2 Tablas de datos
2.1 ¿Qué es una tabla de datos?
Responder a esta pregunta se siente muy parecido a responder a “¿qué es un vaso de agua?”, parece ser difícil hacerlo sin caer en algo de redundancia. Pero bueno, aquí vamos:
Una tabla de datos es una representación de cualquier tipo de información en forma tabular, es decir, ordenada en filas y columnas.
Los ejemplos de tablas de datos son muchos y los hay muy antiguos como esta tableta de arcilla que data de alrededor del 3000 A.C., usada para mantener cuentas de granos de malta y cebada3:
 Otro ejemplo más conocido, es la tabla periódica de los elementos4:
Otro ejemplo más conocido, es la tabla periódica de los elementos4:
Las tablas de datos que en realidad nos interesan aquí son más tradicionales: aquellas que tienen información representada por números o cadenas de caracteres (o strings).
2.1.1 Tablas tidy
Notemos que tal y como señala la definición de tabla de datos que hemos entregado más arriba, una tabla es sólo una representación de ciertos datos. Esto implica que puede haber más de una tabla para representar a un conjunto de datos.
Por ejemplo, consideremos la siguiente tabla que representa los resultados de dos exámenes médicos para tres personas:
| Examen 1 | Examen 2 | |
|---|---|---|
| Juan | 10 | 2 |
| Clara | 15 | 5 |
| Lin | 9 | 4 |
Otra manera de representar la misma información es simplemente trasponiendo la tabla anterior (cambiando las filas por columnas):
| Juan | Clara | Lin | |
|---|---|---|---|
| Examen 1 | 10 | 15 | 9 |
| Examen 2 | 2 | 5 | 4 |
Una tercera manera, que puede parecer un poco menos eficiente, es la siguiente:
| Nombre | Examen | Resultado |
|---|---|---|
| Juan | Examen 1 | 10 |
| Clara | Examen 1 | 15 |
| Lin | Examen 1 | 9 |
| Juan | Examen 2 | 2 |
| Clara | Examen 2 | 5 |
| Lin | Examen 2 | 4 |
En esta tabla parece que estuviésemos repitiendo información, sin embargo tiene una característica que la hacen mucho más sencilla de manipular, analizar y visualizar:
Cada columna corresponde a una variable y cada fila corresponde a una observación.
Una tabla de datos con esta característica se dice tidy (ordenada).
La razón por la que este tipo de tablas es útil tiene que ver principalmente con que entrega una manera estandarizada de representar datos. Quien hace el análisis (o incluso un computador) puede extraer fácilmente cualquier variable que sea de interés.
En nuestro ejemplo, las dos primeras versiones de la tabla no es claro (a menos que alguien nos lo explique previamente) dónde están las variables y las observaciones. Por otra parte, en una tabla tidy, el rol de filas y columnas es claro.
La utilidad de este formato se hará más evidente a medida que avancemos en las siguientes secciones.
2.2 Bienvenido al tidyverse
En lo que sigue usaremos el paquete tidyverse5. En realidad tidyverse es un conjunto de paquetes que permiten explorar, modificar y visualizar datos de forma intuitiva y robusta. Nota el guiño a las tablas tidy en el nombre del paquete, esto no es casual.
Puedes pensar en tidyverse como una gran caja de organizadora de herramientas, dentro de la cual hay cajas más pequeñas (paquetes) que tienen herramientas especializadas en ciertas tareas.
Pese a que faltan par de secciones para empezar a usar tidyverse realmente, es bueno que sepas cómo cargarlo en R.
- Primero debemos instalar tidyverse a través de siguiente comando (el cual debes ejecutar en la Consola):
Esto puede tomar un poco tiempo (R descargará el paquete desde internet y lo instalará), pero sólo debemos hacerlo una vez.
- Luego, cada vez que trabajemos con tidyverse, cargamos el paquete con el comando (esto puede ser ejecutado tanto en la Consola como en un script o archivo Rmarkdown):
## ── Attaching core tidyverse packages ──────────────
## ✔ dplyr 1.1.4 ✔ readr 2.1.5
## ✔ forcats 1.0.0 ✔ stringr 1.5.1
## ✔ ggplot2 3.5.0 ✔ tibble 3.2.1
## ✔ lubridate 1.9.3 ✔ tidyr 1.3.1
## ✔ purrr 1.0.2
## ── Conflicts ───────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors── Attaching packages ──────────────────────────────────────────────────────── tidyverse 1.3.0 ──
✓ ggplot2 3.3.2 ✓ purrr 0.3.4
✓ tibble 3.0.4 ✓ dplyr 1.0.2
✓ tidyr 1.1.2 ✓ stringr 1.4.0
✓ readr 1.4.0 ✓ forcats 0.5.0
── Conflicts ─────────────────────────────────────────────────────────── tidyverse_conflicts() ──
x dplyr::filter() masks stats::filter()
x dplyr::lag() masks stats::lag()Notarás que aparecen algunos mensajes y advertencias, pero no son nada malo. Si tu salida es parecida a la que está aquí, todo está bien.
Importante: En el resto de este capítulo asumiremos que tidyverse ya ha sido cargado
2.2.1 Recetas y cañerías (pipes)
Antes de seguir entrando en detalles, es importante hablar de cómo se estructura el trabajo en tidyverse. Para ello nos inspiraremos en un ejemplo culinario: cocinar panqueques.
Si buscamos una receta de panqueques, nos encontraremos con algo más o menos así6:
Ingredientes
- 200 gr de harina
- 2 huevos
- 1 cucharada de polvos de hornear
- 50 ml de aceite
- 1 pizca bicarbonato de sodio
- 1/2 cucharadita de sal
- 300 ml de leche
- 30 gr de azúcar
Pasos:
- Volcar todos los ingredientes en un bowl y batir a potencia máxima por un minuto.
- Dejar la mezcla en la heladera por media hora.
- En una sartén con manteca, ir volcando en el medio un poco de mezcla. Dar vuelta cuando aparezcan burbujitas.
La receta está compuesta por ingredientes y pasos. Algo que es de sentido común para alguien que haya cocinado alguna vez es que para que una receta tenga éxito, aparte de procurar tener los ingredientes correspondientes, es muy importante tener claro los pasos a seguir y en qué orden realizarlos. No tiene sentido dejar la mezcla en la heladera si todavía no hemos mezclado los ingredientes en el bolo.
En el contexto de la computación, estos elementos básicos de una receta (ingredientes y pasos) reciben el nombre de entradas (o input) y algoritmo, respectivamente.
Cuando analizamos o manipulamos datos, también debemos tener claro cuáles son nuestros ingredientes y pasos. Usemos otro ejemplo, esta vez relacionado con datos.
Supongamos que tenemos una tabla de datos con los nombres, países de origen y edad de un grupo de personas:
| Nombre | País | Edad |
|---|---|---|
| Bernarda | Chile | 25 |
| Marcia | Perú | 23 |
| Tito | Perú | 40 |
| Diego | Chile | 39 |
| Esteban | Costa Rica | 27 |
Ante la pregunta “¿cuál es la edad promedio de las personas de Chile en esta tabla?”, quizás nuestra propuesta incial sería: “¡Fácil!, basta con promediar la edad de Bernarda y Diego”. Sin embargo, si quisiéramos responder a esta pregunta para cualquier tabla que datos similar (que quizás tenga miles de personas), es conveniente ordenar nuestras ideas a través de una receta:
Ingredientes
- Tabla de datos con países de origen y edades
Pasos
- Filtrar a todas aquellas personas cuyo país de origen sea Chile
- Calcular el promedio de las edades de dichas personas
Esta receta puede verse muy parecida a nuestra primera propuesta, pero tiene algunas ventajas:
- No depende de la tabla que se ingrese (antes hicimos referencia a “Bernarda” y “Diego”).
- Puede ser fácilmente entendida por otra persona, o incluso por un computador.
Al usar tidyverse las instrucciones que daremos a R también tendrán esta estructura de receta, pero en un formato particular. En tidyverse, la receta anterior se vería más o menos así:
¡No te asustes!, no pretendemos que entiendas esto todavía. Más adelante explicaremos en detalle qué significa cada parte de esta serie de comandos. Lo importante es que reconozcas los elementos principales de estas instrucciones:
- La primera línea tiene los ingredientes, la tabla de datos.
- La segunda línea realiza el primer paso de la receta: filtrar (filter) a las personas cuyo país de origen sea Chile.
- La tercera línea realiza el segundo paso de la receta: calcular (summarize o resumir) el promedio de la edad de dichas personas (mean o media).
Notarás que hay unos símbolos extraños (%>%) que están al final de las dos primeras líneas. Estos símbolos en tidyverse se llaman pipes (cañerías) y sirven para conectar las distintas partes de una receta. Es decir, lo que sea que salga de un paso de la receta es redirigido por el pipe hacia el siguiente paso:
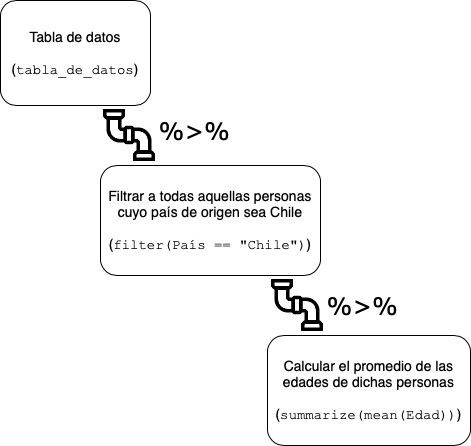
Una buena manera de leer estas cañerías al momento de revisar tu código es usando la expresión “y luego”, así en nuestro ejemplo el código se leería como:
“Tomamos la tabla de datos y luego filtramos a las personas cuyo país de origen es Chile. Y luego, calculamos el promedio de la edad de dichas personas.”
De ahora en adelante ten siempre presente esta forma de pensar al analizar y manipular tus datos.
2.2.2 dplyr
Una de las cajas pequeñas que conforman tidyverse es dplyr, un paquete especializado en manipular datos. Su nombre proviene de la palabra plyer (alicate), así que podemos decir que dplyr será nuestra caja de alicates para filtrar, modificar y resumir datos.
dplyr es en realidad una gramática de manipulación de datos, que a través de “verbos” permite realizar la mayoría de los pasos en una receta de manipulación de una tabla de datos. Los principales verbos de dplyr son:
filter()para filtrar filas, reduciendo la tabla a un subconjunto de filas que satisfaga alguna característica de interés.select()para seleccionar variables (columnas), reduciendo la tabla a un subconjunto de columnas que satisfaga alguna característica de interés.summarize()para resumir todos los valores de una columna (o varias) en un solo valor.mutate()para agregar nuevas variables a partir de variables existentes, modificar los valores en columnas ya existentes, o eliminar columnas.arrange()para cambiar el orden de filas (organizar) según algún criterio.
En general nos referiremos a estos verbos como comandos o funciones de dplyr.
Nota además que ya nos encontramos con dos de estos comandos en el ejemplo anterior (filter(País == "Chile") y summarize(mean(Edad))).
En las secciones que siguen, aprenderás a cómo usar estos comandos junto a otros de tidyverse y R. Lo haremos de la mejor manera para familiarizarse con algo desconocido: ¡poniendo manos a la obra!
2.3 Cargado de tablas
Razonar cuantitativamente con datos no se puede hacer sin datos, es equivalente a surfear sin agua. Partamos por usar R para cargar datos.
Los datos tienen en general varias fuentes, estas pueden ser:
- datos incluídos en un paquete de R,
- datos almacenados en una disco duro local o remoto,
- datos almacenados en servidores online.
2.3.1 Cargado desde un archivo
Al cargar datos que están almacenados en un archivo, hay dos preguntas a responder:
- ¿En qué formato están almacenados los datos del archivo?
- ¿Dónde está ubicado el archivo?
Hay muchas formas en que es posible almacenar datos en un archivo. Algunos de los formatos más comunes son:
- El formato
csv. La sigla “csv” proviene de “comma separated values” (valores separados por coma). - El formato
xls. Este corresponde a un formato de archivos usado por Microsoft Excel hasta el año 2006. - El formato
xlsx. Este corresponde a un formato de archivos usado por Microsoft Excel a partir del año 2007. Es un formato más moderno basado en Open XML, otro formato más general aún. - Formatos propietaros de sistemas de software para el análisis de datos como
dta(Stata),sav(SPSS),sas7bdat,sd7,sd2,ssd01(SAS), y otros.
Lo importante es que R puede leer todos los formatos antes mencionados, y muchos otros. Los más comunes de estos son CSV y XLS.
Para cargar un archivo desde excel:
Es posible leer de distintos sheets, o leer parte de un sheet, etc. Mayores informaciones en: https://readxl.tidyverse.org.
Para cargar un archivo desde un archivo CSV usamos:
Observa que en el ejemplo anterior, además de indicar el nombre del archivo, indicamos el directorio en que está ubicado. En este caso, el archivo está dentro de un directorio llamado data.
Prueba cargando el archivo ejemplo-notas.csv, que está disponible en el siguiente link7. De hecho, usaremos este archivo en el resto de este capítulo.
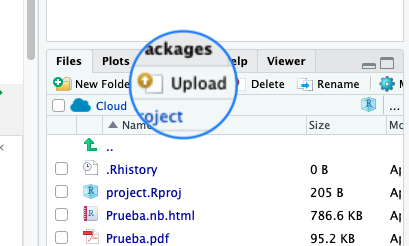
Si te encuentras trabajando en Posit Cloud, lo que en realidad estás haciendo es ejecutar R en un computador ubicado remotamente. Esto significa que para cargar un archivo de datos ubicado en tu computador, será necesario primero subir el archivo a Posit Cloud. Para esto:
- En el navegador de archivos de Posit Cloud, haz click en Upload:
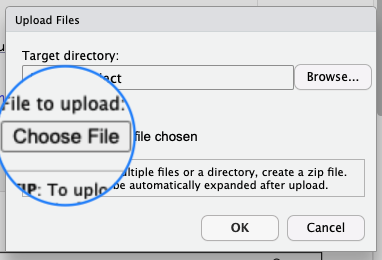
- Selecciona el, haciendo click en Choose File (lo cual abrirá un navegador de archivos en tu computador):
- El archivo aparecerá en el navegador de archivos de RStudio:
- Ya podrás cargar el archivo usando:
2.3.2 Cargando desde un archivo en internet
También podemos cargar datos desde un archivo disponible online. Para esto basta conocer la dirección (o URL) del archivo en cuestión. Por ejemplo, también podrías cargar la base de datos ejemplo-notas.csv
usando el comando:
2.4 Inspección de tablas
En esta sección veremos como usar R y tidyverse para inspeccionar una tabla de datos. Es decir, para determinar rápidamente cuántas variables y observaciones tiene, y más o menos, qué valores toman. Para ellos, usaremos la base de datos notas que cargamos a modo de ejemplo en la sección “Cargado desde un archivo”.
Esta base de datos tienes las características de algunos alumnos de un curso ficticio, junto con sus notas y asistencia.
Podemos mirar la base de datos simplemente escribiendo su nombre:
## # A tibble: 10 × 11
## Nombre Género Edad País `Prueba 1` `Prueba 2` `Tarea 1` `Tarea 2` `Tarea 3`
## <chr> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Diego… Mascu… 23 Chile 7 3.5 6.3 3.5 6
## 2 Berna… Femen… 25 Perú 3 4.1 4.4 5 6.7
## 3 Tito … Mascu… 40 Cost… 5.3 4.8 4.5 5.5 6
## 4 María… Femen… 25 Chile 6.8 7 7 7 6.8
## 5 Claud… Femen… 24 Perú 5.8 1 6.2 7 6.2
## 6 José … Mascu… 18 Cost… 3.8 2.3 4.1 3.7 5
## 7 Feder… Femen… 22 Alem… 6 5 6 6.1 6
## 8 Rodol… Mascu… 29 Boli… 6.8 4 7 6.5 4.3
## 9 Adria… Femen… 20 Chile 5.1 5.2 7 7 5
## 10 Qingx… Femen… 26 Cost… 6 5.8 1 4 5.5
## # ℹ 2 more variables: Examen <dbl>, Asistencia <dbl>El problema de esta forma de ver la tabla es RStudio no muestra todas las columnas (nota que la salida advierte "# … with 2 more variables: Examen <dbl>, Asistencia <dbl>", dependiendo del tamaño de tu pantalla). Esto mismo pasa si tenemos una tabla con muchas filas.
Otra forma de ver la tabla es usando el comando View():
Esto hace que la tabla se abra en el visor de RStudio. Puedes ver que es una interfaz muy familiar y parecida a lo que se ve al usar una hoja de cálculo. Pero no te engañes, no hay mucho que hacer en esta vista, más que dar una mirada general a los datos.
Para poder mirar rápidamente algunas características de la tabla de datos, tenemos los comandos que se listan a continuación. Si la descripción no te queda muy clara en una primera lectura, no te preocupes porque mostraremos ejemplos de su uso a continuación.
dim(): Entrega las dimensiones de la tabla (número filas y columnas).names(): Entrega los nombres de las columnas de la tabla.glimpse(): Entrega un listado de las variables junto a algunos estadísticos básicos.distinct(): Entrega el conjunto de valores únicos que toman una o más columnas.count(): Cuenta el número de valores únicos que toman una o más columnas.
Ejemplo
Inspeccionemos la base de datos notas.
Empecemos determinando el número de filas (observaciones) y columnas (variables) que esta base tiene.
## [1] 10 11Vemos que tiene 10 filas (alumnos), y 11 columnas (variables).
Nota: También podríamos haber usado el comando de la siguiente manera:
El resultado es el mismo, pero te recomendamos acostumbrarte a usar el formato de pipes (
%>%) ya que será útil al momento de usar comandos más complejos.
Podemos conocer el nombre de estas 11 columnas usando el comando names.
## [1] "Nombre" "Género" "Edad" "País" "Prueba 1"
## [6] "Prueba 2" "Tarea 1" "Tarea 2" "Tarea 3" "Examen"
## [11] "Asistencia"Al parecer esta tabla tiene las notas de los alumnos en dos pruebas, 4 tareas y el examen. Además hay una variable que tiene la asistencia de cada alumnos a clases.
Supongamos que nos interesa explorar la variable País con mayor profundidad. Empecemos viendo qué valores puede tomar esta variable, usando el método distinct.
## # A tibble: 5 × 1
## País
## <chr>
## 1 Chile
## 2 Perú
## 3 Costa Rica
## 4 Alemania
## 5 BoliviaEsto nos muestra que la variable País toma 5 valores posibles (hay alumnos de 5 países). Si queremos ver en más detalle cómo se distribuyen estos valores, podemos usar la función count.
notas %>% count(País, sort=TRUE) # Agregamos sort=TRUE para que se ordene de mayor a menor las frecuencias## # A tibble: 5 × 2
## País n
## <chr> <int>
## 1 Chile 3
## 2 Costa Rica 3
## 3 Perú 2
## 4 Alemania 1
## 5 Bolivia 1Es decir, la mayor cantidad de alumnos provienen de Chile y Costa Rica.
Si nos interesa ver, por ejemplo, cuántas observaciones hay de cada valor de País y género, podemos usar count también.
## # A tibble: 7 × 3
## País Género n
## <chr> <chr> <int>
## 1 Chile Femenino 2
## 2 Costa Rica Masculino 2
## 3 Perú Femenino 2
## 4 Alemania Femenino 1
## 5 Bolivia Masculino 1
## 6 Chile Masculino 1
## 7 Costa Rica Femenino 1Es decir, la combinaciones más frecuentes de País y Género en la clase son: mujeres chilenas, hombres costarricenses y mujeres peruanas.
2.5 Subconjuntos de filas
Una tarea común al explorar una tabla de datos es seleccionar o filtrar algunas observaciones. Para ello, utilizamos el comando filter() de dplyr.
Por ejemplo, si queremos seleccionar sólo a las alumnas del curso:
## # A tibble: 6 × 11
## Nombre Género Edad País `Prueba 1` `Prueba 2` `Tarea 1` `Tarea 2` `Tarea 3`
## <chr> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Bernar… Femen… 25 Perú 3 4.1 4.4 5 6.7
## 2 María … Femen… 25 Chile 6.8 7 7 7 6.8
## 3 Claudi… Femen… 24 Perú 5.8 1 6.2 7 6.2
## 4 Federi… Femen… 22 Alem… 6 5 6 6.1 6
## 5 Adrian… Femen… 20 Chile 5.1 5.2 7 7 5
## 6 Qingxi… Femen… 26 Cost… 6 5.8 1 4 5.5
## # ℹ 2 more variables: Examen <dbl>, Asistencia <dbl>Puedes notar que la salida de este comando es una tabla de datos, pero que sólo contiene filas correspondientes a alumnas del curso.
El formato general en que usamos este comando es:
datos %>% filter(<condición>)
en donde <condición> es alguna condición sobre ciertas variables que tienen que satisfacer las filas a seleccionar (por ejemplo, “alumnos que hayan obtenido nota mayor o igual a 4.0 en la Prueba 2”).
2.5.1 Subconjuntos por valor
Para generar las condiciones que nos permitirán seleccionar filas, usaremos los siguientes comparadores, operadores y comandos:
>, <, >=, <=, ==: Comparadores de orden (más detalles en la sección “Operadores de comparación”).|, &, xor, !: Operadores lógicos (más detalles en la sección “Conectores lógicos y negación”).between: Permite identificar valores que caen en un rango determinado.str_detect: Detectar un string dentro de una variable.%in%: Condición de pertenencia a una colección de valores.
Ejemplos
Veamos ahora qué alumnas aprobaron la Prueba 1 (obtuvieron una nota mayor o igual a 4.0). Es decir, la condición que buscamos es “alumna” y “nota en Prueba 1 mayor o igual a 4.0”.
Nota que podemos obtener el mismo resultado usando cualquiera de los siguientes comandos:
notas %>% filter(Género == "Femenino" & `Prueba 1` >= 4.0)
notas %>% filter(Género == "Femenino", `Prueba 1` >= 4.0)
notas %>% filter(Género == "Femenino") %>% filter(`Prueba 1` >= 4.0)Mención especial merece el último comando. Filtrar usando un criterio compuesto por dos condiciones que se deben satisfacer simultáneamente, es equivalente a filtrar por el primer criterio y luego filtrar la tabla de datos resultante por el segundo criterio. ¡Es un buen ejemplo de las pipes en acción!
Si queremos seleccionar a los alumnos cuya edad está entre 25 y 30 años, pordemos usar el comando between() en la condición:
## # A tibble: 4 × 11
## Nombre Género Edad País `Prueba 1` `Prueba 2` `Tarea 1` `Tarea 2` `Tarea 3`
## <chr> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Bernar… Femen… 25 Perú 3 4.1 4.4 5 6.7
## 2 María … Femen… 25 Chile 6.8 7 7 7 6.8
## 3 Rodolf… Mascu… 29 Boli… 6.8 4 7 6.5 4.3
## 4 Qingxi… Femen… 26 Cost… 6 5.8 1 4 5.5
## # ℹ 2 more variables: Examen <dbl>, Asistencia <dbl>Para filtrar strings que contienen algún texto en particular se puede usar el método str_detect(). Por ejemplo, podemos seleccionar sólo a aquellos alumnos que tengan nombre “María” o “José”:
## # A tibble: 4 × 11
## Nombre Género Edad País `Prueba 1` `Prueba 2` `Tarea 1` `Tarea 2` `Tarea 3`
## <chr> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 María … Femen… 25 Chile 6.8 7 7 7 6.8
## 2 Claudi… Femen… 24 Perú 5.8 1 6.2 7 6.2
## 3 José E… Mascu… 18 Cost… 3.8 2.3 4.1 3.7 5
## 4 Rodolf… Mascu… 29 Boli… 6.8 4 7 6.5 4.3
## # ℹ 2 more variables: Examen <dbl>, Asistencia <dbl>Si queremos filtrar usando algunos valores particulares de las variables, usamos la condición de pertenencia usando la expresión %in%. Por ejemplo, si queremos sólo seleccionar a los alumnos de Chile y Costa Rica:
## # A tibble: 6 × 11
## Nombre Género Edad País `Prueba 1` `Prueba 2` `Tarea 1` `Tarea 2` `Tarea 3`
## <chr> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Diego … Mascu… 23 Chile 7 3.5 6.3 3.5 6
## 2 Tito L… Mascu… 40 Cost… 5.3 4.8 4.5 5.5 6
## 3 María … Femen… 25 Chile 6.8 7 7 7 6.8
## 4 José E… Mascu… 18 Cost… 3.8 2.3 4.1 3.7 5
## 5 Adrian… Femen… 20 Chile 5.1 5.2 7 7 5
## 6 Qingxi… Femen… 26 Cost… 6 5.8 1 4 5.5
## # ℹ 2 more variables: Examen <dbl>, Asistencia <dbl>Nota: La razón por la que escribimos
c("Chile", "Costa Rica")es porque en realidad estamos creando un vector con los valores"Chile"y"Costa Rica". Para más detalles acerca de vectores en R, ver sección “Vectores”
Este comando es equivalente a:
## # A tibble: 6 × 11
## Nombre Género Edad País `Prueba 1` `Prueba 2` `Tarea 1` `Tarea 2` `Tarea 3`
## <chr> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Diego … Mascu… 23 Chile 7 3.5 6.3 3.5 6
## 2 Tito L… Mascu… 40 Cost… 5.3 4.8 4.5 5.5 6
## 3 María … Femen… 25 Chile 6.8 7 7 7 6.8
## 4 José E… Mascu… 18 Cost… 3.8 2.3 4.1 3.7 5
## 5 Adrian… Femen… 20 Chile 5.1 5.2 7 7 5
## 6 Qingxi… Femen… 26 Cost… 6 5.8 1 4 5.5
## # ℹ 2 more variables: Examen <dbl>, Asistencia <dbl>Pero puede ser más compacto cuando se trata de filtrar usando muchos valores.
2.5.2 Subconjuntos por posición
Otra de las maneras de seleccionar filas en una tabla de datos es través de su posición en esta. Para ello usamos las funciones head() y tail(), las cuales entregan las primeras filas (cabeza) o las últimas filas (cola) de la tabla. Esta función recibe como argumento el número de filas que queremos.
Ejemplos
Por ejemplo, si queremos los 3 primeros alumnos de lista:
## # A tibble: 3 × 11
## Nombre Género Edad País `Prueba 1` `Prueba 2` `Tarea 1` `Tarea 2` `Tarea 3`
## <chr> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Diego … Mascu… 23 Chile 7 3.5 6.3 3.5 6
## 2 Bernar… Femen… 25 Perú 3 4.1 4.4 5 6.7
## 3 Tito L… Mascu… 40 Cost… 5.3 4.8 4.5 5.5 6
## # ℹ 2 more variables: Examen <dbl>, Asistencia <dbl>O los últimos 4 alumnos de la lista:
## # A tibble: 4 × 11
## Nombre Género Edad País `Prueba 1` `Prueba 2` `Tarea 1` `Tarea 2` `Tarea 3`
## <chr> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Federi… Femen… 22 Alem… 6 5 6 6.1 6
## 2 Rodolf… Mascu… 29 Boli… 6.8 4 7 6.5 4.3
## 3 Adrian… Femen… 20 Chile 5.1 5.2 7 7 5
## 4 Qingxi… Femen… 26 Cost… 6 5.8 1 4 5.5
## # ℹ 2 more variables: Examen <dbl>, Asistencia <dbl>Nota que cuando nos referimos a las “primeras” o “últimas” filas, esto es sólo relativo a la forma en que la tabla venía ordenada originalmente. Dependiendo de cómo ordenemos la tabla, estas filas tendrán o un sentido. Lo veremos más adelante, en la sección “Ordenamiento de filas”.
2.6 Subconjuntos de columnas
Otra tarea útil es la selección de algunas columnas o variables. Esto lo conseguimos a través del comando select().
Podemos usar este comando para seleccionar por nombre o por posición.
2.6.1 Selección de columnas por nombre
Aquí el criterio de selección es a través de los nombres de las variables. Por ejemplo, si queremos tener una tabla que sólo contenga el nombre y la edad de los alumnos:
## # A tibble: 10 × 2
## Nombre Edad
## <chr> <dbl>
## 1 Diego Alberto Rojas 23
## 2 Bernarda Antonia Chen 25
## 3 Tito Lenin Pérez 40
## 4 María Marcia González 25
## 5 Claudia María Valencia 24
## 6 José Esteban Iruarrizaga 18
## 7 Federica Von Müller 22
## 8 Rodolfo José Mamani 29
## 9 Adriana Violeta Antillán 20
## 10 Qingxia Esmeralda Quiñones 26Nota que el resultado de este comando es una tabla de datos pero que tiene menos columnas (pero la misma cantidad de filas que antes).
La forma general en la que usamos el comando select() en esta caso es:
datos %>% select(variable1, variable2, ..., variablek)
Ejemplos
Seleccionemos las columnas Nombre, País y Género:
## # A tibble: 10 × 3
## Nombre País Género
## <chr> <chr> <chr>
## 1 Diego Alberto Rojas Chile Masculino
## 2 Bernarda Antonia Chen Perú Femenino
## 3 Tito Lenin Pérez Costa Rica Masculino
## 4 María Marcia González Chile Femenino
## 5 Claudia María Valencia Perú Femenino
## 6 José Esteban Iruarrizaga Costa Rica Masculino
## 7 Federica Von Müller Alemania Femenino
## 8 Rodolfo José Mamani Bolivia Masculino
## 9 Adriana Violeta Antillán Chile Femenino
## 10 Qingxia Esmeralda Quiñones Costa Rica FemeninoPodemos también aprovechar de cambiar el orden y los nombres de las columnas, junto con seleccionar:
## # A tibble: 10 × 3
## Nombre prueba2 prueba1
## <chr> <dbl> <dbl>
## 1 Diego Alberto Rojas 3.5 7
## 2 Bernarda Antonia Chen 4.1 3
## 3 Tito Lenin Pérez 4.8 5.3
## 4 María Marcia González 7 6.8
## 5 Claudia María Valencia 1 5.8
## 6 José Esteban Iruarrizaga 2.3 3.8
## 7 Federica Von Müller 5 6
## 8 Rodolfo José Mamani 4 6.8
## 9 Adriana Violeta Antillán 5.2 5.1
## 10 Qingxia Esmeralda Quiñones 5.8 6También podemos usar select() para eliminar columnas, seleccionando todas
las columnas de la tabla de datos menos ciertas columnas específicas, a las
cuales anteponemos un signo -:
## # A tibble: 10 × 10
## Nombre Género Edad `Prueba 1` `Prueba 2` `Tarea 1` `Tarea 2` `Tarea 3`
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Diego Alber… Mascu… 23 7 3.5 6.3 3.5 6
## 2 Bernarda An… Femen… 25 3 4.1 4.4 5 6.7
## 3 Tito Lenin … Mascu… 40 5.3 4.8 4.5 5.5 6
## 4 María Marci… Femen… 25 6.8 7 7 7 6.8
## 5 Claudia Mar… Femen… 24 5.8 1 6.2 7 6.2
## 6 José Esteba… Mascu… 18 3.8 2.3 4.1 3.7 5
## 7 Federica Vo… Femen… 22 6 5 6 6.1 6
## 8 Rodolfo Jos… Mascu… 29 6.8 4 7 6.5 4.3
## 9 Adriana Vio… Femen… 20 5.1 5.2 7 7 5
## 10 Qingxia Esm… Femen… 26 6 5.8 1 4 5.5
## # ℹ 2 more variables: Examen <dbl>, Asistencia <dbl>2.6.2 Selección de columnas por condición
En este caso usamos una condición sobre los nombres de las variables. Un ejemplo sería seleccionar todas las variables que correspondan a tareas.
La forma general en que se usa el comando select() en este caso es:
datos %>% select(<condicion>)
Para realizar este tipo de selección, podemos usar los siguiente comandos auxiliares:
starts_with(),ends_with(): Chequea si el nombre de una columna comienza o termina con un cierto string.contains(): Chequea si el nombre de una columna contiene un cierto string.
Ejemplos
Seleccionemos todas las variables que corresponden a notas de tareas:
## # A tibble: 10 × 3
## `Tarea 1` `Tarea 2` `Tarea 3`
## <dbl> <dbl> <dbl>
## 1 6.3 3.5 6
## 2 4.4 5 6.7
## 3 4.5 5.5 6
## 4 7 7 6.8
## 5 6.2 7 6.2
## 6 4.1 3.7 5
## 7 6 6.1 6
## 8 7 6.5 4.3
## 9 7 7 5
## 10 1 4 5.5Podríamos seleccionar las columnas que corresponden a segundas evaluaciones (Prueba 2 y Tarea 2), usando como condición que contengan el string “2”:
## # A tibble: 10 × 2
## `Prueba 2` `Tarea 2`
## <dbl> <dbl>
## 1 3.5 3.5
## 2 4.1 5
## 3 4.8 5.5
## 4 7 7
## 5 1 7
## 6 2.3 3.7
## 7 5 6.1
## 8 4 6.5
## 9 5.2 7
## 10 5.8 42.7 Cambio de nombre de columnas
Pese a que al momento de seleccionar columnas con el comando select() podemos
renombrarlas, la manera más conveniente y recomendada de cambiar el nombre de
una columna es usando el comando rename().
El formato de uso de este comando es:
datos %>% rename(nuevo_nombre_columna = viejo_nombre_columna)
Es también posible renombrar más de una columna a la vez, entregandos múltiples
expresiones nuevo_nombre_columna = viejo_nombre_columna separadas por coma.
Ejemplos
Saquemos los espacios en los nombres de las columnas de tareas, por ejemplo
cambiando Tarea 1 por Tarea_1:
## # A tibble: 10 × 11
## Nombre Género Edad País `Prueba 1` `Prueba 2` Tarea1 Tarea2 Tarea3 Examen
## <chr> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Diego A… Mascu… 23 Chile 7 3.5 6.3 3.5 6 5.7
## 2 Bernard… Femen… 25 Perú 3 4.1 4.4 5 6.7 4.2
## 3 Tito Le… Mascu… 40 Cost… 5.3 4.8 4.5 5.5 6 5
## 4 María M… Femen… 25 Chile 6.8 7 7 7 6.8 6.5
## 5 Claudia… Femen… 24 Perú 5.8 1 6.2 7 6.2 7
## 6 José Es… Mascu… 18 Cost… 3.8 2.3 4.1 3.7 5 4
## 7 Federic… Femen… 22 Alem… 6 5 6 6.1 6 7
## 8 Rodolfo… Mascu… 29 Boli… 6.8 4 7 6.5 4.3 3.8
## 9 Adriana… Femen… 20 Chile 5.1 5.2 7 7 5 5.5
## 10 Qingxia… Femen… 26 Cost… 6 5.8 1 4 5.5 4.9
## # ℹ 1 more variable: Asistencia <dbl>2.8 Creación y modificación de columnas
Muchas veces queremos hacer hacer cálculos o modificaciones a las variables de una tabla y eventualmente crear nuevas variables para simplicar y ordenar el análisis.
En este caso usamos el comando mutate(), de la siguiente manera:
datos %>% mutate(variable_resultado = <función de variables existentes>)
La expresión <función de variables existentes>, es alguna operación o función aplicada sobre las variables de la base de datos. variable_resultado puede ser una variable existente (y por ende estaremos sobre-escribiendo sus valores) o el nombre de una nueva variable (dplyr la creará por nosotros). Además, si omitimos variable_resultado, se creará una nueva columna con un nombre igual a la expresión que hayamos usado para calcularla.
Importante: Cualquier operación o función usada a través del comando mutate es aplicada a los valores de las variables correspondientes, fila por fila.
Ejemplos
Calculemos el porcentaje de asistencia de cada alumno. Para ello debemos dividir la columna Asistencia por el total de clases (digamos que se trata de un curso con 16 clases):
## # A tibble: 10 × 2
## Nombre Asistencia
## <chr> <dbl>
## 1 Diego Alberto Rojas 75
## 2 Bernarda Antonia Chen 56.2
## 3 Tito Lenin Pérez 81.2
## 4 María Marcia González 87.5
## 5 Claudia María Valencia 93.8
## 6 José Esteban Iruarrizaga 37.5
## 7 Federica Von Müller 100
## 8 Rodolfo José Mamani 68.8
## 9 Adriana Violeta Antillán 100
## 10 Qingxia Esmeralda Quiñones 75Nota que en este caso, hemos guardado el resultado de la operación Asistencia / 16 * 100 en la misma columna Asistencia y por ende estamos reemplazado sus valores.
Realicemos ahora un cálculo que todo alumno debe hacer al final de un curso, obtener el promedio de las notas de tareas:
notas %>%
mutate(promedio_tareas = (`Tarea 1`+ `Tarea 2` + `Tarea 3`)/3) %>%
select(Nombre, promedio_tareas)## # A tibble: 10 × 2
## Nombre promedio_tareas
## <chr> <dbl>
## 1 Diego Alberto Rojas 5.27
## 2 Bernarda Antonia Chen 5.37
## 3 Tito Lenin Pérez 5.33
## 4 María Marcia González 6.93
## 5 Claudia María Valencia 6.47
## 6 José Esteban Iruarrizaga 4.27
## 7 Federica Von Müller 6.03
## 8 Rodolfo José Mamani 5.93
## 9 Adriana Violeta Antillán 6.33
## 10 Qingxia Esmeralda Quiñones 3.5Nota que Diego tiene un promedio de tareas igual a 5.266667, pero en realidad el valor que necesitamos es el promedio aproximado a un decimal. Para ello usamos la función round(), la cual recibe como argumento el nombre de la variable que queremos redondear y el número de decimales (digits) que queremos conservar:
notas %>%
mutate(promedio_tareas = (`Tarea 1`+ `Tarea 2` + `Tarea 3`)/3) %>%
mutate(promedio_tareas = round(promedio_tareas, digits = 1))## # A tibble: 10 × 12
## Nombre Género Edad País `Prueba 1` `Prueba 2` `Tarea 1` `Tarea 2` `Tarea 3`
## <chr> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Diego… Mascu… 23 Chile 7 3.5 6.3 3.5 6
## 2 Berna… Femen… 25 Perú 3 4.1 4.4 5 6.7
## 3 Tito … Mascu… 40 Cost… 5.3 4.8 4.5 5.5 6
## 4 María… Femen… 25 Chile 6.8 7 7 7 6.8
## 5 Claud… Femen… 24 Perú 5.8 1 6.2 7 6.2
## 6 José … Mascu… 18 Cost… 3.8 2.3 4.1 3.7 5
## 7 Feder… Femen… 22 Alem… 6 5 6 6.1 6
## 8 Rodol… Mascu… 29 Boli… 6.8 4 7 6.5 4.3
## 9 Adria… Femen… 20 Chile 5.1 5.2 7 7 5
## 10 Qingx… Femen… 26 Cost… 6 5.8 1 4 5.5
## # ℹ 3 more variables: Examen <dbl>, Asistencia <dbl>, promedio_tareas <dbl>2.8.1 Creación de columnas usando condiciones lógicas
Hay veces en que la nueva columna a crear no puede ser expresada de manera sencilla con una expresión algebraica (como una suma, una división, un promedio, etc.) y es conveniente usar una condición lógica para determinar su valor. Esto pasa, por ejemplo, al crear una nueva columna cuyo objetivo es etiquetar a todas las filas en la tabla de datos que satisfacen una condición.
En este caso, junto con mutate(), usamos el comando if_else().
El formato en el que usamos este comando es:
datos %>% mutate(nueva_columna = if_else(<condicion>, <valor_si_verdadero>, <valor_si_falso>)
En donde:
<condicion>es una condición lógica, tal y como las que usamos con el comandofilter().<valor_si_verdadero>es el valor que tomará la nueva columna, si la condición se satisface para esta fila.<valor_si_falso>es el valor que tomará la nueva columna en caso contrario.
Ejemplos
Creemos una nueva columna que indique qué alumnos tienen una nota menor que 4.0 en el Examen:
## # A tibble: 10 × 12
## Nombre Género Edad País `Prueba 1` `Prueba 2` `Tarea 1` `Tarea 2` `Tarea 3`
## <chr> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Diego… Mascu… 23 Chile 7 3.5 6.3 3.5 6
## 2 Berna… Femen… 25 Perú 3 4.1 4.4 5 6.7
## 3 Tito … Mascu… 40 Cost… 5.3 4.8 4.5 5.5 6
## 4 María… Femen… 25 Chile 6.8 7 7 7 6.8
## 5 Claud… Femen… 24 Perú 5.8 1 6.2 7 6.2
## 6 José … Mascu… 18 Cost… 3.8 2.3 4.1 3.7 5
## 7 Feder… Femen… 22 Alem… 6 5 6 6.1 6
## 8 Rodol… Mascu… 29 Boli… 6.8 4 7 6.5 4.3
## 9 Adria… Femen… 20 Chile 5.1 5.2 7 7 5
## 10 Qingx… Femen… 26 Cost… 6 5.8 1 4 5.5
## # ℹ 3 more variables: Examen <dbl>, Asistencia <dbl>, reprueba_examen <chr>Los valores de salida pueden ser también numéricos. Por ejemplo, supongamos que queremos crear una nueva columna llamada “Bonus” que contenga cinco décimas extra para todos aquellos alumnos que hayan tenido una asistencia perfecta (16 clases):
## # A tibble: 10 × 12
## Nombre Género Edad País `Prueba 1` `Prueba 2` `Tarea 1` `Tarea 2` `Tarea 3`
## <chr> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Diego… Mascu… 23 Chile 7 3.5 6.3 3.5 6
## 2 Berna… Femen… 25 Perú 3 4.1 4.4 5 6.7
## 3 Tito … Mascu… 40 Cost… 5.3 4.8 4.5 5.5 6
## 4 María… Femen… 25 Chile 6.8 7 7 7 6.8
## 5 Claud… Femen… 24 Perú 5.8 1 6.2 7 6.2
## 6 José … Mascu… 18 Cost… 3.8 2.3 4.1 3.7 5
## 7 Feder… Femen… 22 Alem… 6 5 6 6.1 6
## 8 Rodol… Mascu… 29 Boli… 6.8 4 7 6.5 4.3
## 9 Adria… Femen… 20 Chile 5.1 5.2 7 7 5
## 10 Qingx… Femen… 26 Cost… 6 5.8 1 4 5.5
## # ℹ 3 more variables: Examen <dbl>, Asistencia <dbl>, Bonus <dbl>Finalmente, veamos que también es posible usar condiciones anidadas. Supongamos que queremos categorizar a los alumnos en tres categorías:
- Asistencia alta: aquellos con una asistencia de 75% o más.
- Asistencia media: aquellos con una asistencia mayor o igual a 50% y menor que 75%.
- Asistencia baja: aquellos con una asistencia menor a 50%.
Creamos una nueva columna llamada “Nivel_Asistencia”:
notas %>%
mutate(Nivel_Asistencia = if_else(Asistencia/16 >= 0.75,
"Alta",
if_else(Asistencia/16 >= 0.5,
"Media",
"Baja")))## # A tibble: 10 × 12
## Nombre Género Edad País `Prueba 1` `Prueba 2` `Tarea 1` `Tarea 2` `Tarea 3`
## <chr> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Diego… Mascu… 23 Chile 7 3.5 6.3 3.5 6
## 2 Berna… Femen… 25 Perú 3 4.1 4.4 5 6.7
## 3 Tito … Mascu… 40 Cost… 5.3 4.8 4.5 5.5 6
## 4 María… Femen… 25 Chile 6.8 7 7 7 6.8
## 5 Claud… Femen… 24 Perú 5.8 1 6.2 7 6.2
## 6 José … Mascu… 18 Cost… 3.8 2.3 4.1 3.7 5
## 7 Feder… Femen… 22 Alem… 6 5 6 6.1 6
## 8 Rodol… Mascu… 29 Boli… 6.8 4 7 6.5 4.3
## 9 Adria… Femen… 20 Chile 5.1 5.2 7 7 5
## 10 Qingx… Femen… 26 Cost… 6 5.8 1 4 5.5
## # ℹ 3 more variables: Examen <dbl>, Asistencia <dbl>, Nivel_Asistencia <chr>2.9 Ordenamiento de filas
A través del comando arrange(),
podemos ordenar las filas de una tabla de datos a partir de los valores de sus columnas.
El formato en el que usamos este comando es:
datos %>% arrange(<expresion1>, <expresion2>, ... , <expresionk>)
En donde cada uno de <expresion1>, <expresion2>, … , <expresionk> puede ser:
- el nombre de una columna, o
- una función de una o más columnas de la tabla.
El resultado de este comando será la una tabla de datos en donde las filas son ordenadas usando los valores asociados a la primera expresión y, en caso de haber empates, estos se resuelven usando los valores de la segunda expresión. De haber a su vez empates usando los valores de la segunda expresión, se usarán los valores de la tercera expresión y así sucesivamente.
Por defecto arrange() ordenará según cada expresión de manera ascendente (de menor a mayor), pero si queremos que ordene según alguna expresión de manera descendente (de mayor a menor), podemos aplicar la función desc() a dicha expresión o anteponiendo el signo -.
Quizás es más claro ver cómo funciona esto en ejemplos.
Ejemplos
Ordenemos a los alumnos según su nota en el examen:
## # A tibble: 10 × 4
## Nombre `Prueba 1` `Prueba 2` Examen
## <chr> <dbl> <dbl> <dbl>
## 1 Rodolfo José Mamani 6.8 4 3.8
## 2 José Esteban Iruarrizaga 3.8 2.3 4
## 3 Bernarda Antonia Chen 3 4.1 4.2
## 4 Qingxia Esmeralda Quiñones 6 5.8 4.9
## 5 Tito Lenin Pérez 5.3 4.8 5
## 6 Adriana Violeta Antillán 5.1 5.2 5.5
## 7 Diego Alberto Rojas 7 3.5 5.7
## 8 María Marcia González 6.8 7 6.5
## 9 Claudia María Valencia 5.8 1 7
## 10 Federica Von Müller 6 5 7Claro, esto está bien, pero el examen fue difícil y el profesor quiere dar un
pequeño premio al alumno que tuvo la mejor nota en el examen. Para ellos usamos
desc() y así dejamos en el primer lugar de la tabla al alumno con el mejor examen:
## # A tibble: 10 × 2
## Nombre Examen
## <chr> <dbl>
## 1 Claudia María Valencia 7
## 2 Federica Von Müller 7
## 3 María Marcia González 6.5
## 4 Diego Alberto Rojas 5.7
## 5 Adriana Violeta Antillán 5.5
## 6 Tito Lenin Pérez 5
## 7 Qingxia Esmeralda Quiñones 4.9
## 8 Bernarda Antonia Chen 4.2
## 9 José Esteban Iruarrizaga 4
## 10 Rodolfo José Mamani 3.8(Acá además seleccionamos sólo las columnas Nombre y Examen para poder ver mejor)
Notemos que también se puede usar - para ordenar de forma decreciente según la
nota en el examen:
## # A tibble: 10 × 2
## Nombre Examen
## <chr> <dbl>
## 1 Claudia María Valencia 7
## 2 Federica Von Müller 7
## 3 María Marcia González 6.5
## 4 Diego Alberto Rojas 5.7
## 5 Adriana Violeta Antillán 5.5
## 6 Tito Lenin Pérez 5
## 7 Qingxia Esmeralda Quiñones 4.9
## 8 Bernarda Antonia Chen 4.2
## 9 José Esteban Iruarrizaga 4
## 10 Rodolfo José Mamani 3.8¡Oh!, tenemos un problema ya que tanto Claudia como Federica obtuvieron nota 7.0 en el examen. Como el profesor sólo quiere premiar a una persona, decide desempatar mirando el promedio de las pruebas:
## # A tibble: 10 × 2
## Nombre Examen
## <chr> <dbl>
## 1 Federica Von Müller 7
## 2 Claudia María Valencia 7
## 3 María Marcia González 6.5
## 4 Diego Alberto Rojas 5.7
## 5 Adriana Violeta Antillán 5.5
## 6 Tito Lenin Pérez 5
## 7 Qingxia Esmeralda Quiñones 4.9
## 8 Bernarda Antonia Chen 4.2
## 9 José Esteban Iruarrizaga 4
## 10 Rodolfo José Mamani 3.8¡Federica es la ganadora!
2.10 Resumiendo una tabla
Otra tarea común al analizar una tabla de datos es resumir los valores de una o
más columnas en un número (o estadístico). Para ello usamos el comando summarize()8.
Por ejemplo, si quisiéramos calcular el promedio de la nota en el examen sobre todos los alumnos del curso:
## # A tibble: 1 × 1
## `Promedio Examen`
## <dbl>
## 1 5.36Esta operación resume la columna que tiene las notas del examen en un sólo número (el promedio). Nota que la salida de este comando es una tabla de datos también, pero con una sola fila y tantas columnas como estadísticos de resumen calculemos.
El formato general en el que se usa este comando es:
datos %>% summarize(nombre_resumen1 = <expresion1>, nombre_resumen2 = <expresion2>, ..., nombre_resumenk = <expresionk>)
En donde nombre_resumen1, nombre_resumen2, …, nombre_resumenk son los nombres que los números (o estadísticos) resumen recibirán y <expresion1>, <expresion2>, …, <expresionk> son expresiones que consisten en funciones de una o más columnas de la tabla de datos. Nota que estas funciones deben resumir valores de dichas columnas, por lo que su salida debe ser un número.
Algunas funciones útiles que podemos usar al momento de resumir datos en una tabla son:
- Medidas de tendencia central:
mean()(promedio) ymedian()(mediana). - Medida de dispersión:
sd()(desviación estándar) - Rangos:
min()(valor mínimo),max()(valor máximo),quantile()(cuantil) - Posición:
first()(primer valor),last()(último valor),nth()(n-ésimo valor) - Conteo:
n()(número de valores),n_distinct()(número de valores distintos) - Lógico:
any(),all()
Para más detalles acerca de qué hacen estas funciones, consulta la sección “Aplicación de funciones a vectores”.
Ejemplos
Calculemos, además del promedio de las notas en el examen, el promedio de las notas en cada prueba:
notas %>% summarize(`Promedio Examen` = mean(Examen),
`Promedio Prueba 1` = mean(`Prueba 1`),
`Promedio Prueba 2` = mean(`Prueba 2`))## # A tibble: 1 × 3
## `Promedio Examen` `Promedio Prueba 1` `Promedio Prueba 2`
## <dbl> <dbl> <dbl>
## 1 5.36 5.56 4.27Vemos que hubo peores notas en la Prueba 2. ¿Pero se debió esto a que hubo muchas malas notas o sólo una nota muy mala y otras regulares? Para ello, veamos más estadísticos para las notas de la Prueba 2:
notas %>%
summarize(`Promedio P2` = mean(`Prueba 2`),
`D.e. P2` = sd(`Prueba 2`),
`Min P2` = min(`Prueba 2`),
`Max P2` = max(`Prueba 2`))## # A tibble: 1 × 4
## `Promedio P2` `D.e. P2` `Min P2` `Max P2`
## <dbl> <dbl> <dbl> <dbl>
## 1 4.27 1.72 1 7Vemos que la desviación estándar es del 1.72 y que hubo notas 1.0 y 7.0. Veamos cómo están distribuídas estas notas, usando los cuantiles 0.25, 0.5 y 0.75:
notas %>%
summarize(`p-0.25 P2` = quantile(`Prueba 2`, 0.25),
`p-0.5 P2` = quantile(`Prueba 2`, 0.5),
`p-0.75 P2` = quantile(`Prueba 2`, 0.75))## # A tibble: 1 × 3
## `p-0.25 P2` `p-0.5 P2` `p-0.75 P2`
## <dbl> <dbl> <dbl>
## 1 3.62 4.45 5.15Un 25% de los alumnos tuvo nota menor o igual que 3.64 y un 75% de los alumnos no superó el 5.2.
Calculemos el porcentaje de alumnos que aprobaron la Prueba 2 (obtuvieron nota mayor o igual a 4.0):
## # A tibble: 1 × 1
## `Aprobados Prueba 2`
## <dbl>
## 1 0.7Nota que para contar el número de alumnos con nota mayor o igual a 4.0, hemos sumado la condición 'Prueba 2' >= 4.0. Lo que esto hace tras bambalinas es:
- Genera un valor
TRUEpara cada fila (alumno) que satisface la condición y un valorFALSEen caso contrario. - Luego suma estos valores, interpretando los valores
TRUEcomo 1’s y los valoresFALSEcomo 0’s.
2.11 Agrupamiento de filas
Una de las ventajas de tener tablas en formato tidy (ver sección “Tablas tidy”) es la posibilidad de agrupar filas según su valor en ciertas columnas y luego realizar resúmenes según estos agrupamientos. Para esto utilizamos el comando group_by(), de tidyverse. Este comando es usualmente usado en conjunto con otro como summarize() para obtener estádisticas resumen por grupo.
Por ejemplo, si quisiéramos ver cuál es el promedio de la nota en el examen pero agrupando a los alumnos por su país de origen:
## # A tibble: 5 × 2
## País `Promedio Examen`
## <chr> <dbl>
## 1 Alemania 7
## 2 Bolivia 3.8
## 3 Chile 5.9
## 4 Costa Rica 4.63
## 5 Perú 5.6Para que nos quede bien claro, veamos por ejemplo lo que hizo R para el caso de Chile. El comando group_by(País) juntó a todos los alumnos de Chile y luego el comando summarize(`Promedio Examen` = mean(Examen)) calculó el promedio de la notas en el examen de dichos alumnos.
El formato general para usar este comando es:
datos %>% groupby(variable1, variable2, ..., variablek) %>% <comando_resumen>
En donde variable1, variable2, …, variablesk son las variables a partir de las cuales se agruparán las filas y <comando_resumen> es otro comando de tidyverse que luego generará un resumen por grupo (usualmente summarize()).
Ejemplos
Veamos ahora cuál es el promedio de notas por país de origen y género:
## `summarise()` has grouped output by 'País'. You
## can override using the `.groups` argument.## # A tibble: 7 × 3
## # Groups: País [5]
## País Género `Promedio Examen`
## <chr> <chr> <dbl>
## 1 Alemania Femenino 7
## 2 Bolivia Masculino 3.8
## 3 Chile Femenino 6
## 4 Chile Masculino 5.7
## 5 Costa Rica Femenino 4.9
## 6 Costa Rica Masculino 4.5
## 7 Perú Femenino 5.6Podemos ver que sólo en el caso de Chile y Costa Rica hay alumnos como alumnas. En el resto de los países en donde sólo hay alumnos de un género, la tabla resultado sólo muestra una fila para dicha combinación País-Género.
El orden en el que colocamos los nombres de las variables dentro del comando group_by() afecta el orden en que la tabla resultante es presentada. En la tabla anterior es fácil comparar, para un país determinado, el promedio de la nota en el examen entre hombres y mujeres; pero no es fácil comparar, para un género dado, los promedios de la nota en el examen entre distintos países.
Veamos qué pasa cuando cambiamos el orden de los argumentos en el comando group_by():
## `summarise()` has grouped output by 'Género'. You
## can override using the `.groups` argument.## # A tibble: 7 × 3
## # Groups: Género [2]
## Género País `Promedio Examen`
## <chr> <chr> <dbl>
## 1 Femenino Alemania 7
## 2 Femenino Chile 6
## 3 Femenino Costa Rica 4.9
## 4 Femenino Perú 5.6
## 5 Masculino Bolivia 3.8
## 6 Masculino Chile 5.7
## 7 Masculino Costa Rica 4.5Ahora es mucho más fácil comparar los promedios de las mujeres de distintos países de origen, por ejemplo.
Fuente: https://www.metmuseum.org/art/collection/search/327385↩︎
Fuente: Sandbh https://commons.wikimedia.org/wiki/File:Taxonomic_PT_wth_halogens.jpg, „Taxonomic PT wth halogens“↩︎
Creado por Hadley Wickham y un gran equipo de desarrolladores.↩︎
Fuente: https://cookpad.com/cl/recetas/2796879-panqueques-esponjosos↩︎
Todas las bases de datos que usaremos están disponibles en https://github.com/rocarvaj/rcd1-uai↩︎
También se puede usar
summarise(), es cosa de si te gusta el Inglés de EE.UU. o del Reino Unido.↩︎
{kind=link}