4 Visualización estática de datos
Fecha última actualización: 2025-08-05
Instalación/carga librerías/datos utilizados
if (!require(wordcloud)) install.packages('wordcloud')
library(wordcloud)
if (!require(RColorBrewer)) install.packages('RColorBrewer')
library(RColorBrewer)
if (!require(GGally)) install.packages('GGally')
library(GGally)
if (!require(openxlsx)) install.packages('openxlsx')
library(openxlsx)
if (!require(pxR)) install.packages('pxR')
library(pxR)
if (!require(patchwork)) install.packages('patchwork')
library(patchwork)
if (!require(ggplot2)) install.packages('ggplot2')
library(ggplot2)
if (!require(tidyverse)) install.packages('tidyverse')
library(tidyverse)En este curso acordamos mucha importancia a la visualización de datos. En este tema vamos a presentar la visualización estática que corresponde a la visualización habitual donde el usuario no interacciona con el gráfico. Veremos que con muy pocas líneas de código se pueden crear gráficos muy atractivos y complejos usando una estructura común, independiente del contenido del gráfico, ello es posible a la denominada gramática de los gráficos que presentaremos a continuación.
4.1 La gramática de los gráficos
La visualización de una colección variada de datos relacionados entre sí requiere de una buena organización de los diferentes elementos que pueden incluir los gráficos. Para facilitar esta tarea de organización se define una gramática (ver [Wi10]), donde un gráfico es el resultado de la combinación de los siguientes elementos que se organizan por capas:
La tabla de datos y una declaración de los elementos de la tabla que intervienen en el gráfico.
Las capas con los atributos geométricos que se van a usar como histogramas, diagramas de cajas, gráfico de líneas, estadísticas de los datos, ajustes de posicionamiento, etc..
Una escala por cada objeto geométrico incluido.
Un sistema de coordenadas
Especificaciones sobre si se incluyen múltiples gráficos (
facets) combinando datos de la tablaEspecificaciones sobre cuestiones de formato y diseño relativas a la salida del gráfico
Esta organización representa una abstracción del proceso de creación de un gráfico y como veremos resulta muy potente para crear, con un código muy compacto, todo tipo de gráficos complejos.
Para generar gráficos utilizando esta gramática utilizaremos la librería ggplot2 y su función ggplot, que, como veremos, es una herramienta de visualización muy potente. Como resumen de esta sección puede ser útil mirar la siguiente ficha resumen.
4.2 Diagramas de barras
Vamos a dibujar, usando ggplot, un diagrama de barras con la población mundial organizada por
continentes. En este caso el gráfico es generado por la llamada a ggplot, y añadiendo
una única capa generada por geom_bar. Para añadir capas nuevas al gráfico se
utiliza el símbolo +.
owid_country %>%
group_by(continent) %>%
summarise(population=sum(population)) %>%
ggplot(aes(x=continent,y=population,fill=continent)) +
geom_bar(stat = "identity") +
theme(legend.position = "none")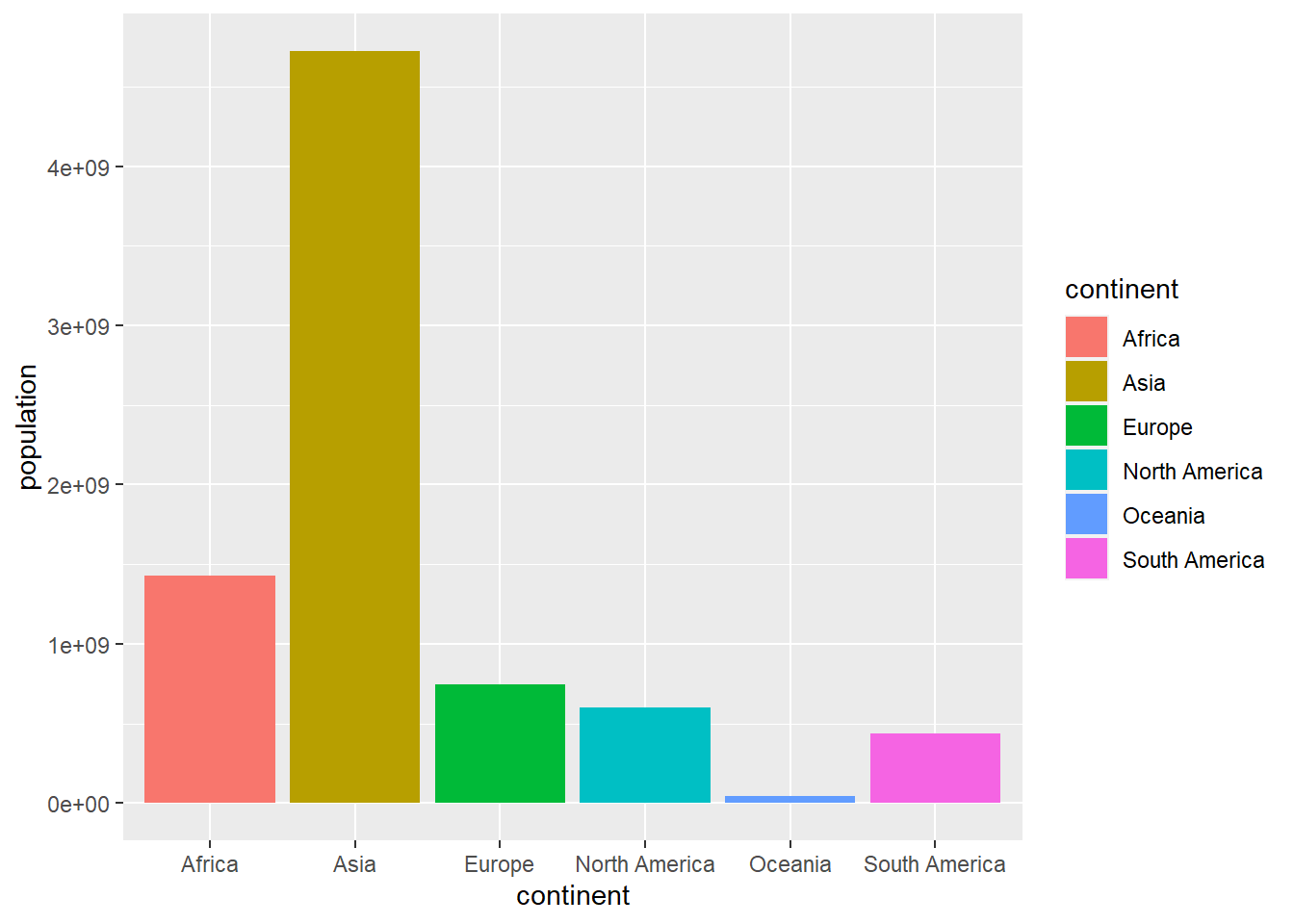
Figure 4.1: Diagrama de barras usando geom_bar
la instrucción fill=continent se utiliza para asignar colores de forma automática
a las barras. Al final del capítulo se verán en detalle estas cuestiones de diseño. Por defecto, las barras se ordenan por orden alfabético. Con frecuencia queremos que las barras nos salgan ordenadas en función del valor mostrado. Para ello podemos ordenar previamente el tibble y después usar la función factor para fijar un orden personalizado que evite la ordenación automática.
owid_country %>%
group_by(continent) %>%
summarise(population=sum(population)) %>%
arrange(population) %>%
mutate(continent= factor(continent, levels = continent)) %>%
ggplot(aes(x=continent,y=population,fill=continent)) +
geom_bar(stat = "identity") +
theme(legend.position = "none")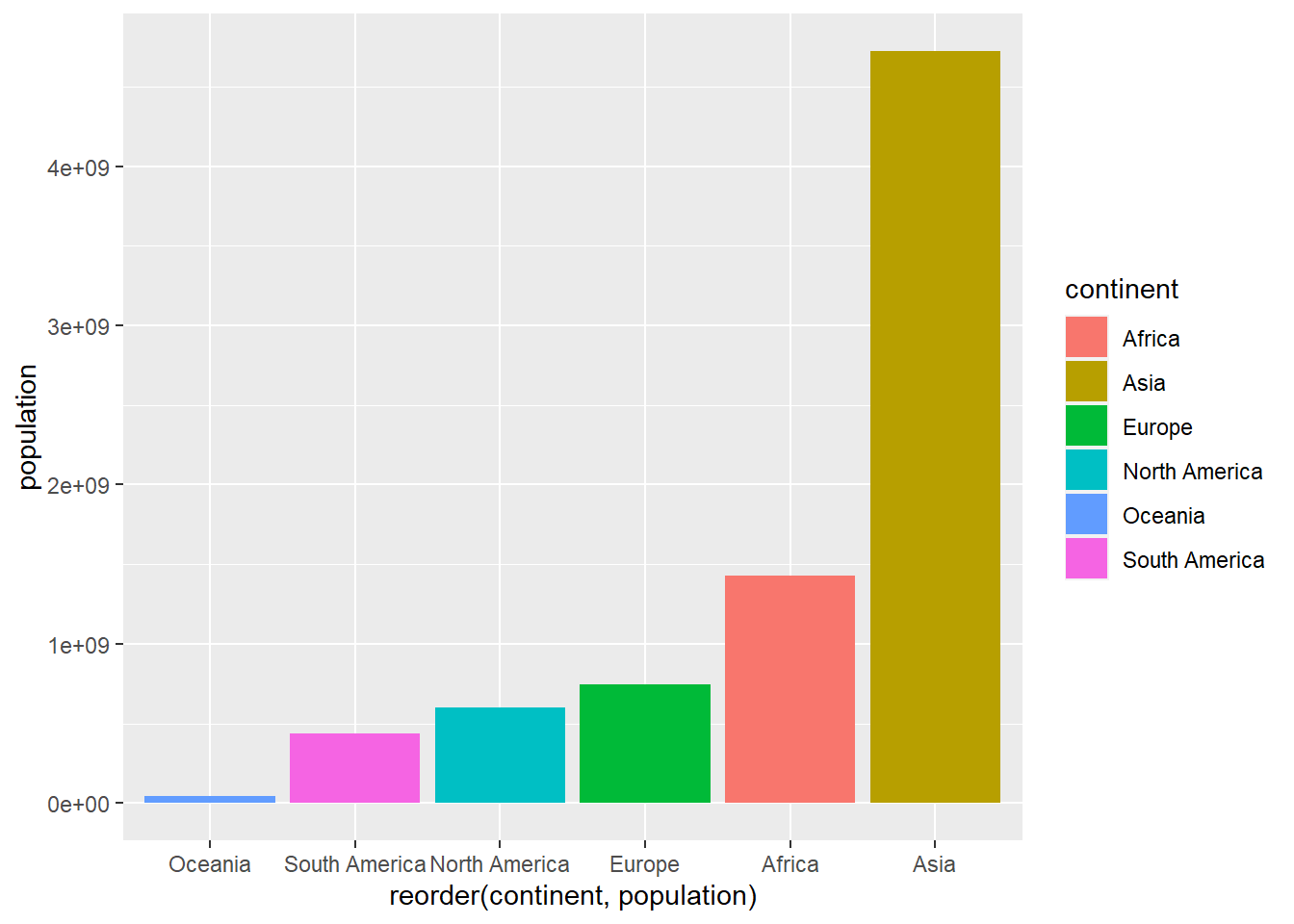
Figure 4.2: Diagrama de barras usando geom_bar con orden personalizado
4.3 Diagramas de barras agrupadas
Vamos a dibujar un diagrama de barras apiladas usando la media, por continentes, del porcentaje de hombres fumadores y de mujeres fumadoras.
owid_country %>%
group_by(continent) %>%
summarise(
male=mean(na.omit(male_smokers)),
female=mean(na.omit(female_smokers))) %>%
pivot_longer(male:female, names_to = "sex", values_to = "smokers") %>%
ggplot(aes(x=continent,y=smokers,fill=sex)) +
geom_bar(stat = "identity") 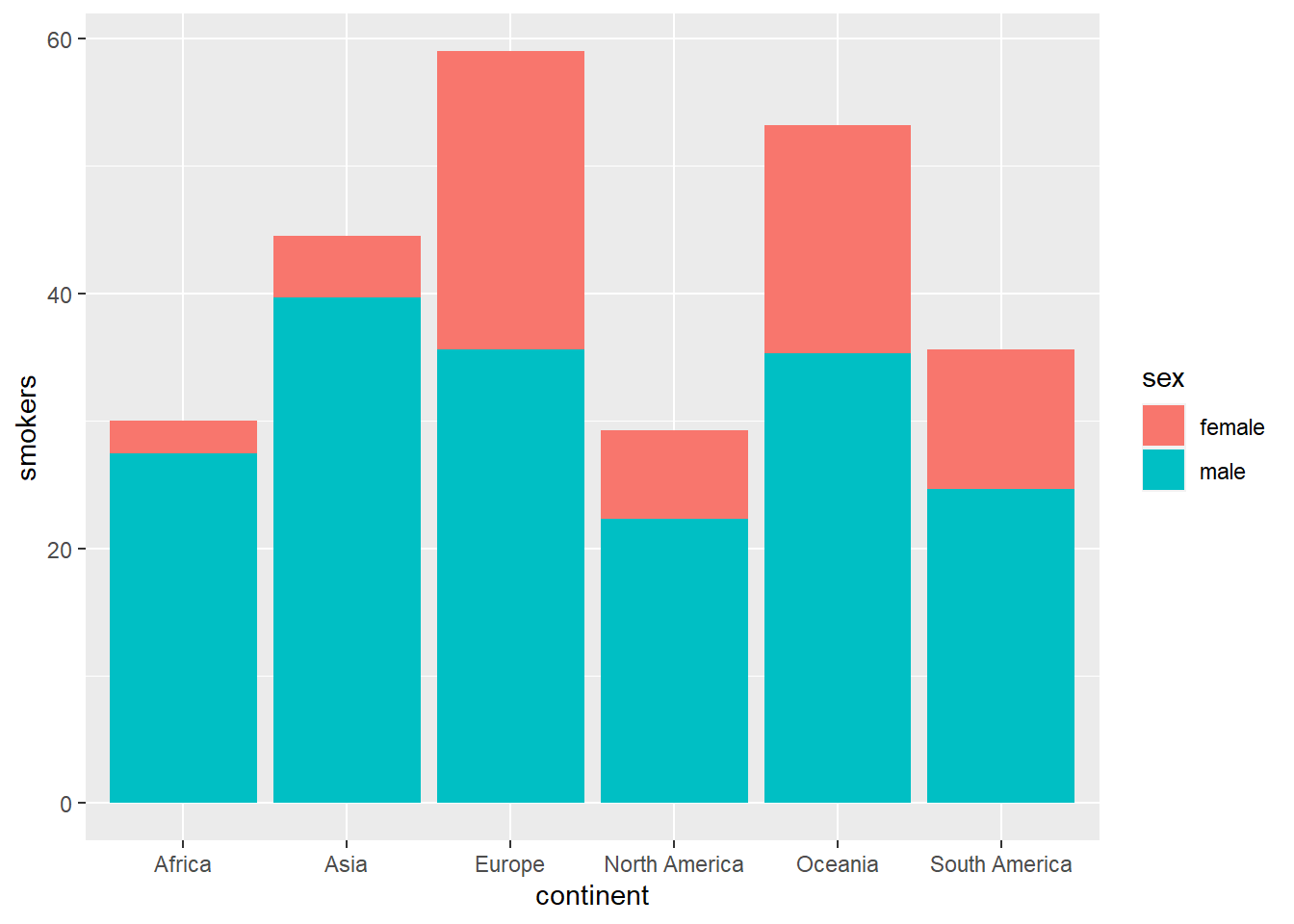
Figure 4.3: Diagrama de barras apilado usando geom_bar
A continuación haremos lo mismo pero poniendo las barras una al lado de otra con la opción position="dodge".
owid_country %>%
group_by(continent) %>%
summarise(
male=mean(na.omit(male_smokers)),
female=mean(na.omit(female_smokers))) %>%
pivot_longer(male:female, names_to = "sex", values_to = "smokers") %>%
ggplot(aes(x=continent,y=smokers,fill=sex)) +
geom_bar(position="dodge",stat = "identity") 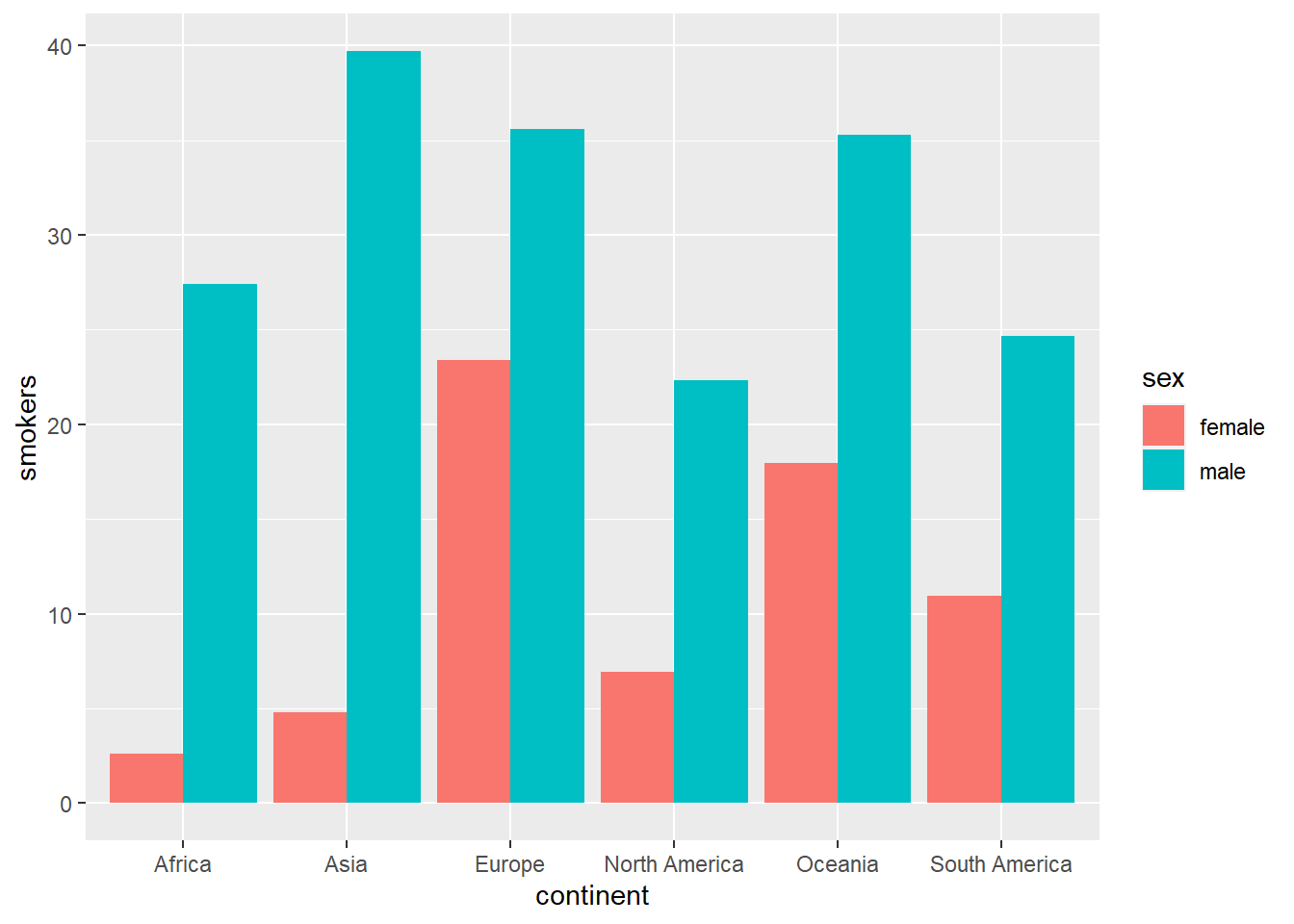
Figure 4.4: Diagrama de barras alineadas usando geom_bar
A continuación vamos a representar el mismo gráfico con barras horizontales y “en espejo”, es decir, la línea vertical central representa el nivel cero y una variable se mueve hacia la derecha y otra hacia la izquierda. Para hacer esto tenemos que usar el truco de asignar un valor negativo a la variable que queremos que salga por la izquierda. Para que los valores del eje no salgan negativos se ponen en valor absoluto con la instrucción scale_y_continuous(labels= abs).
owid_country %>%
group_by(continent) %>%
summarise(
male=mean(na.omit(male_smokers)),
female=-mean(na.omit(female_smokers))) %>% # cambiamos el signo de esta variable
pivot_longer(male:female, names_to = "sex", values_to = "smokers") %>%
ggplot(aes(x=continent,y=smokers,fill=sex)) +
geom_col() +
coord_flip() + # giramos el gráfico 90 grados
scale_y_continuous(labels= abs) # valores del eje en valor absoluto 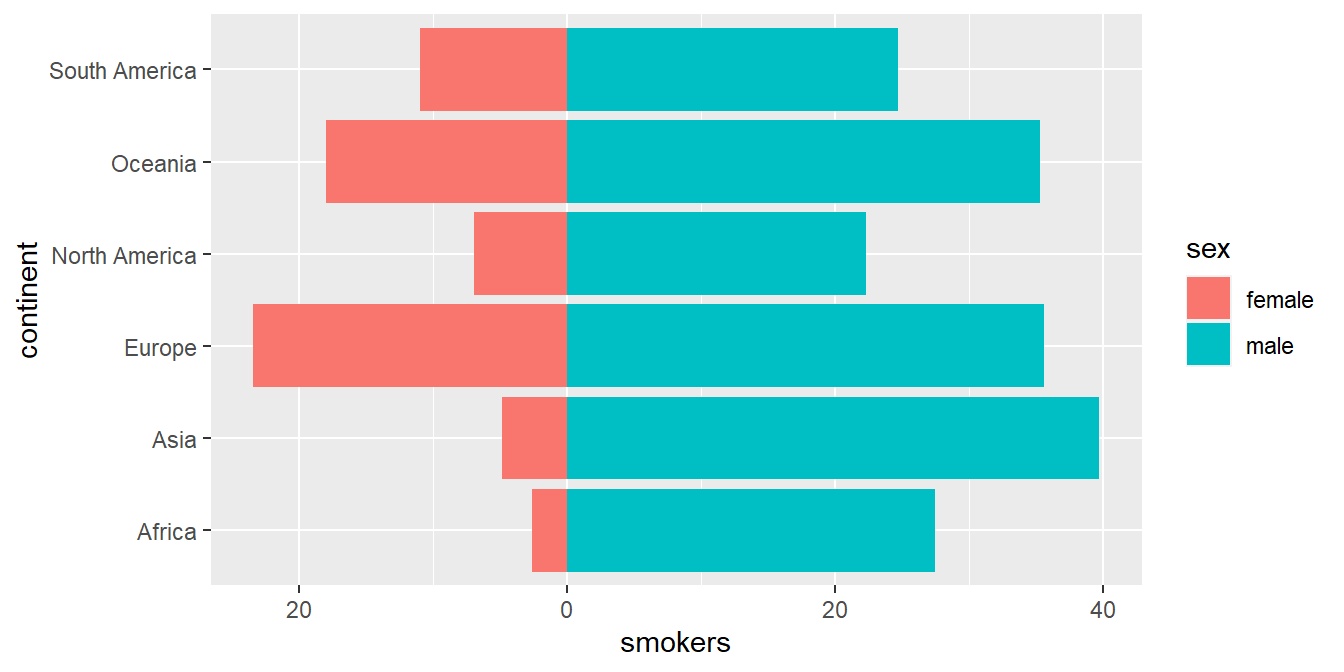
Figure 4.5: Diagrama de barras horizontal para comparar 2 variables usando geom_col
4.4 Gráficos circulares
Cuando el número de datos es pequeño, una manera eficaz de visualizar la relación entre los datos es utilizar los conocidos diagramas circulares (pie charts). En el siguiente ejemplo se muestra como construir uno usando la población mundial agrupada por continentes:
owid_country %>%
group_by(continent) %>%
summarise(population=sum(population)) %>%
mutate(labels = scales::percent(population/sum(population))) %>%
ggplot(aes(x="",y=population,fill=continent)) +
geom_col() +
geom_text(aes(x=1.6,label = labels),position = position_stack(vjust = 0.5)) +
coord_polar(theta = "y")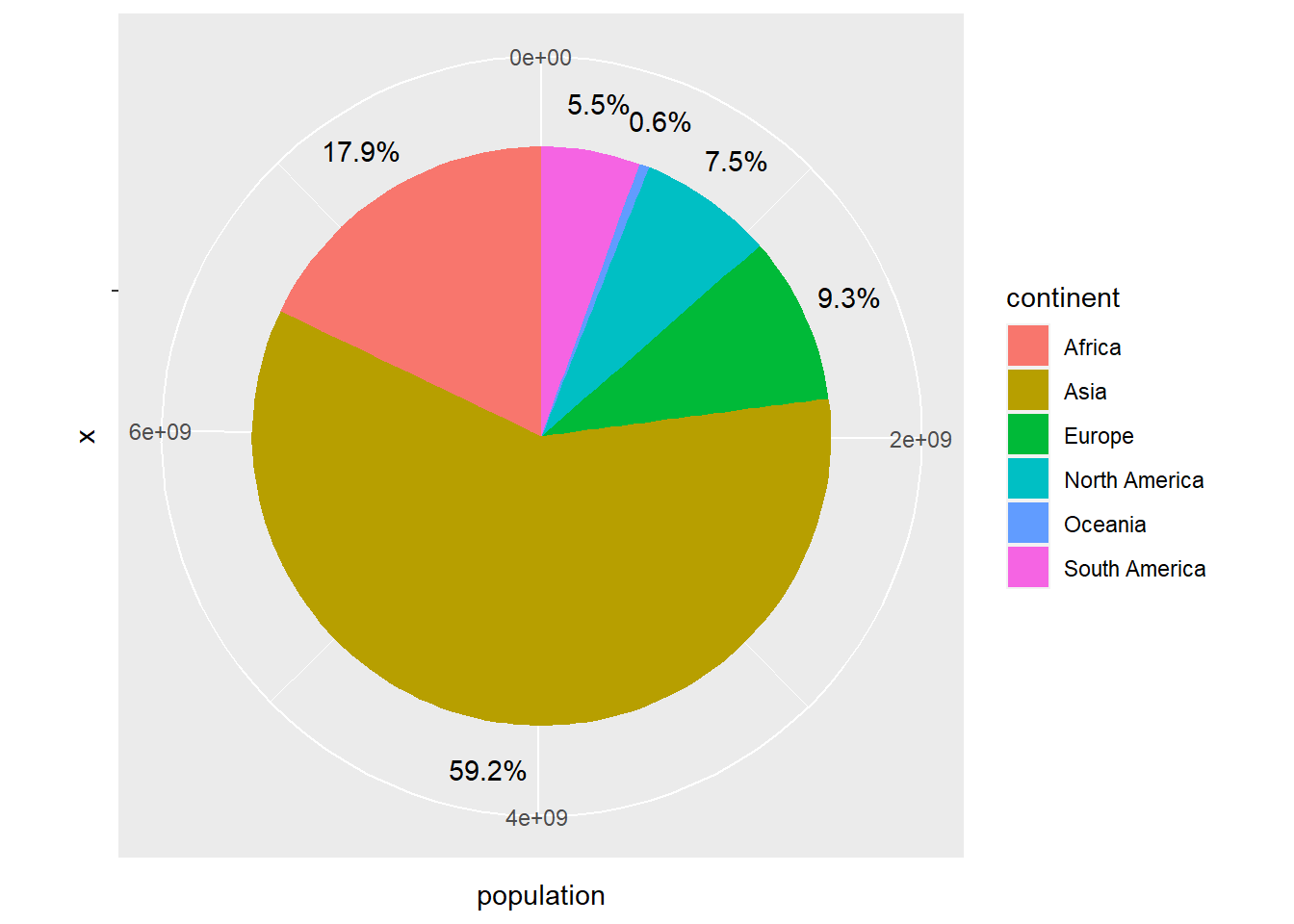
Figure 4.6: Gráfico circular usando geom_col
La función coord_polar se puede usar para transformar un gráfico de barras en un gráfico de sectores circulares. Veamos como queda el gráfico de barras apilado de la sección anterior al transformarlo en un gráfico de sectores circulares
owid_country %>%
group_by(continent) %>%
summarise(
male=mean(na.omit(male_smokers)),
female=mean(na.omit(female_smokers))) %>%
pivot_longer(male:female, names_to = "sex", values_to = "smokers") %>%
ggplot(aes(x=continent,y=smokers,fill=sex)) +
geom_bar(stat = "identity",width = 1) +
coord_polar(theta = "x")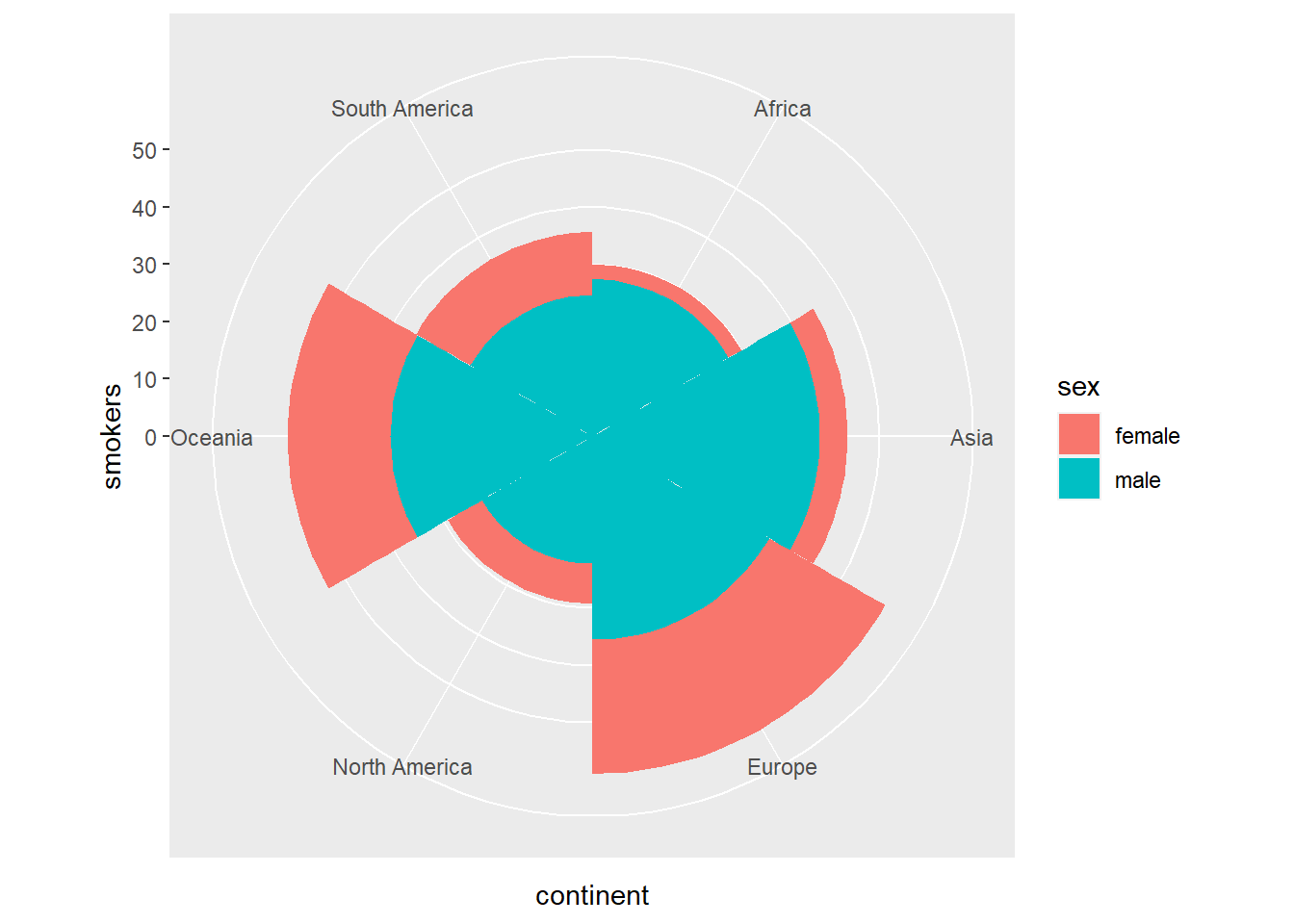
Figure 4.7: Diagrama de barras apilado transformado en sectores circulares usando coord_polar
4.5 Gráficos de donuts
Los gráficos de donuts son muy parecidos a los circulares dejando un hueco circular dentro del gráfico. Utilizaremos la variable hsize para fijar el tamaño del agujero.
hsize <- 2
owid_country %>%
group_by(continent) %>%
summarise(population=sum(population)) %>%
mutate(labels = scales::percent(population/sum(population))) %>%
ggplot(aes(x=hsize,y=population,fill=continent)) +
geom_col() +
geom_text(aes(x=hsize + 0.1,label = labels),position = position_stack(vjust = 0.5)) +
coord_polar(theta = "y") +
xlim(c(0.2, hsize + 0.5))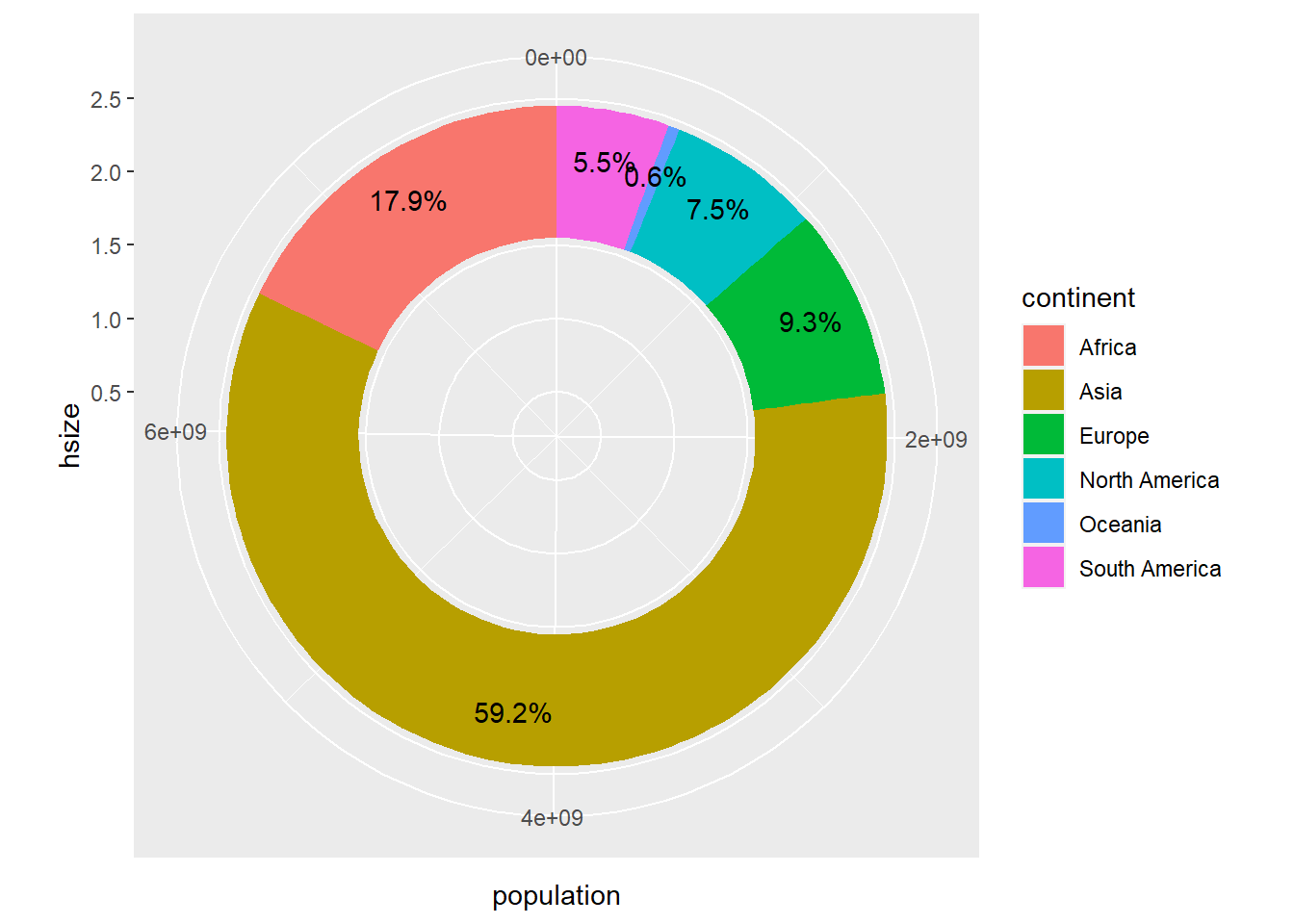
Figure 4.8: Gráfico de donuts usando geom_col
4.6 Histogramas
Vamos, a continuación, a dibujar un histograma del PIB por habitante en los diferentes países del mundo usando ggplot.
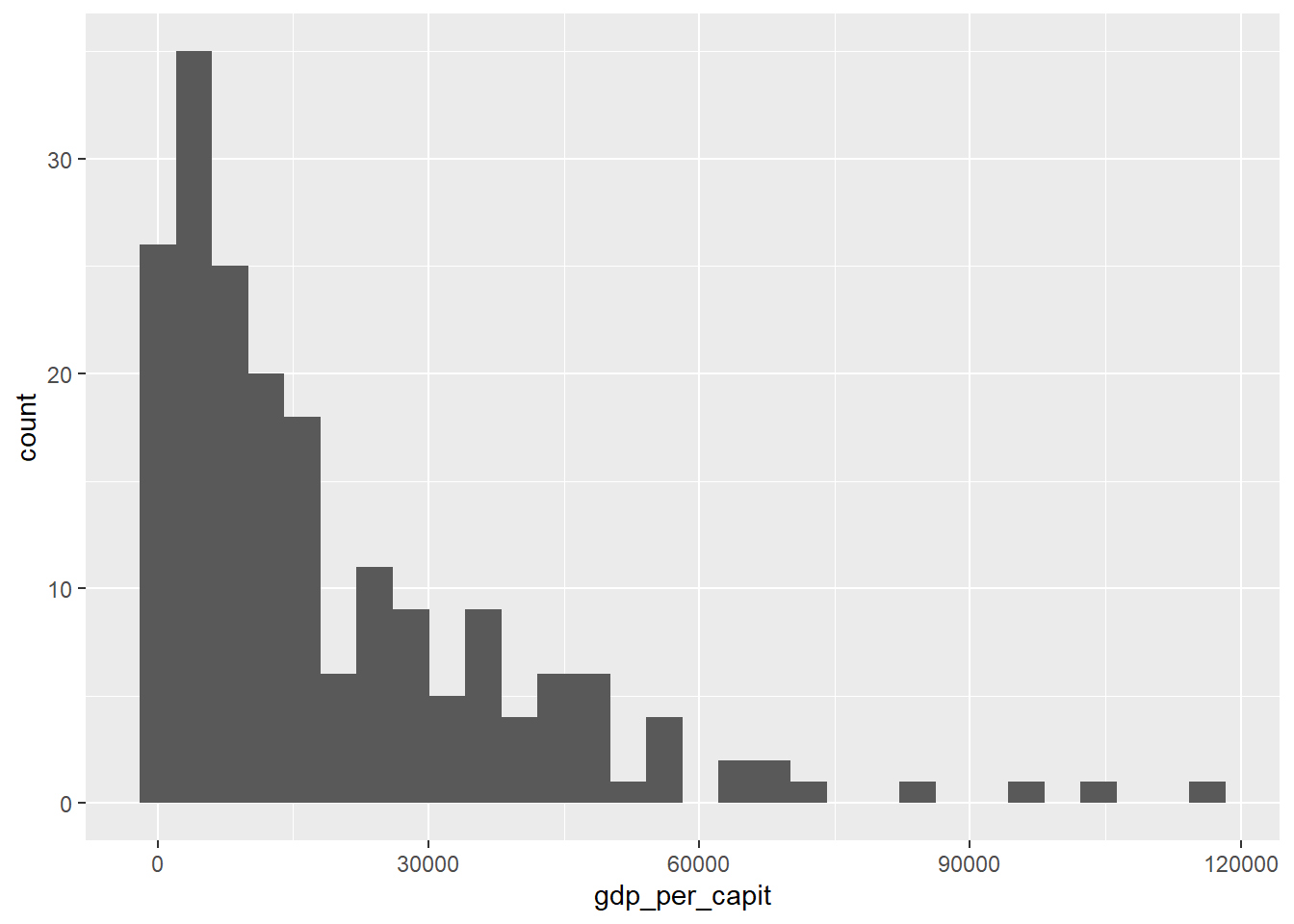
Figure 4.9: Gráfico de histogram usando geom_histogram()
A continuación haremos lo mismo pero ajustando el histograma a una función de densidad de probabilidad.
owid_country %>%
ggplot(aes(x=gdp_per_capit)) +
geom_histogram(aes(y=after_stat(density))) +
geom_density(alpha=0.6)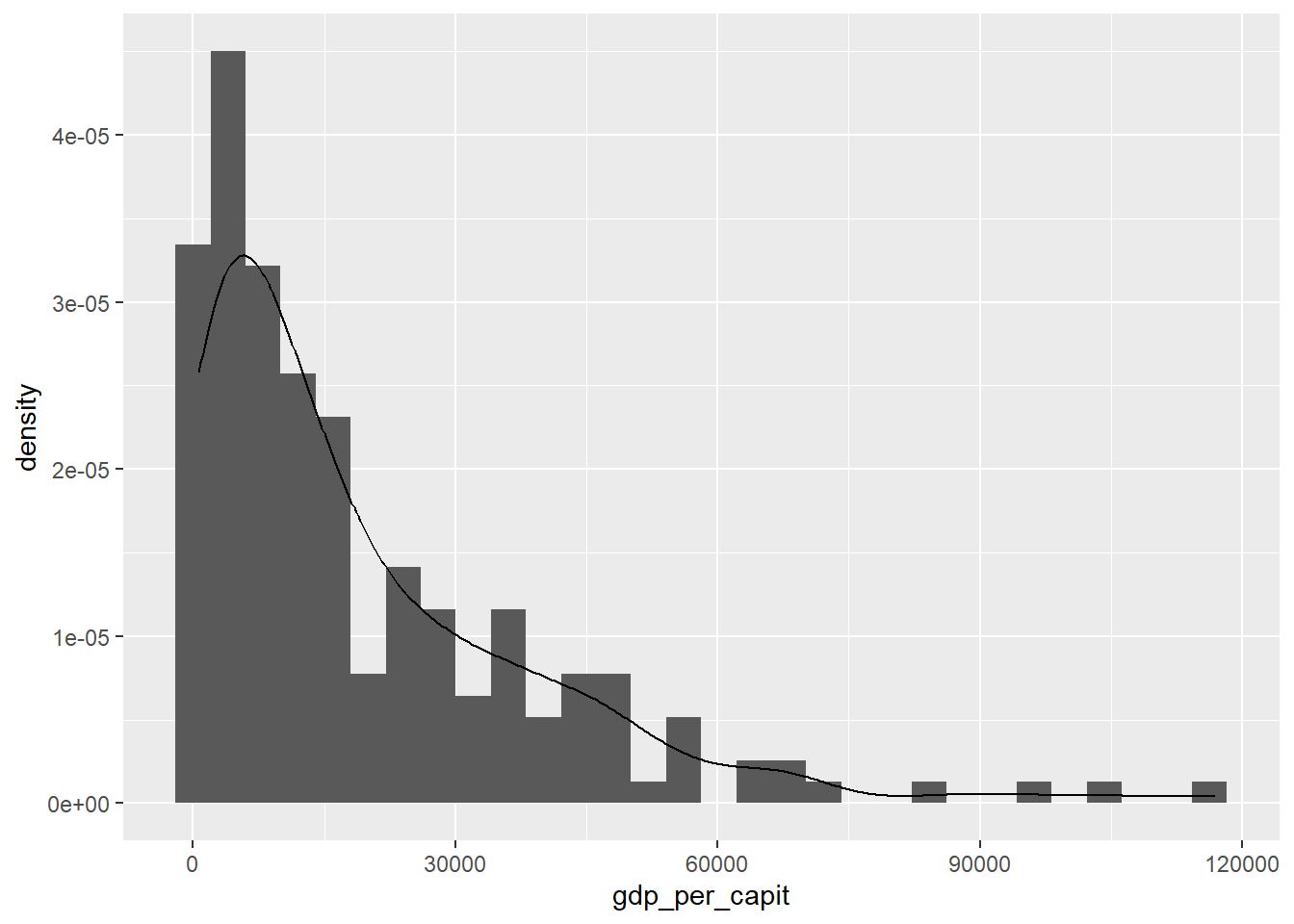
Figure 4.10: Histograma y función de densidad con geom_histogram y geom_density
A continuación presentamos el histograma organizado por continentes.
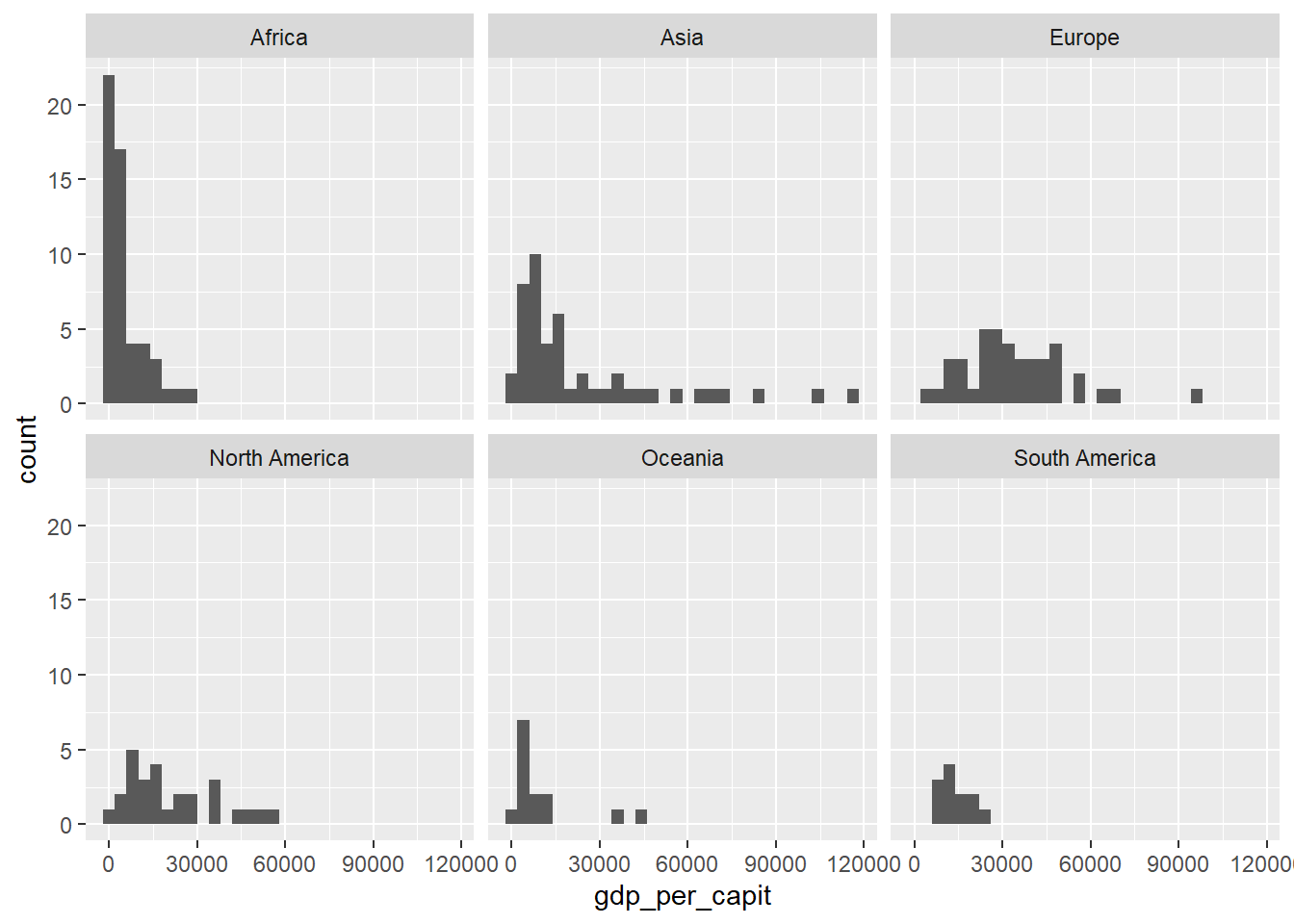
Figure 4.11: Dibujo de una cuadrícula con los histogramas de gdp_per_capit organizados por continentes usando facet_wrap
Por último dibujamos el histograma de la población por países. Como esta variable varía mucho entre los países usamos una escala logarítmica en los ejes. Añadimos además unas líneas verticales con la posición de la media y los percentiles 0.25, 0.5 (la mediana) y 0.75.
owid_country %>%
ggplot(aes(x=population)) +
geom_histogram() +
scale_y_continuous(trans = 'log2') +
scale_x_continuous(trans = 'log2') +
geom_vline(aes(xintercept=mean(population)),linetype="dashed") +
geom_vline(aes(xintercept=quantile(population,0.25)),linetype="solid") +
geom_vline(aes(xintercept=quantile(population,0.5)),linetype="solid") +
geom_vline(aes(xintercept=quantile(population,0.75)),linetype="solid") 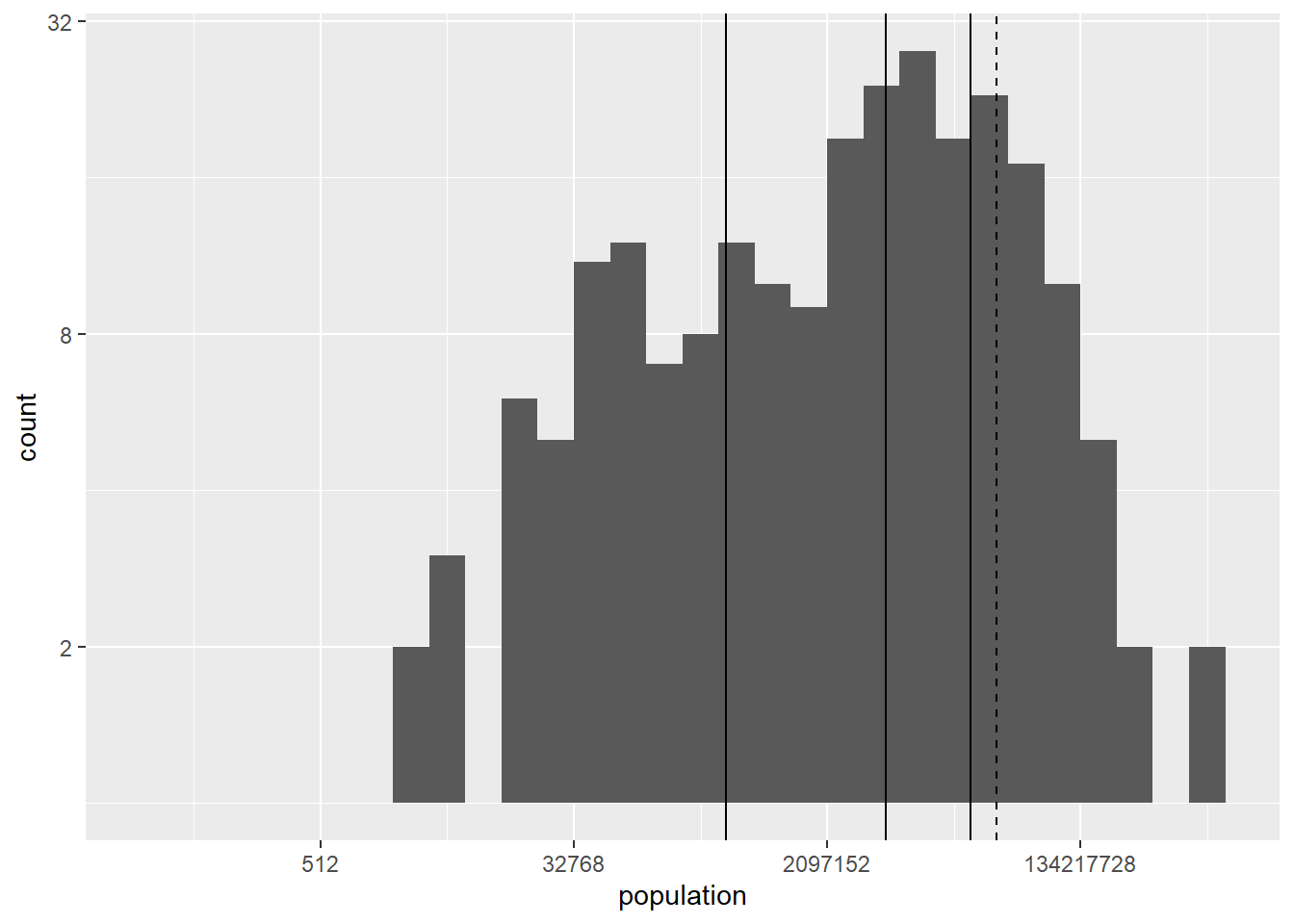
Figure 4.12: Histograma usando una escala logarítmica para los ejes incluyendo líneas verticales en la posición de la media y percentiles principales usando geom_vline
4.7 Diagramas de cajas (box-plots)
Los diagramas de cajas son una herramienta muy potente para ilustrar la diferencia entre diferentes distribuciones. Los diagramas de cajas verticales contienen la siguiente información
\(Q_1\) : la base del rectángulo corresponde al cuartil 1 (percentil 25%).
\(Q_2\) : la línea central del rectángulo corresponde al cuartil 2 (percentil 50%, la mediana).
\(Q_3\) : la altura del rectángulo corresponde al cuartil 3 (percentil 75%).
Para dibujar las líneas por arriba y debajo se utiliza el valor \(IQR=Q_3-Q_1\).
La línea inferior corresponde al máximo entre \(Q_1 - 1.5IQR\) y el mínimo de los valores de los datos.
La línea superior corresponde al mínimo entre \(Q_3 + 1.5IQR\) y el máximo de los valores de los datos.
Además se dibujan, en forma de puntos, los valores de los datos que quedan por debajo y por encima del box-plot. Estos valores se consideran “outliers” (valores fuera del rango esperado).
owid_country %>%
ggplot(aes(x=continent,y=gdp_per_capit,fill=continent)) +
geom_boxplot() +
theme(legend.position = "none")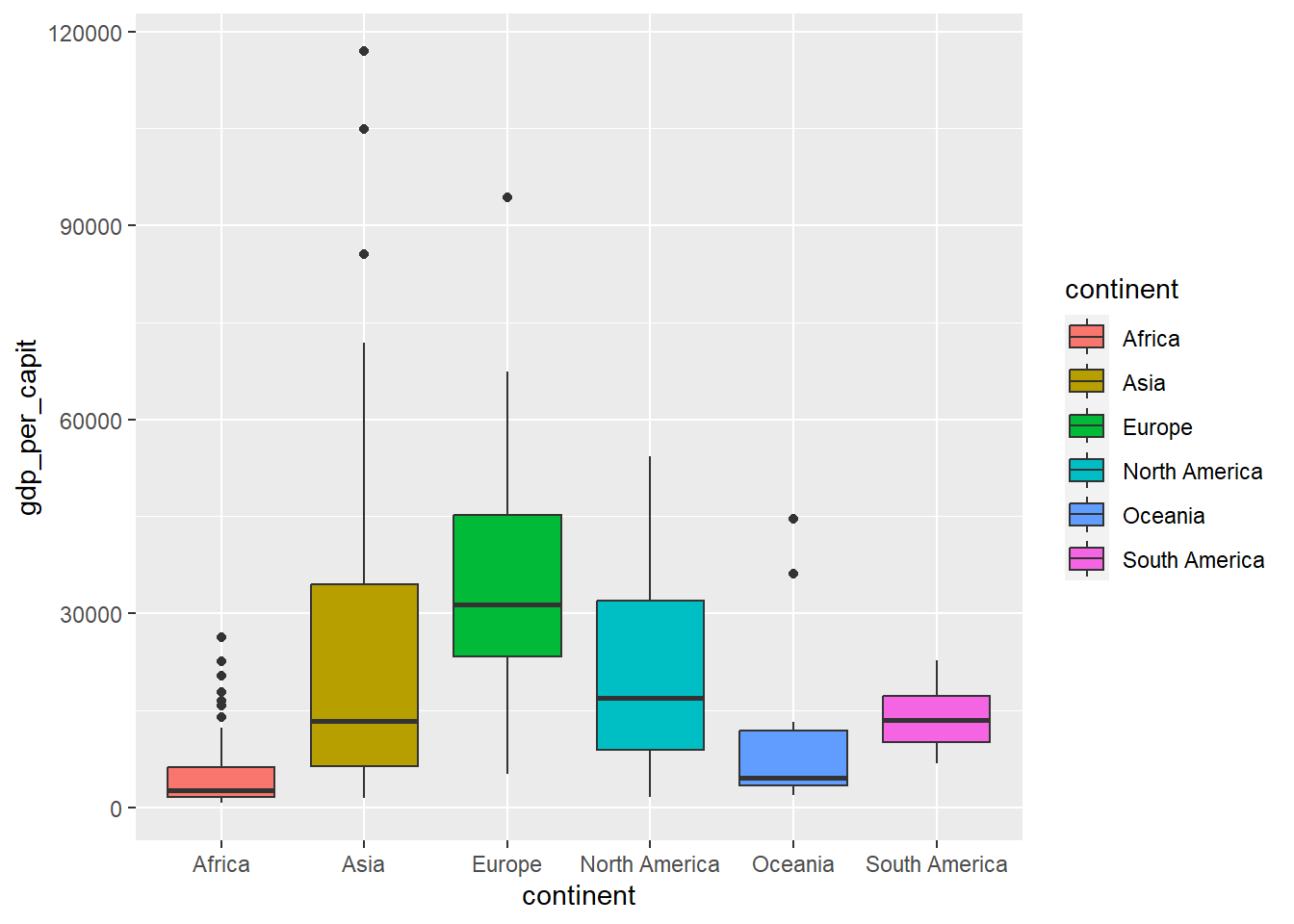
Figure 4.13: Diagrama de cajas usando geom_boxplot
Cuando el conjunto de valores no es muy grande se suelen dibujar los valores en forma de puntos para ilustrar mejor la distribución
owid_country %>%
ggplot(aes(x=continent,y=gdp_per_capit,fill=continent)) +
geom_boxplot(outlier.shape = NA) +
geom_jitter(shape=16, position=position_jitter(0.2)) +
theme(legend.position = "none")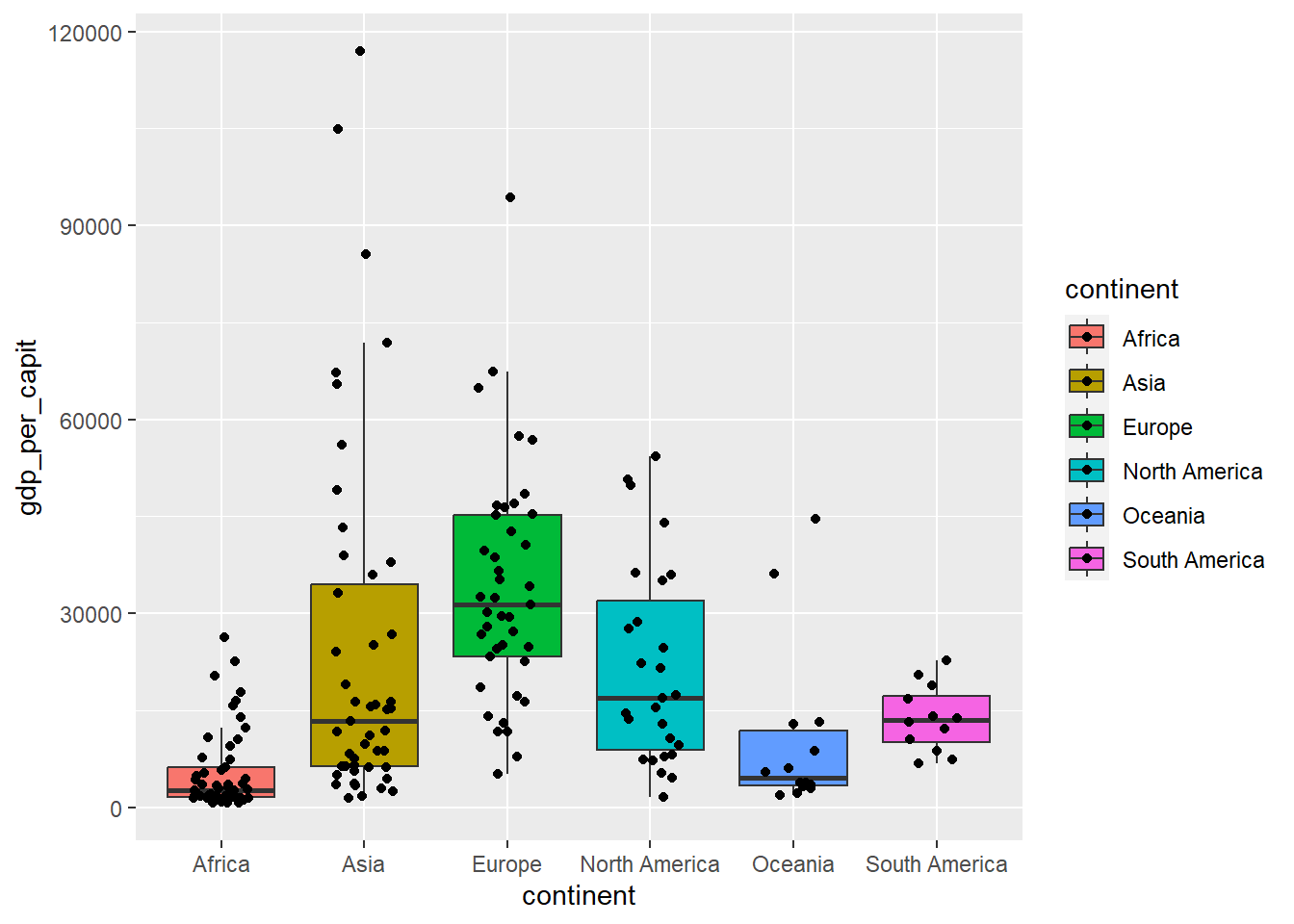
Figure 4.14: Diagrama de cajas que incluye todos los valores como puntos, usando geom_jitter
Cuando el conjunto de valores es muy grande se suelen dibujar los “box-plots” en forma de violín, donde la curva lateral (lado del violín) representa la función de densidad de la distribución.
owid_country %>%
ggplot(aes(x=continent,y=gdp_per_capit,fill=continent)) +
geom_violin() +
theme(legend.position = "none")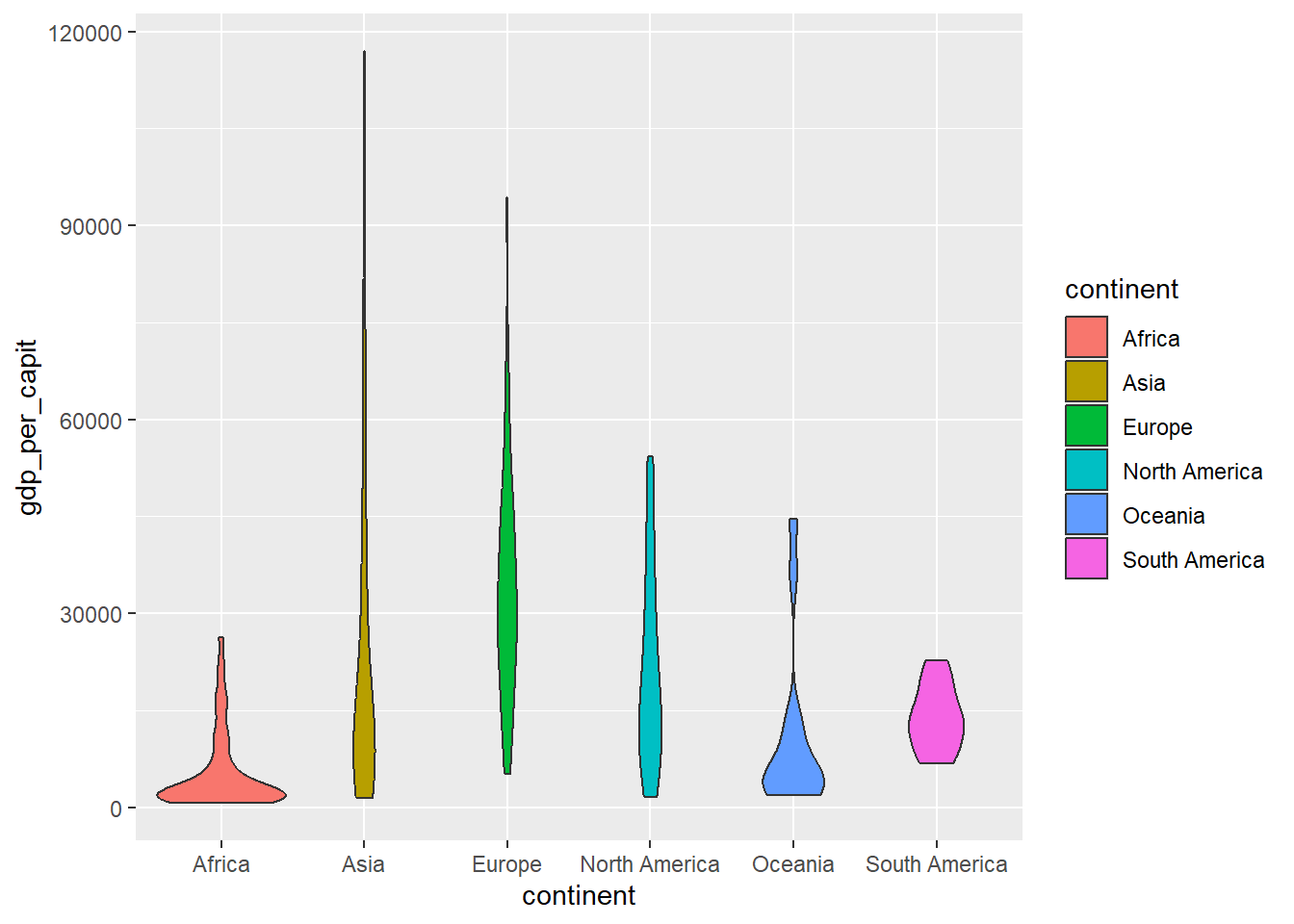
Figure 4.15: Diagrama en forma de violín usando geom_violin
4.8 Diagramas de dispersión (scatterplot)
Para comparar variables resulta muy útil visualizar, en forma de puntos, los valores de una variable frente a otra. En la siguiente figura se compara el PIB por habitante y la esperanza de vida.
owid_country %>%
ggplot(aes(x=gdp_per_capit,y=life_expectancy)) +
geom_point() + # gráfico de puntos
scale_x_continuous(trans = 'log2') + # se transforma la variable x con log
geom_smooth(method = lm, se = FALSE) # dibujo recta de regresión 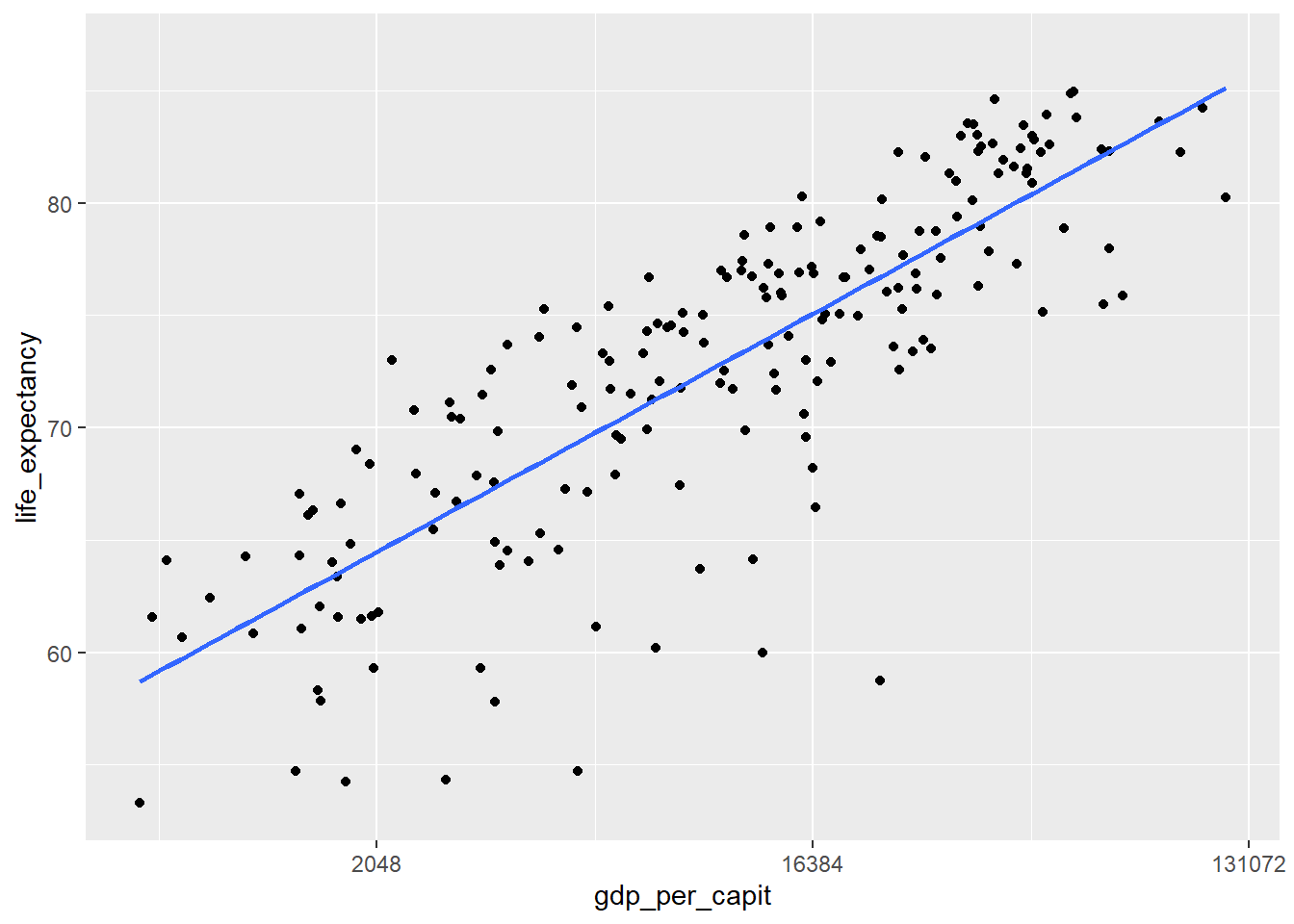
Figure 4.16: Diagrama de dispersión usando geom_point y con el eje x en escala logarítmica
En la siguiente gráfica agrupamos por continentes
owid_country %>%
ggplot(aes(x=gdp_per_capit,y=life_expectancy,color=continent)) +
geom_point() +
scale_x_continuous(trans = 'log2') +
geom_smooth(method = lm, se = FALSE)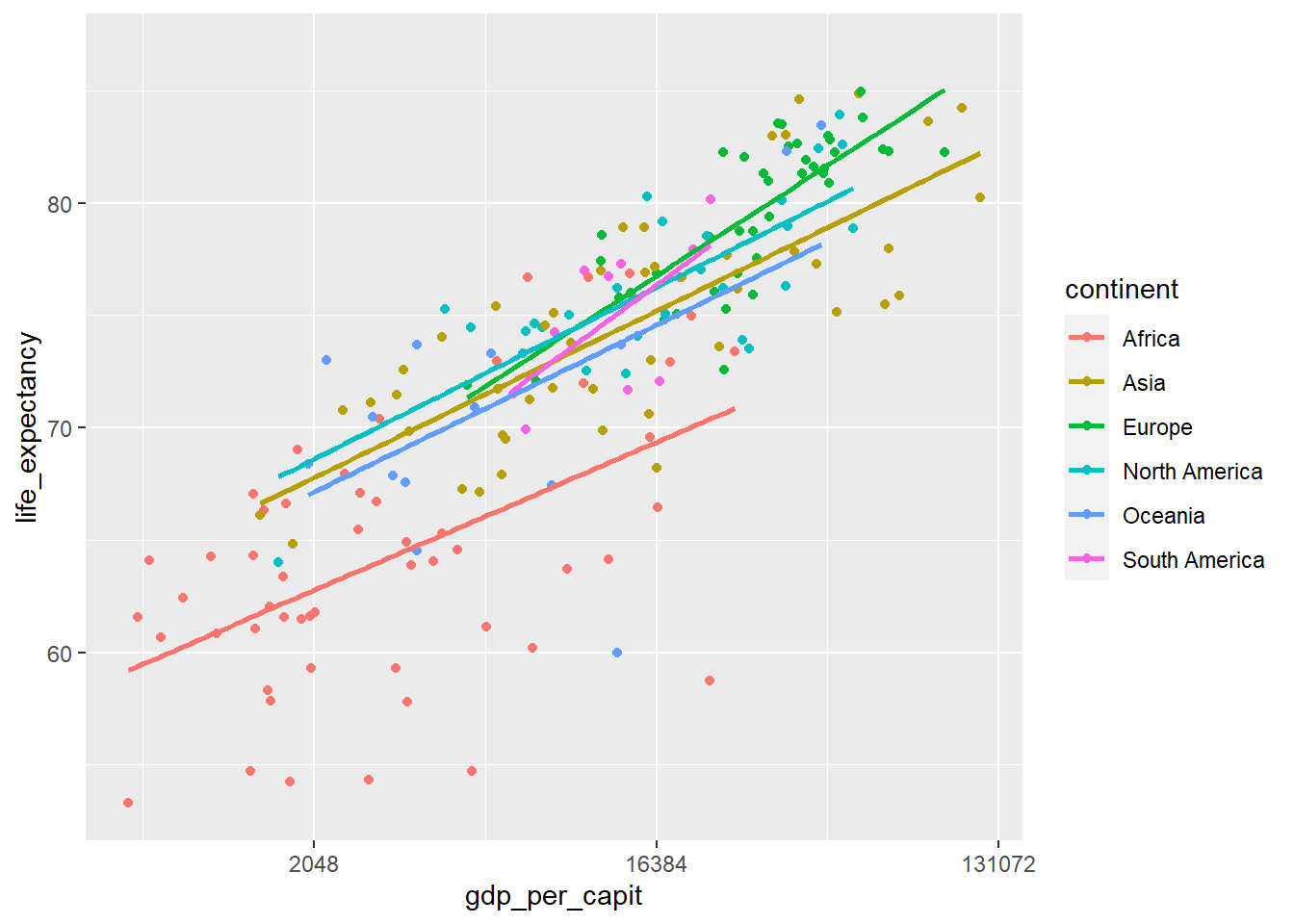
Figure 4.17: Diagrama de dispersión usando geom_point y con el eje x en escala logarítmica
4.9 Gráficos de líneas
Cuando exista en nuestra tabla una variable ordenada (por ejemplo fechas) podemos dibujar curvas donde se muestra la evolución de otras variables respecto a la variable ordenada que se pone en el eje horizontal. Veamos un ejemplo con la evolución de fallecidos diarios en el Reino Unido por la COVID-19 usando datos suministrados por la OWID.
# leemos los datos
owid_covid <- read.xlsx("https://ctim.es/AEDV/data/owid_covid.xlsx",sheet=1) %>%
as_tibble()
# dibujamos la gráfica de línea
owid_covid %>%
filter(iso_code=="GBR") %>% # seleccionamos datos del Reino Unido
mutate(date=as.Date(date)) %>% # convertimos la variable date a fechas
select(fecha=date,fallecidos=new_deaths_restored_EpiInvert) %>% # seleccionamos la fecha y los fallecidos
ggplot(aes(x=fecha,y=fallecidos))+ # dibujamos
geom_line()+ # generamos gráfico de línea
theme_bw() # ponemos el background a blanco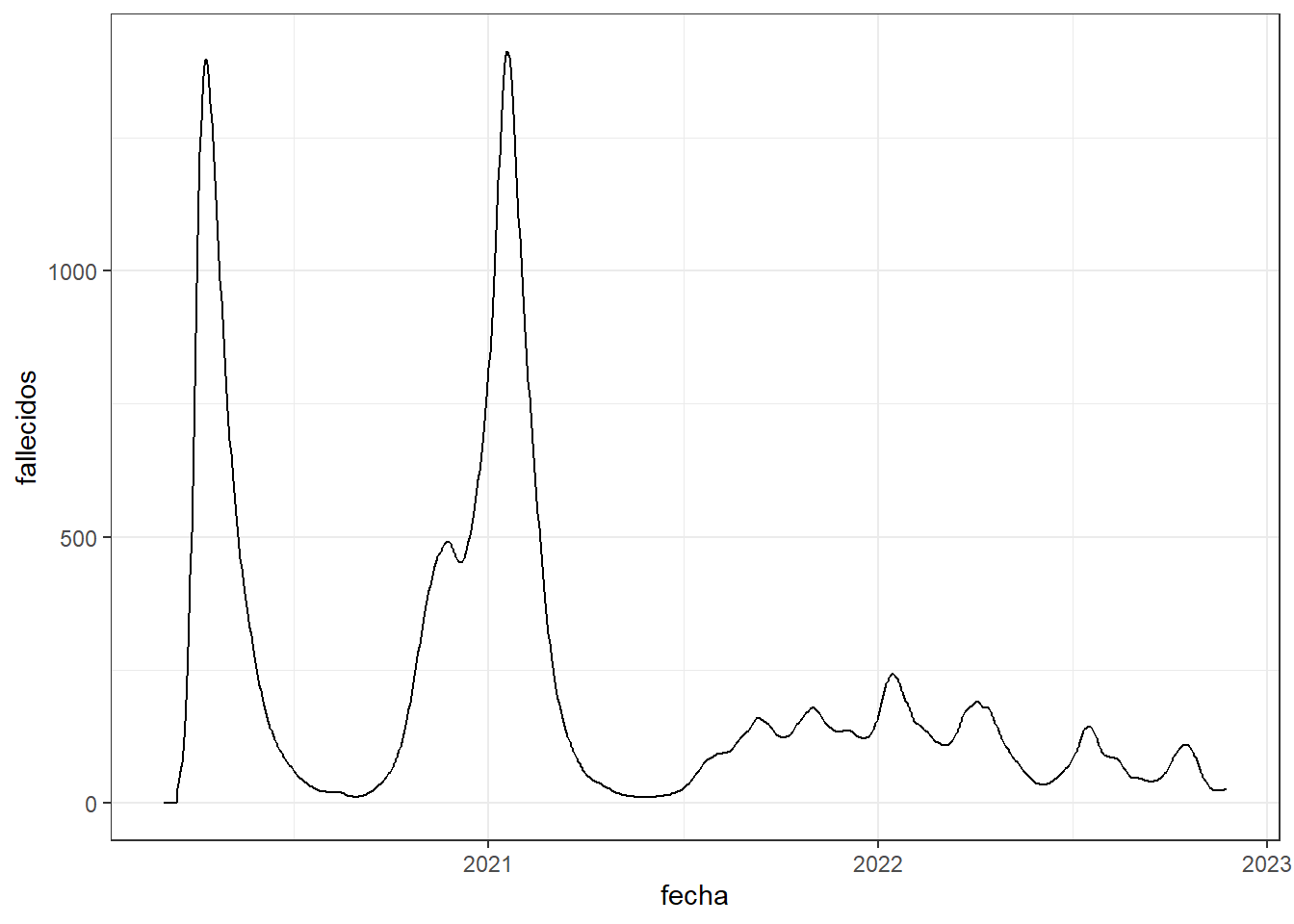
Figure 4.18: Gráfico de líneas usando geom_line
A continuación vamos a añadir a este gráfico de línea unas zonas coloreadas para identificar a las diferentes olas epidémicas
# creamos una tabla con las fechas de principio y final de cada ola epidémica con el nombre de la variante del virus.
data_breaks <- tibble(
start = as.Date(c("2020-03-23","2020-09-07","2021-05-28","2021-12-15","2022-06-24")),
end = as.Date(c("2020-05-30","2021-04-21","2021-12-14","2022-04-29","2022-08-03")),
variants =c("1. wild-type","2. Alpha","3. Delta","4. Omicron","5. Omicron")
)
# dibujamos la gráfica de línea
owid_covid %>%
filter(iso_code=="GBR") %>%
mutate(date=as.Date(date)) %>%
select(fecha=date,fallecidos=new_deaths_restored_EpiInvert) %>%
ggplot(aes(x=fecha,y=fallecidos))+
# añadimos las zonas coloreadas
geom_rect(data = data_breaks,aes(xmin = start,xmax = end,ymin = - Inf,ymax = Inf,fill = variants),inherit.aes = FALSE,alpha = 0.2) +
geom_line()+
theme_bw()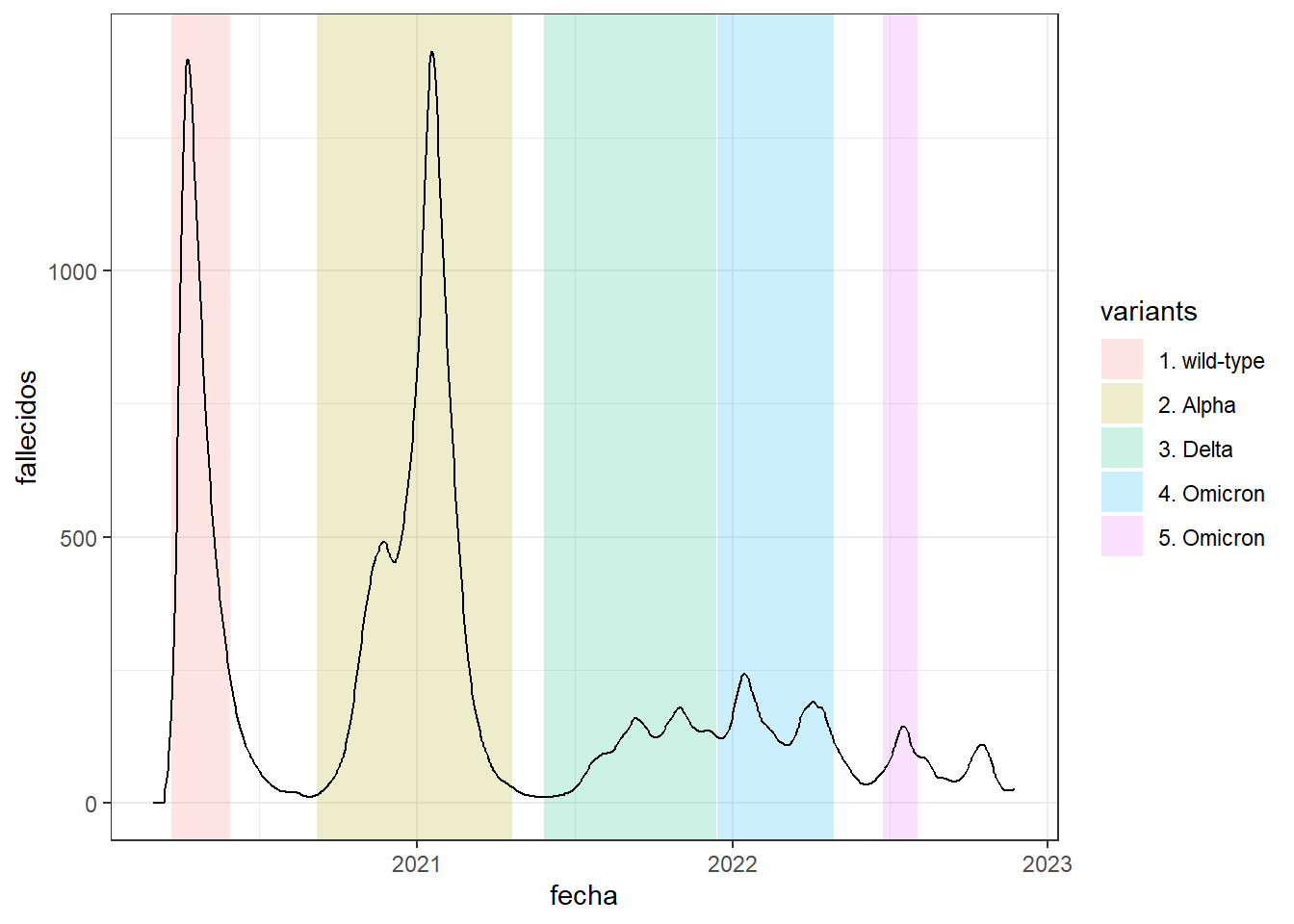
Figure 4.19: Se añade al gráfico anterior zonas coloreadas con la función geom_rect
En ocasiones, queremos comparar en la misma gráfica de línea dos variables de magnitudes muy distintas, para ello usamos un doble eje vertical, uno por la izquierda y otro por la derecha. Veamos un ejemplo comparando la incidencia diaria de casos (nº de infectados registrados) y los fallecidos por la COVID-19 en Francia. Para facilitar la generación de este tipo de gráfico primero implementamos en una función la construcción del gráfico y después simplemente llamamos a dicha función:
DrawDualAxes <- function(
tb, # tibble con los datos
namex, # string con el nombre de la variable del eje x en el tibble
namey1, # string con el nombre de la variable del eje y en el tibble por la izquierda
color1, # string con el nombre del color para dibujar el eje y por la izquierda
namey2, # string con el nombre de la variable del eje y en el tibble por la derecha
color2 # string con el nombre del color para dibujar el eje y por la derecha
){
y1.min<-min(tb[[namey1]])
y2.min<-min(tb[[namey2]])
m1<-(max(tb[[namey1]])-y1.min)/(max(tb[[namey2]])-y2.min)
p <- tibble(
x=tb[[namex]],
y1=tb[[namey1]],
y2=tb[[namey2]]
) %>% ggplot(aes(x=x)) +
geom_line(aes(y = y1, color = color1)) + # dibujamos la primera variable
geom_line(aes(y = y1.min+(y2-y2.min)*m1), color=color2) + # dibujamos la segunda variable escalada
#asignamos títulos a los ejes y creamos los valores del eje vertical por la derecha
scale_y_continuous(name =namey1,sec.axis = sec_axis(~ (. - y1.min)/m1+y2.min, name=namey2)) +
theme(
axis.title.y = element_text(color =color1),
axis.title.y.right = element_text(color = color2),
legend.position="none"
)
return(p)
}Generación del gráfico con doble eje vértical
data <- owid_covid %>%
filter(iso_code=="FRA") %>%
mutate(date=as.Date(date)) %>%
select(fecha=date,fallecidos=new_deaths_restored_EpiInvert,incidencia=new_cases_restored_EpiInvert)
DrawDualAxes(data,"fecha","incidencia","red","fallecidos","blue")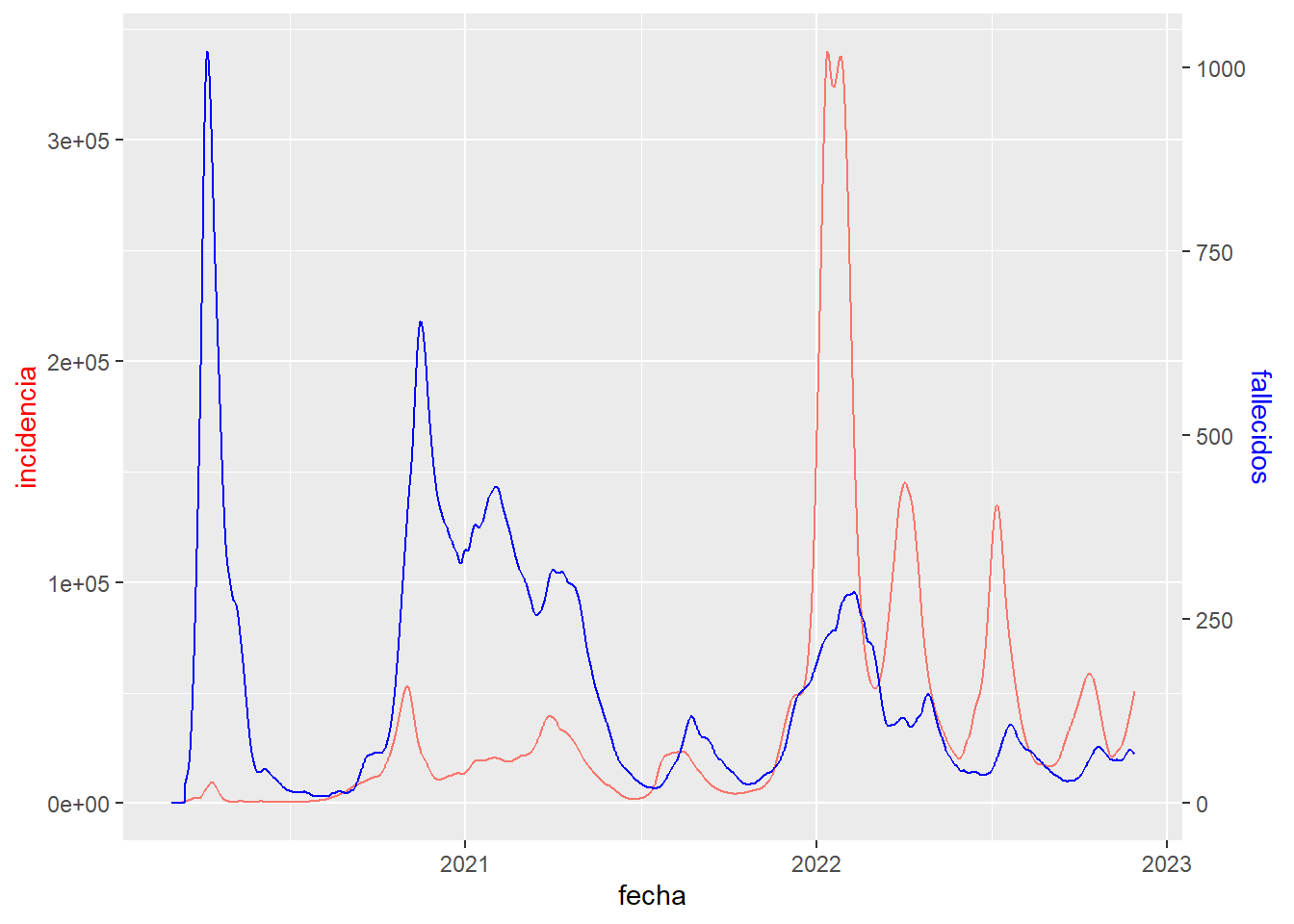
Figure 4.20: Gráfico de líneas con doble eje vértical
Veamos ahora como añadir texto al gráfico de fallecimientos en Francia para señalar cuando se produce el máximo diario de fallecimientos:
tb <- owid_covid %>%
filter(iso_code=="FRA" & date<"2021-12-30") %>%
mutate(date=as.Date(date)) %>%
select(fecha=date,fallecidos=new_deaths_restored_EpiInvert)
# calculamos el máximo de los fallecimientos diarios y cuando se alcanza
yl <- max(tb$fallecidos)
xl <- tb$fecha[which(tb$fallecidos==yl)]
tb %>%
ggplot(aes(x=fecha,y=fallecidos))+
geom_line()+
theme_bw()+
# escribimos la anotación ligeramente desplazada de la posición del máximo
annotate(geom="label",x=xl+40,y=yl-20,hjust="left",
label=paste(yl," fue el máximo de fallecidos diarios\n",
"y se alcanzó el ",xl))+
# dibujamos un vector desde la anotación hasta la posición del máximo
annotate(
geom="segment",x=xl+40,y=yl-20,xend=xl,yend=yl,size=0.5,
arrow=arrow(length=unit(2,"mm"),angle=25,type="closed")
) 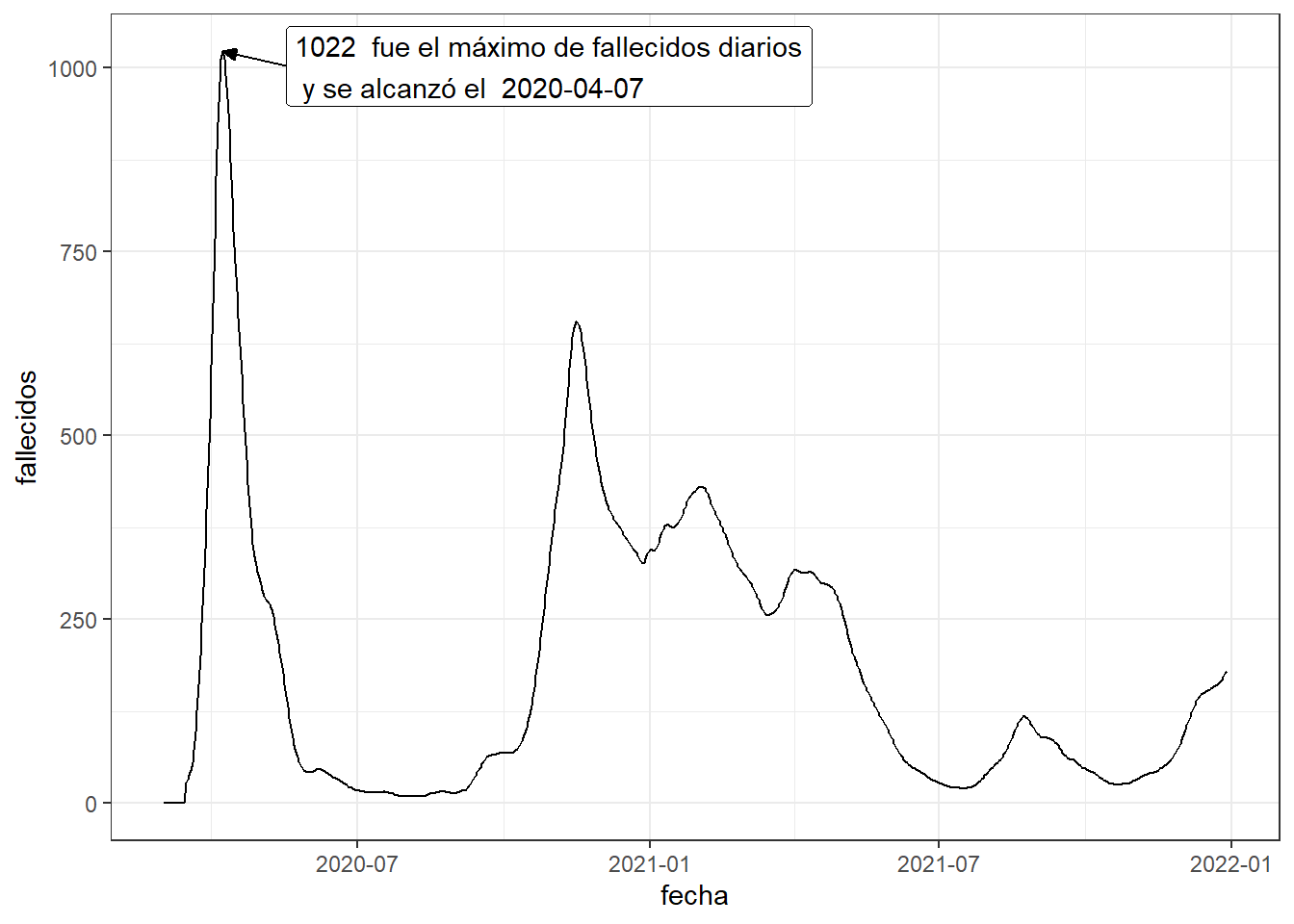
Figure 4.21: Gráfico de líneas con anotaciones
Estos datos que acabamos de mostrar sobre la COVID-19 son casos particulares de series temporales donde tenemos datos que van variando con el tiempo. En el próximo tema estudiaremos más en detalle las series temporales.
4.10 Combinando gráficos
Cada gráfico que genera ggplot se puede manejar como un objeto que posteriormente
se puede combinar con otros gráficos. Para combinar gráficos utilizaremos la librería
patchwork. Veamos un ejemplo combinando gráficos que comparan diferentes variables
del tibble owid_country
p1 <- owid_country %>%
ggplot(aes(x=gdp_per_capit,y=life_expectancy)) +
geom_point() +
scale_x_continuous(trans = 'log2')
p2 <- owid_country %>%
ggplot(aes(x=gdp_per_capit,y=handwashing_facilities)) +
geom_point() +
scale_x_continuous(trans = 'log2')
p3 <- owid_country %>%
ggplot(aes(x=gdp_per_capit,y=hospital_beds_per_thousand)) +
geom_point() +
scale_x_continuous(trans = 'log2')
p4 <- owid_country %>%
ggplot(aes(x=gdp_per_capit,y=human_development_index)) +
geom_point() +
scale_x_continuous(trans = 'log2')
wrap_plots(p1, p2, p3, p4, ncol = 2, nrow = 2)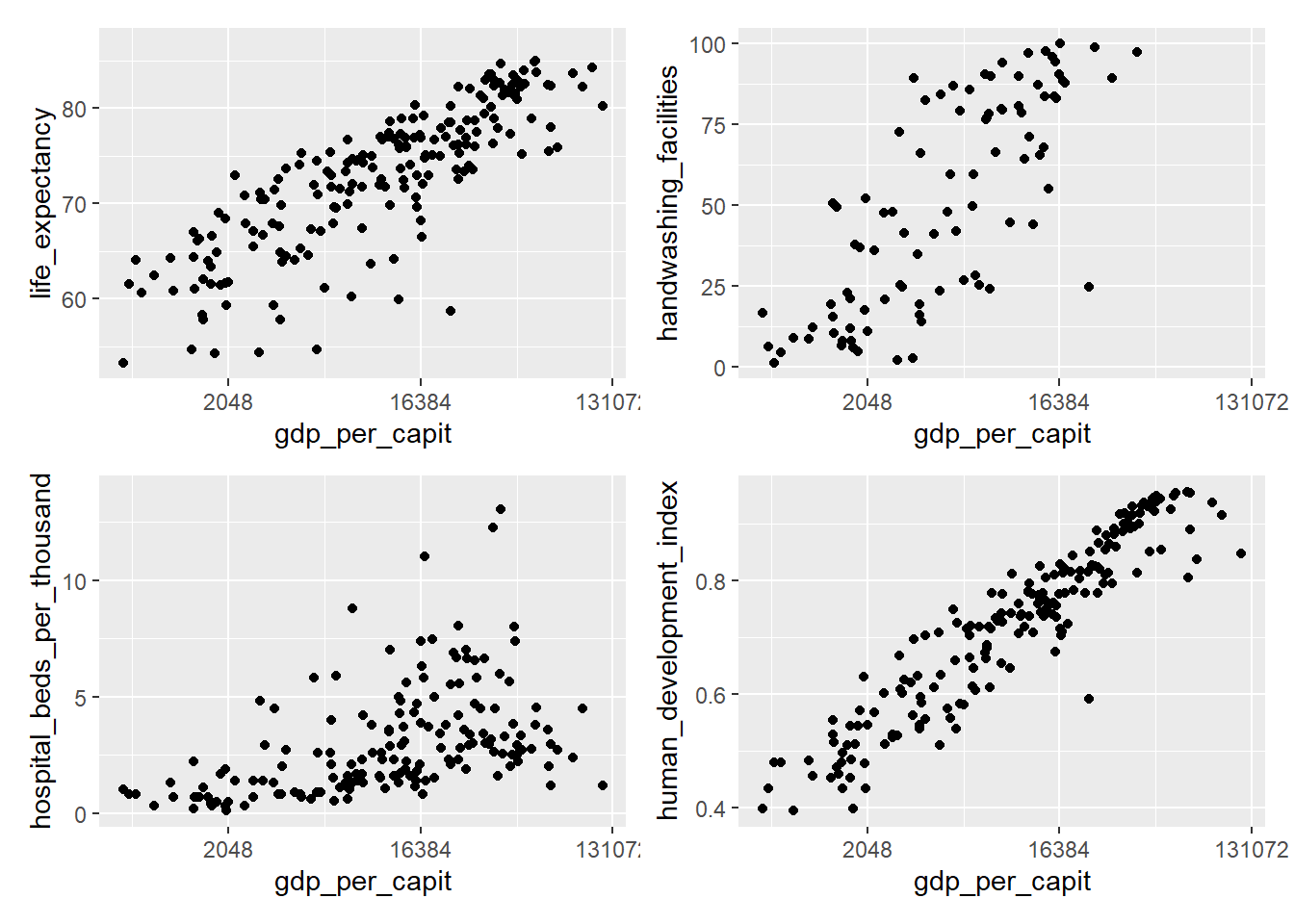
Figure 4.22: Combinación de gráficos usando wrap_plots
4.11 ggpairs para comparar variables
La función ggpairs de la librería GGally ofrece una forma avanzada de comparar
variables. En la siguiente figura se muestra un ejemplo de su uso para comparar
3 indicadores de la tabla owid_country haciendo una comparación con todos los
datos y otra comparación agrupando por continentes. ggpairs genera una cuadrícula
donde en la diagonal aparecen las funciones de densidad de las distribuciones del
valores por continentes. En la parte inferior de la cuadrícula se dibujan los diagramas
de dispersión formados por los valores de 2 indicadores y en la parte superior de
la cuadrícula se pone el valor de correlación entre cada par de indicadores,
cuanto más cercano sea este valor, más se aproxima a una línea la nube de puntos
de la parte inferior de la cuadrícula
owid_country %>%
select(continent,
cardiovasc_death_rat,
life_expectancy,
human_development_index) %>%
ggpairs(columns = 2:4, # columnas del tibble que se compararán
aes(color = continent,alpha=0.5)) # colorea por continente 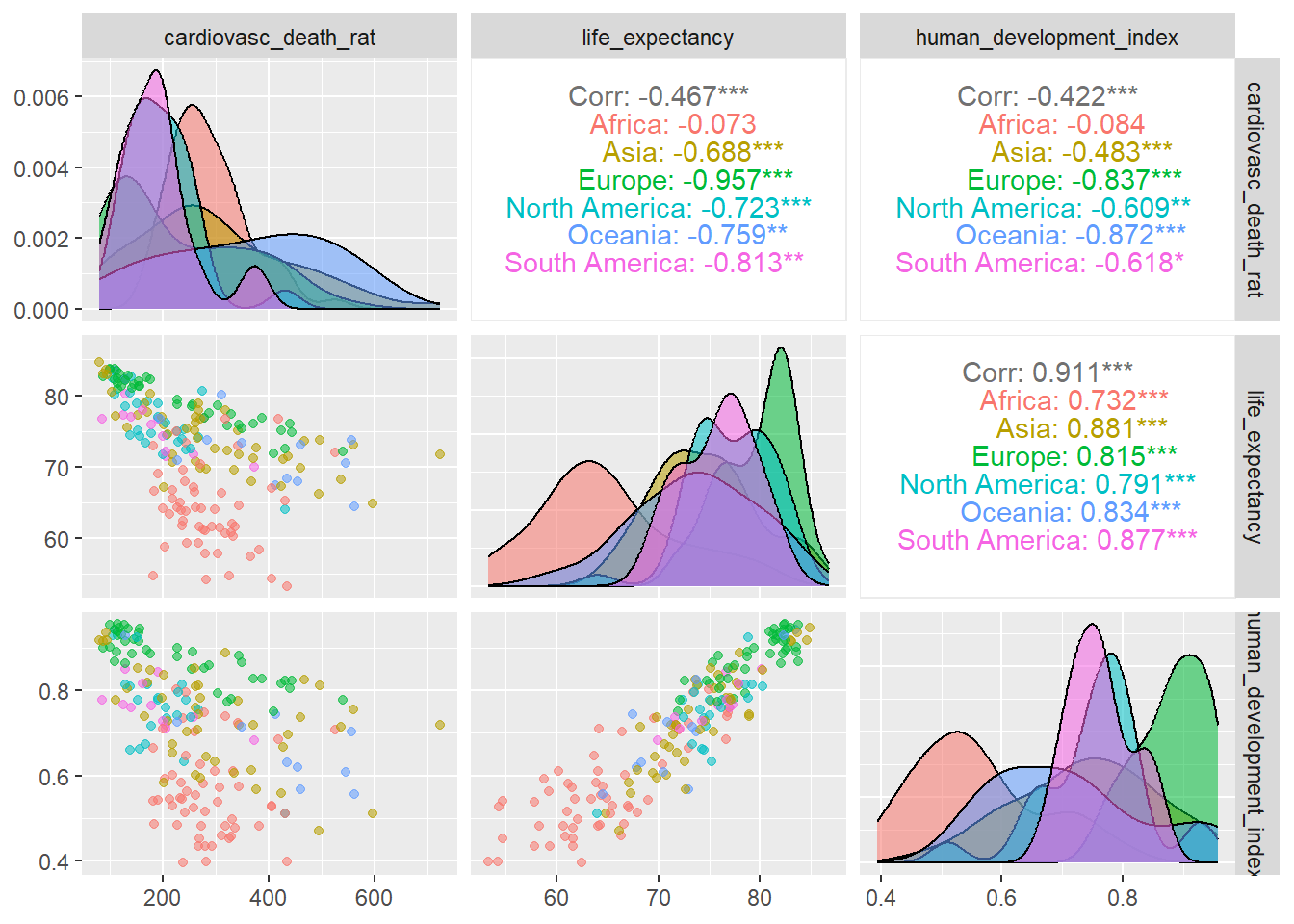
Figure 4.23: Comparación de variables usando ggpairs
4.12 Colores
A la hora de presentar de manera eficiente y atractiva nuestro análisis de datos, es muy importante prestar atención a los elementos de diseño estético. En las secciones finales de este capítulo veremos cuestiones relacionadas con este aspecto, empezando por la gestión de los colores. En la gran mayoría de los gráficos de ejemplos que se muestran en este libro no se incluyen estos elementos estéticos, no porque no se les considere importante, sino para simplificar la presentación y poner énfasis en las cuestiones técnicas de los elementos geométricos. Sin embargo, todos estos gráficos son estéticamente mejorables usando las herramientas que se muestran en las secciones que siguen.
Los colores son un elemento de diseño muy importante en los gráficos.
Hay varias formas diferentes de definir un color. Por ejemplo,
podemos definir un color utilizando su nombre o su código HEX. En
r-charts.com se puede encontrar una detallada lista
de colores con su nombre y código HEX. A continuación se muestra
una selección de colores con sus nombres asociados.
Figure 4.24: Tabla con una selección de colores con sus nombre asociados
otra forma de definir los colores esa través de su nivel de rojo (R), verde (G),
y azul (B), así como un valor alpha (opcional) que indica su transparencia cuando se superpone a otras
figuras ya pintadas. Cada componente se mueve entre valores 0 y 1. Por ejemplo rgb(1.,0.,0.) sería el color rojo y rgb(0.,0.,1.,0.9) sería el color azul con una ligera transparencia.
A cada elemento geométrico dibujable de ggplot le podemos asignar colores
utilizando los atributos color (color del objeto geométrico) y fill (color de relleno interior de la forma). Además, la asignación puede ser automática o manual. Veamos algunos ejemplos con un diagrama
de barras
owid_country %>%
group_by(continent) %>%
summarise(population=sum(population)) %>%
ggplot(aes(x=continent,y=population)) +
geom_bar(stat = "identity",fill="lightblue",color="black") 
Figure 4.25: Diagrama de barras definiendo un solo color en geom_bar
owid_country %>%
group_by(continent) %>%
summarise(population=sum(population)) %>%
ggplot(aes(x=continent,y=population,fill=continent)) +
geom_bar(stat = "identity") +
theme(legend.position = "none")
Figure 4.26: Diagrama de barras con colores generados automáticamente en el aes de ggplot
owid_country %>%
group_by(continent) %>%
summarise(population=sum(population)) %>%
ggplot(aes(x=continent,y=population,fill=continent)) +
geom_bar(stat = "identity") +
scale_fill_manual(values = c("white","black","blue","red","green","yellow")) +
theme(legend.position = "none")
Figure 4.27: Diagrama de barras con colores asignados manualmente usando scale_fill_manual
Otra forma de definir colores es usando paletas. La librería RColorBrewer suministra las siguientes paletas de colores:
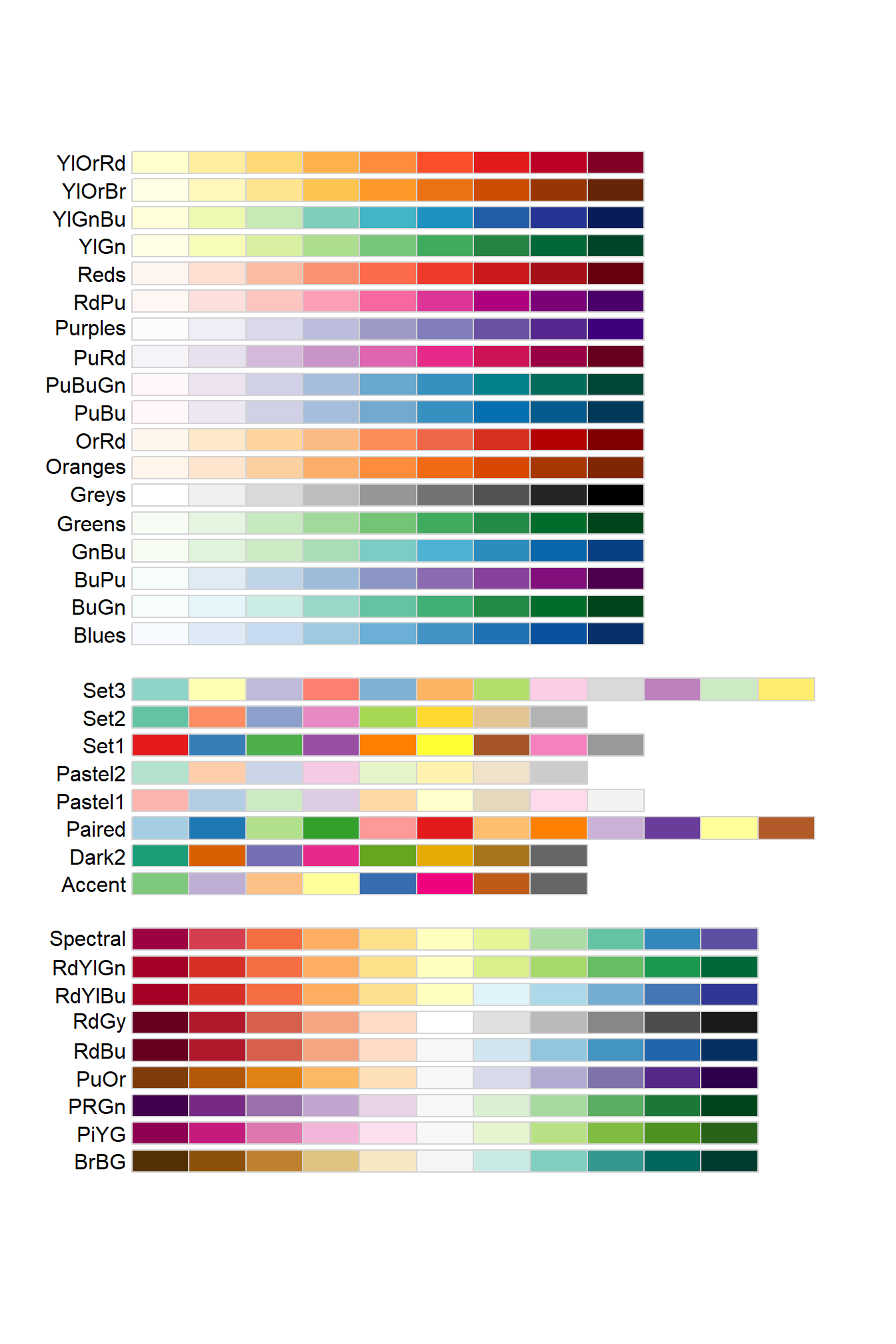
Figure 4.28: Paletas de colores de la librería RColorBrewer
Podemos distinguir 3 tipos de paletas :
Paletas de un solo color con luminosidad decreciente : el color se mantiene pero disminuye su luminosidad a lo largo de la paleta.
Paletas divergentes : la luminosidad y color no siguen un patrón progresivo.
Paletas con varios colores : la paleta empieza con un color oscuro que se va aclarando hasta llegar a la mitad de la tabla, después cambia de color y se oscureciendo progresivamente.
Los paletas con colores progresivos son especialmente adecuadas cuando asociamos un color a un valor numérico, de tal forma que queremos que el color cambie progresivamente en función del valor numérico. Una aplicación de esto lo veremos en la siguiente sección donde se explicarán los heatmaps.
owid_country %>%
group_by(continent) %>%
summarise(population=sum(population)) %>%
ggplot(aes(x=continent,y=population,fill=continent)) +
geom_bar(stat = "identity") +
scale_fill_brewer(palette = "Paired") +
theme(legend.position = "none")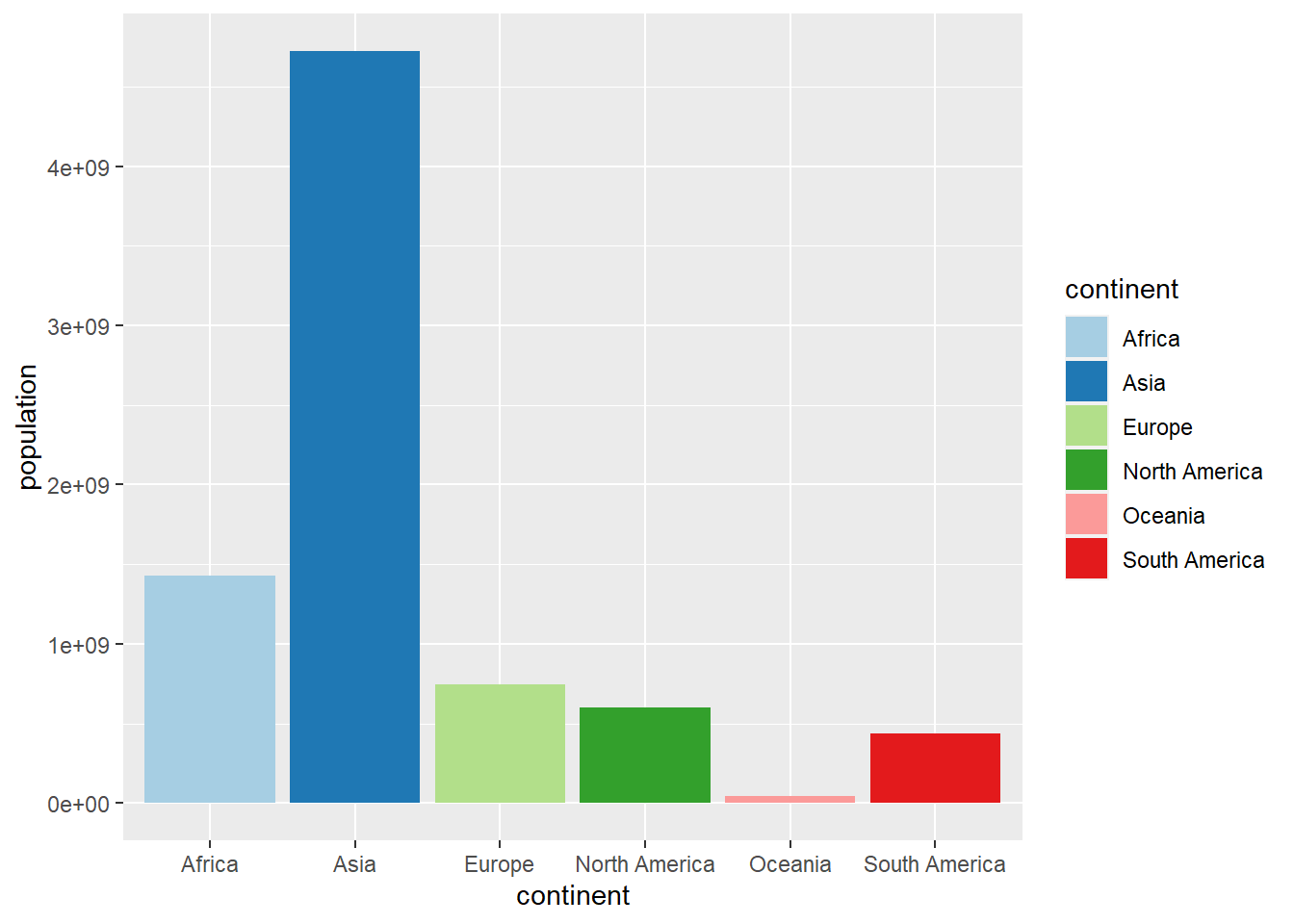
Figure 4.29: Diagrama de barras con colores usando scale_fill_brewer
Como vemos, el máximo número de colores que ofrecen las paletas de RColorBrewer es 12, si necesitamos dibujar más de 12 objetos, podemos extender la paleta de colores usando colorRampPalette. Además, para ello necesitamos también saber cuantos objetos necesitamos colorear en la gráfica. En el siguiente ejemplo necesitamos colorear 20 objetos y por tanto necesitamos 20 colores:
getPalette = colorRampPalette(brewer.pal(12, "Set3"))
NúmeroDeColores <- 20
owid_country %>%
arrange(population) %>%
tail(20) %>%
mutate(location=factor(location,levels=location)) %>%
ggplot(aes(x=location,y=population,fill=getPalette(NúmeroDeColores))) +
geom_bar(stat = "identity") +
coord_flip() +
theme(legend.position="none")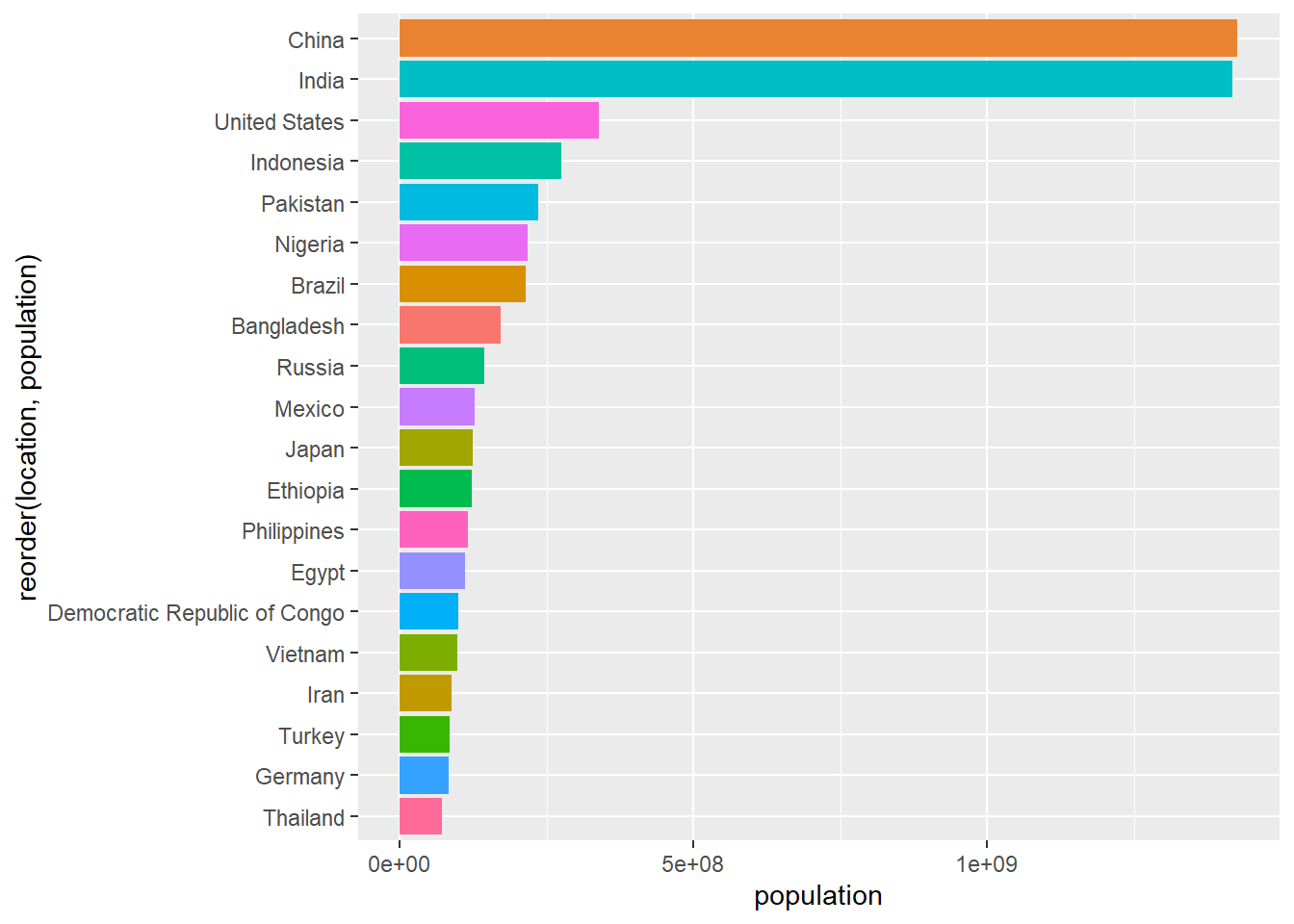
Figure 4.30: Diagrama de barras con interpolación de colores brewer usando colorRampPalette
4.13 Mapas de calor
Un mapa de calor (Heatmap) es una tabla de valores numéricos donde las celdas tienen un color que varía de acuerdo con el valor numérico de la celda. Para ilustrar esta herramienta vamos a hacer un mapa de calor con los valores de algunos indicadores de los países de Europa almacenados en el tibble owid_country. Como en este caso los valores de los indicadores se mueven en rangos muy distintos los vamos a normalizar dividiéndolos por su máximo. De esta manera el valor 1 corresponde al país con mayor valor y en el resto de países el valor indica la proporción del valor del país con respecto al máximo.
En las siguientes instrucciones se filtra el tibble owid_country, se seleccionan
los campos que intervienen en el mapa de calor y se normalizan
sel_owid_country <- owid_country %>%
filter(continent=="Europe" & is.na(aged_65_older)==FALSE ) %>%
select(location,population:gdp_per_capit,hospital_beds_per_thousand, human_development_index)
for( i in 2:ncol(sel_owid_country)){
sel_owid_country[i] <- round(sel_owid_country[i]/max(na.omit(sel_owid_country[i])),digits = 2)
}A continuación creamos el mapa de calor utilizando la paleta de colores YlOrRd. Previamente tenemos que modificar, usando pivot_longer, la organización del tibble para pasarlo al formato tidy data que requiere ggplot
sel_owid_country %>%
pivot_longer(population:human_development_index, names_to = "indicator", values_to = "value") %>%
ggplot(aes(indicator,location,fill=value)) +
geom_tile(color = "lightblue",
lwd = 0.5,
linetype = 1) +
scale_fill_gradientn(colors = brewer.pal(9, 'YlOrRd'))+
theme(axis.text.x = element_text(angle = 45,hjust=1))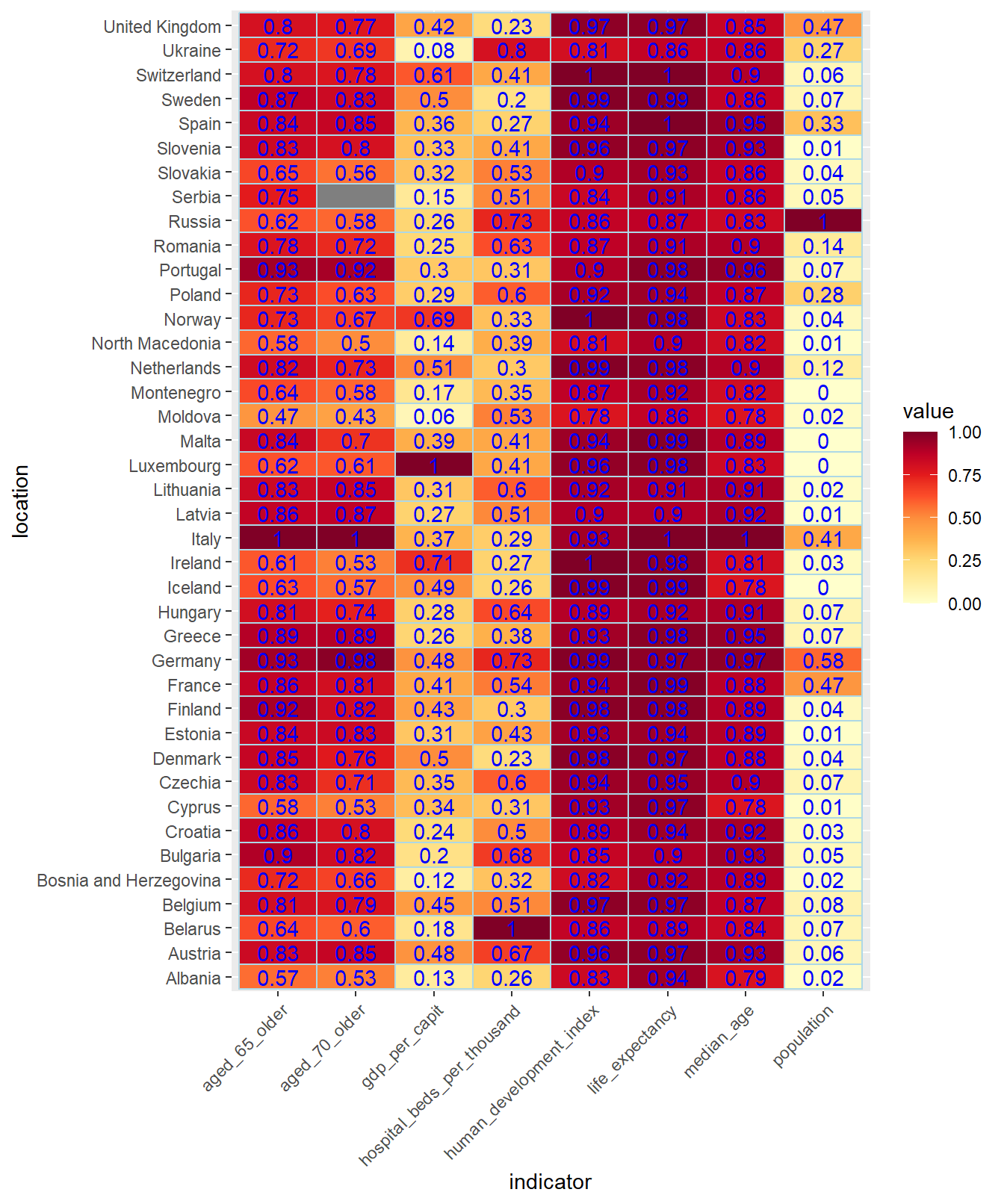
Figure 4.31: Mapa de calor, usando la paleta YlOrRd, de algunos indicadores europeos normalizados diviendo por su máximo
Vamos ahora a hacer algunos cambios: añadimos un texto a las celdas con los valores escalados para que se muevan aproximadamente entre 0 y 100. Para colorear normalizamos entre 0 y 1 y cambiamos la paleta:
owid_country %>%
filter(continent=="Europe" & is.na(aged_65_older)==FALSE ) %>%
select(location,population:gdp_per_capit,hospital_beds_per_thousand, human_development_index) %>%
mutate(population=population/1000000) %>%
rename(`population (÷ 1000000)`=population) %>%
mutate(gdp_per_capit=gdp_per_capit/1000) %>%
rename(`gdp_per_capit (÷ 1000)`=gdp_per_capit) %>%
mutate(human_development_index=human_development_index*100) %>%
rename(`human_development_index (x 100)`=human_development_index) %>%
pivot_longer(`population (÷ 1000000)`:`human_development_index (x 100)`, names_to = "indicator", values_to = "value") %>%
group_by(indicator) %>%
mutate(norm_value = (value - min(na.omit(value))) / (max(na.omit(value)) - min(na.omit(value)))) %>%
ungroup() %>%
mutate(value=round(value,digits = 2)) %>%
ggplot(aes(indicator,location,fill=norm_value)) +
geom_tile(color = "grey80") +
scale_fill_gradient(low = "white", high = "steelblue") +
geom_text(aes(label = value), color = "black") +
theme(axis.text.x = element_text(angle = 45,hjust=1),legend.position = "none")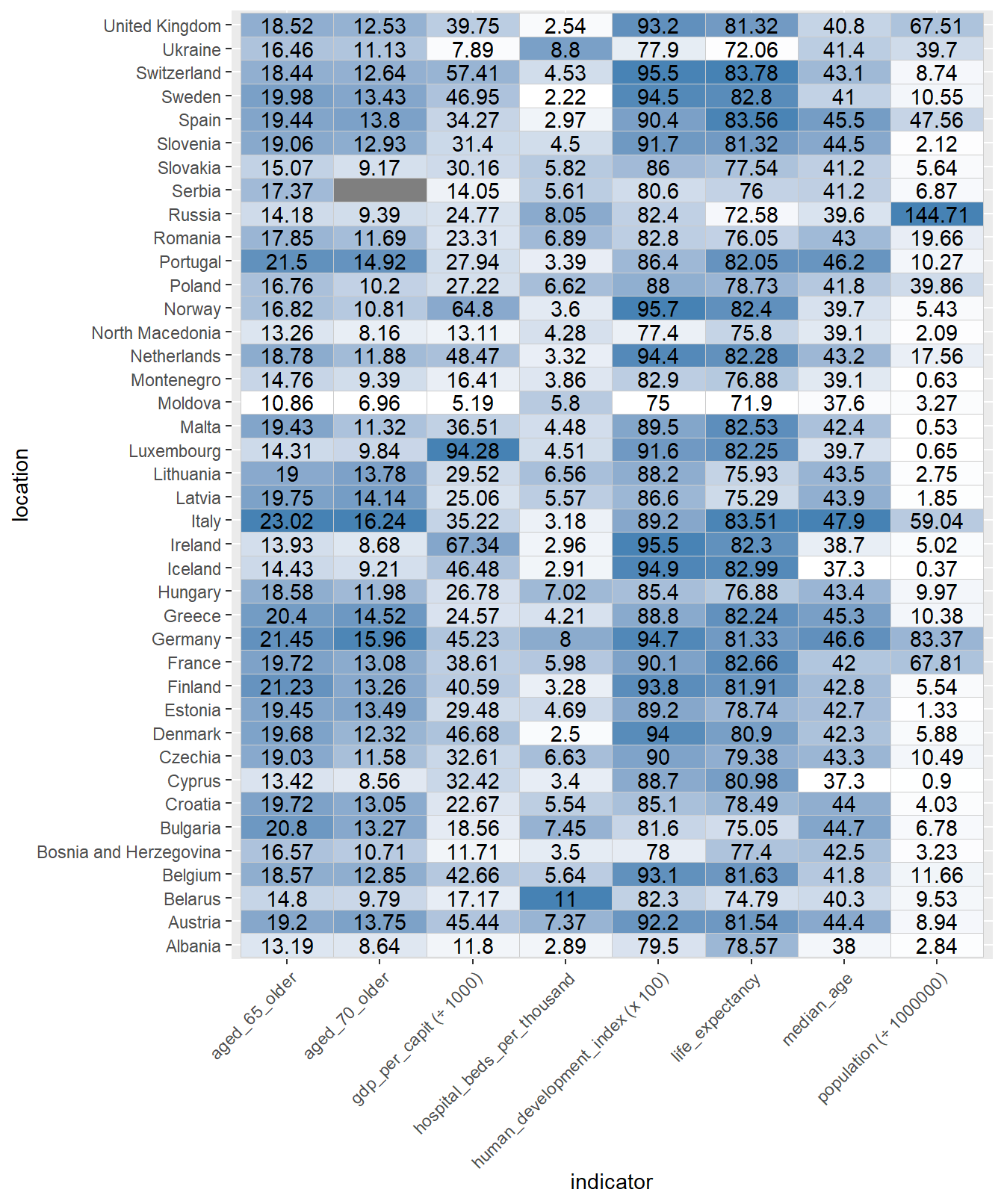
Figure 4.32: Mapa de calor similar al anterior, cambiando la paleta, normalizando para colorear y poniendo etiquetas con los valores
4.14 Wordcloud
wordcloud es una librería que permite crear atractivos gráficos combinando strings cuyo tamaño depende de una variable numérica. Veamos un ejemplo donde el tamaño de los nombres de los países europeos depende de su PIB por habitante.
wordcloud(words = sel_owid_country$location, freq = sel_owid_country$gdp_per_capit, min.freq = 0,
max.words=200, random.order=FALSE, colors=brewer.pal(8, "Dark2"))
Figure 4.33: Worcloud de los países europeos usando su PIB por habitante con la paleta de colores Dark2
4.15 Themes
El diseño general de la salida de un gráfico de ggplot se controla a través de la capa theme. Podemos modificar todos los atributos por
defecto de diseño de salida usando diferentes themes. De hecho hay paquetes en R dedicados exclusivamente
al diseño de themes. Para ilustrar esto con un ejemplo, utilizaremos el theme theme_bw en
un gráfico :
owid_country %>%
ggplot(aes(x=gdp_per_capit,y=life_expectancy,color=continent)) +
geom_point() +
theme_bw() +
scale_x_continuous(trans = 'log2') +
labs(title="Distribución, por continentes, del PIB por habitante ",x="gdp_per_capit", y = "life_expectancy")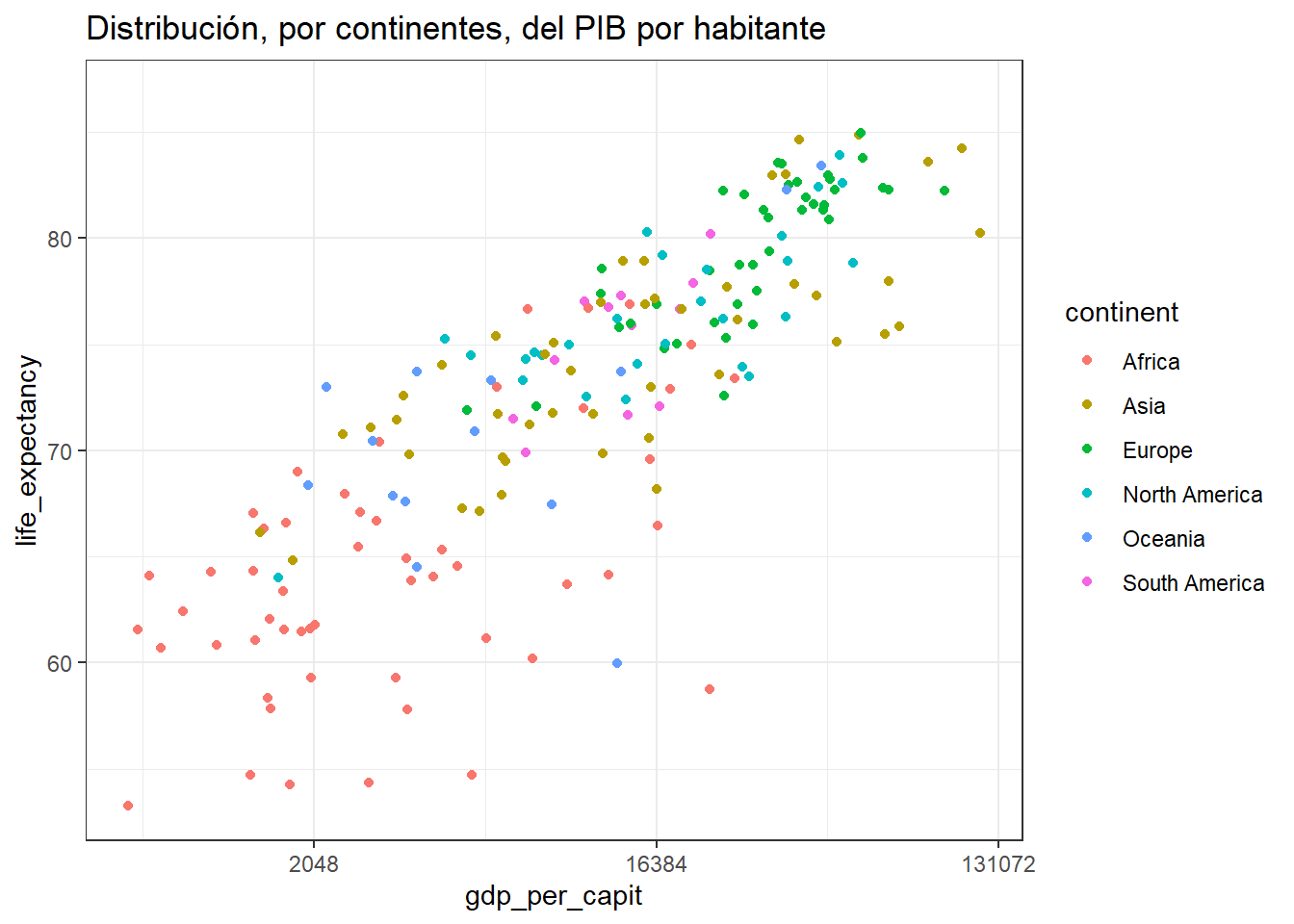
Figure 4.34: Usando el theme theme_bw
Además de definir un theme general para el gráfico, podemos controlar
los atributos individuales del theme, añadiendo al gráfico una capa theme adicional.
A continuación se muestran algunos atributos que se pueden configurar con la capa
theme
owid_country %>%
ggplot(aes(x=gdp_per_capit,y=life_expectancy,color=continent)) +
geom_point() +
scale_x_continuous(trans = 'log2') +
theme(
panel.background = element_rect( fill = "ivory", #color de fondo
color = "black", # color del borde
linewidth = 2), # grosor borde
panel.grid = element_line( color = "blue", #color cuadrícula
linewidth = 0.5, # grosor cuadrícula
linetype = 2), # tipo línea
axis.title.y = element_blank(), # quitar título eje y
axis.text.x = element_text(angle = 45,hjust=1), # inclinar texto eje x
legend.position="none", # quitar leyenda situada a la derecha
text = element_text(size = 20) # modifica el tamaño de la letra
)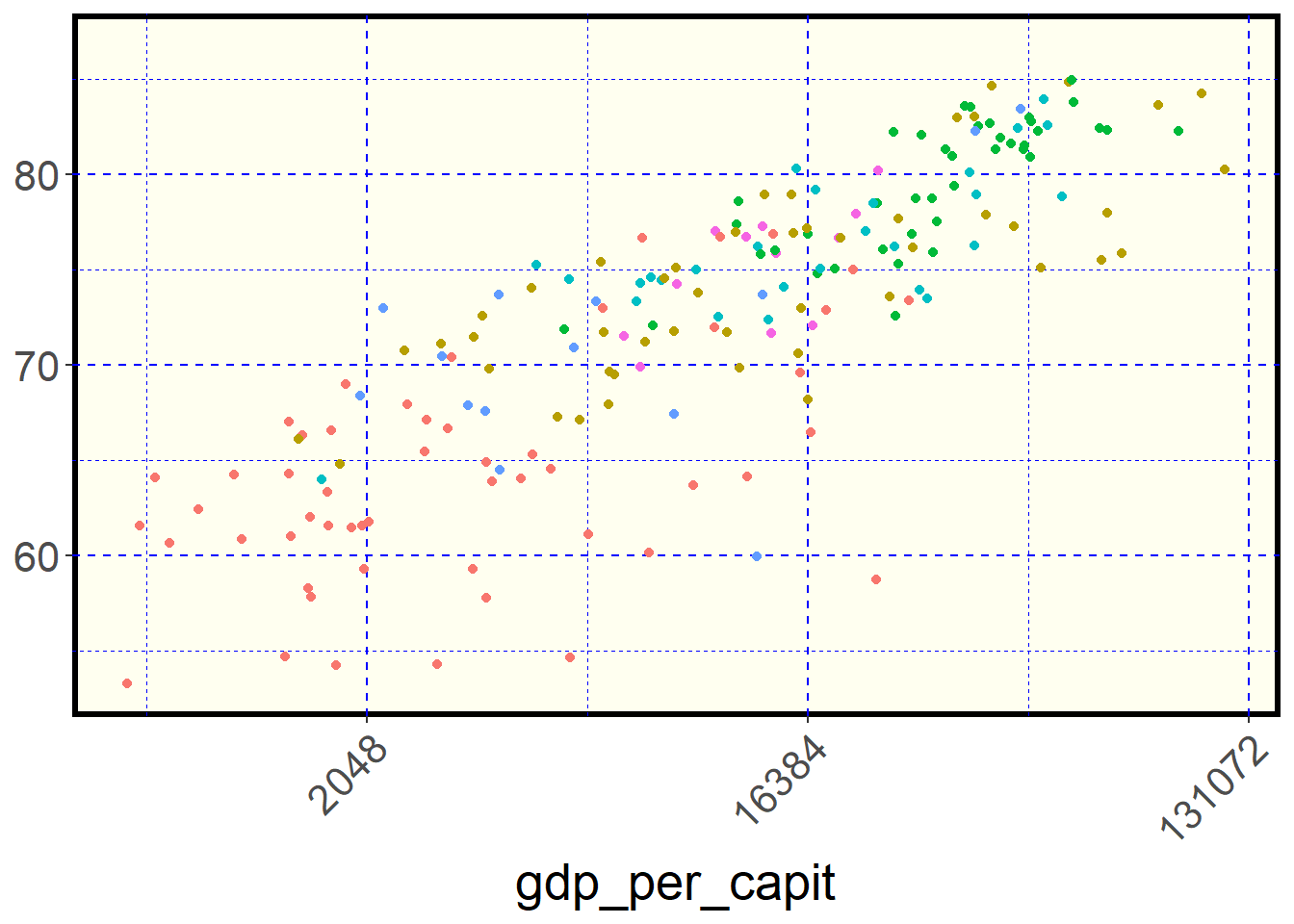
Figure 4.35: Algunas opciones de theme
Si queremos modificar el tema por defecto en todo el documento podemos poner la siguiente instrucción al principio del documento
4.16 Diseño títulos y ejes
owid_country %>%
ggplot(aes(x=gdp_per_capit,y=life_expectancy,color=continent)) +
geom_point() +
labs( title = "Mi Título",
subtitle = "Mi Subtítulo",
x= "Título eje x",
y= "Título eje y"
) +
scale_x_continuous(trans = 'log2', # función transformación eje x
n.break = 10, # número cortes eje x
) +
scale_y_continuous(n.break = 10) # número cortes eje y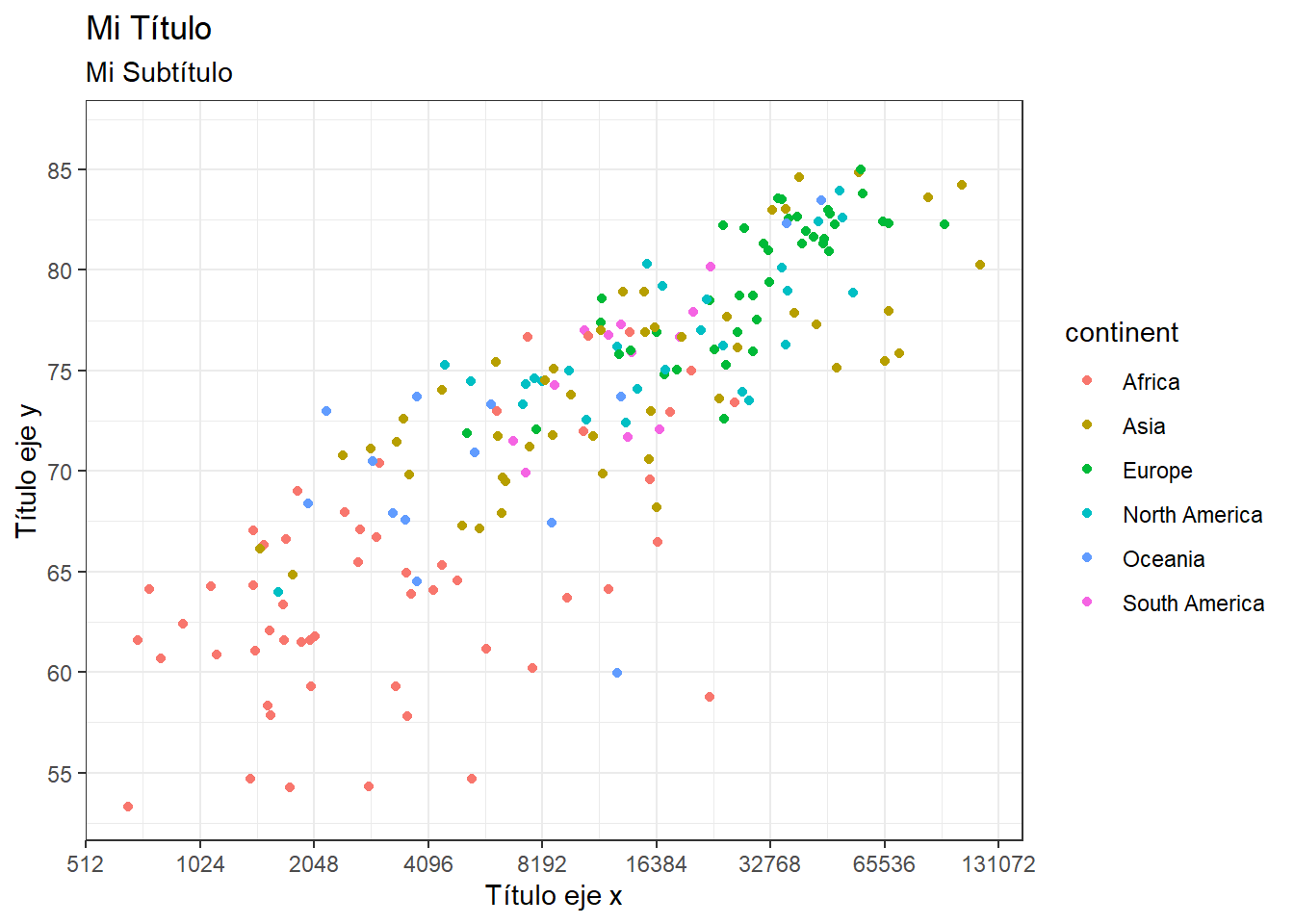
Referencias
[Ka20] Rob Kabacoff. Data Visualization with R, 2020.
[Rc] R CODER. R CHARTS.
[He19] Kieran Healy. Data Visualization, Princeton University Press, 2019.
[Ho] Yan Holtz. The R Graph Gallery.
[Wi10] Wickham, Hadley. A Layered Grammar of Graphics, Journal of Computational and Graphical Statistics, 3–28, 2010.
[WiÇeGa23] Wickham, Hadley, Mine Çetinkaya-Rundel and Garrett Grolemund. R for Data Science (2e), O’Reilly Media, 2023.
[Wi19] Claus O. Wilke. Fundamentals of Data Visualization, O’Reilly, 2019.