Country and Regions: Classifications for countries
Inspecting different approaches to classify countries by international organizations (World Bank and United Nations Statistics Division)
Understanding the country classification usedby my data sources (WID and WHR.
Deciding which classification system I am going to use.
Modifying the country classification of WID and WHR where necessary so that the country classification conforms to the internationally recognized and approved systems.
I aim to compare different aspects of Austria with those of other countries. I want, for instance, to know how well Austria is doing compared to other European countries, the other member states of the European Union, or other OECD countries. It is, therefore, vital to have different categorization systems.
A.1 Country groupings in WHR and WID
There are already different classification systems in place: International organizations (e.g., World Bank, United Nations) have developed them with several grouping variants.
On the other hand the WID database also uses different categorizations scheme and some of the WHR years have also incorporated regional groupings (2013, 2015, 2020, and 2021). For an interpretation of my analysis in relation to theirs it is important to know if we are using the same classifications or if not, where the differences are.
As I am listing several classification variants it pays the effort to develop a function for the repetitive task.
A.1.1 Function class_scheme()
R Code A.1 : Function class_scheme() for showing classification scheme
Listing / Output A.1: Function class_scheme() for showing results of a classification system
Code
class_scheme<-function(df, sel1, sel2){## df = dataframe to show## sel1 = name of the first column (country names) to select## sel2 = name of the column with the regional indicatordf|>dplyr::select(!!sel1, !!sel2)|>dplyr::nest_by(!!sel2)|>dplyr::mutate(data =as.vector(data))|>dplyr::mutate(data =stringr::str_c(data, collapse ="; "))|>dplyr::mutate(data =paste(data, ";"))|>dplyr::mutate(N =lengths(gregexpr(";", data)))|>dplyr::rename(Country =data)|>dplyr::arrange(!!sel2)|>DT::datatable(class ='cell-border compact stripe', options =list( pageLength =25, lengthMenu =c(5, 10, 15, 20, 25, 50)))}df_whr<-base::readRDS("data/whr/raw/whr_raw_2021.rds")df_wid<-base::readRDS("data/chap80/country_codes.rds")df_wid<-df_wid|>dplyr::mutate(dplyr::across(tidyselect::where(base::is.factor), base::as.character))
Using {dplyr} programming code in functions needs some special consideration. I have learned the details from “Bang Bang – How to program with dplyr” (Berroth 2019).
A.1.2 Grouping Schemata
As our function is now in place, we can display the different grouping schemes.
Code Collection A.1 : Grouping schemata of WHR and WID datasets
The datasets for 2013, 2015, 2020 and 2021 use all the same classification scheme with 149 countries in 10 regions.
149 are by far not all countries of the world. Their number is about 195 with some insecurities about Holy See (Vatican), the State of Palestine, Taiwan and Kosovo. (Compare: How Many Countries Are There In The World?) The reason for this lower number is simple: For only those 149 countries are subjective well-being data in one of the study years available.
R Code A.3 : Classifications of the WID data with column “region1”
region1 is a classification scheme with 216 countries in 5 regions.
216 is more than the 195 countries mentioned in How Many Countries Are There In The World?. I believe the reason for this larger amount of “countries” is that it includes also 29 economies with populations of more than 30,000 as explained in the World Bank classification with 218 countries mentioned in Section A.2.3.1.2. There is still a small difference of two countries (218 - 216 = 2).
R Code A.4 : Classifications of the WID data with column “region2”
region5 is a classification scheme with 216 countries in 8 regions.
R Code A.8 : Classifications of the WID data with column “region6”
Code
## replace NAs of region4 with values of region5df_wid6<-df_wid|>dplyr::mutate(region6 =base::ifelse(is.na(region4), region5, region4))(wid_class6<-class_scheme( df =df_wid6, sel1 =rlang::quo(shortname), sel2 =rlang::quo(region6)))
region6 is a classification scheme with 216 countries in 17 regions.
A.1.3 Summary
XY = STILL TO WRITE!
A.2 Official classifications
In a first step I want to find out where these classifications systems come from and compare them to the country groupings in the WID and WHR data. I will look into the two official classifications schemes of World Bank and United Nations and apply the following procedure:
Procedure A.1 : Understand structure and content of the official classifications schemata
Create a directory for storing the different country classification files (see Section A.2.1).
Download classification files and store them for faster access as R objects with rds format (see Section A.2.2.1 and Section A.2.2.2).
Inspect the data classification files of World Bank (Section A.2.3.1) and of the United Nations (Section A.2.3.2) in detail.
A.2.1 Create data directories
R Code A.9 : Create folders for country classification files
The World Bank Classification can be downloaded from How does the World Bank classify countries?. At the bottom of the page you can see the line “Download an Excel file of historical classifications by income.”, providing a link with word “Download”. The downloaded file CLASS.xlsx does not contain a historical classification by income but the general classification system of the last available year (2023).
Yes, there is another Excel file OGHIST.xslx with the historical cutoffs for incomes and lending categories, dating from 1987 to 2023. But the download link for this file is located at another web page: World Bank Country and Lending Groups. On this page you will also find the updates for the cutoffs for countries GNI income per capita which is important for the lending eligibility of countries. World Bank country classifications by income level for 2024-2025 has the current updated values and changes over the last year.
The file CLASS.xlsx am interested here consists of three sheets:
“List of Economoies”
“compositions” and
“Notes”
I am going to download the first two Excel sheets.
R Code A.10 : Numbered R Code Title
Run this code chunk manually if the file still needs to be downloaded.
Code
## download wb-class file ##############downloader::download( url ="https://datacatalogfiles.worldbank.org/ddh-published/0037712/DR0090755/CLASS.xlsx", destfile =base::paste0(here::here(), "/data/country-class/wb-class.xlsx"))## create R object ############wb_class_economies<-readxl::read_xlsx(base::paste0(here::here(), "/data/country-class/wb-class.xlsx"), sheet ="List of economies")wb_class_compositions<-readxl::read_xlsx(base::paste0(here::here(), "/data/country-class/wb-class.xlsx"), sheet ="compositions")## save as .rds files ###############pb_save_data_file("country-class", wb_class_economies, "wb_class_economies.rds")pb_save_data_file("country-class", wb_class_compositions, "wb_class_compositions.rds")
(For this R code chunk is no output available)
A.2.2.2 UNSD-M49
Another more detailed classification system expressively developed for statistical purposes is developed by the United Nations Statistics Division UNSD using the M49 methodology.
The result is called Standard country or area codes for statistical use (M49) and can be downloaded manually in different languages and formats (Copy into the clipboard, Excel or CSV) from the Overview page. On this page is no URL for an R script available, because triggering one of the buttons copies or downloads the data with the help of Javascript. So I had to download the file manually or to find another location where I could download it programmatically. I stored it as unsd-class.csv under the “data/country-class” folder.
I found with the OMNIKA DataStore an external source for the UNSD-M49 country classification. The OMNIKA DataStore is an open-access data science resource for researchers, authors, and technologists. OMNIKA Foundation is a 501c3 nonprofit whose mission is to digitize, organize, and make freely available important contents. For security reason I checked the two files with base::all.equal() to determine if those two files are identical. Yes, they are!
R Code A.11 : Numbered R Code Title
Run this code chunk manually if the file still needs to be downloaded.
Code
## download unsd-m49 file ############url<-"https://github.com/omnika-datastore/unsd-m49-standard-area-codes/raw/refs/heads/main/2022-09-24__CSV_UNSD_M49.csv"downloader::download( url =url, destfile =base::paste0(here::here(), "/data/country-class/unsd-class.csv"))## create R object ###############unsd_class<-readr::read_delim( file =base::paste0(here::here(), "/data/country-class/unsd-class.csv"), delim =";")## save as .rds file ################pb_save_data_file("country-class", unsd_class, "unsd_class.rds")
(For this R code chunk is no output available)
A.2.3 Inspect classification files
To get an detailed understanding of the data structures I will provide the following outputs:
R Code A.12 : Inspect sheet List of Economies of the World Bank classification file
Code
wb_class_economies<-base::readRDS("data/country-class/wb_class_economies.rds")glue::glue("******************* Using skimr::skim() ***************************")skimr::skim(wb_class_economies)glue::glue("")glue::glue("****************** Using dplyr::glimpse() *************************")dplyr::glimpse(wb_class_economies)
#> ******************* Using skimr::skim() ***************************
R Code A.13 : Inspect sheet compositions of the World Bank classification file
Code
wb_class_compositions<-base::readRDS("data/country-class/wb_class_compositions.rds")glue::glue("******************* Using skimr::skim() ***************************")skimr::skim(wb_class_compositions)glue::glue("")glue::glue("****************** Using dplyr::glimpse() *************************")dplyr::glimpse(wb_class_compositions)
#> ******************* Using skimr::skim() ***************************
WB_Group_Name in the “compositions” file contains all available groups. They are not restricted to regional groups because they are formed by economical and political criteria as well. There is no 1:1 match, because almost all countries belong to two or more groups. There are 48 groups with a total of 2084 elements.
R Code A.16 : Groups formed by regional criteria (without the redundant World region)
Browsing through the composition data I have defined 15 WB_GROUP_CODEs as regional codes. These regional classification criteria results per definition to 15 regions containing 379 countries.
R Code A.17 : Groups formed by regional criteria (without the redundant World region)
Browsing through the composition data I have declassified all small states for an alternative regional group. These regional classification criteria are smaller and results to 11 regions containing 299 countries.
A.2.3.1.1 Description of the four tabs
WB economies displays the “List of Economies” and has five columns:
Economy with the country names (2-219) and regional names (221-268)
Code with the ISO alpha3 codes for countries (2-219) and for the regional names (221-268)
Region with seven different regional names:
East Asia and Pacific,
Europe and Central Asia,
Latin America & the Caribbean,
Middle East and North Africa,
North America
South Asia and
Sub-Saharan Africa
Income group with four groups: Low income, Lower middle income, Higher middle income, and High income.
Lending category with three groups: IBRD, Blend, and IDA.
WB compositions has four columns: WB_Group_Code, WB_Group_Name, WB_Country_Code, WB_Country_Name. The 2084 rows are combinations of the regional and income group with their ISO alpha 3 codes and country names.
WB Standard shows the World Bank seven standard regional groups with their countries. The 218 countries involved in the taxonomy of the World Bank consists of all member countries of the World Bank (189) and other economies with populations of more than 30,000 (29).
WB All includes the seven regions from the “WB Standard” tab but much more. But it is important to note that there is no alternative regional structure comprises systematically all countries of the world — the overall category “World” obviously excluded.
Five of the seven regional groups of “WB Standard” are also clustered without high income countries.
There are six other regional subcategories: “Arab World”, “Caribbean small states”, “Central Europe and Baltics”, “Other small states”, “Pacific island small states”, “Small states”.
Additionally there are some political groups like European Union, OECD and
several economical classification like “Euro area”,
different combinations of the four income groups and different combinations of the three lending statuses.
More details
The cut off limits for the income groups are:
low income, $1,145 or less;
lower middle income, $1,146 to $4,515;
upper middle income, $4,516 to $14,005; and
high income, more than $14,005.
The effective operational cutoff for IDA eligibility is $1,335 or less. The three lending categories and their relation to each other are:
IDA countries are those that lack the financial ability to borrow from IBRD. IDA credits are deeply concessional—interest-free loans and grants for programs aimed at boosting economic growth and improving living conditions. IBRD loans are non-concessional. Blend countries are eligible for IDA credits because of their low per capita incomes but are also eligible for IBRD because they are financially creditworthy.
Three additional remark relating to the Notes sheet:
In the Notes I found the sentence: “Geographic classifications in this table cover all income levels.” But there is a difference of one missing data value more in the Income group column compared with the Region column (50:49). The reason is that Venezuela RB is lacking an income group because it has been temporarily unclassified since July 2021 pending release of revised national accounts statistics. Venezuela, RB was classified as an upper-middle income country until FY21, has been unclassified since then due to the unavailability of data. But it is now again classified as Upper middle income (See the World Bank page about Venezuela, RB).
The term country, used interchangeably with economy, does not imply political independence but refers to any territory for which authorities report separate social or economic statistics.
What follows is a quote about some details of the income classifications for the 2023 file:
Set on 1 July 2022 remain in effect until 1 July 2023. Venezuela has been temporarily unclassified since July 2021 pending release of revised national accounts statistics. Argentina, which was temporarily unclassified in July 2016 pending release of revised national accounts statistics, was classified as upper middle income for FY17 as of 29 September 2016 based on alternative conversion factors. Also effective 29 September 2016, Syrian Arab Republic is reclassified from IBRD lending category to IDA-only. On 29 March 2017, new country codes were introduced to align World Bank 3-letter codes with ISO 3-letter codes: Andorra (AND), Dem. Rep. Congo (COD), Isle of Man (IMN), Kosovo (XKX), Romania (ROU), Timor-Leste (TLS), and West Bank and Gaza (PSE). It is to be noted that Venezuela, RB classified as an upper-middle income country until FY21, has been unclassified since then due to the unavailability of data.
A.2.3.1.2 Summary
The only missing data in the columns Economy and Code corresponds to the empty line #220 that separates the country codes from the regional codes. The missing data in the other columns stem from the different structure of the second part (starting with row #221) of the data, which consists only of the two columns ‘Economy’ and ‘Code’.
Essentially this means that we have in the CLASS.xslx file two different data sets: One for economies and the other one to explicate regional, economical and political grouping codes. In the Excel sheet compositions you will find an extended list of all available group names and their three letter codes combined with the country names and their three letter codes. These group names comprise different kinds of regional groups but also names and codes for different combination of country incomes and lending categories.
All these groups may be of interests for analysis of different trends. But the regional (sub)groups of the compositions sheet do not add up to the complete number of countries (218). This is in contrast to the different regional groups of the WID database because all their regional groups (region1 = 5, region2 = 18, region4 = 10, and region5 = 8 groups) includes all countries (in this case: 216).
The World Bank file CLASS.xslx classifies all World Bank member countries (189), and all other economies with populations of more than 30,000 (29) in a coarse grid of only seven regions. For operational and analytical purposes, these economies are divided among income groups according to their gross national income (GNI) per capita in 2023, calculated using the World Bank Atlas method.
R Code A.18 : Inspect UNSD M49 geoscheme classification
Code
unsd_class<-base::readRDS("data/country-class/unsd_class.rds")glue::glue("******************* Using skimr::skim() ***************************")skimr::skim(unsd_class)glue::glue("")glue::glue("****************** Using dplyr::glimpse() *************************")dplyr::glimpse(unsd_class)
#> ******************* Using skimr::skim() ***************************
R Code A.19 : Clean UNSD M49 geoscheme classification
Code
## column renaming vector ########m49_cols=c( region_c ="Region Code", region_n ="Region Name", subr_c ="Sub-region Code", subr_n ="Sub-region Name", midr_c ="Intermediate Region Code", midr_n ="Intermediate Region Name", country ="Country or Area", m49 ="M49 Code", iso2 ="ISO-alpha2 Code", iso3 ="ISO-alpha3 Code", ldc ="Least Developed Countries (LDC)", lldc ="Land Locked Developing Countries (LLDC)", sids ="Small Island Developing States (SIDS)")## clean data ###############################unsd_class<-base::readRDS("data/country-class/unsd_class.rds")unsd_class_clean<-unsd_class|>dplyr::select(-(1:2))|>dplyr::rename(tidyselect::all_of(m49_cols))|>dplyr::filter(country!="Antarctica")|>dplyr::mutate(iso2 =base::ifelse(country=="Namibia", "NA", iso2))|>dplyr::relocate(country, .before =region_c)|># .x = anonymous function; "x" = value in cols of unsd_classdplyr::mutate(dplyr::across(ldc:sids, ~dplyr::if_else(.x=="x", "1", "999", "0")))|>dplyr::arrange(country)## save new tibble ##########pb_save_data_file("country-class",unsd_class_clean,"unsd_class_clean.rds")## prepare skimmers ##########my_skim<-skimr::skim_with( character =skimr::sfl( whitespace =NULL, min =NULL, max =NULL, empty =NULL))## display results ##########unsd_class<-base::readRDS("data/country-class/unsd_class.rds")glue::glue("******************* Using skimr::skim() ***************************")my_skim(unsd_class_clean)|>dplyr::select(-complete_rate)glue::glue("")glue::glue("****************** Using dplyr::glimpse() *************************")dplyr::glimpse(unsd_class_clean)
#> ******************* Using skimr::skim() ***************************
midr_n2 is a classification scheme with 248 countries in 23 regions.
A.2.3.2.1 Descriptions of the XY tabs
The file has 15 columns as you can also see online from the Overview page.
The many missing values (NAs) for the categories LDC, LLDC and SIDS are easy explained: These three columns are coded with an ‘x’ if the country of this row belong to this category. Recoding these three columns with 1 and 0 (1 = yes, belongs to this category, 0 = no, does not belong to this category) will reduce most of their missing values.
One missing value in the regional categories (Region, Sub-Region and Intermediate Region) is related to Antarctica which is not seen by the M49 scheme as a separated region. It has therefore no regional codes and names with the exception of the overall comprising global region. But it has M49 as well ISO-alpha codes.
One of the missing values for ISO-alpha2 and ISO-alpha3 is related to Sark, which is “recognized by the United Nations Statistics Division (UNSD) as a separate territory” but was not accepted by ISO now for more than 20 years (McCarthy 2020). Recently a new application (see PDF) will change that but currently Sark is still waiting for ISO 3166 codes.
The other missing value for ISO-alpha2 codes belongs to Namibia because its abbreviation NA is interpreted by R as a missing value!
To clean the data I will
Remove the global codes and names because they a redundant: All rows have global code “001” (“World”).
Rename the columns to get shorter names.
Remove Antarctica because it is not seen as separate country.
Replace NA in the column ISO-alpha2 Code” of Namibia with the string “NA”.
Recode the columns LDC, LLDC and SIDS with 0 and 1.
Relocate the column “country” (previously “Country or Area”) to the first column because than it easier to find some relevant content
Sort the data alphabetically by “country”.
A.2.3.2.2 Summary
A.3 XY STOPPED HERE - WHAT FOLLOW ARE SOME (OLDER) TEXT MODULES
A.3.1 Modul: Why looking at classification systems?
Only sometimes are they used identically in the data I will look at. So I also have to understand these data-driven differences (e.g., in the WID database or the WHR data) with the official country nomenclatures.
I could have used just the approach used in my data set. But that approach poses two problems:
Not always are the classification used coherently in my available datasets. So uses WHR (slightly) different country names in their yearly reports. For instance “Turkiye” in 2024 and “Turkey” in 2012, but the official name is “Türkiye”. Instead of the current 27 member states of the European Union the WID assigns the label “European Union” to 32 countries, including still United Kingdom but also British Overseas Territory (Gibraltar, Montserrat),and self-governing British Crown dependencies (Isle of Man, Jersey) that never had been member status in the EU.
Sometimes the available data use their own categorization schema. Most of the data analysis in the World Inequality Report 2022 (WIR2022) condense data into eight different regions: Europe, South & South-East Asia, East Asia, North America, Sub-Saharan Africa, Russia & Central Asia, MENA, Latin America. I couldn’t find exact this classification schema in one of the internationally approved taxonomies.
Some of the groupings I am interested in (e.g., OECD, or countries that applied for EU membership status are not part of the international standardized statistical groupings.
After some research I found out that the most detailed and for statistical purposes most relevant classification system is M49 standard, developed and maintained by the United Nations Statistics Division (UNSD). Guided by the United Nations Geoscheme it divides all countries of the world into different types of regions:
22 Sub-regions: (Missing three in Appendix 1. United Nations Geoscheme: Polynesia, and other differentiation of the Americas: North America, Central America, Caribbean, South America )
Africa:
Northern Africa,
Eastern Africa,
Middle Africa,
Southern Africa,
Western Africa
Americas:
Latin America and the Caribbean,
Northern America
Asia:
Central Asia,
Eastern Asia,
Southeastern Asia,
Southern Asia,
Western Asia
Europe:
Eastern Europe,
Northern Europe,
Southern Europe,
Western Europe
Oceania:
Australia and New Zealand,
Melanesia,
Micronesia
Sub-regions (18 in M49, missing 4: Sub-Saharan Africa = Eastern Africa, Middle Africa, Southern Africa, and Western Africa, and Latin America = South America and Caribbean is separated)
“Northern Africa”
“Sub-Saharan Africa”
“Latin America and the Caribbean”
“Northern America”
“Central Asia”
“Eastern Asia”
“South-eastern Asia”
“Southern Asia”
“Western Asia”
“Eastern Europe”
“Northern Europe”
“Southern Europe”
“Western Europe”
“Australia and New Zealand”
“Melanesia”
“Micronesia”
“Polynesia”
Intermediate Regions: (2, but 7)
Sub-Saharan Africa: Eastern Africa, Middle Africa, Southern Africa and Western Africa
Latin America and the Caribbean: Caribbean, Central America, South America
Note A.1
The UN geoscheme is a statistical classification and does not imply any political or other affiliation of countries or territories.
It may differ from geographical definitions used by autonomous UN specialized agencies, such as the United Nations Industrial Development Organization and UNESCO, for their own organizational convenience.
Other alternative groupings include the World Bank regional classification and CIA World Factbook regions, and Internet Corporation for Assigned Names and Numbers Geographic Regions.
Important A.1
How to get the 22 sub-regions from the m49 data?
Take the Intermediate Region Name if it is not NA.
If the Intermediate Region Name is NA then take the Sub-region name.
R Code A.24 : Download the M49 Geoscheme of the United Nations
Run this code chunk only once manually: It downloads the M49 Geoscheme of the United Nations as a .csv file and saves it as an R .rds object.
Code
## run this code chunk only once (manually)## get the file from an external source, ## https://github.com/omnika-datastore/unsd-m49-standard-area-codes## OMNIKA DataStore is an open-access data science resource ## for researchers, authors, and technologists interested in mythology. ## Managed by OMNIKA Foundation which is a 501c3 nonprofit ## whose mission is to digitize, organize, ## and make freely available all the world's mythological contents.## at the official UN site is no URL provided## the file is downloaded via a javascript## I checked the two files with base::all.equal()`## they are identical ## define variablesurl<-"https://github.com/omnika-datastore/unsd-m49-standard-area-codes/raw/refs/heads/main/2022-09-24__CSV_UNSD_M49.csv"folder="country-class"## create folder for chapter if not already donedata_folder<-base::paste0(here::here(),paste0("/data/", folder, "/"))if(!base::file.exists(data_folder)){base::dir.create(data_folder)}## get the UNSD M49 .csv file from the OMNIKA Foundation GitHubdestfile<-base::paste0(data_folder, "unsd_m49.csv")utils::download.file(url, destfile)tmp<-readr::read_csv2(destfile)## save original file without changespb_save_data_file("country-class", tmp, "unsd_m49.rds")
A.3.3 Modul: WIR2022 data inspection & exploration
List regions of the WIR2022 and their countries
The World Inequality Report 2022 (WIR2022) describes global trends in inequality. It mostly condense data in eight different regions. See the following graph as an example:
Graph A.1: A typical example for a graph in the World Inequality Report 2022 (WIR2022), showing the division of the world into eight different world regions (“MENA” stands for Middle East & North Arfica).
In this appendix I want to know the countries that form each of these eight regions.
A.4 Data
My first task was to look for data where I could extract the information I am interested in. I scanned the files of the free accessible GitHub repository of the WID. I found country-codes-core.xlsx, an Excel file with the data I am looking for. It is sorted by a two letter code in the first column named appropriately code. “Core” means – in contrast to other country-codes files – that it includes a column corecountry where the number 1 functions as a marker for a core country. The file itself has many hidden rows which feature either regions smaller than a country (like Alabama for US or Bavaria for Germany) or bigger than a country (like Asia or Western Europe).
Important
country-codes-core.xlsx contains many hidden rows. It is therefore necessary to filter by corecountry == 1.
A.4.1 Download data
The following code chunk is only applied once. The file contains rows with all two letter combinations. Many of these combinations do not refer to an existing country. To eliminate these records one needs to select corecountry == 1.
The following chunk downloads the dataset from the internet and saves this Excel file untouched. I selected only rows for core-countries and converted all string columns to factor variable. I stored the result as country-codes.rds.
R Code A.25 : Download the country-codes-core file, manipulate and save it
Code
## run this code chunk only once (manually)## define variablesurl<-"https://github.com/WIDworld/wid-world/raw/master/data-input/country-codes/country-codes-core.xlsx"chapter_folder="chap80"## create folder for chapter if not already donechap_folder<-base::paste0(here::here(),paste0("/data/", chapter_folder, "/"))if(!base::file.exists(chap_folder)){base::dir.create(chap_folder)}## get country-codes-core.xlsxdestfile<-base::paste0(chap_folder, "country-codes-core.xlsx")utils::download.file(url, destfile)tmp<-readxl::read_xlsx(destfile)country_codes<-tmp|>## filter for core countriesdplyr::filter(corecountry==1)|>## convert all region columns to factor variablesdplyr::mutate(dplyr::across(tidyselect::starts_with("region"), forcats::as_factor))## save cleaned datapb_save_data_file("chap80", country_codes, "country_codes.rds")
(For this R code chunk is no output available)
A.4.2 Eplore Data
An inspection of the data file shows that column region5 contains the regions used in WIR2022.
R Code A.26 : Explore Data
Code
country_codes<-base::readRDS("data/chap80/country_codes.rds")skimr::skim(country_codes)glue::glue(" ")glue::glue("############################################################")glue::glue("Display number of countries for each region")glue::glue("############################################################")glue::glue(" ")country_codes|>dplyr::pull(region5)|>forcats::fct_count()
Data summary
Name
country_codes
Number of rows
216
Number of columns
10
_______________________
Column type frequency:
character
3
factor
5
numeric
2
________________________
Group variables
None
Variable type: character
skim_variable
n_missing
complete_rate
min
max
empty
n_unique
whitespace
code
0
1
2
2
0
216
0
titlename
0
1
4
32
0
216
0
shortname
0
1
3
32
0
216
0
Variable type: factor
skim_variable
n_missing
complete_rate
ordered
n_unique
top_counts
region1
0
1.00
FALSE
5
Afr: 54, Asi: 53, Ame: 47, Eur: 46
region2
0
1.00
FALSE
18
Wes: 27, Car: 23, Wes: 20, Eas: 19
region3
184
0.15
FALSE
1
Eur: 32
region4
24
0.89
FALSE
9
Oth: 48, Oth: 38, Oth: 22, Oth: 18
region5
0
1.00
FALSE
8
Sub: 49, Eur: 46, Lat: 43, MEN: 20
Variable type: numeric
skim_variable
n_missing
complete_rate
mean
sd
p0
p25
p50
p75
p100
hist
corecountry
0
1
1.00
0.00
1
1
1
1
1
▁▁▇▁▁
TH
0
1
0.19
0.39
0
0
0
0
1
▇▁▁▁▂
#>
#> ############################################################
#> Display number of countries for each region
#> ############################################################
#>
#> # A tibble: 8 × 2
#> f n
#> <fct> <int>
#> 1 Europe 46
#> 2 MENA 20
#> 3 South & South-East Asia 20
#> 4 Latin America 43
#> 5 Russia & Central Asia 11
#> 6 Sub-Saharan Africa 49
#> 7 North America & Oceania 19
#> 8 East Asia 8
A.5 List countries
Code Collection A.4 : List countries for each regions used in WIR2022
#> # A tibble: 46 × 5
#> code shortname region1 region2 region4
#> <chr> <chr> <fct> <fct> <fct>
#> 1 AD Andorra Europe Western Europe Other Western Europe
#> 2 AL Albania Europe Eastern Europe Other Eastern Europe
#> 3 AT Austria Europe Western Europe Other Western Europe
#> 4 BA Bosnia and Herzegovina Europe Eastern Europe Other Eastern Europe
#> 5 BE Belgium Europe Western Europe Other Western Europe
#> 6 BG Bulgaria Europe Eastern Europe Other Eastern Europe
#> 7 CH Switzerland Europe Western Europe Other Western Europe
#> 8 CY Cyprus Europe Eastern Europe Other Eastern Europe
#> 9 CZ Czech Republic Europe Eastern Europe Other Eastern Europe
#> 10 DE Germany Europe Western Europe <NA>
#> 11 DK Denmark Europe Western Europe Other Western Europe
#> 12 EE Estonia Europe Eastern Europe Other Eastern Europe
#> 13 ES Spain Europe Western Europe <NA>
#> 14 FI Finland Europe Western Europe Other Western Europe
#> 15 FR France Europe Western Europe <NA>
#> 16 GB United Kingdom Europe Western Europe <NA>
#> 17 GG Guernsey Europe Western Europe Other Western Europe
#> 18 GI Gibraltar Europe Western Europe Other Western Europe
#> 19 GR Greece Europe Western Europe Other Western Europe
#> 20 HR Croatia Europe Eastern Europe Other Eastern Europe
#> 21 HU Hungary Europe Eastern Europe Other Eastern Europe
#> 22 IE Ireland Europe Western Europe Other Western Europe
#> 23 IM Isle of Man Europe Western Europe Other Western Europe
#> 24 IS Iceland Europe Western Europe Other Western Europe
#> 25 IT Italy Europe Western Europe <NA>
#> 26 JE Jersey Europe Western Europe Other Western Europe
#> 27 KS Kosovo Europe Eastern Europe Other Western Europe
#> 28 LI Liechtenstein Europe Western Europe Other Western Europe
#> 29 LT Lithuania Europe Eastern Europe Other Eastern Europe
#> 30 LU Luxembourg Europe Western Europe Other Western Europe
#> 31 LV Latvia Europe Eastern Europe Other Eastern Europe
#> 32 MC Monaco Europe Western Europe Other Western Europe
#> 33 MD Moldova Europe Eastern Europe Other Eastern Europe
#> 34 ME Montenegro Europe Eastern Europe Other Eastern Europe
#> 35 MK North Macedonia Europe Eastern Europe Other Eastern Europe
#> 36 MT Malta Europe Western Europe Other Western Europe
#> 37 NL Netherlands Europe Western Europe Other Western Europe
#> 38 NO Norway Europe Western Europe Other Western Europe
#> 39 PL Poland Europe Eastern Europe Other Eastern Europe
#> 40 PT Portugal Europe Western Europe Other Western Europe
#> 41 RO Romania Europe Eastern Europe Other Eastern Europe
#> 42 RS Serbia Europe Eastern Europe Other Eastern Europe
#> 43 SE Sweden Europe Western Europe <NA>
#> 44 SI Slovenia Europe Eastern Europe Other Eastern Europe
#> 45 SK Slovakia Europe Eastern Europe Other Eastern Europe
#> 46 SM San Marino Europe Western Europe Other Western Europe
#> # A tibble: 32 × 5
#> code shortname region1 region2 region4
#> <chr> <chr> <fct> <fct> <fct>
#> 1 AT Austria Europe Western Europe Other Western Europe
#> 2 BE Belgium Europe Western Europe Other Western Europe
#> 3 BG Bulgaria Europe Eastern Europe Other Eastern Europe
#> 4 HR Croatia Europe Eastern Europe Other Eastern Europe
#> 5 CY Cyprus Europe Eastern Europe Other Eastern Europe
#> 6 CZ Czech Republic Europe Eastern Europe Other Eastern Europe
#> 7 DK Denmark Europe Western Europe Other Western Europe
#> 8 EE Estonia Europe Eastern Europe Other Eastern Europe
#> 9 FI Finland Europe Western Europe Other Western Europe
#> 10 FR France Europe Western Europe <NA>
#> 11 DE Germany Europe Western Europe <NA>
#> 12 GI Gibraltar Europe Western Europe Other Western Europe
#> 13 GR Greece Europe Western Europe Other Western Europe
#> 14 HU Hungary Europe Eastern Europe Other Eastern Europe
#> 15 IE Ireland Europe Western Europe Other Western Europe
#> 16 IM Isle of Man Europe Western Europe Other Western Europe
#> 17 IT Italy Europe Western Europe <NA>
#> 18 JE Jersey Europe Western Europe Other Western Europe
#> 19 LV Latvia Europe Eastern Europe Other Eastern Europe
#> 20 LT Lithuania Europe Eastern Europe Other Eastern Europe
#> 21 LU Luxembourg Europe Western Europe Other Western Europe
#> 22 MT Malta Europe Western Europe Other Western Europe
#> 23 MS Montserrat Americas Caribbean Other Latin America
#> 24 NL Netherlands Europe Western Europe Other Western Europe
#> 25 PL Poland Europe Eastern Europe Other Eastern Europe
#> 26 PT Portugal Europe Western Europe Other Western Europe
#> 27 RO Romania Europe Eastern Europe Other Eastern Europe
#> 28 SK Slovakia Europe Eastern Europe Other Eastern Europe
#> 29 SI Slovenia Europe Eastern Europe Other Eastern Europe
#> 30 ES Spain Europe Western Europe <NA>
#> 31 SE Sweden Europe Western Europe <NA>
#> 32 GB United Kingdom Europe Western Europe <NA>
R Code A.29 : Countries of the MENA region (Middle East & North Afrika)
#> # A tibble: 20 × 5
#> code shortname region1 region2 region4
#> <chr> <chr> <fct> <fct> <fct>
#> 1 AE United Arab Emirates Asia West Asia Other MENA
#> 2 BH Bahrain Asia West Asia Other MENA
#> 3 DZ Algeria Africa North Africa <NA>
#> 4 EG Egypt Africa North Africa <NA>
#> 5 IL Israel Asia West Asia Other MENA
#> 6 IQ Iraq Asia West Asia Other MENA
#> 7 IR Iran Asia South Asia Other MENA
#> 8 JO Jordan Asia West Asia Other MENA
#> 9 KW Kuwait Asia West Asia Other MENA
#> 10 LB Lebanon Asia West Asia Other MENA
#> 11 LY Libya Africa North Africa Other MENA
#> 12 MA Morocco Africa North Africa Other MENA
#> 13 OM Oman Asia West Asia Other MENA
#> 14 PS Palestine Asia West Asia Other MENA
#> 15 QA Qatar Asia West Asia Other MENA
#> 16 SA Saudi Arabia Asia West Asia Other MENA
#> 17 SY Syrian Arab Republic Asia West Asia Other MENA
#> 18 TN Tunisia Africa North Africa Other MENA
#> 19 TR Turkey Asia West Asia <NA>
#> 20 YE Yemen Asia West Asia Other MENA
R Code A.30 : Countries of the South & South-East Asia region used in the WIR2022
#> # A tibble: 20 × 5
#> code shortname region1 region2 region4
#> <chr> <chr> <fct> <fct> <fct>
#> 1 AF Afghanistan Asia South Asia Other …
#> 2 BD Bangladesh Asia South Asia Other …
#> 3 BN Brunei Darussalam Asia South-East Asia Other …
#> 4 BT Bhutan Asia South Asia Other …
#> 5 ID Indonesia Asia South-East Asia <NA>
#> 6 IN India Asia South Asia <NA>
#> 7 KH Cambodia Asia South-East Asia Other …
#> 8 LA Lao PDR Asia South-East Asia Other …
#> 9 LK Sri Lanka Asia South Asia Other …
#> 10 MM Myanmar Asia South-East Asia Other …
#> 11 MV Maldives Asia South Asia Other …
#> 12 MY Malaysia Asia South-East Asia Other …
#> 13 NP Nepal Asia South Asia Other …
#> 14 PG Papua New Guinea Oceania Oceania (excl. Australia and New Zea… Other …
#> 15 PH Philippines Asia South-East Asia Other …
#> 16 PK Pakistan Asia South Asia Other …
#> 17 SG Singapore Asia South-East Asia Other …
#> 18 TH Thailand Asia South-East Asia Other …
#> 19 TL Timor-Leste Asia South-East Asia Other …
#> 20 VN Viet Nam Asia South-East Asia Other …
R Code A.31 : Countries of the Latin America region used in the WIR2022
#> # A tibble: 43 × 5
#> code shortname region1 region2 region4
#> <chr> <chr> <fct> <fct> <fct>
#> 1 AG Antigua and Barbuda Americas Caribbean Other Latin …
#> 2 AI Anguilla Americas Caribbean Other Latin …
#> 3 AR Argentina Americas South America <NA>
#> 4 AW Aruba Americas Caribbean Other Latin …
#> 5 BB Barbados Americas Caribbean Other Latin …
#> 6 BO Bolivia Americas South America Other Latin …
#> 7 BQ Bonaire, Sint Eustatius and Saba Americas Caribbean Other Latin …
#> 8 BR Brazil Americas South America <NA>
#> 9 BS Bahamas Americas Caribbean Other Latin …
#> 10 BZ Belize Americas Central America Other Latin …
#> 11 CL Chile Americas South America <NA>
#> 12 CO Colombia Americas South America <NA>
#> 13 CR Costa Rica Americas Central America Other Latin …
#> 14 CU Cuba Americas Caribbean Other Latin …
#> 15 CW Curacao Americas Caribbean Other Latin …
#> 16 DM Dominica Americas Caribbean Other Latin …
#> 17 DO Dominican Republic Americas Caribbean Other Latin …
#> 18 EC Ecuador Americas South America Other Latin …
#> 19 GD Grenada Americas Caribbean Other Latin …
#> 20 GT Guatemala Americas Central America Other Latin …
#> 21 GY Guyana Americas South America Other Latin …
#> 22 HN Honduras Americas Central America Other Latin …
#> 23 HT Haiti Americas Caribbean Other Latin …
#> 24 JM Jamaica Americas Caribbean Other Latin …
#> 25 KN Saint Kitts and Nevis Americas Caribbean Other Latin …
#> 26 KY Cayman Islands Americas Caribbean Other Latin …
#> 27 LC Saint Lucia Americas Caribbean Other Latin …
#> 28 MS Montserrat Americas Caribbean Other Latin …
#> 29 MX Mexico Americas Central America <NA>
#> 30 NI Nicaragua Americas Central America Other Latin …
#> 31 PA Panama Americas Central America Other Latin …
#> 32 PE Peru Americas South America Other Latin …
#> 33 PR Puerto Rico Americas Caribbean Other Latin …
#> 34 PY Paraguay Americas South America Other Latin …
#> 35 SR Suriname Americas South America Other Latin …
#> 36 SV El Salvador Americas Central America Other Latin …
#> 37 SX Sint Maarten (Dutch part) Americas Caribbean Other Latin …
#> 38 TC Turks and Caicos Islands Americas Caribbean Other Latin …
#> 39 TT Trinidad and Tobago Americas Caribbean Other Latin …
#> 40 UY Uruguay Americas South America Other Latin …
#> 41 VC Saint Vincent and the Grenadines Americas Caribbean Other Latin …
#> 42 VE Venezuela Americas South America Other Latin …
#> 43 VG Virgin Islands, British Americas Caribbean Other Latin …
R Code A.32 : Countries of the Russia & Central Asia region used in the WIR2022
Code
wir2022_country_codes|>dplyr::filter(region5=="Russia & Central Asia")|>dplyr::select(-region5, -region3)|>print(n =50)
#> # A tibble: 11 × 5
#> code shortname region1 region2 region4
#> <chr> <chr> <fct> <fct> <fct>
#> 1 AM Armenia Asia West Asia Other Russia & Central Asia
#> 2 AZ Azerbaijan Asia West Asia Other Russia & Central Asia
#> 3 BY Belarus Asia West Asia Other Russia & Central Asia
#> 4 GE Georgia Asia West Asia Other Russia & Central Asia
#> 5 KG Kyrgyzstan Asia Central Asia Other Russia & Central Asia
#> 6 KZ Kazakhstan Asia Central Asia Other Russia & Central Asia
#> 7 RU Russian Federation Asia West Asia <NA>
#> 8 TJ Tajikistan Asia Central Asia Other Russia & Central Asia
#> 9 TM Turkmenistan Asia Central Asia Other Russia & Central Asia
#> 10 UA Ukraine Asia West Asia Other Russia & Central Asia
#> 11 UZ Uzbekistan Asia Central Asia Other Russia & Central Asia
R Code A.33 : Countries of the Sub-Saharan African region used in the WIR2022
#> # A tibble: 49 × 5
#> code shortname region1 region2 region4
#> <chr> <chr> <fct> <fct> <fct>
#> 1 AO Angola Africa Middle Africa Other Sub-Saharan Africa
#> 2 BF Burkina Faso Africa West Africa Other Sub-Saharan Africa
#> 3 BI Burundi Africa East Africa Other Sub-Saharan Africa
#> 4 BJ Benin Africa West Africa Other Sub-Saharan Africa
#> 5 BW Botswana Africa South Africa Other Sub-Saharan Africa
#> 6 CD DR Congo Africa Middle Africa Other Sub-Saharan Africa
#> 7 CF Central African Republic Africa Middle Africa Other Sub-Saharan Africa
#> 8 CG Congo Africa Middle Africa Other Sub-Saharan Africa
#> 9 CI Cote d'Ivoire Africa West Africa Other Sub-Saharan Africa
#> 10 CM Cameroon Africa Middle Africa Other Sub-Saharan Africa
#> 11 CV Cabo Verde Africa West Africa Other Sub-Saharan Africa
#> 12 DJ Djibouti Africa East Africa Other Sub-Saharan Africa
#> 13 ER Eritrea Africa East Africa Other Sub-Saharan Africa
#> 14 ET Ethiopia Africa East Africa Other Sub-Saharan Africa
#> 15 GA Gabon Africa Middle Africa Other Sub-Saharan Africa
#> 16 GH Ghana Africa West Africa Other Sub-Saharan Africa
#> 17 GM Gambia Africa West Africa Other Sub-Saharan Africa
#> 18 GN Guinea Africa West Africa Other Sub-Saharan Africa
#> 19 GQ Equatorial Guinea Africa Middle Africa Other Sub-Saharan Africa
#> 20 GW Guinea-Bissau Africa West Africa Other Sub-Saharan Africa
#> 21 KE Kenya Africa East Africa Other Sub-Saharan Africa
#> 22 KM Comoros Africa East Africa Other Sub-Saharan Africa
#> 23 LR Liberia Africa West Africa Other Sub-Saharan Africa
#> 24 LS Lesotho Africa South Africa Other Sub-Saharan Africa
#> 25 MG Madagascar Africa East Africa Other Sub-Saharan Africa
#> 26 ML Mali Africa West Africa Other Sub-Saharan Africa
#> 27 MR Mauritania Africa West Africa Other Sub-Saharan Africa
#> 28 MU Mauritius Africa East Africa Other Sub-Saharan Africa
#> 29 MW Malawi Africa East Africa Other Sub-Saharan Africa
#> 30 MZ Mozambique Africa East Africa Other Sub-Saharan Africa
#> 31 NA Namibia Africa South Africa Other Sub-Saharan Africa
#> 32 NE Niger Africa West Africa Other Sub-Saharan Africa
#> 33 NG Nigeria Africa West Africa Other Sub-Saharan Africa
#> 34 RW Rwanda Africa East Africa Other Sub-Saharan Africa
#> 35 SC Seychelles Africa East Africa Other Sub-Saharan Africa
#> 36 SD Sudan Africa North Africa Other Sub-Saharan Africa
#> 37 SL Sierra Leone Africa West Africa Other Sub-Saharan Africa
#> 38 SN Senegal Africa West Africa Other Sub-Saharan Africa
#> 39 SO Somalia Africa East Africa Other Sub-Saharan Africa
#> 40 SS South Sudan Africa North Africa Other Sub-Saharan Africa
#> 41 ST Sao Tome and Principe Africa Middle Africa Other Sub-Saharan Africa
#> 42 SZ Swaziland Africa South Africa Other Sub-Saharan Africa
#> 43 TD Chad Africa Middle Africa Other Sub-Saharan Africa
#> 44 TG Togo Africa West Africa Other Sub-Saharan Africa
#> 45 TZ Tanzania Africa East Africa Other Sub-Saharan Africa
#> 46 UG Uganda Africa East Africa Other Sub-Saharan Africa
#> 47 ZA South Africa Africa South Africa <NA>
#> 48 ZM Zambia Africa East Africa Other Sub-Saharan Africa
#> 49 ZW Zimbabwe Africa East Africa Other Sub-Saharan Africa
R Code A.34 : Countries of the North America & Oceania region used in the WIR2022
Code
wir2022_country_codes|>dplyr::filter(region5=="North America & Oceania")|>dplyr::select(-region5, -region3)|>print(n =50)
#> # A tibble: 19 × 5
#> code shortname region1 region2 region4
#> <chr> <chr> <fct> <fct> <fct>
#> 1 AU Australia Oceania Australia and New Zealand <NA>
#> 2 BM Bermuda Americas North America Other …
#> 3 CA Canada Americas North America <NA>
#> 4 FJ Fiji Oceania Oceania (excl. Australia and New Zea… Other …
#> 5 FM Micronesia Oceania Oceania (excl. Australia and New Zea… Other …
#> 6 GL Greenland Americas North America Other …
#> 7 KI Kiribati Oceania Oceania (excl. Australia and New Zea… Other …
#> 8 MH Marshall Islands Oceania Oceania (excl. Australia and New Zea… Other …
#> 9 NC New Caledonia Oceania Oceania (excl. Australia and New Zea… Other …
#> 10 NR Nauru Oceania Oceania (excl. Australia and New Zea… Other …
#> 11 NZ New Zealand Oceania Australia and New Zealand <NA>
#> 12 PF French Polynesia Oceania Oceania (excl. Australia and New Zea… Other …
#> 13 PW Palau Oceania Oceania (excl. Australia and New Zea… Other …
#> 14 SB Solomon Islands Oceania Oceania (excl. Australia and New Zea… Other …
#> 15 TO Tonga Oceania Oceania (excl. Australia and New Zea… Other …
#> 16 TV Tuvalu Oceania Oceania (excl. Australia and New Zea… Other …
#> 17 US USA Americas North America <NA>
#> 18 VU Vanuatu Oceania Oceania (excl. Australia and New Zea… Other …
#> 19 WS Samoa Oceania Oceania (excl. Australia and New Zea… Other …
R Code A.35 : Countries of the East Asia region used in the WIR2022
#> # A tibble: 8 × 5
#> code shortname region1 region2 region4
#> <chr> <chr> <fct> <fct> <fct>
#> 1 CN China Asia East Asia <NA>
#> 2 HK Hong Kong Asia East Asia Other East Asia
#> 3 JP Japan Asia East Asia <NA>
#> 4 KP North Korea Asia East Asia Other East Asia
#> 5 KR Korea Asia East Asia Other East Asia
#> 6 MN Mongolia Asia East Asia Other East Asia
#> 7 MO Macao Asia East Asia Other East Asia
#> 8 TW Taiwan Asia East Asia Other East Asia
A.6 Glossary
term
definition
EU Membership Applications
The following countries have end of 2024 an open application for EU membership: Albania, Bosnia and Herzegovina, Georgia, Kosovo, Moldavia, Montenegro, North Macedonia, Serbia, Turkey, Ukraine.
EUx
The European Union (EU) is a supranational political and economic union of 27 member states. It comprises end of 2024: Austria, Belgium, Bulgaria, Croatia, Cyprus, Czech Republic, Denmark, Estonia, Finland, France, Germany, Greece, Hungary, Ireland, Italy, Latvia, Lithuania, Luxembourg, Malta, Netherlands, Poland, Portugal, Romania, Slovakia, Slovenia, Spain Sweden.
GNI
Gross National Income (GNI) is a measure of a country's income, which includes all the income earned by a country's residents, businesses, and earnings from foreign sources. It is defined as the total amount of money earned by a nation's people and businesses, no matter where it was earned. GNI is an alternative to GDP as a way to measure and track a nation’s wealth, as it calculates income instead of output.
IBRD
The International Bank for Reconstruction and Development (IBRD) is a global development cooperative owned by 189 member countries. As the largest development bank in the world, it supports the World Bank Group’s mission by providing loans, guarantees, risk management products, and advisory services to middle-income and creditworthy low-income countries, as well as by coordinating responses to regional and global challenges. (https://www.worldbank.org/en/who-we-are/ibrd)
IDAx
The International Development Association (IDA) is the part of the World Bank that helps the world’s low-income countries. IDA's grants and low-interest loans help countries invest in their futures, improve lives, and create safer, more prosperous communities around the world. (https://ida.worldbank.org/en/what-is-ida)
M49
The United Nations publication "Standard Country or Area Codes for Statistical Use" was originally published as Series M, No. 49 and is now commonly referred to as the M49 standard. M49 is a country/areas classification system prepared by the Statistics Division of the United Nations Secretariat primarily for use in its publications and databases.
MENA
The Middle East and North Africa (MENA) region is a statistical grouping used by the United Nations (UN) to categorize 20 countries in the region. The UN defines MENA as comprising: Bahrain, Egypt, Iran, Iraq, Israel, Jordan, Kuwait, Lebanon, Oman, Qatar, Saudi Arabia, Syria, United Arab Emirates, and Yemen (Middle East). Algeria, Libya, Morocco, and Tunisia (North Africa).
OECD
Organisation for Economic Co-operation and Development (OECD) is an intergovernmental economic organization founded in 1961. End of 2024 it comprises 38 member countries: Australia, Austria, Belgium, Canada, Chile, Colombia, Costa Rica, Czechia, Denmark, Estonia, Finland, France, Germany, Greece, Hungary, Iceland, Ireland, Israel, Italy, Japan, Korea, Latvia, Lithuania, Luxembourg, Mexico, Netherlands, New Zealand, Norway, Poland, Portugal, Slovak Republic, Slovenia, Spain, Sweden, Switzerland, Türkiye, United Kingdom, United States.
RDS
The abbreviation “RDS” in file endings `.rds` refers to “R Data Serialized”. It is a format used by the R programming language to serialize and store R objects, such as data frames, lists, and functions, in a compact and portable binary format.
United Nations Geoscheme
The United Nations geoscheme is a system which divides 248 countries and territories in the world into six continental regions, 22 geographical subregions, and two intermediary regions. It was devised by the United Nations Statistics Division (UNSD) based on the M49 coding classification
UNSD
The United Nations Statistics Division (UNSD) is committed to the advancement of the global statistical system. It compiles and disseminates global statistical information, develop standards and norms for statistical activities, and support countries' efforts to strengthen their national statistical systems.
WHR
The World Happiness Reports are a partnership of Gallup, the Oxford Wellbeing Research Centre, the UN Sustainable Development Solutions Network, and the WHR’s Editorial Board. The report is produced under the editorial control of the WHR Editorial Board. The Reports reflects a worldwide demand for more attention to happiness and well-being as criteria for government policy. It reviews the state of happiness in the world today and shows how the science of happiness explains personal and national variations in happiness. (https://worldhappiness.report/about/)
WID
The 'World Inequality Database' (WID) aims to provide open and convenient access to the most extensive available database on the historical evolution of the world distribution of income and wealth, both within countries and between countries. [WID.WORLD](https://wid.world/wid-world/)
# Regions and their Countries {#sec-countries-in-regions}```{r}#| label: setup#| results: hold#| include: falsebase::source(file =paste0(here::here(), "/R/helper.R"))ggplot2::theme_set(ggplot2::theme_bw())options(show.signif.stars =FALSE)```## Objectives {.unnumbered}::::: my-objectives::: my-objectives-headerCountry and Regions: Classifications for countries:::::: my-objectives-container1. Inspecting different approaches to classify countries by international organizations (World Bank and United Nations Statistics Division)2. Understanding the country classification usedby my data sources (`r glossary("WID")` and `r glossary("WHR")`.3. Deciding which classification system I am going to use.4. Modifying the country classification of WID and WHR where necessary so that the country classification conforms to the internationally recognized and approved systems.I aim to compare different aspects of Austria with those of othercountries. I want, for instance, to know how well Austria is doingcompared to other European countries, the other member states of theEuropean Union, or other OECD countries. It is, therefore, vital to havedifferent categorization systems.::::::::## Country groupings in WHR and WIDThere are already different classification systems in place:International organizations (e.g., [WorldBank](https://datahelpdesk.worldbank.org/knowledgebase/articles/906519),[United Nations](https://unstats.un.org/unsd/methodology/m49/)) havedeveloped them with several grouping variants.On the other hand the WID database also uses different categorizationsscheme and some of the WHR years have also incorporated regionalgroupings (2013, 2015, 2020, and 2021). For an interpretation of myanalysis in relation to theirs it is important to know if we are usingthe same classifications or if not, where the differences are.As I am listing several classification variants it pays the effort todevelop a function for the repetitive task.### Function `class_scheme()`::::::: my-r-code:::: my-r-code-header::: {#cnj-show-class-scheme}: Function `class_scheme()` for showing classification scheme::::::::::: my-r-code-container::: {#lst-chaplisting-ID}```{r}#| label: function-class-scheme#| code-fold: showclass_scheme <-function(df, sel1, sel2) {## df = dataframe to show## sel1 = name of the first column (country names) to select## sel2 = name of the column with the regional indicator df |> dplyr::select(!!sel1, !!sel2) |> dplyr::nest_by(!!sel2) |> dplyr::mutate(data =as.vector(data)) |> dplyr::mutate(data = stringr::str_c(data, collapse ="; ")) |> dplyr::mutate(data =paste(data, ";")) |> dplyr::mutate(N =lengths(gregexpr(";", data))) |> dplyr::rename(Country = data) |> dplyr::arrange(!!sel2) |> DT::datatable(class ='cell-border compact stripe', options =list(pageLength =25,lengthMenu =c(5, 10, 15, 20, 25, 50) ) )}df_whr <- base::readRDS("data/whr/raw/whr_raw_2021.rds")df_wid <- base::readRDS("data/chap80/country_codes.rds")df_wid <- df_wid |> dplyr::mutate(dplyr::across(tidyselect::where( base::is.factor), base::as.character))```Function `class_scheme()` for showing results of a classification system:::Using {**dplyr**} programming code in functions needs some specialconsideration. I have learned the details from "Bang Bang – How toprogram with dplyr" [@berroth-2019].:::::::::::### Grouping SchemataAs our function is now in place, we can display the different groupingschemes.::: {.my-code-collection}:::: {.my-code-collection-header}::::: {.my-code-collection-icon}:::::::: {#exm-country-classifications}: Grouping schemata of WHR and WID datasets::::::::::::: my-code-collection-container::: panel-tabset###### WHR:::::: my-r-code:::: my-r-code-header::: {#cnj-whr-class}: Classification of the WHR data:::::::::: my-r-code-container```{r}#| label: whr-class( whr_class <-class_scheme(df = df_whr,sel1 = rlang::quo(`Country name`),sel2 = rlang::quo(`Regional indicator`) ))```------------------------------------------------------------------------The datasets for 2013, 2015, 2020 and 2021 use all the sameclassification scheme with **`r sum(whr_class$x$data$N)` countries in`r length(whr_class$x$data$N)` regions**.`r sum(whr_class$x$data$N)` are by far not all countries of the world. Their number is about 195 with some insecurities about Holy See (Vatican), the State of Palestine, Taiwan and Kosovo. (Compare: [How Many Countries Are There In The World?](https://www.worldatlas.com/geography/how-many-countries-are-there-in-the-world.html)) The reason for this lower number is simple: For only those `r sum(whr_class$x$data$N)` countries are subjective well-being data in one of the study years available.:::::::::###### WID1:::::: my-r-code:::: my-r-code-header::: {#cnj-wid1-class}: Classifications of the WID data with column "region1":::::::::: my-r-code-container```{r}#| label: wid1-class( wid1_class <-class_scheme(df = df_wid,sel1 = rlang::quo(shortname),sel2 = rlang::quo(region1) ))```------------------------------------------------------------------------`region1` is a classification scheme with **`r sum(wid1_class$x$data$N)`countries in `r length(wid1_class$x$data$N)` regions**.`r sum(wid1_class$x$data$N)` is more than the 195 countries mentioned in [How Many Countries Are There In The World?](https://www.worldatlas.com/geography/how-many-countries-are-there-in-the-world.html). I believe the reason for this larger amount of "countries" is that it includes also 29 economies with populations of more than 30,000 as explained in the World Bank classification with 218 countries mentioned in @sec-80-wb-summary. There is still a small difference of two countries (218 - `r sum(wid1_class$x$data$N)` = `r 218 - sum(wid1_class$x$data$N)`).:::::::::###### WID2:::::: my-r-code:::: my-r-code-header::: {#cnj-wid2-class}: Classifications of the WID data with column "region2":::::::::: my-r-code-container```{r}#| label: wid2-class( wid2_class <-class_scheme(df = df_wid,sel1 = rlang::quo(shortname),sel2 = rlang::quo(region2) ))```------------------------------------------------------------------------`region2` is a classification scheme with **`r sum(wid2_class$x$data$N)`countries in `r length(wid2_class$x$data$N)` regions**.:::::::::###### WID3:::::: my-r-code:::: my-r-code-header::: {#cnj-wid3-class}: Classifications of the WID data with column "region3":::::::::: my-r-code-container```{r}#| label: wid3-class( wid3_class <-class_scheme(df = df_wid,sel1 = rlang::quo(shortname),sel2 = rlang::quo(region3) ))```------------------------------------------------------------------------`region3` is a classification scheme with **`r sum(wid3_class$x$data$N)`countries in `r length(wid3_class$x$data$N)` regions**.:::::::::###### WID4:::::: my-r-code:::: my-r-code-header::: {#cnj-wid4-class}: Classifications of the WID data with column "region4":::::::::: my-r-code-container```{r}#| label: wid4-class( wid4_class <-class_scheme(df = df_wid,sel1 = rlang::quo(shortname),sel2 = rlang::quo(region4) ))```------------------------------------------------------------------------`region4` is a classification scheme with **`r sum(wid4_class$x$data$N)`countries in `r length(wid4_class$x$data$N)` regions**.:::::::::###### WID5:::::: my-r-code:::: my-r-code-header::: {#cnj-wid5-class}: Classifications of the WID data with column "region5":::::::::: my-r-code-container```{r}#| label: wid5-class( wid5_class <-class_scheme(df = df_wid,sel1 = rlang::quo(shortname),sel2 = rlang::quo(region5) ))```------------------------------------------------------------------------`region5` is a classification scheme with **`r sum(wid5_class$x$data$N)`countries in `r length(wid5_class$x$data$N)` regions**.:::::::::###### WID6:::::: my-r-code:::: my-r-code-header::: {#cnj-wid6-class}: Classifications of the WID data with column "region6":::::::::: my-r-code-container```{r}#| label: wid6-class## replace NAs of region4 with values of region5df_wid6 <- df_wid |> dplyr::mutate(region6 = base::ifelse(is.na(region4), region5, region4) )( wid_class6 <-class_scheme(df = df_wid6,sel1 = rlang::quo(shortname),sel2 = rlang::quo(region6) ))```------------------------------------------------------------------------`region6` is a classification scheme with **`r sum(wid_class6$x$data$N)`countries in `r length(wid_class6$x$data$N)` regions**.:::::::::::::::::::::### SummaryXY = STILL TO WRITE!## Official classificationsIn a first step I want to find out where these classifications systems come from and comparethem to the country groupings in the WID and WHR data. I will look into the two official classifications schemes of World Bank and United Nations and apply the following procedure::::::{.my-procedure}:::{.my-procedure-header}:::::: {#prp-country-class}: Understand structure and content of the official classifications schemata:::::::::::::{.my-procedure-container}1. Create a directory for storing the different country classification files (see @sec-80-create-data-dirs).2. Download classification files and store them for faster access as R objects with `r glossary("rds")` format (see @sec-80-wb-download and @sec-80-unsd-download).3. Inspect the data classification files of World Bank (@sec-80-inspect-wb) and of the United Nations (@sec-80-inspect-unsd) in detail.:::::::::### Create data directories {#sec-80-create-data-dirs}:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-create-class-dirs}: Create folders for country classification files:::::::::::::{.my-r-code-container}```{r}#| label: create-class-dirs#| code-fold: showpb_create_folder(base::paste0(here::here(), "/data/"))pb_create_folder(base::paste0(here::here(), "/data/country-class"))```<center>(*For this R code chunk is no output available*)</center>:::::::::### Download classification files {#sec-80-download-class-files}#### World Bank {#sec-80-wb-download}The World Bank Classification can be downloaded from [How does the World Bank classify countries?](https://datahelpdesk.worldbank.org/knowledgebase/articles/378834-how-does-the-world-bank-classify-countries). At the bottom of the page you can see the line "Download an Excel file of historical classifications by income.", providing a link with word "Download". The downloaded file `CLASS.xlsx` does *not* contain a historical classification by income but the general classification system of the last available year (2023). Yes, there is another Excel file `OGHIST.xslx` with the historical cutoffsfor incomes and lending categories, dating from 1987 to 2023. But the download link for this file is located at another web page: [World Bank Country and Lending Groups](https://datahelpdesk.worldbank.org/knowledgebase/articles/906519). On this page you will also find the updates for the cutoffs for countries `r glossary("GNI")` income per capita which is important for the lending eligibility of countries. [World Bank country classifications by income level for2024-2025](https://blogs.worldbank.org/en/opendata/world-bank-country-classifications-by-income-level-for-2024-2025) has the current updated values and changes over the last year.The file `CLASS.xlsx` am interested here consists of three sheets:1. "List of Economoies"2. "compositions" and3. "Notes"I am going to download the first two Excel sheets.:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-ID-text}: Numbered R Code Title:::::::::::::{.my-r-code-container}<center>**Run this code chunk manually if the file still needs to be downloaded.**</center>```{r}#| label: wb-class#| code-fold: show#| eval: false## download wb-class file ##############downloader::download(url ="https://datacatalogfiles.worldbank.org/ddh-published/0037712/DR0090755/CLASS.xlsx",destfile = base::paste0(here::here(), "/data/country-class/wb-class.xlsx"))## create R object ############wb_class_economies <- readxl::read_xlsx( base::paste0(here::here(), "/data/country-class/wb-class.xlsx"),sheet ="List of economies") wb_class_compositions <- readxl::read_xlsx( base::paste0(here::here(), "/data/country-class/wb-class.xlsx"),sheet ="compositions")## save as .rds files ###############pb_save_data_file("country-class", wb_class_economies, "wb_class_economies.rds")pb_save_data_file("country-class", wb_class_compositions, "wb_class_compositions.rds")```<center>(*For this R code chunk is no output available*)</center>:::::::::#### UNSD-M49 {#sec-80-unsd-download}Another more detailed classification system expressively developed forstatistical purposes is developed by the United Nations StatisticsDivision `r glossary("UNSD")` using the `r glossary("M49")` methodology.The result is called [Standard country or area codes for statistical use(M49)](https://unstats.un.org/unsd/methodology/m49/) and can bedownloaded manually in different languages and formats (Copy into theclipboard, Excel or CSV) from the [Overviewpage](https://unstats.un.org/unsd/methodology/m49/overview/). On this page isno URL for an R script available, because triggering one of the buttonscopies or downloads the data with the help of Javascript. So I had to download the file manually or to find another location where I could download it programmatically. I stored it as `unsd-class.csv` under the "data/country-class" folder. I found with the OMNIKA DataStore an [external source for the UNSD-M49 country classification](https://github.com/omnika-datastore/unsd-m49-standard-area-codes). The OMNIKA DataStore is an open-access data science resource for researchers, authors, and technologists. OMNIKA Foundation is a 501c3 nonprofit whose mission is to digitize, organize, and make freely available important contents. For security reason I checked the two files with `base::all.equal()` to determine if those two files are identical. Yes, they are!:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-ID-text}: Numbered R Code Title:::::::::::::{.my-r-code-container}<center>**Run this code chunk manually if the file still needs to be downloaded.**</center>```{r}#| label: unsd-class#| code-fold: show#| eval: false## download unsd-m49 file ############url <-"https://github.com/omnika-datastore/unsd-m49-standard-area-codes/raw/refs/heads/main/2022-09-24__CSV_UNSD_M49.csv"downloader::download(url = url,destfile = base::paste0(here::here(), "/data/country-class/unsd-class.csv"))## create R object ###############unsd_class <- readr::read_delim(file = base::paste0(here::here(), "/data/country-class/unsd-class.csv"),delim =";" )## save as .rds file ################pb_save_data_file("country-class", unsd_class, "unsd_class.rds")```<center>(*For this R code chunk is no output available*)</center>:::::::::### Inspect classification files {#sec-80-inspect-class-files}To get an detailed understanding of the data structures I will provide the following outputs:1. A summary statistics with `skimr::skim()` followed by inspection of the first data with `dplyr::glimpse()`.2. Several detailed outputs of the classifications categories (regions) and their elements (countries) in different code chunks (tabs).#### World Bank {#sec-80-inspect-wb}::: {.my-code-collection}:::: {.my-code-collection-header}::::: {.my-code-collection-icon}::::::::::: {#exm-inspect-wb-class-files}: Inspect the structure of the World Bank classification::::::::::::::{.my-code-collection-container}::: {.panel-tabset}###### WB `economies`:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-inspect-wb-sheet1}: Inspect sheet `List of Economies` of the World Bank classification file:::::::::::::{.my-r-code-container}```{r}#| label: inspect-wb-sheet1#| results: holdwb_class_economies <- base::readRDS("data/country-class/wb_class_economies.rds")glue::glue("******************* Using skimr::skim() ***************************")skimr::skim(wb_class_economies)glue::glue("")glue::glue("****************** Using dplyr::glimpse() *************************")dplyr::glimpse(wb_class_economies)```:::::::::###### WB `compositions`:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-inspect-wb-sheet2}: Inspect sheet `compositions` of the World Bank classification file:::::::::::::{.my-r-code-container}```{r}#| label: inspect-wb-sheet2#| results: holdwb_class_compositions <- base::readRDS("data/country-class/wb_class_compositions.rds")glue::glue("******************* Using skimr::skim() ***************************")skimr::skim(wb_class_compositions)glue::glue("")glue::glue("****************** Using dplyr::glimpse() *************************")dplyr::glimpse(wb_class_compositions)```:::::::::###### WB standard:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-wb-class-standard}: Pre-defined standard categorization:::::::::::::{.my-r-code-container}```{r}#| label: wb-class-standarddf_wb_standard <- base::readRDS("data/country-class/wb_class_economies.rds") |> dplyr::slice(1:218)( wb_class_standard <-class_scheme(df = df_wb_standard,sel1 = rlang::quo(`Economy`),sel2 = rlang::quo(`Region`) ))```***`Region` is a coarse classification scheme with only **`r length(wb_class_standard$x$data$N)` regions formed by `r sum(wb_class_standard$x$data$N)` countries**.:::::::::###### WB All:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-wb-class-all}: All provided groups, regional, economical and political:::::::::::::{.my-r-code-container}```{r}#| label: wb-class-alldf_wb_all <- base::readRDS("data/country-class/wb_class_compositions.rds")( wb_class_all <-class_scheme(df = df_wb_all,sel1 = rlang::quo(`WB_Country_Name`),sel2 = rlang::quo(`WB_Group_Name`) ))```***`WB_Group_Name` in the "compositions" file contains all available groups. They are not restricted to regional groups because they are formed by economical and political criteria as well. There is no 1:1 match, because almost all countries belong to two or more groups. There are **`r length(wb_class_all$x$data$N)` groups with a total of `r sum(wb_class_all$x$data$N)` elements**.:::::::::###### Region1:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-wb-class-regional}: Groups formed by regional criteria (without the redundant `World` region):::::::::::::{.my-r-code-container}```{r}#| label: wb-class-regionalstr_reg <-c("AFE", "AFW", "ARB", "CSS", "CEB","EAS", "ECS", "LCN", "MEA", "NAC","OSS", "PSS", "SST", "SAS", "SSF")df_wb_reg <- base::readRDS("data/country-class/wb_class_compositions.rds") |> dplyr::filter(WB_Group_Code %in% str_reg)( wb_class_reg <-class_scheme(df = df_wb_reg,sel1 = rlang::quo(`WB_Country_Name`),sel2 = rlang::quo(`WB_Group_Name`) ))```***Browsing through the `composition` data I have defined 15 `WB_GROUP_CODE`s as regional codes. These regional classification criteria results per definition to **`r length(wb_class_reg$x$data$N)` regions containing `r sum(wb_class_reg$x$data$N)` countries**.:::::::::###### Region2:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-wb-class-regional}: Groups formed by regional criteria (without the redundant `World` region):::::::::::::{.my-r-code-container}```{r}#| label: wb-class-regional2str_reg2 <-c("AFE", "AFW", "ARB", "CEB","EAS", "ECS", "LCN", "MEA", "NAC","SAS", "SSF")df_wb_reg2 <- base::readRDS("data/country-class/wb_class_compositions.rds") |> dplyr::filter(WB_Group_Code %in% str_reg2)( wb_class_reg2 <-class_scheme(df = df_wb_reg2,sel1 = rlang::quo(`WB_Country_Name`),sel2 = rlang::quo(`WB_Group_Name`) ))```***Browsing through the `composition` data I have declassified all small states for an alternative regional group. These regional classification criteria are smaller and results to **`r length(wb_class_reg2$x$data$N)` regions containing `r sum(wb_class_reg2$x$data$N)` countries**.:::::::::::::::::::::##### Description of the four tabs1. **WB economies** displays the "List of Economies" and has five columns: - `Economy` with the country names (2-219) and regional names (221-268) - `Code` with the ISO alpha3 codes for countries (2-219) and for the regional names (221-268) - `Region` with seven different regional names: - East Asia and Pacific, - Europe and Central Asia, - Latin America & the Caribbean, - Middle East and North Africa, - North America - South Asia and - Sub-Saharan Africa - `Income group` with four groups: Low income, Lower middle income, Higher middle income, and High income. - `Lending category` with three groups: `IBRD`, `Blend`, and`IDA`.2. **WB compositions** has four columns: `WB_Group_Code`, `WB_Group_Name`,`WB_Country_Code`, `WB_Country_Name`. The 2084 rows are combinations of the regional and income group with their ISO alpha 3 codes and country names.3. **WB Standard** shows the World Bank seven standard regional groups with their countries. The 218 countries involved in the taxonomy of the World Bank consists of all member countries of the World Bank (189) and other economies with populations of more than 30,000 (29).4. **WB All** includes the seven regions from the "WB Standard" tab but much more. But it is important to note that there is no alternative *regional* structure comprises systematically all countries of the world --- the overall category "World" obviously excluded. - Five of the seven regional groups of "WB Standard" are also clustered without high income countries. - There are six other regional subcategories: "Arab World", "Caribbean small states", "Central Europe and Baltics", "Other small states", "Pacific island small states", "Small states". - Additionally there are some political groups like European Union, OECD and - several economical classification like "Euro area", - different combinations of the four income groups and different combinations of the three lending statuses.**More details**The cut off limits for the income groups are: - low income, $1,145 or less; - lower middle income, $1,146 to $4,515; - upper middle income, $4,516 to $14,005; and - high income, more than $14,005. The effective operational cutoff for `r glossary("IDAx", "IDA")` eligibility is $1,335 or less. The three lending categories and their relation to each other are:> `r glossary("IDAx", "IDA")` countries are those that lack the financial ability to borrow from `r glossary("IBRD")`. IDA credits are deeply concessional—interest-free loans and grants for programs aimed at boosting economic growth and improving living conditions. IBRD loans are non-concessional. `Blend` countries are eligible for IDA credits because of their low per capita incomes but are also eligible for IBRD because they are financially creditworthy.Three additional remark relating to the `Notes` sheet: 1. In the `Notes` I found the sentence: "Geographic classifications in this table cover all income levels." But there is a difference of one missing data value more in the `Income group` column compared with the `Region` column (50:49). The reason is that `Venezuela RB` is lacking an income group because it has been temporarily unclassified since July 2021 pending release of revised national accounts statistics. Venezuela, RB was classified as an upper-middle income country until FY21, has been unclassified since then due to the unavailability of data. But it is now again classified as `Upper middle income` (See the World Bank [page about Venezuela, RB](https://archive.doingbusiness.org/en/data/exploreeconomies/venezuela)).2. The term country, used interchangeably with economy, does not imply political independence but refers to any territory for which authorities report separate social or economic statistics. 3. What follows is a quote about some details of the income classifications for the 2023 file:> Set on 1 July 2022 remain in effect until 1 July 2023. Venezuela has been temporarily unclassified since July 2021 pending release of revised national accounts statistics. Argentina, which was temporarily unclassified in July 2016 pending release of revised national accounts statistics, was classified as upper middle income for FY17 as of 29 September 2016 based on alternative conversion factors. Also effective 29 September 2016, Syrian Arab Republic is reclassified from IBRD lending category to IDA-only. On 29 March 2017, new country codes were introduced to align World Bank 3-letter codes with ISO 3-letter codes: Andorra (AND), Dem. Rep. Congo (COD), Isle of Man (IMN), Kosovo (XKX), Romania (ROU), Timor-Leste (TLS), and West Bank and Gaza (PSE). It is to be noted that Venezuela, RB classified as an upper-middle income country until FY21, has been unclassified since then due to the unavailability of data.##### Summary {#sec-80-wb-summary}The only missing data in the columns `Economy` and `Code` corresponds to the empty line #220 that separates the country codes from the regional codes. The missing data in the other columns stem from the different structure of the second part (starting with row #221) of the data, which consists only of the two columns 'Economy' and 'Code'. Essentially this means that we have in the `CLASS.xslx` file two different data sets: One for economies and the other one to explicate regional, economical and political grouping codes. In the Excel sheet `compositions` you will find an extended list of all available group names and their three letter codes combined with the country names and their three letter codes. These group names comprise different kinds of regional groups but also names and codes for different combination of country incomes and lending categories.All these groups may be of interests for analysis of different trends. But the regional (sub)groups of the `compositions` sheet do not add up to the complete number of countries (218). This is in contrast to the different regional groups of the WID database because all their regional groups (region1 = 5, region2 = 18, region4 = 10, and region5 = 8 groups) includes all countries (in this case: 216).The World Bank file `CLASS.xslx` classifies all World Bank member countries (189), and all other economies with populations of more than 30,000 (29) in a coarse grid of only seven regions. For operational and analytical purposes, these economies are divided among income groups according to their [gross national income (GNI) per capita](https://datahelpdesk.worldbank.org/knowledgebase/articles/378831-why-use-gni-per-capita-to-classify-economies-into) in 2023, calculated using the [World Bank Atlas method](https://datahelpdesk.worldbank.org/knowledgebase/articles/378832-what-is-the-world-bank-atlas-method). #### United Nations {#sec-80-inspect-unsd}::: {.my-code-collection}:::: {.my-code-collection-header}::::: {.my-code-collection-icon}::::::::::: {#exm-inspect-unsd}: Inspect UNSD-M49 geoscheme classification::::::::::::::{.my-code-collection-container}::: {.panel-tabset}###### raw:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-inspect-unsd-m49}: Inspect UNSD M49 geoscheme classification:::::::::::::{.my-r-code-container}```{r}#| label: inspect-unsd-m49#| results: holdunsd_class <- base::readRDS("data/country-class/unsd_class.rds")glue::glue("******************* Using skimr::skim() ***************************")skimr::skim(unsd_class)glue::glue("")glue::glue("****************** Using dplyr::glimpse() *************************")dplyr::glimpse(unsd_class)```:::::::::###### clean :::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-clean-unsc-m49}: Clean UNSD M49 geoscheme classification:::::::::::::{.my-r-code-container}```{r}#| label: clean-unsd-49#| results: hold## column renaming vector ########m49_cols =c(region_c ="Region Code", region_n ="Region Name",subr_c ="Sub-region Code", subr_n ="Sub-region Name", midr_c ="Intermediate Region Code", midr_n ="Intermediate Region Name",country ="Country or Area", m49 ="M49 Code", iso2 ="ISO-alpha2 Code", iso3 ="ISO-alpha3 Code",ldc ="Least Developed Countries (LDC)", lldc ="Land Locked Developing Countries (LLDC)", sids ="Small Island Developing States (SIDS)" )## clean data ###############################unsd_class <- base::readRDS("data/country-class/unsd_class.rds")unsd_class_clean <- unsd_class |> dplyr::select(-(1:2)) |> dplyr::rename(tidyselect::all_of(m49_cols)) |> dplyr::filter(country !="Antarctica") |> dplyr::mutate(iso2 = base::ifelse(country =="Namibia", "NA", iso2)) |> dplyr::relocate(country, .before = region_c) |># .x = anonymous function; "x" = value in cols of unsd_class dplyr::mutate(dplyr::across( ldc:sids, ~ dplyr::if_else(.x =="x", "1", "999", "0") )) |> dplyr::arrange(country)## save new tibble ##########pb_save_data_file("country-class", unsd_class_clean,"unsd_class_clean.rds")## prepare skimmers ##########my_skim <- skimr::skim_with(character = skimr::sfl(whitespace =NULL,min =NULL,max =NULL,empty =NULL ))## display results ##########unsd_class <- base::readRDS("data/country-class/unsd_class.rds")glue::glue("******************* Using skimr::skim() ***************************")my_skim(unsd_class_clean) |> dplyr::select(-complete_rate)glue::glue("")glue::glue("****************** Using dplyr::glimpse() *************************")dplyr::glimpse(unsd_class_clean)```:::::::::###### Region:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-ID-text}: Numbered R Code Title:::::::::::::{.my-r-code-container}```{r}#| label: unsd-class1df_unsd <- base::readRDS("data/country-class/unsd_class_clean.rds")( unsd_class1 <-class_scheme(df = df_unsd,sel1 = rlang::quo(`country`),sel2 = rlang::quo(`region_n`) ))```:::::::::###### Sub-region:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-ID-text}: Numbered R Code Title:::::::::::::{.my-r-code-container}```{r}#| label: unsd-class2df_unsd <- base::readRDS("data/country-class/unsd_class_clean.rds")( unsd_class2 <-class_scheme(df = df_unsd,sel1 = rlang::quo(`country`),sel2 = rlang::quo(`subr_n`) ))```:::::::::###### Intermediate:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-ID-text}: Numbered R Code Title:::::::::::::{.my-r-code-container}```{r}#| label: unsd-class3df_unsd <- base::readRDS("data/country-class/unsd_class_clean.rds")( unsd_class3 <-class_scheme(df = df_unsd,sel1 = rlang::quo(`country`),sel2 = rlang::quo(`midr_n`) ))```:::::::::###### Intermediate2:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-ID-text}: Numbered R Code Title:::::::::::::{.my-r-code-container}```{r}#| label: unsd-class4unsd_class4 <- base::readRDS("data/country-class/unsd_class_clean.rds")unsd_class4 <- unsd_class4 |> dplyr::mutate(midr_n2 = base::ifelse(is.na(midr_n), subr_n, midr_n) )( unsd_class4 <-class_scheme(df = unsd_class4,sel1 = rlang::quo(`country`),sel2 = rlang::quo(`midr_n2`) )) ````midr_n2` is a classification scheme with **`r sum(unsd_class4$x$data$N)`countries in `r length(unsd_class4$x$data$N)` regions**.:::::::::::::::::::::##### Descriptions of the XY tabsThe file has 15 columns as you can also see online from the [Overviewpage](https://unstats.un.org/unsd/methodology/m49/overview/). The many missing values (`NAs`) for the categories LDC, LLDC and SIDS are easy explained: These three columns are coded with an 'x' if the country of this row belong to this category. Recoding these three columns with 1 and 0 (1 = yes, belongs to this category, 0 = no, does not belong to this category) will reduce most of their missing values.One missing value in the regional categories (Region, Sub-Region and Intermediate Region) is related to Antarctica which is not seen by the M49 scheme as a separated region. It has therefore no regional codes and names with the exception of the overall comprising global region. But it has M49 as well ISO-alpha codes.One of the missing values for ISO-alpha2 and ISO-alpha3 is related to Sark, which is "recognized by the United Nations Statistics Division (UNSD) as a separate territory" but was not accepted by ISO now for more than 20 years [@mccarthy-2020]. Recently a new application (see [PDF](https://www.sarkid.org/assets/pdf/SarkID%20Identity%20info%20v1_2.pdf)) will change that but currently Sark is still waiting for [ISO 3166 codes](https://www.iso.org/iso-3166-country-codes.html).The other missing value for ISO-alpha2 codes belongs to Namibia because its abbreviation `NA` is interpreted by R as a missing value!To clean the data I will- Remove the global codes and names because they a redundant: All rows have global code "001" ("World").- Rename the columns to get shorter names.- Remove Antarctica because it is not seen as separate country.- Replace `NA` in the column ISO-alpha2 Code" of Namibia with the string "NA".- Recode the columns LDC, LLDC and SIDS with 0 and 1.- Relocate the column "country" (previously "Country or Area") to the first column because than it easier to find some relevant content- Sort the data alphabetically by "country".##### Summary## XY STOPPED HERE - WHAT FOLLOW ARE SOME (OLDER) TEXT MODULES### Modul: Why looking at classification systems?Only sometimes are they used identically in the data I will look at. SoI also have to understand these data-driven differences (e.g., in the`r glossary("WID")` database or the `r glossary("WHR")` data) with theofficial country nomenclatures.I could have used just the approach used in my data set. But thatapproach poses two problems:1. Not always are the classification used coherently in my available datasets. So uses WHR (slightly) different country names in their yearly reports. For instance "Turkiye" in 2024 and "Turkey" in 2012, but the official name is "Türkiye". Instead of the current 27 member states of the European Union the WID assigns the label "European Union" to 32 countries, including still United Kingdom but also British Overseas Territory (Gibraltar, Montserrat),and self-governing British Crown dependencies (Isle of Man, Jersey) that never had been member status in the `r glossary("EUx", "EU")`.2. Sometimes the available data use their own categorization schema. Most of the data analysis in the World Inequality Report 2022 (WIR2022) condense data into eight different regions: Europe, South & South-East Asia, East Asia, North America, Sub-Saharan Africa, Russia & Central Asia, `r glossary("MENA")`, Latin America. I couldn't find exact this classification schema in one of the internationally approved taxonomies.3. Some of the groupings I am interested in (e.g.,`r glossary("OECD")`, or countries that applied for`r glossary("EU membership applications", "EU membership status")` are not part of the international standardized statistical groupings.### Modul: UNSD M49 geoscheme preliminiary rsultsAfter some research I found out that the most detailed and forstatistical purposes most relevant classification system is`r glossary("M49")` standard, developed and maintained by the UnitedNations Statistics Division (`r glossary("UNSD")`). Guided by the`r glossary("United Nations Geoscheme")` it divides all countries of theworld into different types of regions:Reference is: [Wikipediamap](https://en.wikipedia.org/wiki/United_Nations_geoscheme#/media/File:United_Nations_geographical_subregions.png)- **6 Regions**: 6 continents: - Africa, - Americas, - Antarctica, - Asia, - Europe and - Oceania.- **22 Sub-regions**: (Missing three in [Appendix 1. United Nations Geoscheme](https://www.emiw.org/fileadmin/emiw/UserActivityDocs/Geograph.Representation/Geographic-Representation-Appendix_1.pdf): Polynesia, and other differentiation of the Americas: North America, Central America, Caribbean, South America ) - Africa: - Northern Africa, - Eastern Africa, - Middle Africa, - Southern Africa, - Western Africa - Americas: - Latin America and the Caribbean, - Northern America - Asia: - Central Asia, - Eastern Asia, - Southeastern Asia, - Southern Asia, - Western Asia - Europe: - Eastern Europe, - Northern Europe, - Southern Europe, - Western Europe - Oceania: - Australia and New Zealand, - Melanesia, - Micronesia------------------------------------------------------------------------- Sub-regions (18 in M49, missing 4: Sub-Saharan Africa = Eastern Africa, Middle Africa, Southern Africa, and Western Africa, and Latin America = South America and Caribbean is separated) - "Northern Africa"\ - "Sub-Saharan Africa"\ - "Latin America and the Caribbean" - "Northern America" - "Central Asia"\ - "Eastern Asia"\ - "South-eastern Asia"\ - "Southern Asia"\ - "Western Asia"\ - "Eastern Europe"\ - "Northern Europe"\ - "Southern Europe"\ - "Western Europe"\ - "Australia and New Zealand"\ - "Melanesia"\ - "Micronesia"\ - "Polynesia"- Intermediate Regions: (2, but 7) - Sub-Saharan Africa: Eastern Africa, Middle Africa, Southern Africa and Western Africa - Latin America and the Caribbean: Caribbean, Central America, South America::: {#nte-qualifications .callout-note}1. The UN geoscheme is a statistical classification and does not imply any political or other affiliation of countries or territories.2. It may differ from geographical definitions used by autonomous UN specialized agencies, such as the United Nations Industrial Development Organization and UNESCO, for their own organizational convenience.3. Other alternative groupings include the World Bank regional classification and CIA World Factbook regions, and Internet Corporation for Assigned Names and Numbers Geographic Regions.:::::: {#imp-procedure .callout-important}How to get the 22 sub-regions from the m49 data?1. Take the `Intermediate Region Name` if it is not `NA`.2. If the `Intermediate Region Name` is `NA` then take the`Sub-region name`.:::::::::: my-r-code:::: my-r-code-header::: {#cnj-download-m49-scheme}: Download the M49 Geoscheme of the United Nations::::::::::: my-r-code-container**Run this code chunk only once manually:** It downloads the M49Geoscheme of the United Nations as a `.csv` file and saves it as an R`.rds` object.```{r}#| label: download-m49-geoscheme#| eval: false## run this code chunk only once (manually)## get the file from an external source, ## https://github.com/omnika-datastore/unsd-m49-standard-area-codes## OMNIKA DataStore is an open-access data science resource ## for researchers, authors, and technologists interested in mythology. ## Managed by OMNIKA Foundation which is a 501c3 nonprofit ## whose mission is to digitize, organize, ## and make freely available all the world's mythological contents.## at the official UN site is no URL provided## the file is downloaded via a javascript## I checked the two files with base::all.equal()`## they are identical ## define variablesurl <-"https://github.com/omnika-datastore/unsd-m49-standard-area-codes/raw/refs/heads/main/2022-09-24__CSV_UNSD_M49.csv"folder ="country-class"## create folder for chapter if not already donedata_folder <- base::paste0( here::here(),paste0("/data/", folder, "/") )if (!base::file.exists(data_folder)) {base::dir.create(data_folder)}## get the UNSD M49 .csv file from the OMNIKA Foundation GitHubdestfile <- base::paste0(data_folder, "unsd_m49.csv")utils::download.file(url, destfile)tmp <- readr::read_csv2(destfile)## save original file without changespb_save_data_file("country-class", tmp, "unsd_m49.rds")```:::::::::::### Modul: WIR2022 data inspection & exploration:::::: {#obj-chapter-template}::::: my-objectives::: my-objectives-headerList regions of the WIR2022 and their countries:::::: my-objectives-containerThe World Inequality Report 2022 (WIR2022) describes global trends ininequality. It mostly condense data in eight different regions. See thefollowing graph as an example: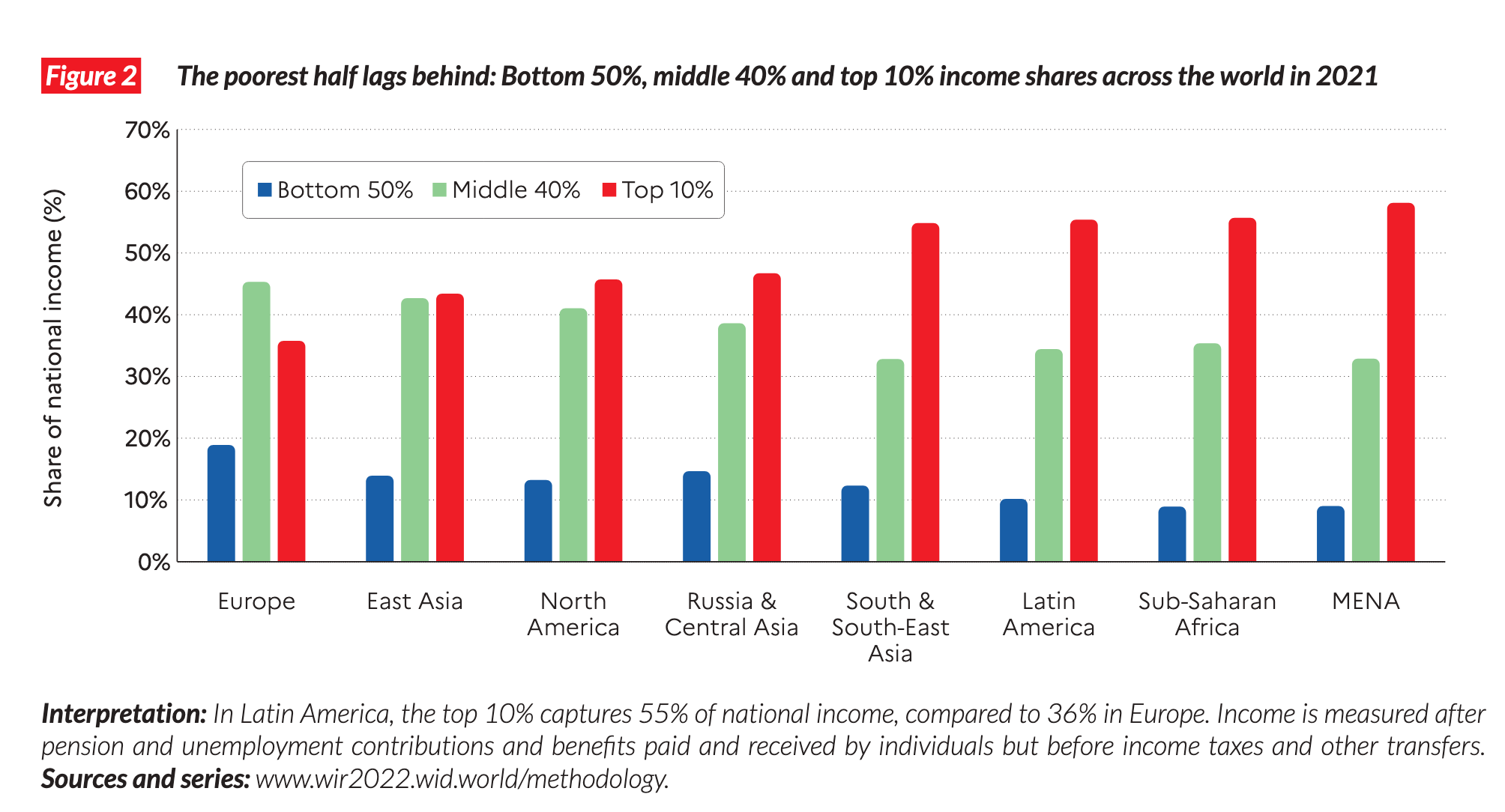{#fig-80-wir2022-examplefig-alt="The image shows the income shares for the bottom 50%, middle 40% and top 10% in 2021 dividing the world into eight different regions. With the exception of Europe the top 10% earn the biggest share of the income with the following order from lowest to the highest 10%: Europe, East Asia, North America, Russia & Central Asia, South & South-East Asia, Latin America, Sub-Saharan Africa, MENA (Middle East & North Africa). Example: In Latin America the top 10% captures 55% of national income compared to 36% of Europe."fig-align="center" width="100%"}In this appendix I want to know the countries that form each of theseeight regions.::::::::::::::## DataMy first task was to look for data where I could extract the informationI am interested in. I scanned the files of the free accessible [GitHubrepository of the WID](https://github.com/WIDworld/wid-world). I found`country-codes-core.xlsx`, an Excel file with the data I am looking for.It is sorted by a two letter code in the first column namedappropriately `code`. "Core" means -- in contrast to [other`country-codes`files](https://github.com/WIDworld/wid-world/tree/master/data-input/country-codes)-- that it includes a column `corecountry` where the number `1`functions as a marker for a core country. The file itself has manyhidden rows which feature either regions smaller than a country (likeAlabama for US or Bavaria for Germany) or bigger than a country (likeAsia or Western Europe).::: callout-important`country-codes-core.xlsx` contains many hidden rows. It is thereforenecessary to filter by `corecountry == 1`.:::### Download dataThe following code chunk is only applied once. The file contains rowswith all two letter combinations. Many of these combinations do notrefer to an existing country. To eliminate these records one needs toselect `corecountry == 1`.The following chunk downloads the dataset from the internet and savesthis Excel file untouched. I selected only rows for core-countries andconverted all string columns to factor variable. I stored the result as`country-codes.rds`.:::::: my-r-code:::: my-r-code-header::: {#cnj-80-download-country-codes-core}: Download the country-codes-core file, manipulate and save it:::::::::: my-r-code-container```{r}#| label: download-country-codes-core#| eval: false## run this code chunk only once (manually)## define variablesurl <-"https://github.com/WIDworld/wid-world/raw/master/data-input/country-codes/country-codes-core.xlsx"chapter_folder ="chap80"## create folder for chapter if not already donechap_folder <- base::paste0( here::here(),paste0("/data/", chapter_folder, "/") )if (!base::file.exists(chap_folder)) {base::dir.create(chap_folder)}## get country-codes-core.xlsxdestfile <- base::paste0(chap_folder, "country-codes-core.xlsx")utils::download.file(url, destfile)tmp <- readxl::read_xlsx(destfile)country_codes <- tmp |>## filter for core countries dplyr::filter(corecountry ==1) |>## convert all region columns to factor variables dplyr::mutate(dplyr::across( tidyselect::starts_with("region"), forcats::as_factor) )## save cleaned datapb_save_data_file("chap80", country_codes, "country_codes.rds")```(*For this R code chunk is no output available*):::::::::### Eplore DataAn inspection of the data file shows that column `region5` contains theregions used in WIR2022.:::::: my-r-code:::: my-r-code-header::: {#cnj-80-explore-data}: Explore Data:::::::::: my-r-code-container```{r}#| label: explore-data#| results: holdcountry_codes <- base::readRDS("data/chap80/country_codes.rds")skimr::skim(country_codes)glue::glue(" ")glue::glue("############################################################")glue::glue("Display number of countries for each region")glue::glue("############################################################")glue::glue(" ")country_codes |> dplyr::pull(region5) |> forcats::fct_count()```:::::::::## List countries::::::::::::::::::::::::::::::::::::::::::: my-example:::: my-example-header::: {#exm-80-list-countries}: List countries for each regions used in WIR2022::::::::::::::::::::::::::::::::::::::::::::::: my-example-container::::::::::::::::::::::::::::::::::::::: panel-tabset###### Europe:::::: my-r-code:::: my-r-code-header::: {#cnj-80-europe}: Countries of the European region used in the WIR2022:::::::::: my-r-code-container```{r}#| label: europe#| results: holdwir2022_country_codes <- country_codes |> dplyr::select(code, shortname, tidyselect::starts_with("region"))wir2022_country_codes |> dplyr::filter(region5 =="Europe") |> dplyr::select(-region5, -region3) |>print(n =50)```:::::::::###### European Union:::::: my-r-code:::: my-r-code-header::: {#cnj-80-eu}: Countries of the European Union:::::::::: my-r-code-container```{r}#| label: eu#| results: holdwir2022_country_codes <- country_codes |> dplyr::select(code, shortname, tidyselect::starts_with("region"))wir2022_country_codes |> dplyr::filter(region3 =="European Union") |> dplyr::select(-region5, -region3) |> dplyr::arrange(shortname) |>print(n =50)```:::::::::###### MENA:::::: my-r-code:::: my-r-code-header::: {#cnj-80-mena}: Countries of the MENA region (Middle East & North Afrika):::::::::: my-r-code-container```{r}#| label: menawir2022_country_codes |> dplyr::filter(region5 =="MENA") |> dplyr::select(-region5, -region3) |>print(n =50)```:::::::::###### South & South-East Asia:::::: my-r-code:::: my-r-code-header::: {#cnj-80-ssea}: Countries of the South & South-East Asia region used in the WIR2022:::::::::: my-r-code-container```{r}#| label: sseawir2022_country_codes |> dplyr::filter(region5 =="South & South-East Asia") |> dplyr::select(-region5, -region3) |>print(n =50)```:::::::::###### Latin America:::::: my-r-code:::: my-r-code-header::: {#cnj-80-latin-america}: Countries of the Latin America region used in the WIR2022:::::::::: my-r-code-container```{r}#| label: latin-americawir2022_country_codes |> dplyr::filter(region5 =="Latin America") |> dplyr::select(-region5, -region3) |>print(n =50)```:::::::::###### Russia & Central Asia:::::: my-r-code:::: my-r-code-header::: {#cnj-80-ruca}: Countries of the Russia & Central Asia region used in the WIR2022:::::::::: my-r-code-container```{r}#| label: rucawir2022_country_codes |> dplyr::filter(region5 =="Russia & Central Asia") |> dplyr::select(-region5, -region3) |>print(n =50)```:::::::::###### Sub-Saharan Africa:::::: my-r-code:::: my-r-code-header::: {#cnj-80-susa}: Countries of the Sub-Saharan African region used in the WIR2022:::::::::: my-r-code-container```{r}#| label: susawir2022_country_codes |> dplyr::filter(region5 =="Sub-Saharan Africa") |> dplyr::select(-region5, -region3) |>print(n =50)```:::::::::###### North America & Oceania:::::: my-r-code:::: my-r-code-header::: {#cnj-80-noac}: Countries of the North America & Oceania region used in the WIR2022:::::::::: my-r-code-container```{r}#| label: noacwir2022_country_codes |> dplyr::filter(region5 =="North America & Oceania") |> dplyr::select(-region5, -region3) |>print(n =50)```:::::::::###### East Asia:::::: my-r-code:::: my-r-code-header::: {#cnj-80-east-asia}: Countries of the East Asia region used in the WIR2022:::::::::: my-r-code-container```{r}#| label: east-asiawir2022_country_codes |> dplyr::filter(region5 =="East Asia") |> dplyr::select(-region5, -region3) |>print(n =50)```:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::------------------------------------------------------------------------## Glossary```{r}#| label: glossary-table#| echo: falseglossary_table()```------------------------------------------------------------------------## Session Info {.unnumbered}::::: my-r-code::: my-r-code-headerSession Info:::::: my-r-code-container```{r}#| label: session-infosessioninfo::session_info()```::::::::

{kind=link}