Data Science for Human-Centered Product Design
2021-02-15
Introduction
This is a data science tutorial with seven open-source projects that show how statistics and machine learning can be applied to user survey data. The purpose is not to prescribe techniques, but to demonstrate the use of data science in the context of product design. I’ve compiled what I know on the topic, and hope readers adopt some of these techniques and use them in concert with qualitative research and entrepreneurial thinking to build better products. Let’s quickly preview the seven different use-cases.
First, we must develop an understanding of the market and the problem space being designed for. This type of activity will generate a long list of specific user pain points and unmet needs. In Project 1, we use factor analysis to reveal patterns among these pain points and unmet needs.
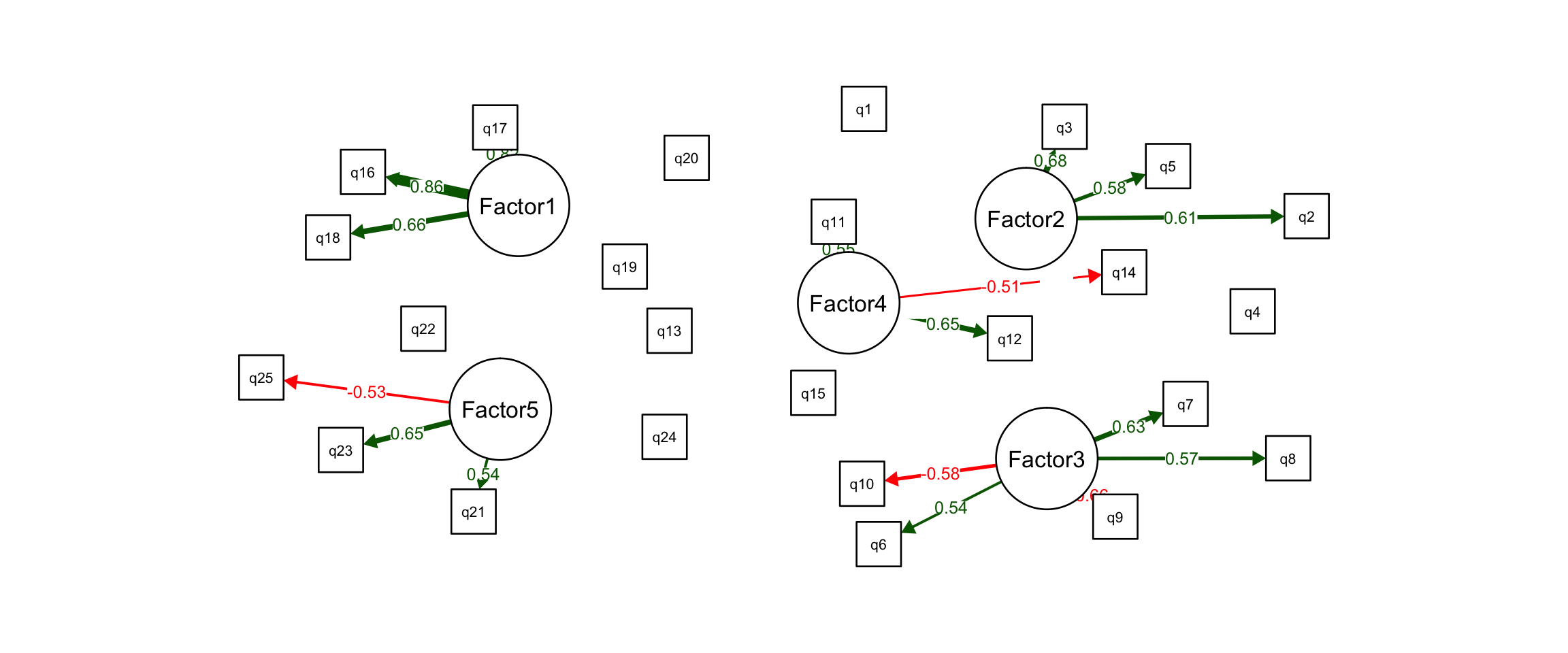
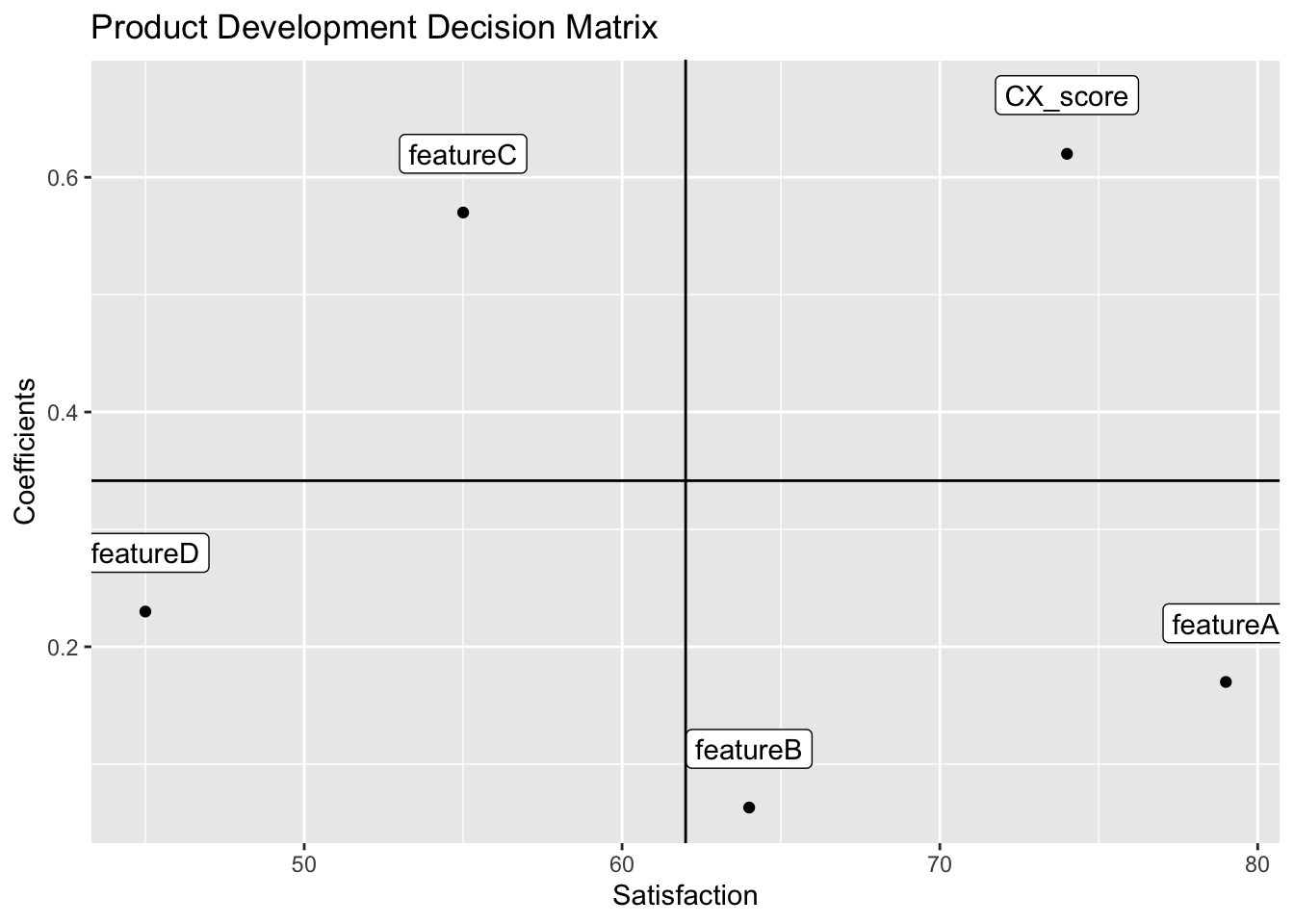
This results in factors, or major problem dimensions, which we can then design a product around. We can also score competitor products on these major problem dimensions and identify gaps in the market. This enables us to properly differentiate the product from competitors and focus product benefits on the most underserved areas in the market.
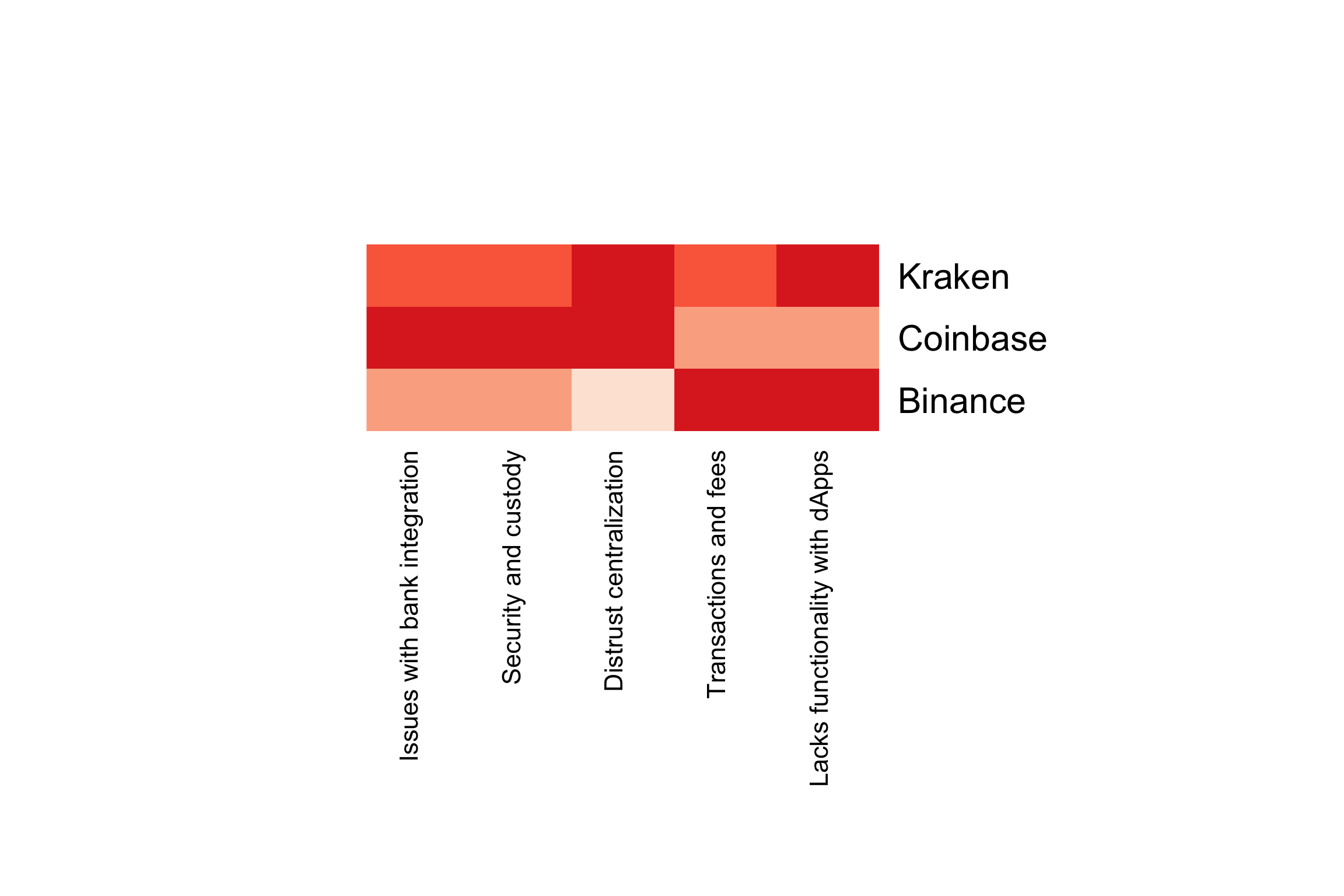
Markets are made up of user groups with different product wants and needs. Rather than designing a product for the average user in a market, we can target a specific user group, and design a product optimized to their wants and needs. This is also a good for identifying early-adopter groups and fine-tuning marketing strategies like content and ad-targeting.
In Project 2, we show how to do this and segment a market into its constituent user groups using a machine learning technique called clustering. Users are grouped together based on their product attitudes and usage. The goal is to maximize the similarity of users in a group, while maximizing dissimilarity with users in other groups. In this way, we get distinct user groups with different product wants and needs from one another. We can then target user groups based on market opportunity and alignment with our product vision.

After talking with target users, and studying their problem space, you will likely have a long list of potential features to include in your product. This is a classic problem for startups - to have too many features to include in the first release; however, lean startup philosophy warns against feature overload and delaying product launch. Companies should launch with the smallest feature set necessary. Clearly, we need a way to prioritize the features in our list, and determine which are most important to our target users.
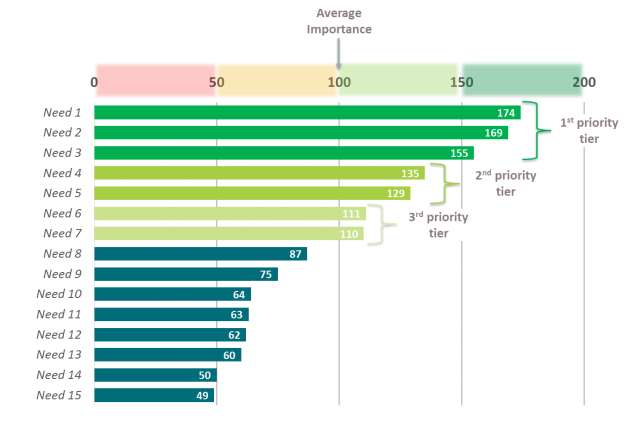
The problem is that users will say they “want it all”. We cannot prioritize features when users rank all of them as highly important. Project 3 gives a solution to this problem with a technique called Max Diff. It forces users to make trade-offs between the features, and results in relative feature importance. In this way, we can rank order the features from greatest to least importance, and decide which features to include in our product, all based on user input.
Project 4 builds on this, and provides a more sophisticated way for deciding on the feature sets and pricing tiers to offer, using a technique called Choice-Based Conjoint (CBC). Basically, a product can be broken down into its constituent parts, like individual features, price and brand, and CBC shows us how users value each of these parts when making their purchase decision. This reveals which product attributes are most important to users, and which feature combinations will perform best in the market. CBC results in dynamic product design tools like market simulators and sensitivity plots, which allow us to predict how a product will perform in a market, given its specific feature set and price.
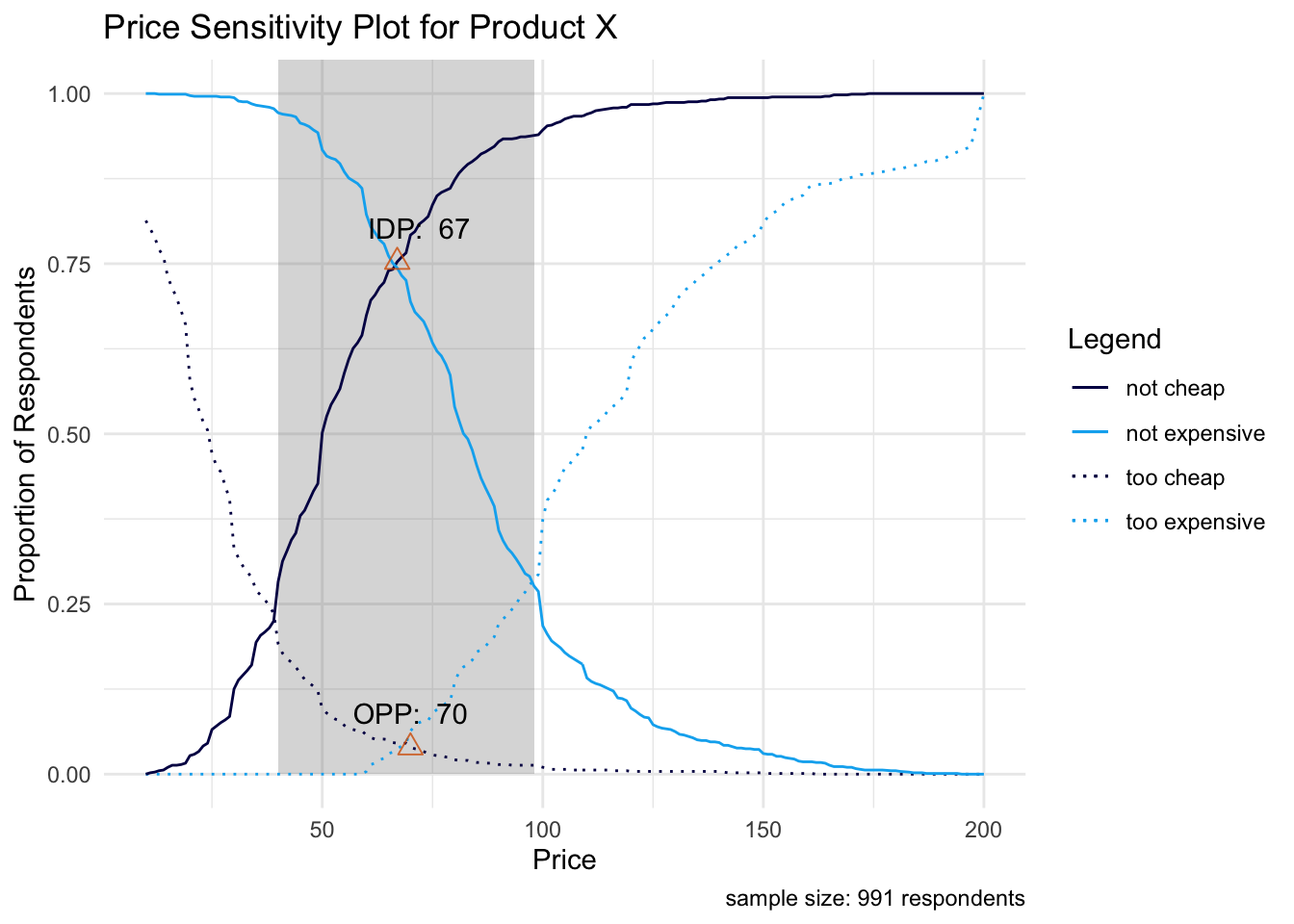
Pricing can be tricky, especially for novel products and categories. Once we have a clearly defined product concept, we can capture price expectations from our target customers. Project 5 shows lightweight price optimization techniques that can be done with 6 survey questions or less. Price can be optimized in several different ways. For example, an early-stage startup may want to slightly lower the price of its product in order to maximize user adoption, and establish a network effect as soon as possible. In other cases, companies may want to be more direct and price the product for maximum revenue.
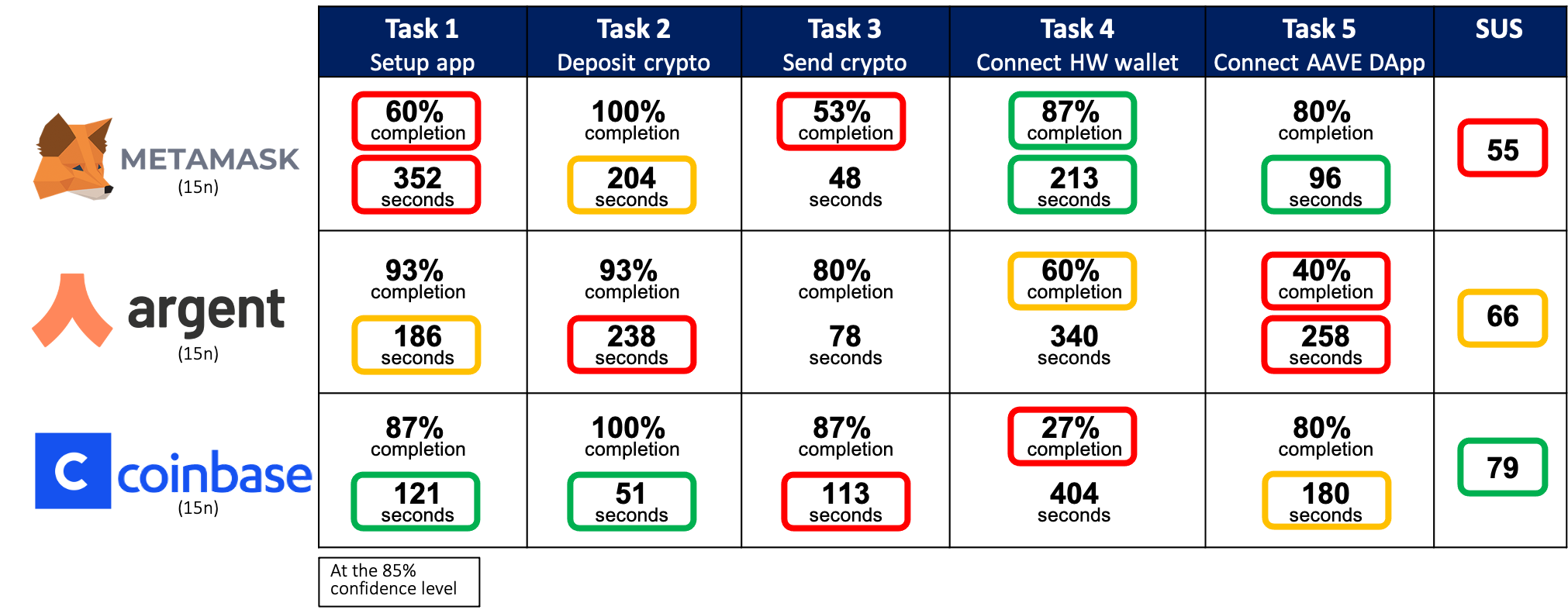
Once your product has been released, you’ll want to measure its user experience and compare its performance with competitors. This will reveal areas of strength and weakness, indicating where to focus product improvement efforts during the next design sprint. Also, we can track user experience across different releases, which allows us to verify product improvements and get an ROI metric for our design decisions. We show how to do this with usability testing and inferential statistics in Project 6, resulting in a scorecard (shown below).
Finally, in Project 7, we show something called a drivers analysis, which uses a technique called multiple linear regression to reveal the features in our product that “drive” satisfaction or dissatisfaction. This tells us which features are most impactful to the user experience as a whole, and gives us a roadmap for which features to improve in the next design sprint.