2 Chapter two: Assembly and description of the P. georgianus mitogenome
2.1 Introduction
The general structure of the mitochondrial genome is typically well conserved among ray-finned and cartilaginous fish and gene rearrangements are uncommon (Satoh et al. 2016). These mitogenomes are typically composed of thirteen protein coding genes, twenty-two tRNA’s, two rRNA’s, one noncoding control region (Avise et al. 1987) and intergenic regions of variable sizes, similar to other vertebrates (Satoh et al. 2016). The start and stop codons for protein coding genes are variable, although there are common gene-specific codons among ray-finned and cartilaginous fish (Satoh et al. 2016). The most variable structure of fish mitogenomes is the gene length (Satoh et al. 2016).
Complete mitogenome sequence data has traditionally been obtained using direct Sanger sequencing and/or mitochondrial DNA re-sequencing (MitoChip) (Ye et al. 2014). With the advent of high-throughput DNA sequencing (e.g. Illumina systems), mitogenome sequences can be obtained by sequencing mitochondrial DNA enriched from nuclear DNA or indirectly through mircoarray hybridization and long-range PCR-based sequencing (Hahn, Bachmann, and Chevreux 2013; Ye et al. 2014). Mitogenome sequences can also be produced indirectly by isolating the mitochondrial sequences from whole genome sequence data in silico. This is done by mapping sequence reads to a reference mitogenome (Ye et al. 2014). For example, this technique has been used to produce the blue cod (Parapercis colias) mitogenome (Smith 2012).
Complete annotated mitogenomes can be used to design species-specific PCR primers which reduces the occurrence of failed or non-specific primer binding which can be an issue with cross-species designed primers. Annotated sequence data can also be used to verify that primers are successfully amplifying the target region. If there are several mitogenomes available for a species of interest or a group of closely related species, conserved and variable regions can be more easily identified. This has the wider implication of reducing the cost and time spent establishing and optimising PCR protocols and therefore improving the success of population genetic studies.
The mitogenomes of several fish species from a wide range of families have been reported and scores of unpublished mitogenomes are also regularly being uploaded to NCBI GenBank producing an extensive genetic database. A quick search for mitogenomes of ray-finned fish in GenBank returns 12,647 results. Yet for many New Zealand fish species, such as the Pseudocaranx genus, there is currently little or no complete mitogenome sequence data available. Constructing the mitogenome of P. georgianus is an important first step in the broader aim to study the taxonomy, population structure and demographic history of P. georgianus and the wider genus.
2.2 Materials and methods
2.2.1 P. georgianus mitogenome assembly
In this chapter, the Pseudocaranx georgianus mitogenome is isolated and assembled from whole genome sequence data in Geneious version 11.1.5 (Kearse et al. 2012). Quality checked whole-genome sequence data for thirteen broodstock P. georgianus was provided by Plant and Food Research (PFR) in Nelson, New Zealand (referred to as Broodstock trevally 1 to Broodstock trevally 13 in this chapter). This data was produced by the Australian Genome Research Facility Ltd. (AGRF) using whole genome Illumina paired-end sequencing on three HiSeq lanes. Between 27 to 36 million reads 125 base pairs in length were produced for each individual. No information was provided on the average depth of coverage of the genomes. The annotated genome is described and compared to a closely related species and the typical features of the mitogenomes of ray-finned and cartilaginous fish. The effect that several methodological choices had on the quality of the contig alignments and consensus P. georgianus mitogenomes are also explored.
BLAST searches and a literature search were used to establish species that are closely related to P. georgianus for which complete annotated mitogenome is available. The COI gene of a P. georgianus individual sampled from Victoria, Australia (GenBank accession: EF609442) was blasted against a nucleotide collection database using a discontiguous megablast that handles more dissimilar sequences like inter-species variation (Biomatters 2018). This BLAST search queried the National Center for Biotechnology Information (NCBI) within Geneious version 11.1.5 (Kearse et al. 2012) and returned a list of genetically similar sequences and their ranked pairwise identity scores.
A reference mitogenome that was returned with a high pairwise identity score to P. georgianus at the COI gene (Carangoides equula, GenBank accession: KM201334) was used to assemble a preliminary P. georgianus mitogenome. From this P. georgianus mitogenome, species specific primers were designed to target the COI gene of P. georgianus in Primer3 version 2.3.7 (Untergasser et al. 2012) within Geneious version 11.1.5 (Kearse et al. 2012). These primers were used to PCR amplify and sequence the COI gene of a few initial New Zealand P. georgianus samples caught off the coast of Raglan on the west coast of New Zealand’s North Island. One of these initial COI sequences was used in a secondary discontiguous megaBLAST search to identify reference mitogenomes that were closely related to P. georgianus from New Zealand waters.
Whole genome sequence data of all thirteen P. georgianus individuals were imported into Geneious version 11.1.5 (Kearse et al. 2012) using FASTQ sequence import. During import, the paired reads were set using the appropriate parameters (read technology: Illumina, pair type: paired end - inward pointing, insert size: 125). For all mitogenome assemblies, the whole genome sequence reads were mapped to a reference mitogenome using Geneious mapper, with medium-low sensitivity and no trimming before mapping. From the resulting contig scaffolds, the consensus sequences were annotated by transferring the annotations of the reference genome to the P. georgianus consensus mitogenome sequence.
To investigate the effect that the mitogenome assembly methods had on the quality of the mitogenome assemblies and the consensus mitogenomes, the whole genome data of all thirteen individuals was assembled to three closely related reference mitogenomes identified in BLAST and literature searches (C. equula 1, C. equula 2 and T. japonicus). Whole genome data of three individuals (Broodstock trevally 1, Broodstock trevally 2 and Broodstock trevally 3) was also mapped to one reference genome (C. equula 2) using 2, 3, 5, 10, 25, 1000, 10000 and 100000 iterations. Lastly, any differences among individuals mapped to the same reference genome (C. equula 2) with the same number of mapping iterations (1000) was compared. The structure and quality of the contig scaffolds and consensus mitogenomes were compared by identifying any differences in their general structure, annotation length or placement, unresolved regions, percentage identities, contig depth and number of identical sites. Uncertainty was calculated by subtracting the pairwise identity at each nucleotide position from one. All pairwise alignments of consensus mitogenomes were created using the Mauve genome alignment plugin (version 1.1.1) (Darling, Mau, and Perna 2010) implemented in Geneious version 11.1.5 (Kearse et al. 2012)
2.2.2 P. georgianus mitogenome description
A final P. georgianus mitogenome was produced using the best methods identified in section 2.2.1; one P. georgianus was mapped to C. equula 2 (1000 mapping iterations). The P. georgianus mitogenome was then described and compared to the mitogenomes of other ray-finned and cartilaginous fish described by Satoh et al. (2016), as well as to the closely related species Carangoides equula (Whitefin Trevally, GenBank accession: NC_025644) (a different individual from that used to assemble the P. georgianus mitogenome). The general features of the whole mitogenome structure as well as the protein coding genes, non-coding regions, tRNA’s, rRNA’s and intergenic regions were identified. The location of the stop and start codons for each gene were identified using typical start and stop codons present in other fish described by Satoh et al. (2016). The level of within-species variation, conserved regions and parsimony informative sites were found using a consensus of mitogenome sequences from all thirteen Broodstock trevally individuals (mapped to C. equula 2 with 1000 mapping iterations). The first half of the control region was mapped to sequence data from 304 P. georgianus individuals sampled from New Zealand (see Section 2.2.1). Within-species variation was quantified by aligning the data and subtracting the percentage identity at each nucleotide position from 1. Conserved regions and parsimony informative sites were identified in DnaSP version 6.12.3 (Rozas et al. 2017). The final presentation of the P. georgianus mitogenome was created using the R Shiny application created by Yu, Ouyang, and Yao (2018).
2.3 Results
2.3.1 P. georgianus mitogenome assembly
The mitogenome of a Carangoides equula (Whitefin Trevally) individual sampled from Victoria, Australia (GenBank accession: KX373635, herein referred to as C. equula 1) was returned as the mitogenome with the highest pairwise identity to the COI gene (92.1%) of P. georgianus in the first BLAST search. This species was also found to be closely related to the Pseudocaranx genus in a phylogenetic study of the Carangidae family (Damerau, Freese, and Hanel 2018).
A second BLAST search returned a mitogenome of another C. equula individual (GenBank accession: KM201334, herein referred to as C. equula 2) with a high pairwise identity to the reference (92.4%). The mitogenome with the second highest pairwise identity was a Trachurus japonicus individual (GenBank accession: AP003092, herein referred to as T. japonicus) with a pairwise identity of 89.7%.
Comparison of reference genomes
When whole genome sequence data of the same P. georgianus individual (Broodstock trevally 1) was assembled to three different reference mitogenomes, most nucleotide positions had a percentage identity to the reference between 0.9 and 1.0 (see Figure 2.1). When C. equula 2 and T. japonicus were used as reference genomes, the percentage identities ranged between 0.59 and 1.0. However, when C. equula 1 was used as a reference genome, some nucleotide positions had a low percentage identity to the reference (percentage identity ranged between 0.25 and 1.0). These nucleotide positions with low percentage identities to the reference arose primarily from four poorly resolved regions along the mitogenome. These included one region in 16S rRNA region, one region in the ATP8 gene and two regions in the D-loop (see Figure 2.2). All four of these regions were uncertain when C. equula 1 was used as a reference genome. When assembled to the C. equula 2 and T. japonicus reference genomes, the unresolved regions in the 16S rRNA region and the first region in the control region were resolved, although the ATP8 region and the second D-loop region remained uncertain (see Figure 2.2). The number of nucleotide positions that are identical to the reference genome (identical sites) was lowest when C. equula 1 was used as a reference genome and highest when C. equula 2 was used as a reference (see Figure 2.3).
The overall placement of the annotations on the consensus mitogenomes were congruent among individuals mapped to the same reference genome. However, there was some variation in the placement of annotations by up to thirteen base pairs (See Figure 2.4). Of the three reference genomes, the whole genome sequences assembled equally well to C. equula 2 and T. japonicus. C. equula 1 performed the poorest as a reference mitogenome, despite being considered taxonomically more closely related to the Pseudocaranx genus than T. japonicus.
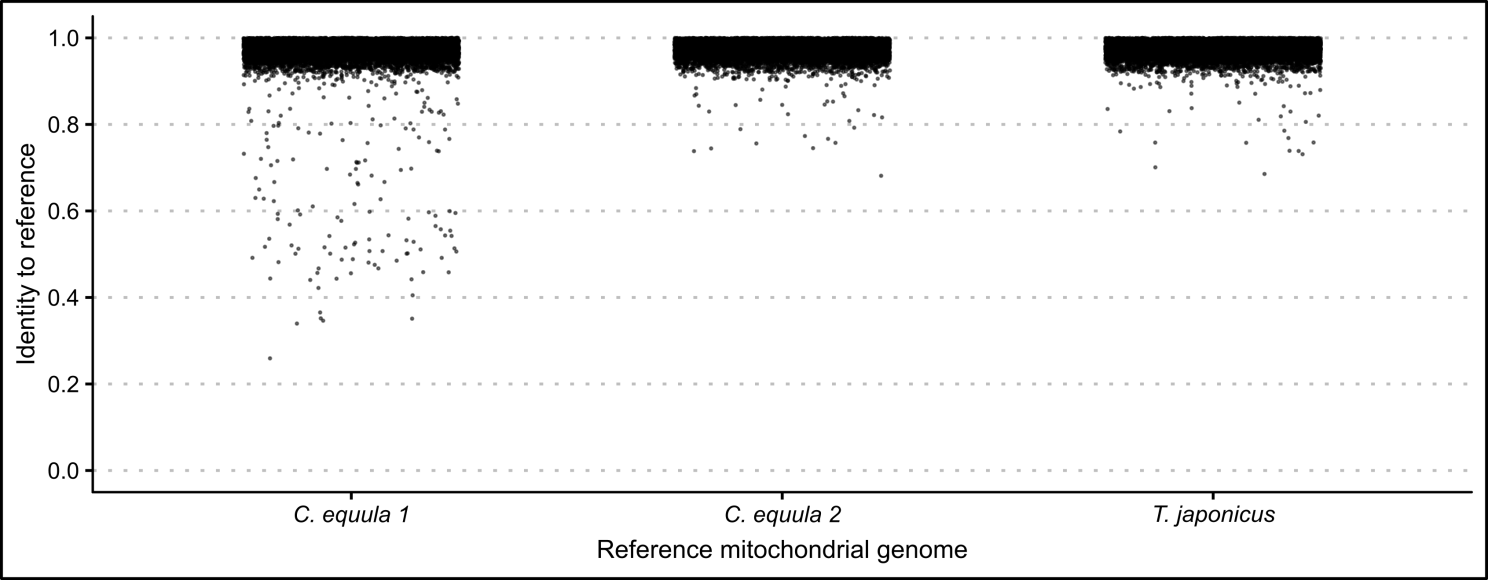
Figure 2.1: Identities of each nucleotide position of whole genome sequence data of one \(\textit{P. georgianus}\) individual (\(\textit{Broodstock trevally 1}\)) mapped to three reference mitogenomes.
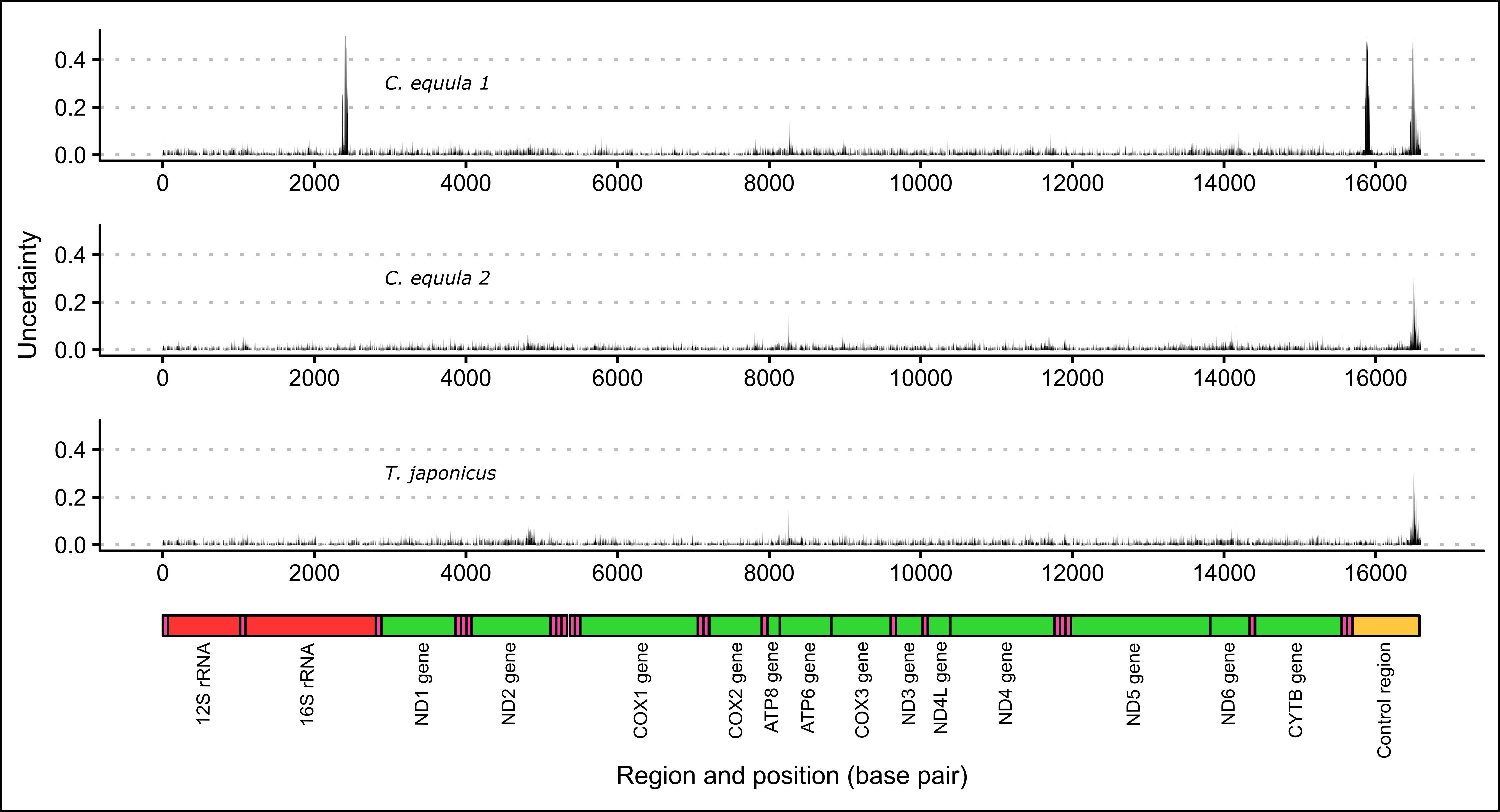
Figure 2.2: Uncertainty in the consensus mitogenome resulting from assembling whole genome data of one P. georgianus individual (Broodstock trevally 1) to three reference mitogenomes.
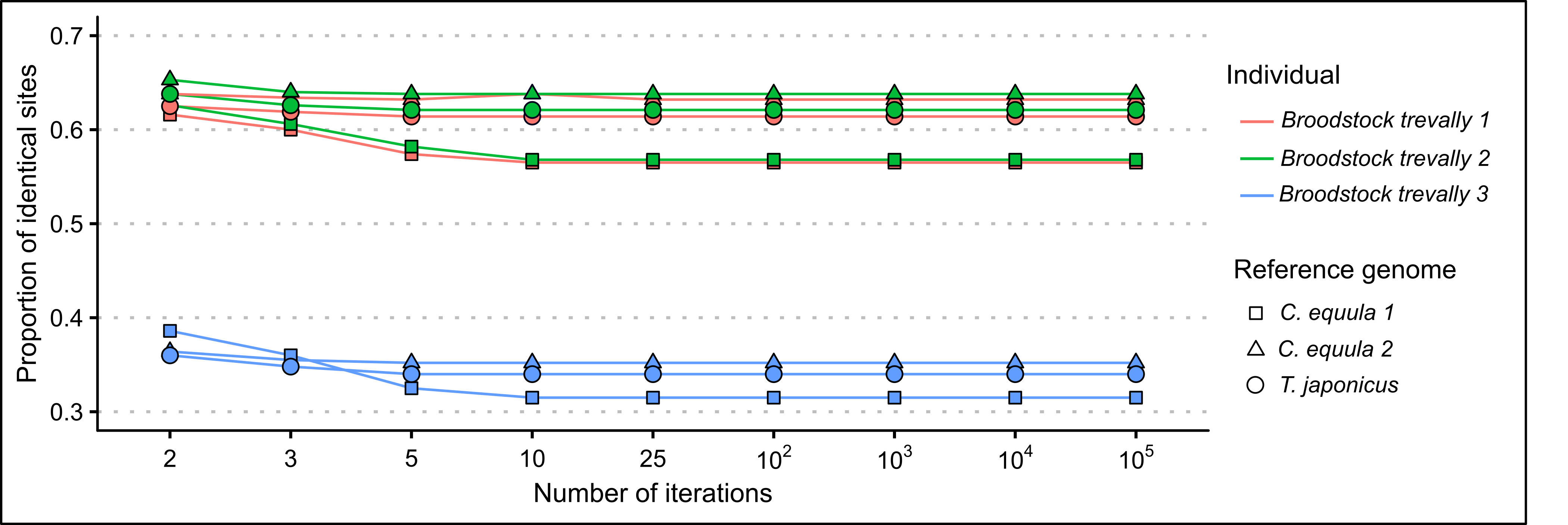
Figure 2.3: Proportion of identical sites of the mitogenome assemblies of three P. georgianus individuals to three reference genomes related to the number of mapping iterations.

Figure 2.4: An example of the annotation conflicts among consensus mitogenomes associated with using three different reference mitogenomes.
Number of mapping iterations
Increasing the number of mapping iterations used in the mitogenome assemblies reduced the frequency of regions with no coverage, low contig depth and nucleotide positions with a low percentage identity to the reference genome (see Figure 2.5). However, a saturation point appears to be reached where increasing the number of mapping iterations provided no further improvement to lower range contig depths, percentage identities values (see Figure 2.5) or some unresolved regions (see Figure 2.6). This saturation point occurred at a different number of mapping iterations depending on which reference mitogenome was used for the assembly. The highest number of mapping iterations were required to reach this saturation point when the data was assembled to the C. equula 1 reference genome (around ten mapping iterations). The saturation point for the contig depth was reached after only three mapping iterations to the C. equula 2 reference genome, and a saturation for percentage identities was reached after five mapping iterations. For the T. japonicus reference genome, the saturation point was reached after 5 mapping iterations. Once these saturation points were reached, comparatively low contig depth and percentage identities values remained when mapped to the C. equula 1 reference genome.
There were six regions of uncertainty along the length of the mitogenome (represented as peaks in uncertainty in Figure 2.6) including two regions in the ND2 gene, one region in the ATP6 gene, one region in the ND6 gene and two regions in the control region. Some of these uncertain regions were resolved by increasing the number of mapping iterations (see Figure 2.6), however three of the six regions (one region in the ND2 gene, one region in the ATP6 gene and one region in the control region) were not fully resolved by increasing the number of mapping iterations.
Surprisingly, the number of nucleotide positions that were identical to the reference mitogenome (identical sites) tended to decrease as the number of mapping iterations increased until around five to ten mapping iterations. At this point, usually no additional reads were mapped to the contig scaffold (see Figure 2.3). This may be due the presence of nucleotide discrepancies within contigs (see Figure 2.7) or mitochondrial heteroplasmy being included in the contig scaffold in higher frequency as more contigs are assembled to the reference genome.
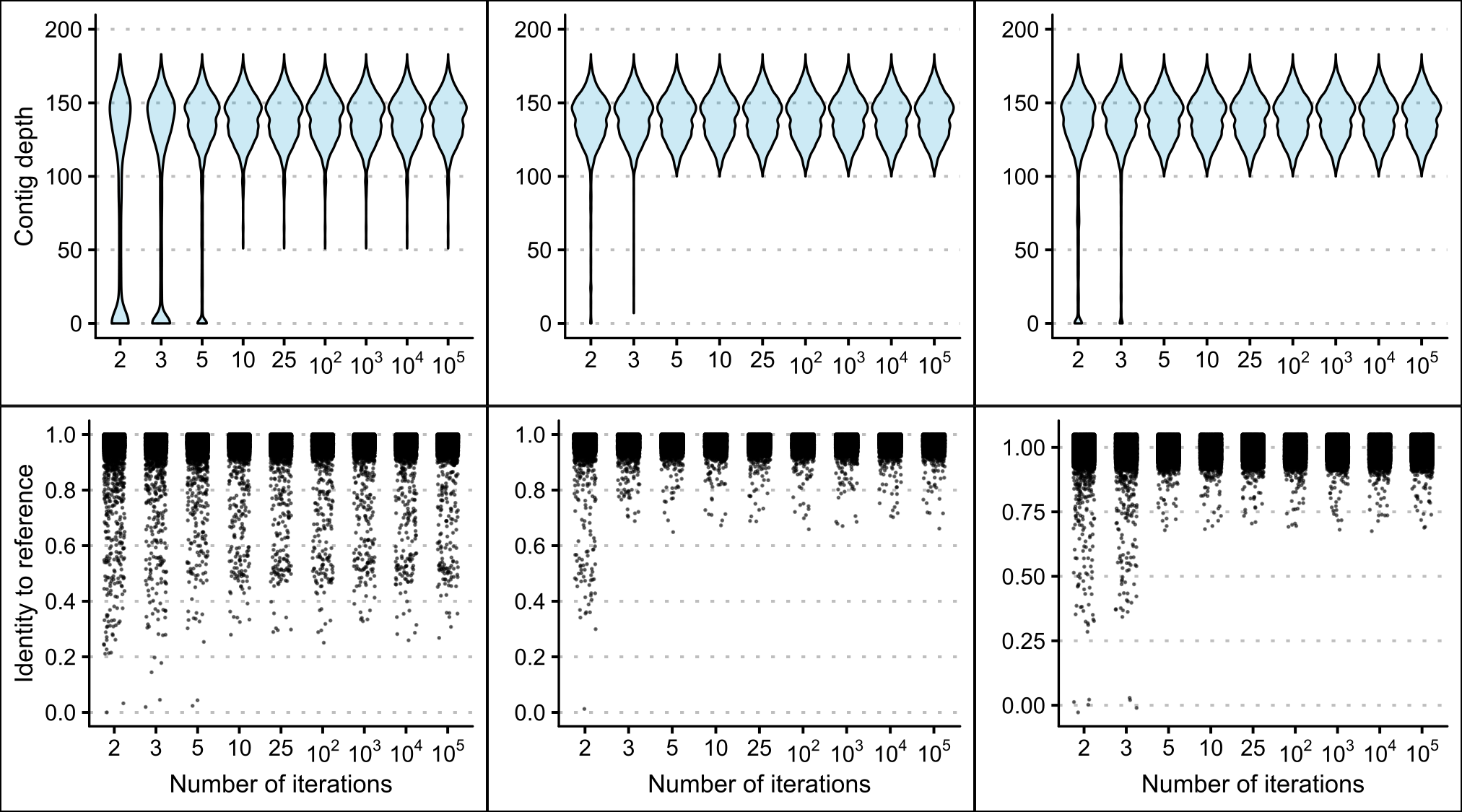
Figure 2.5: The contig depths and percentage identities of whole genome data of one individual (Broodstock trevally 1) mapped to the C. equula 2 reference mitogenome using different numbers of mapping iterations.
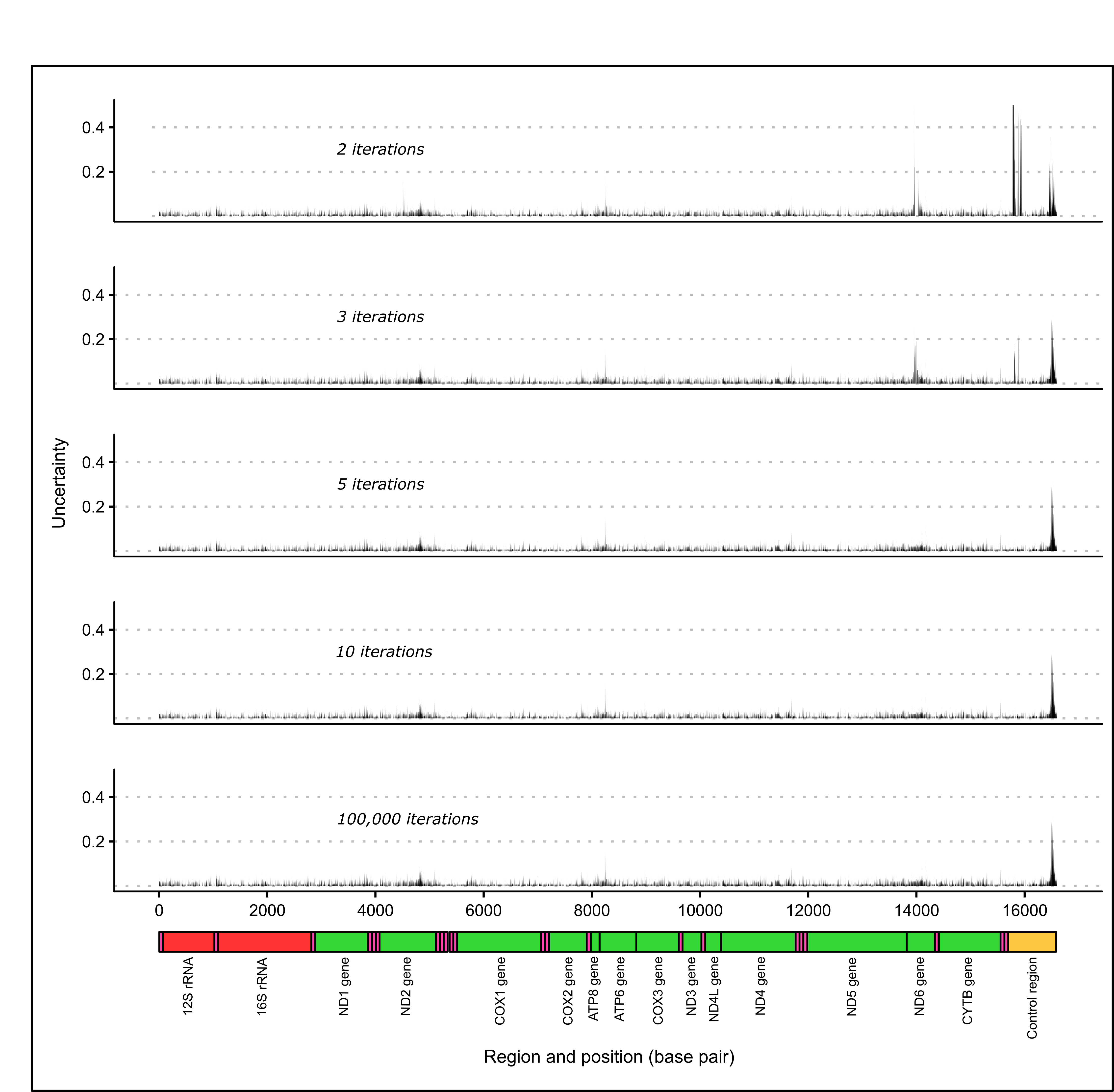
Figure 2.6: Unresolved regions along the mitogenome of one individual (Broodstock trevally 1) mapped to C. equula 2 using different numbers of mapping iterations.

Figure 2.7: An example contig scaffold assembled in Geneious version 11.1.5 including nucleotide discrepancies within contigs.
Comparison of individuals
The contig depth was highly variable among P. georgianus individuals mapped to the C. equula 2 reference genome, ranging from 67 and 175 (Broodstock trevally 13) to 307 and 540 (Broodstock trevally 5). In contrast, the percentage identity of the contigs to the reference was consistent among individuals (see Figure 2.8). As the average contig depth increased, the average number of identical sites in the consensus genomes decreased (ranging from 67.2% and 34.8%) (see Figure 2.9). In comparison, the average pairwise identity of the consensus genomes remained around 99% for all average contig depths.
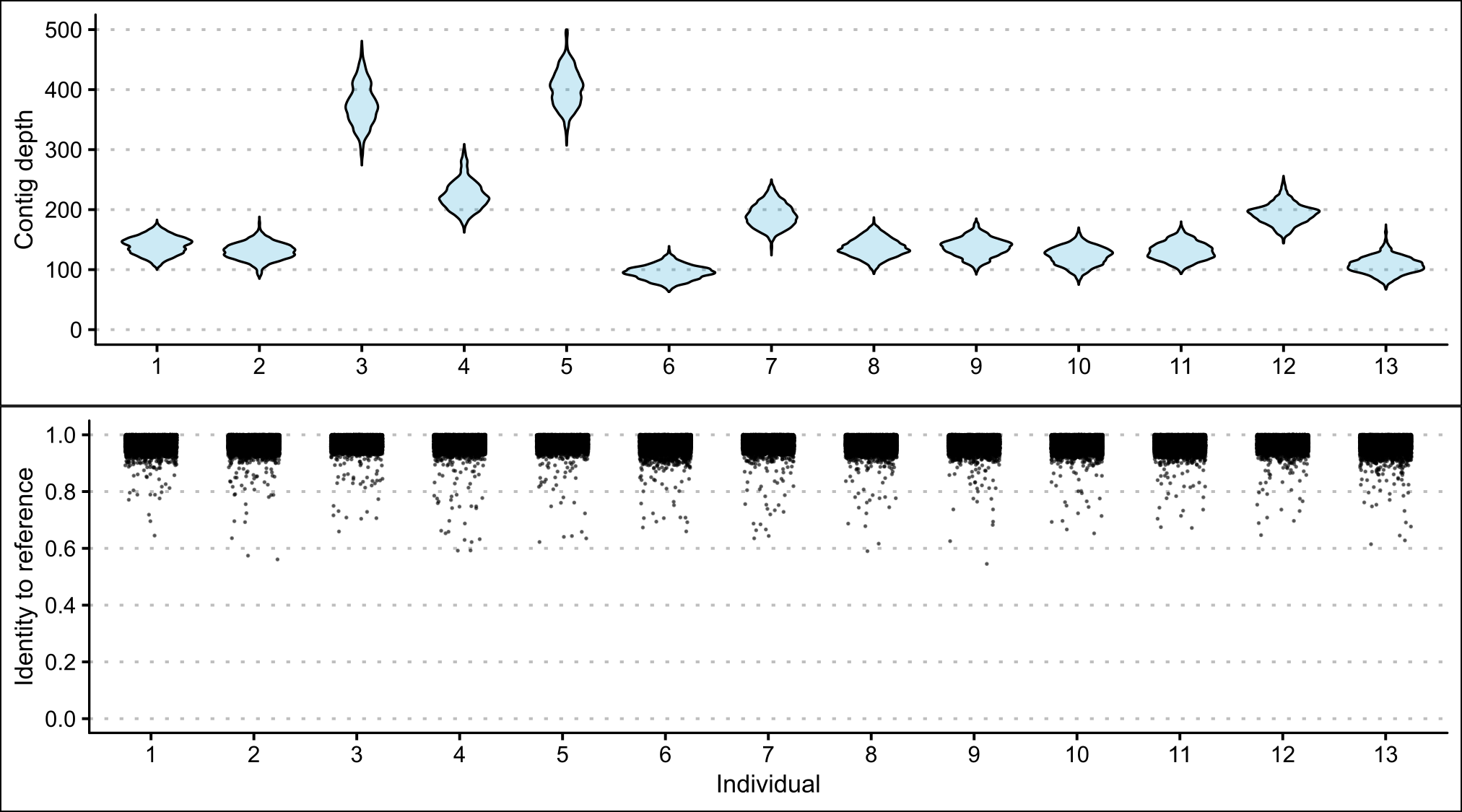
Figure 2.8: A comparison of contig scaffolds from thirteen P. georgianus individuals mapped to C. equula 2 including the range in contig depth and percentage identity at each nucleotide position.
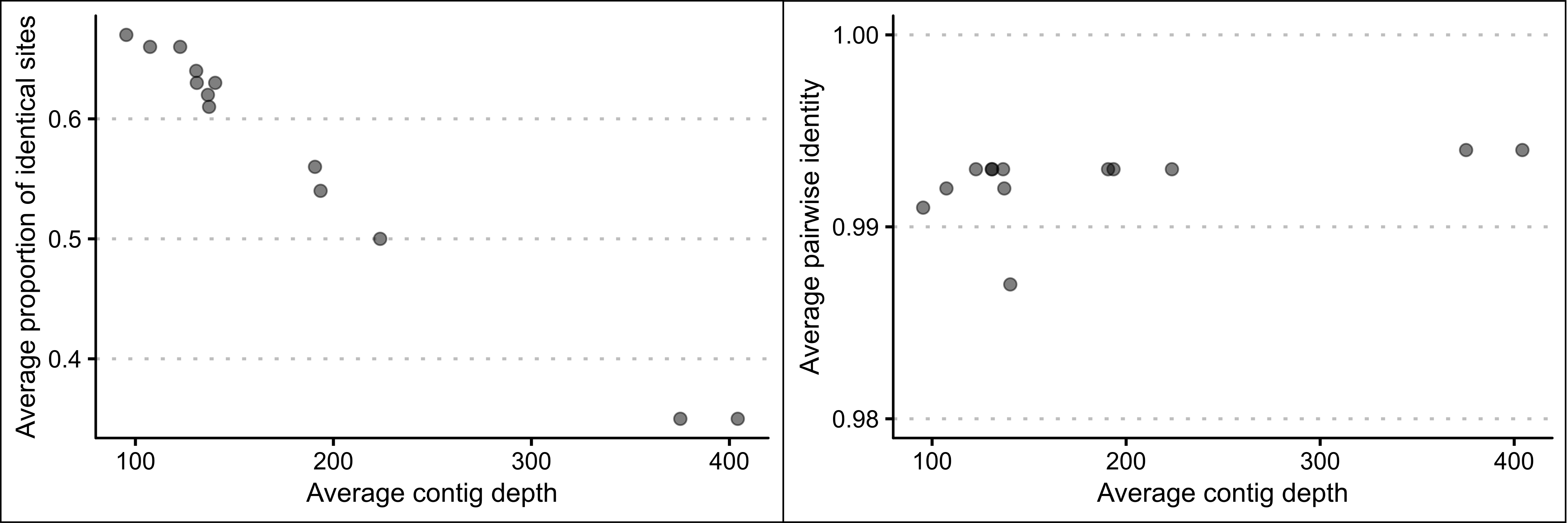
Figure 2.9: The association between the average number of identical sites and the average pairwise identity along the length of the mitogenome with contig depth of whole genome data of thirteen P. georgianus individuals assembled to C. equula 2.
2.3.2 P. georgianus mitogenome description
The description of the P. georgianus mitogenome is based on the most robust method identified in Section 2.3.1 (Broodstock trevally 1 mapped to C. equula 2, 1,000 mapping iterations). In this assembly, 18,611 of 36,114,914 whole genome sequence reads were assembled to C. equula 2. Four mapping iterations were performed before no more whole genome sequences were aligned to the assembly. The consensus mitogenome presented here represents the light strand (L-strand) with a lower proportion of heavier A and G nucleotides (44.6%) than are found on the complimentary strand (55.4%).
Overall structure
The P. georgianus mitogenome is 16,578 base pairs in length with a base composition of 27.6% A, 29.7% C, 16.9% G and 25.7% T (see Figure 2.10. The P. georgianus mitogenome is slightly more AT rich than the average cartilaginous fish (28.3% A, 28.7% C, 16.6% G and 26.5% T (Satoh et al. 2016)) and the C. equula mitogenome (26.3% A, 30.2% C, 18.1% G, 25.3% T). The P. georgianus mitogenome is organised in a typical fashion with no gene rearrangements compared to the mitogenomes of fish and other vertebrates described by (Satoh et al. 2016). The genome consisted of thirteen protein coding genes, twenty-two tRNA’s, two rRNA’s and one non-coding region (D-loop/control region). There were ten intergenic regions that ranged from one to thirty-six base pairs in length (see Table 2.11) with the largest intergenic region bordering tRNA-Asn and tRNA-Cys. (See Figure A.1 in the Appendix for the full DNA sequence of the P. georgianus mitogenome).
Figure 2.10: The final annotated P. georgianus mitogenome.
Figure 2.11: Intergenic regions in the P. georgianus mitogenome.
Genes
There are thirteen protein coding genes encoded on the P. georgianus mitogenome (see Table 2.12). A handful of these genes overlap with neighbouring genes or tRNA’s such as ATP8 with ATP6 and ND4 with ND5 (see Table 2.12). The percentage of GC content for a given gene ranges between 43.3% for COX2 and 50.4% for COX3. Two types of start codons were used for protein coding genes, with ATG being the most common start codon in the P. georgianus mitogenome as it is for many other fish species (Satoh et al. 2016). Four types of stop codons were present and roughly half of the protein coding genes had incomplete stop codons either one or two base pairs in length. These are likely to be completed with the addition of a poly A tail during RNA processing (Ojala, Montoya, and Attardi 1981).
Figure 2.12: Description of the genes in the P. georgianus mitogenome.
tRNA’s and rRNA’s
The P. georgianus mitogenome also encodes two rRNA’s on the light strand and twenty-two tRNA’s in the light and heavy strands, including two duplicate tRNA’s (Ser, Leu) (see Table 2.13). Three pairs of tRNA’s overlap (Ile with Gln, Gln with Met and Thr with Pro). The GC content of the tRNA’s and rRNA’s range from 30.4% for tRNA-Arg to 50.7% for tRNA-Ile. The length of the tRNA’s are roughly similar (68-75 base-pairs).
Figure 2.13: Description of the tRNA’s and rRNA’s in the P. georgianus mitogenome.
Comparison to close relatives
The DNA sequence and gene arrangements of the P. georgianus mitogenome are generally well conserved with its close relative (C. equula). They have similar overall lengths, start and stop codons and GC contents of genes, tRNA’s and rRNA’s, but there are some minor differences. For protein-coding genes, P. georgianus and C. equula share deviations from the most common lengths including a slightly shorter length ATP8 gene and a slightly longer ATP6 gene and ND2 gene. Start codons for protein-coding genes are typically conserved between P. georgianus and C. equula although P. georgianus does not share the C. equula novel start codon for the ATP6 gene (GTG) described by Zou and Li (2016).
Figure 2.14: A comparison of the general features of the mitogenomes of P. georgianus and C. equula.
Variable and conserved regions
The within-species genetic variation of the P. georgianus mitogenome was 2.1%, which was comprised of 356 single nucleotide polymorphisms (SNP’s). The most variable region was the control region (see Figure 2.17) with 100 SNP’s (11.2% of the region) and 41 parsimony informative sites (4.6% of the region) (see Table 2.15). The ND2 gene was the second most variable (4.2% of the region) with 1.7% of region consisting of parsimony informative sites. rRNA’s (12S and 16S) and tRNA’s were the least variable and containing several conserved regions (see Figure 2.17). One conserved region was identified in the first half of the control region, although the conservation value was low (conservation: 0.757, \(p\)-value < 0.0001) (see Figure 2.17).
Figure 2.15: Within species variation along the P. georgianus mitogenome.
Figure 2.16: Conserved regions in the P. georgianus mitogenome.
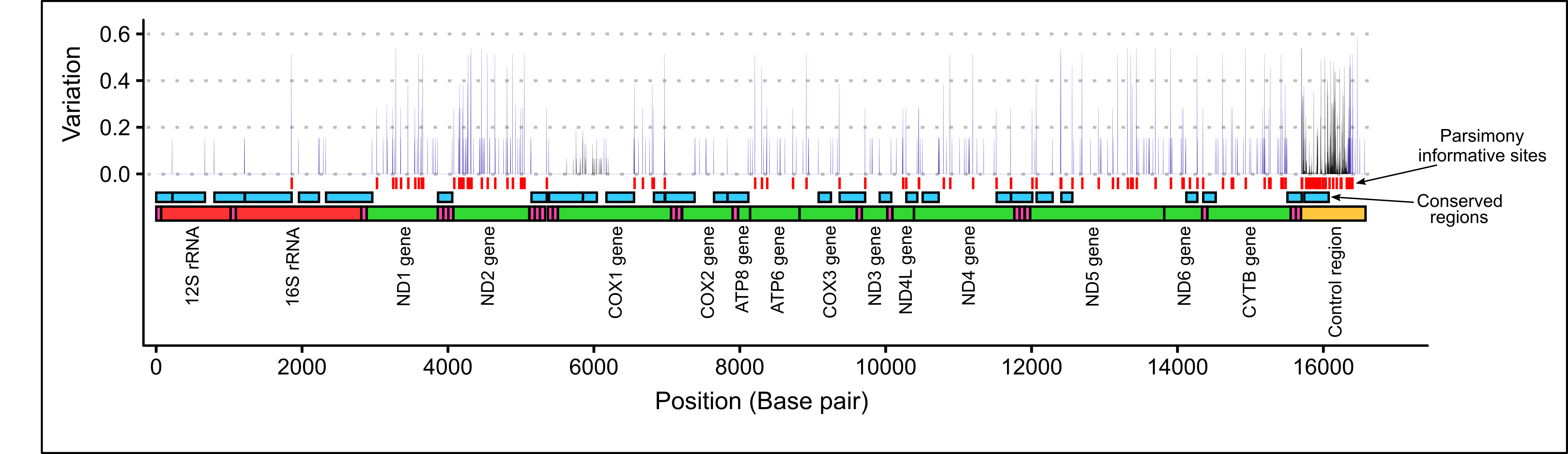
Figure 2.17: Within species variation at each nucleotide position among thirteen \(\textit{P. georgianus}\) whole mitogenomes (blue), 304 partial control region sequences (black) and 30 partial COI sequences (black) as well as conserved regions and parsimony informative sites.
2.4 Discussion
2.4.1 Methods for mitogenome assembly
An exploration into the key choices made when assembling the P. georgianus mitogenome from whole genome sequence data revealed some subtleties in how the assembly algorithm handles real life data.
Reference mitogenome
When assembling the P. georgianus mitogenome, the choice of reference genome had an important impact on the mitogenome assembly and the consensus mitogenomes. This included the annotation of gene and spacer regions, the identity of the whole genome data to the reference mitogenomes and resolution of uncertain regions.
Importantly, two reference mitogenomes from the same species (Carangoides equula) performed differently as reference genomes. In fact, a reference genome of a species from a more distantly related genus (T. japonicus) performed better as a reference genome than a genome from a genus that is considered more closely related to the Pseudocaranx genus (C. equula 1). It is unknown if this difference is due to incorrect taxonomic labelling of the reference genomes, within-species variation or differences in the quality of the reference mitogenomes. Nonetheless, it highlights the importance of establishing how a mitogenome is performing as a reference during the assembly process. More specifically, a reference mitogenome from a taxonomically closely related species does not guarantee it will perform as well as a reference mitogenome.
In the case where only a portion of the mitogenome requires assembly, how genetically closely related the reference genome will need to be will depend on the mutation rate of the region. Less sequencing reads were mapped to highly variable regions such as the control region and in turn more sequencing reads were mapped to conserved regions such as 12S rRNA and 16S rRNA. This means that highly variable regions will require assembly to a closer relative than more conserved regions.
Number of mapping iterations
Increasing the number of mapping iterations past the so called ‘saturation point’ minimized the number of regions with no contig coverage, low coverage depth or low identity to the reference. Reaching this saturation point produced a more complete and robust consensus sequence as more whole genome sequence data is contributed to the contig scaffold. The number of mapping iterations required to reach this saturation point was intuitively associated with the similarity of the whole genome data to the reference mitogenome (the overall genetic similarity of the two individuals). The number of identical sites does not appear to be affected by the number of mapping iterations, instead there is a stronger influence from the average contig depth. The difference suggests that the low proportion of identical sites in some individuals could be caused by sequencing errors or contamination of sequences in during high-throughput sequencing. For the map to reference algorithm (Geneious version 11.1.5 (Kearse et al. 2012)) there does not appear to be a downside associated with using many mapping iterations such as 100 or 10,000. This is because the mapping iterations are discontinued once no additional sequence reads are aligned to the reference. When using this approach, caution is advised because using large numbers of mapping iterations could introduce mistakes or bias in the consensus sequence as more sequencing errors are included in the assembly.
The number of mapping iterations required to produce the most robust mitogenome was intuitively related to the similarity of the reference genome to the whole genome data. Less similar reference genomes required more mapping iterations to reach the highest quality contig scaffold. A reduction in quality in the contig scaffold and consensus mitogenome sequence, which was produced when using a more distantly related reference, could not be mitigated by simply increasing the number of mapping iterations. The individuals with a high contig depth also tended to have a larger spread of contig depths along the mitogenome, indicating that some regions of the mitogenome were receiving a disproportionately higher number of sequencing reads in the contig scaffolds. This indicates that the number of mapping iterations required to produce accurate mitogenome sequence data is variable among whole genome sequences of different P. georgianus individuals and among DNA regions. More specifically, an individual for which a high number of mapping reads have been produced may require fewer mapping iterations because more conserved regions such as 12S rRNA and 16S rRNA anchor the first parts of the assembly process.
Different P. georgianus individuals
Despite the pairwise identity along the length of the mitogenomes being highly consistent among individuals mapped to the same reference genome, the contig depth and proportion of identical sites was highly variable among the individuals that were sequenced. These observations appear related, since a negative trend between the average contig depth and proportion of identical sites was independent to how many mapping iterations were used. The decrease in the proportion of identical sites with increased coverage could be a result of an uneven number of sequencing reads across the genome and therefore variability in the number of reads mapped to the reference.
Recommendations
Use a high quality reference mitogenome of a close relative. Although it is tempting to rely on a high number of mapping iterations when using a reference genome that is dissimilar or distantly related to the whole genome data, there is a limit to what a large number of mapping iterations can do to resolve uncertainties in the contig scaffold and the consensus mitogenome. In the case where only a portion of the mitogenome requires assembly, the genetic similarity of the reference genome can be tailored to suit the mutation rate of the region. To ensure the genetic similarity of the reference genome, it is advisable to conduct BLAST searches of several regions of the mitogenome including highly variable regions such as the control region. This will verify whether the reference genome is genetically similar as opposed to simply taxonomically similar to the whole genome data.
Ensure enough mapping iterations are used. Doing so will reduce and in some cases eliminate low coverage and low percentage identity regions. The number of mapping iterations required to reach this saturation point will depend on the data set. For example, if the reference is highly similar to the whole genome data, fewer iterations will likely be required and in turn, a highly dissimilar data set will require more mapping iterations.
Investigate the quality of the assembly. Mapping the whole genome data to a few different reference genomes, comparing the percentage identity along the length of the genome and looking for annotation conflicts will aid in establishing a robust reference mitogenome.
Report data confidence. The quality of the contig scaffolds and consensus mitogenomes produced in this study were highly variable. A lower quality assembly could carry errors into downstream analyses. Reporting confidence in the data by plotting and reporting contig depth, percentage identity along the length of the mitogenome as well as omitting poorly resolved regions would minimize uncertainties in the data resulting from sequencing or assembly errors.
This study was by no means an exhaustive investigation into the methods for assembling mitogenomes from whole genome sequence data, although it addresses a few central method choices that are made during the assembly process. It acts as a reminder to keep a genetic perspective when dealing with genetic data, to understand as well as report how the chosen methods affect and works for or against a given data set.
2.4.2 P. georgianus mitogenome
The P. georgianus mitogenome is typical of ray-finned and cartilaginous fish (see Satoh et al. (2016)), with no gene rearrangements identified, typical gene region lengths and gene stop and start codons. However, these results should be verified with direct mitochondrial sequencing methods to ensure the assemblies produced in this chapter are not simply reflecting the gene arrangements of the reference mitogenomes. For future research, this P. georgianus mitogenome assebly has highlighted several possible target gene-regions for population genetic and taxonomic studies. The COI gene of P. georgianus was moderately variable and is a common “bar coding” target used to delimit boundaries among different fish species (Ward, Hanner, and Hebert (2009)). With a good database of fish COI sequences, this makes it a good target for taxonomic investigation of the Pseudocaranx genus. The control region was the most variable and can be used for fine-scale population structure of P. georgianus. Furthermore, the P. georgianus mitogenome produced here provides the opportunity for it to be used as a reference mitogenome for the assembly of other fish species.
References
Avise, J., J. Arnold, R. Ball, E. Bermingham, T. Lamb, J. Neigel, C. Reeb, and N. Saunders. 1987. “Intraspecific Phylogeography - the Mitochondrial Dna Bridge Between Population Genetics and Systematics.” Journal Article. Annual Review of Ecology and Systematics 18: 489–522. https://doi.org/10.1146/annurev.ecolsys.18.1.489.
Biomatters. 2018. “Geneious 11.1.” Report. Geneious.
Damerau, M., M. Freese, and R. Hanel. 2018. “Multi-Gene Phylogeny of Jacks and Pompanos (Carangidae), Including Placement of Monotypic Vadigo Campogramma Glaycos.” Journal Article. Journal of Fish Biology 92: 190–202. https://doi.org/10.1111/jfb.13509.
Darling, A., B. Mau, and N. Perna. 2010. “progressiveMauve: Multiple Genome Alignment with Gene Gain, Loss and Rearrangement.” Journal Article. Plos One 5 (6). https://doi.org/10.1371/journal.pone.0011147.
Hahn, C., L. Bachmann, and B. Chevreux. 2013. “Reconstructing Mitochondrial Genomes Directly from Genomic Next-Generation Sequencing Reads-a Baiting and Iterative Mapping Approach.” Journal Article. Nucleic Acids Research 41 (13). https://doi.org/10.1093/nar/gkt371.
Kearse, M., R. Moir, A. Wilson, S. Stones-Havas, M. Cheung, S. Sturrock, S. Buxton, et al. 2012. “Geneious Basic: An Integrated and Extendable Desktop Software Platform for the Organization and Analysis of Sequence Data.” Journal Article. Bioinformatics 28 (12): 1647–9. https://doi.org/10.1093/bioinformatics/bts199.
Ojala, D., J. Montoya, and G. Attardi. 1981. “Transfer-RNA Punctuation Model of RNA Processing in Human Mitochondria.” Journal Article. Nature 290 (5806): 470–74. https://doi.org/10.1038/290470a0.
Rozas, J., A. Ferrer-Mata, J. Sanchez-DelBarrio, S. Guirao-Rico, P. Librado, S. Ramos-Onsins, and A. Sanchez-Gracia. 2017. “DnaSP 6: DNA Sequence Polymorphism Analysis of Large Data Sets.” Journal Article. Molecular Biology and Evolution 34 (12): 3299–3302. https://doi.org/10.1093/molbev/msx248.
Satoh, T., M. Miya, K. Mabuchi, and M. Nishida. 2016. “Structure and Variation of the Mitochondrial Genome of Fishes.” Journal Article. BMC Genomics 17. https://doi.org/10.1186/s12864-016-3054-y.
Smith, H. 2012. “Characterisation of the Mitochondrial Genome and the Phylogeographic Structure of Blue Cod (Parapercis Colias).” Thesis, Victoria University of Wellington.
Untergasser, A., I. Cutcutache, T. Koressaar, J. Ye, B. Faircloth, M. Remm, and S. Rozen. 2012. “Primer3-New Capabilities and Interfaces.” Journal Article. Nucleic Acids Research 40 (15). https://doi.org/10.1093/nar/gks596.
Ward, R., R. Hanner, and P. Hebert. 2009. “The Campaign to DNA Barcode All Fishes.” Journal Article. Journal of Fish Biology 74 (2): 329–56. https://doi.org/10.1111/j.1095-8649.2008.02080.x.
Ye, F., D. Samuels, T. Clark, and Y. Guo. 2014. “High-Throughput Sequencing in Mitochondrial DNA Research.” Journal Article. Mitochondrion 17: 157–63. https://doi.org/10.1016/j.mito.2014.05.004.
Yu, Y., Y. Ouyang, and W. Yao. 2018. “ShinyCircos: An R/Shiny Application for Interactive Creation of Circos Plot.” Journal Article. Bioinformatics 34 (7): 1229–31. https://doi.org/10.1093/bioinformatics/btx763.
Zou, K., and M. Li. 2016. “Characterization of the Mitochondrial Genome of the Whitefin Trevally Carangoides Equula (Perciformes: Carangidae): A Novel Initiation Codon for ATP6 Gene.” Journal Article. Mitochondrial DNA Part A 27 (3): 1779–80. https://doi.org/10.3109/19401736.2014.963809.