Chapter 2 Build Database
2.1 SQL
對於專題接下來會用到的資料,因為繁雜眾多,我們決定透過SQL來整合成一個資料庫,因此我們學了RSQLite以及DBI這兩個新package。學習過程中我們快速了解到SQL的核心是──CRUD。
以下為SQL插入資料的範例指令
insert_statement <- "INSERT INTO reits_stock (time, stock_price, outstanding_share, market_value, stock_id, name) VALUES ('2005-10-05', 6.198, 1393000, 8633814, '01002T', '國泰一號');"
dbExecute(con, statement = insert_statement) 若想將幾千筆以上的excel資料整合到db檔案,上述一筆一筆手動插入絕對行不通。因此我們運用string format的技巧,利用For loop快速插入。
首先定義一個運算子。
`%--%` <- function(x, y)
{
do.call(sprintf, c(list(x), y))
}接下來轉化原本的插入指令成
insert_data <- function(a1,a2,a3,a4,a5,a6)
{
insert_statement <- "INSERT INTO sat (time, stock_price, outstanding_share, market_value, stock_id, name) VALUES (%s, %s, %s, %s, %s, %s);" %--% c(a1,a2,a3,a4,a5,a6)
dbExecute(con, statement = insert_statement)
}就可以很快把excel資料匯進我們的資料庫。
而我們專題設定了6個表格。
con <- dbConnect(RSQLite::SQLite(), dbname = db_path)
dbListTables(con)## [1] "all_index" "m_index" "re" "sp"
## [5] "tr_index" "wr"2.2 網路爬蟲獲得國外REITs資料
Yahoo Finance有日本REITs股價資料,我們想起老師曾介紹的quantmod套件,真的很快速又方便下載到我們想要的資料。
data <- read_excel("C:/User/Downloads/Japan.xlsx")
getSymbols(data$stock_id, src = "yahoo", from = "2016-06-28", to = "2021-06-28")
數據爬下來後為xts檔,其好用之處在於,即使各檔第一列起始時間不同,merge()會自動對齊時間,用在時間序列資料處理真的很方便。
dataset<- xts()
for(i in data$stock_id)
{
dataset <- merge(dataset, Cl(get(i)))
}
write.zoo(dataset, file = "Japan_Close.csv", index.name = "time",
row.names = FALSE, col.names = TRUE, sep = ",")2.3 NA值處理
當我們在處理NA值發現,NA值過多的資料在轉換時出現布林值而非我們所設定的0。
2.3.1 guess_max的運用
查閱相關資料後發現原來guess_max預設值為1000,當超過前1000筆資料都是NA值,系統將自動判斷vector為logi型態,在處理缺失值data[is.na(data)] <- 0將會得到False,導致無法進行後面運算。
因此我們學到,如果資料樣本數大且NA值可能很多(例如京城樂富一號2018.12.05起才有資料),應在讀取檔案時提高guess_max上限。
data <- read_excel("C:/Users/Download/t-reits.xlsx", guess_max = 10000)
# NA
data[is.na(data)] <- 02.4 Outlier處理
在處理outlier這一方面,我們利用ggplot畫出箱型圖來找出outlier,再使用新函數layer_data(),可以清楚看到數據的統計量,很實用!
data %>% ggplot + geom_boxplot(aes(x = Nation,y = `Average Return`))## Warning: Removed 102 rows containing non-finite values
## (stat_boxplot).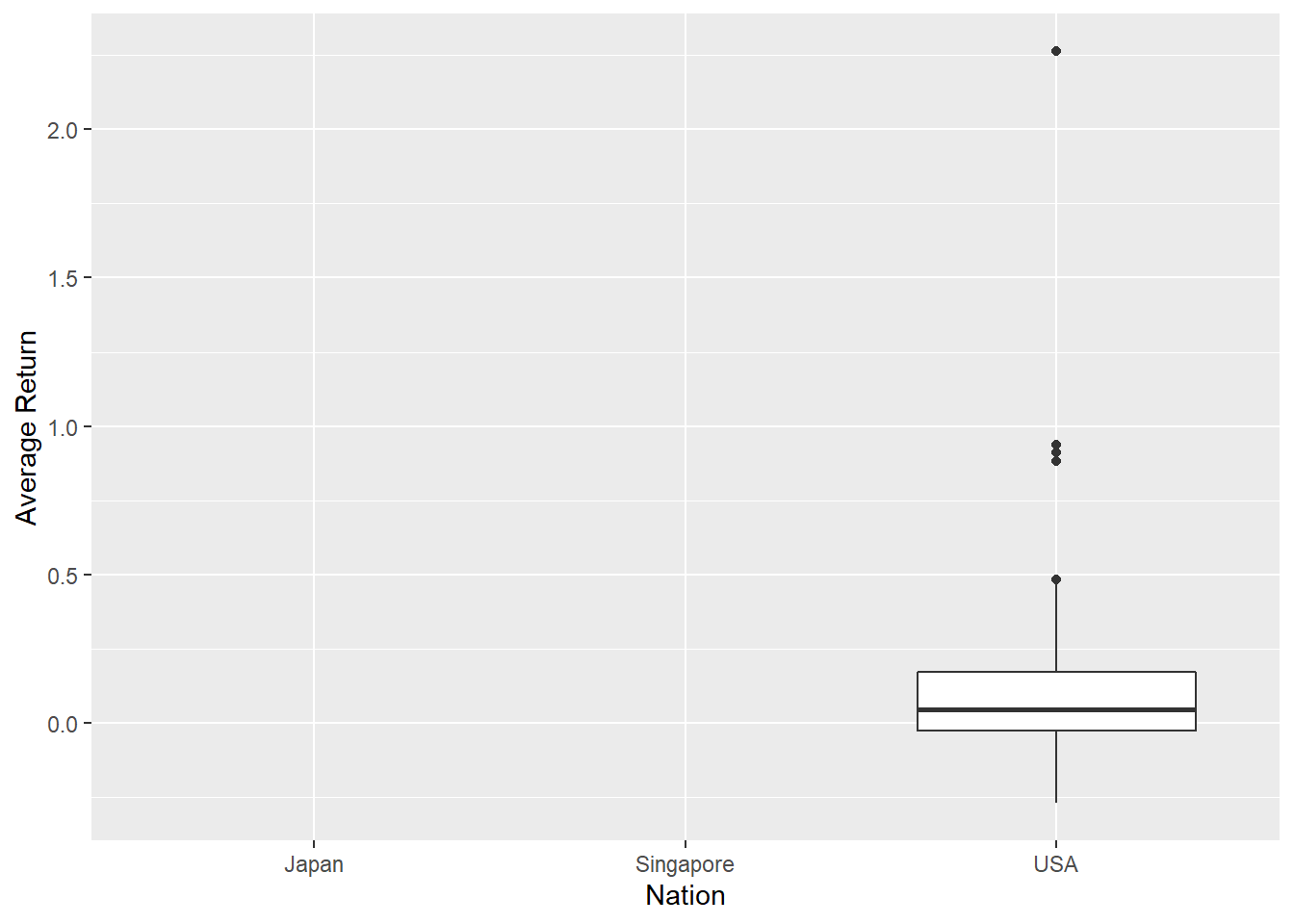
plot <- data %>% ggplot + geom_boxplot(aes(x = Nation,y = `Average Return`))
plot_data <- layer_data(plot)## Warning: Removed 102 rows containing non-finite values
## (stat_boxplot).outlier_data <- layer_data(plot)['outliers']## Warning: Removed 102 rows containing non-finite values
## (stat_boxplot).outlier_data## outliers
## 1 0.4828, 0.9388, 2.2629, 0.9112, 0.8813