2 Understanding Gene Structure
In this chapter, you will learn how genes are structured and how to recognize the different parts of a gene as illustrated in the UCSC genome browser. To follow along with the text and to answer the “Test Your Understanding” questions, start with the BBS1 session link. You can also use this link as a starting point to view gene structure for any gene of interest by typing the name of your gene of interest in the search window.
2.1 Exons and Introns
During gene expression, one continuous strand of genomic DNA is used as a template to produce a single-stranded RNA transcript. This process is called transcription. The sequence of this RNA transcript is identical to the nontemplate strand of genomic DNA (although uracil replaces thymine in RNA). Before the transcript is exported out into the cytoplasm, it is processed including the removal of internal segments called introns (or intervening regions). All the RNA segments that remain are called exons (or expressed regions). They are then linked back together in order. To view the exon/intron organization of BBS1, click on the BBS1 session link, and review the schematic within the NCBI RefSeq Gene Prediction Evidence Track. Notice, the BBS1 gene consists of “boxes” connected by lines (Figure 2.1). The boxes represent exons (two examples are highlighted with a red bracket/asterix). The lines represent introns (one example is highlighted with a purple bracket/asterix). Now, hover your mouse over various parts of the gene schematic within the Browser window. If you pause long enough a popup window should appear indicating which intron or exon you are pointing to among the total number! Thus, this popup window also reveals the location of the beginning of a gene (i.e. exon 1 is always at the beginning of the gene!). This is the part of the gene that is transcribed first. For BBS1, exon 1 is located on the left side of the gene schematic.

Figure 2.1: Understanding the gene prediction evidence track schematic. Boxes represent exons (two examples are bracketed and highlighted with a red asterix). The lines represent introns (one example is bracketed and highlighted with a purple asterix)
A close up view of an intron-exon junction is displayed in Figure 2.2, See the asterix, the intron is to the left, exon to the right). Now you try it. Zoom into any exon-intron junction.
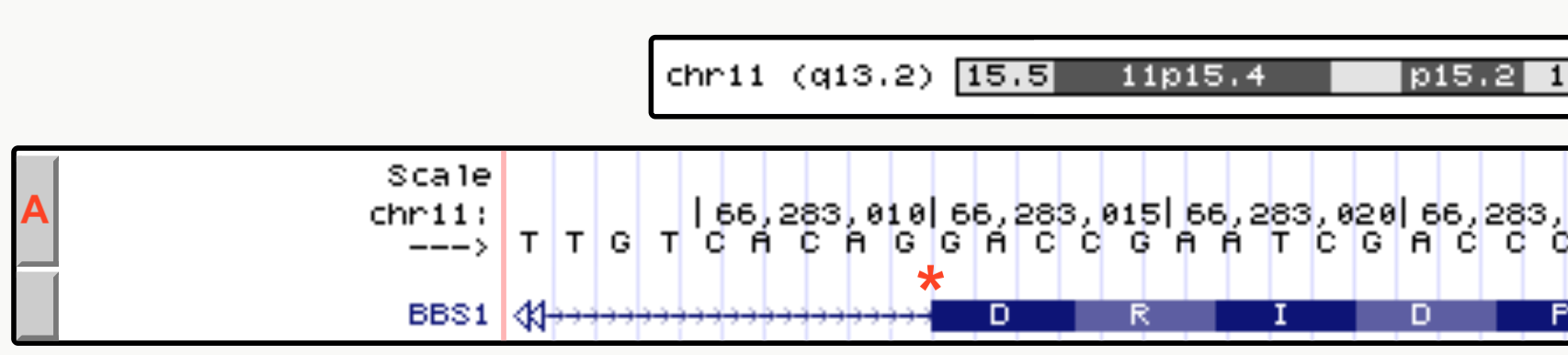
Figure 2.2: The drag-select tool was used to zoom in close to a small portion of an exon intron junction of BBS1. As you can see the first 4 nucleotides of the exon shown are G-A-C-C.
2.1.1 Test your understanding
Click the link above to see the TYU questions.
2.2 Coding and Noncoding Exons
The spliced transcript or messenger RNA (mRNA) is used as a template to create a polypeptide11. This process is called translation and is mediated in part by the ribosome12. Ribosomes “read” the mRNA from 5’ to 3’, three nucleotides at a time, translating the triple nucleotide code into a sequence of amino acids. Each set of three nucleotides is called a codon. Codons either specify the incorporation of an amino acid in a growing polypeptide chain or signal the end of polypeptide synthesis. Codons with the latter function are called “termination codons” or simply “stop codons” (Figure 2.3).
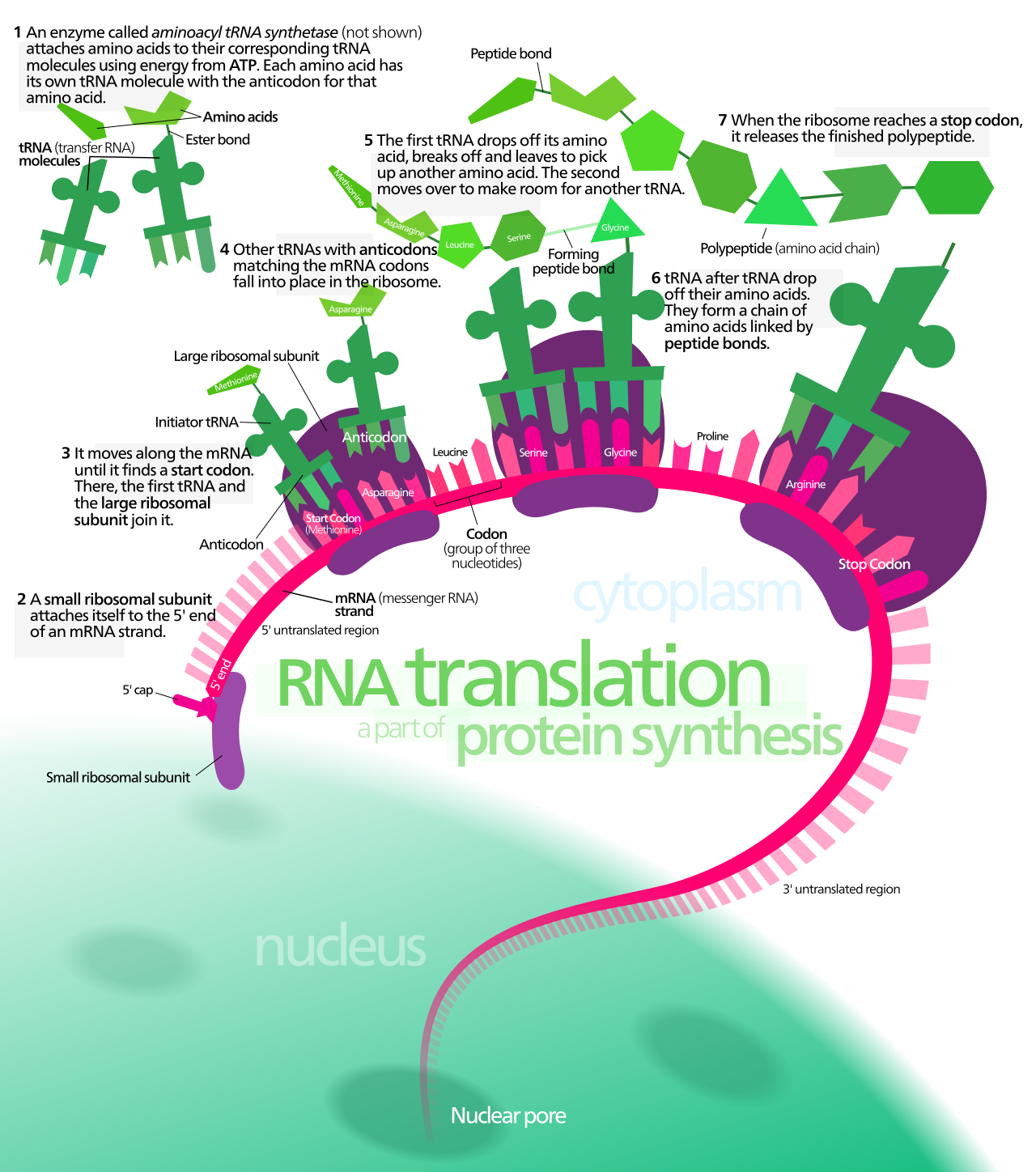
Figure 2.3: A schematic representation of translation. Image by Kelvinsong
That said, ribosomes don’t start translation at the 5’ end of the mRNA but from a “start codon” located internally. Nor do ribosomes read to the end of the mRNA but only until they encounter a stop codon. Thus, an mRNA is more than just codons and those codons only occupy the central region of an mRNA. The 5’ and 3’ ends of the mRNA not “read” by the ribosome are called “noncoding regions” or “untranslated regions” (UTRs). The noncoding region at the 5’ end is called the 5’ untranslated region (5’ UTR) while the noncoding region at the 3’ end is called the 3’ untranslated region (3’ UTR).
Figure 2.4 shows how noncoding (blue box) and coding regions (green box) of an exon (red box) are illustrated in the UCSC Genome Browser. The noncoding portion is not as thick as the coding portion. At this zoom level, the coding portion also displays the amino acid sequence that this exon codes for: M-A-A-A-S-S-S-D-S-D-A-C-G-A-E-S (notice each amino acid is placed below 3 nucleotides, the codon). Again, notice how the amino acid sequence does not start at the beginning of exon 1 (red box). This thinner portion of exon 1 is the 5’ untranslated region (5’ UTR). Importantly, exon 1 includes both the noncoding and coding portions. To confirm that you are looking in the right places, the BBS1 5’ UTR (the beginning of exon 1) begins with the sequence G-G-T-T. The coding portion of exon 1 begins with the sequence A-T-G-G. Exon 1 ends with the sequence, AGAG. The intron begins with the sequence G-T-G-A.

Figure 2.4: Exon 1 (red box) of BBS1 is part noncoding exon (blue box) and part coding exon (green box)
Now use the BBS1 session link to go to BBS1 in the UCSC genome browser. Notice how the transition from noncoding to coding (at the 5’ end of the transcript) and back to noncoding (at the 3’ end of the transcript) does not coincide with exon/intron boundaries. Thus, an exon can be categorized as a coding exon, a noncoding exon or an exon of mixed character. In fact, exon 1 of BBS1 is part noncoding (5’ UTR) and part coding. The same is true for exon 17 of BBS1 (the last exon). The remaining exons are all coding exons.
Now zoom into the last coding exon of BBS1 (the coding portion of the last exon) by using the “drag and select” tool. If your view does not resemble Figure 2.5, you may have selected the entire last exon when you should have just selected the coding portion of the last exon OR your evidence is configured incorrectly13.
In Figure 2.5, you can clearly see that the amino acid sequence stops before the end of the last exon and the exon schematic transitions from thick to thin. You can also see that the stop codon is represented by an asterix and colored red. In many genes, the first and last exons include both noncoding and coding sequence. As you explore more genes in the genome, you will see there are many exceptions. Sometimes the first one or more exons and/or the last one or more exons are completely noncoding! Finally, notice that while red codons ALWAYS represent stop codons, green codons do not ALWAYS represent start codons! In fact there is a green codon in the last coding exon. The UCSC genome browser simply highlights all A-T-G codons in green. Only those green codons at the beginning of a coding sequence are called start codons.

Figure 2.5: The coding portion of the last exon of BBS1 ends with the stop codon, a red codon containing an asterix. The 3’ UTR begins directly after the stop codon.
2.2.1 Test your understanding
Click the link above to see the TYU questions.
2.3 Coding Exons Determine Protein Sequence
A polypeptide is a sequence of amino acids linked together by peptide bonds. The amino acid sequence is determined by the order of codons present in the central portion of an mRNA (the coding exons). Each codon consists of a nonoverlapping set of three nucleotides. Since there are four nucleotides in total (G, A, T and C), there are a total of 64 possible codons (4 x 4 x 4). Most of the 64 codons code for an amino acid. Three do not and therefore act as STOP signals also known as “termination codons” or “stop codons”. Figure 2.6 is one way to display the genetic code. In this graphic, RNA codons are read from the center out to the periphery (from 5’ to 3’). For example, G-C-A codes for Alanine. Ala and A are the standard three letter and single letter codes, respectively. U-U-G codes for Leucine. Confirm this for yourself to make sure you know how to use this genetic code.
](static/images/circulargeneticcode.png)
Figure 2.6: Image from Wikipedia: Aminoacids_table.svg
{kind=link}
Click on the BBS1 session link, then use the “Drag-and-Select” method to get a close-up view of exon 1. Look directly above the beginning of the coding portion of BBS1 and you will see that the first codon of BBS1 is A-T-G. Using the genetic code from Figure 2.6 you can confirm that this codes for Methionine, Met or M and is labelled as a start codon14. Also confirm that you read the second codon as G-C-C and the third codon as G-C-T. Both code for Alanine (Ala, A). This exercise also shows that the mRNA sequence for BBS1 is identical in sequence and orientation to the top strand of the genome (but of course without the introns). Recall, by default the top strand (+ strand) is displayed in the browser window. It is oriented from 5’ on the left to 3’ end on the right. You can confirm this by checking the arrow positioned in the top left corner (See the asterix in Figure 2.4). Your arrow should be pointing to the right. The orientation of the mRNA is also consistent with the fact that codons are read from 5’ to 3’ (in this case from left to right).
2.3.1 Test your understanding
Click the link above to see the TYU questions.
2.4 One gene, many splice variants
A single RNA transcipt is sometimes spliced in a variety of different ways to produce more than one unique mRNA. This is called alternative splicing and each mRNA produced is called a splice variant. Since each splice variant has the potential to produce a unique protein or isoform, the 24,000 protein-coding genes in the human genome can actually produce many more than 24,000 unique proteins!
To see how the UCSC genome browser illustrates splice variants, click on the BBS1 session link then zoom out exactly 10X to explore a larger section of chromosome eleven15. Now more than one gene is present in the browser window. Again, the name of each gene is given on the left side of each gene/transcript schematic. Regions of the genome that are transcribed to produce multiple mRNAs are indicated by a series of box/line schematics that are stacked vertically. How do I know these stacks represent a single gene? Each graphical representation in the stack has the same gene name (Figure 2.7). That said, each graphical representation in the stack has a unique mRNA ID (i.e. NM_005700.5). This is your indication that each mRNA sequence is unique in some way. One obvious difference observed for DPP3 is highlighted with a red arrow in Figure 2.7. Notice that the 2nd and 3rd splice forms have an exon not included in the topmost splice form listed.

Figure 2.7: Notice how DPP3, highlighted with a red box, begins and ends transcription at the same location but the RNA transcript that is produced is spliced in three distinct ways to produce three alternative splice forms. One obvious difference is highlighted with a red arrow. The 2nd and 3rd splice forms have an exon not included in the topmost splice form listed.
Alternative splicing is only one way multiple unique mRNAs are produced from a single region of DNA (a single gene)? There are three main methods:
- Use of an alternative transcriptional start site (Figure 2.8),
- Use of an alternative transcriptional termination site (Figure 2.9) and
- Alternative splicing (Figure 2.7).

Figure 2.8: Transcription initiation for the LGALS12 gene can be found at two distinct places according to the NCBI RefSeq gene database. The red arrow points to the two transcription start sites

Figure 2.9: Transcription termination for the TTC17 gene occurs at two different sites according to the NCBI RefSeq gene database. Each is highlighted with a red arrow
Again, multiple mRNA variants produced by the same gene can (but don’t always) produce multiple, unique protein isoforms. In some cases, these unique proteins differ enough to function distinctly. For a hilarious illustration of this concept see Figure 2.10.
Figure 2.10: Concept/Art by Allan James from the University of Glasgow
2.4.1 Test Your Understanding
Click the link above to see the TYU questions.
2.5 Top strand and bottom strand genes
We learned in a previous section that BBS1 codons can be viewed in the top strand of the genome (also known as the + strand). This is because BBS1 uses the bottom strand (- strand) as template during transcription to produce a transcript identical in sequence to the top strand of DNA16. I like to call BBS1 a top strand gene (or + strand gene). For top strand genes, the top strand can be described as the sense strand, coding strand, informational strand or nontemplate strand. My favorites are “nontemplate strand” and “informational strand”17. For top strand genes, the bottom strand (- strand) is known as the template strand. This is because the bottom strand of DNA is used as the template to create the RNA transcript.
Not all genes are top strand genes (+). To determine if a gene is a top strand gene (+) or a bottom strand gene (-), click on the gene schematic to open a pop up window of information about the gene. Scroll down to find the word, “Strand:” (See Figure 2.17). Alternatively, look at the gene schematic itself. Figure 2.11 displays the first half of BBS1 and a neighboring gene, ZDHHC24. Notice there are “orientation wedges” spaced regularly along the introns. They are either oriented to the right (red box, Figure 2.11) or to the left (green box, Figure 2.11). These “orientation wedges” indicate the direction RNA polymerase travels during transcription and thus the orientation of the gene on the chromosome. These “orientation wedges” indicate that BBS1 is a top strand gene (+) and ZDHHC24 is a bottom strand gene (-).

Figure 2.11: The orientation wedges are visible within introns. When they point to the right (red box), the gene is a top strand gene (plus strand). When they point to the left (green box), the gene is a bottom strand gene (minus strand).
When the orientation wedges point to the right, “) ) ) )” (i.e. see BBS1),
- This is a top strand gene (+).
- The beginning of the gene is on the left.
- The top strand of DNA is the informational strand (nontemplate strand)
- The bottom strand of DNA is the template strand.
- You would read this gene from left to right.
When the orientation wedges point to the left, “( ( ( (”, the reverse is true (i.e. see ZDHHC24),
- This is a bottom strand gene (-).
- The beginning of the gene is on the right.
- The top strand of DNA is the template strand.
- The bottom strand of DNA is the informational strand (nontemplate strand)
- You would read this gene from right to left!
2.5.1 Test your understanding
Click the link above to see the TYU questions.
Now let’s look at a bottom strand gene (ZDHHC24) more closely. Click on my saved session for BBS1 then zoom out 3X to search for the beginning of ZDHHC24 (it should be on the right). “Drag-and-Select” as many times necessary to zoom into the first half of the coding portion of exon one for ZDHHC24. Your “NCBI Refseq Gene Track should look something like Figure 2.12. If not, you may have zoomed into the first half of exon one which is noncoding. Or maybe you are at the wrong end of the gene!

Figure 2.12: This is the first half of the first coding exon of ZDHHC24. The noncoding portion of exon 1 extends to the right this time because ZDHHC24 is a bottom strand (or minus strand) gene. The red oval highlights the strand you are currently viewing. Since the arrow points to the right, the top strand (5’ on the left) is displayed. You can toggle this arrow with your mouse.

Figure 2.13: Again, this is the first half of the first coding exon of ZDHHC24. The red oval highlights the strand you are currently viewing. Since the arrow points to the left, the bottom strand (5’ on the right) is displayed. Notice that the DNA sequence is gray. Compare to the top image. This is a visual reminder of which strand you are viewing.
Look at the three nucleotides centered above the Methionine (colored in green on the right side of Figure 2.12). Notice that the nucleotides listed from left to right is NOT an A-T-G as you might expect but instead C-A-T! This is because you are “reading” the top strand of the genomic DNA and ZDHHC24 is a bottom strand gene. To view the bottom strand of the genomic DNA, click on the far left arrow within the Base Position Track (See the red oval, Figure 2.12). Notice the orientation of the arrow will flip and the genome sequence in your “Base Position” Track will become light gray (red oval, 2.13). Now there is an A-T-G directly above the Methionine (M) but only if you read it from right to left! This is because the bottom strand of DNA is oriented with 5’ end on the right.
2.5.2 Test your understanding
Click the link above to see the TYU questions.
To summarize . . . while DNA is double-stranded, RNA transcripts are single-stranded and thus use only one DNA strand as template (either the top or bottom strand). Some genes, like BBS1, use the bottom strand as template to create an RNA transcript with a sequence that matches the top strand. Other genes, like ZDHHC24, use the top strand as template to create an RNA transcript with a sequence that matches the bottom strand.
2.6 Reading Frames
Translation begins at the start codon. This is the first codon “read” by the ribosome. All subsequent codons are read in nonoverlapping groups of three. Thus, the start codon “sets” the reading frame. A reading frame ends only when a stop codon is encountered that is in the same reading frame as the start codon. This is the last codon “read” by the ribosome.
Imagine you isolate and sequence a short random stretch of DNA pulled from the ocean. It is likely genomic DNA and you want to see if it corresponds to a coding portion of a gene. Specifically, you want to see if this short stretch of DNA codes for a previously studied protein. Of course, you have no clue which strand might be used as a template for transcription nor where the start codon is. Here is a thought question: What is the maximum number of polypeptide sequences that can hypothetically be created by a single segment of double-stranded DNA? Your answer will be revealed below.
To view all possible reading frames associated with a given segment of DNA zoom into to the first exon of BBS1. Next, right click on the grey rectangle corresponding to the Base Position track (See arrow, Figure 2.14). A pop-up menu will appear. Choose “full”.

Figure 2.14: How to view all three reading frames for a single strand of DNA. Right click on the gray rectangle on the left of the Base Position Track (red arrow). A pulldown menu will open. Choose Full.
You should now see three reading frames displayed below the nucleotide sequence. Why three? This is the maximum number of unique polypeptides that can be theoretically produced from a given segment of the top strand of DNA. See what happens when you toggle to the bottom strand of DNA (click the arrow —> on the far left of the DNA sequence). Now you can view the three reading frames that correspond to the bottom strand of DNA. Both views are shown one on top of the other in Figure 2.15. Notice they are different.


Figure 2.15: Once you change the base position track to Full, the three possible reading frames for a single DNA strand will be displayed. When the arrow points to the right, the three reading frames will be of the top strand (top image). Notice the start codon in green matches the start codon in the third reading frame (NOTE: This image comes from the 2013 genome assembly and will look different for you.) In fact, nearly all of the amino acids in exon one match the amino acids in the third reading frame. We expect one of the three top strand reading frames to match BBS1 since BBS1 is a top strand gene. Now , however, when the arrow points to the left (circled in red), the three reading frames displayed are for the bottom strand (bottom image). Now none of the amino acids in the three reading frames match the amino acids found in BBS1.
The three reading frames corresponding to the top strand are numbered +1 (top), +2 (middle) and +3 (bottom). The three reading frames corresponding to the bottom strand are numbered -1 (top), -2 (middle) and -3 (bottom). For convenience, the position of all possible start codons are highlighted in green and all possible stop codons (*) are highlighted in red.
Now, zoom out until you can see the first three exons of BBS1 (Figure 2.16). At this level of zoom, you should still be able to read the amino acid sequence within the gene schematic and within the base position track. Notice there are many “start” and “stop” codons scattered throughout this segment of the genome (red and green boxes). This should not be surprising given that start and stop codons are only three nucleotides in length and thus they occur by chance. That said, the ability of an ATG or TGA, TAA, TAG to function as a start or stop codon, respectively, depends on context. For example, the real start codon for a given gene is typically the first start codon encountered in an mRNA as the Ribosome scans the mRNA from 5’ to 3’ (more about this later).
Figure 2.16: All ATG codons are colored green regardless if they function as a start codon or not. Similarly, all TGA, TAA and TAG codons are colored red regardless if they function as a stop codon. How these triplets function depends on context.
Now, notice that the amino acid sequence within the coding exons of BBS1 always match one of the three reading frames. For our example, the coding portion of exon 1 begins with a methionine (highlighted in green). The +3 reading frame also has a methionine in this same position. Compare a few more amino acids in BBS1 and the +3 reading frame. You should see that all match (except one - do you see which one?). Thus, coding exon 1 utilizes the +3 reading frame!
Which reading frame do the other coding exons utilize? Is it always the same reading frame? Or does it change from exon to exon. New trick: To easily view exons farther downstream (or 3’ of), click on the open arrow head on the far right (See hot pink arrow at the far right of the image, Figure 2.16). Also, if you hover over the open triangle and don’t click, a small pop up will appear with information about which exon you are jumping to! This may come in handy while answering the following questions.
2.6.1 Test your understanding
Click the link above to see the TYU questions.
2.7 To learn more about your gene of interest.
Click on the gene schematic in the “Gene and Gene Predictions track”. This action will open a page that provides many useful links including links to view and analyze the mRNA and protein sequences (Figure 2.17). Do this for BBS1.

Figure 2.17: When you click on a gene/transcript schematic in the gene prediction track you are taken to its gene information page. BBS1 only has one isoform and so there is only one gene information page. In other words, this information is transcript specific and depends on which isoform you click on. Useful links are highlighted. Some links will help you answer Test Your Understanding questions. Explore!
For example, to view information about the BBS1 mRNA, click on the NM_024649.5 link. To view information specifically about the protein sequence, click on the NP_078925.3 link. NM_024649.5 and NP_078925.3 are so-called as accession codes. Accession codes that begin with NM_ correspond to mRNA sequences. While those that begin with NP_ correspond to protein sequences. By default, both sequence pages are in so-called “Genbank format”. This format includes useful annotations that can be “read” by sequence analysis software programs. The actual mRNA or protein sequence is at the very bottom of the page. Scroll down. Alternatively, click the “FASTA” link to see the sequence in a simpler format. One thing you might notice: There are no uracil bases (U) in the mRNA sequence! Sequence databases do not expend any computational energy to convert thymines (T) to uracils (U) for display purposes only. Explore the remaining links and bits of information as this information will help you answer the Test Your Understanding questions below.
2.7.1 Test Your Understanding
Click the link above to see the TYU questions.
© 2025, Maria Gallegos. All rights reserved.
A polypeptide is a chain of amino acids linked together by peptide bonds. While the words “protein” and “polypeptide” are often used interchangeably, the term protein is more vague. It could refer to a single polypeptide or it might mean multiple polypeptides bound together in a complex. On the other hand, polypeptide always refers to a single sequence of amino acids↩︎
A cytoplasmic machine (comprised of RNA and protein) which uses the mRNA as a template to synthesize a polypeptide.↩︎
IMPORTANT: If you do not see the amino acid sequence displayed over the coding exon schematic, you may need to zoom in farther. That said, if you are zoomed in enough to see the genome sequence, and you still don’t see the amino acid sequence then something else is wrong. Right click on the gray rectangle corresponding to the NCBI RefSeq Gene Prediction track and choose, “Configure RefSeq Curated”. Then change “Color track by codons:” from “OFF” to “genomic codons”↩︎
NOTE: Genome browsers only display DNA sequence. So you will always need to mentally change all “T” nucleotides to “U” nucleotides in order to use a genetic code↩︎
Notice that at this zoom level some exons simply look like vertical lines. This is because, exons are typically shorter than introns (at least in mammals) and so at this zoom level exons look like lines instead of boxes↩︎
Except that Uracil replaces Thymine↩︎
“Coding strand” is misleading because it implies that the entire transcript is coding - not true. “Sense strand” is just not very informative. I like “informational strand” because this is the DNA strand where you will find important sequence information in the RNA - for example, the codons or RNA binding sites that might impact translation or RNA stability. You can’t argue with the term “nontemplate strand”. It’s clearly accurate↩︎