1 Reveal patterns among user needs with Factor Analysis
Exploratory Factor Analysis (EFA) seeks to reveal hidden constructs in our data and is based on the “Common Factors Model” shown below (DeCoster 1998).
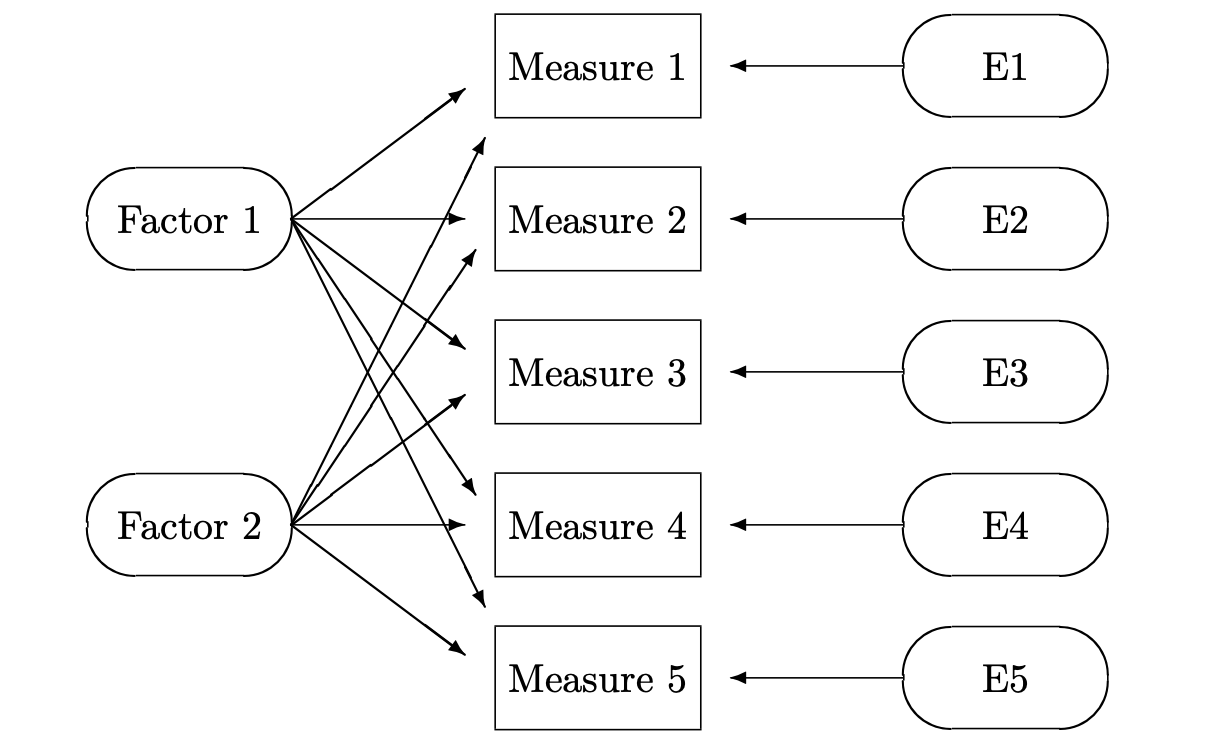
The basic idea is that we can capture direct measures of things like user attitudes and behaviors, and these measures are influenced by underlying “factors”, or latent variables, that we cannot directly measure (Qualtrics 2020a). The field of psychology made use of EFA in establishing its Big Five Personality Theory - that there exist five dimensions on which personalities vary across individuals in the population (Srivastava and John 1999).
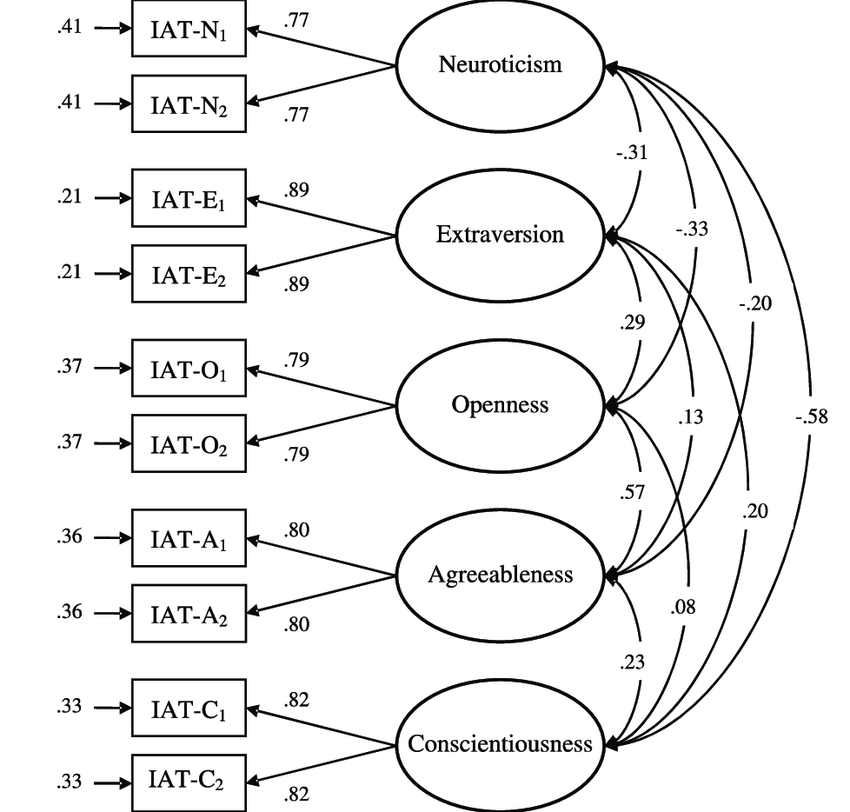
Here, the factors are the five personality dimensions. We cannot directly measure something abstract like extraversion, but we can show respondents attitudinal statements and capture agree/disagree ratings for each. These statements might be:
IAT-E1: “Talk a lot.”
IAT-E2: “Find it easy to approach others.”
IAT-E3: “Know how to captivate people.”
IAT-E4: “Make friends easily.”
IAT-E5: “Am the life of the party.”
I think most would agree that those who give high ratings on these statements are more extraverted, and those with low ratings are less extraverted (i.e. more introverted). To think about it in terms of the personality model, a person’s level of extraversion dictates, or influences, his or her responses on these five statements.
Also, if you give one statement a high rating, you’re likely to give the other four statements relatively high ratings. Intuitively we understand this to be true, if you “find it easy to approach others” you probably also “make friends easily”. Technically, this means that these five statements are correlated, and co-vary, with one another, thus indicating a common factor between them.
Let’s back up and pretend that the Big Five Personality theory has not been established, and we don’t have any intuition about the components of personality. We can show respondents a broad list of adjectives and descriptive statements about people (like the five above), and get agree/disagree ratings. EFA searches the data, looking for correlation patterns between the variables. Groups of variables that are highly correlated with each other are likely influenced by the same factors. We determine that five factors best describe our data (more on this later) and run an EFA.
The output shows to what degree each of the five factors influences our original variables - these are called factor loadings. This allows us to interpret the new factors in terms of the original attitudinal statements shown to respondents. For example, one of the five factors will have relatively high loadings on the five statements shown above - we will name this factor “extraversion”. This is done for the other four factors - look at the statements with the highest loadings and assign that factor a name based on our judgment. One by one we discover the other four personality dimensions (openness, neuroticism, agreeableness, and conscientiousness). This was how the Big Five Personality theory was originally developed (Srivastava and John 1999).
1.1 Factor Analysis for Product Design
Now let’s see how this all relates to product design. In this example, we run a two-phase, mixed-methods study. In Phase 1, we conduct thirty 1-on-1 interviews with users of several different Centralized Cryptocurrency Exchanges (CCE’s). The interviews are focused on uncovering user issues, and result in a list of 25 pain points related to the usage of CCE’s. Five of them are shown below.
## [1] "I worry about harmful government regulation that CCE’s may be subject to in the future."
## [2] "It bothers me that I don’t have full control of my assets (i.e. no private key)."
## [3] "I don’t have access to all the crypto assets I want to buy."
## [4] "My daily deposit limit is too small."
## [5] "I do not earn interest on my assets like I do in my traditional savings account."In this qualitative phase we go for breadth - we want to understand all the different aspects of CCE usage to get good coverage across the universe of pain points. Then, in Phase 2, we use Exploratory Factor Analysis (EFA) to see how user pain points relate to one another, and if there are major, underlying problem areas that cause these detailed issues. Understanding high-level problem areas will inform our product planning - it helps us zoom out and define the major dimensions of our product rather than trying to fix each pain point.
Some might wonder how this is different from qualitative methods like “affinity diagrams” and “thematic analysis”, which build-up high-level categories from individual user verbatims or observations. The end-goal is the same, but EFA is quantitative and defines categories based on correlated variables, rather than a product team’s assumptions about what the categories might be. This is not to besmirch qualitative methods - the product team may have more useful ways of categorizing the pain points. In practice, EFA and affinity diagrams are a complement to one another. For example, the Phase 2 EFA can be used to validate the Phase 1 affinity diagram.
After establishing the major problem areas we then score the current CCE platforms on each problem area. This competitive benchmark indicates where gaps exist in the market and helps to optimize our product positioning/differentiation strategy. Ideally, it leads us to blue oceans, rather than competing in red oceans (Kim and Mauborgne 2005).
1.2 Data Collection
Putting this into practice, we begin by capturing accurate/inaccurate ratings (6-pt scale) for each of the 25 pain points. We are trying to understand how relevant the pain point statements are to the CCE users. Matrix multiple choice questions work well for long lists of attribute ratings, but we randomize the pain points and divide them into five separate blocks.
Breaking up long lists is good practice to not discourage the respondent with long questions. It’s intended to slow down the answering process and improve data quality. Below is an example of one question block, just know that this was followed by four other question blocks.
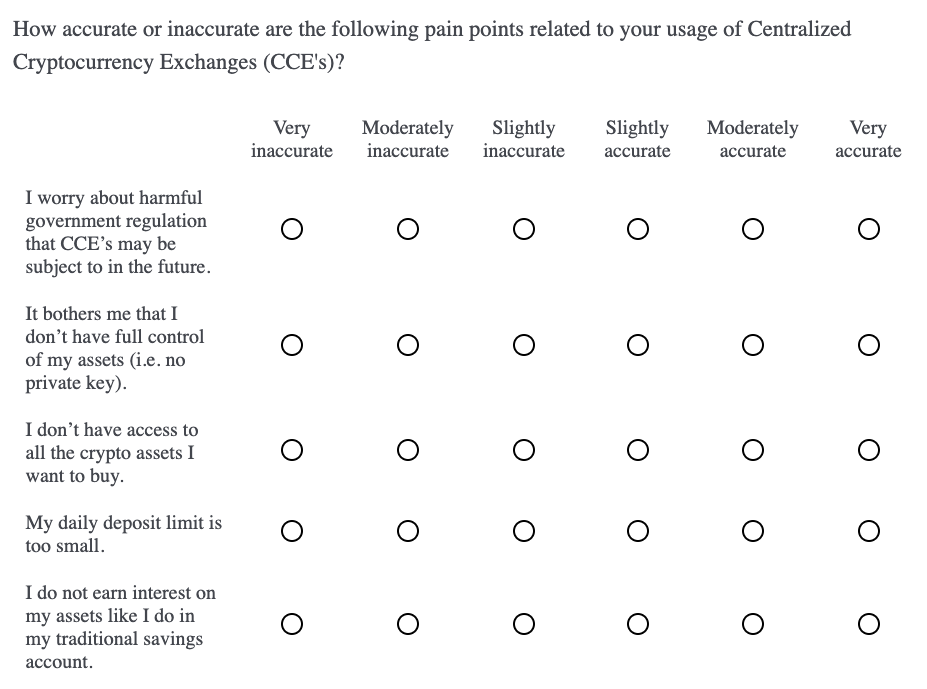
We administer this survey to 2436 current users of centralized cryptocurrency exchanges (CCE’s). This is a relatively large sample as experts say anything over 300n is adequate (Thompson 2004). Another rule of thumb is to have at least 10 respondents per measure in the factor model. This would suggest at least 250n (25 pain points x 10) in our case. Also, we stratify the sample across several different platforms (i.e. Coinbase, Kraken and Binance) to get representation of the CCE category as a whole.
1.3 Analysis
In the resulting data frame we have a 1-6 likert scale rating for each of the 25 pain points.
## q1 q2 q3 q4 q5 q6 q7 q8 q9 q10 q11 q12 q13 q14 q15 q16 q17 q18 q19 q20 q21
## 1 6 6 5 6 5 6 6 6 1 3 2 1 6 5 6 3 5 2 2 3 4
## 2 4 3 1 5 1 3 2 4 2 4 3 6 4 2 1 6 3 2 6 4 3
## 3 4 4 5 6 5 4 3 5 3 2 1 3 2 5 4 3 3 4 2 3 5
## 4 4 5 2 2 1 5 5 5 2 2 3 4 3 6 5 2 4 2 2 3 5
## 5 1 5 6 5 6 4 3 2 4 5 2 1 2 5 2 2 2 2 2 2 6
## 6 2 6 5 6 5 3 5 6 3 6 2 2 4 6 6 4 4 4 6 6 6
## q22 q23 q24 q25 platform
## 1 3 5 6 1 Coinbase
## 2 2 4 5 3 Binance
## 3 3 5 6 3 Binance
## 4 2 5 5 5 Binance
## 5 1 5 5 2 Binance
## 6 1 5 6 1 CoinbaseStandardizing likert data allows for better comparison between respondents and reduces the negative effects of scale-use biases (e.g. respondents are known to use scales differently from one another) (Chapman and Feit 2019). This is done by subtracting the mean rating of a pain point from each rating for that pain point ( q1.centered = q1 - mean(q1) ). The new vector is then divided by the standard deviation of that vector ( [q1.centered] / [sd(q1)] ). Luckily, we can standardize all variables in our data set at once with one simple function.
## q1 q2 q3 q4
## Min. :-0.9809 Min. :-3.3141 Min. :-2.8147 Min. :-2.5896
## 1st Qu.:-0.9809 1st Qu.:-0.7209 1st Qu.:-0.4880 1st Qu.:-0.5177
## Median :-0.2625 Median : 0.1434 Median : 0.2875 Median : 0.1730
## Mean : 0.0000 Mean : 0.0000 Mean : 0.0000 Mean : 0.0000
## 3rd Qu.: 0.4559 3rd Qu.: 1.0078 3rd Qu.: 1.0631 3rd Qu.: 0.8636
## Max. : 2.6111 Max. : 1.0078 Max. : 1.0631 Max. : 0.8636
## q5 q6 q7 q8
## Min. :-2.8547 Min. :-2.9342 Min. :-2.5937 Min. :-2.5816
## 1st Qu.:-0.4658 1st Qu.:-0.4683 1st Qu.:-0.3059 1st Qu.:-0.2509
## Median : 0.3305 Median : 0.3536 Median : 0.4567 Median : 0.5260
## Mean : 0.0000 Mean : 0.0000 Mean : 0.0000 Mean : 0.0000
## 3rd Qu.: 1.1268 3rd Qu.: 0.3536 3rd Qu.: 0.4567 3rd Qu.: 0.5260
## Max. : 1.1268 Max. : 1.1756 Max. : 1.2193 Max. : 1.3030
## q9
## Min. :-1.1013
## 1st Qu.:-1.1013
## Median :-0.3675
## Mean : 0.0000
## 3rd Qu.: 1.1000
## Max. : 2.5676Looking at variable correlation is a good first step, since we know that EFA uses inter-variable correlation when calculating the factors. The “hclust” argument in the function below helps us see these patterns by grouping variables with high correlation next to each other.
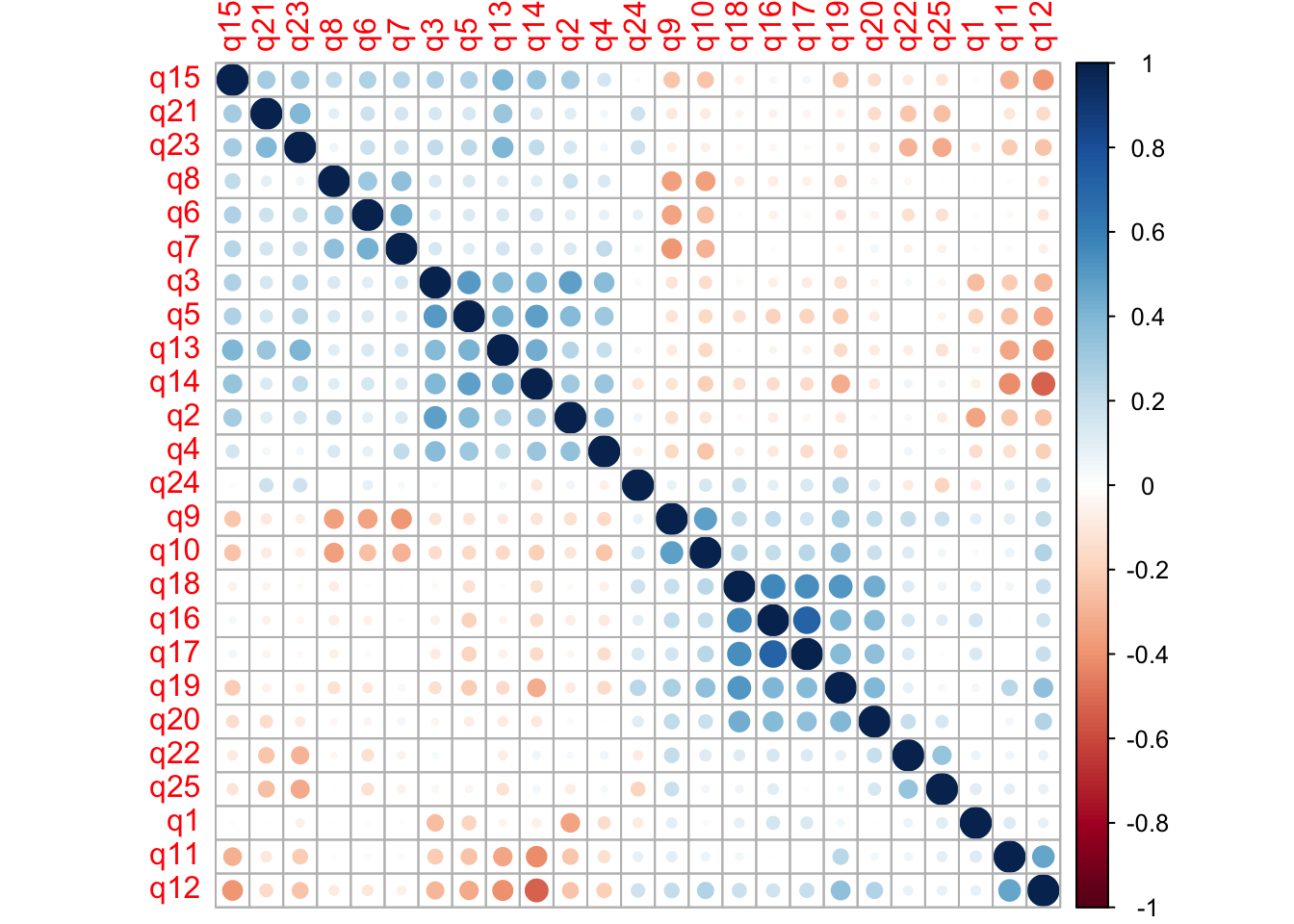
At a quick glance I see high positive correlation between q16-q20. There’s another group of high positive correlation between q2-q5 and q13-q15. I also see high negative correlation between q6-q10. We don’t need to read any further into it, other than it’s good to see high inter-variable correlations at this point.
1.3.1 Estimate Number of Factors
In EFA, we must pre-specify the number of factors that we want to include in the model. Perhaps we already have an idea from our qualitative analysis and affinity mapping. There are quantitative methods for estimating the best number of factors to be included, called scree tests. Essentially, scree tests make recommendations that maximize the percentage of variance explained with the least amount of factors (Chapman and Feit 2019).
## noc naf nparallel nkaiser
## 1 6 1 6 6Three of the four tests suggest a 6 factor model. Another method is to include only factors with an eigenvalue of 1 or more. Eigenvalues of zero are considered unimportant because the original variables have eigenvalues of 1 (Chapman and Feit 2019). This means that factors with eigenvalues less than 1 explain less variance than a single one of our original variables. This is the opposite of what we are trying to do in EFA - explain variance in our data with a reduced number of dimensions.
## [1] 5.0685162 2.7624793 2.1526230 1.8923330 1.5175329 1.0788293 0.8309057
## [8] 0.8045002 0.7140883 0.7015381 0.6808421 0.6489735 0.6312563 0.5880320
## [15] 0.5659652 0.5448396 0.5199335 0.4938686 0.4827362 0.4425003 0.4288706
## [22] 0.4070974 0.3888753 0.3847626 0.2681008We see the first 6 factors have eigenvalues greater than one, although the 6th barely makes the cut. Still, we will proceed with 6 factors in our initial model and can make changes, if necessary, based on personal judgment.
1.3.2 Factor Model
The first step of EFA extracts the factors from our data’s correlation matrix. Then, the factors are “rotated”. Rotation is a complex subject, but in essence, it tries to improve the interpretability of the factors (Chapman and Feit 2019). The default rotation method is “varimax”, which assumes factors to be independent, and thus uncorrelated, from one another. In this case, I believe that the high-level user problems are related to one another, so I proceed with an oblique, rather than orthogonal, rotation method called “oblimin”. This allows for inter-factor correlation.
The output shows how the pain points “load” onto each factor. The higher the absolute value of the loading, the more that factor influences a particular pain point. You can also think about these factor loadings as regression coefficients, where the factor is regressed on each pain point (DeCoster 1998). Thus, larger regression coefficients indicate a stronger relationship. Positive and negative sign matter as well (more on this below).
##
## Loadings:
## Factor1 Factor2 Factor3 Factor4 Factor5 Factor6
## q1 0.108 -0.131 -0.562 0.273
## q2 0.696
## q3 -0.119 0.608 0.127
## q4 0.194 0.406 -0.153 0.137
## q5 -0.163 -0.203 0.446 0.225
## q6 0.546 0.181
## q7 0.150 0.668 0.193
## q8 0.561
## q9 -0.662 0.287
## q10 0.131 0.188 -0.555
## q11 -0.136 0.579 0.108 -0.148
## q12 0.671
## q13 -0.361 0.139 0.372 0.262
## q14 -0.546 0.218 0.274
## q15 0.177 -0.409 0.261 0.226
## q16 0.855
## q17 0.853
## q18 0.639 0.163 0.116
## q19 0.381 0.463 -0.135 0.119
## q20 0.400 0.252 0.163 -0.131 0.189
## q21 0.549
## q22 0.119 0.100 -0.448 0.273
## q23 -0.108 0.661
## q24 0.350 0.143 0.359
## q25 -0.517 0.324
##
## Factor1 Factor2 Factor3 Factor4 Factor5 Factor6
## SS loadings 2.321 1.988 1.974 1.722 1.656 0.716
## Proportion Var 0.093 0.080 0.079 0.069 0.066 0.029
## Cumulative Var 0.093 0.172 0.251 0.320 0.386 0.415It can be a little daunting to look at this raw output. One thing I do notice is that Factor 6 has relatively small loadings compared to the first five factors. Thus, I drop down to a five factor model. Since we only care about relatively high factor loadings, I will not print factor loadings with an absolute value of .5 or lower.
According to experts, factor loadings should be at least greater than .5, but ideally all would be greater than .7 (Hair 2010). I’ve also seen EFA’s that set the threshold at .3, so this cutoff is somewhat arbitrary and dependent on the data (Chapman and Feit 2019). Just know that lower factor loadings indicate a weaker relationship between the factors and the variables.
final.factors <- factanal(dat.scaled, factors = 5, rotation = "oblimin")
print(final.factors$loadings, cutoff = .5)##
## Loadings:
## Factor1 Factor2 Factor3 Factor4 Factor5
## q1
## q2 0.606
## q3 0.676
## q4
## q5 0.581
## q6 0.536
## q7 0.633
## q8 0.572
## q9 -0.662
## q10 -0.577
## q11 0.545
## q12 0.651
## q13
## q14 -0.513
## q15
## q16 0.862
## q17 0.818
## q18 0.662
## q19
## q20
## q21 0.536
## q22
## q23 0.646
## q24
## q25 -0.534
##
## Factor1 Factor2 Factor3 Factor4 Factor5
## SS loadings 2.409 1.998 1.966 1.819 1.640
## Proportion Var 0.096 0.080 0.079 0.073 0.066
## Cumulative Var 0.096 0.176 0.255 0.328 0.393Now the noise really drops away and we see clear variable groupings with large factor loadings. You may notice that some loadings are positive and others are negative. This is due to the actual statements that we used during data collection. When creating the statements, some pain points were reversed and phrased in positive terms. For example, one pain point was “expensive transactions fees”. The corresponding statement shown to respondents was: “CCE’s fees are reasonable - I’m willing to pay for the convenience.” Lower ratings of this statement correspond to greater pain point relevance; therefore, a negative factor loading makes sense for this statement (q14).
We flip statement polarity like this as an attention check for respondents - it makes the survey flow less predictable to the respondent, thus discouraging him/her from hurrying through and giving rushed answers. Make sure to check that all negative factor loadings correspond to questions with reversed phrasing.
We now use something called a “path analysis”, which shows the dependencies between factors and variables. These path diagrams imply causation - that major problem areas (i.e. our factors) cause the individual pain points.
suppressWarnings(semPaths(final.factors, what="est", residuals=FALSE, cut=0.5,
posCol=c("white", "darkgreen"),
negCol=c("white", "red"), dge.label.cex=0.75,
nCharNodes=7, sizeMan = 3.5, sizeMan2 = 3.5,
layout = "spring"))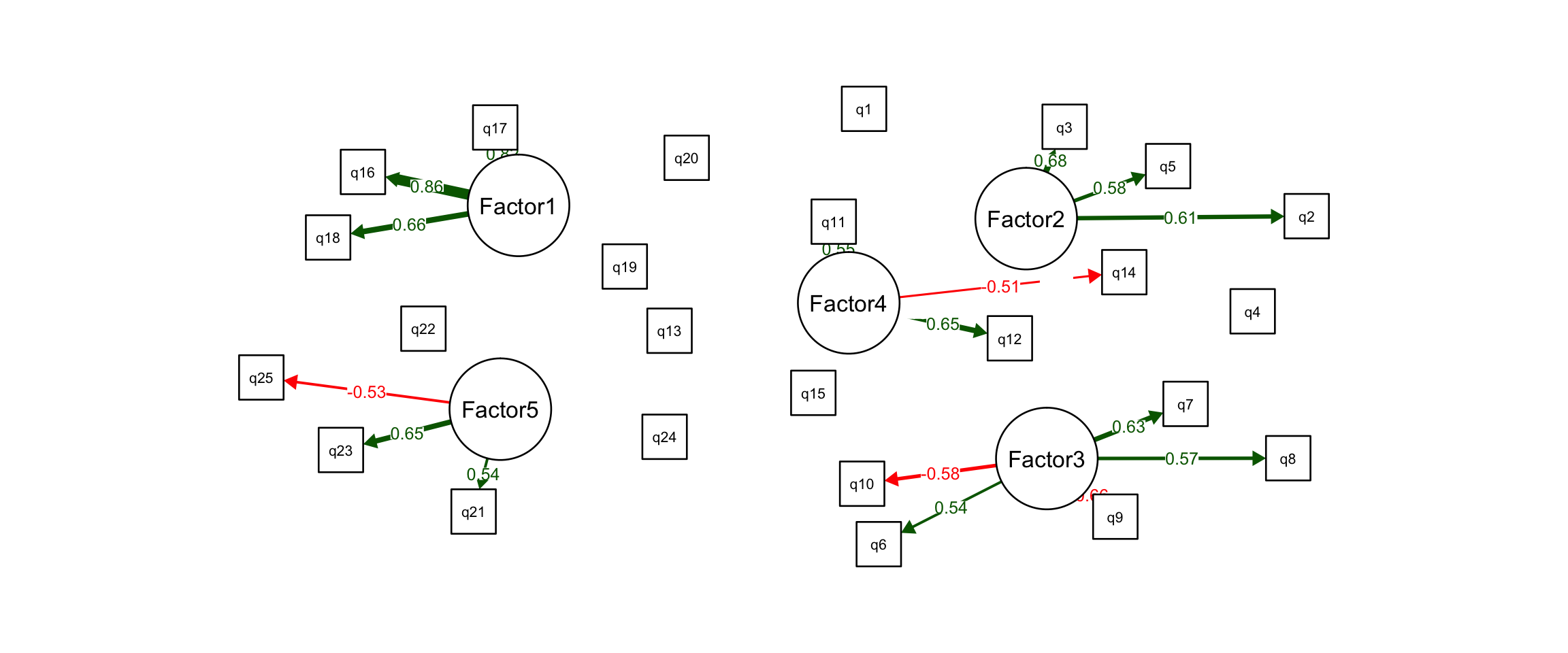
Now, let’s actually look at the pain point statements that group together in our model. Hopefully they make sense to us and relate to one another in a way that we can interpret them, and thus “discover” the major problems areas.
attributes(final.factors$loadings)$dimnames[[1]] <- key
F1 <- names(final.factors$loadings[grep(pattern = TRUE,
x = abs(final.factors$loadings[,1]) > .5),1])
F2 <- names(final.factors$loadings[grep(pattern = TRUE,
x = abs(final.factors$loadings[,2]) > .5),2])
F3 <- names(final.factors$loadings[grep(pattern = TRUE,
x = abs(final.factors$loadings[,3]) > .5),3])
F4 <- names(final.factors$loadings[grep(pattern = TRUE,
x = abs(final.factors$loadings[,4]) > .5),4])
F5 <- names(final.factors$loadings[grep(pattern = TRUE,
x = abs(final.factors$loadings[,5]) > .5),5])
user.problems <- list("Factor 1" = F1,
"Factor 2" = F2,
"Factor 3" = F3,
"Factor 4" = F4,
"Factor 5" = F5)
print(user.problems)## $`Factor 1`
## [1] "My daily deposit limit is too small."
## [2] "My daily withdrawal limit is too small."
## [3] "I had trouble transferring funds into my CCE wallet."
##
## $`Factor 2`
## [1] "I worry about harmful government regulation that CCE’s may be subject to in the future."
## [2] "The ethics of CCE’s concern me like faking trade volume, insider trading, and price manipulation."
## [3] "Centralization concerns me from the perspective of infrastructure risk like network downtimes."
##
## $`Factor 3`
## [1] "It bothers me that I don’t have full control of my assets (i.e. no private key)."
## [2] "As a central repository of assets, CCE’s are a prime target for thieves and hackers."
## [3] "Immediately after purchasing I transfer my assets to cold storage anyways."
## [4] "I trust CCE’s to properly custody my assets with the highest security and privacy procedures."
## [5] "I’m okay leaving my assets in the CCE hot wallets."
##
## $`Factor 4`
## [1] "I do not understand how transaction fees are calculated."
## [2] "I never run into issues with daily purchase limits."
## [3] "CCE’s fees are reasonable - I’m willing to pay for the convenience."
##
## $`Factor 5`
## [1] "I do not earn interest on my assets like I do in my traditional savings account."
## [2] "It bothers me that I am unable to lend, borrow or collateralize my assets from my CCE wallet."
## [3] "I don’t need smart contract functionality with the assets in my CCE wallet."Issues with bank integration (Factor 1)
These pain points relate to transferring funds in and out of the CCE, and to and from a user’s traditional bank account.
Distrust centralization (Factor 2)
These pain points relate to a general distrust in the policies, regulations and infrastructure of centralized entities. We know that one of the largest themes in the crypto space is “decentralization” so it makes sense that users are somewhat at odds with centralized exchanges.
Security and custody (Factor 3)
These pain points relate to custody concerns with a CCE due to the of risk of theft, lack of control over assets, or preference for self-custody (i.e. cold storage).
Transactions and fees (Factor 4)
These pain points relate to the UX of purchasing crypto assets on CCE’s. Some have trouble with purchase limits imposed by CCE’s and do not understand fee structure, or believe the fees are too expensive.
Lacks functionality with dApps (Factor 5)
These pain points relate to a general lack of CCE wallet functionality. Users are required to transfer their assets into decentralized wallets to gain access to DeFi and other dApps, which grant new functionalities to their crypto assets.
1.4 Factor Scores by Brand for Market Gap Analysis
Now that we have built a factor model and understand the constituent factors, we can score each centralized cryptocurrency exchange (CCE) on the five factors. Again, the factors are the major user problems, so we do this to see how our competitors perform in these areas. If we see a gap in the market where our competitors perform poorly, then a new product offering may fill this unmet market need.
We do this by, first, generating a factor score for each respondent on each of the five factors. Then we calculate a mean factor score for the three CCE platforms, by averaging the factor scores across users of the same platform.
final.factors.bartlett <- factanal(dat.scaled, factors = 5,
rotation = "oblimin", scores = "Bartlett")
factor.scores <- as.data.frame(final.factors.bartlett$scores)
factor.scores[,"platform"] <- dat[,26]
factor.scores.mean <- aggregate(. ~ platform, data=factor.scores, mean)
rownames(factor.scores.mean) <- factor.scores.mean[,1]
factor.scores.mean <- factor.scores.mean[,-1]
names(factor.scores.mean) <- c("Issues with bank integration",
"Distrust centralization",
"Security and custody",
"Transactions and fees",
"Lacks functionality with dApps")
factor.scores.mean## Issues with bank integration Distrust centralization
## Binance -0.14387198 -0.3702239
## Coinbase 0.11105559 0.2007045
## Kraken -0.02289722 0.1366543
## Security and custody Transactions and fees
## Binance -0.127726776 0.09412115
## Coinbase 0.085858750 -0.09076918
## Kraken 0.008947095 0.05662751
## Lacks functionality with dApps
## Binance 0.1454758
## Coinbase -0.1934813
## Kraken 0.2097951The greater the score, the worse a platform performs for its users on that problem area. Coinbase performs worst on the first three problem areas, but does best on the last two: “transactions and fees” and “lacks functionality with dApps”. Binance does best on the first three factors: “issues with bank integration”, “distrust centralization”, and “security and custody”. Kraken performs relatively poorly across all five. In this way, we can search for gaps in the market, where major problem areas go unmet. Coinbase by far has the greatest market share. Perhaps we can improve the bank integration process and emphasize ease-of-transfer between CCE wallet and cold storage. See the scorecard below for a quick visual of factor scores by brand. Darker red means worse.
heatmap.2(x = as.matrix(factor.scores.mean), margins = c(25,25), key = FALSE, dend = "none", trace = "none", col=brewer.pal(5, "Reds"))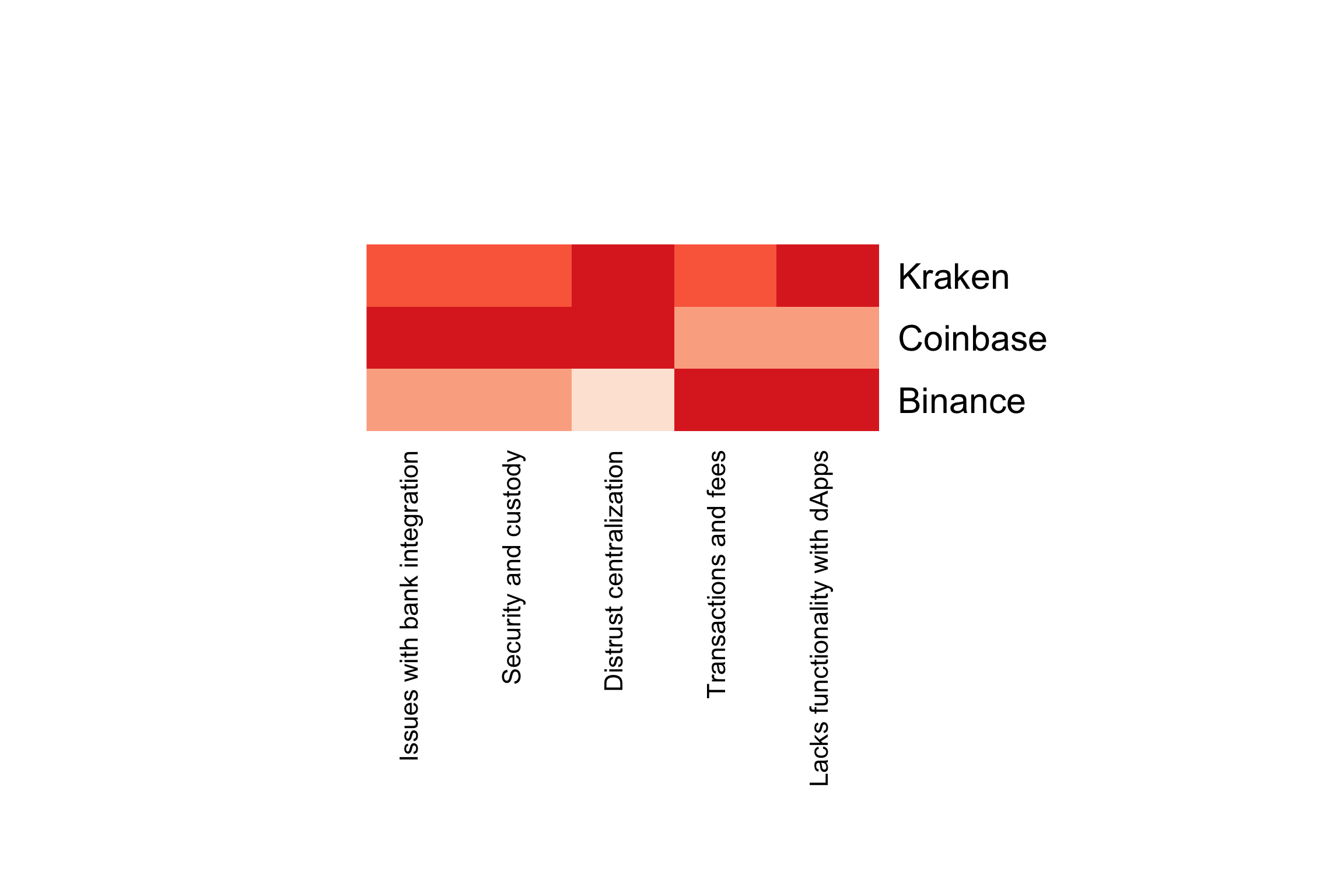
1.5 Conclusion
We began this study with a list of 25 specific pain points related to CCE usage and captured in previous 1-on-1 interviews. Exploratory factor analysis (EFA) was used to uncover the major problem areas that cause these pain points. We ended with a 5 factor model and interpreted the factors based on small variable groups with large factor loadings. Finally, factor scores were calculated for each respondent and averaged to get mean factor scores for each brand. Comparing the brand scores across the 5 factors reveals gaps in the market.
Factor analysis can also be used to improve on brand- and product-tracking metrics like CSAT or SEQ. Take “customer experience” for example - it’s an abstract concept that we cannot directly measure, but we can capture ratings on the different facets of a customer’s experience. For example, “based on your most recent experience, rate your satisfaction with brand X on…”
- overall quality
- value
- purchase experience
- user experience
We can build a 1-factor model on these four variables. This has an advantage over a simple average of the four scores, because the factor weights the variables based on the proportion of variance they explain. A factor like this may more accurately gauge CX than a single metric like CSAT.
Bibliography
Chapman, C, and E Feit. 2019. R for Marketing Research and Analytics. New York, NY: Springer Berlin Heidelberg.
DeCoster, Jamie. 1998. “Overview of Factor Analysis.” Stat Help. http://www.stat-help.com/notes.html.
Hair, Joseph F., ed. 2010. Multivariate Data Analysis. 7th ed. Upper Saddle River, NJ: Prentice Hall.
Kim, W. Chan, and Renée Mauborgne. 2005. Blue Ocean Strategy: How to Create Uncontested Market Space and Make the Competition Irrelevant. Boston, Mass: Harvard Business School Press.
Qualtrics. 2020a. “Factor Analysis: Definition, Methods & Examples // Qualtrics.” Qualtrics. https://www.qualtrics.com/experience-management/research/factor-analysis/.
Srivastava, Sanjay, and Oliver P. John, eds. 1999. “The Big-Five Trait Taxonomy: History, Measurement, and Theoretical Perspectives.” In Handbook of Personality: Theory and Research, 2nd ed, 2:102–38. New York: Guilford Press.
Thompson, Bruce. 2004. Exploratory and Confirmatory Factor Analysis: Understanding Concepts and Applications. Washington: American Psychological Association. https://doi.org/10.1037/10694-000.