Sentiment Analysis of 49 years of Warren Buffett’s Letters to Shareholders of Berkshire Hathaway
2021-01-19
Chapter 1 Overview of the Project
1.1 tl;dr1 Otherwise Known as an Executive Summary
The goal of this project is to perform a sentiment analysis in R of 49 years of letters to Berkshire Hathaway shareholders written by Warren Buffett between 1971 and 2019.
What these data show is that IF, and that is a big if, the sentiment lexica are measuring the sentiment of Buffett’s letters accurately, that while Buffett says his focus is primarily on book value, the sentiment of his letters is actually more closely correlated with Berkshire’s stock price and the S&P 500 as shown in Figures 6.1 and 6.2.
The sentiment of the letters appears to be negatively correlated with relative performance as shown in Figures 6.3 and 6.4. Taken at face value, this implies that the greater Berskhire’s outperformance versus the market, the more negative the sentiment of his letters. Although, the real reason could be that Berkshire tends to outperform by a greater margin when markets are down such as the 1973-1974 Bear Market, 2001 which followed 9/11 and the dot-com crash and the financial crisis of 2008. So while Berkshire produces the greatest alpha in these years, they are years where book value decreases (2001 and 2008) or book value has small increases (1973 and 1974). There are no surprises here - the sentiment of Buffett’s letters are very negative when Berkshire’s book value shows a small gain or loss, even in years which Berkshire outperforms the market by a wide margin.
While the main goal of the project was to analyze sentiment, a large portion of Chapter 4 discusses how lexica misclassify words in Berkshire’s letters2. If these lexica are not accurate, my analysis will have a “garbage-in, garbage-out” problem which renders the entire work invalid.
1.2 Overview of this document
This will be a living document and will change over time as I learn new techniques and apply them. Rather than being a dense, dry, technical work3, the tone will be more conversational.
Segments of different areas of exploration will be broken out by chapter. Chapter 2 will consist of “data wrangling” and how I imported and extracted text from pdf and html documents. In Chapter 3 the data will be tokenized and cleaned. Chapter 4 will discuss the various sentiment lexica and an analysis of sentiment will be performed. Chapter 5 will detail obtaining performance data, deconstructing it and then merging it with sentiment measures. Chapter 6 will analyze and discuss sentiment vs. performance. Chapter 7 provides some information about me, Chapter 8 contains a list of books and online tutorials that I found to be helpful and finally Chapter 9 will list areas or methods I would like to explore in the future.
1.3 Learning Goals
The overall goal of this project is for me to explore various natural language processing techniques using 49 years of Berkshire Hathaway’s chairman’s letters, written by Warren Buffett, as exemplars.
Other goals of this project are to become more proficient using R, as well as learning R Markdown, Bookdown and Python. I am also looking to improve my skills of linguistics, math, statistics, logic and programming.
In term of natural language processing (“NLP”), there are countless analyses that can be done on a corpus such as sentiment, lexical variety, word count, readability etc… That being said, in my view, there are two main “families” of analysis - techniques that capture relationships between words and those that do not. What I will initially focus on are techniques that ignore the order and context of words which is known as a “bag of words” approach. The plan is to eventually move on to techniques which take into account the context and sequence of words.
1.4 Roadmap
Figure 1.1 shows the high level roadmap of the project (the circles correspond to chapter numbers). Textual data will be acquired, pre-processed and tokenized. Then various sentiment analyses will be performed. Performance data will be acquired and returns deconstructed. Then measures of sentiment will be compared to various measures of performance. Finally, conclusions will be reached and discussed.
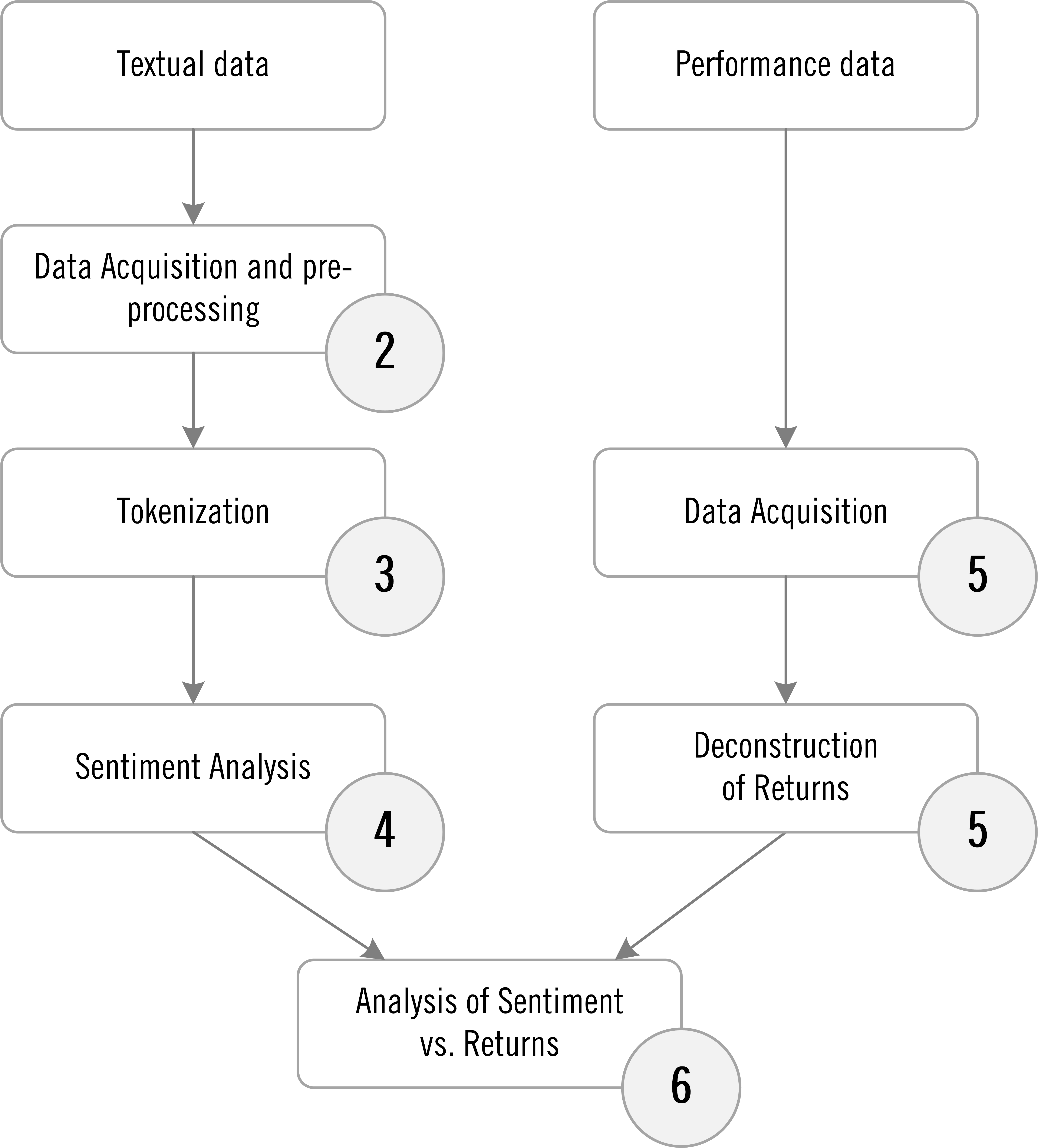
Figure 1.1: High Level Project Roadmap
1.5 The Corpus to be Used in this Project
The corpus for this project will be the 49 letters to shareholders of Berkshire Hathaway penned by Warren Buffett between 1971 and 2019.
First a little background on Buffett and Berkshire. After Buffett graduated from Columbia Business School in 1951 he went to work for Benjamin Graham at the Graham-Newman Corporation. In 1956 Graham liquidated his fund and Buffett started his own partnership. In December of 1962 he started purchasing shares in a small New England textile company called Berkshire Hathaway which he eventually took control of in 19654. In 1969 Buffett dissolved his partnership and distributed cash and Berkshire Stock to his investors. Berkshire later became Buffett’s primary investment vehicle.
Being a public company, Berkshire sends annual reports to shareholders. Annual reports contain the financial results of the company for the a given year and while not required, the annual report often includes a letter to shareholders from the Chairman or CEO of the company.
The first letter penned by Buffett was in Berkshire’s 1971 annual report which you can read by clicking this link. In 2020 Buffett wrote his 49th letter. These 49 letters are the corpus we will analyze in this project.
1.6 Software used for data analysis
Most of the data analysis will be done using R. In some rare instances, Microsoft Excel was also used for charting and data wrangling. I am assuming that the reader has a certain level of proficiency in R, but I will try to do the analysis in a step-by-step fashion, including code and output, so that it can be replicated.
The first step is to load various libraries that will be required for the analysis.
###libraries to load----------
suppressPackageStartupMessages({
library(tidyverse) #collection of packages including ggplot, dplyr and stingr
library(scales) #to change scales in ggplot
library(tidytext) #for text mining
library(readtext) #to read in text files
library(gridExtra) #used with ggplot to arrange graphics
library(GGally) #for ggpairs correlation
library(syuzhet) #to access syuzhet sentiment dictionary
library(ggrepel) #to prevent overlap in text labels in geom_text
library(tufte) #for quote block
library(SnowballC) #for text cleaning, stop words and also stemming
library(lexicon) #for Sentiword and SenticNet lexica
library(readr) #to read in csv files
library(corrplot) #for correlation plots
library(corrr) #for network correlation plots
library(tidyquant) #need for "palette_light" in network plot
library(plotly) #to use plotly - ggplotly
library(kableExtra) #for tables
library(gt) #to format tables with percentages
library(ggpubr) #for cool plot
library(DT) #for interactive datatables you can sort by
})On to the data…
Internet slang which means “too long; didn’t read.”↩︎
The reason for this might be specific to Berkshire given the nature of their operations or the fact that the lexica were not designed to be used in the domain of finance. That being said, even the Loughran-McDonald lexicon, which was designed to be used on SEC filings, appears to have misclassifed numerous words. ↩︎
Unfortunately, this is going to be a dense, dry, technical work.↩︎
source: https://www.cnbc.com/2017/12/12/buffett-bought-berkshire-hathaway-shares-for-7-dollars-and-50-cents-each.html↩︎