: 한국갤럽 연구1본부 블로그)
오늘은 첫 시간에 공유드렸던 Kaggle에 올라와 있는 IBM의 HR 데이터를 활용하여 내용 공유 드리겠습니다.
우선 필요한 라이브러리를 불러옵니다.
7.1 데이터 불러오기/전처리
7.1.1 데이터 가져오기
- 데이터 가져오기에서 공유드렸던 내용을 참고하시어, 첨부된 엑셀 데이터를 변수로 저장합니다.
- ANOVA 에서도 해당 데이터를 사용할 예정이므로, RDS 데이터로 저장해둡니다.
7.1.2 데이터 확인하기
- 데이터를 잘 가져왔는지 확인해줍니다.
## Rows: 1,470
## Columns: 35
## $ Age <int> 41, 49, 37, 33, 27, 32, 59, 30, 38, 36, 35,…
## $ Attrition <chr> "Yes", "No", "Yes", "No", "No", "No", "No",…
## $ BusinessTravel <chr> "Travel_Rarely", "Travel_Frequently", "Trav…
## $ DailyRate <int> 1102, 279, 1373, 1392, 591, 1005, 1324, 135…
## $ Department <chr> "Sales", "Research & Development", "Researc…
## $ DistanceFromHome <int> 1, 8, 2, 3, 2, 2, 3, 24, 23, 27, 16, 15, 26…
## $ Education <int> 2, 1, 2, 4, 1, 2, 3, 1, 3, 3, 3, 2, 1, 2, 3…
## $ EducationField <chr> "Life Sciences", "Life Sciences", "Other", …
## $ EmployeeCount <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
## $ EmployeeNumber <int> 1, 2, 4, 5, 7, 8, 10, 11, 12, 13, 14, 15, 1…
## $ EnvironmentSatisfaction <int> 2, 3, 4, 4, 1, 4, 3, 4, 4, 3, 1, 4, 1, 2, 3…
## $ Gender <chr> "Female", "Male", "Male", "Female", "Male",…
## $ HourlyRate <int> 94, 61, 92, 56, 40, 79, 81, 67, 44, 94, 84,…
## $ JobInvolvement <int> 3, 2, 2, 3, 3, 3, 4, 3, 2, 3, 4, 2, 3, 3, 2…
## $ JobLevel <int> 2, 2, 1, 1, 1, 1, 1, 1, 3, 2, 1, 2, 1, 1, 1…
## $ JobRole <chr> "Sales Executive", "Research Scientist", "L…
## $ JobSatisfaction <int> 4, 2, 3, 3, 2, 4, 1, 3, 3, 3, 2, 3, 3, 4, 3…
## $ MaritalStatus <chr> "Single", "Married", "Single", "Married", "…
## $ MonthlyIncome <int> 5993, 5130, 2090, 2909, 3468, 3068, 2670, 2…
## $ MonthlyRate <int> 19479, 24907, 2396, 23159, 16632, 11864, 99…
## $ NumCompaniesWorked <int> 8, 1, 6, 1, 9, 0, 4, 1, 0, 6, 0, 0, 1, 0, 5…
## $ Over18 <chr> "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y"…
## $ OverTime <chr> "Yes", "No", "Yes", "Yes", "No", "No", "Yes…
## $ PercentSalaryHike <int> 11, 23, 15, 11, 12, 13, 20, 22, 21, 13, 13,…
## $ PerformanceRating <int> 3, 4, 3, 3, 3, 3, 4, 4, 4, 3, 3, 3, 3, 3, 3…
## $ RelationshipSatisfaction <int> 1, 4, 2, 3, 4, 3, 1, 2, 2, 2, 3, 4, 4, 3, 2…
## $ StandardHours <int> 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80,…
## $ StockOptionLevel <int> 0, 1, 0, 0, 1, 0, 3, 1, 0, 2, 1, 0, 1, 1, 0…
## $ TotalWorkingYears <int> 8, 10, 7, 8, 6, 8, 12, 1, 10, 17, 6, 10, 5,…
## $ TrainingTimesLastYear <int> 0, 3, 3, 3, 3, 2, 3, 2, 2, 3, 5, 3, 1, 2, 4…
## $ WorkLifeBalance <int> 1, 3, 3, 3, 3, 2, 2, 3, 3, 2, 3, 3, 2, 3, 3…
## $ YearsAtCompany <int> 6, 10, 0, 8, 2, 7, 1, 1, 9, 7, 5, 9, 5, 2, …
## $ YearsInCurrentRole <int> 4, 7, 0, 7, 2, 7, 0, 0, 7, 7, 4, 5, 2, 2, 2…
## $ YearsSinceLastPromotion <int> 0, 1, 0, 3, 2, 3, 0, 0, 1, 7, 0, 0, 4, 1, 0…
## $ YearsWithCurrManager <int> 5, 7, 0, 0, 2, 6, 0, 0, 8, 7, 3, 8, 3, 2, 3…복사해온 데이터를 glimpse() 함수로 확인해보면, 총 1,470개의 관측치(행) 이 있고, 35개의 변수(열) 이 있습니다.
이는 35개 문항에 대한 1,470명의 정보를 의미합니다.
7.1.3 데이터 응답 고유 값 확인하기
오늘 집단간 차이 검정은 여러 변수 중 학력, 직무만족, 일과 삶의 균형 세 변수만 활용하여 아래의 내용을 확인하고자 합니다.
1. '학력'에 따른 '직무만족'의 차이 2. '학력'에 따른 '일과 삶의 균형'의 차이먼저, 해당 변수에 어떤 값들이 입력되어 있는지 unique 함수를 통해 살펴보겠습니다.
## [1] 2 1 4 3 5## [1] 4 2 3 1## [1] 1 3 2 4kaggle 홈페이지에는 숫자별로 어떤 값을 의미하는지 상세 설명이 나와 있습니다.
Education JobSatisfaction WorkLifeBalance 1 ‘Below College’ 1 ‘Low’ 1 ‘Bad’ 2 ‘College’ 2 ‘Medium’ 2 ‘Good’ 3 ‘Bachelor’ 3 ‘High’ 3 ‘Better’ 4 ‘Master’ 4 ‘Very High’ 4 ‘Best’ 5 ‘Doctor’ - -
7.2 t test 준비
7.2.1 원하는 데이터만 불러오기
두 집단 간 차이를 분석하는 T test 실습을 위해, 우선 대졸(Bachelor)과 전문대졸 미만 (Below College) 두 집단을 비교해보겠습니다.
대졸과 전문대졸 미만의 학력을 갖고 있는 인원의 직무만족 데이터만 가져오기 위해 아래와 같이 select 함수, subset 함수를 활용했습니다.
IBM.HR%>%dplyr::select(Education,JobSatisfaction)%>%
subset(Education=="1"|Education=="3")->IBM.HR.test
glimpse(IBM.HR.test)## Rows: 742
## Columns: 2
## $ Education <int> 1, 1, 3, 1, 3, 3, 3, 1, 3, 3, 1, 3, 1, 3, 3, 3, 3, 3…
## $ JobSatisfaction <int> 2, 2, 1, 3, 3, 3, 2, 3, 3, 4, 1, 3, 1, 4, 4, 4, 4, 1…IBM.HR%>%select(Education,JobSatisfaction)%>%subset(Education==“1”|Education==“3”)->IBM.HR.test
- IBM.HR 데이터에서 Education 과 JobSatisfaction 열만 Select 하고, Education 관측치 중 1과 3인 데이터만 IBM.HR.test 변수에 넣으라는 뜻입니다.
7.2.2 데이터의 등분산성 확인
이제, IBM.HR.test 데이터를 활용하여 t test를 진행하겠습니다.
t test를 실시하기 위해서는 데이터가 등분산성과 정규성을 만족해야 합니다.설문조사 응답 데이터는 대부분 정규성과 등분산성을 만족하지만, 간혹 그렇지 않은 경우도 있습니다.
등분산성을 만족하지 않는 경우, 아래와 같이 다양한 검정 방법이 준비되어 있으니, 데이터에 맞게 활용하시면 됩니다.
등분산성은 비교 대상이 되는 모집단이 동일한 분산을 가져야 한다는 가정을 말하며,
정규성은 데이터가 정규분포를 따르고 있는지를 말합니다.데이터의 관측치가 31개 이상이면 정규성을 따르기 때문에,
보유하고 계신 거의 대부분의 데이터가 정규성은 만족할 것입니다.따라서 등분산성만 확인하시면 되며, 아래와 같이 var.test() 함수를 통해 두 집단이 등분산성을 만족하는지 확인하실 수 있습니다.
var.test(IBM.HR.test[IBM.HR.test$Education=="1",2],
IBM.HR.test[IBM.HR.test$Education=="3",2], conf.level = 0.95)##
## F test to compare two variances
##
## data: IBM.HR.test[IBM.HR.test$Education == "1", 2] and IBM.HR.test[IBM.HR.test$Education == "3", 2]
## F = 0.98675, num df = 169, denom df = 571, p-value = 0.9322
## alternative hypothesis: true ratio of variances is not equal to 1
## 95 percent confidence interval:
## 0.7799196 1.2689366
## sample estimates:
## ratio of variances
## 0.9867542var.test(IBM.HR.test[IBM.HR.test$Education==“1”,2], IBM.HR.test[IBM.HR.test$Education==“3”,2], conf.level = 0.95)
I BM.HR.test[IBM.HR.test$Education==“1”,2]는 IBM.HR.test 데이터에서 Education이 1(전문대졸 미만)인 관측치의 JobSatisfaction 만 가져오라는 것이며,
IBM.HR.test[IBM.HR.test$Education==“3”,2]는 IBM.HR.test 데이터에서 Education이 3(대졸)인 관측치의 JobSatisfaction 값 만 가져오라는 뜻 입니다.
conf.level은 신뢰구간을 95%로 설정 한다는 뜻 입니다.
두 집단의 등분산성을 검정한 결과를 보면, p-value 가 0.05 보다 크기 때문에 등분산성을 만족한다고 볼 수 있습니다.
var.test는 두 데이터의 분산이 같다 는 영가설을 기준으로 검정을 하는 것입니다. 따라서, p-value가 0.05보다 크면 영가설이 참이기에 두 집단의 분산이 같다. 즉, 등분산성을 만족한다고 볼 수 있습니다.
p-value=0.9322로 0.05보다 현저하게 크므로, 대졸미만과 대졸의 직무만족 응답 값은 등분산성을 만족합니다.
7.3 t test 시행
t.test() 함수에도 Data의 수, 데이터가 짝을 이루는지, 등분산성/정규성을 만족하는지에 따라 다양한 방식이 존재합니다.
저희는 Data의 수가 30개가 넘고, 짝을 이루고 있지 않으면서 등분산성을 만족하기에 2-sample T-test를 시행하면 됩니다.
2-sample T test외, 다른 방식의 검정 방법에 대해서는 향후 하나씩 공유드리겠습니다.
2 sample Test는 아래와 같이 t.test()를 실행하시면 되며, t.test함수는 아래와 같이 작성하시면 됩니다.
t.test(관측치~집단 구분 기준, 데이터프레임, t-test 유형, 신뢰범위)
##
## Welch Two Sample t-test
##
## data: JobSatisfaction by Education
## t = 1.5417, df = 278.65, p-value = 0.1243
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -0.04094193 0.33674613
## sample estimates:
## mean in group 1 mean in group 3
## 2.800000 2.652098두 그룹 간의 평균 차이는 2.8 - 2.652098 = 0.147902 인데,
p-value = 0.1243으로 유의미한 차이가 아닌 것으로 나타났습니다.대졸 미만과, 대졸 구성원 간 직무만족의 차이는 통계적으로 유의미하지 않은 것으로 확인 되었습니다.
동일한 방법으로 WorkLifeBalance도 시행해보았으나, 통계적으로 유의미한 차이는 없었습니다.
보다 자세한 내용에 대해서는 T-test에 대한 유튜브 강의 링크 참고 부탁 드립니다.