1 Genes, Genomes and Genome Browsers
1.1 What is a gene?
There are many ways to define a gene. One definition: A gene is a segment of double-stranded DNA that directs the production of a functional product (i.e. protein). A significant number of eukaroytic genes are protein coding. Each protein-coding gene first directs the production of an RNA transcript through a process called transcription. This RNA transcript is then processed into a messenger RNA (mRNA). The most notable change that occurs during RNA processing is that intron sequences are removed (thin lines in Figure 1.1). The mRNA is then exported from the nucleus and used as a template to make a protein in a process called translation. This entire process (transcription, RNA processing and translation) is called Gene expression. The final products, often proteins, do much of the work necessary to create and maintain organismal structure and function.
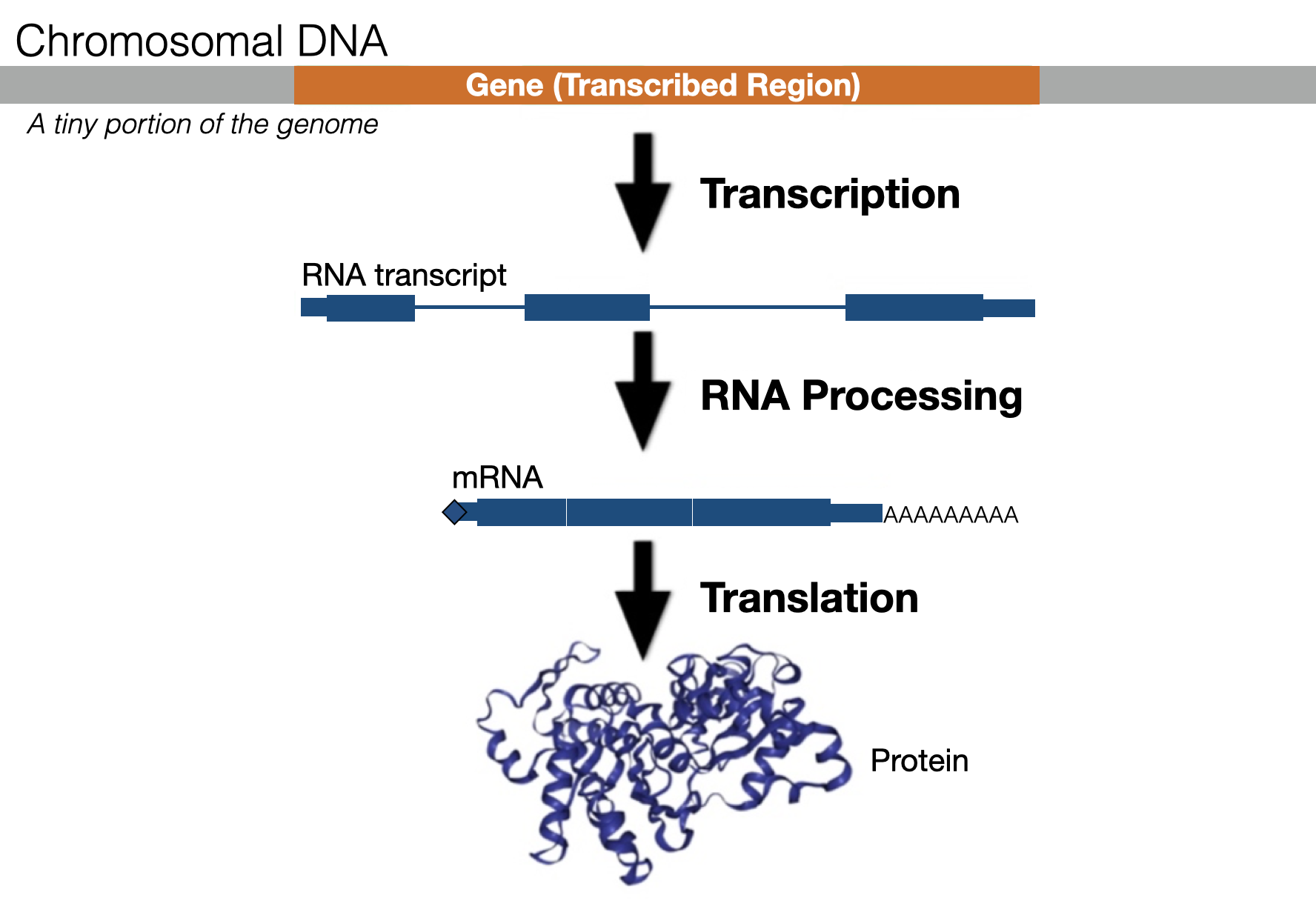
Figure 1.1: An overview of Gene Expression. A small segment of a chromosome (light grey) containing a single gene (orange) is shown. The RNA transcript is highlighted as blue rectangles (exons) and blue lines (introns). Introns are removed during RNA processing to create a mature messenger RNA (mRNA)
While the transcribed region of a gene requires adjacent sequence (i.e. the promoter, see Chapter 5) to become transcribed at the right time and place, for simplicity, the size of a gene (number of base pairs) is typically defined by where transcription begins and ends. Thus, the sites of transcription initiation and transcription termination define both gene size and RNA transcript size (but not mRNA size which is typically shorter as most eukaryotic genes have introns).
1.2 What is a genome?
Genes are distributed linearly along chromosomes2 (Figure 1.2). One complete, nonredundant set of chromosomes for a given species makes up what we call a genome (also called a “haploid genome”)3.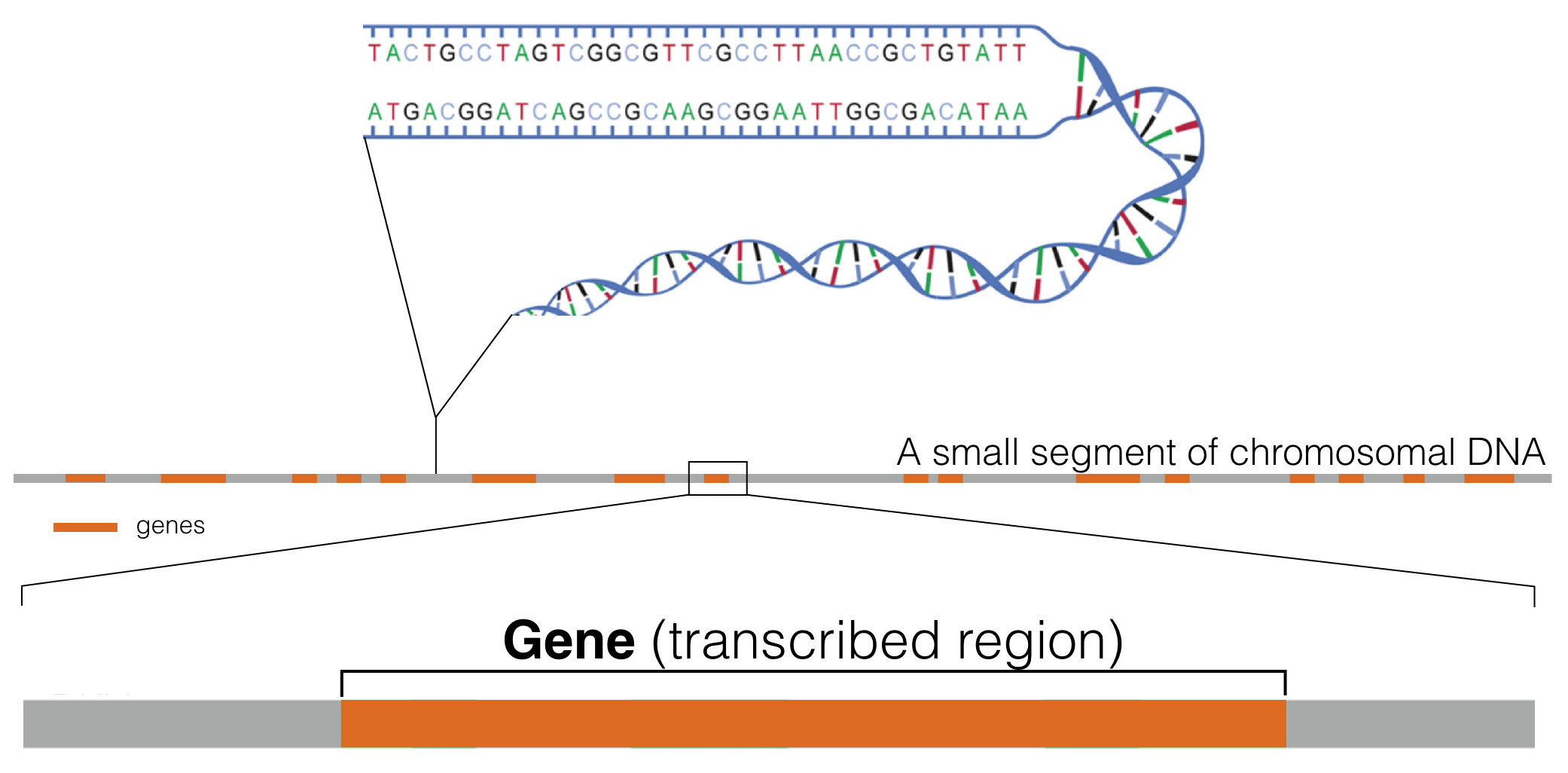
Figure 1.2: This schematic represents a hypothetical segment of a chromosome with orange rectangles representing genes distributed linearly along the DNA segment shown.
The haploid genome for humans consists of 24 linear chromosomes (Figure 1.3) and one circular mitochondrial chromosome (not shown). Each chromosome varies in length. For example, chromosome one is the longest at 248,956,422 base pairs (bp). Given that 10 bp of a double helix measures 34 angstroms in length, chromosome one is 82.7 mm (more than three inches if pulled taut)!4 (Figure 1.3).

Figure 1.3: Actual length of the human genome when scale bar equals one centimeter. Naken mitochondrial DNA is too small to be shown. It is a small circular DNA molecule, with a circumference of 55 microns.
Like most animals, humans are diploid. Thus, their somatic cells5 harbor 22 pairs of autosomes6 and one pair of sex chromosomes (either XX or XY). Thus, over two meters (2000 mm) of DNA is crammed into each somatic nucleus! But the diameter of the average mammalian nucleus is only 6 microns or 0.006 of a millimeter! How does the diploid genome fit in the nucleus? And how does it prevented from becoming a tangled mess? First, the diameter of the DNA double helix is only twenty angstroms7 but also, each chromosome is carefully packaged by proteins in a systematic and stereotypical manner (Figure 1.4).
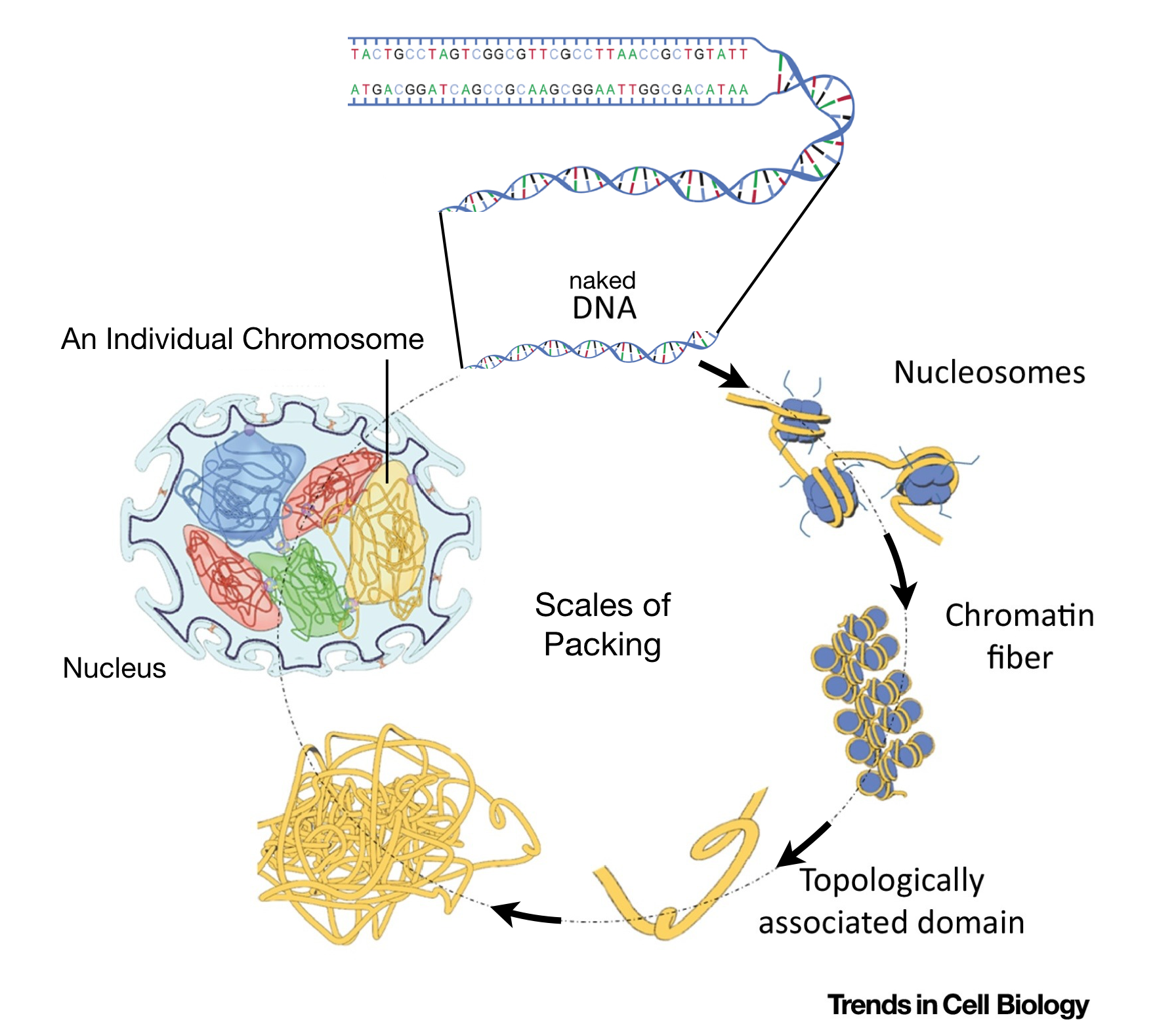
Figure 1.4: This image is modified from Uhler and Shivashankar, 2017. It shows the various levels of chromosome packing found in nuclei during interphase of the cell cycle. The first level of packing requires an octamer of histone proteins that assemble into a ball-like structure called a nucleosome. Naked DNA wraps around these octamers forming ‘beads on a string’. Additional levels of packing into chromatin fibers and topological associated domains requires additional proteins. Individual chromosomes (23 pairs in humans) are then carefully orgnanized within the cell nucleus in a cell type-dependent manner.
1.2.1 Test Your Understanding
Click the link above to see the TYU questions.
1.3 What is a Genome Browser?
According to Wikipedia, Genome browsers enable researchers to visualize genes in the genomes with annotated data including gene structure, information about gene expression, positions of disease causing mutations etc. They differ from ordinary biological databases in that they display data contributed by multiple sources in a graphical format. The top strand of the genome sequence is typically displayed (by default) along the X-axis (when the sequence is not visible, coordinates are given). The annotations and graphics that describe a given region of the genome are stacked below the genome sequence.
There are numerous Genome Browsers available. We will use the UCSC Genome Browser. The UCSC Genome Browser harbors the sequence of genomes representative of numerous species called “reference genomes”8. Our initial focus will be on a single gene in the human genome, BBS1. In this chapter, using BBS1 as our example, you will learn how the UCSC Genome Browser is organized, how to configure so-called “evidence tracks”9, how to navigate through Genome Browser window (scrolling left and right, zooming in and out) and how to understand the graphical data that describe specific gene features.
1.4 Navigating the UCSC Genome Browser
To get started, click the BBS1 session link. You should be taken to the human BBS1 gene in the UCSC Genome Browser. Your web browser window will look like Figure 1.5. Near the top of the page you will find the “Navigational Toolbar”(Figure 1.5, A-D). Notice the genome coordinates and the amount of DNA (in base pairs) that is displayed in the browser window (Figure 1.5, C). Below that is a schematic of chromosome eleven showing where BBS1 is located - see red vertical line (Figure 1.5, E). Below that you will find the genome browser window centered around the human BBS1 gene. In fact, it is centered around the transcribed protion of BBS1. Regulatory sequence that orchestrates when and where a gene is transcribed is poorly characterized and thus not included in the gene annotation.
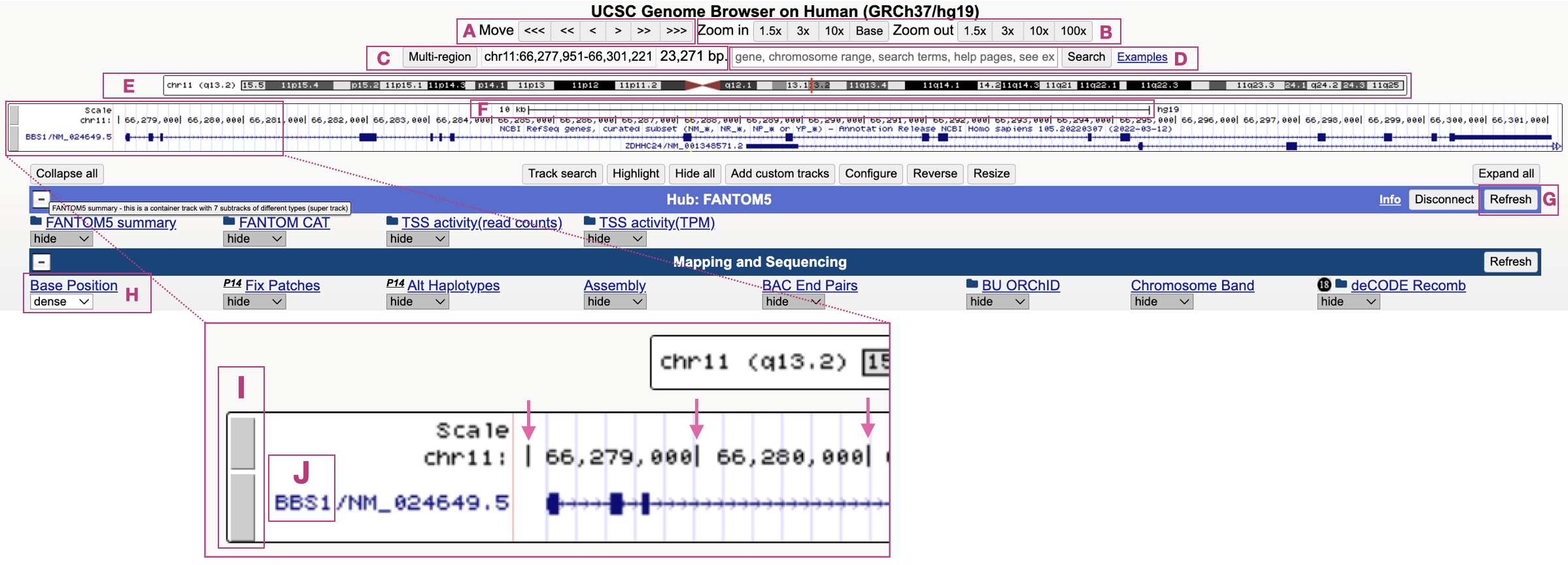
Figure 1.5: An annotated version of the Genome Browser as it will appear when you click the BBS1 session link provided. See text for annotation details.
This BBS1 session link has been configured to contain only two so-called evidence tracks. See the two gray rectangles on the left side of the browser window to count (Figure 1.5, I). There is the Base Position track on top and a Gene Prediction track on bottom. At this zoom level, the Base Position track is a graphical display of the genome as a ruler and the units are in kilobase pairs. Like any ruler, you will see a series of numbers separated by vertical tick marks, “|” ((Figure 1.5, see arrows in the inset). Those represent base pair positions within the genome. Each number corresponds to the vertical tick mark to its right. At this zoom level, each tick mark represents a distance of 1000 bp. To view the genome sequence in the Base Position track you need to zoom in quite a bit or click “base” as your zoom in option. Try it! Notice that the scale of the ruler changes as well (they are now in base pairs). In general, the Gene Prediction track displays gene schematics indicating the position, orientation and structure of each gene in the browser window. Our window currently shows BBS1 and part of another overlapping gene, ZDHHC24. Gene names are displayed on the far left of each gene schematic (For BBS1, see Figure 1.5, J). You can see that ZDHHC24 extends farther to the right as indicated by the presence of open triangles on the far right of the gene schematic.
You can use the navigational toolbar to scroll left <<< or right >>> (Figure 1.5, A) or zoom in or out (Figure 1.5, B). The length of DNA (in bp) displayed in the browser window is also indicated including exact coordinates (Figure 1.5, C). Finally, there is a window that one can use to jump to a new gene (Figure 1.5, D). Try it (i.e. jump to ACVR1). You will notice that when you start to type in the gene name, a drop down menu will appear. Click on the correct gene (more than one may be listed). This will take you directly to that gene in the genome browser (don’t click “Search”!). If you click “Search” you will be taken to an intermediate page containing a long list of genome databases (BTW, I like to use “NCBI RefSeq genes”. This page can be confusing. I recommend that you avoid it. Just go back and search again. You can also use this Search window to look for a specific sequence variant (i.e. NM_024649.5:c.274T>C) or genome coordinates (i.e. chr2:157,736,446-157,876,330). The former will be useful in Chapter 7). If you get hopelessly lost and need to get back BBS1, properly formatted, click once again on the BBS1 session link.
The gray rectangles on the left side of the genome browser window (Figure 1.5, I) delineate the boundary of each evidence track displayed. Click on one of the gray rectangles and you will be taken to a “track settings” page for that particular evidence track. Try it. Explore the new page and the information it provides. Then click the back button to get back. You can also right click on a gray rectangle. This will open a small popup window for quick formatting. Quick formatting options include changing the way the information in the evidence track is displayed (you can choose hide, dense, squish, pack or full). You can also choose “View Image” to display a high resolution image of the browser window (NOTE: This knowledge will be useful for your Independent Project! - See the end of Chapter 8).
Popular evidence tracks are listed below the genome browser window. An advanced user might choose to show an evidence track from this list although any changes you make will not be displayed until you click the “Refresh” button (Figure 1.5, G). You can also see which evidence tracks are currently displayed (Figure 1.5, H). WARNING: The “GENCODE” evidence track will sometimes appear unexpectedly. This is a bug! When this happens the GENCODE evidence track will no longer be hidden. To minimize confusion, you should hide the track (right click on its gray rectangle and choose “hide”. It can be confusing when two gene prediction tracks are open at the same time.
Practice navigating through the genome browser. Zoom in. Zoom out. Scroll left. Scroll right. Click on a random position within the chromosome schematic. Hover your mouse over various elements within the browser window to read pop-up messages. Click on any feature for more details. Change track settings to see the impact. Then when you become hopelessly lost within the human genome or the formatting changes unexpectedly, use the BBS1 session link to get back.
The most important navigational trick to learn is how to “drag-and-select or click to zoom”. This trick will allow you to zoom in to a specific location within the browser window, a navigational trick we will use repeatedly. Master it now. To start, hover your mouse anywhere within the base position track until a tiny “drag select or click to zoom” popup message appears. This tells you that you are in the right place to “click” then “drag” (with your finger on the trackpad). When you do it correctly, you will create a box around a portion of the gene/genome you want to zoom into (red arrow, Figure 1.6) AND a “Drag-and-Select” popup window will open. Click “Zoom In” and you are done.
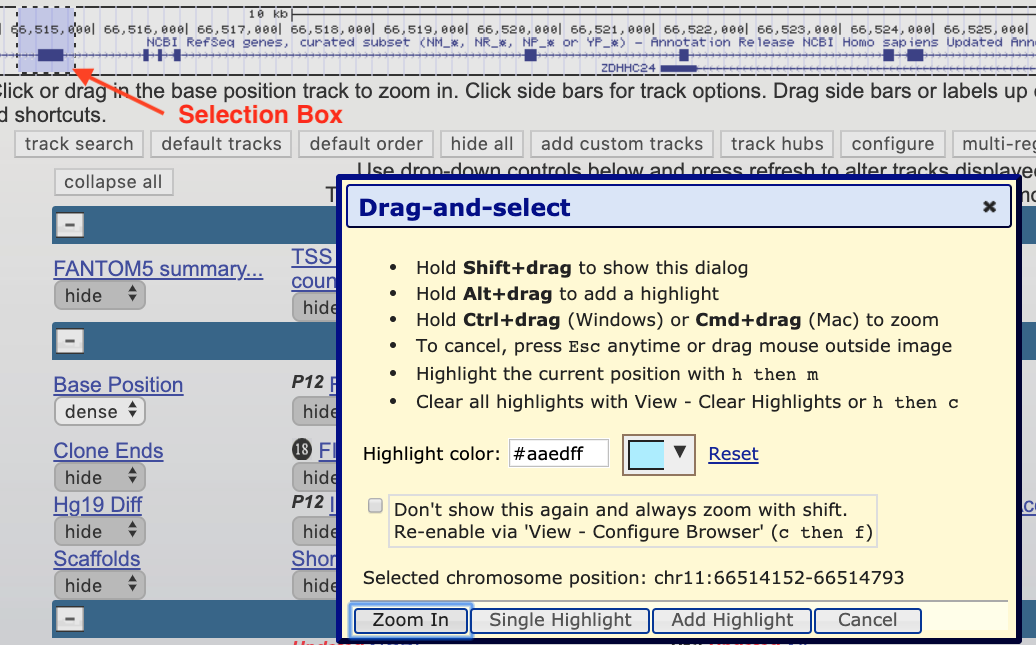
Figure 1.6: The drag select or click to zoom tool is very useful.
Again, if you zoom in close enough you will see the actual genome sequence (top strand only) within the Base Position evidence track (Figure 2.2, A). How do I know the genome sequence displayed is the top strand10? Because the arrow to the left of the genome sequence (see red Asterix, Figure 2.4) is pointing to the right (—>). In molecular biology, the blunt end of an arrow represents the 5’ end of a DNA strand while the pointed end of an arrow represents the 3’ end. Always.
1.4.1 Test Your Understanding
Click the link above to see the TYU questions.
1.5 Addendum
Now that you have more familiarity with gene structure, the following tutorials are highly recommended. They were created by the UCSC Genome Browser team. These are also worth revisiting before you embark on your Independent Project at the end of the term.
- UCSC Genome Browser Basics. Part 1: Getting around in the Browser
- UCSC Genome Browser Basics, Part 2: Configuring the Browser
- UCSC Genome Browser Basics. Part 3: Configuration + DNA navigation
- Saving and Sharing Sessions on the UCSC Genome Browser
- Controlling the visibility of data tracks on the UCSC Genome Browser
- and there is more!
© 2025, Maria Gallegos. All rights reserved.
a chromosome is a single, long molecule of double stranded DNA↩︎
Many organisms are diploid (including humans) meaning they have two copies of every chromosome. Thus the phrase “haploid genome” is more precise, although the word “haploid” is often omitted and simply assumed↩︎
to calculate the length of a chromosome: Multiply the length of a chromosome in base pairs (bp) with 0.000000332, the length (in mm) of each bp.↩︎
Cells of a multicellular organism can be divided into two main types: germ cells and somatic cells. Germ cells are destined to become the reproductive cells like sperm and oocytes. Somatic cells are destined to become all the other cell types like skin, neurons and muscle. This distinction is made as somatic cells die with the death of the organism while germ cells have the potential to pass their DNA on to the next generation.↩︎
An autosome is one of the numbered chromosomes, as opposed to the sex chromosomes. Autosomes are numbered roughly in relation to their sizes. The largest autosome — chromosome 1 — has approximately 2,800 genes; the smallest autosome — chromosome 22 — has approximately 750 genes. This definition is found at https://www.genome.gov/genetics-glossary/Autosome↩︎
an angstrom is a unit of length equal to one ten-millionth of a millimeter!↩︎
A “reference genome” (also called a “reference assembly”) is a genome sequence created from thousands of sequence runs assembled in silico to represent the sequence of a genome of one idealized individual organism. Since it is assembled from sequence data obtained from a number of donors, reference genomes do not represent the sequence of any single individual or organism, but rather a mosaic of multiple donors↩︎
each evidence track harbors specific biological data from a single source pertaining to the sequence displayed in the browser window)↩︎
The top strand of DNA is also referred to as the “+ strand”↩︎