5 DNA motifs for transcription initiation
The expression of a gene starts with transcription. During transcription, one contiguous segment of genomic DNA is used to make a single RNA transcript. But how does the transcription machinery know where transcription should begin? This chapter reviews what we know about DNA sequences that promote transcription initiation and how these sequences provide bioinformatic evidence (albeit weak) for the position of genes in the genome. To follow along in the text and to answer “Test Your Understanding” questions, use the “TSS-Seq” Session link.
5.1 The Core Promoter
There are three RNA polymerases that catalyze transcription in eukaryotes (RNA Pol I, II and III). Transcription of protein coding genes, like BBS1, require RNA Pol II and will be our focus. Transcription begins once RNA pol II binds near a transcriptional start site (TSS) of a gene. But RNA polymerase on its own cannot bind promoter DNA. Instead, transcription initiation requires a number of so-called General Transcription Factors or GTFs 31. These factors bind to a core promoter sequence that spans the TSS. Once bound they recruit RNA polymerase to the start of the gene.
A core promoter is defined as the minimal DNA sequence that directs initiation of transcription of a gene. TSS-seq data indicates that there are two main types of core promoters: focused and dispersed (Danino et al. 2015). A focused core promoter (also called a “sharp peak” or “narrow peak” promoter) contains a single predominant TSS that is confined to a small number of nucleotides. A dispersed promoter, by contrast, contains a large number of transcriptional start sites of equal potency that are dispersed over a 50 to 100 nucleotide region. This type of promoter is also called a “broad peak” or “wide peak” promoter. Both terms “sharp peak” and “broad peak” essentially describe the shape of the TSS-seq histogram data (See Chapter 4). In reality, TSS-seq data and other genome-wide studies of transcription initiation suggest that these two main types of core promoters are in fact two ends of a continuum. In other words, promoters cannot be categorized easily and also include promoters of mixed character (i.e. “broad with peak”) (Figure 5.1).
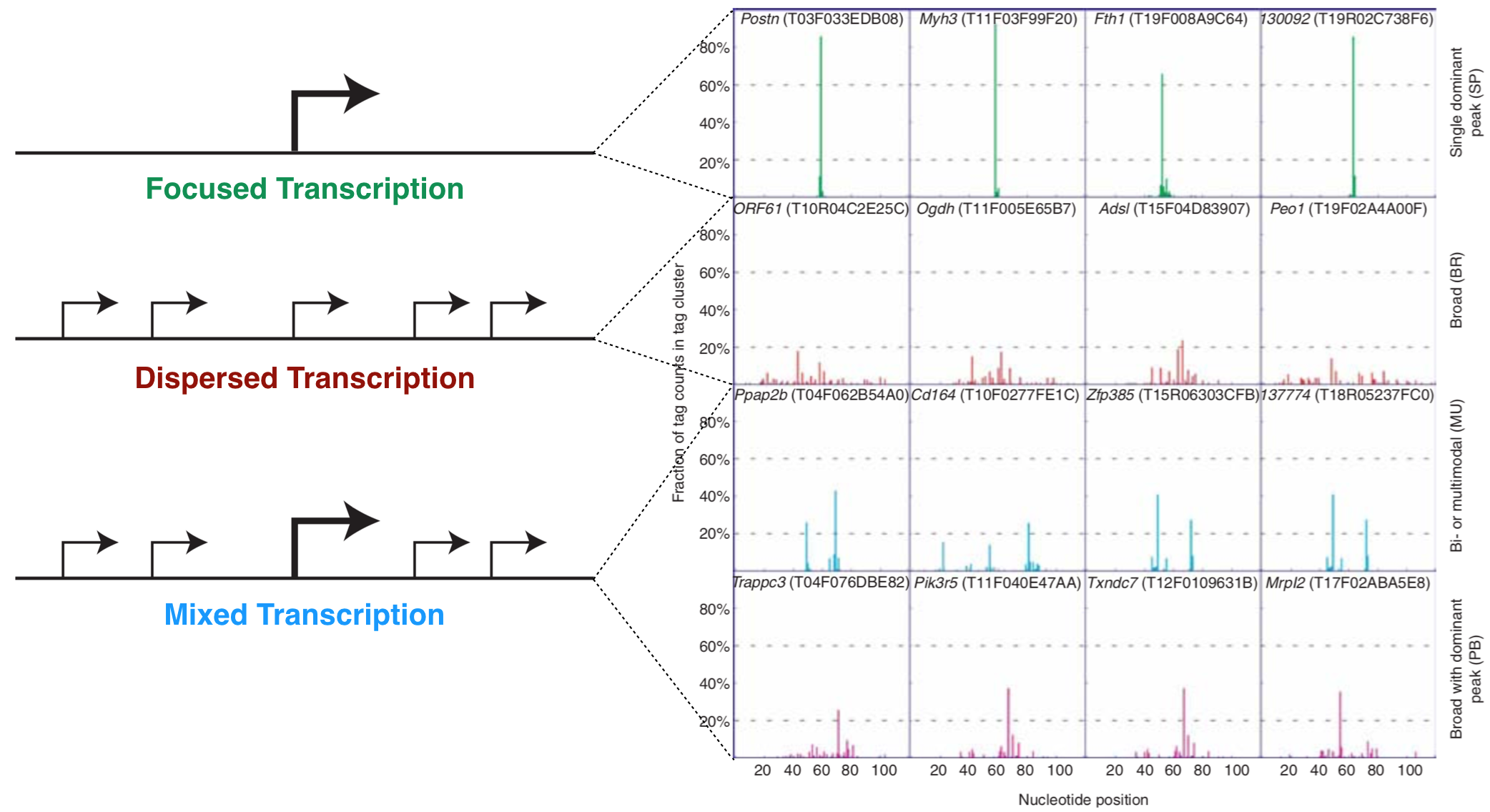
Figure 5.1: The left schematic from Vo ngoc et al. 2017 illustrates the three main types of promoters that are found in animals: Focused, Dispersed and Mixed. The right image from Carninci et al. 2006 displays TSS seq data for a number of genes that illustrate each type of promoter.
Focused core promoters were the first described and are the best characterized (See Griffiths). In humans, they are about 80 nt in length and flank32 the TSS, the so-called +1 position of transcription (Figure 5.2). Each includes a set of short, DNA sequences called core promoter motifs33. These DNA motifs serve as binding sites for GTFs (namely TFIID and TFIIB). Once TFIID and TFIIB bind a focused core promoter, they recruit and stabilize other GTFs which together recruit and stabilize RNA polymerase II to the TSS. This large, multiprotien complex (called the preinitiation complex or PIC) initiates basal levels of transcription34. Basal levels of transcription are often modified by transcriptional activators and/or repressors.
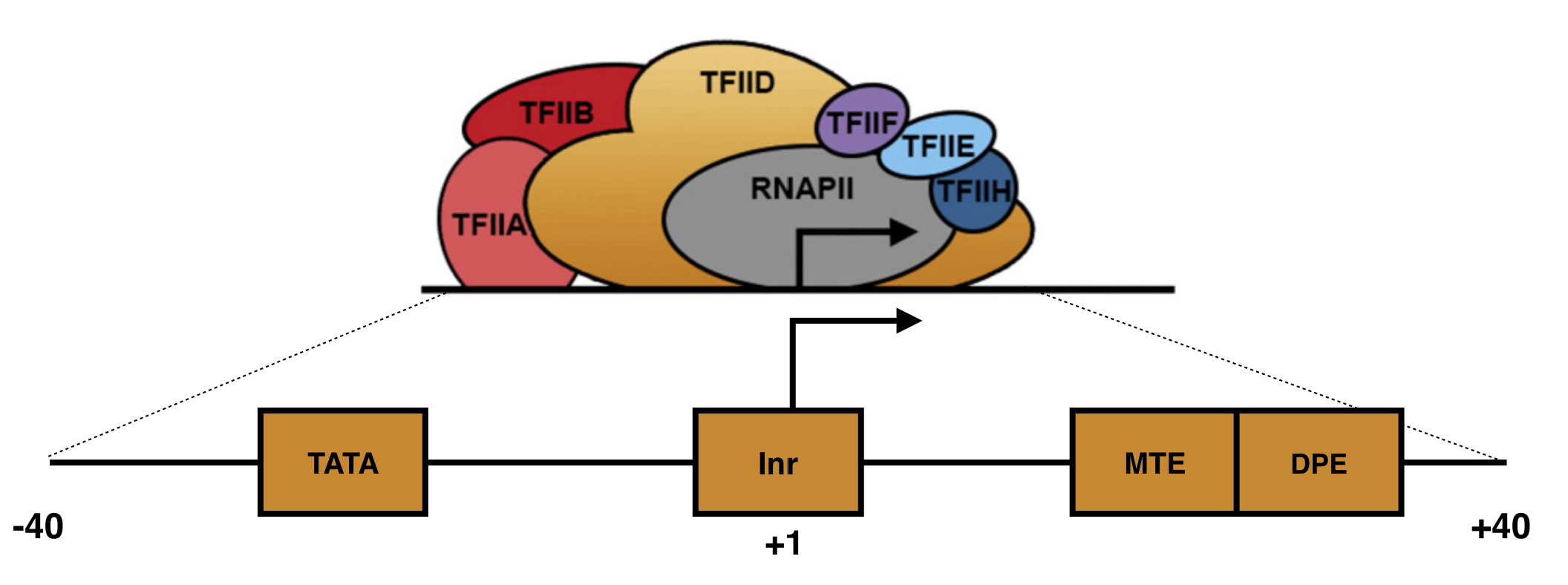
Figure 5.2: A schematic of a focused core promoter and the GTFs/RNA polymerase II that bind to it. The horizontal line is the genomic DNA. TATA, Inr, MTE and DPE are DNA sequence motifs positioned along the core promoter as shown. The Inr spans the TSS (+1) while the TATA-box is upstream and the MTE and DPE motifs are downstream. Image from Danino et al. 2015.
One of the first core promoter motif identified was the TATA-box. The TATA-box recruits TFIID to the core promoter. Initially, it was thought to be an essential motif that most core promoters possess. We now know it is only present in a small minority. For example, 24% of human genes have a TATA-box. The core promoter motif found most often is the Initiator (Inr). This DNA motif spans the TSS and also recruits TFIID. That said, nearly half of human promoters lack both a TATA-box and an Inr! The take home message? There are no universal sequence motif required for transcription initiation in Eukaryotes. Not only that, but the sequence of each core promoter motif (i.e. TATA-Box) is variable to some degree. For example, the TATA-box in ACTA2 is TATATAA while the TATA-box in HERPUD1 is TATAAAA (ACTA2 and HERPUD1 are names of two distinct human genes).
In summary, textbooks imply that transcription starts at a precise location for any given gene. This appears to be more true for focused core promoters only. In reality, the majority of mammalian promoters are of the broad peak (BR) or dispersed type. Less is known about how these promoters recruit GTFs and initiate transcription.
5.2 Consensus Sequences
Sequence conservation can highlight which nucleotides are critical for trans-acting factor binding35 as “conservation indicates that a sequence has been maintained by natural selection”36. That said, sequence conservation is rarely absolute. For example, the actual sequence of a core promoter motif is variable to some degree. By creating a multiple sequence alignment of a conserved motif (ie. the TATA-box), one can evaluate the degree of conservation and create a consensus sequence. A consensus sequence (also known as a canonical sequence) can be defined as the “the most frequent residues, either nucleotide or amino acid, that are found at each position in a multiple sequence alignment” (Wikipedia). For a simple example, see Figure 5.3. Notice that the multiple sequence alignment contains only G, A, T and C while this consensus sequence contains additional letters (Y, N and R). Y,N and R belong to an agreed upon list of IUPAC nucleotide codes also known as IUPAC ambiguity codes. Here, Y = C or T, N = any nucleotide and R = G or A.
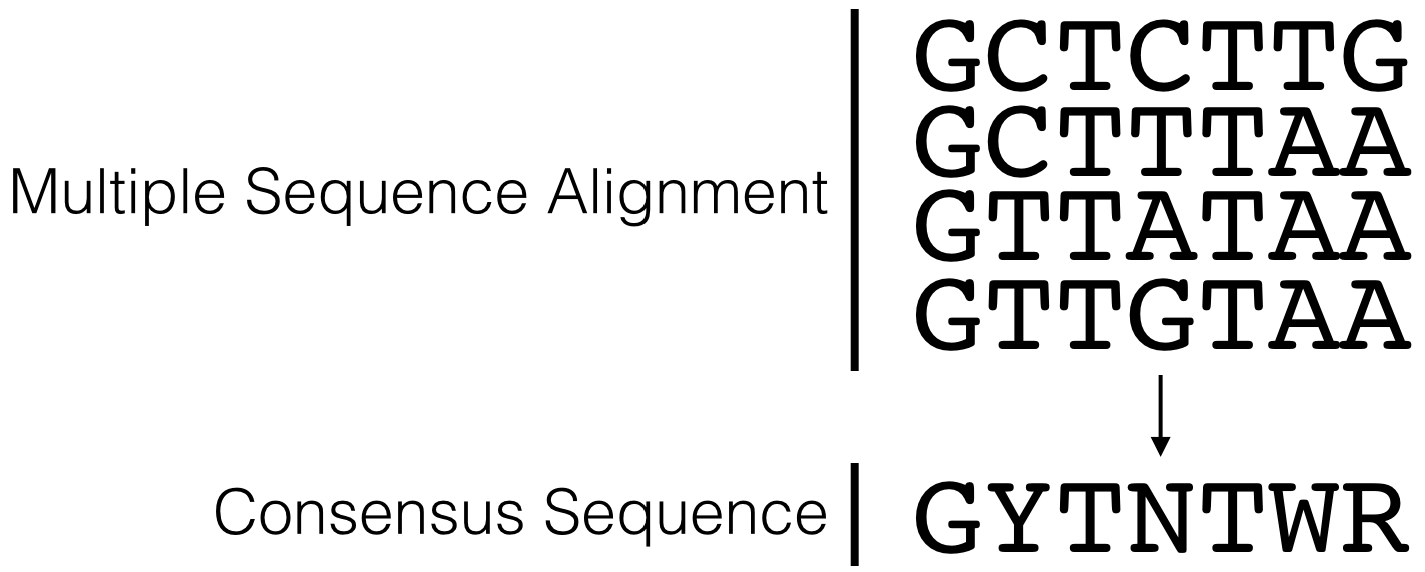
Figure 5.3: This is a simple multiple sequence alignment (MSA) that includes only 4 sequences. The consensus sequence corresponding to this alignment is written directly below. It was created by examining the observed frequency of each nucleotide present in each column of sequence in the MSA.
Figure 5.4 lists the consensus sequences for each core promoter motif bound by TFIID in mammals. In this figure the Inr consensus sequence is listed as BBCA(+1)BW (where B = C, G or T; W= A or T and the A is at the +1 position of the TSS). That said, there have been so many exceptions to this consensus sequence that some argue it should be reduced to YR(+1) where R is at the +1 position of the TSS (Haberle and Stark 2018)! My feeling is that this consensus sequence is so short and degenerate that it ceases to be useful. Probability suggests that this motif should present in the genome (on average) every 4 bp just by chance (1/2 x 1/2 = 1/4).
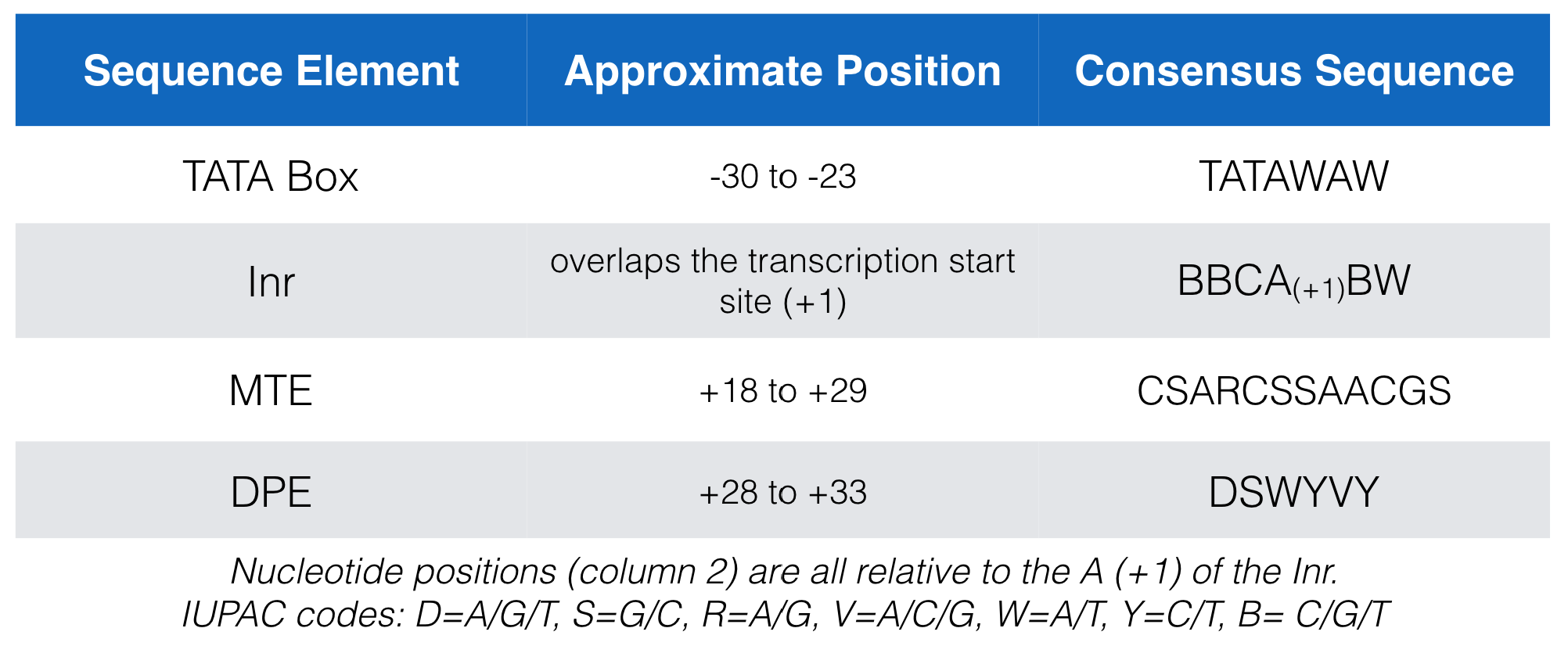
Figure 5.4: A list of the consensus sequences for each core promoter motif bound by TFIID in mammals.
5.3 Searching for a consensus sequence
You can search for a consensus sequence containing IUPAC codes using an evidence track called, “Short Match”. Before you open Short Match, open the saved “TSS-Seq” Session then zoom in to view the sequence surrounding the TSS for BBS1. Now scroll down to find an evidence track entitled, “Short Match” (1) within the section entitled, “Mapping and Sequencing” (Figure 5.5). Change this evidence track from “hide” to “pack” and click “refresh” (2). A new evidence track will open (3). Click on the gray rectangle at left to open the track settings page for this track (4).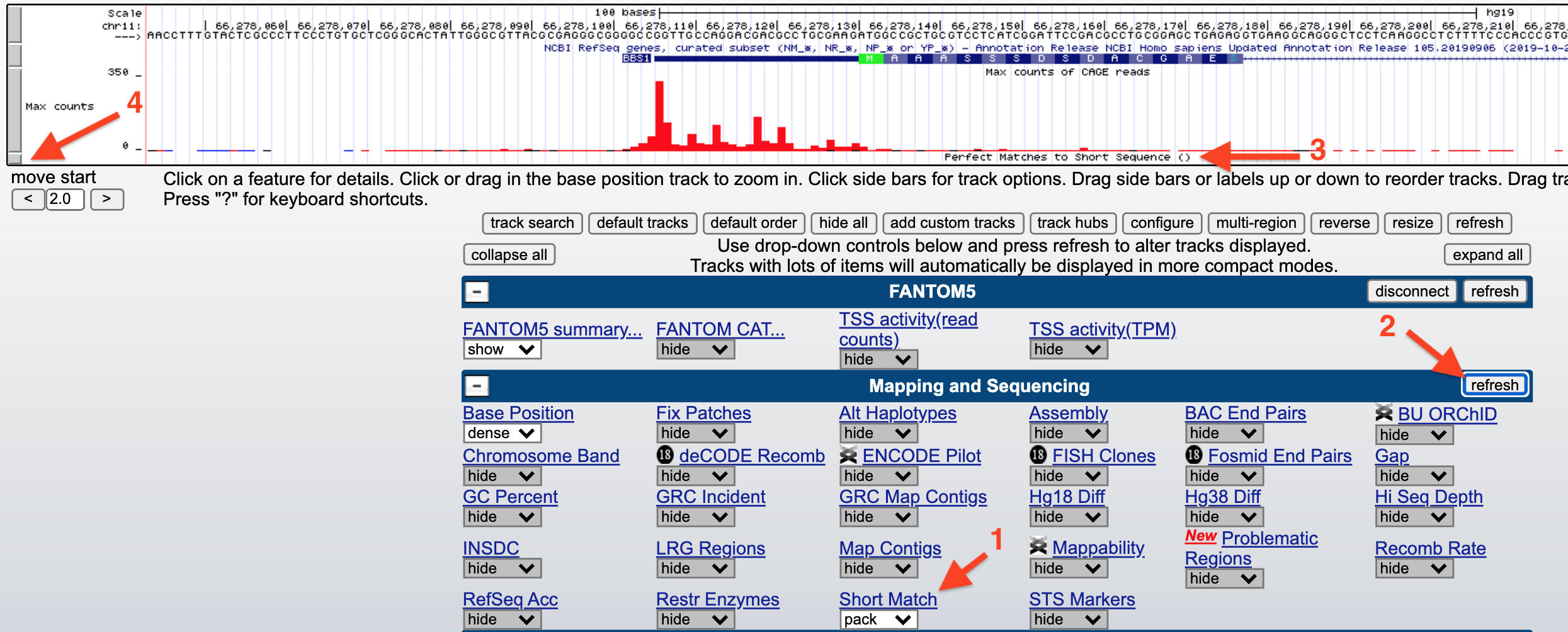
Figure 5.5: How to search for a consensus sequence: 1) change the Short Match evidence track from hide to pack. 2) Click Refresh. 3) A new evidence track will open. 4) Click on the gray rectangle to open the track settings page. Now see figure below.
Finally, input any sequence (i.e. ATG) into the search window (1) provided at the Track Settings page for Short Match (Figure 5.6) then hit “Submit” (2).
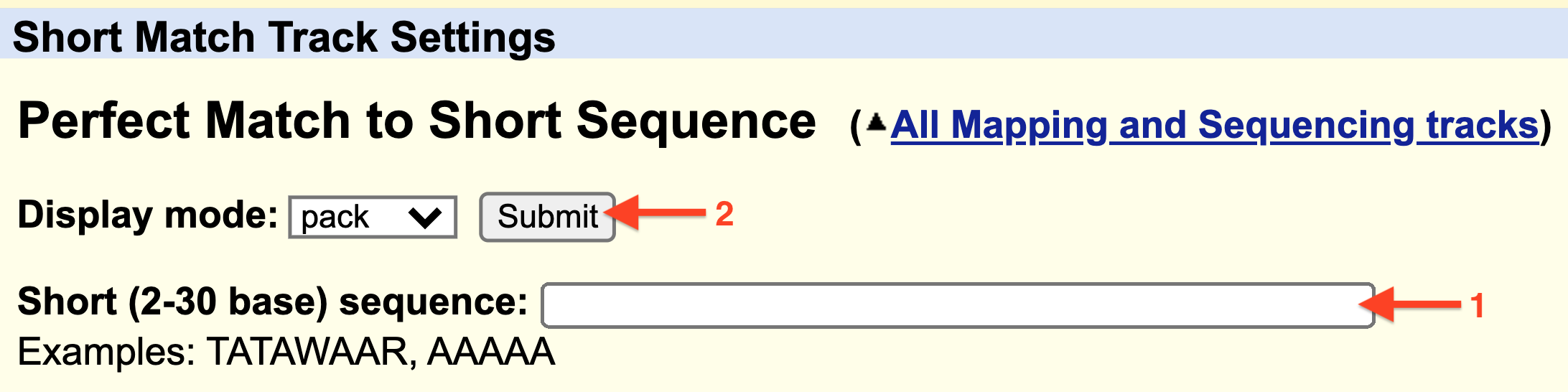
Figure 5.6: 1) Enter a consensus sequence in the window provided. 2) Click Submit.

Figure 5.7: Horizonatal black bars within the ‘Short Match’ evidence track describe the position of each consensus sequence (BBCA(+1)BW) found within this genomic region. Information about the precise nucleotide position and orientation is provided on the left (see boxed consensus on the left). The putative Inr for CCT2 is highlighted with a red asterix. This consensus sequence is found on the plus strand (same as CCT2) and is positioned directly below the experimentally defined TSS at 69,979,236 with the A at the putative +1 position.
5.3.1 Test your understanding
Click the link above to see the TYU questions.
5.4 Sequence Logos
Sequence conservation, trends and patterns revealed by a multiple sequence alignment (MSA) can also be visualized with a “sequence logo” where the predominant residue is drawn as the tallest and placed at the top among all the residues found at a given position in an alignment. For example, let’s say at position 3 of an MSA there is a T in every single sequence (For a simple example see Figure 5.8). In a sequence logo, this would be displayed as a T of maximum height (illustrating that the T in that position is invariant and important). Now let’s say position 6 has an A in 75% of the sequences and a T in the remaining 25%. At this position of a sequence logo you would see an A on top of the T, the A would be proportionally larger than the T but the overall height of the two letters combined would be shorter than the T in position 3. And in the extreme case where G, A, T or C are found in equal proportion that position in the sequence logo would be left blank (see position 4 in Figure 5.8)! This indicates that that position of the alignment is utterly uninformative. In a traditional consensus sequence using IUPAC codes, this would be written as “N” for any nucleotide. One can also draw a sequence logo using frequency for the Y-axis. This type of sequence logo is more intuitive but many think it is less able to emphasize important sequence trends. What do you think?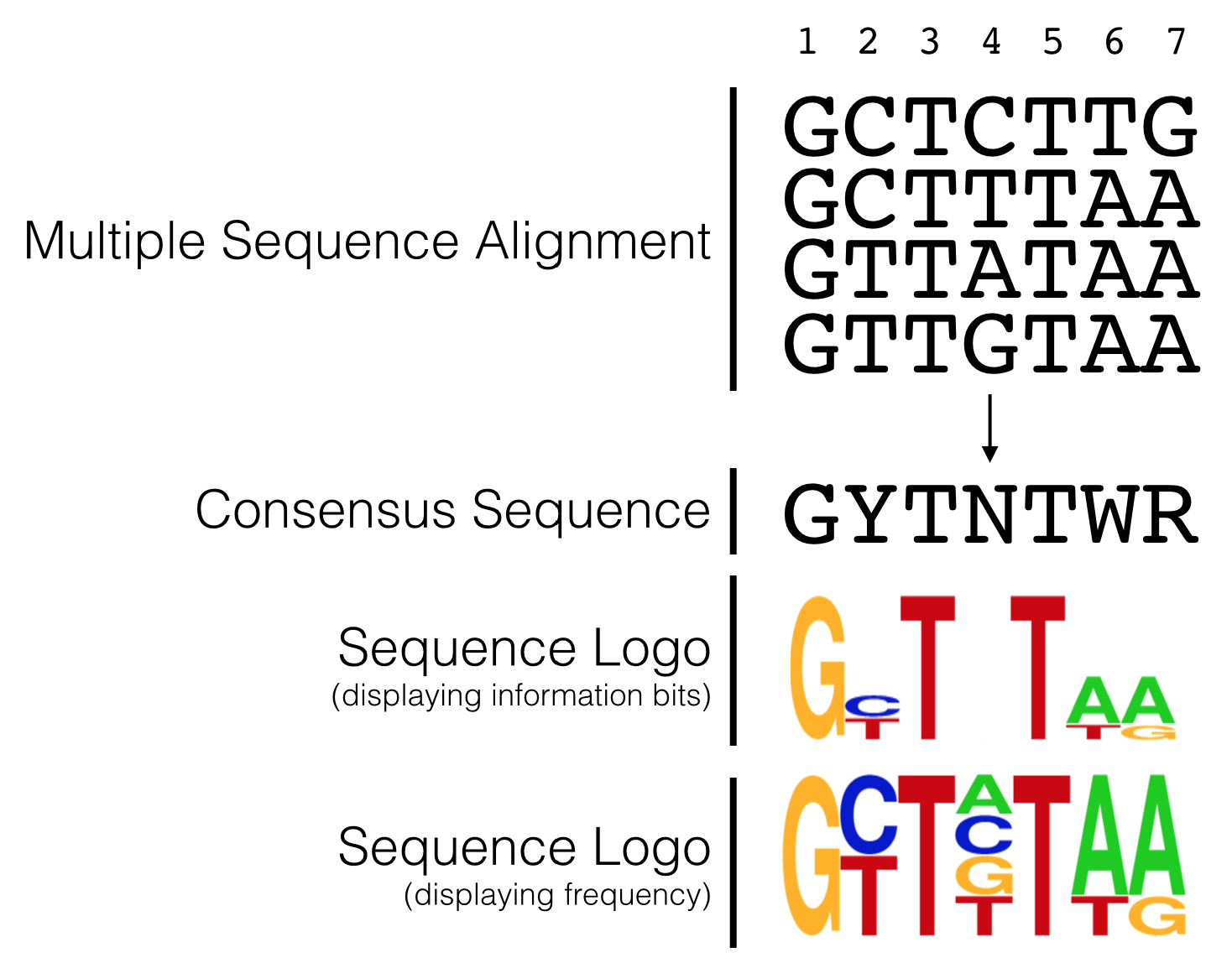
Figure 5.8: The hypothetical multiple sequence alignment is redrawn as a consensus sequence including IUPAC codes, or as a sequence logo with either information bits or frequency as the Y axis.
In 2006, Carninci et al. performed an unbiased, systematic analysis of all core promoter sequences identified by TSS-seq data obtained from RNA extracted multiple human tissue types. In their analysis confirmed the diversity of promoter types classifying them into four discrete categories (Figure 5.1) including the two extremes: Single Predominant Peak (SP) and Broad Peak (BR). They aligned core promoter sequences by category, placing the +1 position of the TSS in a single column then adding the surrounding sequences to create a large multiple sequence alignment. They then created a sequence logo for each multiple sequence alignment (MSA). Two are displayed in Figure 5.9. As you can see, the SP promoters are more likely to contain a TATA-box-like sequence about 30 nt upstream of the so-called Inr and there is a strong bias for a purine (G or A) at the +1 position of the TSS. Broad Peak (BR) promoters were found to be similar to SP promoters only in that they have a a strong bias for a purine at the +1 position of the TSS but they clearly lack a TATA-box and are enriched overall with Gs and Cs. Take home message: There are no universal promoter motifs. There may be sequence trends but there is a tremendous amount of sequence diversity at the core promoter. Clearly it would be very difficult to identify genes based solely on the presence of conserved core promoter sequence motifs.
What I have not discussed in this chapter is how a cell “knows” when and which tissue a gene should be transcribed. That requires far more than the core promoter sequence and can sometimes involves DNA sequence on other chromosomes! This is a topic for another course.
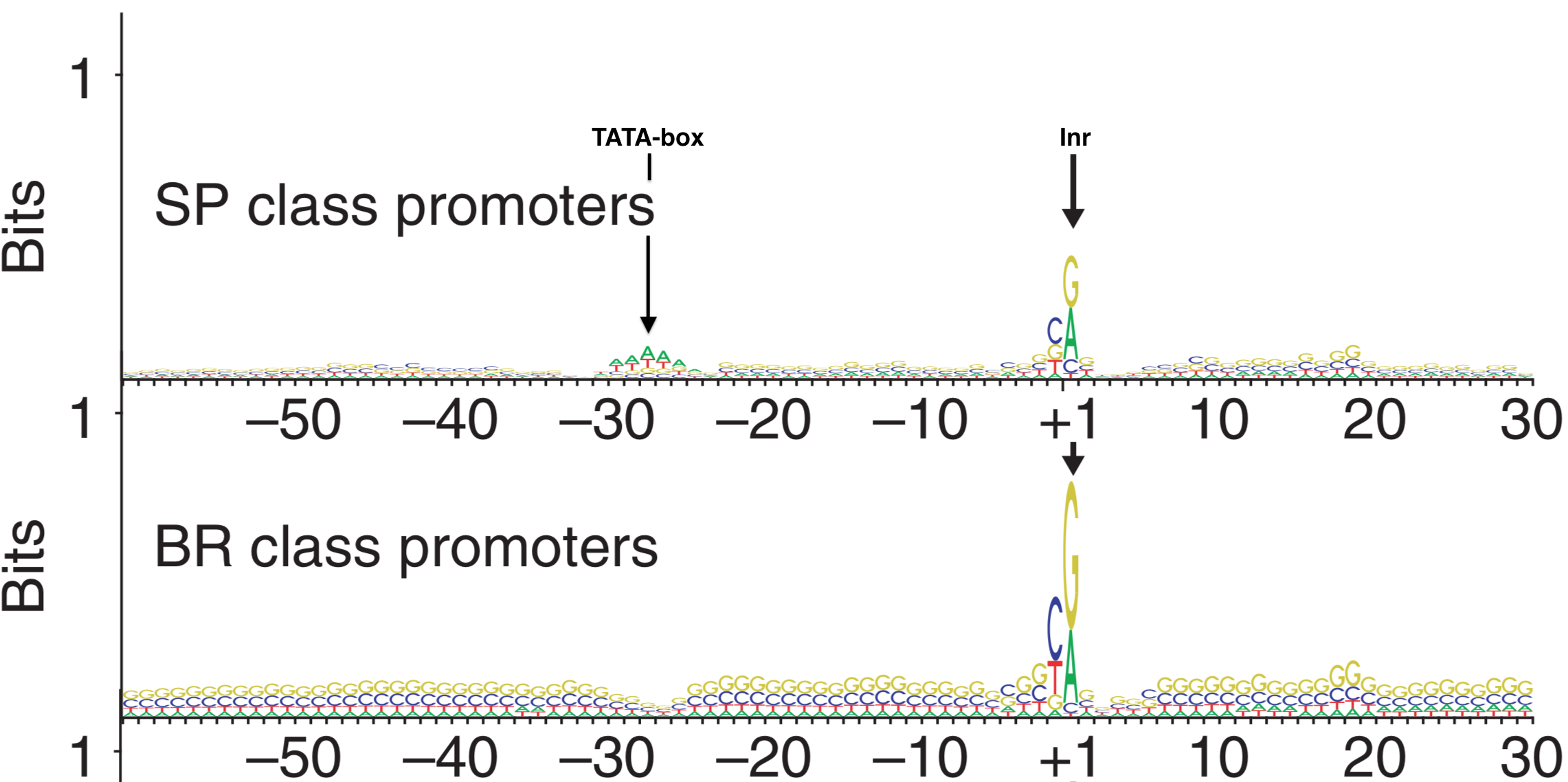
Figure 5.9: Sequence Logos for Single Predominent Peak (SP) and Broad Peak (BR) promoter types. The position of the TATA-box and Inr are highlighted in the SP class of promoters. The +1 represents the TSS.
5.4.1 Test Your Understanding
Click the link above to see the TYU questions.
© 2025, Maria Gallegos. All rights reserved.
GTFs for RNA polymerase II include TFIIA, B, D, E, F and H. Each GTF is a complex of proteins. For example, TFIID consists of 15 individual polypeptides encoded by 15 genes↩︎
extend both upstream and downstream of the TSS↩︎
Sequence motifs are short, recurring patterns in DNA that are presumed to have a biological function. Often they indicate sequence-specific binding sites for proteins - D’haeseleer 2006↩︎
formally defined as the level of transcription observed in an in vitro transcription system where only DNA containing a core promoter, an RNA polymerase II and GTFs are added. In other words, the level of transcription that is detected in the absence of other proteins that enhance or repress transcription (so called transcription factors). In fact, GTFs are also called Basal Transcription Factors.↩︎
I am deliberately vague here as the trans-acting factor, a freely diffusible molecule might be a protein, nucleic acid sequence or small molecule↩︎
Quote from Wikipedia article about conserved sequences↩︎
potential, possible, not experimentally proven without a doubt but some evidence in support of the possibility↩︎