There are figures for all countries trajectories during the years. This also includes Austria (Helliwell et al. 2024, 10). My general aim is to provide a comparison of the series of rankings for Austria with other selected countries. I will focus on the so-called Cantril ladder of subjective life evaluation (Nilsson et al. 2024).
As far as I can see from my first inspection, there are at least three challenges:
Compatibility: Check if all the data are compatible.
Completeness: Check if the data for the time series are complete. I noticed already that there is no Excel data file for 2013. Bu there data in a PDF file. How to get these data? Another issue are the number of observed countries by year. How to get consistent rankings if the number of countries varies?
Visualization Choose an appropriate visualization of the data. There are already up-to-date (2005-2023) visualization of trajectories. But these plots are visualizing the absolute value of the life evaluations country-by-country as the following example of Austria shows.
Graph 3.1: Series of the values of subjective life evaluations for Austria (2005-2023)
Graph 3.1 is a valuable figure to compare the development of the Austrian life evaluation index. But it is not useful for a comparison with other countries. Here I am thinking of two different visualizations:
Series of several selected countries in one figure so that it facilitates a comparison. In this case I will develop a graph with different colored lines for different countries.
With another figure I will try to capture the changes in rankings of some selected countries. The development of the absolute values of the life evaluations does not necessarily reflect the progress inside countries because they are also influenced by global developments (e.g., COVID-19).
3.1 Import data
3.1.1 Folder and file oganization
The first step is to find the life-evaluation data for each year and to store the files for further R processing. I will store the files in the “whr” folder inside my “data” folder. (As I do not know the chapter number for this well-being chapter, I am not going to use my traditional format “chapXX” (“XX” standing for the chapter number) but just “whr” as folder name.)
The pb_create_folder() function in the following code chunk checks if the folder already exists. If this is the case it leaves it untouched, otherwise it creates the folder at the desired path. The code for my private functions are in the file helper.R inside the R folder at root level of this working directory.
Resource 3.1 : File Organization for WHR files
I will organize the many files into several subfolders:
/data/: main folder for all data files related this project
/data/whr/: files related to the analysis of the the World Happiness Reports
/data/whr/excel/: untouched original Excel files resp. the one PDF for the 2013 report (to prevent possible link rot at the original source)
/data/whr/rds/: R objects of the original data of the Excel files
/data/whr/analysis/: changed or created R objects during the analysis process
/data/whr/2013-coord/ R object containing page coordinates of the 2013 PDF file
R Code 3.1 : Create folders for data files of the World Happiness Reports
The next code chunks combines two actions for each year:
At first I had to get the URL manually. Starting from the WHR-Analysis website I had to open each year and to look for the “Appendices & data” link. There I had to look for a data file.
After downloading all data file as Excel files I had to inspect them manually to find the sheet with the Cantril ladder data. I had to note the sheet number for the appropriate download. (Default is sheet 1). Additionally I had to note the file format “xls” or “xlsx” for each year to call the correct function readxl::read_xls or readxl::read_xlsx. (I refrained from the format guessing with the more general readxl::read_exel() function.) Furthermore I had to skip the first three comment lines in the 2015 dataset.
I am using the utility package downloader by Winston Chang because it provides a wrapper for the utils::download.file() function with the advantage that the download procedure works on Windows, Mac OS X, and other Unix-like platforms.
After the download I converted the Excel file to an R data object .rds and stored this raw data into the folder “data/whr/raw” with the syntax “whr_raw_”.
R Code 3.2 : Download Data for the World Happiness Reports (WHR)
Run the code just once manually. It will download the data from the World Happiness Report (WHR) website for every year where data are available.
Data for the World Happiness Report 2013 are not available in Excel format, unlike data from the other reports. Instead, the data are provided as a PDF file. (See also the second question of the Frequently Asked Question)
This section extracts data I am interested in — the survey measure of SWB (Subjective Well-being) from the Gallup World Poll (GWP) — with the help of the tabulapdf package.
At first, I had to look for an appropriate R package because the one I had already used (tabulizer) was removed from CRAN. I found several packages for extracting PDF text (e.g., pdftools, PDE, PDFR), but only tabulapdf is specialized in extracting table data.
I read the introductory vignette completely because only in the final section I found a solution for my specific PDF. To understand the descriptions of the problems I had to master have a look at Chapter 2 Appendix. We need the cantril ladder data presented in “Table A2. National Averages in 2010-12”. To extract the data I had to overcome three separate problems:
Table A2 spans over several pages (1-6).
On page 6 starts already the next table “Table A3. National Averages in 2005-07” which has to be excluded.
Pages 2-6 do not have column names.
Some of the column names in page 1 span two lines
The difficulties 1 and 2 arise because tabulapdf works page-oriented. Difficulty 3 originates from a faulty table design in the PDF. Difficulty 4 is a common problem that can be solved by setting the col_names argument to FALSE.
The solution I found is an interactive table extraction for each page with the tabulapdf::locate_area() function and to select only the figures without columns names as demonstrated in the use case section of the vignette.
Tidying the dataset for WHR 2013 includes to join country names if the span two lines into one column name and to delete the empty lines consisting of just NA’s. Note also that there is a data entry error in the original PDF (see: page 5, second last line, column 6 from the right) that has to be corrected.
Code Collection 3.1 : Extract WHR 2013 Table Data from PDF and Tidy Data
Run the code just once manually. It will download the WHR 2013 PDF, generate interactively the table coordinates and save them for further processing.
Code
library(tabulapdf)# set Java memory limit to 600 MB (optional)options(java.parameters ="-Xmx600m")# get the remote file and copy it to a temporary directory internally handled by Rf<-"https://s3.amazonaws.com/happiness-report/2013/Chapter-2_online-appendix_9-5-13_final.pdf"# manual interactivity selection# appropriate page will appear in the RStudio viewer# point and drag to locate the areas coordinates# see details in screenshot for interactive table extraction# https://docs.ropensci.org/tabulapdf/articles/tabulapdf.html#interactive-table-extractionpage1<-locate_areas(f, pages =1)[[1]]page2_5<-locate_areas(f, pages =2)[[1]]page6<-locate_areas(f, pages =6)[[1]]## store areas coordinates of WHR 2013 PDF data ## into "/data/whr/2013-coord" created at @cnj-create-whr-folderpb_save_data_file("whr/2013-coord", page1, "page1.rds")pb_save_data_file("whr/2013-coord", page2_5, "page2_5.rds")pb_save_data_file("whr/2013-coord", page6, "page6.rds")
(For this R code chunk is no output available)
R Code 3.4 : Tidy 2013 WHR Data
Run the code just once manually. It will restore the coordinates of the table data for the WHR 2013 PDF, tidy the dataset and save the result as R data object in .rds format.
Code
page1 <- base::readRDS("data/whr/2013-coord/page1.rds")page2_5 <- base::readRDS("data/whr/2013-coord/page2_5.rds")page6 <- base::readRDS("data/whr/2013-coord/page6.rds")table1 <-extract_tables( f,pages =1, guess =FALSE, col_names =FALSE,area =list(page1))table2_5 <-extract_tables( f,pages =c(2, 3, 4, 5), guess =FALSE, col_names =FALSE,area =list(page2_5))table6 <-extract_tables( f,pages =6, guess =FALSE, col_names =FALSE,area =list(page6))whr_raw_2013 <- dplyr::bind_rows(table1[[1]], table2_5[[1]], table2_5[[2]], table2_5[[3]], table2_5[[4]], table6[[1]])column_names =c("Country", "Region", "Ladder", "Social support","Freedom", "Corruption", "Donation", "Generosity","Positive affect", "Negative affect", "Happiness (Yesterday)","GDP per capita", "Healthy life expectancy")whr_raw_2013 <- whr_raw_2013 |> dplyr::rename_with(~column_names, dplyr::everything()) |>whr_raw_2013[17, 1] <-"Bosnia and Herzegovina"whr_raw_2013[27, 1] <-"Central African Republic"whr_raw_2013[34, 1] <-"Congo (Brazzaville)"whr_raw_2013[43, 1] <-"Dominican Republic"whr_raw_2013[146, 1] <-"Trinidad and Tobago"whr_raw_2013[154, 1] <-"United Arab Emirates"## missing data (data is in wrong previous NA row)## the error already appears in the original PDF ## (see: page 5, second last line, column 6 from the right)whr_raw_2013[154, 6] <-0.355whr_raw_2013 <-na.omit(whr_raw_2013)pb_save_data_file("whr/raw", whr_raw_2013, "whr_raw_2013.rds")
(For this R code chunk is no output available)
3.2 Clean data
3.2.1 General Procedure
Procedure 3.1 : Clean Data
Load raw data file
Select only the columns with country names and ladder respectively happiness score. (Listing / Output 3.2)
Rename the two columns to country, s_<year>. (“s” stands for score.) (Listing / Output 3.2)
Create third column r_<year> with the calculated rank. (“r” stands for rank) (Listing / Output 3.2)
Detect country names that are not a standard name. (You can see an example with the year 2024 in Listing / Output 3.1)
Clean country names according to the unifying classification schema of country names. (Listing / Output 3.2)
Run the code just once manually. It will download and save the World Bank country classification Excel file from the World Bank website, do some data cleaning and store the resulting file as an R object (.rds-format).
It turned out that there are well-being datasets for “North Cyprus” and “Somaliland Region”. As both regions are not officially accepted as countries and therefore not listed by the World Bank I have added them to the country data file.
Including “Somaliland Region” and “Norther Cyprus” there 220 different country names. I will match the country names of the happiness data with this reference list. whenever there are difference I will adapt the hwr country names.
3.2.3 Compare country names
The following code chunk is an example. It compares the WHR data of 2024 with the World Bank country names. The result are country names that do not fit into the World Bank classification. I have to change these names in the WHR data. This is done in
R Code 3.6 : Compare country names 2024
Listing / Output 3.1: Compare country names from the 2024 WHR data with the World Bank list of standardized country names
Code
country_names<-base::readRDS("data/country-names/countries_only.rds")names_2024<-base::readRDS("data/whr/raw/whr_raw_2024.rds")|>dplyr::select(1)country_2024<-dplyr::full_join(country_names,names_2024, by =dplyr::join_by(Country==`Country name`))|>dplyr::slice(221:dplyr::n())country_2024
#> # A tibble: 17 × 1
#> Country
#> <chr>
#> 1 Taiwan Province of China
#> 2 Slovakia
#> 3 South Korea
#> 4 Russia
#> 5 Kyrgyzstan
#> 6 Venezuela
#> 7 Hong Kong S.A.R. of China
#> 8 Congo (Brazzaville)
#> 9 Laos
#> 10 Ivory Coast
#> 11 Turkiye
#> 12 Iran
#> 13 State of Palestine
#> 14 Gambia
#> 15 Egypt
#> 16 Yemen
#> 17 Congo (Kinshasa)
3.2.4 Prepare WHR data for analysis
Inspecting the datasets it turned out that there is some variety in the number of rows (observed countries), number of columns (variables) and column names. I am interested only in the country column and the “ladder score” (sometimes “happiness score” and in 2012 & 2013 just “ladder”).
But for my later functions to create ladder score and ranks time series I need the same order of columns. The concrete name is not important because that can be changed in one line. My preferred order is:
first column: country (or similar name)
second column: score (ladder, happiness score or similar )
Inspecting all raw data files manually I learned with only four exceptions the two columns I need to select are in the first (= country) and second (= score) position. The exceptions are
R Code 3.7 : Function: Clean and prepare WHR data for the comparative analysis
Listing / Output 3.2: Select and rename columns, calculate ranks, clean country names and save result.
Code
prepare_whr_data<-function(year, first, second){## definitionsdf<-base::paste0("data/whr/raw/whr_raw_", year, ".rds")s_year<-paste0("s_", year)# happiness scoresr_year<-paste0("r_", year)# ranksdf2<-base::readRDS(df)|>dplyr::select(tidyselect::all_of(c(first, second)))|>dplyr::mutate(r_year =base::as.integer(dplyr::row_number()))|>dplyr::rename_with(.fn =~c("country", s_year, r_year))|>dplyr::mutate(country =gsub("\\*", "", country))|>## correct country namesdplyr::mutate(country =dplyr::case_when(country=="Czech Republic"~"Czechia",country=="Congo (Kinshasa)"~"Congo, Dem. Rep.",country=="Congo (Brazzaville)"~"Congo, Rep.",country=="Congo"~"Congo, Rep.",country=="Ivory Coast"~"Côte d’Ivoire",country=="Egypt"~"Egypt, Arab Rep.",country=="Eswatini, Kingdom of"~"Eswatini",country=="Swaziland"~"Eswatini",country=="Gambia"~"Gambia, The",country=="Hong Kong S.A.R. of China"~"Hong Kong SAR, China",country=="Hong Kong S.A.R., China"~"Hong Kong SAR, China",country=="Hong Kong"~"Hong Kong SAR, China",country=="Iran"~"Iran, Islamic Rep.",country=="South Korea"~"Korea, Rep.",country=="Kyrgyzstan"~"Kyrgyz Republic",country=="Laos"~"Lao PDR",country=="North Cyprus"~"Northern Cyprus",country=="Macedonia"~"North Macedonia",country=="Russia"~"Russian Federation",country=="Slovakia"~"Slovak Republic",country=="Somaliland region"~"Somaliland Region",country=="Somaliland"~"Somaliland Region",country=="Syria"~"Syrian Arab Republic",country=="Taiwan Province of China"~"Taiwan, China",country=="Taiwan"~"Taiwan, China",country=="Trinidad & Tobago"~"Trinidad and Tobago",country=="Turkiye"~"Türkiye",country=="Turkey"~"Türkiye",country=="Venezuela"~"Venezuela, RB",country=="State of Palestine"~"West Bank and Gaza",country=="Palestinian Territories"~"West Bank and Gaza",country=="Palestine"~"West Bank and Gaza",country=="Yemen"~"Yemen, Rep.",TRUE~country))|>dplyr::filter(!(country=="xx"|country==is.na(country)))|>## sort countries alphabeticallydplyr::arrange(country)## save resulting data filepb_save_data_file("whr/clean", df2, base::paste0("whr_clean_", year, ".rds"))}
(For this R code chunk is no output available)
R Code 3.8 : Call prepare-whr-data() with all WHR files
Listing / Output 3.3: Call the function in Listing / Output 3.2 with the year of the data file and the position of the country and happiness score column.
Run the code just once manually. It will call the function in Listing / Output 3.2 to select and rename columns, calculate ranks, clean country names and save result.
Code
prepare_whr_data("2024", 1, 2)prepare_whr_data("2023", 1, 2)prepare_whr_data("2022", 2, 3)prepare_whr_data("2021", 1, 3)prepare_whr_data("2020", 1, 3)prepare_whr_data("2019", 1, 2)prepare_whr_data("2018", 1, 2)prepare_whr_data("2017", 1, 2)prepare_whr_data("2016", 1, 2)prepare_whr_data("2015", 2, 4)prepare_whr_data("2013", 1, 2)prepare_whr_data("2012", 1, 2)tbl3<-tibble::tibble(id =letters[1:3], x =9:11)%>%dplyr::mutate( y =x+1, z =x*x, v =y+z, lag =dplyr::lag(x, default =x[[1]]), sin =sin(x), mean =mean(v), var =var(x))tbl3tbl4<-tbl3|>dplyr::mutate(dplyr::across(tidyselect::where(is.integer), ~formattable::digits(.x, 1)),dplyr::across(tidyselect::where(is.numeric)&!tidyselect::where(is.integer), ~formattable::digits(.x, 3)))tbl4
3.3 Join data
We have now prepared the data for every year separately and can now join them to a single tibble.
R Code 3.9 : Join score and rank data from all years
For sorting ranks for a certain year click the happiness score value s_ of the appropriate year twice.
Code
whr_join_score<-dplyr::full_join(base::readRDS("data/whr/clean/whr_clean_2024.rds"),base::readRDS("data/whr/clean/whr_clean_2023.rds"), by ="country")|>dplyr::full_join(base::readRDS("data/whr/clean/whr_clean_2022.rds"), by ="country")|>dplyr::full_join(base::readRDS("data/whr/clean/whr_clean_2021.rds"), by ="country")|>dplyr::full_join(base::readRDS("data/whr/clean/whr_clean_2020.rds"), by ="country")|>dplyr::full_join(base::readRDS("data/whr/clean/whr_clean_2019.rds"), by ="country")|>dplyr::full_join(base::readRDS("data/whr/clean/whr_clean_2018.rds"), by ="country")|>dplyr::full_join(base::readRDS("data/whr/clean/whr_clean_2017.rds"), by ="country")|>dplyr::full_join(base::readRDS("data/whr/clean/whr_clean_2016.rds"), by ="country")|>dplyr::full_join(base::readRDS("data/whr/clean/whr_clean_2015.rds"), by ="country")|>dplyr::full_join(base::readRDS("data/whr/clean/whr_clean_2013.rds"), by ="country")|>dplyr::full_join(base::readRDS("data/whr/clean/whr_clean_2012.rds"), by ="country")|>dplyr::arrange(country)DT::datatable(whr_join_score, extensions ='FixedColumns', options =list( dom ='Blfrtip', scrollX =TRUE, fixedColumns =TRUE, pageLength =10, lengthMenu =c(5, 10, 20, 50, 100, 200)), rownames =FALSE)|>DT::formatRound(columns =c(2,4,6,8,10,12,14,16,18,20), digits =3)# DT::datatable(whr_join_score,# extensions = 'FixedColumns',# options = list(# dom = 't',# scrollX = TRUE,# fixedColumns = TRUE# ),# rownames = FALSE# ) |> # DT::formatRound(columns = c(2,4,6,8,10,12,14,16,18,20), digits = 3)pb_save_data_file("whr/analysis", whr_join_score, "whr_join_score.rds")
Helliwell, John F., Richard Layard, Jeffrey D. Sachs, Jan-Emmanuel De-Neve, Jara B Aknin, and Shun Wang. 2024. “WHR 2024: Statistical Appendix for Chapter 2.”https://worldhappiness.report/.
Nilsson, August Håkan, Johannes C. Eichstaedt, Tim Lomas, Andrew Schwartz, and Oscar Kjell. 2024. “The Cantril Ladder Elicits Thoughts about Power and Wealth.”Scientific Reports 14 (1): 2642. https://doi.org/10.1038/s41598-024-52939-y.
---execute: cache: true---# WHR Data {#sec-whr-data}```{r}#| label: setup#| results: hold#| include: falsebase::source(file =paste0(here::here(), "/R/helper.R"))ggplot2::theme_set(ggplot2::theme_bw())```:::::: {#obj-chapter-template}::::: my-objectives::: my-objectives-headerMy objective for this chapter:::::: my-objectives-containerIn this chapter, I will take a first take on the well-being ranking dataprovided by the different [World Happiness Reports2012-2024](https://worldhappiness.report/analysis/)[@whr-download-analysis].There are figures for all countries trajectories during the years. Thisalso includes Austria [@helliwell2024a, p.10]. My general aim is toprovide a comparison of the series of rankings for Austria with otherselected countries. I will focus on the so-called Cantril ladder ofsubjective life evaluation [@nilsson2024].As far as I can see from my first inspection, there are at least threechallenges:1. **Compatibility**: Check if all the data are compatible.2. **Completeness**: Check if the data for the time series are complete. I noticed already that there is no Excel data file for 2013. Bu there data in a PDF file. How to get these data? Another issue are the number of observed countries by year. How to get consistent rankings if the number of countries varies?3. **Visualization** Choose an appropriate visualization of the data. There are already up-to-date (2005-2023) visualization of trajectories. But these plots are visualizing the absolute value of the life evaluations country-by-country as the following example of Austria shows.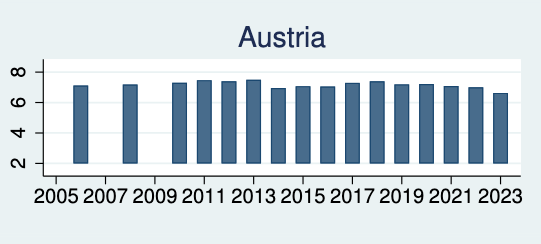{#fig-09-life-evaluation-austriafig-alt="alt-text" fig-align="center" width="80%"}@fig-09-life-evaluation-austria is a valuable figure to compare the development of the Austrian life evaluation index. But it is not useful for a comparison with other countries. Here I am thinking of two different visualizations:1. Series of several selected countries in one figure so that it facilitates a comparison. In this case I will develop a graph with different colored lines for different countries.2. With another figure I will try to capture the changes in rankings of some selected countries. The development of the absolute values of the life evaluations does not necessarily reflect the progress inside countries because they are also influenced by global developments (e.g., COVID-19).::::::::::::::## Import data### Folder and file oganizationThe first step is to find the life-evaluation data for each year and to store the files for further R processing. I will store the files in the "whr" folder inside my "data" folder. (As I do not know the chapter number for this well-being chapter, I am not going to use my traditional format "chapXX" ("XX" standing for the chapter number) but just "whr" as folder name.)The `pb_create_folder()` function in the following code chunk checks if the folder already exists. If this is the case it leaves it untouched, otherwise it creates the folder at the desired path. The code for my private functions are in the file `helper.R` inside the `R` folder at root level of this working directory.:::::{.my-resource}:::{.my-resource-header}:::::: {#lem-folder-structure}: File Organization for WHR files:::::::::::::{.my-resource-container}I will organize the many files into several subfolders:- **/data/**: main folder for all data files related this project- **/data/whr/**: files related to the analysis of the the World Happiness Reports- **/data/whr/excel/**: untouched original Excel files resp. the one PDF for the 2013 report (to prevent possible link rot at the original source)- **/data/whr/rds/**: R objects of the original data of the Excel files- **/data/whr/analysis/**: changed or created R objects during the analysis process- **/data/whr/2013-coord/** R object containing page coordinates of the 2013 PDF file:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-create-whr-folder}: Create folders for data files of the World Happiness Reports:::::::::::::{.my-r-code-container}```{r}#| label: create-whr-folders#| code-fold: showpb_create_folder(base::paste0(here::here(), "/data/"))pb_create_folder(base::paste0(here::here(), "/data/whr"))pb_create_folder(base::paste0(here::here(), "/data/whr/excel"))pb_create_folder(base::paste0(here::here(), "/data/whr/rds"))pb_create_folder(base::paste0(here::here(), "/data/whr/raw"))pb_create_folder(base::paste0(here::here(), "/data/whr/clean"))pb_create_folder(base::paste0(here::here(), "/data/whr/analysis"))pb_create_folder(base::paste0(here::here(), "/data/whr/2013-coord"))pb_create_folder(base::paste0(here::here(), "/data/country-names"))```(*For this R code chunk is no output available*)::::::::::::::::::### Download and save WHR dataThe next code chunks combines two actions for each year:1. At first I had to get the URL manually. Starting from the [WHR-Analysis website](https://worldhappiness.report/analysis/) I had to open each year and to look for the "Appendices & data" link. There I had to look for a data file.2. After downloading all data file as Excel files I had to inspect them manually to find the sheet with the Cantril ladder data. I had to note the sheet number for the appropriate download. (Default is sheet 1). Additionally I had to note the file format "xls" or "xlsx" for each year to call the correct function `readxl::read_xls` or `readxl::read_xlsx`. (I refrained from the format guessing with the more general `readxl::read_exel()` function.) Furthermore I had to skip the first three comment lines in the 2015 dataset.I am using the utility package [downloader](https://cran.r-project.org/web/packages/downloader/index.html) by Winston Chang because it provides a wrapper for the `utils::download.file()` function with the advantage that the download procedure works on Windows, Mac OS X, and other Unix-like platforms.After the download I converted the Excel file to an R data object `.rds` and stored this raw data into the folder "data/whr/raw" with the syntax "whr_raw_<year>".:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-download-whr-data}: Download Data for the World Happiness Reports (WHR):::::::::::::{.my-r-code-container}**Run the code just once manually**. It will download the data from the World Happiness Report (WHR) website for every year where data are available.```{r}#| label: download-whr-data#| eval: false## 2024 #########################################downloader::download(url ="https://happiness-report.s3.amazonaws.com/2024/DataForFigure2.1+with+sub+bars+2024.xls",destfile = base::paste0(here::here(), "/data/whr/excel/WHR-2024.xls"))whr_raw_2024 <- readxl::read_xls(base::paste0(here::here(), "/data/whr/excel/WHR-2024.xls"))pb_save_data_file("whr/raw", whr_raw_2024, "whr_raw_2024.rds")## 2023 #########################################downloader::download(url ="https://happiness-report.s3.amazonaws.com/2023/DataForFigure2.1WHR2023.xls",destfile = base::paste0(here::here(), "/data/whr/excel/WHR-2023.xls"))whr_raw_2023 <- readxl::read_xls(base::paste0(here::here(), "/data/whr/excel/WHR-2023.xls"))pb_save_data_file("whr/raw", whr_raw_2023, "whr_raw_2023.rds")## 2022 #########################################downloader::download(url ="https://happiness-report.s3.amazonaws.com/2022/Appendix_2_Data_for_Figure_2.1.xls",destfile = base::paste0(here::here(), "/data/whr/excel/WHR-2022.xls"))whr_raw_2022 <- readxl::read_xls(base::paste0(here::here(), "/data/whr/excel/WHR-2022.xls"))pb_save_data_file("whr/raw", whr_raw_2022, "whr_raw_2022.rds")## 2021 #########################################downloader::download(url ="https://happiness-report.s3.amazonaws.com/2021/DataForFigure2.1WHR2021C2.xls",destfile = base::paste0(here::here(), "/data/whr/excel/WHR-2021.xls"))whr_raw_2021 <- readxl::read_xls(base::paste0(here::here(), "/data/whr/excel/WHR-2021.xls"))pb_save_data_file("whr/raw", whr_raw_2021, "whr_raw_2021.rds")# 2020 #########################################downloader::download(url ="https://happiness-report.s3.amazonaws.com/2020/WHR20_DataForFigure2.1.xls",destfile = base::paste0(here::here(), "/data/whr/excel/WHR-2020.xls"))whr_raw_2020 <- readxl::read_xls(base::paste0(here::here(), "/data/whr/excel/WHR-2020.xls"))pb_save_data_file("whr/raw", whr_raw_2020, "whr_raw_2020.rds")# 2019 #########################################downloader::download(url ="https://s3.amazonaws.com/happiness-report/2019/Chapter2OnlineData.xls",destfile = base::paste0(here::here(), "/data/whr/excel/WHR-2019.xls"))whr_raw_2019 <- readxl::read_xls(path = base::paste0(here::here(), "/data/whr/excel/WHR-2019.xls"), sheet =2)pb_save_data_file("whr/raw", whr_raw_2019, "whr_raw_2019.rds")# 2018 #########################################downloader::download(url ="https://s3.amazonaws.com/happiness-report/2018/WHR2018Chapter2OnlineData.xls",destfile = base::paste0(here::here(), "/data/whr/excel/WHR-2018.xls"))whr_raw_2018 <- readxl::read_xls(path = base::paste0(here::here(), "/data/whr/excel/WHR-2018.xls"), sheet =2)pb_save_data_file("whr/raw", whr_raw_2018, "whr_raw_2018.rds")# 2017 #########################################downloader::download(url ="https://s3.amazonaws.com/happiness-report/2017/online-data-chapter-2-whr-2017.xlsx",destfile = base::paste0(here::here(), "/data/whr/excel/WHR-2017.xlsx"))whr_raw_2017 <- readxl::read_xlsx(path = base::paste0(here::here(), "/data/whr/excel/WHR-2017.xlsx"), sheet =3)pb_save_data_file("whr/raw", whr_raw_2017, "whr_raw_2017.rds")# 2016 #########################################downloader::download(url ="https://s3.amazonaws.com/happiness-report/2016/Online-data-for-chapter-2-whr-2016.xlsx",destfile = base::paste0(here::here(), "/data/whr/excel/WHR-2015.xlsx"))whr_raw_2016 <- readxl::read_xlsx(path = base::paste0(here::here(), "/data/whr/excel/WHR-2016.xlsx"), sheet =3)pb_save_data_file("whr/raw", whr_raw_2016, "whr_raw_2016.rds")# 2015 #########################################downloader::download(url ="https://s3.amazonaws.com/happiness-report/2015/Chapter2OnlineData_Expanded-with-Trust-and-Governance.xlsx",destfile = base::paste0(here::here(), "/data/whr/excel/WHR-2015.xlsx"))whr_raw_2015 <- readxl::read_xlsx(path = base::paste0(here::here(), "/data/whr/excel/WHR-2015.xlsx"), sheet =2,skip =3)pb_save_data_file("whr/raw", whr_raw_2015, "whr_raw_2015.rds")## 2014 missing ######################################### 2013 data in PDF #################################### store PDF file locally to prevent link rottingdownloader::download(url ="https://s3.amazonaws.com/happiness-report/2013/Chapter-2_online-appendix_9-5-13_final.pdf",destfile = base::paste0(here::here(), "/data/whr/excel/WHR-PDF-2013.pdf"))## whr_raw_2013 will be generated and saved in the next section. # 2012 #########################################downloader::download(url ="https://happiness-report.s3.amazonaws.com/2012/2012.xlsx",destfile = base::paste0(here::here(), "/data/whr/excel/WHR-2012.xlsx"))whr_raw_2012 <- readxl::read_xlsx(path = base::paste0(here::here(), "/data/whr/excel/WHR-2012.xlsx"), sheet =2)pb_save_data_file("whr/raw", whr_raw_2012, "whr_raw_2012.rds")```(*For this R code chunk is no output available*):::::::::### Extract 2013 WHR Data from PDFData for the [World Happiness Report 2013](https://worldhappiness.report/ed/2013/#appendices-and-data) are not available in Excel format, unlike data from the other reports. Instead, the data are provided as a PDF file. (See also the second question of the [Frequently Asked Question](https://s3.amazonaws.com/happiness-report/2013/WHR-2013_FAQs_final.pdf))This section extracts data I am interested in --- the survey measure of SWB (Subjective Well-being) from the Gallup World Poll (GWP) --- with the help of the `tabulapdf` package.At first, I had to look for an appropriate R package because the one I had already used ([tabulizer](https://cran.r-project.org/web/packages/tabulizer/index.html)) was removed from CRAN. I found several packages for extracting PDF text (e.g., [pdftools](https://docs.ropensci.org/pdftools/), [PDE](https://cran.r-project.org/web/packages/PDE/vignettes/PDE.html), [PDFR](https://github.com/AllanCameron/PDFR)), but only [tabulapdf](https://docs.ropensci.org/tabulapdf/) is specialized in extracting table data.I read the [introductory vignette](https://docs.ropensci.org/tabulapdf/articles/tabulapdf.html) completely because only in the final section I found a solution for my specific PDF. To understand the descriptions of the problems I had to master have a look at [Chapter 2 Appendix](https://s3.amazonaws.com/happiness-report/2013/Chapter-2_online-appendix_9-5-13_final.pdf). We need the cantril ladder data presented in "Table A2. National Averages in 2010-12". To extract the data I had to overcome three separate problems:1. Table A2 spans over several pages (1-6).2. On page 6 starts already the next table "Table A3. National Averages in 2005-07" which has to be excluded.3. Pages 2-6 do not have column names.4. Some of the column names in page 1 span two linesThe difficulties 1 and 2 arise because `tabulapdf` works page-oriented. Difficulty 3 originates from a faulty table design in the PDF. Difficulty 4 is a common problem that can be solved by setting the `col_names` argument to `FALSE`.The solution I found is an [interactive table extraction](https://docs.ropensci.org/tabulapdf/articles/tabulapdf.html#interactive-table-extraction) for each page with the `tabulapdf::locate_area()` function and to select only the figures without columns names as demonstrated in the [use case section](https://docs.ropensci.org/tabulapdf/articles/tabulapdf.html#use-case-covid-19-treatments-in-italy) of the vignette.Tidying the dataset for WHR 2013 includes to join country names if the span two lines into one column name and to delete the empty lines consisting of just NA's. Note also that there is a data entry error in the original PDF (see: page 5, second last line, column 6 from the right) that has to be corrected.:::::{.my-code-collection}:::{.my-code-collection-header}:::::: {#exm-extract-whr-table-data-2013}: Extract WHR 2013 Table Data from PDF and Tidy Data:::::::::::::{.my-code-collection-container}::: {.panel-tabset}###### Extract:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-extract-pdf-table}: Extract 2013 Table Data from PDF:::::::::::::{.my-r-code-container}**Run the code just once manually**. It will download the WHR 2013 PDF, generate interactively the table coordinates and save them for further processing.```{r}#| label: extract-pdf-table#| eval: falselibrary(tabulapdf)# set Java memory limit to 600 MB (optional)options(java.parameters ="-Xmx600m")# get the remote file and copy it to a temporary directory internally handled by Rf <-"https://s3.amazonaws.com/happiness-report/2013/Chapter-2_online-appendix_9-5-13_final.pdf"# manual interactivity selection# appropriate page will appear in the RStudio viewer# point and drag to locate the areas coordinates# see details in screenshot for interactive table extraction# https://docs.ropensci.org/tabulapdf/articles/tabulapdf.html#interactive-table-extractionpage1 <-locate_areas(f, pages =1)[[1]]page2_5 <-locate_areas(f, pages =2)[[1]]page6 <-locate_areas(f, pages =6)[[1]]## store areas coordinates of WHR 2013 PDF data ## into "/data/whr/2013-coord" created at @cnj-create-whr-folderpb_save_data_file("whr/2013-coord", page1, "page1.rds")pb_save_data_file("whr/2013-coord", page2_5, "page2_5.rds")pb_save_data_file("whr/2013-coord", page6, "page6.rds")```(*For this R code chunk is no output available*):::::::::###### Tidy PDF Data:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-tidy-pdf-data}: Tidy 2013 WHR Data:::::::::::::{.my-r-code-container}**Run the code just once manually**. It will restore the coordinates of the table data for the WHR 2013 PDF, tidy the dataset and save the result as R data object in `.rds` format.```{r}#| label: tidy-pdf-data#| eval: falsepage1 <- base::readRDS("data/whr/2013-coord/page1.rds")page2_5 <- base::readRDS("data/whr/2013-coord/page2_5.rds")page6 <- base::readRDS("data/whr/2013-coord/page6.rds")table1 <-extract_tables( f,pages =1, guess =FALSE, col_names =FALSE,area =list(page1))table2_5 <-extract_tables( f,pages =c(2, 3, 4, 5), guess =FALSE, col_names =FALSE,area =list(page2_5))table6 <-extract_tables( f,pages =6, guess =FALSE, col_names =FALSE,area =list(page6))whr_raw_2013 <- dplyr::bind_rows(table1[[1]], table2_5[[1]], table2_5[[2]], table2_5[[3]], table2_5[[4]], table6[[1]])column_names =c("Country", "Region", "Ladder", "Social support","Freedom", "Corruption", "Donation", "Generosity","Positive affect", "Negative affect", "Happiness (Yesterday)","GDP per capita", "Healthy life expectancy")whr_raw_2013 <- whr_raw_2013 |> dplyr::rename_with(~column_names, dplyr::everything()) |>whr_raw_2013[17, 1] <-"Bosnia and Herzegovina"whr_raw_2013[27, 1] <-"Central African Republic"whr_raw_2013[34, 1] <-"Congo (Brazzaville)"whr_raw_2013[43, 1] <-"Dominican Republic"whr_raw_2013[146, 1] <-"Trinidad and Tobago"whr_raw_2013[154, 1] <-"United Arab Emirates"## missing data (data is in wrong previous NA row)## the error already appears in the original PDF ## (see: page 5, second last line, column 6 from the right)whr_raw_2013[154, 6] <-0.355whr_raw_2013 <-na.omit(whr_raw_2013)pb_save_data_file("whr/raw", whr_raw_2013, "whr_raw_2013.rds")```(*For this R code chunk is no output available*):::::::::::::::::::::***## Clean data### General Procedure:::::{.my-procedure}:::{.my-procedure-header}:::::: {#prp-clean-data}: Clean Data:::::::::::::{.my-procedure-container}1. Load raw data file2. Select only the columns with country names and ladder respectively happiness score. (@lst-prepare-whr-data)3. Rename the two columns to `country`, `s_<year>`. ("s" stands for score.) (@lst-prepare-whr-data)4. Create third column `r_<year>` with the calculated rank. ("r" stands for rank) (@lst-prepare-whr-data)5. Detect country names that are not a standard name. (You can see an example with the year 2024 in @lst-compare-country-names-2024)5. Clean country names according to the unifying classification schema of country names. (@lst-prepare-whr-data)6. Sort data by country name. (@lst-prepare-whr-data)7. Save data file under the folder "data/whr/clean" with the name pattern `whr_clean_<year>`.lst-call-prepare-whr-data:::::::::### Load and store country classification schemaThere are different classifications schemes for country names: The most detailed one is the [Geoschema of the United Nations](https://unstats.un.org/unsd/methodology/m49/). I do not need this complex system and will apply the [classification of the World Bank](https://datahelpdesk.worldbank.org/knowledgebase/articles/906519).:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-country-names}: Get file for official country names:::::::::::::{.my-r-code-container}**Run the code just once manually**. It will download and save the World Bank country classification Excel file from the World Bank website, do some data cleaning and store the resulting file as an R object (`.rds`-format).```{r}#| label: get-file-for-country-names#| code-fold: show#| eval: falsedownloader::download(url ="https://datacatalogfiles.worldbank.org/ddh-published/0037712/DR0090755/CLASS.xlsx",destfile = base::paste0(here::here(), "/data/country-names/country-class_world_bank.xlsx"))country_class <- readxl::read_xlsx(base::paste0(here::here(), "/data/country-names/country-class_world_bank.xlsx")) pb_save_data_file("country-names", country_class, "country_class.rds")countries_only <- country_class |> dplyr::select(Economy) |> dplyr::rename(Country = Economy) |> dplyr::slice_head(n =218) |> tibble::add_row(Country ="Northen Cyprus") |> tibble::add_row(Country ="Somaliland Region") |> dplyr::arrange(Country)pb_save_data_file("country-names", countries_only, "countries_only.rds")```(*For this R code chunk is no output available*):::::::::::: {.callout-warning}It turned out that there are well-being datasets for "North Cyprus" and "Somaliland Region". As both regions are not officially accepted as countries and therefore not listed by the World Bank I have added them to the country data file.See more details about these two regions:**Somalia vs. Somaliland**- [Somaliland - Wikipedia](https://en.wikipedia.org/wiki/Somaliland)- [Somalia/Somaliland: the differences and issues explained | ActionAid UK](https://www.actionaid.org.uk/about-us/where-we-work/somaliland/somalia-somaliland-differences-explained)- [Somaliland vs Somalia | Republic of Somaliland](https://www.republicofsomaliland.com/somaliland-vs-somalia)**Cyprus vs. Northern Cyprus**- [Northern Cyprus - Wikipedia](https://en.wikipedia.org/wiki/Northern_Cyprus)- [The Turkish Republic of Northern Cyprus-The Status of the two Communities in Cyprus (10 July 1990) Prof. Elihu Lauterpacht, C.B.E., Q.C. / Republic of Türkiye Ministry of Foreign Affairs](https://www.mfa.gov.tr/chapter2.en.mfa)- [An Island Divided: Next Steps for Troubled Cyprus | Crisis Group](https://www.crisisgroup.org/europe-central-asia/western-europemediterranean/cyprus/268-island-divided-next-steps-troubled-cyprus):::Including "Somaliland Region" and "Norther Cyprus" there 220 different country names. I will match the country names of the happiness data with this reference list. whenever there are difference I will adapt the `hwr` country names.### Compare country namesThe following code chunk is an example. It compares the WHR data of 2024 with the World Bank country names. The result are country names that do not fit into the World Bank classification. I have to change these names in the WHR data. This is done in :::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-compare-country-names-2024}: Compare country names 2024:::::::::::::{.my-r-code-container}::: {#lst-compare-country-names-2024}```{r}#| label: compare-country-names-2024country_names <- base::readRDS("data/country-names/countries_only.rds")names_2024 <- base::readRDS("data/whr/raw/whr_raw_2024.rds") |> dplyr::select(1)country_2024 <- dplyr::full_join( country_names, names_2024,by = dplyr::join_by(Country ==`Country name`) ) |> dplyr::slice(221:dplyr::n())country_2024```Compare country names from the 2024 WHR data with the World Bank list of standardized country names::::::::::::### Prepare WHR data for analysis {#sec-whr-data-preparation}Inspecting the datasets it turned out that there is some variety in the number of rows (observed countries), number of columns (variables) and column names. I am interested only in the country column and the "ladder score" (sometimes "happiness score" and in 2012 & 2013 just "ladder").But for my later functions to create ladder score and ranks time series I need the same order of columns. The concrete name is not important because that can be changed in one line. My preferred order is:- first column: country (or similar name)- second column: score (ladder, happiness score or similar )Inspecting all raw data files manually I learned with only four exceptions the two columns I need to select are in the first (= country) and second (= score) position. The exceptions are- **2022**: Position 2 and 3- **2021**: Position 1 and 3- **2020**: Position 1 and 3- **2015**: Position 2 and 4::: {.my-code-collection}:::: {.my-code-collection-header}::::: {.my-code-collection-icon}::::::::::: {#exm-ID}::::::::::::::{.my-code-collection-container}::: {.panel-tabset}###### Preparing data (function):::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-select-columns}: Function: Clean and prepare WHR data for the comparative analysis:::::::::::::{.my-r-code-container}::: {#lst-prepare-whr-data}```{r}#| label: prepare-whr-data#| code-fold: showprepare_whr_data <-function(year, first, second) {## definitions df <- base::paste0("data/whr/raw/whr_raw_", year, ".rds") s_year <-paste0("s_", year) # happiness scores r_year <-paste0("r_", year) # ranks df2 <- base::readRDS(df) |> dplyr::select(tidyselect::all_of(c(first, second))) |> dplyr::mutate(r_year = base::as.integer(dplyr::row_number())) |> dplyr::rename_with(.fn =~c("country", s_year, r_year)) |> dplyr::mutate(country =gsub("\\*", "", country)) |>## correct country names dplyr::mutate(country = dplyr::case_when( country =="Czech Republic"~"Czechia", country =="Congo (Kinshasa)"~"Congo, Dem. Rep.", country =="Congo (Brazzaville)"~"Congo, Rep.", country =="Congo"~"Congo, Rep.", country =="Ivory Coast"~"Côte d’Ivoire", country =="Egypt"~"Egypt, Arab Rep.", country =="Eswatini, Kingdom of"~"Eswatini", country =="Swaziland"~"Eswatini", country =="Gambia"~"Gambia, The", country =="Hong Kong S.A.R. of China"~"Hong Kong SAR, China", country =="Hong Kong S.A.R., China"~"Hong Kong SAR, China", country =="Hong Kong"~"Hong Kong SAR, China", country =="Iran"~"Iran, Islamic Rep.", country =="South Korea"~"Korea, Rep.", country =="Kyrgyzstan"~"Kyrgyz Republic", country =="Laos"~"Lao PDR", country =="North Cyprus"~"Northern Cyprus", country =="Macedonia"~"North Macedonia", country =="Russia"~"Russian Federation", country =="Slovakia"~"Slovak Republic", country =="Somaliland region"~"Somaliland Region", country =="Somaliland"~"Somaliland Region", country =="Syria"~"Syrian Arab Republic", country =="Taiwan Province of China"~"Taiwan, China", country =="Taiwan"~"Taiwan, China", country =="Trinidad & Tobago"~"Trinidad and Tobago", country =="Turkiye"~"Türkiye", country =="Turkey"~"Türkiye", country =="Venezuela"~"Venezuela, RB", country =="State of Palestine"~"West Bank and Gaza", country =="Palestinian Territories"~"West Bank and Gaza", country =="Palestine"~"West Bank and Gaza", country =="Yemen"~"Yemen, Rep.",TRUE~ country)) |> dplyr::filter(!(country =="xx"| country ==is.na(country))) |>## sort countries alphabetically dplyr::arrange(country)## save resulting data filepb_save_data_file("whr/clean", df2, base::paste0("whr_clean_", year, ".rds"))}```Select and rename columns, calculate ranks, clean country names and save result.:::(*For this R code chunk is no output available*):::::::::###### Preparing data (call to function):::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-call-prepare-whr-data}: Call `prepare-whr-data()` with all WHR files:::::::::::::{.my-r-code-container}::: {#lst-call-prepare-whr-data}**Run the code just once manually**. It will call the function in @lst-prepare-whr-data to select and rename columns, calculate ranks, clean country names and save result.```{r}#| label: call-prepare-whr-data#| code-fold: show#| eval: falseprepare_whr_data("2024", 1, 2)prepare_whr_data("2023", 1, 2)prepare_whr_data("2022", 2, 3)prepare_whr_data("2021", 1, 3)prepare_whr_data("2020", 1, 3)prepare_whr_data("2019", 1, 2)prepare_whr_data("2018", 1, 2)prepare_whr_data("2017", 1, 2)prepare_whr_data("2016", 1, 2)prepare_whr_data("2015", 2, 4)prepare_whr_data("2013", 1, 2)prepare_whr_data("2012", 1, 2)tbl3 <- tibble::tibble(id = letters[1:3], x =9:11) %>% dplyr::mutate(y = x +1,z = x * x,v = y + z,lag = dplyr::lag(x, default = x[[1]]),sin =sin(x),mean =mean(v),var =var(x) )tbl3tbl4 <- tbl3 |> dplyr::mutate( dplyr::across(tidyselect::where(is.integer), ~ formattable::digits(.x, 1)), dplyr::across(tidyselect::where(is.numeric) &!tidyselect::where(is.integer), ~ formattable::digits(.x, 3)) )tbl4```Call the function in @lst-prepare-whr-data with the year of the data file and the position of the country and happiness score column.::::::::::::::::::::::::## Join dataWe have now prepared the data for every year separately and can now join them to a single tibble.:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-join-ladder-data-clean}: Join score and rank data from all years:::::::::::::{.my-r-code-container}For sorting ranks for a certain year click the happiness score value `s_` of the appropriate year **twice**.```{r}#| label: join-data#| results: holdwhr_join_score <- dplyr::full_join( base::readRDS("data/whr/clean/whr_clean_2024.rds"), base::readRDS("data/whr/clean/whr_clean_2023.rds"), by ="country") |> dplyr::full_join(base::readRDS("data/whr/clean/whr_clean_2022.rds"), by ="country") |> dplyr::full_join(base::readRDS("data/whr/clean/whr_clean_2021.rds"), by ="country") |> dplyr::full_join(base::readRDS("data/whr/clean/whr_clean_2020.rds"), by ="country") |> dplyr::full_join(base::readRDS("data/whr/clean/whr_clean_2019.rds"), by ="country") |> dplyr::full_join(base::readRDS("data/whr/clean/whr_clean_2018.rds"), by ="country") |> dplyr::full_join(base::readRDS("data/whr/clean/whr_clean_2017.rds"), by ="country") |> dplyr::full_join(base::readRDS("data/whr/clean/whr_clean_2016.rds"), by ="country") |> dplyr::full_join(base::readRDS("data/whr/clean/whr_clean_2015.rds"), by ="country") |> dplyr::full_join(base::readRDS("data/whr/clean/whr_clean_2013.rds"), by ="country") |> dplyr::full_join(base::readRDS("data/whr/clean/whr_clean_2012.rds"), by ="country") |> dplyr::arrange(country) DT::datatable(whr_join_score, extensions ='FixedColumns',options =list(dom ='Blfrtip',scrollX =TRUE,fixedColumns =TRUE,pageLength =10, lengthMenu =c(5, 10, 20, 50, 100, 200) ),rownames =FALSE ) |> DT::formatRound(columns =c(2,4,6,8,10,12,14,16,18,20), digits =3)# DT::datatable(whr_join_score,# extensions = 'FixedColumns',# options = list(# dom = 't',# scrollX = TRUE,# fixedColumns = TRUE# ),# rownames = FALSE# ) |> # DT::formatRound(columns = c(2,4,6,8,10,12,14,16,18,20), digits = 3)pb_save_data_file("whr/analysis", whr_join_score, "whr_join_score.rds")```:::::::::
