3 Visualización de datos con gráficos
En esta capítulo aprenderás a visualizar datos en R. Para esto usarás el paquete ggplot2. Si bien hay muchos paquetes en R que permiten visualizar datos, ggplot2 se destaca por ser muy versátil y fácil de usar. Una de las ventajas pricipales de ggplot2 es que utiliza un lenguaje, o una gramática, especialmente diseñada para describir y construir gráficos.
Este capítulo no pretende ser una referencia exahustiva del paquete ggplot2. Más bien, resume los conocimientos básicos que vas a necesitar para poder empezar a construir los gráficos más comunes. Para más detalles, recomendamos dos libros:
El primero de estos libros explica en mayor profundidad la gramática de gráficos de ggplot2. El segundo es un compendio ordenado de ejemplos que permite buscar rápidamente el tipo de gráfico que uno quiere construir, y copiar el código fuente que permite hacerlo.
El paquete ggplot2 está incluído en tidyverse. Por lo mismo, para empezar basta usar el siguiente comando:
3.1 Ejemplo: Pingüinos de Palmer
En este capítulo, usaremos la base de datos del paquete palmerpenguins11. Esta base de datos contiene distintas mediciones para tres especies de pingüinos encontrados en el archipiélago de Palmer, en la Antártica. Estas tres especies son los Chinstrap, Gentoo y Adélie.

Figure 3.1: Las tres especies de pingüinos. Arte por Allison Horst.
La primera vez que uses esta base de datos un computadores necesario instalar el paquete palmerpenguins:
Cada vez que lo vayas a usar, es necesario que cargues el paquete:
La base de datos quedará automáticamente disponible en el entorno de R y se llamará penguins. Para ver más información respecto a la base de datos (origen, variables, etc.) puedes ejecutar:
## starting httpd help server ... doneLa base de datos tiene 8 variables, entre las cuales se encuentran bill_length_mm y bill_depth_mm. Estas representan el largo y profundidad del pico de cada pingüino. Para entender mejor qué significan estas medidas, considera la siguiente figura:
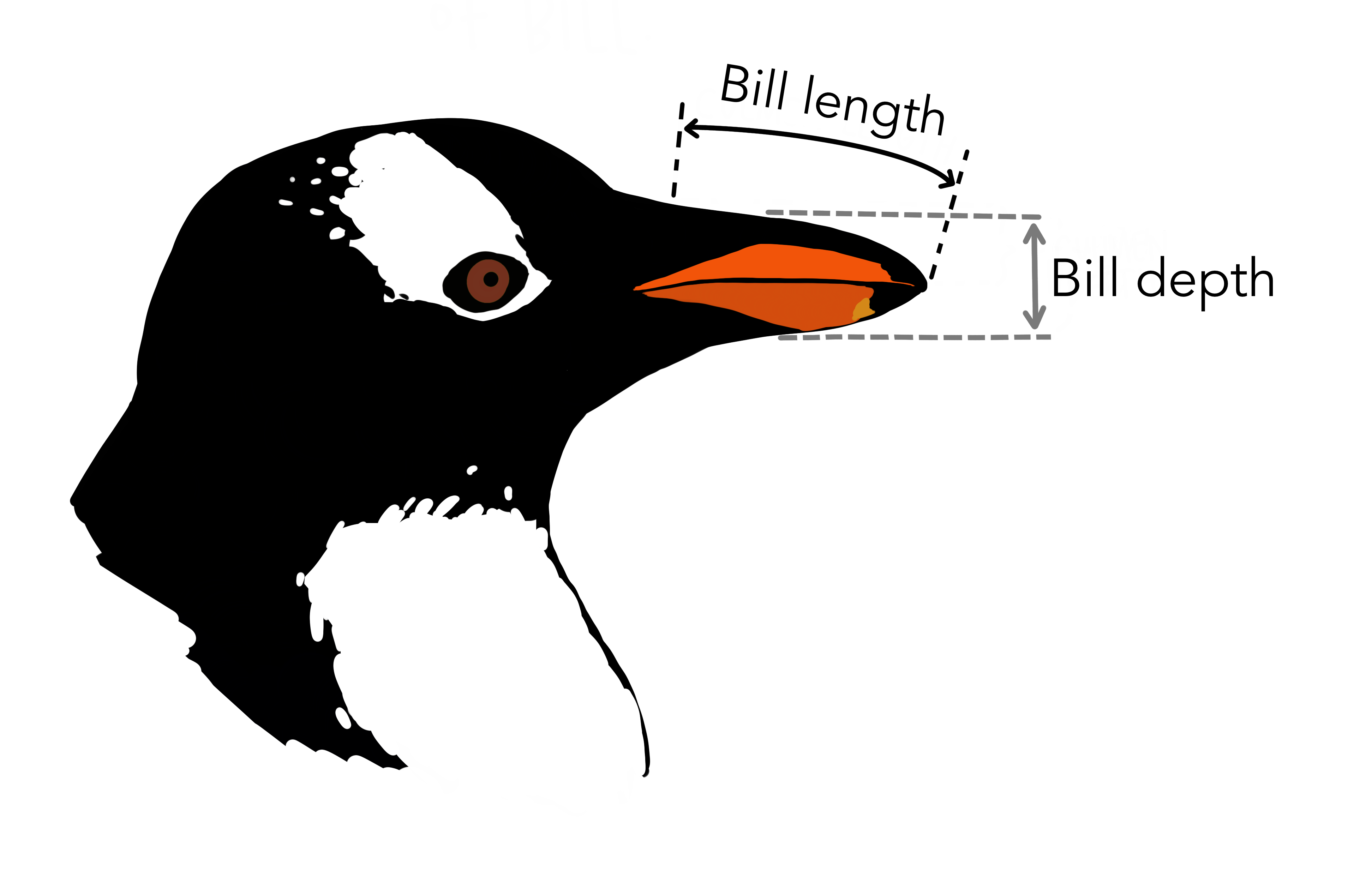
Figure 3.2: Las medidas de largo y profundidad del pico. Arte por Allison Horst.
Usando skimr puedes mirar rápidamente las variables contenidas en la base de datos:
| Name | penguins |
| Number of rows | 344 |
| Number of columns | 8 |
| _______________________ | |
| Column type frequency: | |
| factor | 3 |
| numeric | 5 |
| ________________________ | |
| Group variables | None |
Variable type: factor
| skim_variable | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|
| species | 0 | 1.00 | FALSE | 3 | Ade: 152, Gen: 124, Chi: 68 |
| island | 0 | 1.00 | FALSE | 3 | Bis: 168, Dre: 124, Tor: 52 |
| sex | 11 | 0.97 | FALSE | 2 | mal: 168, fem: 165 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| bill_length_mm | 2 | 0.99 | 43.92 | 5.46 | 32.1 | 39.23 | 44.45 | 48.5 | 59.6 | ▃▇▇▆▁ |
| bill_depth_mm | 2 | 0.99 | 17.15 | 1.97 | 13.1 | 15.60 | 17.30 | 18.7 | 21.5 | ▅▅▇▇▂ |
| flipper_length_mm | 2 | 0.99 | 200.92 | 14.06 | 172.0 | 190.00 | 197.00 | 213.0 | 231.0 | ▂▇▃▅▂ |
| body_mass_g | 2 | 0.99 | 4201.75 | 801.95 | 2700.0 | 3550.00 | 4050.00 | 4750.0 | 6300.0 | ▃▇▆▃▂ |
| year | 0 | 1.00 | 2008.03 | 0.82 | 2007.0 | 2007.00 | 2008.00 | 2009.0 | 2009.0 | ▇▁▇▁▇ |
Es posible ver que hay algunas observaciones con variables faltantes (columna n_missing). Por ahora, elimina esas observaciones con el comando drop_na:
3.2 Introducción a ggplot2
ggplot2 es uno de los paquetes que componen el tidyverse y su rol es facilitar la visualización de datos. A diferencia de lo que quizás haríamos en Excel para elaborar un gráfico, en ggplot2 es necesario pensar cuidaodosamente respecto a las partes que componen un gráfico.
ggplot2 se basa en un sistema formal para construir gráficos llamado “gramática de gráficos”. La gramática de gráficos está basada en la idea de que uno puede describir de manera única cualquier gráfico como una combinación (entre otros) de:
- un conjunto de datos,
- una geometría y
- mapeos de variables a estéticas.
De manera simple, la forma en la que se elabora un gráfico en ggplot2 es:
A partir de una base de datos, se ordenan los datos a visualizar en un tibble. Este tibble puede ser ser la fuente de datos originales con que estamos trabajando, como también puede ser una transformación o resúmen de ésta (normalizaciones, estadísticos, conteos, etc.).
Se selecciona una geometría para representar cada observación en los datos. Esta geometría puede ser un punto, una barra, una línea, etc.
Se mapean los valores de cada variable a ser visualizada a una estética. Esta estética puede ser un eje de coordenadas, un color, una forma, un tamaño, etc.
En general, una llamada a ggplot2 tiene el siguiente formato:
La función aes() recibe su nombre de la palabra aesthetics (estéticas).
También es posible usar pipes para ingresar datos a ggplot2:
En este caso podemos omitir mappings =, ya que ggplot2 entiende que la función aes() debe ser asignada al argumento mappings.
Para hacerte una idea inicial de cómo se usa ggplot2, considera el siguiente ejemplo:
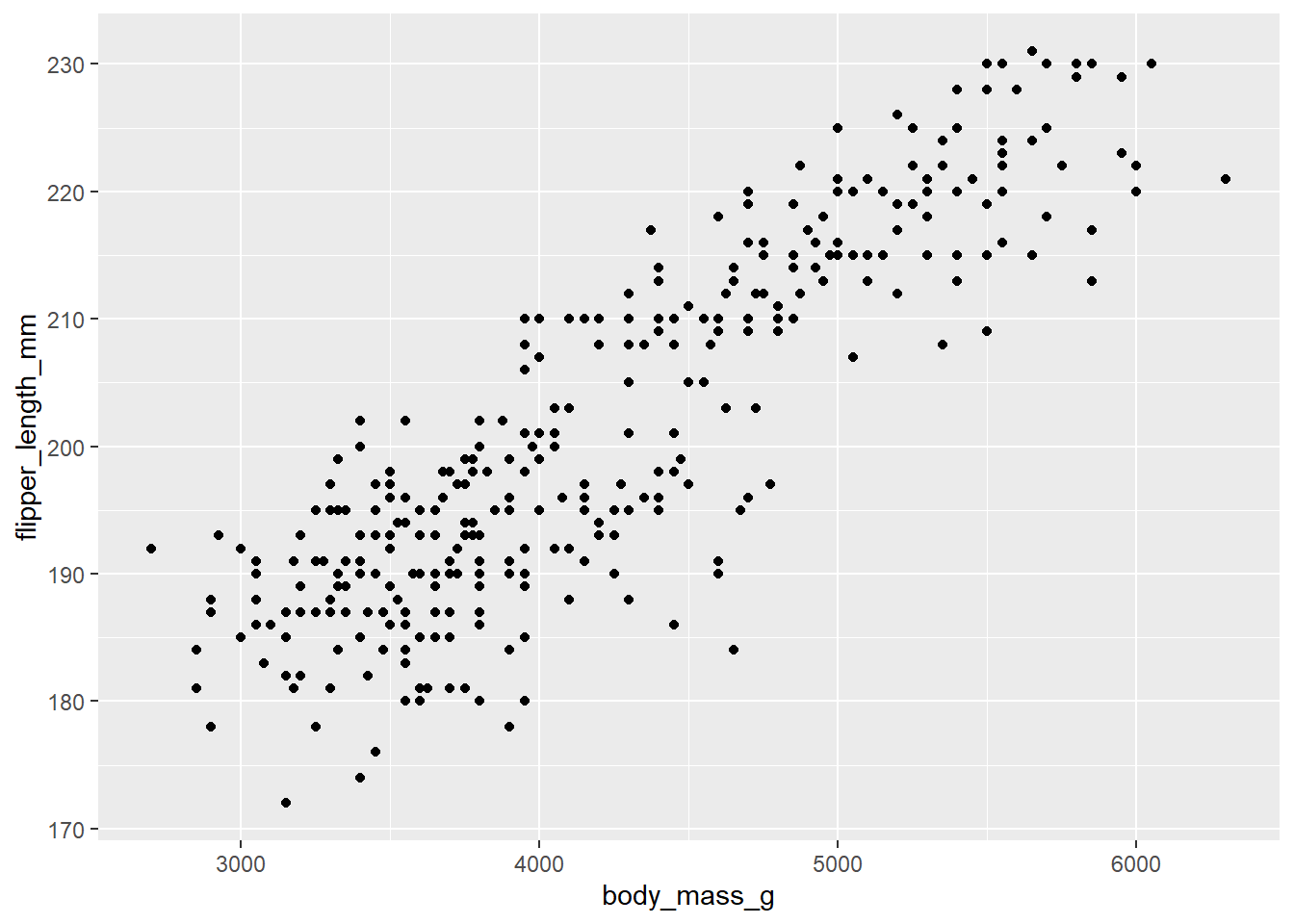 La función
La función geom_point() indica que se usará una geometría de puntos (dispersión) para el gráfico. La función aes() indica que se hará un mapeado de la variable body_mass_g al eje x y de la variable flipper_length_mm al eje y.
Si esto no se entiende muy bien ahora, no te preocupes. En las secciones siguientes mostraremos las maneras más comunes de usar ggplot2, con ejemplos usando la base de datos de los pingüinos de Palmer.
3.3 Visualización de una sola variable
En esta sección describimos como visualizar los valores que toman las observaciones de una variable en una base de datos. Los tipos de gráficos que podemos usar para describir una variable están determinados por el tipo de dicha variable. En particular, van a depender de si la variable es numérica o no, y en caso de ser numérica, si es continua o no.
3.3.1 Variables discretas y continuas
Para simplificar la descripción de este capítulo vamos a clasificar las variables de una base de datos como continuas o discretas. Variables continuas corresponden a variables de tipo numeric que pueden tomar cualquier valor numérico. Las variables discretas, en cambio, pueden ser de tipo numeric, bool, date, o char, pero los valores que pueden tomar, están restrictos a una lista finita de posibilidades.
Nota: Al hacer visualizaciones con gráficos, es muy importante ser cuidadoso con variables discretas de tipo numeric, ya que ggplot2 las puede tratar distinto, dependiendo de si son categóricas (factores) o no.
A modo de ejemplo, consideremos una base de datos que tiene una variable discreta x de tipo numeric cuyos valores están en {1,3,4,7}.
Si la variable es categórica, podría ser posible que el conjunto de valores admisibles para esta variable sea precisamente el conjunto {1,3,4,7}. Esto podría ser el caso, por ejemplo, si los números describen el nombre de un equipo, y si no existen equipos 2, 5 y 6.
La distinción, aunque sutil, es importante, pues en el caso de que la variable no se defina como categórica, R va a entender de que es posible que esta variable tome valor 2,5 y 7, pero que simplemente ninguna observación lo hace. Sin embargo, si la variable se define como categórica, R va a entender que las observaciones toman todos los valores posibles. Esta diferencia podría resultar en gráficos que se ven distintos. Esto lo ejemplificaremos en la Sección YY.
3.3.2 Gráficos de Barras
Para describir una variable discreta se puede usar un gráfico de frecuencias. Es decir, un gráfico de barras que ilustra el número de ocurrencias de cada posible valor de la variable discreta
En ggplot2, los gráficos de frecuencias se construyen usando la geometría geom_bar() en la cual se especifica la variable discreta a describir.
Veamos cómo se distribuyen los pinguinos de Palmer, según la isla en que habitan:
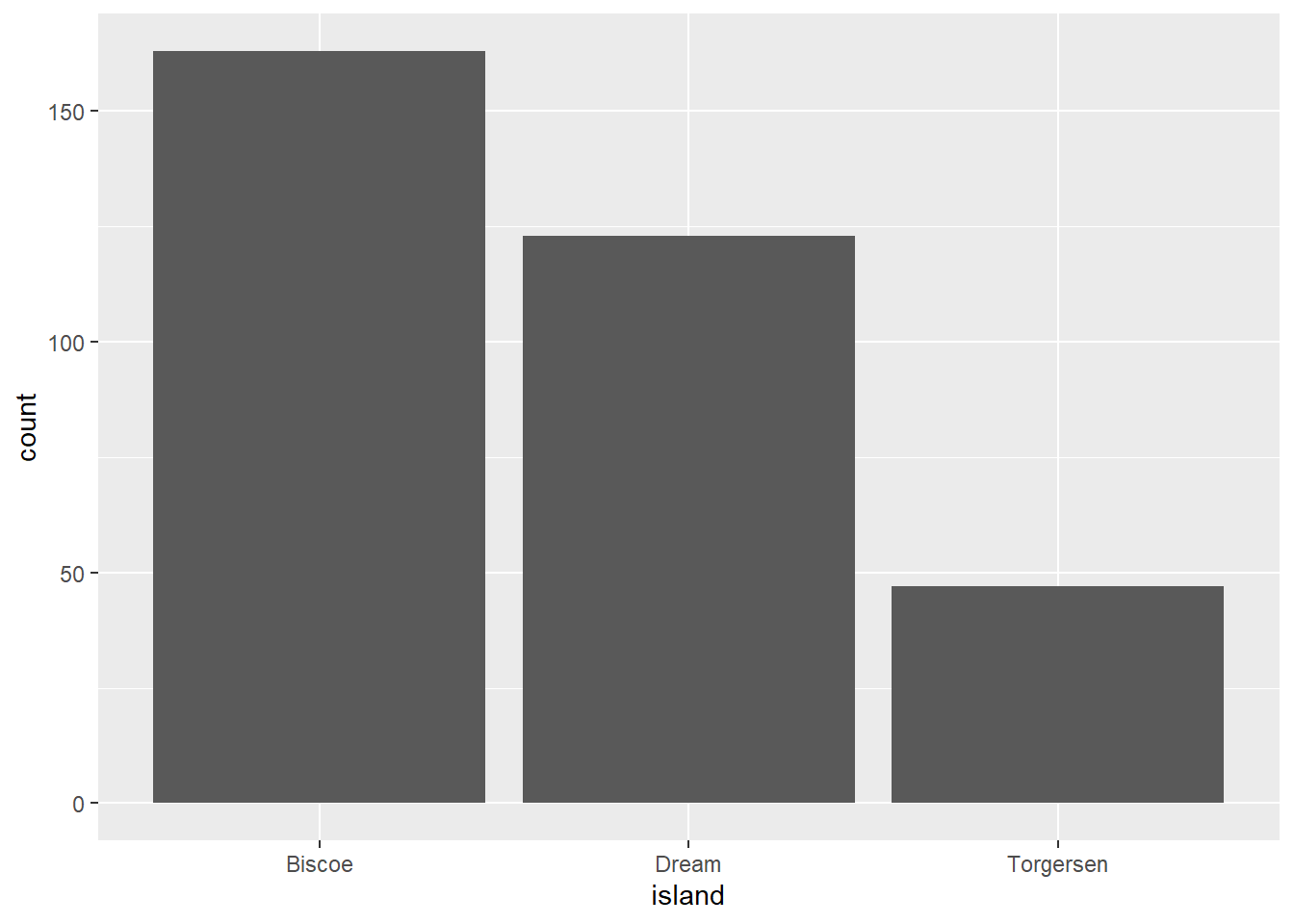
En el gráfico se puede observar que la isla de Biscoe es donde más habitan pinguinos de la muestra, y que la isla de Torgersen es donde menos.
3.3.3 Histogramas y Boxplots
Hay varios tipos de gráficos que permiten describir variables contínuas Algunos ejemplos son:
- Histograma
- Boxplot
- Gráfico de densidad
- Gráfico de violín
- Ojiva o gráfico de distribución acumulada
A continuación describimos los dos primeros.
Un histograma subdivide el rango de valores que toma la variable en intervalos (llamados bins), cuenta la cantidad de ocurrencias de la variable en cada intervalo, y luego grafica.
En un histograma uno puede construir los intervalos de distintas maneras. Por defecto, ggplot2 construye los intervalos automáticamente, de tal manera que no hayan más de 30 intervalos.
Por ejemplo, para ver como se distribuyen los largo de pico de los pinguinos en Palmer:
## `stat_bin()` using `bins = 30`. Pick better value
## with `binwidth`.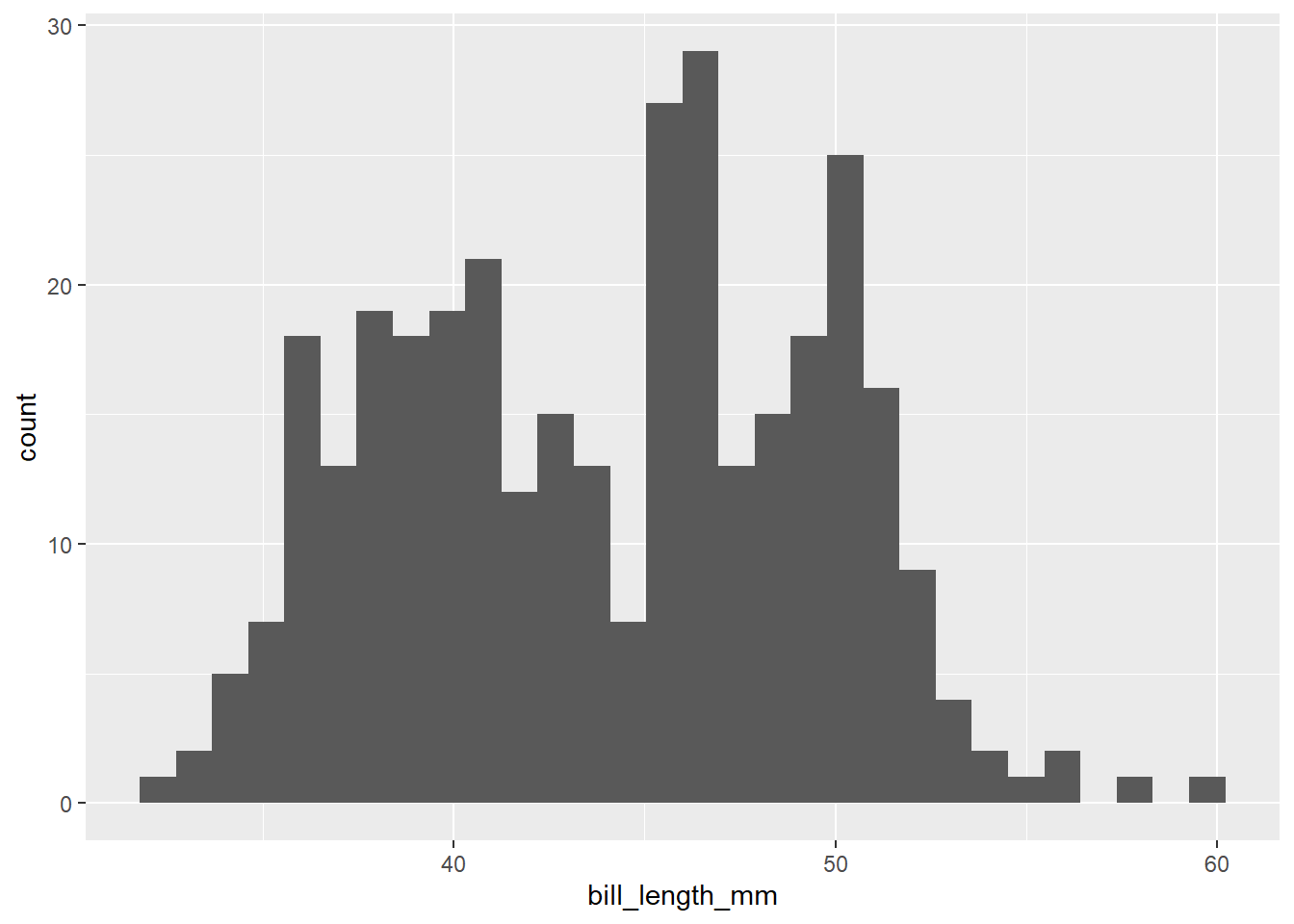
Si se cambia el número de bins a 15, el gráfico cambia así:
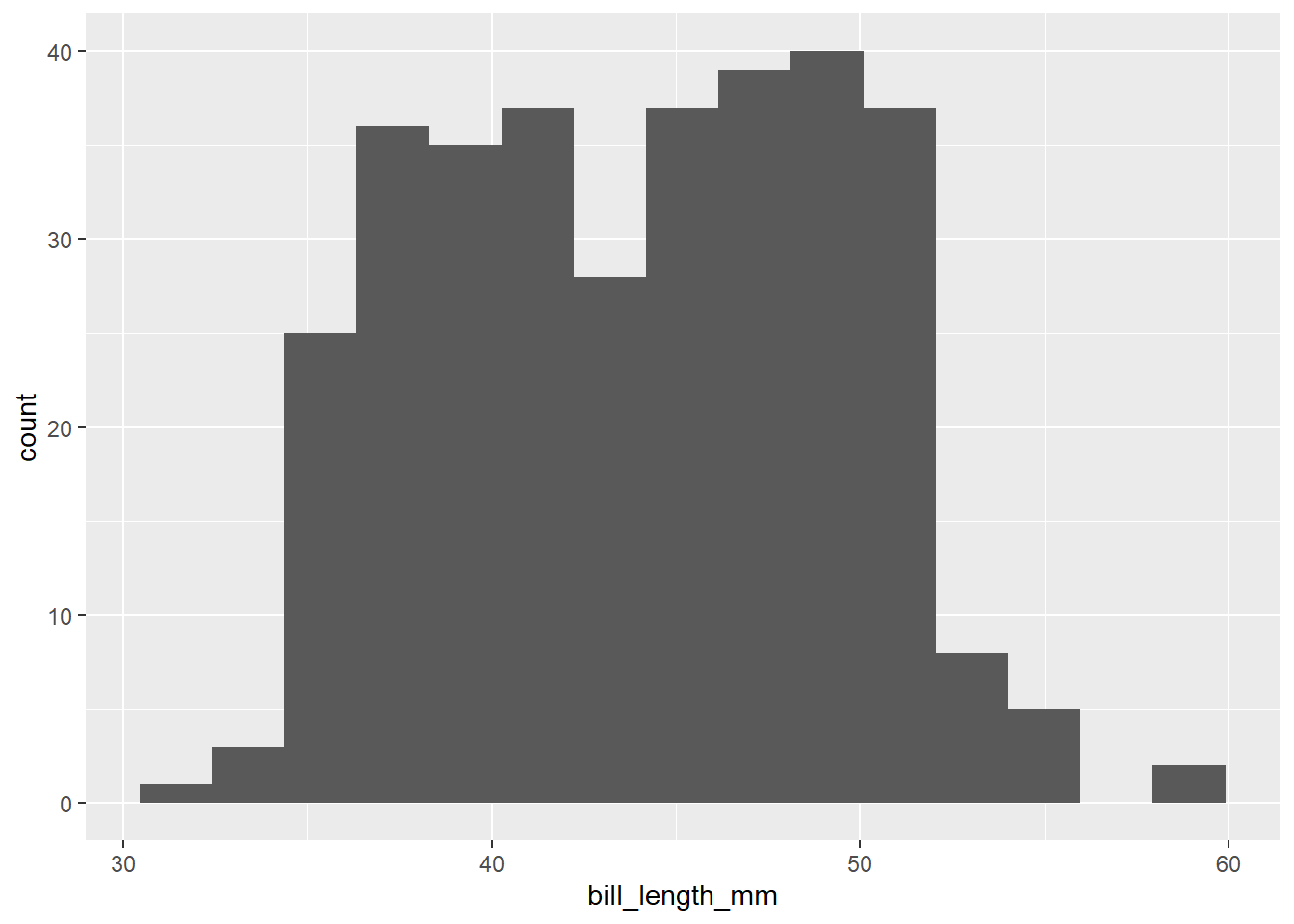
También es posible especificar el ancho de los bins, lo cual es una forma alternativa de controlar el número de éstos:
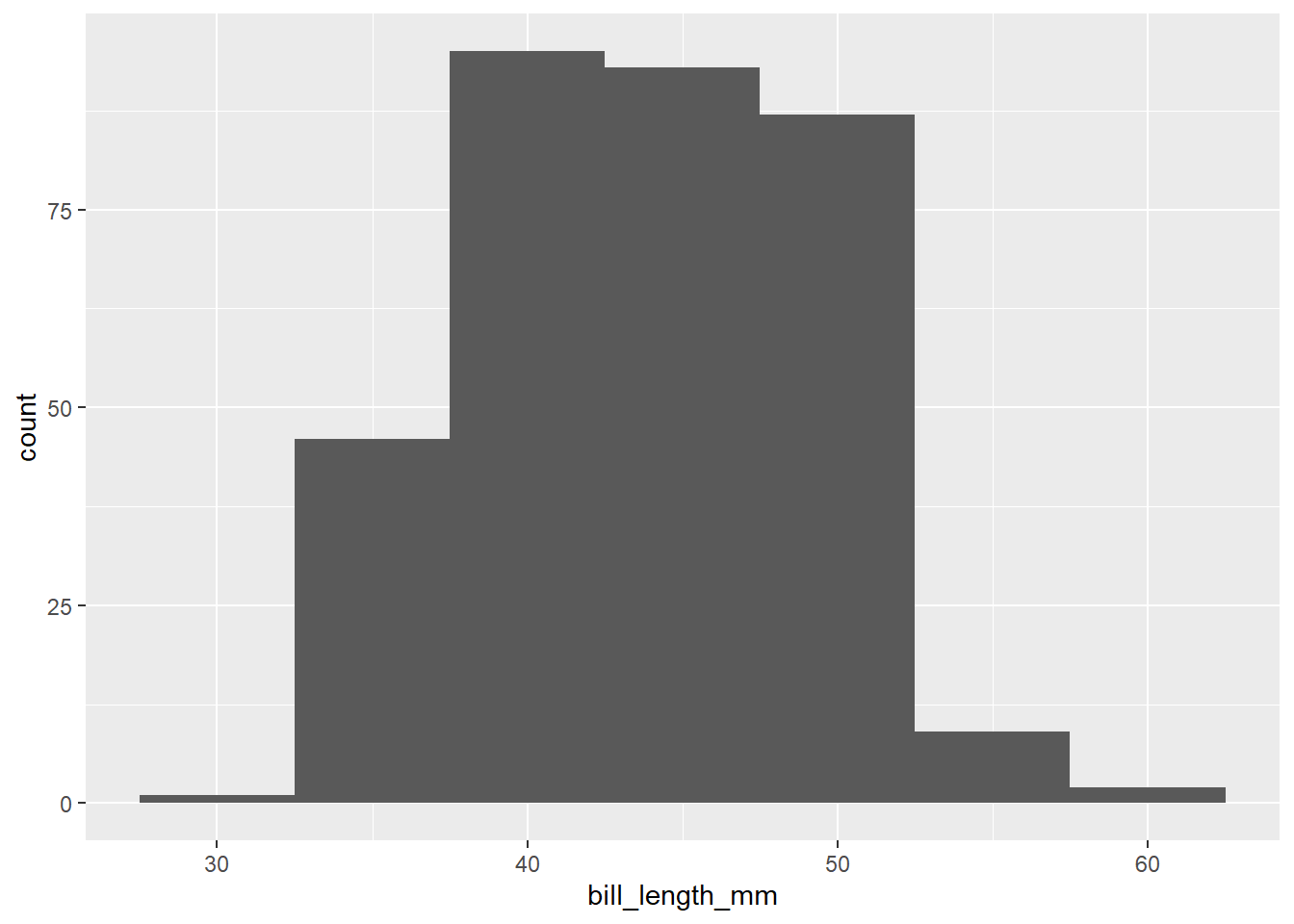
Un boxplot permite resumir la distribución de una variable numérica ilustrando información derivada de sus cuartiles y outliers.
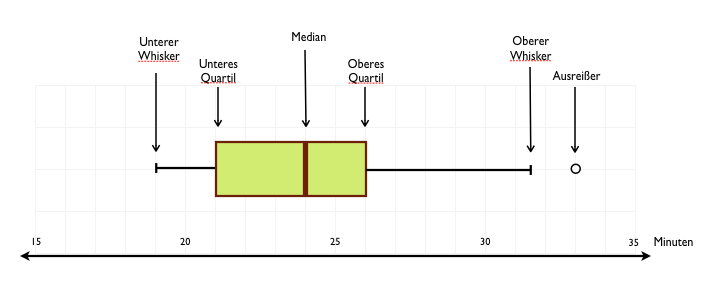
Para elaborar un boxplot en ggplot2, se usa la geometría geom_boxplot().
Veamos nuevamente, esta vez con un boxplot, la distribución de los largos de pico:
3.4 Visualización de dos variables
En esta sección describimos como visualizar los valores que toman dos variables en las observaciones de una base de datos. Al igual que cuando se visualiza solo una variable, los tipos de gráficos que podemos usar para describir dos variables están determinados por el tipo de las variable a visualizar. Hay tres casos posibles a considerar: El caso en que ambas variables a visualizar sean discretas, el caso en que ambas sean contínuas, y el caso en que una sea discreta y la otra contínua
Hay varios tipos de gráficos que permiten describir la relación entre dos variables. Los gráficos más comunmente usados para esto son:
- El gráfico de barras o columnas, usado cuando una o ambas variables son discretas.
- El gráfico de línea, usado cuando ambas variables son numéricas, y una de ellas representa una escala de tiempo.
- El gráfico de dispersión o scatter, también usado cuando ambas variables son numéricas.
3.4.1 Gráficos de columnas
Los gráficos de columnas se usan para visualizar la relación entre lo que se llama una variable explicativa y una variable de respuesta, que es función de la variable explicativa.
En el caso de un gráfico de columnas, se asume que la variable explicativa es discreta y la variable de respuesta es numérica.
Para poder usar estos gráficos a fin de visualizar dos variables, es necesario que haya sola una observación para cada valor que toma la variable explicativa.
Tomando como ejemplo la base de datos de los pinguinos de Palmer, no podríamos hacer un gráfico de columnas que ilustre la relación entre la especie de los pinguinos y el largo de sus picos. Esto debido a que en cada especie, hay muchos pinguinos que tienen picos de largo distinto entre si. Lo que sí podríamos hacer es un gráfico de columnas para ilustrar la relación entre la especie los pinguinos, y el largo promedio de sus picos Esto requiere, eso sí, crear un nuevo tibble. Este gráfico lo podemos construir usando la geometría geom_col():
penguins %>%
group_by(species) %>%
summarise(largo_promedio = mean(bill_length_mm)) %>%
ggplot(aes(x = species, y = largo_promedio)) +
geom_col()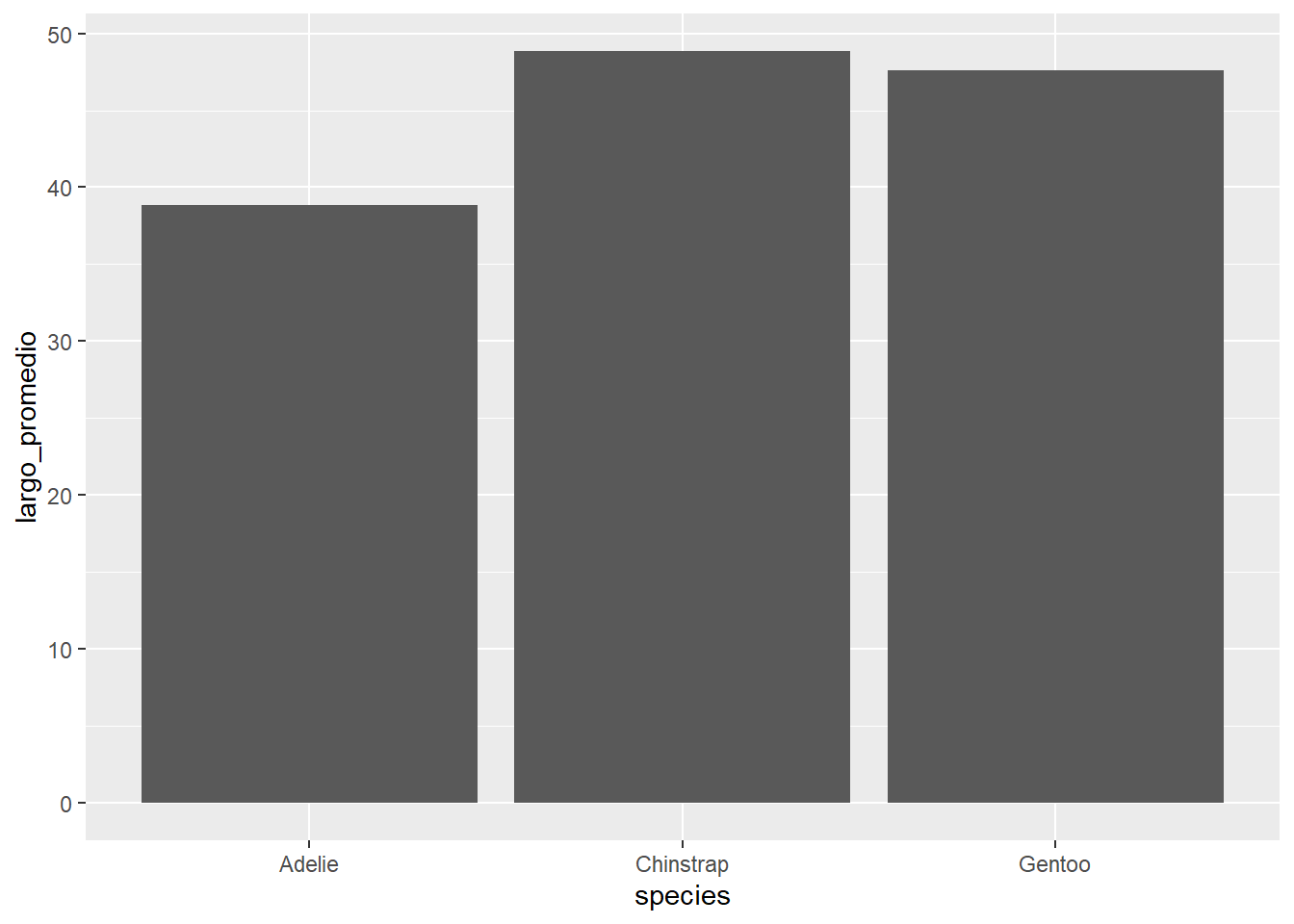
Nota: Un gráfico de frecuencias, como el que vimos en la Sección Gráficos de Barras, también lo podemos generar con la geometría
geom_col(), si creamos una variable de respuesta que cuente el número de ocurrencias de la variable a evaluar. Es decir:
penguins %>% group_by(island) %>% summarise(count = n()) %>% ggplot(aes(x = species, y = count)) + geom_col()es equivalente a
penguins %>% ggplot(aes(x = species)) + geom_bar()
3.4.2 Gráficos de línea
Los gráficos de línea tienen por objetivo mostrar la tendencia que sigue una variable respuesta numérica a lo largo de una escala temporal. Esta escala temporal puede no ser necesariamente tiempo cronológico, sino que también puede representar generaciones, iteraciones de un procedimiento, etc.
Para mostrar la construcción de este tipo de gráficos usaremos una base de datos diferente, que contiene datos de distintos países junto con información durante diversos años de indicadores como felicidad, generosidad, esperanza de vida, percepción de corrupción, etc.
happiness <- read_csv("https://github.com/rocarvaj/rcd1-uai/raw/main/data/world-happiness/world-happiness-report.csv")## Rows: 1949 Columns: 11
## ── Column specification ───────────────────────────
## Delimiter: ","
## chr (1): Country name
## dbl (10): year, Life Ladder, Log GDP per capita, Social support, Healthy lif...
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.## # A tibble: 6 × 11
## `Country name` year `Life Ladder` `Log GDP per capita` `Social support`
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Afghanistan 2008 3.72 7.37 0.451
## 2 Afghanistan 2009 4.40 7.54 0.552
## 3 Afghanistan 2010 4.76 7.65 0.539
## 4 Afghanistan 2011 3.83 7.62 0.521
## 5 Afghanistan 2012 3.78 7.70 0.521
## 6 Afghanistan 2013 3.57 7.72 0.484
## # ℹ 6 more variables: `Healthy life expectancy at birth` <dbl>,
## # `Freedom to make life choices` <dbl>, Generosity <dbl>,
## # `Perceptions of corruption` <dbl>, `Positive affect` <dbl>,
## # `Negative affect` <dbl>Los gráficos de línea se elaboran en ggplot2 a través de la geometría grom_line(), especificando las variables a ser analizadas. Los gráficos de línea se parecen a los gráficos de columna en que están diseñados para graficar la relación entre una variable explicativa y una variable respuesta, sin embargo la variable explicativa representa una escala temporal.
Al construir un gráfico de línea, los puntos correspondientes a cada observación se ubican en posiciones del eje X de acuerdo a su valor. Estos puntos se conectan con una línea como se puede observar a continuación en el siguiente gráfico que permite visualizar la evolución de la percepción de generosidad en Chile a lo largo de los años:
happiness %>%
filter(`Country name` == "Chile") %>%
ggplot(aes(x = year, y = Generosity)) +
geom_line()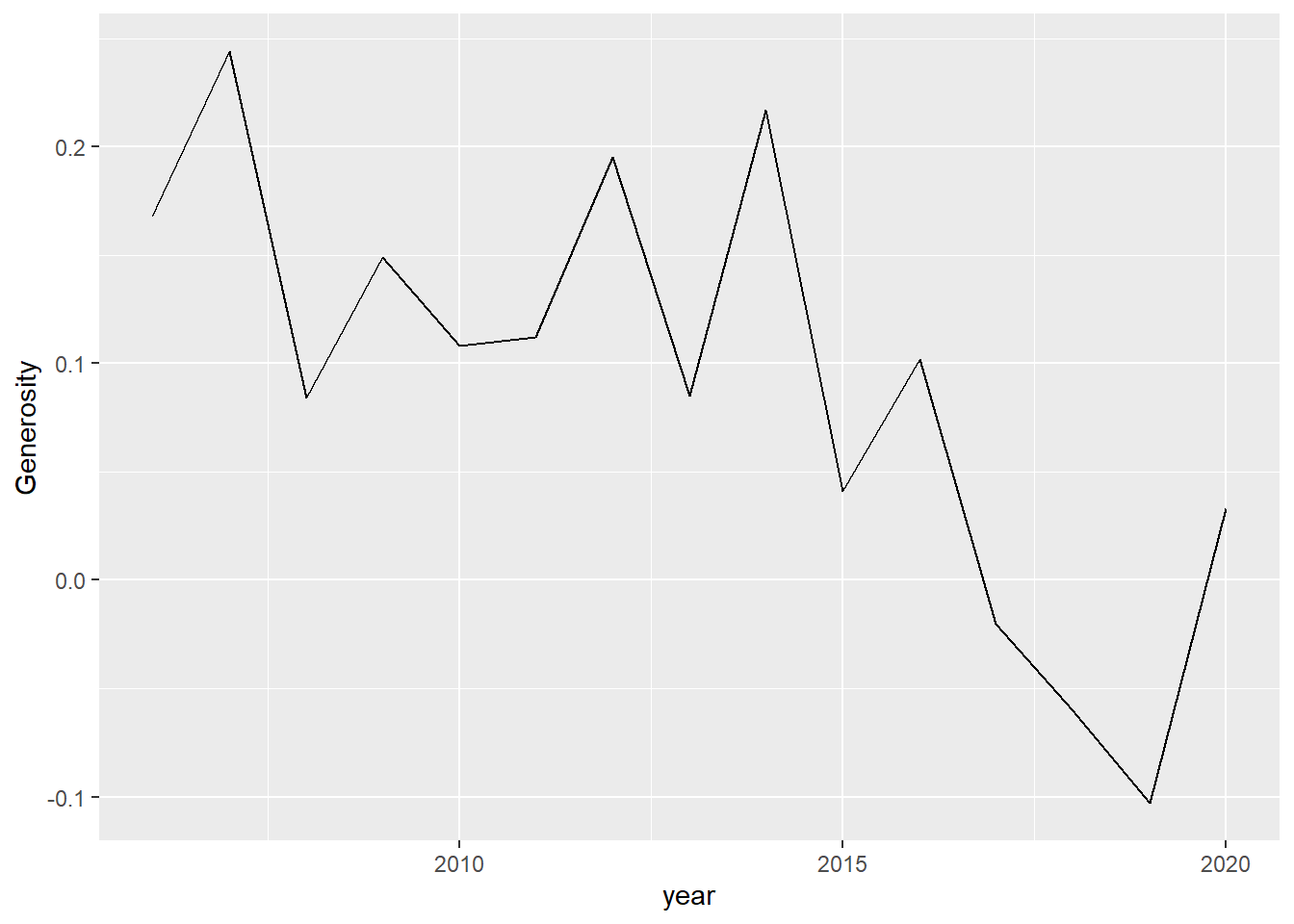
Si además de las líneas trazadas queremos ver los puntos que hay en la muestra se pueden agregar éstos superponiendo la geometría geom_point():
happiness %>%
filter(`Country name` == "Chile") %>%
ggplot(aes(x = year, y = Generosity)) +
geom_line() +
geom_point()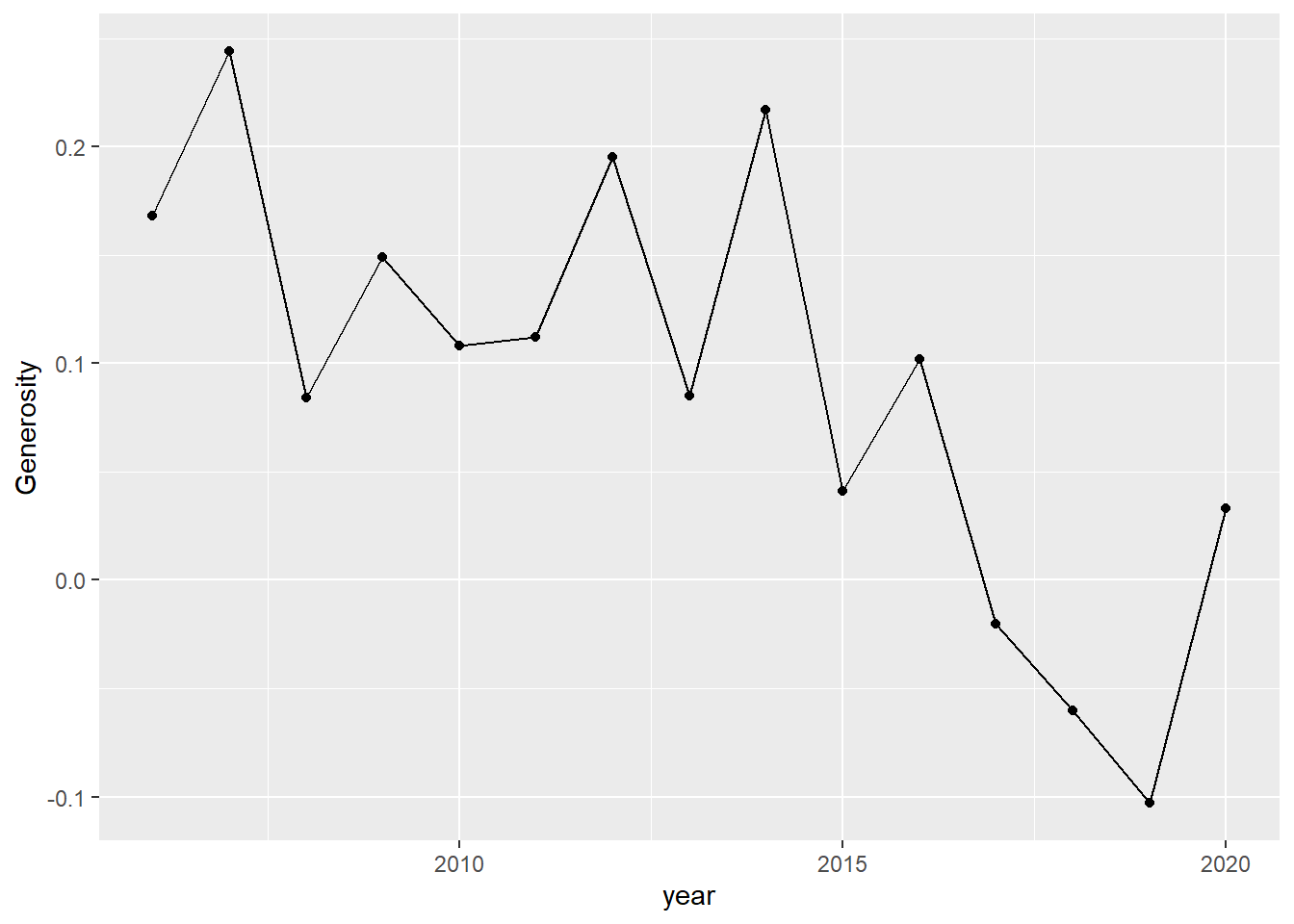
3.4.3 Gráficos de dispersión, o scatter
Los gráficos de dispersión sirven para visualizar la correlación entre dos variables numéricas. Un gráfico de dispersión toma cada observación en la base de datos y grafica un punto, cuyas coordenadas corresponden al par de valores de las variables a visualizar. A diferencia de los gráficos de línea y bárras, no es necesario diferenciar entre variables explicativas y de respuesta.
En ggplot2, usamos la geometría geom_point() para crear gráficos de dispersión, especificando las variables a visualizar.
Por ejemplo, veamos la relación entre largo y profundidad del pico de los pingüinos observados:
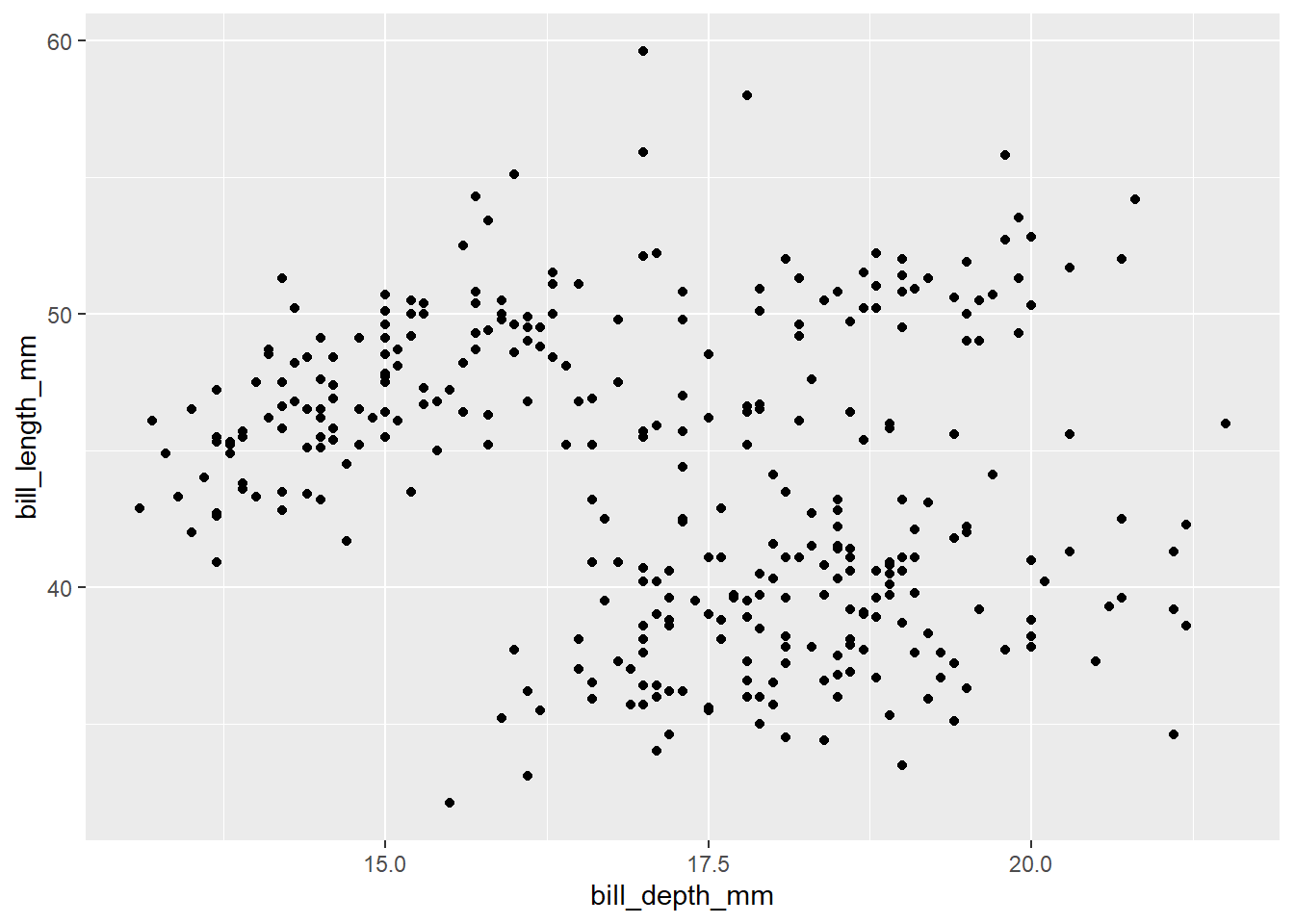
3.5 Visualización de tres o más variables
Visualizar más de dos variables a la vez en un gráfico puede ser de gran utilidad para observar relaciones más complejas. Las formas de agregar variables adicionales a un gráfico en ggplot2, incluyen la superposición de un gráfico sobre otro o el mapeo de variables adicionales a estéticas como la forma o el color del gráfico original.
3.5.1 Gráficos de columnas
En el caso de gráficos de columnas, podemos agregar una segunda variable explicativa al análisis. Esto solo tiene sentido si esta segunda variable explicativa también es discreta, y si podemos construir una tabla de entrada tal que, para cada combinación posible de valores de estas variables expplictivas, haya un único valor de respuesta.
Para construir el gráfico con geom_col a partir de la tabla de entrada simplemente es necesario indicar a ggplot2 cuál variable se mapeará al eje x, y cuál se mapeará al color de relleno fill. También es necesario indicar cómo se posicionaran las columnas de distintos colores. Para esto hay tres opciones:
stack- Esta es la opción por defecto, y consiste en apilar las columnas una encima de otra. Esta opción es más natural cuando uno quiere ilustrar el efecto acumulativo de la variable de respuesta.dodge- Esta opción consiste en posicionar las columnas una al lado de la otra. Esta opción es más natural cuando se busca comparar magnitudes de la variable de respuesta.fill- Esta variante de la opciónstackes más natural cuando uno busca comparar proporciones más que magnitudes.
Por ejemplo, retomemos el ejemplo en la sección “Gráficos de barras”, en el cual graficamos el largo de pico promedio por especie de pinguino en la isla Palmer. Un análisis interesante podría consistir en visualizar el largo promedio de pico para cada cambinación de las variables sex y species. Agregar la variable sex al análisis no es problema, pues sex es una variable discreta (solo toma los valores male y female). Generar la tabla de entrada tampoco es problema, pues podemos usar group_by y summarise para calcular el largo promedio de pico para cada par de valores que pueden tomar las variables explicativas. El posicionamiento de las barras que más tiene sentido para este gráfico es dodge:
penguins %>%
group_by(species, sex) %>%
summarise(largo_promedio = mean(bill_length_mm)) %>%
ggplot(aes(x = species, y = largo_promedio, fill = sex)) +
geom_col(position = "dodge")## `summarise()` has grouped output by 'species'. You
## can override using the `.groups` argument.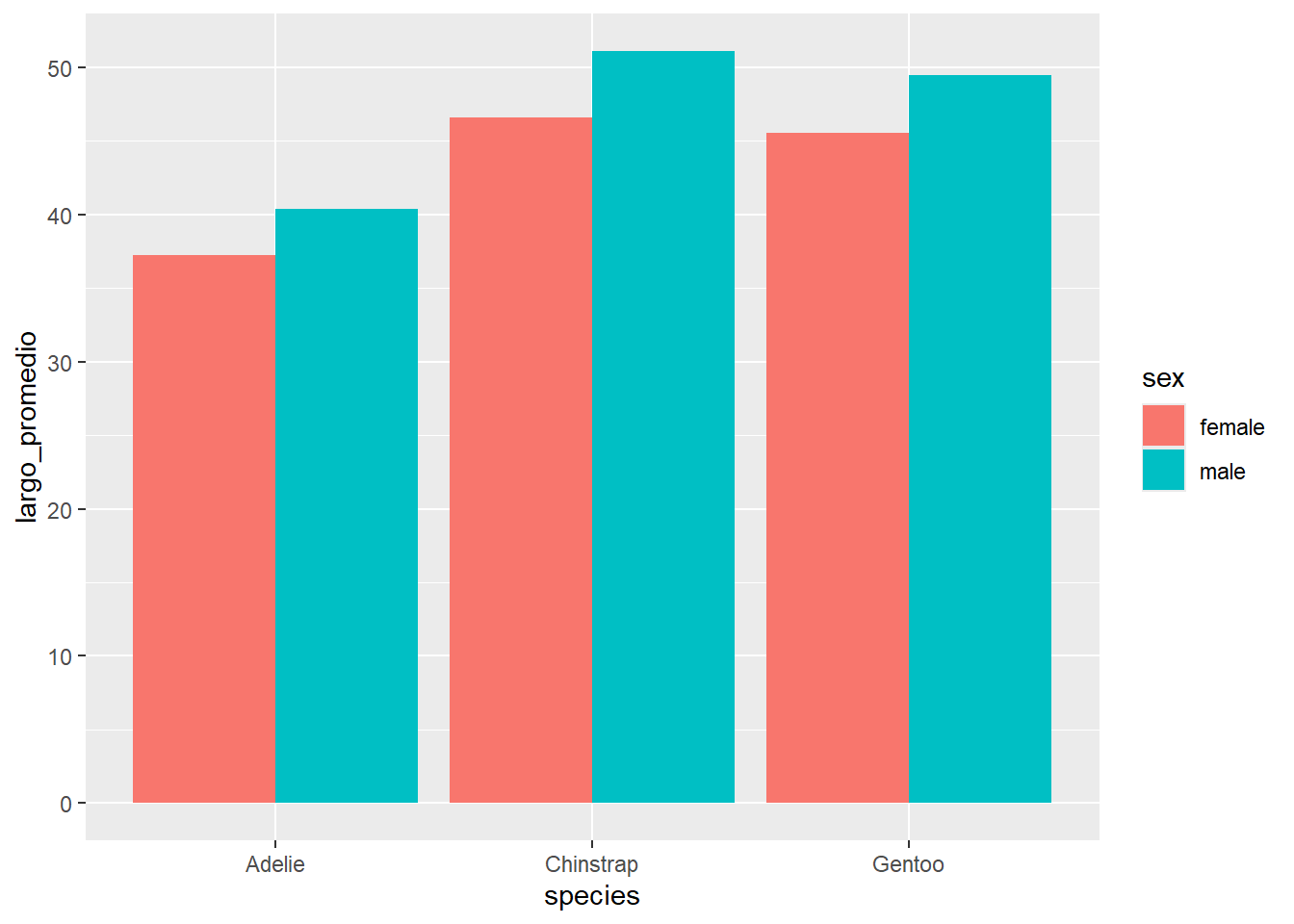
Observemos que las dos variables explicativas son intercambiables. También es posible visualizar estos datos así:
penguins %>%
group_by(species, sex) %>%
summarise(largo_promedio = mean(bill_length_mm)) %>%
ggplot(aes(x = sex, y = largo_promedio, fill = species)) +
geom_col(position = "dodge")## `summarise()` has grouped output by 'species'. You
## can override using the `.groups` argument.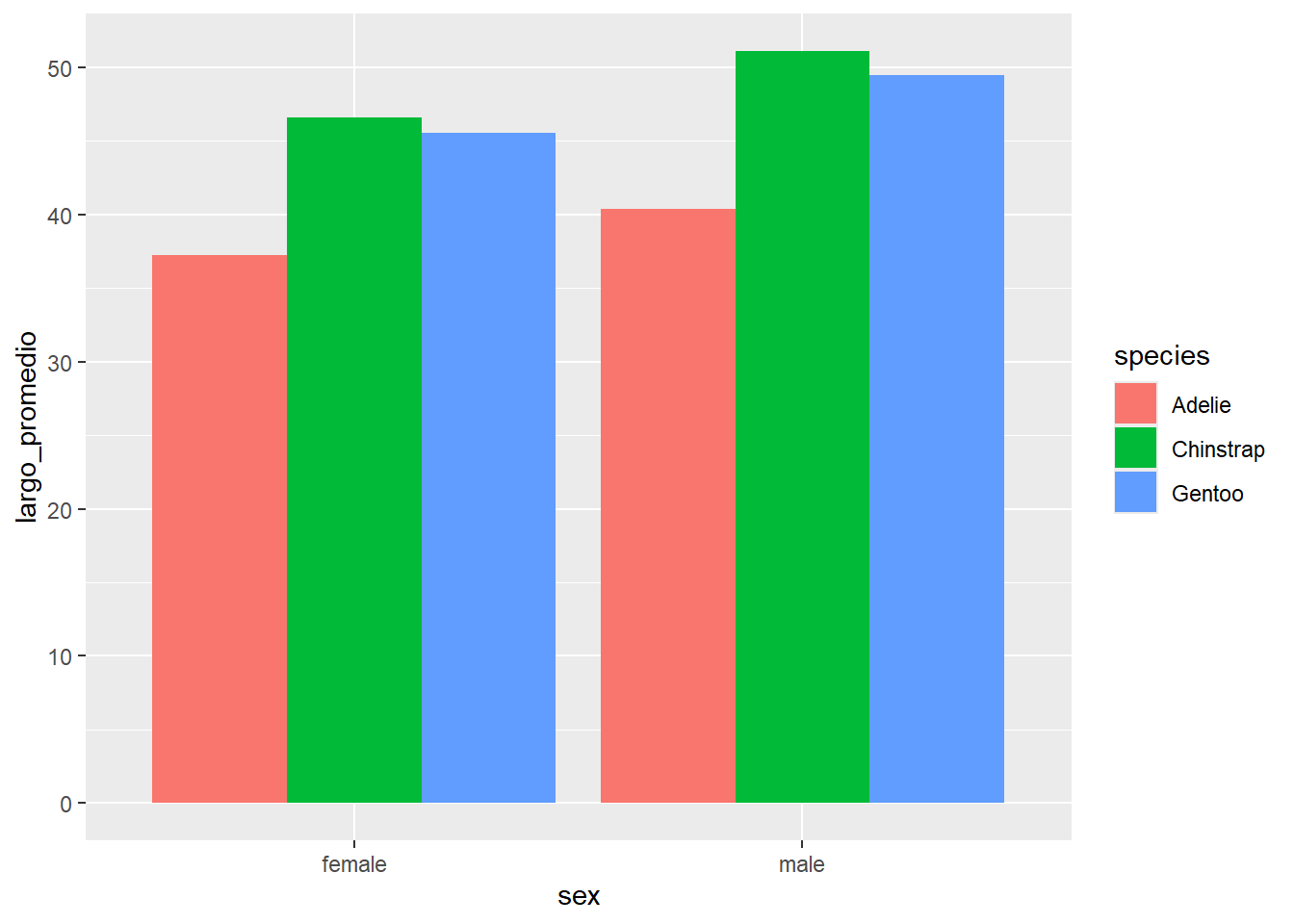
Este gráfico permite visualizar la misma información, mapeando variables a estéticas de manera diferente.
Comparemos ahora la variedad de especies de pinguino entre las distintas islas.
penguins %>%
group_by(species, island) %>%
summarise(tot = n()) %>%
ggplot(aes(x = island, y = tot, fill = species)) +
geom_col(position = "stack")## `summarise()` has grouped output by 'species'. You
## can override using the `.groups` argument.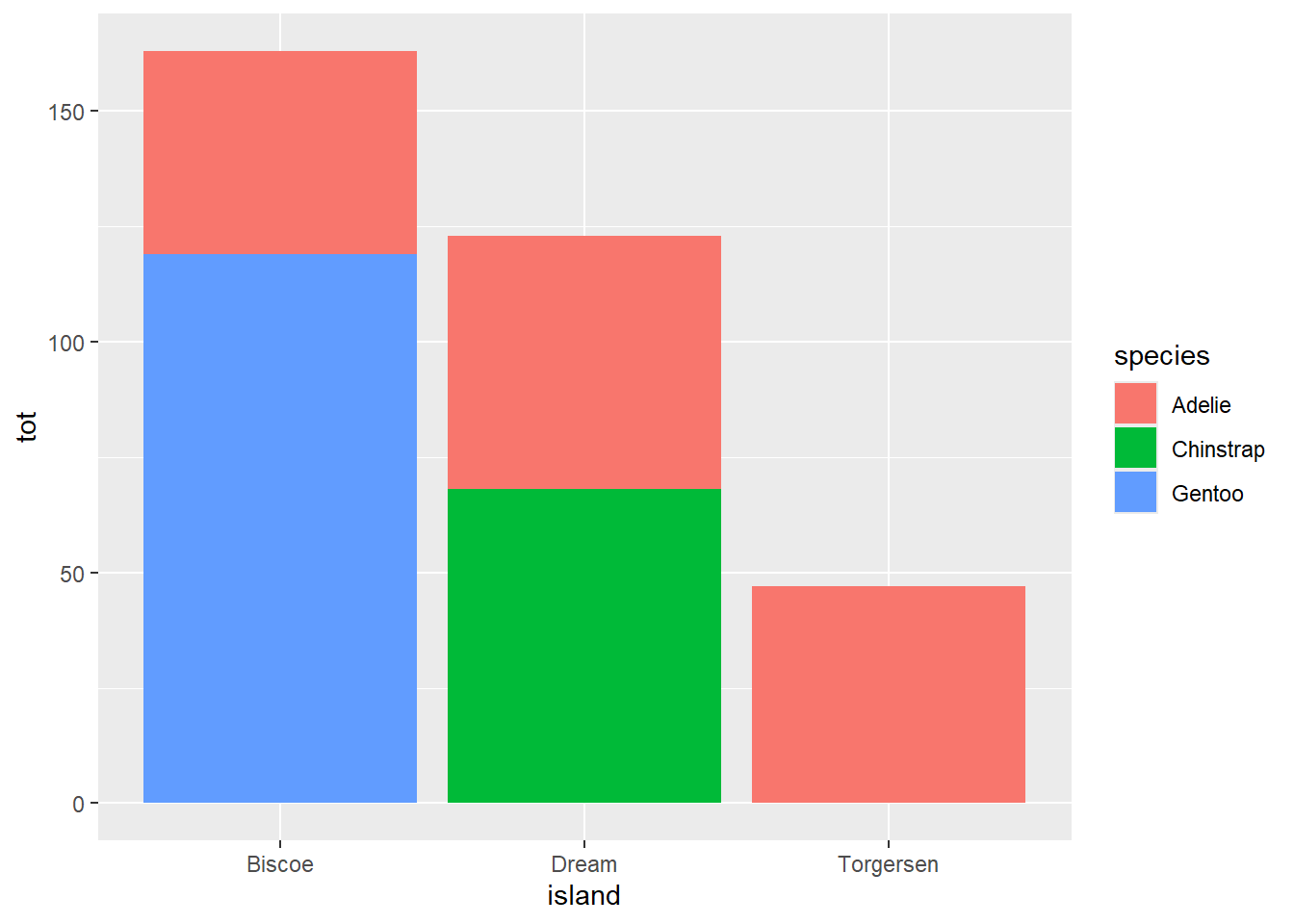
Este gráfico permite ver que la mayor parte de los pinguinos está concentrada en la isla de Biscoe. También permite ver la isla de Torgesen solo alberga pinguinos de tipo Adelie.
Si queremos comparar las islas en cuanto a la proporción de pinguinos que albergan de cada raza, podemos cambiar el tipo de posicionamiento a fill:
penguins %>%
group_by(species, island) %>%
summarise(tot = n()) %>%
ggplot(aes(x = island, y = tot, fill = species)) +
geom_col(position = "fill")## `summarise()` has grouped output by 'species'. You
## can override using the `.groups` argument.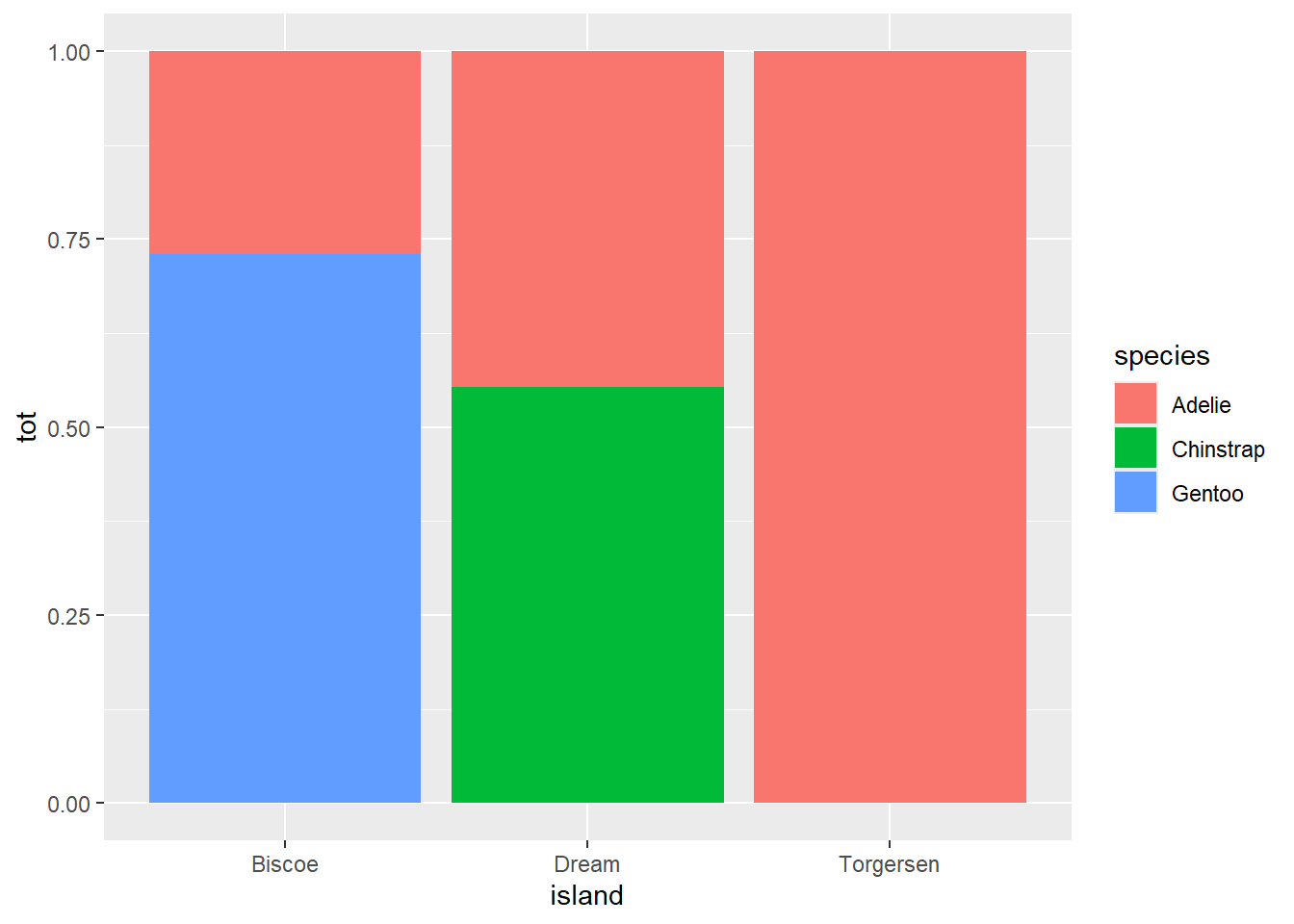
Este gráfico normaliza la población de cada isla a fin de poder facilitar la comparación de proporciones. En este caso, podemos er que la isla de Torgersen es la que alberga la mayor proporción de pinguinos Adelie, y que la isla de Biscoe, la que alberga la menor.
3.5.2 Gráficos de línea
En el caso de gráficos de línea, podemos agregar una tercera variable mapeando cada uno de sus valores posibles a un color o al tipo de línea. Esto se consigue adicionando los argumentos color o linetype a la función de estéticas aes() del gráfico.
Retomemos el ejemplo en la sección “Gráficos de línea”, en el cual graficamos la evolución de la percepción de generosidad en Chile a lo largo de los años. Qué pasa si queremos comparar la generosidad ente Chile, Argentina y Bolivia. Filtremos dichos países en la base de datos y mapeemos la variable Country name a la estética de color.
happiness %>%
filter(`Country name` %in% c("Chile", "Argentina", "Bolivia")) %>%
ggplot(aes(x = year, y = Generosity, color = `Country name`)) +
geom_line()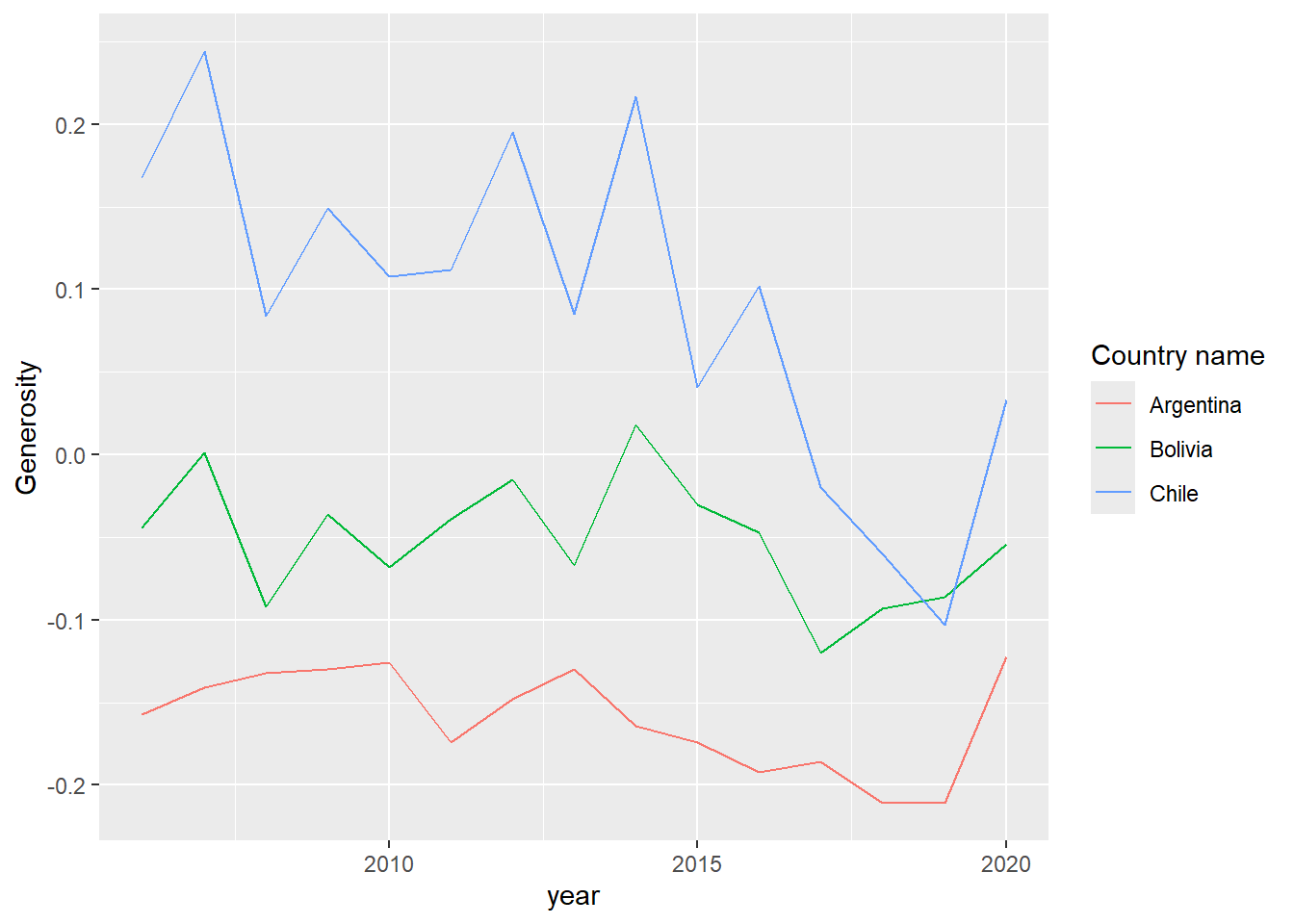
Ahora probemos mapeando al tipo de línea:
happiness %>%
filter(`Country name` %in% c("Chile", "Argentina", "Bolivia")) %>%
ggplot(aes(x = year, y = Generosity, linetype = `Country name`)) +
geom_line()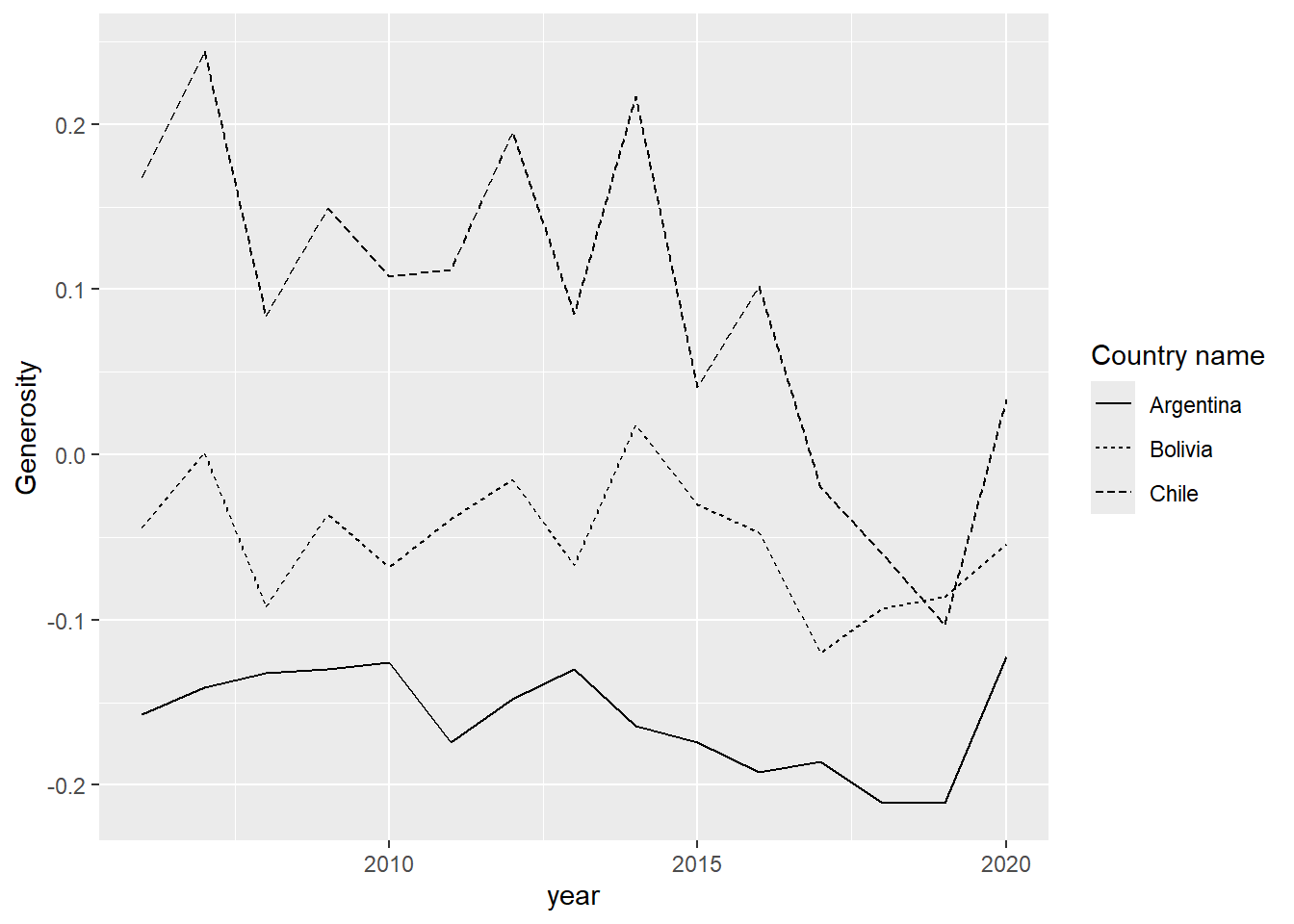
3.5.3 Gráficos de dispersión
En el caso de gráficos de dispersión, también podemos agregar variables adicionales mapeándolas a estéticas como el color, la forma y el tamaño de los puntos. Esto se consigue adicionando los argumentos color, shape y size a la función de estéticas aes() del gráfico, respectivamente.
Aquí es importante hacer la diferencia entre el caso de variables adicionales categóricas o numéricas discretas y el caso de variables adicionales numéricas continuas.
Retomemos el ejemplo de la sección “Gráficos de dispersión, o scatter” en el que comparamos el largo y la profundidad de pico. Agreguemos la variable species (que es una variable categórica).
Comencemos mapeándola a las estética de color y de forma:
penguins %>%
ggplot(aes(x = bill_depth_mm, y = bill_length_mm, color = species)) +
geom_point()
penguins %>%
ggplot(aes(x = bill_depth_mm, y = bill_length_mm, shape = species)) +
geom_point()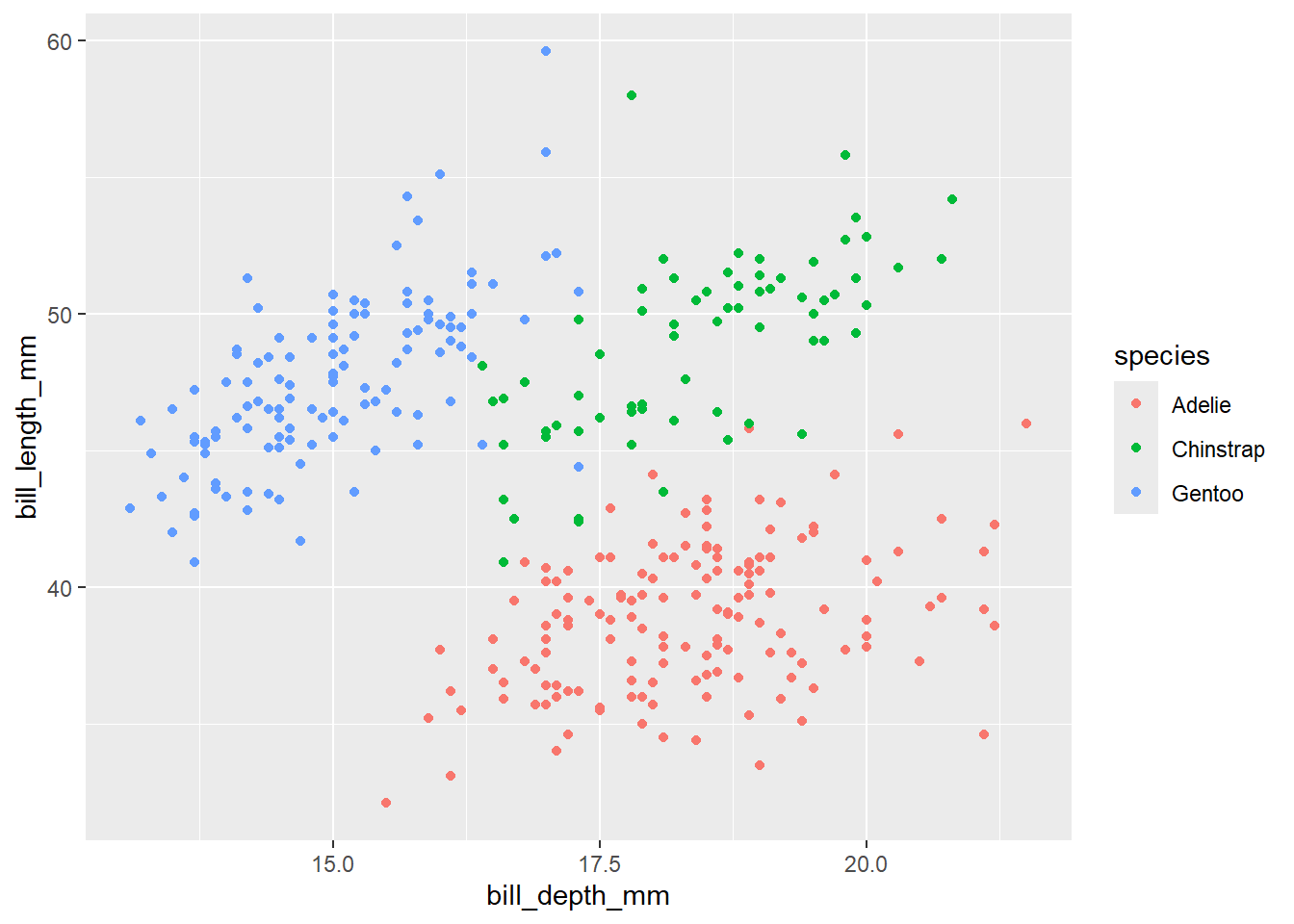
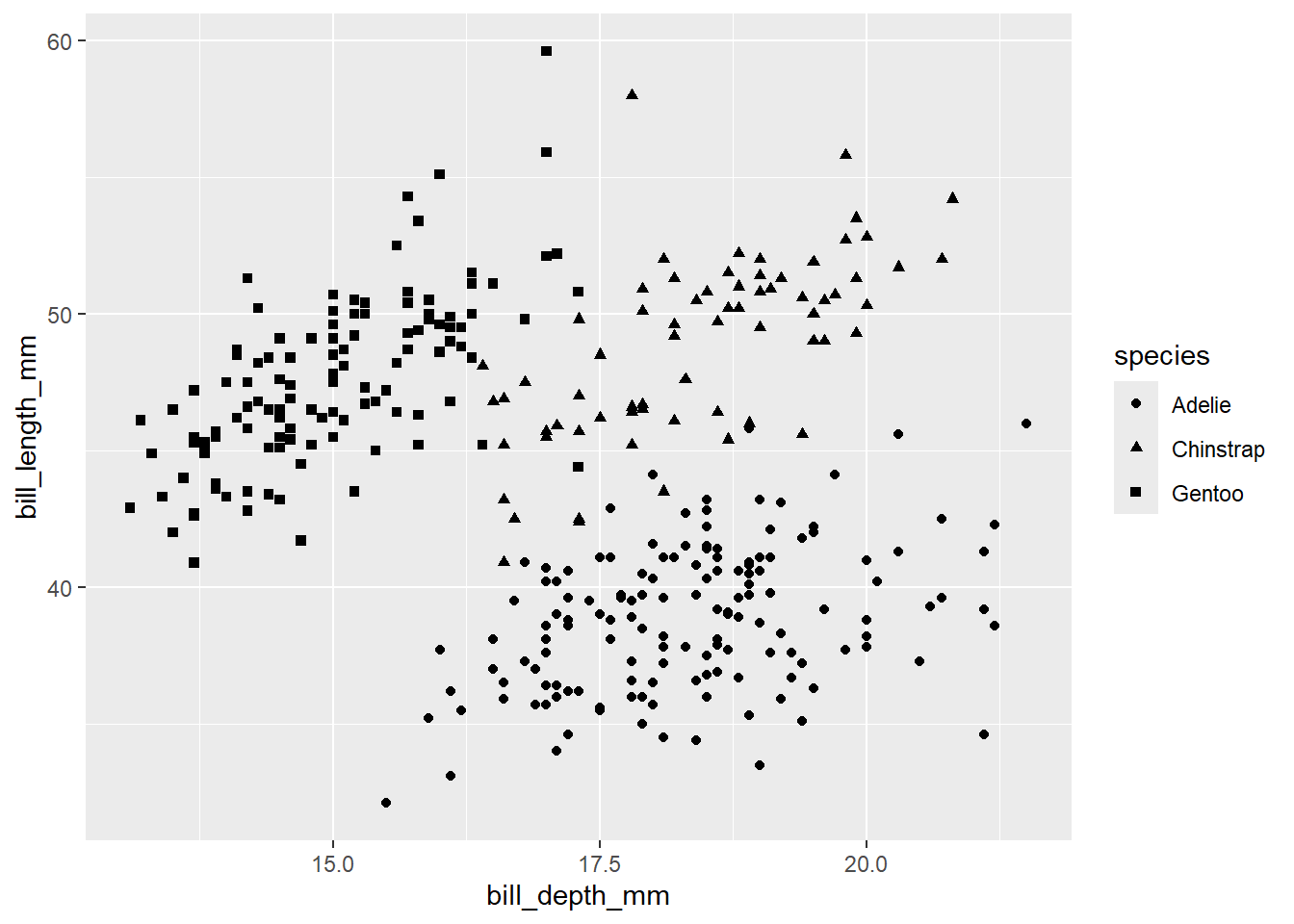
Sin embargo si mapeamos la variable a la estética de tamaño, ggplot nos indica que no es recomendado:
## Warning: Using size for a discrete variable is not advised.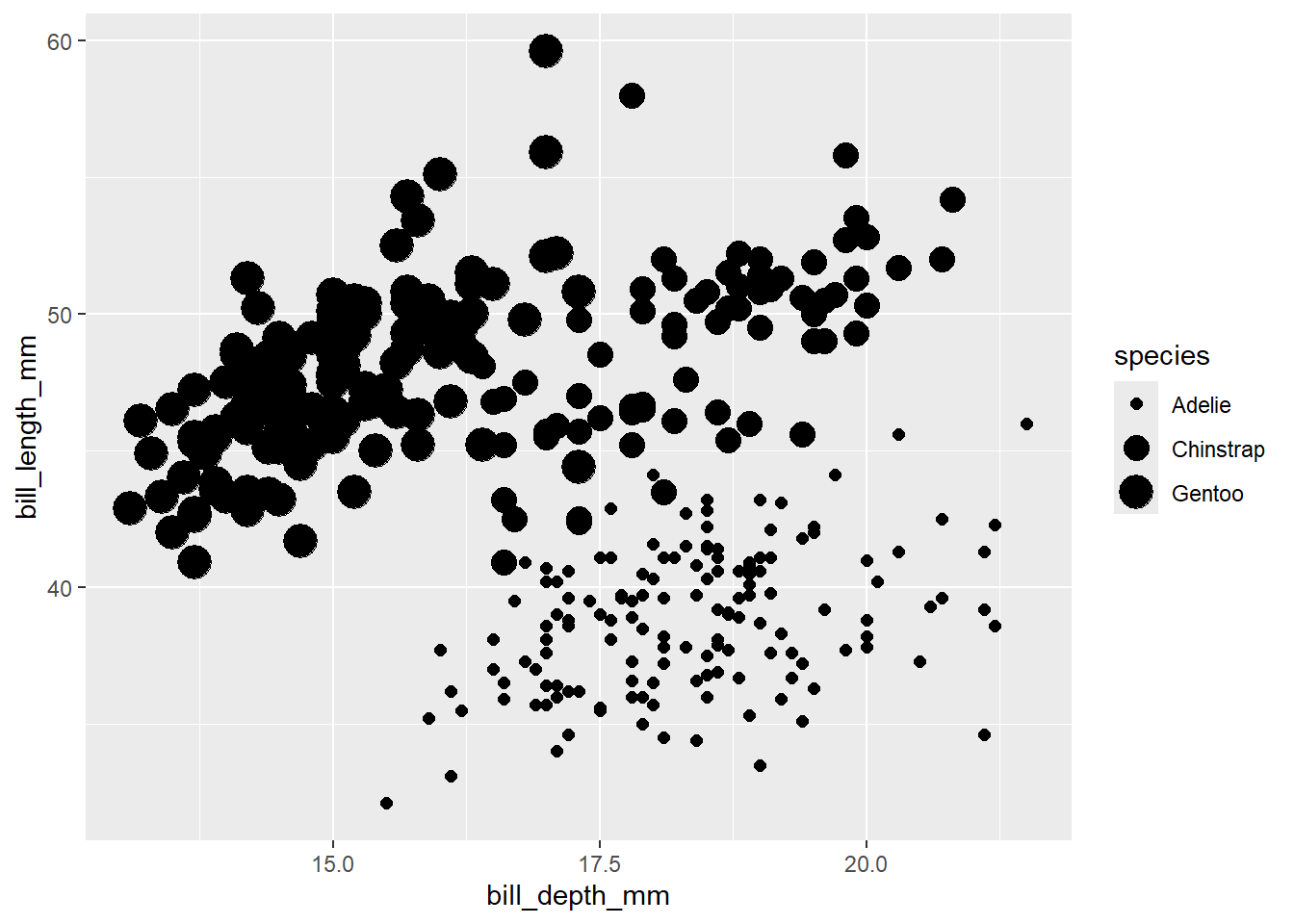
Agreguemos ahora la variable adicional flipper_length_mm (numérica continua).
Primero mapeémosla a las estética de color y de tamaño:
penguins %>%
ggplot(aes(x = bill_depth_mm, y = bill_length_mm, color = flipper_length_mm)) +
geom_point()
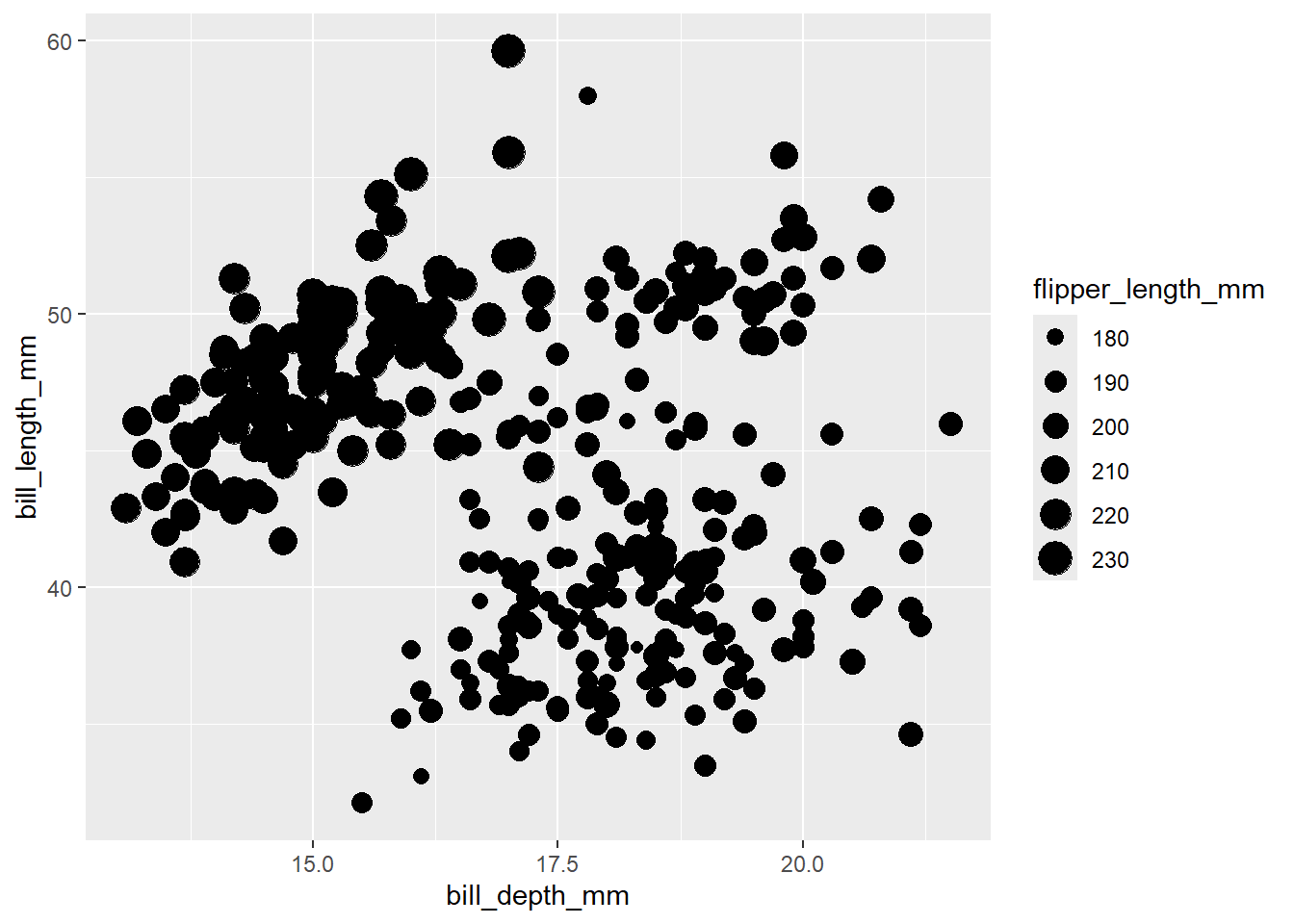
penguins %>%
ggplot(aes(x = bill_depth_mm, y = bill_length_mm, size = flipper_length_mm)) +
geom_point()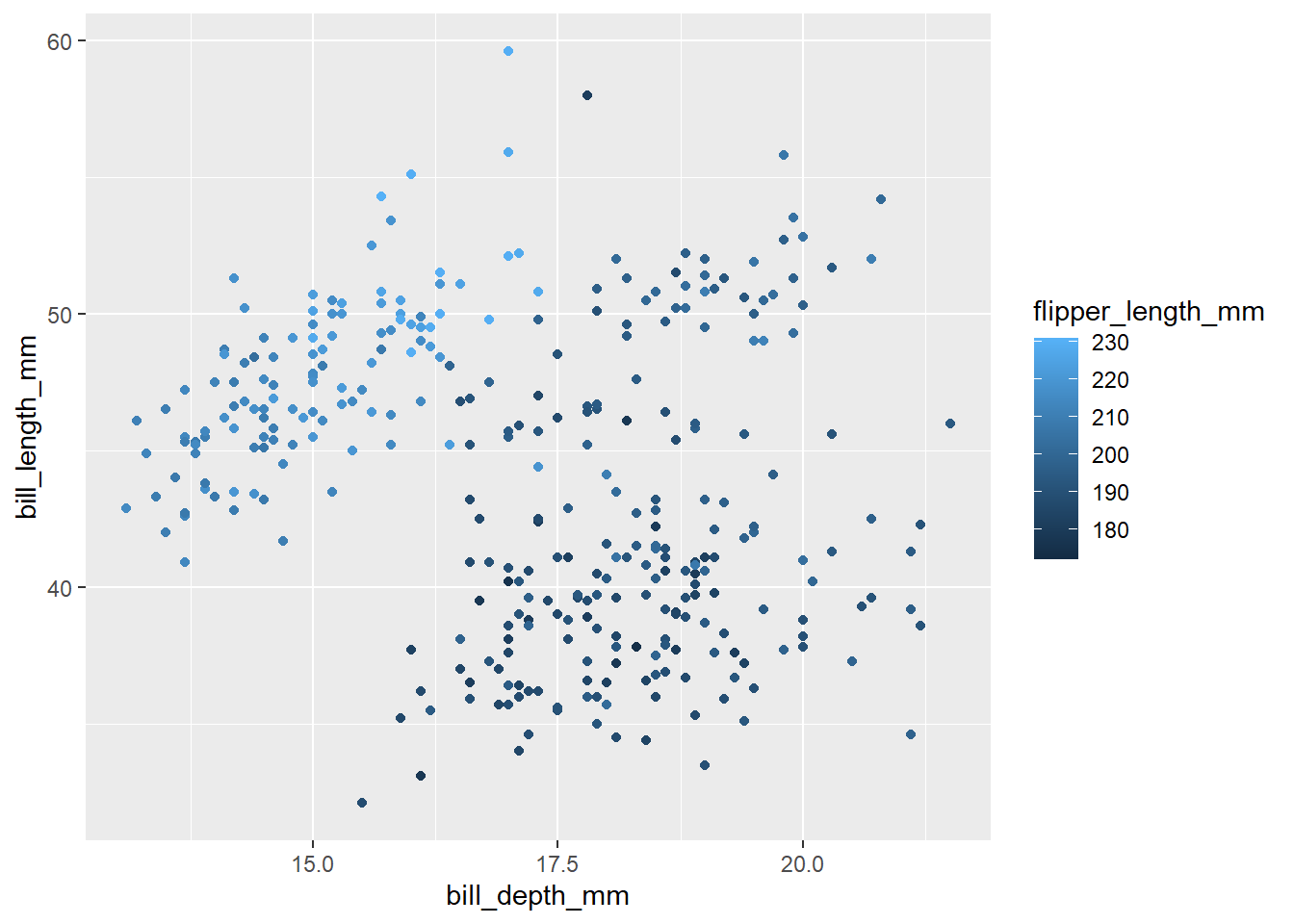
Sin embargo al mapearla a la estética de forma, ggplot2 genera un error indicando que no es posible hacerlo:
penguins %>%
ggplot(aes(x = bill_depth_mm, y = bill_length_mm, shape = flipper_length_mm)) +
geom_point()Error: A continuous variable can not be mapped to shape
También es posible agregar más de una variable adicional, usando varias estéticas:
penguins %>%
ggplot(aes(x = bill_depth_mm, y = bill_length_mm, shape = species, color = flipper_length_mm)) +
geom_point()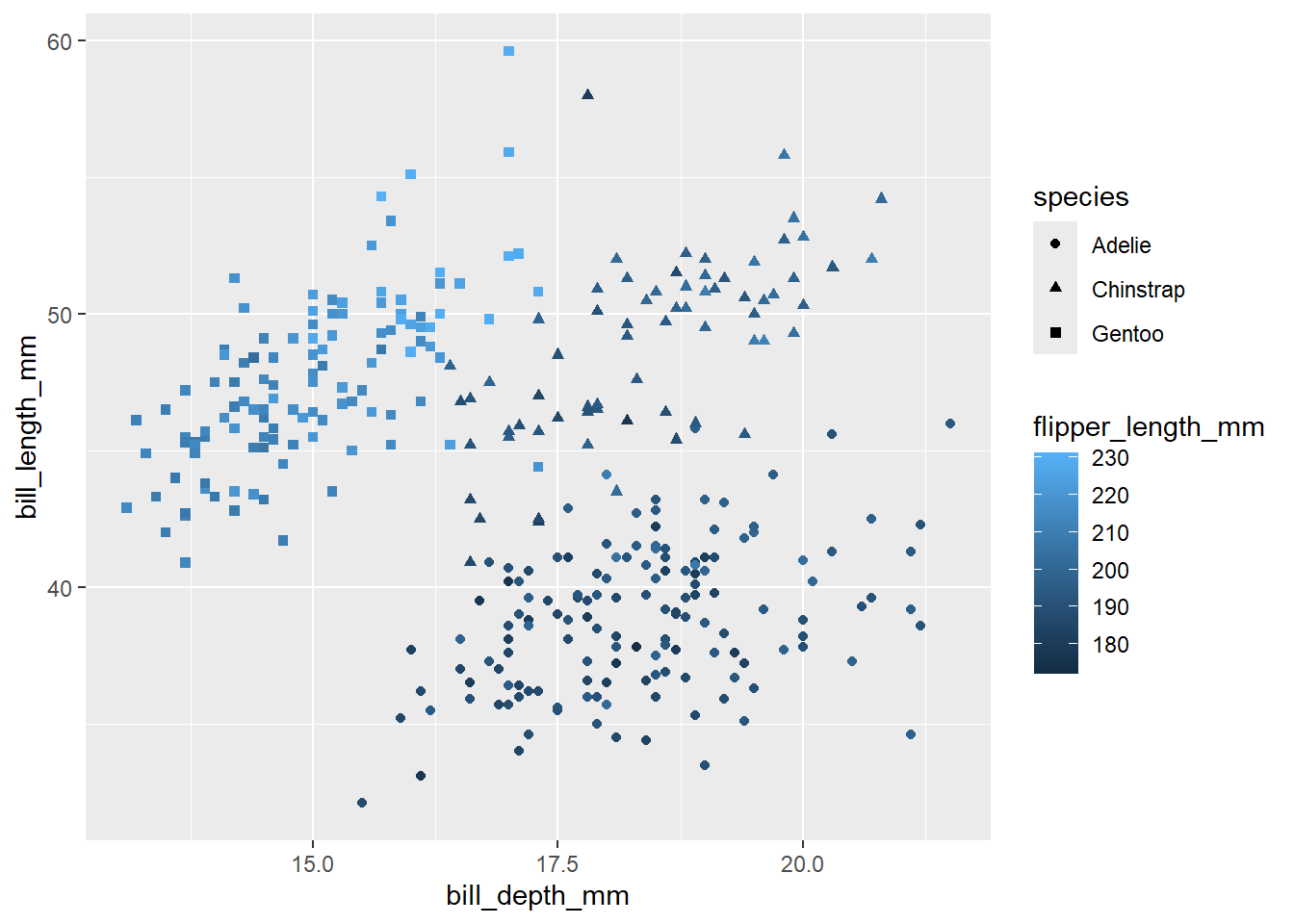
Horst AM, Hill AP, Gorman KB (2020). palmerpenguins: Palmer Archipelago (Antarctica) penguin data. R package version 0.1.0. https://allisonhorst.github.io/palmerpenguins/↩︎