Análisis Exploratorio de Datos y Visualización
2025-11-24
1 Introducción
Este libro cubre los contenidos de un curso introductorio sobre análisis exploratorio de datos y visualización en un grado universitario en Ciencias de Datos. El análisis exploratorio de datos es un campo muy amplio, y no es posible impartir, en un solo curso, todos sus aspectos en profundidad. Este curso, de carácter introductorio, tiene como objetivo brindar una base sólida en las herramientas más importantes en este campo, pero cualquiera de los aspectos que se van a estudiar puede dar lugar a un estudio mucho más profundo y detallado del que vamos a presentar aquí.
1.1 Fases de un análisis exploratorio de datos
El análisis exploratorio de una colección de datos pasa por las siguientes fases :
Establecer los objetivos de nuestro análisis de datos. Con independencia de los objetivos particulares de cada caso, siempre hay un objetivo genérico general que podemos resumir en : descubrir y presentar la realidad que hay detrás de los datos.
Buscar los datos necesarios para nuestro estudio e importarlos a nuestro entorno de trabajo.
Entender la información que contienen los datos y como están organizados.
Seleccionar las herramientas adecuadas para procesar y visualizar la información suministrada por los datos.
Transformar y ordenar los datos en función de los objetivos del estudio y los requerimientos de las herramientas que vamos a usar.
Aplicar modelos para establecer relaciones entre los datos o hacer predicciones
Comunicar los resultados de nuestro análisis de datos explicando las conclusiones, justificando los resultados de forma eficiente con gráficos atractivos.
Todas estas fases interaccionan entre sí, por ejemplo, a la vista del resultado final del estudio puede ser necesario incorporar nuevos datos para completar o confirmar resultados. Por tanto hay que interpretar el desarrollo de estas fases como un proceso por iteraciones.
1.2 Contenido del curso
El contenido del curso se organiza de la siguiente forma :
Tema 1 : Introducción. Se presentan las fases de un análisis exploratorio de datos, un resumen del contenido del curso y la justificación razonada de la elección de
Rcomo entorno unificado de desarrollo.Tema 2 : Aspectos básicos de
R. Se hará un repaso de los tipos y estructuras de datos que usaremos y de las funciones enR.Tema 3 : Procesado de datos . Se introducirán las bases de datos que usaremos, el manejo de los formatos habituales de almacenamiento de datos y las herramientas de manipulación de datos que suministra la librería
dplyr.Tema 4 : Visualización estática de datos. Se abordará la gramática de los gráficos, su implementación en el contexto de la potente librería
ggploty su uso para la generación de gráficos estáticos.Tema 5 : Series temporales . Por su importancia práctica, se estudia, en este tema, el caso particular del análisis exploratorio de series temporales incluyendo modelos de predicción.
Tema 6 : Visualización dinámica. A través del uso de las librerías
ggplotly,highcharteryleafletse introducen potentes herramientas de visualización interactiva donde el usuario puede interactuar con los gráficos o generar animaciones.Tema 7 : Cuadros de mando. A través del uso de las librerías
shinyyflexdashboardse introduce el diseño e implementación de cuadros de mandos que permiten representar, de forma dinámica, atractiva y coherente, los indicadores principales de nuestra exploración de datos.Tema 8 : Análisis de atributos. Se estudia la relación que puede existir entre diferentes variables a través, por ejemplo, de la correlación entre pares de variables, y como reducir el número de variables usando combinaciones lineales entre ellas a través del método del análisis de componentes principales.
1.3 La elección de R
El entorno de trabajo que vamos a usar se basa en la habitual combinación de R, Rstudio y RMarkdown. En este curso, supondremos que el estudiante está mínimamente familiarizado con estas herramientas. Se recomiendan los siguientes tutoriales: tutorial 1, tutorial 2 y tutorial 3 como introducción básica al uso combinado de estas herramientas. También pueden ser útiles la ficha resumen de Rstudio y la ficha resumen de Markdown. En cualquier caso, el tema 1 se dedica a repasar el uso básico de R y se ha añadido un apéndice con la sintaxis básica de RMarkdown.
De entre las diferentes posibilidades de plataformas de desarrollo utilizables en Ciencias de Datos se ha decidido unificar todo el contenido del curso alrededor de R por los siguientes motivos :
Res un entorno libre de desarrollo de aplicaciones estadísticas y análisis de datos que ha tenido un enorme éxito e implantación a nivel mundial. Funciona muy bien, es robusto, es decir genera muy pocos fallos inesperados y se instala y gestiona fácilmente.Al ser
Rla plataforma de referencia para el análisis de datos, para cualquier librería importante relacionada con el tema que se implemente en otros lenguajes comopython,javascript, etc.., aparecen paquetes enRque sirven de interfaz para estas librerías. Esto es algo que se usa intensamente en este curso y tiene como efecto que la curva de aprendizaje de esas herramientas es mucho menor dado que se realiza todo desde el mismo entorno de desarrollo. Esto permite, en particular, abordar en un solo curso una gran colección de potentes herramientas que si se estudiaran cada una en sus particulares entornos de desarrollo, el aprendizaje sería mucho más complejo y sería imposible abordarlas en un solo curso.Unificar todas las herramientas alrededor de
Rnos permite concentrarnos en los aspectos conceptuales, que es, sin duda, lo más importante que vamos a aprender en este curso. Por otro lado, las herramientas de IA que existen actualmente permiten, fácilmente, transformar los códigos de un entorno de programación a otro, por ejemplo del entorno dado por la combinación de python - jupiter - notebook, que también es muy usado en Ciencias de Datos al entorno R - RStudio - Rmarkdown.La combinación de
R,RstudioyRMarkdownresulta idónea para experimentar y familiarizarse con todos los conceptos que se estudian en el curso. Además, estas herramientas son usadas por un número tan grande de personas, que prácticamente, cualquier problema o error que surja, ha sido ya resuelto y buscando por Internet, generalmente es fácil encontrar la solución.El número de librerías con herramientas desarrolladas en
Res inmenso, solo en el repositorio CRAN, que es el repositorio oficial de referencia para almacenar y gestionar las librerías, hay más de 22000 librerías registradas. Hay librerías, comoggplot2, que usamos en el curso, que tienen más de 165 millones de descargas. El autor de este libro ha publicado en CRAN la librería EpiInvert especializada en el procesado de series temporales en Epidemiología. Cualquier persona puede, en teoría, publicar gratuitamente una librería en CRAN. Ahora bien, se piden unos requisitos técnicos de calidad bastante exigentes para que la librería sea aceptada.
1.4 Las virtudes de un científico de datos
Neutralidad: Los datos deben hablar por si solos, hay que eliminar cualquier idea preconcebida que tengamos sobre los resultados de nuestro Análisis de Datos que pueden introducir un sesgo en la selección de datos y conclusiones.
Espíritu crítico. Hay que analizar y valorar en detalle la calidad, veracidad y fiabilidad de la fuente de los datos que manejamos. Por ejemplo, los datos que suministra una estación meteorológica son muy fiables porque los instrumentos de medida que utiliza lo son. Los datos sobre el número de infectados diarios por la COVID-19 contienen errores importantes porque la forma de medir no es precisa dado que la logística de registro de casos no es capaz, sobre todo al principio de la epidemia, de gestionar y registrar todos los casos. Además, muchos casos, como los que no presentan síntomas, quedan directamente fuera del radar. Mas allá de los errores en los sistemas de medición, otra fuente importante de falta de fiabilidad es el sesgo con el que pueden ser comunicados, en función del interés del que comunica los datos. Por ejemplo, decir que se han bajado los impuestos cuando el volumen de lo que se ha bajado es irrelevante y solo afecta a un grupo escaso de la población, no es técnicamente falso, pero el dato se está comunicando con un sesgo que desvirtúa la información que aportan los datos en su conjunto. De acuerdo con este espíritu crítico, al valorar la fiabilidad de la información que suministra una encuesta hay que tener muy en cuenta si la selección de la muestra de la población ha sido adecuada, por ejemplo, los encuestados no pueden proponerse ellos mismos para responder (por ejemplo una encuesta online voluntaria). Un ejemplo paradigmático sobre este asunto es la pregunta que realizó a sus lectores la periodista Ann Landers en 1976 donde consultaba a los padres en USA si volverían a tener hijos en caso de volver atrás y tener la opción de elegir. De los 10000 padres que respondieron a la pregunta de forma voluntaria, el 70% respondió que no volverían a tener hijos. Posteriormente, el periódico NewsDay realizó una encuesta seleccionando ellos de forma aleatoria a los padres para responder a la pregunta, y el resultado fue que el 91% respondió que si volvería a tener hijos, es decir algo diametralmente opuesto a lo obtenido en la primera encuesta. La justificación de esta enorme diferencia es muy sencilla. Los padres que están más inclinados a responder voluntariamente a la pregunta son aquellos que tienen problemas con sus hijos, los padres a los que les va bien con sus hijos y están contentos de haberlos tenidos, tienen mucho menos interés en participar voluntariamente en la encuesta. Este mismo principio se puede aplicar a las encuestas online voluntarias que se realiza a los alumnos para evaluar a los profesores.
Valoración relevancia de atributos. No todos los atributos son igualmente importantes. Por ejemplo, a la hora de valorar el grado de desarrollo de un país (ver [RRR18]), el dato de mortalidad infantil es especialmente relevante porque el esfuerzo de las familias para mantener vivos a sus hijos es siempre máximo y es uno de los primeros parámetros que mejora/empeora cuando varía la situación de un país.
Un ratio es mejor que un valor numérico aislado. En general un valor numérico aislado suministra información difícil de interpretar. Por ejemplo, el beneficio anual de una empresa es un dato difícil de interpretar si no se compara con algo. Comparar ese dato, con los beneficios de la anualidad anterior o con la cantidad de capital invertido y gastos de funcionamiento suministra una información más útil. De la misma forma, a efectos de comparar la riqueza entre países, la renta per capita, suministra un dato más útil que la renta de todo el país.
Ser consciente de la limitación de los datos que manejamos. En general, los datos que manejamos son el resultado de la acumulación de valores muy diversos. Por ejemplo, la renta per capita de un país no nos dice nada de la desigualdades, en términos de riqueza, que existen dentro de dicho país.
Evitar las generalizaciones. Nuestra tendencia natural es generalizar a partir de los datos particulares conocidos. Por ejemplo, los medios de comunicación ponen mucho énfasis en comunicar los actos violentos, lo que nos puede llevar a pensar, generalizando, que vivimos en una sociedad muy violenta. Sin embargo, la realidad que suministran los datos es que vivimos en la sociedad menos violenta que ha existido nunca.
Las conclusiones siempre deben estar soportadas por datos. En cualquier memoria, proyecto o informe realizado por un científico de datos, todas las afirmaciones y conclusiones deben estar soportadas por una correcta interpretación de datos con indicación de la fuente.
1.5 La trampa del pensamiento binario y la simplificación de la realidad.
Los seres humanos nos encontramos cómodos dividiendo la realidad que nos rodea en 2 partes que se contraponen. Por ejemplo países ricos versus países pobres, ser de izquierdas o ser de derechas, personas buenas versus personas malas, nuestro entorno versus el resto del mundo, etc.. Nuestra tendencia natural a este pensamiento binario nos facilita la interpretación de la realidad y nos hace la vida más fácil. Sin embargo, y es algo que debe tener en cuenta siempre el científico de datos, la realidad es mucho más compleja y tiene muchos más matices que lo que puede reflejar esta tendencia a separarla en dos grupos contrapuestos. Otra forma de simplificación frecuente es el uso de un único atributo para analizar una realidad compleja. Tomemos como ejemplo la media de ingresos diarios por persona, en dolares, y en algunos países, obtenidos a partir de la OWID y reflejada en el siguiente gráfico:
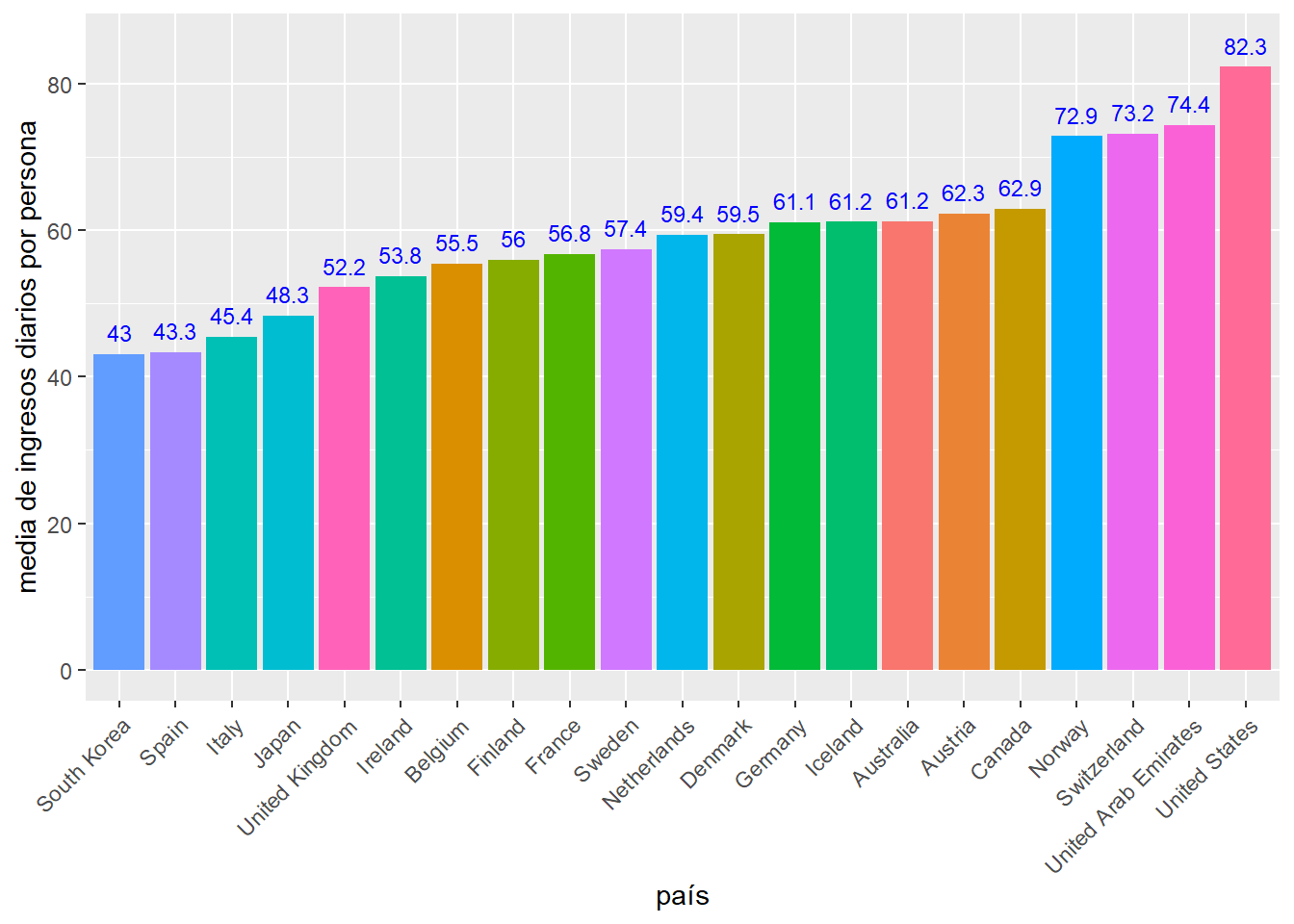
Vemos que utilizar la media de ingresos nos da una información útil para hacer una primera comparativa entre países. Sin embargo, usar solo la media, aunque nos da una información importante, oculta matices relevantes de la realidad, como es, por ejemplo, los niveles de igualdad entre la población de un país, en términos de los ingresos que reciben. Por ejemplo, Estados Unidos tiene una media de ingresos significativamente superior a Noruega. Sin embargo, si dividimos el nivel de salarios en 10 grupos (deciles) y comparamos los resultados para estos dos países obtenemos:
es decir, en Estados Unidos hay un 10% de la población que gana más de 158 dolares diarios y, por debajo, hay un 10% que gana menos de 23 dolares. Sin embargo, en Noruega, el 10% que mas gana, lo hace a partir de 116 dolares y el 10% que menos gana, por debajo de 34 dolares, es decir Noruega es un país con mucha menos desigualdad de ingresos que los Estados Unidos, lo que produce que la media en Estados Unidos sea más alta que en Noruega es que los que más ganan, ganan mucho más en Estados Unidos. Por tanto, la pregunta : ¿En cual de los dos países la población tiene un mayor nivel de ingresos? puede tener respuestas distintas en función de como se haga el análisis. Esto ejemplo nos muestra algo muy importante: en el análisis de datos, una misma cuestión puede tener dos respuestas contradictorias, siendo ambas coherentes y bien fundamentadas en función de los datos utilizados y su interpretación. Es decir, las respuestas a nuestras preguntas que obtenemos de nuestro análisis de datos, no es una verdad absoluta, a lo más que podemos aspirar es a que sean coherentes con los datos analizados. Volviendo al ejemplo de los ingresos por persona en un país, otro aspecto importante a tener en cuenta es la variabilidad de los ingresos en diferentes zonas del país. Por ejemplo si examinamos como se distribuye el salario medio bruto mensual por Comunidades en España en 2022:
observamos que mientras en el País Vasco el salario medio es de 2546 euros, en Canarias es de 1869 euros, lo cual refleja un nivel de riqueza y realidades muy distintas que no observamos al ver solo la media del país.
El objetivo de este análisis es mostrar como el científico de datos debe ir mas allá de la tendencia al pensamiento binario y simplificación del ser humano y mostrar la realidad, a partir de los datos, con la mayor riqueza de matices posibles.
1.6 El principio de Pareto para simplificar los datos
Con frecuencia manejamos tablas con mucha información donde resulta difícil extraer una visión global. Por ejemplo, supongamos que estamos manejando información por países de las emisiones de gases de efecto invernadero (GHG) en el 2020. Tenemos 193 países en nuestra tabla, pero para tener una idea global del problema, podemos concentrarnos en estudiar los países que más emiten, pues unos pocos países son los responsables de la mayor parte del total de emisiones. Esto es, esencialmente, el principio de Pareto, también llamado regla 80/20, que viene a decirnos que, en general, el 80% de los efectos proviene del 20% de las causas. Podemos aplicar este principio a nuestro problema de dos formas: seleccionar para el estudio el 20% de los países que más emiten (es decir unos 39 países), o, una opción que a mi me gusta más, seleccionar para el estudio los países que más emiten y que entre ellos superan globalmente el 80% de las emisiones totales de GHG, de esta manera aseguramos que estamos cubriendo un 80% del total de emisiones. Apliquemos esto a las emisiones en el año 2020, que alcanzaron globalmente en el mundo unas 46187 millones de toneladas. En la siguiente tabla, obtenida procesando datos de la OWID, presentamos las emisiones por países en 2020 ordenados en función de los gases emitidos, así como el acumulado del total de emisiones añadiendo los países progresivamente. También aparecen los porcentajes sobre el total de emisiones. Por ejemplo, observamos que solo China emite el 26,62% del total de emisiones y que los primeros 5 países ya emiten más del 50% del total de emisiones. Para alcanzar el 80% del total de emisiones debemos quedarnos con los primeros 28 países. La participación de España es del 0.56% del total de emisiones. Tomar el 80% es solo una referencia y en función de las necesidades y objetivos del estudio se puede modificar. Una vez seleccionados los países en que vamos a concentrar el estudio pasaríamos a analizar en detalle todas las variables asociadas a la emisión de GHG que tengamos para esos países. Es decir, hemos conseguido simplificar el problema para poder concentrarnos en el análisis de lo más relevante.
| country | year | GHG | GHG_ACUMULADO |
|---|---|---|---|
| China | 2020 | 12295.62 (26.62%) | 12295.62 (26.62%) |
| United States | 2020 | 5289.13 (11.45%) | 17584.75 (38.07%) |
| India | 2020 | 3166.95 (6.86%) | 20751.7 (44.93%) |
| Russia | 2020 | 1799.98 (3.9%) | 22551.68 (48.83%) |
| Indonesia | 2020 | 1475.83 (3.2%) | 24027.51 (52.02%) |
| Brazil | 2020 | 1469.64 (3.18%) | 25497.15 (55.2%) |
| Japan | 2020 | 1062.78 (2.3%) | 26559.93 (57.51%) |
| Iran | 2020 | 844.71 (1.83%) | 27404.64 (59.33%) |
| Canada | 2020 | 731.54 (1.58%) | 28136.18 (60.92%) |
| Saudi Arabia | 2020 | 712.59 (1.54%) | 28848.77 (62.46%) |
| Democratic Republic of Congo | 2020 | 688.06 (1.49%) | 29536.83 (63.95%) |
| Germany | 2020 | 681.18 (1.47%) | 30218.01 (65.43%) |
| South Korea | 2020 | 613.54 (1.33%) | 30831.55 (66.75%) |
| Mexico | 2020 | 609.07 (1.32%) | 31440.62 (68.07%) |
| Australia | 2020 | 585.42 (1.27%) | 32026.04 (69.34%) |
| South Africa | 2020 | 508.38 (1.1%) | 32534.42 (70.44%) |
| Turkey | 2020 | 476.34 (1.03%) | 33010.76 (71.47%) |
| Vietnam | 2020 | 458.14 (0.99%) | 33468.9 (72.46%) |
| Thailand | 2020 | 451.42 (0.98%) | 33920.32 (73.44%) |
| Pakistan | 2020 | 443.6 (0.96%) | 34363.92 (74.4%) |
| United Kingdom | 2020 | 411.12 (0.89%) | 34775.04 (75.29%) |
| Argentina | 2020 | 394.76 (0.85%) | 35169.8 (76.15%) |
| Nigeria | 2020 | 369.38 (0.8%) | 35539.18 (76.95%) |
| Malaysia | 2020 | 367.76 (0.8%) | 35906.94 (77.74%) |
| Italy | 2020 | 339.21 (0.73%) | 36246.15 (78.48%) |
| Poland | 2020 | 320.92 (0.69%) | 36567.07 (79.17%) |
| France | 2020 | 314.57 (0.68%) | 36881.64 (79.85%) |
| Egypt | 2020 | 299.96 (0.65%) | 37181.6 (80.5%) |
| Kazakhstan | 2020 | 291.82 (0.63%) | 37473.42 (81.13%) |
| Colombia | 2020 | 270.31 (0.59%) | 37743.73 (81.72%) |
| Algeria | 2020 | 267.01 (0.58%) | 38010.74 (82.3%) |
| Iraq | 2020 | 261.79 (0.57%) | 38272.53 (82.86%) |
| Spain | 2020 | 256.41 (0.56%) | 38528.94 (83.42%) |
Referencias
[He19] Kieran Healy. Data Visualization, Princeton University Press, 2019.
[Ir19] Rafael A. Irizarry. Introduction to Data Science, Taylor & Francis, 2019.
[RRR18] Hans Rosling, Ola Rosling and Anna Rosling. Factfulness: Diez razones por las que estamos equivocados sobre el mundo, Deusto, 2018.
[SH16] Angelo Santana y Carmen N. Hernández. R4ULPGC: Introducción a R, Grupo de Estadística de la Universidad de Las Palmas de G.C., 2016.
[WiÇeGa23] Wickham, Hadley, Mine Çetinkaya-Rundel and Garrett Grolemund. R for Data Science (2e), O’Reilly Media, 2023.
[Xie15] Xie, Yihui. Dynamic Documents with R and Knitr. (2e). Boca Raton, Florida: Chapman; Hall/CRC*, 2015.
[Xie23] Xie, Yihui. Bookdown: Authoring Books and Technical Documents with r Markdown, 2023.