Capítulo 4 Analises descritivas
Antes de qualquer análise estatística é fundamental realizar uma boa análise exploratória dos seus dados. Fazemos isso por meio de análises descritivas, que consistem em criar tabelas de frequências, gráficos e medidas de resumo. Nos tópicos a seguir mostraremos como realizar esse tipo de análise no R/RStudio. O R possui alguns bancos de dados já carregados. Informações sobre eles podem ser obtidas usando a função help(nome do banco). Usaremos o banco “airquality” para exemplificar a aplicação das funções que serão apresentadas a seguir. Esse banco de dados traz informações sobre a qualidade do ar em Nova York durante um período do ano de 1973.
4.1 Tabelas de frequência
A frequência absoluta de uma observação é o número de vezes em que tal observação apareceu na amostra. Uma tabela de frequências contém as informações a respeito das frequências dos diferentes níveis de uma variável. Tomando como base o banco de dados “airquality”, imagine que você esteja interessado em analisar apenas a temperatura da região no período observado. Seria interessante obter uma tabela de frequência para essa variável. Para isso usamos o comando table. Veja:
##
## 56 57 58 59 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82
## 1 3 2 2 3 2 1 2 2 3 4 4 3 1 3 3 5 4 4 9 7 6 6 5 11 9
## 83 84 85 86 87 88 89 90 91 92 93 94 96 97
## 4 5 5 7 5 3 2 3 2 5 3 2 1 1Perceba que para cada valor de temperatura (em Fahrenheit), a tabela mostra em quantos dias essa foi a temperatura média. Caso estejamos interessados na frequência relativa temos duas opções: a primeira é simplesmente dividir o resultado pelo total de pacientes e a segunda é usar a função prop.table. Perceba que o cifrão usado entre o nome do banco de dados e o nome da variável é responsável por filtrar apenas as observações da variável em questão, ou seja, só foram usados os dados sobre o temperatura na execução da função. Veja abaixo o código com as duas opções:
#Opção 1:
Tab = table(airquality$Temp) #salva a tabela em Tab
Total = sum(Tab) #soma os valores da tabela
Tab/Total #frequência absoluta dividido pelo total é igual à frequência relativa##
## 56 57 58 59 61 62
## 0.006535948 0.019607843 0.013071895 0.013071895 0.019607843 0.013071895
## 63 64 65 66 67 68
## 0.006535948 0.013071895 0.013071895 0.019607843 0.026143791 0.026143791
## 69 70 71 72 73 74
## 0.019607843 0.006535948 0.019607843 0.019607843 0.032679739 0.026143791
## 75 76 77 78 79 80
## 0.026143791 0.058823529 0.045751634 0.039215686 0.039215686 0.032679739
## 81 82 83 84 85 86
## 0.071895425 0.058823529 0.026143791 0.032679739 0.032679739 0.045751634
## 87 88 89 90 91 92
## 0.032679739 0.019607843 0.013071895 0.019607843 0.013071895 0.032679739
## 93 94 96 97
## 0.019607843 0.013071895 0.006535948 0.006535948## [1] 0.005622692 0.006042296 0.006210138 0.005203088 0.004699564 0.005538771
## [7] 0.005454851 0.004951326 0.005119168 0.005790534 0.006210138 0.005790534
## [13] 0.005538771 0.005706613 0.004867405 0.005370930 0.005538771 0.004783484
## [19] 0.005706613 0.005203088 0.004951326 0.006126217 0.005119168 0.005119168
## [25] 0.004783484 0.004867405 0.004783484 0.005622692 0.006797583 0.006629742
## [31] 0.006377979 0.006545821 0.006210138 0.005622692 0.007049345 0.007133266
## [37] 0.006629742 0.006881504 0.007301108 0.007552870 0.007301108 0.007804632
## [43] 0.007720712 0.006881504 0.006713662 0.006629742 0.006461900 0.006042296
## [49] 0.005454851 0.006126217 0.006377979 0.006461900 0.006377979 0.006377979
## [55] 0.006377979 0.006294058 0.006545821 0.006126217 0.006713662 0.006461900
## [61] 0.006965425 0.007049345 0.007133266 0.006797583 0.007049345 0.006965425
## [67] 0.006965425 0.007385029 0.007720712 0.007720712 0.007468949 0.006881504
## [73] 0.006126217 0.006797583 0.007636791 0.006713662 0.006797583 0.006881504
## [79] 0.007049345 0.007301108 0.007133266 0.006210138 0.006797583 0.006881504
## [85] 0.007217187 0.007133266 0.006881504 0.007217187 0.007385029 0.007217187
## [91] 0.006965425 0.006797583 0.006797583 0.006797583 0.006881504 0.007217187
## [97] 0.007133266 0.007301108 0.007468949 0.007552870 0.007552870 0.007720712
## [103] 0.007217187 0.007217187 0.006881504 0.006713662 0.006629742 0.006461900
## [109] 0.006629742 0.006377979 0.006545821 0.006545821 0.006461900 0.006042296
## [115] 0.006294058 0.006629742 0.006797583 0.007217187 0.007385029 0.008140316
## [121] 0.007888553 0.008056395 0.007888553 0.007636791 0.007720712 0.007804632
## [127] 0.007804632 0.007301108 0.007049345 0.006713662 0.006545821 0.006294058
## [133] 0.006126217 0.006797583 0.006377979 0.006461900 0.005958375 0.005958375
## [139] 0.006545821 0.005622692 0.006377979 0.005706613 0.006881504 0.005370930
## [145] 0.005958375 0.006797583 0.005790534 0.005287009 0.005874455 0.006461900
## [151] 0.006294058 0.006377979 0.005706613Experimente executar o código acima para treinar. Note que todo o texto escrito após o # será desconsiderado pelo R. Isso ocorre pois o texto é considerado apenas como um comentário, uma maneira de lembrar o que foi feito no momento em que você criou o script. Também podemos criar uma tabela de contingência, que registra a frequência de observações de 2 ou mais variáveis categóricas. Fazemos isso novamente utilizando o comando table. Suponha que você esteja interessado em verificar se existe uma associação entre a temperatura e o mês do ano. Para isso, basta colocar as duas variáveis como argumento da função table. Observe:
##
## 5 6 7 8 9
## 56 1 0 0 0 0
## 57 3 0 0 0 0
## 58 2 0 0 0 0
## 59 2 0 0 0 0
## 61 3 0 0 0 0
## 62 2 0 0 0 0
## 63 0 0 0 0 1
## 64 1 0 0 0 1
## 65 1 1 0 0 0
## 66 3 0 0 0 0
## 67 2 1 0 0 1
## 68 2 0 0 0 2
## 69 2 0 0 0 1
## 70 0 0 0 0 1
## 71 0 0 0 0 3
## 72 1 1 0 1 0
## 73 1 2 1 0 1
## 74 2 1 1 0 0
## 75 0 1 0 1 2
## 76 1 4 0 1 3
## 77 0 3 0 2 2
## 78 0 2 0 2 2
## 79 1 2 0 3 0
## 80 0 2 1 1 1
## 81 1 0 5 3 2
## 82 0 2 4 2 1
## 83 0 1 3 0 0
## 84 0 1 3 0 1
## 85 0 1 3 1 0
## 86 0 0 3 4 0
## 87 0 2 1 1 1
## 88 0 0 2 1 0
## 89 0 0 1 1 0
## 90 0 1 0 2 0
## 91 0 0 1 0 1
## 92 0 1 2 1 1
## 93 0 1 0 0 2
## 94 0 0 0 2 0
## 96 0 0 0 1 0
## 97 0 0 0 1 0Para cada coluna (mês) temos a frequência absoluta das temperaturas. Observe que nos meses mais frios a frequência é concentrada majoritariamente nos valores mais baixos de temperatura, enquanto nos meses mais quentes ocorre o contrário. Tambem podemos analisar a tabela com as frequências relativas:
##
## 5 6 7 8 9
## 56 0.03225806 0.00000000 0.00000000 0.00000000 0.00000000
## 57 0.09677419 0.00000000 0.00000000 0.00000000 0.00000000
## 58 0.06451613 0.00000000 0.00000000 0.00000000 0.00000000
## 59 0.06451613 0.00000000 0.00000000 0.00000000 0.00000000
## 61 0.09677419 0.00000000 0.00000000 0.00000000 0.00000000
## 62 0.06451613 0.00000000 0.00000000 0.00000000 0.00000000
## 63 0.00000000 0.00000000 0.00000000 0.00000000 0.03333333
## 64 0.03225806 0.00000000 0.00000000 0.00000000 0.03333333
## 65 0.03225806 0.03333333 0.00000000 0.00000000 0.00000000
## 66 0.09677419 0.00000000 0.00000000 0.00000000 0.00000000
## 67 0.06451613 0.03333333 0.00000000 0.00000000 0.03333333
## 68 0.06451613 0.00000000 0.00000000 0.00000000 0.06666667
## 69 0.06451613 0.00000000 0.00000000 0.00000000 0.03333333
## 70 0.00000000 0.00000000 0.00000000 0.00000000 0.03333333
## 71 0.00000000 0.00000000 0.00000000 0.00000000 0.10000000
## 72 0.03225806 0.03333333 0.00000000 0.03225806 0.00000000
## 73 0.03225806 0.06666667 0.03225806 0.00000000 0.03333333
## 74 0.06451613 0.03333333 0.03225806 0.00000000 0.00000000
## 75 0.00000000 0.03333333 0.00000000 0.03225806 0.06666667
## 76 0.03225806 0.13333333 0.00000000 0.03225806 0.10000000
## 77 0.00000000 0.10000000 0.00000000 0.06451613 0.06666667
## 78 0.00000000 0.06666667 0.00000000 0.06451613 0.06666667
## 79 0.03225806 0.06666667 0.00000000 0.09677419 0.00000000
## 80 0.00000000 0.06666667 0.03225806 0.03225806 0.03333333
## 81 0.03225806 0.00000000 0.16129032 0.09677419 0.06666667
## 82 0.00000000 0.06666667 0.12903226 0.06451613 0.03333333
## 83 0.00000000 0.03333333 0.09677419 0.00000000 0.00000000
## 84 0.00000000 0.03333333 0.09677419 0.00000000 0.03333333
## 85 0.00000000 0.03333333 0.09677419 0.03225806 0.00000000
## 86 0.00000000 0.00000000 0.09677419 0.12903226 0.00000000
## 87 0.00000000 0.06666667 0.03225806 0.03225806 0.03333333
## 88 0.00000000 0.00000000 0.06451613 0.03225806 0.00000000
## 89 0.00000000 0.00000000 0.03225806 0.03225806 0.00000000
## 90 0.00000000 0.03333333 0.00000000 0.06451613 0.00000000
## 91 0.00000000 0.00000000 0.03225806 0.00000000 0.03333333
## 92 0.00000000 0.03333333 0.06451613 0.03225806 0.03333333
## 93 0.00000000 0.03333333 0.00000000 0.00000000 0.06666667
## 94 0.00000000 0.00000000 0.00000000 0.06451613 0.00000000
## 96 0.00000000 0.00000000 0.00000000 0.03225806 0.00000000
## 97 0.00000000 0.00000000 0.00000000 0.03225806 0.00000000O argumento margin = 2 indica que a proporção deve somar 100% em cada coluna, ou seja, dado um determinado mês, qual a chance de ocorrer cada valor de temperatura. Se você indicar margin = 1, o total de 100% será obtido em cada linha e caso esse argumento não seja informado a proporção será distribuída em toda tabela.
4.1.0.1 No R Commander:
Primeiro você deve assegurar que as variáveis são do tipo fator, que é como o R interpreta as variáveis categóricas. Para isso vá em:
Dados -> Modificação de variáveis no conjunto de dados -> Converter variável numérica para fator Irá surgir uma janela onde você deve selecionar a variável que deseja converter e pode optar por definir o nome das categorias ou usar números, caso a variável desejada não apareça na lista significa que o R já reconheceu que essa variável é categórica. Após informar ao R que a variável é categórica vá em:
Estatísticas -> Resumos-> Distribuições de frequência
ou Estatísticas -> Tabelas de Contingência -> Tabela de dupla entrada. Note que a aba “Estatísticas” permite configurar como você deseja calcular as frequências relativas.
4.1.1 Tabelas de Frequência para variáveis contínuas
Em algumas situações, como quando estiver trabalhando com variáveis númericas, será necessário contar o número de observações que estão dentro de um intervalo. No caso do banco de dados utilizado, por exemplo, seria mais visual trabalhar com um intervalo de valores do que com valores separados. Para isso, terá que categorizar a variável em questão e depois colocar os valores em uma tabela de frequência. Para categorizar uma variável contínua no R, você pode usar o comando cut, os argumentos dessa função são as observações, um argumento chamado breaks, em que se armazenam os limites dos intervalos e o argumento labels, que são os nomes que os elementos receberão. Confira:
categorizada <- cut(airquality$Temp, breaks = c(55,70,84,97),
labels = c("56-70","70-84","84-97"))
#Aplicando a tabela, temos:
table(categorizada)## categorizada
## 56-70 70-84 84-97
## 33 81 39##
## categorizada 5 6 7 8 9
## 56-70 24 2 0 0 7
## 70-84 7 22 18 16 18
## 84-97 0 6 13 15 5Perceba que o gráfico de contingência utilizando valores agrupados ficou muito mais visual nesse caso.
4.1.1.1 No R Commander:
Para categorizar uma variável numérica no R Commander é necessário ir em:
Dados > Modificação de variáveis no conjunto de dados... > agrupar em classes uma variável numérica (para criar fator)... na janela que abrirá é possível escolher a variável que deseja categorizar, o nome da nova variável, o número de classes e como elas serão separadas e posteriormente o nome de cada classe. Após a categorização, para tabelar as frequências basta seguir o passo a passo anterior com a nova variável criada.
4.2 Medidas de Resumo
As medidas de resumo são algumas informações que nos ajudam a resumir importantes características da amostra em um único valor. No decorrer da seção será mostrado como calcular tais medidas no R e suas respectivas interpretações.
4.2.1 Média
A média é uma das mais conhecidas medidas de resumo. Assim como sugere o nome, ela é o valor que estima em média onde os valores da amostra se encontram. Para calculá-la, utiliza-se a seguinte fórmula:
\[\bar{x} = \frac{\sum_{i=1}^{n}x_{i}}{n}= \frac{x_{1}+x_{2}+...+x_{n}}{n} \] No R, o cálculo pode ser simplificado com a função mean, que recebe como argumento o banco de dados a ser utilizado. Veja nos exemplos as duas formas de calcular a média: Um engenheiro deseja estimar a temperatura média de um equipamento em um determinado dia. Para isso, ele coletou a seguinte amostra:
## [1] 316.5## [1] 316.5Como conclusão temos que a média do conjunto de dados Como conclusão temos que a média do conjunto de dados {323,345,297,324,289,334,320,299,310,324} é 316.5 Ou, contextualizando o exemplo, a temperatura média da máquina é de 316.5 K.
Caso pretenda avaliar a média de uma variável para diferentes grupos, é possível utilizar a função by, cujos argumentos são a varíavel de interesse, seguida da variável categórica e a função que deseja calcular.
No exemplo mostrado abaixo é possível compreender melhor. Nesse caso, queremos comparar a média de preços de uma amostra de carros novos e usados.
Essa função também pode ser aplicada em conjunto com as outras medidas de resumo que serão vistas a seguir:
## carro$condition: New
## [1] 98500
## ------------------------------------------------------------
## carro$condition: Used
## [1] 35262.59Logo, a média de preço dos carros novos é de R$ 98.500,00, enquanto que o dos usados é de R$ 35.262,59.
4.2.1.1 No R Commander
No R Commander há duas formas de obter a média. Na primeira, você pode ir em :
Estatísticas > Resumos > Resumos numéricos... e escolher a variável em questão, com isso, o software te retornará uma tabela com a média na primeira posição e , em seguida, outras medidas de resumo que serão vistas posteriormente. A segunda forma é ir em :
Estatísticas > Resumos > Tabelas de Estatísticas... selecionar Média e a variável que será utilizada como fator, bem como a variável que você tem interesse de calcular a média. Observe que dessa forma não é possível gerar uma única média para toda a amostra, apenas médias para diferentes grupos.
4.2.2 Mediana
A mediana é uma medida de tendência central cujo objetivo é mostrar o valor da amostra que é maior ou igual a pelo menos metade dos valores observados na amostra, e ao mesmo tempo, menor ou igual a pelo menos metade dessa mesma amostra. Ela também pode ser chamada de segundo quartil ou percentil 50. No R é possível utilizar o comando median que tem como argumento apenas o banco de dados em questão, ou a função quantile cujos argumentos serão, o vetor com os valores da amostra e probs que deve ser igualado a 0.5. Veja os exemplos a seguir: Um técnico anotou o tempo em dias que determinada máquina precisou de manutenção. Os dados obtidos foram 20, 26, 26, 18 e 30 dias, ele deseja calcular a mediana dessa amostra, logo, utilizou o seguinte argumento:
## [1] 26Nesse primeiro exemplo, vemos que a mediana da amostra é 26, ou seja, pelo menos 50% das observações são menores que 26 e pelo menos 50% das obeservação são maiores que 26, isto é, 26 é maior ou igual a (18, 20, 26), que corresponde a 66.7% da amostra e é menor ou igual a (26, 30), que também corresponde a 66.7% da amostra. Analisando de acordo com o contexto mostrado, temos que a mediana dos dias que o equipamento levou para precisar de manuternção é igual a 26.
Agora, considere uma fábrica que deseja avaliar o número de produtos defeituosos por lote de produção. Uma amostra de seis lotes obteve , 10, 8, 12, 14 e 7 produtos com defeito. Para calcular a mediana desses números, utilizaram-se os comandos:
## 50%
## 11Já nesse exemplo, percebe-se que a mediana é igual a 11, porque pelo menos 50% das observações são menores que 11 e pelo menos 50% das observações são maiores que 11. Perceba que 11 é a média entre 10 e 12, esse é o procedimento utilizado quando o tamanho da amostra é par.
4.2.2.1 No R Commander
Assim, como com a média, há duas formas de obter a mediana no RCommander. Na primeira, você pode ir em :
Estatísticas > Resumos > Resumos numéricos... e escolher a variável em questão, com isso, o software te retornará uma tabela e mediana será o sexto elemento da mesma. A segunda forma é ir em:
Estatísticas > Resumos > Tabelas de Estatísticas...escolher mediana e a variável de interesse, bem como uma variável como categoria, dessa forma não é possível gerar uma mediana geral da amostra.
4.2.3 Quartis
Como dito na seção anterior, a mediana também é chamada de segundo quartil, mas também existem outros dois quartis, o primeiro e terceiro, que representam respectivamente os valores que são maiores que pelo menos 25% e 75% da amostra. Para calculá-los usando o R, basta utilizar novamente o comando quantile, mas dessa vez usando o argumento probs igual a 0.25 para o primeiro quartil e 0.75 para o terceiro, mas se você não definir nenhum valor para esse argumento, função retornará uma tabela com o menor valor, o primeiro, segundo e terceiro quartil e o maior valor da amostra. Veja os exemplos a seguir:
A gerente de uma loja de carros deseja analisar a simetria das vendas nos últimos 5 mese. Veja alguns dos cálculos feitos por ela:
## 25%
## 9Ou seja o primeiro quartil da amostra é 9 ,que é maior ou igual que (8,9). Uma interpretação mais prática desse resultado é dizer que pelo menos em um quarto da amostra observada houve a venda de até 9 carros.
## 75%
## 13*Enquanto que o terceiro quartil é 13, por ser maior ou igual a (8, 9, 10, 13). Da mesma forma, pode-se interpretar que pelo menos em três quartos da amostra houve a venda de,no mínimo, 13 carros.
## 0% 25% 50% 75% 100%
## 8 9 10 13 14Como a amostra tem tamanho 5, cada percentil é representado por um elemento da amostra.
4.2.3.1 No R Commander
Para encontrar os valores do primeiro e terceiro quartis utilizando o RCommander você pode seguir os mesmos passos que os anteriores, isto é,
Estatísticas > Resumos > Resumos numéricos... e escolher a variável em questão, nesse caso, o quinto e o sétimo valores representados na tabela corresponderão ao primeiro e terceiro quartil.
4.2.4 Função Summary
Com apenas um comando é possível obter uma tabela com algumas das principais medidas de resumo, no R base isso é possível usando o comando summary, que recebe como argumento apenas o banco de dados.
A seguir é mostrado o exemplo: Suponha que uma revista tenha pegado informações sobre os carros de determiada região de Belo Horizonte. Para avaliar a tendência central e a simetria do ano do modelo dos carror da amostra observada, eles utilizaram a seguinte função:*
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 2006 2008 2012 2012 2014 2019*Avaliando os resultados percebe-se que o ano médio do modelo dos carros é igual a 2012 e que a mediana também é igual a 2012. Ao avaliar o primeiro e terceiro quartis, que foram iguais a respectivamente 2008 e 2014, em conjunto dos valores mínimos e máximos da amostra, é possível concluir que pelo menos 25% das observações da amostra são mais antigas que 2008, bem como pelo menos 25% da amostra está no intervalo [2006; 2008]. Como o intervalo entre o primeiro quartil e a mediana é maior que o intervalo entre a mediana e o terceiro quartil, há indícios de que os valores na amostra não são simétricos. A representação gráfica utilizada nesse tipo de análise é o Boxplot, em geral facilita a conclusão, o gráfico mencionado será visto posteriormente.
4.2.5 Variância e Desvio Padrão
Nessa seção discutiremos sobre Desvio Padrão e Variância. O Desvio Padrão é a distância média entre os valores observados na amostra e a média da mesma, como pode-se ver na fórmula abaixo:
\[ s = \sqrt\frac{\sum_{i=1}^{n}(x_{i}- \bar{x})^2}{n-1}= \sqrt \frac{(x_{1}- \bar{x})^2+(x_{2}- \bar{x})^2+...+(x_{n}- \bar{x})^2}{n-1}\]
Já a Variância, é o quadrado do desvio padrão, isto é,$ Var(X) = s^2$. Ambas medidas são usadas para avaliar o quanto os valores de uma amostra variam, no caso, quanto maior a variância ou o desvio, maior será a variabilidade. Lembre-se que ambas medidas só podem assumir valores positivos. Para calculá-las no R, é possível usar as funções sd e var, respectivamente para calcular desvio padrão e variância, ou, a partir de uma função é possível encontrar ambas medidas, dado as relações mostradas anteriormente. Veja:
## [1] 3.892236O desvio padrão do ano do modelo dos carros dessa região é de 3.892236 anos.
## [1] 15.1495Enquanto a variância é igual a 15.1495 anos.
## [1] 15.1495Repare que esse valor é exatamente igual ao anterior.
4.2.5.1 No R Commander
Novamente, há duas formas de obter o desvio no RCommander.
Na primeira, você pode ir em:
Estatísticas > Resumos > Resumos numéricos...e escolher a variável em questão, com isso, o software te retornará uma tabela e o desvio padrão será o segunda elemento da mesma, representado por sd.
A segunda forma é ir em:
Estatísticas > Resumos > Tabelas de Estatísticas...escolher Desvio Padrão e a variável de interesse, bem como uma variável como categoria, dessa forma não é possível gerar uma mediana geral da amostra. Se você deseja trabalhar com a variância basta colocar os resultados ao quadrado.
4.2.6 Escore Padronizado
Quando se deseja comparar dois valores de diferentes amostras, que têm médias e desvios padrões diferentes, costuma-se padronizar os valores segundo a fórmula a seguir: \[ z_{i} =\frac{ x_{i} −x} {s}\]
Dessa forma, é possível avaliar quantos desvios padrões de distância tal observação se encontra da média. No R, utiliza-se a função scale. O argumento pedido pela função é o banco de dados, e, nesse caso, todos os valores da amostra são padronizados. Observe os próximos comandos.
Em uma colheita, cinco macieiras foram escolhidas para contar o número de maçãs que cada uma gerou. Para avaliar melhor a dispersão da maior observação das demais, calculou-se seu escore padronizado.
## [1] 1.140206Assim, o valor padronizado de 44 é 1.140206. Isto é, a macieira que gerou 44 maçãs está a 1.140206 desvios da média da amostra.
## [,1]
## [1,] 1.1402056
## [2,] -0.7281985
## [3,] -0.6323829
## [4,] -0.8240141
## [5,] 1.0443900
## attr(,"scaled:center")
## [1] 20.2
## attr(,"scaled:scale")
## [1] 20.87343Observe que o valor padronizado de 44 é igual ao calculado anteriormente.
4.2.7 Coeficiente de Variação
Nas seções anteriores vimos que a variância e o desvio padrão são utilizados para avaliar a variação entre os valores de uma amostra, porém se deseja-se comparar a variação em amostras cujos elementos estão em escalas de grandezas totalmente diferentes, como por exemplo se você quiser comparar a variação no peso de um grupo formigas e a variação no peso de um grupo de elefantes, mesmo se a variação no grupo das formigas for maior, isso nunca seria identificado avaliando apenas a variância ou desvio padrão. Para isso, utilizamos o Coeficiente de Variação, que calcula o quanto a amostra varia em relação à média, sua fórmula é mostrada a seguir: \[ CV = \frac{s∗100\%} {x} \]
No R, você pode seguir a função a seguir. Vamos considerar o exemplo anterior das macieiras:
## [1] 103.3338Logo, o coeficiente de variação dessa amostra é igual a 103.3338%.
Agora vamos calcular o coeficiente de variação da quantidade de bananas geradas em uma amostra de bananeiras na mesma fazenda do exemplo anterior.
## [1] 27.18251Nesse caso, o coeficiente de variação foi igual a 27.18251, logo, podemos concluir que o número de maçãs por macieria varia mais que o número de bananas por bananeira.
4.2.7.1 No R Commander
Para calcular o Coeficiente de Variação no RCommander é preciso dar uma passo a mais em comparação às outras medidas, depois de realizar o seguinte passo a passo:
Estatísticas > Resumos > Resumos numéricos... você deve clicar em Estatísticas e selecionar Coeficiente de variação, assim, ele aparecerá na quarta posição da tabela.
4.2.8 Coeficiente de Correlação de Pearson
O Coeficiente de Correlação de Pearson é utilizado quando queremos mensurar o quanto duas variáveis estão relacionadas, ou seja, se o fato de uma das variáveis aumentar faz com que a outra aumente ou diminua. Ele é representado pela letra r, em que -1 < r < 1. Quanto maior o módulo de r, maior a correlação, que pode ser negativa ou positiva.
A fórmula do Coeficiente de Correlação de Pearson é:
\[ r= \frac{\sum_{i=1}^{n}(x_{i}- \bar{x})^2(y_{i}-{\bar{y})^2}}{{\sqrt{\sum_{i=1}^{n}(x_{i}- \bar{x})^2}}\sqrt{\sum_{i=1}^{n}(y_{i}- \bar{y})^2}}\] Que pode ser também calculado com o comando cor, cujos argumentos serão as variáveis que deseja estudar. Veja o exemplo a seguir, em que estamos avaliando a o ano e o preço dos carros:
## [1] 0.2559376Observe que o Coeficiente de Correlação está muito próxima de zero, logo, não há evidência de que as variáveis estudadas sejam correlacionadas.
4.2.8.1 No R Commander
Para calcular o Coeficiente de Correlação de Pearson no R Commander, você deve seguir as seguintes especificações:
Estatísticas > Resumos > Matriz de Correlaçãoquando a janela de escolha abrir, se atente em selecionar a segunda variável com a tecla Ctrl pressionada e de escolher o tipo de correlação “Produto-momento de Pearson”.
Deve reparar também que não será retornado um valor único, mas sim uma matriz de valores, nessa matriz os valores contidos na 2° e 3° célula, que devem ser o mesmo, representa o valor do coeficiente de correlação.
4.3 Gráficos no RStudio
O RStudio, como um software de análise de dados, nos permite fazer diversos tipos de gráficos e apresenta diversos métodos e pacotes para tal. Nesta apostila, nos focaremos em fazer gráficos no R base, sem nenhum tipo de pacote.
4.3.1 Setores.
O gráfico de setores, também conhecido como ‘pizza’, nos permite uma noção visual para a prevalência de certos fatores com relação a outros, e é adequado para variáveis categóricas (qualitativas). Para fazer um gráfico de pizza, devemos gerar uma tabela de frequência com os dados desejados e então, fazê-lo de fato. Veja o exemplo abaixo, utilizando o banco de dados “carro”, que se refere a vendas de carro na Arábia Saudita. Nele, decidimos ver quais as marcas mais vendidas por lá:
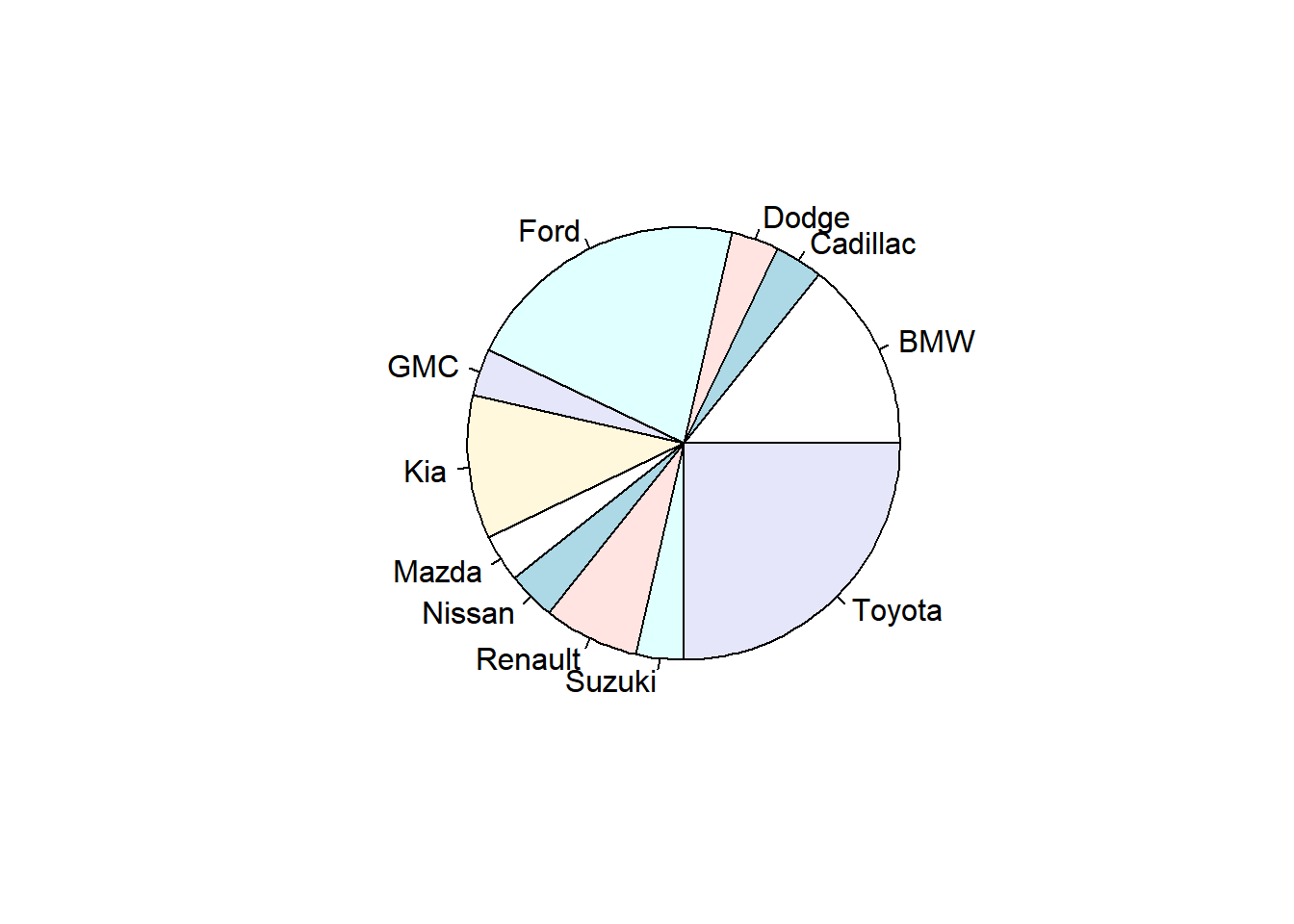
Caso desejemos mudar a cor dos setores, podemos utilizar o parâmetro “col” e colocar um vetor com as cores desejadas como argumento.
tabela <- table(carro$car_maker)
pie(tabela,col=c('slateblue1','tan3','indianred1','grey4','azure3','gray73','lightsteelblue','lightskyblue','grey96','brown','palevioletred2'))
Você também pode definir as cores a partir de uma paleta pronta:
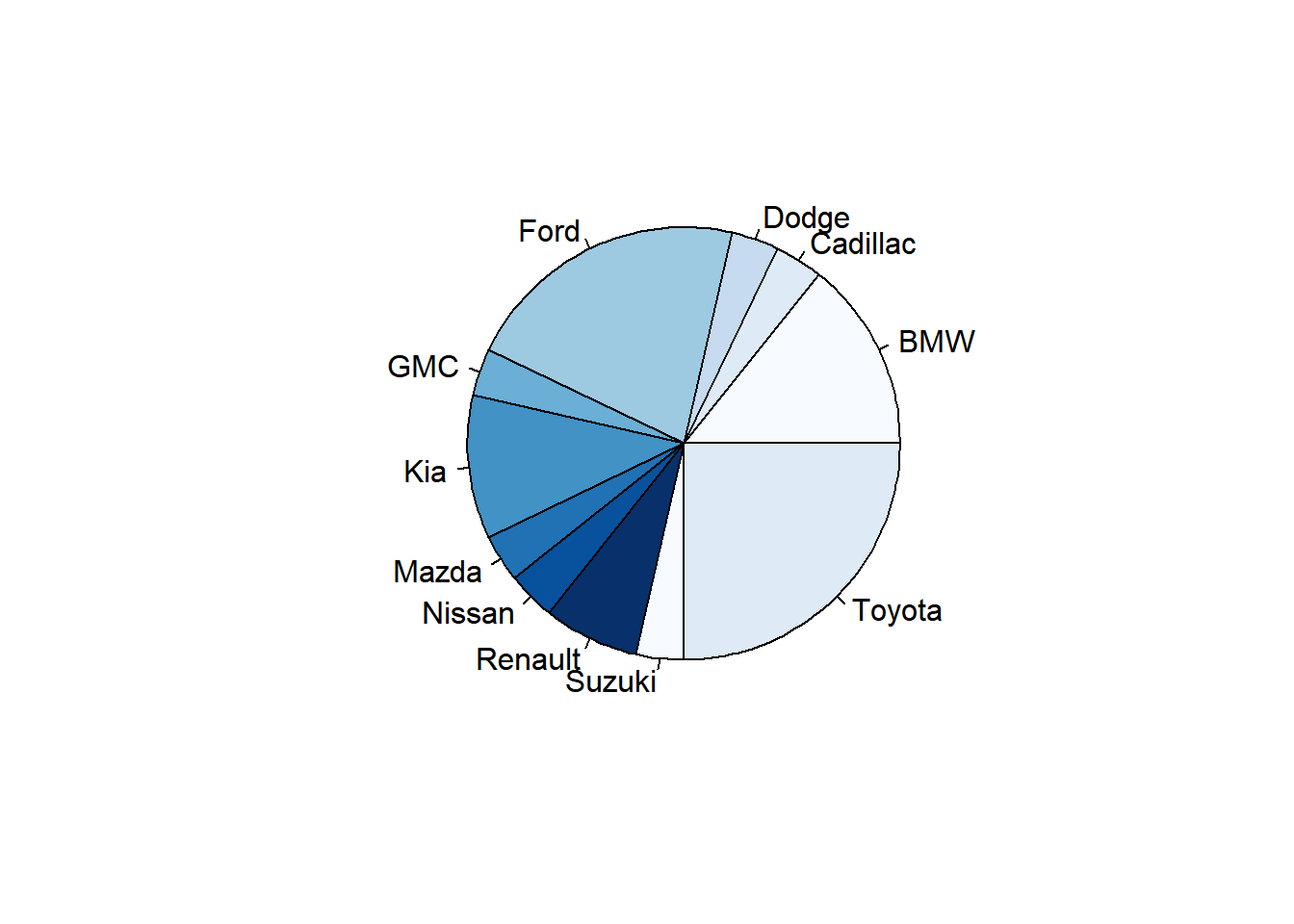
Para dar um título ao gráfico, podemos utilizar o parâmetro main e colocar, entre aspas, o título desejado.
tabela <- table(carro$car_maker)
pie(tabela,col=blues9, main="Vendas de carros na Arábia Saudita por marca")
Se desejarmos ver quantos carros são vendidos em cada classe, podemos utilizar o parâmetro labels:
tabela <- table(carro$car_maker)
pie(tabela,col=blues9, main="Vendas de carros na Arábia Saudita por marca",labels=tabela)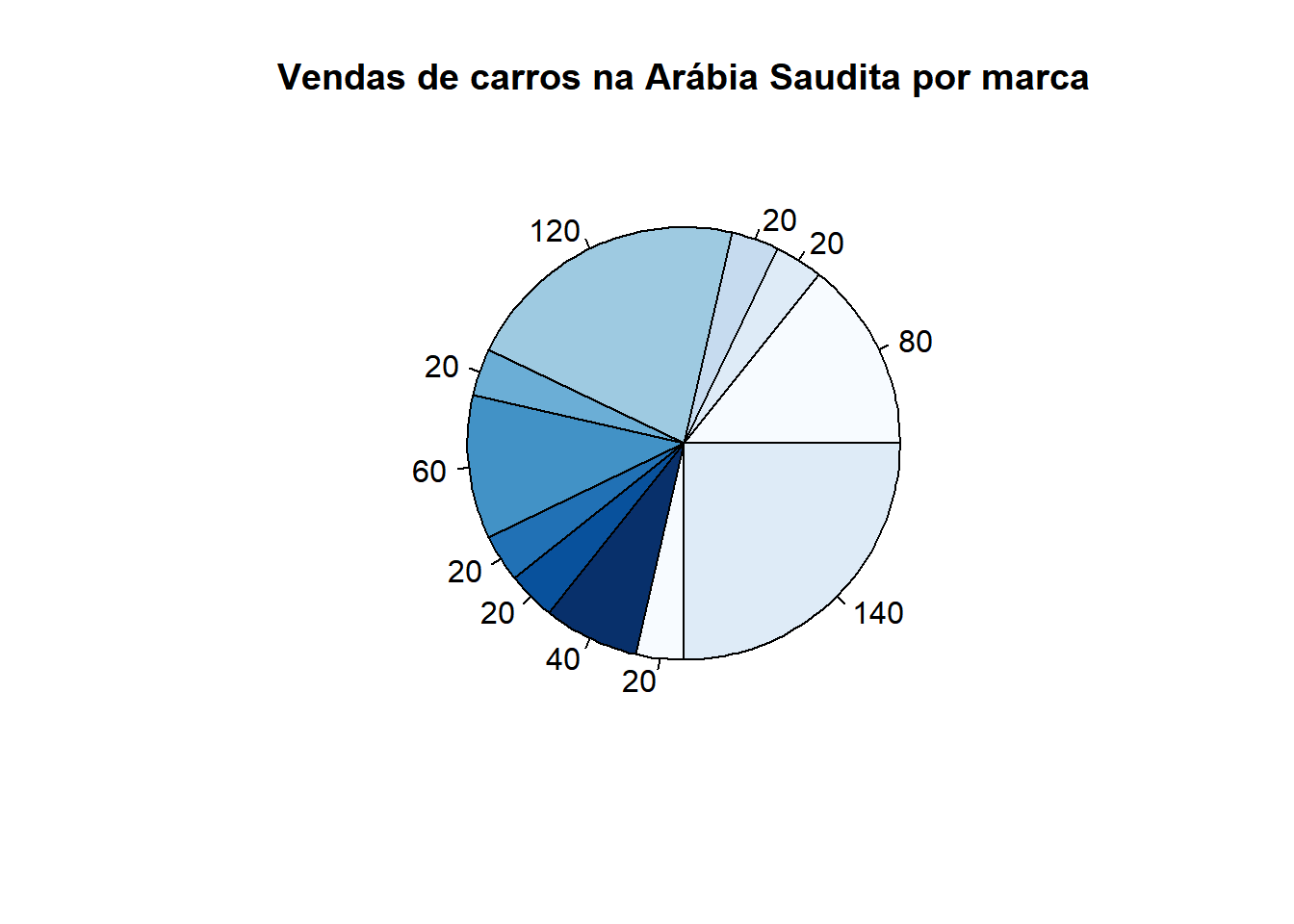
4.3.2 Barras
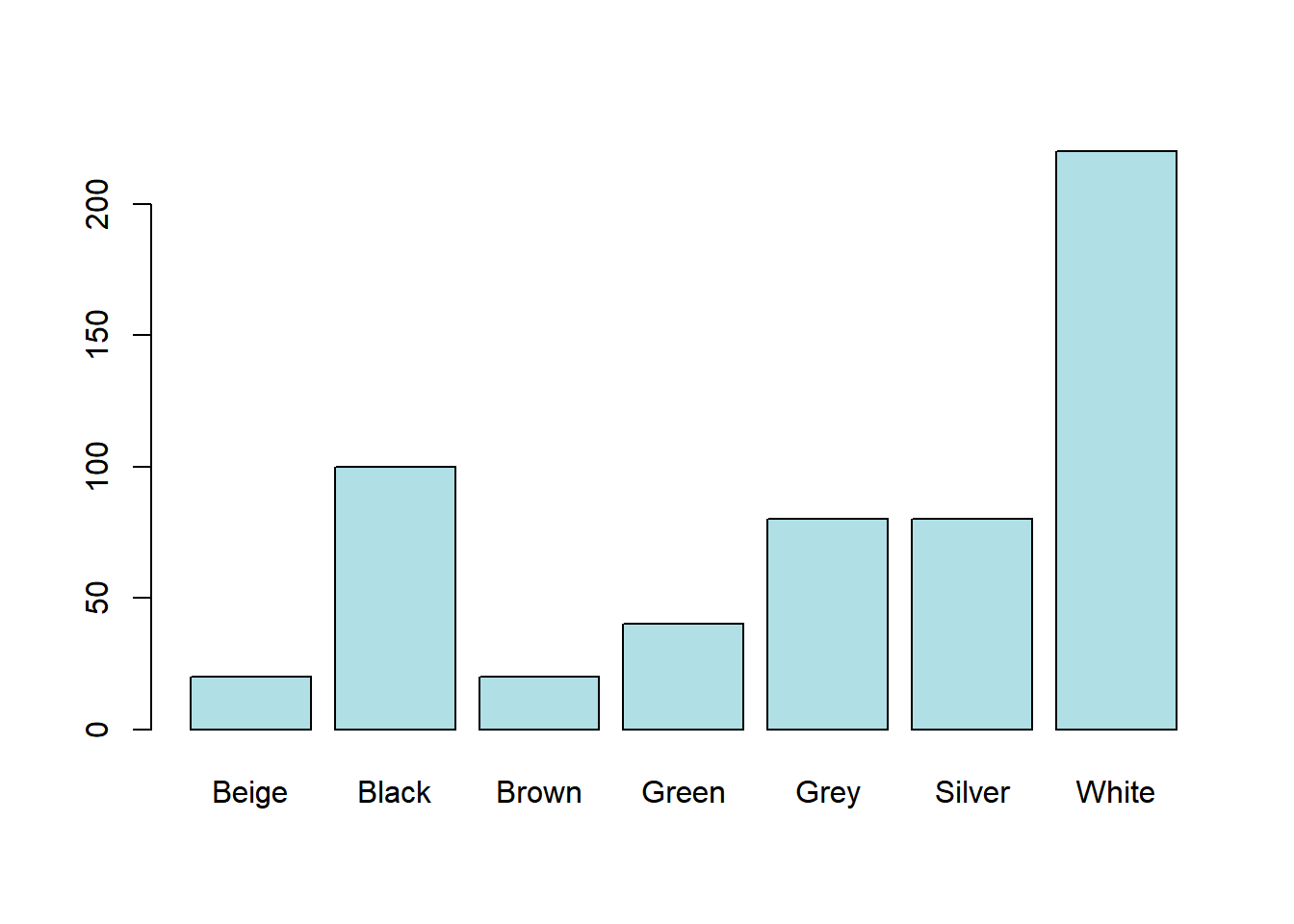
Gráficos de barras são uma boa ferramenta para visualizarmos a frequência da presença de todos os valores que certa variável assumiu. Normalmente, ele é indicado para variáveis categóricas e pode ser feito no R, a partir de uma tabela de frequência, usando o comando “barplot()” Como exemplo, usaremos o banco de dados ‘carro’, que tem como tema vendas de carro na Arábia Saudita. Decidimos avaliar quais as cores de carros mais vendidas.
Para definir a cor podemos usar o comando “col” e colocar em sequência a cor desejada entre aspas:
Caso desejemos colocar uma cor distinta para cada barra, podemos criar um vetor com uma cor para cada barra:
tabela <- table(carro$color)
barplot(tabela,col=c("beige",'grey10','tan4','forestgreen','gray20','gray75','white'))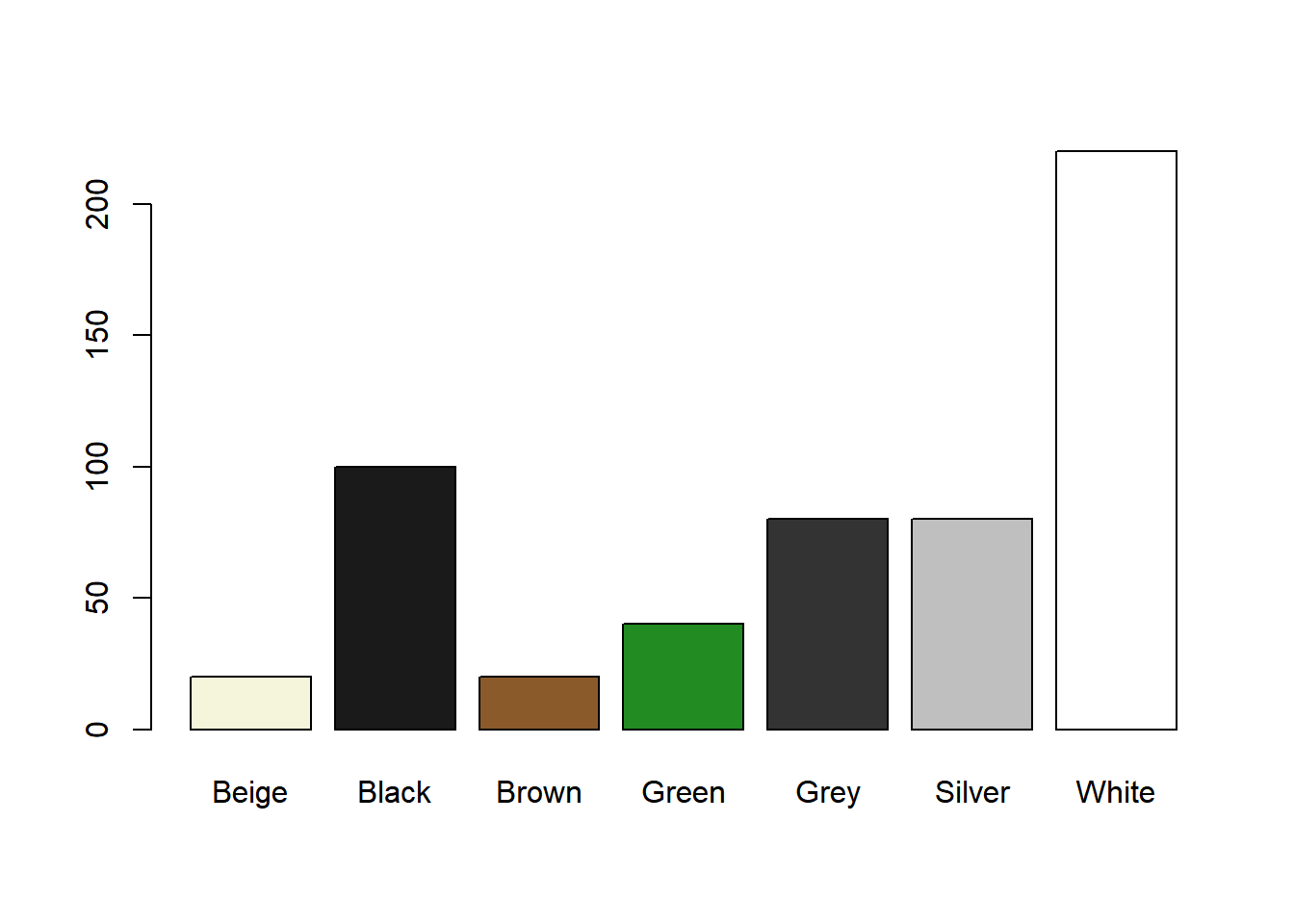
Para dar um título ao gráfico, podemos utilizar o argumento “main”:
tabela <- table(carro$color)
barplot(tabela,col=c("beige",'grey10','tan4','forestgreen','gray20','gray75','white'),main=" Cores de carro mais vendidas na Arábia Saudita")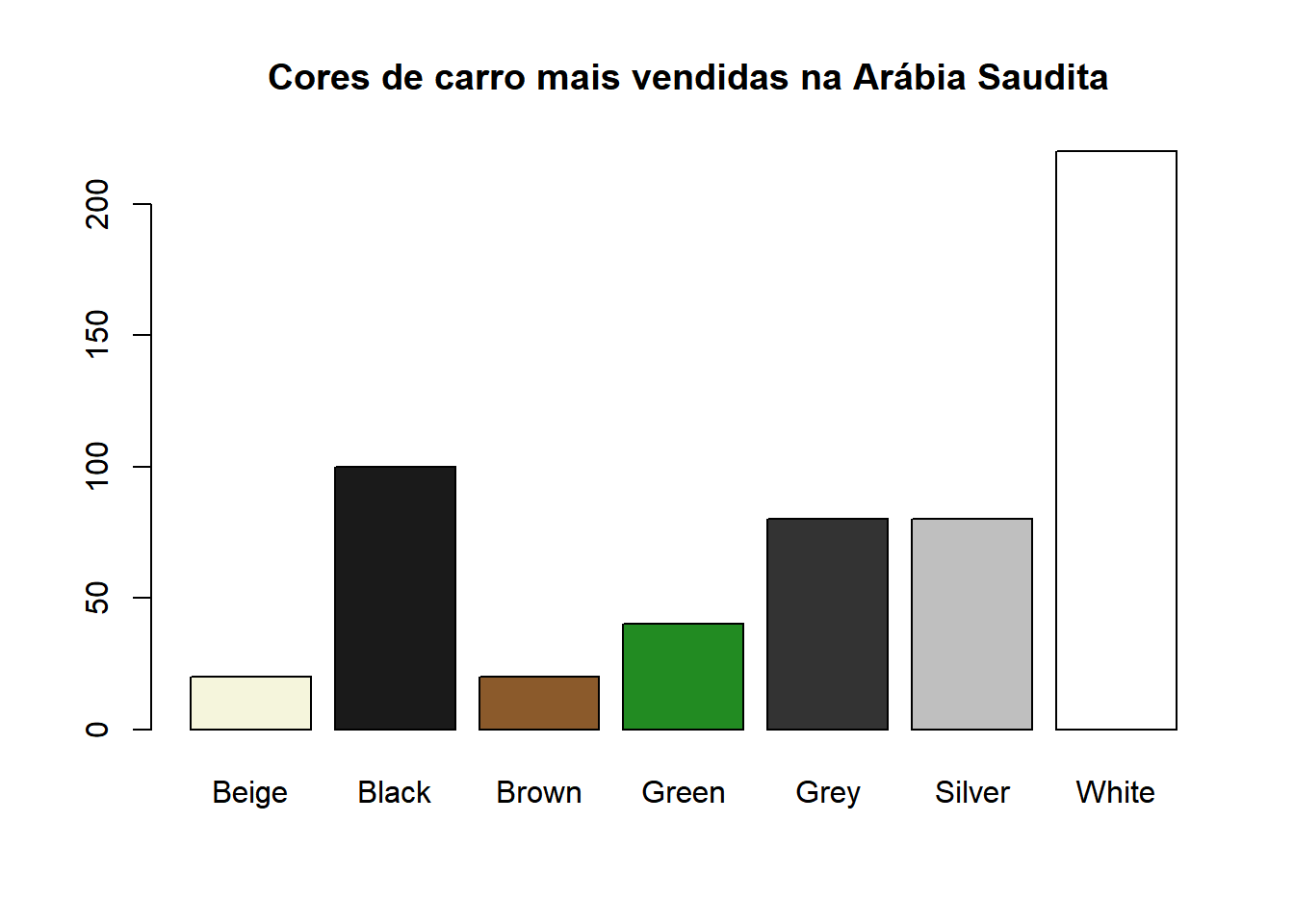
Também é possível dar nome ao eixo y e definir limites de vetor para ele (um vetor indo do mínimo ao máximo), por meio dos argumentos “ylab” e “ylim” (Obs: para fazer o mesmo no eixo x, é análogo, apenas trocando xlab e xlim por ylab e ylim)
tabela <- table(carro$color)
barplot(tabela,col=c("beige",'grey10','tan4','forestgreen','gray20','gray75','white'),main=" Cores de carro mais vendidas na Arábia Saudita",ylab='Frequência',ylim=c(0,250))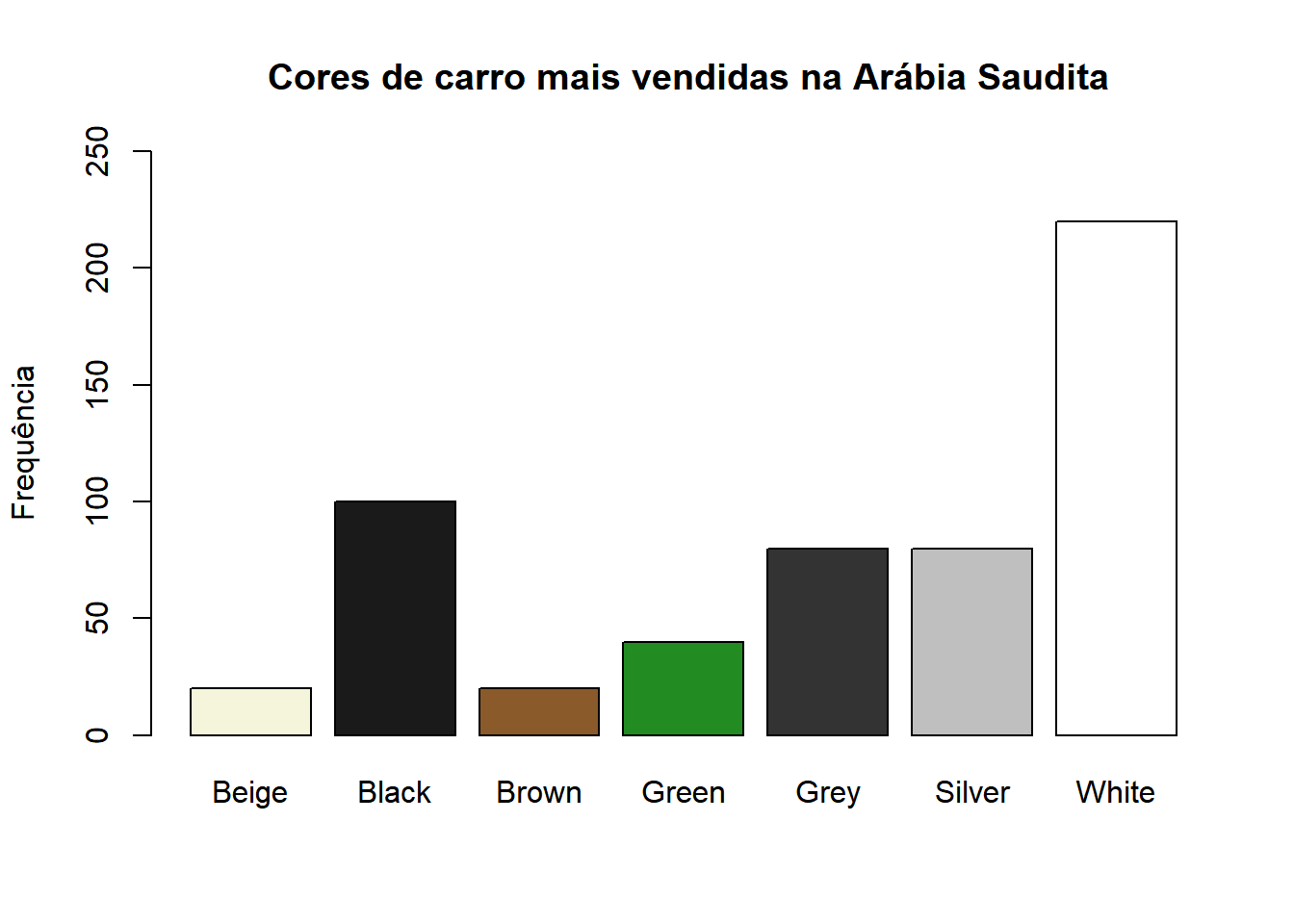
Também é possível fazer gráficos de barra para variáveis conjuntas. Por exemplo, podemos ver a frequência de cada fabricante para cada tipo de transmissão Para isso, usamos tabelas de contingência como argumento do gráfico.
tabcont <- table(carro$car_maker,carro$transmission)
barplot(tabcont,main="Marcas de carro mais vendidas na Arábia Saudita por tipo de transmissão ",ylab='Frequência')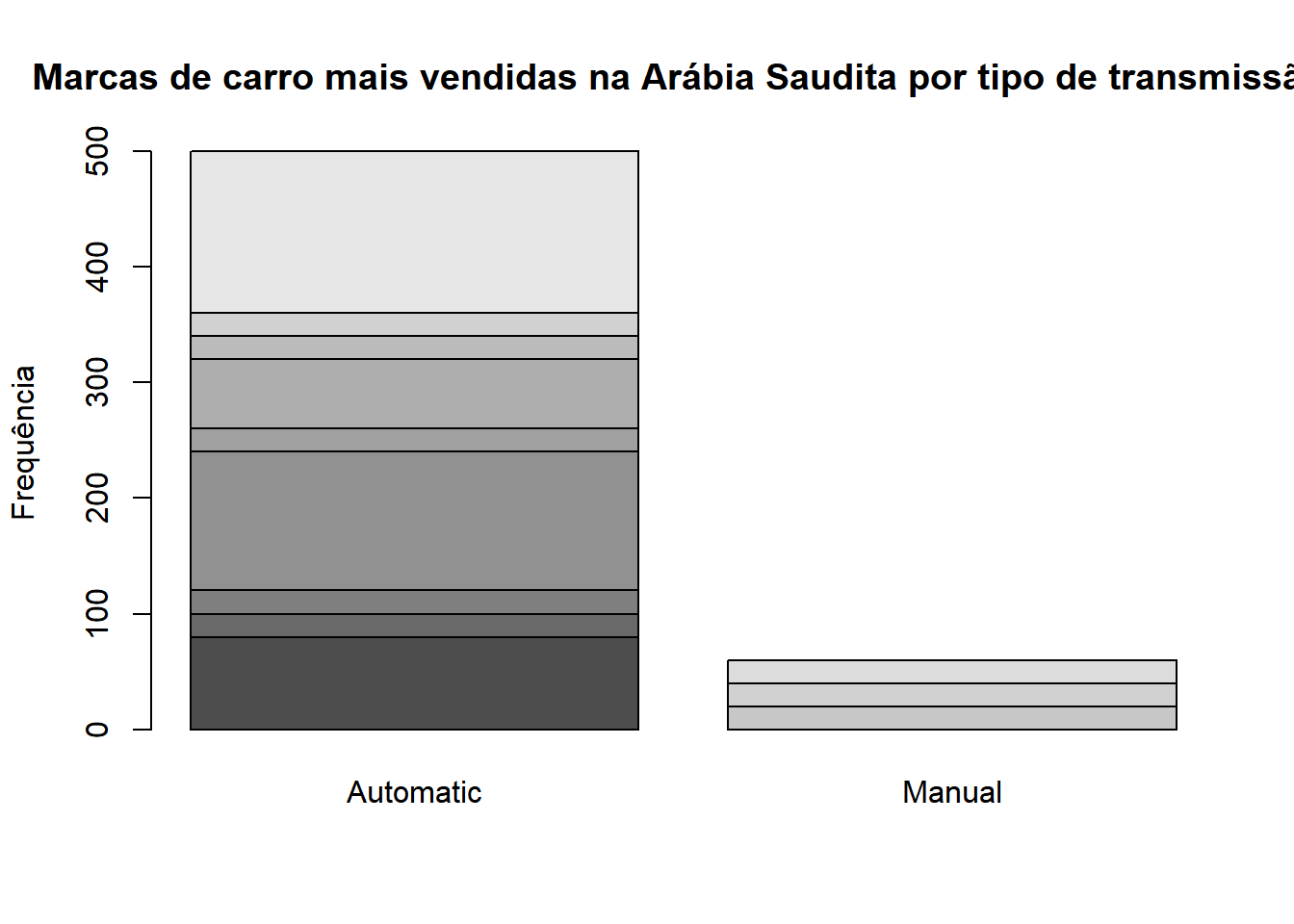
Veja que não conseguimos saber qual cor é associada a cada marca. Para isso, precisamos de uma legenda, que pode ser criada colocando como TRUE o argumento “legend”:
tabcont <- table(carro$car_maker,carro$transmission)
barplot(tabcont,main=" Marcas mais vendidas na Arábia Saudita por tipo de transmissão",ylab='Frequência',legend=TRUE)
Caso desejemos trocar a disposição das barras para um mesmo tipo de transimssão (de empilhadas para lado a lado), podemos colocar o argumento “beside” como TRUE.
tabcont <- table(carro$car_maker,carro$transmission)
barplot(tabcont,main=" Marcas mais vendidas na Arábia Saudita por tipo de transmissão",ylab='Frequência',legend=TRUE,beside=TRUE)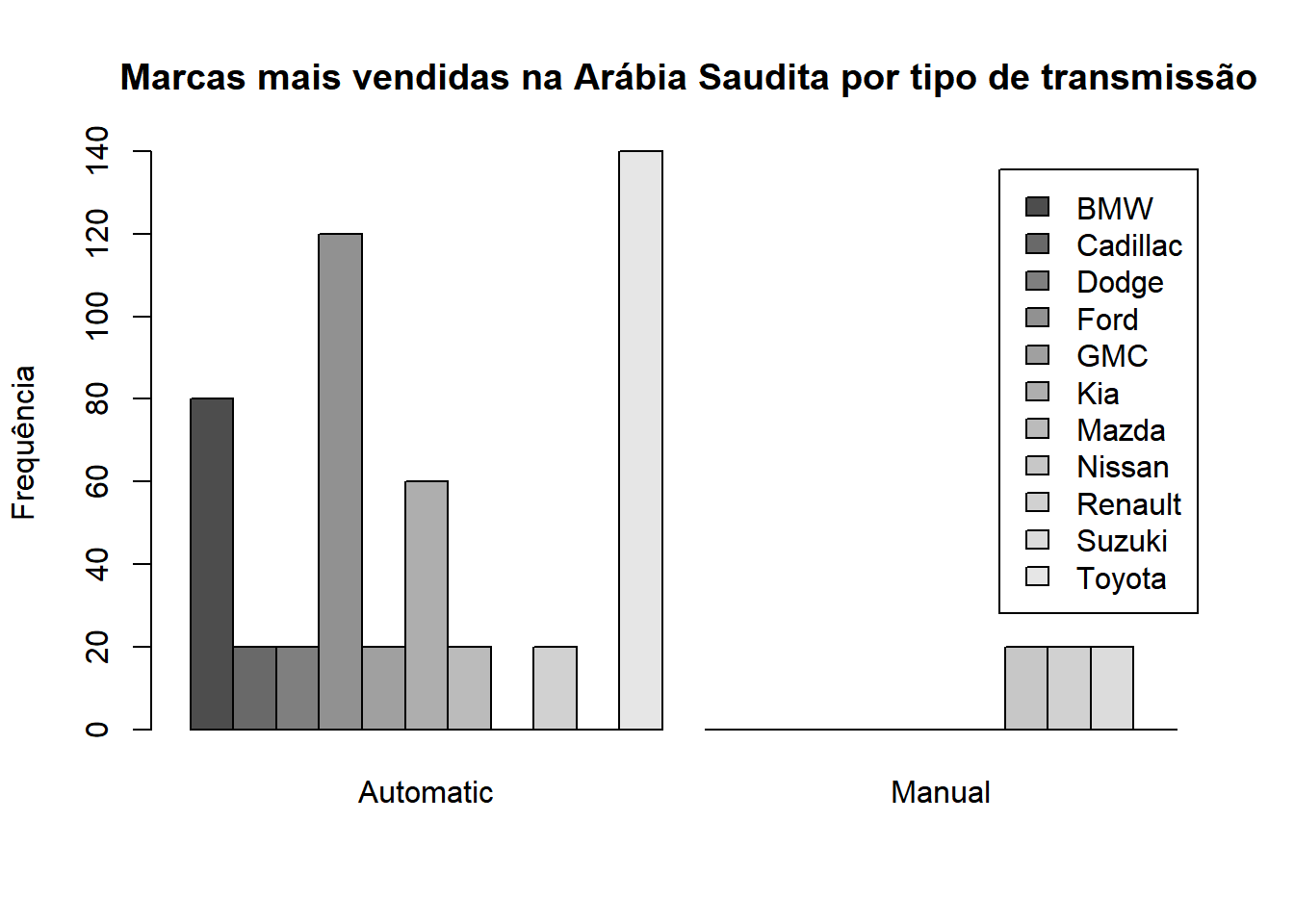
4.3.3 Gráfico de Dispersão
Gráficos de dispersão estão entre os mais complexos e são excelentes para mostrar a distribuição conjunta de duas variáveis numéricas. Esse gráfico consiste na representação de cada indivíduo como um ponto no plano cartesiano correspondente ao valor das variáveis no mesmo. Podemos criar um gráfico de dispersão com o comando “plot(variavel_y~variavel_x)”. Aqui, utilizaremos a partir do banco de dados ‘carro’, que traz informações sobre vendas de carros na Arábia Saudita. Podemos, por exemplo, cruzar preço do automóvel por quilometragem do mesmo:
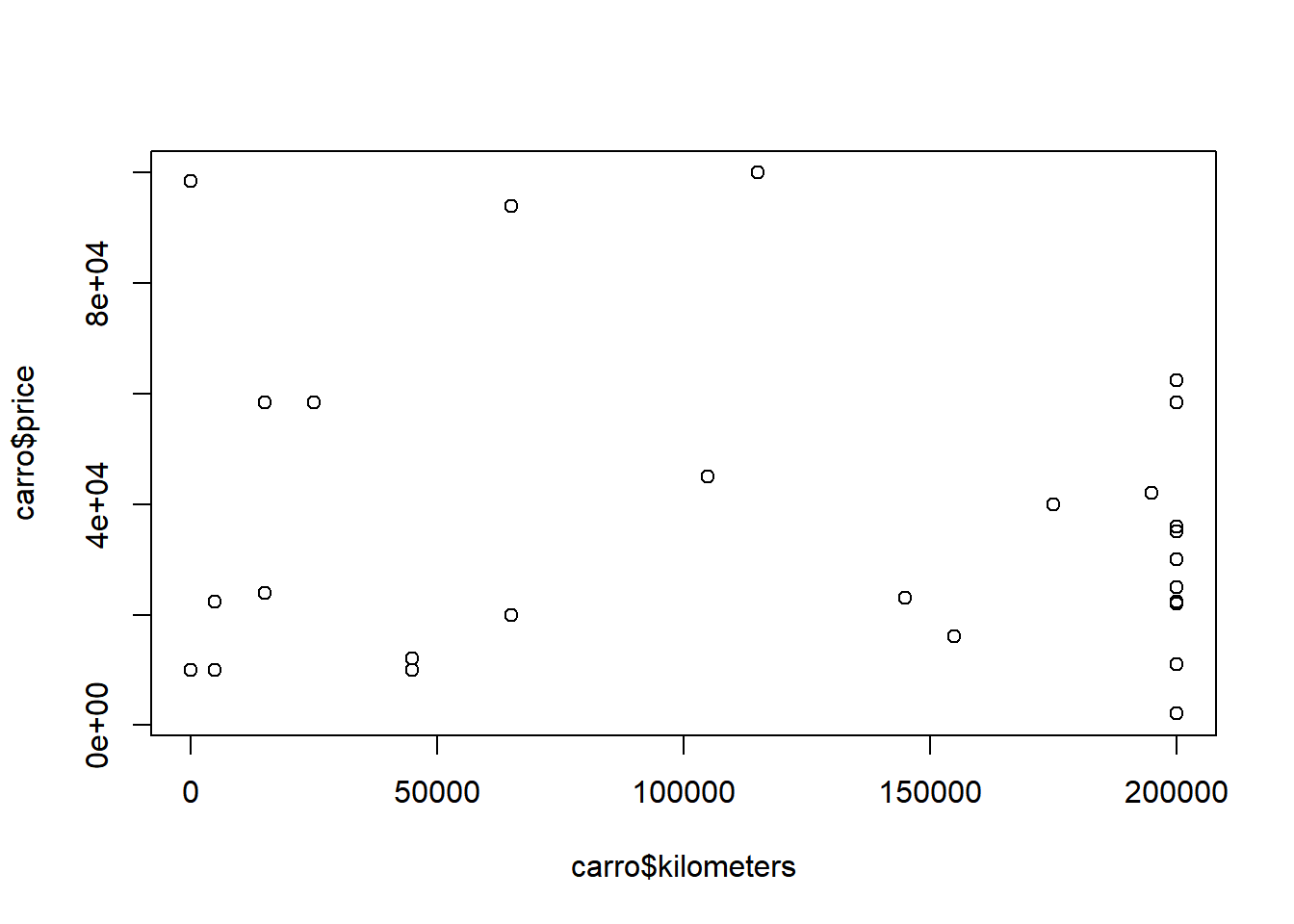
Para dar título ao gráfico, podemos utilizar o argumento “main”, e para definir cor, podemos utilizar “col”. Para renomar os eixos, temos os comandos “xlab” e “ylab”. Usando o parâmetro “cex”, podemos modificar o tamanho dos pontos:
plot(carro$price~carro$kilometers,main="Dispersão de preço do carro e quilometragem",col="darkred",
xlab="Quilometragem",ylab="Preço",cex=1.5)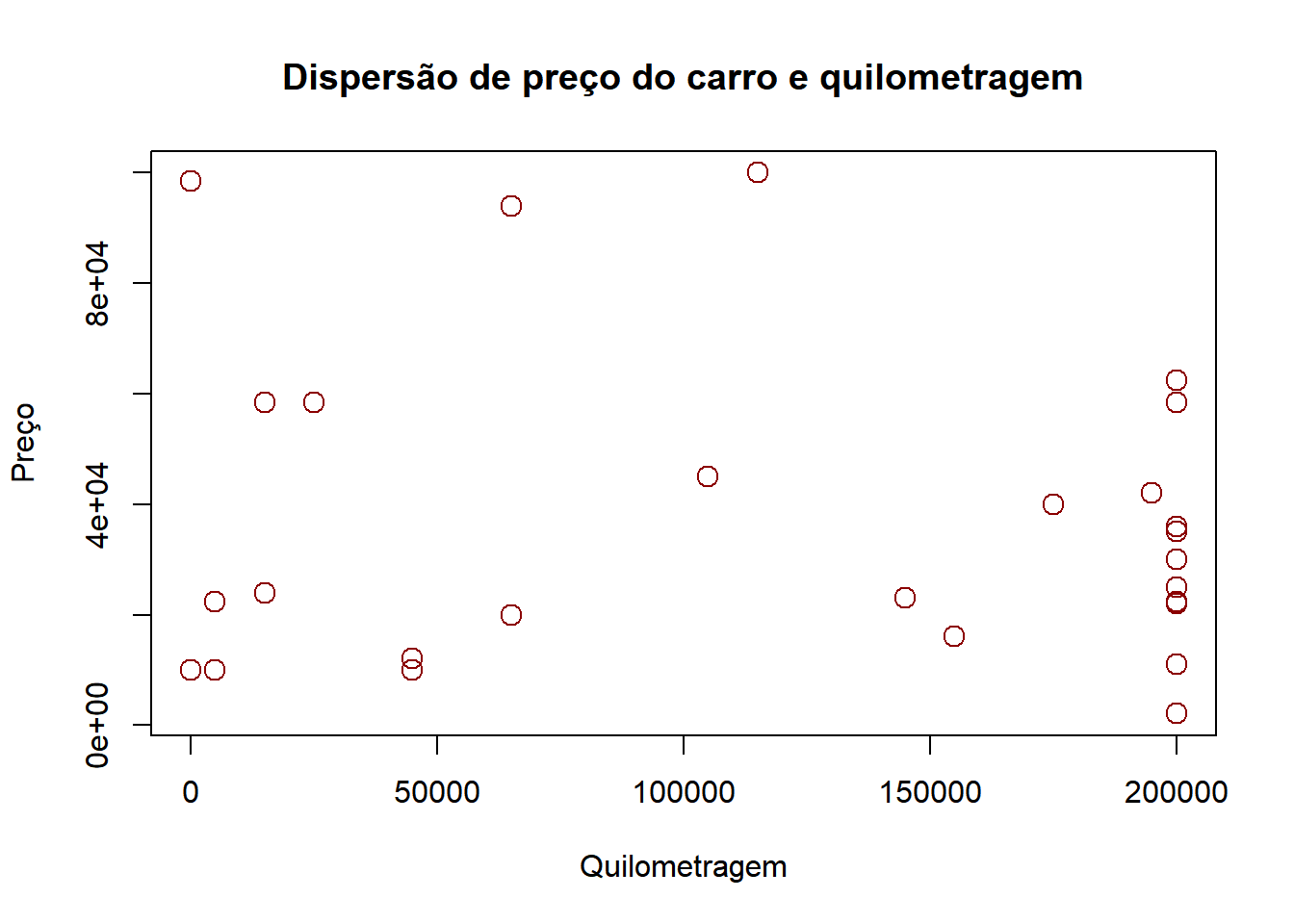
4.3.4 Gráfico de Linhas
Umm gráfico de linhas é uma excelente maneira de mostrar a progressão de uma variável numérica através do tempo. Para criar um no R, devemos utilizar o comando ‘plot()’, o mesmo do gráfico de dispersão. Entretanto, devemos alterar um argumento, chamado “type” e devêmos atribuir “l” a ele. No exemplo a seguir, fizemos um gráfico de linhas, utilizando o banco de dados “camada_de_ozônio” , que mostra o estado da camada de ozônio a cada ano entre 1992 e 2015. Decidimos uma linha mostrando a progressão do valor de CFC na camada a cada ano. Observe que parâmetros como ‘col’, ‘main’, ‘xlab’ e ‘ylab’ ainda funcionam normalmente.
plot(camada_de_ozônio$'CFC - clorofluorcarbonos'~camada_de_ozônio$...1, type="l",main="CFC na camada de ozônio por ano",col="cadetblue4",
xlab="Ano",ylab="CFC")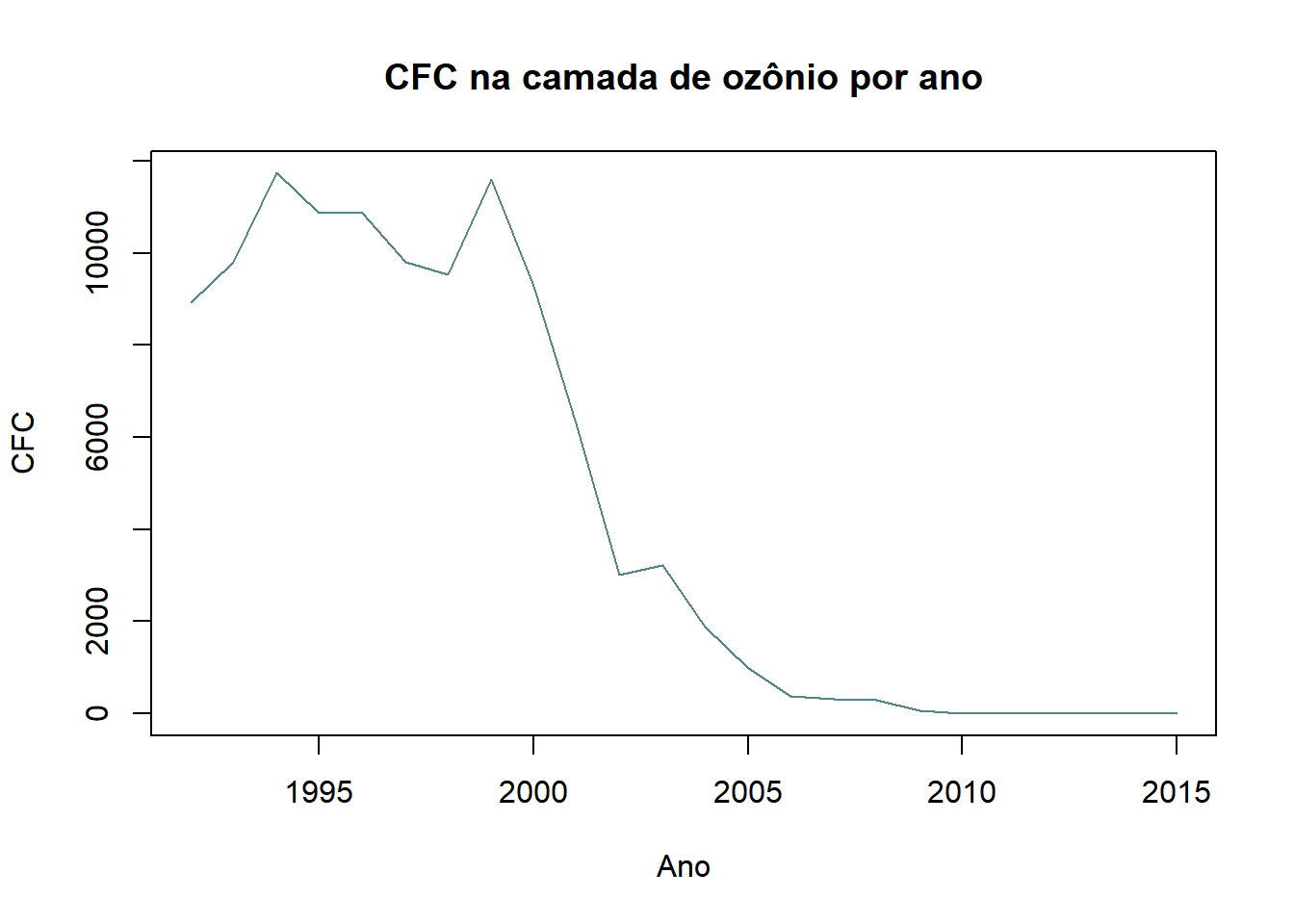
Caso desejemos que além das linhas, apareçam pontos, podemos simplesmente trocar o valor atribuído a type para “b”.
plot(camada_de_ozônio$'CFC - clorofluorcarbonos'~camada_de_ozônio$...1, type="b",main="CFC na camada de ozônio por ano",col="cadetblue4",
xlab="Ano",ylab="CFC")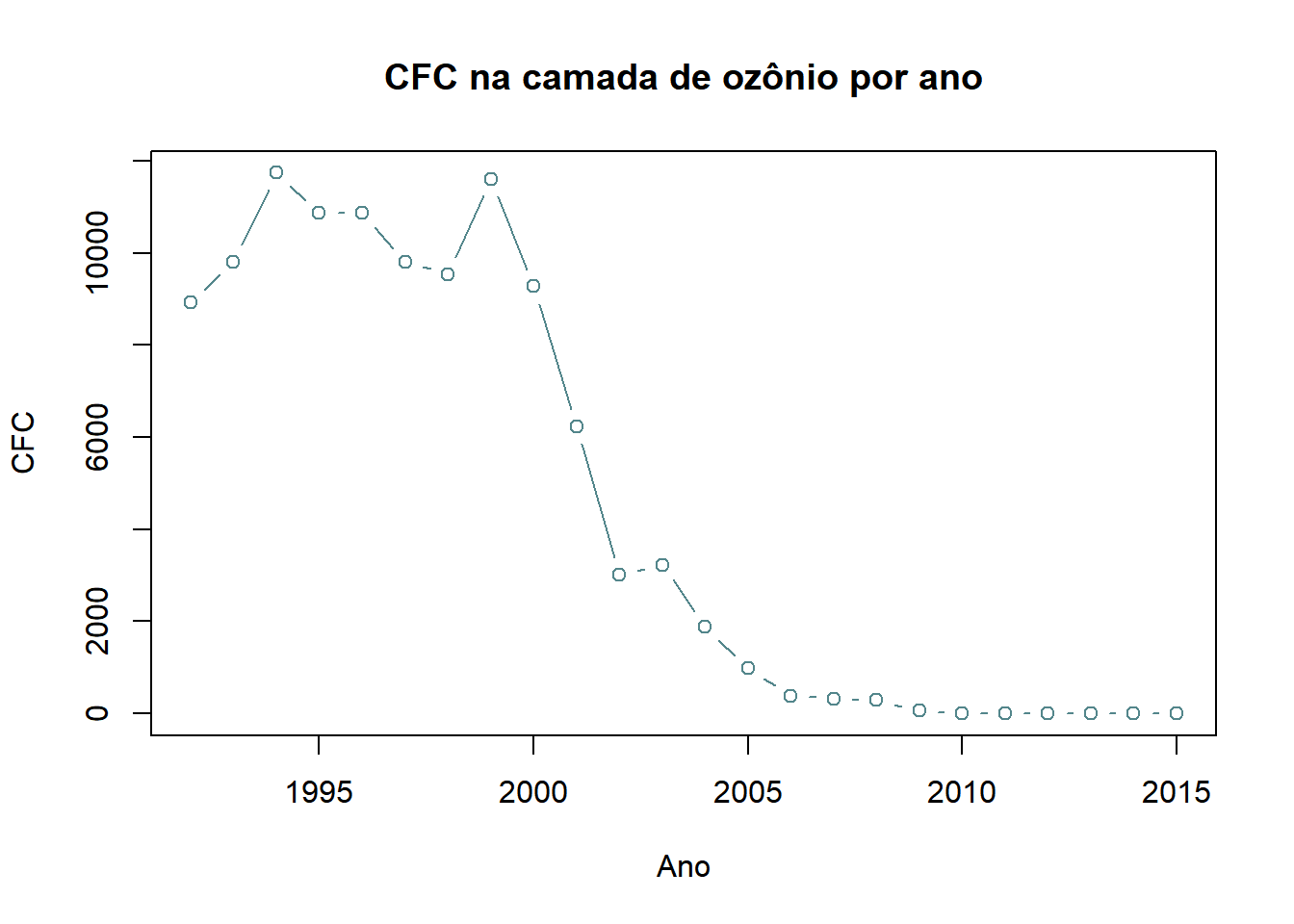
Se quisermos colocar duas linhas distintas para duas variáveis, podemos criar um gráfico para a primeira, e então utilizar o comando “lines” para sobreescrever uma linha em cima do gráfico anterior:
plot(camada_de_ozônio$'CFC - clorofluorcarbonos'~camada_de_ozônio$...1, type="l",main="CFC(azul) e TCA(vermelho) na camada de ozônio por ano",col="cadetblue4",
xlab="Ano",ylab= 'Concentração') # Gráfico anterior
lines(camada_de_ozônio$'TCA - ácido tricloroacético'~camada_de_ozônio$...1, type="l",main="CFC na camada de ozônio por ano",col="darkred") 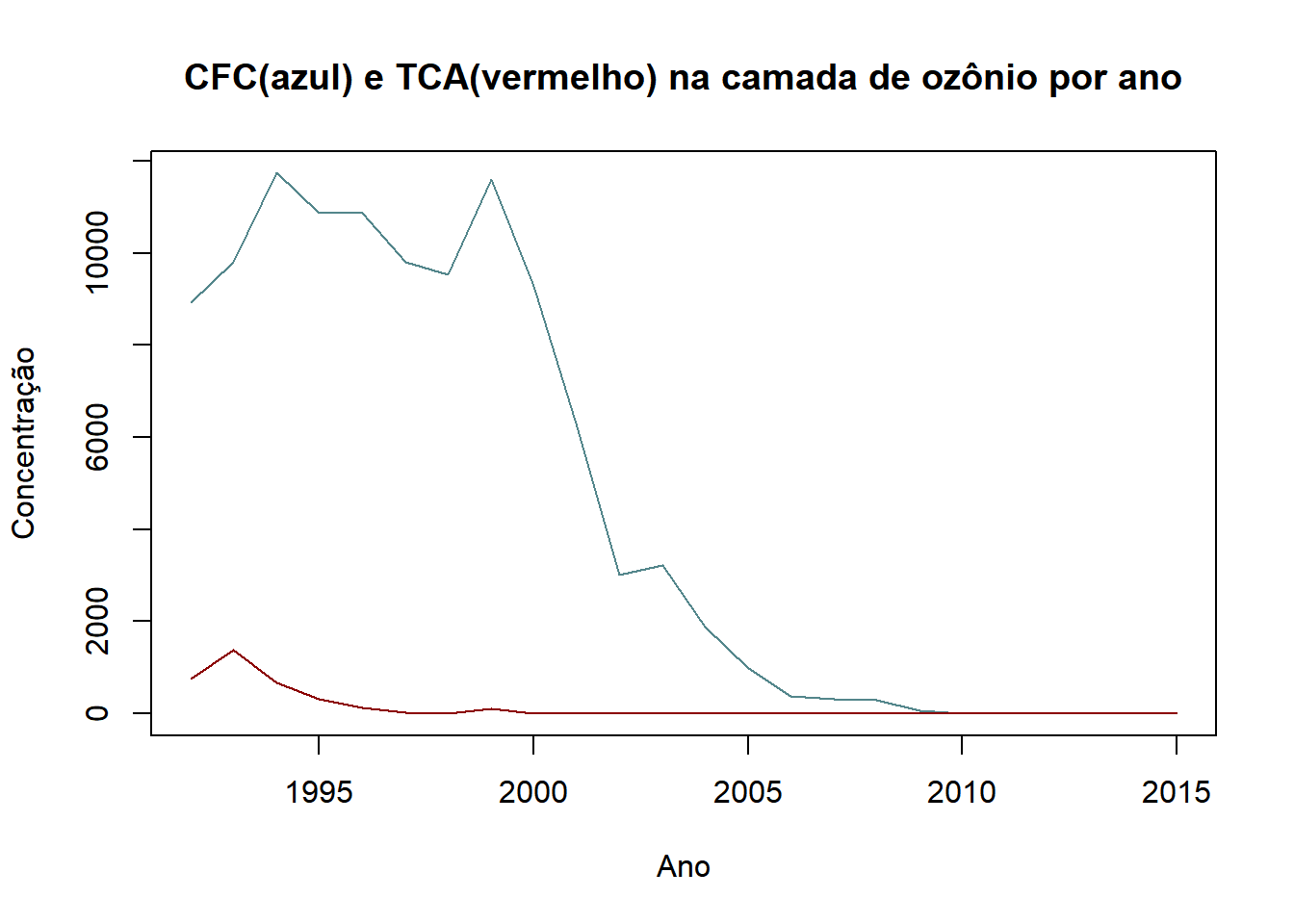
4.3.5 Boxplot
Um boxplot é um tipo de gráfico que condensa muita informação, como a mediana, os demais quartis e observações atípicas. Ele é normalmente adequado quando queremos comparar distribuições de variáveis numéricas. Para fazê-lo, utilizamos o comando “boxplot()”. O nosso exemplo utilizará o banco de dados “tempo” que traz dados sobre o tempo no aeroporto de Raleigh, Carolina do Norte, EUA a cada dia em determinado período. Decidimos ver a distribuição da velocidade do vento. Veja que argumentos como main, col e ylab funcionam normalmente.
library(exatas)
boxplot(as.numeric(tempo$avgwindspeed),main= "Boxplot da velocidade do vento",col="darksalmon", ylab="Velocidade do vento")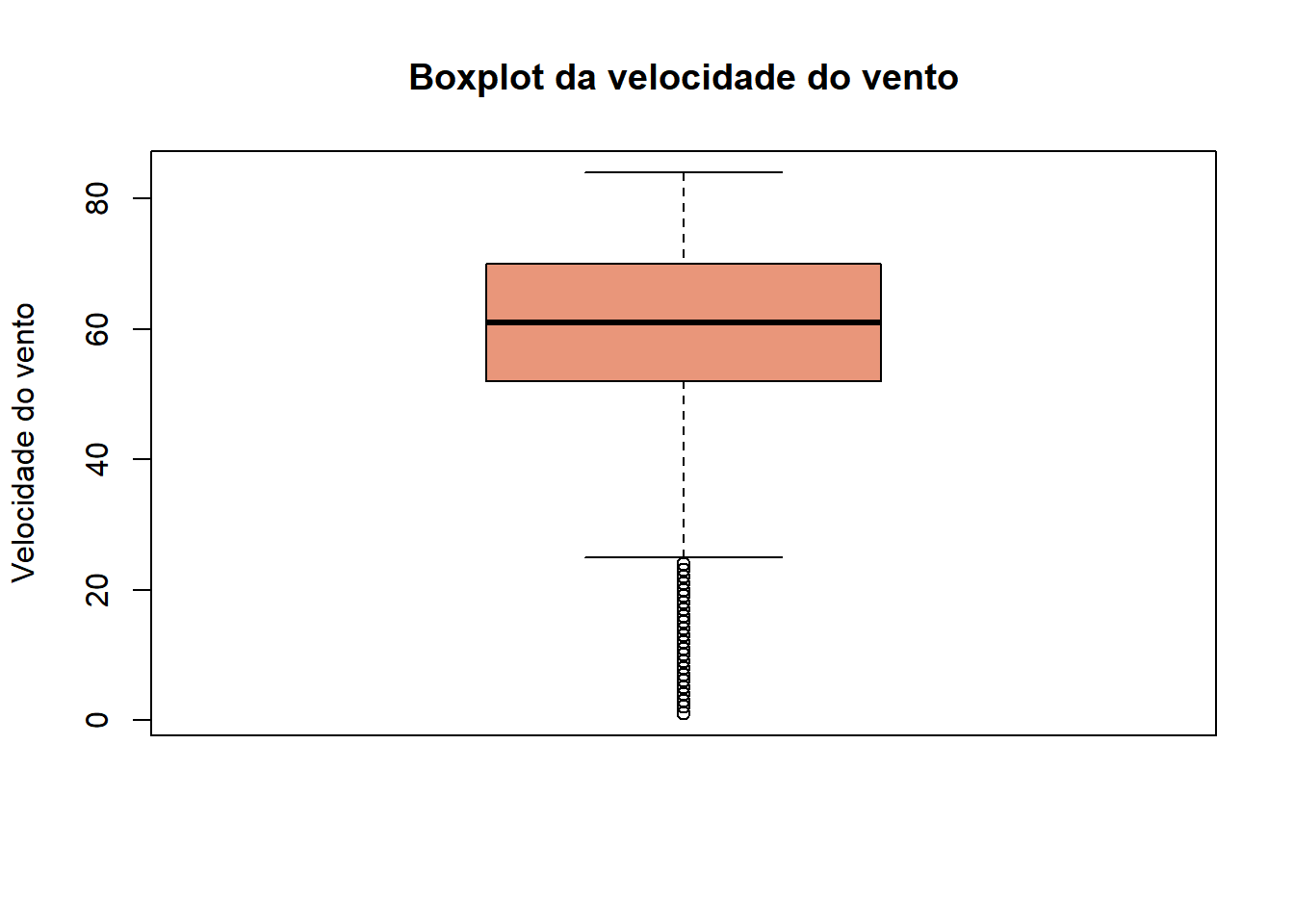
Também é possível fazer boxplots para a distribuição de uma variável númerica para cada valor de uma categórica. No R, basta fazer boxplot(numerica~categórica). Fizemos um exemplo cruzando a velocidade do vento com a presença ou não de chuva no dia. Nesse caso, podemos definir uma cor para cada um dos boxplot usando um vetor como valor do argumento “col”.
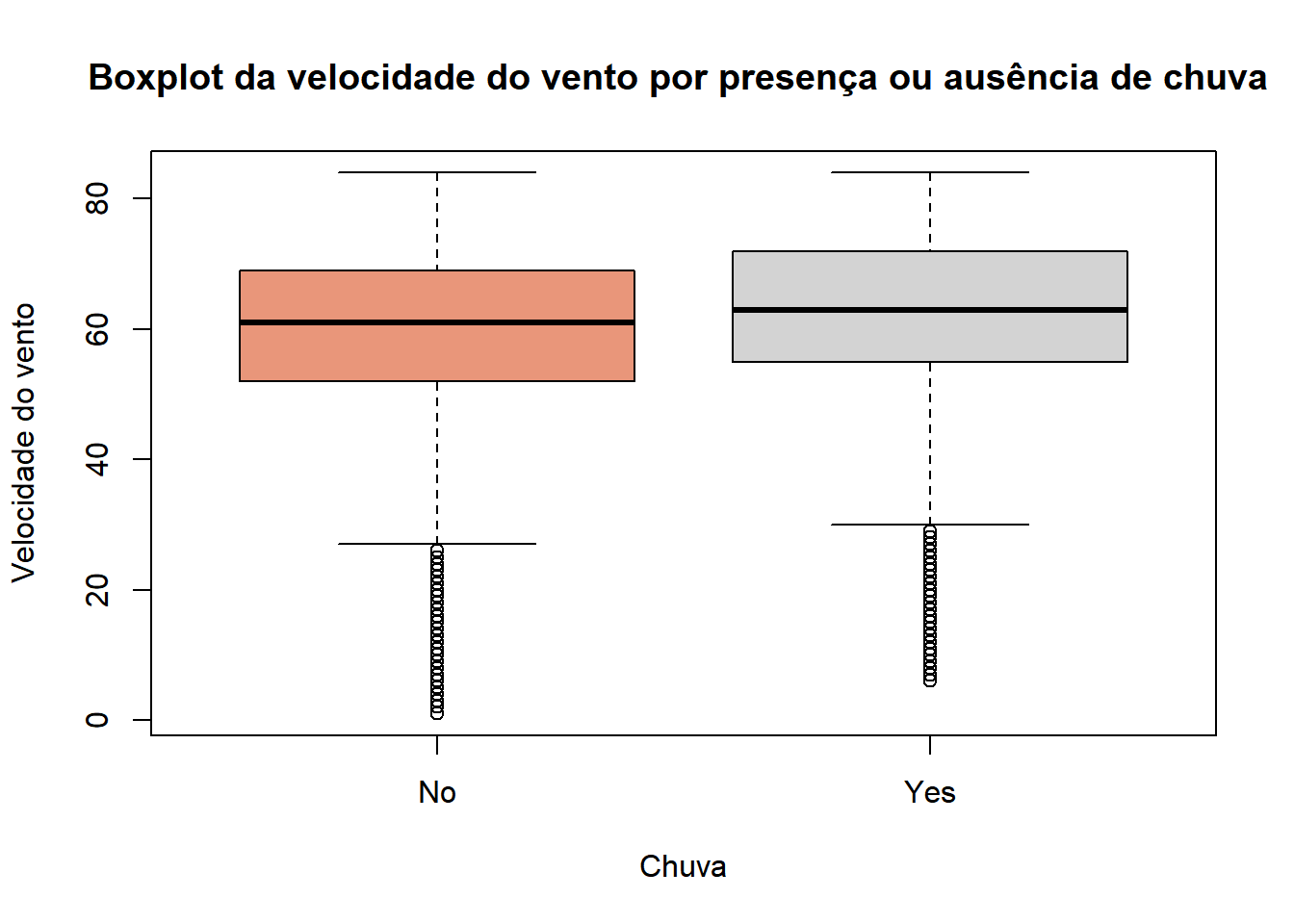
4.3.6 Histograma
Um outro modo de avaliar a distribuição de uma variável numérica é um histograma, que mostra a frequência dela em classes de valores. Para fazê-lo no R, usamos o comando ‘hist()’. Aqui, faremos um histograma da temperatura máxima ocorrida em um dia no aeroporto de Raleigh (utilizando o banco de dados “tempo”). Argumentos como col, xlab,ylab e main são aceitos, assim como nos demais gráficos.
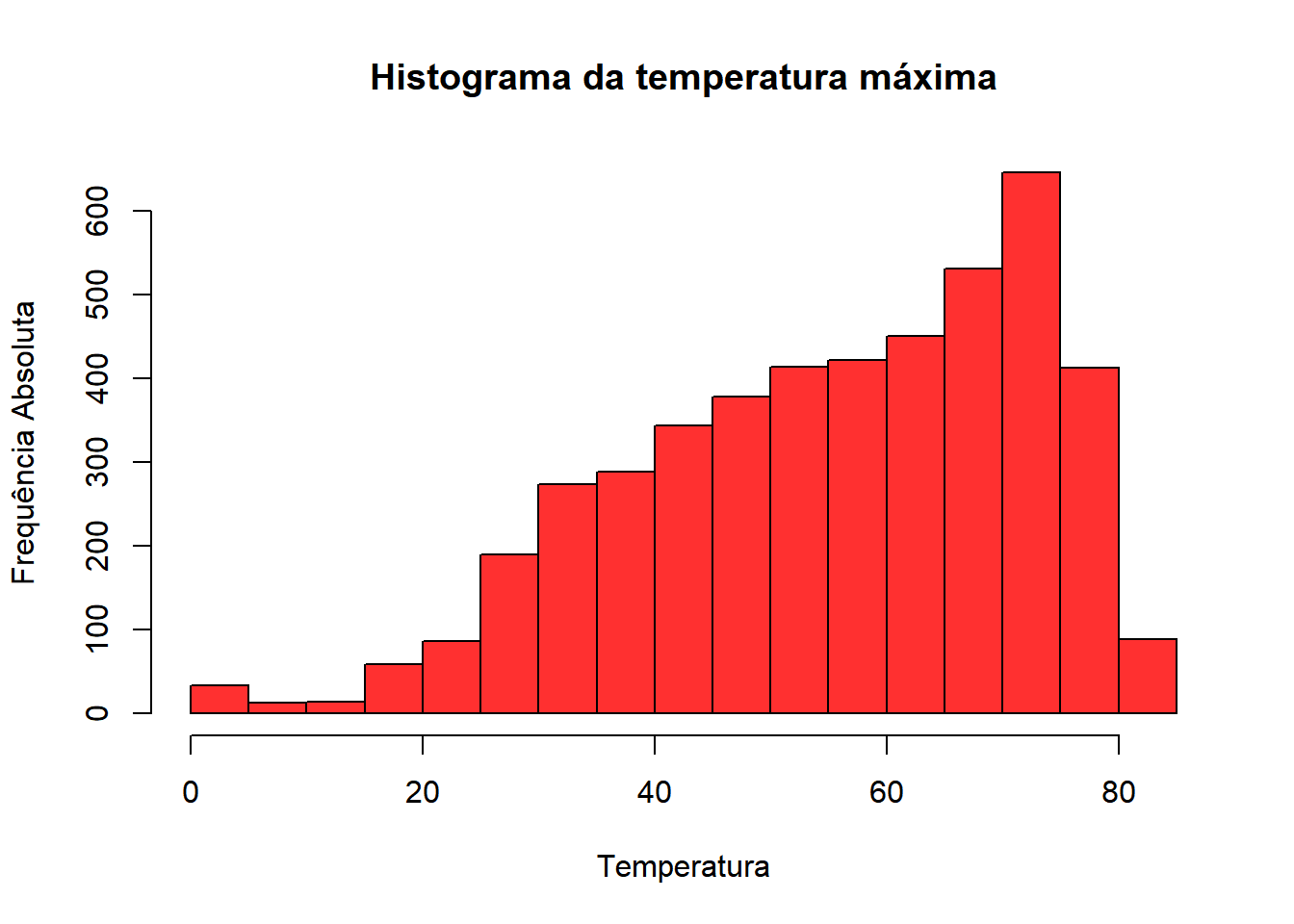
Podemos também fazer um hsitograma com frequência relativa, colocando o valor FALSE no argumento “freq”.
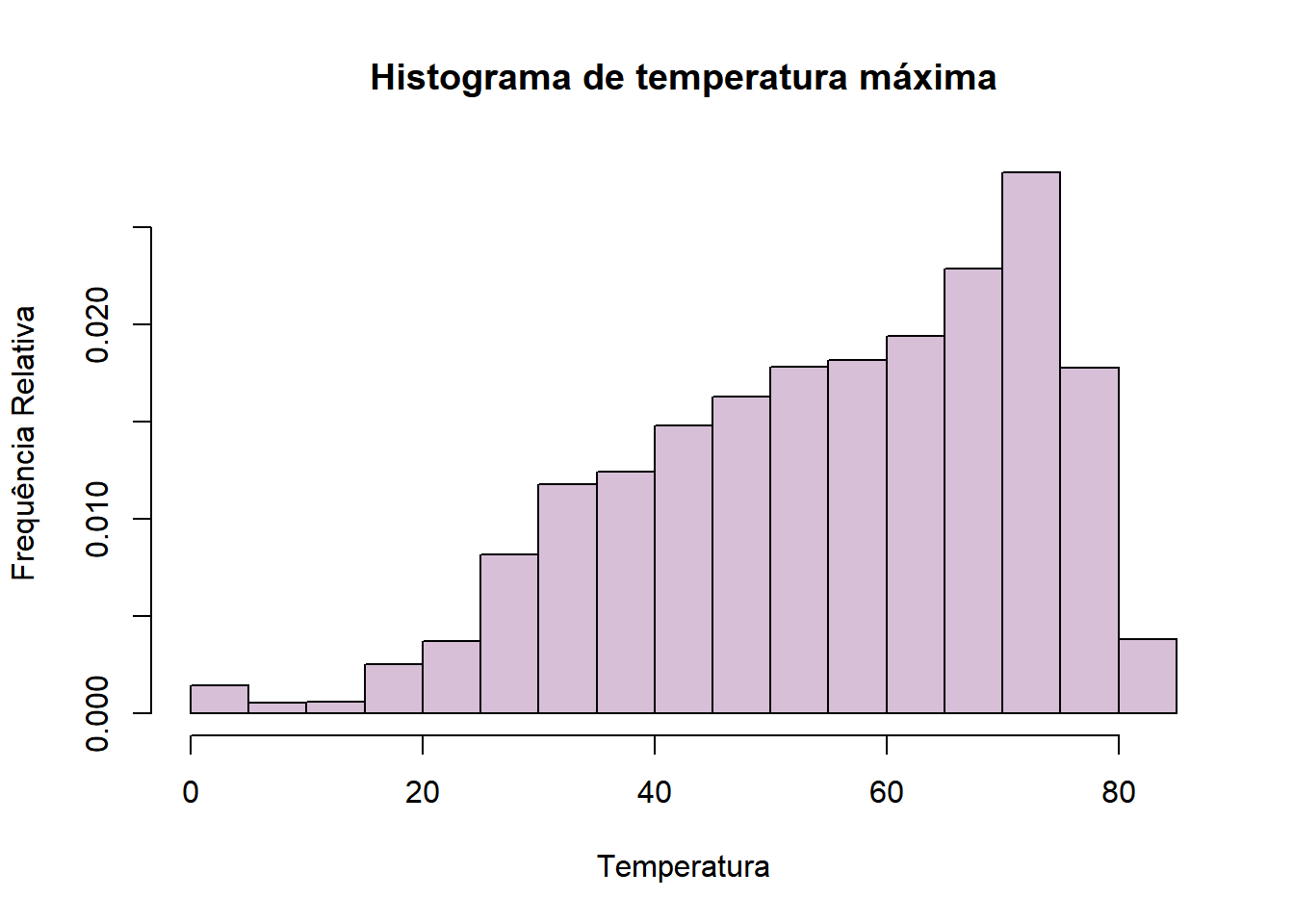
Podemos alterar os limites dos intervalos a partir do parâmetro “breaks”. Nele, podemos colocar um número, que será definido como o número de classes, ou um vetor que delimite todos os pontos de quebra. Fazendo do primeiro modo:
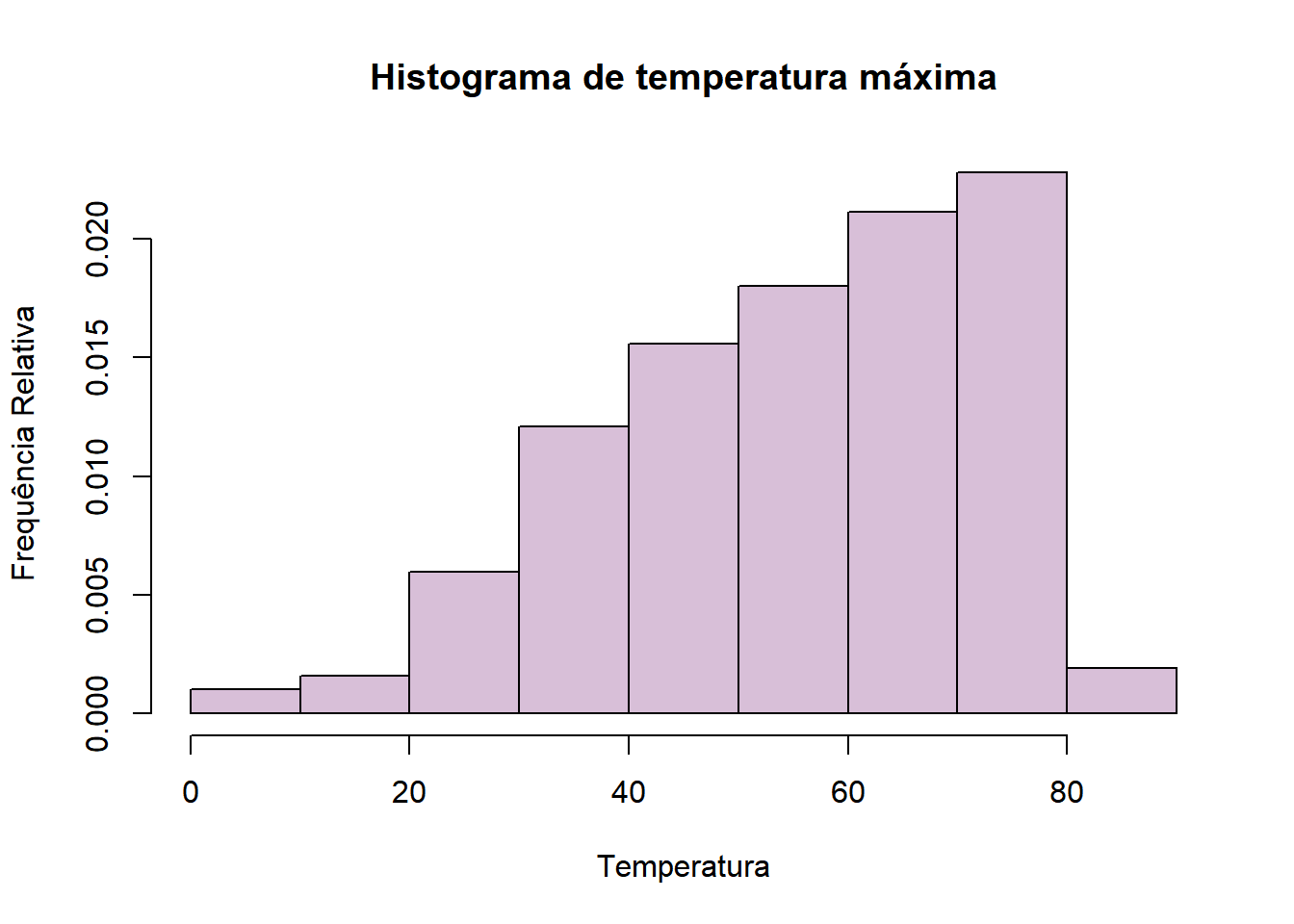
Agora, usando um vetor com os limites:
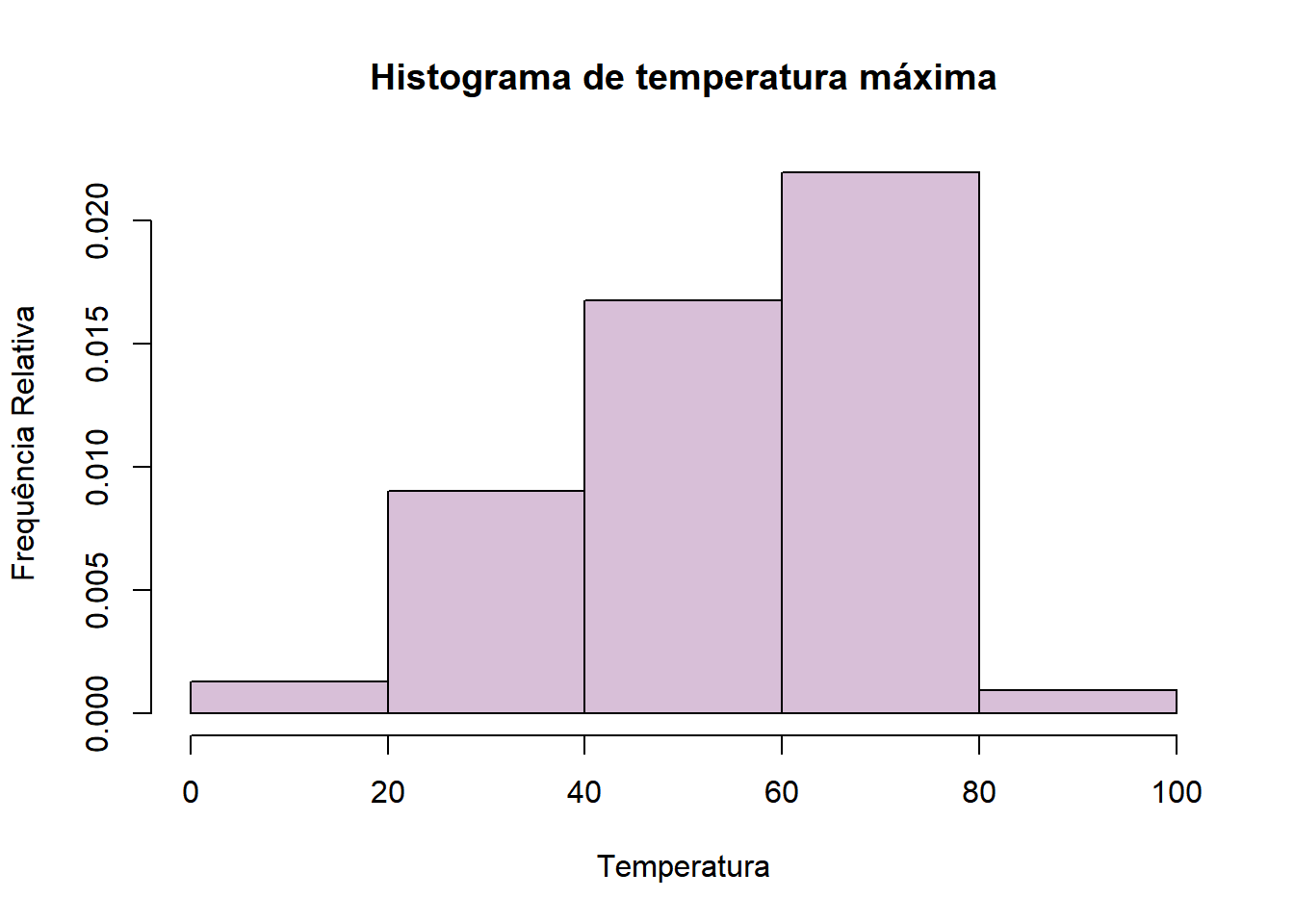
4.4 Gráficos no RCommander
Aqui, ensinaremos a fazer gráficos usando o RCommander, interface do R que permite análise de dados sem o uso direto de programação. Para começar, deve-se ter o RCommander instalado e o carregar.
4.4.1 Gráfico de Setores
Depois de fixar o banco de dados no RCommander, vá em Gráficos > Gráficos de Pizza selecionar a variável desejada e clique em ‘OK’ que seu gráfico será gerado. Ao lado das opções das variáveis é possível escolher os nomes dos eixos (o que não custuma ser necessário em gráficos de setores) e o título.
4.4.2 Gráfico de Barras
Depois de fixar o banco de dados no RCommander, vá em Gráficos > Gráficos de Barras indique a variável desejada e a partir de qual será categorizada e clique em OK que seu gráfico será gerado. Só é possível gerar gráficos de barras que relacionam duas variáveis. Para “desempilhar” os gráficos, vá em Opções > Estilo de barras agrupadas > Lado a lado (paralelo).
4.4.3 Gráfico de Dispersão
Depois de indicar o banco de dados no RCommander, vá em Gráficos > Diagrama de Dispersão. Escolha as variáveis de interesse e clique em OK que seu gráfico será gerado.
4.4.4 Boxplot
Depois de definir o banco de dados no RCommander, basta ir em Gráficos > Boxplot, escolher a variável desejada e clicar em OK e o gráfico será gerado. Também é possível fazer um boxplot relecionando duas variáveis: para isso, antes de gerar o boxplot clique em “Gráfico por grupos” e selecione a variável de interesse.
4.4.5 Histograma
Depois de indicar o banco de dados no RCommander, basta ir em Gráficos > Histograma, selecionar a variável desejada e clicar em OK para gerar um histograma.
4.5 Exercícios
Todos os exercícios que seguem devem ser feitos exclusivamente no R ou RStudio. Além disso, aconselha-se sempre procurar pela documentação dos bancos de dados, onde haverá mais detalhes a seu respeito. (Utilize o comando: ?nome_do_banco)
1- Monte uma tabela de contingência para as variáveis ‘rain’ e ‘snow’ do banco de dados ‘tempo’.
2- Deseja-se contabilizar a frequência da variável ‘condition’ (Condição do carro(novo/usado)) em relação à variável ‘transmition’ (câmbio automático ou manual) , no banco de dados ‘carro’. Qual ferramenta será mais útil nessa situação? Utilize tal ferramenta.
3- Faça uma tabela de frequência para a variável ‘ano’ do banco de dados ‘fertilizante’ com 6 intervalos com amplitude de 4 anos cada. OBS.: pode ser que ocorra um erro com o banco de dados, se necessário, utilize o comando x = as.numeric(fertilizante$ano).
4- Calcule a média, a mediana e o desvio padrão da variável ‘cimento’ do banco de dados ‘construcao’.
5- Encontre o 1°, 2° e 3° quartis da taxa de investimento entre os anos de 1995 e 2014 no banco de dados ‘investimento’.
6- Calcule quantidade média para cada uma das substâncias presentes no banco de dados ‘camada_de_azonio’.
7- Compare em termos de tendência central a quantidade reservas de petróleo no Brasil, em milhões de barris, utilizando os informações do banco de dados ‘petroleo’.
8- Calcule a Variância e Desvio Padrão do consumo de materiais de construção do banco de dados ‘construcao’.
9- Números índices são valores correspondentes à razão entre o nível de um fenômeno sobre o mesmo em um período base. Dependendo do produto a ser avaliado, deve-se considerar a sazonalidade, como é o caso dos produtos agrícolas. Por exemplo, não é ideal comparar a produção relativa de milho em um período distinto do da colheita, desse modo, deve-se fazer um ajuste sazonal.
Observando o banco de dados ‘farmacia’, qual a variação média entre os valores observados e a média do índice de base fixa com ajuste sazonal, entre janeiro de 2002 e janeiro de 2018?
Faça o mesmo com o banco de dados ‘quimicos’.
Dentre os dois índices, qual é o mais heterogêneo? O que isso significa?
10- Compare em termos de variabilidade da quantidade de sorvete produzida, em toneladas, entre 2005 e 2013. Utilize o banco de dados ‘sorvete’.
11- Ainda utilizando o banco de dados ‘sorvete’, calcule o escore padronizado das observações da quantidade vendida nesse mesmo período.
12- No banco de dados ‘plantio’, qual produção foi a mais heterogênea: batata ou tomate ?
13- Utilizando o mesmo banco de dados, qual produção foi a mais homogênea: cana de açúcar ou abacaxi?
14- Qual o comando utilizado para saber se duas variáveis tenham relação entre si? Utilizando o banco de dados ‘petroleo’, pode-se dizer que a descoberta de reservas de petróleo e de gás natural estão correlacionadas?
15- Por meio de qual gráfico também poderia ser feita a análise da questão 14?
16- Pode-se dizer que há relação entre os índices mensais de produção de óleos vegetais refinados (exceto o milho) e o índice de fabricação de laticínios? Utilize o banco de dados ‘indice’.
17- A partir de um gráfico de setores, qual lavoura temporária produziu mais em 2018? Utilise o banco de dados ‘plantio’.
18- Construa um gráfico de barras para comparar as variáveis condition e pay_method do banco de dados ‘carro’. Você diria que existe alguma associação entre essas duas variáveis?
19- Para o exercício a seguir, use o banco de dados ‘tempo’:
- Deseja-se comparar a temperatura mínima representada pela variável temperaturemin em dias que choveram ou não, ou seja, relacionar com a variável rain. Quais gráficos podem ser utilizados nessa situação?
- Construa o gráfico de sua preferência e interprete-o.
20- Considere o banco de dados ‘camada_de_ozonio’. Um cientista deseja encontrar o intervalo de tempo, não houve detecção de CFC - clorofluorcarbonos. Com quais gráficos é possível encontrar essa informação? E qual é esse intervalo?
21- Existe uma relação entre horário e a energia gerada em uma usina eólica? Verifique esse questionamento utilizando o banco de dados ‘vento’.
22- Utilizando o banco de dados ‘tempo’, analise a proporção de dias que nevaram ou não (variável snow).
23- Com quais ferramentas pode-se avaliar qual categoria é mais frequente que as demais? Utilize a de sua preferência para dizer qual tipo de vidro foi mais utilizado no banco de dados ‘vidro’.
24- Utilizando o banco de ‘carro’, crie tabelas de frequência absoluta e relativa para a variável “cor”. Comente os resultados.
25- Ainda utilizando o banco de dados ‘carro’, construa um gráfico de setores para investigar a variável car_maker. Qual a marca de carro de maior preferência?
4.6 Gabarito
1- As linhas correspondem à variável ‘rain’ e as colunas à variável ‘snow’ .
No Yes
No 3759 9
Yes 835 382-
Automatic Manual
New 1.0000000 0.0000000
Used 0.8888889 0.1111111