Chapter 10 텍스트 데이터-재료 준비
- 전 시간에 이어, 텍스트 전처리에 사용할 패키지를 불러옵니다.
10.1 Corpus/DTM/TDM 생각해보기
- 텍스트 데이터의 경우, 전처리가 정말 중요합니다. 특히 한글 텍스트 데이터를 분석하신다면, 사용자 사전을 만드시거나, 형태소 분석 이후 띄어쓰기가 제대로 되어 있는지 확인하시고 분석을 진행하셔야 합니다.
예를 들어 형태소 분석을 한 뒤, "기업문화" 라고 Parsing되어야 하는데,
"기업"과 "문화" 로 Parsing이 되었다면 사용자 사전을 통해 다시 잡아주거나, 직접 수정해줘야 합니다. - 앞서 텍스트 데이터 전처리에 대해 시간을 내어 차근차근 진행하시면서 어떤 방식으로 전처리를 하는지 완전히 이해하시는 것을 추천드립니다.
10.1.1 Corpus
한 사람의 주관식 응답 값을 형태소 분석하여 (명사+동사+형용사)로 만들고,
그것을 한 주머니에 담아 놓은 것을 Corpus 라고 생각하시면 쉽습니다.
- 그 예로 제가 공유 드렸던 현대자동차 기업 평판 데이터 첫 행에는 “대기업인 만큼 복지와 급여가 안정적이고 네임밸류가 아직 있고 문화도 좋아 지는 중” 이라는 문장이 들어 있었습니다.
## [1] "대기업인만큼복지와급여가안정적이고네임밸류가아직있고문화도좋아지는중"- 이를 NLP4kec 형태소 분석기를 활용하여 형태소 분석을 하면
“기업 만큼 복지 급여 안정 네임 밸류 있다 문화 좋다 지다 중” 으로 parsing 됩니다.
## [1] "기업 만큼 복지 급여 안정 네임 밸류 있다 문화 좋다 지다 중 "- 이렇게 Parsing된 결과와 Meta data와 content가 합쳐져서 Corpus가 됩니다.
## [1] "기업 만큼 복지 급여 안정 네임 밸류 있다 문화 좋다 지다 중 "## author : character(0)
## datetimestamp: 2020-07-12 13:19:43
## description : character(0)
## heading : character(0)
## id : 1
## language : en
## origin : character(0)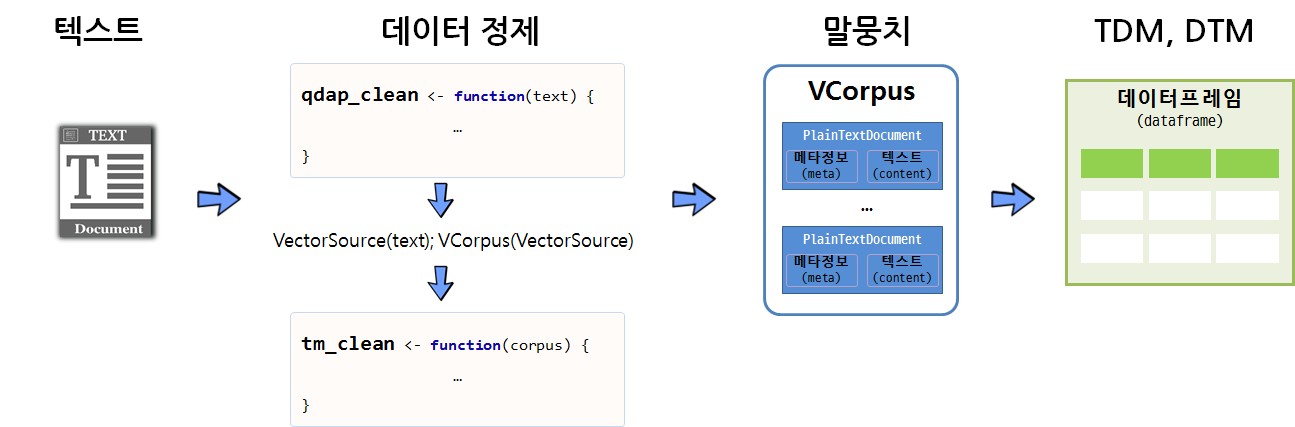
텍스트 분석 작업 흐름도 (출처: software carpentry)
10.1.2 DTM/TDM
TermDocumentMartix(), DocumentTermMatrix(): Corpus를 TermDocumentMartix() 함수에 넣으면 단어 -문서 행렬이 만들어지고, DocumentTermMatrix() 함수에 넣으면 문서 - 단어 행렬이 만들어집니다.
위와 같이 함수 하나로 간단하게 Corpus로부터 TDM, DTM을 만드실 수 있습니다.
inspect 함수를 사용하여 만든 TDM과 DTM을 확인해보면 문서 고유 번호와 해당 문서에 특정 단어가 몇 번 나오는지(단어 출현 횟수, Term Frequency) 정리된 테이블을 보실 수 있습니다.
TDM을 치환(Transpose) 한 것이 DTM 이라고 생각하시면 됩니다. 아래와 같이 dtm과 tdm을 들여다 보면 차이가 확실히 보이실 겁니다.
## <<DocumentTermMatrix (documents: 1214, terms: 664)>>
## Non-/sparse entries: 2854/803242
## Sparsity : 100%
## Maximal term length: 6
## Weighting : term frequency (tf)
## Sample :
## Terms
## Docs 글로벌 다니다 다양하다 대하다 따르다 분위기 비하다 자동차 자부심 편하다
## 109 0 0 0 0 0 0 0 1 1 0
## 116 1 0 0 0 0 1 1 0 0 0
## 1168 0 0 0 1 0 0 0 0 0 0
## 264 0 0 0 0 2 2 0 0 0 0
## 328 0 0 0 0 4 0 0 0 0 0
## 448 0 0 0 0 0 0 0 0 0 0
## 726 1 0 1 0 0 1 0 0 0 0
## 766 0 1 0 0 1 1 1 0 0 0
## 927 0 0 0 1 0 2 0 0 0 0
## 931 1 0 0 0 0 0 0 1 1 0## <<TermDocumentMatrix (terms: 664, documents: 1214)>>
## Non-/sparse entries: 2854/803242
## Sparsity : 100%
## Maximal term length: 6
## Weighting : term frequency (tf)
## Sample :
## Docs
## Terms 109 116 1168 264 328 448 726 766 927 931
## 글로벌 0 1 0 0 0 0 1 0 0 1
## 다니다 0 0 0 0 0 0 0 1 0 0
## 다양하다 0 0 0 0 0 0 1 0 0 0
## 대하다 0 0 1 0 0 0 0 0 1 0
## 따르다 0 0 0 2 4 0 0 1 0 0
## 분위기 0 1 0 2 0 0 1 1 2 0
## 비하다 0 1 0 0 0 0 0 1 0 0
## 자동차 1 0 0 0 0 0 0 0 0 1
## 자부심 1 0 0 0 0 0 0 0 0 1
## 편하다 0 0 0 0 0 0 0 0 0 010.2 텍스트 분석- 기본
10.2.1 단어 빈도 확인
이제 단어-문서 행렬까지 만들었으니, 직접 활용해볼 차례입니다.
활용에 앞서, DTM/TDM 을 만들 때 부여하는 가중치(weighting)에 대해 말씀드리고자 합니다.
weighting은 각 셀에 저장할 값을 계산하는 가중치 함수를 지정합니다. 기본은 단어의 출현 빈도 중심의 term frequency(TF)로 되어 있고, 이를 TF-IDF, Bin, Smart 등의 옵션으로 바꿀 수도 있습니다.
Term Frequency 는 단어의 빈도 수를 볼 때 사용하고, 대부분의 분석 기법에는 TF-IDF 가중치를 활용합니다.
## <<DocumentTermMatrix (documents: 1214, terms: 664)>>
## Non-/sparse entries: 2854/803242
## Sparsity : 100%
## Maximal term length: 6
## Weighting : term frequency (tf)## <<TermDocumentMatrix (terms: 664, documents: 1214)>>
## Non-/sparse entries: 2854/803242
## Sparsity : 100%
## Maximal term length: 6
## Weighting : term frequency (tf)dtm_corp, 문서 - 단어 행렬을 활용하여 단어별 출현한 빈도수를 계산해 보겠습니다.
dtm_corp는 단어 하나 당 하나의 열로 구성되어 있으므로, 단어의 출현 빈도 계산을 위해서는 열에 나타난 숫자를 모두 더해주면 됩니다.
열 기준 합계는 colsums() 함수로 구할 수 있는데, 현재 dtm_corp는 List 안에 List가 있는 형태이기 때문에 colsums 함수를 사용할 수 있는 matrix형태로 바꿔줘야 합니다.
# dtm_corp 를 matrix로 변환해서 열 합계를 구한 뒤, 그것을 wordFreq 로 만들어라
dtm_corp %>% as.matrix() %>% colSums()-> wordFreq
wordFreq[1:10]## 1000원 10개 10분 10퍼센트 12시 13년 14년 17시
## 1 1 1 1 2 1 1 1
## 19시 1시간
## 1 3위와 같이, wordFreq 를 보시면 단어와 해당 단어의 출현 횟수로 구성되어 있음을 알 수 있습니다.
wordFreq는 벡터나 데이터프레임이 아닌 value 입니다. 이름이 붙어 있는 숫자로 구성되어 있으며, 그 숫자 별로 단어가 속성(attribute) 값으로 포함되어 있습니다.
많이 출현한 단어가 가장 위로 올라오도록 조정하고, 상위 20개만 보겠습니다.
# wordFreq 변수를 내림 차순으로 정렬하라는 뜻입니다.
wordFreq <- wordFreq[order(wordFreq, decreasing = TRUE)]
head(x = wordFreq, n = 20)## 자동차 자부심 분위기 글로벌 다니다 비하다 따르다 대하다
## 126 125 122 81 72 58 50 49
## 다양하다 편하다 느끼다 괜찮다 배우다 다르다 가지다 나오다
## 48 44 43 41 38 37 36 30
## 생산직 계약직 대한민국 연구소
## 30 28 28 28저희는 처음 형태소 분석을 할 때, 명사+동사+형용사 를 포함하여 구분하였기 때문인지 있다, 하다, 좋다, 많다 와 같은 동사가 가장 많이 나왔습니다.
wordFreq라는 벡터를 데이터 프레임으로 보기 좋게 정리해보겠습니다.
wordDf <- data.frame( word = names(x = wordFreq),
freq = wordFreq,
row.names = NULL) %>% arrange(desc(x = freq))wordFreq는 value이기에 데이터프레임으로 바꿔줄 때, 속성(attribute)으로 포함되어 있는 이름을 word 열로 구성하고 해당 word의 출현 빈도를 freq 열로 만들어서 내림 차순으로 만들라는 뜻입니다.
그리고 그 두개의 열을 wordDf라는 데이터 프레임으로 만들었습니다.
위와 같이 단어와 빈도수로 구성된 단어-빈도 데이터프레임을 쉽게 만들 수 있습니다.
10.2.2 wordcloud 그리기
- R에서는 단어구름을 쉽게 만들 수 있는 wordcloud 패키지를 제공합니다. 해당 패키지를 설치하신 후, 라이브러리를 불러오시면, 아래와 같이 간단하게 단어구름을 그려보실 수 있습니다.
# install.packages('wordcloud')
library(wordcloud)
library(RColorBrewer)
#dev.new()
blues <- brewer.pal(8, "Blues")[-(1:2)]
wordcloud(wordDf$word, wordDf$freq, max.words=100, colors=blues,family="AppleGothic")
#wordDf 데이터 프레임에 들어있는 단어와 빈도를 활용하여, blues 색을 가지고 단어구름을 그려라
# family = AppleGothic 은 Mac OS 에서 한글 깨짐 현상 방지를 위해 넣은 옵션입니다. window를 사용하시면 지우시면 됩니다. 단어 구름을 그릴 때는, 형태소 분석 하실 때 명사만 가지고 하시는 것이 좋습니다.
KONLP 패키지의 extraNoun함수를 사용해서 형태소 분석을 다시 하신 뒤 dtm 변환하시고, 빈도수 데이터 프레임을 만드셔서 단어 구름 그리시면 됩니다!
아래와 같이 KONLP 패키지로 명사만 추출하여 그려보기도 했는데, 비슷하지만 다르게 나오는 것을 확인하실 수 있습니다.
library(KoNLP)
HMC_txt2 <- readRDS('현대자동차_기업평판_장점.RDS')
HMC_txt2 <- unique(HMC_txt2)
parsed_HMC_bykonlp <- extractNoun(HMC_txt2)
corp2 <- VCorpus(VectorSource(parsed_HMC_bykonlp))
corp2 <- tm_map(corp2, removePunctuation)
dtm_corp2 <- DocumentTermMatrix(corp2)
dtm_corp2 %>% as.matrix() %>% colSums()-> wordFreq2
wordDf2 <- data.frame( word = names(x = wordFreq2),
freq = wordFreq2,
row.names = NULL) %>% arrange(desc(x = freq))
wordcloud(wordDf2$word, wordDf2$freq, max.words=100, colors=blues, ,family="AppleGothic") * 세부 옵션은 wordcloud 함수 옵션 참고하시면 됩니다.
* 세부 옵션은 wordcloud 함수 옵션 참고하시면 됩니다.
10.2.3 트리맵 그리기
단어구름과 동일하게, treemap 패키지를 활용하시면 아주 쉽게 트리맵도 그리실 수 있습니다.
트리맵 패키지를 설치하시고, 아래와 같이 실행하시면 트리맵이 완성됩니다.
# install.packages('treemap')
library(treemap)
treemap(dtf = wordDf, title = '고빈도 단어 트리맵', index = c('word'), vSize = 'freq', fontsize.labels = 14, border.col = 'white', fontfamily.title = "AppleGothic", fontfamily.labels = "AppleGothic")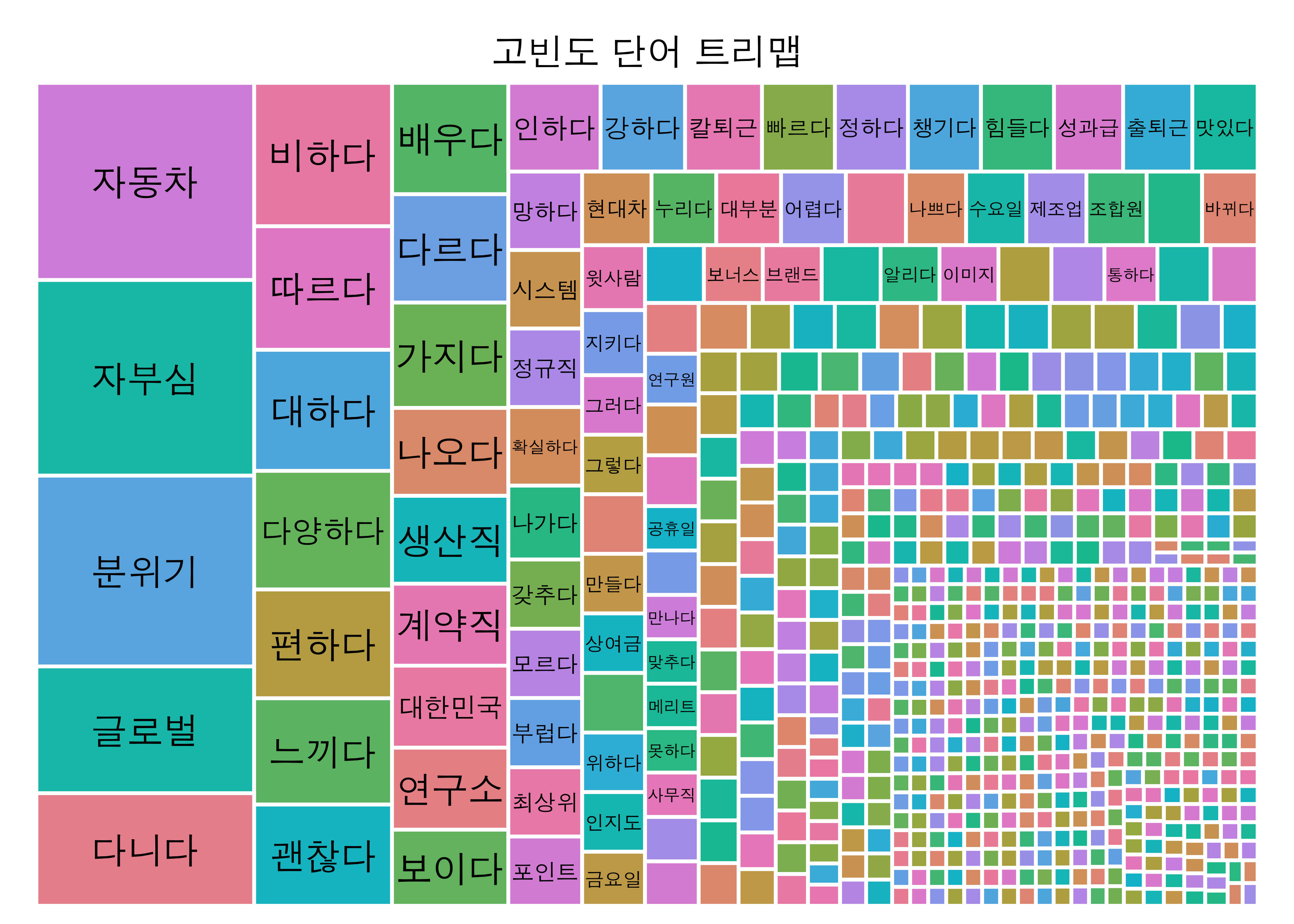
- treemap 함수의 세부 옵션은 treemap 옵션 참고 부탁드립니다.
10.2.4 단어 상관 행렬
앞서 빈도 수를 활용한 단어구름과 트리맵 그리기는 그 단어가 정말 중요한지, 그 단어가 어떤 맥락에서 나온 것인지 알 수가 없기에 개인적으로 거의 활용하지 않습니다.
저는 단어가 어떤 맥락에서 사용되었고, 어느정도 중요한지 알게 해주는 단어-네트워크맵, 토픽 모델링 등의 방법을 주로 사용하고 있으며, 이를 잘 사용하시기 위해서는 TF-IDF(단어 빈도 - 역 문서 빈도)에 대한 이해가 반드시 필요합니다.
이를 위해 TF-IDF에 대한 이해에 대한 글 먼저 읽고 오시면 좋을 것 같습니다.
단어간 상관 행렬은 앞서 만든 dtm을 가지고 간단하게 한 줄로 만드실 수 있습니다.
dtm_corp %>% as.matrix() %>% cor() -> corTerms
# dtm_corp를 cor()함수가 사용 가능한 매트릭스 형태로 바꾸고, 상관분석을 진행하라. 그리고 그 결과를 corTerms에 넣어라.
corTerms[1:5,1:5]## 1000원 10개 10분 10퍼센트 12시
## 1000원 1.0000000000 -0.0008244023 -0.0008244023 -0.0008244023 -0.001166362
## 10개 -0.0008244023 1.0000000000 -0.0008244023 -0.0008244023 -0.001166362
## 10분 -0.0008244023 -0.0008244023 1.0000000000 -0.0008244023 -0.001166362
## 10퍼센트 -0.0008244023 -0.0008244023 -0.0008244023 1.0000000000 -0.001166362
## 12시 -0.0011663618 -0.0011663618 -0.0011663618 -0.0011663618 1.000000000위와 같이 단어 간 상관계수가 나온 것을 확인하실 수 있습니다.
일반적으로 단어 상관 행렬을 만들 때는 DTM에서 가중치를 TF-IDF로 주고, 이를 활용해 상관 행렬을 만들어 활용합니다. 하지만, 저희가 만든 dtm_corp는 단순히 단어의 빈도(Term Frequency)를 가중치로 주었기 때문에 단어의 중요도를 고려한 상관행렬이 아닙니다.
다음 chapter에서 단어-상관 행렬에 대해 본격적으로 다뤄 보겠습니다.